

用logstash-input-jdbc 导入oracle数据到es,加中文列名导入失败(logstash 6.3),求解
Logstash | 作者 moqipa | 发布于2018年07月06日 | 阅读数:3137
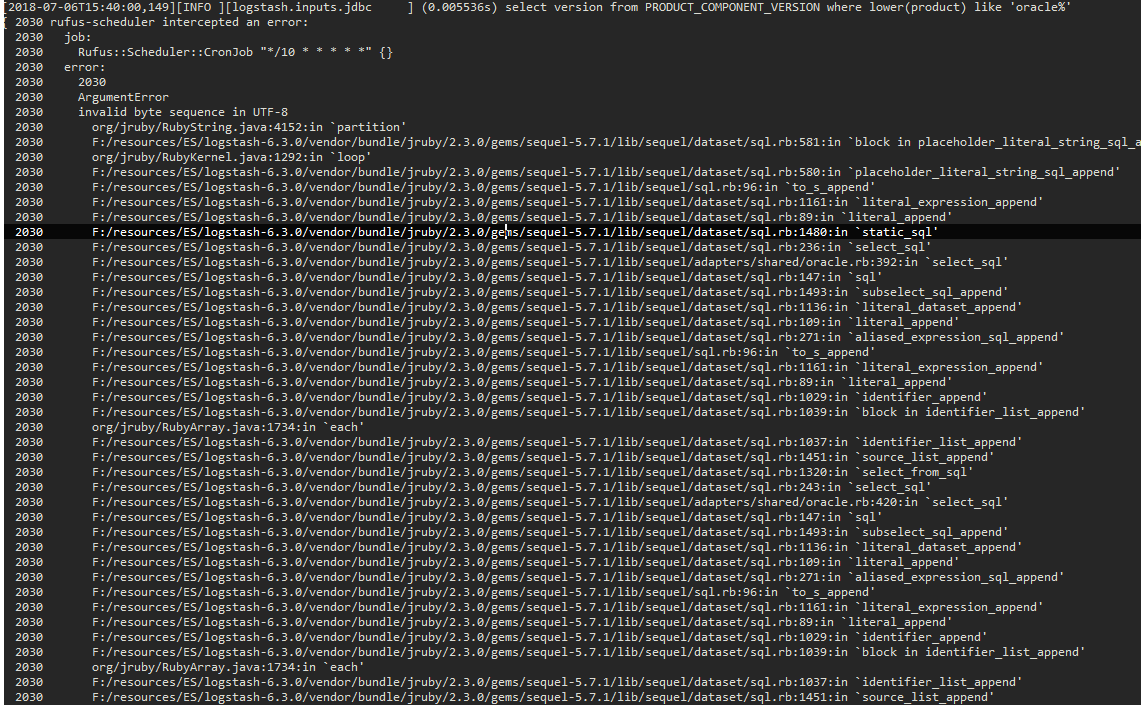
报错是这样的:
{ 2030 rufus-scheduler intercepted an error:
2030 job:
2030 Rufus::Scheduler::CronJob "*/10 * * * * *" {}
2030 error:
2030 2030
2030 ArgumentError
2030 invalid byte sequence in UTF-8
2030 org/jruby/RubyString.java:4152:in `partition'
{ 2030 rufus-scheduler intercepted an error:
2030 job:
2030 Rufus::Scheduler::CronJob "*/10 * * * * *" {}
2030 error:
2030 2030
2030 ArgumentError
2030 invalid byte sequence in UTF-8
2030 org/jruby/RubyString.java:4152:in `partition'

0 个回复