

原本是5个 node(node0-node4),每个1.5T 的 disk,新增一个1.5T 的 node5后,集群自动做了 rebalance。
在 node5上用 dstat 1查看 recv 在45M/s,但是 write达到了125M/s,均衡1T的数据到 node5上用了3.5小时。
如果按照 recv 的速度算,远远超过3.5小时。
刚开始 rebalance 使用的是默认参数,后期调整了如下参数
{
"cluster": {
"routing": {
"allocation": {
"cluster_concurrent_rebalance": "6",
"node_concurrent_recoveries": "6"
}
}
},
"indices": {
"recovery": {
"max_bytes_per_sec": "300m"
}
}
}
疑问:为何write速度远远大于recv 的速度,难道数据在 rebalance 是使用了压缩?
若使用了压缩,有没有相应的文档介绍或者源码?在 github 上未找到。。。
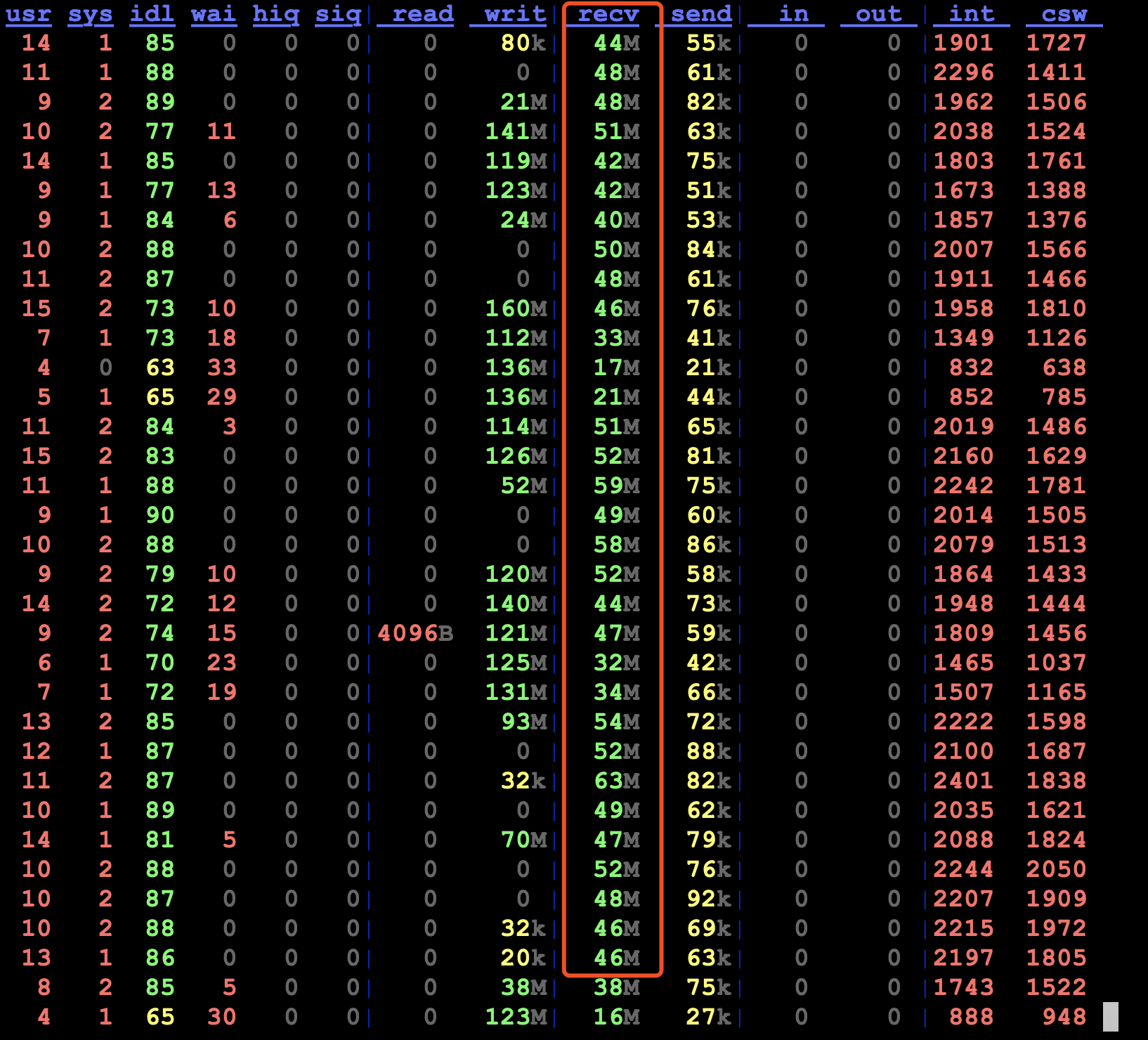
在 node5上用 dstat 1查看 recv 在45M/s,但是 write达到了125M/s,均衡1T的数据到 node5上用了3.5小时。
如果按照 recv 的速度算,远远超过3.5小时。
刚开始 rebalance 使用的是默认参数,后期调整了如下参数
{
"cluster": {
"routing": {
"allocation": {
"cluster_concurrent_rebalance": "6",
"node_concurrent_recoveries": "6"
}
}
},
"indices": {
"recovery": {
"max_bytes_per_sec": "300m"
}
}
}
疑问:为何write速度远远大于recv 的速度,难道数据在 rebalance 是使用了压缩?
若使用了压缩,有没有相应的文档介绍或者源码?在 github 上未找到。。。

3 个回复
zqc0512 - andy zhou
赞同来自:
Jea - 一只猿
赞同来自:
zhangrui90 - z
赞同来自: