
Elastic Stack 8.0 安装 - 保护你的 Elastic Stack 现在比以往任何时候都简单
然而,我们知道设置安全性并不好玩,你需要专注于你的项目目标。 好消息给你! 从 8.0 开始,自管理集群默认启用 Elastic Stack 安全性,配置工作几乎为零。 只需启动新的 Elasticsearch 和 Kibana 版本并继续充分利用 Elastic Stack,我们将为你提供支持! 如果你使用的是 Elastic Cloud,请不要担心——我们已经为你解决了安全问题。
轻松获得所需的所有安全性
简化的安全性包括以下功能,这些功能跨越多个层和产品,默认启用:
用户认证
具有基于角色的访问控制的用户授权
Kibana Spaces 多租户
使用 TLS 的加密节点到节点通信
使用 HTTPS 与 Elasticsearch API 进行加密通信
原文链接:https://elasticstack.blog.csdn ... 74932
然而,我们知道设置安全性并不好玩,你需要专注于你的项目目标。 好消息给你! 从 8.0 开始,自管理集群默认启用 Elastic Stack 安全性,配置工作几乎为零。 只需启动新的 Elasticsearch 和 Kibana 版本并继续充分利用 Elastic Stack,我们将为你提供支持! 如果你使用的是 Elastic Cloud,请不要担心——我们已经为你解决了安全问题。
轻松获得所需的所有安全性
简化的安全性包括以下功能,这些功能跨越多个层和产品,默认启用:
用户认证
具有基于角色的访问控制的用户授权
Kibana Spaces 多租户
使用 TLS 的加密节点到节点通信
使用 HTTPS 与 Elasticsearch API 进行加密通信
原文链接:https://elasticstack.blog.csdn ... 74932 收起阅读 »
极限科技招聘啦,快来看看 :)
极限科技开始招聘啦,目前正在寻找攻城狮,方向分别是 Golang 后端和 React 前端。
目前正在开发的两款产品:
两款产品都是围绕 Elasticsearch 来打造,大家可以去体验试试,使用和下载都是非常简单,因为我们产品的设计理念是:简单、易用、极致、创新,和大家喜爱的 Elasticsearch 一样,我们只做简单好用的产品,现寻觅优秀的工程师一起来打造世界级的数据产品!
欢迎加入我们,挑战数据极限,简历投递:hello@infini.ltd
目前开放的职位坐标位于长沙研发中心。
React 前端开发工程师(10k-30k)
岗位职责:
- 负责公司数据管理产品前端端部分的开发和维护;
- 参与前端框架和组件易用性改善、基础建设,提升团队开发效率;
- 持续学习和分享前端前沿技术;
- 编写可以在多平台使用的响应式/自适应的网页解决方案;
- 与团队合作,编写最出色的用户界面;
- 优化用户体验,与设计师和产品经理合作,编写用户喜爱的用户界面。
岗位要求
- 计算机相关专业大学本科及以上学历;
- 具有扎实的计算机基础知识;
- 熟练掌握 react 框架,有一定项目经验;
- 熟悉 ES6, antd, react-router, webpack, 有一定的项目经验;
- 熟悉大型网站页面结构与布局,了解网站性能和技术体验优化方案;
- 对前端工程化、组件化、模块化有自己的理解;
- 具有文档撰写,code review 和单元测试,确保项目的进度和质量能力;
- 良好英语读、写能力;
- 对于新技术的自主学习和探索能力。
加分项:
- 有自己的博客、Github、开源项目优先;
- 有管理后台相关工作经验优先;
- 有数据可视化相关工作经验优先。
Golang 后端开发工程师(10k-30k)
岗位职责:
1、负责 Golang 开发与后端数据模型设计; 2、合理定义后端接口 API,并实现 API 业务逻辑; 3、确保业务逻辑正确性,能通过 Unit Test 进行检验; 4、与前端工程师紧密合作,确保项目准时上线,且保证交付质量; 5、对后端技术的发展趋势保持关注,不断学习并升级现有的后端技术; 6、关注产品的代码质量、高性能、服务可靠性、系统可扩展性、可维护性等。
岗位要求:
1、本科及以上学历,1 年以上 Golang 开发经验; 2、熟悉 Golang 编程语言,熟练掌握技术核心原理; 3、熟悉 Linux,了解服务器性能优化、负载均衡、文件系统等知识; 4、了解 Redis、Elasticsearch 等常用 NoSQL 解决方案; 5、具备分布式基础理论知识; 6、有代码洁癖;
- 具有文档撰写,code review 和单元测试,确保项目的进度和质量能力;
- 良好英语读、写能力;
- 对于新技术的自主学习和探索能力。
加分项:
- 有自己的博客、Github、开源项目优先
- 具备 ToB SaaS 相关开发经验;
- 熟悉其他后端编程语言,包括但不限于 Java、Nodejs、Python 等;
- 有较强的学习能力,愿意致力于新技术的研究。
关于极限科技
极限数据(北京)科技有限公司,简称极限科技,我们是一家专注于开源搜索与实时数据分析的软件公司。公司产品的设计理念是:简单、易用、极致、创新,旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。自研产品及解决方案包括:Elasticsearch 多集群管理、企业级异地多活容灾、平台化数据治理等多种解决方案。
追求极致无限可能!
欢迎投递简历:hello@infini.ltd
极限科技开始招聘啦,目前正在寻找攻城狮,方向分别是 Golang 后端和 React 前端。
目前正在开发的两款产品:
两款产品都是围绕 Elasticsearch 来打造,大家可以去体验试试,使用和下载都是非常简单,因为我们产品的设计理念是:简单、易用、极致、创新,和大家喜爱的 Elasticsearch 一样,我们只做简单好用的产品,现寻觅优秀的工程师一起来打造世界级的数据产品!
欢迎加入我们,挑战数据极限,简历投递:hello@infini.ltd
目前开放的职位坐标位于长沙研发中心。
React 前端开发工程师(10k-30k)
岗位职责:
- 负责公司数据管理产品前端端部分的开发和维护;
- 参与前端框架和组件易用性改善、基础建设,提升团队开发效率;
- 持续学习和分享前端前沿技术;
- 编写可以在多平台使用的响应式/自适应的网页解决方案;
- 与团队合作,编写最出色的用户界面;
- 优化用户体验,与设计师和产品经理合作,编写用户喜爱的用户界面。
岗位要求
- 计算机相关专业大学本科及以上学历;
- 具有扎实的计算机基础知识;
- 熟练掌握 react 框架,有一定项目经验;
- 熟悉 ES6, antd, react-router, webpack, 有一定的项目经验;
- 熟悉大型网站页面结构与布局,了解网站性能和技术体验优化方案;
- 对前端工程化、组件化、模块化有自己的理解;
- 具有文档撰写,code review 和单元测试,确保项目的进度和质量能力;
- 良好英语读、写能力;
- 对于新技术的自主学习和探索能力。
加分项:
- 有自己的博客、Github、开源项目优先;
- 有管理后台相关工作经验优先;
- 有数据可视化相关工作经验优先。
Golang 后端开发工程师(10k-30k)
岗位职责:
1、负责 Golang 开发与后端数据模型设计; 2、合理定义后端接口 API,并实现 API 业务逻辑; 3、确保业务逻辑正确性,能通过 Unit Test 进行检验; 4、与前端工程师紧密合作,确保项目准时上线,且保证交付质量; 5、对后端技术的发展趋势保持关注,不断学习并升级现有的后端技术; 6、关注产品的代码质量、高性能、服务可靠性、系统可扩展性、可维护性等。
岗位要求:
1、本科及以上学历,1 年以上 Golang 开发经验; 2、熟悉 Golang 编程语言,熟练掌握技术核心原理; 3、熟悉 Linux,了解服务器性能优化、负载均衡、文件系统等知识; 4、了解 Redis、Elasticsearch 等常用 NoSQL 解决方案; 5、具备分布式基础理论知识; 6、有代码洁癖;
- 具有文档撰写,code review 和单元测试,确保项目的进度和质量能力;
- 良好英语读、写能力;
- 对于新技术的自主学习和探索能力。
加分项:
- 有自己的博客、Github、开源项目优先
- 具备 ToB SaaS 相关开发经验;
- 熟悉其他后端编程语言,包括但不限于 Java、Nodejs、Python 等;
- 有较强的学习能力,愿意致力于新技术的研究。
关于极限科技
极限数据(北京)科技有限公司,简称极限科技,我们是一家专注于开源搜索与实时数据分析的软件公司。公司产品的设计理念是:简单、易用、极致、创新,旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。自研产品及解决方案包括:Elasticsearch 多集群管理、企业级异地多活容灾、平台化数据治理等多种解决方案。
追求极致无限可能!
欢迎投递简历:hello@infini.ltd
收起阅读 »Kibana:Kibana 入门 (一)
Kibana 是你进入 Elastic Stack 的窗口。 Kibana 使你能够:
分析和可视化你的数据。搜索隐藏的见解,编制图表仪表板,仪表、地图和其他可视化显示您发现的内容,并与他人分享。
搜索、观察和保护你的数据。向你的应用或网站添加搜索框,分析日志,指标,并发现安全漏洞。
管理、监控和保护 Elastic Stack。管理您的索引和摄入管道,监控 Elastic Stack 集群的运行状况,并控制哪些用户可以访问哪些特征和数据。
在今天的练习中,你将学习如何在 Kibana 中探索数据,如何使用 Kibana 创建可视化镜头,并将它们组合在仪表板中。你将使用 Kibana 的示例数据集。一个数据集描述了过去 10 天的航班信息。第二个数据集代表电子商务平台的订单。你将使用不同的 Kibana可视化来探索数据。你将深入了解运营商的典型延误等主题,以及票价波动。
在今天的练习中,我们将使用最新的 Elastic Stack 7.17 来进行展示。针对之前的版本,界面可能有所不同,但是很多操作基本是一样的。
原文链接:https://elasticstack.blog.csdn ... 05096
Kibana 是你进入 Elastic Stack 的窗口。 Kibana 使你能够:
分析和可视化你的数据。搜索隐藏的见解,编制图表仪表板,仪表、地图和其他可视化显示您发现的内容,并与他人分享。
搜索、观察和保护你的数据。向你的应用或网站添加搜索框,分析日志,指标,并发现安全漏洞。
管理、监控和保护 Elastic Stack。管理您的索引和摄入管道,监控 Elastic Stack 集群的运行状况,并控制哪些用户可以访问哪些特征和数据。
在今天的练习中,你将学习如何在 Kibana 中探索数据,如何使用 Kibana 创建可视化镜头,并将它们组合在仪表板中。你将使用 Kibana 的示例数据集。一个数据集描述了过去 10 天的航班信息。第二个数据集代表电子商务平台的订单。你将使用不同的 Kibana可视化来探索数据。你将深入了解运营商的典型延误等主题,以及票价波动。
在今天的练习中,我们将使用最新的 Elastic Stack 7.17 来进行展示。针对之前的版本,界面可能有所不同,但是很多操作基本是一样的。
原文链接:https://elasticstack.blog.csdn ... 05096 收起阅读 »
Elasticsearch 查询示例 - 动手练习(一)
在本指南中,你将学习许多 带有详细解释的流行查询示例。 此处涵盖的每个查询将分为 2 种类型:
- 结构化查询:用于检索结构化数据的查询,例如日期、数字、密码等。
- 全文查询:用于查询纯文本的查询。
原文链接:https://blog.csdn.net/UbuntuTo ... 53295
在本指南中,你将学习许多 带有详细解释的流行查询示例。 此处涵盖的每个查询将分为 2 种类型:
- 结构化查询:用于检索结构化数据的查询,例如日期、数字、密码等。
- 全文查询:用于查询纯文本的查询。
原文链接:https://blog.csdn.net/UbuntuTo ... 53295 收起阅读 »
社区日报 第1322期 (2021-01-27)
https://logit.io/blog/post/aws ... istro
2.如何看懂 Elastic 解决方案与 Gartner 的魔力象限
https://lex-lee.blog.csdn.net/ ... .5502
3.Elasticsearch 的新 range 丰富策略使上下文数据分析更上一层楼
https://elasticstack.blog.csdn ... .5502
编辑:Se7en
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
https://logit.io/blog/post/aws ... istro
2.如何看懂 Elastic 解决方案与 Gartner 的魔力象限
https://lex-lee.blog.csdn.net/ ... .5502
3.Elasticsearch 的新 range 丰富策略使上下文数据分析更上一层楼
https://elasticstack.blog.csdn ... .5502
编辑:Se7en
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup 收起阅读 »
欢迎您参加 Elastic 全球社区大会 - 2022年2月11日至12日线上直播
继2021年成功举办之后,第2届Elastic全球社区大会 #ElasticCC 将于2022年2月11日至12日隆重召开。大会继续秉承 “来自社区,面向社区” 的办会宗旨,采用多语言轮流线上直播的方式,面向全体开发者与技术人员、初级用户与资深玩家、行业客户与合作伙伴,提供横跨时间与空间的技术分享盛宴。详细阅读,请参阅 https://blog.csdn.net/UbuntuTo ... 98829
继2021年成功举办之后,第2届Elastic全球社区大会 #ElasticCC 将于2022年2月11日至12日隆重召开。大会继续秉承 “来自社区,面向社区” 的办会宗旨,采用多语言轮流线上直播的方式,面向全体开发者与技术人员、初级用户与资深玩家、行业客户与合作伙伴,提供横跨时间与空间的技术分享盛宴。详细阅读,请参阅 https://blog.csdn.net/UbuntuTo ... 98829 收起阅读 »
社区日报 第1320期 (2021-01-26)
https://medium.com/geekculture ... 57527
2. 使用 Prometheus 和 grafana 监控ES(需要梯子)
https://medium.com/rahasak/mon ... b6712
3. Elasticsearch:Dissect 和 Grok 处理器之间的区别
https://elasticstack.blog.csdn ... 26264
编辑:kin122
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
https://medium.com/geekculture ... 57527
2. 使用 Prometheus 和 grafana 监控ES(需要梯子)
https://medium.com/rahasak/mon ... b6712
3. Elasticsearch:Dissect 和 Grok 处理器之间的区别
https://elasticstack.blog.csdn ... 26264
编辑:kin122
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup 收起阅读 »
社区日报 第1319期 (2021-01-25)
1. ES 不同数据类型对于全文搜索的性能对比(需要梯子)
https://levelup.gitconnected.c ... 939a4
2. ES 速度和吞吐量提升的最佳实践(需要梯子)
https://luis-sena.medium.com/t ... f9e92
3. ES/OpenSearch 架构详解(需要梯子)
https://instaclustr.medium.com ... 5731b
编辑:斯蒂文
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
1. ES 不同数据类型对于全文搜索的性能对比(需要梯子)
https://levelup.gitconnected.c ... 939a4
2. ES 速度和吞吐量提升的最佳实践(需要梯子)
https://luis-sena.medium.com/t ... f9e92
3. ES/OpenSearch 架构详解(需要梯子)
https://instaclustr.medium.com ... 5731b
编辑:斯蒂文
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
收起阅读 »
Elasticsearch 的新 range 丰富策略使上下文数据分析更上一层楼 - 7.16

在之前我的文章 “Elasticsearch:enrich processor (7.5发行版新功能)” 已经详细描述了 geo_match 及 match 的丰富策略。详细使用,请阅读那篇文章。
更多阅读,请参阅 https://elasticstack.blog.csdn ... .5502
在之前我的文章 “Elasticsearch:enrich processor (7.5发行版新功能)” 已经详细描述了 geo_match 及 match 的丰富策略。详细使用,请阅读那篇文章。
更多阅读,请参阅 https://elasticstack.blog.csdn ... .5502 收起阅读 »
社区日报 第1318期 (2022-01-24)
https://medium.com/free-code-c ... c16cb
2.使用 Filebeat 将 Mysql 日志发送至 ES(自备梯子)
https://alibaba-cloud.medium.c ... 567f8
3.从 Kubernetes 收集日志——fluentd vs filebeat(自备梯子)
https://itnext.io/logz-io-coll ... 08cfe
编辑:pangying
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
https://medium.com/free-code-c ... c16cb
2.使用 Filebeat 将 Mysql 日志发送至 ES(自备梯子)
https://alibaba-cloud.medium.c ... 567f8
3.从 Kubernetes 收集日志——fluentd vs filebeat(自备梯子)
https://itnext.io/logz-io-coll ... 08cfe
编辑:pangying
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup 收起阅读 »
社区日报 第1317期 (2022-01-23)
https://juejin.cn/post/6897126942537941005
2.ES多线程调用,线程阻塞超时问题解决
https://blog.csdn.net/sej520/a ... 25842
3.ES查询查询超市问题排查
https://segmentfault.com/a/1190000021669853
编辑:cyberdak
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
https://juejin.cn/post/6897126942537941005
2.ES多线程调用,线程阻塞超时问题解决
https://blog.csdn.net/sej520/a ... 25842
3.ES查询查询超市问题排查
https://segmentfault.com/a/1190000021669853
编辑:cyberdak
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup 收起阅读 »
社区日报 第1315期 (2021-01-21)
1、使用 TheHive、Cortex 和 Elasticsearch 实现 SOC
https://blog.devgenius.io/soc- ... 19f0c
2、使用 Oura + Elasticsearch + React 的开源项目
https://github.com/txpipe/cip25-search-engine
3、Elasticsearch 时序数据分析实战
https://dzone.com/articles/tim ... -java
编辑:铭毅天下
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
1、使用 TheHive、Cortex 和 Elasticsearch 实现 SOC
https://blog.devgenius.io/soc- ... 19f0c
2、使用 Oura + Elasticsearch + React 的开源项目
https://github.com/txpipe/cip25-search-engine
3、Elasticsearch 时序数据分析实战
https://dzone.com/articles/tim ... -java
编辑:铭毅天下
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup 收起阅读 »
社区日报 第1314期 (2021-01-20)
https://mp.weixin.qq.com/s/uqchdrkhdFsof0ZFtECujg
2.详解 Elasticsearch 中的路由机制
http://niyanchun.com/routing-in-es.html
3.Elasticsearch 与SQL-style Join
https://mp.weixin.qq.com/s/yg60lZlBvIUKnHmGp5deDQ
编辑:Se7en
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
https://mp.weixin.qq.com/s/uqchdrkhdFsof0ZFtECujg
2.详解 Elasticsearch 中的路由机制
http://niyanchun.com/routing-in-es.html
3.Elasticsearch 与SQL-style Join
https://mp.weixin.qq.com/s/yg60lZlBvIUKnHmGp5deDQ
编辑:Se7en
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup 收起阅读 »
社区日报 第1313期 (2021-01-19)
https://cloud.tencent.com/deve ... 01555
2. 如何正确处理 Elasticsearch ingest pipeline故障(需要梯子)
https://medium.zenika.com/how- ... a1c1f
3. Elasticsearch:深入理解 Dissect ingest processor
https://elasticstack.blog.csdn ... 20145
编辑:kin122
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
https://cloud.tencent.com/deve ... 01555
2. 如何正确处理 Elasticsearch ingest pipeline故障(需要梯子)
https://medium.zenika.com/how- ... a1c1f
3. Elasticsearch:深入理解 Dissect ingest processor
https://elasticstack.blog.csdn ... 20145
编辑:kin122
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup 收起阅读 »
Elasticsearch 与SQL-style Join 前篇
Elasticsearch 与SQL-style Join 前篇
1.上下文
Elasticsearch(后面简称ES)作为火热的开源&分布式&Json文档形式的搜索引擎在互联网行业被广泛应用. 作为一种NoSQL数据存储服务, ES的侧重点放在了扩展性(Scalability) 与可用性(Availability)上, 提供了极快的搜索与索引文档能力(省略各种对ES的赞美.....就如同你知道的.....主要提供搜索的能力!) 然而, 来自SQL世界的我们, 日常被各种关系性数据充斥着, 使用ES常常疑惑为什么大量MySql中适用的法则在ES中行不通: 不同于SQL的ES DSL语言风格, 搜到/搜不到想要的结果集, 复杂的聚合分析,众多正在不断演进的新功能与永远记不完的APIs....... 本文不会对ES的基本功能作太多的讲解, 侧重放在了对SQL中的join查询与ES提供的join方案的对比与分析上, 基于本人的实践经验, 提供了数种可行的跨索引关联查询方案
本文分为"前篇"与"后篇" ,分别覆盖了不同的ES中实现SQL-style join的技术方案
2.引子
2.1 建议
- 不要用Mysql上的规则去理解一款NoSql DB(Elastic search)
- Join查询与简单的"向多个索引查询数据"并不等价: join查询体现一个"数据关联",后文将重点描述
- 有时候, 为了达到某些效果, 可能意味着"pay some price" (e.g 空间换时间)
2.2 Join查询
开始正文前, 聊聊什么是join查询, join查询在绝大数情况下是SQL中的概念, SQL-style join查询是体现关系型数据库中"关系"的重要方式, 通过驱动表与被驱动表的字段关联, 表与表之间建立了联系方式, 并可以把多个表中的字段值一起返回到结果集:
- 表与表之间有关联性(由连接字段确定)
- 结果集中体现了这种关联性
看到这....或许你会疑惑为什么在解释join查询时反复强调"关联"二字, 相信你应该熟悉SQL中的笛卡尔积现象, 如果不通过连接字段对数据进行筛选, 那么表与表之间连接后产生的"宽表"的数据量会是一个很恐怖的数字(表A行数X表B行数X表C行数.....以此类推), 业务往往需要对产生的结果集进行二次数据筛选, 最后才能从大量的数据中找到少量感兴趣的信息. 而通过指定SQL-style中的join关联关系(e.g table A.字段1 =tableB.字段1)就能在SQL服务中就完成数据筛选, 并且返回的结果集中体现了这种关联性, 降低了业务上筛选相关的工作量.
作为一款 Nosql 且 Schemaless的数据存储, ElasticSearch没有对数据的结构进行强限制, 对客户端而言,返回的结果集都是由弱类型的json对象组成. ES没有像SQL DB那样做到对join查询的友好支持. 但是数据与数据之间的关联在ES中同样非常重要!(或许在任何数据存储服务中都重要). 本文前后篇通过对比讨论 "denormalization(反范式)" , "应用层join", "ES nested query" ,"ES has parent/child query", "ES服务层join(open distro开源生态下)"这些技术的方式(部分将在后篇描述), 探讨join查询在不同环境下的有效解决方案.
3. 方案
3.0 前言: 需解决的问题
如果需要在ES中实现一个SQL:
select * from tablea a join tableb b
on a.field1 =b.field1 order by a.create_time desc等价查询效果, 并且应用层能通过分页的方式滚动查询到所有数据
3.1 方案一: denormalization(反范式)
这可能是最"直接"的方案了, 通过修改数据模型来“flatten”数据,每个ES文档在被index时就已经有了所需要的全部关联数据.
如果是搭建异构索引场景(可理解为RDS从库), 根据关联关系的不同(1 to N, N to M)索引的文档量最高将会是 2乘以 tablea行数乘以 tableb行数(有点笛卡尔积的感觉). Denormalization通过建立"超级宽"的索引维系了1 to N 或 N to M的关联关系, 应用层与ES不需要做任何join处理, 因为一个文档已经拥有了客户端需要的全部数据(数据层面上已经做到了聚合)
对于平时与关系型数据库打交道的童鞋而言, 建 "超级宽表" 映射的索引与数据冗余可能是一件"非正常"的行为, 第一反应就是数据的冗余与空间资源浪费. 但是这种方案的确是目前广泛使用的建立数据关联关系的解决方案(如同前文说的------不要用Mysql上的规则去理解ES).
3.1.1 优势
- 应用端 & ES端都不需要做任何join操作(一个ES文档有全部客户端想要的数据)
- 分布式环境下因聚合结果集相关操作产生的延迟问题得到有效解决
- 在空间资源足够下, 方案可行性高(至少有信心吼一句"能做到")
3.1.2 挑战
- 数据的冗余与空间资源浪费(空间换时间)
- 如何梳理业务模型与flatten数据: 关系型数据中通过外键,schema约束, 查询语句(join)等方式建立的关联关系要被体现到ES的索引mapping中
- 应用层(访问ES的服务)需要的编码调整(有些工程会在dao层做统一适配处理)
- 更新操作涉及到的数据大幅度增加: 原本一个涉及单表单行update SQL可能会牵扯到多个文档中的某个字段, 且每个文档占用的空间资源更高
- 新增文档的频率会更高: 理由同上
总结: Denormation方案的通用性高, 并且能够满足快速搜索的需求(最快的查询关联数据的方式), 但是额外的存储资源使用带来的相应开销问题与数据模型梳理上的问题会带来挑战
3.2 方案二: ES SQL join(open distro开源生态)
xpack 增加了有限度的SQL支持
然而...不支持join语法....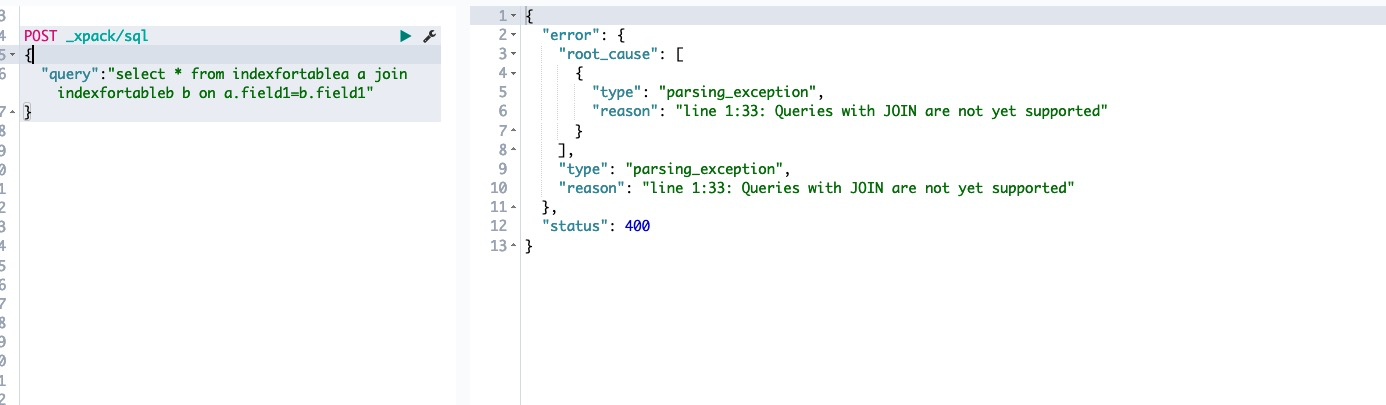
安装扩展插件获取更强的SQL支持能力(open distro)
LINK
更为强大的SQL支持(包括join语法)
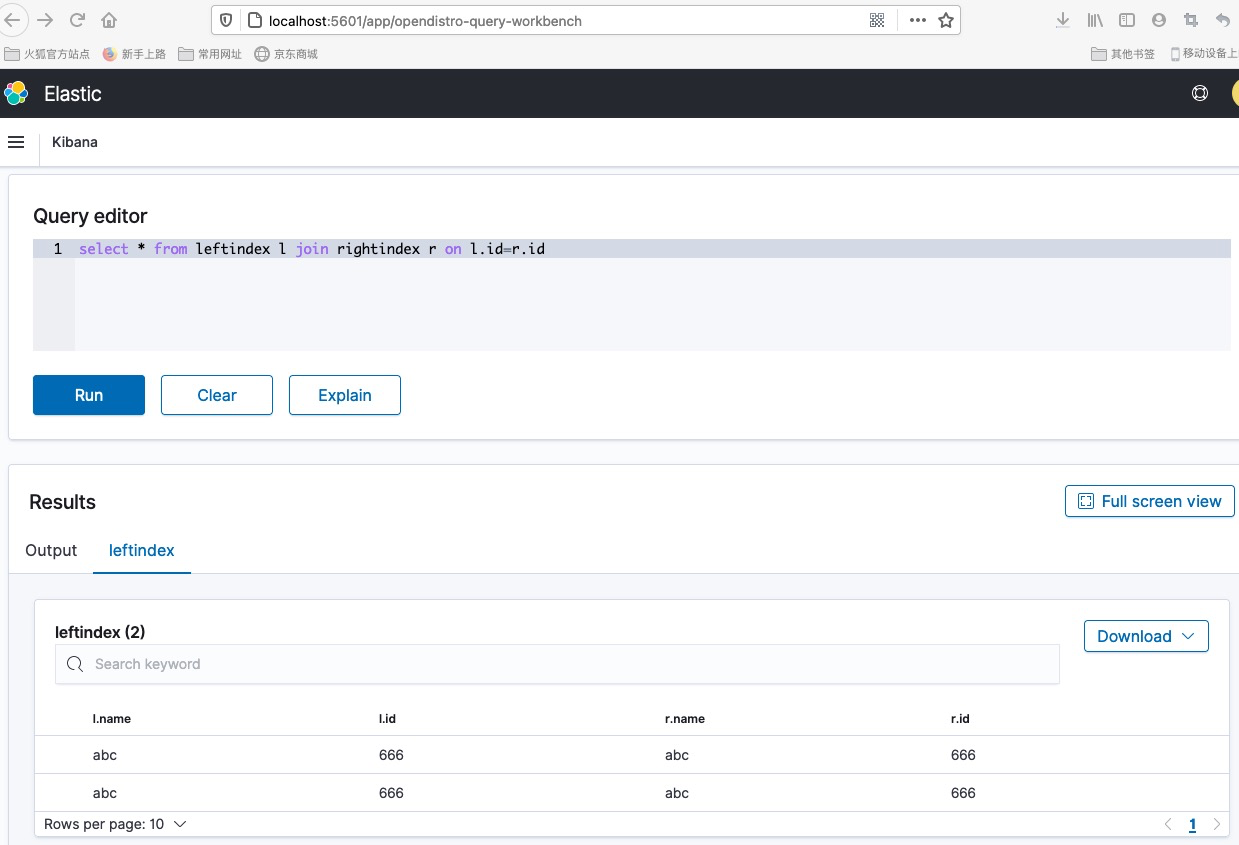 挑战:
挑战:
- 额外的ES插件(第三方插件对ES不同版本的兼容性?)
- 业务方调整(语句改为SQL-style, 且要使用open distro提供的JDBC相关依赖)
- open distro是一整套ES工具集(AWS上自带集成)
- 对该产品特性的学习LINK
3.3 方案三: 应用层join
通过应用工程对不同索引的多次访问,在组装结果集的过程中建立数据的关联关系
3.3.1 实现方式
可以仿照MySQL的join实现方式: 例如为了实现
select * from tablea a join tableb b
on a.field1 =b.field1 where a.field2 in ('value1','value2','value3') order by a.create_time desc这句SQL的等效查询
应用层可以:
- 1 选择 tablea 对应的异构索引作为驱动索引, 通过结构化查询, 获取field2 为'value1','value2','value3' 的文档中_id值(N个)
- 2 以文档field1作为连接条件, 从被驱动索引(tableb对应的异构索引)中找到字段field1满足条件( a.field1 =b.field1)的文档
- 3 用获取到的文档拼接结果集返回
如果配合ES terms-lookup 则为:
/**从tablea fetch符合条件的文档集**/
GET tablea/_search
{
"query": {
"terms": {
"field2": [
"value1",
"value2",
"value3"
]
}
}
}
/**假使仅获得一个文档且_id值为6666**/
GET tableb/_search
{
"query": {
"terms": {
"field1": {
"index" : "tablea",
"type" : "_doc",
"id" : "6666",
"path" : "field1"
}
}
}
}
/**利用ES terms-lookup进行连接查询**/
以上查询在应用层可用ES high-level-client实现, 数据的拼接,过滤, 循环查询等挑战都需要在应用层克服(难)
3.3.2 该方案面临几个挑战
- 如果文档数过多(被驱动表/驱动表中任意一张表获取的文档过多) -> 内存,网络等资源占用过高
- 应用层join引发的多次请求
- 应用层join引发的ES服务端压力
- 应用层代码的改动: 驱动表的选择, join的实现, 应用层缓存数据的压力...
- 一套稳定的join机制的实现会很复杂......
4. End
本文分为前篇与后篇, 我会在后篇文章中对这些技术进行进一步描述与对比, 并且引入可实践的方案.
原稿作者:Yukai糖在江湖
原稿链接:https://blog.csdn.net/fanduifandui/article/details/117264084
Elasticsearch 与SQL-style Join 前篇
1.上下文
Elasticsearch(后面简称ES)作为火热的开源&分布式&Json文档形式的搜索引擎在互联网行业被广泛应用. 作为一种NoSQL数据存储服务, ES的侧重点放在了扩展性(Scalability) 与可用性(Availability)上, 提供了极快的搜索与索引文档能力(省略各种对ES的赞美.....就如同你知道的.....主要提供搜索的能力!) 然而, 来自SQL世界的我们, 日常被各种关系性数据充斥着, 使用ES常常疑惑为什么大量MySql中适用的法则在ES中行不通: 不同于SQL的ES DSL语言风格, 搜到/搜不到想要的结果集, 复杂的聚合分析,众多正在不断演进的新功能与永远记不完的APIs....... 本文不会对ES的基本功能作太多的讲解, 侧重放在了对SQL中的join查询与ES提供的join方案的对比与分析上, 基于本人的实践经验, 提供了数种可行的跨索引关联查询方案
本文分为"前篇"与"后篇" ,分别覆盖了不同的ES中实现SQL-style join的技术方案
2.引子
2.1 建议
- 不要用Mysql上的规则去理解一款NoSql DB(Elastic search)
- Join查询与简单的"向多个索引查询数据"并不等价: join查询体现一个"数据关联",后文将重点描述
- 有时候, 为了达到某些效果, 可能意味着"pay some price" (e.g 空间换时间)
2.2 Join查询
开始正文前, 聊聊什么是join查询, join查询在绝大数情况下是SQL中的概念, SQL-style join查询是体现关系型数据库中"关系"的重要方式, 通过驱动表与被驱动表的字段关联, 表与表之间建立了联系方式, 并可以把多个表中的字段值一起返回到结果集:
- 表与表之间有关联性(由连接字段确定)
- 结果集中体现了这种关联性
看到这....或许你会疑惑为什么在解释join查询时反复强调"关联"二字, 相信你应该熟悉SQL中的笛卡尔积现象, 如果不通过连接字段对数据进行筛选, 那么表与表之间连接后产生的"宽表"的数据量会是一个很恐怖的数字(表A行数X表B行数X表C行数.....以此类推), 业务往往需要对产生的结果集进行二次数据筛选, 最后才能从大量的数据中找到少量感兴趣的信息. 而通过指定SQL-style中的join关联关系(e.g table A.字段1 =tableB.字段1)就能在SQL服务中就完成数据筛选, 并且返回的结果集中体现了这种关联性, 降低了业务上筛选相关的工作量.
作为一款 Nosql 且 Schemaless的数据存储, ElasticSearch没有对数据的结构进行强限制, 对客户端而言,返回的结果集都是由弱类型的json对象组成. ES没有像SQL DB那样做到对join查询的友好支持. 但是数据与数据之间的关联在ES中同样非常重要!(或许在任何数据存储服务中都重要). 本文前后篇通过对比讨论 "denormalization(反范式)" , "应用层join", "ES nested query" ,"ES has parent/child query", "ES服务层join(open distro开源生态下)"这些技术的方式(部分将在后篇描述), 探讨join查询在不同环境下的有效解决方案.
3. 方案
3.0 前言: 需解决的问题
如果需要在ES中实现一个SQL:
select * from tablea a join tableb b
on a.field1 =b.field1 order by a.create_time desc等价查询效果, 并且应用层能通过分页的方式滚动查询到所有数据
3.1 方案一: denormalization(反范式)
这可能是最"直接"的方案了, 通过修改数据模型来“flatten”数据,每个ES文档在被index时就已经有了所需要的全部关联数据.
如果是搭建异构索引场景(可理解为RDS从库), 根据关联关系的不同(1 to N, N to M)索引的文档量最高将会是 2乘以 tablea行数乘以 tableb行数(有点笛卡尔积的感觉). Denormalization通过建立"超级宽"的索引维系了1 to N 或 N to M的关联关系, 应用层与ES不需要做任何join处理, 因为一个文档已经拥有了客户端需要的全部数据(数据层面上已经做到了聚合)
对于平时与关系型数据库打交道的童鞋而言, 建 "超级宽表" 映射的索引与数据冗余可能是一件"非正常"的行为, 第一反应就是数据的冗余与空间资源浪费. 但是这种方案的确是目前广泛使用的建立数据关联关系的解决方案(如同前文说的------不要用Mysql上的规则去理解ES).
3.1.1 优势
- 应用端 & ES端都不需要做任何join操作(一个ES文档有全部客户端想要的数据)
- 分布式环境下因聚合结果集相关操作产生的延迟问题得到有效解决
- 在空间资源足够下, 方案可行性高(至少有信心吼一句"能做到")
3.1.2 挑战
- 数据的冗余与空间资源浪费(空间换时间)
- 如何梳理业务模型与flatten数据: 关系型数据中通过外键,schema约束, 查询语句(join)等方式建立的关联关系要被体现到ES的索引mapping中
- 应用层(访问ES的服务)需要的编码调整(有些工程会在dao层做统一适配处理)
- 更新操作涉及到的数据大幅度增加: 原本一个涉及单表单行update SQL可能会牵扯到多个文档中的某个字段, 且每个文档占用的空间资源更高
- 新增文档的频率会更高: 理由同上
总结: Denormation方案的通用性高, 并且能够满足快速搜索的需求(最快的查询关联数据的方式), 但是额外的存储资源使用带来的相应开销问题与数据模型梳理上的问题会带来挑战
3.2 方案二: ES SQL join(open distro开源生态)
xpack 增加了有限度的SQL支持
然而...不支持join语法....
安装扩展插件获取更强的SQL支持能力(open distro)
LINK
更为强大的SQL支持(包括join语法)
挑战:
- 额外的ES插件(第三方插件对ES不同版本的兼容性?)
- 业务方调整(语句改为SQL-style, 且要使用open distro提供的JDBC相关依赖)
- open distro是一整套ES工具集(AWS上自带集成)
- 对该产品特性的学习LINK
3.3 方案三: 应用层join
通过应用工程对不同索引的多次访问,在组装结果集的过程中建立数据的关联关系
3.3.1 实现方式
可以仿照MySQL的join实现方式: 例如为了实现
select * from tablea a join tableb b
on a.field1 =b.field1 where a.field2 in ('value1','value2','value3') order by a.create_time desc这句SQL的等效查询
应用层可以:
- 1 选择 tablea 对应的异构索引作为驱动索引, 通过结构化查询, 获取field2 为'value1','value2','value3' 的文档中_id值(N个)
- 2 以文档field1作为连接条件, 从被驱动索引(tableb对应的异构索引)中找到字段field1满足条件( a.field1 =b.field1)的文档
- 3 用获取到的文档拼接结果集返回
如果配合ES terms-lookup 则为:
/**从tablea fetch符合条件的文档集**/
GET tablea/_search
{
"query": {
"terms": {
"field2": [
"value1",
"value2",
"value3"
]
}
}
}
/**假使仅获得一个文档且_id值为6666**/
GET tableb/_search
{
"query": {
"terms": {
"field1": {
"index" : "tablea",
"type" : "_doc",
"id" : "6666",
"path" : "field1"
}
}
}
}
/**利用ES terms-lookup进行连接查询**/
以上查询在应用层可用ES high-level-client实现, 数据的拼接,过滤, 循环查询等挑战都需要在应用层克服(难)
3.3.2 该方案面临几个挑战
- 如果文档数过多(被驱动表/驱动表中任意一张表获取的文档过多) -> 内存,网络等资源占用过高
- 应用层join引发的多次请求
- 应用层join引发的ES服务端压力
- 应用层代码的改动: 驱动表的选择, join的实现, 应用层缓存数据的压力...
- 一套稳定的join机制的实现会很复杂......
4. End
本文分为前篇与后篇, 我会在后篇文章中对这些技术进行进一步描述与对比, 并且引入可实践的方案.
原稿作者:Yukai糖在江湖
原稿链接:https://blog.csdn.net/fanduifandui/article/details/117264084


