

本文同步发布在腾讯云+社区Elasticsearch专栏:https://cloud.tencent.com/developer/column/4008
Elasticsearch是当前主流的分布式大数据存储和搜索引擎,可以为用户提供强大的全文本检索能力,广泛应用于日志检索,全站搜索等领域。Logstash作为Elasicsearch常用的实时数据采集引擎,可以采集来自不同数据源的数据,并对数据进行处理后输出到多种输出源,是Elastic Stack 的重要组成部分。本文从Logstash的工作原理,使用示例,部署方式及性能调优等方面入手,为大家提供一个快速入门Logstash的方式。文章最后也给出了一些深入了解Logstash的的链接,以方便大家根据需要详细了解。
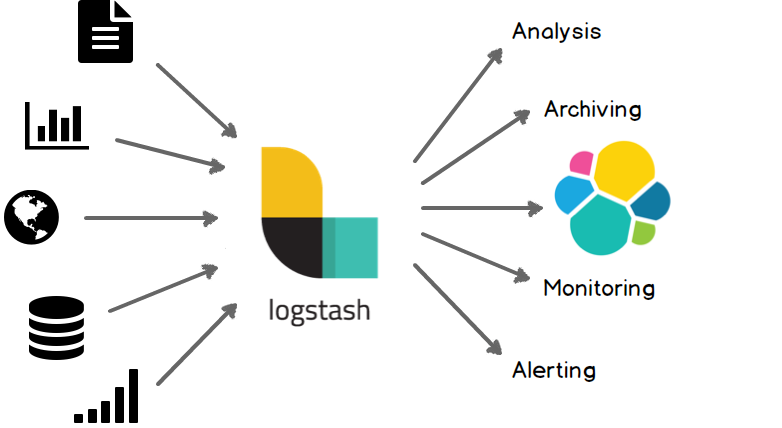
1 Logstash工作原理
1.1 处理过程
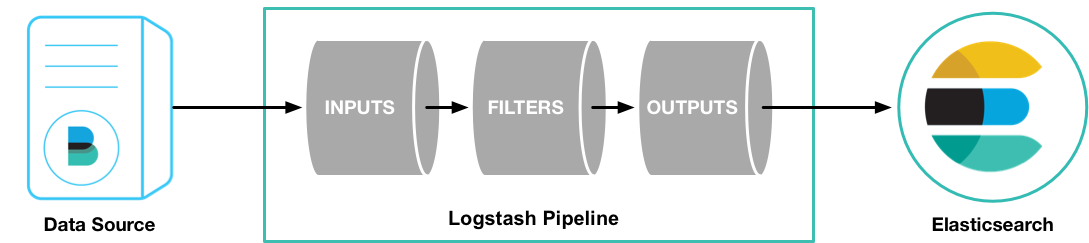
如上图,Logstash的数据处理过程主要包括:Inputs, Filters, Outputs 三部分, 另外在Inputs和Outputs中可以使用Codecs对数据格式进行处理。这四个部分均以插件形式存在,用户通过定义pipeline配置文件,设置需要使用的input,filter,output, codec插件,以实现特定的数据采集,数据处理,数据输出等功能
- (1)Inputs:用于从数据源获取数据,常见的插件如file, syslog, redis, beats 等[详细参考]
- (2)Filters:用于处理数据如格式转换,数据派生等,常见的插件如grok, mutate, drop, clone, geoip等[详细参考]
- (3)Outputs:用于数据输出,常见的插件如elastcisearch,file, graphite, statsd等[详细参考]
- (4)Codecs:Codecs不是一个单独的流程,而是在输入和输出等插件中用于数据转换的模块,用于对数据进行编码处理,常见的插件如json,multiline[详细参考]
可以点击每个模块后面的_详细参考_链接了解该模块的插件列表及对应功能
1.2 执行模型:
- (1)每个Input启动一个线程,从对应数据源获取数据
- (2)Input会将数据写入一个队列:默认为内存中的有界队列(意外停止会导致数据丢失)。为了防止数丢失Logstash提供了两个特性: Persistent Queues:通过磁盘上的queue来防止数据丢失 Dead Letter Queues:保存无法处理的event(仅支持Elasticsearch作为输出源)
- (3)Logstash会有多个pipeline worker, 每一个pipeline worker会从队列中取一批数据,然后执行filter和output(worker数目及每次处理的数据量均由配置确定)
2 Logstash使用示例
2.1 Logstash Hello world
第一个示例Logstash将采用标准输入和标准输出作为input和output,并且不指定filter
- (1)下载Logstash并解压(需要预先安装JDK8)
- (2)cd到Logstash的根目录,并执行启动命令如下:
cd logstash-6.4.0
bin/logstash -e 'input { stdin { } } output { stdout {} }'- (3)此时Logstash已经启动成功,-e表示在启动时直接指定pipeline配置,当然也可以将该配置写入一个配置文件中,然后通过指定配置文件来启动
- (4)在控制台输入:hello world,可以看到如下输出:
{
"@version" => "1",
"host" => "localhost",
"@timestamp" => 2018-09-18T12:39:38.514Z,
"message" => "hello world"
} Logstash会自动为数据添加@version, host, @timestamp等字段
在这个示例中Logstash从标准输入中获得数据,仅在数据中添加一些简单字段后将其输出到标准输出。
2.2 日志采集
这个示例将采用Filebeat input插件(Elastic Stack中的轻量级数据采集程序)采集本地日志,然后将结果输出到标准输出
filebeat.yml配置如下(paths改为日志实际位置,不同版本beats配置可能略有变化,请根据情况调整)
filebeat.prospectors:
- input\_type: log
paths:
- /path/to/file/logstash-tutorial.log
output.logstash:
hosts: "localhost:5044"启动命令:
./filebeat -e -c filebeat.yml -d "publish"- (3)配置logstash并启动
1)创建first-pipeline.conf文件内容如下(该文件为pipeline配置文件,用于指定input,filter, output等):
input {
beats {
port => "5044"
}
}
#filter {
#}
output {
stdout { codec => rubydebug }
}codec => rubydebug用于美化输出[参考]
2)验证配置(注意指定配置文件的路径):
./bin/logstash -f first-pipeline.conf --config.test_and_exit3)启动命令:
./bin/logstash -f first-pipeline.conf --config.reload.automatic--config.reload.automatic选项启用动态重载配置功能
4)预期结果:
可以在Logstash的终端显示中看到,日志文件被读取并处理为如下格式的多条数据
{
"@timestamp" => 2018-10-09T12:22:39.742Z,
"offset" => 24464,
"@version" => "1",
"input_type" => "log",
"beat" => {
"name" => "VM_136_9_centos",
"hostname" => "VM_136_9_centos",
"version" => "5.6.10"
},
"host" => "VM_136_9_centos",
"source" => "/data/home/michelmu/workspace/logstash-tutorial.log",
"message" => "86.1.76.62 - - [04/Jan/2015:05:30:37 +0000] \"GET /style2.css HTTP/1.1\" 200 4877 \"http://www.semicomplete.com/projects/xdotool/\" \"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"type" => "log",
"tags" => [
[0] "beats_input_codec_plain_applied"
]
}相对于示例2.1,该示例使用了filebeat input插件从日志中获取一行记录,这也是Elastic stack获取日志数据最常见的一种方式。另外该示例还采用了rubydebug codec 对输出的数据进行显示美化。
2.3 日志格式处理
可以看到虽然示例2.2使用filebeat从日志中读取数据,并将数据输出到标准输出,但是日志内容作为一个整体被存放在message字段中,这样对后续存储及查询都极为不便。可以为该pipeline指定一个grok filter来对日志格式进行处理
- (1)在first-pipeline.conf中增加filter配置如下
input {
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
}
output {
stdout { codec => rubydebug }
}- (2)到filebeat的根目录下删除之前上报的数据历史(以便重新上报数据),并重启filebeat
sudo rm data/registry
sudo ./filebeat -e -c filebeat.yml -d "publish"- (3)由于之前启动Logstash设置了自动更新配置,因此Logstash不需要重新启动,这个时候可以获取到的日志数据如下:
{
"request" => "/style2.css",
"agent" => "\"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"offset" => 24464,
"auth" => "-",
"ident" => "-",
"input_type" => "log",
"verb" => "GET",
"source" => "/data/home/michelmu/workspace/logstash-tutorial.log",
"message" => "86.1.76.62 - - [04/Jan/2015:05:30:37 +0000] \"GET /style2.css HTTP/1.1\" 200 4877 \"http://www.semicomplete.com/projects/xdotool/\" \"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"type" => "log",
"tags" => [
[0] "beats_input_codec_plain_applied"
],
"referrer" => "\"http://www.semicomplete.com/projects/xdotool/\"",
"@timestamp" => 2018-10-09T12:24:21.276Z,
"response" => "200",
"bytes" => "4877",
"clientip" => "86.1.76.62",
"@version" => "1",
"beat" => {
"name" => "VM_136_9_centos",
"hostname" => "VM_136_9_centos",
"version" => "5.6.10"
},
"host" => "VM_136_9_centos",
"httpversion" => "1.1",
"timestamp" => "04/Jan/2015:05:30:37 +0000"
}可以看到message中的数据被详细解析出来了
2.4 数据派生和增强
Logstash中的一些filter可以根据现有数据生成一些新的数据,如geoip可以根据ip生成经纬度信息
- (1)在first-pipeline.conf中增加geoip配置如下
input {
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
geoip {
source => "clientip"
}
}
output {
stdout { codec => rubydebug }
}- (2)如2.3一样清空filebeat历史数据,并重启
- (3)当然Logstash仍然不需要重启,可以看到输出变为如下:
{
"request" => "/style2.css",
"agent" => "\"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"geoip" => {
"timezone" => "Europe/London",
"ip" => "86.1.76.62",
"latitude" => 51.5333,
"continent_code" => "EU",
"city_name" => "Willesden",
"country_name" => "United Kingdom",
"country_code2" => "GB",
"country_code3" => "GB",
"region_name" => "Brent",
"location" => {
"lon" => -0.2333,
"lat" => 51.5333
},
"postal_code" => "NW10",
"region_code" => "BEN",
"longitude" => -0.2333
},
"offset" => 24464,
"auth" => "-",
"ident" => "-",
"input_type" => "log",
"verb" => "GET",
"source" => "/data/home/michelmu/workspace/logstash-tutorial.log",
"message" => "86.1.76.62 - - [04/Jan/2015:05:30:37 +0000] \"GET /style2.css HTTP/1.1\" 200 4877 \"http://www.semicomplete.com/projects/xdotool/\" \"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"type" => "log",
"tags" => [
[0] "beats_input_codec_plain_applied"
],
"referrer" => "\"http://www.semicomplete.com/projects/xdotool/\"",
"@timestamp" => 2018-10-09T12:37:46.686Z,
"response" => "200",
"bytes" => "4877",
"clientip" => "86.1.76.62",
"@version" => "1",
"beat" => {
"name" => "VM_136_9_centos",
"hostname" => "VM_136_9_centos",
"version" => "5.6.10"
},
"host" => "VM_136_9_centos",
"httpversion" => "1.1",
"timestamp" => "04/Jan/2015:05:30:37 +0000"
}可以看到根据ip派生出了许多地理位置信息数据
2.5 将数据导入Elasticsearch
Logstash作为Elastic stack的重要组成部分,其最常用的功能是将数据导入到Elasticssearch中。将Logstash中的数据导入到Elasticsearch中操作也非常的方便,只需要在pipeline配置文件中增加Elasticsearch的output即可。
- (1)首先要有一个已经部署好的Logstash,当然可以使用腾讯云快速创建一个Elasticsearch创建地址
- (2)在first-pipeline.conf中增加Elasticsearch的配置,如下
input {
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
geoip {
source => "clientip"
}
}
output {
elasticsearch {
hosts => [ "localhost:9200" ]
}
}- (3)清理filebeat历史数据,并重启
- (4)查询Elasticsearch确认数据是否正常上传(注意替换查询语句中的日期)
curl -XGET 'http://172.16.16.17:9200/logstash-2018.10.09/_search?pretty&q=response=200'- (5)如果Elasticsearch关联了Kibana也可以使用kibana查看数据是否正常上报
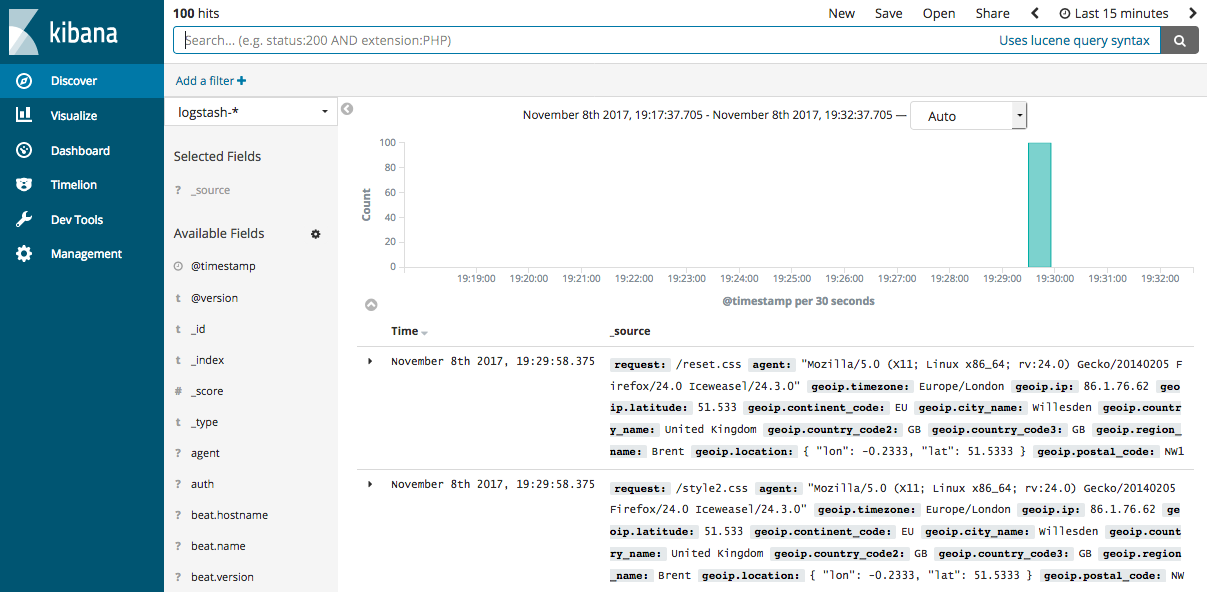
Logstash提供了大量的Input, filter, output, codec的插件,用户可以根据自己的需要,使用一个或多个组件实现自己的功能,当然用户也可以自定义插件以实现更为定制化的功能。自定义插件可以参考[logstash input插件开发]
3 部署Logstash
演示过如何快速使用Logstash后,现在详细讲述一下Logstash的部署方式。
3.1 安装
- 安装JDK:Logstash采用JRuby编写,运行需要JDK环境,因此安装Logstash前需要先安装JDK。(当前6.4仅支持JDK8)
- 安装Logstash:可以采用直接下载压缩包方式安装,也通过APT或YUM安装,另外Logstash支持安装到Docker中。[Logstash安装参考]
- 安装X-PACK:在6.3及之后版本X-PACK会随Logstash安装,在此之前需要手动安装[参考链接]
3.2 目录结构
logstash的目录主要包括:根目录、bin目录、配置目录、日志目录、插件目录、数据目录
不同安装方式各目录的默认位置参考[此处]
3.3 配置文件
- Pipeline配置文件,名称可以自定义,在启动Logstash时显式指定,编写方式可以参考前面示例,对于具体插件的配置方式参见具体插件的说明(使用Logstash时必须配置): 用于定义一个pipeline,数据处理方式和输出源
- Settings配置文件(可以使用默认配置): 在使用Logstash时可以不用设置,用于性能调优,日志记录等
- 为了保证敏感配置的安全性,logstash提供了配置加密功能[参考链接]
3.4 启动关闭方式
3.4.1 启动
- 命令行启动
- 在debian和rpm上以服务形式启动
- 在docker中启动3.4.2 关闭
- 关闭Logstash
- Logstash的关闭时会先关闭input停止输入,然后处理完所有进行中的事件,然后才完全停止,以防止数据丢失,但这也导致停止过程出现延迟或失败的情况。
3.5 扩展Logstash
当单个Logstash无法满足性能需求时,可以采用横向扩展的方式来提高Logstash的处理能力。横向扩展的多个Logstash相互独立,采用相同的pipeline配置,另外可以在这多个Logstash前增加一个LoadBalance,以实现多个Logstash的负载均衡。
4 性能调优
[详细调优参考]
- (1)Inputs和Outputs的性能:当输入输出源的性能已经达到上限,那么性能瓶颈不在Logstash,应优先对输入输出源的性能进行调优。
- (2)系统性能指标:
- CPU:确定CPU使用率是否过高,如果CPU过高则先查看JVM堆空间使用率部分,确认是否为GC频繁导致,如果GC正常,则可以通过调节Logstash worker相关配置来解决。
- 内存:由于Logstash运行在JVM上,因此注意调整JVM堆空间上限,以便其有足够的运行空间。另外注意Logstash所在机器上是否有其他应用占用了大量内存,导致Logstash内存磁盘交换频繁。
- I/O使用率: 1)磁盘IO: 磁盘IO饱和可能是因为使用了会导致磁盘IO饱和的创建(如file output),另外Logstash中出现错误产生大量错误日志时也会导致磁盘IO饱和。Linux下可以通过iostat, dstat等查看磁盘IO情况 2)网络IO: 网络IO饱和一般发生在使用有大量网络操作的插件时。linux下可以使用dstat或iftop等查看网络IO情况
- (3)JVM堆检查:
- 如果JVM堆大小设置过小会导致GC频繁,从而导致CPU使用率过高
- 快速验证这个问题的方法是double堆大小,看性能是否有提升。注意要给系统至少预留1GB的空间。
- 为了精确查找问题可以使用jmap或VisualVM。[参考]
- 设置Xms和Xmx为相同值,防止堆大小在运行时调整,这个过程非常消耗性能。
- (4)Logstash worker设置:
worker相关配置在logstash.yml中,主要包括如下三个:
- pipeline.workers: 该参数用以指定Logstash中执行filter和output的线程数,当如果发现CPU使用率尚未达到上限,可以通过调整该参数,为Logstash提供更高的性能。建议将Worker数设置适当超过CPU核数可以减少IO等待时间对处理过程的影响。实际调优中可以先通过-w指定该参数,当确定好数值后再写入配置文件中。
- pipeline.batch.size: 该指标用于指定单个worker线程一次性执行flilter和output的event批量数。增大该值可以减少IO次数,提高处理速度,但是也以为这增加内存等资源的消耗。当与Elasticsearch联用时,该值可以用于指定Elasticsearch一次bluck操作的大小。
- pipeline.batch.delay: 该指标用于指定worker等待时间的超时时间,如果worker在该时间内没有等到pipeline.batch.size个事件,那么将直接开始执行filter和output而不再等待。
结束语
Logstash作为Elastic Stack的重要组成部分,在Elasticsearch数据采集和处理过程中扮演着重要的角色。本文通过简单示例的演示和Logstash基础知识的铺陈,希望可以帮助初次接触Logstash的用户对Logstash有一个整体认识,并能较为快速上手。对于Logstash的高阶使用,仍需要用户在使用过程中结合实际情况查阅相关资源深入研究。当然也欢迎大家积极交流,并对文中的错误提出宝贵意见。
MORE:
本文地址:http://elasticsearch.cn/article/6141

