

Elasticsearch:使用 pipelines 路由文档到想要的 Elasticsearch 索引中去
Elasticsearch | 作者 liuxg | 发布于2023年02月23日 | | 阅读数:5121原文地址 elasticstack.blog.csdn.net

路由文件
当应用程序需要向 Elasticsearch 添加文档时,它们首先要知道目标索引是什么。在很多的应用案例中,特别是针对时序数据,我们想把每个月的数据写入到一个特定的索引中。一方面便于管理索引,另外一方面在将来搜索的时候可以按照每个月的索引来进行搜索,这样速度更快,更便捷。
当你处于某种类型的文档总是转到特定索引的琐碎情况时,这似乎很明显,但当你的索引名称可能根据杂项参数(无论它们是否在你的系统外部 - 当前例如日期 - 或者你尝试存储的文档的固有属性 - 大多数时候是文档字段之一的值)。
当发生最后一种情况时(我们指的是索引名称可以变化的情况),在向 Elasticsearch 发出索引命令之前,你的应用程序需要计算目标索引的名称。
此外 —— 即使一开始这看起来像是一种反模式 —— 你可以有多个应用程序需要在索引中索引相同类型的文档,这些文档的名称可能会发生变化。 现在你必须维护跨多个组件重复的索引名称计算逻辑:就可维护性和敏捷性而言,这不是好消息。
Logstash —— Elastic Stack 的一个知名成员 —— 可以帮助集中这样的逻辑,但代价是维护另一个正在运行的软件,这需要配置、知识等。
我们想要在本文中展示的是通过将索引名称计算委托给 Elasticsearch 而不是我们的应用程序来解决此问题的解决方案。
Date index name processor 介绍
该处理器的目的是通过使用日期数学索引名称支持,根据文档中的日期或时间戳字段将文档指向基于正确时间的索引。
处理器根据提供的索引名称前缀、正在处理的文档中的日期或时间戳字段以及提供的日期舍入,使用日期数学索引名称表达式设置 _index 元数据字段。
首先,此处理器从正在处理的文档中的字段中获取日期或时间戳。 或者,可以根据字段值应如何解析为日期来配置日期格式。 然后这个日期、提供的索引名称前缀和提供的日期舍入被格式化为日期数学索引名称表达式。 此处还可以选择日期格式指定日期应如何格式化为日期数学索引名称表达式。
将文档指向每月索引的示例管道,该索引以基于 date1 字段中的日期的 my-index-prefix 开头:
1. PUT _ingest/pipeline/monthlyindex
2. {
3. "description": "monthly date-time index naming",
4. "processors" : [
5. {
6. "date_index_name" : {
7. "field" : "date1",
8. "index_name_prefix" : "my-",
9. "date_rounding" : "M"
10. }
11. }
12. ]
13. }
使用该管道进行索引请求:
1. PUT /my-index/_doc/1?pipeline=monthlyindex
2. {
3. "date1" : "2016-04-25T12:02:01.789Z"
4. }
上面命令运行的结果是:
1. {
2. "_index": "my-index-2016-04-01",
3. "_id": "1",
4. "_version": 1,
5. "result": "created",
6. "_shards": {
7. "total": 2,
8. "successful": 1,
9. "failed": 0
10. },
11. "_seq_no": 0,
12. "_primary_term": 1
13. }
上面的请求不会将这个文档索引到 my-index 索引中,而是索引到 my-index-2016-04-01 索引中,因为它是按月取整的。 这是因为 date-index-name-processor 覆盖了文档的 _index 属性。
要查看导致上述文档被索引到 my-index-2016-04-01 中的实际索引请求中提供的索引的日期数学(date-math)值,我们可以使用模拟请求检查处理器的效果。
1. POST _ingest/pipeline/_simulate
2. {
3. "pipeline" :
4. {
5. "description": "monthly date-time index naming",
6. "processors" : [
7. {
8. "date_index_name" : {
9. "field" : "date1",
10. "index_name_prefix" : "my-",
11. "date_rounding" : "M"
12. }
13. }
14. ]
15. },
16. "docs": [
17. {
18. "_source": {
19. "date1": "2016-04-25T12:02:01.789Z"
20. }
21. }
22. ]
23. }
上面命令返回结果:
`
1. {
2. "docs": [
3. {
4. "doc": {
5. "_index": "<my-index-{2016-04-25||/M{yyyy-MM-dd|UTC}}>",
6. "_id": "_id",
7. "_version": "-3",
8. "_source": {
9. "date1": "2016-04-25T12:02:01.789Z"
10. },
11. "_ingest": {
12. "timestamp": "2023-02-23T01:15:52.214364Z"
13. }
14. }
15. }
16. ]
17. }
`以上示例显示 _index 设置为 <my-index-{2016-04-25||/M{yyyy-MM-dd|UTC}}>。 Elasticsearch 将其理解为 2016-04-01,如日期数学索引名称文档中所述。
日期索引名称选项
以下是使用 date index name 的一些选项
| no | - | 处理器的描述。 用于描述处理器的用途或其配置。 | |
| if | no | - | 有条件地执行处理器。 请参阅有条件地运行处理器。 |
| ignore_failure | no | false | 忽略处理器的故障。 请参阅处理管道故障。 |
| on_failure | no | - | 处理处理器的故障。 请参阅处理管道故障。 |
| tag | no | - | 处理器的标识符。 用于调试和指标 |
使用案例 - 基于时间的时序索引
这是一个众所周知的用例,通常在您要处理日志时发现。这个想法是索引文档,索引的名称由根名称和根据日志事件的日期计算的值组成。 该日期实际上是你要索引的文档的一个字段。
这不是本文的重点,但以这种方式索引文档有几个优点,包括更容易的数据管理、启用冷/暖架构等。让我们举个例子。
假设我们必须处理来自多个来源的数据 —— 例如物联网。 我们的每个对象每分钟都会向不同的后端发送一些数据(是的,这真的很可悲,但我们的对象不通过相同的网络进行通信,因此选择通过多个系统来处理这个问题)。
对象发送的数据被转换成如下所示的 JSON 文档:
1. POST data/_doc?pipeline=compute-index-name
2. {
3. "objectId": 1234,
4. "manufacturer": "SHIELD",
5. "payload": "some_data",
6. "date": "2019-04-01T12:10:30.000Z"
7. }
我们有一个用于传输数据的对象的 UID、一个制造商 ID、一个有效负载部分和一个日期字段。
索引名称计算
假设我们要将对象的数据存储在名为 data-{YYYYMMDD} 的索引中,其中根名称是数据后跟日期模式。基于上面的例子,后端收到这个文档应该怎么办呢?
首先它必须解析它以提取日期字段的值,然后它必须根据它在文档中找到的日期计算目标索引名称。 最后,它向 Elasticsearch 向刚刚计算出名称的索引发出索引请求。
1. document.date = "2019-04-01T12:10:30Z"
2. index.name = "" + "20190401"
在我们的例子中,我们有几个后端必须知道如何计算索引名称,因此必须知道索引的命名逻辑。
如果索引名的计算直接由 Elasticsearch 进行,岂不是更聪明?
Ingest pipeline 的力量

从 Elasticsearch 的第 5 版开始,我们现在有了一种称为摄取的节点。默认情况下,集群的所有节点都具有 ingest 类型。这些节点有权在索引文档之前执行所谓的管道。 管道是一组处理器,每个处理器都可以以某种特定方式转换输入文档。当一个文档被摄入到 Elasticsearch 集群时,它的工作流是这样的。
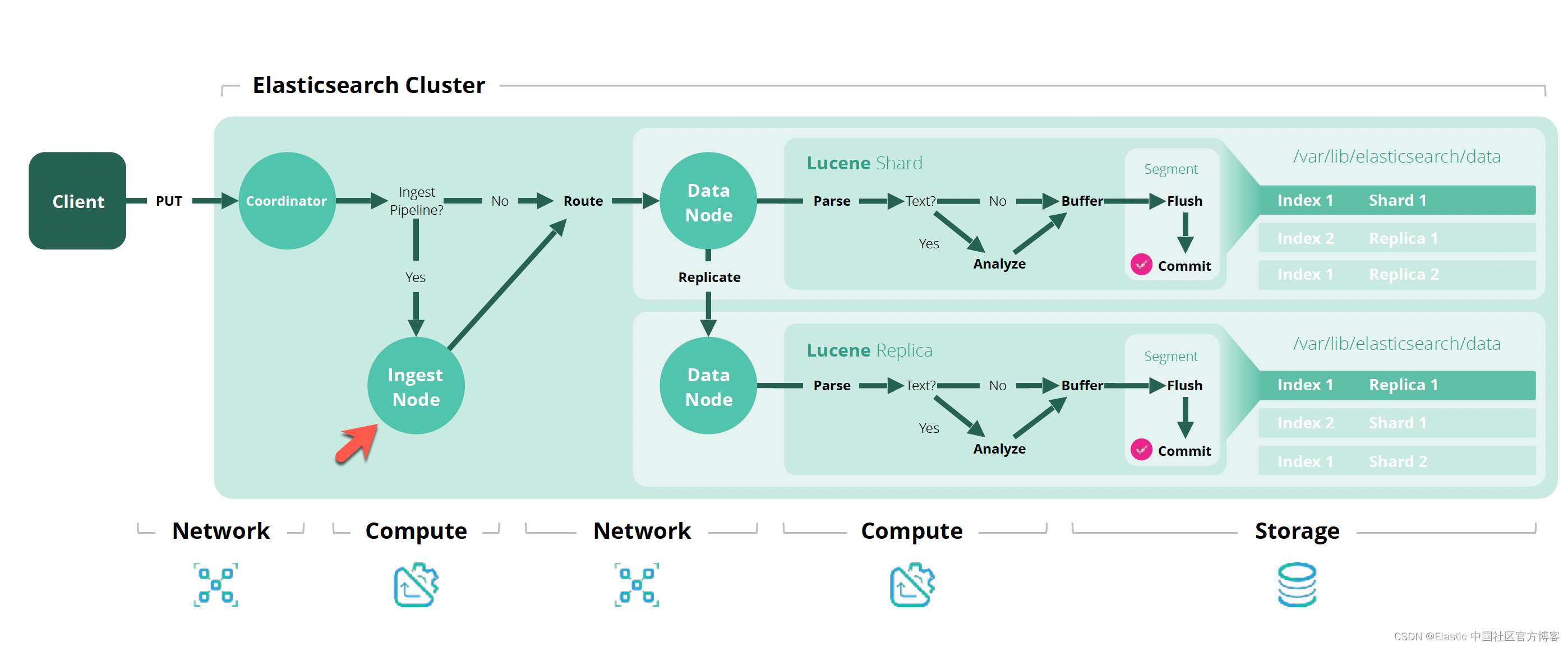
从上面,我们可以看出来,在文档被写入之前,它必须经过 ingest node 进行处理。我们可以通过 date index name processor 来获得我们想要的 index 名称,进而写入到我们想要的索引中去。 这里有用的是,管道不仅可以转换文档的固有数据,还可以修改文档元数据,特别是它的 _index 属性。
现在让我们回到我们的例子。我们建议定义一个管道来完成这项工作,而不是将索引名称计算委托给应用程序。根据文档,此处理器允许你定义包含日期的字段名称、索引的根名称(前缀)以及计算附加到此前缀的日期的舍入方法。
如果我们想将 IoT 数据添加到模式为 data-{YYYYMMDD} 的索引中,我们只需创建如下所示的管道:
1. PUT _ingest/pipeline/compute-index-name
2. {
3. "description": "Set the document destination index by appending a prefix and its 'date' field",
4. "processors": [
5. {
6. "date_index_name": {
7. "field": "date",
8. "index_name_prefix": "",
9. "date_rounding": "d",
10. "index_name_format": "yyyyMMdd"
11. }
12. }
13. ]
14. }
一个索引 = 一个管道?
好的,现在我们知道如何定义一个管道来为特定的目标索引建立一个名称。 但是我们可以通过操纵文档元数据来做更多的事情!
假设我们有不同类型的文档,每个文档都有一个日期字段,但需要在不同的索引中进行索引。计算目标索引名称的逻辑对于每种文档类型都是相同的,但使用上述策略将导致创建多个管道。
让我们试着做一些更简单和可重用的东西。
回到我们的示例,我们现在有两种文档类型:一种需要在 adata-{YYYYMMDD} 索引(和以前一样)中建立索引,另一种其目的地是名为 new_data-{YYYYMMDD} 的索引。
目标为 new_data 的文档具有以下结构:
1. {
2. "newObjectId": 1234,
3. "source": "HYDRA",
4. "payload": "some_data",
5. "date": "2019-04-02T13:10:30.000Z"
6. }
该结构与标准 IoT 文档略有不同,但重要的是日期字段存在于两个映射中。
现在我们要定义一个管道来计算我们两种文档类型的目标索引。 我们所要做的就是通过分析通过索引 API 发出的请求目的地来构建目的地索引名称。
1. PUT _ingest/pipeline/compute-index-name
2. {
3. "description": "Set the document destination index by appending the requested index and its 'date' field",
4. "processors": [
5. {
6. "date_index_name": {
7. "field": "date",
8. "index_name_prefix": "{{ _index }}-",
9. "date_rounding": "d",
10. "index_name_format": "yyyyMMdd"
11. }
12. }
13. ]
14. }
请注意,索引名称前缀现在位于名为_index 的索引元数据字段中。 通过使用这个字段,我们的管道现在是通用的并且可以与任何索引一起使用 —— 假设目标索引是根据相同的规则计算的。
使用我们的 “路由” 管道
现在我们有了一个能够根据文档的日期字段计算目标索引名称的通用管道,让我们看看如何让 Elasticsearch 使用它。
我们可以通过两种方式告诉 Elasticsearch 使用管道,让我们评估一下。
Index API 调用
第一个 —— 也是直接的解决方案——是使用 Index API 的管道参数。
换句话说:每次你想索引一个文档,你必须告诉 Elasticsearch 要使用的管道。
1. POST data/_doc?pipeline=compute-index-name
2. {
3. "objectId": 1234,
4. "manufacturer": "SHIELD",
5. "payload": "some_data",
6. "date": "2019-04-01T12:10:30.000Z"
7. }
现在,每次我们通过指示 compute-index-name 管道将文档添加到索引中时,该文档将被添加到正确的基于时间的索引中。 在此示例中,目标索引将为 data-20190401 。
我们提供给 Index API 的 data 索引名称呢? 它可以被看作是一个假索引:它只是用来执行 API 调用并且是真正目标索引的根,它不一定存在!
默认管道:引入 “虚拟索引”
索引默认管道(default pipeline)是使用管道的另一种有用方式:当你创建索引时,有一个名为 index.default_pipeline 的设置可以设置为管道的名称,只要你将文档添加到相应的索引就会执行该管道并且没有管道被添加到 API 调用中。 你还可以在索引文档时使用特殊管道名称 _none 来绕过此默认索引。 通过使用此功能,你可以定义我称之为 “虚拟索引” 的内容,并将其与默认管道相关联,该默认管道将充当我们上面看到的路由管道。
让我们将其应用到我们的示例中。
我们假设我们的通用路由管道 compute-index-name 已经创建。 我们现在可以创建一个名为 data 的索引,它将使用此管道作为其默认管道。
1. PUT data
2. {
3. "settings" : {
4. "index" : {
5. "number_of_shards" : 3,
6. "number_of_replicas" : 1,
7. "default_pipeline" : "compute-index-name"
8. }
9. }
10. }
现在,每次我们要求 Elasticsearch 为数据索引中的文档编制索引时,计算索引名称管道将负责该文档的实际路由。 因此,数据索引中永远不会有单个文档被索引,但我们将调用管道的责任完全委托给 Elasticsearch。
运行完上面的命令后,我们来尝试写入一个文档:
1. POST data/_doc
2. {
3. "objectId": 1234,
4. "manufacturer": "SHIELD",
5. "payload": "some_data",
6. "date": "2019-04-01T12:10:30.000Z"
7. }
上面的命令返回的结果是:
1. {
2. "_index": "data-20190401",
3. "_id": "2DMGfIYBaog4blQ55Qr7",
4. "_version": 1,
5. "result": "created",
6. "_shards": {
7. "total": 2,
8. "successful": 1,
9. "failed": 0
10. },
11. "_seq_no": 1,
12. "_primary_term": 1
13. }
结论
我们刚刚在这里看到了如何利用 Elasticsearch 中的管道功能根据文档的固有属性来路由文档。Ingest pipeline 不仅仅可以替代 Logstash 过滤器:你可以定义复杂的管道,使用多个处理器(一个特定的处理器甚至允许你调用另一个管道)、条件等。有关 ingest pipeline 的更多文章,请参阅 “Elastic:开发者上手指南” 文章中的 “Ingest pipeline” 章节。
在我看来,本文末尾看到的 “虚拟索引” 非常有趣。 包含创建这样一个并非真正的索引的索引只是为了创建路由管道的入口点的功能甚至可以成为 Elasticsearch 的一个新的和有用的功能,为什么不呢?
本文地址:http://elasticsearch.cn/article/14825
