

语义搜索
Easysearch 集成阿里云与 Ollama Embedding API,构建端到端的语义搜索系统
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 108 次浏览 • 9 小时前
背景
在当前 AI 与搜索深度融合的时代,语义搜索已成为企业级应用的核心能力之一。作为 Elasticsearch 的国产化替代方案,Easysearch 不仅具备高性能、高可用、弹性伸缩等企业级特性,更通过灵活的插件化架构,支持多种主流 Embedding 模型服务,包括 阿里云通义千问(DashScope) 和 本地化 Ollama 服务,实现对 OpenAI 接口规范的完美兼容。
本文将详细介绍如何在 Easysearch 中集成阿里云和 Ollama 的 Embedding API,构建端到端的语义搜索系统,并提供完整的配置示例与流程图解析。
一、为什么选择 Easysearch?
Easysearch 是由极限科技(INFINI Labs)自主研发的分布式近实时搜索型数据库,具备以下核心优势:
- ✅ 完全兼容 Elasticsearch 7.x API 及 8.x 常用操作
- ✅ 原生支持向量检索(kNN)、语义搜索、混合检索
- ✅ 内置数据摄入管道与搜索管道,支持 AI 模型集成
- ✅ 支持国产化部署、数据安全可控
- ✅ 高性能、低延迟、可扩展性强
尤其在 AI 增强搜索场景中,Easysearch 提供了强大的 text_embedding 和 semantic_query_enricher 处理器,允许无缝接入外部 Embedding 模型服务。
二、支持的 Embedding 服务
Easysearch 通过标准 OpenAI 兼容接口无缝集成各类第三方 Embedding 模型服务,理论上支持所有符合 OpenAI Embedding API 规范的模型。以下是已验证的典型服务示例:
| 服务类型 | 模型示例 | 接口协议 | 部署方式 | 特点 |
|---|---|---|---|---|
| 云端 SaaS | 阿里云 DashScope | OpenAI 兼容 | 云端 | 开箱即用,高可用性 |
OpenAI text-embedding-3 |
OpenAI 原生 | 云端 | ||
| 其他兼容 OpenAI 的云服务 | OpenAI 兼容 | 云端 | ||
| 本地部署 | Ollama (nomic-embed-text等) |
自定义 API | 本地/私有化 | 数据隐私可控 |
| 自建开源模型(如 BGE、M3E) | OpenAI 兼容 | 本地/私有化 | 灵活定制 |
核心优势:
-
广泛兼容性
支持任意实现 OpenAI Embedding API 格式(/v1/embeddings)的服务,包括:- 请求格式:
{ "input": "text", "model": "model_name" } - 响应格式:
{ "data": [{ "embedding": [...] }] }
- 请求格式:
-
即插即用
仅需配置服务端点的base_url和api_key即可快速接入新模型。 - 混合部署
可同时配置多个云端或本地模型,根据业务需求灵活切换。
三、结合 AI 服务流程图
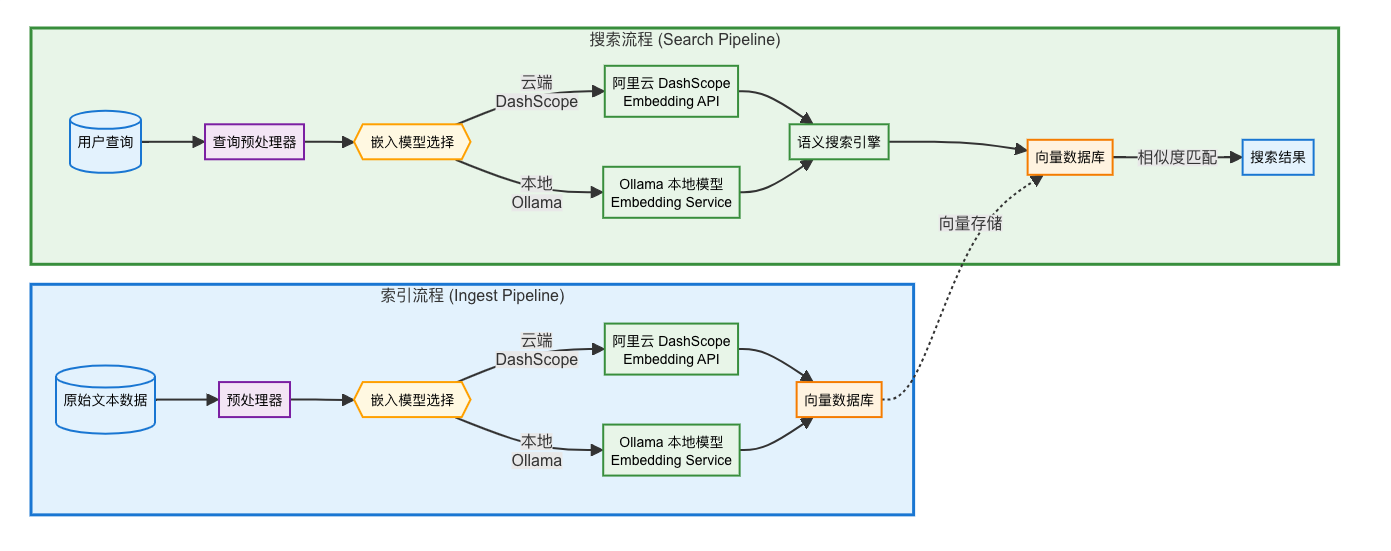
说明:
- 索引阶段:通过 Ingest Pipeline 调用 Embedding API,将文本转为向量并存储。
- 搜索阶段:通过 Search Pipeline 动态生成查询向量,执行语义相似度匹配。
- 所有 API 调用均兼容 OpenAI 接口格式,降低集成成本。
四、集成阿里云 DashScope(通义千问)
阿里云 DashScope 提供高性能文本嵌入模型 text-embedding-v4,支持 256 维向量输出,适用于中文语义理解任务。
1. 创建 Ingest Pipeline(索引时生成向量)
PUT _ingest/pipeline/text-embedding-aliyun
{
"description": "阿里云用于生成文本嵌入向量的管道",
"processors": [
{
"text_embedding": {
"url": "https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings",
"vendor": "openai",
"api_key": "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"text_field": "input_text",
"vector_field": "text_vector",
"model_id": "text-embedding-v4",
"dims": 256,
"batch_size": 5
}
}
]
}2. 创建索引并定义向量字段
PUT /my-index
{
"mappings": {
"properties": {
"input_text": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"text_vector": {
"type": "knn_dense_float_vector",
"knn": {
"dims": 256,
"model": "lsh",
"similarity": "cosine",
"L": 99,
"k": 1
}
}
}
}
}3. 使用 Pipeline 批量写入数据
POST /_bulk?pipeline=text-embedding-aliyun&refresh=wait_for
{ "index": { "_index": "my-index", "_id": "1" } }
{ "input_text": "风急天高猿啸哀,渚清沙白鸟飞回..." }
{ "index": { "_index": "my-index", "_id": "2" } }
{ "input_text": "月落乌啼霜满天,江枫渔火对愁眠..." }
...4. 配置 Search Pipeline(搜索时动态生成向量)
PUT /_search/pipeline/search_model_aliyun
{
"request_processors": [
{
"semantic_query_enricher": {
"tag": "tag1",
"description": "阿里云 search embedding model",
"url": "https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings",
"vendor": "openai",
"api_key": "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"default_model_id": "text-embedding-v4",
"vector_field_model_id": {
"text_vector": "text-embedding-v4"
}
}
}
]
}5. 设置索引默认搜索管道
PUT /my-index/_settings
{
"index.search.default_pipeline": "search_model_aliyun"
}6. 执行语义搜索
GET /my-index/_search
{
"_source": "input_text",
"query": {
"semantic": {
"text_vector": {
"query_text": "风急天高猿啸哀,渚清沙白鸟飞回...",
"candidates": 10,
"query_strategy": "LSH_COSINE"
}
}
}
}搜索结果示例:
"hits": [
{
"_id": "1",
"_score": 2.0,
"_source": { "input_text": "风急天高猿啸哀..." }
},
{
"_id": "4",
"_score": 1.75,
"_source": { "input_text": "白日依山尽..." }
},
...
]结果显示:相同诗句匹配得分最高,其他古诗按语义相似度排序,效果理想。
五、集成本地 Ollama 服务
Ollama 支持在本地运行开源 Embedding 模型(如 nomic-embed-text),适合对数据隐私要求高的场景。
1. 启动 Ollama 服务
ollama serve
ollama pull nomic-embed-text:latest2. 创建 Ingest Pipeline(使用 Ollama)
PUT _ingest/pipeline/ollama-embedding-pipeline
{
"description": "Ollama embedding 示例",
"processors": [
{
"text_embedding": {
"url": "http://localhost:11434/api/embed",
"vendor": "ollama",
"text_field": "input_text",
"vector_field": "text_vector",
"model_id": "nomic-embed-text:latest"
}
}
]
}3. 创建 Search Pipeline(搜索时使用 Ollama)
PUT /_search/pipeline/ollama_model_pipeline
{
"request_processors": [
{
"semantic_query_enricher": {
"tag": "tag1",
"description": "Sets the ollama model",
"url": "http://localhost:11434/api/embed",
"vendor": "ollama",
"default_model_id": "nomic-embed-text:latest",
"vector_field_model_id": {
"text_vector": "nomic-embed-text:latest"
}
}
}
]
}后续步骤与阿里云一致:创建索引 → 写入数据 → 搜索查询。
六、安全性说明
Easysearch 在处理 API Key 时采取以下安全措施:
- 🔐 所有
api_key在返回时自动加密脱敏(如TfUmLjPg...infinilabs) - 🔒 支持密钥管理插件(如 Hashicorp Vault 集成)
- 🛡️ 支持 HTTPS、RBAC、审计日志等企业级安全功能
确保敏感信息不被泄露,满足合规要求。
七、总结
通过 Easysearch 的 Ingest Pipeline 与 Search Pipeline,我们可以轻松集成:
- ✅ 阿里云 DashScope(云端高性能)
- ✅ Ollama(本地私有化部署)
- ✅ 其他支持 OpenAI 接口的 Embedding 服务
无论是追求性能还是数据安全,Easysearch 都能提供灵活、高效的语义搜索解决方案。
八、下一步建议
- 尝试混合检索:结合关键词匹配与语义搜索
- 使用 Rerank 模型提升排序精度
- 部署多节点集群提升吞吐量
- 接入 INFINI Gateway 实现统一 API 网关管理
参考链接
关于 Easysearch

INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
官网文档:https://docs.infinilabs.com/easysearch
作者:张磊,极限科技(INFINI Labs)搜索引擎研发负责人,对 Elasticsearch 和 Lucene 源码比较熟悉,目前主要负责公司的 Easysearch 产品的研发以及客户服务工作。
原文:https://infinilabs.cn/blog/2025/Easysearch-Integration-with-Alibaba-CloudOllama-Embedding-API/
Easysearch:语义搜索、知识图和向量数据库概述
Easysearch • liaosy 发表了文章 • 0 个评论 • 5575 次浏览 • 2024-01-24 20:56
什么是语义搜索?
语义搜索是一种使用自然语言处理算法来理解单词和短语的含义和上下文以提供更准确的搜索结果的搜索技术。旨在更好地理解用户的意图和查询内容,而不仅仅是根据关键词匹配,还通过分析查询的语义和上下文来提供更准确和相关的搜索结果。
传统的关键词搜索主要依赖于对关键词的匹配,而忽略了查询的含义和语境。但语义搜索的优点在于它可以更好地满足用户的意图,尤其是对于复杂的查询和问题。它能够理解查询的上下文,处理模糊或不完整的查询,并提供更相关和有用的搜索结果。例如,当用户搜索"最近的餐厅"时,语义搜索可以根据用户的位置信息和上下文,提供附近的餐厅列表,而不仅仅是简单地匹配关键词"最近"和"餐厅"。

语义搜索的历史
语义搜索的概念可以追溯到计算机科学的早期,在 20 世纪 50 年代和 1960 年代就有人尝试开发自然语言处理系统。然而,直到 20 世纪 90 年代和 2000 年代,语义搜索领域才取得了重大进展,这在一定程度上要归功于机器学习和人工智能的进步。
语义搜索最早的例子之一是 Douglas Lenat 在 1984 年创建的 Cyc 项目。该项目旨在建立一个全面的常识知识本体或知识库,可用于理解自然语言查询。虽然 Cyc 项目面临诸多挑战,最终没有实现其目标,但它为未来语义搜索的研究奠定了基础。
20 世纪 90 年代末,Ask Jeeves(现称为 Ask.com)等搜索引擎开始尝试自然语言查询和语义搜索技术。这些早期的努力受到当时技术的限制,但它们展示了更复杂的搜索算法的潜力。
2000 年代初 Web 本体语言 (OWL) 的发展提供了一种以机器可读格式表示知识和关系的标准化方法,使得开发语义搜索算法变得更加容易。2008 年被微软收购的 Powerset 和 2007 年推出的 Hakia 等公司开始使用语义搜索技术来提供更相关的搜索结果。
如今,许多搜索引擎和公司正在使用语义搜索来提高搜索结果的准确性和相关性。其中包括于 2012 年推出知识图谱的谷歌,以及使用语义搜索为其 Alexa 虚拟助手提供支持的亚马逊。随着人工智能领域的不断发展,语义搜索可能会变得更加复杂且适用于广泛的应用。
语义搜索的最新改进
语义搜索的最新改进有助于进一步推动该领域的发展。一些最值得注意的包括:
基于 Transformer 的模型:基于 Transformer 的模型,例如 BERT(来自 Transformers 的双向编码器表示),彻底改变了自然语言处理和语义搜索。这些模型能够更好地理解单词和短语的上下文,从而更容易提供更相关的搜索结果。
多模态搜索:多模态搜索是指跨文本、图像、视频等多种模式搜索信息的能力。机器学习的最新进展使得开发更准确、更复杂的多模态搜索算法成为可能。
对话式搜索:对话式搜索涉及使用自然语言处理和机器学习来为用户查询提供更准确、更人性化的响应。这项技术已经被用于虚拟助手,例如亚马逊的 Alexa 和苹果的 Siri。
个性化:个性化是指根据用户的偏好和之前的搜索历史来定制搜索结果的能力。随着在线可用数据量的不断增长,这一点变得越来越重要。
特定领域搜索:特定领域搜索涉及使用语义搜索技术在特定领域或行业(例如医疗保健或金融)内进行搜索。这有助于为这些行业的用户提供更准确、更相关的搜索结果。
总体而言,语义搜索的最新进展使得在线查找信息变得更加容易,并为未来更复杂的搜索算法铺平了道路。
语义搜索和知识图谱有什么关系?
语义搜索和知识图(knowledge graph)密切相关,因为两者都涉及使用语义技术来改进搜索结果。
知识图是一种用于组织和表示知识的图形结构,通过节点和边的连接展示实体和关系之间的语义关联性。例如,知识图可能包含有关特定公司的信息,包括其位置、产品和员工以及这些实体之间的关系。
另一方面,语义搜索是一种使用自然语言处理和机器学习来更好地理解搜索查询中单词和短语的含义的搜索技术。语义搜索算法使用知识图和其他语义技术来分析实体和概念之间的关系,并基于此分析提供更相关的搜索结果。
换句话说,知识图谱为语义搜索提供了丰富的知识背景,帮助理解查询意图和提供准确的搜索结果。同时,语义搜索可以帮助构建和扩展知识图谱,提高搜索的准确性和语义理解能力。
例如,谷歌的知识图使用庞大的结构化数据数据库来支持其搜索结果,并提供有关搜索结果中出现的实体(例如人物、地点和事物)的附加信息。这使得用户更容易找到他们正在寻找的信息并探索相关的概念和实体。
向量数据库、知识图谱和语义搜索
向量数据库是另一种可以与语义搜索和知识图相结合使用以改进搜索结果的技术。它主要用于处理和分析具有向量特征的数据,如图像、音频、文本、时间序列等。
传统的关系型数据库主要用于存储结构化的数据,而向量数据库则专注于存储和处理高维向量。它的设计目标是能够高效地进行向量相似性搜索和聚类等操作,以支持复杂的数据分析和机器学习任务。向量数据库使用机器学习算法将数据表示为向量,向量是数据的数学表示,可用于各种计算任务,例如,向量可用于表示人、地点和事物等实体以及它们之间的关系。通过比较这些向量,搜索算法可以识别数据本身可能无法立即显现的关系和模式。
在语义搜索和知识图的背景下,向量数据库可以通过更好地理解实体和概念之间的关系来提高搜索结果的准确性。
例如,当用户搜索“ London ”时,语义搜索算法可以使用知识图和向量数据库来了解用户可能指的是英国伦敦市,而不是其他同名实体。
通过使用向量数据库来表示和比较实体和概念,搜索算法可以提供更相关和更准确的搜索结果。
总体而言,向量数据库、语义搜索和知识图谱都是共同提高搜索算法的准确性和效率的技术。通过利用这些技术,搜索引擎和其他应用程序可以更好地理解实体和概念之间的关系,从而更轻松地找到用户正在寻找的信息。
关于 Easysearch

INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
官网文档:https://infinilabs.com/docs/latest/easysearch
参考资料
Easysearch 集成阿里云与 Ollama Embedding API,构建端到端的语义搜索系统
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 108 次浏览 • 9 小时前
背景
在当前 AI 与搜索深度融合的时代,语义搜索已成为企业级应用的核心能力之一。作为 Elasticsearch 的国产化替代方案,Easysearch 不仅具备高性能、高可用、弹性伸缩等企业级特性,更通过灵活的插件化架构,支持多种主流 Embedding 模型服务,包括 阿里云通义千问(DashScope) 和 本地化 Ollama 服务,实现对 OpenAI 接口规范的完美兼容。
本文将详细介绍如何在 Easysearch 中集成阿里云和 Ollama 的 Embedding API,构建端到端的语义搜索系统,并提供完整的配置示例与流程图解析。
一、为什么选择 Easysearch?
Easysearch 是由极限科技(INFINI Labs)自主研发的分布式近实时搜索型数据库,具备以下核心优势:
- ✅ 完全兼容 Elasticsearch 7.x API 及 8.x 常用操作
- ✅ 原生支持向量检索(kNN)、语义搜索、混合检索
- ✅ 内置数据摄入管道与搜索管道,支持 AI 模型集成
- ✅ 支持国产化部署、数据安全可控
- ✅ 高性能、低延迟、可扩展性强
尤其在 AI 增强搜索场景中,Easysearch 提供了强大的 text_embedding 和 semantic_query_enricher 处理器,允许无缝接入外部 Embedding 模型服务。
二、支持的 Embedding 服务
Easysearch 通过标准 OpenAI 兼容接口无缝集成各类第三方 Embedding 模型服务,理论上支持所有符合 OpenAI Embedding API 规范的模型。以下是已验证的典型服务示例:
| 服务类型 | 模型示例 | 接口协议 | 部署方式 | 特点 |
|---|---|---|---|---|
| 云端 SaaS | 阿里云 DashScope | OpenAI 兼容 | 云端 | 开箱即用,高可用性 |
OpenAI text-embedding-3 |
OpenAI 原生 | 云端 | ||
| 其他兼容 OpenAI 的云服务 | OpenAI 兼容 | 云端 | ||
| 本地部署 | Ollama (nomic-embed-text等) |
自定义 API | 本地/私有化 | 数据隐私可控 |
| 自建开源模型(如 BGE、M3E) | OpenAI 兼容 | 本地/私有化 | 灵活定制 |
核心优势:
-
广泛兼容性
支持任意实现 OpenAI Embedding API 格式(/v1/embeddings)的服务,包括:- 请求格式:
{ "input": "text", "model": "model_name" } - 响应格式:
{ "data": [{ "embedding": [...] }] }
- 请求格式:
-
即插即用
仅需配置服务端点的base_url和api_key即可快速接入新模型。 - 混合部署
可同时配置多个云端或本地模型,根据业务需求灵活切换。
三、结合 AI 服务流程图
说明:
- 索引阶段:通过 Ingest Pipeline 调用 Embedding API,将文本转为向量并存储。
- 搜索阶段:通过 Search Pipeline 动态生成查询向量,执行语义相似度匹配。
- 所有 API 调用均兼容 OpenAI 接口格式,降低集成成本。
四、集成阿里云 DashScope(通义千问)
阿里云 DashScope 提供高性能文本嵌入模型 text-embedding-v4,支持 256 维向量输出,适用于中文语义理解任务。
1. 创建 Ingest Pipeline(索引时生成向量)
PUT _ingest/pipeline/text-embedding-aliyun
{
"description": "阿里云用于生成文本嵌入向量的管道",
"processors": [
{
"text_embedding": {
"url": "https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings",
"vendor": "openai",
"api_key": "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"text_field": "input_text",
"vector_field": "text_vector",
"model_id": "text-embedding-v4",
"dims": 256,
"batch_size": 5
}
}
]
}2. 创建索引并定义向量字段
PUT /my-index
{
"mappings": {
"properties": {
"input_text": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"text_vector": {
"type": "knn_dense_float_vector",
"knn": {
"dims": 256,
"model": "lsh",
"similarity": "cosine",
"L": 99,
"k": 1
}
}
}
}
}3. 使用 Pipeline 批量写入数据
POST /_bulk?pipeline=text-embedding-aliyun&refresh=wait_for
{ "index": { "_index": "my-index", "_id": "1" } }
{ "input_text": "风急天高猿啸哀,渚清沙白鸟飞回..." }
{ "index": { "_index": "my-index", "_id": "2" } }
{ "input_text": "月落乌啼霜满天,江枫渔火对愁眠..." }
...4. 配置 Search Pipeline(搜索时动态生成向量)
PUT /_search/pipeline/search_model_aliyun
{
"request_processors": [
{
"semantic_query_enricher": {
"tag": "tag1",
"description": "阿里云 search embedding model",
"url": "https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings",
"vendor": "openai",
"api_key": "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"default_model_id": "text-embedding-v4",
"vector_field_model_id": {
"text_vector": "text-embedding-v4"
}
}
}
]
}5. 设置索引默认搜索管道
PUT /my-index/_settings
{
"index.search.default_pipeline": "search_model_aliyun"
}6. 执行语义搜索
GET /my-index/_search
{
"_source": "input_text",
"query": {
"semantic": {
"text_vector": {
"query_text": "风急天高猿啸哀,渚清沙白鸟飞回...",
"candidates": 10,
"query_strategy": "LSH_COSINE"
}
}
}
}搜索结果示例:
"hits": [
{
"_id": "1",
"_score": 2.0,
"_source": { "input_text": "风急天高猿啸哀..." }
},
{
"_id": "4",
"_score": 1.75,
"_source": { "input_text": "白日依山尽..." }
},
...
]结果显示:相同诗句匹配得分最高,其他古诗按语义相似度排序,效果理想。
五、集成本地 Ollama 服务
Ollama 支持在本地运行开源 Embedding 模型(如 nomic-embed-text),适合对数据隐私要求高的场景。
1. 启动 Ollama 服务
ollama serve
ollama pull nomic-embed-text:latest2. 创建 Ingest Pipeline(使用 Ollama)
PUT _ingest/pipeline/ollama-embedding-pipeline
{
"description": "Ollama embedding 示例",
"processors": [
{
"text_embedding": {
"url": "http://localhost:11434/api/embed",
"vendor": "ollama",
"text_field": "input_text",
"vector_field": "text_vector",
"model_id": "nomic-embed-text:latest"
}
}
]
}3. 创建 Search Pipeline(搜索时使用 Ollama)
PUT /_search/pipeline/ollama_model_pipeline
{
"request_processors": [
{
"semantic_query_enricher": {
"tag": "tag1",
"description": "Sets the ollama model",
"url": "http://localhost:11434/api/embed",
"vendor": "ollama",
"default_model_id": "nomic-embed-text:latest",
"vector_field_model_id": {
"text_vector": "nomic-embed-text:latest"
}
}
}
]
}后续步骤与阿里云一致:创建索引 → 写入数据 → 搜索查询。
六、安全性说明
Easysearch 在处理 API Key 时采取以下安全措施:
- 🔐 所有
api_key在返回时自动加密脱敏(如TfUmLjPg...infinilabs) - 🔒 支持密钥管理插件(如 Hashicorp Vault 集成)
- 🛡️ 支持 HTTPS、RBAC、审计日志等企业级安全功能
确保敏感信息不被泄露,满足合规要求。
七、总结
通过 Easysearch 的 Ingest Pipeline 与 Search Pipeline,我们可以轻松集成:
- ✅ 阿里云 DashScope(云端高性能)
- ✅ Ollama(本地私有化部署)
- ✅ 其他支持 OpenAI 接口的 Embedding 服务
无论是追求性能还是数据安全,Easysearch 都能提供灵活、高效的语义搜索解决方案。
八、下一步建议
- 尝试混合检索:结合关键词匹配与语义搜索
- 使用 Rerank 模型提升排序精度
- 部署多节点集群提升吞吐量
- 接入 INFINI Gateway 实现统一 API 网关管理
参考链接
关于 Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
官网文档:https://docs.infinilabs.com/easysearch
作者:张磊,极限科技(INFINI Labs)搜索引擎研发负责人,对 Elasticsearch 和 Lucene 源码比较熟悉,目前主要负责公司的 Easysearch 产品的研发以及客户服务工作。
原文:https://infinilabs.cn/blog/2025/Easysearch-Integration-with-Alibaba-CloudOllama-Embedding-API/
Easysearch:语义搜索、知识图和向量数据库概述
Easysearch • liaosy 发表了文章 • 0 个评论 • 5575 次浏览 • 2024-01-24 20:56
什么是语义搜索?
语义搜索是一种使用自然语言处理算法来理解单词和短语的含义和上下文以提供更准确的搜索结果的搜索技术。旨在更好地理解用户的意图和查询内容,而不仅仅是根据关键词匹配,还通过分析查询的语义和上下文来提供更准确和相关的搜索结果。
传统的关键词搜索主要依赖于对关键词的匹配,而忽略了查询的含义和语境。但语义搜索的优点在于它可以更好地满足用户的意图,尤其是对于复杂的查询和问题。它能够理解查询的上下文,处理模糊或不完整的查询,并提供更相关和有用的搜索结果。例如,当用户搜索"最近的餐厅"时,语义搜索可以根据用户的位置信息和上下文,提供附近的餐厅列表,而不仅仅是简单地匹配关键词"最近"和"餐厅"。
语义搜索的历史
语义搜索的概念可以追溯到计算机科学的早期,在 20 世纪 50 年代和 1960 年代就有人尝试开发自然语言处理系统。然而,直到 20 世纪 90 年代和 2000 年代,语义搜索领域才取得了重大进展,这在一定程度上要归功于机器学习和人工智能的进步。
语义搜索最早的例子之一是 Douglas Lenat 在 1984 年创建的 Cyc 项目。该项目旨在建立一个全面的常识知识本体或知识库,可用于理解自然语言查询。虽然 Cyc 项目面临诸多挑战,最终没有实现其目标,但它为未来语义搜索的研究奠定了基础。
20 世纪 90 年代末,Ask Jeeves(现称为 Ask.com)等搜索引擎开始尝试自然语言查询和语义搜索技术。这些早期的努力受到当时技术的限制,但它们展示了更复杂的搜索算法的潜力。
2000 年代初 Web 本体语言 (OWL) 的发展提供了一种以机器可读格式表示知识和关系的标准化方法,使得开发语义搜索算法变得更加容易。2008 年被微软收购的 Powerset 和 2007 年推出的 Hakia 等公司开始使用语义搜索技术来提供更相关的搜索结果。
如今,许多搜索引擎和公司正在使用语义搜索来提高搜索结果的准确性和相关性。其中包括于 2012 年推出知识图谱的谷歌,以及使用语义搜索为其 Alexa 虚拟助手提供支持的亚马逊。随着人工智能领域的不断发展,语义搜索可能会变得更加复杂且适用于广泛的应用。
语义搜索的最新改进
语义搜索的最新改进有助于进一步推动该领域的发展。一些最值得注意的包括:
基于 Transformer 的模型:基于 Transformer 的模型,例如 BERT(来自 Transformers 的双向编码器表示),彻底改变了自然语言处理和语义搜索。这些模型能够更好地理解单词和短语的上下文,从而更容易提供更相关的搜索结果。
多模态搜索:多模态搜索是指跨文本、图像、视频等多种模式搜索信息的能力。机器学习的最新进展使得开发更准确、更复杂的多模态搜索算法成为可能。
对话式搜索:对话式搜索涉及使用自然语言处理和机器学习来为用户查询提供更准确、更人性化的响应。这项技术已经被用于虚拟助手,例如亚马逊的 Alexa 和苹果的 Siri。
个性化:个性化是指根据用户的偏好和之前的搜索历史来定制搜索结果的能力。随着在线可用数据量的不断增长,这一点变得越来越重要。
特定领域搜索:特定领域搜索涉及使用语义搜索技术在特定领域或行业(例如医疗保健或金融)内进行搜索。这有助于为这些行业的用户提供更准确、更相关的搜索结果。
总体而言,语义搜索的最新进展使得在线查找信息变得更加容易,并为未来更复杂的搜索算法铺平了道路。
语义搜索和知识图谱有什么关系?
语义搜索和知识图(knowledge graph)密切相关,因为两者都涉及使用语义技术来改进搜索结果。
知识图是一种用于组织和表示知识的图形结构,通过节点和边的连接展示实体和关系之间的语义关联性。例如,知识图可能包含有关特定公司的信息,包括其位置、产品和员工以及这些实体之间的关系。
另一方面,语义搜索是一种使用自然语言处理和机器学习来更好地理解搜索查询中单词和短语的含义的搜索技术。语义搜索算法使用知识图和其他语义技术来分析实体和概念之间的关系,并基于此分析提供更相关的搜索结果。
换句话说,知识图谱为语义搜索提供了丰富的知识背景,帮助理解查询意图和提供准确的搜索结果。同时,语义搜索可以帮助构建和扩展知识图谱,提高搜索的准确性和语义理解能力。
例如,谷歌的知识图使用庞大的结构化数据数据库来支持其搜索结果,并提供有关搜索结果中出现的实体(例如人物、地点和事物)的附加信息。这使得用户更容易找到他们正在寻找的信息并探索相关的概念和实体。
向量数据库、知识图谱和语义搜索
向量数据库是另一种可以与语义搜索和知识图相结合使用以改进搜索结果的技术。它主要用于处理和分析具有向量特征的数据,如图像、音频、文本、时间序列等。
传统的关系型数据库主要用于存储结构化的数据,而向量数据库则专注于存储和处理高维向量。它的设计目标是能够高效地进行向量相似性搜索和聚类等操作,以支持复杂的数据分析和机器学习任务。向量数据库使用机器学习算法将数据表示为向量,向量是数据的数学表示,可用于各种计算任务,例如,向量可用于表示人、地点和事物等实体以及它们之间的关系。通过比较这些向量,搜索算法可以识别数据本身可能无法立即显现的关系和模式。
在语义搜索和知识图的背景下,向量数据库可以通过更好地理解实体和概念之间的关系来提高搜索结果的准确性。
例如,当用户搜索“ London ”时,语义搜索算法可以使用知识图和向量数据库来了解用户可能指的是英国伦敦市,而不是其他同名实体。
通过使用向量数据库来表示和比较实体和概念,搜索算法可以提供更相关和更准确的搜索结果。
总体而言,向量数据库、语义搜索和知识图谱都是共同提高搜索算法的准确性和效率的技术。通过利用这些技术,搜索引擎和其他应用程序可以更好地理解实体和概念之间的关系,从而更轻松地找到用户正在寻找的信息。
关于 Easysearch
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
官网文档:https://infinilabs.com/docs/latest/easysearch
