

一、目前框架采用 kafka ---> sparkStream --> ES 的方式将数据实时写入es.
二、目前单集群的规模:
硬件配置: 20台物理(8C,128G ,16T(普通磁盘)配置)
软件配置: elasticsearch单集群: 40数据节点,分配10个master节点, 20个主分片,2个副本。 单个索引的大小平均:1.7T, 每个分片的大小:50G
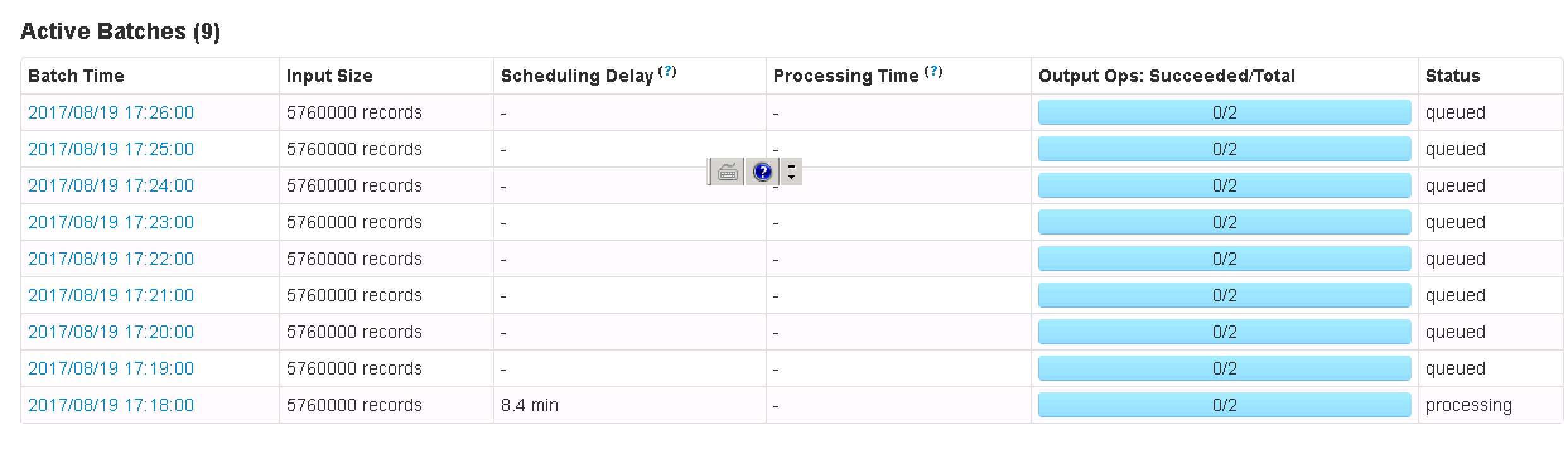
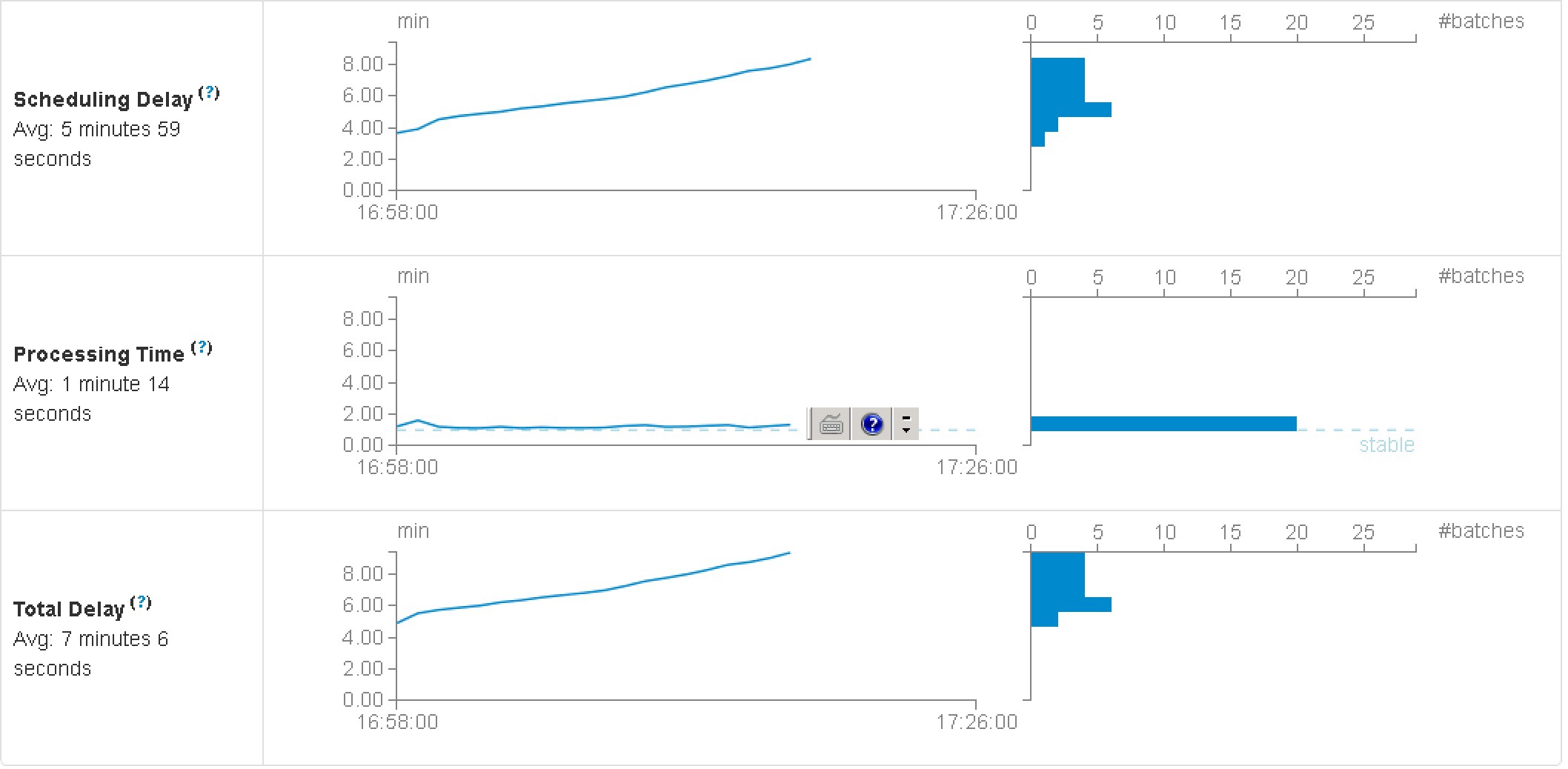
目前运行看来,出现问题,1:该单集群与硬件的配备,没有达到预想的写入量。 目前:每一分钟的batch情况(分配:32个cpu, 3G的内存給这个长任务):
Input Size: 5760000 records Scheduling Delay : 8.0 min Processing Time 1.3 min Total Delay 9.4 min
2、请问一下,sparkStream saveto ES , 还可以从哪些地方优化?
二、目前单集群的规模:
硬件配置: 20台物理(8C,128G ,16T(普通磁盘)配置)
软件配置: elasticsearch单集群: 40数据节点,分配10个master节点, 20个主分片,2个副本。 单个索引的大小平均:1.7T, 每个分片的大小:50G
目前运行看来,出现问题,1:该单集群与硬件的配备,没有达到预想的写入量。 目前:每一分钟的batch情况(分配:32个cpu, 3G的内存給这个长任务):
Input Size: 5760000 records Scheduling Delay : 8.0 min Processing Time 1.3 min Total Delay 9.4 min
2、请问一下,sparkStream saveto ES , 还可以从哪些地方优化?

1 个回复
rockybean - Elastic Certified Engineer, ElasticStack Fans,公众号:ElasticTalk
赞同来自:
比如es现在写入性能如何?Index Rate是怎样的?写入队列有无 reject 的情况?
第一步还是先确定是要优化spark还是es