
Easysearch 压缩模式深度比较:ZSTD + source_reuse 的优势分析
引言
在使用 Easysearch 时,如何在存储和查询性能之间找到平衡是一个常见的挑战。Easysearch 具备多种压缩模式,各有千秋。本文将重点探讨一种特别的压缩模式:zstd + source_reuse,我们最近重新优化了 source_reuse,使得它在吞吐量和存储效率方面都表现出色。
测试概览
测试条件选用了 esrally 工具和 geonames 数据集来进行压力测试。数据集包含了 11396503 条记录,往单个 shard 写入,对以下几种压缩模式进行压测对比:
defaultbest_compressionzstd-
zstd + source_reuse
下图是对 CPU 的监控,可以看到各个模式对 CPU 的使用是基本相近的。
default
best_compression
zstd
zstd+reuse
关键数据点
测试结果主要围绕两个指标:
- 中位吞吐量:单位为“每秒操作数”,数值越大表示性能越好。
- 存储大小:单位为 “GB”,数值越小表示存储更加高效。
| 测试数据如下: | 压缩模式 | 中位吞吐量 (docs/s) | 存储大小 (GB) |
|---|---|---|---|
| default | 37834 | 2.7 | |
| best_compression | 37404 | 2.2 | |
| zstd | 38878 | 2.1 | |
| zstd + source_reuse | 38942 | 1.6 |
zstd + source_reuse:压缩原理
该模式采用了 source_reuse 压缩算法,该算法通过对 keyword、long、int、short、boolean 等类型的字段值进行复用,并结合 zstd 压缩算法,大大提高了存储效率。
压缩效率
zstd + source_reuse 在存储大小上的表现尤为出色,针对 geonames 数据集只需 1.6 GB 的存储空间,相比于 best_compression 模式的 2.2 GB,压缩效率显著提高
。
吞吐量表现
高压缩率并没有让 zstd + source_reuse 在吞吐量上做出妥协,因为高压缩率使得其需要持久化的数据大大减小,其中位吞吐量为 38942 docs/s,在 4 种模式中表现最好。
结论
zstd + source_reuse 压缩模式在存储效率和查询性能之间找到了一种极佳的平衡,强烈推荐各位在使用 Easysearch 时,当存储成本比较敏感时,考虑使用 zstd + source_reuse 压缩模式。无论是在存储成本还是写入性能方面,它都能为你带来显著的优势。
关于 Easysearch

INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。 与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
官网文档:https://www.infinilabs.com/docs/latest/easysearch
下载地址:https://www.infinilabs.com/download
原文:https://www.infinilabs.com/blog/2023/deep-comparison-of-easysearch-compression-modes/
引言
在使用 Easysearch 时,如何在存储和查询性能之间找到平衡是一个常见的挑战。Easysearch 具备多种压缩模式,各有千秋。本文将重点探讨一种特别的压缩模式:zstd + source_reuse,我们最近重新优化了 source_reuse,使得它在吞吐量和存储效率方面都表现出色。
测试概览
测试条件选用了 esrally 工具和 geonames 数据集来进行压力测试。数据集包含了 11396503 条记录,往单个 shard 写入,对以下几种压缩模式进行压测对比:
defaultbest_compressionzstd-
zstd + source_reuse
下图是对 CPU 的监控,可以看到各个模式对 CPU 的使用是基本相近的。
defaultbest_compressionzstdzstd+reuse
关键数据点
测试结果主要围绕两个指标:
- 中位吞吐量:单位为“每秒操作数”,数值越大表示性能越好。
- 存储大小:单位为 “GB”,数值越小表示存储更加高效。
| 测试数据如下: | 压缩模式 | 中位吞吐量 (docs/s) | 存储大小 (GB) |
|---|---|---|---|
| default | 37834 | 2.7 | |
| best_compression | 37404 | 2.2 | |
| zstd | 38878 | 2.1 | |
| zstd + source_reuse | 38942 | 1.6 |
zstd + source_reuse:压缩原理
该模式采用了 source_reuse 压缩算法,该算法通过对 keyword、long、int、short、boolean 等类型的字段值进行复用,并结合 zstd 压缩算法,大大提高了存储效率。
压缩效率
zstd + source_reuse 在存储大小上的表现尤为出色,针对 geonames 数据集只需 1.6 GB 的存储空间,相比于 best_compression 模式的 2.2 GB,压缩效率显著提高
。
吞吐量表现
高压缩率并没有让 zstd + source_reuse 在吞吐量上做出妥协,因为高压缩率使得其需要持久化的数据大大减小,其中位吞吐量为 38942 docs/s,在 4 种模式中表现最好。
结论
zstd + source_reuse 压缩模式在存储效率和查询性能之间找到了一种极佳的平衡,强烈推荐各位在使用 Easysearch 时,当存储成本比较敏感时,考虑使用 zstd + source_reuse 压缩模式。无论是在存储成本还是写入性能方面,它都能为你带来显著的优势。
关于 Easysearch
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。 与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
官网文档:https://www.infinilabs.com/docs/latest/easysearch
下载地址:https://www.infinilabs.com/download
收起阅读 »原文:https://www.infinilabs.com/blog/2023/deep-comparison-of-easysearch-compression-modes/
社区日报 第1713期 (2023-10-09)
https://mp.weixin.qq.com/s/4dCRJr1sS-10iMOuNMtFLA
2. Elasticsearch系列---并发控制及乐观锁实现原理
https://zhuanlan.zhihu.com/p/649371864
3. elasticsearch中的Translog详解 及其参数与调优
https://zhuanlan.zhihu.com/p/648751324
编辑:yuebancanghai
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili
https://mp.weixin.qq.com/s/4dCRJr1sS-10iMOuNMtFLA
2. Elasticsearch系列---并发控制及乐观锁实现原理
https://zhuanlan.zhihu.com/p/649371864
3. elasticsearch中的Translog详解 及其参数与调优
https://zhuanlan.zhihu.com/p/648751324
编辑:yuebancanghai
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili 收起阅读 »
ES 关于 remote_cluster 的一记小坑
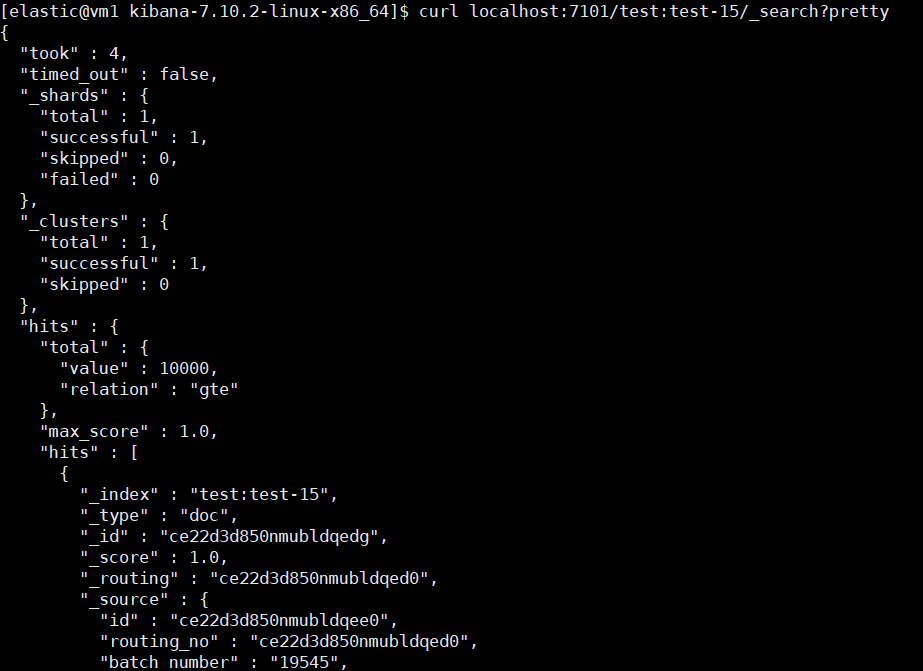
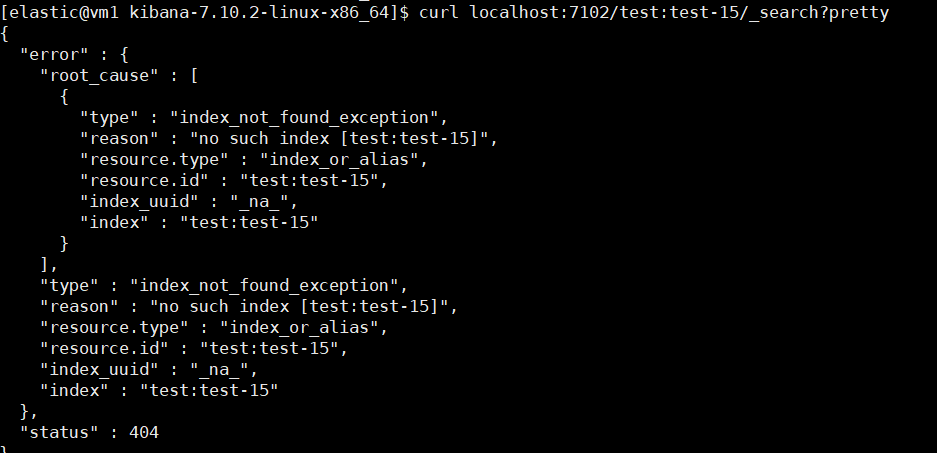
最近有小伙伴找到我们说 Kibana 上添加不了 Remote Cluster,填完信息点 Save 直接跳回原界面了。具体页面,就和没添加前一样。
我们和小伙伴虽然隔着网线但还是进行了深入、详细的交流,梳理出来了如下信息:
- 两个集群:集群 A 和集群 B ,版本都是 7.10.0 ;
- 集群 A 没区分节点角色;
- 集群 B 设置了 独立的 master 节点、coordinator 节点和 data 节点,其中 data 节点还带 remote_cluster_client 角色;
- 在集群 A 的 Kibana 可以添加 集群 B 为远程集群;
- 在集群 B 添加 集群 A 就不行,Kibana 跳回之前的页面;
- 网络组确认已经放开策略,网络测试也正常;
翻看了 ES 和 Kibana 的日志, ES 日志中有连接失败的错误信息, Kibana 日志中无对应输出。
[2023-09-13T11:38:41,055][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.mode] from [SNIFF] to [sniff]
[2023-09-13T11:38:41,055][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.seeds] from [[]] to [["127.0.0.1:7102"]]
[2023-09-13T11:38:41,056][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.mode] from [SNIFF] to [sniff]
[2023-09-13T11:38:41,056][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.seeds] from [[]] to [["127.0.0.1:7102"]]
[2023-09-13T11:38:41,057][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.mode] from [SNIFF] to [sniff]
[2023-09-13T11:38:41,057][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.seeds] from [[]] to [["127.0.0.1:7102"]]
[2023-09-13T11:38:41,093][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.mode] from [SNIFF] to [sniff]
[2023-09-13T11:38:41,094][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.seeds] from [[]] to [["127.0.0.1:7102"]]
[2023-09-13T11:38:41,094][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.mode] from [SNIFF] to [sniff]
[2023-09-13T11:38:41,094][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.seeds] from [[]] to [["127.0.0.1:7102"]]
[2023-09-13T11:38:41,095][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.mode] from [SNIFF] to [sniff]
[2023-09-13T11:38:41,096][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.seeds] from [[]] to [["127.0.0.1:7102"]]
[2023-09-13T11:38:51,099][WARN ][o.e.t.RemoteClusterService] [710-1] failed to connect to new remote cluster test within 10s
[2023-09-13T11:39:11,101][WARN ][o.e.t.SniffConnectionStrategy] [710-1] fetching nodes from external cluster [test] failed
org.elasticsearch.transport.ConnectTransportException: [][127.0.0.1:7102] handshake_timeout[30s]
at org.elasticsearch.transport.TransportHandshaker.lambda$sendHandshake$1(TransportHandshaker.java:73) ~[elasticsearch-7.10.2.jar:7.10.2]
at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingRunnable.run(ThreadContext.java:684) ~[elasticsearch-7.10.2.jar:7.10.2]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1130) [?:?]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:630) [?:?]
at java.lang.Thread.run(Thread.java:832) [?:?]已经测试过网络是通的,开始尝试把集群 B 的角色配置统统去掉再尝试。
嘿,添加成功了。
接下来为了找出问题,开始一步一步给每个节点再加回原来的角色。而且如果节点原来没有 remote_cluster_client 角色,这次也一并加上。
操作过程
- 先从 data 节点开始,恢复角色,尝试添加远程集群,失败。
- 接着 coordinate 节点 , 恢复角色且新增 remote_cluster_client 角色,尝试添加远程集群,失败。
- 最后 master 节点,恢复角色且新增 remote_cluster_client 角色,尝试添加远程集群,成功。
最终直到所有节点都有 remote_cluster_client 角色后,才成功添加远程集群。
结论: ES 集群添加远程集群所有节点都必须拥有 remote_cluster_client 角色。
事情到这里,似乎没什么问题。但当我们对这个结论进行检验时,又有了新发现。
上面的场景忽视了一个因素 -- Kibana 。于是我们搭建了一个两个节点的集群,其中节点 A 是全角色节点,节点 B 只是 data 节点。让 Kibana 分别连接两个节点进行测试。
验证结果
- 当 Kibana 连接节点 A 时,可以正常添加。
- Kibana 连接节点 B 时,添加失败,跳回界面。
结论:ES 集群添加远程集群时,Kibana 连接的 ES 节点必须拥有 remote_cluster_client 角色。
很显然,这个结论更合理。
原因分析
我们是通过 Kibana 界面操作去添加远程集群的, Kibana 连接的节点就被当作 remote_client 。该节点要向远程集群发起连接并执行相关调用。但这一切有个前提,该节点必须有 remote_cluster_client 角色才能向远程集群发起连接。
 引申
引申
我们的 CCS 操作也必须发送到一个具有 remote_cluster_client 角色的节点,才能成功执行。

参考连接 https://www.elastic.co/guide/en/elasticsearch/reference/7.10/modules-node.html
最近有小伙伴找到我们说 Kibana 上添加不了 Remote Cluster,填完信息点 Save 直接跳回原界面了。具体页面,就和没添加前一样。
我们和小伙伴虽然隔着网线但还是进行了深入、详细的交流,梳理出来了如下信息:
- 两个集群:集群 A 和集群 B ,版本都是 7.10.0 ;
- 集群 A 没区分节点角色;
- 集群 B 设置了 独立的 master 节点、coordinator 节点和 data 节点,其中 data 节点还带 remote_cluster_client 角色;
- 在集群 A 的 Kibana 可以添加 集群 B 为远程集群;
- 在集群 B 添加 集群 A 就不行,Kibana 跳回之前的页面;
- 网络组确认已经放开策略,网络测试也正常;
翻看了 ES 和 Kibana 的日志, ES 日志中有连接失败的错误信息, Kibana 日志中无对应输出。
[2023-09-13T11:38:41,055][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.mode] from [SNIFF] to [sniff]
[2023-09-13T11:38:41,055][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.seeds] from [[]] to [["127.0.0.1:7102"]]
[2023-09-13T11:38:41,056][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.mode] from [SNIFF] to [sniff]
[2023-09-13T11:38:41,056][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.seeds] from [[]] to [["127.0.0.1:7102"]]
[2023-09-13T11:38:41,057][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.mode] from [SNIFF] to [sniff]
[2023-09-13T11:38:41,057][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.seeds] from [[]] to [["127.0.0.1:7102"]]
[2023-09-13T11:38:41,093][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.mode] from [SNIFF] to [sniff]
[2023-09-13T11:38:41,094][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.seeds] from [[]] to [["127.0.0.1:7102"]]
[2023-09-13T11:38:41,094][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.mode] from [SNIFF] to [sniff]
[2023-09-13T11:38:41,094][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.seeds] from [[]] to [["127.0.0.1:7102"]]
[2023-09-13T11:38:41,095][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.mode] from [SNIFF] to [sniff]
[2023-09-13T11:38:41,096][INFO ][o.e.c.s.ClusterSettings ] [710-1] updating [cluster.remote.test.seeds] from [[]] to [["127.0.0.1:7102"]]
[2023-09-13T11:38:51,099][WARN ][o.e.t.RemoteClusterService] [710-1] failed to connect to new remote cluster test within 10s
[2023-09-13T11:39:11,101][WARN ][o.e.t.SniffConnectionStrategy] [710-1] fetching nodes from external cluster [test] failed
org.elasticsearch.transport.ConnectTransportException: [][127.0.0.1:7102] handshake_timeout[30s]
at org.elasticsearch.transport.TransportHandshaker.lambda$sendHandshake$1(TransportHandshaker.java:73) ~[elasticsearch-7.10.2.jar:7.10.2]
at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingRunnable.run(ThreadContext.java:684) ~[elasticsearch-7.10.2.jar:7.10.2]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1130) [?:?]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:630) [?:?]
at java.lang.Thread.run(Thread.java:832) [?:?]已经测试过网络是通的,开始尝试把集群 B 的角色配置统统去掉再尝试。
嘿,添加成功了。
接下来为了找出问题,开始一步一步给每个节点再加回原来的角色。而且如果节点原来没有 remote_cluster_client 角色,这次也一并加上。
操作过程
- 先从 data 节点开始,恢复角色,尝试添加远程集群,失败。
- 接着 coordinate 节点 , 恢复角色且新增 remote_cluster_client 角色,尝试添加远程集群,失败。
- 最后 master 节点,恢复角色且新增 remote_cluster_client 角色,尝试添加远程集群,成功。
最终直到所有节点都有 remote_cluster_client 角色后,才成功添加远程集群。
结论: ES 集群添加远程集群所有节点都必须拥有 remote_cluster_client 角色。
事情到这里,似乎没什么问题。但当我们对这个结论进行检验时,又有了新发现。
上面的场景忽视了一个因素 -- Kibana 。于是我们搭建了一个两个节点的集群,其中节点 A 是全角色节点,节点 B 只是 data 节点。让 Kibana 分别连接两个节点进行测试。
验证结果
- 当 Kibana 连接节点 A 时,可以正常添加。
- Kibana 连接节点 B 时,添加失败,跳回界面。
结论:ES 集群添加远程集群时,Kibana 连接的 ES 节点必须拥有 remote_cluster_client 角色。
很显然,这个结论更合理。
原因分析
我们是通过 Kibana 界面操作去添加远程集群的, Kibana 连接的节点就被当作 remote_client 。该节点要向远程集群发起连接并执行相关调用。但这一切有个前提,该节点必须有 remote_cluster_client 角色才能向远程集群发起连接。
引申
我们的 CCS 操作也必须发送到一个具有 remote_cluster_client 角色的节点,才能成功执行。
参考连接 https://www.elastic.co/guide/en/elasticsearch/reference/7.10/modules-node.html
收起阅读 »社区日报 第1712期 (2023-09-28)
https://mp.weixin.qq.com/s/nsGNFCSPKW-ayieSf5yRZQ
2.使用基于 Arm 的 Amazon EC2 M6g 实例优化您的 Elasticsearch 部署
https://community.arm.com/arm- ... 2-m6g
3.通过 Elastic Universal Profiling 解锁整个系统的可见性
https://www.elastic.co/blog/wh ... iling
编辑:Se7en
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
https://mp.weixin.qq.com/s/nsGNFCSPKW-ayieSf5yRZQ
2.使用基于 Arm 的 Amazon EC2 M6g 实例优化您的 Elasticsearch 部署
https://community.arm.com/arm- ... 2-m6g
3.通过 Elastic Universal Profiling 解锁整个系统的可见性
https://www.elastic.co/blog/wh ... iling
编辑:Se7en
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili 收起阅读 »
社区日报 第1711期 (2023-09-27)
https://cloud.tencent.com/deve ... 75753
2. Elasticsearch:什么是向量和向量存储数据库,我们为什么关心?
https://blog.csdn.net/UbuntuTo ... 26501
3.使用HuggingFace和Elasticsearch进行语义搜索(需要梯子)
https://betterprogramming.pub/ ... 3dd9d
编辑:kin122
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili
https://cloud.tencent.com/deve ... 75753
2. Elasticsearch:什么是向量和向量存储数据库,我们为什么关心?
https://blog.csdn.net/UbuntuTo ... 26501
3.使用HuggingFace和Elasticsearch进行语义搜索(需要梯子)
https://betterprogramming.pub/ ... 3dd9d
编辑:kin122
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili
收起阅读 »
社区日报 第1710期 (2023-09-26)
https://medium.com/%40utkarsh- ... b89dd
https://blog.devops.dev/system ... 6bbff
https://blog.stackademic.com/s ... f372b
2. 围绕着 .Net core,我是怎么用ES家族搭建的日志平台的(需要梯子)
https://tohidhaghighi.medium.c ... 6b56a
3. 巅峰对决?OpenSearch VS ElasticSearch(需要梯子)
https://medium.com/%40bhongale ... e1482
编辑:斯蒂文
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
https://medium.com/%40utkarsh- ... b89dd
https://blog.devops.dev/system ... 6bbff
https://blog.stackademic.com/s ... f372b
2. 围绕着 .Net core,我是怎么用ES家族搭建的日志平台的(需要梯子)
https://tohidhaghighi.medium.c ... 6b56a
3. 巅峰对决?OpenSearch VS ElasticSearch(需要梯子)
https://medium.com/%40bhongale ... e1482
编辑:斯蒂文
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
收起阅读 »
通过 Helm Chart 部署 Easysearch

Easysearch 可以通过 Helm 快速部署了,快来看看吧!
Easysearch 的 Chart 仓库地址在这里 https://helm.infinilabs.com。
使用 Helm 部署 Easysearch 有两个前提条件:
我们先按照 Chart 仓库的说明来快速部署一下。
~ helm repo add infinilabs https://helm.infinilabs.com
~ cat << EOF | kubectl apply -n test -f -
apiVersion: cert-manager.io/v1
kind: Issuer
metadata:
name: easysearch-ca-issuer
spec:
selfSigned: {}
---
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: easysearch-ca-certificate
spec:
commonName: easysearch-ca-certificate
duration: 87600h0m0s
isCA: true
issuerRef:
kind: Issuer
name: easysearch-ca-issuer
privateKey:
algorithm: ECDSA
size: 256
renewBefore: 2160h0m0s
secretName: easysearch-ca-secret
EOF
~ helm install easysearch infinilabs/easysearch -n test执行上面的两个命令之后,查看一下部署情况
~ kubectl get pod -n test
NAME READY STATUS RESTARTS AGE
easysearch-0 1/1 Running 0 38s
~ kubectl get svc -n test
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
easysearch-svc-headless ClusterIP None <none> 9200/TCP,9300/TCP 67s
~ kubectl exec -n test easysearch-0 -it -- curl -ku'admin:admin' https://localhost:9200
Defaulted container "easysearch" out of: easysearch, init-config (init)
{
"name" : "easysearch-0",
"cluster_name" : "infinilabs",
"cluster_uuid" : "JwhwwWHMQKy8l6_US7rB1A",
"version" : {
"distribution" : "easysearch",
"number" : "1.5.0",
"distributor" : "INFINI Labs",
"build_hash" : "5b5b117bc43e6793e7bb0cd8bd83567a5ef35be0",
"build_date" : "2023-09-07T14:55:21.232870Z",
"build_snapshot" : false,
"lucene_version" : "8.11.2",
"minimum_wire_lucene_version" : "7.7.0",
"minimum_lucene_index_compatibility_version" : "7.7.0"
},
"tagline" : "You Know, For Easy Search!"
}通过上面的验证,我们可以看到 Easysearch 已经部署完成,是不是很方便。
按照 Chart 仓库的指导说明部署的是一个单节点集群,那如果要部署多节点的要怎么办呢?下面让我们来研究一下 Easysearch Chart 包的源码 https://github.com/infinilabs/helm-charts/tree/main/charts/easysearch。
熟悉 Chart 包结构的小伙伴都清楚,Chart 包的变量配置一般都是在 values.yaml 文件中配置的。
我们先来看一下默认的 values.yaml 文件内容(这里只截选了一些可能需要变更的配置,完整内容请查阅源码):
- pod 副本数以及使用资源的配置
replicaCount: 1
resources:
limits:
cpu: 1000m
memory: 2Gi
requests:
cpu: 1000m
memory: 2Gi- 使用存储类型以及容量的配置
storageClassName: local-path
dataVolumeStorage: 100Gi- 集群名、主节点列表以及节点角色配置
clusterName: infinilabs
masterHosts: '"easysearch-0"'
discoverySeedHosts: '"easysearch-0.easysearch-svc-headless"'
nodeRoles: '"master","data","ingest","remote_cluster_client"'根据研究源码的结果,多节点集群的部署只需要我们调整部署的 pod 副本数、集群名、主节点列表以及节点角色这几个配置。下面让我们来实践一下:
1、集群规划
集群名:es-test
规模:3 主节点 + 3 数据节点 + 2 协调节点
2、Chart 的版本名
主节点:es-test-master
数据节点:es-test-data
协调节点:es-test-coordinate
3、根据节点角色创建不同的 values.yaml 文件
- es-test-master.yaml
replicaCount: 3
clusterName: es-test
masterHosts: '"es-test-master-easysearch-0","es-test-master-easysearch-1","es-test-master-easysearch-2"'
discoverySeedHosts: '"es-test-master-easysearch-0.es-test-master-easysearch-svc-headless","es-test-master-easysearch-1.es-test-master-easysearch-svc-headless","es-test-master-easysearch-2.es-test-master-easysearch-svc-headless"'
nodeRoles: '"master","ingest","remote_cluster_client"'- es-test-data.yaml
replicaCount: 3
clusterName: es-test
masterHosts: '"es-test-master-easysearch-0","es-test-master-easysearch-1","es-test-master-easysearch-2"'
discoverySeedHosts: '"es-test-master-easysearch-0.es-test-master-easysearch-svc-headless","es-test-master-easysearch-1.es-test-master-easysearch-svc-headless","es-test-master-easysearch-2.es-test-master-easysearch-svc-headless"'
nodeRoles: '"data","ingest","remote_cluster_client"'- es-test-coordinate.yaml
replicaCount: 2
clusterName: es-test
masterHosts: '"es-test-master-easysearch-0","es-test-master-easysearch-1","es-test-master-easysearch-2"'
discoverySeedHosts: '"es-test-master-easysearch-0.es-test-master-easysearch-svc-headless","es-test-master-easysearch-1.es-test-master-easysearch-svc-headless","es-test-master-easysearch-2.es-test-master-easysearch-svc-headless"'
nodeRoles: ""4、使用各节点角色的配置文件部署
~ helm install es-test-master infinilabs/easysearch -n test -f es-test-master.yaml
~ helm install es-test-data infinilabs/easysearch -n test -f es-test-data.yaml
~ helm install es-test-coordinate infinilabs/easysearch -n test -f es-test-coordinate.yaml5、验证
~ kubectl get pod -n test|grep es-test
es-test-master-easysearch-0 1/1 Running 0 5m57s
es-test-data-easysearch-0 1/1 Running 0 5m29s
es-test-coordinate-easysearch-0 1/1 Running 0 5m10s
es-test-master-easysearch-1 1/1 Running 0 4m57s
es-test-data-easysearch-1 1/1 Running 0 4m29s
es-test-coordinate-easysearch-1 1/1 Running 0 4m10s
es-test-master-easysearch-2 1/1 Running 0 3m56s
es-test-data-easysearch-2 1/1 Running 0 3m29s
~ kubectl exec -n test es-test-master-easysearch-0 -it -- curl -ku'admin:admin' https://localhost:9200/_cat/nodes?v
Defaulted container "easysearch" out of: easysearch, init-config (init)
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
10.42.0.130 12 63 12 1.53 2.67 2.11 - - es-test-coordinate-easysearch-0
10.42.0.136 53 65 52 1.53 2.67 2.11 dir - es-test-data-easysearch-1
10.42.0.139 6 63 14 1.53 2.67 2.11 - - es-test-coordinate-easysearch-1
10.42.0.133 10 63 14 1.53 2.67 2.11 imr - es-test-master-easysearch-1
10.42.0.149 58 65 59 1.53 2.67 2.11 dir - es-test-data-easysearch-2
10.42.0.124 53 68 35 1.53 2.67 2.11 imr * es-test-master-easysearch-0
10.42.0.127 56 65 46 1.53 2.67 2.11 dir - es-test-data-easysearch-0
10.42.0.146 15 63 18 1.53 2.67 2.11 imr - es-test-master-easysearch-2至此,多集群已部署完成。
关于 Easysearch
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。 与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
Easysearch 可以通过 Helm 快速部署了,快来看看吧!
Easysearch 的 Chart 仓库地址在这里 https://helm.infinilabs.com。
使用 Helm 部署 Easysearch 有两个前提条件:
我们先按照 Chart 仓库的说明来快速部署一下。
~ helm repo add infinilabs https://helm.infinilabs.com
~ cat << EOF | kubectl apply -n test -f -
apiVersion: cert-manager.io/v1
kind: Issuer
metadata:
name: easysearch-ca-issuer
spec:
selfSigned: {}
---
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: easysearch-ca-certificate
spec:
commonName: easysearch-ca-certificate
duration: 87600h0m0s
isCA: true
issuerRef:
kind: Issuer
name: easysearch-ca-issuer
privateKey:
algorithm: ECDSA
size: 256
renewBefore: 2160h0m0s
secretName: easysearch-ca-secret
EOF
~ helm install easysearch infinilabs/easysearch -n test执行上面的两个命令之后,查看一下部署情况
~ kubectl get pod -n test
NAME READY STATUS RESTARTS AGE
easysearch-0 1/1 Running 0 38s
~ kubectl get svc -n test
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
easysearch-svc-headless ClusterIP None <none> 9200/TCP,9300/TCP 67s
~ kubectl exec -n test easysearch-0 -it -- curl -ku'admin:admin' https://localhost:9200
Defaulted container "easysearch" out of: easysearch, init-config (init)
{
"name" : "easysearch-0",
"cluster_name" : "infinilabs",
"cluster_uuid" : "JwhwwWHMQKy8l6_US7rB1A",
"version" : {
"distribution" : "easysearch",
"number" : "1.5.0",
"distributor" : "INFINI Labs",
"build_hash" : "5b5b117bc43e6793e7bb0cd8bd83567a5ef35be0",
"build_date" : "2023-09-07T14:55:21.232870Z",
"build_snapshot" : false,
"lucene_version" : "8.11.2",
"minimum_wire_lucene_version" : "7.7.0",
"minimum_lucene_index_compatibility_version" : "7.7.0"
},
"tagline" : "You Know, For Easy Search!"
}通过上面的验证,我们可以看到 Easysearch 已经部署完成,是不是很方便。
按照 Chart 仓库的指导说明部署的是一个单节点集群,那如果要部署多节点的要怎么办呢?下面让我们来研究一下 Easysearch Chart 包的源码 https://github.com/infinilabs/helm-charts/tree/main/charts/easysearch。
熟悉 Chart 包结构的小伙伴都清楚,Chart 包的变量配置一般都是在 values.yaml 文件中配置的。
我们先来看一下默认的 values.yaml 文件内容(这里只截选了一些可能需要变更的配置,完整内容请查阅源码):
- pod 副本数以及使用资源的配置
replicaCount: 1
resources:
limits:
cpu: 1000m
memory: 2Gi
requests:
cpu: 1000m
memory: 2Gi- 使用存储类型以及容量的配置
storageClassName: local-path
dataVolumeStorage: 100Gi- 集群名、主节点列表以及节点角色配置
clusterName: infinilabs
masterHosts: '"easysearch-0"'
discoverySeedHosts: '"easysearch-0.easysearch-svc-headless"'
nodeRoles: '"master","data","ingest","remote_cluster_client"'根据研究源码的结果,多节点集群的部署只需要我们调整部署的 pod 副本数、集群名、主节点列表以及节点角色这几个配置。下面让我们来实践一下:
1、集群规划
集群名:es-test
规模:3 主节点 + 3 数据节点 + 2 协调节点
2、Chart 的版本名
主节点:es-test-master
数据节点:es-test-data
协调节点:es-test-coordinate
3、根据节点角色创建不同的 values.yaml 文件
- es-test-master.yaml
replicaCount: 3
clusterName: es-test
masterHosts: '"es-test-master-easysearch-0","es-test-master-easysearch-1","es-test-master-easysearch-2"'
discoverySeedHosts: '"es-test-master-easysearch-0.es-test-master-easysearch-svc-headless","es-test-master-easysearch-1.es-test-master-easysearch-svc-headless","es-test-master-easysearch-2.es-test-master-easysearch-svc-headless"'
nodeRoles: '"master","ingest","remote_cluster_client"'- es-test-data.yaml
replicaCount: 3
clusterName: es-test
masterHosts: '"es-test-master-easysearch-0","es-test-master-easysearch-1","es-test-master-easysearch-2"'
discoverySeedHosts: '"es-test-master-easysearch-0.es-test-master-easysearch-svc-headless","es-test-master-easysearch-1.es-test-master-easysearch-svc-headless","es-test-master-easysearch-2.es-test-master-easysearch-svc-headless"'
nodeRoles: '"data","ingest","remote_cluster_client"'- es-test-coordinate.yaml
replicaCount: 2
clusterName: es-test
masterHosts: '"es-test-master-easysearch-0","es-test-master-easysearch-1","es-test-master-easysearch-2"'
discoverySeedHosts: '"es-test-master-easysearch-0.es-test-master-easysearch-svc-headless","es-test-master-easysearch-1.es-test-master-easysearch-svc-headless","es-test-master-easysearch-2.es-test-master-easysearch-svc-headless"'
nodeRoles: ""4、使用各节点角色的配置文件部署
~ helm install es-test-master infinilabs/easysearch -n test -f es-test-master.yaml
~ helm install es-test-data infinilabs/easysearch -n test -f es-test-data.yaml
~ helm install es-test-coordinate infinilabs/easysearch -n test -f es-test-coordinate.yaml5、验证
~ kubectl get pod -n test|grep es-test
es-test-master-easysearch-0 1/1 Running 0 5m57s
es-test-data-easysearch-0 1/1 Running 0 5m29s
es-test-coordinate-easysearch-0 1/1 Running 0 5m10s
es-test-master-easysearch-1 1/1 Running 0 4m57s
es-test-data-easysearch-1 1/1 Running 0 4m29s
es-test-coordinate-easysearch-1 1/1 Running 0 4m10s
es-test-master-easysearch-2 1/1 Running 0 3m56s
es-test-data-easysearch-2 1/1 Running 0 3m29s
~ kubectl exec -n test es-test-master-easysearch-0 -it -- curl -ku'admin:admin' https://localhost:9200/_cat/nodes?v
Defaulted container "easysearch" out of: easysearch, init-config (init)
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
10.42.0.130 12 63 12 1.53 2.67 2.11 - - es-test-coordinate-easysearch-0
10.42.0.136 53 65 52 1.53 2.67 2.11 dir - es-test-data-easysearch-1
10.42.0.139 6 63 14 1.53 2.67 2.11 - - es-test-coordinate-easysearch-1
10.42.0.133 10 63 14 1.53 2.67 2.11 imr - es-test-master-easysearch-1
10.42.0.149 58 65 59 1.53 2.67 2.11 dir - es-test-data-easysearch-2
10.42.0.124 53 68 35 1.53 2.67 2.11 imr * es-test-master-easysearch-0
10.42.0.127 56 65 46 1.53 2.67 2.11 dir - es-test-data-easysearch-0
10.42.0.146 15 63 18 1.53 2.67 2.11 imr - es-test-master-easysearch-2至此,多集群已部署完成。
关于 Easysearch
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。 与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
官网文档:https://www.infinilabs.com/docs/latest/easysearch
下载地址:https://www.infinilabs.com/download
收起阅读 »社区日报 第1709期 (2023-09-25)
https://blog.csdn.net/yangshan ... 07786
2. Elasticsearch:如何在 Elasticsearch 中轻松编写 Painless 脚本
https://blog.csdn.net/UbuntuTo ... 26782
3. Elasticsearch 主从同步之跨集群复制
https://blog.51cto.com/elasticsearch/5768458
编辑:yuebancanghai
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili
https://blog.csdn.net/yangshan ... 07786
2. Elasticsearch:如何在 Elasticsearch 中轻松编写 Painless 脚本
https://blog.csdn.net/UbuntuTo ... 26782
3. Elasticsearch 主从同步之跨集群复制
https://blog.51cto.com/elasticsearch/5768458
编辑:yuebancanghai
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili 收起阅读 »
社区日报 第1708期 (2023-09-22)
https://www.computer.org/publi ... ience
2、在 Elasticsearch 中实现时序数据的热温架构
https://codersite.dev/hot-warm ... arch/
3、在 Elasticsearch 中更新同义词:同义词 API 简介
https://www.elastic.co/cn/blog ... s-api
编辑:铭毅天下
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
https://www.computer.org/publi ... ience
2、在 Elasticsearch 中实现时序数据的热温架构
https://codersite.dev/hot-warm ... arch/
3、在 Elasticsearch 中更新同义词:同义词 API 简介
https://www.elastic.co/cn/blog ... s-api
编辑:铭毅天下
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili 收起阅读 »
INFINI Labs 产品更新 | Gateway 支持基于 Kafka 的复制能力,发布 Helm Charts 部署方式

INFINI Labs 产品又更新啦~。本次更新概要如下:Easysearch 新增了索引字段相关统计 API,优化了 source_reuse 提升压缩效率;Gateway 新增诸多新特性,如:支持基于 Kafka 的复制能力,添加可插拔的分布式锁实现,新增 CPU 资源限制等功能;Console 本次主要优化了数据迁移功能,迁移任务详情页新增了若干指标图和日志查看等功能。
欢迎大家下载使用和反馈。
INFINI Helm Charts v0.1.0
INFINI Helm Charts 是一组 Kubernetes 部署包管理工具。基于 Helm Charts,我们将 INFINI Labs 旗下相关产品预先配置好程序资源包,大大简化了部署流程。Github 仓库地址:https://github.com/infinilabs/helm-charts。
Helm Charts 本次更新如下:
Features
- 添加 Console Chart
- 添加 Easysearch Chart,支持单节点以及多节点(节点角色可配置)部署
部署视频演示:
博客文章:
INFINI Easysearch v1.6.0
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。
Easysearch 本次更新如下:
Features
- 新增 _field_usage_stats API,统计索引每个字段的访问次数
- 新增 _disk_usage API,可以分析指定索引每个字段的磁盘占用大小
- 增加 flattened 类型,将 JSON 对象作为字符串处理,可以减少嵌套 JSON 型的文档的大小
Improvements
- source_reuse 增加对 _source 中数字类型的值进行复用压缩,可进一步降低 _source 磁盘占用
- 改进 source_reuse 筛选字段的逻辑
INFINI Gateway v1.18.0
INFINI Gateway 是一个面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway 可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
Gateway 本次更新如下:
Breaking changes
- 彻底移除了 request_body_truncate 和 response_body_truncate 过滤器
Features
- 支持基于 Kafka 的复制能力
- 在请求上下文中添加 _util.generate_uuid
- 在请求上下文中添加 _util.increment_id.BUCKET_NAME
- 在 Pipeline 配置中添加 singleton,防止多个 Pipeline 同时运行
- 添加可插拔的分布式锁实现
- 添加通用应用程序的 preference 配置
- 泛化队列抽象,重构磁盘队列,完善 Kafka 实现
- 添加 merge_to_bulk 处理器, 废弃 indexing_merge 处理器
- 添加 flow_replay 处理器,废弃 flow_runner 处理器
- 为复制场景添加 replication_correlation
- 添加 hash_mod 过滤器
- 在 bulk_response_process 过滤器中添加新参数
- 添加 request_reshuffle 过滤器
- 添加资源限制,允许设置最大 CPU 数或绑定亲和性
- 支持模板中的嵌套变量
- 添加 rewrite_to_bulk 过滤器
Bug fix
- 修复了 Pipeline 中重试延迟未生效的问题
- 修复了模板中不支持数字的问题
- 修复了队列选择器通过标签的问题,如果指定了多个标签,它们都应该一起匹配
Improvements
- 将所有模块名称转换为小写
- 在启动期间预取 Elasticsearch 元数据
- 添加应用程序范围的关闭信号
- 重构队列 API,支持 Kafka 管理
- 在 Badger 模块中添加 enabled
- 允许使用优先级注册模块/插件
- 统一队列的使用和初始化
- 优化 bulk_reshuffle 过滤器的性能,添加响应头 X-Bulk-Reshuffled
- 支持在 queue 过滤器中使用变量,允许输出最后生成的消息偏移量
INFINI Console v1.8.0
INFINI Console 是一款非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管, 企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 在线体验: http://demo.infini.cloud (用户名/密码:readonly/readonly)。
Console 本次更新如下:
Features
- 数据迁移任务支持自定义名称和添加标签
- 数据迁移任务详情页新增若干指标
- 数据迁移任务详情页新增查看日志
Improvements
- 数据迁移 UI 优化
- 优化监控报表、数据看板、数据探索的时间控件 UI

期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
- INFINI Gateway: https://github.com/infinilabs/gateway/issues
- INFINI Console: https://github.com/infinilabs/console/issues
- 下载地址: https://www.infinilabs.com/download
您还可以通过邮件联系我们:hello@infini.ltd
或者拨打我们的热线电话:(+86) 400-139-9200
欢迎加入 Discord 聊天室:https://discord.com/invite/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。

关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
INFINI Labs 产品又更新啦~。本次更新概要如下:Easysearch 新增了索引字段相关统计 API,优化了 source_reuse 提升压缩效率;Gateway 新增诸多新特性,如:支持基于 Kafka 的复制能力,添加可插拔的分布式锁实现,新增 CPU 资源限制等功能;Console 本次主要优化了数据迁移功能,迁移任务详情页新增了若干指标图和日志查看等功能。
欢迎大家下载使用和反馈。
INFINI Helm Charts v0.1.0
INFINI Helm Charts 是一组 Kubernetes 部署包管理工具。基于 Helm Charts,我们将 INFINI Labs 旗下相关产品预先配置好程序资源包,大大简化了部署流程。Github 仓库地址:https://github.com/infinilabs/helm-charts。
Helm Charts 本次更新如下:
Features
- 添加 Console Chart
- 添加 Easysearch Chart,支持单节点以及多节点(节点角色可配置)部署
部署视频演示:
博客文章:
INFINI Easysearch v1.6.0
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。
Easysearch 本次更新如下:
Features
- 新增 _field_usage_stats API,统计索引每个字段的访问次数
- 新增 _disk_usage API,可以分析指定索引每个字段的磁盘占用大小
- 增加 flattened 类型,将 JSON 对象作为字符串处理,可以减少嵌套 JSON 型的文档的大小
Improvements
- source_reuse 增加对 _source 中数字类型的值进行复用压缩,可进一步降低 _source 磁盘占用
- 改进 source_reuse 筛选字段的逻辑
INFINI Gateway v1.18.0
INFINI Gateway 是一个面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway 可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
Gateway 本次更新如下:
Breaking changes
- 彻底移除了 request_body_truncate 和 response_body_truncate 过滤器
Features
- 支持基于 Kafka 的复制能力
- 在请求上下文中添加 _util.generate_uuid
- 在请求上下文中添加 _util.increment_id.BUCKET_NAME
- 在 Pipeline 配置中添加 singleton,防止多个 Pipeline 同时运行
- 添加可插拔的分布式锁实现
- 添加通用应用程序的 preference 配置
- 泛化队列抽象,重构磁盘队列,完善 Kafka 实现
- 添加 merge_to_bulk 处理器, 废弃 indexing_merge 处理器
- 添加 flow_replay 处理器,废弃 flow_runner 处理器
- 为复制场景添加 replication_correlation
- 添加 hash_mod 过滤器
- 在 bulk_response_process 过滤器中添加新参数
- 添加 request_reshuffle 过滤器
- 添加资源限制,允许设置最大 CPU 数或绑定亲和性
- 支持模板中的嵌套变量
- 添加 rewrite_to_bulk 过滤器
Bug fix
- 修复了 Pipeline 中重试延迟未生效的问题
- 修复了模板中不支持数字的问题
- 修复了队列选择器通过标签的问题,如果指定了多个标签,它们都应该一起匹配
Improvements
- 将所有模块名称转换为小写
- 在启动期间预取 Elasticsearch 元数据
- 添加应用程序范围的关闭信号
- 重构队列 API,支持 Kafka 管理
- 在 Badger 模块中添加 enabled
- 允许使用优先级注册模块/插件
- 统一队列的使用和初始化
- 优化 bulk_reshuffle 过滤器的性能,添加响应头 X-Bulk-Reshuffled
- 支持在 queue 过滤器中使用变量,允许输出最后生成的消息偏移量
INFINI Console v1.8.0
INFINI Console 是一款非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管, 企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 在线体验: http://demo.infini.cloud (用户名/密码:readonly/readonly)。
Console 本次更新如下:
Features
- 数据迁移任务支持自定义名称和添加标签
- 数据迁移任务详情页新增若干指标
- 数据迁移任务详情页新增查看日志
Improvements
- 数据迁移 UI 优化
- 优化监控报表、数据看板、数据探索的时间控件 UI
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
- INFINI Gateway: https://github.com/infinilabs/gateway/issues
- INFINI Console: https://github.com/infinilabs/console/issues
- 下载地址: https://www.infinilabs.com/download
您还可以通过邮件联系我们:hello@infini.ltd
或者拨打我们的热线电话:(+86) 400-139-9200
欢迎加入 Discord 聊天室:https://discord.com/invite/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »社区日报 第1707期 (2023-09-21)
https://dev.to/jainec/ingest-d ... -3af4
2.Elasticsearch 集成 Slack 发送告警(需要梯子)
https://medium.com/%40kulekci/ ... cf126
3.了解并解决文档更新后 Elasticsearch 分数变化的问题(需要梯子)
https://kulekci.medium.com/und ... 76e38
编辑:Se7en
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
https://dev.to/jainec/ingest-d ... -3af4
2.Elasticsearch 集成 Slack 发送告警(需要梯子)
https://medium.com/%40kulekci/ ... cf126
3.了解并解决文档更新后 Elasticsearch 分数变化的问题(需要梯子)
https://kulekci.medium.com/und ... 76e38
编辑:Se7en
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili 收起阅读 »
社区日报 第1706期 (2023-09-20)
https://mp.weixin.qq.com/s/mFD-W2_D4PDscsoO3SDbIQ
2. Elasticsearch:为具有许多 and/or 高频术语的 top-k 查询带来加速
https://blog.csdn.net/UbuntuTo ... 54687
3.ES 字段设计的建议(需要梯子)
https://medium.com/elasticsear ... 2991d
编辑:kin122
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili
https://mp.weixin.qq.com/s/mFD-W2_D4PDscsoO3SDbIQ
2. Elasticsearch:为具有许多 and/or 高频术语的 top-k 查询带来加速
https://blog.csdn.net/UbuntuTo ... 54687
3.ES 字段设计的建议(需要梯子)
https://medium.com/elasticsear ... 2991d
编辑:kin122
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili 收起阅读 »
社区日报 第1705期 (2023-09-19)
1. 最简学习 + 测试 ES,java + docker本地搞起来
https://medium.com/%40dfalcone ... efc46
1. M1 芯片的Mac里怎么用docker玩ES?(需要梯子)
https://medium.com/%40guillem. ... c7ad2
1. es 8 + spring boot3 不完全手册(需要梯子)
https://medium.com/%40truongbu ... 15197
编辑:斯蒂文
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
1. 最简学习 + 测试 ES,java + docker本地搞起来
https://medium.com/%40dfalcone ... efc46
1. M1 芯片的Mac里怎么用docker玩ES?(需要梯子)
https://medium.com/%40guillem. ... c7ad2
1. es 8 + spring boot3 不完全手册(需要梯子)
https://medium.com/%40truongbu ... 15197
编辑:斯蒂文
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
收起阅读 »
社区日报 第1704期 (2023-09-18)
1. Function Score Query 优化算分和Term&PhraseSuggester
https://blog.csdn.net/zhougube ... 98402
2. Elasticsearch 中字段类型(Field Type)详解
https://blog.csdn.net/aben_sky ... 15175
3. Elasticsearch 从搜索中获取选定的字段 fields
https://blog.csdn.net/UbuntuTo ... 53365
编辑:yuebancanghai
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili
1. Function Score Query 优化算分和Term&PhraseSuggester
https://blog.csdn.net/zhougube ... 98402
2. Elasticsearch 中字段类型(Field Type)详解
https://blog.csdn.net/aben_sky ... 15175
3. Elasticsearch 从搜索中获取选定的字段 fields
https://blog.csdn.net/UbuntuTo ... 53365
编辑:yuebancanghai
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili 收起阅读 »
社区日报 第1703期 (2023-09-15)
https://www.elastic.co/es/blog ... -data
2、【视频】如何计算 Elasticsearch 或 Kibana 中的时差?(梯子)
https://www.youtube.com/watch?v=JD08pJsx27w
3、使用 E5 嵌入模型进行多语言矢量搜索
https://search-labs.elastic.co ... model
编辑:铭毅天下
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
https://www.elastic.co/es/blog ... -data
2、【视频】如何计算 Elasticsearch 或 Kibana 中的时差?(梯子)
https://www.youtube.com/watch?v=JD08pJsx27w
3、使用 E5 嵌入模型进行多语言矢量搜索
https://search-labs.elastic.co ... model
编辑:铭毅天下
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili 收起阅读 »

