

ES版本:6.5.1 jdk版本:1.8,使用的G1GC,系统64G,分配32G内存,并且已锁定
3台ES组成一个集群
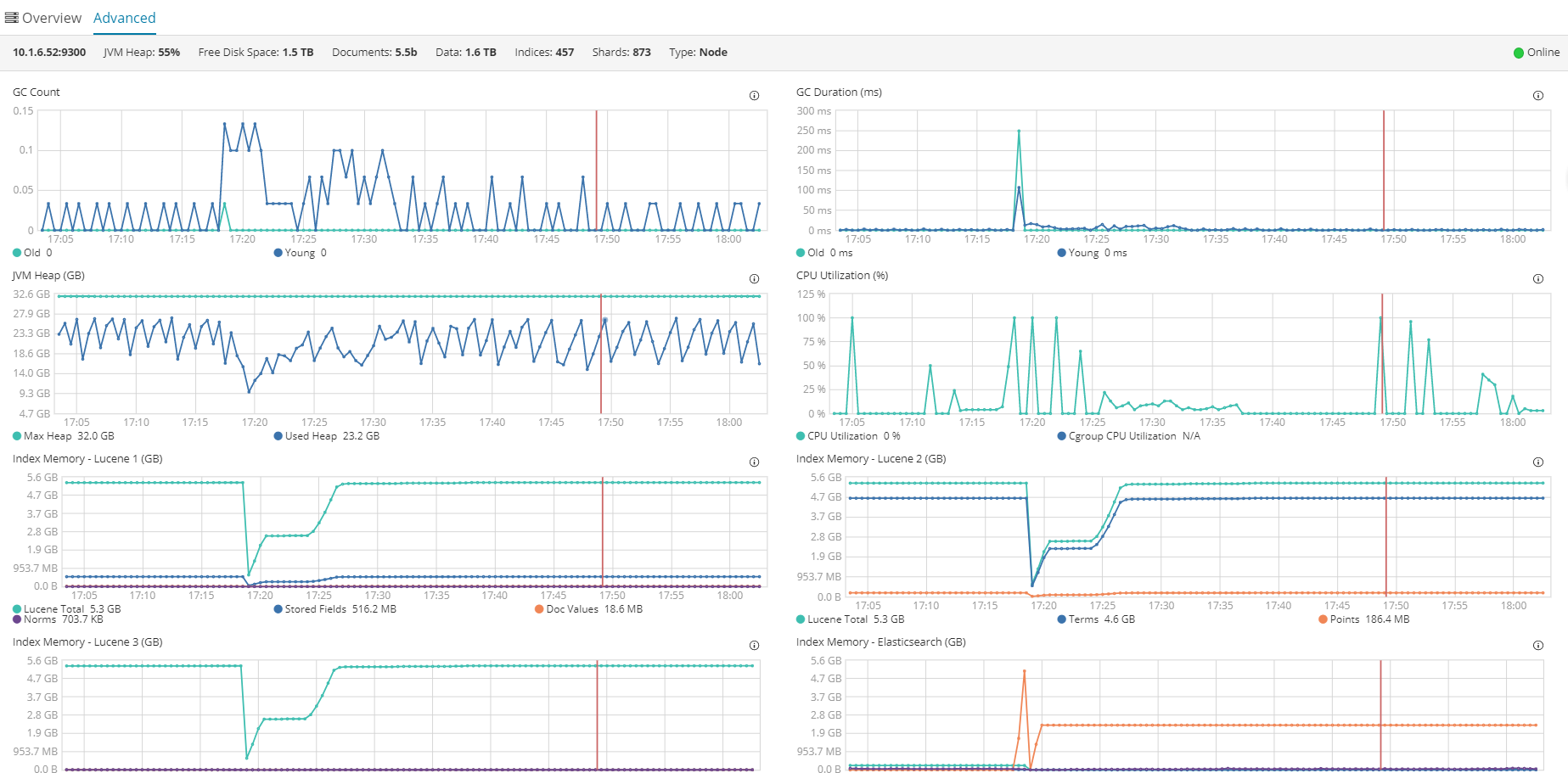
其中一台日志显示GC ,感觉是GC时间过长,导致主节点ES判断此台ES无响应,踢掉此节点,造成集群抖动。
以下配置是es内部超时时间
discovery.zen.fd.ping_interval: 5s
discovery.zen.fd.ping_timeout: 500ms
discovery.zen.fd.ping_retries: 10
请问有什么办法控制集群的抖动么?
比如增加超时时间?
或者控制比如ES 查询的内部内存之类的?

3台ES组成一个集群
其中一台日志显示GC ,感觉是GC时间过长,导致主节点ES判断此台ES无响应,踢掉此节点,造成集群抖动。
以下配置是es内部超时时间
discovery.zen.fd.ping_interval: 5s
discovery.zen.fd.ping_timeout: 500ms
discovery.zen.fd.ping_retries: 10
请问有什么办法控制集群的抖动么?
比如增加超时时间?
或者控制比如ES 查询的内部内存之类的?

4 个回复
rane - 上升期资深工程师
赞同来自:
主要还是看什么原因导致的大gc。
设置分片延迟分配,减少集群抖动
zmc - ES PAAS、JuiceFS
赞同来自:
2.看监控的截图,是突然有的大GC,heap可能并没有增长很多,看起来像是垃圾region积累过多了。其实如果没有必要,不一定非要设置那么大的heap。
3.GC几百ms,也不至于会将节点踢出去,看看是不是线程池积压了,然后被高优先级的task占用了线程和cpu,导致不响应
4.可以看一下master节点是不是压力过大,比如动态mapping更新的时候,导致master压力大,ping出去的消息即使响应了,master也接收不到,也有可能将data节点踢出去
FFFrp
赞同来自:
daier9498060
赞同来自: