

sql
INFINI Labs 产品更新 | 发布 Easysearch Java 客户端,Console 支持 SQL 查询等功能
Easysearch • liaosy 发表了文章 • 0 个评论 • 2721 次浏览 • 2023-11-17 18:56

INFINI Labs 产品又更新啦~,本次更新概要如下:发布 Easysearch-client Java 客户端,开发者通过 client 与 Easysearch 集群的交互变得更加简洁和直观;Console 开发工具新增 SQL 特性,支持 SELECT 查询等语法高亮和自动提示等;Gateway 的系统 API 添加了基于基本身份验证的安全功能。
以下是本次更新的详细说明。
INFINI Easysearch-client v1.0.1
正式发布 Easysearch Java 客户端。
这一里程碑式的更新为开发人员带来了前所未有的便利性,使得与 Easysearch 集群的交互变得更加简洁和直观。现在,通过 Easysearch-client 客户端,开发者可以直接使用 Java 方法和数据结构来进行交互,而不再需要依赖于传统的 HTTP 方法和 JSON。这一变化大大简化了操作流程,使得数据管理和索引更加高效。高级客户端的功能范围包括处理数据操作,管理集群,包括查看和维护集群的健康状态,并对 Security 模块全面兼容。它提供了一系列 API,用于管理角色、用户、权限、角色映射和账户。这意味着安全性和访问控制现在可以更加细粒度地管理,确保了数据的安全性和合规性。
使用说明参见:快速开始
INFINI Console v1.11.0
INFINI Console 是一款非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管, 企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 在线体验: http://demo.infini.cloud (用户名/密码:readonly/readonly)。
Console 本次更新如下:
Features
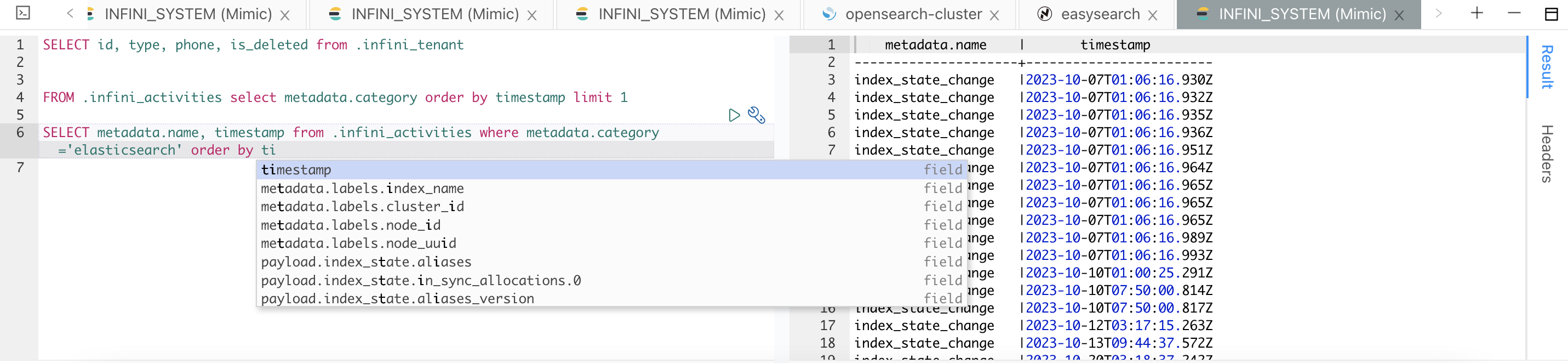
- 开发工具 SQL 查询支持
- 支持 SELECT 查询及语法高亮
- 支持索引和字段自动提示
- 支持 FROM 前置语法
Bug fix
- 修复平台概览集群指标为空的问题
Improvements
- LDAP 支持从 DN 中解析 OU 属性
- 集群动态优化显示,新增节点名称和索引名称的聚合统计过滤
INFINI Gateway v1.19.0
INFINI Gateway 是一个面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway 可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
Gateway 本次更新如下:
Features
- 添加
http处理器 - 在 API 模块中添加基于基本身份验证的安全性
- 允许将自身注册到配置管理器
- 允许在配置错误时触发 panic
Bug fix
- 修复
rewrite_to_bulk在较新版本中缺少_type的问题 - 修复
rewrite_to_bulk,支持无索引文档操作
Improvements
- 更新测试,断言解析结果
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
您还可以通过邮件联系我们:hello@infini.ltd
或者拨打我们的热线电话:(+86) 400-139-9200
欢迎加入 Discord 聊天室:https://discord.gg/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。

关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
Elasticsearch 与SQL-style Join 前篇
Elasticsearch • liaosy 发表了文章 • 1 个评论 • 2620 次浏览 • 2022-01-18 19:27
Elasticsearch 与SQL-style Join 前篇
1.上下文
Elasticsearch(后面简称ES)作为火热的开源&分布式&Json文档形式的搜索引擎在互联网行业被广泛应用. 作为一种NoSQL数据存储服务, ES的侧重点放在了扩展性(Scalability) 与可用性(Availability)上, 提供了极快的搜索与索引文档能力(省略各种对ES的赞美.....就如同你知道的.....主要提供搜索的能力!) 然而, 来自SQL世界的我们, 日常被各种关系性数据充斥着, 使用ES常常疑惑为什么大量MySql中适用的法则在ES中行不通: 不同于SQL的ES DSL语言风格, 搜到/搜不到想要的结果集, 复杂的聚合分析,众多正在不断演进的新功能与永远记不完的APIs....... 本文不会对ES的基本功能作太多的讲解, 侧重放在了对SQL中的join查询与ES提供的join方案的对比与分析上, 基于本人的实践经验, 提供了数种可行的跨索引关联查询方案
本文分为"前篇"与"后篇" ,分别覆盖了不同的ES中实现SQL-style join的技术方案
2.引子
2.1 建议
- 不要用Mysql上的规则去理解一款NoSql DB(Elastic search)
- Join查询与简单的"向多个索引查询数据"并不等价: join查询体现一个"数据关联",后文将重点描述
- 有时候, 为了达到某些效果, 可能意味着"pay some price" (e.g 空间换时间)
2.2 Join查询
开始正文前, 聊聊什么是join查询, join查询在绝大数情况下是SQL中的概念, SQL-style join查询是体现关系型数据库中"关系"的重要方式, 通过驱动表与被驱动表的字段关联, 表与表之间建立了联系方式, 并可以把多个表中的字段值一起返回到结果集:
- 表与表之间有关联性(由连接字段确定)
- 结果集中体现了这种关联性
看到这....或许你会疑惑为什么在解释join查询时反复强调"关联"二字, 相信你应该熟悉SQL中的笛卡尔积现象, 如果不通过连接字段对数据进行筛选, 那么表与表之间连接后产生的"宽表"的数据量会是一个很恐怖的数字(表A行数X表B行数X表C行数.....以此类推), 业务往往需要对产生的结果集进行二次数据筛选, 最后才能从大量的数据中找到少量感兴趣的信息. 而通过指定SQL-style中的join关联关系(e.g table A.字段1 =tableB.字段1)就能在SQL服务中就完成数据筛选, 并且返回的结果集中体现了这种关联性, 降低了业务上筛选相关的工作量.
作为一款 Nosql 且 Schemaless的数据存储, ElasticSearch没有对数据的结构进行强限制, 对客户端而言,返回的结果集都是由弱类型的json对象组成. ES没有像SQL DB那样做到对join查询的友好支持. 但是数据与数据之间的关联在ES中同样非常重要!(或许在任何数据存储服务中都重要). 本文前后篇通过对比讨论 "denormalization(反范式)" , "应用层join", "ES nested query" ,"ES has parent/child query", "ES服务层join(open distro开源生态下)"这些技术的方式(部分将在后篇描述), 探讨join查询在不同环境下的有效解决方案.
3. 方案
3.0 前言: 需解决的问题
如果需要在ES中实现一个SQL:
select * from tablea a join tableb b
on a.field1 =b.field1 order by a.create_time desc等价查询效果, 并且应用层能通过分页的方式滚动查询到所有数据
3.1 方案一: denormalization(反范式)
这可能是最"直接"的方案了, 通过修改数据模型来“flatten”数据,每个ES文档在被index时就已经有了所需要的全部关联数据.
如果是搭建异构索引场景(可理解为RDS从库), 根据关联关系的不同(1 to N, N to M)索引的文档量最高将会是 2乘以 tablea行数乘以 tableb行数(有点笛卡尔积的感觉). Denormalization通过建立"超级宽"的索引维系了1 to N 或 N to M的关联关系, 应用层与ES不需要做任何join处理, 因为一个文档已经拥有了客户端需要的全部数据(数据层面上已经做到了聚合)
对于平时与关系型数据库打交道的童鞋而言, 建 "超级宽表" 映射的索引与数据冗余可能是一件"非正常"的行为, 第一反应就是数据的冗余与空间资源浪费. 但是这种方案的确是目前广泛使用的建立数据关联关系的解决方案(如同前文说的------不要用Mysql上的规则去理解ES).
3.1.1 优势
- 应用端 & ES端都不需要做任何join操作(一个ES文档有全部客户端想要的数据)
- 分布式环境下因聚合结果集相关操作产生的延迟问题得到有效解决
- 在空间资源足够下, 方案可行性高(至少有信心吼一句"能做到")
3.1.2 挑战
- 数据的冗余与空间资源浪费(空间换时间)
- 如何梳理业务模型与flatten数据: 关系型数据中通过外键,schema约束, 查询语句(join)等方式建立的关联关系要被体现到ES的索引mapping中
- 应用层(访问ES的服务)需要的编码调整(有些工程会在dao层做统一适配处理)
- 更新操作涉及到的数据大幅度增加: 原本一个涉及单表单行update SQL可能会牵扯到多个文档中的某个字段, 且每个文档占用的空间资源更高
- 新增文档的频率会更高: 理由同上
总结: Denormation方案的通用性高, 并且能够满足快速搜索的需求(最快的查询关联数据的方式), 但是额外的存储资源使用带来的相应开销问题与数据模型梳理上的问题会带来挑战
3.2 方案二: ES SQL join(open distro开源生态)
xpack 增加了有限度的SQL支持
然而...不支持join语法....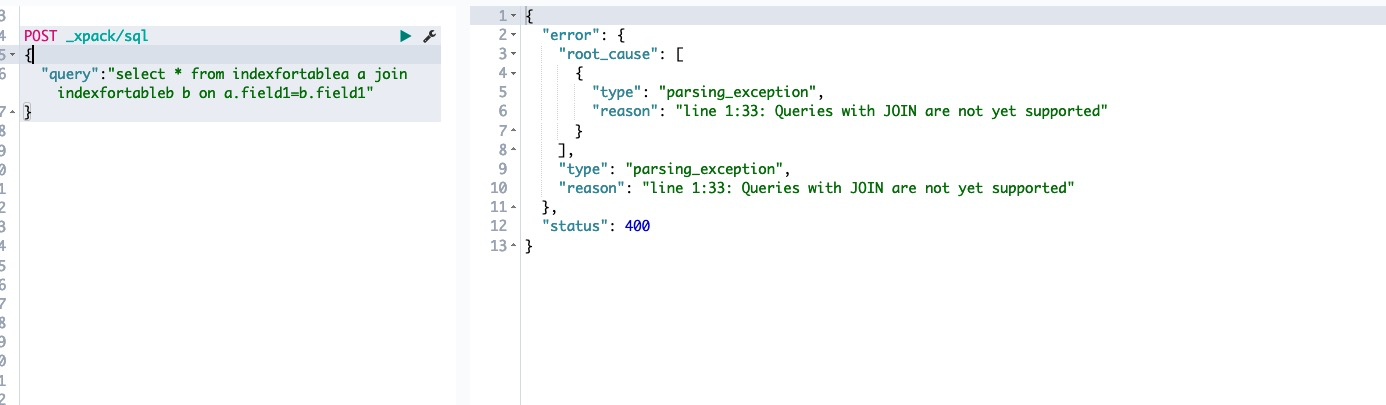
安装扩展插件获取更强的SQL支持能力(open distro)
LINK
更为强大的SQL支持(包括join语法)
 挑战:
挑战:
- 额外的ES插件(第三方插件对ES不同版本的兼容性?)
- 业务方调整(语句改为SQL-style, 且要使用open distro提供的JDBC相关依赖)
- open distro是一整套ES工具集(AWS上自带集成)
- 对该产品特性的学习LINK
3.3 方案三: 应用层join
通过应用工程对不同索引的多次访问,在组装结果集的过程中建立数据的关联关系
3.3.1 实现方式
可以仿照MySQL的join实现方式: 例如为了实现
select * from tablea a join tableb b
on a.field1 =b.field1 where a.field2 in ('value1','value2','value3') order by a.create_time desc这句SQL的等效查询
应用层可以:
- 1 选择 tablea 对应的异构索引作为驱动索引, 通过结构化查询, 获取field2 为'value1','value2','value3' 的文档中_id值(N个)
- 2 以文档field1作为连接条件, 从被驱动索引(tableb对应的异构索引)中找到字段field1满足条件( a.field1 =b.field1)的文档
- 3 用获取到的文档拼接结果集返回
如果配合ES terms-lookup 则为:
/**从tablea fetch符合条件的文档集**/
GET tablea/_search
{
"query": {
"terms": {
"field2": [
"value1",
"value2",
"value3"
]
}
}
}
/**假使仅获得一个文档且_id值为6666**/
GET tableb/_search
{
"query": {
"terms": {
"field1": {
"index" : "tablea",
"type" : "_doc",
"id" : "6666",
"path" : "field1"
}
}
}
}
/**利用ES terms-lookup进行连接查询**/
以上查询在应用层可用ES high-level-client实现, 数据的拼接,过滤, 循环查询等挑战都需要在应用层克服(难)
3.3.2 该方案面临几个挑战
- 如果文档数过多(被驱动表/驱动表中任意一张表获取的文档过多) -> 内存,网络等资源占用过高
- 应用层join引发的多次请求
- 应用层join引发的ES服务端压力
- 应用层代码的改动: 驱动表的选择, join的实现, 应用层缓存数据的压力...
- 一套稳定的join机制的实现会很复杂......
4. End
本文分为前篇与后篇, 我会在后篇文章中对这些技术进行进一步描述与对比, 并且引入可实践的方案.
原稿作者:Yukai糖在江湖
原稿链接:https://blog.csdn.net/fanduifandui/article/details/117264084

elasticsearch-SQL查询报错,错误如下,是哪里的问题?
Elasticsearch • JackGe 回复了问题 • 2 人关注 • 2 个回复 • 4622 次浏览 • 2018-09-02 08:47
玩转 Elasticsearch 的 SQL 功能
Elasticsearch • medcl 发表了文章 • 9 个评论 • 75256 次浏览 • 2018-06-27 21:54
最近发布的 Elasticsearch 6.3 包含了大家期待已久的 SQL 特性,今天给大家介绍一下具体的使用方法。
首先看看接口的支持情况
目前支持的 SQL 只能进行数据的查询只读操作,不能进行数据的修改,所以我们的数据插入还是要走之前的常规索引接口。
目前 Elasticsearch 的支持 SQL 命令只有以下几个:
| 命令 | 说明 |
|---|---|
| DESC table | 用来描述索引的字段属性 |
| SHOW COLUMNS | 功能同上,只是别名 |
| SHOW FUNCTIONS | 列出支持的函数列表,支持通配符过滤 |
| SHOW TABLES | 返回索引列表 |
| SELECT .. FROM table_name WHERE .. GROUP BY .. HAVING .. ORDER BY .. LIMIT .. | 用来执行查询的命令 |
我们分别来看一下各自怎么用,以及有什么效果吧,自己也可以动手试一下,看看。
首先,我们创建一条数据:
POST twitter/doc/
{
"name":"medcl",
"twitter":"sql is awesome",
"date":"2018-07-27",
"id":123
}RESTful下调用SQL
在 ES 里面执行 SQL 语句,有三种方式,第一种是 RESTful 方式,第二种是 SQL-CLI 命令行工具,第三种是通过 JDBC 来连接 ES,执行的 SQL 语句其实都一样,我们先以 RESTful 方式来说明用法。
RESTful 的语法如下:
POST /_xpack/sql?format=txt
{
"query": "SELECT * FROM twitter"
}因为 SQL 特性是 xpack 的免费功能,所以是在 _xpack 这个路径下面,我们只需要把 SQL 语句传给 query 字段就行了,注意最后面不要加上 ; 结尾,注意是不要!
我们执行上面的语句,查询返回的结果如下:
date | id | name | twitter
------------------------+---------------+---------------+---------------
2018-07-27T00:00:00.000Z|123 |medcl |sql is awesome ES 俨然已经变成 SQL 数据库了,我们再看看如何获取所有的索引列表:
POST /_xpack/sql?format=txt
{
"query": "SHOW tables"
}返回如下:
name | type
---------------------------------+---------------
.kibana |BASE TABLE
.monitoring-alerts-6 |BASE TABLE
.monitoring-es-6-2018.06.21 |BASE TABLE
.monitoring-es-6-2018.06.26 |BASE TABLE
.monitoring-es-6-2018.06.27 |BASE TABLE
.monitoring-kibana-6-2018.06.21 |BASE TABLE
.monitoring-kibana-6-2018.06.26 |BASE TABLE
.monitoring-kibana-6-2018.06.27 |BASE TABLE
.monitoring-logstash-6-2018.06.20|BASE TABLE
.reporting-2018.06.24 |BASE TABLE
.triggered_watches |BASE TABLE
.watcher-history-7-2018.06.20 |BASE TABLE
.watcher-history-7-2018.06.21 |BASE TABLE
.watcher-history-7-2018.06.26 |BASE TABLE
.watcher-history-7-2018.06.27 |BASE TABLE
.watches |BASE TABLE
apache_elastic_example |BASE TABLE
forum-mysql |BASE TABLE
twitter 有点多,我们可以按名称过滤,如 twitt 开头的索引,注意通配符只支持 %和 _,分别表示多个和单个字符(什么,不记得了,回去翻数据库的书去!):
POST /_xpack/sql?format=txt
{
"query": "SHOW TABLES 'twit%'"
}
POST /_xpack/sql?format=txt
{
"query": "SHOW TABLES 'twitte_'"
}上面返回的结果都是:
name | type
---------------+---------------
twitter |BASE TABLE
如果要查看该索引的字段和元数据,如下:
POST /_xpack/sql?format=txt
{
"query": "DESC twitter"
}返回:
column | type
---------------+---------------
date |TIMESTAMP
id |BIGINT
name |VARCHAR
name.keyword |VARCHAR
twitter |VARCHAR
twitter.keyword|VARCHAR 都是动态生成的字段,包含了 .keyword 字段。 还能使用下面的命令来查看,主要是兼容 SQL 语法。
POST /_xpack/sql?format=txt
{
"query": "SHOW COLUMNS IN twitter"
}另外,如果不记得 ES 支持哪些函数,只需要执行下面的命令,即可得到完整列表:
SHOW FUNCTIONS返回结果如下,也就是当前6.3版本支持的所有函数,如下:
name | type
----------------+---------------
AVG |AGGREGATE
COUNT |AGGREGATE
MAX |AGGREGATE
MIN |AGGREGATE
SUM |AGGREGATE
STDDEV_POP |AGGREGATE
VAR_POP |AGGREGATE
PERCENTILE |AGGREGATE
PERCENTILE_RANK |AGGREGATE
SUM_OF_SQUARES |AGGREGATE
SKEWNESS |AGGREGATE
KURTOSIS |AGGREGATE
DAY_OF_MONTH |SCALAR
DAY |SCALAR
DOM |SCALAR
DAY_OF_WEEK |SCALAR
DOW |SCALAR
DAY_OF_YEAR |SCALAR
DOY |SCALAR
HOUR_OF_DAY |SCALAR
HOUR |SCALAR
MINUTE_OF_DAY |SCALAR
MINUTE_OF_HOUR |SCALAR
MINUTE |SCALAR
SECOND_OF_MINUTE|SCALAR
SECOND |SCALAR
MONTH_OF_YEAR |SCALAR
MONTH |SCALAR
YEAR |SCALAR
WEEK_OF_YEAR |SCALAR
WEEK |SCALAR
ABS |SCALAR
ACOS |SCALAR
ASIN |SCALAR
ATAN |SCALAR
ATAN2 |SCALAR
CBRT |SCALAR
CEIL |SCALAR
CEILING |SCALAR
COS |SCALAR
COSH |SCALAR
COT |SCALAR
DEGREES |SCALAR
E |SCALAR
EXP |SCALAR
EXPM1 |SCALAR
FLOOR |SCALAR
LOG |SCALAR
LOG10 |SCALAR
MOD |SCALAR
PI |SCALAR
POWER |SCALAR
RADIANS |SCALAR
RANDOM |SCALAR
RAND |SCALAR
ROUND |SCALAR
SIGN |SCALAR
SIGNUM |SCALAR
SIN |SCALAR
SINH |SCALAR
SQRT |SCALAR
TAN |SCALAR
SCORE |SCORE 同样支持通配符进行过滤:
POST /_xpack/sql?format=txt
{
"query": "SHOW FUNCTIONS 'S__'"
}结果:
name | type
---------------+---------------
SUM |AGGREGATE
SIN |SCALAR 那如果要进行模糊搜索呢,Elasticsearch 的搜索能力大家都知道,强!在 SQL 里面,可以用 match 关键字来写,如下:
POST /_xpack/sql?format=txt
{
"query": "SELECT SCORE(), * FROM twitter WHERE match(twitter, 'sql is') ORDER BY id DESC"
}最后,还能试试 SELECT 里面的一些其他操作,如过滤,别名,如下:
POST /_xpack/sql?format=txt
{
"query": "SELECT SCORE() as score,name as myname FROM twitter as mytable where name = 'medcl' OR name ='elastic' limit 5"
}结果如下:
score | myname
---------------+---------------
0.2876821 |medcl 或是分组和函数计算:
POST /_xpack/sql?format=txt
{
"query": "SELECT name,max(id) as max_id FROM twitter as mytable group by name limit 5"
}结果如下:
name | max_id
---------------+---------------
medcl |123.0 SQL-CLI下的使用
上面的例子基本上把 SQL 的基本命令都介绍了一遍,很多情况下,用 RESTful 可能不是很方便,那么可以试试用 CLI 命令行工具来执行 SQL 语句,妥妥的 SQL 操作体验。
切换到命令行下,启动 cli 程序即可进入命令行交互提示界面,如下:
➜ elasticsearch-6.3.0 ./bin/elasticsearch-sql-cli
.sssssss.` .sssssss.
.:sXXXXXXXXXXo` `ohXXXXXXXXXho.
.yXXXXXXXXXXXXXXo` `oXXXXXXXXXXXXXXX-
.XXXXXXXXXXXXXXXXXXo` `oXXXXXXXXXXXXXXXXXX.
.XXXXXXXXXXXXXXXXXXXXo. .oXXXXXXXXXXXXXXXXXXXXh
.XXXXXXXXXXXXXXXXXXXXXXo``oXXXXXXXXXXXXXXXXXXXXXXy
`yXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX.
`oXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXo`
`oXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXo`
`oXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXo`
`oXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXo`
`oXXXXXXXXXXXXXXXXXXXXXXXXXXXXo`
.XXXXXXXXXXXXXXXXXXXXXXXXXo`
.oXXXXXXXXXXXXXXXXXXXXXXXXo`
`oXXXXXXXXXXXXXXXXXXXXXXXXo` `odo`
`oXXXXXXXXXXXXXXXXXXXXXXXXo` `oXXXXXo`
`oXXXXXXXXXXXXXXXXXXXXXXXXo` `oXXXXXXXXXo`
`oXXXXXXXXXXXXXXXXXXXXXXXXo` `oXXXXXXXXXXXXXo`
`yXXXXXXXXXXXXXXXXXXXXXXXo` oXXXXXXXXXXXXXXXXX.
.XXXXXXXXXXXXXXXXXXXXXXo` `oXXXXXXXXXXXXXXXXXXXy
.XXXXXXXXXXXXXXXXXXXXo` /XXXXXXXXXXXXXXXXXXXXX
.XXXXXXXXXXXXXXXXXXo` `oXXXXXXXXXXXXXXXXXX-
-XXXXXXXXXXXXXXXo` `oXXXXXXXXXXXXXXXo`
.oXXXXXXXXXXXo` `oXXXXXXXXXXXo.
`.sshXXyso` SQL `.sshXhss.`
sql> 当你看到一个硕大的创口贴,表示 SQL 命令行已经准备就绪了,查看一下索引列表,不,数据表的列表:

各种操作妥妥的,上面已经测试过的命令就不在这里重复了,只是体验不一样罢了。
如果要连接远程的 ES 服务器,只需要启动命令行工具的时候,指定服务器地址,如果有加密,指定 keystone 文件,完整的帮助如下:
➜ elasticsearch-6.3.0 ./bin/elasticsearch-sql-cli --help
Elasticsearch SQL CLI
Non-option arguments:
uri
Option Description
------ -----------
-c, --check <Boolean> Enable initial connection check on startup (default:
true)
-d, --debug Enable debug logging
-h, --help show help
-k, --keystore_location Location of a keystore to use when setting up SSL. If
specified then the CLI will prompt for a keystore
password. If specified when the uri isn't https then
an error is thrown.
-s, --silent show minimal output
-v, --verbose show verbose output JDBC 对接
JDBC 对接的能力,让我们可以与各个 SQL 生态系统打通,利用众多现成的基于 SQL 之上的工具来使用 Elasticsearch,我们以一个工具来举例。
和其他数据库一样,要使用 JDBC,要下载该数据库的 JDBC 的驱动,我们打开: https://www.elastic.co/downloads/jdbc-client

只有一个 zip 包下载链接,下载即可。
然后,我们这里使用 DbVisualizer 来连接 ES 进行操作,这是一个数据库的操作和分析工具,DbVisualizer 下载地址是:https://www.dbvis.com/。
下载安装启动之后的程序主界面如下图:

我们如果要使用 ES 作为数据源,我们第一件事需要把 ES 的 JDBC 驱动添加到 DbVisualizer 的已知驱动里面。我们打开 DbVisualizer 的菜单【Tools】-> 【Driver Manager】,打开如下设置窗口:

点击绿色的加号按钮,新增一个名为 Elasticsearch-SQL 的驱动,url format 设置成 jdbc:es:,如下图:

然后点击上图黄色的文件夹按钮,添加我们刚刚下载好且解压之后的所有 jar 文件,如下:

添加完成之后,如下图:

就可以关闭这个 JDBC 驱动的管理窗口了。下面我们来连接到 ES 数据库。
选择主程序左侧的新建连接图标,打开向导,如下:

选择刚刚加入的 Elasticsearch-SQL 驱动:

设置连接字符串,此处没有登录信息,如果有可以对应的填上:

点击 Connect,即可连接到 ES,左侧导航可以展开看到对应的 ES 索引信息:

同样可以查看相应的库表结果和具体的数据:

用他自带的工具执行 SQL 也是不在话下:

同理,各种 ETL 工具和基于 SQL 的 BI 和可视化分析工具都能把 Elasticsearch 当做 SQL 数据库来连接获取数据了。
最后一个小贴士,如果你的索引名称包含横线,如 logstash-201811,只需要做一个用双引号包含,对双引号进行转义即可,如下:
POST /_xpack/sql?format=txt
{
"query":"SELECT COUNT(*) FROM \"logstash-*\""
}关于 SQL 操作的文档在这里:
https://www.elastic.co/guide/en/elasticsearch/reference/current/sql-jdbc.html
Enjoy!
有老铁测试了es6.3.0的sql功能吗?
Elasticsearch • feloxx 发表了文章 • 16 个评论 • 5823 次浏览 • 2018-06-19 16:26
sql> show tables;
name | type
----------------+---------------
hello |BASE TABLE
sql> select * from hello;
Server error [Server encountered an error [Cannot extract value [deliveraddress.address] from source]. [SqlIllegalArgumentException[Cannot extract value [deliveraddress.address] from source]
at org.elasticsearch.xpack.sql.execution.search.extractor.FieldHitExtractor.extractFromSource(FieldHitExtractor.java:139)
at org.elasticsearch.xpack.sql.execution.search.extractor.FieldHitExtractor.extract(FieldHitExtractor.java:95)
at org.elasticsearch.xpack.sql.execution.search.SearchHitRowSet.getColumn(SearchHitRowSet.java:114)
at org.elasticsearch.xpack.sql.session.AbstractRowSet.column(AbstractRowSet.java:18){
"test2": {
"properties": {
"deliveraddress": {
"properties": {
"phone_no": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},
"default": {
"type": "boolean"
},
"address": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},
"province": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},
"city": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},
"mapping_id": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},
"name": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},
"full_address": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},
"zip_code": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
}
}
},
"alipaywealth": {
"properties": {
"balance": {
"type": "long"
},
"total_quotient": {
"type": "long"
},
"huabei_creditamount": {
"type": "long"
},
"mapping_id": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},
"huabei_totalcreditamount": {
"type": "long"
},
"total_profit": {
"type": "long"
}
}
},
"id": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
}
}
}
}{
"_id": "5b1cbc7935eb6e0007a154bb",
"deliveraddress": [
{
"phone_no": "13*******98",
"default": true,
"address": "江苏省无asdads市徐***镇",
"province": "江苏",
"city": "无锡",
"mapping_id": "3561511087asdasd341",
"name": "b***",
"full_address": "湖asd***上7号",
"zip_code": "214400"
},
{
"phone_no": "15*******70",
"default": false,
"address": "江苏省苏州asdasdasd张家港经济技术开发区",
"province": "江苏",
"city": "苏州",
"mapping_id": "3561511asdasd505341",
"name": "a**",
"full_address": "新asd路***德***",
"zip_code": "215600"
}
],
"alipaywealth": {
"balance": 0,
"total_quotient": 0,
"huabei_creditamount": 500,
"mapping_id": "3561511asdsa63505341",
"huabei_totalcreditamount": 500,
"total_profit": 0
}
} @SuppressWarnings("unchecked")
Object extractFromSource(Map<String, Object> map) {
Object value = map;
boolean first = true;
// each node is a key inside the map
for (String node : path) {
if (value == null) {
return null;
} else if (first || value instanceof Map) {
first = false;
value = ((Map<String, Object>) value).get(node);
} else {
throw new SqlIllegalArgumentException("Cannot extract value [{}] from source", fieldName);
}
}
return unwrapMultiValue(value);
}elastic 5.x 有支持的 sql 查询的jar包吗
Elasticsearch • strglee 回复了问题 • 2 人关注 • 1 个回复 • 2474 次浏览 • 2018-04-12 11:31

Elasticsearch sql 怎么实现高亮

Elasticsearch • xinfanwang 回复了问题 • 2 人关注 • 1 个回复 • 5684 次浏览 • 2017-08-18 15:57
Sql on Elasticsearch
Elasticsearch • hill 发表了文章 • 9 个评论 • 8710 次浏览 • 2017-04-28 11:25

create table my_index.my_table (
id keyword,
name text,
age long,
birthday date
);
select * from my_index.my_type;
select count(*) from my_index.my_table group by age;
#Create table
字段参数,ES中分词规则、索引类型、字段格式等高级参数的支持
create table my_table (
name text (analyzer = ik_max_word),
dd text (index=no),
age long (include_in_all=false)
);
对象、嵌套字段支持 as
create table my_index (
id long,
name text,
obj object as (
first_name text,
second_name text (analyzer=pinyin)
)
);
create table my_index (
id long,
name text,
obj nested as (
first_name text,
second_name text (analyzer=pinyin)
)
);
ES索引高级参数支持 with option
create table my_index (
id long,
name text
) with option (
index.number_of_shards=10,
index.number_of_replicas = 1
);
#Insert/Bulk
单条数据插入
insert into my_index.index (name,age) values ('zhangsan',24);
多条插入
bulk into my_index.index (name,age) values ('zhangsan',24),('lisi',24);
对象数据插入,list,{}Map
insert into my_index.index (ds) values (['zhejiang','hangzhou']);
insert into my_index.index (dd) values ({address='zhejiang',postCode='330010'});
#select/Aggregations
select * from my_table.my_index where name like 'john *' and age between 20 and 30 and (hotel = 'hanting' or flight = 'MH4510');
地理位置中心点查询
select * from hz_point where geo_distance({distance='1km',location='30.306378,120.247427'});
地理坐标区域查询
select * from hz_point where geo_bounding_box({location={top_left='31.306378,119.247427',bottom_right='29.285797,122.172329'}});
pipeline统计 move_avg
select count(*) as total, moving_avg({buckets_path=total}) from my_index group by date_histogram({field=timestamp,interval='1h'});
Getting Started
环境要求python >= 2.7
export PYTHONHOME=(%python_path)
export PATH=$PYTHONHOME/bin:$PATH
安装第三方依赖包
pip install -r esql5.egg-info/requires.txt
或python setup.py install
运行esql5服务
(standalone):
cd esql5
python -m App.app
(with uwsgi)
cd esql5
uwsgi --ini conf/uwsgi.ini
shell终端:
python -m elsh.Commandelasticsearch-query-tookit一款基于SQL查询elasticsearch编程工具包,支持SQL解析生成DSL,支持JDBC驱动,支持和Spring、MyBatis集成
Elasticsearch • chennanlcy 发表了文章 • 1 个评论 • 9458 次浏览 • 2017-03-24 23:09
String sql = "select * from index.order where status='SUCCESS' and price > 100 order by nvl(pride, 0) asc routing by 'JD' limit 0, 20";
ElasticSql2DslParser sql2DslParser = new ElasticSql2DslParser();
//解析SQL
ElasticSqlParseResult parseResult = sql2DslParser.parse(sql);
//生成DSL(可用于rest api调用)
String dsl = parseResult.toDsl();
//toRequest方法接收一个clinet对象参数
SearchRequestBuilder searchReq = parseResult.toRequest(esClient);
//执行查询
SearchResponse response = searchReq.execute().actionGet();{
"from" : 0,
"size" : 20,
"query" : {
"bool" : {
"filter" : {
"bool" : {
"must" : [ {
"term" : {
"status" : "SUCCESS"
}
}, {
"range" : {
"price" : {
"from" : 100,
"to" : null,
"include_lower" : false,
"include_upper" : true
}
}
} ]
}
}
}
},
"sort" : [ {
"pride" : {
"order" : "asc",
"missing" : 0
}
} ]
}<bean id="elasticDataSource" class="org.elasticsearch.jdbc.api.ElasticSingleConnectionDataSource" destroy-method="destroy">
<property name="driverClassName" value="org.elasticsearch.jdbc.api.ElasticDriver" />
<property name="url" value="jdbc:elastic:192.168.0.109:9300/product_cluster" />
</bean>
<bean id="sqlMapClient" class="org.springframework.orm.ibatis.SqlMapClientFactoryBean">
<property name="dataSource" ref="elasticDataSource" />
<property name="configLocation" value="classpath:sqlMapConfig.xml"/>
</bean><sqlMapConfig>
<settings
cacheModelsEnabled="true"
lazyLoadingEnabled="true"
enhancementEnabled="true"
maxSessions="64"
maxTransactions="20"
maxRequests="128"
useStatementNamespaces="true"/>
<sqlMap resource="sqlmap/PRODUCT.xml"/>
</sqlMapConfig><sqlMap namespace="PRODUCT">
<select id="getProductByCodeAndMatchWord" parameterClass="java.util.Map" resultClass="java.lang.String">
SELECT *
FROM index.product
QUERY match(productName, #matchWord#) or prefix(productName, #prefixWord#, 'boost:2.0f')
WHERE productCode = #productCode#
AND advicePrice > #advicePrice#
AND $$buyers.buyerName IN ('china', 'usa')
ROUTING BY #routingVal#
</select>
</sqlMap>@Repository
public class ProductDao {
@Autowired
@Qualifier("sqlMapClient")
private SqlMapClient sqlMapClient;
public List<Product> getProductByCodeAndMatchWord(String matchWord, String productCode) throws SQLException {
Map<String, Object> paramMap = Maps.newHashMap();
paramMap.put("productCode", productCode);
paramMap.put("advicePrice", 1000);
paramMap.put("routingVal", "A");
paramMap.put("matchWord", matchWord);
paramMap.put("prefixWord", matchWord);
String responseGson = (String) sqlMapClient.queryForObject("PRODUCT.getProductByCodeAndMatchWord", paramMap);
//反序列化查询结果
JdbcSearchResponseResolver responseResolver = new JdbcSearchResponseResolver(responseGson);
JdbcSearchResponse<Product> searchResponse = responseResolver.resolveSearchResponse(Product.class);
return searchResponse.getDocList();
}
}@Test
public void testProductQuery() throws Exception {
BeanFactory factory = new ClassPathXmlApplicationContext("application-context.xml");
ProductDao productDao = factory.getBean(ProductDao.class);
List<Product> productList = productDao.getProductByCodeAndMatchWord("iphone 6s", "IP_6S");
for (Product product : productList) {
System.out.println(product.getProductName());
}
}
有木有人用elasticsearch-sql?
Elasticsearch • ansj 回复了问题 • 7 人关注 • 5 个回复 • 6919 次浏览 • 2016-12-02 22:02
Sql 语法转换es node版本


Elasticsearch • wwfalcon 回复了问题 • 6 人关注 • 3 个回复 • 7554 次浏览 • 2016-03-17 15:31

有没有可能搞一个综合的Kafka/Elasticsearch集群
回复Elasticsearch • taowen 发起了问题 • 1 人关注 • 0 个回复 • 5128 次浏览 • 2016-03-06 16:20
使用 SQL 查询 Elasticsearch
Elasticsearch • taowen 发表了文章 • 4 个评论 • 15868 次浏览 • 2016-02-21 16:19
$ cat << EOF | ./es_query.py http://127.0.0.1:9200
WITH SELECT MAX(market_cap) AS max_all_times FROM symbol AS all_symbols;
WITH SELECT MAX(market_cap) AS max_at_2000 FROM all_symbols WHERE ipo_year=2000 AS year_2000;
WITH SELECT MAX(market_cap) AS max_at_2001 FROM all_symbols WHERE ipo_year=2001 AS year_2001;
EOF
Elasticsearch 整合 SQL 嵌套group by
Elasticsearch • DengShk 回复了问题 • 2 人关注 • 2 个回复 • 6869 次浏览 • 2015-12-10 09:44
elasticsearch-SQL查询报错,错误如下,是哪里的问题?
回复Elasticsearch • JackGe 回复了问题 • 2 人关注 • 2 个回复 • 4622 次浏览 • 2018-09-02 08:47
elastic 5.x 有支持的 sql 查询的jar包吗
回复Elasticsearch • strglee 回复了问题 • 2 人关注 • 1 个回复 • 2474 次浏览 • 2018-04-12 11:31
Elasticsearch sql 怎么实现高亮
回复Elasticsearch • xinfanwang 回复了问题 • 2 人关注 • 1 个回复 • 5684 次浏览 • 2017-08-18 15:57
有没有可能搞一个综合的Kafka/Elasticsearch集群
回复Elasticsearch • taowen 发起了问题 • 1 人关注 • 0 个回复 • 5128 次浏览 • 2016-03-06 16:20
Elasticsearch 整合 SQL 嵌套group by
回复Elasticsearch • DengShk 回复了问题 • 2 人关注 • 2 个回复 • 6869 次浏览 • 2015-12-10 09:44
INFINI Labs 产品更新 | 发布 Easysearch Java 客户端,Console 支持 SQL 查询等功能
Easysearch • liaosy 发表了文章 • 0 个评论 • 2721 次浏览 • 2023-11-17 18:56
INFINI Labs 产品又更新啦~,本次更新概要如下:发布 Easysearch-client Java 客户端,开发者通过 client 与 Easysearch 集群的交互变得更加简洁和直观;Console 开发工具新增 SQL 特性,支持 SELECT 查询等语法高亮和自动提示等;Gateway 的系统 API 添加了基于基本身份验证的安全功能。
以下是本次更新的详细说明。
INFINI Easysearch-client v1.0.1
正式发布 Easysearch Java 客户端。
这一里程碑式的更新为开发人员带来了前所未有的便利性,使得与 Easysearch 集群的交互变得更加简洁和直观。现在,通过 Easysearch-client 客户端,开发者可以直接使用 Java 方法和数据结构来进行交互,而不再需要依赖于传统的 HTTP 方法和 JSON。这一变化大大简化了操作流程,使得数据管理和索引更加高效。高级客户端的功能范围包括处理数据操作,管理集群,包括查看和维护集群的健康状态,并对 Security 模块全面兼容。它提供了一系列 API,用于管理角色、用户、权限、角色映射和账户。这意味着安全性和访问控制现在可以更加细粒度地管理,确保了数据的安全性和合规性。
使用说明参见:快速开始
INFINI Console v1.11.0
INFINI Console 是一款非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管, 企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 在线体验: http://demo.infini.cloud (用户名/密码:readonly/readonly)。
Console 本次更新如下:
Features
- 开发工具 SQL 查询支持
- 支持 SELECT 查询及语法高亮
- 支持索引和字段自动提示
- 支持 FROM 前置语法
Bug fix
- 修复平台概览集群指标为空的问题
Improvements
- LDAP 支持从 DN 中解析 OU 属性
- 集群动态优化显示,新增节点名称和索引名称的聚合统计过滤
INFINI Gateway v1.19.0
INFINI Gateway 是一个面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway 可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
Gateway 本次更新如下:
Features
- 添加
http处理器 - 在 API 模块中添加基于基本身份验证的安全性
- 允许将自身注册到配置管理器
- 允许在配置错误时触发 panic
Bug fix
- 修复
rewrite_to_bulk在较新版本中缺少_type的问题 - 修复
rewrite_to_bulk,支持无索引文档操作
Improvements
- 更新测试,断言解析结果
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
您还可以通过邮件联系我们:hello@infini.ltd
或者拨打我们的热线电话:(+86) 400-139-9200
欢迎加入 Discord 聊天室:https://discord.gg/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
Elasticsearch 与SQL-style Join 前篇
Elasticsearch • liaosy 发表了文章 • 1 个评论 • 2620 次浏览 • 2022-01-18 19:27
Elasticsearch 与SQL-style Join 前篇
1.上下文
Elasticsearch(后面简称ES)作为火热的开源&分布式&Json文档形式的搜索引擎在互联网行业被广泛应用. 作为一种NoSQL数据存储服务, ES的侧重点放在了扩展性(Scalability) 与可用性(Availability)上, 提供了极快的搜索与索引文档能力(省略各种对ES的赞美.....就如同你知道的.....主要提供搜索的能力!) 然而, 来自SQL世界的我们, 日常被各种关系性数据充斥着, 使用ES常常疑惑为什么大量MySql中适用的法则在ES中行不通: 不同于SQL的ES DSL语言风格, 搜到/搜不到想要的结果集, 复杂的聚合分析,众多正在不断演进的新功能与永远记不完的APIs....... 本文不会对ES的基本功能作太多的讲解, 侧重放在了对SQL中的join查询与ES提供的join方案的对比与分析上, 基于本人的实践经验, 提供了数种可行的跨索引关联查询方案
本文分为"前篇"与"后篇" ,分别覆盖了不同的ES中实现SQL-style join的技术方案
2.引子
2.1 建议
- 不要用Mysql上的规则去理解一款NoSql DB(Elastic search)
- Join查询与简单的"向多个索引查询数据"并不等价: join查询体现一个"数据关联",后文将重点描述
- 有时候, 为了达到某些效果, 可能意味着"pay some price" (e.g 空间换时间)
2.2 Join查询
开始正文前, 聊聊什么是join查询, join查询在绝大数情况下是SQL中的概念, SQL-style join查询是体现关系型数据库中"关系"的重要方式, 通过驱动表与被驱动表的字段关联, 表与表之间建立了联系方式, 并可以把多个表中的字段值一起返回到结果集:
- 表与表之间有关联性(由连接字段确定)
- 结果集中体现了这种关联性
看到这....或许你会疑惑为什么在解释join查询时反复强调"关联"二字, 相信你应该熟悉SQL中的笛卡尔积现象, 如果不通过连接字段对数据进行筛选, 那么表与表之间连接后产生的"宽表"的数据量会是一个很恐怖的数字(表A行数X表B行数X表C行数.....以此类推), 业务往往需要对产生的结果集进行二次数据筛选, 最后才能从大量的数据中找到少量感兴趣的信息. 而通过指定SQL-style中的join关联关系(e.g table A.字段1 =tableB.字段1)就能在SQL服务中就完成数据筛选, 并且返回的结果集中体现了这种关联性, 降低了业务上筛选相关的工作量.
作为一款 Nosql 且 Schemaless的数据存储, ElasticSearch没有对数据的结构进行强限制, 对客户端而言,返回的结果集都是由弱类型的json对象组成. ES没有像SQL DB那样做到对join查询的友好支持. 但是数据与数据之间的关联在ES中同样非常重要!(或许在任何数据存储服务中都重要). 本文前后篇通过对比讨论 "denormalization(反范式)" , "应用层join", "ES nested query" ,"ES has parent/child query", "ES服务层join(open distro开源生态下)"这些技术的方式(部分将在后篇描述), 探讨join查询在不同环境下的有效解决方案.
3. 方案
3.0 前言: 需解决的问题
如果需要在ES中实现一个SQL:
select * from tablea a join tableb b
on a.field1 =b.field1 order by a.create_time desc等价查询效果, 并且应用层能通过分页的方式滚动查询到所有数据
3.1 方案一: denormalization(反范式)
这可能是最"直接"的方案了, 通过修改数据模型来“flatten”数据,每个ES文档在被index时就已经有了所需要的全部关联数据.
如果是搭建异构索引场景(可理解为RDS从库), 根据关联关系的不同(1 to N, N to M)索引的文档量最高将会是 2乘以 tablea行数乘以 tableb行数(有点笛卡尔积的感觉). Denormalization通过建立"超级宽"的索引维系了1 to N 或 N to M的关联关系, 应用层与ES不需要做任何join处理, 因为一个文档已经拥有了客户端需要的全部数据(数据层面上已经做到了聚合)
对于平时与关系型数据库打交道的童鞋而言, 建 "超级宽表" 映射的索引与数据冗余可能是一件"非正常"的行为, 第一反应就是数据的冗余与空间资源浪费. 但是这种方案的确是目前广泛使用的建立数据关联关系的解决方案(如同前文说的------不要用Mysql上的规则去理解ES).
3.1.1 优势
- 应用端 & ES端都不需要做任何join操作(一个ES文档有全部客户端想要的数据)
- 分布式环境下因聚合结果集相关操作产生的延迟问题得到有效解决
- 在空间资源足够下, 方案可行性高(至少有信心吼一句"能做到")
3.1.2 挑战
- 数据的冗余与空间资源浪费(空间换时间)
- 如何梳理业务模型与flatten数据: 关系型数据中通过外键,schema约束, 查询语句(join)等方式建立的关联关系要被体现到ES的索引mapping中
- 应用层(访问ES的服务)需要的编码调整(有些工程会在dao层做统一适配处理)
- 更新操作涉及到的数据大幅度增加: 原本一个涉及单表单行update SQL可能会牵扯到多个文档中的某个字段, 且每个文档占用的空间资源更高
- 新增文档的频率会更高: 理由同上
总结: Denormation方案的通用性高, 并且能够满足快速搜索的需求(最快的查询关联数据的方式), 但是额外的存储资源使用带来的相应开销问题与数据模型梳理上的问题会带来挑战
3.2 方案二: ES SQL join(open distro开源生态)
xpack 增加了有限度的SQL支持
然而...不支持join语法....
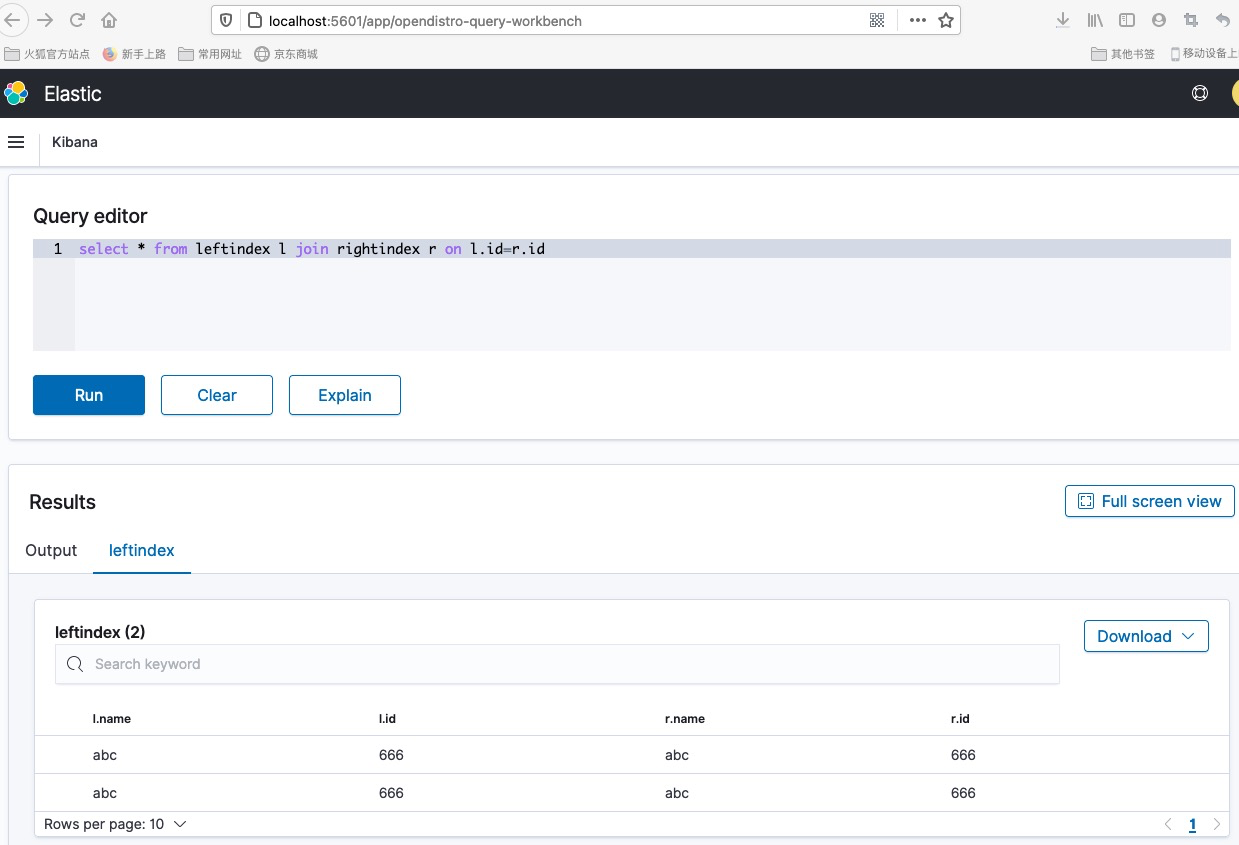
安装扩展插件获取更强的SQL支持能力(open distro)
LINK
更为强大的SQL支持(包括join语法)
挑战:
- 额外的ES插件(第三方插件对ES不同版本的兼容性?)
- 业务方调整(语句改为SQL-style, 且要使用open distro提供的JDBC相关依赖)
- open distro是一整套ES工具集(AWS上自带集成)
- 对该产品特性的学习LINK
3.3 方案三: 应用层join
通过应用工程对不同索引的多次访问,在组装结果集的过程中建立数据的关联关系
3.3.1 实现方式
可以仿照MySQL的join实现方式: 例如为了实现
select * from tablea a join tableb b
on a.field1 =b.field1 where a.field2 in ('value1','value2','value3') order by a.create_time desc这句SQL的等效查询
应用层可以:
- 1 选择 tablea 对应的异构索引作为驱动索引, 通过结构化查询, 获取field2 为'value1','value2','value3' 的文档中_id值(N个)
- 2 以文档field1作为连接条件, 从被驱动索引(tableb对应的异构索引)中找到字段field1满足条件( a.field1 =b.field1)的文档
- 3 用获取到的文档拼接结果集返回
如果配合ES terms-lookup 则为:
/**从tablea fetch符合条件的文档集**/
GET tablea/_search
{
"query": {
"terms": {
"field2": [
"value1",
"value2",
"value3"
]
}
}
}
/**假使仅获得一个文档且_id值为6666**/
GET tableb/_search
{
"query": {
"terms": {
"field1": {
"index" : "tablea",
"type" : "_doc",
"id" : "6666",
"path" : "field1"
}
}
}
}
/**利用ES terms-lookup进行连接查询**/
以上查询在应用层可用ES high-level-client实现, 数据的拼接,过滤, 循环查询等挑战都需要在应用层克服(难)
3.3.2 该方案面临几个挑战
- 如果文档数过多(被驱动表/驱动表中任意一张表获取的文档过多) -> 内存,网络等资源占用过高
- 应用层join引发的多次请求
- 应用层join引发的ES服务端压力
- 应用层代码的改动: 驱动表的选择, join的实现, 应用层缓存数据的压力...
- 一套稳定的join机制的实现会很复杂......
4. End
本文分为前篇与后篇, 我会在后篇文章中对这些技术进行进一步描述与对比, 并且引入可实践的方案.
原稿作者:Yukai糖在江湖
原稿链接:https://blog.csdn.net/fanduifandui/article/details/117264084
玩转 Elasticsearch 的 SQL 功能
Elasticsearch • medcl 发表了文章 • 9 个评论 • 75256 次浏览 • 2018-06-27 21:54
最近发布的 Elasticsearch 6.3 包含了大家期待已久的 SQL 特性,今天给大家介绍一下具体的使用方法。
首先看看接口的支持情况
目前支持的 SQL 只能进行数据的查询只读操作,不能进行数据的修改,所以我们的数据插入还是要走之前的常规索引接口。
目前 Elasticsearch 的支持 SQL 命令只有以下几个:
| 命令 | 说明 |
|---|---|
| DESC table | 用来描述索引的字段属性 |
| SHOW COLUMNS | 功能同上,只是别名 |
| SHOW FUNCTIONS | 列出支持的函数列表,支持通配符过滤 |
| SHOW TABLES | 返回索引列表 |
| SELECT .. FROM table_name WHERE .. GROUP BY .. HAVING .. ORDER BY .. LIMIT .. | 用来执行查询的命令 |
我们分别来看一下各自怎么用,以及有什么效果吧,自己也可以动手试一下,看看。
首先,我们创建一条数据:
POST twitter/doc/
{
"name":"medcl",
"twitter":"sql is awesome",
"date":"2018-07-27",
"id":123
}RESTful下调用SQL
在 ES 里面执行 SQL 语句,有三种方式,第一种是 RESTful 方式,第二种是 SQL-CLI 命令行工具,第三种是通过 JDBC 来连接 ES,执行的 SQL 语句其实都一样,我们先以 RESTful 方式来说明用法。
RESTful 的语法如下:
POST /_xpack/sql?format=txt
{
"query": "SELECT * FROM twitter"
}因为 SQL 特性是 xpack 的免费功能,所以是在 _xpack 这个路径下面,我们只需要把 SQL 语句传给 query 字段就行了,注意最后面不要加上 ; 结尾,注意是不要!
我们执行上面的语句,查询返回的结果如下:
date | id | name | twitter
------------------------+---------------+---------------+---------------
2018-07-27T00:00:00.000Z|123 |medcl |sql is awesome ES 俨然已经变成 SQL 数据库了,我们再看看如何获取所有的索引列表:
POST /_xpack/sql?format=txt
{
"query": "SHOW tables"
}返回如下:
name | type
---------------------------------+---------------
.kibana |BASE TABLE
.monitoring-alerts-6 |BASE TABLE
.monitoring-es-6-2018.06.21 |BASE TABLE
.monitoring-es-6-2018.06.26 |BASE TABLE
.monitoring-es-6-2018.06.27 |BASE TABLE
.monitoring-kibana-6-2018.06.21 |BASE TABLE
.monitoring-kibana-6-2018.06.26 |BASE TABLE
.monitoring-kibana-6-2018.06.27 |BASE TABLE
.monitoring-logstash-6-2018.06.20|BASE TABLE
.reporting-2018.06.24 |BASE TABLE
.triggered_watches |BASE TABLE
.watcher-history-7-2018.06.20 |BASE TABLE
.watcher-history-7-2018.06.21 |BASE TABLE
.watcher-history-7-2018.06.26 |BASE TABLE
.watcher-history-7-2018.06.27 |BASE TABLE
.watches |BASE TABLE
apache_elastic_example |BASE TABLE
forum-mysql |BASE TABLE
twitter 有点多,我们可以按名称过滤,如 twitt 开头的索引,注意通配符只支持 %和 _,分别表示多个和单个字符(什么,不记得了,回去翻数据库的书去!):
POST /_xpack/sql?format=txt
{
"query": "SHOW TABLES 'twit%'"
}
POST /_xpack/sql?format=txt
{
"query": "SHOW TABLES 'twitte_'"
}上面返回的结果都是:
name | type
---------------+---------------
twitter |BASE TABLE
如果要查看该索引的字段和元数据,如下:
POST /_xpack/sql?format=txt
{
"query": "DESC twitter"
}返回:
column | type
---------------+---------------
date |TIMESTAMP
id |BIGINT
name |VARCHAR
name.keyword |VARCHAR
twitter |VARCHAR
twitter.keyword|VARCHAR 都是动态生成的字段,包含了 .keyword 字段。 还能使用下面的命令来查看,主要是兼容 SQL 语法。
POST /_xpack/sql?format=txt
{
"query": "SHOW COLUMNS IN twitter"
}另外,如果不记得 ES 支持哪些函数,只需要执行下面的命令,即可得到完整列表:
SHOW FUNCTIONS返回结果如下,也就是当前6.3版本支持的所有函数,如下:
name | type
----------------+---------------
AVG |AGGREGATE
COUNT |AGGREGATE
MAX |AGGREGATE
MIN |AGGREGATE
SUM |AGGREGATE
STDDEV_POP |AGGREGATE
VAR_POP |AGGREGATE
PERCENTILE |AGGREGATE
PERCENTILE_RANK |AGGREGATE
SUM_OF_SQUARES |AGGREGATE
SKEWNESS |AGGREGATE
KURTOSIS |AGGREGATE
DAY_OF_MONTH |SCALAR
DAY |SCALAR
DOM |SCALAR
DAY_OF_WEEK |SCALAR
DOW |SCALAR
DAY_OF_YEAR |SCALAR
DOY |SCALAR
HOUR_OF_DAY |SCALAR
HOUR |SCALAR
MINUTE_OF_DAY |SCALAR
MINUTE_OF_HOUR |SCALAR
MINUTE |SCALAR
SECOND_OF_MINUTE|SCALAR
SECOND |SCALAR
MONTH_OF_YEAR |SCALAR
MONTH |SCALAR
YEAR |SCALAR
WEEK_OF_YEAR |SCALAR
WEEK |SCALAR
ABS |SCALAR
ACOS |SCALAR
ASIN |SCALAR
ATAN |SCALAR
ATAN2 |SCALAR
CBRT |SCALAR
CEIL |SCALAR
CEILING |SCALAR
COS |SCALAR
COSH |SCALAR
COT |SCALAR
DEGREES |SCALAR
E |SCALAR
EXP |SCALAR
EXPM1 |SCALAR
FLOOR |SCALAR
LOG |SCALAR
LOG10 |SCALAR
MOD |SCALAR
PI |SCALAR
POWER |SCALAR
RADIANS |SCALAR
RANDOM |SCALAR
RAND |SCALAR
ROUND |SCALAR
SIGN |SCALAR
SIGNUM |SCALAR
SIN |SCALAR
SINH |SCALAR
SQRT |SCALAR
TAN |SCALAR
SCORE |SCORE 同样支持通配符进行过滤:
POST /_xpack/sql?format=txt
{
"query": "SHOW FUNCTIONS 'S__'"
}结果:
name | type
---------------+---------------
SUM |AGGREGATE
SIN |SCALAR 那如果要进行模糊搜索呢,Elasticsearch 的搜索能力大家都知道,强!在 SQL 里面,可以用 match 关键字来写,如下:
POST /_xpack/sql?format=txt
{
"query": "SELECT SCORE(), * FROM twitter WHERE match(twitter, 'sql is') ORDER BY id DESC"
}最后,还能试试 SELECT 里面的一些其他操作,如过滤,别名,如下:
POST /_xpack/sql?format=txt
{
"query": "SELECT SCORE() as score,name as myname FROM twitter as mytable where name = 'medcl' OR name ='elastic' limit 5"
}结果如下:
score | myname
---------------+---------------
0.2876821 |medcl 或是分组和函数计算:
POST /_xpack/sql?format=txt
{
"query": "SELECT name,max(id) as max_id FROM twitter as mytable group by name limit 5"
}结果如下:
name | max_id
---------------+---------------
medcl |123.0 SQL-CLI下的使用
上面的例子基本上把 SQL 的基本命令都介绍了一遍,很多情况下,用 RESTful 可能不是很方便,那么可以试试用 CLI 命令行工具来执行 SQL 语句,妥妥的 SQL 操作体验。
切换到命令行下,启动 cli 程序即可进入命令行交互提示界面,如下:
➜ elasticsearch-6.3.0 ./bin/elasticsearch-sql-cli
.sssssss.` .sssssss.
.:sXXXXXXXXXXo` `ohXXXXXXXXXho.
.yXXXXXXXXXXXXXXo` `oXXXXXXXXXXXXXXX-
.XXXXXXXXXXXXXXXXXXo` `oXXXXXXXXXXXXXXXXXX.
.XXXXXXXXXXXXXXXXXXXXo. .oXXXXXXXXXXXXXXXXXXXXh
.XXXXXXXXXXXXXXXXXXXXXXo``oXXXXXXXXXXXXXXXXXXXXXXy
`yXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX.
`oXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXo`
`oXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXo`
`oXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXo`
`oXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXo`
`oXXXXXXXXXXXXXXXXXXXXXXXXXXXXo`
.XXXXXXXXXXXXXXXXXXXXXXXXXo`
.oXXXXXXXXXXXXXXXXXXXXXXXXo`
`oXXXXXXXXXXXXXXXXXXXXXXXXo` `odo`
`oXXXXXXXXXXXXXXXXXXXXXXXXo` `oXXXXXo`
`oXXXXXXXXXXXXXXXXXXXXXXXXo` `oXXXXXXXXXo`
`oXXXXXXXXXXXXXXXXXXXXXXXXo` `oXXXXXXXXXXXXXo`
`yXXXXXXXXXXXXXXXXXXXXXXXo` oXXXXXXXXXXXXXXXXX.
.XXXXXXXXXXXXXXXXXXXXXXo` `oXXXXXXXXXXXXXXXXXXXy
.XXXXXXXXXXXXXXXXXXXXo` /XXXXXXXXXXXXXXXXXXXXX
.XXXXXXXXXXXXXXXXXXo` `oXXXXXXXXXXXXXXXXXX-
-XXXXXXXXXXXXXXXo` `oXXXXXXXXXXXXXXXo`
.oXXXXXXXXXXXo` `oXXXXXXXXXXXo.
`.sshXXyso` SQL `.sshXhss.`
sql> 当你看到一个硕大的创口贴,表示 SQL 命令行已经准备就绪了,查看一下索引列表,不,数据表的列表:
各种操作妥妥的,上面已经测试过的命令就不在这里重复了,只是体验不一样罢了。
如果要连接远程的 ES 服务器,只需要启动命令行工具的时候,指定服务器地址,如果有加密,指定 keystone 文件,完整的帮助如下:
➜ elasticsearch-6.3.0 ./bin/elasticsearch-sql-cli --help
Elasticsearch SQL CLI
Non-option arguments:
uri
Option Description
------ -----------
-c, --check <Boolean> Enable initial connection check on startup (default:
true)
-d, --debug Enable debug logging
-h, --help show help
-k, --keystore_location Location of a keystore to use when setting up SSL. If
specified then the CLI will prompt for a keystore
password. If specified when the uri isn't https then
an error is thrown.
-s, --silent show minimal output
-v, --verbose show verbose output JDBC 对接
JDBC 对接的能力,让我们可以与各个 SQL 生态系统打通,利用众多现成的基于 SQL 之上的工具来使用 Elasticsearch,我们以一个工具来举例。
和其他数据库一样,要使用 JDBC,要下载该数据库的 JDBC 的驱动,我们打开: https://www.elastic.co/downloads/jdbc-client
只有一个 zip 包下载链接,下载即可。
然后,我们这里使用 DbVisualizer 来连接 ES 进行操作,这是一个数据库的操作和分析工具,DbVisualizer 下载地址是:https://www.dbvis.com/。
下载安装启动之后的程序主界面如下图:
我们如果要使用 ES 作为数据源,我们第一件事需要把 ES 的 JDBC 驱动添加到 DbVisualizer 的已知驱动里面。我们打开 DbVisualizer 的菜单【Tools】-> 【Driver Manager】,打开如下设置窗口:
点击绿色的加号按钮,新增一个名为 Elasticsearch-SQL 的驱动,url format 设置成 jdbc:es:,如下图:
然后点击上图黄色的文件夹按钮,添加我们刚刚下载好且解压之后的所有 jar 文件,如下:
添加完成之后,如下图:
就可以关闭这个 JDBC 驱动的管理窗口了。下面我们来连接到 ES 数据库。
选择主程序左侧的新建连接图标,打开向导,如下:
选择刚刚加入的 Elasticsearch-SQL 驱动:
设置连接字符串,此处没有登录信息,如果有可以对应的填上:
点击 Connect,即可连接到 ES,左侧导航可以展开看到对应的 ES 索引信息:
同样可以查看相应的库表结果和具体的数据:
用他自带的工具执行 SQL 也是不在话下:
同理,各种 ETL 工具和基于 SQL 的 BI 和可视化分析工具都能把 Elasticsearch 当做 SQL 数据库来连接获取数据了。
最后一个小贴士,如果你的索引名称包含横线,如 logstash-201811,只需要做一个用双引号包含,对双引号进行转义即可,如下:
POST /_xpack/sql?format=txt
{
"query":"SELECT COUNT(*) FROM \"logstash-*\""
}关于 SQL 操作的文档在这里:
https://www.elastic.co/guide/en/elasticsearch/reference/current/sql-jdbc.html
Enjoy!
有老铁测试了es6.3.0的sql功能吗?
Elasticsearch • feloxx 发表了文章 • 16 个评论 • 5823 次浏览 • 2018-06-19 16:26
sql> show tables;
name | type
----------------+---------------
hello |BASE TABLE
sql> select * from hello;
Server error [Server encountered an error [Cannot extract value [deliveraddress.address] from source]. [SqlIllegalArgumentException[Cannot extract value [deliveraddress.address] from source]
at org.elasticsearch.xpack.sql.execution.search.extractor.FieldHitExtractor.extractFromSource(FieldHitExtractor.java:139)
at org.elasticsearch.xpack.sql.execution.search.extractor.FieldHitExtractor.extract(FieldHitExtractor.java:95)
at org.elasticsearch.xpack.sql.execution.search.SearchHitRowSet.getColumn(SearchHitRowSet.java:114)
at org.elasticsearch.xpack.sql.session.AbstractRowSet.column(AbstractRowSet.java:18){
"test2": {
"properties": {
"deliveraddress": {
"properties": {
"phone_no": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},
"default": {
"type": "boolean"
},
"address": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},
"province": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},
"city": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},
"mapping_id": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},
"name": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},
"full_address": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},
"zip_code": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
}
}
},
"alipaywealth": {
"properties": {
"balance": {
"type": "long"
},
"total_quotient": {
"type": "long"
},
"huabei_creditamount": {
"type": "long"
},
"mapping_id": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},
"huabei_totalcreditamount": {
"type": "long"
},
"total_profit": {
"type": "long"
}
}
},
"id": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
}
}
}
}{
"_id": "5b1cbc7935eb6e0007a154bb",
"deliveraddress": [
{
"phone_no": "13*******98",
"default": true,
"address": "江苏省无asdads市徐***镇",
"province": "江苏",
"city": "无锡",
"mapping_id": "3561511087asdasd341",
"name": "b***",
"full_address": "湖asd***上7号",
"zip_code": "214400"
},
{
"phone_no": "15*******70",
"default": false,
"address": "江苏省苏州asdasdasd张家港经济技术开发区",
"province": "江苏",
"city": "苏州",
"mapping_id": "3561511asdasd505341",
"name": "a**",
"full_address": "新asd路***德***",
"zip_code": "215600"
}
],
"alipaywealth": {
"balance": 0,
"total_quotient": 0,
"huabei_creditamount": 500,
"mapping_id": "3561511asdsa63505341",
"huabei_totalcreditamount": 500,
"total_profit": 0
}
} @SuppressWarnings("unchecked")
Object extractFromSource(Map<String, Object> map) {
Object value = map;
boolean first = true;
// each node is a key inside the map
for (String node : path) {
if (value == null) {
return null;
} else if (first || value instanceof Map) {
first = false;
value = ((Map<String, Object>) value).get(node);
} else {
throw new SqlIllegalArgumentException("Cannot extract value [{}] from source", fieldName);
}
}
return unwrapMultiValue(value);
}Sql on Elasticsearch
Elasticsearch • hill 发表了文章 • 9 个评论 • 8710 次浏览 • 2017-04-28 11:25
create table my_index.my_table (
id keyword,
name text,
age long,
birthday date
);
select * from my_index.my_type;
select count(*) from my_index.my_table group by age;
#Create table
字段参数,ES中分词规则、索引类型、字段格式等高级参数的支持
create table my_table (
name text (analyzer = ik_max_word),
dd text (index=no),
age long (include_in_all=false)
);
对象、嵌套字段支持 as
create table my_index (
id long,
name text,
obj object as (
first_name text,
second_name text (analyzer=pinyin)
)
);
create table my_index (
id long,
name text,
obj nested as (
first_name text,
second_name text (analyzer=pinyin)
)
);
ES索引高级参数支持 with option
create table my_index (
id long,
name text
) with option (
index.number_of_shards=10,
index.number_of_replicas = 1
);
#Insert/Bulk
单条数据插入
insert into my_index.index (name,age) values ('zhangsan',24);
多条插入
bulk into my_index.index (name,age) values ('zhangsan',24),('lisi',24);
对象数据插入,list,{}Map
insert into my_index.index (ds) values (['zhejiang','hangzhou']);
insert into my_index.index (dd) values ({address='zhejiang',postCode='330010'});
#select/Aggregations
select * from my_table.my_index where name like 'john *' and age between 20 and 30 and (hotel = 'hanting' or flight = 'MH4510');
地理位置中心点查询
select * from hz_point where geo_distance({distance='1km',location='30.306378,120.247427'});
地理坐标区域查询
select * from hz_point where geo_bounding_box({location={top_left='31.306378,119.247427',bottom_right='29.285797,122.172329'}});
pipeline统计 move_avg
select count(*) as total, moving_avg({buckets_path=total}) from my_index group by date_histogram({field=timestamp,interval='1h'});
Getting Started
环境要求python >= 2.7
export PYTHONHOME=(%python_path)
export PATH=$PYTHONHOME/bin:$PATH
安装第三方依赖包
pip install -r esql5.egg-info/requires.txt
或python setup.py install
运行esql5服务
(standalone):
cd esql5
python -m App.app
(with uwsgi)
cd esql5
uwsgi --ini conf/uwsgi.ini
shell终端:
python -m elsh.Commandelasticsearch-query-tookit一款基于SQL查询elasticsearch编程工具包,支持SQL解析生成DSL,支持JDBC驱动,支持和Spring、MyBatis集成
Elasticsearch • chennanlcy 发表了文章 • 1 个评论 • 9458 次浏览 • 2017-03-24 23:09
String sql = "select * from index.order where status='SUCCESS' and price > 100 order by nvl(pride, 0) asc routing by 'JD' limit 0, 20";
ElasticSql2DslParser sql2DslParser = new ElasticSql2DslParser();
//解析SQL
ElasticSqlParseResult parseResult = sql2DslParser.parse(sql);
//生成DSL(可用于rest api调用)
String dsl = parseResult.toDsl();
//toRequest方法接收一个clinet对象参数
SearchRequestBuilder searchReq = parseResult.toRequest(esClient);
//执行查询
SearchResponse response = searchReq.execute().actionGet();{
"from" : 0,
"size" : 20,
"query" : {
"bool" : {
"filter" : {
"bool" : {
"must" : [ {
"term" : {
"status" : "SUCCESS"
}
}, {
"range" : {
"price" : {
"from" : 100,
"to" : null,
"include_lower" : false,
"include_upper" : true
}
}
} ]
}
}
}
},
"sort" : [ {
"pride" : {
"order" : "asc",
"missing" : 0
}
} ]
}<bean id="elasticDataSource" class="org.elasticsearch.jdbc.api.ElasticSingleConnectionDataSource" destroy-method="destroy">
<property name="driverClassName" value="org.elasticsearch.jdbc.api.ElasticDriver" />
<property name="url" value="jdbc:elastic:192.168.0.109:9300/product_cluster" />
</bean>
<bean id="sqlMapClient" class="org.springframework.orm.ibatis.SqlMapClientFactoryBean">
<property name="dataSource" ref="elasticDataSource" />
<property name="configLocation" value="classpath:sqlMapConfig.xml"/>
</bean><sqlMapConfig>
<settings
cacheModelsEnabled="true"
lazyLoadingEnabled="true"
enhancementEnabled="true"
maxSessions="64"
maxTransactions="20"
maxRequests="128"
useStatementNamespaces="true"/>
<sqlMap resource="sqlmap/PRODUCT.xml"/>
</sqlMapConfig><sqlMap namespace="PRODUCT">
<select id="getProductByCodeAndMatchWord" parameterClass="java.util.Map" resultClass="java.lang.String">
SELECT *
FROM index.product
QUERY match(productName, #matchWord#) or prefix(productName, #prefixWord#, 'boost:2.0f')
WHERE productCode = #productCode#
AND advicePrice > #advicePrice#
AND $$buyers.buyerName IN ('china', 'usa')
ROUTING BY #routingVal#
</select>
</sqlMap>@Repository
public class ProductDao {
@Autowired
@Qualifier("sqlMapClient")
private SqlMapClient sqlMapClient;
public List<Product> getProductByCodeAndMatchWord(String matchWord, String productCode) throws SQLException {
Map<String, Object> paramMap = Maps.newHashMap();
paramMap.put("productCode", productCode);
paramMap.put("advicePrice", 1000);
paramMap.put("routingVal", "A");
paramMap.put("matchWord", matchWord);
paramMap.put("prefixWord", matchWord);
String responseGson = (String) sqlMapClient.queryForObject("PRODUCT.getProductByCodeAndMatchWord", paramMap);
//反序列化查询结果
JdbcSearchResponseResolver responseResolver = new JdbcSearchResponseResolver(responseGson);
JdbcSearchResponse<Product> searchResponse = responseResolver.resolveSearchResponse(Product.class);
return searchResponse.getDocList();
}
}@Test
public void testProductQuery() throws Exception {
BeanFactory factory = new ClassPathXmlApplicationContext("application-context.xml");
ProductDao productDao = factory.getBean(ProductDao.class);
List<Product> productList = productDao.getProductByCodeAndMatchWord("iphone 6s", "IP_6S");
for (Product product : productList) {
System.out.println(product.getProductName());
}
}使用 SQL 查询 Elasticsearch
Elasticsearch • taowen 发表了文章 • 4 个评论 • 15868 次浏览 • 2016-02-21 16:19
$ cat << EOF | ./es_query.py http://127.0.0.1:9200
WITH SELECT MAX(market_cap) AS max_all_times FROM symbol AS all_symbols;
WITH SELECT MAX(market_cap) AS max_at_2000 FROM all_symbols WHERE ipo_year=2000 AS year_2000;
WITH SELECT MAX(market_cap) AS max_at_2001 FROM all_symbols WHERE ipo_year=2001 AS year_2001;
EOF