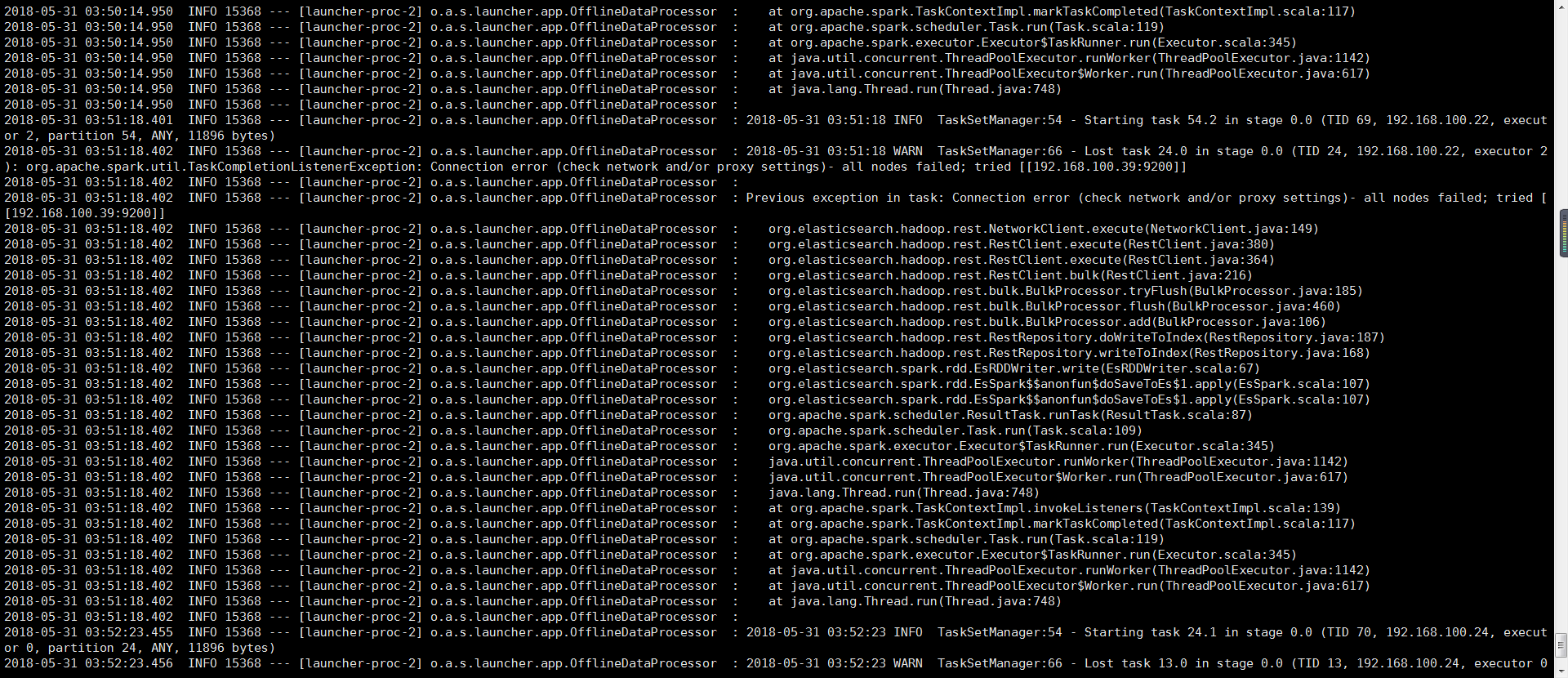
现在场景是从一个索引中获取数据,经过清洗以后写入到另外一个索引,第一跑的时候不会有什么问题,但是如果重复跑这部分数据就会有如下图所示的异常


本站服务器及带宽由 ![]() 提供赞助 · 网站程序: WeCenter · 湘ICP备17007482号 · 湘公网安备43010402002319号
提供赞助 · 网站程序: WeCenter · 湘ICP备17007482号 · 湘公网安备43010402002319号

0 个回复