
INFINI Labs 产品更新 | Easysearch 1.7.1发布,改进跨集群复制的数据加载等

INFINI Labs 产品又更新啦~,包括 Console,Gateway,Agent 1.23.0 和 Easysearch 1.7.1。本次各产品更新了很多亮点功能,如 Console 优化实例管理中增加磁盘空闲空间显示,Easysearch 改进 HierarchyCircuitBreakerService 并添加断路器、改进跨集群复制的数据加载,增加对 source_reuse 索引的支持等。欢迎大家下载体验。
以下是本次更新的详细说明。
INFINI Easysearch v1.7.1
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。
Easysearch 本次更新如下:
Bug fix
- 修复 source_reuse 与字段别名冲突
- 改进 HierarchyCircuitBreakerService 并添加断路器
- 修复 _meta 不为空且 启用 source_reuse 时的映射解析错误
- 修复 source_reuse 下对多值还原不正确的问题
Improvements
- 改进 HierarchyCircuitBreakerService 并添加断路器
- 改进跨集群复制的数据加载,增加对 source_reuse 索引的支持
INFINI Console v1.23.0
INFINI Console 是一款非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管, 企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 在线体验: http://demo.infini.cloud (用户名/密码:readonly/readonly)。
Console 本次更新如下:
Bug fix
- 修复数据迁移中数据分片范围因精度导致数据溢出显示为负数
- 修复删除实例队列后消费的 Offset 未重置问题
- 修复网友提出的各种问题,如集群设置默认打开节点、索引采集等
Improvements
- 优化初始化配置向导,分步骤执行
- 优化实例管理中增加磁盘空闲空间显示
- 优化实例队列名称显示
INFINI Gateway v1.23.0
INFINI Gateway 是一个面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway 可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
Gateway 本次更新如下:
Bug fix
- 修复删除实例队列后消费的 Offset 未重置问题
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
您还可以通过邮件联系我们:hello@infini.ltd
或者拨打我们的热线电话:(+86) 400-139-9200
欢迎加入 Discord 聊天室:https://discord.gg/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。

关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
INFINI Labs 产品又更新啦~,包括 Console,Gateway,Agent 1.23.0 和 Easysearch 1.7.1。本次各产品更新了很多亮点功能,如 Console 优化实例管理中增加磁盘空闲空间显示,Easysearch 改进 HierarchyCircuitBreakerService 并添加断路器、改进跨集群复制的数据加载,增加对 source_reuse 索引的支持等。欢迎大家下载体验。
以下是本次更新的详细说明。
INFINI Easysearch v1.7.1
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。
Easysearch 本次更新如下:
Bug fix
- 修复 source_reuse 与字段别名冲突
- 改进 HierarchyCircuitBreakerService 并添加断路器
- 修复 _meta 不为空且 启用 source_reuse 时的映射解析错误
- 修复 source_reuse 下对多值还原不正确的问题
Improvements
- 改进 HierarchyCircuitBreakerService 并添加断路器
- 改进跨集群复制的数据加载,增加对 source_reuse 索引的支持
INFINI Console v1.23.0
INFINI Console 是一款非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管, 企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 在线体验: http://demo.infini.cloud (用户名/密码:readonly/readonly)。
Console 本次更新如下:
Bug fix
- 修复数据迁移中数据分片范围因精度导致数据溢出显示为负数
- 修复删除实例队列后消费的 Offset 未重置问题
- 修复网友提出的各种问题,如集群设置默认打开节点、索引采集等
Improvements
- 优化初始化配置向导,分步骤执行
- 优化实例管理中增加磁盘空闲空间显示
- 优化实例队列名称显示
INFINI Gateway v1.23.0
INFINI Gateway 是一个面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway 可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
Gateway 本次更新如下:
Bug fix
- 修复删除实例队列后消费的 Offset 未重置问题
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
您还可以通过邮件联系我们:hello@infini.ltd
或者拨打我们的热线电话:(+86) 400-139-9200
欢迎加入 Discord 聊天室:https://discord.gg/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »【搜索客社区日报】 第1790期 (2024-03-04)
1. ElasticSearch—数据迁移
https://blog.csdn.net/bbsxb520 ... 14931
2、记一次Elasticsearch集群迁移架构实战
https://blog.csdn.net/x275920/ ... 73879
3、Elasticsearch 使用极限网关助力 ES 集群无缝升级、迁移上/下云
https://mp.weixin.qq.com/s/bT7KiSqLMkoYIcUrwNSMuQ
编辑:yuebancanghai
更多资讯:http://news.searchkit.cn
1. ElasticSearch—数据迁移
https://blog.csdn.net/bbsxb520 ... 14931
2、记一次Elasticsearch集群迁移架构实战
https://blog.csdn.net/x275920/ ... 73879
3、Elasticsearch 使用极限网关助力 ES 集群无缝升级、迁移上/下云
https://mp.weixin.qq.com/s/bT7KiSqLMkoYIcUrwNSMuQ
编辑:yuebancanghai
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1787期 (2024-02-27)
1. 用google cloud处理snapshot的最佳实践(需要梯子)
https://medium.com/%40musabdog ... c59f4
2. 一个收录了(几乎)全部独立开发用得到的内容,教程、网站、数据集…(需要梯子)
https://github.com/ripienaar/free-for-dev
3. 有关GPU的科普(需要梯子)
https://journal.hexmos.com/gpu-survival-toolkit/
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
1. 用google cloud处理snapshot的最佳实践(需要梯子)
https://medium.com/%40musabdog ... c59f4
2. 一个收录了(几乎)全部独立开发用得到的内容,教程、网站、数据集…(需要梯子)
https://github.com/ripienaar/free-for-dev
3. 有关GPU的科普(需要梯子)
https://journal.hexmos.com/gpu-survival-toolkit/
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
【搜索客社区日报】第1789期 (2024-02-29)
https://journal.everypixel.com ... ition
2.当事人复盘 GitLab 史上最严重的数据库故障
https://mp.weixin.qq.com/s/Y7qAaYt2uIylqlPve9DGzg
3.在单机模式下进行原型设计和比较 Milvus 和 Elasticsearch(需要梯子)
https://medium.com/%40piscarie ... 390ef
4.从 Elasticsearch 到 Apache Doris,统一日志检索与报表分析,360 企业安全浏览器的数据架构升级实践
https://mp.weixin.qq.com/s/WJIa44Qtp9wzv5QwNUoNOg
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://journal.everypixel.com ... ition
2.当事人复盘 GitLab 史上最严重的数据库故障
https://mp.weixin.qq.com/s/Y7qAaYt2uIylqlPve9DGzg
3.在单机模式下进行原型设计和比较 Milvus 和 Elasticsearch(需要梯子)
https://medium.com/%40piscarie ... 390ef
4.从 Elasticsearch 到 Apache Doris,统一日志检索与报表分析,360 企业安全浏览器的数据架构升级实践
https://mp.weixin.qq.com/s/WJIa44Qtp9wzv5QwNUoNOg
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
搜索客社区日报 第1788期 (2024-02-28)
https://blog.csdn.net/UbuntuTo ... 51152
2.Elasticsearch:BM25 及 使用 Elasticsearch 和 LangChain 的自查询检索器
https://blog.csdn.net/UbuntuTo ... 58515
3.使用 Chainlit, Langchain 及 Elasticsearch 轻松实现对 PDF 文件的查询
https://blog.csdn.net/UbuntuTo ... 11385
4.Elasticsearch:基于 Langchain 的 Elasticsearch Agent 对文档的搜索
https://elasticstack.blog.csdn ... 53286
编辑:kin122
更多资讯:http://news.searchkit.cn
https://blog.csdn.net/UbuntuTo ... 51152
2.Elasticsearch:BM25 及 使用 Elasticsearch 和 LangChain 的自查询检索器
https://blog.csdn.net/UbuntuTo ... 58515
3.使用 Chainlit, Langchain 及 Elasticsearch 轻松实现对 PDF 文件的查询
https://blog.csdn.net/UbuntuTo ... 11385
4.Elasticsearch:基于 Langchain 的 Elasticsearch Agent 对文档的搜索
https://elasticstack.blog.csdn ... 53286
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
如何防止 Elasticsearch 服务 OOM?
Elasticsearch(简称:ES) 和传统关系型数据库有很多区别, 比如传统数据中普遍都有一个叫“最大连接数”的设置。目的是使数据库系统工作在可控的负载下,避免出现负载过高,资源耗尽,谁也无法登录的局面。
那 ES 在这方面有类似参数吗?答案是没有,这也是为何 ES 会被流量打爆的原因之一。
针对大并发访问 ES 服务,造成 ES 节点 OOM,服务中断的情况,极限科技旗下的 INFINI Gateway 产品(以下简称 “极限网关”)可从两个方面入手,保障 ES 服务的可用性。
- 限制最大并发访问连接数。
- 限制非重要索引的请求速度,保障重要业务索引的访问速度。
下面我们来详细聊聊。
架构图
 所有访问 ES 的请求都发给网关,可部署多个网关。
所有访问 ES 的请求都发给网关,可部署多个网关。
限制最大连接数
在网关配置文件中,默认有最大并发连接数限制,默认最大 10000。
entry:
- name: my_es_entry
enabled: true
router: my_router
max_concurrency: 10000
network:
binding: $[[env.GW_BINDING]]
# See `gateway.disable_reuse_port_by_default` for more information.
reuse_port: true使用压测程序测试,看看到达10000个连接后,能否限制新的连接。
 超过的连接请求,被丢弃。更多信息参考官方文档。
超过的连接请求,被丢弃。更多信息参考官方文档。
限制索引写入速度
我们先看看不做限制的时候,测试环境的写入速度,在 9w - 15w docs/s 之间波动。虽然峰值很高,但不稳定。
 接下来,我们通过网关把写入速度控制在最大 1w docs/s 。
对网关的配置文件 gateway.yml ,做以下修改。
接下来,我们通过网关把写入速度控制在最大 1w docs/s 。
对网关的配置文件 gateway.yml ,做以下修改。
env: # env 下添加
THROTTLE_BULK_INDEXING_MAX_BYTES: 40485760 #40MB/s
THROTTLE_BULK_INDEXING_MAX_REQUESTS: 10000 #10k docs/s
THROTTLE_BULK_INDEXING_ACTION: retry #retry,drop
THROTTLE_BULK_INDEXING_MAX_RETRY_TIMES: 10 #1000
THROTTLE_BULK_INDEXING_RETRY_DELAY_IN_MS: 100 #10
router: # route 部分修改 flow
- name: my_router
default_flow: default_flow
tracing_flow: logging_flow
rules:
- method:
- "*"
pattern:
- "/_bulk"
- "/{any_index}/_bulk"
flow:
- write_flow
flow: #flow 部分增加下面两段
- name: write_flow
filter:
- flow:
flows:
- bulking_indexing_limit
- elasticsearch:
elasticsearch: prod
max_connection_per_node: 1000
- name: bulking_indexing_limit
filter:
- bulk_request_throttle:
indices:
"test-index":
max_bytes: $[[env.THROTTLE_BULK_INDEXING_MAX_BYTES]]
max_requests: $[[env.THROTTLE_BULK_INDEXING_MAX_REQUESTS]]
action: $[[env.THROTTLE_BULK_INDEXING_ACTION]]
retry_delay_in_ms: $[[env.THROTTLE_BULK_INDEXING_RETRY_DELAY_IN_MS]]
max_retry_times: $[[env.THROTTLE_BULK_INDEXING_MAX_RETRY_TIMES]]
message: "bulk writing too fast" #触发限流告警message自定义
log_warn_message: true
再次压测,test-index 索引写入速度被限制在了 1w docs/s 。

限制多个索引写入速度
上面的配置是针对 test-index 索引的写入速度控制。如果想添加其他的索引,新增一段配置即可。 比如,我允许 abc 索引写入达到 2w docs/s,test-index 索引最多不超过 1w docs/s ,可配置如下。
- name: bulking_indexing_limit
filter:
- bulk_request_throttle:
indices:
"abc":
max_requests: 20000
action: drop
message: "abc doc写入超阈值" #触发限流告警message自定义
log_warn_message: true
"test-index":
max_bytes: $[[env.THROTTLE_BULK_INDEXING_MAX_BYTES]]
max_requests: $[[env.THROTTLE_BULK_INDEXING_MAX_REQUESTS]]
action: $[[env.THROTTLE_BULK_INDEXING_ACTION]]
retry_delay_in_ms: $[[env.THROTTLE_BULK_INDEXING_RETRY_DELAY_IN_MS]]
max_retry_times: $[[env.THROTTLE_BULK_INDEXING_MAX_RETRY_TIMES]]
message: "bulk writing too fast" #触发限流告警message自定义
log_warn_message: true限速效果如下

限制读请求速度
我们先看看不做限制的时候,测试环境的读取速度,7w qps 。
 接下来我们通过网关把读取速度控制在最大 1w qps 。
继续对网关的配置文件 gateway.yml 做以下修改。
接下来我们通过网关把读取速度控制在最大 1w qps 。
继续对网关的配置文件 gateway.yml 做以下修改。
- name: default_flow
filter:
- request_path_limiter:
message: "Hey, You just reached our request limit!" rules:
- pattern: "/(?P<index_name>abc)/_search"
max_qps: 10000
group: index_name
- elasticsearch:
elasticsearch: prod
max_connection_per_node: 1000再次进行测试,读取速度被限制在了 1w qps 。

限制多个索引读取速度
上面的配置是针对 abc 索引的写入速度控制。如果想添加其他的索引,新增一段配置即可。 比如,我允许 abc 索引读取达到 1w qps,test-index 索引最多不超过 2w qps ,可配置如下。
- name: default_flow
filter:
- request_path_limiter:
message: "Hey, You just reached our request limit!"
rules:
- pattern: "/(?P<index_name>abc)/_search"
max_qps: 10000
group: index_name
- pattern: "/(?P<index_name>test-index)/_search"
max_qps: 20000
group: index_name
- elasticsearch:
elasticsearch: prod
max_connection_per_node: 1000
多个网关限速
限速是每个网关自身的控制,如果有多个网关,那么后端 ES 集群收到的请求数等于多个网关限速的总和。
 本次介绍就到这里了。相信大家在使用 ES 的过程中也遇到过各种各样的问题。欢迎大家来我们这个平台分享自己的问题、解决方案等。如有任何问题,请随时联系我,期待与您交流!
本次介绍就到这里了。相信大家在使用 ES 的过程中也遇到过各种各样的问题。欢迎大家来我们这个平台分享自己的问题、解决方案等。如有任何问题,请随时联系我,期待与您交流!

Elasticsearch(简称:ES) 和传统关系型数据库有很多区别, 比如传统数据中普遍都有一个叫“最大连接数”的设置。目的是使数据库系统工作在可控的负载下,避免出现负载过高,资源耗尽,谁也无法登录的局面。
那 ES 在这方面有类似参数吗?答案是没有,这也是为何 ES 会被流量打爆的原因之一。
针对大并发访问 ES 服务,造成 ES 节点 OOM,服务中断的情况,极限科技旗下的 INFINI Gateway 产品(以下简称 “极限网关”)可从两个方面入手,保障 ES 服务的可用性。
- 限制最大并发访问连接数。
- 限制非重要索引的请求速度,保障重要业务索引的访问速度。
下面我们来详细聊聊。
架构图
所有访问 ES 的请求都发给网关,可部署多个网关。
限制最大连接数
在网关配置文件中,默认有最大并发连接数限制,默认最大 10000。
entry:
- name: my_es_entry
enabled: true
router: my_router
max_concurrency: 10000
network:
binding: $[[env.GW_BINDING]]
# See `gateway.disable_reuse_port_by_default` for more information.
reuse_port: true使用压测程序测试,看看到达10000个连接后,能否限制新的连接。
超过的连接请求,被丢弃。更多信息参考官方文档。
限制索引写入速度
我们先看看不做限制的时候,测试环境的写入速度,在 9w - 15w docs/s 之间波动。虽然峰值很高,但不稳定。
接下来,我们通过网关把写入速度控制在最大 1w docs/s 。
对网关的配置文件 gateway.yml ,做以下修改。
env: # env 下添加
THROTTLE_BULK_INDEXING_MAX_BYTES: 40485760 #40MB/s
THROTTLE_BULK_INDEXING_MAX_REQUESTS: 10000 #10k docs/s
THROTTLE_BULK_INDEXING_ACTION: retry #retry,drop
THROTTLE_BULK_INDEXING_MAX_RETRY_TIMES: 10 #1000
THROTTLE_BULK_INDEXING_RETRY_DELAY_IN_MS: 100 #10
router: # route 部分修改 flow
- name: my_router
default_flow: default_flow
tracing_flow: logging_flow
rules:
- method:
- "*"
pattern:
- "/_bulk"
- "/{any_index}/_bulk"
flow:
- write_flow
flow: #flow 部分增加下面两段
- name: write_flow
filter:
- flow:
flows:
- bulking_indexing_limit
- elasticsearch:
elasticsearch: prod
max_connection_per_node: 1000
- name: bulking_indexing_limit
filter:
- bulk_request_throttle:
indices:
"test-index":
max_bytes: $[[env.THROTTLE_BULK_INDEXING_MAX_BYTES]]
max_requests: $[[env.THROTTLE_BULK_INDEXING_MAX_REQUESTS]]
action: $[[env.THROTTLE_BULK_INDEXING_ACTION]]
retry_delay_in_ms: $[[env.THROTTLE_BULK_INDEXING_RETRY_DELAY_IN_MS]]
max_retry_times: $[[env.THROTTLE_BULK_INDEXING_MAX_RETRY_TIMES]]
message: "bulk writing too fast" #触发限流告警message自定义
log_warn_message: true
再次压测,test-index 索引写入速度被限制在了 1w docs/s 。
限制多个索引写入速度
上面的配置是针对 test-index 索引的写入速度控制。如果想添加其他的索引,新增一段配置即可。 比如,我允许 abc 索引写入达到 2w docs/s,test-index 索引最多不超过 1w docs/s ,可配置如下。
- name: bulking_indexing_limit
filter:
- bulk_request_throttle:
indices:
"abc":
max_requests: 20000
action: drop
message: "abc doc写入超阈值" #触发限流告警message自定义
log_warn_message: true
"test-index":
max_bytes: $[[env.THROTTLE_BULK_INDEXING_MAX_BYTES]]
max_requests: $[[env.THROTTLE_BULK_INDEXING_MAX_REQUESTS]]
action: $[[env.THROTTLE_BULK_INDEXING_ACTION]]
retry_delay_in_ms: $[[env.THROTTLE_BULK_INDEXING_RETRY_DELAY_IN_MS]]
max_retry_times: $[[env.THROTTLE_BULK_INDEXING_MAX_RETRY_TIMES]]
message: "bulk writing too fast" #触发限流告警message自定义
log_warn_message: true限速效果如下
限制读请求速度
我们先看看不做限制的时候,测试环境的读取速度,7w qps 。
接下来我们通过网关把读取速度控制在最大 1w qps 。
继续对网关的配置文件 gateway.yml 做以下修改。
- name: default_flow
filter:
- request_path_limiter:
message: "Hey, You just reached our request limit!" rules:
- pattern: "/(?P<index_name>abc)/_search"
max_qps: 10000
group: index_name
- elasticsearch:
elasticsearch: prod
max_connection_per_node: 1000再次进行测试,读取速度被限制在了 1w qps 。
限制多个索引读取速度
上面的配置是针对 abc 索引的写入速度控制。如果想添加其他的索引,新增一段配置即可。 比如,我允许 abc 索引读取达到 1w qps,test-index 索引最多不超过 2w qps ,可配置如下。
- name: default_flow
filter:
- request_path_limiter:
message: "Hey, You just reached our request limit!"
rules:
- pattern: "/(?P<index_name>abc)/_search"
max_qps: 10000
group: index_name
- pattern: "/(?P<index_name>test-index)/_search"
max_qps: 20000
group: index_name
- elasticsearch:
elasticsearch: prod
max_connection_per_node: 1000
多个网关限速
限速是每个网关自身的控制,如果有多个网关,那么后端 ES 集群收到的请求数等于多个网关限速的总和。
本次介绍就到这里了。相信大家在使用 ES 的过程中也遇到过各种各样的问题。欢迎大家来我们这个平台分享自己的问题、解决方案等。如有任何问题,请随时联系我,期待与您交流!
【搜索客社区日报】 第1786期 (2024-02-26)
https://mp.weixin.qq.com/s/6bB31_xsJ3IUnV_GxBGR-g
2、Elasticsearch 实战之xpack安装、解密和更换证书以及head加密
https://blog.csdn.net/weixin_4 ... 74362
3、Elasticsearch 如何实现文件名自定义排序
https://mp.weixin.qq.com/s/yzhkbt7fsgIgKee7zwDJYQ
编辑:yuebancanghai
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/6bB31_xsJ3IUnV_GxBGR-g
2、Elasticsearch 实战之xpack安装、解密和更换证书以及head加密
https://blog.csdn.net/weixin_4 ... 74362
3、Elasticsearch 如何实现文件名自定义排序
https://mp.weixin.qq.com/s/yzhkbt7fsgIgKee7zwDJYQ
编辑:yuebancanghai
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1779期 (2024-02-20)
https://medium.com/%40callmezy ... b36a0
2. OpenAI 的视频生成模型Sora的技术报告(需要梯子)
https://openai.com/research/vi ... ators
3. Nvidia 出品的个人Ai 聊天机器人(需要梯子)
https://www.nvidia.com/en-us/a ... e-ai/
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://medium.com/%40callmezy ... b36a0
2. OpenAI 的视频生成模型Sora的技术报告(需要梯子)
https://openai.com/research/vi ... ators
3. Nvidia 出品的个人Ai 聊天机器人(需要梯子)
https://www.nvidia.com/en-us/a ... e-ai/
编辑:斯蒂文
更多资讯:http://news.searchkit.cn 收起阅读 »
用 Easysearch 帮助大型车企降本增效
最近某头部汽车集团需要针对当前 ES 集群进行优化,背景如下: ES 用于支撑包括核心营销系统、管理支持系统、财务类、IT 基础设施类、研发、自动驾驶等多个重要应用,合计超 50 余套集群,累计数据超 1.5PB 。 本文针对其中一个 ES 集群进行分享,该集群原本使用的是 ES 7.3.2 免费版,数据已经 130TB 了,14 个节点。写入数据时经常掉节点,写入性能也不稳定,当天的数据写不完。迫切需要新的解决方案。 分析业务场景后总结需求要点:主要是写,很少查。审计需求,数据需要长期保存。 这个需求比较普遍,处理起来也很简单:
- 使用 Easysearch 软件,只需少量节点存储近两天的数据。
- 索引设置开启 ZSTD 压缩功能,节省磁盘空间。
- 每天索引数据写完后,第二天执行快照备份存放到 S3 存储。
- 备份成功后,删除索引释放磁盘空间。
- 需要搜索数据时,直接从快照搜索。
 将近期的数据,存放到本地磁盘,保障写入速度。写入完毕的索引,在执行快照备份后,可删除索引,释放本地磁盘空间。
将近期的数据,存放到本地磁盘,保障写入速度。写入完毕的索引,在执行快照备份后,可删除索引,释放本地磁盘空间。
Easysearch 配置要点
path.repo: ["/S3-path"]
node.roles: ["data","search"]
node.search.cache.size: 500mb- path.repo : 指定 S3 存储路径,上传快照用。
- node.roles : 只有 search 角色的节点,才能去搜索快照中的数据。
- node.search.cache.size : 执行快照搜索时的,缓存大小。
更多信息请参考官方文档。
旧数据迁移
通过 Console 将原 ES 集群的数据,迁移到新 Easysearch 集群。迁移时,复制 mapping 和 setting,并在 setting 中添加如下设置。
"codec": "ZSTD",
"source_reuse": true,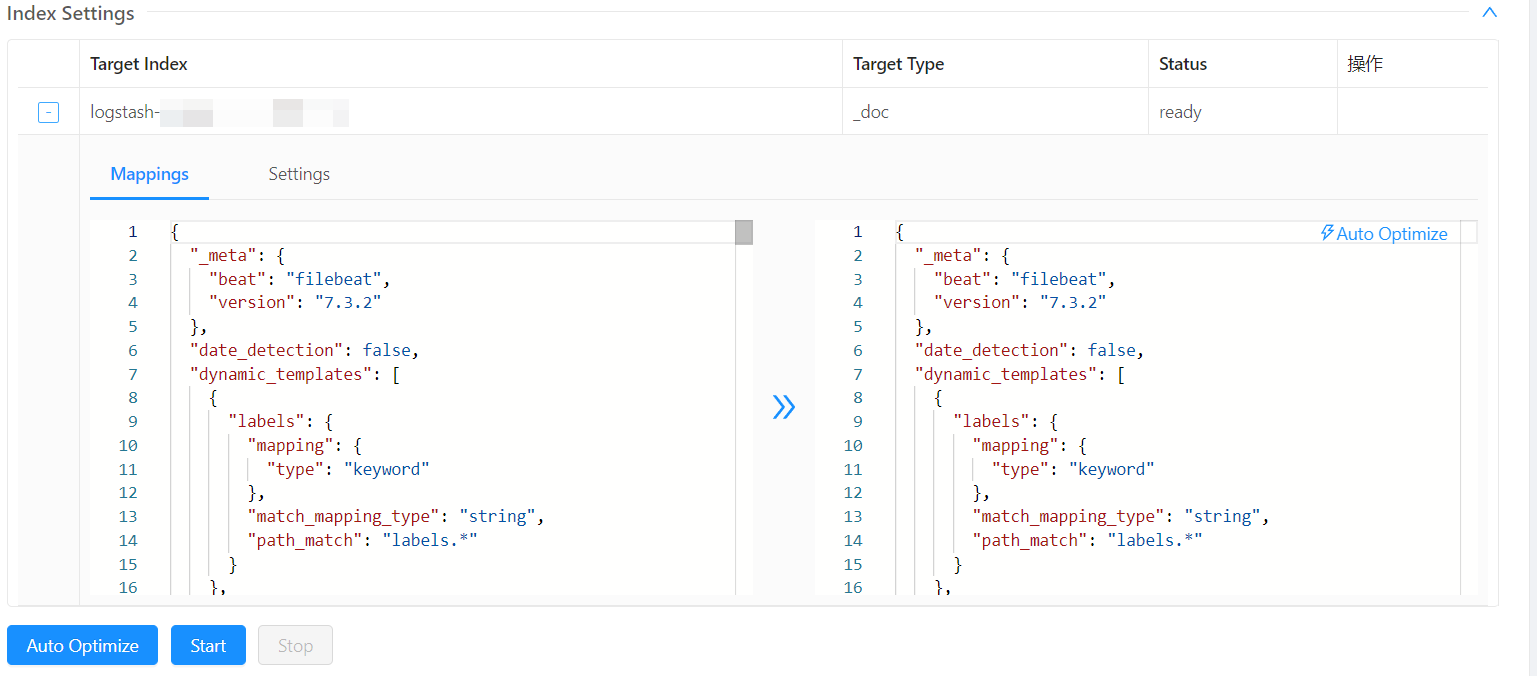
 原索引数据量大,可拆分成多个小任务。
原索引数据量大,可拆分成多个小任务。
 迁移完,索引存储空间一般节省 50% 左右。
原索引 279GB ,迁移完后 138GB。
迁移完,索引存储空间一般节省 50% 左右。
原索引 279GB ,迁移完后 138GB。

搜索快照数据
挂载快照后,搜索快照里的索引和搜索本地的索引,语法完全一样。
 如何判断一个索引是在快照还是本地磁盘呢?可以查看索引设置里的 settings.index.store.type
如何判断一个索引是在快照还是本地磁盘呢?可以查看索引设置里的 settings.index.store.type
 如果是 remote_snapshot ,说明是快照中的数据。如果是空值,则是集群本地的数据。
如果是 remote_snapshot ,说明是快照中的数据。如果是空值,则是集群本地的数据。
这次迁移,节省了 6 台主机资源。更重要的是,用上对象存储后,主机磁盘空间压力骤减。
这次介绍就到这里了,有问题联系我。
关于 Easysearch

INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
最近某头部汽车集团需要针对当前 ES 集群进行优化,背景如下: ES 用于支撑包括核心营销系统、管理支持系统、财务类、IT 基础设施类、研发、自动驾驶等多个重要应用,合计超 50 余套集群,累计数据超 1.5PB 。 本文针对其中一个 ES 集群进行分享,该集群原本使用的是 ES 7.3.2 免费版,数据已经 130TB 了,14 个节点。写入数据时经常掉节点,写入性能也不稳定,当天的数据写不完。迫切需要新的解决方案。 分析业务场景后总结需求要点:主要是写,很少查。审计需求,数据需要长期保存。 这个需求比较普遍,处理起来也很简单:
- 使用 Easysearch 软件,只需少量节点存储近两天的数据。
- 索引设置开启 ZSTD 压缩功能,节省磁盘空间。
- 每天索引数据写完后,第二天执行快照备份存放到 S3 存储。
- 备份成功后,删除索引释放磁盘空间。
- 需要搜索数据时,直接从快照搜索。
将近期的数据,存放到本地磁盘,保障写入速度。写入完毕的索引,在执行快照备份后,可删除索引,释放本地磁盘空间。
Easysearch 配置要点
path.repo: ["/S3-path"]
node.roles: ["data","search"]
node.search.cache.size: 500mb- path.repo : 指定 S3 存储路径,上传快照用。
- node.roles : 只有 search 角色的节点,才能去搜索快照中的数据。
- node.search.cache.size : 执行快照搜索时的,缓存大小。
更多信息请参考官方文档。
旧数据迁移
通过 Console 将原 ES 集群的数据,迁移到新 Easysearch 集群。迁移时,复制 mapping 和 setting,并在 setting 中添加如下设置。
"codec": "ZSTD",
"source_reuse": true,
原索引数据量大,可拆分成多个小任务。
迁移完,索引存储空间一般节省 50% 左右。
原索引 279GB ,迁移完后 138GB。
搜索快照数据
挂载快照后,搜索快照里的索引和搜索本地的索引,语法完全一样。
如何判断一个索引是在快照还是本地磁盘呢?可以查看索引设置里的 settings.index.store.type
如果是 remote_snapshot ,说明是快照中的数据。如果是空值,则是集群本地的数据。
这次迁移,节省了 6 台主机资源。更重要的是,用上对象存储后,主机磁盘空间压力骤减。
这次介绍就到这里了,有问题联系我。
关于 Easysearch
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
官网文档:https://infinilabs.com/docs/latest/easysearch
收起阅读 »【搜索客社区日报】第1778期 (2024-01-23)
1. 一个新的代码生成模型的原理说明(需要梯子)
https://www.codium.ai/blog/alp ... ests/
(这个是水友的翻译版)https://baoyu.io/translations/ ... tests
2. 计算机科学相关的书单,全套免费电子书下载(需要梯子)
(根域名是全球最大的免费电子书分发网站,之前被FBI x了的z-library)
https://zh.singlelogin.re/booklist/165858/538e6d/计算机系列丛书.html
3. AI 领域关键词词典表(需要梯子)
https://a16z.com/ai-glossary/
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
1. 一个新的代码生成模型的原理说明(需要梯子)
https://www.codium.ai/blog/alp ... ests/
(这个是水友的翻译版)https://baoyu.io/translations/ ... tests
2. 计算机科学相关的书单,全套免费电子书下载(需要梯子)
(根域名是全球最大的免费电子书分发网站,之前被FBI x了的z-library)
https://zh.singlelogin.re/booklist/165858/538e6d/计算机系列丛书.html
3. AI 领域关键词词典表(需要梯子)
https://a16z.com/ai-glossary/
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
【搜索客社区日报】第1785期 (2024-02-01)
https://www.elastic.co/search- ... earch
2.使用 Python、Elasticsearch 和 Kibana 分析波士顿凯尔特人队
https://www.elastic.co/search- ... ibana
3.使用 Flink、Elasticsearch 和 Redpanda 构建闪电般的搜索索引(需要梯子)
https://redpanda-data.medium.c ... c5939
4.万字长文:AIGC技术与应用全解析
https://zhuanlan.zhihu.com/p/607822576
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://www.elastic.co/search- ... earch
2.使用 Python、Elasticsearch 和 Kibana 分析波士顿凯尔特人队
https://www.elastic.co/search- ... ibana
3.使用 Flink、Elasticsearch 和 Redpanda 构建闪电般的搜索索引(需要梯子)
https://redpanda-data.medium.c ... c5939
4.万字长文:AIGC技术与应用全解析
https://zhuanlan.zhihu.com/p/607822576
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
搜索客社区日报 第1784期 (2024-01-31)
https://blog.csdn.net/UbuntuTo ... 39714
2.Apache Lucene 9.9,有史以来最快的 Lucene 版本
https://elasticstack.blog.csdn ... 80899
3.Elastic Search 8.12:让 Lucene 更快,让开发人员更快
https://blog.csdn.net/UbuntuTo ... 42767
4.Elasticsearch:Simulate ingest API
https://blog.csdn.net/UbuntuTo ... 50006
编辑:kin122
更多资讯:http://news.searchkit.cn
https://blog.csdn.net/UbuntuTo ... 39714
2.Apache Lucene 9.9,有史以来最快的 Lucene 版本
https://elasticstack.blog.csdn ... 80899
3.Elastic Search 8.12:让 Lucene 更快,让开发人员更快
https://blog.csdn.net/UbuntuTo ... 42767
4.Elasticsearch:Simulate ingest API
https://blog.csdn.net/UbuntuTo ... 50006
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1783期 (2024-01-30)
https://mp.weixin.qq.com/s/K3mjmkLye79Khem18QHORw
2. 哈佛CS的入门课程上线了(需要梯子)
https://cs50.harvard.edu/x/2024/
3. 贾扬清同款,ai 赋能的搜索引擎开源了
这个是后台模型服务
https://github.com/leptonai/leptonai
这个是前台的搜索引擎
https://github.com/leptonai/search_with_lepton
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/K3mjmkLye79Khem18QHORw
2. 哈佛CS的入门课程上线了(需要梯子)
https://cs50.harvard.edu/x/2024/
3. 贾扬清同款,ai 赋能的搜索引擎开源了
这个是后台模型服务
https://github.com/leptonai/leptonai
这个是前台的搜索引擎
https://github.com/leptonai/search_with_lepton
编辑:斯蒂文
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】 第1782期 (2024-01-29)
https://mp.weixin.qq.com/s/nmK1nptmV-pBiHlwV9Ynjg
2、结合AI大模型与向量检索的新一代云端检索分析引擎
https://blog.csdn.net/cloudbig ... 22650
3、腾讯万亿级 Elasticsearch 架构实践
https://blog.csdn.net/yangshan ... 09592
编辑:yuebancanghai
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/nmK1nptmV-pBiHlwV9Ynjg
2、结合AI大模型与向量检索的新一代云端检索分析引擎
https://blog.csdn.net/cloudbig ... 22650
3、腾讯万亿级 Elasticsearch 架构实践
https://blog.csdn.net/yangshan ... 09592
编辑:yuebancanghai
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1781期 (2024-01-26)
https://eliatra.com/blog/chatg ... lity/
2、Elasticsearch 命令行工具 – elasticsearch-croneval
https://toughcoding.net/elasti ... neval
3、将数据从 Snowflake 摄取到 Elasticsearch
https://www.elastic.co/search- ... earch
4、Elasticsearc 8.12 新特性:对大模型兼容更友好
https://www.elastic.co/cn/blog ... -12-0
编辑:铭毅天下
更多资讯:http://news.searchkit.cn
https://eliatra.com/blog/chatg ... lity/
2、Elasticsearch 命令行工具 – elasticsearch-croneval
https://toughcoding.net/elasti ... neval
3、将数据从 Snowflake 摄取到 Elasticsearch
https://www.elastic.co/search- ... earch
4、Elasticsearc 8.12 新特性:对大模型兼容更友好
https://www.elastic.co/cn/blog ... -12-0
编辑:铭毅天下
更多资讯:http://news.searchkit.cn
收起阅读 »


