


Elastisearch
使用 AWS EKS 部署 Easysearch
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 3887 次浏览 • 2024-08-15 15:47
随着企业对数据搜索和分析需求的增加,高效的搜索引擎解决方案变得越来越重要。Easysearch 作为一款强大的企业级搜索引擎,可以帮助企业快速构建高性能、可扩展的数据检索系统。在云计算的背景下,使用容器化技术来部署和管理这些解决方案已经成为主流选择,而 Amazon Elastic Kubernetes Service (EKS) 则提供了一个强大且易于使用的平台来运行容器化的应用程序。
本文旨在探索如何在 AWS EKS 上部署 Easysearch,并通过实践操作展示从集群配置到服务部署的完整过程。通过本文,读者可以了解如何在云环境中快速搭建高效的搜索服务,最大化利用云资源的弹性和可扩展性。
准备工作
- 准备一个 AWS Global 账户,本文选择东京区域(ap-northeast-1)进行部署。
- 部署 EKS 集群版本为 1.30,同时需要在 Linux 环境中安装 AWS CLI、Helm、eksctl 和 kubectl 等命令行工具。本文使用 eksctl 管理 EKS 集群,eksctl 是 AWS 官方推出的高效管理 EKS 集群的命令行工具。
- 本文将使用 EBS-CSI-Driver 作为存储驱动来部署 Easysearch 服务,并通过 AWS LoadBalancer Controller 将 Easysearch Console 服务以 AWS 负载均衡器的方式对外提供服务,连接集群内部的 Easysearch。
命令行工具的安装
安装 AWS CLI:
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscliv2.zip
./aws/install -i /usr/local/aws-cli -b /usr/local/bin
aws --version安装 Helm:
curl https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 > get_helm.sh
chmod 700 get_helm.sh
./get_helm.sh安装 eksctl:
# 对于 ARM 系统,设置 ARCH 为:`arm64`、`armv6` 或 `armv7`
ARCH=amd64
PLATFORM=$(uname -s)_$ARCH
curl -sLO "https://github.com/eksctl-io/eksctl/releases/latest/download/eksctl_$PLATFORM.tar.gz"
# (可选)验证校验和
curl -sL "https://github.com/eksctl-io/eksctl/releases/latest/download/eksctl_checksums.txt" | grep $PLATFORM | sha256sum --check
tar -xzf eksctl_$PLATFORM.tar.gz -C /tmp && rm eksctl_$PLATFORM.tar.gz
sudo mv /tmp/eksctl /usr/local/bin安装 kubectl:
curl -O https://s3.us-west-2.amazonaws.com/amazon-eks/1.30.2/2024-07-12/bin/linux/amd64/kubectl
chmod +x ./kubectl
mkdir -p $HOME/bin && cp ./kubectl $HOME/bin/kubectl && export PATH=$HOME/bin:$PATH配置 EKS 集群环境
我们使用 eksctl 创建一个 1.30 版本的集群,这里通过 YAML 模板定义 EKS 集群的 VPC 网络配置,并根据 eksctl 官方文档调整相关字段。将以下模板保存为 my-cluster.yaml 文件:
# 创建一个包含 2 个 m5.2xlarge 实例的节点组
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: LAB-1-30
region: ap-northeast-1
vpc:
subnets:
private:
ap-northeast-1a: { id: subnet-11223344 }
ap-northeast-1c: { id: subnet-55667788 }
ap-northeast-1d: { id: subnet-99001122 }
nodeGroups:
- name: managed-workers-01
labels: { role: workers }
instanceType: m5.2xlarge
minSize: 2
maxSize: 4
desiredCapacity: 3
privateNetworking: true
volumeSize: 30通过以下命令创建集群:
eksctl create cluster -f my-cluster.yaml集群创建完成后,使用以下命令检查集群是否就绪:
# 更新 kubeconfig 的凭证文件
aws eks update-kubeconfig --name LAB-1-30 --region ap-northeast-1
kubectl get node
[ec2-user@ip-10-0-0-84 ~]$ kubectl get node
NAME STATUS ROLES AGE VERSION
ip-10-0-100-132.ap-northeast-1.compute.internal Ready <none> 16m v1.30.2-eks-1552ad0
ip-10-0-101-148.ap-northeast-1.compute.internal Ready <none> 16m v1.30.2-eks-1552ad0安装 EBS-CSI-Driver 插件,后续部署时可以指定 StorageClass 来使用亚马逊云的 EBS 块存储服务:
eksctl utils associate-iam-oidc-provider --region=ap-northeast-1 --cluster=LAB-1-30 --approve
eksctl create iamserviceaccount \
--name ebs-csi-controller-sa \
--namespace kube-system \
--cluster LAB-1-30 \
--region ap-northeast-1 \
--role-name AmazonEKS_EBS_CSI_DriverRole \
--role-only \
--attach-policy-arn arn:aws:iam::aws:policy/service-role/AmazonEBSCSIDriverPolicy \
--approve
eksctl create addon --cluster LAB-1-30 --name aws-ebs-csi-driver --version latest --region ap-northeast-1 \
--service-account-role-arn arn:aws:iam::112233445566:role/AmazonEKS_EBS_CSI_DriverRole --force
[ec2-user@ip-10-0-0-84 ~]$ kubectl get pod -n kube-system | grep -i ebs
ebs-csi-controller-868598b64f-pwmxq 6/6 Running 0 11m
ebs-csi-controller-868598b64f-qn2lz 6/6 Running 0 11m
ebs-csi-node-fplxg 3/3 Running 0 11m
ebs-csi-node-v6qwj 3/3 Running 0 11m安装 AWS LoadBalancer Controller 组件:
eksctl create iamserviceaccount \
--cluster=LAB-1-30 \
--region ap-northeast-1 \
--namespace=kube-system \
--name=aws-load-balancer-controller \
--role-name AmazonEKSLoadBalancerControllerRole_130 \
--attach-policy-arn=arn:aws:iam::112233445566:policy/AWSLoadBalancerControllerIAMPolicy \
--approve
helm repo add eks https://aws.github.io/eks-charts
helm repo update eks
wget https://raw.githubusercontent.com/aws/eks-charts/master/stable/aws-load-balancer-controller/crds/crds.yaml
kubectl apply -f crds.yaml
helm install aws-load-balancer-controller eks/aws-load-balancer-controller \
-n kube-system \
--set clusterName=LAB-1-30 \
--set serviceAccount.create=false \
--set serviceAccount.name=aws-load-balancer-controller \
--set region=ap-northeast-1
# 验证安装
kubectl get deployment -n kube-system aws-load-balancer-controller
NAME READY UP-TO-DATE AVAILABLE AGE
aws-load-balancer-controller 2/2 2 2 39s至此,我们已经完成了 EKS 集群的配置。
安装 Easysearch 服务
本文中,将通过 AWS LoadBalancer 部署 Console 服务。首先,通过 Helm 将 Console 相关的模板文件拉取到本地,执行以下命令:
helm pull infinilabs/console
tar -zxvf console-0.2.0.tgz
cd console目录结构如下:
[ec2-user@ip-10-0-0-84 console]$ tree
.
├── Chart.yaml
├── templates
│ ├── NOTES.txt
│ ├── _helpers.tpl
│ ├── hpa.yaml
│ ├── ingress.yaml
│ ├── service.yaml
│ ├── serviceaccount.yaml
│ └── statefulset.yaml
└── values.yaml我们需要修改 service.yaml 和 values.yaml 中的部分配置:
# serivce.yaml
# 参考 AWS Load Balancer Controller 的文档,配置负载均衡器面向公网
metadata:
annotations:
service.beta.kubernetes.io/aws-load-balancer-scheme: internet-facing
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: instance
service.beta.kubernetes.io/aws-load-balancer-subnets: subnet-11223344, subnet-55667788, subnet-9911223344
# values.yaml
# 使用 GP2 StorageClass,并指定 Service Type 为 LoadBalancer
service:
type: LoadBalancer
storageClassName: gp2使用 Helm 部署 console 服务:
kubectl create ns Easysearch
helm upgrade --install console . -f values.yaml -n Easysearch
# 检查是否创建了 Service 并获取负载均衡器的 DNS 地址
kubectl get svc -n Easysearch
NAME TYPE CL
USTER-IP EXTERNAL-IP PORT(S) AGE
console LoadBalancer 172.20.237.237 k8s-xxxx.elb.ap-northeast-1.amazonaws.com 9000:32190/TCP 6h49m接下来是创建 Easysearch 单节点集群服务。创建一个新的 values.yaml 文件并定义使用 GP2 类型的 StorageClass,如下:
cd ~
echo 'storageClassName: gp2' > values.yaml
cat << EOF | kubectl apply -n Easysearch -f -
apiVersion: cert-manager.io/v1
kind: Issuer
metadata:
name: Easysearch-ca-issuer
spec:
selfSigned: {}
---
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: Easysearch-ca-certificate
spec:
commonName: Easysearch-ca-certificate
duration: 87600h0m0s
isCA: true
issuerRef:
kind: Issuer
name: Easysearch-ca-issuer
privateKey:
algorithm: ECDSA
size: 256
renewBefore: 2160h0m0s
secretName: Easysearch-ca-secret
EOF
helm install Easysearch infinilabs/Easysearch -n Easysearch -f values.yaml至此,我们已在 AWS EKS 平台上完成了 Easysearch 的部署。可以通过 Kubernetes 中的 Service DNS 地址在 Console 中验证连接到内部的 Easysearch 服务。本文中使用的地址为:Easysearch.Easysearch.svc.cluster.local:9200。
也可以在 Easysearch 的 Pod 中使用命令进行连接验证:
kubectl exec -n Easysearch Easysearch-0 -it -- curl -ku 'admin:admin' https://Easysearch.Easysearch.svc.cluster.local:9200
{
"name" : "Easysearch-0",
"cluster_name" : "infinilabs",
"cluster_uuid" : "fq3r_ZaHSFuZDjDtKyJY_w",
"version" : {
"distribution" : "Easysearch",
"number" : "1.6.0",
"distributor" : "INFINI Labs",
"build_hash" : "e5d1ff9067b3dd696d52c61fbca1f8daed931fb7",
"build_date" : "2023-09-22T00:55:32.292580Z",
"build_snapshot" : false,
"lucene_version" : "8.11.2",
"minimum_wire_lucene_version" : "7.7.0",
"minimum_lucene_index_compatibility_version" : "7.7.0"
},
"tagline" : "You Know, For Easy Search!"
}总结
通过本文的实践操作,我们成功地在 AWS EKS 平台上部署了 Easysearch 服务,验证了其在云环境中的高效运行能力。从 EKS 集群的配置、存储和网络资源的准备,到最终的 Easysearch 部署与测试,整个过程展示了如何利用 AWS 提供的工具和服务,快速构建企业级搜索引擎解决方案。
通过这次部署,我们不仅了解了 Easysearch 在 Kubernetes 环境中的部署方法,还深入体验了 AWS EKS 平台的强大功能。未来,随着企业数据量的不断增长,结合云计算的弹性和容器化技术的优势,将会为企业的数据管理和搜索提供更加高效的解决方案。
参考文档
关于 Easysearch 有奖征文活动

无论你是 Easysearch 的老用户,还是第一次听说这个名字,只要你对 INFINI Labs 旗下的 Easysearch 产品感兴趣,或者是希望了解 Easysearch,都可以参加这次活动。
详情查看:Easysearch 征文活动
作者:韩旭,亚马逊云技术支持,亚马逊云科技技领云博主,目前专注于云计算开发和大数据领域。
原文:https://infinilabs.cn/blog/2024/deploy-easysearch-using-aws-eks/
从 Elasticsearch 到 Easysearch:国产搜索型数据库的崛起与未来展望
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 6896 次浏览 • 2024-08-14 12:17

1. 引言:数据库的定义与作用
1.1 数据库的定义
数据库是一个专门用于组织、存储和管理数据的系统(Database System,简称 DBS),它以高效的方式为用户提供数据的存储、访问和管理功能。数据库的定义涵盖了各种数据模型和结构,主要可以分为关系型数据库(RDBMS)和非关系型数据库(NoSQL)两大类。
-
关系型数据库:以二维表格的形式组织数据,通过主键、外键来维持表与表之间的关系。这种数据库模型擅长处理结构化数据,并且通过 SQL(Structured Query Language)来管理数据。其最大的优势在于数据的一致性和完整性,但在处理大量非结构化数据时可能表现不佳。
- 非关系型数据库:也称为 NoSQL 数据库,适合存储和处理非结构化或半结构化数据,如文档、键值对、图形和列族等。NoSQL 数据库通常具有更高的灵活性和扩展性,尤其适合处理大规模分布式数据集和实时数据处理任务。
1.2 数据库在现代计算中的作用
在现代计算环境中,数据库是信息系统的核心。无论是互联网企业,还是传统行业的数字化转型,都依赖于强大的数据库系统来支撑各种应用程序的运行。数据库的作用包括:
-
数据存储:数据库能够安全地存储大规模数据,无论是结构化数据如表格,还是非结构化数据如图像和文本。
-
数据管理:数据库提供了复杂的查询、排序、更新、删除等操作,确保数据可以被有效地管理和利用。
-
数据分析:借助数据库中的索引和搜索功能,用户可以对海量数据进行快速检索和分析,从而支持实时决策和业务优化。
- 数据安全:数据库系统通常包含访问控制、加密、备份和恢复等功能,保护数据的机密性、完整性和可用性。
数据库已经成为现代企业运作的基石,为电子商务、社交媒体、金融服务、健康医疗等领域提供了不可或缺的数据支持。
2. 数据库的演变
2.1 关系型数据库的崛起
数据库的发展主要历经三个阶段,前关系型、关系型和后关系型。
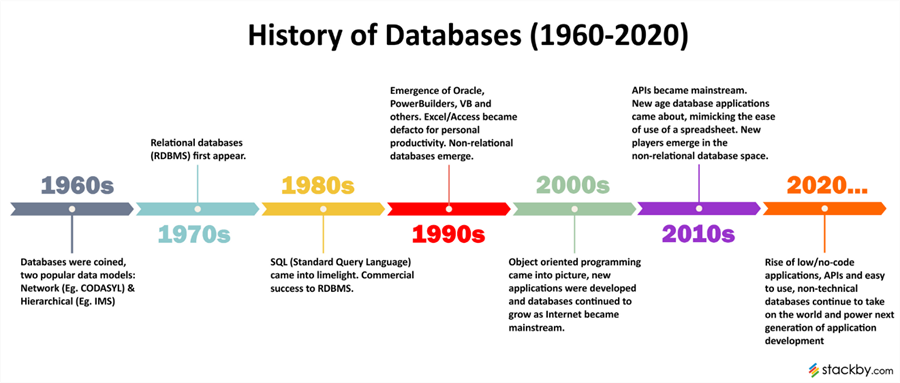
20 世纪 70 年代,埃德加·科德提出了关系型数据库模型的概念,这一创新彻底改变了数据管理的方式。关系型数据库以关系代数为理论基础,将数据组织为多个相互关联的二维表格,这种模型极大简化了数据存储与检索的复杂性。
-
表格结构:数据以表的形式存储,每个表由行和列组成,行代表记录,列代表字段。表与表之间通过主键和外键来建立关系。
-
SQL 的引入:为了管理关系型数据库,科德引入了结构化查询语言(SQL),这是一种强大的数据操作语言,允许用户通过简单的语句执行复杂的查询操作。
- 数据的一致性和完整性:关系型数据库通过事务处理机制(ACID 特性:原子性、一致性、隔离性和持久性),确保数据在并发操作和系统故障情况下保持一致性和完整性。
由于其高效的数据管理能力和强大的查询功能,关系型数据库迅速成为企业级应用的主流选择,在银行、保险、制造业等领域得到了广泛应用。
2.2 关系型数据库的局限性
随着信息技术的飞速发展,数据量呈现爆炸式增长,数据类型也日益多样化,这使得关系型数据库逐渐暴露出其局限性。
-
扩展性不足:关系型数据库通常依赖垂直扩展(增加单个服务器的硬件能力)来提升性能,但这种方式在面对海量数据时成本高昂且效率有限。而对于需要分布式处理的大规模数据集,关系型数据库的横向扩展能力(增加服务器节点)较弱,难以满足分布式系统的需求。
-
非结构化数据处理困难:关系型数据库擅长处理结构化数据,但对于文本、图像、视频等非结构化数据的处理效率较低,需要额外的处理步骤和存储空间。这种局限性使其在面对现代大数据环境时显得捉襟见肘。
- 灵活性不足:关系型数据库的表结构和模式是预定义的,这意味着在数据模型发生变化时,修改数据库结构的成本和风险都较高,影响了系统的灵活性和适应性。
这些局限性推动了新型数据库技术的发展,尤其是 NoSQL 数据库的兴起,它们能够更好地处理分布式环境下的大规模非结构化数据。
3. 搜索型数据库的兴起
3.1 非结构化数据处理的需求
随着互联网和信息技术的发展,数据的类型和规模发生了巨大变化。除了传统的结构化数据,非结构化数据(如文本、图像、音频、视频等)也在迅速增长。这类数据并不适合存储在传统的关系型数据库中,因为它们无法以固定的表格形式进行有效的组织和管理。
在这种背景下,企业和组织对非结构化数据的处理和分析需求日益强烈。例如,社交媒体平台需要实时分析大量用户生成的文本内容,电子商务网站需要对用户的搜索和购买历史进行个性化推荐。这些需求促使数据库技术朝着更灵活和高效的方向发展。
为了应对这一挑战,NoSQL 数据库应运而生。NoSQL 数据库不依赖于固定的表格结构,而是支持多种数据模型,如文档、键值对、列族和图数据库等。它们在处理大规模分布式数据和非结构化数据时表现优异,尤其是在扩展性和灵活性方面。
然而,随着搜索需求的日益复杂,简单的 NoSQL 数据库已无法满足企业对快速全文检索、实时分析以及复杂查询的需求。这时,搜索型数据库逐渐成为焦点。它们不仅能够处理大规模数据,还能在数秒内从庞大的数据集中检索出相关信息,大大提升了数据的利用价值。
3.2 搜索型数据库的定义与特点
搜索型数据库是一类专门设计用于处理和检索大量非结构化数据的数据库系统。与传统的关系型数据库不同,搜索型数据库的主要功能是快速、准确地进行全文检索和复杂查询,尤其是在处理文本数据时表现出色。
核心技术与特点:
-
倒排索引:这是搜索型数据库的核心技术,它通过为每个单词建立索引来加速查询过程。当用户输入查询时,系统可以直接通过索引定位相关文档,而无需逐个扫描整个数据库。
-
分布式架构:搜索型数据库通常采用分布式架构,以便能够处理大规模的数据集。它们将数据分布在多个节点上,确保即使在高并发或大数据量的情况下,系统仍然能够高效运行。
-
实时数据处理:现代搜索型数据库不仅支持批量数据处理,还能处理实时数据,这使得它们非常适合用于日志管理、监控和数据流分析等场景。
- 可扩展性:由于采用了分布式设计,搜索型数据库可以通过增加节点轻松扩展,从而处理日益增长的数据量和查询需求。
通过这些特点,搜索型数据库已经成为处理海量非结构化数据的关键工具,为企业和组织提供了强大的数据检索和分析能力。
4. Elasticsearch:革命性的搜索型数据库
4.1 Elasticsearch 的背景与发展

Elasticsearch 是由 Shay Banon 于 2010 年基于开源搜索引擎库 Apache Lucene 开发的。它的出现,标志着搜索型数据库进入了一个新的时代。Elasticsearch 旨在为现代数据驱动的应用程序提供高效、灵活的搜索和分析功能。由于其强大的功能和易用性,Elasticsearch 迅速在全球范围内获得了广泛的采用。
Elasticsearch 的诞生源于对大规模数据处理和全文检索的需求。随着互联网的快速发展,企业需要一种能够高效处理和搜索海量数据的工具,而传统的关系型数据库和早期的 NoSQL 解决方案无法满足这一需求。Elasticsearch 在此背景下应运而生,成为解决这些挑战的理想选择。
4.2 核心特性与架构
Elasticsearch 之所以能够在众多搜索型数据库中脱颖而出,主要得益于其强大的核心特性和先进的架构设计。
核心特性:
-
分布式架构:Elasticsearch 的分布式设计使其能够在多个节点上分片存储数据,从而实现高可用性和可扩展性。每个分片都是一个独立的搜索引擎,可以在多个节点之间进行复制,以确保数据的冗余和安全。
-
RESTful API:Elasticsearch 提供了一个易于使用的 RESTful API,开发者可以通过简单的 HTTP 请求与其进行交互。这种设计使得 Elasticsearch 可以轻松集成到各种应用程序中。
-
实时索引和搜索:Elasticsearch 支持实时数据索引,这意味着数据在写入后几乎可以立即被搜索到。这一特性使其非常适合用于日志管理、监控和实时分析等需要快速响应的场景。
- 灵活的查询语言:Elasticsearch 提供了功能强大的查询 DSL(Domain Specific Language),允许用户进行复杂的查询操作,如布尔查询、范围查询、模糊查询等。它还支持聚合查询,使用户能够对数据进行高级分析。
架构设计:
Elasticsearch 的架构基于分片(Shard)和副本(Replica)的概念。每个索引被划分为若干个分片,每个分片可以有一个或多个副本。这种设计不仅提高了数据的可用性和容错性,还使得系统能够轻松处理大规模数据集。
此外,Elasticsearch 还使用了 Apache Lucene 作为底层搜索库,充分利用了 Lucene 强大的全文检索能力和索引机制。这使得 Elasticsearch 在处理复杂搜索任务时表现得非常高效。
4.3 典型应用场景
Elasticsearch 在多个行业和场景中得到了广泛应用,其灵活性和强大的搜索能力使其成为许多企业的首选解决方案。
-
日志和基础设施监控:在 IT 运维中,Elasticsearch 常用于收集和分析系统日志、应用日志和安全日志。通过与 Kibana(一个开源的分析和可视化平台)结合,用户可以实时监控系统状态,并快速识别和解决问题。
-
企业搜索:Elasticsearch 被广泛应用于企业内部文档和数据的搜索管理。无论是知识管理系统还是文档管理平台,Elasticsearch 都能够提供高效的全文检索和信息聚合能力,帮助企业提升工作效率。
- 电子商务搜索:在电子商务领域,Elasticsearch 用于实现快速、精确的产品搜索和推荐系统。它不仅可以处理大量产品数据,还能根据用户行为提供个性化推荐,提升用户体验和转化率。
5. Elasticsearch 的挑战与发展
5.1 扩展性问题
尽管 Elasticsearch 在处理大规模数据方面表现优异,但在面对极端大规模的应用场景时,其扩展性仍然是一个挑战。由于分布式系统的复杂性,网络分区、节点故障等问题可能导致数据不一致,甚至影响系统的整体性能。
为了应对这些挑战,开发者们引入了多种扩展性优化措施,例如改进分片管理策略、优化分布式查询算法等。这些改进旨在提高 Elasticsearch 在大规模集群中的稳定性和效率,但随着数据量的持续增长,扩展性问题仍然是一个需要持续关注和解决的问题。
5.2 性能优化
随着使用 Elasticsearch 的企业和应用越来越多,性能优化成为了一个关键议题。为了保证 Elasticsearch 在大规模数据处理中的高效性,开发者们采取了多种优化手段,包括改进索引策略、调整缓存机制、优化查询执行路径等。
此外,为了满足不同场景下的性能需求,Elasticsearch 还引入了多种配置选项,允许用户根据具体应用场景进行调整。例如,通过调整分片数量和副本数,用户可以在性能和数据冗余之间找到平衡。
5.3 安全与合规
随着全球数据隐私和安全法律法规的日益严格,Elasticsearch 在安全和合规性方面的挑战也日益凸显。企业在使用 Elasticsearch 时,必须确保数据的安全性和合规性,尤其是在处理敏感数据时。
为了解决这些问题,Elasticsearch 提供了一系列安全功能,如访问控制、数据加密、审计日志等。此外,开发者们还可以通过配置和插件,实现更高级别的安全措施,以满足特定行业和地区的合规要求。
但是,Elasticsearch 的安全性和合规性仍然是一个需要不断优化的领域。近几年 ES 数据泄露事件频发,很多 ES 库连基本的安全认证都没有,导致很多企业直接把 ES 当做存储库,数据泄露后直接被黑客利用。
结合今年 OpenAi 停止对中国内地和香港地区提供 API 服务可以看出,依赖国外技术可能带来技术封锁风险,一旦国外企业因政治或经济原因停止服务,中国企业的业务连续性和数据安全性将受到威胁。
6. 国内搜索型数据库的发展
6.1 中国搜索数据库的发展背景
随着国家对科技自主创新的重视,中国的数据库技术在过去十年中取得了显著进展。尤其是在中美技术竞争加剧的背景下,减少对国外技术的依赖成为了中国科技发展的战略目标。这种背景促使了国产数据库的加速发展,特别是在搜索型数据库领域。众多中国企业开始自主研发具备核心技术的数据库产品,试图在这一领域实现突破。
政策推动与市场需求
中国政府出台了一系列政策,鼓励本土企业在关键技术领域实现自主可控。这些政策不仅为企业提供了资金支持和政策优惠,还明确了在一些关键行业中优先使用国产软件的导向。同时,随着中国企业在互联网、电子商务、智能制造等领域的快速发展,对高效搜索和数据处理的需求愈发迫切,这也成为国产搜索型数据库发展的强大推动力。
6.2 Easysearch 的兴起

在此背景下,Easysearch 作为中国本土开发的搜索型数据库脱颖而出。Easysearch 的设计目标是为中国企业提供一个高效、可靠且适应本土需求的搜索与数据分析解决方案。与国外的 Elasticsearch 相似,Easysearch 基于分布式架构和倒排索引技术,能够处理大规模数据,并支持复杂的全文搜索和分析。
然而,Easysearch 并非只是简单的模仿或复制 Elasticsearch。它在多个方面进行了本地化优化,以更好地适应中国市场的独特需求。例如,在处理中文文本时,Easysearch 针对中文的特殊语法结构进行了优化,增强了中文分词的准确性和查询效率。此外,Easysearch 还在性能和可扩展性上进行了改进,使其能够更好地应对大规模企业级应用的需求。
不仅如此,Easysearch 还是国内首个通过搜索型数据库产品能力测试的国产搜索型数据库。自 2023 年 10 月起,Easysearch 凭借其卓越的性能和深度的本土化优化,成功在墨天轮搜索型数据库排行榜上长期占据榜首位置。这一成绩不仅体现了 Easysearch 在技术层面的突破,也反映了市场对其产品的高度认可。在短短几个月的时间里,Easysearch 以其稳定的表现和不断创新的步伐,赢得了众多企业用户的信赖。

6.3 Easysearch 与 Elasticsearch 的对比
虽然 Easysearch 与 Elasticsearch 在架构和基本功能上有很多相似之处,但它们在具体的实现和应用场景中表现出了一些显著的差异。
-
中文文本处理:Elasticsearch 虽然支持多语言环境,但其在中文处理上的表现并不如 Easysearch 那么出色。Easysearch 针对中文的语法和分词进行了专门的优化,尤其是在处理同义词、短语匹配和模糊查询时,能够提供更高的准确性。
-
本地化支持:Easysearch 提供了更强的本地化支持,包括符合中国法律法规的安全和合规性功能。此外,它还集成了许多国内常用的第三方系统,简化了企业的集成和部署过程。
-
性能优化:在处理大规模数据集时,Easysearch 通过定制化的优化策略,如特定的索引压缩技术和内存管理方案,提升了系统的响应速度和资源利用率。这使得它在某些特定应用场景下,能够提供比 Elasticsearch 更高的性能和稳定性。
- 安全可靠:Easysearch 提供了多种安全和合规性功能,如 TLS 加密、磁盘加密等。此外,它还支持多种第三方认证方式,如 LDAP、AD
6.4 国产搜索型数据库的未来
根据第一新声研究,2022-2027 年中国数据库整体市场将维持增长态势 ,2024 年整体市场规模预计为 543.1 亿,到 2027 年将增长至 1183.8 亿,2022-2027 年复合增长率达到 30.67%。
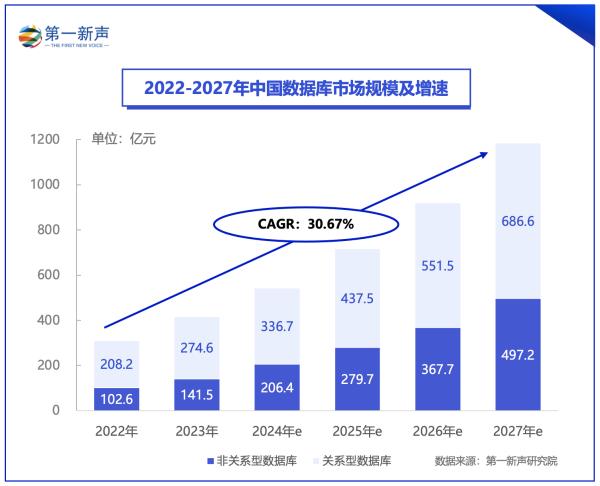
随着全球对数据安全和本地化需求的不断增加,国产搜索型数据库在未来有望占据更大的市场份额。
Easysearch 及其他国产数据库将进一步提升技术水平,持续创新,以满足不断变化的市场需求。
全球化与竞争力
虽然当前 Easysearch 主要面向国内市场,但其潜在的全球化前景不容小觑。通过持续的技术创新和市场拓展,Easysearch 及其他国产数据库有望在全球范围内与国际巨头展开竞争,特别是在亚非拉等新兴市场。这不仅有助于提升中国数据库技术的国际影响力,也将推动全球数据库产业的多样化发展。
7. 结论
通过对搜索型数据库的发展历程和未来趋势的探讨,可以看出,随着大数据和人工智能技术的不断进步,搜索型数据库将在更多领域发挥重要作用。Elasticsearch 作为全球领先的搜索型数据库,其开创性的架构和功能为行业树立了标杆。而以 Easysearch 为代表的国产数据库,也正在迅速崛起,展现出强大的竞争力。未来,搜索型数据库将继续朝着多模态、智能化、本地化的方向发展,为全球信息技术的发展提供更加坚实的基础。
参考资料
- 搜索引擎数据库
- 搜索型数据库的技术发展历程与趋势前瞻
- 数据库行业分析:国产数据库百花齐放,搜索引擎数据库风口已至
- 浅谈搜索引擎和传统数据库(ES,solr)
- 什么是 Elasticsearch?
- INFINI Labs 产品更新 | 重磅推出 Easysearch v1.1
- 墨天轮中国数据库流行度排行
- 喜讯!INFINI Easysearch 在墨天轮搜索型数据库排名中荣登榜首
- 《2024 年中国数据库市场研究报告》重磅发布 | 第一新声
- 国内首家 | 极限科技率先完成信通院搜索型数据库行业标准测试
- 危险!超 9000 个 Elasticsearch 集群暴露在公网上
- 从 OpenAI 停服看中国市场:国产替代崛起的机遇与挑战
- 什么是数据库
- 数据库发展史
关于 Easysearch 有奖征文活动

无论你是 Easysearch 的老用户,还是第一次听说这个名字,只要你对 INFINI Labs 旗下的 Easysearch 产品感兴趣,或者是希望了解 Easysearch,都可以参加这次活动。
详情查看:Easysearch 征文活动
作者:李家兴
换掉ES? Redis官方搜索引擎,效率大幅提升
默认分类 • Fred2000 发表了文章 • 2 个评论 • 5457 次浏览 • 2024-05-30 10:08
RediSearch是一个Redis模块,为Redis提供查询、二次索引和全文搜索。要使用RediSearch,首先要在Redis数据上声明索引。然后可以使用重新搜索查询语言来查询该数据。
RedSearch使用压缩的反向索引进行快速索引,占用内存少。RedSearch索引通过提供精确的短语匹配、模糊搜索和数字过滤等功能增强了
实现特性
- 基于文档的多个字段全文索引
- 高性能增量索引
- 文档排序(由用户在索引时手动提供)
- 在子查询之间使用 AND 或 NOT 操作符的复杂布尔查询
- 可选的查询子句
- 基于前缀的搜索
- 支持字段权重设置
- 自动完成建议(带有模糊前缀建议)
- 精确的短语搜索
- 在许多语言中基于词干分析的查询扩展
- 支持用于查询扩展和评分的自定义函数
- 将搜索限制到特定的文档字段
- 数字过滤器和范围
- 使用 Redis 自己的地理命令进行地理过滤
- Unicode 支持(需要 UTF-8 字符集)
- 检索完整的文档内容或只是ID 的检索
- 支持文档删除和更新与索引垃圾收集
- 支持部分更新和条件文档更新
对比 Elasticsearch
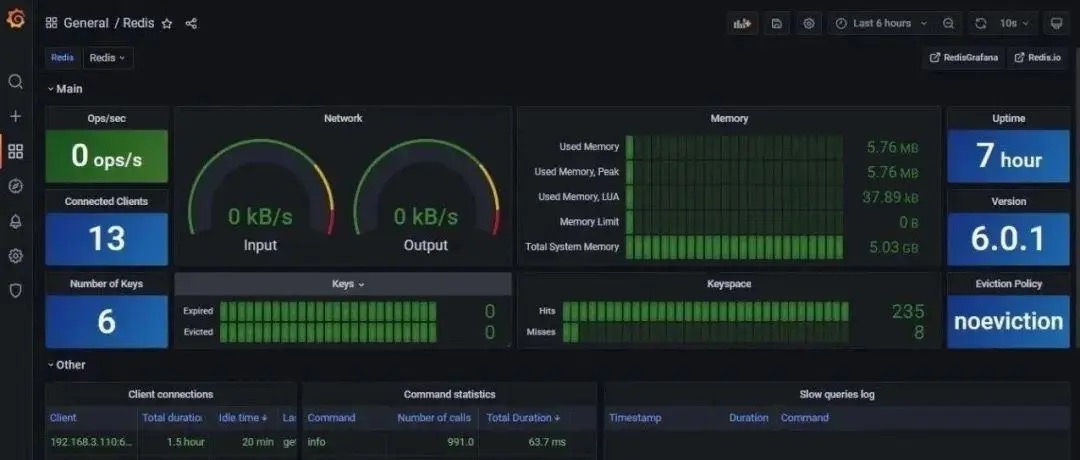
如下图所示,RediSearch 构建索引的时间为 221 秒,而 Elasticsearch 为 349 秒,快了 58%。
索引构建测试
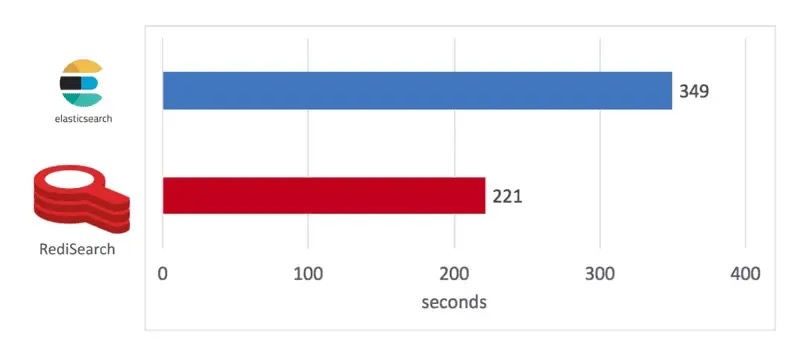
我们模拟了一个多租户电子商务应用程序,其中每个租户代表一个产品类别并维护自己的索引。对于此基准测试,我们构建了 50K 个索引(或产品),每个索引最多存储 500 个文档(或项目),总共 2500 万个文档。
RediSearch 仅用了 201 秒就构建了索引,平均每秒运行 125K 个索引。然而,Elasticsearch 在 921 个索引后崩溃了,显然它不是为应对这种负载而设计的。
查询性能测试
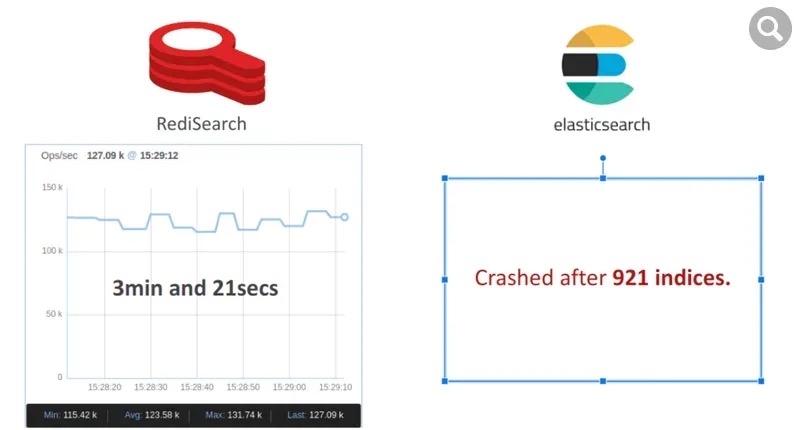
一旦数据集被索引,我们就使用在专用负载生成器服务器上运行的 32 个客户端启动两个单词的搜索查询。如下图所示,RediSearch 吞吐量达到了 12.5K 操作/秒,而 Elasticsearch 为 3.1K 操作/秒,速度提高了 4 倍。
此外,RediSearch 延迟稍好一些,平均为 8 毫秒,而 Elasticsearch 为 10 毫秒。
安装
安装目前分为源码和docker安装两种方式。
源码安装
git clone https://github.com/RediSearch/RediSearch.git
cd RediSearch # 进入模块目录
make setup
make installdocker安装
note: RediSearch的安装比较复杂原包无法进行编译操作所以我们使用docker安装
docker run -p 6379:6379 redislabs/redisearch:latest判断是否安装成功
127.0.0.1:0>module list
1) 1) "name"
2) "ReJSON"
3) "ver"
4) "20007"
2) 1) "name"
2) "search"
3) "ver"
4) "20209"返回数组存在“ft”或 “search”(不同版本),表明 RediSearch 模块已经成功加载。
命令行操作
1、创建
1.1 创建索引
创建索引不妨想象成创建表结构,表一般基本属性有表名、字段和字段类别等,所以我们可以考虑将索引名代表表名,字段代表字段,属性即表示属性。
xxx.xxx.xxx.xxx:0>ft.create "student" schema "name" text weight 5.0 "sex" text "desc" text "class" tag
"OK"student 表示索引名,name、sex、desc表示字段,text表示类型(这样表示只是为了便于理解)
“weight”为权重,默认值为 1.0
type student
"none"我们创建的索引redis是不认识的,这证明使用的是插件。
1.2 创建文档
创建文档上下文的过程不妨想想成向表中插入数据,这里请注意字段名可以使用双引号但切记一定要用英文,这里之所以着重提出是因为有些编译器中文双引号和英文双引号用肉眼实在难以辨认否则会出现 “Fields must be specified in FIELD VALUE pairs”(其实是将“ 当作内容处理了以至于缺少了字段)
ft.add student 001 1.0 language "chinese" fields name "张三" sex "男" desc "这是一个学生" class "一班"
"OK"其中001为文档ID,"1.0"为评分缺少此值会报"Could not parse document score"异常,language 指明使用的语言默认是英文编码 如果没有此标记存储是没有问题的但不可以通过中文字符查询
1.3 查询
1.3.1 基本查询
1.3.1.1 全量查询
xxx.xxx.xxx.xxx:0>FT.SEARCH student * SORTBY sex desc RETURN 3 name sex desc
1) "2"
2) "001"
3) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
4) "002"
5) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"1.3.1.2 匹配查询
xxx.xxx.xxx.xxx:0>ft.search student "张三" limit 0 10 RETURN 3 name sex desc
1) "2"
2) "001"
3) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
4) "002"
5) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
limit 与mysql相识主要用于分页,此处是全量匹配,如果没有设置language “chinese” 此处查询为0,
1.3.2 模糊匹配
1.3.2.1 后置匹配
ft.search student "李*" SORTBY sex desc RETURN 3 name sex desc
1) "1"
2) "003"
3) 1) "name"
2) "李四"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"1.3.2.2 模糊搜索
xxx.xxx.xxx.xxx:0>FT.SEARCH beers "%%张店%%"
1) "1"
2) "beer:1"
3) 1) "name"
2) "集团本部已发布【文明就餐公约】,2号楼办公人员午餐的就餐时间是11:45~13:00,现经行政服务部进行抽查,发现我们部门有员工违规就餐现象。请大家务必遵守,相互转告,对于外地回到集团办公的同事,亦请遵守,谢谢!"
3) "org"
4) "山东省淄博市张店区"
5) "school"
6) "山东理工大学"别高兴太早全量模糊匹配是由很大限制的,他基于Levenshtein距离(LD)进行模糊匹配。术语的模糊匹配是通过在术语周围加“%”来实现的,模糊匹配的最大LD为3,确切的说这只是一种相识度查询,并非一般意义上的模糊搜索,但是如果仔细观察会发现通过精确匹配时不仅能够将完整value值查询出来而且还查询出其他处于文档某个位置的key请看官方提供的一个例子:
FT.CREATE idx SCHEMA txt TEXT
FT.ADD idx docCn 1.0 LANGUAGE chinese FIELDS txtRedis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。从盘可以有意无意的对数据进行写操作。
由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。
FT.CREATE idx SCHEMA txt TEXT
FT.ADD idx docCn 1.0 LANGUAGE chinese FIELDS txt "Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。从盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。[8]"
FT.SEARCH idx "数据" LANGUAGE chinese HIGHLIGHT SUMMARIZE
# Outputs:
# <b>数据</b>?... <b>数据</b>进行写操作。由于完全实现了发布... <b>数据</b>冗余很有帮助。[8...之所以会出现这样的效果是因为redisearch对文本进行了分词,其使用的工具是friso相比es的ik还是弱一些前者主要是对中文分词,体积小可移植性强。
从而我们可以结合后后置匹配算法
xxx.xxx.xxx.xxx:0>FT.SEARCH idx "数*" LANGUAGE chinese HIGHLIGHT
1) "1"
2) "docCn"
3) 1) "txt"
2) "Redis支持主从同步。<b>数据</b>可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。从盘可以有意无意的对<b>数据</b>进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和<b>数据</b>冗余很有帮助。[8]"
或者结合Levenshtein算法这样基本上能够满足业务查询需求
xxx.xxx.xxx.xxx:0>FT.SEARCH idx "%%单的树%%" LANGUAGE chinese HIGHLIGHT
1) "1"
2) "docCn"
3) 1) "txt"
2) "Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层<b>树</b>复制。从盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步<b>树</b>时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。[8]"1.3.2.3 字段查询
通过字段查询也可以实现模糊搜索,直接给例子,后面跟着官网上给的sql 和 redisearch的对照表
ft.search student *
1) "2"
2) "doudou"
3) 1) "name"
2) "豆豆"
3) "jtzz"
4) "“检索”是很多产品中"
5) "phone"
6) "18563717107"
4) "ttao"
5) 1) "name"
2) "姚元涛"
3) "jtzz"
4) "一个生病的人只"
5) "phone"
6) "18563717107"
ft.search student '@phone:185* @name:豆豆'
1) "1"
2) "doudou"
3) 1) "name"
2) "豆豆"
3) "jtzz"
4) "“检索”是很多产品中"
5) "phone"
6) "18563717107"1.4 删除
1.4.1 删除文档
xxx.xxx.xxx.xxx:0>ft.del student 002
"1"1.4.3 删除索引
xxx.xxx.xxx.xxx:0>ft.drop student
"OK"1.5 查看
1.5.1 查看所有索引
xxx.xxx.xxx.xxx:0>FT._LIST
1) "student1"
2) "ttao"
3) "idx"
4) "student"
5) "myidx"
6) "123"
7) "myIndex"
8) "testung"
9) "student2"1.5.2 查看索引文档中的数据
1.5.2.1 获取单条数据
xxx.xxx.xxx.xxx:0>ft.get student 001
1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
7) "class"
8) "一班"1.5.2.2 获取多条数据
xxx.xxx.xxx.xxx:0>ft.mget student 001 002
1) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
7) "class"
8) "一班"
2) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
7) "class"
8) "一班"1.6 索引别名操作
1.6.1 添加别名
123.232.112.84:0>FT.ALIASADD xs student
"OK"给索引student起个xs的别名,一个索引可以起多个别名
1.6.2 修改别名
1.6.3 删除别名
123.232.112.84:0>FT.ALIASDEL xs
"OK"作者:架构师公众号
来源:https://mp.weixin.qq.com/s/TmCXx3rLjLPggvOFjGqS9w
版权申明:内容来源网络,仅供学习研究,版权归原创者所有。如有侵权烦请告知,我们会立即删除并表示歉意。谢谢!
INFINI Labs 产品更新 | 重磅推出 Easysearch 一个分布式的近实时搜索与分析引擎
资讯动态 • liaosy 发表了文章 • 0 个评论 • 5993 次浏览 • 2023-05-16 11:57

INFINI Labs 产品又更新啦,包括 Easysearch v1.1.0、Gateway v1.13.0、Console v1.1.0、Agent v0.4.0,其中 Easysearch 经过团队的数月打磨,现正式对外推出。Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 衍生自基于开源协议 Apache 2.0 的 Elasticsearch 7.10.2 版本。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。欢迎大家下载体验。
INFINI Easysearch v1.1.0
INFINI Easysearch 本次更新最重要的功能是引入了 ZSTD 压缩算法,对索引进行全方位的压缩,尤其针对日志数据压缩效果更加明显,针对 1.1G 的 Nginx 日志进行测试,采用 ZSTD 策略后,膨胀率只有 0.94,甚至比原始数据还要小,而且还能进一步压缩,和 index.source_reuse 结合使用后,膨胀率只有 0.7,索引大小只有 Elasticsearch 原生 best_compression 的 59%,是 Elasticsearch 6.x 的 49%。下面是一张索引大小对比图:

更多介绍查看 详情。
其他更新功能如下:
Breaking changes
- Lucene 版本升级到 8.11.2
Breaking changes
- 增加 ZSTD codec, 引入 ZSTD 压缩算法,对存储字段,doc_values,词典进行压缩。
- 增加 index.source_reuse 索引级别配置,对 _source 进一步压缩。
- 提供索引生命周期管理 ILM 模块的功能,绝大部分 api 兼容 elasticsearch
Breaking changes
- 减少冗余日志输出。
- 减少 modules 模块整体大小。
下载地址:https://www.infinilabs.com/download
INFINI Gateway v1.13.0
极限网关本次更新如下:
Features
router.rules增加 enabled 选项,控制是否启用 flow- 增加对 loong64 架构的支持
- 增加对 riscv64 架构的支持
- elasticsearch filter 增加 dial_timeout 选项
Bug fix
- 修复 http/elasticsearch 转发后 HTTP 响应头丢失的问题
- 修复 pipeline 热加载出现重复 pipeline 同时运行的问题
- 修复 bulk_indexing 退出后泄漏 goroutine 的问题
Improvements
- 优化 HTTP 头设置方式,避免出现重复的 HTTP 头
- 优化 pipeline 停止的响应速度
- pipeline 增加 enabled 选项,控制是否启用 pipeline
更多 Gateway 更新可参考【Gateway 版本历史】。
INFINI Console v1.1.0
本次 INFINI Console 版本发布主要新增了网关实时日志查看功能、完善了数据迁移功能和数据看板的可视化能力、以及修复了已知 Bug。
实时日志
登录 Console,进入 [资源管理][网关管理] 界面,可以看到网关实时日志入口(前提需要注册网关)如下图所示:

进入实时日志展示界面,点击“开始”按钮后,服务端将 Gateway 日志实时推送到 Console 界面展示,在该界面可以动态调整输出不同的日志级别(DEBUG、INFO、WARN、ERROR 等),同时也支持文件名、方法名、消息内容加通配符进行过滤。
数据迁移
数据迁移模块,基于上个版本做了优化,添加 ILM,Template,Alias 初始化操作。方便用户根据各自的需求迁移索引生命周期、模板、别名等。

数据看板
数据看板图表支持复制、快速切换、时间框选、缩放、标记高亮,进一步增强 Console 可视化能力。
详情查看 操作演示视频。
除以上主要功能更新外,Console 其他功能优化如下:
Bug fix
- 修复数据探索保存查询出现 mapping 错误的问题
- 修复数据看板组件数据源配置的问题
- 修复数据探索左侧字段栏样式的问题
- 修复集群注册向导点击跳转后丢失集群类型的问题
Improvements
- 数据看板汉化
更多 Console 更新可参考【Console 版本历史】。
INFINI Agent v0.4.0
数据采集工具探针(INFINI Agent)更新如下:
Features
- 新增 logs_processor ,配置采集本地日志文件
Breaking changes
- es_logs_processor 调整日志字段
- created 重命名为 timestamp
- 自动提取 payload.timestamp payload.@timestmap 字段到 timestamp
- es_logs_processor 删除 enable 选项
下载地址: https://www.infinilabs.com/download/?product=agent
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
- INFINI Gateway: https://github.com/infinilabs/gateway/issues
- INFINI Console: https://github.com/infinilabs/console/issues
- 下载地址: https://www.infinilabs.com/download
您还可以通过邮件联系我们:hello@infini.ltd
或者拨打我们的热线电话:(+86) 400-139-9200
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群讨论,或者扫码加入我们的知识星球一起学习交流。

关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
详情参见官网:https://www.infinilabs.com
使用 AWS EKS 部署 Easysearch
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 3887 次浏览 • 2024-08-15 15:47
随着企业对数据搜索和分析需求的增加,高效的搜索引擎解决方案变得越来越重要。Easysearch 作为一款强大的企业级搜索引擎,可以帮助企业快速构建高性能、可扩展的数据检索系统。在云计算的背景下,使用容器化技术来部署和管理这些解决方案已经成为主流选择,而 Amazon Elastic Kubernetes Service (EKS) 则提供了一个强大且易于使用的平台来运行容器化的应用程序。
本文旨在探索如何在 AWS EKS 上部署 Easysearch,并通过实践操作展示从集群配置到服务部署的完整过程。通过本文,读者可以了解如何在云环境中快速搭建高效的搜索服务,最大化利用云资源的弹性和可扩展性。
准备工作
- 准备一个 AWS Global 账户,本文选择东京区域(ap-northeast-1)进行部署。
- 部署 EKS 集群版本为 1.30,同时需要在 Linux 环境中安装 AWS CLI、Helm、eksctl 和 kubectl 等命令行工具。本文使用 eksctl 管理 EKS 集群,eksctl 是 AWS 官方推出的高效管理 EKS 集群的命令行工具。
- 本文将使用 EBS-CSI-Driver 作为存储驱动来部署 Easysearch 服务,并通过 AWS LoadBalancer Controller 将 Easysearch Console 服务以 AWS 负载均衡器的方式对外提供服务,连接集群内部的 Easysearch。
命令行工具的安装
安装 AWS CLI:
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscliv2.zip
./aws/install -i /usr/local/aws-cli -b /usr/local/bin
aws --version安装 Helm:
curl https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 > get_helm.sh
chmod 700 get_helm.sh
./get_helm.sh安装 eksctl:
# 对于 ARM 系统,设置 ARCH 为:`arm64`、`armv6` 或 `armv7`
ARCH=amd64
PLATFORM=$(uname -s)_$ARCH
curl -sLO "https://github.com/eksctl-io/eksctl/releases/latest/download/eksctl_$PLATFORM.tar.gz"
# (可选)验证校验和
curl -sL "https://github.com/eksctl-io/eksctl/releases/latest/download/eksctl_checksums.txt" | grep $PLATFORM | sha256sum --check
tar -xzf eksctl_$PLATFORM.tar.gz -C /tmp && rm eksctl_$PLATFORM.tar.gz
sudo mv /tmp/eksctl /usr/local/bin安装 kubectl:
curl -O https://s3.us-west-2.amazonaws.com/amazon-eks/1.30.2/2024-07-12/bin/linux/amd64/kubectl
chmod +x ./kubectl
mkdir -p $HOME/bin && cp ./kubectl $HOME/bin/kubectl && export PATH=$HOME/bin:$PATH配置 EKS 集群环境
我们使用 eksctl 创建一个 1.30 版本的集群,这里通过 YAML 模板定义 EKS 集群的 VPC 网络配置,并根据 eksctl 官方文档调整相关字段。将以下模板保存为 my-cluster.yaml 文件:
# 创建一个包含 2 个 m5.2xlarge 实例的节点组
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: LAB-1-30
region: ap-northeast-1
vpc:
subnets:
private:
ap-northeast-1a: { id: subnet-11223344 }
ap-northeast-1c: { id: subnet-55667788 }
ap-northeast-1d: { id: subnet-99001122 }
nodeGroups:
- name: managed-workers-01
labels: { role: workers }
instanceType: m5.2xlarge
minSize: 2
maxSize: 4
desiredCapacity: 3
privateNetworking: true
volumeSize: 30通过以下命令创建集群:
eksctl create cluster -f my-cluster.yaml集群创建完成后,使用以下命令检查集群是否就绪:
# 更新 kubeconfig 的凭证文件
aws eks update-kubeconfig --name LAB-1-30 --region ap-northeast-1
kubectl get node
[ec2-user@ip-10-0-0-84 ~]$ kubectl get node
NAME STATUS ROLES AGE VERSION
ip-10-0-100-132.ap-northeast-1.compute.internal Ready <none> 16m v1.30.2-eks-1552ad0
ip-10-0-101-148.ap-northeast-1.compute.internal Ready <none> 16m v1.30.2-eks-1552ad0安装 EBS-CSI-Driver 插件,后续部署时可以指定 StorageClass 来使用亚马逊云的 EBS 块存储服务:
eksctl utils associate-iam-oidc-provider --region=ap-northeast-1 --cluster=LAB-1-30 --approve
eksctl create iamserviceaccount \
--name ebs-csi-controller-sa \
--namespace kube-system \
--cluster LAB-1-30 \
--region ap-northeast-1 \
--role-name AmazonEKS_EBS_CSI_DriverRole \
--role-only \
--attach-policy-arn arn:aws:iam::aws:policy/service-role/AmazonEBSCSIDriverPolicy \
--approve
eksctl create addon --cluster LAB-1-30 --name aws-ebs-csi-driver --version latest --region ap-northeast-1 \
--service-account-role-arn arn:aws:iam::112233445566:role/AmazonEKS_EBS_CSI_DriverRole --force
[ec2-user@ip-10-0-0-84 ~]$ kubectl get pod -n kube-system | grep -i ebs
ebs-csi-controller-868598b64f-pwmxq 6/6 Running 0 11m
ebs-csi-controller-868598b64f-qn2lz 6/6 Running 0 11m
ebs-csi-node-fplxg 3/3 Running 0 11m
ebs-csi-node-v6qwj 3/3 Running 0 11m安装 AWS LoadBalancer Controller 组件:
eksctl create iamserviceaccount \
--cluster=LAB-1-30 \
--region ap-northeast-1 \
--namespace=kube-system \
--name=aws-load-balancer-controller \
--role-name AmazonEKSLoadBalancerControllerRole_130 \
--attach-policy-arn=arn:aws:iam::112233445566:policy/AWSLoadBalancerControllerIAMPolicy \
--approve
helm repo add eks https://aws.github.io/eks-charts
helm repo update eks
wget https://raw.githubusercontent.com/aws/eks-charts/master/stable/aws-load-balancer-controller/crds/crds.yaml
kubectl apply -f crds.yaml
helm install aws-load-balancer-controller eks/aws-load-balancer-controller \
-n kube-system \
--set clusterName=LAB-1-30 \
--set serviceAccount.create=false \
--set serviceAccount.name=aws-load-balancer-controller \
--set region=ap-northeast-1
# 验证安装
kubectl get deployment -n kube-system aws-load-balancer-controller
NAME READY UP-TO-DATE AVAILABLE AGE
aws-load-balancer-controller 2/2 2 2 39s至此,我们已经完成了 EKS 集群的配置。
安装 Easysearch 服务
本文中,将通过 AWS LoadBalancer 部署 Console 服务。首先,通过 Helm 将 Console 相关的模板文件拉取到本地,执行以下命令:
helm pull infinilabs/console
tar -zxvf console-0.2.0.tgz
cd console目录结构如下:
[ec2-user@ip-10-0-0-84 console]$ tree
.
├── Chart.yaml
├── templates
│ ├── NOTES.txt
│ ├── _helpers.tpl
│ ├── hpa.yaml
│ ├── ingress.yaml
│ ├── service.yaml
│ ├── serviceaccount.yaml
│ └── statefulset.yaml
└── values.yaml我们需要修改 service.yaml 和 values.yaml 中的部分配置:
# serivce.yaml
# 参考 AWS Load Balancer Controller 的文档,配置负载均衡器面向公网
metadata:
annotations:
service.beta.kubernetes.io/aws-load-balancer-scheme: internet-facing
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: instance
service.beta.kubernetes.io/aws-load-balancer-subnets: subnet-11223344, subnet-55667788, subnet-9911223344
# values.yaml
# 使用 GP2 StorageClass,并指定 Service Type 为 LoadBalancer
service:
type: LoadBalancer
storageClassName: gp2使用 Helm 部署 console 服务:
kubectl create ns Easysearch
helm upgrade --install console . -f values.yaml -n Easysearch
# 检查是否创建了 Service 并获取负载均衡器的 DNS 地址
kubectl get svc -n Easysearch
NAME TYPE CL
USTER-IP EXTERNAL-IP PORT(S) AGE
console LoadBalancer 172.20.237.237 k8s-xxxx.elb.ap-northeast-1.amazonaws.com 9000:32190/TCP 6h49m接下来是创建 Easysearch 单节点集群服务。创建一个新的 values.yaml 文件并定义使用 GP2 类型的 StorageClass,如下:
cd ~
echo 'storageClassName: gp2' > values.yaml
cat << EOF | kubectl apply -n Easysearch -f -
apiVersion: cert-manager.io/v1
kind: Issuer
metadata:
name: Easysearch-ca-issuer
spec:
selfSigned: {}
---
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: Easysearch-ca-certificate
spec:
commonName: Easysearch-ca-certificate
duration: 87600h0m0s
isCA: true
issuerRef:
kind: Issuer
name: Easysearch-ca-issuer
privateKey:
algorithm: ECDSA
size: 256
renewBefore: 2160h0m0s
secretName: Easysearch-ca-secret
EOF
helm install Easysearch infinilabs/Easysearch -n Easysearch -f values.yaml至此,我们已在 AWS EKS 平台上完成了 Easysearch 的部署。可以通过 Kubernetes 中的 Service DNS 地址在 Console 中验证连接到内部的 Easysearch 服务。本文中使用的地址为:Easysearch.Easysearch.svc.cluster.local:9200。
也可以在 Easysearch 的 Pod 中使用命令进行连接验证:
kubectl exec -n Easysearch Easysearch-0 -it -- curl -ku 'admin:admin' https://Easysearch.Easysearch.svc.cluster.local:9200
{
"name" : "Easysearch-0",
"cluster_name" : "infinilabs",
"cluster_uuid" : "fq3r_ZaHSFuZDjDtKyJY_w",
"version" : {
"distribution" : "Easysearch",
"number" : "1.6.0",
"distributor" : "INFINI Labs",
"build_hash" : "e5d1ff9067b3dd696d52c61fbca1f8daed931fb7",
"build_date" : "2023-09-22T00:55:32.292580Z",
"build_snapshot" : false,
"lucene_version" : "8.11.2",
"minimum_wire_lucene_version" : "7.7.0",
"minimum_lucene_index_compatibility_version" : "7.7.0"
},
"tagline" : "You Know, For Easy Search!"
}总结
通过本文的实践操作,我们成功地在 AWS EKS 平台上部署了 Easysearch 服务,验证了其在云环境中的高效运行能力。从 EKS 集群的配置、存储和网络资源的准备,到最终的 Easysearch 部署与测试,整个过程展示了如何利用 AWS 提供的工具和服务,快速构建企业级搜索引擎解决方案。
通过这次部署,我们不仅了解了 Easysearch 在 Kubernetes 环境中的部署方法,还深入体验了 AWS EKS 平台的强大功能。未来,随着企业数据量的不断增长,结合云计算的弹性和容器化技术的优势,将会为企业的数据管理和搜索提供更加高效的解决方案。
参考文档
关于 Easysearch 有奖征文活动
无论你是 Easysearch 的老用户,还是第一次听说这个名字,只要你对 INFINI Labs 旗下的 Easysearch 产品感兴趣,或者是希望了解 Easysearch,都可以参加这次活动。
详情查看:Easysearch 征文活动
作者:韩旭,亚马逊云技术支持,亚马逊云科技技领云博主,目前专注于云计算开发和大数据领域。
原文:https://infinilabs.cn/blog/2024/deploy-easysearch-using-aws-eks/
从 Elasticsearch 到 Easysearch:国产搜索型数据库的崛起与未来展望
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 6896 次浏览 • 2024-08-14 12:17
1. 引言:数据库的定义与作用
1.1 数据库的定义
数据库是一个专门用于组织、存储和管理数据的系统(Database System,简称 DBS),它以高效的方式为用户提供数据的存储、访问和管理功能。数据库的定义涵盖了各种数据模型和结构,主要可以分为关系型数据库(RDBMS)和非关系型数据库(NoSQL)两大类。
-
关系型数据库:以二维表格的形式组织数据,通过主键、外键来维持表与表之间的关系。这种数据库模型擅长处理结构化数据,并且通过 SQL(Structured Query Language)来管理数据。其最大的优势在于数据的一致性和完整性,但在处理大量非结构化数据时可能表现不佳。
- 非关系型数据库:也称为 NoSQL 数据库,适合存储和处理非结构化或半结构化数据,如文档、键值对、图形和列族等。NoSQL 数据库通常具有更高的灵活性和扩展性,尤其适合处理大规模分布式数据集和实时数据处理任务。
1.2 数据库在现代计算中的作用
在现代计算环境中,数据库是信息系统的核心。无论是互联网企业,还是传统行业的数字化转型,都依赖于强大的数据库系统来支撑各种应用程序的运行。数据库的作用包括:
-
数据存储:数据库能够安全地存储大规模数据,无论是结构化数据如表格,还是非结构化数据如图像和文本。
-
数据管理:数据库提供了复杂的查询、排序、更新、删除等操作,确保数据可以被有效地管理和利用。
-
数据分析:借助数据库中的索引和搜索功能,用户可以对海量数据进行快速检索和分析,从而支持实时决策和业务优化。
- 数据安全:数据库系统通常包含访问控制、加密、备份和恢复等功能,保护数据的机密性、完整性和可用性。
数据库已经成为现代企业运作的基石,为电子商务、社交媒体、金融服务、健康医疗等领域提供了不可或缺的数据支持。
2. 数据库的演变
2.1 关系型数据库的崛起
数据库的发展主要历经三个阶段,前关系型、关系型和后关系型。
20 世纪 70 年代,埃德加·科德提出了关系型数据库模型的概念,这一创新彻底改变了数据管理的方式。关系型数据库以关系代数为理论基础,将数据组织为多个相互关联的二维表格,这种模型极大简化了数据存储与检索的复杂性。
-
表格结构:数据以表的形式存储,每个表由行和列组成,行代表记录,列代表字段。表与表之间通过主键和外键来建立关系。
-
SQL 的引入:为了管理关系型数据库,科德引入了结构化查询语言(SQL),这是一种强大的数据操作语言,允许用户通过简单的语句执行复杂的查询操作。
- 数据的一致性和完整性:关系型数据库通过事务处理机制(ACID 特性:原子性、一致性、隔离性和持久性),确保数据在并发操作和系统故障情况下保持一致性和完整性。
由于其高效的数据管理能力和强大的查询功能,关系型数据库迅速成为企业级应用的主流选择,在银行、保险、制造业等领域得到了广泛应用。
2.2 关系型数据库的局限性
随着信息技术的飞速发展,数据量呈现爆炸式增长,数据类型也日益多样化,这使得关系型数据库逐渐暴露出其局限性。
-
扩展性不足:关系型数据库通常依赖垂直扩展(增加单个服务器的硬件能力)来提升性能,但这种方式在面对海量数据时成本高昂且效率有限。而对于需要分布式处理的大规模数据集,关系型数据库的横向扩展能力(增加服务器节点)较弱,难以满足分布式系统的需求。
-
非结构化数据处理困难:关系型数据库擅长处理结构化数据,但对于文本、图像、视频等非结构化数据的处理效率较低,需要额外的处理步骤和存储空间。这种局限性使其在面对现代大数据环境时显得捉襟见肘。
- 灵活性不足:关系型数据库的表结构和模式是预定义的,这意味着在数据模型发生变化时,修改数据库结构的成本和风险都较高,影响了系统的灵活性和适应性。
这些局限性推动了新型数据库技术的发展,尤其是 NoSQL 数据库的兴起,它们能够更好地处理分布式环境下的大规模非结构化数据。
3. 搜索型数据库的兴起
3.1 非结构化数据处理的需求
随着互联网和信息技术的发展,数据的类型和规模发生了巨大变化。除了传统的结构化数据,非结构化数据(如文本、图像、音频、视频等)也在迅速增长。这类数据并不适合存储在传统的关系型数据库中,因为它们无法以固定的表格形式进行有效的组织和管理。
在这种背景下,企业和组织对非结构化数据的处理和分析需求日益强烈。例如,社交媒体平台需要实时分析大量用户生成的文本内容,电子商务网站需要对用户的搜索和购买历史进行个性化推荐。这些需求促使数据库技术朝着更灵活和高效的方向发展。
为了应对这一挑战,NoSQL 数据库应运而生。NoSQL 数据库不依赖于固定的表格结构,而是支持多种数据模型,如文档、键值对、列族和图数据库等。它们在处理大规模分布式数据和非结构化数据时表现优异,尤其是在扩展性和灵活性方面。
然而,随着搜索需求的日益复杂,简单的 NoSQL 数据库已无法满足企业对快速全文检索、实时分析以及复杂查询的需求。这时,搜索型数据库逐渐成为焦点。它们不仅能够处理大规模数据,还能在数秒内从庞大的数据集中检索出相关信息,大大提升了数据的利用价值。
3.2 搜索型数据库的定义与特点
搜索型数据库是一类专门设计用于处理和检索大量非结构化数据的数据库系统。与传统的关系型数据库不同,搜索型数据库的主要功能是快速、准确地进行全文检索和复杂查询,尤其是在处理文本数据时表现出色。
核心技术与特点:
-
倒排索引:这是搜索型数据库的核心技术,它通过为每个单词建立索引来加速查询过程。当用户输入查询时,系统可以直接通过索引定位相关文档,而无需逐个扫描整个数据库。
-
分布式架构:搜索型数据库通常采用分布式架构,以便能够处理大规模的数据集。它们将数据分布在多个节点上,确保即使在高并发或大数据量的情况下,系统仍然能够高效运行。
-
实时数据处理:现代搜索型数据库不仅支持批量数据处理,还能处理实时数据,这使得它们非常适合用于日志管理、监控和数据流分析等场景。
- 可扩展性:由于采用了分布式设计,搜索型数据库可以通过增加节点轻松扩展,从而处理日益增长的数据量和查询需求。
通过这些特点,搜索型数据库已经成为处理海量非结构化数据的关键工具,为企业和组织提供了强大的数据检索和分析能力。
4. Elasticsearch:革命性的搜索型数据库
4.1 Elasticsearch 的背景与发展
Elasticsearch 是由 Shay Banon 于 2010 年基于开源搜索引擎库 Apache Lucene 开发的。它的出现,标志着搜索型数据库进入了一个新的时代。Elasticsearch 旨在为现代数据驱动的应用程序提供高效、灵活的搜索和分析功能。由于其强大的功能和易用性,Elasticsearch 迅速在全球范围内获得了广泛的采用。
Elasticsearch 的诞生源于对大规模数据处理和全文检索的需求。随着互联网的快速发展,企业需要一种能够高效处理和搜索海量数据的工具,而传统的关系型数据库和早期的 NoSQL 解决方案无法满足这一需求。Elasticsearch 在此背景下应运而生,成为解决这些挑战的理想选择。
4.2 核心特性与架构
Elasticsearch 之所以能够在众多搜索型数据库中脱颖而出,主要得益于其强大的核心特性和先进的架构设计。
核心特性:
-
分布式架构:Elasticsearch 的分布式设计使其能够在多个节点上分片存储数据,从而实现高可用性和可扩展性。每个分片都是一个独立的搜索引擎,可以在多个节点之间进行复制,以确保数据的冗余和安全。
-
RESTful API:Elasticsearch 提供了一个易于使用的 RESTful API,开发者可以通过简单的 HTTP 请求与其进行交互。这种设计使得 Elasticsearch 可以轻松集成到各种应用程序中。
-
实时索引和搜索:Elasticsearch 支持实时数据索引,这意味着数据在写入后几乎可以立即被搜索到。这一特性使其非常适合用于日志管理、监控和实时分析等需要快速响应的场景。
- 灵活的查询语言:Elasticsearch 提供了功能强大的查询 DSL(Domain Specific Language),允许用户进行复杂的查询操作,如布尔查询、范围查询、模糊查询等。它还支持聚合查询,使用户能够对数据进行高级分析。
架构设计:
Elasticsearch 的架构基于分片(Shard)和副本(Replica)的概念。每个索引被划分为若干个分片,每个分片可以有一个或多个副本。这种设计不仅提高了数据的可用性和容错性,还使得系统能够轻松处理大规模数据集。
此外,Elasticsearch 还使用了 Apache Lucene 作为底层搜索库,充分利用了 Lucene 强大的全文检索能力和索引机制。这使得 Elasticsearch 在处理复杂搜索任务时表现得非常高效。
4.3 典型应用场景
Elasticsearch 在多个行业和场景中得到了广泛应用,其灵活性和强大的搜索能力使其成为许多企业的首选解决方案。
-
日志和基础设施监控:在 IT 运维中,Elasticsearch 常用于收集和分析系统日志、应用日志和安全日志。通过与 Kibana(一个开源的分析和可视化平台)结合,用户可以实时监控系统状态,并快速识别和解决问题。
-
企业搜索:Elasticsearch 被广泛应用于企业内部文档和数据的搜索管理。无论是知识管理系统还是文档管理平台,Elasticsearch 都能够提供高效的全文检索和信息聚合能力,帮助企业提升工作效率。
- 电子商务搜索:在电子商务领域,Elasticsearch 用于实现快速、精确的产品搜索和推荐系统。它不仅可以处理大量产品数据,还能根据用户行为提供个性化推荐,提升用户体验和转化率。
5. Elasticsearch 的挑战与发展
5.1 扩展性问题
尽管 Elasticsearch 在处理大规模数据方面表现优异,但在面对极端大规模的应用场景时,其扩展性仍然是一个挑战。由于分布式系统的复杂性,网络分区、节点故障等问题可能导致数据不一致,甚至影响系统的整体性能。
为了应对这些挑战,开发者们引入了多种扩展性优化措施,例如改进分片管理策略、优化分布式查询算法等。这些改进旨在提高 Elasticsearch 在大规模集群中的稳定性和效率,但随着数据量的持续增长,扩展性问题仍然是一个需要持续关注和解决的问题。
5.2 性能优化
随着使用 Elasticsearch 的企业和应用越来越多,性能优化成为了一个关键议题。为了保证 Elasticsearch 在大规模数据处理中的高效性,开发者们采取了多种优化手段,包括改进索引策略、调整缓存机制、优化查询执行路径等。
此外,为了满足不同场景下的性能需求,Elasticsearch 还引入了多种配置选项,允许用户根据具体应用场景进行调整。例如,通过调整分片数量和副本数,用户可以在性能和数据冗余之间找到平衡。
5.3 安全与合规
随着全球数据隐私和安全法律法规的日益严格,Elasticsearch 在安全和合规性方面的挑战也日益凸显。企业在使用 Elasticsearch 时,必须确保数据的安全性和合规性,尤其是在处理敏感数据时。
为了解决这些问题,Elasticsearch 提供了一系列安全功能,如访问控制、数据加密、审计日志等。此外,开发者们还可以通过配置和插件,实现更高级别的安全措施,以满足特定行业和地区的合规要求。
但是,Elasticsearch 的安全性和合规性仍然是一个需要不断优化的领域。近几年 ES 数据泄露事件频发,很多 ES 库连基本的安全认证都没有,导致很多企业直接把 ES 当做存储库,数据泄露后直接被黑客利用。
结合今年 OpenAi 停止对中国内地和香港地区提供 API 服务可以看出,依赖国外技术可能带来技术封锁风险,一旦国外企业因政治或经济原因停止服务,中国企业的业务连续性和数据安全性将受到威胁。
6. 国内搜索型数据库的发展
6.1 中国搜索数据库的发展背景
随着国家对科技自主创新的重视,中国的数据库技术在过去十年中取得了显著进展。尤其是在中美技术竞争加剧的背景下,减少对国外技术的依赖成为了中国科技发展的战略目标。这种背景促使了国产数据库的加速发展,特别是在搜索型数据库领域。众多中国企业开始自主研发具备核心技术的数据库产品,试图在这一领域实现突破。
政策推动与市场需求
中国政府出台了一系列政策,鼓励本土企业在关键技术领域实现自主可控。这些政策不仅为企业提供了资金支持和政策优惠,还明确了在一些关键行业中优先使用国产软件的导向。同时,随着中国企业在互联网、电子商务、智能制造等领域的快速发展,对高效搜索和数据处理的需求愈发迫切,这也成为国产搜索型数据库发展的强大推动力。
6.2 Easysearch 的兴起
在此背景下,Easysearch 作为中国本土开发的搜索型数据库脱颖而出。Easysearch 的设计目标是为中国企业提供一个高效、可靠且适应本土需求的搜索与数据分析解决方案。与国外的 Elasticsearch 相似,Easysearch 基于分布式架构和倒排索引技术,能够处理大规模数据,并支持复杂的全文搜索和分析。
然而,Easysearch 并非只是简单的模仿或复制 Elasticsearch。它在多个方面进行了本地化优化,以更好地适应中国市场的独特需求。例如,在处理中文文本时,Easysearch 针对中文的特殊语法结构进行了优化,增强了中文分词的准确性和查询效率。此外,Easysearch 还在性能和可扩展性上进行了改进,使其能够更好地应对大规模企业级应用的需求。
不仅如此,Easysearch 还是国内首个通过搜索型数据库产品能力测试的国产搜索型数据库。自 2023 年 10 月起,Easysearch 凭借其卓越的性能和深度的本土化优化,成功在墨天轮搜索型数据库排行榜上长期占据榜首位置。这一成绩不仅体现了 Easysearch 在技术层面的突破,也反映了市场对其产品的高度认可。在短短几个月的时间里,Easysearch 以其稳定的表现和不断创新的步伐,赢得了众多企业用户的信赖。
6.3 Easysearch 与 Elasticsearch 的对比
虽然 Easysearch 与 Elasticsearch 在架构和基本功能上有很多相似之处,但它们在具体的实现和应用场景中表现出了一些显著的差异。
-
中文文本处理:Elasticsearch 虽然支持多语言环境,但其在中文处理上的表现并不如 Easysearch 那么出色。Easysearch 针对中文的语法和分词进行了专门的优化,尤其是在处理同义词、短语匹配和模糊查询时,能够提供更高的准确性。
-
本地化支持:Easysearch 提供了更强的本地化支持,包括符合中国法律法规的安全和合规性功能。此外,它还集成了许多国内常用的第三方系统,简化了企业的集成和部署过程。
-
性能优化:在处理大规模数据集时,Easysearch 通过定制化的优化策略,如特定的索引压缩技术和内存管理方案,提升了系统的响应速度和资源利用率。这使得它在某些特定应用场景下,能够提供比 Elasticsearch 更高的性能和稳定性。
- 安全可靠:Easysearch 提供了多种安全和合规性功能,如 TLS 加密、磁盘加密等。此外,它还支持多种第三方认证方式,如 LDAP、AD
6.4 国产搜索型数据库的未来
根据第一新声研究,2022-2027 年中国数据库整体市场将维持增长态势 ,2024 年整体市场规模预计为 543.1 亿,到 2027 年将增长至 1183.8 亿,2022-2027 年复合增长率达到 30.67%。
随着全球对数据安全和本地化需求的不断增加,国产搜索型数据库在未来有望占据更大的市场份额。
Easysearch 及其他国产数据库将进一步提升技术水平,持续创新,以满足不断变化的市场需求。
全球化与竞争力
虽然当前 Easysearch 主要面向国内市场,但其潜在的全球化前景不容小觑。通过持续的技术创新和市场拓展,Easysearch 及其他国产数据库有望在全球范围内与国际巨头展开竞争,特别是在亚非拉等新兴市场。这不仅有助于提升中国数据库技术的国际影响力,也将推动全球数据库产业的多样化发展。
7. 结论
通过对搜索型数据库的发展历程和未来趋势的探讨,可以看出,随着大数据和人工智能技术的不断进步,搜索型数据库将在更多领域发挥重要作用。Elasticsearch 作为全球领先的搜索型数据库,其开创性的架构和功能为行业树立了标杆。而以 Easysearch 为代表的国产数据库,也正在迅速崛起,展现出强大的竞争力。未来,搜索型数据库将继续朝着多模态、智能化、本地化的方向发展,为全球信息技术的发展提供更加坚实的基础。
参考资料
- 搜索引擎数据库
- 搜索型数据库的技术发展历程与趋势前瞻
- 数据库行业分析:国产数据库百花齐放,搜索引擎数据库风口已至
- 浅谈搜索引擎和传统数据库(ES,solr)
- 什么是 Elasticsearch?
- INFINI Labs 产品更新 | 重磅推出 Easysearch v1.1
- 墨天轮中国数据库流行度排行
- 喜讯!INFINI Easysearch 在墨天轮搜索型数据库排名中荣登榜首
- 《2024 年中国数据库市场研究报告》重磅发布 | 第一新声
- 国内首家 | 极限科技率先完成信通院搜索型数据库行业标准测试
- 危险!超 9000 个 Elasticsearch 集群暴露在公网上
- 从 OpenAI 停服看中国市场:国产替代崛起的机遇与挑战
- 什么是数据库
- 数据库发展史
关于 Easysearch 有奖征文活动
无论你是 Easysearch 的老用户,还是第一次听说这个名字,只要你对 INFINI Labs 旗下的 Easysearch 产品感兴趣,或者是希望了解 Easysearch,都可以参加这次活动。
详情查看:Easysearch 征文活动
作者:李家兴
换掉ES? Redis官方搜索引擎,效率大幅提升
默认分类 • Fred2000 发表了文章 • 2 个评论 • 5457 次浏览 • 2024-05-30 10:08
RediSearch是一个Redis模块,为Redis提供查询、二次索引和全文搜索。要使用RediSearch,首先要在Redis数据上声明索引。然后可以使用重新搜索查询语言来查询该数据。
RedSearch使用压缩的反向索引进行快速索引,占用内存少。RedSearch索引通过提供精确的短语匹配、模糊搜索和数字过滤等功能增强了
实现特性
- 基于文档的多个字段全文索引
- 高性能增量索引
- 文档排序(由用户在索引时手动提供)
- 在子查询之间使用 AND 或 NOT 操作符的复杂布尔查询
- 可选的查询子句
- 基于前缀的搜索
- 支持字段权重设置
- 自动完成建议(带有模糊前缀建议)
- 精确的短语搜索
- 在许多语言中基于词干分析的查询扩展
- 支持用于查询扩展和评分的自定义函数
- 将搜索限制到特定的文档字段
- 数字过滤器和范围
- 使用 Redis 自己的地理命令进行地理过滤
- Unicode 支持(需要 UTF-8 字符集)
- 检索完整的文档内容或只是ID 的检索
- 支持文档删除和更新与索引垃圾收集
- 支持部分更新和条件文档更新
对比 Elasticsearch
如下图所示,RediSearch 构建索引的时间为 221 秒,而 Elasticsearch 为 349 秒,快了 58%。
索引构建测试
我们模拟了一个多租户电子商务应用程序,其中每个租户代表一个产品类别并维护自己的索引。对于此基准测试,我们构建了 50K 个索引(或产品),每个索引最多存储 500 个文档(或项目),总共 2500 万个文档。
RediSearch 仅用了 201 秒就构建了索引,平均每秒运行 125K 个索引。然而,Elasticsearch 在 921 个索引后崩溃了,显然它不是为应对这种负载而设计的。
查询性能测试
一旦数据集被索引,我们就使用在专用负载生成器服务器上运行的 32 个客户端启动两个单词的搜索查询。如下图所示,RediSearch 吞吐量达到了 12.5K 操作/秒,而 Elasticsearch 为 3.1K 操作/秒,速度提高了 4 倍。
此外,RediSearch 延迟稍好一些,平均为 8 毫秒,而 Elasticsearch 为 10 毫秒。
安装
安装目前分为源码和docker安装两种方式。
源码安装
git clone https://github.com/RediSearch/RediSearch.git
cd RediSearch # 进入模块目录
make setup
make installdocker安装
note: RediSearch的安装比较复杂原包无法进行编译操作所以我们使用docker安装
docker run -p 6379:6379 redislabs/redisearch:latest判断是否安装成功
127.0.0.1:0>module list
1) 1) "name"
2) "ReJSON"
3) "ver"
4) "20007"
2) 1) "name"
2) "search"
3) "ver"
4) "20209"返回数组存在“ft”或 “search”(不同版本),表明 RediSearch 模块已经成功加载。
命令行操作
1、创建
1.1 创建索引
创建索引不妨想象成创建表结构,表一般基本属性有表名、字段和字段类别等,所以我们可以考虑将索引名代表表名,字段代表字段,属性即表示属性。
xxx.xxx.xxx.xxx:0>ft.create "student" schema "name" text weight 5.0 "sex" text "desc" text "class" tag
"OK"student 表示索引名,name、sex、desc表示字段,text表示类型(这样表示只是为了便于理解)
“weight”为权重,默认值为 1.0
type student
"none"我们创建的索引redis是不认识的,这证明使用的是插件。
1.2 创建文档
创建文档上下文的过程不妨想想成向表中插入数据,这里请注意字段名可以使用双引号但切记一定要用英文,这里之所以着重提出是因为有些编译器中文双引号和英文双引号用肉眼实在难以辨认否则会出现 “Fields must be specified in FIELD VALUE pairs”(其实是将“ 当作内容处理了以至于缺少了字段)
ft.add student 001 1.0 language "chinese" fields name "张三" sex "男" desc "这是一个学生" class "一班"
"OK"其中001为文档ID,"1.0"为评分缺少此值会报"Could not parse document score"异常,language 指明使用的语言默认是英文编码 如果没有此标记存储是没有问题的但不可以通过中文字符查询
1.3 查询
1.3.1 基本查询
1.3.1.1 全量查询
xxx.xxx.xxx.xxx:0>FT.SEARCH student * SORTBY sex desc RETURN 3 name sex desc
1) "2"
2) "001"
3) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
4) "002"
5) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"1.3.1.2 匹配查询
xxx.xxx.xxx.xxx:0>ft.search student "张三" limit 0 10 RETURN 3 name sex desc
1) "2"
2) "001"
3) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
4) "002"
5) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
limit 与mysql相识主要用于分页,此处是全量匹配,如果没有设置language “chinese” 此处查询为0,
1.3.2 模糊匹配
1.3.2.1 后置匹配
ft.search student "李*" SORTBY sex desc RETURN 3 name sex desc
1) "1"
2) "003"
3) 1) "name"
2) "李四"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"1.3.2.2 模糊搜索
xxx.xxx.xxx.xxx:0>FT.SEARCH beers "%%张店%%"
1) "1"
2) "beer:1"
3) 1) "name"
2) "集团本部已发布【文明就餐公约】,2号楼办公人员午餐的就餐时间是11:45~13:00,现经行政服务部进行抽查,发现我们部门有员工违规就餐现象。请大家务必遵守,相互转告,对于外地回到集团办公的同事,亦请遵守,谢谢!"
3) "org"
4) "山东省淄博市张店区"
5) "school"
6) "山东理工大学"别高兴太早全量模糊匹配是由很大限制的,他基于Levenshtein距离(LD)进行模糊匹配。术语的模糊匹配是通过在术语周围加“%”来实现的,模糊匹配的最大LD为3,确切的说这只是一种相识度查询,并非一般意义上的模糊搜索,但是如果仔细观察会发现通过精确匹配时不仅能够将完整value值查询出来而且还查询出其他处于文档某个位置的key请看官方提供的一个例子:
FT.CREATE idx SCHEMA txt TEXT
FT.ADD idx docCn 1.0 LANGUAGE chinese FIELDS txtRedis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。从盘可以有意无意的对数据进行写操作。
由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。
FT.CREATE idx SCHEMA txt TEXT
FT.ADD idx docCn 1.0 LANGUAGE chinese FIELDS txt "Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。从盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。[8]"
FT.SEARCH idx "数据" LANGUAGE chinese HIGHLIGHT SUMMARIZE
# Outputs:
# <b>数据</b>?... <b>数据</b>进行写操作。由于完全实现了发布... <b>数据</b>冗余很有帮助。[8...之所以会出现这样的效果是因为redisearch对文本进行了分词,其使用的工具是friso相比es的ik还是弱一些前者主要是对中文分词,体积小可移植性强。
从而我们可以结合后后置匹配算法
xxx.xxx.xxx.xxx:0>FT.SEARCH idx "数*" LANGUAGE chinese HIGHLIGHT
1) "1"
2) "docCn"
3) 1) "txt"
2) "Redis支持主从同步。<b>数据</b>可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。从盘可以有意无意的对<b>数据</b>进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和<b>数据</b>冗余很有帮助。[8]"
或者结合Levenshtein算法这样基本上能够满足业务查询需求
xxx.xxx.xxx.xxx:0>FT.SEARCH idx "%%单的树%%" LANGUAGE chinese HIGHLIGHT
1) "1"
2) "docCn"
3) 1) "txt"
2) "Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层<b>树</b>复制。从盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步<b>树</b>时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。[8]"1.3.2.3 字段查询
通过字段查询也可以实现模糊搜索,直接给例子,后面跟着官网上给的sql 和 redisearch的对照表
ft.search student *
1) "2"
2) "doudou"
3) 1) "name"
2) "豆豆"
3) "jtzz"
4) "“检索”是很多产品中"
5) "phone"
6) "18563717107"
4) "ttao"
5) 1) "name"
2) "姚元涛"
3) "jtzz"
4) "一个生病的人只"
5) "phone"
6) "18563717107"
ft.search student '@phone:185* @name:豆豆'
1) "1"
2) "doudou"
3) 1) "name"
2) "豆豆"
3) "jtzz"
4) "“检索”是很多产品中"
5) "phone"
6) "18563717107"1.4 删除
1.4.1 删除文档
xxx.xxx.xxx.xxx:0>ft.del student 002
"1"1.4.3 删除索引
xxx.xxx.xxx.xxx:0>ft.drop student
"OK"1.5 查看
1.5.1 查看所有索引
xxx.xxx.xxx.xxx:0>FT._LIST
1) "student1"
2) "ttao"
3) "idx"
4) "student"
5) "myidx"
6) "123"
7) "myIndex"
8) "testung"
9) "student2"1.5.2 查看索引文档中的数据
1.5.2.1 获取单条数据
xxx.xxx.xxx.xxx:0>ft.get student 001
1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
7) "class"
8) "一班"1.5.2.2 获取多条数据
xxx.xxx.xxx.xxx:0>ft.mget student 001 002
1) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
7) "class"
8) "一班"
2) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
7) "class"
8) "一班"1.6 索引别名操作
1.6.1 添加别名
123.232.112.84:0>FT.ALIASADD xs student
"OK"给索引student起个xs的别名,一个索引可以起多个别名
1.6.2 修改别名
1.6.3 删除别名
123.232.112.84:0>FT.ALIASDEL xs
"OK"作者:架构师公众号
来源:https://mp.weixin.qq.com/s/TmCXx3rLjLPggvOFjGqS9w
版权申明:内容来源网络,仅供学习研究,版权归原创者所有。如有侵权烦请告知,我们会立即删除并表示歉意。谢谢!
INFINI Labs 产品更新 | 重磅推出 Easysearch 一个分布式的近实时搜索与分析引擎
资讯动态 • liaosy 发表了文章 • 0 个评论 • 5993 次浏览 • 2023-05-16 11:57
INFINI Labs 产品又更新啦,包括 Easysearch v1.1.0、Gateway v1.13.0、Console v1.1.0、Agent v0.4.0,其中 Easysearch 经过团队的数月打磨,现正式对外推出。Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 衍生自基于开源协议 Apache 2.0 的 Elasticsearch 7.10.2 版本。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。欢迎大家下载体验。
INFINI Easysearch v1.1.0
INFINI Easysearch 本次更新最重要的功能是引入了 ZSTD 压缩算法,对索引进行全方位的压缩,尤其针对日志数据压缩效果更加明显,针对 1.1G 的 Nginx 日志进行测试,采用 ZSTD 策略后,膨胀率只有 0.94,甚至比原始数据还要小,而且还能进一步压缩,和 index.source_reuse 结合使用后,膨胀率只有 0.7,索引大小只有 Elasticsearch 原生 best_compression 的 59%,是 Elasticsearch 6.x 的 49%。下面是一张索引大小对比图:
更多介绍查看 详情。
其他更新功能如下:
Breaking changes
- Lucene 版本升级到 8.11.2
Breaking changes
- 增加 ZSTD codec, 引入 ZSTD 压缩算法,对存储字段,doc_values,词典进行压缩。
- 增加 index.source_reuse 索引级别配置,对 _source 进一步压缩。
- 提供索引生命周期管理 ILM 模块的功能,绝大部分 api 兼容 elasticsearch
Breaking changes
- 减少冗余日志输出。
- 减少 modules 模块整体大小。
下载地址:https://www.infinilabs.com/download
INFINI Gateway v1.13.0
极限网关本次更新如下:
Features
router.rules增加 enabled 选项,控制是否启用 flow- 增加对 loong64 架构的支持
- 增加对 riscv64 架构的支持
- elasticsearch filter 增加 dial_timeout 选项
Bug fix
- 修复 http/elasticsearch 转发后 HTTP 响应头丢失的问题
- 修复 pipeline 热加载出现重复 pipeline 同时运行的问题
- 修复 bulk_indexing 退出后泄漏 goroutine 的问题
Improvements
- 优化 HTTP 头设置方式,避免出现重复的 HTTP 头
- 优化 pipeline 停止的响应速度
- pipeline 增加 enabled 选项,控制是否启用 pipeline
更多 Gateway 更新可参考【Gateway 版本历史】。
INFINI Console v1.1.0
本次 INFINI Console 版本发布主要新增了网关实时日志查看功能、完善了数据迁移功能和数据看板的可视化能力、以及修复了已知 Bug。
实时日志
登录 Console,进入 [资源管理][网关管理] 界面,可以看到网关实时日志入口(前提需要注册网关)如下图所示:
进入实时日志展示界面,点击“开始”按钮后,服务端将 Gateway 日志实时推送到 Console 界面展示,在该界面可以动态调整输出不同的日志级别(DEBUG、INFO、WARN、ERROR 等),同时也支持文件名、方法名、消息内容加通配符进行过滤。
数据迁移
数据迁移模块,基于上个版本做了优化,添加 ILM,Template,Alias 初始化操作。方便用户根据各自的需求迁移索引生命周期、模板、别名等。
数据看板
数据看板图表支持复制、快速切换、时间框选、缩放、标记高亮,进一步增强 Console 可视化能力。
详情查看 操作演示视频。
除以上主要功能更新外,Console 其他功能优化如下:
Bug fix
- 修复数据探索保存查询出现 mapping 错误的问题
- 修复数据看板组件数据源配置的问题
- 修复数据探索左侧字段栏样式的问题
- 修复集群注册向导点击跳转后丢失集群类型的问题
Improvements
- 数据看板汉化
更多 Console 更新可参考【Console 版本历史】。
INFINI Agent v0.4.0
数据采集工具探针(INFINI Agent)更新如下:
Features
- 新增 logs_processor ,配置采集本地日志文件
Breaking changes
- es_logs_processor 调整日志字段
- created 重命名为 timestamp
- 自动提取 payload.timestamp payload.@timestmap 字段到 timestamp
- es_logs_processor 删除 enable 选项
下载地址: https://www.infinilabs.com/download/?product=agent
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
- INFINI Gateway: https://github.com/infinilabs/gateway/issues
- INFINI Console: https://github.com/infinilabs/console/issues
- 下载地址: https://www.infinilabs.com/download
您还可以通过邮件联系我们:hello@infini.ltd
或者拨打我们的热线电话:(+86) 400-139-9200
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群讨论,或者扫码加入我们的知识星球一起学习交流。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
详情参见官网:https://www.infinilabs.com
