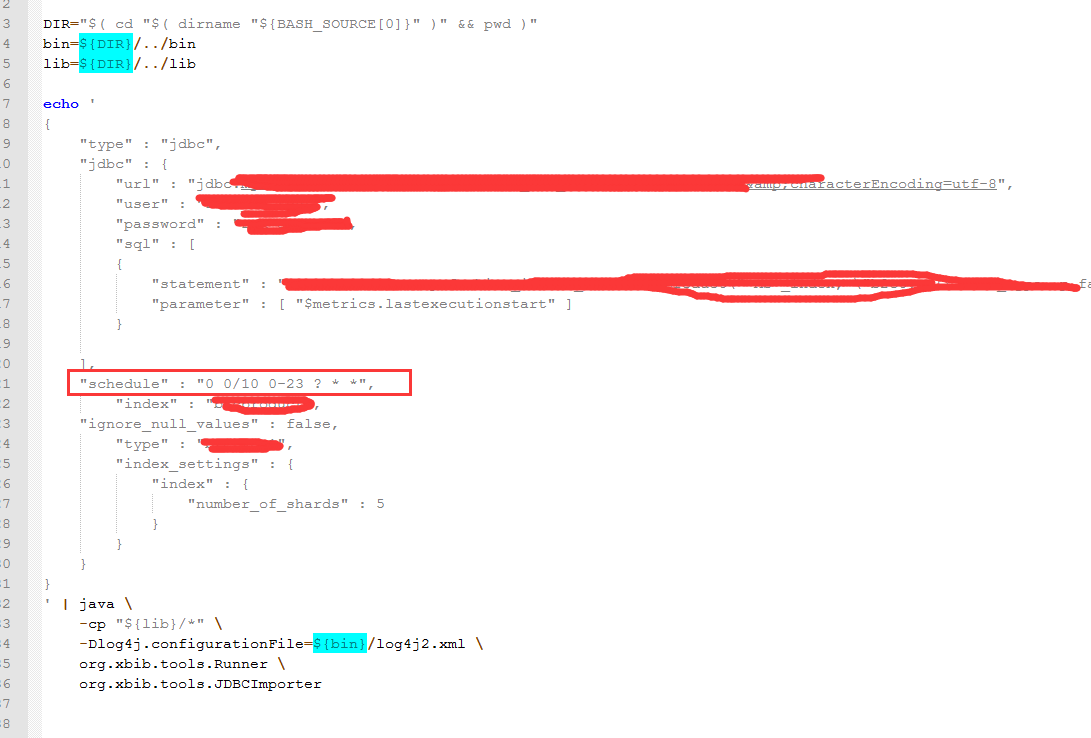
elasticsearch使用river同步mysql数据,schedule设置问题
Elasticsearch | 作者 znketophawk | 发布于2015年12月29日 | 阅读数:5820
schedule 设置的是10分钟,进行一次同步,同步的数据,是单条的时候,可以同步成功,但是,如果是多条数据,就不能增量同步到索引。当设置在1分钟以内,则可增量同步到索引库。请教一下是不是我写的脚本哪里有问题。


本站服务器及带宽由 ![]() 提供赞助 · 网站程序: WeCenter · 湘ICP备17007482号 · 湘公网安备43010402002319号
提供赞助 · 网站程序: WeCenter · 湘ICP备17007482号 · 湘公网安备43010402002319号

2 个回复
medcl - 今晚打老虎。
赞同来自:
znketophawk
赞同来自:
符合条件的数据不能增加到索引库,但是,括号里面的数字会有变化。