

【搜索客社区日报】第2265期 (2026-07-13)
https://elasticstack.blog.csdn ... 70873
2、谁来评判评判者?在 Elasticsearch Workflows 中使用 LLM-as-a-Judge
https://elasticstack.blog.csdn ... 51391
3、如何使用 OpenTelemetry 在 Elastic 上构建搜索分析,无需额外的管道
https://elasticstack.blog.csdn ... 15352
4、Agent 评测:方法论与体系设计
https://mp.weixin.qq.com/s/7a2L-GatYYwI6s1uK9mTjA
5、一份可信来源,终结 Skill 管理混乱:Skill 治理最佳实践
https://mp.weixin.qq.com/s/b88VRdAQ2u7IhQBqvNcnVg
编辑:Muse
更多资讯:http://news.searchkit.cn
https://elasticstack.blog.csdn ... 70873
2、谁来评判评判者?在 Elasticsearch Workflows 中使用 LLM-as-a-Judge
https://elasticstack.blog.csdn ... 51391
3、如何使用 OpenTelemetry 在 Elastic 上构建搜索分析,无需额外的管道
https://elasticstack.blog.csdn ... 15352
4、Agent 评测:方法论与体系设计
https://mp.weixin.qq.com/s/7a2L-GatYYwI6s1uK9mTjA
5、一份可信来源,终结 Skill 管理混乱:Skill 治理最佳实践
https://mp.weixin.qq.com/s/b88VRdAQ2u7IhQBqvNcnVg
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2264期 (2026-07-09)
https://mp.weixin.qq.com/s/GEZFQXx3dXltS8kYvJGguw
2.用 HAMi 与 vCluster 搭建一个迷你本地 AI 工厂
https://mp.weixin.qq.com/s/NCEJ5rGIPHbepdhO_LV6NA
3. 实现搜索反馈回路
https://spinscale.de/posts/202 ... .html
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/GEZFQXx3dXltS8kYvJGguw
2.用 HAMi 与 vCluster 搭建一个迷你本地 AI 工厂
https://mp.weixin.qq.com/s/NCEJ5rGIPHbepdhO_LV6NA
3. 实现搜索反馈回路
https://spinscale.de/posts/202 ... .html
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2263期 (2026-07-08)
https://mp.weixin.qq.com/s/aKZxOL_AOcJR5z5H_czYNQ
2.简短查询,正式文档: HyDE 如何在 Elasticsearch 中将语义搜索精度提升了 50%
https://blog.csdn.net/UbuntuTo ... 82914
3.不要再在账单日才发现你的 Claude 账单:Anthropic API 监控现已进入 Elastic
https://elasticstack.blog.csdn ... 40183
4.Elasticsearch 与 OpenSearch 2026:终极搜索引擎对比
https://tech-insider.org/elast ... 2026/
编辑:kin122
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/aKZxOL_AOcJR5z5H_czYNQ
2.简短查询,正式文档: HyDE 如何在 Elasticsearch 中将语义搜索精度提升了 50%
https://blog.csdn.net/UbuntuTo ... 82914
3.不要再在账单日才发现你的 Claude 账单:Anthropic API 监控现已进入 Elastic
https://elasticstack.blog.csdn ... 40183
4.Elasticsearch 与 OpenSearch 2026:终极搜索引擎对比
https://tech-insider.org/elast ... 2026/
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2261期 (2026-07-06)
https://mp.weixin.qq.com/s/DrO11iB4h_ieheu8I9uHIg
2、30分钟上手:Docker 部署 Easysearch 完整教程
https://mp.weixin.qq.com/s/g2JqCJwkVsUdMBW9ti_aHA
3、Elasticsearch:日志领域的最佳,如今也是指标领域的最佳
https://elasticstack.blog.csdn ... 78471
4、一条命令。自然语言。你的 Elasticsearch 数据,直接进入终端
https://elasticstack.blog.csdn ... 16104
5、AutoResearch-LLM:让 Agent 接手 LLM 训练优化
https://mp.weixin.qq.com/s/9qEgOV9FGk6u9_9zMLSI6A
编辑:Muse
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/DrO11iB4h_ieheu8I9uHIg
2、30分钟上手:Docker 部署 Easysearch 完整教程
https://mp.weixin.qq.com/s/g2JqCJwkVsUdMBW9ti_aHA
3、Elasticsearch:日志领域的最佳,如今也是指标领域的最佳
https://elasticstack.blog.csdn ... 78471
4、一条命令。自然语言。你的 Elasticsearch 数据,直接进入终端
https://elasticstack.blog.csdn ... 16104
5、AutoResearch-LLM:让 Agent 接手 LLM 训练优化
https://mp.weixin.qq.com/s/9qEgOV9FGk6u9_9zMLSI6A
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2262期 (2026-07-07)
1. 部署 Apache SeaTunnel 2.3.11 还能这么玩?手把手教你用 Docker 丝滑同步 Kafka 数据到 Hive 和 ES!(需要梯子)
https://dev.to/seatunnel/deplo ... -1kgi
2. 看清别人看不见的盲区!对话 Gigamon COO 深度解读安全与可观测性!
https://www.elastic.co/blog/gigamon-partnership
3. 可观测性架构变天了?从搜索堡垒走向统一数据库的演进之路!(需要梯子)
https://chenemiabrahams.medium ... 739eb
4. 别再怪你的 AI 智商低了,其实是你的数据底座没搭好!
https://www.elastic.co/blog/ai ... xxing
5. 降本增效大招!Elastic Observability 指标计费更新,性能更强价格更香!
https://www.elastic.co/blog/metrics-pricing
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
1. 部署 Apache SeaTunnel 2.3.11 还能这么玩?手把手教你用 Docker 丝滑同步 Kafka 数据到 Hive 和 ES!(需要梯子)
https://dev.to/seatunnel/deplo ... -1kgi
2. 看清别人看不见的盲区!对话 Gigamon COO 深度解读安全与可观测性!
https://www.elastic.co/blog/gigamon-partnership
3. 可观测性架构变天了?从搜索堡垒走向统一数据库的演进之路!(需要梯子)
https://chenemiabrahams.medium ... 739eb
4. 别再怪你的 AI 智商低了,其实是你的数据底座没搭好!
https://www.elastic.co/blog/ai ... xxing
5. 降本增效大招!Elastic Observability 指标计费更新,性能更强价格更香!
https://www.elastic.co/blog/metrics-pricing
编辑:斯蒂文
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2260期 (2026-07-03)
https://mp.weixin.qq.com/s/m2UMBTYEPoNOyrdG1-jRDw
2、RAG 准确率上不去?先别换模型,搞清楚你的 "命中率" 死在哪里
https://www.toutiao.com/articl ... 2566/
3、Zvec:内嵌式向量检索引擎,全端低延迟向量检索解决方案
https://www.toutiao.com/articl ... 6578/
4、我如何在 Elasticsearch 中实现查询性能的深度调优
https://blog.51cto.com/u_16213567/14700530
5、Easysearch 索引胖了三成?两个 Mapping 写法我改完立刻瘦下去
https://mp.weixin.qq.com/s/5bu ... %3D17
编辑:Fred
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/m2UMBTYEPoNOyrdG1-jRDw
2、RAG 准确率上不去?先别换模型,搞清楚你的 "命中率" 死在哪里
https://www.toutiao.com/articl ... 2566/
3、Zvec:内嵌式向量检索引擎,全端低延迟向量检索解决方案
https://www.toutiao.com/articl ... 6578/
4、我如何在 Elasticsearch 中实现查询性能的深度调优
https://blog.51cto.com/u_16213567/14700530
5、Easysearch 索引胖了三成?两个 Mapping 写法我改完立刻瘦下去
https://mp.weixin.qq.com/s/5bu ... %3D17
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2259期 (2026-07-02)
https://mp.weixin.qq.com/s/2YjxvuXPNJCz7JSbilsF8w
2.英伟达力荐,小团队两个月开源一款「光速级」智能体推理引擎
https://mp.weixin.qq.com/s/dx8T76mEGxbySqTH88X94g
3.万字深度|做了8年向量数据库后,我们决定为Milvus重构AI时代的存储引擎
https://mp.weixin.qq.com/s/8hnMM3tdzWd6UrmrtonYnw
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/2YjxvuXPNJCz7JSbilsF8w
2.英伟达力荐,小团队两个月开源一款「光速级」智能体推理引擎
https://mp.weixin.qq.com/s/dx8T76mEGxbySqTH88X94g
3.万字深度|做了8年向量数据库后,我们决定为Milvus重构AI时代的存储引擎
https://mp.weixin.qq.com/s/8hnMM3tdzWd6UrmrtonYnw
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2258期 (2026-07-01)
https://mp.weixin.qq.com/s/zSjNWjnDuZqI_teie8Z47A
2.向量、索引、Faiss、Milvus 到底是什么关系
https://mp.weixin.qq.com/s/Iu0RZgewZ1HhOt27oKLP_A
3.DiskANN:面向 SSD 的大规模图索引
https://mp.weixin.qq.com/s/fABsTYNab_MA_gal_tqRdQ
4.Elasticsearch 不愿公开命名的 hash(),以及证明它是 Murmur3 的 12 个字节
https://elasticstack.blog.csdn ... 30194
5.jina-clip-v2 为 Elasticsearch 带来覆盖 89 种语言的文本到图像搜索,无需 GPU
https://elasticstack.blog.csdn ... 56813
编辑:kin122
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/zSjNWjnDuZqI_teie8Z47A
2.向量、索引、Faiss、Milvus 到底是什么关系
https://mp.weixin.qq.com/s/Iu0RZgewZ1HhOt27oKLP_A
3.DiskANN:面向 SSD 的大规模图索引
https://mp.weixin.qq.com/s/fABsTYNab_MA_gal_tqRdQ
4.Elasticsearch 不愿公开命名的 hash(),以及证明它是 Murmur3 的 12 个字节
https://elasticstack.blog.csdn ... 30194
5.jina-clip-v2 为 Elasticsearch 带来覆盖 89 种语言的文本到图像搜索,无需 GPU
https://elasticstack.blog.csdn ... 56813
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2257期 (2026-06-30)
https://dev.to/u11d/reciprocal ... -56jk
2. 打通任督二脉!手把手教你用 Bold Data Hub 将 MySQL 丝滑同步至 Elasticsearch!(需要梯子)
https://dev.to/boldbi/integrat ... -3g63
3. Elastic 变天了?CEO Ash Kulkarni 内部组织架构调整全员信解读!
https://www.elastic.co/blog/ce ... oyees
4. 安全防线升级!迁移到 Elastic Security 助数字安全公司降低 85% 故障,UnderDefense 实战分享!
https://www.elastic.co/blog/el ... fense
5. 免费版 ES 上的 RRF:超实用的开源许可证规避指南与避坑姿势!(需要梯子)
https://medium.com/u11d-tech-b ... e285f
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://dev.to/u11d/reciprocal ... -56jk
2. 打通任督二脉!手把手教你用 Bold Data Hub 将 MySQL 丝滑同步至 Elasticsearch!(需要梯子)
https://dev.to/boldbi/integrat ... -3g63
3. Elastic 变天了?CEO Ash Kulkarni 内部组织架构调整全员信解读!
https://www.elastic.co/blog/ce ... oyees
4. 安全防线升级!迁移到 Elastic Security 助数字安全公司降低 85% 故障,UnderDefense 实战分享!
https://www.elastic.co/blog/el ... fense
5. 免费版 ES 上的 RRF:超实用的开源许可证规避指南与避坑姿势!(需要梯子)
https://medium.com/u11d-tech-b ... e285f
编辑:斯蒂文
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2256期 (2026-06-29)
https://elasticstack.blog.csdn ... 28311
2、与你的 Elasticsearch 数据对话:使用 Google ADK 和 MCP 构建一个实时语音 agent ,分为 3 个组件
https://blog.csdn.net/UbuntuTo ... 83519
3、火种&起源:一个运营从0到1搭建CI自动化流水线的实战记录
https://mp.weixin.qq.com/s/GNEshVzcCV5HvGJXSQ4W6w
4、Easysearch 索引生命周期管理(ILM):自动处理冷热数据
https://mp.weixin.qq.com/s/5Tb0bFNBE1gfjyQ7xcZq7g
5、Easysearch 性能优化实践:高并发、大数据量下的索引与搜索优化
https://mp.weixin.qq.com/s/webvXtf6PyMkXTnb_x1HtQ
编辑:Muse
更多资讯:http://news.searchkit.cn
https://elasticstack.blog.csdn ... 28311
2、与你的 Elasticsearch 数据对话:使用 Google ADK 和 MCP 构建一个实时语音 agent ,分为 3 个组件
https://blog.csdn.net/UbuntuTo ... 83519
3、火种&起源:一个运营从0到1搭建CI自动化流水线的实战记录
https://mp.weixin.qq.com/s/GNEshVzcCV5HvGJXSQ4W6w
4、Easysearch 索引生命周期管理(ILM):自动处理冷热数据
https://mp.weixin.qq.com/s/5Tb0bFNBE1gfjyQ7xcZq7g
5、Easysearch 性能优化实践:高并发、大数据量下的索引与搜索优化
https://mp.weixin.qq.com/s/webvXtf6PyMkXTnb_x1HtQ
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2255期 (2026-06-26)
https://mp.weixin.qq.com/s/YxRGwfHImAI8hO5Xf499tA
2、MongoDB 全文索引 与 展示查询数据的一部分,提高性能
https://mp.weixin.qq.com/s/LqChlWycoTYx-1f4anwbSA
3、Easysearch 索引生命周期管理(ILM):自动处理冷热数据
https://mp.weixin.qq.com/s/5Tb0bFNBE1gfjyQ7xcZq7g
4、我如何在 Elasticsearch 中实现查询性能的深度调优
https://blog.51cto.com/u_16213567/14700530
5、Easysearch vs MySQL
https://easysearch.cn/knowledg ... rison
编辑:Fred
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/YxRGwfHImAI8hO5Xf499tA
2、MongoDB 全文索引 与 展示查询数据的一部分,提高性能
https://mp.weixin.qq.com/s/LqChlWycoTYx-1f4anwbSA
3、Easysearch 索引生命周期管理(ILM):自动处理冷热数据
https://mp.weixin.qq.com/s/5Tb0bFNBE1gfjyQ7xcZq7g
4、我如何在 Elasticsearch 中实现查询性能的深度调优
https://blog.51cto.com/u_16213567/14700530
5、Easysearch vs MySQL
https://easysearch.cn/knowledg ... rison
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2254期 (2026-06-25)
https://mp.weixin.qq.com/s/-Y7SKHjik8Ey3usZG7KLQA
2.用 AI 修复最难搞的测试:Kong 团队的实战经验
https://mp.weixin.qq.com/s/NhHQ2_00rLYjgoWxPgAy8A
3.RAG 的尽头,是 SQL?
https://mp.weixin.qq.com/s/fh45m297Ekn4RvcwI0Uwpw
4.一条信息在 Agent 记忆系统中的完整旅程 :从记住、衰减,再到遗忘的工程拆解
https://mp.weixin.qq.com/s/pn2cdLppACcmE1vbJcdinw
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/-Y7SKHjik8Ey3usZG7KLQA
2.用 AI 修复最难搞的测试:Kong 团队的实战经验
https://mp.weixin.qq.com/s/NhHQ2_00rLYjgoWxPgAy8A
3.RAG 的尽头,是 SQL?
https://mp.weixin.qq.com/s/fh45m297Ekn4RvcwI0Uwpw
4.一条信息在 Agent 记忆系统中的完整旅程 :从记住、衰减,再到遗忘的工程拆解
https://mp.weixin.qq.com/s/pn2cdLppACcmE1vbJcdinw
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
信创环境下部署 INFINI Console:一站式搭建搜索基础设施统一管控平台
引言
在前面的文章中,我们分别进行了 Easysearch 在信创环境下的部署 以及 INFINI Gateway 数据网关的部署。到目前为止,整套搜索服务体系的核心组件已经就位 —— Easysearch 负责存储和检索,Gateway 负责进行流量管控。
但你可能注意到一个问题:Easysearch 虽然有着自己的管理界面。但随着集群数量增多、业务变得更加复杂,管理者不得不在多个系统之间切换,效率低下且容易遗漏告警。有没有一个 “管理中枢” ,将所有搜索集群统一纳管,一站式完成监控、告警、安全审计和数据探索?
这正是 INFINI Console 要解决的问题。本文将延续“小白友好”风格,带你完成系列第四篇——部署 INFINI Console,用它为整个搜索服务体系装上统一的“指挥中心”。
一、INFINI Console 是什么?为什么需要它?
1. 精准定位
INFINI Console 是一款 轻量级、跨版本、多集群的搜索基础设施统一管控平台,也是整个极限科技产品体系中承担“可观测性与集中管理”角色的核心组件。它可以将不同业务、不同版本的多个 Easysearch 或 Elasticsearch 集群集中纳管,让管理者和运维人员在一个平台上完成日常运维工作。

2. 它能做什么?
INFINI Console 的核心能力可以概括为以下五大板块:
- 平台管理:在一个平台内统一纳管任意多套 Easysearch / Elasticsearch 集群,支持跨版本(5.x 到 8.x)、跨云混合部署,新集群动态注册接入,目标集群无需安装任何插件。
- 可观察性监控:一键开启对目标集群的全维度监控,覆盖集群、节点、索引等级的详细指标,慢查询、异常日志、集群动态一览无余,帮你快速定位问题、缩短故障时间。
- 主动告警:支持灵活的告警规则配置,7×24 小时自动巡检集群关键指标和业务数据,一旦触发阈值立即通知,让你从“被动等故障”变成“主动防问题”。
- 安全审计:支持企业级 LDAP、AD、SSO 对接,提供集群、索引、字段、文档级别的统一访问控制,支持查询请求审计与分析,可智能识别和阻断异常查询。
- 开发者工具与数据探索:内置智能语法提示、多集群工作区、常用指令快捷加载,支持索引管理、数据浏览、文档编辑、时序数据快速查看等功能。
3. 轻量级特性
INFINI Console 使用 Golang 编写,安装包非常小,只有约 11MB,没有任何外部环境依赖(除了需要一个 Easysearch 或 Elasticsearch 集群作为存储后端),部署安装非常简单,只需下载对应平台的二进制可执行文件,启动即可。
此外,INFINI Console 已经通过了华为鲲鹏 Kunpeng 920 兼容性认证和统信 UOS 适配认证,并获得了 KUNPENG COMPATIBLE 证书,在信创环境下的稳定性和兼容性得到了官方验证.
二、部署前提
1. 环境前提:需要一个 Easysearch 集群作为“系统集群”
Console 本身不存储业务数据,但它需要将自身的配置信息(用户、角色、告警规则、监控数据等)存储到一个 Easysearch 集群中,这个集群被称为 “系统集群” 。
如果你已经按照本系列前面的文章Easysearch 在信创环境下的部署 安装了 Easysearch ,可以直接用它作为系统集群。而在部署 Console 之前,请确保该集群已正常启动:
curl -ku admin:你的密码 https://localhost:92002. 确认 CPU 架构
先确认你的信创服务器架构:
uname -m本文示例使用的信创环境为:
- CPU :鲲鹏 Kunpeng-920、aarch64
- 操作系统:统信服务器操作系统A版 V20
三、部署流程
步骤 1:下载 INFINI Console
使用命令下载
#创建文件安装目录
mkdir -p /opt/console
# 一键下载并安装到 /opt/console
curl -sSL http://get.infini.cloud | bash -s -- -p console -d /opt/console
步骤 2:修改配置文件
安装好后在安装目录下得到可执行程序 console-linux-arm64 与配置文件 console.yml,修改配置文件
network:
#找到 network 下的 binding 项,修改为想要放置服务的端点(默认为 9000)
bingding:9001步骤 3:启动程序
进入程序安装路径,运行可执行程序,首次运行建议直接运行程序启动,方便查看运行日志
#进入程序安装目录下
cd /opt/console
#运行可执行程序(console-linux-arm64 为可执行程序名)
./console-linux-arm64
从上述启动信息来看,意味着程序已经成功运行并监听了 9001 端口
如果想要关闭程序,按住 :Ctrl+C
如果想将 Console 作为后台任务运行,请执行以下命令:
./console-linux-arm64 -service install
./console-linux-arm64 -service start若是想要卸载服务的话,执行下列命令即可:
./console-linux-arm64 -service stop
./console-linux-arm64 -service uninstall步骤 4:程序初始化
在浏览器中输入地址:http://0.0.0.0:9001,首次访问会自动进入初始化流程
连接已安装的集群

进行初始化系统索引和模板

设置用户,可以选择重置管理员账户

初始化完成,请妥善保存账号数据避免遗失

初始化流程结束后会回到登录界面,此时就可以使用设置好的账号信息进行登录

登陆后进入工作台页面

总结
到这里,你已经完成了 INFINI Console 在信创平台上的部署与初步上手。我们回顾一下整个流程:
- 确认环境 — Easysearch 已启动,明确 CPU 架构;
- 下载安装 — 执行命令一键下载与安装;
- 编写配置 — 修改配置文件
console.yml,指定服务监听地址; - 启动服务 — 先前台验证,再以后台模式运行;
- 初始化 — 浏览器访问服务端口,创建管理员账号;
- 注册集群 — 将 Easysearch 集群接入 Console,开启监控和管理。
部署完成后,你就拥有了一个统一的搜索服务管理中枢,可以在一个界面内完成多集群的监控、告警、安全审计和数据探索。
如果在部署过程中遇到困难,欢迎查阅官方文档。祝你部署顺利!
引言
在前面的文章中,我们分别进行了 Easysearch 在信创环境下的部署 以及 INFINI Gateway 数据网关的部署。到目前为止,整套搜索服务体系的核心组件已经就位 —— Easysearch 负责存储和检索,Gateway 负责进行流量管控。
但你可能注意到一个问题:Easysearch 虽然有着自己的管理界面。但随着集群数量增多、业务变得更加复杂,管理者不得不在多个系统之间切换,效率低下且容易遗漏告警。有没有一个 “管理中枢” ,将所有搜索集群统一纳管,一站式完成监控、告警、安全审计和数据探索?
这正是 INFINI Console 要解决的问题。本文将延续“小白友好”风格,带你完成系列第四篇——部署 INFINI Console,用它为整个搜索服务体系装上统一的“指挥中心”。
一、INFINI Console 是什么?为什么需要它?
1. 精准定位
INFINI Console 是一款 轻量级、跨版本、多集群的搜索基础设施统一管控平台,也是整个极限科技产品体系中承担“可观测性与集中管理”角色的核心组件。它可以将不同业务、不同版本的多个 Easysearch 或 Elasticsearch 集群集中纳管,让管理者和运维人员在一个平台上完成日常运维工作。
2. 它能做什么?
INFINI Console 的核心能力可以概括为以下五大板块:
- 平台管理:在一个平台内统一纳管任意多套 Easysearch / Elasticsearch 集群,支持跨版本(5.x 到 8.x)、跨云混合部署,新集群动态注册接入,目标集群无需安装任何插件。
- 可观察性监控:一键开启对目标集群的全维度监控,覆盖集群、节点、索引等级的详细指标,慢查询、异常日志、集群动态一览无余,帮你快速定位问题、缩短故障时间。
- 主动告警:支持灵活的告警规则配置,7×24 小时自动巡检集群关键指标和业务数据,一旦触发阈值立即通知,让你从“被动等故障”变成“主动防问题”。
- 安全审计:支持企业级 LDAP、AD、SSO 对接,提供集群、索引、字段、文档级别的统一访问控制,支持查询请求审计与分析,可智能识别和阻断异常查询。
- 开发者工具与数据探索:内置智能语法提示、多集群工作区、常用指令快捷加载,支持索引管理、数据浏览、文档编辑、时序数据快速查看等功能。
3. 轻量级特性
INFINI Console 使用 Golang 编写,安装包非常小,只有约 11MB,没有任何外部环境依赖(除了需要一个 Easysearch 或 Elasticsearch 集群作为存储后端),部署安装非常简单,只需下载对应平台的二进制可执行文件,启动即可。
此外,INFINI Console 已经通过了华为鲲鹏 Kunpeng 920 兼容性认证和统信 UOS 适配认证,并获得了 KUNPENG COMPATIBLE 证书,在信创环境下的稳定性和兼容性得到了官方验证.
二、部署前提
1. 环境前提:需要一个 Easysearch 集群作为“系统集群”
Console 本身不存储业务数据,但它需要将自身的配置信息(用户、角色、告警规则、监控数据等)存储到一个 Easysearch 集群中,这个集群被称为 “系统集群” 。
如果你已经按照本系列前面的文章Easysearch 在信创环境下的部署 安装了 Easysearch ,可以直接用它作为系统集群。而在部署 Console 之前,请确保该集群已正常启动:
curl -ku admin:你的密码 https://localhost:92002. 确认 CPU 架构
先确认你的信创服务器架构:
uname -m本文示例使用的信创环境为:
- CPU :鲲鹏 Kunpeng-920、aarch64
- 操作系统:统信服务器操作系统A版 V20
三、部署流程
步骤 1:下载 INFINI Console
使用命令下载
#创建文件安装目录
mkdir -p /opt/console
# 一键下载并安装到 /opt/console
curl -sSL http://get.infini.cloud | bash -s -- -p console -d /opt/console
步骤 2:修改配置文件
安装好后在安装目录下得到可执行程序 console-linux-arm64 与配置文件 console.yml,修改配置文件
network:
#找到 network 下的 binding 项,修改为想要放置服务的端点(默认为 9000)
bingding:9001步骤 3:启动程序
进入程序安装路径,运行可执行程序,首次运行建议直接运行程序启动,方便查看运行日志
#进入程序安装目录下
cd /opt/console
#运行可执行程序(console-linux-arm64 为可执行程序名)
./console-linux-arm64
从上述启动信息来看,意味着程序已经成功运行并监听了 9001 端口
如果想要关闭程序,按住 :Ctrl+C
如果想将 Console 作为后台任务运行,请执行以下命令:
./console-linux-arm64 -service install
./console-linux-arm64 -service start若是想要卸载服务的话,执行下列命令即可:
./console-linux-arm64 -service stop
./console-linux-arm64 -service uninstall步骤 4:程序初始化
在浏览器中输入地址:http://0.0.0.0:9001,首次访问会自动进入初始化流程
连接已安装的集群
进行初始化系统索引和模板
设置用户,可以选择重置管理员账户
初始化完成,请妥善保存账号数据避免遗失
初始化流程结束后会回到登录界面,此时就可以使用设置好的账号信息进行登录
登陆后进入工作台页面
总结
到这里,你已经完成了 INFINI Console 在信创平台上的部署与初步上手。我们回顾一下整个流程:
- 确认环境 — Easysearch 已启动,明确 CPU 架构;
- 下载安装 — 执行命令一键下载与安装;
- 编写配置 — 修改配置文件
console.yml,指定服务监听地址; - 启动服务 — 先前台验证,再以后台模式运行;
- 初始化 — 浏览器访问服务端口,创建管理员账号;
- 注册集群 — 将 Easysearch 集群接入 Console,开启监控和管理。
部署完成后,你就拥有了一个统一的搜索服务管理中枢,可以在一个界面内完成多集群的监控、告警、安全审计和数据探索。
如果在部署过程中遇到困难,欢迎查阅官方文档。祝你部署顺利!
收起阅读 »【搜索客社区日报】第2253期 (2026-06-24)
https://mp.weixin.qq.com/s/0yLpeMXqWT1w641X6UpAlA
2.Elasticsearch 到 pgvector:Instacart 如何用 Postgres 干掉一堆专业搜索引擎
https://mp.weixin.qq.com/s/Zc6StD8bRprUf6NvgEGPPQ
3.为什么你的 Elasticsearch 集群触发了磁盘水位线:14 个真实世界原因解析
https://elasticstack.blog.csdn ... 41601
4.Jingra:一个可复现的向量搜索基准测试框架
https://elasticstack.blog.csdn ... 15386
5.提取标准 OCR 遗漏的图表数据:Elastic Agent Builder 和 LlamaParse 在一个管道中
https://elasticstack.blog.csdn ... 88799
编辑:kin122
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/0yLpeMXqWT1w641X6UpAlA
2.Elasticsearch 到 pgvector:Instacart 如何用 Postgres 干掉一堆专业搜索引擎
https://mp.weixin.qq.com/s/Zc6StD8bRprUf6NvgEGPPQ
3.为什么你的 Elasticsearch 集群触发了磁盘水位线:14 个真实世界原因解析
https://elasticstack.blog.csdn ... 41601
4.Jingra:一个可复现的向量搜索基准测试框架
https://elasticstack.blog.csdn ... 15386
5.提取标准 OCR 遗漏的图表数据:Elastic Agent Builder 和 LlamaParse 在一个管道中
https://elasticstack.blog.csdn ... 88799
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
Bboss v7.5.6 正式发布,全面兼容国产分布式搜索引擎 Easysearch
一、引言
2026 年 6 月 21 日,经过 Bboss 开源社区与极限科技(INFINI Labs)的紧密合作, Bboss v7.5.6 正式发布!
作为国内领先的 AI 智能体开发框架、数据采集同步 ETL 工具以及流批一体化计算引擎,Bboss 在本次更新中与国产分布式搜索引擎 Easysearch 完成深度兼容,其 Elasticsearch Java 客户端 全面兼容 Easysearch 1.x、2.x 全系列版本。开发者现在可以无缝使用 Bboss 客户端操作 Easysearch 集群,享受与 Elasticsearch 一致的开发体验。
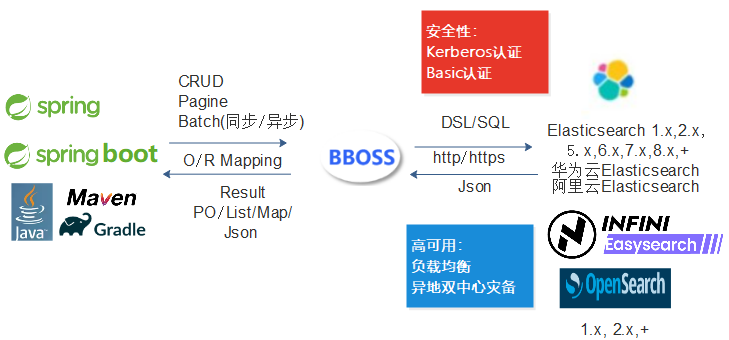
二、Bboss Elasticsearch 客户端简介
Bboss 是一款高性能、高兼容性的搜索引擎 Java REST 客户端框架,基于 Apache License 2.0 开源,原生支持 Elasticsearch、Easysearch 和 Opensearch。
自带客户端集群节点负载均衡和容灾,多集群多数据源,自动索引托管,多种分页机制,傻瓜级 CRUD,脚本,SQL,JDBC,高亮,权重,聚合,IP,GEO 地理位置,父子嵌套,应有尽有。
核心特性
| 特性 | 说明 |
|---|---|
| 原生多引擎支持 | 完美支持 ES 1.x ~ 9.x、Easysearch 1.x ~ 2.x、Opensearch 1.x ~ 3.x |
| 学习成本低 | 无需学习额外 API,只需掌握 Elasticsearch DSL,极简使用方式 |
| 开箱即用 | Spring Boot 自动配置,无需复杂设置 |
| 高效异步处理 | 内置 BulkProcessor 异步批处理器,大幅提升写入性能 |
| 灵活查询方式 | 支持 DSL、SQL、O/R Mapping 多种查询模式 |
| 多数据源支持 | 一个应用可同时操作多个不同版本的搜索引擎集群 |
| 客户端负载均衡 | 默认启用客户端负载均衡,容灾性更好 |
| 完整的结果封装 | 返回结果支持 JSON、PO 对象、List 集合、Map 等多种类型 |
三、为什么选择 Bboss + Easysearch
将 Bboss 作为 Easysearch 的 Java 客户端,您将获得以下独特优势:
- 国产化技术栈:从底层搜索引擎到上层客户端框架,完全国产化自主可控,满足信创合规要求,无许可证风险。
- 极低迁移成本:如果您正在使用 Elasticsearch + Bboss 技术栈,切换到 Easysearch 几乎零成本,只需修改连接配置即可。
- 成熟稳定的客户端:Bboss 经过多年发展,已在国内众多企业和项目中得到广泛应用和验证,拥有活跃的中文社区和完善的文档支持。
- 丰富的生态能力:除了基础的 CRUD 操作,还提供数据采集 ETL、流批一体化计算、AI 智能体等丰富的扩展能力。
四、快速开始
通过以下简单步骤,即可在 Bboss 中接入 Easysearch:
1. 添加 Maven 依赖
<dependency>
<groupId>com.bbossgroups.plugins</groupId>
<artifactId>bboss-datatran-jdbc</artifactId>
<version>7.5.6</version>
</dependency>2. 配置 Easysearch 连接
spring:
elasticsearch:
bboss:
elasticsearch:
rest:
hostNames: localhost:9200
useHttps: true # Easysearch 默认启用 HTTPS
elasticUser: admin
elasticPassword: your_password3. 基础操作
@Service
public class DocumentService {
@Autowired
private BBossESStarter bbossESStarter;
// 插入文档
public void insertDocument() {
ClientInterface client = bbossESStarter.getRestClient();
Document doc = new Document();
doc.setId("1");
doc.setTitle("Easysearch 与 Bboss 集成");
doc.setContent("这是一篇关于集成的文章");
client.addDocument("documents", doc, "refresh=true");
}
// 查询文档
public Document getDocument(String id) {
ClientInterface client = bbossESStarter.getRestClient();
return client.getDocument("documents", id, Document.class);
}
// 按字段查询
public ESDatas<Document> searchByAuthor(String author) {
ClientInterface client = bbossESStarter.getRestClient();
return client.searchListByField(
"documents", "author.keyword", author,
Document.class, 0, 10
);
}
}五、结语
Bboss v7.5.6 与 Easysearch 的深度兼容,是国产开源生态建设的又一重要成果。作为 Easysearch 原厂,我们欢迎更多像 Bboss 这样的优秀开源项目加入国产搜索引擎生态,共同推动国内搜索型数据库的发展与繁荣。
对于正在评估搜索引擎选型或计划进行国产替代的企业用户,Bboss + Easysearch 的组合无疑是值得信赖的选择。
立即体验 Easysearch,开启国产搜索引擎之旅:
- Easysearch 官网: https://easysearch.cn
- Bboss 官方文档: https://esdoc.bbossgroups.com
- Easysearch x Bboss 详细集成文档: https://docs.infinilabs.com/easysearch/main/docs/integrations/third-party/bboss
六、关于 Easysearch

INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。作为国内领先的国产搜索引擎产品,Easysearch 具备以下核心优势:
1. 国产化自主可控
自主研发,符合信创要求,无许可证风险,为企业提供安全可靠的技术保障。在当前国际形势日益复杂、信创需求持续提升的大背景下,Easysearch 为政府、金融、电信、能源等关键行业提供了值得信赖的搜索引擎基础设施。
2. 轻量级架构
相比传统搜索引擎,Easysearch 资源占用更少,启动更快速,显著降低企业运维成本。其精简的架构设计使得在同等硬件条件下可以承载更多的业务负载,特别适合资源受限的私有化部署场景。
3. 卓越性能表现
查询性能优异,能够满足大部分业务场景需求,用户体验流畅。通过持续的内核优化和算法改进,Easysearch 在多项基准测试中展现出媲美甚至超越同类产品的性能水平。
4. 良好兼容性
与 Elasticsearch 的 API 接口基本兼容,迁移成本较低,保护用户现有投资。这一特性使得基于 Elasticsearch 开发的应用可以快速平滑地迁移至 Easysearch,大大降低了国产替代的技术门槛。
社区福利
为感谢广大社区开发者的支持,Bboss 与 Easysearch 厂商极限科技联合发起抽奖活动,奖品为开源T恤。6 月 29 日上午 10 点自动开奖,欢迎大家扫码抽奖参与。

一、引言
2026 年 6 月 21 日,经过 Bboss 开源社区与极限科技(INFINI Labs)的紧密合作, Bboss v7.5.6 正式发布!
作为国内领先的 AI 智能体开发框架、数据采集同步 ETL 工具以及流批一体化计算引擎,Bboss 在本次更新中与国产分布式搜索引擎 Easysearch 完成深度兼容,其 Elasticsearch Java 客户端 全面兼容 Easysearch 1.x、2.x 全系列版本。开发者现在可以无缝使用 Bboss 客户端操作 Easysearch 集群,享受与 Elasticsearch 一致的开发体验。
二、Bboss Elasticsearch 客户端简介
Bboss 是一款高性能、高兼容性的搜索引擎 Java REST 客户端框架,基于 Apache License 2.0 开源,原生支持 Elasticsearch、Easysearch 和 Opensearch。
自带客户端集群节点负载均衡和容灾,多集群多数据源,自动索引托管,多种分页机制,傻瓜级 CRUD,脚本,SQL,JDBC,高亮,权重,聚合,IP,GEO 地理位置,父子嵌套,应有尽有。
核心特性
| 特性 | 说明 |
|---|---|
| 原生多引擎支持 | 完美支持 ES 1.x ~ 9.x、Easysearch 1.x ~ 2.x、Opensearch 1.x ~ 3.x |
| 学习成本低 | 无需学习额外 API,只需掌握 Elasticsearch DSL,极简使用方式 |
| 开箱即用 | Spring Boot 自动配置,无需复杂设置 |
| 高效异步处理 | 内置 BulkProcessor 异步批处理器,大幅提升写入性能 |
| 灵活查询方式 | 支持 DSL、SQL、O/R Mapping 多种查询模式 |
| 多数据源支持 | 一个应用可同时操作多个不同版本的搜索引擎集群 |
| 客户端负载均衡 | 默认启用客户端负载均衡,容灾性更好 |
| 完整的结果封装 | 返回结果支持 JSON、PO 对象、List 集合、Map 等多种类型 |
三、为什么选择 Bboss + Easysearch
将 Bboss 作为 Easysearch 的 Java 客户端,您将获得以下独特优势:
- 国产化技术栈:从底层搜索引擎到上层客户端框架,完全国产化自主可控,满足信创合规要求,无许可证风险。
- 极低迁移成本:如果您正在使用 Elasticsearch + Bboss 技术栈,切换到 Easysearch 几乎零成本,只需修改连接配置即可。
- 成熟稳定的客户端:Bboss 经过多年发展,已在国内众多企业和项目中得到广泛应用和验证,拥有活跃的中文社区和完善的文档支持。
- 丰富的生态能力:除了基础的 CRUD 操作,还提供数据采集 ETL、流批一体化计算、AI 智能体等丰富的扩展能力。
四、快速开始
通过以下简单步骤,即可在 Bboss 中接入 Easysearch:
1. 添加 Maven 依赖
<dependency>
<groupId>com.bbossgroups.plugins</groupId>
<artifactId>bboss-datatran-jdbc</artifactId>
<version>7.5.6</version>
</dependency>2. 配置 Easysearch 连接
spring:
elasticsearch:
bboss:
elasticsearch:
rest:
hostNames: localhost:9200
useHttps: true # Easysearch 默认启用 HTTPS
elasticUser: admin
elasticPassword: your_password3. 基础操作
@Service
public class DocumentService {
@Autowired
private BBossESStarter bbossESStarter;
// 插入文档
public void insertDocument() {
ClientInterface client = bbossESStarter.getRestClient();
Document doc = new Document();
doc.setId("1");
doc.setTitle("Easysearch 与 Bboss 集成");
doc.setContent("这是一篇关于集成的文章");
client.addDocument("documents", doc, "refresh=true");
}
// 查询文档
public Document getDocument(String id) {
ClientInterface client = bbossESStarter.getRestClient();
return client.getDocument("documents", id, Document.class);
}
// 按字段查询
public ESDatas<Document> searchByAuthor(String author) {
ClientInterface client = bbossESStarter.getRestClient();
return client.searchListByField(
"documents", "author.keyword", author,
Document.class, 0, 10
);
}
}五、结语
Bboss v7.5.6 与 Easysearch 的深度兼容,是国产开源生态建设的又一重要成果。作为 Easysearch 原厂,我们欢迎更多像 Bboss 这样的优秀开源项目加入国产搜索引擎生态,共同推动国内搜索型数据库的发展与繁荣。
对于正在评估搜索引擎选型或计划进行国产替代的企业用户,Bboss + Easysearch 的组合无疑是值得信赖的选择。
立即体验 Easysearch,开启国产搜索引擎之旅:
- Easysearch 官网: https://easysearch.cn
- Bboss 官方文档: https://esdoc.bbossgroups.com
- Easysearch x Bboss 详细集成文档: https://docs.infinilabs.com/easysearch/main/docs/integrations/third-party/bboss
六、关于 Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。作为国内领先的国产搜索引擎产品,Easysearch 具备以下核心优势:
1. 国产化自主可控
自主研发,符合信创要求,无许可证风险,为企业提供安全可靠的技术保障。在当前国际形势日益复杂、信创需求持续提升的大背景下,Easysearch 为政府、金融、电信、能源等关键行业提供了值得信赖的搜索引擎基础设施。
2. 轻量级架构
相比传统搜索引擎,Easysearch 资源占用更少,启动更快速,显著降低企业运维成本。其精简的架构设计使得在同等硬件条件下可以承载更多的业务负载,特别适合资源受限的私有化部署场景。
3. 卓越性能表现
查询性能优异,能够满足大部分业务场景需求,用户体验流畅。通过持续的内核优化和算法改进,Easysearch 在多项基准测试中展现出媲美甚至超越同类产品的性能水平。
4. 良好兼容性
与 Elasticsearch 的 API 接口基本兼容,迁移成本较低,保护用户现有投资。这一特性使得基于 Elasticsearch 开发的应用可以快速平滑地迁移至 Easysearch,大大降低了国产替代的技术门槛。
社区福利
为感谢广大社区开发者的支持,Bboss 与 Easysearch 厂商极限科技联合发起抽奖活动,奖品为开源T恤。6 月 29 日上午 10 点自动开奖,欢迎大家扫码抽奖参与。


