

请教下各位大佬
现状: windows server 2008 服务器, 机械硬盘 六核CPU 16G内存, ES分配4G ,其他应用(比如tomcat mysql等约占用3到4G),lucene可用堆外内存大约8G左右。
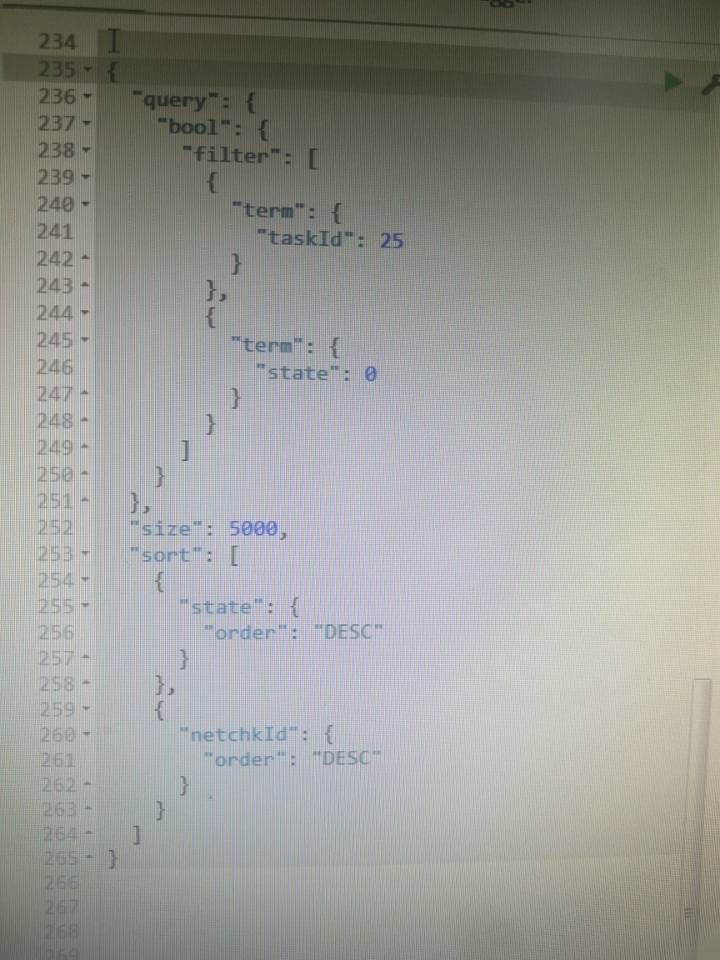
现在索引A,4千万数据,应用初次查询 (fileSystem Cache无数据)HDD机械盘 耗时 35秒+ (对比了下 在固态下,同样的数据,应用首次查询仅需2S+) ,后续的查询都在几百毫秒以内。 抱歉,办公网络无法上外网,查询DSL拍了照 在附件(排序字段netChkId为自定义的字段 UUID生成)
现在的思路
1.查看segment,发现小的segment比较多,合并了下segment
2.设置了index.store.preload:[“nvd”,“dvd”] ,经测试,发现对windows server 2008无效
3.预热数据,用户进入任务列表,在用户查看某个task的的时候,后台开启另外一个线程去执行dsl, 但是这个执行时间较长(35S+),还没执行完用户可能已经点击对应的查询了,这个时候预热就不起什么作用了。
请教下还有什么预热优化的思路吗?
另外请教下
1.数据是根据taskId来的,lucene应该是把该数据对应的segment全部缓存到内存里吧
2.存在fileSystem Cache中的数据,有过期策略吗?
感谢各位大佬回复,提前预祝端午安康 谢谢
现状: windows server 2008 服务器, 机械硬盘 六核CPU 16G内存, ES分配4G ,其他应用(比如tomcat mysql等约占用3到4G),lucene可用堆外内存大约8G左右。
现在索引A,4千万数据,应用初次查询 (fileSystem Cache无数据)HDD机械盘 耗时 35秒+ (对比了下 在固态下,同样的数据,应用首次查询仅需2S+) ,后续的查询都在几百毫秒以内。 抱歉,办公网络无法上外网,查询DSL拍了照 在附件(排序字段netChkId为自定义的字段 UUID生成)
现在的思路
1.查看segment,发现小的segment比较多,合并了下segment
2.设置了index.store.preload:[“nvd”,“dvd”] ,经测试,发现对windows server 2008无效
3.预热数据,用户进入任务列表,在用户查看某个task的的时候,后台开启另外一个线程去执行dsl, 但是这个执行时间较长(35S+),还没执行完用户可能已经点击对应的查询了,这个时候预热就不起什么作用了。
请教下还有什么预热优化的思路吗?
另外请教下
1.数据是根据taskId来的,lucene应该是把该数据对应的segment全部缓存到内存里吧
2.存在fileSystem Cache中的数据,有过期策略吗?
感谢各位大佬回复,提前预祝端午安康 谢谢

1 个回复
laoyang360 - 《一本书讲透Elasticsearch》作者,Elastic认证工程师 [死磕Elasitcsearch]知识星球地址:http://t.cn/RmwM3N9;微信公众号:铭毅天下; 博客:https://elastic.blog.csdn.net
赞同来自:
1、你只配置了4G堆内存,4千万数据的支撑,如果35秒慢,很大程度是这里的原因。
考虑:硬件隔离,ES节点只ES不要mysql等共存。
2、你可以考虑:profile:true, 看看时间花在哪里了?
3、lucene是把该数据对应的segment全部缓存到堆之外的内存。
4、由于你的内存相对有限,官网的明确提示:对于大于主机主内存大小的索引,此设置可能会有危险,因为这会导致在大型合并后重新打开时文件系统缓存会被删除,这会使索引和搜索 速度变慢。
5、关于filter缓存:
每个节点都有一个缓存,所有分片都会共享。
缓存实现LRU驱逐策略。
因此,如果您在一个群集上有多个用例,例如使用不同的索引,它们会相互影响,您可能不会将默认值10%的堆增加到20%(内存太有限)
indices.queries.cache.size: "20%"
如果您的索引不断更新,缓存也会失效。
因此,请检查您的缓存统计信息。