


Easysearch
INFINI Easysearch 向量搜索实战(一)
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 2731 次浏览 • 4 天前

Easysearch 提供了强大的向量搜索能力,打破传统关键词匹配的局限,实现真正的“懂你”的语义搜索。助力企业快速构建智能推荐、图像识别和内容理解等 AI 应用,释放数据深层价值。
核心能力
| 能力 | 说明 |
|---|---|
| 两种向量类型 | 稠密浮点向量(knn_dense_float_vector)和稀疏布尔向量(knn_sparse_bool_vector) |
| 多种索引模型 | lsh(局部敏感哈希,近似搜索)、permutation_lsh(置换 LSH)、sparse_indexed(倒排索引)、exact(精确搜索) |
| 多种相似度 | cosine(余弦)、l1(曼哈顿距离)、l2(欧氏距离)、jaccard、hamming |
| 与全文搜索融合 | 向量字段与文本字段存储在同一索引,支持 Hybrid 混合检索 |
| function_score 集成 | 向量相似度可作为 function_score 的评分函数 |
典型应用场景
- 语义搜索:文本通过 Embedding 模型转为向量,按语义相似度检索
- RAG 检索增强生成:为大语言模型提供知识库检索能力
- 推荐系统:用户/商品特征向量的相似推荐
- 图像/多模态搜索:图像特征向量的相似检索
- 去重与异常检测:通过向量距离判断内容相似度
Embedding 服务
在使用向量搜索前,先要准备一个 Embedding 模型,支持与 OpenAI API 兼容的 embedding 接口和 Ollama embedding 接口。本文使用阿里云上的 Embedding 模型进行演示。
写入方法
方法一:写入链路嵌入(推荐)
在数据写入 Easysearch 时,通过 Ingest Pipeline 自动调用 Embedding 服务:
应用写数据 → Easysearch → Ingest Pipeline → 调用 Embedding API → 写入向量字段
优势是写入后即可搜索,无需维护外部向量化流程。需要确保集群应至少有一个节点拥有 ingest 角色。
方法二:离线批处理
在应用侧完成向量化,再将向量字段直接写入 Easysearch:
原始数据 → 应用 → 调用模型 Embedding API → 写入 Easysearch(含向量字段)
参考文档。
实战
我们实战演示模式一,分为以下几个步骤:
- 建立带有向量字段的索引
- 创建对应的 Ingest Pipeline
- 写入数据到索引
1. 建立带有向量字段的索引
先建立一个带向量字段的索引,注意 dims 要与向量模型的输出匹配。
PUT /my-index
{
"mappings": {
"properties": {
"text_vector": {
"type": "knn_dense_float_vector",
"knn": {
"dims": 1024,
"model": "lsh",
"similarity": "cosine",
"L": 99,
"k": 1
}
}
}
}
}
2. 创建对应的 Ingest Pipeline
写入数据前先建立 Ingest Pipeline,注意 vendor 必须根据使用的模型来指定,比如本文使用的是阿里云 text-embedding-v4 模型,该模型提供了 OpenAI 格式的 API 接口,这里 vendor 我们就写 openai。
PUT _ingest/pipeline/text-embedding-pipeline
{
"description": "用于生成文本嵌入向量的管道",
"processors": [
{
"text_embedding": {
"url": "https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings",
"vendor": "openai",
"api_key": "xxxxxx",
"text_field": "input_text",
"vector_field": "text_vector",
"model_id": "text-embedding-v4",
"dims": 1024,
"ignore_missing": false,
"ignore_failure": false
}
}
]
}
text_field:指定原始文本字段,Pipeline 会将该字段的内容转换成向量。
vector_field:指定向量存储的字段,保存上面转换的向量。
3. 写入数据
POST /_bulk?pipeline=text-embedding-pipeline&pretty
{"index": {"_index": "my-index", "_id": "1"}}
{"input_text": "苹果发布了新款iPhone 15 Pro手机,搭载A17芯片"}
{"index": {"_index": "my-index", "_id": "2"}}
{"input_text": "特斯拉宣布将在上海建第二座超级工厂"}
{"index": {"_index": "my-index", "_id": "3"}}
{"input_text": "今天天气真好,阳光明媚适合去公园散步"}
{"index": {"_index": "my-index", "_id": "4"}}
{"input_text": "程序员用Python写了一个自动化数据清洗脚本"}
{"index": {"_index": "my-index", "_id": "5"}}
{"input_text": "故宫博物院推出了夏季特展,展出珍贵文物"}
{"index": {"_index": "my-index", "_id": "6"}}
{"input_text": "小明每天坚持跑步五公里,身体越来越健康"}
{"index": {"_index": "my-index", "_id": "7"}}
{"input_text": "人工智能大模型在自然语言处理领域取得突破"}
{"index": {"_index": "my-index", "_id": "8"}}
{"input_text": "这家咖啡店的拿铁口感丝滑,推荐给咖啡爱好者"}
{"index": {"_index": "my-index", "_id": "9"}}
{"input_text": "量子计算机有望在药物研发中发挥重要作用"}
{"index": {"_index": "my-index", "_id": "10"}}
{"input_text": "周末和朋友一起去爬山,山顶的风景美极了"}
4. 检查数据
搜索索引数据,看看是否成功转换成了向量。可以看到原始数据保存在 input_text 字段中,其向量保存到了 text_vector。

OK,下一步我们看看怎么方便地实现向量搜索。

关于 Easysearch

INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
官网文档:https://docs.infinilabs.com/easysearch
相关文章:
Bboss v7.5.6 正式发布,全面兼容国产分布式搜索引擎 Easysearch
资讯动态 • INFINI Labs 小助手 发表了文章 • 0 个评论 • 12960 次浏览 • 2026-06-23 23:31
一、引言
2026 年 6 月 21 日,经过 Bboss 开源社区与极限科技(INFINI Labs)的紧密合作, Bboss v7.5.6 正式发布!
作为国内领先的 AI 智能体开发框架、数据采集同步 ETL 工具以及流批一体化计算引擎,Bboss 在本次更新中与国产分布式搜索引擎 Easysearch 完成深度兼容,其 Elasticsearch Java 客户端 全面兼容 Easysearch 1.x、2.x 全系列版本。开发者现在可以无缝使用 Bboss 客户端操作 Easysearch 集群,享受与 Elasticsearch 一致的开发体验。
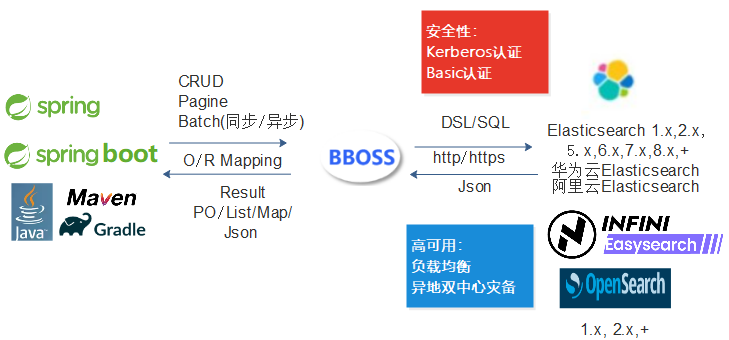
二、Bboss Elasticsearch 客户端简介
Bboss 是一款高性能、高兼容性的搜索引擎 Java REST 客户端框架,基于 Apache License 2.0 开源,原生支持 Elasticsearch、Easysearch 和 Opensearch。
自带客户端集群节点负载均衡和容灾,多集群多数据源,自动索引托管,多种分页机制,傻瓜级 CRUD,脚本,SQL,JDBC,高亮,权重,聚合,IP,GEO 地理位置,父子嵌套,应有尽有。
核心特性
| 特性 | 说明 |
|---|---|
| 原生多引擎支持 | 完美支持 ES 1.x ~ 9.x、Easysearch 1.x ~ 2.x、Opensearch 1.x ~ 3.x |
| 学习成本低 | 无需学习额外 API,只需掌握 Elasticsearch DSL,极简使用方式 |
| 开箱即用 | Spring Boot 自动配置,无需复杂设置 |
| 高效异步处理 | 内置 BulkProcessor 异步批处理器,大幅提升写入性能 |
| 灵活查询方式 | 支持 DSL、SQL、O/R Mapping 多种查询模式 |
| 多数据源支持 | 一个应用可同时操作多个不同版本的搜索引擎集群 |
| 客户端负载均衡 | 默认启用客户端负载均衡,容灾性更好 |
| 完整的结果封装 | 返回结果支持 JSON、PO 对象、List 集合、Map 等多种类型 |
三、为什么选择 Bboss + Easysearch
将 Bboss 作为 Easysearch 的 Java 客户端,您将获得以下独特优势:
- 国产化技术栈:从底层搜索引擎到上层客户端框架,完全国产化自主可控,满足信创合规要求,无许可证风险。
- 极低迁移成本:如果您正在使用 Elasticsearch + Bboss 技术栈,切换到 Easysearch 几乎零成本,只需修改连接配置即可。
- 成熟稳定的客户端:Bboss 经过多年发展,已在国内众多企业和项目中得到广泛应用和验证,拥有活跃的中文社区和完善的文档支持。
- 丰富的生态能力:除了基础的 CRUD 操作,还提供数据采集 ETL、流批一体化计算、AI 智能体等丰富的扩展能力。
四、快速开始
通过以下简单步骤,即可在 Bboss 中接入 Easysearch:
1. 添加 Maven 依赖
<dependency>
<groupId>com.bbossgroups.plugins</groupId>
<artifactId>bboss-datatran-jdbc</artifactId>
<version>7.5.6</version>
</dependency>2. 配置 Easysearch 连接
spring:
elasticsearch:
bboss:
elasticsearch:
rest:
hostNames: localhost:9200
useHttps: true # Easysearch 默认启用 HTTPS
elasticUser: admin
elasticPassword: your_password3. 基础操作
@Service
public class DocumentService {
@Autowired
private BBossESStarter bbossESStarter;
// 插入文档
public void insertDocument() {
ClientInterface client = bbossESStarter.getRestClient();
Document doc = new Document();
doc.setId("1");
doc.setTitle("Easysearch 与 Bboss 集成");
doc.setContent("这是一篇关于集成的文章");
client.addDocument("documents", doc, "refresh=true");
}
// 查询文档
public Document getDocument(String id) {
ClientInterface client = bbossESStarter.getRestClient();
return client.getDocument("documents", id, Document.class);
}
// 按字段查询
public ESDatas<Document> searchByAuthor(String author) {
ClientInterface client = bbossESStarter.getRestClient();
return client.searchListByField(
"documents", "author.keyword", author,
Document.class, 0, 10
);
}
}五、结语
Bboss v7.5.6 与 Easysearch 的深度兼容,是国产开源生态建设的又一重要成果。作为 Easysearch 原厂,我们欢迎更多像 Bboss 这样的优秀开源项目加入国产搜索引擎生态,共同推动国内搜索型数据库的发展与繁荣。
对于正在评估搜索引擎选型或计划进行国产替代的企业用户,Bboss + Easysearch 的组合无疑是值得信赖的选择。
立即体验 Easysearch,开启国产搜索引擎之旅:
- Easysearch 官网: https://easysearch.cn
- Bboss 官方文档: https://esdoc.bbossgroups.com
- Easysearch x Bboss 详细集成文档: https://docs.infinilabs.com/easysearch/main/docs/integrations/third-party/bboss
六、关于 Easysearch

INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。作为国内领先的国产搜索引擎产品,Easysearch 具备以下核心优势:
1. 国产化自主可控
自主研发,符合信创要求,无许可证风险,为企业提供安全可靠的技术保障。在当前国际形势日益复杂、信创需求持续提升的大背景下,Easysearch 为政府、金融、电信、能源等关键行业提供了值得信赖的搜索引擎基础设施。
2. 轻量级架构
相比传统搜索引擎,Easysearch 资源占用更少,启动更快速,显著降低企业运维成本。其精简的架构设计使得在同等硬件条件下可以承载更多的业务负载,特别适合资源受限的私有化部署场景。
3. 卓越性能表现
查询性能优异,能够满足大部分业务场景需求,用户体验流畅。通过持续的内核优化和算法改进,Easysearch 在多项基准测试中展现出媲美甚至超越同类产品的性能水平。
4. 良好兼容性
与 Elasticsearch 的 API 接口基本兼容,迁移成本较低,保护用户现有投资。这一特性使得基于 Elasticsearch 开发的应用可以快速平滑地迁移至 Easysearch,大大降低了国产替代的技术门槛。
社区福利
为感谢广大社区开发者的支持,Bboss 与 Easysearch 厂商极限科技联合发起抽奖活动,奖品为开源T恤。6 月 29 日上午 10 点自动开奖,欢迎大家扫码抽奖参与。

Easysearch v2.3.0 发布 | 管理体验升级,稳定性与兼容性全面增强
资讯动态 • INFINI Labs 小助手 发表了文章 • 0 个评论 • 11618 次浏览 • 2026-06-23 14:11

INFINI Easysearch v2.3.0 正式发布。本次版本围绕“更易用的管理体验、更稳健的集群能力、更可靠的运行表现”持续优化,重点覆盖数据流与管道管理、CCR 与 Rollup 稳定性、安全权限语义一致性,以及 ZSTD 压缩链路在复杂环境下的兼容性与内存表现。
功能特性 (Features)
- 新增管道管理 UI
- Agent UI 新增 API Token 管理能力
- 新增数据流 bootstrap 创建 API,在缺少匹配模板时可自动补齐默认模板并继续创建数据流,简化联调与初始化流程
- 在数据流页面新增“添加数据流”入口
- 新增“修改当前用户密码”UI
改进优化 (Improvements)
- Security enrollment token 新增
endpoints字段(保留endpoint兼容单值),便于多节点地址感知。 - 默认
admin角色映射补充replication_leader与replication_follower,降低 CCR 角色配置复杂度。 - 强化 Rollup/ILM/SLM 启动期保护:在配置索引、安全模块或主分片未就绪时延后周期任务,减少冷启动误报。
- 优化 Rollup Search 索引路由策略,在 alias/wildcard 场景下可更准确区分 live 与 rollup 索引。
- 优化 CCR 同步调度与升级保护,减少空轮询、无效重试,并提升跨版本滚动升级期间可控性。
- 新增状态过滤能力(如
BOOTSTRAPPING、PAUSED、FAILED),便于运维排障。 - 优化初始化与安装流程:重复初始化默认保留关键数据文件,macOS 自动处理隔离标签,安装更顺畅。
- 增强 ZSTD 在非理想运行环境下的兼容回退与内存生命周期管理,降低后台合并内存峰值。
问题修复(Bug Fixes)
- 修复
source_reuse在 tombstone 与非 JSON/二进制_source场景下的解析异常与潜在写入阻塞。 - 修复 Rollup mixed search 在空字段、空索引与边界分流下的聚合异常,避免统计重复、丢失或合并失败。
- 修复 Rollup 索引识别与跨版本传输兼容问题,降低混合集群反序列化失败风险。
- 修复 cluster-state 全局请求在安全过滤后的模板、数据流与索引可见性语义不一致问题。
- 修复 cluster-state 转发、反序列化与超时响应链路中的边界问题,避免 metadata 泄漏与 REST 500/NPE。
- 修复 Security API 在内部用户查询与账户更新中的权限边界问题,恢复 404/403 契约一致性。
- 修复安全模式下
/_cluster/settings与跨集群搜索(CCS)在权限过滤后的返回不完整问题。 - 修复 CCR 在重启、停止复制、proxy 远程集群和 SecurityManager 环境下的稳定性问题。
- 修复可搜索快照在小缓存配置下的启动失败,提升低资源场景可用性。
- 修复 ZSTD 在高压力 merge 场景下的 OOM 与异常传播问题,增强压缩链路健壮性。
- 修复远程集群管理 UI 在代理模式下无法删除的问题。
- 修复数据探索侧边栏对象字段丢失问题。
以上为本版本重点更新摘要,更多详情请查看 Easysearch 产品 Release Notes 或联系我们的技术支持团队!
获取新版本
INFINI Easysearch v2.3.0 已正式发布,欢迎升级体验:
- 下载地址:https://infinilabs.cn/download/
- 快速开始:https://docs.infinilabs.com/easysearch/main/docs/quick-start/
关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。

【搜索客社区日报】第2249期 (2026-06-15)
社区日报 • Muses 发表了文章 • 0 个评论 • 12057 次浏览 • 2026-06-16 21:09
信创环境下部署 INFINI Gateway:为 Easysearch 构建高性能安全入口
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 11659 次浏览 • 2026-06-11 17:17
引言
上一篇文章里,我们已经完成了 Easysearch 在信创环境下的部署。搜索服务能跑起来只是第一步,要让它真正用于生产,还需要补上“入口治理”这一环。
例如,下面这些问题在生产环境中非常常见:
- 如何防止某个应用或用户发出超大查询请求,把 Easysearch 集群拖垮?
- 如果 Easysearch 某个节点突然宕机,请求能不能自动切换到健康节点,让业务无感知?
- 如何知道每天有多少次查询、哪些查询慢、哪些请求不合法,有没有办法对请求进行审计?
这些正是 INFINI Gateway(极限网关) 擅长解决的问题。本文延续“小白友好”风格,带你完成 Gateway 的安装与验证,为 Easysearch 增加一层高性能、安全、可观测的入口防护。

一、INFINI Gateway 是什么?和 Easysearch 是什么关系?
如果把 Easysearch 比作大型图书馆,那么 INFINI Gateway 就像门口的 “前台总台”。过去读者(应用程序)直接进入书库检索;现在所有请求先经过前台,再转发到书库。这样做的好处很直接:可以缓存热门请求,减少后端压力;可以限制流量,避免集群被突发请求冲垮;还可以记录访问日志,方便审计与分析。
从技术层面讲,INFINI Gateway 的定位如下:
- 高性能数据网关:面向搜索场景设计,请求先在网关完成处理,再转发到后端 Easysearch 集群。
- 代理 + 增强:位于客户端与 Easysearch 之间,可在转发链路中叠加限流、缓存加速、请求审计、结果改写等能力。
- 兼容原生 API:对外接口兼容 Elasticsearch / Easysearch 原生 API,应用只需把连接地址从直连 Easysearch 改为指向网关,无需改业务代码。
- 轻量易部署:基于 Golang 开发,安装包约 10MB,无额外外部依赖。
- 信创兼容认证:已通过华为鲲鹏 Kunpeng 920 兼容性认证,并获得 KUNPENG COMPATIBLE 证书。
整个系列的组件关系如下:
应用程序 → INFINI Gateway(流量入口) → Easysearch(数据存储与检索)
有了 Gateway,你就可以更放心地将搜索服务开放给更多应用和用户,而不必过度担心安全与性能失控问题。
二、部署前置条件
1. 信创环境
- CPU :鲲鹏 Kunpeng-920、aarch64
- 操作系统:统信服务器操作系统A版 V20
2. 确保 Easysearch 已正常运行
Gateway 本身不存储数据,核心职责是代理与增强 Easysearch。因此部署前请先确认 Easysearch 已启动,并且网络可达:
curl -ku admin:你的密码 https://localhost:9200三、部署步骤
步骤 1:下载 INFINI Gateway
下面脚本会自动下载对应平台的 Gateway 最新版本,并解压到 /opt/gateway:
# 一键下载并安装到 /opt/gateway
curl -sSL http://get.infini.cloud | bash -s -- -p gateway -d /opt/gateway
步骤 2:编写 Gateway 配置文件
Gateway 启动依赖 YAML 配置文件,用来声明监听端口、后端 Easysearch 地址和认证信息。进入安装目录后,找到 gateway.yml 并按实际环境修改:
# 按实际情况填写可访问的 Easysearch 地址
LOGGING_ES_ENDPOINT:https://localhost:9200/
LOGGING_ES_USER:admin
LOGGING_ES_PASS:"你的 Easysearch 密码"
# 按实际情况填写可访问的 Easysearch 地址
PROD_ES_ENDPOINT:https://localhost:9200/
PROD_ES_USER:admin
PROD_ES_PASS:"你的 Easysearch 密码"
# 按需设置 Gateway 对外监听端口
GW_BINDING:"0.0.0.0:8000"步骤 3:启动 Gateway
进入 Gateway 安装目录,执行下面命令启动程序:
# 进入安装目录
cd /opt/gateway
# 运行程序(gateway-linux-arm64 为可执行文件名)
./gateway-linux-arm64

程序启动后,即可通过配置端口访问 Easysearch 服务。

在前台运行模式下,如需停止 Gateway,按 Ctrl+C 即可。

如果希望将 Gateway 作为后台服务运行,可执行:
# 命令中的 gateway-linux-arm64 为可执行文件名
./gateway-linux-arm64 -service install && ./gateway-linux-arm64 -service start如需卸载服务,执行以下命令:
./gateway-linux-arm64 -service stop
./gateway-linux-arm64 -service uninstall步骤 4:验证 Gateway 是否正常工作
通过 Gateway 间接访问 Easysearch,确认转发通路正常:
# 通过 Gateway(8000 端口)访问 Easysearch
curl http://0.0.0.0:8000
# 对比直连 Easysearch 的结果
curl -ku admin:你的密码 https://localhost:9200两条命令返回的 JSON 结果应基本一致。若都能正常响应,说明 Gateway 已成功接管 Easysearch 的访问入口。
如果你的生产环境需要将搜索服务开放给大量应用和用户,建议将 Gateway 纳入标准部署方案。借助 Gateway,你可以更好地保护后端 Easysearch 集群,并获得限流限速、缓存加速、安全防护、审计日志等增强能力,让整体架构更健壮、更安全、更可观测。
如果在部署过程中遇到问题,欢迎查阅官方文档。祝你部署顺利!
作者:小袁
原文:https://infinilabs.cn/blog/2026/gateway-install-at-xc-platform/
极限科技 Easysearch 与鼎甲备份系统完成深度兼容适配认证
资讯动态 • INFINI Labs 小助手 发表了文章 • 0 个评论 • 11321 次浏览 • 2026-06-10 09:21
近日,极限科技与鼎甲科技顺利完成双向兼容适配认证,国产分布式检索数据库 Easysearch V2.0 与鼎甲数据备份与恢复系统 DBackup V8.0 全面通过功能、性能、稳定性联合测试,产品适配顺畅、运行表现优异,成功实现国产检索存储与国产数据灾备全链路深度打通。

为保障适配落地效果,双方组建专项技术团队,围绕 Easysearch 海量索引、向量索引等特色数据结构开展定制化调优,覆盖全量与增量备份、瞬时恢复、故障回滚、集群高可用等核心业务场景。经过多轮严苛验证,两套自研产品可无缝协同,能够为检索类数据提供覆盖全生命周期的安全防护能力。
作为国产化核心检索引擎,Easysearch V2.0 原生兼容 ES 生态,支持全文检索、向量检索、多模态检索等丰富能力,深度适配国产软硬件环境,可有效助力政务、金融、大数据等行业实现搜索引擎国产化替换。鼎甲 DBackup V8.0 是国内主流政企级灾备产品,具备全域数据备份、极速恢复、异地容灾、勒索防护等成熟能力,长期为海量关键业务数据提供安全保障。
未来,极限科技与鼎甲科技将持续深化技术与生态合作,持续跟进产品版本迭代适配,联合打磨标准化行业解决方案,拓展金融、政务、能源等落地场景,携手完善国产基础软件产业链,持续赋能政企信创数字化建设。
国产统信 UOS 部署 Coco Server 全指南:从零搭建企业级 AI 搜索服务端
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 9852 次浏览 • 2026-06-09 14:19
一、引言
在上一篇文章《从零到跑起来:Easysearch 信创环境安装全流程》中,我们成功在信创平台上安装并运行起了 Easysearch。但 Easysearch 是一个底层搜索引擎,直接操作有一定门槛。如果我们想让团队里的每个人都能方便地“搜文件、聊文档、问知识”,就需要一个更贴近日常使用、又能把 AI 能力融入进来的上层应用——这就是 Coco AI 。
本文将继续手把手带你从零开始,在国产统信 UOS 服务器操作系统上部署 Coco Server,并与已安装的 Easysearch 进行对接。全文依然零基础可读,跟着步骤一步步来即可。
二、Coco Server 是什么?它和 Easysearch 什么关系?
先对我们的产品进行一个简单的介绍:
- Easysearch 是底层引擎,负责存储和检索数据,像汽车的发动机和底盘;
- Coco Server 是基于 Easysearch 之上的服务端应用程序,提供 Web 管理界面、统一搜索、AI 聊天、知识库管理等高级功能,类似车身和智能驾驶系统;
- Coco AI 桌面客户端则是连接 Coco Server 的终端软件,安装在个人电脑上使用。
而在本文中部署的 Coco Server,是整个 Coco AI 体系的“大脑”:
- 它负责连接各类数据源(飞书、语雀、GitHub、本地文件等);
- 它管理大模型提供商(Deepseek、通义千问、OpenAI 等);
- 它提供 Web 管理后台,让管理员可以可视化地完成所有配置。
部署完成之后,团队成员只需通过客户端或浏览器,就能享受统一搜索与 AI 智能问答带来的便利。Coco AI 的整体架构图如下:

三、部署前置条件
1. 进行服务器相关优化
#内核参数优化
cat << SETTINGS | sudo tee /etc/sysctl.d/70-infini.conf
fs.file-max = 10485760
fs.nr_open = 10485760
vm.max_map_count = 262145
net.core.somaxconn = 65535
net.core.netdev_max_backlog = 65535
net.core.rmem_default = 262144
net.core.wmem_default = 262144
net.core.rmem_max = 4194304
net.core.wmem_max = 4194304
net.ipv4.ip_forward = 1
net.ipv4.ip_nonlocal_bind = 1
net.ipv4.ip_local_port_range = 1024 65535
net.ipv4.conf.default.accept_redirects = 0
net.ipv4.conf.default.rp_filter = 1
net.ipv4.conf.all.accept_redirects = 0
net.ipv4.conf.all.send_redirects = 0
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_max_tw_buckets = 300000
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 65535
net.ipv4.tcp_synack_retries = 0
net.ipv4.tcp_keepalive_intvl = 30
net.ipv4.tcp_keepalive_time = 900
net.ipv4.tcp_keepalive_probes = 3
net.ipv4.tcp_fin_timeout = 10
net.ipv4.tcp_max_orphans = 131072
net.ipv4.tcp_rmem = 4096 4096 16777216
net.ipv4.tcp_wmem = 4096 4096 16777216
net.ipv4.tcp_mem = 786432 3145728 4194304
SETTINGS
sysctl -p /etc/sysctl.d/70-infini.conf
2. 环境前提:Easysearch 已经运行好
Coco Server 运行强依赖 Easysearch,所以在继续之前,请确保你的信创服务器上已经安装并成功启动了 Easysearch。如果不确定,可以执行下面的命令验证:
curl -k -u admin:你的密码 https://localhost:9200运行命令后,看到正常的 JSON 响应即可。
如果还没有安装,可以参考上一篇文章《从零到跑起来:Easysearch 信创环境安装全流程》先行完成。
3. 信创平台信息确认
和 Easysearch 一样,你需要明确当前服务器的 CPU 架构和操作系统版本。在终端执行:
# 查看 CPU 架构
uname -m
# 查看操作系统信息
cat /etc/os-release根据输出,确认 CPU 架构和操作系统,后续下载时选择对应版本。
部署环境如下表中所示:
4. 软件环境
| 名称 | 版本 | 备注 |
|---|---|---|
| Coco AI 智能搜索软件 | V1.0.0 | Coco Server |
| 统信服务器操作系统 A 版 | V20 | |
| Easysearch 搜索型数据库 | V2.2.0 | 用于 Coco 数据存储 |
| 360安全浏览器 | V13 |
5. Coco AI 大语言模型 推荐配置
| 模型名称 | 上下文长度 | 最大输出长度 | 描述 |
|---|---|---|---|
| deepseek-r1 | 128K | 16K | 数学、代码、自然语言推理等任务上,性能较高,能力较强 |
| qwen3-max | 256K | 32K | 配场景复杂的智能体需求 |
| tongyi-intent-detect-v3 | 8K | 8K | 用于意图识别和槽位填充,负责对话系统中的基础任务 |
5. 网络端口配置
| 服务名 | 端口 | 配置文件 | 说明 |
|---|---|---|---|
| Coco Server | 9000(默认) | coco.yml | |
| INFINI Easysearch | 9200(默认) | config/easysearch.yml | 默认仅监控 127.0.0.0,可通过配置 network.host: 0.0.0.0 调整 |
| 9300(默认) | config/easysearch.yml |
四、部署步骤
步骤 1:下载 Coco Server
# 调整为 Coco 实际要安装的路径
cd /opt
#下载Coco v1.0.0压缩包
curl -O https://release.infinilabs.com/.testing/coco-1.0.0.zip
#解压到当前文件夹
unzip coco-1.0.0.zip
#选择对应的版本解压tar.gz文件
tar -xzf coco-1.0.0-2002-linux-arm64.tar.gz
#解压后在对应文件夹下得到可执行程序coco-linux-arm64(arm64版本)和配置文件coco.yml步骤 2:配置 Easysearch 连接信息
Coco Server 需要得到 Easysearch 的地址和登录凭证才能进行工作。
在 安装路径的目录下,找到配置文件 进行配置,比如监听的端口地址 WEB_BINDING, 将 Easysearch 的服务地址环境变量 ES_ENDPOINT 和用户名 ES_USERNAME 设置为实际的,参考如下:
env:
# 调整为实际可以访问的 Easysearch 访问地址
ES_ENDPOINT: https://localhost:9200
# 调整为实际可以访问的 Easysearch 的用户
ES_USERNAME: admin
# 使用 keystore 存储的密码
ES_PASSWORD: $[[keystore.ES_PASSWORD]]
# Coco Server 对外提供服务的端口(默认9000端口)
WEB_BINDING: 0.0.0.0:9000步骤 3:使用keystore对密码进行加密处理
Easysearch 的服务密码通过 Keystore 进行加密存放,避免明文存放到配置文件,减少数据泄露风险
# 调整为 Coco 实际安装路径进行配置
cd /opt
# 创建 coco 软链接,可不区分 amd64/arm64 平台进行操作
ln -s coco-linux-`arch | grep -q "x86_64" && echo "amd64" || echo "arm64"` coco
# 根据之前拿到的 Easysearch 密码进行初始化 ES_PASSWORD 变量
ES_PASSWORD=xxx
# 将 ES_PASSWORD 变量的值存储到 keystore(./coco-linux-arm64替换为对应版本名,下同)
echo "$ES_PASSWORD" | ./coco-linux-arm64 keystore add --stdin ES_PASSWORD
# 检查 keystore 存储列表,确认 ES_PASSWORD 添加成功
./coco-linux-arm64 keystore list步骤 4:启动服务
以上配置完成后,设置 Coco Server 以服务方式启动
#安装系统服务(./coco-linux-arm64替换为对应版本名,下同)
./coco-linux-arm64 -service install
#启动服务
./coco-linux-arm64 -service start
步骤 5:初始化设置
服务启动后,在信创服务器的桌面环境下,打开浏览器,访问 UI 界面:
http://localhost:9000/#/\_guide/
你将看到 Coco Server 的 Web 引导界面。因为是首次访问,所以需要创建管理员账号,按页面引导填写即可。

创建完管理员账户后,下一步
设置一个模型提供商,Coco Server 支持:
- Deepseek
- Ollama
- 任何和 OpenAI 格式兼容的模型提供商
如果设置的模型是推理模型,需要打开“推理模式”。我们推荐使用参数较大的模型,来获得更好的使用体验。同时请注意:Endpoint 地址的配置要准确。

Coco Server 默认配置了一些小助手,建议在初始化向导的时候直接配置一个可用的模型,这样进入系统之后就可以直接使用,避免一个个的手动配置。
向导设置完成后,就会跳转到登录页面,输入刚才创建的账户和密码,就可以进行登录了,如下图:

管理员首次登录之后的第一件事是确认服务器的地址是否正确,如果 Coco server 前面增加了负载均衡或者配置了域名,需要在这里设置一下正确的 Coco Server 对外服务地址,如下图:

五、总结
到这里,你已经完成了 Coco Server 在信创平台上的部署与初始化。我们回顾一下整个部署流程:
- 确认环境 — Easysearch 已部署成功,并明确 CPU 架构;
- 下载安装 — 下载 Coco Server 的压缩包进行解压;
- 配置连接 — 编辑
coco.yml,填入 Easysearch 端点和密码; - 启动服务 — 将 Coco Server 以服务方式启动;
- 初始化 — 浏览器打开 http://localhost:9000/#/\_guide/ 进行管理员账户的创建; 添加大模型、连接数据源、创建助手。
Coco Server 部署完成后,你就拥有了一个完全私有化、自主可控的企业级统一搜索与 AI 智能助手服务端。下一步可以安装 Coco AI 桌面客户端,让团队成员真正体验“一个搜索框搜遍全公司”的高效便捷。
如果在部署过程中遇到任何困难,欢迎查阅官方文档,祝你部署顺利!
Easysearch 信创环境安装实践
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 10854 次浏览 • 2026-06-05 18:10
一、Easysearch 介绍
在动手安装之前,我们先花一点时间了解这个工具。 INFINI Easysearch (以下简称 Easysearch)是由极限科技(INFINI Labs)自主研发的一款分布式 AI 搜索型数据库。用通俗的话讲,它是一个“超级搜索引擎”,能帮你在海量数据中快速查找信息,支持结构化和非结构化的数据检索、全文检索、向量检索、空间地理位置信息检索、组合查询、多语种支持、语义分析和聚合分析等多种功能,被广泛应用于企业搜索、日志分析、知识库管理等场景。它的安装包仅50MB,非常轻量。
Easysearch 的“自主可控”特性十分突出:
- 完全国产化:已适配龙芯、鲲鹏、飞腾、海光、兆芯、申威等主流国产 CPU;
- 全面兼容国产操作系统:支持银河麒麟、统信 UOS、中标麒麟等国产操作系统;
- 国密算法支持:全量支持 SM2/SM3/SM4 国密算法,满足等保三级及信创合规要求;
- ES生态兼容:完全兼容 Elasticsearch 的 API 接口,可无缝平替。

二、安装前需知
1.你的信创平台属于哪种?
信创平台的组合通常是“国产 CPU + 国产操作系统”,你需要确认你的环境属于哪种:
| 国产CPU | 架构 | 常见搭配操作系统 |
|---|---|---|
| 鲲鹏(Kunpeng) | ARM64 | 银河麒麟V10、统信UOS |
| 飞腾(Phytium) | ARM64 | 银河麒麟V10、统信UOS |
| 海光(Hygon) | x86 | 统信UOS、银河麒麟V10 |
| 龙芯(Loongson) | LoongArch | 银河麒麟V10、统信UOS |
| 兆芯(Zhaoxin) | x86 | 银河麒麟V10、统信UOS |
| 申威(Sunway) | SW64 | 统信UOS |
不确定的话,可以在终端执行以下命令查看:
#查看操作系统信息
cat /etc/os-release
#查看CPU架构
uname -m2.在线部署or离线部署?
Easysearch 提供了两种安装方式:
联网环境:如果服务器能正常访问外网,推荐使用一键安装部署,简单快速;
离线环境:如果服务器在内网、无法访问外网(常见信创环境),则下载 Bundle 包进行离线部署。
在这篇文章中所使用的是在线部署方式。
三、安装环境简介
以统信 UOS 信创平台为例,以下表中为本机采用的安装环境
1.硬件信息
| 硬件 | 信息 |
|---|---|
| 处理器 | 架构:aarch64 型号:Kunpeng-920 |
| 内存 | 容量:8G 类型:RAM |
| 硬盘 | 类型:QEMU HARDDISK 容量:100G |
2.软件环境
| 名称 | 版本 |
|---|---|
| 统信服务器操作系统A版 | V20 |
| Easysearch 搜索型数据库 | V2.2.0 |
| 360安全浏览器 | V13 |
3.网络端口设置
| 服务名 | 端口 | 配置文件 | 说明 |
|---|---|---|---|
| INFINI Easysearch | 9200(默认) | config/easysearch.yml | 默认仅监控 127.0.0.0,可通过配置 network.host: 0.0.0.0 调整 |
| 9300(默认) | config/easysearch.yml |
四、部署流程
具体细节详见部署手册
步骤1:系统初始化
安装前需要完成两项系统准备工作:调整内核参数和创建专用用户。无论在线还是离线安装,这两步都必须先做好,并且需要使用 root 账户或 sudo 权限执行。
# 1. 调整内核参数(vm.max_map_count,Easysearch 运行的必要条件)
echo "vm.max_map_count=262144" >> /etc/sysctl.conf && sysctl -p
# 2. 创建 Easysearch 专用用户组和用户
groupadd -r easysearch && useradd -r -g easysearch -d /home/easysearch -s /sbin/nologin -c "Easysearch Service Account" easysearch
步骤2:安装 Easysearch
如果服务器能正常访问外网,直接使用官方一键安装脚本:
# 创建数据安装目录
mkdir -p /opt/easysearch
# 下载最新版本并安装
curl -sSL http://get.infini.cloud | bash -s -- -p easysearch -d /opt/easysearch
脚本会自动检测系统架构( ARM64 还是 x86 ),并下载对应的安装包。

步骤3:初始化并启动 Easysearch
# 进入 Easysearch 目录
cd /opt/easysearch
# 初始化 Easysearch (初始化过程中,日志将输出管理员访问密码,请妥善保存)
bin/initialize.sh -s
# 调整目录权限
chown -R easysearch:easysearch /opt/easysearch
# 启动 Easysearch
runuser -u easysearch -- /opt/easysearch/bin/easysearch -d -p /opt/easysearch/easysearch.pid
步骤4:验证服务运行
启动后,可以使用 curl 命令快速测试服务是否正常运行:
# 使用初始化时显示的 admin 密码测试连接
curl -ku admin:你的密码 https://localhost:9200

步骤5:访问服务运行端口
服务运行后,访问设置好的服务端点
https://localhost:9200/\_ui/(默认服务端点)
输入之前保存的账号与密码进行登录

进入 ui 界面

之后就可以实现对 Easysearch 可视化管理了
结语
以上就是 Easyserach 在信创平台部署的全流程了,整个过程操作下来,应该能在 10-20 分钟左右完成 Easysearch 支持从单机测试到 PB 级生产集群的平滑扩展,无论是个人学习还是企业级业务,都能灵活适配。如果在操作过程中遇到任何问题,建议优先查阅官方文档。预祝你在信创平台的探索之旅顺利!
Elasticsearch 6/7/8 到 Easysearch 2.x 迁移指南
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 11088 次浏览 • 2026-06-04 14:14

最近在协助客户进行 Elasticsearch 到 Easysearch 的迁移时,发现大家最关心的问题是"当前版本能否直接使用快照迁移"。这个问题看似简单,但不同版本的答案差异较大。本文将基于实际测试经验,梳理各版本的迁移路径和注意事项。
迁移路径速览
根据源 ES 版本,可以直接对照下表选择迁移方案:
| 源 ES 版本 | 能否直接快照恢复 | 推荐方案 | 实施复杂度 |
|---|---|---|---|
| ES 6.x | 否 | INFINI Gateway 迁移 或 ES 7.10.x 中转 | 较低 |
| ES 7.0 - 7.11 | 是 | 直接快照恢复 | 较低 |
| ES 7.12 - 7.17 | 否 | INFINI Gateway 迁移 | 较低 |
| ES 8.x | 否 | INFINI Gateway 迁移 | 较低 |
结论:ES 7.0-7.11 是迁移最顺畅的版本窗口,可直接快照恢复;其他版本也有成熟的迁移方案,只是路径不同。
版本差异的原因
迁移路径的差异主要源于两方面:Lucene 版本兼容性和快照元数据格式变化。
Lucene 兼容性:Easysearch 2.x 底层要求的最低 Lucene 版本对应 ES 7.0.0。ES 6.x 的索引文件使用老版本 Lucene,直接恢复会报错:
The index was created with version [6.8.23] but the minimum compatible version is [7.0.0].快照元数据格式:ES 7.12 开始在快照中引入 uuid、cluster_id 字段,7.14 增加 writer_uuid,8.x 又引入 transport_version。这些字段与 Easysearch 2.x 的快照解析器不兼容。
因此,ES 7.0-7.11 成为迁移的"黄金窗口"——既满足 Lucene 兼容性要求,快照格式又足够简洁。
ES 7.0-7.11:直接快照恢复
这是测试最充分的迁移路径,已验证版本包括 ES 7.0.1、7.8.1、7.10.2 OSS、7.11.2。
已验证能力:
- 单索引 / 多索引 / 通配符批量恢复
- 常见字段类型与别名
- 自定义 settings、多分片索引
- ILM 托管索引、数据流后备索引、冻结索引
操作步骤:
# 1. 源 ES 创建快照
PUT /_snapshot/my_backup/snapshot_1
{
"indices": "索引列表",
"include_global_state": false
}
# 2. Easysearch 注册同一快照仓库
PUT /_snapshot/my_backup
{
"type": "fs",
"settings": {
"location": "/path/to/snapshot/repo",
"readonly": true
}
}
# 3. 恢复快照
POST /_snapshot/my_backup/snapshot_1/_restore
{
"indices": "索引列表",
"include_global_state": false
}ES 6.x:Gateway 迁移或中转方案
ES 6.x 无法直接快照恢复到 Easysearch 2.x,有两种迁移方案可选:
方案一:INFINI Gateway 迁移(推荐)
直接使用 Gateway 从 ES 6.x 迁移数据到 Easysearch,无需中转集群。Gateway 已验证支持 ES 6.8.x 的数据迁移。
方案二:ES 7.10.x 中转
ES 6.8 -> 快照 -> ES 7.10.x -> 快照 -> Easysearch 2.xES 7.10.x 可以正常恢复 ES 6.x 的快照,恢复完成后再创建快照供 Easysearch 使用。该方案数据完整性有保障,但需要额外的中转存储和迁移窗口。
ES 6.x 特有字段:ES 6.x 的 string 类型在 Easysearch 中需映射为 text 或 keyword(根据实际使用场景选择)。
ES 7.12+ 和 8.x:INFINI Gateway 迁移
这两个版本段的快照格式与 Easysearch 2.x 不兼容,推荐使用 INFINI Gateway 进行迁移。Gateway 是 INFINI Labs 提供的数据迁移工具,专门针对 Elasticsearch 到 Easysearch 的迁移场景进行了优化。
架构示意
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ Elasticsearch │ ──── │ INFINI Gateway │ ──── │ Easysearch │
│ (源集群) │ │ (迁移工具) │ │ (目标集群) │
└─────────────────┘ └─────────────────┘ └─────────────────┘Gateway 内部通过 Scroll API 从源集群分批拉取数据,再通过 Bulk API 写入目标集群,整个过程对业务透明。
主要优势
- 配置简单:只需配置源集群和目标集群地址、索引名称即可
- 断点续传:支持从断点恢复,避免网络抖动导致重头再来
- 进度可视:实时显示迁移进度和速率
- 多索引并行:支持同时迁移多个索引
基本步骤
- 在目标集群创建索引的 mapping 和 setting
- 准备 Gateway 配置文件,填写源集群和目标集群连接信息
- 运行 Gateway 执行迁移
- 迁移完成后进行数据校验
详细的配置说明和操作示例,可参考 ES 数据迁移之 INFINI Gateway。
备选方案
如果需要更灵活的控制,也可以自行编写脚本,通过 Scroll API 读取源数据、Bulk API 写入目标。这种方式适合有定制化需求的场景,但需要自行处理断点续传、错误重试等逻辑。
字段类型兼容性
直接兼容类型:text、keyword、long、double、boolean、date、object、nested、geo_point、geo_shape、ip、completion、wildcard、flattened、alias、join、rank_feature、rank_features、integer_range、long_range、date_range、match_only_text 等。
ES 7.x / 8.x 需替换类型:
| ES 类型 | Easysearch 替代方案 | 数据保留 | 说明 |
|---|---|---|---|
dense_vector |
knn_dense_float_vector |
是 | 需安装 knn 插件,向量数据格式兼容 |
knn_vector |
knn_dense_float_vector |
是 | 需安装 knn 插件 |
sparse_vector |
knn_sparse_bool_vector |
是 | 需安装 knn 插件 |
constant_keyword |
keyword |
是 | 需手动维护常量值 |
runtime |
移除或转为普通字段 | 是 | Easysearch 不支持运行时字段 |
histogram |
object |
是 | 聚合 histogram 功能丢失 |
aggregate_metric_double |
object |
是 | 需手动计算聚合 |
unsigned_long |
long 或 keyword |
是 | 注意数值范围 |
semantic |
暂不支持 | - | ES 专有 AI 功能 |
向量迁移要点:ES 的 dense_vector 数据可直接迁移到 Easysearch 的 knn_dense_float_vector,数据格式 [0.1, 0.2, ...] 完全兼容。需预先在目标索引创建正确的 mapping。
建议迁移前先用小索引测试,确认 mapping 无问题后再全量迁移。
常见问题与避坑指南
1. include_global_state 参数设置
该参数控制是否恢复集群级配置(模板、ILM 策略等)。不同版本的情况:
| ES 版本 | 发行版 | global_state | 说明 |
|---|---|---|---|
| 7.0-7.7 | 任意 | 兼容 | 无 _index_template API |
| 7.8-7.10 | OSS | 兼容 | 无内置 _index_template |
| 7.8-7.10 | default | 可能不兼容 | 取决于是否使用 _index_template |
| 7.11+ | 任意 | 不兼容 | 有 9 个内置 _index_template |
建议:迁移时统一使用 include_global_state=false,先恢复数据再重建配置。
2. ILM 和 data stream 迁移
- ILM:索引的 lifecycle 设置保留,但 policy 需在 Easysearch 中重建
- 数据流 (data stream):后备索引 (backing index) 数据完整恢复,语义需在目标侧重建
- 冻结索引 (frozen index):自动恢复为普通可访问状态
3. 迁移验收标准
建议至少完成三项验证:
- 文档量一致
- 关键查询结果一致
- 核心业务链路压测通过
4. 迁移窗口规划
- 快照方案通常需要短停机窗口完成切换
- Gateway 迁移可实现近实时同步,仅在切换连接时短暂停服
快照格式变化参考
| 字段 | ES 7.0-7.11 | ES 7.12-7.17 | ES 8.x | Easysearch 2.x |
|---|---|---|---|---|
min_version |
7.9.0 或无 | 7.12.0 | 7.12.0 | 支持 |
uuid(仓库级) |
无 | 有 | 有 | 不支持 |
cluster_id |
无 | 有 | 有 | 不支持 |
writer_uuid |
无 | 有(7.14+) | 有 | 不支持 |
transport_version |
无 | 无 | 有 | 不支持 |
总结
本文梳理了 Easysearch 2.x 对 ES 6/7/8 的迁移路径:
- ES 7.0-7.11:直接快照恢复,路径最短
- ES 6.x:INFINI Gateway 迁移 或 ES 7.10.x 中转
- ES 7.12+ / 8.x:使用 INFINI Gateway 迁移
建议在正式迁移前,先选择非核心索引进行小规模验证,确认数据完整性和业务兼容性后再扩大迁移范围。
如有迁移相关问题,欢迎联系我们。
【搜索客社区日报】第2241期 (2026-06-01)
社区日报 • Muses 发表了文章 • 0 个评论 • 12061 次浏览 • 2026-06-01 11:33
【搜索客社区日报】第2231期 (2026-05-15)
社区日报 • Fred2000 发表了文章 • 0 个评论 • 13144 次浏览 • 2026-05-15 10:19
Easysearch analysis-ik 多词典性能优化:从性能回退到分词性能提升 25%~30%
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 15754 次浏览 • 2026-05-08 14:34
Easysearch 版 analysis-ik 相比开源 IK 有一个重要的增强:支持多词典。简单说就是不同字段可以挂不同词库,可以叠加默认词典,也可以只用自定义词典。这是开源单词典 IK 做不到的。
功能实现初期,主要精力放在把能力跑通上。但在后来的一次写入压测中,我们发现 Easysearch 的写入吞吐和 Elasticsearch 有明显差距,最终定位到问题出在多词典的实现方式上——字段最终该用哪套词典,本来应该在分词前就算好,结果代码里把这个选择丢进了分词的热路径,每次分词都要反复切词典、重复扫同一段文本。
这篇文章记录的就是我们怎么一步步把性能拉回来、最终反超基线的过程。
问题怎么冒出来的
4 月 20 号,我们跑了一轮系统级写入压测。数据、mapping、settings、并发和 bulk 参数都一样,Elasticsearch 8.19.5 和 Easysearch 2.1.2 的写入吞吐差距大得有点不对劲:
| 时间 | 场景 | Elasticsearch | Easysearch | 说明 |
|---|---|---|---|---|
| 2026-04-20 第 2 次有效重跑 | 29900 docs / bulk=250 / concurrency=3 端到端写入压测 |
129.44 docs/s |
31.21 docs/s |
这是整条写入链路的 docs/s,不是单独分词吞吐 |
| 2026-04-20 诊断样本 | 5000 docs / bulk=250 / concurrency=3 |
156.25 docs/s |
30.67 docs/s |
Easysearch 的累计索引耗时约为 Elasticsearch 的 8.0x |

当时服务器上跑的就是早期多词典版本。后面修性能,追的就是这个版本和开源单词典 IK 基线之间的差距。
这一步还不能直接确定问题就在分词器。但差距摆在这儿了,得继续往下排。我们先排除了几个常见干扰因素:
refresh_interval- 动态同义词 HTTP 服务
- mapping / settings 不一致
- 网络层和 bulk 客户端本身
采样结果很快把范围收窄了。Elasticsearch 那边热点比较分散,Easysearch 这边呢,分词链路里出现了异常集中的开销——分词过程中反复做词典选择和字典查找。
瓶颈不在 Lucene 写入链路本身,就在 analysis-ik 的多词典实现上。
根因分析
第一类问题出在实现模型上。多词典想表达的是”这个字段最终用哪套词典”,这件事完全可以在分词前算好。但早期代码里,硬是把它变成了运行时的事:
- “字段用哪个词典”变成了”运行时多轮扫描”——同一段文本对着多套词典各来一遍。
- 全局字典切换的动作放进了每字符的热路径。
- 结果就是同一段文本的扫描和查找成本翻了好几倍。
所以问题不是多词典天然慢,是实现把本该提前算好的东西塞进了热路径反复做。
第二类问题是后续优化过程中留下的额外开销。后面加的跨边界、停用词、长文本等测试本身不是性能问题的来源,它们的作用是把正确性边界补齐,确保每次优化不会改变分词结果。
最后通过性能分析确认,残留开销主要来自两处:缓存命中前还在做不必要的数据复制;诊断逻辑在生产热路径上产生了额外开销。修完之后这两处热点都从火焰图上消失了,说明性能回退确实来自真实的代码路径成本,不是测试抖动。
修复过程
整个修复分四个阶段。
第一阶段:把多词典从”运行时分发”收敛为”最终有效词典视图”
多词典能力保留,但不再让分词器在热路径里反复切词典、重复扫文本。改成在分词前就把字段最终生效的词典算好,分词过程只面对一个已经收敛好的词典视图。
说白了就是把模型拉回正确方向——多词典管表达能力,热路径只管分词。
第二阶段:逐步打掉热路径上的常数开销
留下来的每一项优化,都经过正式性能测试和采样分析验证。原则就一条:不改分词语义,只减少热路径上反复发生的查找、分配和判断。
第三阶段:补齐正确性护栏
正确性测试必须先到位,不然吞吐提升没有意义——万一分词结果变了,跑得再快也白搭。
这一轮重点覆盖了这些容易出问题的场景:
- 真跨边界场景
- 数字和量词合并,如
1号 - 自定义词典里的含符号词
- 补充平面字符跨边界稳定性
- 停用词过滤后的偏移量
- 长文本样本的稳定性
- 正式性能测试数据集的分词结果对齐
后面所有的吞吐数字,前提都是分词结果一致,避免把分词行为的变化误当成性能提升。
第四阶段:清理最后的残留开销
到 4 月 28 号,最后一轮修复集中处理两个地方:
- 词典视图命中缓存时直接返回,不再多做一次数据复制
- 诊断逻辑默认关掉,不让线上请求为调试能力买单
这两处修完,Easysearch 版 IK 就不只是恢复到单词典版本附近了,在正式测试里已经明显领先。
用数据看恢复过程
为了不把系统级写入压测和分词器性能测试混在一起,下面只看几个关键节点。2026-04-20 的 docs/s 是系统级写入吞吐,后面的 tok/s 是单独的分词器吞吐。
这里说的”开源 IK 基线”就是开源 IK 的单词典实现对照版本。所有正式吞吐结论都建立在同一数据集、同一测试方法、分词结果一致的前提上。
| 时间 | 口径 | 关键结果 | 说明 |
|---|---|---|---|
| 2026-04-23 17:02 CST | 初期本地复现 | 服务器多词典版本 61.39 万 tok/s,单词典版本 114.48 万 tok/s |
单词典版本快 86.49%,性能差距被明确复现 |
| 2026-04-24 09:51:12~09:55:15 CST | 第一次正式追平 | smart 相对开源单词典基线 +7.26% |
从明显落后追到略微领先 |
| 2026-04-25 04:14~04:16 CST | 双模式阶段复核 | smart +16.88%,max_word +20.09% |
领先优势开始扩大 |
| 2026-04-28 12:30:56 CST | 最新正式复核 | smart +30.96%,max_word +21.31% |
当前最新结果 |
整个过程就是:
- 先暴露出明显的性能退化
- 逐步缩小差距
- 追平,然后开始领先
- 最终在分词结果完全一致的前提下,正式反超
最早的本地复现数据很关键:服务器当时跑的多词典版本只有 613896.67 tok/s,单词典版本 1144843.77 tok/s。后面所有修复就是冲着这个差距去的。


三张图分别对应问题暴露、分词复现和修复结果:第一张展示服务器 bulk 写入吞吐的系统级差距;第二张展示多词典版本和单词典版本的本地分词差距;第三张展示分词结果对齐后,Easysearch 版 IK 怎么一步步追上来,最终实现 25%~30% 的分词性能提升。
为什么说 Easysearch 版 IK 现在更好
这次修复的价值不只是消灭了几个热点,更重要的是把多词典能力、分词正确性和性能测试体系一起补齐了。
1. 功能更强,性能代价可控
开源单词典 IK 模型简单,但表达能力也弱。Easysearch 的多词典能力要解决的是字段级词库隔离、自定义词典叠加这些实际需求。
关键问题是:能不能把这些能力的性能开销压到足够低。修复后的结果证明,可以。
2. 正确性护栏更完整
这轮补上的测试不只是几个短样例,覆盖了更容易翻车的边界条件:
- 真跨边界场景
- 长文本稳定性
- 自定义词典和符号词
- 数字量词合并
- 停用词过滤后的偏移量
这意味着以后再做性能优化,必须同时保证分词结果不变。想靠改分词行为换吞吐,测试会先拦住。
3. 性能测试体系更严格
这轮之后,Easysearch 对 analysis-ik 的正式性能结论统一按一套标准出:
- 同一数据集
- 同一测试方法
smart和max_word双模式- 分词结果一致
- 有性能分析结果支撑
这套体系能避免两个常见坑:只看单轮吞吐波动就下结论,或者分词结果已经变了还在比性能。
小结
多词典能力在实现初期,主要精力放在功能补齐上——先把字段级词库隔离、自定义词典叠加这些能力跑通,性能优化是后面分阶段来的事,没办法一蹴而就。
这轮优化下来,核心思路其实就一条:把词典选择从分词热路径里挪出去,提前收敛好,让分词过程只面对最终的词典视图。再配合热点清理和正确性护栏,增强功能和更高性能完全可以兼得。
截至 2026 年 4 月 28 日,在本地 Mac 笔记本上的多轮 benchmark 中,Easysearch 版 IK 在 smart 模式大约领先开源单词典 IK 基线 25%~30%,max_word 模式大约领先 20% 左右,分词结果完全一致。具体数字每次跑会有波动,但趋势是稳定的。
这也是 Easysearch 版 IK 相对开源版更有价值的地方:不是多了几个配置项,而是在多词典能力、分词正确性和分词性能三个方面都给出了可验证的结果。
关于 Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
作者:张磊,极限科技(INFINI Labs)搜索引擎研发负责人,对 Elasticsearch 和 Lucene 源码比较熟悉,目前主要负责公司的 Easysearch 产品的研发以及客户服务工作。
相关文章:
Easysearch 正式支持插件开发:让你的搜索系统真正"为你所用"
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 17444 次浏览 • 2026-04-27 22:02
从"用搜索"到"造搜索"
搜索系统的需求千差万别。标准功能覆盖不了所有场景——行业特定的分词规则、定制化的业务逻辑、与外部系统的深度集成……
以往,这类定制需求需要依赖厂商支持。从 Easysearch 2.1.2 开始,你可以自己动手了。
随着构建依赖库正式发布到 Maven 中央仓库,Easysearch 的插件开发能力正式对外开放。这意味着 Easysearch 不再是一个黑盒产品,而是一个可扩展、可定制的搜索平台。你可以基于官方接口开发自定义插件,像使用原生功能一样使用它们。
插件能做什么
Easysearch 提供三类核心扩展点,覆盖搜索系统的关键环节:
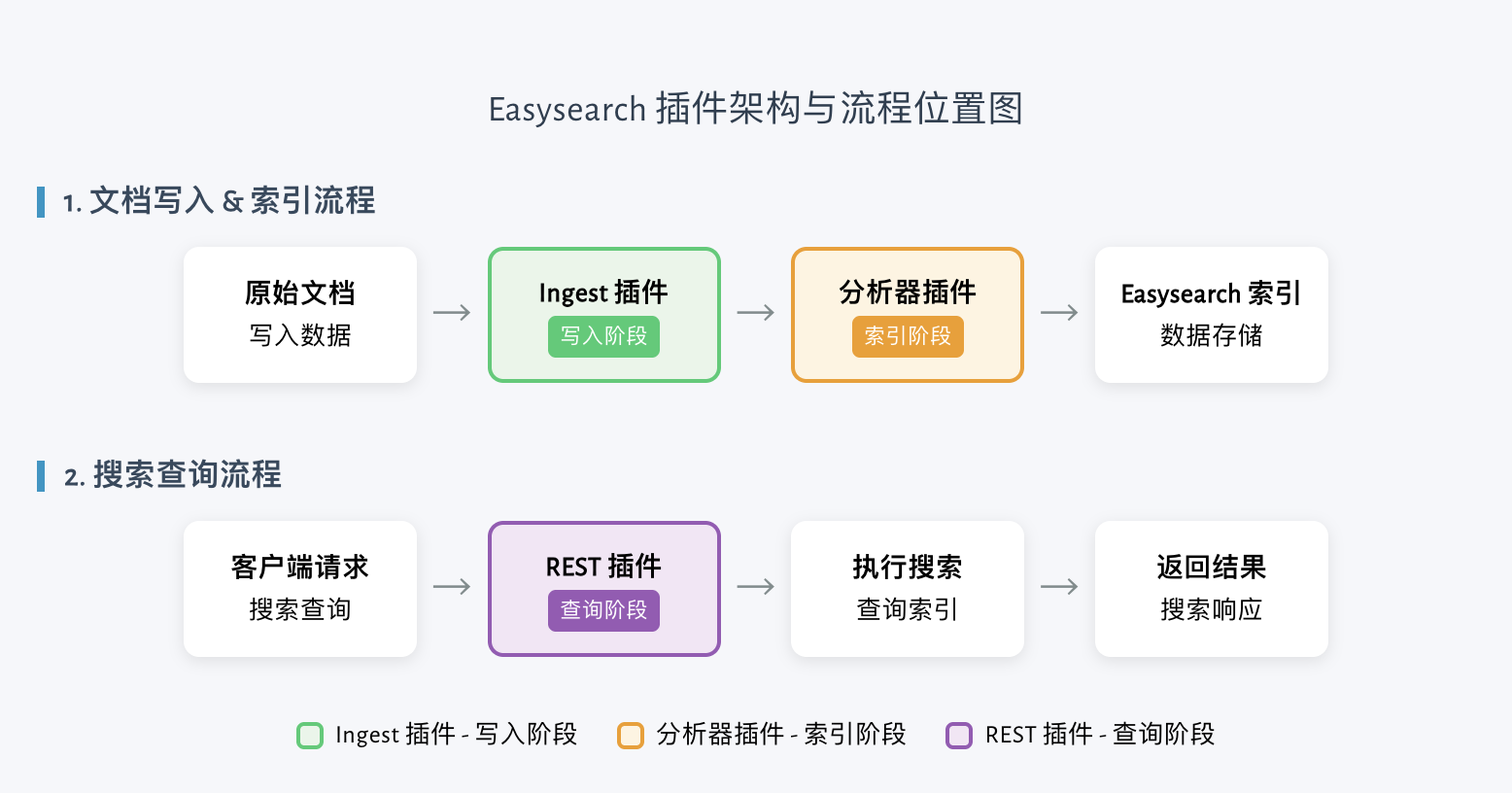
1. 分析器插件(AnalysisPlugin)
自定义分词器、Token 过滤器、字符过滤器。适用于:
- 电商 SKU 的型号规格解析
- 医疗、法律等领域的专业术语分词
- 特殊符号或空格的规范化处理
注册后直接在索引设置中使用,与原生分析器完全等同。

2. REST/API 插件(ActionPlugin)
新增自定义 HTTP 接口。适用于:
- 封装业务查询逻辑,对外暴露简化 API
- 对接企业内部权限中心或监控系统
- 暴露插件自身的管理接口(如状态检查)

3. Ingest 插件(IngestPlugin)
在文档写入前进行字段转换。适用于:
- 自定义业务字段转换(如根据业务规则计算衍生字段)
- 数据标准化(统一日期格式、大小写转换)
- 富文本提取或元数据生成

5 分钟上手
我们准备了官方模板仓库,让你从克隆到运行只需几条命令:
# 克隆模板
git clone https://github.com/infinilabs/easysearch-plugin-template.git my-plugin
cd my-plugin
# 修改包名和类名,编写你的逻辑
# ...方式一:开发调试——直接运行
# 构建插件并运行
./gradlew run
# 验证插件
curl -s "http://localhost:9200/_cat/plugins?v" | grep my-plugin方式二:构建后安装到外部集群
# 构建插件
./gradlew build
# 安装到 Easysearch
bin/easysearch-plugin install file:///$(pwd)/build/distributions/my-plugin-0.1.0.zip
# 启动验证
bin/easysearch
curl -s "http://localhost:9200/_cat/plugins?v" | grep my-plugin完整的开发指南请参考插件开发文档。
设计哲学
Easysearch 插件系统的设计遵循三个原则:
渐进式扩展——从最简单的 Plugin 类开始,按需实现 AnalysisPlugin、ActionPlugin 等接口,不必一次性掌握全部 API。
与原生同等——插件注册的分析器、处理器与系统原生组件在使用方式上完全一致,用户无需关心实现来源。
版本安全——插件加载时校验 easysearch.version,版本不匹配会拒绝加载,避免运行时异常。
从插件到生态
插件开发不只是技术能力的开放,更是产品理念的转变。
你可以将开发的插件发布到 GitHub Releases,通过 URL 直接安装:

bin/easysearch-plugin install https://github.com/yourname/my-plugin/releases/download/v0.1.0/my-plugin-0.1.0.zip我们也欢迎社区贡献。如果你有通用的插件想法,欢迎与我们交流。
结语
搜索系统的最后一公里,只有业务开发者最清楚该怎么走。
Easysearch 2.1.2 的插件开发能力,让你能够自主掌控搜索系统的"最后一公里"。从"用搜索"到"造搜索",现在你可以让你的搜索系统真正"为你所用"。
关于 Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
INFINI Agent v1.31.0 发布 | 全新 Easysearch 向导:一站式集群拉起与精细化管理
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 17746 次浏览 • 2026-04-23 18:01
INFINI Agent v1.31.0 带来了本版本最重要的特性——Easysearch 安装向导。用户无需手动编辑任何配置文件,通过图形界面即可完成 Easysearch 集群的安装、配置和日常管理。
Easysearch 安装向导
一键拉起新集群
向导支持开发模式和生产模式两种方式创建 Easysearch 节点。用户只需填写集群名称、节点名称、监听地址、端口、数据目录等基本信息,向导便会自动完成软件下载、JDK 配置、安全证书生成、参数配置、插件安装、节点启动等全部步骤,并实时展示每一步的进度,支持随时暂停和恢复。

一键加入已有集群
通过粘贴现有集群提供的 Token,向导可自动从目标集群拉取证书、版本、插件等配置信息,完成新节点的安装和接入,全程无需手动复制任何证书文件。


安装前环境预检
向导在开始安装前会对当前机器进行全面检测,帮助用户提前发现潜在问题:
- 操作系统和 CPU 架构是否受支持
- 内存是否满足推荐要求
- 端口是否已被占用
- 数据目录磁盘空间是否充足、路径是否可写
- 系统参数(文件描述符限制、内核
max_map_count等)是否满足 Easysearch 运行需求 - TLS 证书填写后实时校验有效性,包括证书链完整性和过期时间

TLS 安全证书灵活配置
支持三种证书配置方式,满足不同安全需求:
- 自动生成:向导一键生成自签名证书,无需任何证书知识
- 手动上传(共享):为 HTTP 和节点通信层提供同一套证书
- 手动上传(分离):为 HTTP 层和节点通信层分别提供独立证书

完整的服务生命周期管理
集群建好后,向导提供持续的管理能力:
- 启动、停止、重启 Easysearch 节点

- 在线安装和卸载插件

- 在线编辑配置,包括
easysearch.yml、JVM 参数、日志配置、证书配置

- 在线日志排查:内置日志阅读器,支持查看节点日志文件列表,并提供类似 tail -f 的自动滚动功能,无需登录服务器即可快速定位报错。”

网络受限环境支持
针对无法直接访问外网的环境,向导支持配置 HTTP 代理,所有软件包(Easysearch、JDK、插件)均可通过代理下载,并提供连通性测试功能。

获取新版本
INFINI Agent v1.31.0 已正式发布,欢迎升级体验:
同样 15,000 条重规则,Percolate Query 比 Easysearch 慢 21.8 倍 —— Heavy-OR 场景实测
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 17481 次浏览 • 2026-04-15 16:44
15,000 条 heavy-OR 规则,200,000 条文档,同一台机器:Easysearch 在线规则引擎全流程 11.68 秒,Percolate Query 仅搜索阶段就跑了 254.30 秒——慢了 21.8 倍。
在"规则先存、文档后到"这类场景下,Percolate Query 的延迟会随规则数量和复杂度的增长快速恶化。规则涨到数千条后,每批文档匹配的耗时可以从秒级攀升至几分钟。这类问题换索引参数、调批次大小、精简 DSL,都治标不治本,根子在执行模型本身。
本文通过一组 heavy-OR 基准测试,量化两种方案的实际差距。
测试配置
测试在同一台主机上运行,使用同一套规则文本和文档样本。Percolate Query 的查询条件由相同规则翻译而来,保证两侧规则语义一致。
| 参数 | 值 |
|---|---|
| 规则总数 | 15,000 |
| 文档总数 | 200,000 |
| 批次大小 | 10,000 / 批 |
| 重规则数量 | 2,500 条大 OR 热点规则 |
| 单条大 OR 规模 | 随机 50 ~ 500 个 OR 条件 |
测试结果
| 路径 | 用时 |
|---|---|
纯写入 plain_bulk |
6.025535s |
在线规则引擎 rules_only |
11.684568s |
Percolate Query 搜索阶段 |
254.304583s |
同样 15,000 条规则 + 200,000 条文档
具体指标:
- Easysearch 在线规则引擎全流程:
11.68s - Percolate Query 搜索阶段:
254.30s - 差值:
242.62s - 倍数:
21.76 倍 - 每批(10,000 文档)平均耗时:Easysearch 约
0.49s,Percolate Query 约12.69s
开启规则引擎的增量成本
规则匹配会对写入链路产生多少额外开销,是评估在线规则引擎可行性的重要指标之一。
开启规则引擎的写入增量
与之对比,Percolate Query 仅搜索阶段就需要 254.30s。换言之,Easysearch 在线规则引擎把规则匹配叠加进写入流程,新增成本约为 Percolate Query 搜索耗时的 1/44.9。
只看匹配引擎本体
上一组数据(11.68s vs 254.30s)包含了 Easysearch 的在线写入、bulk 解析和索引处理等通用开销。为了单独衡量规则匹配引擎自身的性能,我们用 Java 直调 JNI 做了一次离线 match,绕过写入链路,只跑规则匹配逻辑。
| 路径 | 用时 |
|---|---|
| Easysearch 纯匹配(JNI 离线) | 5.046934s |
| Percolate Query 搜索阶段 | 254.304583s |
只比匹配本身
这组数据说明两点:Easysearch 的性能优势并非来自写入链路的整合效率,即便剔除通用写入成本,规则匹配引擎本体与 Percolate Query 之间依然存在约 50 倍的差距。
为什么 Percolate Query 会慢
根因在执行模型,OR 条件多只是放大器。
每批文档到达时,Percolate Query 都要走完这套流程:
- 把文档放进临时内存索引
- 基于规则中的 terms 筛选候选规则
- 对候选规则逐条验证
以本次测试为例,各阶段耗时分布如下:
- 规则翻译:
9.560294s - 规则导入:
7.451857s - percolate 搜索:
254.304583s
搜索阶段是每批文档都必须重新支付的代价。
Heavy-OR 规则在这套流程里两头放大:规则覆盖面广,候选集更难剪掉;单条规则条件多,逐条验证也更重。
Easysearch 规则引擎把规则提前编译好,文档到达后直接匹配,不走这套每批重建的流程,差距就在这里。
适用场景
以下场景对规则匹配的吞吐和延迟要求较高,是 Easysearch 在线规则引擎的典型适用范围:
- 内容审核:规则持续增长且复杂度高,需要稳定的处理吞吐,对单批延迟敏感。
- 舆情监测:热点词、别名、邻近词组合多,规则天然形成大 OR 结构,是 Percolate Query 最容易触及性能瓶颈的场景。
- 广告定向:人群包条件不断叠加,文档流量高,规则匹配需要足够轻量,避免影响整条投放链路。
- 告警规则:延迟直接影响告警有效性,规则命中需要尽量贴近文档写入时刻。
- 实时反欺诈:规则复杂、变更频繁、吞吐高,要求文档到达后立即完成判断。
小结
在本次 heavy-OR 基准测试中:
- 相同规则集(15,000 条)和文档量(200,000 条),Easysearch 在线规则引擎全流程耗时 11.68s,Percolate Query 仅搜索阶段耗时 254.30s,相差 21.8 倍。
- 开启规则引擎带来的写入链路增量成本为 5.66s,约为 Percolate Query 搜索阶段耗时的 1/44.9。
- 剔除写入通用开销后,规则匹配引擎本体的差距约为 50 倍。
如果你的业务已经有 Percolate Query 延迟随规则增长持续上升的问题,不用看 demo 数据——把你线上最重的那批规则拿出来,跑一次就知道差距在哪。
规则引擎功能当前需要试用 License。你可以先下载 Easysearch:https://infinilabs.cn/download,再联系售前申请试用 License 并获取开通指引。
关于 Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
官网文档:https://docs.infinilabs.com/easysearch
作者:张磊,极限科技(INFINI Labs)搜索引擎研发负责人,对 Elasticsearch 和 Lucene 源码比较熟悉,目前主要负责公司的 Easysearch 产品的研发以及客户服务工作。
相关文章:
【 INFINI Workshop 北京站】1月18日一起动手实验玩转 Easysearch
活动 • liaosy 发表了文章 • 0 个评论 • 6146 次浏览 • 2023-12-15 16:22
与 INFINI Labs 的技术专家面对面,第一时间了解极限实验室的发布最新产品和功能特性,通过动手实战,快速掌握最前沿的搜索技术,并用于实际项目中。欢迎大家扫描海报二维码免费报名参加。
活动时间:2024-01-18 13:30~17:30
活动地点:北京市海淀区 Wework 辉煌时代大厦 3 楼 3E 会议室
分享议题
- Easysearch 总体介绍及搭建实战
- 基于 INFINI Console 实现跨版本、跨引擎统一管控
- Elasticsearch -> Easysearch 在线迁移实操
参会提示
- 请务必自备电脑(Windows 系统环境请提前安装好 Linux 虚拟机)
- 请提前在 INFINI Labs 官网下载对应平台最新安装包(INFINI Easysearch、INFINI Gateway、INFINI Console)
- 下载地址:https://www.infinilabs.com/download
- 如有任何疑问可添加 INFINI Labs 小助手(微信号: INFINI-Labs)进行联系

【INFINI Workshop 上海站】7 月 27 日一起动手实验玩转 Easysearch
资讯动态 • liaosy 发表了文章 • 1 个评论 • 4398 次浏览 • 2023-07-07 16:30

INFINI Easysearch 向量搜索实战(一)
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 2731 次浏览 • 4 天前
Easysearch 提供了强大的向量搜索能力,打破传统关键词匹配的局限,实现真正的“懂你”的语义搜索。助力企业快速构建智能推荐、图像识别和内容理解等 AI 应用,释放数据深层价值。
核心能力
| 能力 | 说明 |
|---|---|
| 两种向量类型 | 稠密浮点向量(knn_dense_float_vector)和稀疏布尔向量(knn_sparse_bool_vector) |
| 多种索引模型 | lsh(局部敏感哈希,近似搜索)、permutation_lsh(置换 LSH)、sparse_indexed(倒排索引)、exact(精确搜索) |
| 多种相似度 | cosine(余弦)、l1(曼哈顿距离)、l2(欧氏距离)、jaccard、hamming |
| 与全文搜索融合 | 向量字段与文本字段存储在同一索引,支持 Hybrid 混合检索 |
| function_score 集成 | 向量相似度可作为 function_score 的评分函数 |
典型应用场景
- 语义搜索:文本通过 Embedding 模型转为向量,按语义相似度检索
- RAG 检索增强生成:为大语言模型提供知识库检索能力
- 推荐系统:用户/商品特征向量的相似推荐
- 图像/多模态搜索:图像特征向量的相似检索
- 去重与异常检测:通过向量距离判断内容相似度
Embedding 服务
在使用向量搜索前,先要准备一个 Embedding 模型,支持与 OpenAI API 兼容的 embedding 接口和 Ollama embedding 接口。本文使用阿里云上的 Embedding 模型进行演示。
写入方法
方法一:写入链路嵌入(推荐)
在数据写入 Easysearch 时,通过 Ingest Pipeline 自动调用 Embedding 服务:
应用写数据 → Easysearch → Ingest Pipeline → 调用 Embedding API → 写入向量字段
优势是写入后即可搜索,无需维护外部向量化流程。需要确保集群应至少有一个节点拥有 ingest 角色。
方法二:离线批处理
在应用侧完成向量化,再将向量字段直接写入 Easysearch:
原始数据 → 应用 → 调用模型 Embedding API → 写入 Easysearch(含向量字段)
参考文档。
实战
我们实战演示模式一,分为以下几个步骤:
- 建立带有向量字段的索引
- 创建对应的 Ingest Pipeline
- 写入数据到索引
1. 建立带有向量字段的索引
先建立一个带向量字段的索引,注意 dims 要与向量模型的输出匹配。
PUT /my-index
{
"mappings": {
"properties": {
"text_vector": {
"type": "knn_dense_float_vector",
"knn": {
"dims": 1024,
"model": "lsh",
"similarity": "cosine",
"L": 99,
"k": 1
}
}
}
}
}
2. 创建对应的 Ingest Pipeline
写入数据前先建立 Ingest Pipeline,注意 vendor 必须根据使用的模型来指定,比如本文使用的是阿里云 text-embedding-v4 模型,该模型提供了 OpenAI 格式的 API 接口,这里 vendor 我们就写 openai。
PUT _ingest/pipeline/text-embedding-pipeline
{
"description": "用于生成文本嵌入向量的管道",
"processors": [
{
"text_embedding": {
"url": "https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings",
"vendor": "openai",
"api_key": "xxxxxx",
"text_field": "input_text",
"vector_field": "text_vector",
"model_id": "text-embedding-v4",
"dims": 1024,
"ignore_missing": false,
"ignore_failure": false
}
}
]
}
text_field:指定原始文本字段,Pipeline 会将该字段的内容转换成向量。
vector_field:指定向量存储的字段,保存上面转换的向量。
3. 写入数据
POST /_bulk?pipeline=text-embedding-pipeline&pretty
{"index": {"_index": "my-index", "_id": "1"}}
{"input_text": "苹果发布了新款iPhone 15 Pro手机,搭载A17芯片"}
{"index": {"_index": "my-index", "_id": "2"}}
{"input_text": "特斯拉宣布将在上海建第二座超级工厂"}
{"index": {"_index": "my-index", "_id": "3"}}
{"input_text": "今天天气真好,阳光明媚适合去公园散步"}
{"index": {"_index": "my-index", "_id": "4"}}
{"input_text": "程序员用Python写了一个自动化数据清洗脚本"}
{"index": {"_index": "my-index", "_id": "5"}}
{"input_text": "故宫博物院推出了夏季特展,展出珍贵文物"}
{"index": {"_index": "my-index", "_id": "6"}}
{"input_text": "小明每天坚持跑步五公里,身体越来越健康"}
{"index": {"_index": "my-index", "_id": "7"}}
{"input_text": "人工智能大模型在自然语言处理领域取得突破"}
{"index": {"_index": "my-index", "_id": "8"}}
{"input_text": "这家咖啡店的拿铁口感丝滑,推荐给咖啡爱好者"}
{"index": {"_index": "my-index", "_id": "9"}}
{"input_text": "量子计算机有望在药物研发中发挥重要作用"}
{"index": {"_index": "my-index", "_id": "10"}}
{"input_text": "周末和朋友一起去爬山,山顶的风景美极了"}
4. 检查数据
搜索索引数据,看看是否成功转换成了向量。可以看到原始数据保存在 input_text 字段中,其向量保存到了 text_vector。
OK,下一步我们看看怎么方便地实现向量搜索。
关于 Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
官网文档:https://docs.infinilabs.com/easysearch
相关文章:
Bboss v7.5.6 正式发布,全面兼容国产分布式搜索引擎 Easysearch
资讯动态 • INFINI Labs 小助手 发表了文章 • 0 个评论 • 12960 次浏览 • 2026-06-23 23:31
一、引言
2026 年 6 月 21 日,经过 Bboss 开源社区与极限科技(INFINI Labs)的紧密合作, Bboss v7.5.6 正式发布!
作为国内领先的 AI 智能体开发框架、数据采集同步 ETL 工具以及流批一体化计算引擎,Bboss 在本次更新中与国产分布式搜索引擎 Easysearch 完成深度兼容,其 Elasticsearch Java 客户端 全面兼容 Easysearch 1.x、2.x 全系列版本。开发者现在可以无缝使用 Bboss 客户端操作 Easysearch 集群,享受与 Elasticsearch 一致的开发体验。
二、Bboss Elasticsearch 客户端简介
Bboss 是一款高性能、高兼容性的搜索引擎 Java REST 客户端框架,基于 Apache License 2.0 开源,原生支持 Elasticsearch、Easysearch 和 Opensearch。
自带客户端集群节点负载均衡和容灾,多集群多数据源,自动索引托管,多种分页机制,傻瓜级 CRUD,脚本,SQL,JDBC,高亮,权重,聚合,IP,GEO 地理位置,父子嵌套,应有尽有。
核心特性
| 特性 | 说明 |
|---|---|
| 原生多引擎支持 | 完美支持 ES 1.x ~ 9.x、Easysearch 1.x ~ 2.x、Opensearch 1.x ~ 3.x |
| 学习成本低 | 无需学习额外 API,只需掌握 Elasticsearch DSL,极简使用方式 |
| 开箱即用 | Spring Boot 自动配置,无需复杂设置 |
| 高效异步处理 | 内置 BulkProcessor 异步批处理器,大幅提升写入性能 |
| 灵活查询方式 | 支持 DSL、SQL、O/R Mapping 多种查询模式 |
| 多数据源支持 | 一个应用可同时操作多个不同版本的搜索引擎集群 |
| 客户端负载均衡 | 默认启用客户端负载均衡,容灾性更好 |
| 完整的结果封装 | 返回结果支持 JSON、PO 对象、List 集合、Map 等多种类型 |
三、为什么选择 Bboss + Easysearch
将 Bboss 作为 Easysearch 的 Java 客户端,您将获得以下独特优势:
- 国产化技术栈:从底层搜索引擎到上层客户端框架,完全国产化自主可控,满足信创合规要求,无许可证风险。
- 极低迁移成本:如果您正在使用 Elasticsearch + Bboss 技术栈,切换到 Easysearch 几乎零成本,只需修改连接配置即可。
- 成熟稳定的客户端:Bboss 经过多年发展,已在国内众多企业和项目中得到广泛应用和验证,拥有活跃的中文社区和完善的文档支持。
- 丰富的生态能力:除了基础的 CRUD 操作,还提供数据采集 ETL、流批一体化计算、AI 智能体等丰富的扩展能力。
四、快速开始
通过以下简单步骤,即可在 Bboss 中接入 Easysearch:
1. 添加 Maven 依赖
<dependency>
<groupId>com.bbossgroups.plugins</groupId>
<artifactId>bboss-datatran-jdbc</artifactId>
<version>7.5.6</version>
</dependency>2. 配置 Easysearch 连接
spring:
elasticsearch:
bboss:
elasticsearch:
rest:
hostNames: localhost:9200
useHttps: true # Easysearch 默认启用 HTTPS
elasticUser: admin
elasticPassword: your_password3. 基础操作
@Service
public class DocumentService {
@Autowired
private BBossESStarter bbossESStarter;
// 插入文档
public void insertDocument() {
ClientInterface client = bbossESStarter.getRestClient();
Document doc = new Document();
doc.setId("1");
doc.setTitle("Easysearch 与 Bboss 集成");
doc.setContent("这是一篇关于集成的文章");
client.addDocument("documents", doc, "refresh=true");
}
// 查询文档
public Document getDocument(String id) {
ClientInterface client = bbossESStarter.getRestClient();
return client.getDocument("documents", id, Document.class);
}
// 按字段查询
public ESDatas<Document> searchByAuthor(String author) {
ClientInterface client = bbossESStarter.getRestClient();
return client.searchListByField(
"documents", "author.keyword", author,
Document.class, 0, 10
);
}
}五、结语
Bboss v7.5.6 与 Easysearch 的深度兼容,是国产开源生态建设的又一重要成果。作为 Easysearch 原厂,我们欢迎更多像 Bboss 这样的优秀开源项目加入国产搜索引擎生态,共同推动国内搜索型数据库的发展与繁荣。
对于正在评估搜索引擎选型或计划进行国产替代的企业用户,Bboss + Easysearch 的组合无疑是值得信赖的选择。
立即体验 Easysearch,开启国产搜索引擎之旅:
- Easysearch 官网: https://easysearch.cn
- Bboss 官方文档: https://esdoc.bbossgroups.com
- Easysearch x Bboss 详细集成文档: https://docs.infinilabs.com/easysearch/main/docs/integrations/third-party/bboss
六、关于 Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。作为国内领先的国产搜索引擎产品,Easysearch 具备以下核心优势:
1. 国产化自主可控
自主研发,符合信创要求,无许可证风险,为企业提供安全可靠的技术保障。在当前国际形势日益复杂、信创需求持续提升的大背景下,Easysearch 为政府、金融、电信、能源等关键行业提供了值得信赖的搜索引擎基础设施。
2. 轻量级架构
相比传统搜索引擎,Easysearch 资源占用更少,启动更快速,显著降低企业运维成本。其精简的架构设计使得在同等硬件条件下可以承载更多的业务负载,特别适合资源受限的私有化部署场景。
3. 卓越性能表现
查询性能优异,能够满足大部分业务场景需求,用户体验流畅。通过持续的内核优化和算法改进,Easysearch 在多项基准测试中展现出媲美甚至超越同类产品的性能水平。
4. 良好兼容性
与 Elasticsearch 的 API 接口基本兼容,迁移成本较低,保护用户现有投资。这一特性使得基于 Elasticsearch 开发的应用可以快速平滑地迁移至 Easysearch,大大降低了国产替代的技术门槛。
社区福利
为感谢广大社区开发者的支持,Bboss 与 Easysearch 厂商极限科技联合发起抽奖活动,奖品为开源T恤。6 月 29 日上午 10 点自动开奖,欢迎大家扫码抽奖参与。
Easysearch v2.3.0 发布 | 管理体验升级,稳定性与兼容性全面增强
资讯动态 • INFINI Labs 小助手 发表了文章 • 0 个评论 • 11618 次浏览 • 2026-06-23 14:11
INFINI Easysearch v2.3.0 正式发布。本次版本围绕“更易用的管理体验、更稳健的集群能力、更可靠的运行表现”持续优化,重点覆盖数据流与管道管理、CCR 与 Rollup 稳定性、安全权限语义一致性,以及 ZSTD 压缩链路在复杂环境下的兼容性与内存表现。
功能特性 (Features)
- 新增管道管理 UI
- Agent UI 新增 API Token 管理能力
- 新增数据流 bootstrap 创建 API,在缺少匹配模板时可自动补齐默认模板并继续创建数据流,简化联调与初始化流程
- 在数据流页面新增“添加数据流”入口
- 新增“修改当前用户密码”UI
改进优化 (Improvements)
- Security enrollment token 新增
endpoints字段(保留endpoint兼容单值),便于多节点地址感知。 - 默认
admin角色映射补充replication_leader与replication_follower,降低 CCR 角色配置复杂度。 - 强化 Rollup/ILM/SLM 启动期保护:在配置索引、安全模块或主分片未就绪时延后周期任务,减少冷启动误报。
- 优化 Rollup Search 索引路由策略,在 alias/wildcard 场景下可更准确区分 live 与 rollup 索引。
- 优化 CCR 同步调度与升级保护,减少空轮询、无效重试,并提升跨版本滚动升级期间可控性。
- 新增状态过滤能力(如
BOOTSTRAPPING、PAUSED、FAILED),便于运维排障。 - 优化初始化与安装流程:重复初始化默认保留关键数据文件,macOS 自动处理隔离标签,安装更顺畅。
- 增强 ZSTD 在非理想运行环境下的兼容回退与内存生命周期管理,降低后台合并内存峰值。
问题修复(Bug Fixes)
- 修复
source_reuse在 tombstone 与非 JSON/二进制_source场景下的解析异常与潜在写入阻塞。 - 修复 Rollup mixed search 在空字段、空索引与边界分流下的聚合异常,避免统计重复、丢失或合并失败。
- 修复 Rollup 索引识别与跨版本传输兼容问题,降低混合集群反序列化失败风险。
- 修复 cluster-state 全局请求在安全过滤后的模板、数据流与索引可见性语义不一致问题。
- 修复 cluster-state 转发、反序列化与超时响应链路中的边界问题,避免 metadata 泄漏与 REST 500/NPE。
- 修复 Security API 在内部用户查询与账户更新中的权限边界问题,恢复 404/403 契约一致性。
- 修复安全模式下
/_cluster/settings与跨集群搜索(CCS)在权限过滤后的返回不完整问题。 - 修复 CCR 在重启、停止复制、proxy 远程集群和 SecurityManager 环境下的稳定性问题。
- 修复可搜索快照在小缓存配置下的启动失败,提升低资源场景可用性。
- 修复 ZSTD 在高压力 merge 场景下的 OOM 与异常传播问题,增强压缩链路健壮性。
- 修复远程集群管理 UI 在代理模式下无法删除的问题。
- 修复数据探索侧边栏对象字段丢失问题。
以上为本版本重点更新摘要,更多详情请查看 Easysearch 产品 Release Notes 或联系我们的技术支持团队!
获取新版本
INFINI Easysearch v2.3.0 已正式发布,欢迎升级体验:
- 下载地址:https://infinilabs.cn/download/
- 快速开始:https://docs.infinilabs.com/easysearch/main/docs/quick-start/
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
【搜索客社区日报】第2249期 (2026-06-15)
社区日报 • Muses 发表了文章 • 0 个评论 • 12057 次浏览 • 2026-06-16 21:09
信创环境下部署 INFINI Gateway:为 Easysearch 构建高性能安全入口
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 11659 次浏览 • 2026-06-11 17:17
引言
上一篇文章里,我们已经完成了 Easysearch 在信创环境下的部署。搜索服务能跑起来只是第一步,要让它真正用于生产,还需要补上“入口治理”这一环。
例如,下面这些问题在生产环境中非常常见:
- 如何防止某个应用或用户发出超大查询请求,把 Easysearch 集群拖垮?
- 如果 Easysearch 某个节点突然宕机,请求能不能自动切换到健康节点,让业务无感知?
- 如何知道每天有多少次查询、哪些查询慢、哪些请求不合法,有没有办法对请求进行审计?
这些正是 INFINI Gateway(极限网关) 擅长解决的问题。本文延续“小白友好”风格,带你完成 Gateway 的安装与验证,为 Easysearch 增加一层高性能、安全、可观测的入口防护。
一、INFINI Gateway 是什么?和 Easysearch 是什么关系?
如果把 Easysearch 比作大型图书馆,那么 INFINI Gateway 就像门口的 “前台总台”。过去读者(应用程序)直接进入书库检索;现在所有请求先经过前台,再转发到书库。这样做的好处很直接:可以缓存热门请求,减少后端压力;可以限制流量,避免集群被突发请求冲垮;还可以记录访问日志,方便审计与分析。
从技术层面讲,INFINI Gateway 的定位如下:
- 高性能数据网关:面向搜索场景设计,请求先在网关完成处理,再转发到后端 Easysearch 集群。
- 代理 + 增强:位于客户端与 Easysearch 之间,可在转发链路中叠加限流、缓存加速、请求审计、结果改写等能力。
- 兼容原生 API:对外接口兼容 Elasticsearch / Easysearch 原生 API,应用只需把连接地址从直连 Easysearch 改为指向网关,无需改业务代码。
- 轻量易部署:基于 Golang 开发,安装包约 10MB,无额外外部依赖。
- 信创兼容认证:已通过华为鲲鹏 Kunpeng 920 兼容性认证,并获得 KUNPENG COMPATIBLE 证书。
整个系列的组件关系如下:
应用程序 → INFINI Gateway(流量入口) → Easysearch(数据存储与检索)
有了 Gateway,你就可以更放心地将搜索服务开放给更多应用和用户,而不必过度担心安全与性能失控问题。
二、部署前置条件
1. 信创环境
- CPU :鲲鹏 Kunpeng-920、aarch64
- 操作系统:统信服务器操作系统A版 V20
2. 确保 Easysearch 已正常运行
Gateway 本身不存储数据,核心职责是代理与增强 Easysearch。因此部署前请先确认 Easysearch 已启动,并且网络可达:
curl -ku admin:你的密码 https://localhost:9200三、部署步骤
步骤 1:下载 INFINI Gateway
下面脚本会自动下载对应平台的 Gateway 最新版本,并解压到 /opt/gateway:
# 一键下载并安装到 /opt/gateway
curl -sSL http://get.infini.cloud | bash -s -- -p gateway -d /opt/gateway
步骤 2:编写 Gateway 配置文件
Gateway 启动依赖 YAML 配置文件,用来声明监听端口、后端 Easysearch 地址和认证信息。进入安装目录后,找到 gateway.yml 并按实际环境修改:
# 按实际情况填写可访问的 Easysearch 地址
LOGGING_ES_ENDPOINT:https://localhost:9200/
LOGGING_ES_USER:admin
LOGGING_ES_PASS:"你的 Easysearch 密码"
# 按实际情况填写可访问的 Easysearch 地址
PROD_ES_ENDPOINT:https://localhost:9200/
PROD_ES_USER:admin
PROD_ES_PASS:"你的 Easysearch 密码"
# 按需设置 Gateway 对外监听端口
GW_BINDING:"0.0.0.0:8000"步骤 3:启动 Gateway
进入 Gateway 安装目录,执行下面命令启动程序:
# 进入安装目录
cd /opt/gateway
# 运行程序(gateway-linux-arm64 为可执行文件名)
./gateway-linux-arm64
程序启动后,即可通过配置端口访问 Easysearch 服务。
在前台运行模式下,如需停止 Gateway,按 Ctrl+C 即可。
如果希望将 Gateway 作为后台服务运行,可执行:
# 命令中的 gateway-linux-arm64 为可执行文件名
./gateway-linux-arm64 -service install && ./gateway-linux-arm64 -service start如需卸载服务,执行以下命令:
./gateway-linux-arm64 -service stop
./gateway-linux-arm64 -service uninstall步骤 4:验证 Gateway 是否正常工作
通过 Gateway 间接访问 Easysearch,确认转发通路正常:
# 通过 Gateway(8000 端口)访问 Easysearch
curl http://0.0.0.0:8000
# 对比直连 Easysearch 的结果
curl -ku admin:你的密码 https://localhost:9200两条命令返回的 JSON 结果应基本一致。若都能正常响应,说明 Gateway 已成功接管 Easysearch 的访问入口。
如果你的生产环境需要将搜索服务开放给大量应用和用户,建议将 Gateway 纳入标准部署方案。借助 Gateway,你可以更好地保护后端 Easysearch 集群,并获得限流限速、缓存加速、安全防护、审计日志等增强能力,让整体架构更健壮、更安全、更可观测。
如果在部署过程中遇到问题,欢迎查阅官方文档。祝你部署顺利!
作者:小袁
原文:https://infinilabs.cn/blog/2026/gateway-install-at-xc-platform/
极限科技 Easysearch 与鼎甲备份系统完成深度兼容适配认证
资讯动态 • INFINI Labs 小助手 发表了文章 • 0 个评论 • 11321 次浏览 • 2026-06-10 09:21
近日,极限科技与鼎甲科技顺利完成双向兼容适配认证,国产分布式检索数据库 Easysearch V2.0 与鼎甲数据备份与恢复系统 DBackup V8.0 全面通过功能、性能、稳定性联合测试,产品适配顺畅、运行表现优异,成功实现国产检索存储与国产数据灾备全链路深度打通。
为保障适配落地效果,双方组建专项技术团队,围绕 Easysearch 海量索引、向量索引等特色数据结构开展定制化调优,覆盖全量与增量备份、瞬时恢复、故障回滚、集群高可用等核心业务场景。经过多轮严苛验证,两套自研产品可无缝协同,能够为检索类数据提供覆盖全生命周期的安全防护能力。
作为国产化核心检索引擎,Easysearch V2.0 原生兼容 ES 生态,支持全文检索、向量检索、多模态检索等丰富能力,深度适配国产软硬件环境,可有效助力政务、金融、大数据等行业实现搜索引擎国产化替换。鼎甲 DBackup V8.0 是国内主流政企级灾备产品,具备全域数据备份、极速恢复、异地容灾、勒索防护等成熟能力,长期为海量关键业务数据提供安全保障。
未来,极限科技与鼎甲科技将持续深化技术与生态合作,持续跟进产品版本迭代适配,联合打磨标准化行业解决方案,拓展金融、政务、能源等落地场景,携手完善国产基础软件产业链,持续赋能政企信创数字化建设。
国产统信 UOS 部署 Coco Server 全指南:从零搭建企业级 AI 搜索服务端
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 9852 次浏览 • 2026-06-09 14:19
一、引言
在上一篇文章《从零到跑起来:Easysearch 信创环境安装全流程》中,我们成功在信创平台上安装并运行起了 Easysearch。但 Easysearch 是一个底层搜索引擎,直接操作有一定门槛。如果我们想让团队里的每个人都能方便地“搜文件、聊文档、问知识”,就需要一个更贴近日常使用、又能把 AI 能力融入进来的上层应用——这就是 Coco AI 。
本文将继续手把手带你从零开始,在国产统信 UOS 服务器操作系统上部署 Coco Server,并与已安装的 Easysearch 进行对接。全文依然零基础可读,跟着步骤一步步来即可。
二、Coco Server 是什么?它和 Easysearch 什么关系?
先对我们的产品进行一个简单的介绍:
- Easysearch 是底层引擎,负责存储和检索数据,像汽车的发动机和底盘;
- Coco Server 是基于 Easysearch 之上的服务端应用程序,提供 Web 管理界面、统一搜索、AI 聊天、知识库管理等高级功能,类似车身和智能驾驶系统;
- Coco AI 桌面客户端则是连接 Coco Server 的终端软件,安装在个人电脑上使用。
而在本文中部署的 Coco Server,是整个 Coco AI 体系的“大脑”:
- 它负责连接各类数据源(飞书、语雀、GitHub、本地文件等);
- 它管理大模型提供商(Deepseek、通义千问、OpenAI 等);
- 它提供 Web 管理后台,让管理员可以可视化地完成所有配置。
部署完成之后,团队成员只需通过客户端或浏览器,就能享受统一搜索与 AI 智能问答带来的便利。Coco AI 的整体架构图如下:
三、部署前置条件
1. 进行服务器相关优化
#内核参数优化
cat << SETTINGS | sudo tee /etc/sysctl.d/70-infini.conf
fs.file-max = 10485760
fs.nr_open = 10485760
vm.max_map_count = 262145
net.core.somaxconn = 65535
net.core.netdev_max_backlog = 65535
net.core.rmem_default = 262144
net.core.wmem_default = 262144
net.core.rmem_max = 4194304
net.core.wmem_max = 4194304
net.ipv4.ip_forward = 1
net.ipv4.ip_nonlocal_bind = 1
net.ipv4.ip_local_port_range = 1024 65535
net.ipv4.conf.default.accept_redirects = 0
net.ipv4.conf.default.rp_filter = 1
net.ipv4.conf.all.accept_redirects = 0
net.ipv4.conf.all.send_redirects = 0
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_max_tw_buckets = 300000
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 65535
net.ipv4.tcp_synack_retries = 0
net.ipv4.tcp_keepalive_intvl = 30
net.ipv4.tcp_keepalive_time = 900
net.ipv4.tcp_keepalive_probes = 3
net.ipv4.tcp_fin_timeout = 10
net.ipv4.tcp_max_orphans = 131072
net.ipv4.tcp_rmem = 4096 4096 16777216
net.ipv4.tcp_wmem = 4096 4096 16777216
net.ipv4.tcp_mem = 786432 3145728 4194304
SETTINGS
sysctl -p /etc/sysctl.d/70-infini.conf
2. 环境前提:Easysearch 已经运行好
Coco Server 运行强依赖 Easysearch,所以在继续之前,请确保你的信创服务器上已经安装并成功启动了 Easysearch。如果不确定,可以执行下面的命令验证:
curl -k -u admin:你的密码 https://localhost:9200运行命令后,看到正常的 JSON 响应即可。
如果还没有安装,可以参考上一篇文章《从零到跑起来:Easysearch 信创环境安装全流程》先行完成。
3. 信创平台信息确认
和 Easysearch 一样,你需要明确当前服务器的 CPU 架构和操作系统版本。在终端执行:
# 查看 CPU 架构
uname -m
# 查看操作系统信息
cat /etc/os-release根据输出,确认 CPU 架构和操作系统,后续下载时选择对应版本。
部署环境如下表中所示:
4. 软件环境
| 名称 | 版本 | 备注 |
|---|---|---|
| Coco AI 智能搜索软件 | V1.0.0 | Coco Server |
| 统信服务器操作系统 A 版 | V20 | |
| Easysearch 搜索型数据库 | V2.2.0 | 用于 Coco 数据存储 |
| 360安全浏览器 | V13 |
5. Coco AI 大语言模型 推荐配置
| 模型名称 | 上下文长度 | 最大输出长度 | 描述 |
|---|---|---|---|
| deepseek-r1 | 128K | 16K | 数学、代码、自然语言推理等任务上,性能较高,能力较强 |
| qwen3-max | 256K | 32K | 配场景复杂的智能体需求 |
| tongyi-intent-detect-v3 | 8K | 8K | 用于意图识别和槽位填充,负责对话系统中的基础任务 |
5. 网络端口配置
| 服务名 | 端口 | 配置文件 | 说明 |
|---|---|---|---|
| Coco Server | 9000(默认) | coco.yml | |
| INFINI Easysearch | 9200(默认) | config/easysearch.yml | 默认仅监控 127.0.0.0,可通过配置 network.host: 0.0.0.0 调整 |
| 9300(默认) | config/easysearch.yml |
四、部署步骤
步骤 1:下载 Coco Server
# 调整为 Coco 实际要安装的路径
cd /opt
#下载Coco v1.0.0压缩包
curl -O https://release.infinilabs.com/.testing/coco-1.0.0.zip
#解压到当前文件夹
unzip coco-1.0.0.zip
#选择对应的版本解压tar.gz文件
tar -xzf coco-1.0.0-2002-linux-arm64.tar.gz
#解压后在对应文件夹下得到可执行程序coco-linux-arm64(arm64版本)和配置文件coco.yml步骤 2:配置 Easysearch 连接信息
Coco Server 需要得到 Easysearch 的地址和登录凭证才能进行工作。
在 安装路径的目录下,找到配置文件 进行配置,比如监听的端口地址 WEB_BINDING, 将 Easysearch 的服务地址环境变量 ES_ENDPOINT 和用户名 ES_USERNAME 设置为实际的,参考如下:
env:
# 调整为实际可以访问的 Easysearch 访问地址
ES_ENDPOINT: https://localhost:9200
# 调整为实际可以访问的 Easysearch 的用户
ES_USERNAME: admin
# 使用 keystore 存储的密码
ES_PASSWORD: $[[keystore.ES_PASSWORD]]
# Coco Server 对外提供服务的端口(默认9000端口)
WEB_BINDING: 0.0.0.0:9000步骤 3:使用keystore对密码进行加密处理
Easysearch 的服务密码通过 Keystore 进行加密存放,避免明文存放到配置文件,减少数据泄露风险
# 调整为 Coco 实际安装路径进行配置
cd /opt
# 创建 coco 软链接,可不区分 amd64/arm64 平台进行操作
ln -s coco-linux-`arch | grep -q "x86_64" && echo "amd64" || echo "arm64"` coco
# 根据之前拿到的 Easysearch 密码进行初始化 ES_PASSWORD 变量
ES_PASSWORD=xxx
# 将 ES_PASSWORD 变量的值存储到 keystore(./coco-linux-arm64替换为对应版本名,下同)
echo "$ES_PASSWORD" | ./coco-linux-arm64 keystore add --stdin ES_PASSWORD
# 检查 keystore 存储列表,确认 ES_PASSWORD 添加成功
./coco-linux-arm64 keystore list步骤 4:启动服务
以上配置完成后,设置 Coco Server 以服务方式启动
#安装系统服务(./coco-linux-arm64替换为对应版本名,下同)
./coco-linux-arm64 -service install
#启动服务
./coco-linux-arm64 -service start
步骤 5:初始化设置
服务启动后,在信创服务器的桌面环境下,打开浏览器,访问 UI 界面:
http://localhost:9000/#/\_guide/
你将看到 Coco Server 的 Web 引导界面。因为是首次访问,所以需要创建管理员账号,按页面引导填写即可。
创建完管理员账户后,下一步
设置一个模型提供商,Coco Server 支持:
- Deepseek
- Ollama
- 任何和 OpenAI 格式兼容的模型提供商
如果设置的模型是推理模型,需要打开“推理模式”。我们推荐使用参数较大的模型,来获得更好的使用体验。同时请注意:Endpoint 地址的配置要准确。
Coco Server 默认配置了一些小助手,建议在初始化向导的时候直接配置一个可用的模型,这样进入系统之后就可以直接使用,避免一个个的手动配置。
向导设置完成后,就会跳转到登录页面,输入刚才创建的账户和密码,就可以进行登录了,如下图:
管理员首次登录之后的第一件事是确认服务器的地址是否正确,如果 Coco server 前面增加了负载均衡或者配置了域名,需要在这里设置一下正确的 Coco Server 对外服务地址,如下图:
五、总结
到这里,你已经完成了 Coco Server 在信创平台上的部署与初始化。我们回顾一下整个部署流程:
- 确认环境 — Easysearch 已部署成功,并明确 CPU 架构;
- 下载安装 — 下载 Coco Server 的压缩包进行解压;
- 配置连接 — 编辑
coco.yml,填入 Easysearch 端点和密码; - 启动服务 — 将 Coco Server 以服务方式启动;
- 初始化 — 浏览器打开 http://localhost:9000/#/\_guide/ 进行管理员账户的创建; 添加大模型、连接数据源、创建助手。
Coco Server 部署完成后,你就拥有了一个完全私有化、自主可控的企业级统一搜索与 AI 智能助手服务端。下一步可以安装 Coco AI 桌面客户端,让团队成员真正体验“一个搜索框搜遍全公司”的高效便捷。
如果在部署过程中遇到任何困难,欢迎查阅官方文档,祝你部署顺利!
Easysearch 信创环境安装实践
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 10854 次浏览 • 2026-06-05 18:10
一、Easysearch 介绍
在动手安装之前,我们先花一点时间了解这个工具。 INFINI Easysearch (以下简称 Easysearch)是由极限科技(INFINI Labs)自主研发的一款分布式 AI 搜索型数据库。用通俗的话讲,它是一个“超级搜索引擎”,能帮你在海量数据中快速查找信息,支持结构化和非结构化的数据检索、全文检索、向量检索、空间地理位置信息检索、组合查询、多语种支持、语义分析和聚合分析等多种功能,被广泛应用于企业搜索、日志分析、知识库管理等场景。它的安装包仅50MB,非常轻量。
Easysearch 的“自主可控”特性十分突出:
- 完全国产化:已适配龙芯、鲲鹏、飞腾、海光、兆芯、申威等主流国产 CPU;
- 全面兼容国产操作系统:支持银河麒麟、统信 UOS、中标麒麟等国产操作系统;
- 国密算法支持:全量支持 SM2/SM3/SM4 国密算法,满足等保三级及信创合规要求;
- ES生态兼容:完全兼容 Elasticsearch 的 API 接口,可无缝平替。
二、安装前需知
1.你的信创平台属于哪种?
信创平台的组合通常是“国产 CPU + 国产操作系统”,你需要确认你的环境属于哪种:
| 国产CPU | 架构 | 常见搭配操作系统 |
|---|---|---|
| 鲲鹏(Kunpeng) | ARM64 | 银河麒麟V10、统信UOS |
| 飞腾(Phytium) | ARM64 | 银河麒麟V10、统信UOS |
| 海光(Hygon) | x86 | 统信UOS、银河麒麟V10 |
| 龙芯(Loongson) | LoongArch | 银河麒麟V10、统信UOS |
| 兆芯(Zhaoxin) | x86 | 银河麒麟V10、统信UOS |
| 申威(Sunway) | SW64 | 统信UOS |
不确定的话,可以在终端执行以下命令查看:
#查看操作系统信息
cat /etc/os-release
#查看CPU架构
uname -m2.在线部署or离线部署?
Easysearch 提供了两种安装方式:
联网环境:如果服务器能正常访问外网,推荐使用一键安装部署,简单快速;
离线环境:如果服务器在内网、无法访问外网(常见信创环境),则下载 Bundle 包进行离线部署。
在这篇文章中所使用的是在线部署方式。
三、安装环境简介
以统信 UOS 信创平台为例,以下表中为本机采用的安装环境
1.硬件信息
| 硬件 | 信息 |
|---|---|
| 处理器 | 架构:aarch64 型号:Kunpeng-920 |
| 内存 | 容量:8G 类型:RAM |
| 硬盘 | 类型:QEMU HARDDISK 容量:100G |
2.软件环境
| 名称 | 版本 |
|---|---|
| 统信服务器操作系统A版 | V20 |
| Easysearch 搜索型数据库 | V2.2.0 |
| 360安全浏览器 | V13 |
3.网络端口设置
| 服务名 | 端口 | 配置文件 | 说明 |
|---|---|---|---|
| INFINI Easysearch | 9200(默认) | config/easysearch.yml | 默认仅监控 127.0.0.0,可通过配置 network.host: 0.0.0.0 调整 |
| 9300(默认) | config/easysearch.yml |
四、部署流程
具体细节详见部署手册
步骤1:系统初始化
安装前需要完成两项系统准备工作:调整内核参数和创建专用用户。无论在线还是离线安装,这两步都必须先做好,并且需要使用 root 账户或 sudo 权限执行。
# 1. 调整内核参数(vm.max_map_count,Easysearch 运行的必要条件)
echo "vm.max_map_count=262144" >> /etc/sysctl.conf && sysctl -p
# 2. 创建 Easysearch 专用用户组和用户
groupadd -r easysearch && useradd -r -g easysearch -d /home/easysearch -s /sbin/nologin -c "Easysearch Service Account" easysearch
步骤2:安装 Easysearch
如果服务器能正常访问外网,直接使用官方一键安装脚本:
# 创建数据安装目录
mkdir -p /opt/easysearch
# 下载最新版本并安装
curl -sSL http://get.infini.cloud | bash -s -- -p easysearch -d /opt/easysearch
脚本会自动检测系统架构( ARM64 还是 x86 ),并下载对应的安装包。
步骤3:初始化并启动 Easysearch
# 进入 Easysearch 目录
cd /opt/easysearch
# 初始化 Easysearch (初始化过程中,日志将输出管理员访问密码,请妥善保存)
bin/initialize.sh -s
# 调整目录权限
chown -R easysearch:easysearch /opt/easysearch
# 启动 Easysearch
runuser -u easysearch -- /opt/easysearch/bin/easysearch -d -p /opt/easysearch/easysearch.pid
步骤4:验证服务运行
启动后,可以使用 curl 命令快速测试服务是否正常运行:
# 使用初始化时显示的 admin 密码测试连接
curl -ku admin:你的密码 https://localhost:9200
步骤5:访问服务运行端口
服务运行后,访问设置好的服务端点
https://localhost:9200/\_ui/(默认服务端点)
输入之前保存的账号与密码进行登录
进入 ui 界面
之后就可以实现对 Easysearch 可视化管理了
结语
以上就是 Easyserach 在信创平台部署的全流程了,整个过程操作下来,应该能在 10-20 分钟左右完成 Easysearch 支持从单机测试到 PB 级生产集群的平滑扩展,无论是个人学习还是企业级业务,都能灵活适配。如果在操作过程中遇到任何问题,建议优先查阅官方文档。预祝你在信创平台的探索之旅顺利!
Elasticsearch 6/7/8 到 Easysearch 2.x 迁移指南
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 11088 次浏览 • 2026-06-04 14:14
最近在协助客户进行 Elasticsearch 到 Easysearch 的迁移时,发现大家最关心的问题是"当前版本能否直接使用快照迁移"。这个问题看似简单,但不同版本的答案差异较大。本文将基于实际测试经验,梳理各版本的迁移路径和注意事项。
迁移路径速览
根据源 ES 版本,可以直接对照下表选择迁移方案:
| 源 ES 版本 | 能否直接快照恢复 | 推荐方案 | 实施复杂度 |
|---|---|---|---|
| ES 6.x | 否 | INFINI Gateway 迁移 或 ES 7.10.x 中转 | 较低 |
| ES 7.0 - 7.11 | 是 | 直接快照恢复 | 较低 |
| ES 7.12 - 7.17 | 否 | INFINI Gateway 迁移 | 较低 |
| ES 8.x | 否 | INFINI Gateway 迁移 | 较低 |
结论:ES 7.0-7.11 是迁移最顺畅的版本窗口,可直接快照恢复;其他版本也有成熟的迁移方案,只是路径不同。
版本差异的原因
迁移路径的差异主要源于两方面:Lucene 版本兼容性和快照元数据格式变化。
Lucene 兼容性:Easysearch 2.x 底层要求的最低 Lucene 版本对应 ES 7.0.0。ES 6.x 的索引文件使用老版本 Lucene,直接恢复会报错:
The index was created with version [6.8.23] but the minimum compatible version is [7.0.0].快照元数据格式:ES 7.12 开始在快照中引入 uuid、cluster_id 字段,7.14 增加 writer_uuid,8.x 又引入 transport_version。这些字段与 Easysearch 2.x 的快照解析器不兼容。
因此,ES 7.0-7.11 成为迁移的"黄金窗口"——既满足 Lucene 兼容性要求,快照格式又足够简洁。
ES 7.0-7.11:直接快照恢复
这是测试最充分的迁移路径,已验证版本包括 ES 7.0.1、7.8.1、7.10.2 OSS、7.11.2。
已验证能力:
- 单索引 / 多索引 / 通配符批量恢复
- 常见字段类型与别名
- 自定义 settings、多分片索引
- ILM 托管索引、数据流后备索引、冻结索引
操作步骤:
# 1. 源 ES 创建快照
PUT /_snapshot/my_backup/snapshot_1
{
"indices": "索引列表",
"include_global_state": false
}
# 2. Easysearch 注册同一快照仓库
PUT /_snapshot/my_backup
{
"type": "fs",
"settings": {
"location": "/path/to/snapshot/repo",
"readonly": true
}
}
# 3. 恢复快照
POST /_snapshot/my_backup/snapshot_1/_restore
{
"indices": "索引列表",
"include_global_state": false
}ES 6.x:Gateway 迁移或中转方案
ES 6.x 无法直接快照恢复到 Easysearch 2.x,有两种迁移方案可选:
方案一:INFINI Gateway 迁移(推荐)
直接使用 Gateway 从 ES 6.x 迁移数据到 Easysearch,无需中转集群。Gateway 已验证支持 ES 6.8.x 的数据迁移。
方案二:ES 7.10.x 中转
ES 6.8 -> 快照 -> ES 7.10.x -> 快照 -> Easysearch 2.xES 7.10.x 可以正常恢复 ES 6.x 的快照,恢复完成后再创建快照供 Easysearch 使用。该方案数据完整性有保障,但需要额外的中转存储和迁移窗口。
ES 6.x 特有字段:ES 6.x 的 string 类型在 Easysearch 中需映射为 text 或 keyword(根据实际使用场景选择)。
ES 7.12+ 和 8.x:INFINI Gateway 迁移
这两个版本段的快照格式与 Easysearch 2.x 不兼容,推荐使用 INFINI Gateway 进行迁移。Gateway 是 INFINI Labs 提供的数据迁移工具,专门针对 Elasticsearch 到 Easysearch 的迁移场景进行了优化。
架构示意
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ Elasticsearch │ ──── │ INFINI Gateway │ ──── │ Easysearch │
│ (源集群) │ │ (迁移工具) │ │ (目标集群) │
└─────────────────┘ └─────────────────┘ └─────────────────┘Gateway 内部通过 Scroll API 从源集群分批拉取数据,再通过 Bulk API 写入目标集群,整个过程对业务透明。
主要优势
- 配置简单:只需配置源集群和目标集群地址、索引名称即可
- 断点续传:支持从断点恢复,避免网络抖动导致重头再来
- 进度可视:实时显示迁移进度和速率
- 多索引并行:支持同时迁移多个索引
基本步骤
- 在目标集群创建索引的 mapping 和 setting
- 准备 Gateway 配置文件,填写源集群和目标集群连接信息
- 运行 Gateway 执行迁移
- 迁移完成后进行数据校验
详细的配置说明和操作示例,可参考 ES 数据迁移之 INFINI Gateway。
备选方案
如果需要更灵活的控制,也可以自行编写脚本,通过 Scroll API 读取源数据、Bulk API 写入目标。这种方式适合有定制化需求的场景,但需要自行处理断点续传、错误重试等逻辑。
字段类型兼容性
直接兼容类型:text、keyword、long、double、boolean、date、object、nested、geo_point、geo_shape、ip、completion、wildcard、flattened、alias、join、rank_feature、rank_features、integer_range、long_range、date_range、match_only_text 等。
ES 7.x / 8.x 需替换类型:
| ES 类型 | Easysearch 替代方案 | 数据保留 | 说明 |
|---|---|---|---|
dense_vector |
knn_dense_float_vector |
是 | 需安装 knn 插件,向量数据格式兼容 |
knn_vector |
knn_dense_float_vector |
是 | 需安装 knn 插件 |
sparse_vector |
knn_sparse_bool_vector |
是 | 需安装 knn 插件 |
constant_keyword |
keyword |
是 | 需手动维护常量值 |
runtime |
移除或转为普通字段 | 是 | Easysearch 不支持运行时字段 |
histogram |
object |
是 | 聚合 histogram 功能丢失 |
aggregate_metric_double |
object |
是 | 需手动计算聚合 |
unsigned_long |
long 或 keyword |
是 | 注意数值范围 |
semantic |
暂不支持 | - | ES 专有 AI 功能 |
向量迁移要点:ES 的 dense_vector 数据可直接迁移到 Easysearch 的 knn_dense_float_vector,数据格式 [0.1, 0.2, ...] 完全兼容。需预先在目标索引创建正确的 mapping。
建议迁移前先用小索引测试,确认 mapping 无问题后再全量迁移。
常见问题与避坑指南
1. include_global_state 参数设置
该参数控制是否恢复集群级配置(模板、ILM 策略等)。不同版本的情况:
| ES 版本 | 发行版 | global_state | 说明 |
|---|---|---|---|
| 7.0-7.7 | 任意 | 兼容 | 无 _index_template API |
| 7.8-7.10 | OSS | 兼容 | 无内置 _index_template |
| 7.8-7.10 | default | 可能不兼容 | 取决于是否使用 _index_template |
| 7.11+ | 任意 | 不兼容 | 有 9 个内置 _index_template |
建议:迁移时统一使用 include_global_state=false,先恢复数据再重建配置。
2. ILM 和 data stream 迁移
- ILM:索引的 lifecycle 设置保留,但 policy 需在 Easysearch 中重建
- 数据流 (data stream):后备索引 (backing index) 数据完整恢复,语义需在目标侧重建
- 冻结索引 (frozen index):自动恢复为普通可访问状态
3. 迁移验收标准
建议至少完成三项验证:
- 文档量一致
- 关键查询结果一致
- 核心业务链路压测通过
4. 迁移窗口规划
- 快照方案通常需要短停机窗口完成切换
- Gateway 迁移可实现近实时同步,仅在切换连接时短暂停服
快照格式变化参考
| 字段 | ES 7.0-7.11 | ES 7.12-7.17 | ES 8.x | Easysearch 2.x |
|---|---|---|---|---|
min_version |
7.9.0 或无 | 7.12.0 | 7.12.0 | 支持 |
uuid(仓库级) |
无 | 有 | 有 | 不支持 |
cluster_id |
无 | 有 | 有 | 不支持 |
writer_uuid |
无 | 有(7.14+) | 有 | 不支持 |
transport_version |
无 | 无 | 有 | 不支持 |
总结
本文梳理了 Easysearch 2.x 对 ES 6/7/8 的迁移路径:
- ES 7.0-7.11:直接快照恢复,路径最短
- ES 6.x:INFINI Gateway 迁移 或 ES 7.10.x 中转
- ES 7.12+ / 8.x:使用 INFINI Gateway 迁移
建议在正式迁移前,先选择非核心索引进行小规模验证,确认数据完整性和业务兼容性后再扩大迁移范围。
如有迁移相关问题,欢迎联系我们。
【搜索客社区日报】第2241期 (2026-06-01)
社区日报 • Muses 发表了文章 • 0 个评论 • 12061 次浏览 • 2026-06-01 11:33
【搜索客社区日报】第2231期 (2026-05-15)
社区日报 • Fred2000 发表了文章 • 0 个评论 • 13144 次浏览 • 2026-05-15 10:19
Easysearch analysis-ik 多词典性能优化:从性能回退到分词性能提升 25%~30%
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 15754 次浏览 • 2026-05-08 14:34
Easysearch 版 analysis-ik 相比开源 IK 有一个重要的增强:支持多词典。简单说就是不同字段可以挂不同词库,可以叠加默认词典,也可以只用自定义词典。这是开源单词典 IK 做不到的。
功能实现初期,主要精力放在把能力跑通上。但在后来的一次写入压测中,我们发现 Easysearch 的写入吞吐和 Elasticsearch 有明显差距,最终定位到问题出在多词典的实现方式上——字段最终该用哪套词典,本来应该在分词前就算好,结果代码里把这个选择丢进了分词的热路径,每次分词都要反复切词典、重复扫同一段文本。
这篇文章记录的就是我们怎么一步步把性能拉回来、最终反超基线的过程。
问题怎么冒出来的
4 月 20 号,我们跑了一轮系统级写入压测。数据、mapping、settings、并发和 bulk 参数都一样,Elasticsearch 8.19.5 和 Easysearch 2.1.2 的写入吞吐差距大得有点不对劲:
| 时间 | 场景 | Elasticsearch | Easysearch | 说明 |
|---|---|---|---|---|
| 2026-04-20 第 2 次有效重跑 | 29900 docs / bulk=250 / concurrency=3 端到端写入压测 |
129.44 docs/s |
31.21 docs/s |
这是整条写入链路的 docs/s,不是单独分词吞吐 |
| 2026-04-20 诊断样本 | 5000 docs / bulk=250 / concurrency=3 |
156.25 docs/s |
30.67 docs/s |
Easysearch 的累计索引耗时约为 Elasticsearch 的 8.0x |
当时服务器上跑的就是早期多词典版本。后面修性能,追的就是这个版本和开源单词典 IK 基线之间的差距。
这一步还不能直接确定问题就在分词器。但差距摆在这儿了,得继续往下排。我们先排除了几个常见干扰因素:
refresh_interval- 动态同义词 HTTP 服务
- mapping / settings 不一致
- 网络层和 bulk 客户端本身
采样结果很快把范围收窄了。Elasticsearch 那边热点比较分散,Easysearch 这边呢,分词链路里出现了异常集中的开销——分词过程中反复做词典选择和字典查找。
瓶颈不在 Lucene 写入链路本身,就在 analysis-ik 的多词典实现上。
根因分析
第一类问题出在实现模型上。多词典想表达的是”这个字段最终用哪套词典”,这件事完全可以在分词前算好。但早期代码里,硬是把它变成了运行时的事:
- “字段用哪个词典”变成了”运行时多轮扫描”——同一段文本对着多套词典各来一遍。
- 全局字典切换的动作放进了每字符的热路径。
- 结果就是同一段文本的扫描和查找成本翻了好几倍。
所以问题不是多词典天然慢,是实现把本该提前算好的东西塞进了热路径反复做。
第二类问题是后续优化过程中留下的额外开销。后面加的跨边界、停用词、长文本等测试本身不是性能问题的来源,它们的作用是把正确性边界补齐,确保每次优化不会改变分词结果。
最后通过性能分析确认,残留开销主要来自两处:缓存命中前还在做不必要的数据复制;诊断逻辑在生产热路径上产生了额外开销。修完之后这两处热点都从火焰图上消失了,说明性能回退确实来自真实的代码路径成本,不是测试抖动。
修复过程
整个修复分四个阶段。
第一阶段:把多词典从”运行时分发”收敛为”最终有效词典视图”
多词典能力保留,但不再让分词器在热路径里反复切词典、重复扫文本。改成在分词前就把字段最终生效的词典算好,分词过程只面对一个已经收敛好的词典视图。
说白了就是把模型拉回正确方向——多词典管表达能力,热路径只管分词。
第二阶段:逐步打掉热路径上的常数开销
留下来的每一项优化,都经过正式性能测试和采样分析验证。原则就一条:不改分词语义,只减少热路径上反复发生的查找、分配和判断。
第三阶段:补齐正确性护栏
正确性测试必须先到位,不然吞吐提升没有意义——万一分词结果变了,跑得再快也白搭。
这一轮重点覆盖了这些容易出问题的场景:
- 真跨边界场景
- 数字和量词合并,如
1号 - 自定义词典里的含符号词
- 补充平面字符跨边界稳定性
- 停用词过滤后的偏移量
- 长文本样本的稳定性
- 正式性能测试数据集的分词结果对齐
后面所有的吞吐数字,前提都是分词结果一致,避免把分词行为的变化误当成性能提升。
第四阶段:清理最后的残留开销
到 4 月 28 号,最后一轮修复集中处理两个地方:
- 词典视图命中缓存时直接返回,不再多做一次数据复制
- 诊断逻辑默认关掉,不让线上请求为调试能力买单
这两处修完,Easysearch 版 IK 就不只是恢复到单词典版本附近了,在正式测试里已经明显领先。
用数据看恢复过程
为了不把系统级写入压测和分词器性能测试混在一起,下面只看几个关键节点。2026-04-20 的 docs/s 是系统级写入吞吐,后面的 tok/s 是单独的分词器吞吐。
这里说的”开源 IK 基线”就是开源 IK 的单词典实现对照版本。所有正式吞吐结论都建立在同一数据集、同一测试方法、分词结果一致的前提上。
| 时间 | 口径 | 关键结果 | 说明 |
|---|---|---|---|
| 2026-04-23 17:02 CST | 初期本地复现 | 服务器多词典版本 61.39 万 tok/s,单词典版本 114.48 万 tok/s |
单词典版本快 86.49%,性能差距被明确复现 |
| 2026-04-24 09:51:12~09:55:15 CST | 第一次正式追平 | smart 相对开源单词典基线 +7.26% |
从明显落后追到略微领先 |
| 2026-04-25 04:14~04:16 CST | 双模式阶段复核 | smart +16.88%,max_word +20.09% |
领先优势开始扩大 |
| 2026-04-28 12:30:56 CST | 最新正式复核 | smart +30.96%,max_word +21.31% |
当前最新结果 |
整个过程就是:
- 先暴露出明显的性能退化
- 逐步缩小差距
- 追平,然后开始领先
- 最终在分词结果完全一致的前提下,正式反超
最早的本地复现数据很关键:服务器当时跑的多词典版本只有 613896.67 tok/s,单词典版本 1144843.77 tok/s。后面所有修复就是冲着这个差距去的。
三张图分别对应问题暴露、分词复现和修复结果:第一张展示服务器 bulk 写入吞吐的系统级差距;第二张展示多词典版本和单词典版本的本地分词差距;第三张展示分词结果对齐后,Easysearch 版 IK 怎么一步步追上来,最终实现 25%~30% 的分词性能提升。
为什么说 Easysearch 版 IK 现在更好
这次修复的价值不只是消灭了几个热点,更重要的是把多词典能力、分词正确性和性能测试体系一起补齐了。
1. 功能更强,性能代价可控
开源单词典 IK 模型简单,但表达能力也弱。Easysearch 的多词典能力要解决的是字段级词库隔离、自定义词典叠加这些实际需求。
关键问题是:能不能把这些能力的性能开销压到足够低。修复后的结果证明,可以。
2. 正确性护栏更完整
这轮补上的测试不只是几个短样例,覆盖了更容易翻车的边界条件:
- 真跨边界场景
- 长文本稳定性
- 自定义词典和符号词
- 数字量词合并
- 停用词过滤后的偏移量
这意味着以后再做性能优化,必须同时保证分词结果不变。想靠改分词行为换吞吐,测试会先拦住。
3. 性能测试体系更严格
这轮之后,Easysearch 对 analysis-ik 的正式性能结论统一按一套标准出:
- 同一数据集
- 同一测试方法
smart和max_word双模式- 分词结果一致
- 有性能分析结果支撑
这套体系能避免两个常见坑:只看单轮吞吐波动就下结论,或者分词结果已经变了还在比性能。
小结
多词典能力在实现初期,主要精力放在功能补齐上——先把字段级词库隔离、自定义词典叠加这些能力跑通,性能优化是后面分阶段来的事,没办法一蹴而就。
这轮优化下来,核心思路其实就一条:把词典选择从分词热路径里挪出去,提前收敛好,让分词过程只面对最终的词典视图。再配合热点清理和正确性护栏,增强功能和更高性能完全可以兼得。
截至 2026 年 4 月 28 日,在本地 Mac 笔记本上的多轮 benchmark 中,Easysearch 版 IK 在 smart 模式大约领先开源单词典 IK 基线 25%~30%,max_word 模式大约领先 20% 左右,分词结果完全一致。具体数字每次跑会有波动,但趋势是稳定的。
这也是 Easysearch 版 IK 相对开源版更有价值的地方:不是多了几个配置项,而是在多词典能力、分词正确性和分词性能三个方面都给出了可验证的结果。
关于 Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
作者:张磊,极限科技(INFINI Labs)搜索引擎研发负责人,对 Elasticsearch 和 Lucene 源码比较熟悉,目前主要负责公司的 Easysearch 产品的研发以及客户服务工作。
相关文章:
Easysearch 正式支持插件开发:让你的搜索系统真正"为你所用"
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 17444 次浏览 • 2026-04-27 22:02
从"用搜索"到"造搜索"
搜索系统的需求千差万别。标准功能覆盖不了所有场景——行业特定的分词规则、定制化的业务逻辑、与外部系统的深度集成……
以往,这类定制需求需要依赖厂商支持。从 Easysearch 2.1.2 开始,你可以自己动手了。
随着构建依赖库正式发布到 Maven 中央仓库,Easysearch 的插件开发能力正式对外开放。这意味着 Easysearch 不再是一个黑盒产品,而是一个可扩展、可定制的搜索平台。你可以基于官方接口开发自定义插件,像使用原生功能一样使用它们。
插件能做什么
Easysearch 提供三类核心扩展点,覆盖搜索系统的关键环节:
1. 分析器插件(AnalysisPlugin)
自定义分词器、Token 过滤器、字符过滤器。适用于:
- 电商 SKU 的型号规格解析
- 医疗、法律等领域的专业术语分词
- 特殊符号或空格的规范化处理
注册后直接在索引设置中使用,与原生分析器完全等同。
2. REST/API 插件(ActionPlugin)
新增自定义 HTTP 接口。适用于:
- 封装业务查询逻辑,对外暴露简化 API
- 对接企业内部权限中心或监控系统
- 暴露插件自身的管理接口(如状态检查)
3. Ingest 插件(IngestPlugin)
在文档写入前进行字段转换。适用于:
- 自定义业务字段转换(如根据业务规则计算衍生字段)
- 数据标准化(统一日期格式、大小写转换)
- 富文本提取或元数据生成
5 分钟上手
我们准备了官方模板仓库,让你从克隆到运行只需几条命令:
# 克隆模板
git clone https://github.com/infinilabs/easysearch-plugin-template.git my-plugin
cd my-plugin
# 修改包名和类名,编写你的逻辑
# ...方式一:开发调试——直接运行
# 构建插件并运行
./gradlew run
# 验证插件
curl -s "http://localhost:9200/_cat/plugins?v" | grep my-plugin方式二:构建后安装到外部集群
# 构建插件
./gradlew build
# 安装到 Easysearch
bin/easysearch-plugin install file:///$(pwd)/build/distributions/my-plugin-0.1.0.zip
# 启动验证
bin/easysearch
curl -s "http://localhost:9200/_cat/plugins?v" | grep my-plugin完整的开发指南请参考插件开发文档。
设计哲学
Easysearch 插件系统的设计遵循三个原则:
渐进式扩展——从最简单的 Plugin 类开始,按需实现 AnalysisPlugin、ActionPlugin 等接口,不必一次性掌握全部 API。
与原生同等——插件注册的分析器、处理器与系统原生组件在使用方式上完全一致,用户无需关心实现来源。
版本安全——插件加载时校验 easysearch.version,版本不匹配会拒绝加载,避免运行时异常。
从插件到生态
插件开发不只是技术能力的开放,更是产品理念的转变。
你可以将开发的插件发布到 GitHub Releases,通过 URL 直接安装:
bin/easysearch-plugin install https://github.com/yourname/my-plugin/releases/download/v0.1.0/my-plugin-0.1.0.zip我们也欢迎社区贡献。如果你有通用的插件想法,欢迎与我们交流。
结语
搜索系统的最后一公里,只有业务开发者最清楚该怎么走。
Easysearch 2.1.2 的插件开发能力,让你能够自主掌控搜索系统的"最后一公里"。从"用搜索"到"造搜索",现在你可以让你的搜索系统真正"为你所用"。
关于 Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
INFINI Agent v1.31.0 发布 | 全新 Easysearch 向导:一站式集群拉起与精细化管理
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 17746 次浏览 • 2026-04-23 18:01
INFINI Agent v1.31.0 带来了本版本最重要的特性——Easysearch 安装向导。用户无需手动编辑任何配置文件,通过图形界面即可完成 Easysearch 集群的安装、配置和日常管理。
Easysearch 安装向导
一键拉起新集群
向导支持开发模式和生产模式两种方式创建 Easysearch 节点。用户只需填写集群名称、节点名称、监听地址、端口、数据目录等基本信息,向导便会自动完成软件下载、JDK 配置、安全证书生成、参数配置、插件安装、节点启动等全部步骤,并实时展示每一步的进度,支持随时暂停和恢复。
一键加入已有集群
通过粘贴现有集群提供的 Token,向导可自动从目标集群拉取证书、版本、插件等配置信息,完成新节点的安装和接入,全程无需手动复制任何证书文件。
安装前环境预检
向导在开始安装前会对当前机器进行全面检测,帮助用户提前发现潜在问题:
- 操作系统和 CPU 架构是否受支持
- 内存是否满足推荐要求
- 端口是否已被占用
- 数据目录磁盘空间是否充足、路径是否可写
- 系统参数(文件描述符限制、内核
max_map_count等)是否满足 Easysearch 运行需求 - TLS 证书填写后实时校验有效性,包括证书链完整性和过期时间
TLS 安全证书灵活配置
支持三种证书配置方式,满足不同安全需求:
- 自动生成:向导一键生成自签名证书,无需任何证书知识
- 手动上传(共享):为 HTTP 和节点通信层提供同一套证书
- 手动上传(分离):为 HTTP 层和节点通信层分别提供独立证书
完整的服务生命周期管理
集群建好后,向导提供持续的管理能力:
- 启动、停止、重启 Easysearch 节点
- 在线安装和卸载插件
- 在线编辑配置,包括
easysearch.yml、JVM 参数、日志配置、证书配置
- 在线日志排查:内置日志阅读器,支持查看节点日志文件列表,并提供类似 tail -f 的自动滚动功能,无需登录服务器即可快速定位报错。”
网络受限环境支持
针对无法直接访问外网的环境,向导支持配置 HTTP 代理,所有软件包(Easysearch、JDK、插件)均可通过代理下载,并提供连通性测试功能。
获取新版本
INFINI Agent v1.31.0 已正式发布,欢迎升级体验:
同样 15,000 条重规则,Percolate Query 比 Easysearch 慢 21.8 倍 —— Heavy-OR 场景实测
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 17481 次浏览 • 2026-04-15 16:44
15,000 条 heavy-OR 规则,200,000 条文档,同一台机器:Easysearch 在线规则引擎全流程 11.68 秒,Percolate Query 仅搜索阶段就跑了 254.30 秒——慢了 21.8 倍。
在"规则先存、文档后到"这类场景下,Percolate Query 的延迟会随规则数量和复杂度的增长快速恶化。规则涨到数千条后,每批文档匹配的耗时可以从秒级攀升至几分钟。这类问题换索引参数、调批次大小、精简 DSL,都治标不治本,根子在执行模型本身。
本文通过一组 heavy-OR 基准测试,量化两种方案的实际差距。
测试配置
测试在同一台主机上运行,使用同一套规则文本和文档样本。Percolate Query 的查询条件由相同规则翻译而来,保证两侧规则语义一致。
| 参数 | 值 |
|---|---|
| 规则总数 | 15,000 |
| 文档总数 | 200,000 |
| 批次大小 | 10,000 / 批 |
| 重规则数量 | 2,500 条大 OR 热点规则 |
| 单条大 OR 规模 | 随机 50 ~ 500 个 OR 条件 |
测试结果
| 路径 | 用时 |
|---|---|
纯写入 plain_bulk |
6.025535s |
在线规则引擎 rules_only |
11.684568s |
Percolate Query 搜索阶段 |
254.304583s |
同样 15,000 条规则 + 200,000 条文档
具体指标:
- Easysearch 在线规则引擎全流程:
11.68s - Percolate Query 搜索阶段:
254.30s - 差值:
242.62s - 倍数:
21.76 倍 - 每批(10,000 文档)平均耗时:Easysearch 约
0.49s,Percolate Query 约12.69s
开启规则引擎的增量成本
规则匹配会对写入链路产生多少额外开销,是评估在线规则引擎可行性的重要指标之一。
开启规则引擎的写入增量
与之对比,Percolate Query 仅搜索阶段就需要 254.30s。换言之,Easysearch 在线规则引擎把规则匹配叠加进写入流程,新增成本约为 Percolate Query 搜索耗时的 1/44.9。
只看匹配引擎本体
上一组数据(11.68s vs 254.30s)包含了 Easysearch 的在线写入、bulk 解析和索引处理等通用开销。为了单独衡量规则匹配引擎自身的性能,我们用 Java 直调 JNI 做了一次离线 match,绕过写入链路,只跑规则匹配逻辑。
| 路径 | 用时 |
|---|---|
| Easysearch 纯匹配(JNI 离线) | 5.046934s |
| Percolate Query 搜索阶段 | 254.304583s |
只比匹配本身
这组数据说明两点:Easysearch 的性能优势并非来自写入链路的整合效率,即便剔除通用写入成本,规则匹配引擎本体与 Percolate Query 之间依然存在约 50 倍的差距。
为什么 Percolate Query 会慢
根因在执行模型,OR 条件多只是放大器。
每批文档到达时,Percolate Query 都要走完这套流程:
- 把文档放进临时内存索引
- 基于规则中的 terms 筛选候选规则
- 对候选规则逐条验证
以本次测试为例,各阶段耗时分布如下:
- 规则翻译:
9.560294s - 规则导入:
7.451857s - percolate 搜索:
254.304583s
搜索阶段是每批文档都必须重新支付的代价。
Heavy-OR 规则在这套流程里两头放大:规则覆盖面广,候选集更难剪掉;单条规则条件多,逐条验证也更重。
Easysearch 规则引擎把规则提前编译好,文档到达后直接匹配,不走这套每批重建的流程,差距就在这里。
适用场景
以下场景对规则匹配的吞吐和延迟要求较高,是 Easysearch 在线规则引擎的典型适用范围:
- 内容审核:规则持续增长且复杂度高,需要稳定的处理吞吐,对单批延迟敏感。
- 舆情监测:热点词、别名、邻近词组合多,规则天然形成大 OR 结构,是 Percolate Query 最容易触及性能瓶颈的场景。
- 广告定向:人群包条件不断叠加,文档流量高,规则匹配需要足够轻量,避免影响整条投放链路。
- 告警规则:延迟直接影响告警有效性,规则命中需要尽量贴近文档写入时刻。
- 实时反欺诈:规则复杂、变更频繁、吞吐高,要求文档到达后立即完成判断。
小结
在本次 heavy-OR 基准测试中:
- 相同规则集(15,000 条)和文档量(200,000 条),Easysearch 在线规则引擎全流程耗时 11.68s,Percolate Query 仅搜索阶段耗时 254.30s,相差 21.8 倍。
- 开启规则引擎带来的写入链路增量成本为 5.66s,约为 Percolate Query 搜索阶段耗时的 1/44.9。
- 剔除写入通用开销后,规则匹配引擎本体的差距约为 50 倍。
如果你的业务已经有 Percolate Query 延迟随规则增长持续上升的问题,不用看 demo 数据——把你线上最重的那批规则拿出来,跑一次就知道差距在哪。
规则引擎功能当前需要试用 License。你可以先下载 Easysearch:https://infinilabs.cn/download,再联系售前申请试用 License 并获取开通指引。
关于 Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
官网文档:https://docs.infinilabs.com/easysearch
作者:张磊,极限科技(INFINI Labs)搜索引擎研发负责人,对 Elasticsearch 和 Lucene 源码比较熟悉,目前主要负责公司的 Easysearch 产品的研发以及客户服务工作。
相关文章:
