
社区日报 第1677期 (2023-08-03)
https://mp.weixin.qq.com/s/h1sZYtyLIJr__Akv0YMC0w
2.Elastic 可观测解决方案 8.9:发布可观测 AI 助手
https://mp.weixin.qq.com/s/XcACwf_ysTcYUxXgQiMP6A
3.奇怪!我的 java 程序只能扛住高并发却扛不住低并发
https://mp.weixin.qq.com/s/Yo8jgxkRO-EKOn4T7IqQCA
编辑:Se7en
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
https://mp.weixin.qq.com/s/h1sZYtyLIJr__Akv0YMC0w
2.Elastic 可观测解决方案 8.9:发布可观测 AI 助手
https://mp.weixin.qq.com/s/XcACwf_ysTcYUxXgQiMP6A
3.奇怪!我的 java 程序只能扛住高并发却扛不住低并发
https://mp.weixin.qq.com/s/Yo8jgxkRO-EKOn4T7IqQCA
编辑:Se7en
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili 收起阅读 »
社区日报 第1676期 (2023-08-02)
https://blog.csdn.net/UbuntuTo ... .5501
2.lucene-forcemerge源码解读(一)
https://www.amazingkoala.com.c ... .html
3.lucene-forcemerge源码解读(二)
https://www.amazingkoala.com.c ... .html
编辑:kin122
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili
https://blog.csdn.net/UbuntuTo ... .5501
2.lucene-forcemerge源码解读(一)
https://www.amazingkoala.com.c ... .html
3.lucene-forcemerge源码解读(二)
https://www.amazingkoala.com.c ... .html
编辑:kin122
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili 收起阅读 »
社区日报 第1675期 (2023-08-01)
1. 两分钟计算7KW个价格数据,你会吗?(I)(需要梯子)
https://medium.com/trendyol-te ... b8c3f
2. 两分钟计算7KW个价格数据,不会我教你啊(II)(需要梯子)
https://medium.com/trendyol-te ... ee292
3. Elastic Watcher 冒险:揭开有效错误日志和 API 监控的秘密(需要梯子)
https://medium.com/%40soniyogi ... 462ac
编辑:斯蒂文
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
1. 两分钟计算7KW个价格数据,你会吗?(I)(需要梯子)
https://medium.com/trendyol-te ... b8c3f
2. 两分钟计算7KW个价格数据,不会我教你啊(II)(需要梯子)
https://medium.com/trendyol-te ... ee292
3. Elastic Watcher 冒险:揭开有效错误日志和 API 监控的秘密(需要梯子)
https://medium.com/%40soniyogi ... 462ac
编辑:斯蒂文
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
收起阅读 »
社区日报 第1674期 (2023-07-31)
1. Elasticsearch:从搜索中获取选定的字段 fields
https://blog.csdn.net/UbuntuTo ... 53365
2. Elasticsearch 字段field参数
https://blog.csdn.net/qq_18218 ... 28857
3. Elasticsearch:分片如何影响 Elasticsearch 中的相关性评分
https://elasticstack.blog.csdn ... 26968
编辑:yuebancanghai
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili
1. Elasticsearch:从搜索中获取选定的字段 fields
https://blog.csdn.net/UbuntuTo ... 53365
2. Elasticsearch 字段field参数
https://blog.csdn.net/qq_18218 ... 28857
3. Elasticsearch:分片如何影响 Elasticsearch 中的相关性评分
https://elasticstack.blog.csdn ... 26968
编辑:yuebancanghai
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili 收起阅读 »
社区日报 第1673期 (2023-07-27)
https://medium.com/%40soniyogi ... 462ac
2.如何将整个 Elasticsearch 索引导出到文件(需要梯子)
https://medium.com/%40disorgan ... 803a0
3.Elasticsearch 和竞争对手的性能基准测试对比(需要梯子)
https://medium.com/gigasearch/ ... 75639
编辑:Se7en
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
https://medium.com/%40soniyogi ... 462ac
2.如何将整个 Elasticsearch 索引导出到文件(需要梯子)
https://medium.com/%40disorgan ... 803a0
3.Elasticsearch 和竞争对手的性能基准测试对比(需要梯子)
https://medium.com/gigasearch/ ... 75639
编辑:Se7en
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili 收起阅读 »
社区日报 第1672期 (2023-07-26)
https://cloud.tencent.com/deve ... 03563
2.改进 Elastic Stack 中的信息检索:对段落检索进行基准测试
https://cloud.tencent.com/deve ... 03595
3.改进 Elastic Stack 中的信息检索:引入 Elastic Learned Sparse Encoder,我们的新检索模型原创
https://cloud.tencent.com/deve ... 03829
编辑:kin122
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili
https://cloud.tencent.com/deve ... 03563
2.改进 Elastic Stack 中的信息检索:对段落检索进行基准测试
https://cloud.tencent.com/deve ... 03595
3.改进 Elastic Stack 中的信息检索:引入 Elastic Learned Sparse Encoder,我们的新检索模型原创
https://cloud.tencent.com/deve ... 03829
编辑:kin122
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili 收起阅读 »
社区日报 第1671期 (2023-07-25)
1. 我们在pelago这样做搜索(需要梯子)
https://medium.com/%40amans.rl ... 3ea3e
2. 担心系统不安全?ES来帮你搭建安全体系(需要梯子)
https://infosecwriteups.com/en ... ba803
3. 安全专家手里的新工具包——ELK(需要梯子)
https://medium.com/%40wenray/t ... d8013
编辑:斯蒂文
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
1. 我们在pelago这样做搜索(需要梯子)
https://medium.com/%40amans.rl ... 3ea3e
2. 担心系统不安全?ES来帮你搭建安全体系(需要梯子)
https://infosecwriteups.com/en ... ba803
3. 安全专家手里的新工具包——ELK(需要梯子)
https://medium.com/%40wenray/t ... d8013
编辑:斯蒂文
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
收起阅读 »
如何在ES中搜索值为空的键值对
问题背景
今天早上,接到开发那边一个特殊的查询需求,在 Kibana 中搜索一个 json 类型日志中值为一个空大括号的键值对, 具体的日志示例如下:
{
"clientIp": "10.111.121.51",
"query": "{}",
"serviceUrl": "/aaa/bbb/cc",
}也就是说针对这个类型的日志过滤出 query 值为空的请求 "query": "{}", 开发同学测试了直接在 kibana 中查询这个字符串 "query": "{}" 根本查不到我们想要的结果。 我们使用的是 ELK 8.3 的全家桶, 这个日志数据使用的默认 standard analyzer 的分词器。
初步分析
我们先对这个要查询的字符串进行下分词测试:
GET /_analyze
{
"analyzer" : "standard",
"text": "\"query\":\"{}\""
}
结果不出所料,我们想要空大括号在分词的时候直接就被干掉了,仅保留了 query 这一个 token:
{
"tokens": [{
"token": "query",
"start_offset": 1,
"end_offset": 6,
"type": "<ALPHANUM>",
"position": 0
}]
}我们使用的 standard analyzer 在数据写入分词时直接抛弃掉{}等特殊字符,看来直接搜索 "query": "{}" 关键词这条路肯定是走不通。
换个思路
在网上搜索了一下解决的办法,有些搜索特殊字符的办法,但需要修改分词器,我们已经写入的日志数据量比较大,不太愿意因为这个搜索请求来修改分词器再 reindex。 但是我们的日志格式是固定的,serviceUrl 这个键值对总是在 query 后面的,那么我们可以结合前后文实现相同的 搜索效果:
GET /_analyze
{
"analyzer" : "standard",
"text": "\"query\":\"{}\",\"serviceUrl\""
}
可以看到这段被分为 2 个相邻的单词
{
"tokens": [{
"token": "query",
"start_offset": 1,
"end_offset": 6,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "serviceurl",
"start_offset": 14,
"end_offset": 24,
"type": "<ALPHANUM>",
"position": 1
}
]
}
那么通过搜索 query 和 serviceUrl 为相邻的 2 个字是完全可以实现 query 的值为空的同样的查询效果。 为了确认在我们已经写入的数据中 query 和 serviceurl 也是相邻的,我们通过 ES termvectors API 确认了已经在 es 中的数据和我们这里测试的情况相同:
GET /<index>/_termvectors/<_id>?fields=message
"query" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 198,
"start_offset" : 2138,
"end_offset" : 2143
}
]
},
"serviceurl" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 199,
"start_offset" : 2151,
"end_offset" : 2161
}
]
},这里我们可以看到 query 在 message 字段里面出现一次,其 end_offset 和 serviceurl 的 start_offset 之前也是相差 8, 和我们测试的结果相同。 这个时候我们就将原来的查询需求,转化为了对 "query serviceurl" 进行按顺序的精准查询就行了, 使用 match_phrase 可以达到我们的目的。
GET /_search
"query": {
"match_phrase": {
"message": {
"query": "query serviceurl",
"slop" : 0
}
}
}这里顺便说一下,slop 这个参数,slop=n 表示,表示可以隔 n 个字(英文词)进行匹配, 这里设置为 0 就强制要求 query 和 serviceurl 这 2 个单词必须相邻,0 也是 slop 的默认值,在这个请求中是可以省略的,这是为什么 match_phrase 是会获得精准查询的原因之一。 好了,我们通过 console 确定了有效的 query 之后,对于开发同学查看日志只需要在 Kibana 的搜索栏中直接使用双引号引起来的精确搜索 "query serviceurl" 就可以了。
继续深挖一下,ngram 分词器
虽然开发同学搜索的问题解决了,但我仍然不太满意,毕竟这次的问题我们的日志格式是固定的,如果我们一定要搜索到 "query": "{}" 这个应该怎么办呢? 首先很明确,使用我们默认的 standard analyzer 不修改任何参数肯定是不行的,"{}" 这些特殊字符都直接被干掉了, 参考了网上找到的这篇文章,https://blog.csdn.net/fox_233/article/details/127388058 按照这个 ngram 分词器的思路,我动手对我们的需求进行了下测试
首先先看看我们使用 ngram 分词器的分词效果, 我们这里简化了一下,去掉了原来的双引号,以避免过多 \:
GET _analyze
{
"tokenizer": "ngram",
"text": "query:{}"
}
{
"tokens" : [
{
"token" : "q",
"start_offset" : 0,
"end_offset" : 1,
"type" : "word",
"position" : 0
},
...
{
"token" : "{",
"start_offset" : 6,
"end_offset" : 7,
"type" : "word",
"position" : 12
},
{
"token" : "{}",
"start_offset" : 6,
"end_offset" : 8,
"type" : "word",
"position" : 13
},
{
"token" : "}",
"start_offset" : 7,
"end_offset" : 8,
"type" : "word",
"position" : 14
}
]
}可以很明显的看到大括号被成功的分词了,果然是有戏。 直接定义一个 index 实战一下搜索效果
PUT specialchar_debug
{
"settings": {
"analysis": {
"analyzer": {
"specialchar_analyzer": {
"tokenizer": "specialchar_tokenizer"
}
},
"tokenizer": {
"specialchar_tokenizer": {
"type": "ngram",
"min_gram": 1,
"max_gram": 2
}
}
}
},
"mappings": {
"properties": {
"text": {
"analyzer": "specialchar_analyzer",
"type": "text"
}
}
}
}插入几条测试数据:
PUT specialchar_debug/_doc/1
{ "text": "query:{},serviceUrl"
}
PUT specialchar_debug/_doc/2
{ "text": "query:{aaa},serviceUrl"
}
PUT specialchar_debug/_doc/3
{ "text": "query:{bbb}, ccc, serviceUrl"
}我们再测试一下搜索效果,
GET specialchar_debug/_search
{
"query": {
"match_phrase": {
"text": "query:{}"
}
}
}结果完全是我们想要的,看来这个方案可行
"hits" : [
{
"_index" : "specialchar_debug",
"_id" : "1",
"_score" : 2.402917,
"_source" : {
"text" : "query:{},serviceUrl"
}
}
]小结
对于日志系统,我们一直在使用 ES 默认的 standard analyzer 的分词器, 基本上满足我们生产遇到的 99% 的需求,但面对特殊字符的这种搜索请求,确实比较无奈。这次遇到的空键值对的需求,我们通过搜索 2 个相邻的键绕过了问题。 如果一定要搜索这个字符串的话,我们也可以使用 ngram 分词器重新进行分词再进行处理, 条条大路通罗马。
作者介绍
卞弘智,研发工程师,10 多年的 SRE 经验,工作经历涵盖 DevOps,日志处理系统,监控和告警系统研发,WAF 和网关等系统基础架构领域,致力于通过优秀的开源软件推动自动化和智能化基础架构平台的演进。
问题背景
今天早上,接到开发那边一个特殊的查询需求,在 Kibana 中搜索一个 json 类型日志中值为一个空大括号的键值对, 具体的日志示例如下:
{
"clientIp": "10.111.121.51",
"query": "{}",
"serviceUrl": "/aaa/bbb/cc",
}也就是说针对这个类型的日志过滤出 query 值为空的请求 "query": "{}", 开发同学测试了直接在 kibana 中查询这个字符串 "query": "{}" 根本查不到我们想要的结果。 我们使用的是 ELK 8.3 的全家桶, 这个日志数据使用的默认 standard analyzer 的分词器。
初步分析
我们先对这个要查询的字符串进行下分词测试:
GET /_analyze
{
"analyzer" : "standard",
"text": "\"query\":\"{}\""
}
结果不出所料,我们想要空大括号在分词的时候直接就被干掉了,仅保留了 query 这一个 token:
{
"tokens": [{
"token": "query",
"start_offset": 1,
"end_offset": 6,
"type": "<ALPHANUM>",
"position": 0
}]
}我们使用的 standard analyzer 在数据写入分词时直接抛弃掉{}等特殊字符,看来直接搜索 "query": "{}" 关键词这条路肯定是走不通。
换个思路
在网上搜索了一下解决的办法,有些搜索特殊字符的办法,但需要修改分词器,我们已经写入的日志数据量比较大,不太愿意因为这个搜索请求来修改分词器再 reindex。 但是我们的日志格式是固定的,serviceUrl 这个键值对总是在 query 后面的,那么我们可以结合前后文实现相同的 搜索效果:
GET /_analyze
{
"analyzer" : "standard",
"text": "\"query\":\"{}\",\"serviceUrl\""
}
可以看到这段被分为 2 个相邻的单词
{
"tokens": [{
"token": "query",
"start_offset": 1,
"end_offset": 6,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "serviceurl",
"start_offset": 14,
"end_offset": 24,
"type": "<ALPHANUM>",
"position": 1
}
]
}
那么通过搜索 query 和 serviceUrl 为相邻的 2 个字是完全可以实现 query 的值为空的同样的查询效果。 为了确认在我们已经写入的数据中 query 和 serviceurl 也是相邻的,我们通过 ES termvectors API 确认了已经在 es 中的数据和我们这里测试的情况相同:
GET /<index>/_termvectors/<_id>?fields=message
"query" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 198,
"start_offset" : 2138,
"end_offset" : 2143
}
]
},
"serviceurl" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 199,
"start_offset" : 2151,
"end_offset" : 2161
}
]
},这里我们可以看到 query 在 message 字段里面出现一次,其 end_offset 和 serviceurl 的 start_offset 之前也是相差 8, 和我们测试的结果相同。 这个时候我们就将原来的查询需求,转化为了对 "query serviceurl" 进行按顺序的精准查询就行了, 使用 match_phrase 可以达到我们的目的。
GET /_search
"query": {
"match_phrase": {
"message": {
"query": "query serviceurl",
"slop" : 0
}
}
}这里顺便说一下,slop 这个参数,slop=n 表示,表示可以隔 n 个字(英文词)进行匹配, 这里设置为 0 就强制要求 query 和 serviceurl 这 2 个单词必须相邻,0 也是 slop 的默认值,在这个请求中是可以省略的,这是为什么 match_phrase 是会获得精准查询的原因之一。 好了,我们通过 console 确定了有效的 query 之后,对于开发同学查看日志只需要在 Kibana 的搜索栏中直接使用双引号引起来的精确搜索 "query serviceurl" 就可以了。
继续深挖一下,ngram 分词器
虽然开发同学搜索的问题解决了,但我仍然不太满意,毕竟这次的问题我们的日志格式是固定的,如果我们一定要搜索到 "query": "{}" 这个应该怎么办呢? 首先很明确,使用我们默认的 standard analyzer 不修改任何参数肯定是不行的,"{}" 这些特殊字符都直接被干掉了, 参考了网上找到的这篇文章,https://blog.csdn.net/fox_233/article/details/127388058 按照这个 ngram 分词器的思路,我动手对我们的需求进行了下测试
首先先看看我们使用 ngram 分词器的分词效果, 我们这里简化了一下,去掉了原来的双引号,以避免过多 \:
GET _analyze
{
"tokenizer": "ngram",
"text": "query:{}"
}
{
"tokens" : [
{
"token" : "q",
"start_offset" : 0,
"end_offset" : 1,
"type" : "word",
"position" : 0
},
...
{
"token" : "{",
"start_offset" : 6,
"end_offset" : 7,
"type" : "word",
"position" : 12
},
{
"token" : "{}",
"start_offset" : 6,
"end_offset" : 8,
"type" : "word",
"position" : 13
},
{
"token" : "}",
"start_offset" : 7,
"end_offset" : 8,
"type" : "word",
"position" : 14
}
]
}可以很明显的看到大括号被成功的分词了,果然是有戏。 直接定义一个 index 实战一下搜索效果
PUT specialchar_debug
{
"settings": {
"analysis": {
"analyzer": {
"specialchar_analyzer": {
"tokenizer": "specialchar_tokenizer"
}
},
"tokenizer": {
"specialchar_tokenizer": {
"type": "ngram",
"min_gram": 1,
"max_gram": 2
}
}
}
},
"mappings": {
"properties": {
"text": {
"analyzer": "specialchar_analyzer",
"type": "text"
}
}
}
}插入几条测试数据:
PUT specialchar_debug/_doc/1
{ "text": "query:{},serviceUrl"
}
PUT specialchar_debug/_doc/2
{ "text": "query:{aaa},serviceUrl"
}
PUT specialchar_debug/_doc/3
{ "text": "query:{bbb}, ccc, serviceUrl"
}我们再测试一下搜索效果,
GET specialchar_debug/_search
{
"query": {
"match_phrase": {
"text": "query:{}"
}
}
}结果完全是我们想要的,看来这个方案可行
"hits" : [
{
"_index" : "specialchar_debug",
"_id" : "1",
"_score" : 2.402917,
"_source" : {
"text" : "query:{},serviceUrl"
}
}
]小结
对于日志系统,我们一直在使用 ES 默认的 standard analyzer 的分词器, 基本上满足我们生产遇到的 99% 的需求,但面对特殊字符的这种搜索请求,确实比较无奈。这次遇到的空键值对的需求,我们通过搜索 2 个相邻的键绕过了问题。 如果一定要搜索这个字符串的话,我们也可以使用 ngram 分词器重新进行分词再进行处理, 条条大路通罗马。
作者介绍
卞弘智,研发工程师,10 多年的 SRE 经验,工作经历涵盖 DevOps,日志处理系统,监控和告警系统研发,WAF 和网关等系统基础架构领域,致力于通过优秀的开源软件推动自动化和智能化基础架构平台的演进。
收起阅读 »社区日报 第1670期 (2023-07-24)
https://blog.csdn.net/UbuntuTo ... 68368
2. Elasticsearch:实用 BM25算法及其变量
https://elasticstack.blog.csdn ... 39480
3. Elasticsearch 倒排索引与相关性算法计算
https://zhuanlan.zhihu.com/p/91603911
编辑:yuebancanghai
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili
https://blog.csdn.net/UbuntuTo ... 68368
2. Elasticsearch:实用 BM25算法及其变量
https://elasticstack.blog.csdn ... 39480
3. Elasticsearch 倒排索引与相关性算法计算
https://zhuanlan.zhihu.com/p/91603911
编辑:yuebancanghai
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili 收起阅读 »
INFINI Labs 产品更新 | Easysearch 新增分词插件、Gateway 支持邮件发送等功能

INFINI Labs 产品又更新啦~,本次更新概要如下:Easysearch 新增了分词插件、优化了生命周期管理功能等;Gateway 新增 smtp 过滤器来支持邮件的发送,支持自动跳过因为异常关闭而损坏的磁盘队列文件等;Console 新增熔断器监控指标、新增矩形树图(Treemap)、优化了探针 Agent 指标采集和集群自动关联操作等。欢迎大家下载体验。
INFINI Easysearch v1.4.0
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 衍生自基于开源协议 Apache 2.0 的 Elasticsearch 7.10 版本。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。
Easysearch 本次更新如下:
Features
- 索引生命周期管理增加 wait_for_snapshot 操作,在删除索引之前,等待执行指定的快照管理策略,这样可以确保已删除索引的快照可用
- 增加 analysis-hanlp 分词插件
- 增加 jieba 分词插件
Bug fix
- 修复启用 index.source_reuse 时,对复杂多层 json 的 source 字段 解析不正确的 Bug
Improvements
- 更新索引生命周期管理 api 文档,增加策略应用和更新说明,增加 wait_for_snapshot 说明
- 执行
initialize.sh命令时增加初始化确认提示,是否将 admin 密码记录日志
INFINI Gateway v1.17.0
INFINI Gateway 是一个面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway 可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
Gateway 本次更新如下:
Features
- 新增 consumer Processor 来标准化订阅消息队列
- 新增 smtp 过滤器来支持邮件的发送
Bug fix
- 支持自动跳过因为异常关闭而损坏的磁盘队列文件
INFINI Console v1.4.0
INFINI Console 是一款非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管, 企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 在线体验: http://demo.infini.cloud (用户名/密码:readonly/readonly)。
Console 本次更新如下:
Features
- 新增熔断器监控指标
- 网关队列管理支持多选删除消费者
- 数据看板新增组件矩形树图
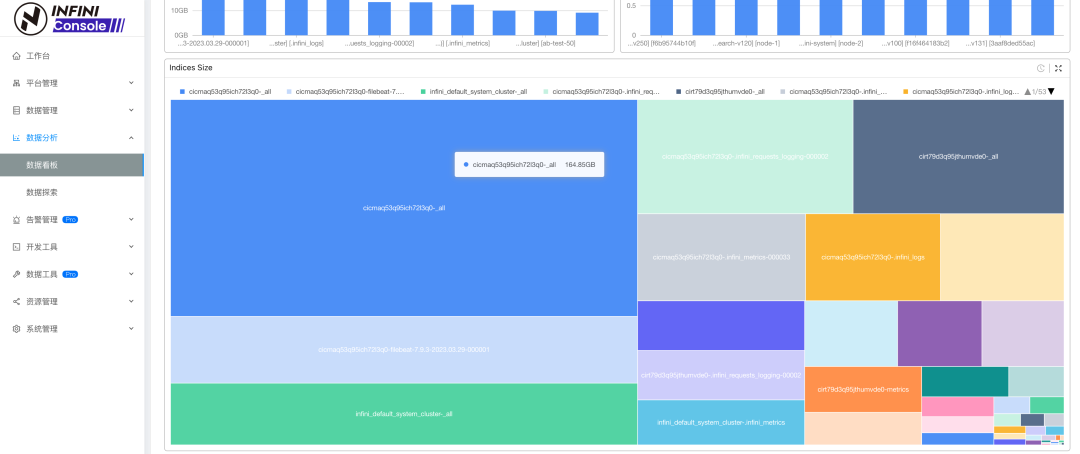
Bug fix
- 修复开发工具智能提示兼容性问题
- 修复探针列表状态显示异常的问题
- 修复探针列表分页不生效的问题
- 修复数据看板 统计函数显示不对的问题
- 修复探针下发采集指标配置重复的问题
- 修复数据看板设置过滤条件不生效的问题
- 修复主机列表探针状态不对的问题
- 修复网关管理删除队列不成功的问题
- 修复数据探索当前集群没索引时跳转的问题
- 修复数据看板编辑状态下点击事件的问题
Improvements
- 探针进程关联支持通过选择集群自动关联,简化操作
- 探针列表支持排序
- 探针支持向上滚动查看节点日志
- 采集监控指标添加 cluster_uuid 信息
- 数据看板支持配置指标排序
INFINI Agent v0.6.0
INFINI Agent 是 INFINI Console 的一个可选探针组件,负责采集和上传集群指标和日志等信息,并可通过 Console 管理。Agent 支持主流操作系统和平台,安装包轻量且无任何外部依赖,可以快速方便地安装。
Agent 本次更新如下:
Features
- 采集监控指标添加 cluster_uuid 信息
Improvements
- 修复发现节点进程信息时获取不到最新集群配置的问题
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
- INFINI Gateway: https://github.com/infinilabs/gateway/issues
- INFINI Console: https://github.com/infinilabs/console/issues
- 下载地址: https://www.infinilabs.com/download
或者通过 Discord 渠道加入聊天室:https://discord.com/invite/tnZ8S5vQ
欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群讨论,或者扫码加入我们的知识星球一起学习交流。

关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
INFINI Labs 产品又更新啦~,本次更新概要如下:Easysearch 新增了分词插件、优化了生命周期管理功能等;Gateway 新增 smtp 过滤器来支持邮件的发送,支持自动跳过因为异常关闭而损坏的磁盘队列文件等;Console 新增熔断器监控指标、新增矩形树图(Treemap)、优化了探针 Agent 指标采集和集群自动关联操作等。欢迎大家下载体验。
INFINI Easysearch v1.4.0
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 衍生自基于开源协议 Apache 2.0 的 Elasticsearch 7.10 版本。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。
Easysearch 本次更新如下:
Features
- 索引生命周期管理增加 wait_for_snapshot 操作,在删除索引之前,等待执行指定的快照管理策略,这样可以确保已删除索引的快照可用
- 增加 analysis-hanlp 分词插件
- 增加 jieba 分词插件
Bug fix
- 修复启用 index.source_reuse 时,对复杂多层 json 的 source 字段 解析不正确的 Bug
Improvements
- 更新索引生命周期管理 api 文档,增加策略应用和更新说明,增加 wait_for_snapshot 说明
- 执行
initialize.sh命令时增加初始化确认提示,是否将 admin 密码记录日志
INFINI Gateway v1.17.0
INFINI Gateway 是一个面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway 可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
Gateway 本次更新如下:
Features
- 新增 consumer Processor 来标准化订阅消息队列
- 新增 smtp 过滤器来支持邮件的发送
Bug fix
- 支持自动跳过因为异常关闭而损坏的磁盘队列文件
INFINI Console v1.4.0
INFINI Console 是一款非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管, 企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 在线体验: http://demo.infini.cloud (用户名/密码:readonly/readonly)。
Console 本次更新如下:
Features
- 新增熔断器监控指标
- 网关队列管理支持多选删除消费者
- 数据看板新增组件矩形树图
Bug fix
- 修复开发工具智能提示兼容性问题
- 修复探针列表状态显示异常的问题
- 修复探针列表分页不生效的问题
- 修复数据看板 统计函数显示不对的问题
- 修复探针下发采集指标配置重复的问题
- 修复数据看板设置过滤条件不生效的问题
- 修复主机列表探针状态不对的问题
- 修复网关管理删除队列不成功的问题
- 修复数据探索当前集群没索引时跳转的问题
- 修复数据看板编辑状态下点击事件的问题
Improvements
- 探针进程关联支持通过选择集群自动关联,简化操作
- 探针列表支持排序
- 探针支持向上滚动查看节点日志
- 采集监控指标添加 cluster_uuid 信息
- 数据看板支持配置指标排序
INFINI Agent v0.6.0
INFINI Agent 是 INFINI Console 的一个可选探针组件,负责采集和上传集群指标和日志等信息,并可通过 Console 管理。Agent 支持主流操作系统和平台,安装包轻量且无任何外部依赖,可以快速方便地安装。
Agent 本次更新如下:
Features
- 采集监控指标添加 cluster_uuid 信息
Improvements
- 修复发现节点进程信息时获取不到最新集群配置的问题
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
- INFINI Gateway: https://github.com/infinilabs/gateway/issues
- INFINI Console: https://github.com/infinilabs/console/issues
- 下载地址: https://www.infinilabs.com/download
或者通过 Discord 渠道加入聊天室:https://discord.com/invite/tnZ8S5vQ
欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群讨论,或者扫码加入我们的知识星球一起学习交流。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »社区日报 第1669期 (2023-07-21)
1、Spring 和 Elasticsearch:将搜索功能构建到您的应用程序中
https://medium.com/%40Alexande ... 8450b
2、使用 PostgreSQL 的全文搜索引擎(第 2 部分):Postgres 与 Elasticsearch
https://xata.io/blog/postgres- ... earch
3、资产管理平台 (AMP) 中的 Elasticsearch 索引策略
https://netflixtechblog.com/el ... 1e541
编辑:铭毅天下
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
1、Spring 和 Elasticsearch:将搜索功能构建到您的应用程序中
https://medium.com/%40Alexande ... 8450b
2、使用 PostgreSQL 的全文搜索引擎(第 2 部分):Postgres 与 Elasticsearch
https://xata.io/blog/postgres- ... earch
3、资产管理平台 (AMP) 中的 Elasticsearch 索引策略
https://netflixtechblog.com/el ... 1e541
编辑:铭毅天下
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili 收起阅读 »
社区日报 第1668期 (2023-07-20)
https://medium.com/globant/an- ... c050a
2.增强恶意软件检测:使用 Elastic SIEM 的端点检测和响应解决方案(需要梯子)
https://medium.com/bugbountywr ... ba803
3.现实世界中的 Rust:使用 Elasticsearch 进行超快速数据索引(需要梯子)
https://itnext.io/rust-in-the- ... 39ba7
编辑:Se7en
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
https://medium.com/globant/an- ... c050a
2.增强恶意软件检测:使用 Elastic SIEM 的端点检测和响应解决方案(需要梯子)
https://medium.com/bugbountywr ... ba803
3.现实世界中的 Rust:使用 Elasticsearch 进行超快速数据索引(需要梯子)
https://itnext.io/rust-in-the- ... 39ba7
编辑:Se7en
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili 收起阅读 »
用极限网关实现ES容灾,简单!
身为 IT 人士,大伙身边的各种系统肯定不少吧。系统虽多,但最最最重要的那套、那几套,大伙肯定是捧在手心,关怀备至。如此重要的系统,万一发生故障了且短期无法恢复,该如何保障业务持续运行? 有过这方面思考或经验的同学,肯定脱口而出--切灾备啊。 是的,接下来我来介绍下我们的 ES 灾备方案。当然如果你有更好的,请使用各种可用的渠道联系我们。
总体设计
通过极限网关将应用对主集群的写操作,复制到灾备集群。应用发送的读请求则直接转发到主集群,并将响应结果转发给应用。应用对网关无感知,访问方式与访问 ES 集群一样。
方案优势
- 轻量级
极限网关使用 Golang 编写,安装包很小,只有 10MB 左右,没有任何外部环境依赖,部署安装都非常简单,只需要下载对应平台的二进制可执行文件,启动网关程序的二进制程序文件执行即可。
- 跨版本支持
极限网关针对不同的 Elasticsearch 版本做了兼容和针对性处理,能够让业务代码无缝的进行适配,后端 Elasticsearch 集群版本升级能够做到无缝过渡,降低版本升级和数据迁移的复杂度。
- 高可用
极限网关内置多种高可用解决方案,前端请求入口支持基于虚拟 IP 的双机热备,后端集群支持集群拓扑的自动感知,节点上下线能自动发现,自动处理后端故障,自动进行请求的重试和迁移。
- 灵活性
主备集群都是可读可写,切换迅速,只需切换网关到另一套配置即可。回切灵活,恢复使用原配置即可。
架构图

网关程序部署
下载
根据操作系统和平台选择下面相应的安装包: 解压到指定目录:
mkdir gateway
tar -zxf xxx.gz -C gateway修改网关配置
在此 下载 网关配置,默认网关会加载配置文件 gateway.yml ,如果要指定其他配置文件使用 -config 选项指定。 网关配置文件内容较多,下面展示必要部分。
#primary
PRIMARY_ENDPOINT: http://192.168.56.3:7171
PRIMARY_USERNAME: elastic
PRIMARY_PASSWORD: password
PRIMARY_MAX_QPS_PER_NODE: 10000
PRIMARY_MAX_BYTES_PER_NODE: 104857600 #100MB/s
PRIMARY_MAX_CONNECTION_PER_NODE: 200
PRIMARY_DISCOVERY_ENABLED: false
PRIMARY_DISCOVERY_REFRESH_ENABLED: false
#backup
BACKUP_ENDPOINT: http://192.168.56.3:9200
BACKUP_USERNAME: admin
BACKUP_PASSWORD: admin
BACKUP_MAX_QPS_PER_NODE: 10000
BACKUP_MAX_BYTES_PER_NODE: 104857600 #100MB/s
BACKUP_MAX_CONNECTION_PER_NODE: 200
BACKUP_DISCOVERY_ENABLED: false
BACKUP_DISCOVERY_REFRESH_ENABLED: falsePRIMARY_ENDPOINT:配置主集群地址和端口
PRIMARY_USERNAME、PRIMARY_PASSWORD: 访问主集群的用户信息
BACKUP_ENDPOINT:配置备集群地址和端口
BACKUP_USERNAME、BACKUP_PASSWORD: 访问备集群的用户信息
运行网关
前台运行 直接运行网关程序即可启动极限网关了,如下:
./gateway-linux-amd64后台运行
./gateway-linux-amd64 -service install
Success
./gateway-linux-amd64 -service start
Success卸载服务
./gateway-linux-amd64 -service stop
Success
./gateway-linux-amd64 -service uninstall
Success灾备功能测试
在灾备场景下,为保证数据一致性,对集群的访问操作都通过网关进行。注意只有 bulk API 的操作才会被复制到备集群。 在此次测试中,网关灾备配置功能为:
- 主备集群正常时
读写请求正常执行; 写请求被记录到队列,备集群实时消费队列数据。
- 当主集群故障时
写入请求报错,主备集群都不写入数据; 查询请求转到备集群执行,并返回结果给客户端。
- 当备集群故障时
读写请求都正常执行; 写操作记录到磁盘队列,待备集群恢复后,自动消费队列数据直到两个集群一致。
主备集群正常时写入、查询测试
写入数据
# 通过网关写入数据
curl -X POST "localhost:18000/_bulk?pretty" -H 'Content-Type: application/json' -uelastic:password -d'
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "create" : { "_index" : "test", "_id" : "2" } }
{ "field2" : "value2" }
'
查询数据
# 查询主集群
curl 192.168.56.3:7171/test/_search?pretty -uelastic:password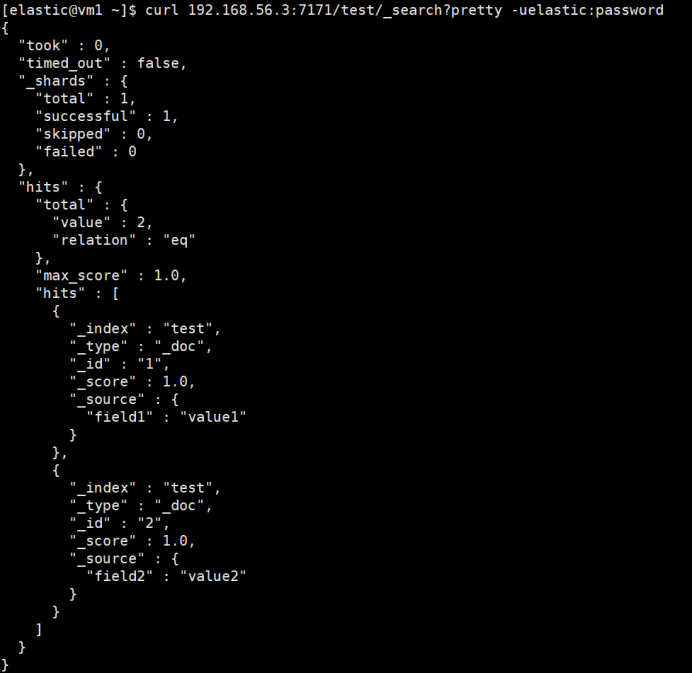
# 查询备集群
curl 192.168.56.3:9200/test/_search?pretty -uadmin:admin
# 查询网关,网关转发给主集群执行
curl 192.168.56.3:18000/test/_search?pretty -uelastic:password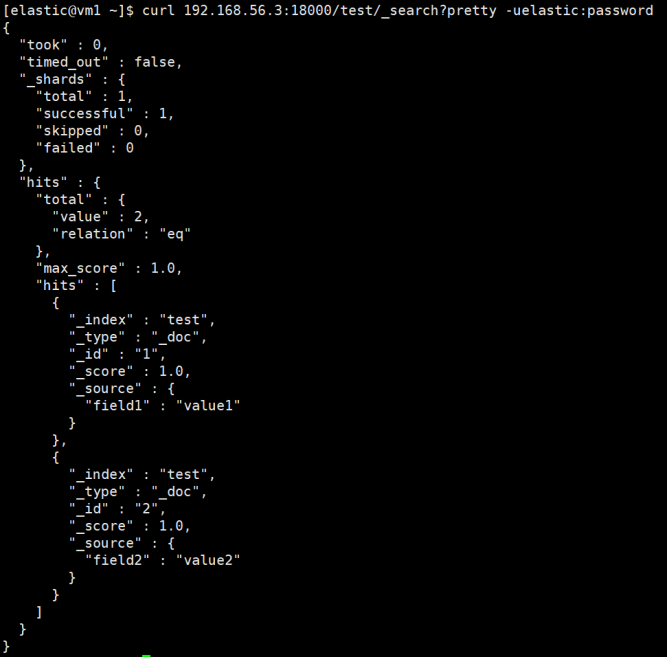
主备集群都已写入数据,且数据一致。通过网关查询,也正常返回。
删除和更新文档
# 通过网关删除和更新文档
curl -X POST "192.168.56.3:18000/_bulk?pretty" -H 'Content-Type: application/json' -uelastic:password -d'
{ "delete" : { "_index" : "test", "_id" : "1" } }
{ "update" : {"_id" : "2", "_index" : "test"} }
{ "doc" : {"field2" : "value2-updated"} }
'
查询数据
# 查询主集群
curl 192.168.56.3:7171/test/_search?pretty -uelastic:password
# 查询备集群
curl 192.168.56.3:9200/test/_search?pretty -uadmin:admin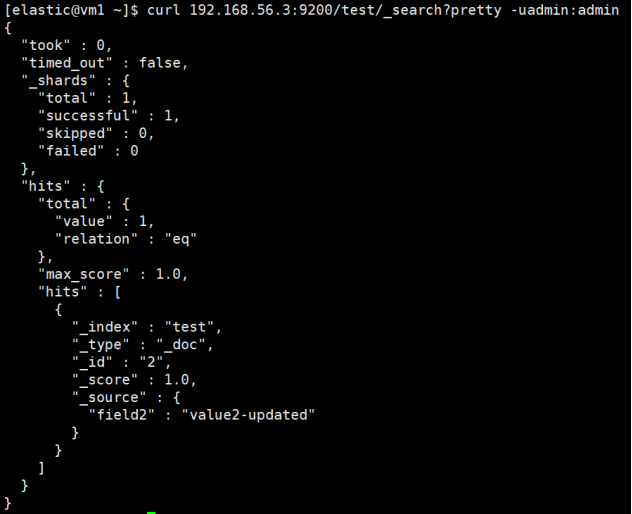
两个集群都已执行删除和更新操作,数据一致。
主集群故障时写入、查询测试
为模拟主集群故障,直接关闭主集群。
写入数据
# 通过网关写入数据
curl -X POST "192.168.56.3:18000/_bulk?pretty" -H 'Content-Type: application/json' -uelastic:password -d'
{ "index" : { "_index" : "test", "_id" : "3" } }
{ "field3" : "value3" }
{ "create" : { "_index" : "test", "_id" : "4" } }
{ "field4" : "value4" }
'写入数据报错

查询数据
# 通过网关查询,因为主集群不可用,网关将查询转发到备集群执行
curl 192.168.56.3:18000/test/_search?pretty -uelastic:password
正常查询到数据,说明请求被转发到了备集群执行。
备集群故障时写入、查询测试
为模拟备集群故障,直接关闭备集群。
写入数据
# 通过网关写入数据
curl -X POST "192.168.56.3:18000/_bulk?pretty" -H 'Content-Type: application/json' -uelastic:password -d'
{ "index" : { "_index" : "test", "_id" : "5" } }
{ "field5" : "value5" }
{ "create" : { "_index" : "test", "_id" : "6" } }
{ "field6" : "value6" }
'
数据正常写入。
查询数据
# 通过网关查询
curl 192.168.56.3:18000/test/_search?pretty -uelastic:password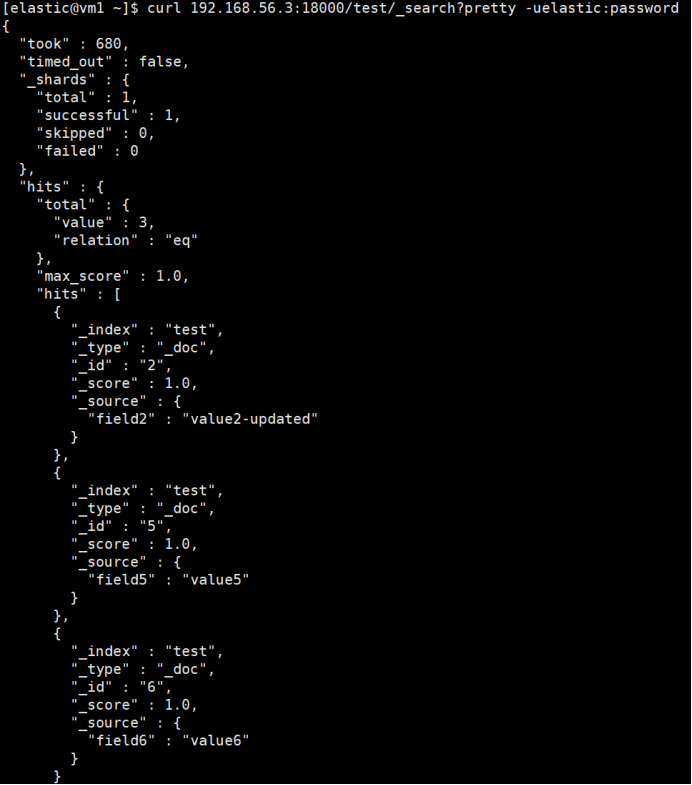
查询成功返回。主集群成功写入了两条新数据。同时此数据会被记录到备集群的队列中,待备集群恢复后,会消费此队列追数据。
恢复备集群
启动备集群。
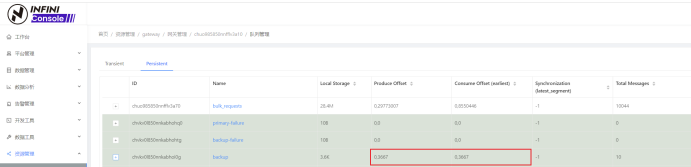
查询数据
等待片刻或通过 INFINI Console 确定网关队列消费完毕后,查询备集群的数据。
(生产和消费 offset 相同,说明消费完毕。)
# 查询备集群的数据
curl 192.168.56.3:9200/test/_search?pretty -uadmin:admin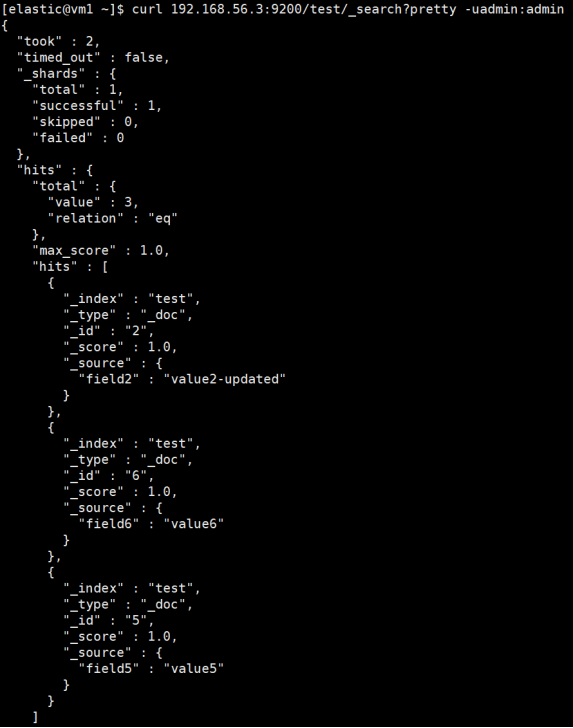
备集群启动后自动消费队列数据,消费完后备集群数据达到与主集群数据一致。
灾备切换
测试了这么多,终于到切换的时刻了。切换前我们判断下主系统是否短期无法修复。

如果我们判断主用系统无法短时间恢复,要执行切换。非常简单,我们直接将配置文件中定义的主备集群互换,然后重启网关程序就行了。但我们推荐在相同主机上另部署一套网关程序--网关B,先前那套用网关A指代。网关B中的配置文件把原备集群定义为主集群,原主集群定义为备集群。若要执行切换,我们先停止网关A,然后启动网关B,此时应用连接到网关(端口不变),就把原备系统当作主系统使用,把原主系统当作备系统,也就完成了主备系统的切换。
灾备回切
当原主集群修复后,正常启动,就会从消费队列追写修复期间产生数据直到主备数据一致,同样我们可通过 INFINI Console 查看消费的进度。如果大家还是担心数据的一致性,INFINI Console 还能帮大家做[校验数据]()任务,做到数据完全一致后(文档数量及文档内容一致),才进行回切。

回切也非常简单,停止网关B,启动网关A即可。
网关高可用
网关自带浮动 IP 模块,可进行双机热备。客户端通过 VIP 连接网关,网关出现故障时,VIP 漂移到备网关。
视频教程戳这里。

这样的优点是简单,不足是只有一个网关在线提供服务。如果想多个网关在线提供服务,则需搭配分布式消息系统一起工作,架构如下。

前端通过负载均衡将流量分散到多个在线网关,网关将消息存入分布式消息系统。此时,网关可看作无状态应用,可根据需要扩缩规模。
以上就是我介绍的ES灾备方案,是不是相当灵活了。有问题还是那句话 Call me 。
关于极限网关
INFINI Gateway 是一个面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway,可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
身为 IT 人士,大伙身边的各种系统肯定不少吧。系统虽多,但最最最重要的那套、那几套,大伙肯定是捧在手心,关怀备至。如此重要的系统,万一发生故障了且短期无法恢复,该如何保障业务持续运行? 有过这方面思考或经验的同学,肯定脱口而出--切灾备啊。 是的,接下来我来介绍下我们的 ES 灾备方案。当然如果你有更好的,请使用各种可用的渠道联系我们。
总体设计
通过极限网关将应用对主集群的写操作,复制到灾备集群。应用发送的读请求则直接转发到主集群,并将响应结果转发给应用。应用对网关无感知,访问方式与访问 ES 集群一样。
方案优势
- 轻量级
极限网关使用 Golang 编写,安装包很小,只有 10MB 左右,没有任何外部环境依赖,部署安装都非常简单,只需要下载对应平台的二进制可执行文件,启动网关程序的二进制程序文件执行即可。
- 跨版本支持
极限网关针对不同的 Elasticsearch 版本做了兼容和针对性处理,能够让业务代码无缝的进行适配,后端 Elasticsearch 集群版本升级能够做到无缝过渡,降低版本升级和数据迁移的复杂度。
- 高可用
极限网关内置多种高可用解决方案,前端请求入口支持基于虚拟 IP 的双机热备,后端集群支持集群拓扑的自动感知,节点上下线能自动发现,自动处理后端故障,自动进行请求的重试和迁移。
- 灵活性
主备集群都是可读可写,切换迅速,只需切换网关到另一套配置即可。回切灵活,恢复使用原配置即可。
架构图
网关程序部署
下载
根据操作系统和平台选择下面相应的安装包: 解压到指定目录:
mkdir gateway
tar -zxf xxx.gz -C gateway修改网关配置
在此 下载 网关配置,默认网关会加载配置文件 gateway.yml ,如果要指定其他配置文件使用 -config 选项指定。 网关配置文件内容较多,下面展示必要部分。
#primary
PRIMARY_ENDPOINT: http://192.168.56.3:7171
PRIMARY_USERNAME: elastic
PRIMARY_PASSWORD: password
PRIMARY_MAX_QPS_PER_NODE: 10000
PRIMARY_MAX_BYTES_PER_NODE: 104857600 #100MB/s
PRIMARY_MAX_CONNECTION_PER_NODE: 200
PRIMARY_DISCOVERY_ENABLED: false
PRIMARY_DISCOVERY_REFRESH_ENABLED: false
#backup
BACKUP_ENDPOINT: http://192.168.56.3:9200
BACKUP_USERNAME: admin
BACKUP_PASSWORD: admin
BACKUP_MAX_QPS_PER_NODE: 10000
BACKUP_MAX_BYTES_PER_NODE: 104857600 #100MB/s
BACKUP_MAX_CONNECTION_PER_NODE: 200
BACKUP_DISCOVERY_ENABLED: false
BACKUP_DISCOVERY_REFRESH_ENABLED: falsePRIMARY_ENDPOINT:配置主集群地址和端口
PRIMARY_USERNAME、PRIMARY_PASSWORD: 访问主集群的用户信息
BACKUP_ENDPOINT:配置备集群地址和端口
BACKUP_USERNAME、BACKUP_PASSWORD: 访问备集群的用户信息
运行网关
前台运行 直接运行网关程序即可启动极限网关了,如下:
./gateway-linux-amd64后台运行
./gateway-linux-amd64 -service install
Success
./gateway-linux-amd64 -service start
Success卸载服务
./gateway-linux-amd64 -service stop
Success
./gateway-linux-amd64 -service uninstall
Success灾备功能测试
在灾备场景下,为保证数据一致性,对集群的访问操作都通过网关进行。注意只有 bulk API 的操作才会被复制到备集群。 在此次测试中,网关灾备配置功能为:
- 主备集群正常时
读写请求正常执行; 写请求被记录到队列,备集群实时消费队列数据。
- 当主集群故障时
写入请求报错,主备集群都不写入数据; 查询请求转到备集群执行,并返回结果给客户端。
- 当备集群故障时
读写请求都正常执行; 写操作记录到磁盘队列,待备集群恢复后,自动消费队列数据直到两个集群一致。
主备集群正常时写入、查询测试
写入数据
# 通过网关写入数据
curl -X POST "localhost:18000/_bulk?pretty" -H 'Content-Type: application/json' -uelastic:password -d'
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "create" : { "_index" : "test", "_id" : "2" } }
{ "field2" : "value2" }
'
查询数据
# 查询主集群
curl 192.168.56.3:7171/test/_search?pretty -uelastic:password
# 查询备集群
curl 192.168.56.3:9200/test/_search?pretty -uadmin:admin
# 查询网关,网关转发给主集群执行
curl 192.168.56.3:18000/test/_search?pretty -uelastic:password
主备集群都已写入数据,且数据一致。通过网关查询,也正常返回。
删除和更新文档
# 通过网关删除和更新文档
curl -X POST "192.168.56.3:18000/_bulk?pretty" -H 'Content-Type: application/json' -uelastic:password -d'
{ "delete" : { "_index" : "test", "_id" : "1" } }
{ "update" : {"_id" : "2", "_index" : "test"} }
{ "doc" : {"field2" : "value2-updated"} }
'
查询数据
# 查询主集群
curl 192.168.56.3:7171/test/_search?pretty -uelastic:password
# 查询备集群
curl 192.168.56.3:9200/test/_search?pretty -uadmin:admin
两个集群都已执行删除和更新操作,数据一致。
主集群故障时写入、查询测试
为模拟主集群故障,直接关闭主集群。
写入数据
# 通过网关写入数据
curl -X POST "192.168.56.3:18000/_bulk?pretty" -H 'Content-Type: application/json' -uelastic:password -d'
{ "index" : { "_index" : "test", "_id" : "3" } }
{ "field3" : "value3" }
{ "create" : { "_index" : "test", "_id" : "4" } }
{ "field4" : "value4" }
'写入数据报错
查询数据
# 通过网关查询,因为主集群不可用,网关将查询转发到备集群执行
curl 192.168.56.3:18000/test/_search?pretty -uelastic:password
正常查询到数据,说明请求被转发到了备集群执行。
备集群故障时写入、查询测试
为模拟备集群故障,直接关闭备集群。
写入数据
# 通过网关写入数据
curl -X POST "192.168.56.3:18000/_bulk?pretty" -H 'Content-Type: application/json' -uelastic:password -d'
{ "index" : { "_index" : "test", "_id" : "5" } }
{ "field5" : "value5" }
{ "create" : { "_index" : "test", "_id" : "6" } }
{ "field6" : "value6" }
'
数据正常写入。
查询数据
# 通过网关查询
curl 192.168.56.3:18000/test/_search?pretty -uelastic:password
查询成功返回。主集群成功写入了两条新数据。同时此数据会被记录到备集群的队列中,待备集群恢复后,会消费此队列追数据。
恢复备集群
启动备集群。
查询数据
等待片刻或通过 INFINI Console 确定网关队列消费完毕后,查询备集群的数据。
(生产和消费 offset 相同,说明消费完毕。)
# 查询备集群的数据
curl 192.168.56.3:9200/test/_search?pretty -uadmin:admin
备集群启动后自动消费队列数据,消费完后备集群数据达到与主集群数据一致。
灾备切换
测试了这么多,终于到切换的时刻了。切换前我们判断下主系统是否短期无法修复。
如果我们判断主用系统无法短时间恢复,要执行切换。非常简单,我们直接将配置文件中定义的主备集群互换,然后重启网关程序就行了。但我们推荐在相同主机上另部署一套网关程序--网关B,先前那套用网关A指代。网关B中的配置文件把原备集群定义为主集群,原主集群定义为备集群。若要执行切换,我们先停止网关A,然后启动网关B,此时应用连接到网关(端口不变),就把原备系统当作主系统使用,把原主系统当作备系统,也就完成了主备系统的切换。
灾备回切
当原主集群修复后,正常启动,就会从消费队列追写修复期间产生数据直到主备数据一致,同样我们可通过 INFINI Console 查看消费的进度。如果大家还是担心数据的一致性,INFINI Console 还能帮大家做[校验数据]()任务,做到数据完全一致后(文档数量及文档内容一致),才进行回切。
回切也非常简单,停止网关B,启动网关A即可。
网关高可用
网关自带浮动 IP 模块,可进行双机热备。客户端通过 VIP 连接网关,网关出现故障时,VIP 漂移到备网关。
视频教程戳这里。
这样的优点是简单,不足是只有一个网关在线提供服务。如果想多个网关在线提供服务,则需搭配分布式消息系统一起工作,架构如下。
前端通过负载均衡将流量分散到多个在线网关,网关将消息存入分布式消息系统。此时,网关可看作无状态应用,可根据需要扩缩规模。
以上就是我介绍的ES灾备方案,是不是相当灵活了。有问题还是那句话 Call me 。
关于极限网关
INFINI Gateway 是一个面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway,可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
官网文档:https://www.infinilabs.com/docs/latest/gateway
收起阅读 »社区日报 第1667期 (2023-07-19)
https://blog.csdn.net/UbuntuTo ... 84570
2.Elasticsearch:语义搜索、知识图和向量数据库概述
https://blog.csdn.net/UbuntuTo ... 58459
3.我们如何在 Elasticsearch 8.6、8.7 和 8.8 中加速数据摄入
https://blog.csdn.net/UbuntuTo ... 53016
编辑:kin122
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili
https://blog.csdn.net/UbuntuTo ... 84570
2.Elasticsearch:语义搜索、知识图和向量数据库概述
https://blog.csdn.net/UbuntuTo ... 58459
3.我们如何在 Elasticsearch 8.6、8.7 和 8.8 中加速数据摄入
https://blog.csdn.net/UbuntuTo ... 53016
编辑:kin122
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili 收起阅读 »
社区日报 第1666期 (2023-07-18)
1. 不会做chatbot?我教你啊(需要梯子)
https://medium.com/%40samzaman ... 4d9f9
2. 能用ES做语义搜索吗(需要梯子)
https://blog.gopenai.com/seman ... d85d5
1. Doris 能一把把 ES + Hive + PG全代替掉吗(需要梯子)
https://blog.devgenius.io/repl ... dc792
编辑:斯蒂文
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
1. 不会做chatbot?我教你啊(需要梯子)
https://medium.com/%40samzaman ... 4d9f9
2. 能用ES做语义搜索吗(需要梯子)
https://blog.gopenai.com/seman ... d85d5
1. Doris 能一把把 ES + Hive + PG全代替掉吗(需要梯子)
https://blog.devgenius.io/repl ... dc792
编辑:斯蒂文
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
收起阅读 »

