


征文
如何在 MacOS 环境下快速安装部署 Easysearch
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 3951 次浏览 • 2024-08-17 14:56
1、什么是 Easysearch

Easysearch 是极限科技研发的一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。 同时也是一款具备自主可控的分布式近实时搜索型数据库产品,具备高性能、高可用、弹性伸缩、高安全性等特性,具备支持丰富的个性化搜索及聚合分析能力,可部署在物理机、虚拟机、容器、私有云和公有云,能承载 PB 级别的海量业务数据,为金融核心系统、运营商、制造业和政企业务系统提供安全、稳定、可靠的快速检索和实时数据探索分析能力,可满足不同业务场景的各项复杂需求。
2、前期准备
在安装 Easysearch 之前,确保您的 MacOS 系统符合以下要求:
- MacOS 操作系统版本应为最新或推荐稳定版本。
- 确保系统上已安装 Java 运行环境,因为 Easysearch 是基于 Java 开发的。
3、下载 Easysearch
打开浏览器,访问 Easysearch 官方下载页面。

找到 MacOS 版本安装包,然后根据自己电脑 CPU 架构选择对应的 Easysearch 安装包。我自己的电脑是 Intel X86 架构,直接选择默认的 amd64,点击下载即可。如果你的电脑是 Apple 的自己的 M 系列芯片,请选择 arm64 版本安装包。
4、安装 Easysearch
打开终端(Terminal)并导航到下载目录,找到 Easysearch 的压缩包,然后双击解压到您选择的目录。或者使用以下命令解压文件:
unzip ./easysearch-1.8.3-265-mac-amd64.zip5、启动 Easysearch
- 执行初始化脚本:
由于 Easysearch 默认自带了安全模块,所以在启动之前需要先执行初始化脚本,脚本里会自动帮我们处理好 Easysearch 安全证书、下载基本的 plugins 插件以及初始用户名和密码等,方便省心。
cd ./easysearch-1.8.3-265-mac-amd64 && bin/initialize.sh
执行过程中遇到 [y/N] 询问,输入 y 即可。最后执行完初始化脚本之后,我们可以在输出的 log 日志中看到 easysearch 的访问用户名和密码,需要注意的是,这个用户名和密码需要自己保存好。 如下图所示:

- 启动 Easysearch: 使用以下命令启动 Easysearch:
./bin/easysearch启动后,Easysearch 将在终端中输出运行日志,您可以在此查看启动过程中的详细信息。
6、验证安装
- 检查运行状态:
打开浏览器,访问 https://localhost:9200,输入上面提到的用户名密码,如果您看到类似以下的 JSON 响应,说明 Easysearch 已成功启动:

- 检查集群健康状况:
在浏览器中输入 https:/localhost:9200/_cluster/health?pretty 或者在终端中执行以下命令来检查集群的健康状况:
curl -ku admin:4395c2f67208ca5ad7de https://localhost:9200/_cluster/health?pretty"这将返回集群的详细健康信息,status 为 green 表示集群状态正常。如下图所示:

7、总结
通过上述步骤,可以轻松地在 MacOS 环境下安装和部署 Easysearch,享受它带来的强大功能和便捷体验。Easysearch 作为 Elasticsearch 的替代产品,不仅在功能上保持了高效和稳定,还进一步优化了搜索业务场景,使其更适合企业级应用。现在,您可以进一步配置集群,开始索引数据,并探索 Easysearch 提供的强大搜索和分析功能。建议参考 官网文档,深入了解并实践更多高级功能。
关于 Easysearch 有奖征文活动

无论你是 Easysearch 的老用户,还是第一次听说这个名字,只要你对 INFINI Labs 旗下的 Easysearch 产品感兴趣,或者是希望了解 Easysearch,都可以参加这次活动。
详情查看:Easysearch 征文活动
作者:Keep simple
原文:https://blog.csdn.net/weixin_48688147/article/details/141238374
Easysearch 新特性:写入限流功能介绍
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 3966 次浏览 • 2024-07-17 14:52
背景
在 Easysearch 的各种使用场景中,高写入吞吐量的场景占了很大一部分,由此也带来了一些使用上的问题,很多用户由于使用经验不足,对集群的写入压测进行的不够充分,不能很好的规划集群的写入量。
导致经常发生以下问题:
- 写入吞吐量过大对内存影响巨大,引发节点 OOM,节点掉线问题。
- 对 CPU 和内存的占用严重影响了其他的查询业务的响应。
- 以及磁盘 IO 负载增加,挤占集群的网络带宽等问题。
之前就有某金融保险类客户遇到了因业务端写入量突然猛增导致数据节点不停的 Full GC,进而掉入了不停的掉线,上线,又掉线的恶性循环中。当时只能建议用户增加一个类似“挡板”的服务,在数据进入到集群之前进行拦截,对客户端写入进行干预限流:

这样做虽然有效,但是也增加了整个系统的部署复杂性,提高了运维成本。
根据客户的实际场景,Easysearch 从 1.8.0 版本开始引入了节点和 Shard 级别的限流功能,不用依赖第三方就可以限制写入压力,并在 1.8.2 版本增加了索引级别的写入限流。 注意:所有写入限流都是针对各数据节点的 Primary Shard 写入进行限流的,算上副本的话吞吐量要乘以 2。
限流示意图:
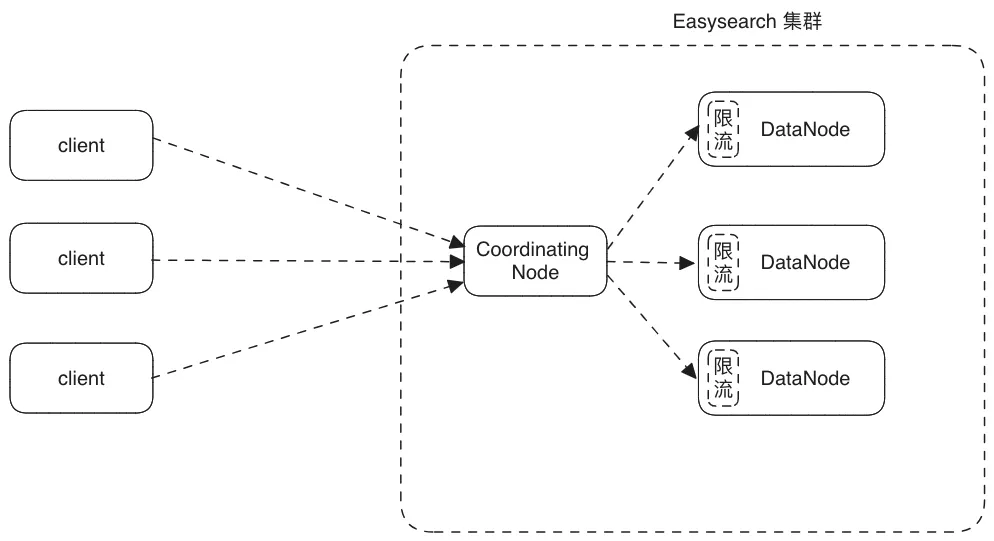
下面是限流前后相同数据节点的吞吐量和 CPU 对比:
测试环境:
ip name http port version role master
10.0.0.3 node-3 10.0.0.3:9209 9303 1.8.0 dimr -
10.0.0.3 node-4 10.0.0.3:9210 9304 1.8.0 im -
10.0.0.3 node-2 10.0.0.3:9208 9302 1.8.0 dimr -
10.0.0.3 node-1 10.0.0.3:9207 9301 1.8.0 dimr *测试索引配置:
PUT test_0
{
"settings": {
"number_of_replicas": 1,
"number_of_shards": 3
}
}压测工具:采用极限科技的 INFINI Loadgen 压测,这款压测工具使用简单,可以方便对任何支持 Rest 接口的库进行压测。
压测命令:
./loadgen-linux-amd64 -d 180 -c 10 -config loadgen-easy-1.8.yml压测 180 秒,10 个并发,每个 bulk 请求 5000 条。
节点级别限流
通过 INFINI Console 监控指标可以看到,限流之前的某个数据节点,CPU 占用 10%,每秒写入 40000 条左右:

在 Cluster Settings 里配置,启用节点级别限流,限制每个节点的每秒最大写入 10000 条,并在默认的 1 秒间隔内进行重试,超过默认间隔后直接拒绝。
PUT _cluster/settings
{
"transient": {
"cluster.throttle.node.write": true,
"cluster.throttle.node.write.max_requests": 10000,
"cluster.throttle.node.write.action": "retry"
}
}限流后,CPU 占用降低了约 50%,算上副本一共 20000 条每秒:

Shard 级别限流
设置每个分片最大写入条数为 2000 条每秒
PUT _cluster/settings
{
"transient": {
"cluster.throttle.shard.write": true,
"cluster.throttle.shard.write.max_requests": 2000,
"cluster.throttle.shard.write.action": "retry"
}
}集群级别的监控,同样是只针对主 Shard。

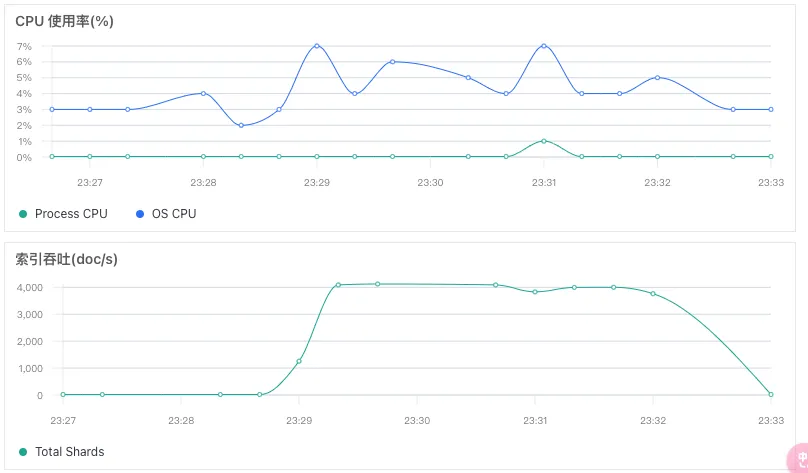
从 Console 的监控指标可以看出,索引 test_0 的 Primary indexing 维持在 6000 左右,正好是 3 个主分片限制的 2000 的写入之和。

再看下数据节点监控,Total Shards 表示主分片和副本分片的写入总和即 4000,单看主分片的话,正好是 2000.
索引级别限流
有时,集群中可能某个索引的写入吞吐过大而影响了其他业务,也可以针对特定的索引配置写入限制。 可以在索引的 Settings 里设置当前索引每秒写入最大条数为 6000:
PUT test_0
{
"settings": {
"number_of_replicas": 1,
"number_of_shards": 3,
"index.throttle.write.max_requests": 6000,
"index.throttle.write.action": "retry",
"index.throttle.write.enable": true
}
}下图索引的 Primary indexing 在 6000 左右,表示索引的所有主分片的写入速度限制在了 6000。

总结
通过本次测试对比,可以看出限流的好处:
-
有效控制写入压力: 写入限流功能能够有效限制每个节点和每个 Shard 的写入吞吐量,防止因写入量过大而导致系统资源被过度消耗的问题。
-
降低系统资源占用: 在限流前,某数据节点的 CPU 占用率约为 10%。限流后,CPU 占用率显著降低至约 5%,减少了约 50%。这表明在高并发写入场景下,写入限流功能显著降低了系统的 CPU 负载。
-
提高系统稳定性: 通过控制写入吞吐量,避免了频繁的 Full GC 和节点掉线问题,从而提升了系统的整体稳定性和可靠性。
- 保障查询业务性能: 写入限流功能减少了写入操作对 CPU 和内存的占用,确保其他查询业务的响应性能不受影响。
综上所述,写入限流功能在高并发写入场景下表现出色,不仅有效控制了写入压力,还显著降低了系统资源占用,从而提高了系统的稳定性和查询业务的性能。
关于 Easysearch 有奖征文活动

无论你是 Easysearch 的老用户,还是第一次听说这个名字,只要你对 INFINI Labs 旗下的 Easysearch 产品感兴趣,或者是希望了解 Easysearch,都可以参加这次活动。
详情查看:Easysearch 征文活动
作者:张磊
原文:https://infinilabs.cn/blog/2024/easysearch-new-feature-write-throttling-introduction/
如何在 MacOS 环境下快速安装部署 Easysearch
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 3951 次浏览 • 2024-08-17 14:56
1、什么是 Easysearch
Easysearch 是极限科技研发的一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。 同时也是一款具备自主可控的分布式近实时搜索型数据库产品,具备高性能、高可用、弹性伸缩、高安全性等特性,具备支持丰富的个性化搜索及聚合分析能力,可部署在物理机、虚拟机、容器、私有云和公有云,能承载 PB 级别的海量业务数据,为金融核心系统、运营商、制造业和政企业务系统提供安全、稳定、可靠的快速检索和实时数据探索分析能力,可满足不同业务场景的各项复杂需求。
2、前期准备
在安装 Easysearch 之前,确保您的 MacOS 系统符合以下要求:
- MacOS 操作系统版本应为最新或推荐稳定版本。
- 确保系统上已安装 Java 运行环境,因为 Easysearch 是基于 Java 开发的。
3、下载 Easysearch
打开浏览器,访问 Easysearch 官方下载页面。
找到 MacOS 版本安装包,然后根据自己电脑 CPU 架构选择对应的 Easysearch 安装包。我自己的电脑是 Intel X86 架构,直接选择默认的 amd64,点击下载即可。如果你的电脑是 Apple 的自己的 M 系列芯片,请选择 arm64 版本安装包。
4、安装 Easysearch
打开终端(Terminal)并导航到下载目录,找到 Easysearch 的压缩包,然后双击解压到您选择的目录。或者使用以下命令解压文件:
unzip ./easysearch-1.8.3-265-mac-amd64.zip5、启动 Easysearch
- 执行初始化脚本:
由于 Easysearch 默认自带了安全模块,所以在启动之前需要先执行初始化脚本,脚本里会自动帮我们处理好 Easysearch 安全证书、下载基本的 plugins 插件以及初始用户名和密码等,方便省心。
cd ./easysearch-1.8.3-265-mac-amd64 && bin/initialize.sh执行过程中遇到 [y/N] 询问,输入 y 即可。最后执行完初始化脚本之后,我们可以在输出的 log 日志中看到 easysearch 的访问用户名和密码,需要注意的是,这个用户名和密码需要自己保存好。 如下图所示:
- 启动 Easysearch: 使用以下命令启动 Easysearch:
./bin/easysearch启动后,Easysearch 将在终端中输出运行日志,您可以在此查看启动过程中的详细信息。
6、验证安装
- 检查运行状态:
打开浏览器,访问 https://localhost:9200,输入上面提到的用户名密码,如果您看到类似以下的 JSON 响应,说明 Easysearch 已成功启动:
- 检查集群健康状况:
在浏览器中输入 https:/localhost:9200/_cluster/health?pretty 或者在终端中执行以下命令来检查集群的健康状况:
curl -ku admin:4395c2f67208ca5ad7de https://localhost:9200/_cluster/health?pretty"这将返回集群的详细健康信息,status 为 green 表示集群状态正常。如下图所示:
7、总结
通过上述步骤,可以轻松地在 MacOS 环境下安装和部署 Easysearch,享受它带来的强大功能和便捷体验。Easysearch 作为 Elasticsearch 的替代产品,不仅在功能上保持了高效和稳定,还进一步优化了搜索业务场景,使其更适合企业级应用。现在,您可以进一步配置集群,开始索引数据,并探索 Easysearch 提供的强大搜索和分析功能。建议参考 官网文档,深入了解并实践更多高级功能。
关于 Easysearch 有奖征文活动
无论你是 Easysearch 的老用户,还是第一次听说这个名字,只要你对 INFINI Labs 旗下的 Easysearch 产品感兴趣,或者是希望了解 Easysearch,都可以参加这次活动。
详情查看:Easysearch 征文活动
作者:Keep simple
原文:https://blog.csdn.net/weixin_48688147/article/details/141238374
Easysearch 新特性:写入限流功能介绍
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 3966 次浏览 • 2024-07-17 14:52
背景
在 Easysearch 的各种使用场景中,高写入吞吐量的场景占了很大一部分,由此也带来了一些使用上的问题,很多用户由于使用经验不足,对集群的写入压测进行的不够充分,不能很好的规划集群的写入量。
导致经常发生以下问题:
- 写入吞吐量过大对内存影响巨大,引发节点 OOM,节点掉线问题。
- 对 CPU 和内存的占用严重影响了其他的查询业务的响应。
- 以及磁盘 IO 负载增加,挤占集群的网络带宽等问题。
之前就有某金融保险类客户遇到了因业务端写入量突然猛增导致数据节点不停的 Full GC,进而掉入了不停的掉线,上线,又掉线的恶性循环中。当时只能建议用户增加一个类似“挡板”的服务,在数据进入到集群之前进行拦截,对客户端写入进行干预限流:
这样做虽然有效,但是也增加了整个系统的部署复杂性,提高了运维成本。
根据客户的实际场景,Easysearch 从 1.8.0 版本开始引入了节点和 Shard 级别的限流功能,不用依赖第三方就可以限制写入压力,并在 1.8.2 版本增加了索引级别的写入限流。 注意:所有写入限流都是针对各数据节点的 Primary Shard 写入进行限流的,算上副本的话吞吐量要乘以 2。
限流示意图:
下面是限流前后相同数据节点的吞吐量和 CPU 对比:
测试环境:
ip name http port version role master
10.0.0.3 node-3 10.0.0.3:9209 9303 1.8.0 dimr -
10.0.0.3 node-4 10.0.0.3:9210 9304 1.8.0 im -
10.0.0.3 node-2 10.0.0.3:9208 9302 1.8.0 dimr -
10.0.0.3 node-1 10.0.0.3:9207 9301 1.8.0 dimr *测试索引配置:
PUT test_0
{
"settings": {
"number_of_replicas": 1,
"number_of_shards": 3
}
}压测工具:采用极限科技的 INFINI Loadgen 压测,这款压测工具使用简单,可以方便对任何支持 Rest 接口的库进行压测。
压测命令:
./loadgen-linux-amd64 -d 180 -c 10 -config loadgen-easy-1.8.yml压测 180 秒,10 个并发,每个 bulk 请求 5000 条。
节点级别限流
通过 INFINI Console 监控指标可以看到,限流之前的某个数据节点,CPU 占用 10%,每秒写入 40000 条左右:
在 Cluster Settings 里配置,启用节点级别限流,限制每个节点的每秒最大写入 10000 条,并在默认的 1 秒间隔内进行重试,超过默认间隔后直接拒绝。
PUT _cluster/settings
{
"transient": {
"cluster.throttle.node.write": true,
"cluster.throttle.node.write.max_requests": 10000,
"cluster.throttle.node.write.action": "retry"
}
}限流后,CPU 占用降低了约 50%,算上副本一共 20000 条每秒:
Shard 级别限流
设置每个分片最大写入条数为 2000 条每秒
PUT _cluster/settings
{
"transient": {
"cluster.throttle.shard.write": true,
"cluster.throttle.shard.write.max_requests": 2000,
"cluster.throttle.shard.write.action": "retry"
}
}集群级别的监控,同样是只针对主 Shard。
从 Console 的监控指标可以看出,索引 test_0 的 Primary indexing 维持在 6000 左右,正好是 3 个主分片限制的 2000 的写入之和。
再看下数据节点监控,Total Shards 表示主分片和副本分片的写入总和即 4000,单看主分片的话,正好是 2000.
索引级别限流
有时,集群中可能某个索引的写入吞吐过大而影响了其他业务,也可以针对特定的索引配置写入限制。 可以在索引的 Settings 里设置当前索引每秒写入最大条数为 6000:
PUT test_0
{
"settings": {
"number_of_replicas": 1,
"number_of_shards": 3,
"index.throttle.write.max_requests": 6000,
"index.throttle.write.action": "retry",
"index.throttle.write.enable": true
}
}下图索引的 Primary indexing 在 6000 左右,表示索引的所有主分片的写入速度限制在了 6000。
总结
通过本次测试对比,可以看出限流的好处:
-
有效控制写入压力: 写入限流功能能够有效限制每个节点和每个 Shard 的写入吞吐量,防止因写入量过大而导致系统资源被过度消耗的问题。
-
降低系统资源占用: 在限流前,某数据节点的 CPU 占用率约为 10%。限流后,CPU 占用率显著降低至约 5%,减少了约 50%。这表明在高并发写入场景下,写入限流功能显著降低了系统的 CPU 负载。
-
提高系统稳定性: 通过控制写入吞吐量,避免了频繁的 Full GC 和节点掉线问题,从而提升了系统的整体稳定性和可靠性。
- 保障查询业务性能: 写入限流功能减少了写入操作对 CPU 和内存的占用,确保其他查询业务的响应性能不受影响。
综上所述,写入限流功能在高并发写入场景下表现出色,不仅有效控制了写入压力,还显著降低了系统资源占用,从而提高了系统的稳定性和查询业务的性能。
关于 Easysearch 有奖征文活动
无论你是 Easysearch 的老用户,还是第一次听说这个名字,只要你对 INFINI Labs 旗下的 Easysearch 产品感兴趣,或者是希望了解 Easysearch,都可以参加这次活动。
详情查看:Easysearch 征文活动
作者:张磊
原文:https://infinilabs.cn/blog/2024/easysearch-new-feature-write-throttling-introduction/
