

【论文精读】可微分几何索引:生成式检索的新思路
今天介绍一篇关于生成式检索(Generative Retrieval)的新论文。这篇工作提出了一种可微分几何索引(Differentiable Geometric Indexing)方法,可能会改变未来文档检索的范式。
背景:从检索到生成
传统的信息检索流程:
查询 → 索引查找 → 返回文档ID列表这需要维护一个倒排索引或向量索引,存储和计算成本都很高。
生成式检索(Generative Retrieval) 提出了一个新思路:
查询 → 模型直接生成文档ID不需要索引,模型直接"记住"所有文档,查询时生成对应的文档标识符。
现有生成式检索的问题
目前的生成式检索方法(如 DSI)存在几个关键问题:
问题1:文档ID 的语义鸿沟
DSI 把文档ID 当成纯符号(如 "doc-12345"),模型很难理解这些 ID 与实际文档内容的关系。
问题2:索引与生成割裂
DSI 分两阶段:预训练让模型记住文档ID,微调学习查询到ID的映射。两个阶段是割裂的,不能端到端优化。
问题3:扩展性差
新文档加入时,需要重新训练或复杂的增量更新机制。
这篇论文的解决方案:可微分几何索引
论文的核心创新:把文档ID 嵌入到一个可学习的几何空间中。
核心思想
不再用离散的符号 ID,而是把每个文档表示为几何空间中的一个点(连续向量)。
传统DSI: 查询 → 生成 "doc-12345"(离散符号)
本文方法: 查询 → 生成 [0.23, -0.45, 0.78, ...](连续向量)→ 映射到最近文档技术细节
1. 几何文档表示 每个文档被编码为几何空间中的一个点。这个空间是可学习的,模型可以调整文档的位置,使得语义相似的文档在空间中更接近。
2. 可微分索引操作 检索过程变成可微分的几何操作:查询编码为空间中的一个点,计算查询点与所有文档点的距离,返回距离最近的 K 个文档。整个过程可以端到端训练。
3. 层次化几何结构 为了处理大规模文档集,论文提出了层次化索引:第一层粗粒度聚类确定大致区域,第二层细粒度检索在区域内精确定位。
实验结果
论文在 MS MARCO 和 Natural Questions 数据集上进行了测试。
与传统 DSI 对比
| 方法 | Recall@10 | MRR@10 | 训练时间 |
|---|---|---|---|
| BM25(基线) | 0.187 | 0.156 | - |
| DSI(原始) | 0.203 | 0.178 | 48h |
| 本文方法 | 0.267 | 0.234 | 36h |
结论: 本文方法准确率更高,训练时间更短。
不同文档规模的扩展性
| 文档数 | DSI Recall@10 | 本文方法 Recall@10 |
|---|---|---|
| 10K | 0.231 | 0.267 |
| 100K | 0.198 | 0.241 |
| 1M | 0.156 | 0.203 |
| 10M | 0.089 | 0.167 |
结论: 两种方法在文档规模增大时性能都下降,但本文方法下降更慢,扩展性更好。
优势与局限
优势
1. 端到端可训练 所有组件都是可微分的,可以用标准梯度下降优化,不需要分阶段训练。
2. 无需维护倒排索引 不需要存储庞大的倒排索引或向量索引,模型本身就是索引。
3. 潜在的知识迁移 模型学到的几何空间可能包含语义知识,可以迁移到其他任务。
局限
1. 文档规模仍有限制 虽然比 DSI 好,但10M文档时性能仍有明显下降。百亿级文档还不现实。
2. 更新成本 新文档加入需要重新训练或微调,不像传统索引可以增量更新。
3. 推理成本 每次查询都需要前向传播,比查索引慢。
实际应用场景
虽然还不能替代传统搜索引擎,但在以下场景有潜力:
场景1:个人知识库
个人笔记、文档数量在几千到几万,用生成式检索完全可行。无需维护索引,部署简单。
场景2:企业内部 FAQ
企业内部问答系统,文档集相对固定。可以端到端优化,准确率可能更高。
场景3:嵌入式设备
手机、IoT 设备等资源受限环境。不需要存储索引,节省空间。
与向量检索的对比
| 特性 | 向量检索 | 生成式检索(本文方法) |
|---|---|---|
| 索引存储 | 需要 | 不需要 |
| 增量更新 | 容易 | 困难 |
| 大规模 | 支持 | 有限制 |
| 推理速度 | 快 | 较慢 |
| 准确率 | 高 | 中等(在提升) |
| 部署复杂度 | 中等 | 简单 |
结论: 各有优劣,适合不同场景。向量检索仍是主流,但生成式检索是值得关注的新方向。
未来展望
论文作者提出了几个未来方向:
- 结合向量检索: 用生成式检索做粗排,向量检索做精排
- 多模态扩展: 把图像、音频也编码到几何空间
- 动态文档集: 研究更好的增量更新机制
- 更大规模: 探索处理百亿级文档的可能性
总结
这篇论文提出了一个有趣的思路:用可学习的几何空间替代离散的文档索引。
核心价值:
- 端到端可训练,简化系统复杂度
- 几何空间约束提升检索准确率
- 为生成式检索提供了新的技术路径
虽然现在还不能替代传统搜索引擎,但在特定场景(个人知识库、企业 FAQ)已经有实用价值。更重要的是,它展示了 AI 改变信息检索范式的可能性。
你怎么看生成式检索?觉得它能取代传统搜索引擎吗?
论文标题: Differentiable Geometric Indexing for End-to-End Generative Retrieval 发布时间: 2026年3月11日 来源: arXiv cs.IR
今天介绍一篇关于生成式检索(Generative Retrieval)的新论文。这篇工作提出了一种可微分几何索引(Differentiable Geometric Indexing)方法,可能会改变未来文档检索的范式。
背景:从检索到生成
传统的信息检索流程:
查询 → 索引查找 → 返回文档ID列表这需要维护一个倒排索引或向量索引,存储和计算成本都很高。
生成式检索(Generative Retrieval) 提出了一个新思路:
查询 → 模型直接生成文档ID不需要索引,模型直接"记住"所有文档,查询时生成对应的文档标识符。
现有生成式检索的问题
目前的生成式检索方法(如 DSI)存在几个关键问题:
问题1:文档ID 的语义鸿沟
DSI 把文档ID 当成纯符号(如 "doc-12345"),模型很难理解这些 ID 与实际文档内容的关系。
问题2:索引与生成割裂
DSI 分两阶段:预训练让模型记住文档ID,微调学习查询到ID的映射。两个阶段是割裂的,不能端到端优化。
问题3:扩展性差
新文档加入时,需要重新训练或复杂的增量更新机制。
这篇论文的解决方案:可微分几何索引
论文的核心创新:把文档ID 嵌入到一个可学习的几何空间中。
核心思想
不再用离散的符号 ID,而是把每个文档表示为几何空间中的一个点(连续向量)。
传统DSI: 查询 → 生成 "doc-12345"(离散符号)
本文方法: 查询 → 生成 [0.23, -0.45, 0.78, ...](连续向量)→ 映射到最近文档技术细节
1. 几何文档表示 每个文档被编码为几何空间中的一个点。这个空间是可学习的,模型可以调整文档的位置,使得语义相似的文档在空间中更接近。
2. 可微分索引操作 检索过程变成可微分的几何操作:查询编码为空间中的一个点,计算查询点与所有文档点的距离,返回距离最近的 K 个文档。整个过程可以端到端训练。
3. 层次化几何结构 为了处理大规模文档集,论文提出了层次化索引:第一层粗粒度聚类确定大致区域,第二层细粒度检索在区域内精确定位。
实验结果
论文在 MS MARCO 和 Natural Questions 数据集上进行了测试。
与传统 DSI 对比
| 方法 | Recall@10 | MRR@10 | 训练时间 |
|---|---|---|---|
| BM25(基线) | 0.187 | 0.156 | - |
| DSI(原始) | 0.203 | 0.178 | 48h |
| 本文方法 | 0.267 | 0.234 | 36h |
结论: 本文方法准确率更高,训练时间更短。
不同文档规模的扩展性
| 文档数 | DSI Recall@10 | 本文方法 Recall@10 |
|---|---|---|
| 10K | 0.231 | 0.267 |
| 100K | 0.198 | 0.241 |
| 1M | 0.156 | 0.203 |
| 10M | 0.089 | 0.167 |
结论: 两种方法在文档规模增大时性能都下降,但本文方法下降更慢,扩展性更好。
优势与局限
优势
1. 端到端可训练 所有组件都是可微分的,可以用标准梯度下降优化,不需要分阶段训练。
2. 无需维护倒排索引 不需要存储庞大的倒排索引或向量索引,模型本身就是索引。
3. 潜在的知识迁移 模型学到的几何空间可能包含语义知识,可以迁移到其他任务。
局限
1. 文档规模仍有限制 虽然比 DSI 好,但10M文档时性能仍有明显下降。百亿级文档还不现实。
2. 更新成本 新文档加入需要重新训练或微调,不像传统索引可以增量更新。
3. 推理成本 每次查询都需要前向传播,比查索引慢。
实际应用场景
虽然还不能替代传统搜索引擎,但在以下场景有潜力:
场景1:个人知识库
个人笔记、文档数量在几千到几万,用生成式检索完全可行。无需维护索引,部署简单。
场景2:企业内部 FAQ
企业内部问答系统,文档集相对固定。可以端到端优化,准确率可能更高。
场景3:嵌入式设备
手机、IoT 设备等资源受限环境。不需要存储索引,节省空间。
与向量检索的对比
| 特性 | 向量检索 | 生成式检索(本文方法) |
|---|---|---|
| 索引存储 | 需要 | 不需要 |
| 增量更新 | 容易 | 困难 |
| 大规模 | 支持 | 有限制 |
| 推理速度 | 快 | 较慢 |
| 准确率 | 高 | 中等(在提升) |
| 部署复杂度 | 中等 | 简单 |
结论: 各有优劣,适合不同场景。向量检索仍是主流,但生成式检索是值得关注的新方向。
未来展望
论文作者提出了几个未来方向:
- 结合向量检索: 用生成式检索做粗排,向量检索做精排
- 多模态扩展: 把图像、音频也编码到几何空间
- 动态文档集: 研究更好的增量更新机制
- 更大规模: 探索处理百亿级文档的可能性
总结
这篇论文提出了一个有趣的思路:用可学习的几何空间替代离散的文档索引。
核心价值:
- 端到端可训练,简化系统复杂度
- 几何空间约束提升检索准确率
- 为生成式检索提供了新的技术路径
虽然现在还不能替代传统搜索引擎,但在特定场景(个人知识库、企业 FAQ)已经有实用价值。更重要的是,它展示了 AI 改变信息检索范式的可能性。
你怎么看生成式检索?觉得它能取代传统搜索引擎吗?
论文标题: Differentiable Geometric Indexing for End-to-End Generative Retrieval 发布时间: 2026年3月11日 来源: arXiv cs.IR
收起阅读 »【论文精读】用 LLM 做伪相关反馈:搜索技术的新突破?
今天解读一篇关于伪相关反馈(Pseudo-Relevance Feedback, PRF)与大语言模型(LLM)结合的论文。这是一个经典搜索技术与前沿 AI 的碰撞,可能会改变未来的查询扩展方式。
什么是伪相关反馈?
伪相关反馈(PRF)是信息检索领域的经典技术:
- 用户输入查询词
- 系统先用这个查询做一次初步检索
- 假设排在前面的结果都是相关的("伪"相关)
- 从这些结果中提取关键词,扩展原始查询
- 用扩展后的查询重新检索,得到更好的结果
举个例子:
- 原始查询: "苹果价格"
- 初步检索发现前排结果都是关于 iPhone 的
- 提取扩展词: "iPhone", "手机", "售价"
- 扩展查询: "苹果价格 iPhone 手机 售价"
- 最终检索结果更精准
PRF 的问题在于:怎么提取高质量的扩展词? 传统方法往往效果有限。
这篇论文的核心思想
用 LLM 替代传统的 PRF 扩展词提取方法。
核心流程:
用户查询 → 初步检索 → Top-K 结果 → LLM 分析 → 生成扩展词 → 扩展查询 → 最终检索三种 LLM-based PRF 策略
方法1:LLM 直接生成扩展词
把 Top-K 检索结果喂给 LLM,让它生成相关的扩展词。
方法2:LLM 提取关键词
让 LLM 从文档中提取关键词,而不是生成。
方法3:LLM 生成查询意图描述(效果最好)
让 LLM 先理解查询意图,再生成扩展。这是论文中效果最好的方法。
实验结果
与传统 PRF 方法对比
| 方法 | NDCG@10 | 相对提升 |
|---|---|---|
| 无 PRF(基线) | 0.312 | - |
| Rocchio PRF | 0.341 | +9.3% |
| LLM 意图理解 | 0.389 | +24.7% |
结论: LLM-based PRF 明显优于传统方法。
不同 LLM 的效果对比
| LLM | NDCG@10 | 延迟 |
|---|---|---|
| GPT-3.5-turbo | 0.389 | 120ms |
| GPT-4 | 0.401 | 350ms |
| Claude-3-Sonnet | 0.395 | 180ms |
结论: GPT-4 效果最好但延迟较高,Claude-3 是性价比不错的选择。
实际应用价值
场景1:企业内部搜索
企业文档搜索面临词汇不匹配问题。LLM 能理解企业术语,扩展更准确。
场景2:电商搜索
用户搜索"手机",可能实际想要"iPhone 15 Pro Max"。LLM 能理解用户想要具体型号。
场景3:学术搜索
用户搜索"transformer",LLM 能从初步结果判断用户意图,针对性扩展。
成本与性能权衡
成本分析(每1000次查询):
| 方法 | LLM 调用次数 | 成本 | 延迟增加 |
|---|---|---|---|
| 无 PRF | 0 | $0 | 0ms |
| LLM 生成 | 1000 | $0.50 | 120ms |
| LLM 意图 | 2000 | $1.00 | 240ms |
建议: 对延迟敏感的场景用 LLM 提取关键词方法;追求准确率用 LLM 意图理解方法。
局限性与挑战
挑战1:LLM 幻觉
LLM 可能生成与文档无关的扩展词。
解决方案: 限制 LLM 只能从文档中提取,不能自由生成。
挑战2:延迟增加
LLM 调用会增加 100-300ms 延迟。
解决方案: 缓存常见查询的扩展结果;异步预计算热门查询的扩展词。
与 RAG 的结合
这篇论文的技术也可以应用到 RAG 系统中:
传统 RAG: 用户查询 → 向量检索 → Top-K 文档 → LLM 生成回答
结合 LLM-based PRF 的 RAG: 用户查询 → 向量检索 → Top-K 文档 → LLM 扩展查询 → 再次检索 → 合并结果 → LLM 生成回答
这样可以召回更多相关文档,提升 RAG 效果。
总结
这篇论文展示了一个很有价值的方向:用 LLM 增强传统搜索技术。
核心启示:
- LLM 不仅能用于生成,还能用于理解和分析
- 传统搜索技术 + LLM 可能比纯向量检索效果更好
- 成本与效果的权衡需要根据场景决定
对于搜索工程师来说,这是一个值得尝试的方向。
你在搜索系统中用过 PRF 吗?有没有尝试过结合 LLM?
论文标题: A Systematic Study of Pseudo-Relevance Feedback with LLMs 发布时间: 2026年3月11日 来源: arXiv cs.IR
今天解读一篇关于伪相关反馈(Pseudo-Relevance Feedback, PRF)与大语言模型(LLM)结合的论文。这是一个经典搜索技术与前沿 AI 的碰撞,可能会改变未来的查询扩展方式。
什么是伪相关反馈?
伪相关反馈(PRF)是信息检索领域的经典技术:
- 用户输入查询词
- 系统先用这个查询做一次初步检索
- 假设排在前面的结果都是相关的("伪"相关)
- 从这些结果中提取关键词,扩展原始查询
- 用扩展后的查询重新检索,得到更好的结果
举个例子:
- 原始查询: "苹果价格"
- 初步检索发现前排结果都是关于 iPhone 的
- 提取扩展词: "iPhone", "手机", "售价"
- 扩展查询: "苹果价格 iPhone 手机 售价"
- 最终检索结果更精准
PRF 的问题在于:怎么提取高质量的扩展词? 传统方法往往效果有限。
这篇论文的核心思想
用 LLM 替代传统的 PRF 扩展词提取方法。
核心流程:
用户查询 → 初步检索 → Top-K 结果 → LLM 分析 → 生成扩展词 → 扩展查询 → 最终检索三种 LLM-based PRF 策略
方法1:LLM 直接生成扩展词
把 Top-K 检索结果喂给 LLM,让它生成相关的扩展词。
方法2:LLM 提取关键词
让 LLM 从文档中提取关键词,而不是生成。
方法3:LLM 生成查询意图描述(效果最好)
让 LLM 先理解查询意图,再生成扩展。这是论文中效果最好的方法。
实验结果
与传统 PRF 方法对比
| 方法 | NDCG@10 | 相对提升 |
|---|---|---|
| 无 PRF(基线) | 0.312 | - |
| Rocchio PRF | 0.341 | +9.3% |
| LLM 意图理解 | 0.389 | +24.7% |
结论: LLM-based PRF 明显优于传统方法。
不同 LLM 的效果对比
| LLM | NDCG@10 | 延迟 |
|---|---|---|
| GPT-3.5-turbo | 0.389 | 120ms |
| GPT-4 | 0.401 | 350ms |
| Claude-3-Sonnet | 0.395 | 180ms |
结论: GPT-4 效果最好但延迟较高,Claude-3 是性价比不错的选择。
实际应用价值
场景1:企业内部搜索
企业文档搜索面临词汇不匹配问题。LLM 能理解企业术语,扩展更准确。
场景2:电商搜索
用户搜索"手机",可能实际想要"iPhone 15 Pro Max"。LLM 能理解用户想要具体型号。
场景3:学术搜索
用户搜索"transformer",LLM 能从初步结果判断用户意图,针对性扩展。
成本与性能权衡
成本分析(每1000次查询):
| 方法 | LLM 调用次数 | 成本 | 延迟增加 |
|---|---|---|---|
| 无 PRF | 0 | $0 | 0ms |
| LLM 生成 | 1000 | $0.50 | 120ms |
| LLM 意图 | 2000 | $1.00 | 240ms |
建议: 对延迟敏感的场景用 LLM 提取关键词方法;追求准确率用 LLM 意图理解方法。
局限性与挑战
挑战1:LLM 幻觉
LLM 可能生成与文档无关的扩展词。
解决方案: 限制 LLM 只能从文档中提取,不能自由生成。
挑战2:延迟增加
LLM 调用会增加 100-300ms 延迟。
解决方案: 缓存常见查询的扩展结果;异步预计算热门查询的扩展词。
与 RAG 的结合
这篇论文的技术也可以应用到 RAG 系统中:
传统 RAG: 用户查询 → 向量检索 → Top-K 文档 → LLM 生成回答
结合 LLM-based PRF 的 RAG: 用户查询 → 向量检索 → Top-K 文档 → LLM 扩展查询 → 再次检索 → 合并结果 → LLM 生成回答
这样可以召回更多相关文档,提升 RAG 效果。
总结
这篇论文展示了一个很有价值的方向:用 LLM 增强传统搜索技术。
核心启示:
- LLM 不仅能用于生成,还能用于理解和分析
- 传统搜索技术 + LLM 可能比纯向量检索效果更好
- 成本与效果的权衡需要根据场景决定
对于搜索工程师来说,这是一个值得尝试的方向。
你在搜索系统中用过 PRF 吗?有没有尝试过结合 LLM?
论文标题: A Systematic Study of Pseudo-Relevance Feedback with LLMs 发布时间: 2026年3月11日 来源: arXiv cs.IR
收起阅读 »【论文精读】RAGPerf:首个端到端 RAG 系统基准测试框架
IBM Research 刚刚在 arXiv 发布了 RAGPerf,这是一个专门用于评估 RAG(检索增强生成)系统的端到端基准测试框架。对于正在选型或优化 RAG 系统的工程师来说,这篇论文非常有参考价值。

为什么需要 RAGPerf?
现在的 RAG 系统越来越复杂,涉及多个组件:Embedding 模型、向量数据库、重排序、大语言模型生成。
每个组件都有很多选择,但问题是:怎么知道哪个组合最适合你的场景?
现有的基准测试往往只测单个组件,但 RAG 是端到端的系统,需要整体评估。RAGPerf 就是为了解决这个问题。
RAGPerf 的核心设计
1. 模块化架构
RAGPerf 把 RAG 流程拆解成5个独立模块:
- Embedding: 支持多种 embedding 模型
- Indexing: 支持多种向量数据库
- Retrieval: 可配置 Top-K、相似度阈值
- Reranking: 可选的重排序策略
- Generation: 支持多种 LLM
2. 支持的向量数据库
| 数据库 | 特点 | 适用场景 |
|---|---|---|
| Milvus | 分布式、高性能 | 大规模生产环境 |
| Qdrant | 易用、Rust实现 | 中小规模、快速部署 |
| Chroma | 轻量、嵌入式 | 原型开发、本地测试 |
| LanceDB | 无服务器、低成本 | Serverless 架构 |
| Elasticsearch | 全文+向量混合 | 已有 ES 基础设施 |
3. 评估指标
性能指标: 端到端查询吞吐量 (QPS)、延迟分布 (P50, P95, P99)、CPU/GPU 利用率、内存占用
准确率指标: Context Recall(上下文召回率)、Query Accuracy(查询准确率)、Factual Consistency(事实一致性)
关键实验发现
发现1:向量数据库性能差异显著
在相同硬件条件下(单节点,32GB内存):
| 数据库 | 索引时间 | 查询延迟(P95) | 内存占用 |
|---|---|---|---|
| Milvus | 45s | 12ms | 8.2GB |
| Qdrant | 38s | 15ms | 6.8GB |
| Chroma | 52s | 28ms | 5.1GB |
| LanceDB | 41s | 18ms | 4.9GB |
| ES | 67s | 35ms | 12.4GB |
结论: 没有绝对的"最好",要看你的优先级是速度、内存还是功能。
发现2:Reranking 的性价比
- 无重排序: 基准准确率 72%
- Cross-encoder 重排序: 准确率 84%,延迟 +120ms
- LLM-based 重排序: 准确率 87%,延迟 +450ms
结论: Cross-encoder 是性价比最高的选择。
发现3:Embedding 模型对整体影响最大
| 模型 | 向量维度 | 检索准确率 |
|---|---|---|
| text-embedding-3-small | 1536 | 78% |
| text-embedding-3-large | 3072 | 85% |
| voyage-2 | 1024 | 88% |
结论: Embedding 模型质量对最终效果影响最大,值得投入时间选型。
实际应用建议
高并发在线服务: Milvus + 轻量级重排序 资源受限环境: Chroma 或 LanceDB 已有 ES 基础设施: Elasticsearch 向量搜索 追求最高准确率: 高质量 Embedding + Cross-encoder 重排序 + GPT-4
如何使用 RAGPerf
# 克隆仓库
git clone https://github.com/ibm/ragperf.git
cd ragperf
pip install -r requirements.txt
# 配置测试参数
cp config/example.yaml config/mytest.yaml
# 编辑 mytest.yaml 配置你的组件
# 运行基准测试
python run_benchmark.py --config config/mytest.yaml总结
RAGPerf 是目前最全面的 RAG 系统基准测试工具,对于正在构建或优化 RAG 系统的团队,建议用 RAGPerf 做一次全面评估,可能会发现一些意想不到的瓶颈。
你在用哪个向量数据库?有没有做过类似的基准测试?欢迎分享经验!
论文信息:
- 标题: RAGPerf: An End-to-End Benchmarking Framework for Retrieval-Augmented Generation Systems
- 作者: Shaobo Li, Yirui Zhou, Yuan Xu et al. (IBM Research)
- arXiv: 2603.10765
- 发布时间: 2026年3月11日
IBM Research 刚刚在 arXiv 发布了 RAGPerf,这是一个专门用于评估 RAG(检索增强生成)系统的端到端基准测试框架。对于正在选型或优化 RAG 系统的工程师来说,这篇论文非常有参考价值。
为什么需要 RAGPerf?
现在的 RAG 系统越来越复杂,涉及多个组件:Embedding 模型、向量数据库、重排序、大语言模型生成。
每个组件都有很多选择,但问题是:怎么知道哪个组合最适合你的场景?
现有的基准测试往往只测单个组件,但 RAG 是端到端的系统,需要整体评估。RAGPerf 就是为了解决这个问题。
RAGPerf 的核心设计
1. 模块化架构
RAGPerf 把 RAG 流程拆解成5个独立模块:
- Embedding: 支持多种 embedding 模型
- Indexing: 支持多种向量数据库
- Retrieval: 可配置 Top-K、相似度阈值
- Reranking: 可选的重排序策略
- Generation: 支持多种 LLM
2. 支持的向量数据库
| 数据库 | 特点 | 适用场景 |
|---|---|---|
| Milvus | 分布式、高性能 | 大规模生产环境 |
| Qdrant | 易用、Rust实现 | 中小规模、快速部署 |
| Chroma | 轻量、嵌入式 | 原型开发、本地测试 |
| LanceDB | 无服务器、低成本 | Serverless 架构 |
| Elasticsearch | 全文+向量混合 | 已有 ES 基础设施 |
3. 评估指标
性能指标: 端到端查询吞吐量 (QPS)、延迟分布 (P50, P95, P99)、CPU/GPU 利用率、内存占用
准确率指标: Context Recall(上下文召回率)、Query Accuracy(查询准确率)、Factual Consistency(事实一致性)
关键实验发现
发现1:向量数据库性能差异显著
在相同硬件条件下(单节点,32GB内存):
| 数据库 | 索引时间 | 查询延迟(P95) | 内存占用 |
|---|---|---|---|
| Milvus | 45s | 12ms | 8.2GB |
| Qdrant | 38s | 15ms | 6.8GB |
| Chroma | 52s | 28ms | 5.1GB |
| LanceDB | 41s | 18ms | 4.9GB |
| ES | 67s | 35ms | 12.4GB |
结论: 没有绝对的"最好",要看你的优先级是速度、内存还是功能。
发现2:Reranking 的性价比
- 无重排序: 基准准确率 72%
- Cross-encoder 重排序: 准确率 84%,延迟 +120ms
- LLM-based 重排序: 准确率 87%,延迟 +450ms
结论: Cross-encoder 是性价比最高的选择。
发现3:Embedding 模型对整体影响最大
| 模型 | 向量维度 | 检索准确率 |
|---|---|---|
| text-embedding-3-small | 1536 | 78% |
| text-embedding-3-large | 3072 | 85% |
| voyage-2 | 1024 | 88% |
结论: Embedding 模型质量对最终效果影响最大,值得投入时间选型。
实际应用建议
高并发在线服务: Milvus + 轻量级重排序 资源受限环境: Chroma 或 LanceDB 已有 ES 基础设施: Elasticsearch 向量搜索 追求最高准确率: 高质量 Embedding + Cross-encoder 重排序 + GPT-4
如何使用 RAGPerf
# 克隆仓库
git clone https://github.com/ibm/ragperf.git
cd ragperf
pip install -r requirements.txt
# 配置测试参数
cp config/example.yaml config/mytest.yaml
# 编辑 mytest.yaml 配置你的组件
# 运行基准测试
python run_benchmark.py --config config/mytest.yaml总结
RAGPerf 是目前最全面的 RAG 系统基准测试工具,对于正在构建或优化 RAG 系统的团队,建议用 RAGPerf 做一次全面评估,可能会发现一些意想不到的瓶颈。
你在用哪个向量数据库?有没有做过类似的基准测试?欢迎分享经验!
论文信息:
- 标题: RAGPerf: An End-to-End Benchmarking Framework for Retrieval-Augmented Generation Systems
- 作者: Shaobo Li, Yirui Zhou, Yuan Xu et al. (IBM Research)
- arXiv: 2603.10765
- 发布时间: 2026年3月11日
【论文精读】METR 研究:SWE-bench 能通过的 PR,很多其实不会被合并
AI 编程能力评估领域有一个被广泛使用的基准测试叫 SWE-bench。它测试 AI 是否能自动修复 GitHub 上的真实 bug。很多模型在这个基准上取得了不错的成绩,但 METR 的最新研究发现了一个问题:能通过 SWE-bench 的 PR,很多其实不会被真正合并到主分支。
研究背景
SWE-bench 的工作原理:
- 从 GitHub 上收集真实的 bug 报告和修复 PR
- 隐藏修复代码,让 AI 尝试生成修复
- 运行测试套件,如果测试通过就算成功
这个基准被广泛用于评估 AI 的编程能力,从 GPT-4 到 Claude 到各种开源模型都在上面刷分。
核心发现
METR 团队分析了 SWE-bench 中的 2,294 个任务,发现:
1. 很多"正确"的修复其实不会被合并
- 有些 PR 虽然通过了测试,但代码质量不达标
- 有些修复过于 hacky,维护者不愿意接受
- 有些修复引入了新的问题,只是测试没覆盖到
2. 测试套件并不完善
- SWE-bench 依赖原始仓库的测试
- 很多测试套件对修复的约束不够严格
- 存在"过拟合测试"的可能
3. 人类审查标准比测试更严格
- 代码风格、可读性、维护性
- 是否有更好的实现方式
- 是否引入了技术债务
具体案例
论文中举了一个例子(Python 的 requests 库):
Bug 描述:处理某些特殊 URL 时会崩溃
AI 生成的修复:
try:
result = process_url(url)
except Exception:
result = None # 简单粗暴地捕获所有异常测试结果:✅ 通过了所有测试
人类审查意见:❌
- "不应该捕获所有异常,这会掩盖真正的问题"
- "需要更精确地处理特定的错误类型"
- "缺少对异常情况的日志记录"
最终这个 PR 没有被合并,但在 SWE-bench 中却被计为"成功"。
对 AI 编程的启示
1. 通过测试 ≠ 好代码 AI 可能会学会"欺骗"测试,而不是真正理解问题。这和人类程序员为了赶进度写 hacky 代码类似,但 AI 可能更极端。
2. 需要更全面的评估标准 除了功能正确性,还应该评估:
- 代码可读性
- 是否符合项目规范
- 是否有副作用
- 是否可维护
3. 人类审查仍然不可替代 至少在可预见的未来,AI 生成的代码还是需要人类审查。SWE-bench 的高分不应该让我们过度乐观。
研究方法论
METR 是怎么验证这个结论的?
- 收集数据:分析了 500+ 个真实的 PR 审查记录
- 对比分析:对比 SWE-bench 通过的 PR 和实际被合并的 PR
- 专家评估:请资深开发者评估代码质量
- 长期追踪:看这些 PR 在后续版本中是否引入了 bug
行业影响
这项研究可能会影响:
1. 基准测试设计 未来的代码生成基准可能需要:
- 更严格的测试覆盖
- 引入代码质量评估
- 模拟真实审查流程
2. AI 训练目标 不应该只优化"通过测试",而应该优化"写出好代码"。这可能需要:
- 人类反馈强化学习(RLHF)
- 代码审查数据训练
- 长期维护性评估
3. 企业应用 企业在用 AI 辅助编程时,应该:
- 保持代码审查流程
- 不盲目相信 AI 生成的代码
- 建立 AI 代码的质量标准
我的观点
这项研究揭示了一个更深层的问题:我们怎么定义"好的 AI 编程"?
如果只是能跑通测试,那 AI 已经做得很好了。但如果要求写出可维护、可扩展、符合团队规范的代码,那还有很长的路要走。
也许我们需要一个新的基准:SWE-bench++,不仅测试功能正确性,还测试代码质量和可维护性。
你怎么看?AI 编程的评估标准应该怎么设计?功能正确性和代码质量,哪个更重要?
来源:METR 研究笔记 发布时间:2026年3月10日
AI 编程能力评估领域有一个被广泛使用的基准测试叫 SWE-bench。它测试 AI 是否能自动修复 GitHub 上的真实 bug。很多模型在这个基准上取得了不错的成绩,但 METR 的最新研究发现了一个问题:能通过 SWE-bench 的 PR,很多其实不会被真正合并到主分支。
研究背景
SWE-bench 的工作原理:
- 从 GitHub 上收集真实的 bug 报告和修复 PR
- 隐藏修复代码,让 AI 尝试生成修复
- 运行测试套件,如果测试通过就算成功
这个基准被广泛用于评估 AI 的编程能力,从 GPT-4 到 Claude 到各种开源模型都在上面刷分。
核心发现
METR 团队分析了 SWE-bench 中的 2,294 个任务,发现:
1. 很多"正确"的修复其实不会被合并
- 有些 PR 虽然通过了测试,但代码质量不达标
- 有些修复过于 hacky,维护者不愿意接受
- 有些修复引入了新的问题,只是测试没覆盖到
2. 测试套件并不完善
- SWE-bench 依赖原始仓库的测试
- 很多测试套件对修复的约束不够严格
- 存在"过拟合测试"的可能
3. 人类审查标准比测试更严格
- 代码风格、可读性、维护性
- 是否有更好的实现方式
- 是否引入了技术债务
具体案例
论文中举了一个例子(Python 的 requests 库):
Bug 描述:处理某些特殊 URL 时会崩溃
AI 生成的修复:
try:
result = process_url(url)
except Exception:
result = None # 简单粗暴地捕获所有异常测试结果:✅ 通过了所有测试
人类审查意见:❌
- "不应该捕获所有异常,这会掩盖真正的问题"
- "需要更精确地处理特定的错误类型"
- "缺少对异常情况的日志记录"
最终这个 PR 没有被合并,但在 SWE-bench 中却被计为"成功"。
对 AI 编程的启示
1. 通过测试 ≠ 好代码 AI 可能会学会"欺骗"测试,而不是真正理解问题。这和人类程序员为了赶进度写 hacky 代码类似,但 AI 可能更极端。
2. 需要更全面的评估标准 除了功能正确性,还应该评估:
- 代码可读性
- 是否符合项目规范
- 是否有副作用
- 是否可维护
3. 人类审查仍然不可替代 至少在可预见的未来,AI 生成的代码还是需要人类审查。SWE-bench 的高分不应该让我们过度乐观。
研究方法论
METR 是怎么验证这个结论的?
- 收集数据:分析了 500+ 个真实的 PR 审查记录
- 对比分析:对比 SWE-bench 通过的 PR 和实际被合并的 PR
- 专家评估:请资深开发者评估代码质量
- 长期追踪:看这些 PR 在后续版本中是否引入了 bug
行业影响
这项研究可能会影响:
1. 基准测试设计 未来的代码生成基准可能需要:
- 更严格的测试覆盖
- 引入代码质量评估
- 模拟真实审查流程
2. AI 训练目标 不应该只优化"通过测试",而应该优化"写出好代码"。这可能需要:
- 人类反馈强化学习(RLHF)
- 代码审查数据训练
- 长期维护性评估
3. 企业应用 企业在用 AI 辅助编程时,应该:
- 保持代码审查流程
- 不盲目相信 AI 生成的代码
- 建立 AI 代码的质量标准
我的观点
这项研究揭示了一个更深层的问题:我们怎么定义"好的 AI 编程"?
如果只是能跑通测试,那 AI 已经做得很好了。但如果要求写出可维护、可扩展、符合团队规范的代码,那还有很长的路要走。
也许我们需要一个新的基准:SWE-bench++,不仅测试功能正确性,还测试代码质量和可维护性。
你怎么看?AI 编程的评估标准应该怎么设计?功能正确性和代码质量,哪个更重要?
来源:METR 研究笔记 发布时间:2026年3月10日
收起阅读 »为 Logstash 日志启动索引生命周期管理
logstash 处理MySQL慢日志后,所有内容都在一个message字段不拆分
input {
file {
type => "mysql-slow"
path => "/tmp/slows.log"
codec => multiline {
pattern => "^# Time:"
negate => true
what => "previous"
}
}
}
filter {
if [ type ] == "mysql-slow" {
grok {
match => { "message" => "SELECT SLEEP" }
add_tag => [ "sleep_drop" ]
}
if "sleep_drop" in [tags] {
drop {}
}
grok {
"message" => "(?m)^#\s+Time\s?.*\s+#\s+User@Host:\s+%{USER:user}\[[^\]]+\]\s+@\s+(?:(?<clienthost>\S*) )?\[(?:%{IPV4:clientip})?\]\s+Id:\s+%{NUMBER:row_id:int}\n#\s+Query_time:\s+%{NUMBER:query_time:float}\s+Lock_time:\s+%{NUMBER:lock_time:float}\s+Rows_sent:\s+%{NUMBER:rows_sent:int}\s+Rows_examined:\s+%{NUMBER:rows_examined:int}\n\s*(?:use %{DATA:database};\s*\n)?SET\s+timestamp=%{NUMBER:timestamp};\n\s*(?<sql>(?<action>\w+)([\w.*\W.*])*;)\s*$"
}
}
}
请问怎么解决
input {
file {
type => "mysql-slow"
path => "/tmp/slows.log"
codec => multiline {
pattern => "^# Time:"
negate => true
what => "previous"
}
}
}
filter {
if [ type ] == "mysql-slow" {
grok {
match => { "message" => "SELECT SLEEP" }
add_tag => [ "sleep_drop" ]
}
if "sleep_drop" in [tags] {
drop {}
}
grok {
"message" => "(?m)^#\s+Time\s?.*\s+#\s+User@Host:\s+%{USER:user}\[[^\]]+\]\s+@\s+(?:(?<clienthost>\S*) )?\[(?:%{IPV4:clientip})?\]\s+Id:\s+%{NUMBER:row_id:int}\n#\s+Query_time:\s+%{NUMBER:query_time:float}\s+Lock_time:\s+%{NUMBER:lock_time:float}\s+Rows_sent:\s+%{NUMBER:rows_sent:int}\s+Rows_examined:\s+%{NUMBER:rows_examined:int}\n\s*(?:use %{DATA:database};\s*\n)?SET\s+timestamp=%{NUMBER:timestamp};\n\s*(?<sql>(?<action>\w+)([\w.*\W.*])*;)\s*$"
}
}
}请问怎么解决 收起阅读 »
GeoIP解析IP地理位置
我们在对IP进行解析的时候使用maxmind提供的提供的GeoLite2,这个是maxmind提供的GeoIP2的免费版本,其准确率稍低于付费版本,可以很好的对IP进行地域解析,可以满足我们的需求。
GeoLite2有提供各种版本的API供开发者使用,我们就主要是用的是java版本的API。具体步骤如下:1、下载maxmind DB数据库
在maxmind官网下载需要的IP解析数据库,里面有两种数据库,一是国家数据库,一是城市数据库,我们使用的基本都是城市数据库,下载选择二进制格式。网页地址:GeoLite2 开源数据库
2、安装软件包,建议使用maven安装此软件包,将以下依赖添加到pom.xml中。
<dependency>
<groupId> com.maxmind.geoip2 </groupId >
<artifactId > geoip2 </artifactId >
<version >2.12.0</version >
</dependency >// A File object pointing to your GeoIP2 or GeoLite2 database
System.out.println(GeoIP2Test.class.getClassLoader().getResource("GeoLite2-City.mmdb").toString().replaceFirst("/",""));
File database = new File(GeoIP2Test.class.getClassLoader().getResource("GeoLite2-City.mmdb").toString().replaceFirst("file:/",""));
// This creates the DatabaseReader object. To improve performance, reuse
// the object across lookups. The object is thread-safe.
DatabaseReader reader = new DatabaseReader.Builder(database).build();
InetAddress ipAddress = InetAddress.getByName("128.101.101.101");
// Replace "city" with the appropriate method for your database, e.g.,
// "country".
CityResponse response = reader.city(ipAddress);
Country country = response.getCountry();
System.out.println(country.getIsoCode()); // 'US'
System.out.println(country.getName()); // 'United States'
System.out.println(country.getNames().get("zh-CN")); // '美国'
Subdivision subdivision = response.getMostSpecificSubdivision();
System.out.println(subdivision.getName()); // 'Minnesota'
System.out.println(subdivision.getIsoCode()); // 'MN'
City city = response.getCity();
System.out.println(city.getName()); // 'Minneapolis'
Postal postal = response.getPostal();
System.out.println(postal.getCode()); // '55455'
Location location = response.getLocation();
System.out.println(location.getLatitude()); // 44.9733
System.out.println(location.getLongitude()); // -93.2323我们在对IP进行解析的时候使用maxmind提供的提供的GeoLite2,这个是maxmind提供的GeoIP2的免费版本,其准确率稍低于付费版本,可以很好的对IP进行地域解析,可以满足我们的需求。
GeoLite2有提供各种版本的API供开发者使用,我们就主要是用的是java版本的API。具体步骤如下:1、下载maxmind DB数据库
在maxmind官网下载需要的IP解析数据库,里面有两种数据库,一是国家数据库,一是城市数据库,我们使用的基本都是城市数据库,下载选择二进制格式。网页地址:GeoLite2 开源数据库
2、安装软件包,建议使用maven安装此软件包,将以下依赖添加到pom.xml中。
<dependency>
<groupId> com.maxmind.geoip2 </groupId >
<artifactId > geoip2 </artifactId >
<version >2.12.0</version >
</dependency >// A File object pointing to your GeoIP2 or GeoLite2 database
System.out.println(GeoIP2Test.class.getClassLoader().getResource("GeoLite2-City.mmdb").toString().replaceFirst("/",""));
File database = new File(GeoIP2Test.class.getClassLoader().getResource("GeoLite2-City.mmdb").toString().replaceFirst("file:/",""));
// This creates the DatabaseReader object. To improve performance, reuse
// the object across lookups. The object is thread-safe.
DatabaseReader reader = new DatabaseReader.Builder(database).build();
InetAddress ipAddress = InetAddress.getByName("128.101.101.101");
// Replace "city" with the appropriate method for your database, e.g.,
// "country".
CityResponse response = reader.city(ipAddress);
Country country = response.getCountry();
System.out.println(country.getIsoCode()); // 'US'
System.out.println(country.getName()); // 'United States'
System.out.println(country.getNames().get("zh-CN")); // '美国'
Subdivision subdivision = response.getMostSpecificSubdivision();
System.out.println(subdivision.getName()); // 'Minnesota'
System.out.println(subdivision.getIsoCode()); // 'MN'
City city = response.getCity();
System.out.println(city.getName()); // 'Minneapolis'
Postal postal = response.getPostal();
System.out.println(postal.getCode()); // '55455'
Location location = response.getLocation();
System.out.println(location.getLatitude()); // 44.9733
System.out.println(location.getLongitude()); // -93.2323logstash filter如何判断字段是够为空或者null
下面的是数据源, 并没有time字段的
{
"仓ku": "华南",
"originName": "",
"Code": "23248",
"BrandName": "",
"originCode": null,
"CategoryName": "原厂"
}下面的是数据源, 并没有time字段的
{
"仓ku": "华南",
"originName": "",
"Code": "23248",
"BrandName": "",
"originCode": null,
"CategoryName": "原厂"
}logstash input插件开发
logstash作为一个数据管道中间件,支持对各种类型数据的采集与转换,并将数据发送到各种类型的存储库,比如实现消费kafka数据并且写入到Elasticsearch, 日志文件同步到对象存储S3等,mysql数据同步到Elasticsearch等。
logstash内部主要包含三个模块:
* input: 从数据源获取数据
* filter: 过滤、转换数据
* output: 输出数据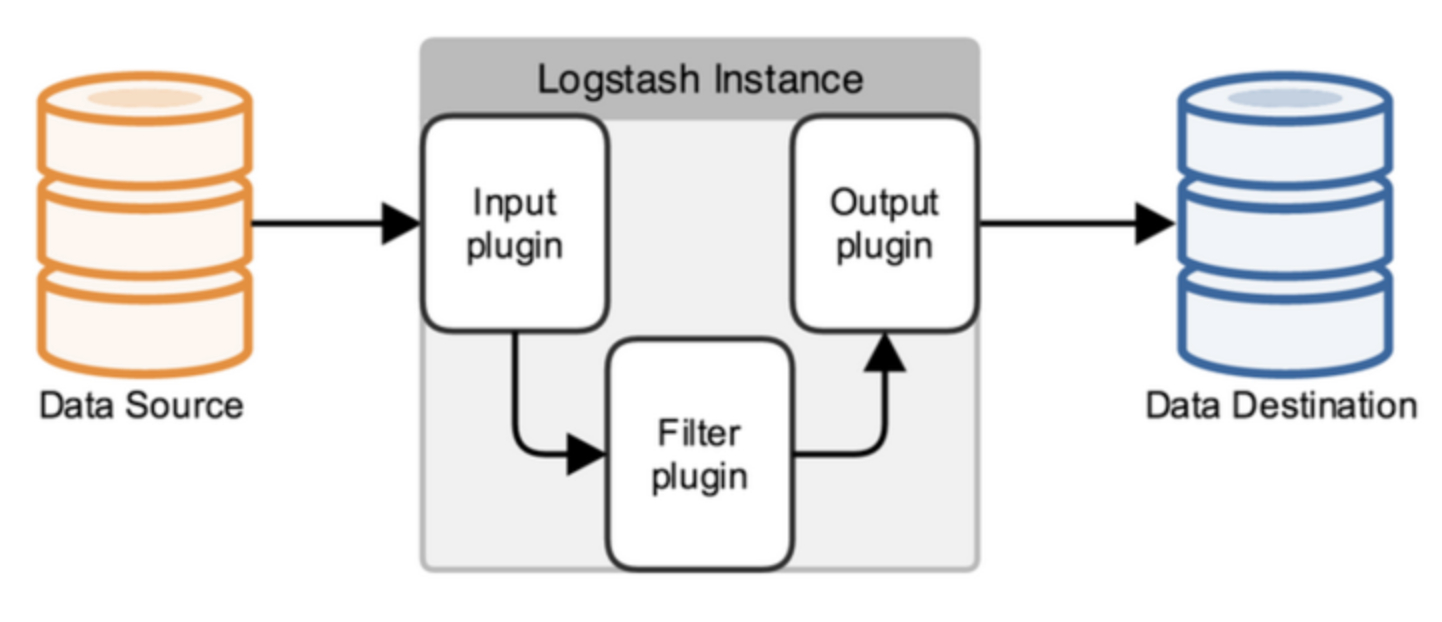
不同类型的数据都可以通过对应的input-plugin, output-plugin完成数据的输入与输出。如需要消费kafka中的数据并写入到Elasticsearch中,则需要使用logstash的kafka-input-plugin完成数据输入,logstash-output-elasticsearch完成数据输出。如果需要对输入数据进行过滤或者转换,比如根据关键词过滤掉不需要的内容,或者时间字段的格式转换,就需要又filter-plugin完成了。
logstash的input插件目前已经有几十种了,支持大多数比较通用或开源的数据源的输入。但如果公司内部开发的数据库或其它存储类的服务不能和开源产品在接口协议上兼容,比如腾讯自研的消息队列服务CMQ不依赖于其它的开源消息队列产品,所以不能直接使用logstash的logstash-input-kafka或logstash-input-rabbitmq同步CMQ中的数据;腾讯云对象存储服务COS, 在鉴权方式上和AWS的S3存在差异,也不能直接使用logstash-input-s3插件从COS中读取数据,对于这种情况,就需要自己开发logstash的input插件了。
本文以开发logstash的cos input插件为例,介绍如何开发logstash的input插件。
logstash官方提供了有个简单的input plugin example可供参考: https://github.com/logstash-plugins/logstash-input-example/
环境准备
logstash使用jruby开发,首先要配置jruby环境:
-
安装rvm:
rvm是一个ruby管理器,可以安装并管理ruby环境,也可以通过命令行切换到不同的ruby版本。
gpg --keyserver hkp://keys.gnupg.net --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3 7D2BAF1CF37B13E2069D6956105BD0E739499BDB\curl -sSL https://get.rvm.io | bash -s stablesource /etc/profile.d/rvm.sh -
安装jruby
rvm install jrubyrvm use jruby -
安装包管理工具bundle和测试工具rspec
gem install bundle gem install rspec
从example开始
-
clone logstash-input-example
git clone https://github.com/logstash-plugins/logstash-input-example.git -
将clone出来的logstash-input-example源码copy到logstash-input-cos目录,并删除.git文件夹,目的是以logstash-input-example的源码为参考进行开发,同时把需要改动名称的地方修改一下:
mv logstash-input-example.gemspec logstash-input-cos.gemspec mv lib/logstash/inputs/example.rb lib/logstash/inputs/cos.rb mv spec/inputs/example_spec.rb spec/inputs/cos_spec.rb - 建立的源码目录结构如图所示:
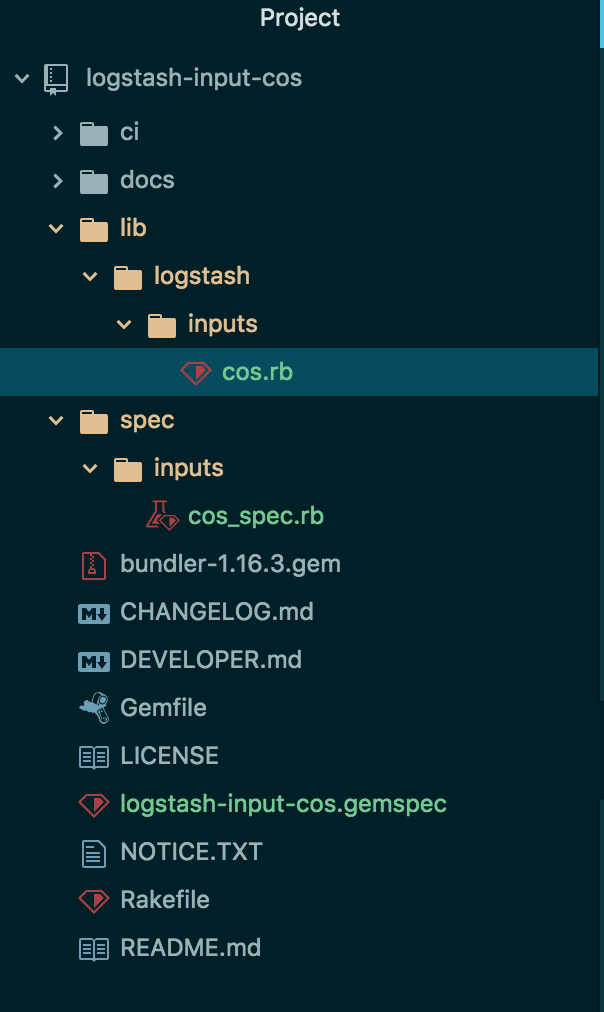
其中,重要文件的作用说明如下:
- cos.rb: 主文件,在该文件中编写logstash配置文件的读写与源数据获取的代码,需要继承LogStash::Inputs::Base基类
- cos_spec.rb: 单元测试文件,通过rspec可以对cos.rb中的代码进行测试
- logstash-input-cos.gemspec: 类似于maven中的pom.xml文件,配置工程的版本、名称、licene,包依赖等,通过bundle命令可以下载依赖包
配置并下载依赖
因为腾讯云COS服务没有ruby sdk, 因为只能依赖其Java sdk进行开发,首先添加对cos java sdk的依赖。在logstash-input-cos.gemspec中Gem dependencies配置栏中增加以下内容:
# Gem dependencies
s.requirements << "jar 'com.qcloud:cos_api', '5.4.4'"
s.add_runtime_dependency "logstash-core-plugin-api", ">= 1.60", "<= 2.99"
s.add_runtime_dependency 'logstash-codec-plain'
s.add_runtime_dependency 'stud', '>= 0.0.22'
s.add_runtime_dependency 'jar-dependencies'
s.add_development_dependency 'logstash-devutils', '1.3.6'相比logstash-input-example.gemspec,增加了对com.qcloud:cos_api包以及jar-dependencies包的依赖,jar-dependencies用于在ruby环境中管理jar包,并且可以跟踪jar包的加载状态。
然后,在logstash-input-cos.gemspec中增加配置:
s.platform = 'java'这样可以成功下载java依赖包,并且可以在ruby代码中直接调用java代码。
最后,执行以下命令下载依赖:
bundle install编写代码
logstash-input-cos的代码逻辑其实比较简单,主要是通过执行定时任务,调用cos java sdk中的listObjects方法,获取到指定bucket里的数据,并在每次定时任务执行结束后设置marker保存在本地,再次执行时从marker位置获取数据,以实现数据的增量同步。
jar包的引用
因为要调用cos java sdk中的代码,先引用该jar包:
require 'cos_api-5.4.4.jar'
java_import com.qcloud.cos.COSClient;
java_import com.qcloud.cos.ClientConfig;
java_import com.qcloud.cos.auth.BasicCOSCredentials;
java_import com.qcloud.cos.auth.COSCredentials;
java_import com.qcloud.cos.exception.CosClientException;
java_import com.qcloud.cos.exception.CosServiceException;
java_import com.qcloud.cos.model.COSObjectSummary;
java_import com.qcloud.cos.model.ListObjectsRequest;
java_import com.qcloud.cos.model.ObjectListing;
java_import com.qcloud.cos.region.Region;读取配置文件
logstash配置文件读取的代码如图所示:
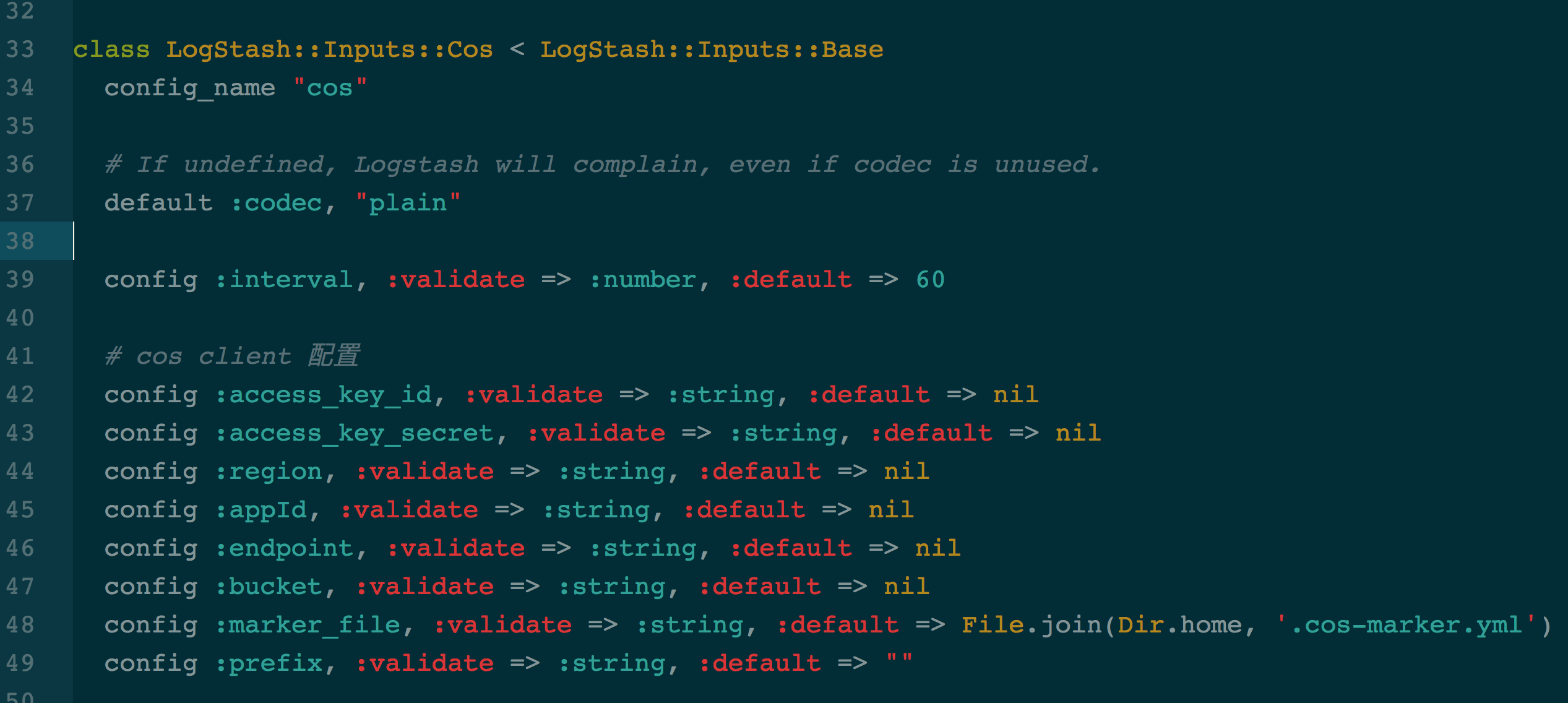
config_name为cos,其它的配置项读取代码按照ruby的代码规范编写,添加类型校验与默认值,就可以从以下配置文件中读取配置项:
input {
cos {
"endpoint" => "cos.ap-guangzhou.myqcloud.com"
"access_key_id" => "*****"
"access_key_secret" => "****"
"bucket" => "******"
"region" => "ap-guangzhou"
"appId" => "**********"
"interval" => 60
}
}
output {
stdout {
codec=>rubydebug
}
}实现register方法
logstash input插件必须实现另个方法:register 和run
register方法类似于初始化方法,在该方法中可以直接使用从配置文件读取并赋值的变量,完成cos client的初始化,代码如下:
# 1 初始化用户身份信息(appid, secretId, secretKey)
cred = com.qcloud.cos.auth.BasicCOSCredentials.new(@access_key_id, @access_key_secret)
# 2 设置bucket的区域, COS地域的简称请参照 https://www.qcloud.com/document/product/436/6224
clientConfig = com.qcloud.cos.ClientConfig.new(com.qcloud.cos.region.Region.new(@region))
# 3 生成cos客户端
@cosclient = com.qcloud.cos.COSClient.new(cred, clientConfig)
# bucket名称, 需包含appid
bucketName = @bucket + "-"+ @appId
@bucketName = bucketName
@listObjectsRequest = com.qcloud.cos.model.ListObjectsRequest.new()
# 设置bucket名称
@listObjectsRequest.setBucketName(bucketName)
# prefix表示列出的object的key以prefix开始
@listObjectsRequest.setPrefix(@prefix)
# 设置最大遍历出多少个对象, 一次listobject最大支持1000
@listObjectsRequest.setMaxKeys(1000)
@listObjectsRequest.setMarker(@markerConfig.getMarker)示例代码中设置了@cosclient和@listObjectRequest为全局变量, 因为在run方法中会用到这两个变量。
注意在ruby中调用java代码的方式:没有变量描述符;不能直接new Object(),而只能Object.new().
实现run方法
run方法获取数据并将数据流转换成event事件
最简单的run方法为:
def run(queue)
Stud.interval(@interval) do
event = LogStash::Event.new("message" => @message, "host" => @host)
decorate(event)
queue << event
end # loop
end # def run代码说明:
- 通过Stud ruby模块执行定时任务,interval可自定义,从配置文件中读取
- 生成event, 示例代码生成了一个包含两个字段数据的event
- 调用decorate()方法, 给该event打上tag,如果配置的话
- queue<<event, 将event插入到数据管道中,发送给filter处理
logstash-input-cos的run方法实现为:
def run(queue)
@current_thread = Thread.current
Stud.interval(@interval) do
process(queue)
end
end
def process(queue)
@logger.info('Marker from: ' + @markerConfig.getMarker)
objectListing = @cosclient.listObjects(@listObjectsRequest)
nextMarker = objectListing.getNextMarker()
cosObjectSummaries = objectListing.getObjectSummaries()
cosObjectSummaries.each do |obj|
# 文件的路径key
key = obj.getKey()
if stop?
@logger.info("stop while attempting to read log file")
break
end
# 根据key获取内容
getObject(key) { |log|
# 发送消息
@codec.decode(log) do |event|
decorate(event)
queue << event
end
}
#记录 marker
@markerConfig.setMarker(key)
@logger.info('Marker end: ' + @markerConfig.getMarker)
end
end
# 获取下载输入流
def getObject(key, &block)
getObjectRequest = com.qcloud.cos.model.GetObjectRequest.new(@bucketName, key)
cosObject = @cosclient.getObject(getObjectRequest)
cosObjectInput = cosObject.getObjectContent()
buffered =BufferedReader.new(InputStreamReader.new(cosObjectInput))
while (line = buffered.readLine())
block.call(line)
end
end测试代码
在spec/inputs/cos_spec.rb中增加如下测试代码:
# encoding: utf-8
require "logstash/devutils/rspec/spec_helper"
require "logstash/inputs/cos"
describe LogStash::Inputs::Cos do
it_behaves_like "an interruptible input plugin" do
let(:config) { {
"endpoint" => 'cos.ap-guangzhou.myqcloud.com',
"access_key_id" => '*',
"access_key_secret" => '*',
"bucket" => '*',
"region" => 'ap-guangzhou',
"appId" => '*',
"interval" => 60 } }
end
end
rspec是一个ruby测试库,通过bundle命令执行rspec:
bundle exec rspec如果cos.rb中的代码没有语法或运行时错误,则会出现如果信息表明测试成功:
Finished in 0.8022 seconds (files took 3.45 seconds to load)
1 example, 0 failures构建并测试input-plugin-cos
build
使用gem对input-plugin-cos插件源码进行build:
gem build logstash-input-cos.gemspec构建完成后会生成一个名为logstash-input-cos-0.0.1-java.gem的文件
test
在logstash的解压目录下,执行一下命令安装logstash-input-cos plugin:
./bin/logstash-plugin install /usr/local/githome/logstash-input-cos/logstash-input-cos-0.0.1-java.gem执行结果为:
Validating /usr/local/githome/logstash-input-cos/logstash-input-cos-0.0.1-java.gem
Installing logstash-input-cos
Installation successful另外,可以通过./bin/logstash-plugin list命令查看logstash已经安装的所有input/output/filter/codec插件。
生成配置文件cos.logstash.conf,内容为:
input {
cos {
"endpoint" => "cos.ap-guangzhou.myqcloud.com"
"access_key_id" => "*****"
"access_key_secret" => "****"
"bucket" => "******"
"region" => "ap-guangzhou"
"appId" => "**********"
"interval" => 60
}
}
output {
stdout {
codec=>rubydebug
}
}该配置文件使用腾讯云官网账号的secret_id和secret_key进行权限验证,拉取指定bucket里的数据,为了测试,将output设置为标准输出。
执行logstash:
./bin/logstash -f cos.logstash.conf输出结果为:
Sending Logstash's logs to /root/logstash-5.6.4/logs which is now configured via log4j2.properties
[2018-07-30T19:26:17,039][WARN ][logstash.runner ] --config.debug was specified, but log.level was not set to 'debug'! No config info will be logged.
[2018-07-30T19:26:17,048][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"netflow", :directory=>"/root/logstash-5.6.4/modules/netflow/configuration"}
[2018-07-30T19:26:17,049][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"fb_apache", :directory=>"/root/logstash-5.6.4/modules/fb_apache/configuration"}
[2018-07-30T19:26:17,252][INFO ][logstash.inputs.cos ] Using version 0.1.x input plugin 'cos'. This plugin isn't well supported by the community and likely has no maintainer.
[2018-07-30T19:26:17,341][INFO ][logstash.pipeline ] Starting pipeline {"id"=>"main", "pipeline.workers"=>4, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>5, "pipeline.max_inflight"=>500}
[2018-07-30T19:26:17,362][INFO ][logstash.inputs.cos ] Registering cos input {:bucket=>"bellengao", :region=>"ap-guangzhou"}
[2018-07-30T19:26:17,528][INFO ][logstash.pipeline ] Pipeline main started
[2018-07-30T19:26:17,530][INFO ][logstash.inputs.cos ] Marker from:
log4j:WARN No appenders could be found for logger (org.apache.http.client.protocol.RequestAddCookies).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
[2018-07-30T19:26:17,574][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
[2018-07-30T19:26:17,714][INFO ][logstash.inputs.cos ] Marker end: access.log
{
"message" => "77.179.66.156 - - [25/Oct/2016:14:49:33 +0200] \"GET / HTTP/1.1\" 200 612 \"-\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.59 Safari/537.36\"",
"@version" => "1",
"@timestamp" => 2018-07-30T11:26:17.710Z
}
{
"message" => "77.179.66.156 - - [25/Oct/2016:14:49:34 +0200] \"GET /favicon.ico HTTP/1.1\" 404 571 \"http://localhost:8080/\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.59 Safari/537.36\"",
"@version" => "1",
"@timestamp" => 2018-07-30T11:26:17.711Z
}在cos中的bucket里上传了名为access.log的nginx日志,上述输出结果中最后打印出来的每个json结构体构成一个event, 其中message消息即为access.log中每一条日志。
logstash作为一个数据管道中间件,支持对各种类型数据的采集与转换,并将数据发送到各种类型的存储库,比如实现消费kafka数据并且写入到Elasticsearch, 日志文件同步到对象存储S3等,mysql数据同步到Elasticsearch等。
logstash内部主要包含三个模块:
* input: 从数据源获取数据
* filter: 过滤、转换数据
* output: 输出数据
不同类型的数据都可以通过对应的input-plugin, output-plugin完成数据的输入与输出。如需要消费kafka中的数据并写入到Elasticsearch中,则需要使用logstash的kafka-input-plugin完成数据输入,logstash-output-elasticsearch完成数据输出。如果需要对输入数据进行过滤或者转换,比如根据关键词过滤掉不需要的内容,或者时间字段的格式转换,就需要又filter-plugin完成了。
logstash的input插件目前已经有几十种了,支持大多数比较通用或开源的数据源的输入。但如果公司内部开发的数据库或其它存储类的服务不能和开源产品在接口协议上兼容,比如腾讯自研的消息队列服务CMQ不依赖于其它的开源消息队列产品,所以不能直接使用logstash的logstash-input-kafka或logstash-input-rabbitmq同步CMQ中的数据;腾讯云对象存储服务COS, 在鉴权方式上和AWS的S3存在差异,也不能直接使用logstash-input-s3插件从COS中读取数据,对于这种情况,就需要自己开发logstash的input插件了。
本文以开发logstash的cos input插件为例,介绍如何开发logstash的input插件。
logstash官方提供了有个简单的input plugin example可供参考: https://github.com/logstash-plugins/logstash-input-example/
环境准备
logstash使用jruby开发,首先要配置jruby环境:
-
安装rvm:
rvm是一个ruby管理器,可以安装并管理ruby环境,也可以通过命令行切换到不同的ruby版本。
gpg --keyserver hkp://keys.gnupg.net --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3 7D2BAF1CF37B13E2069D6956105BD0E739499BDB\curl -sSL https://get.rvm.io | bash -s stablesource /etc/profile.d/rvm.sh -
安装jruby
rvm install jrubyrvm use jruby -
安装包管理工具bundle和测试工具rspec
gem install bundle gem install rspec
从example开始
-
clone logstash-input-example
git clone https://github.com/logstash-plugins/logstash-input-example.git -
将clone出来的logstash-input-example源码copy到logstash-input-cos目录,并删除.git文件夹,目的是以logstash-input-example的源码为参考进行开发,同时把需要改动名称的地方修改一下:
mv logstash-input-example.gemspec logstash-input-cos.gemspec mv lib/logstash/inputs/example.rb lib/logstash/inputs/cos.rb mv spec/inputs/example_spec.rb spec/inputs/cos_spec.rb - 建立的源码目录结构如图所示:
其中,重要文件的作用说明如下:
- cos.rb: 主文件,在该文件中编写logstash配置文件的读写与源数据获取的代码,需要继承LogStash::Inputs::Base基类
- cos_spec.rb: 单元测试文件,通过rspec可以对cos.rb中的代码进行测试
- logstash-input-cos.gemspec: 类似于maven中的pom.xml文件,配置工程的版本、名称、licene,包依赖等,通过bundle命令可以下载依赖包
配置并下载依赖
因为腾讯云COS服务没有ruby sdk, 因为只能依赖其Java sdk进行开发,首先添加对cos java sdk的依赖。在logstash-input-cos.gemspec中Gem dependencies配置栏中增加以下内容:
# Gem dependencies
s.requirements << "jar 'com.qcloud:cos_api', '5.4.4'"
s.add_runtime_dependency "logstash-core-plugin-api", ">= 1.60", "<= 2.99"
s.add_runtime_dependency 'logstash-codec-plain'
s.add_runtime_dependency 'stud', '>= 0.0.22'
s.add_runtime_dependency 'jar-dependencies'
s.add_development_dependency 'logstash-devutils', '1.3.6'相比logstash-input-example.gemspec,增加了对com.qcloud:cos_api包以及jar-dependencies包的依赖,jar-dependencies用于在ruby环境中管理jar包,并且可以跟踪jar包的加载状态。
然后,在logstash-input-cos.gemspec中增加配置:
s.platform = 'java'这样可以成功下载java依赖包,并且可以在ruby代码中直接调用java代码。
最后,执行以下命令下载依赖:
bundle install编写代码
logstash-input-cos的代码逻辑其实比较简单,主要是通过执行定时任务,调用cos java sdk中的listObjects方法,获取到指定bucket里的数据,并在每次定时任务执行结束后设置marker保存在本地,再次执行时从marker位置获取数据,以实现数据的增量同步。
jar包的引用
因为要调用cos java sdk中的代码,先引用该jar包:
require 'cos_api-5.4.4.jar'
java_import com.qcloud.cos.COSClient;
java_import com.qcloud.cos.ClientConfig;
java_import com.qcloud.cos.auth.BasicCOSCredentials;
java_import com.qcloud.cos.auth.COSCredentials;
java_import com.qcloud.cos.exception.CosClientException;
java_import com.qcloud.cos.exception.CosServiceException;
java_import com.qcloud.cos.model.COSObjectSummary;
java_import com.qcloud.cos.model.ListObjectsRequest;
java_import com.qcloud.cos.model.ObjectListing;
java_import com.qcloud.cos.region.Region;读取配置文件
logstash配置文件读取的代码如图所示:
config_name为cos,其它的配置项读取代码按照ruby的代码规范编写,添加类型校验与默认值,就可以从以下配置文件中读取配置项:
input {
cos {
"endpoint" => "cos.ap-guangzhou.myqcloud.com"
"access_key_id" => "*****"
"access_key_secret" => "****"
"bucket" => "******"
"region" => "ap-guangzhou"
"appId" => "**********"
"interval" => 60
}
}
output {
stdout {
codec=>rubydebug
}
}实现register方法
logstash input插件必须实现另个方法:register 和run
register方法类似于初始化方法,在该方法中可以直接使用从配置文件读取并赋值的变量,完成cos client的初始化,代码如下:
# 1 初始化用户身份信息(appid, secretId, secretKey)
cred = com.qcloud.cos.auth.BasicCOSCredentials.new(@access_key_id, @access_key_secret)
# 2 设置bucket的区域, COS地域的简称请参照 https://www.qcloud.com/document/product/436/6224
clientConfig = com.qcloud.cos.ClientConfig.new(com.qcloud.cos.region.Region.new(@region))
# 3 生成cos客户端
@cosclient = com.qcloud.cos.COSClient.new(cred, clientConfig)
# bucket名称, 需包含appid
bucketName = @bucket + "-"+ @appId
@bucketName = bucketName
@listObjectsRequest = com.qcloud.cos.model.ListObjectsRequest.new()
# 设置bucket名称
@listObjectsRequest.setBucketName(bucketName)
# prefix表示列出的object的key以prefix开始
@listObjectsRequest.setPrefix(@prefix)
# 设置最大遍历出多少个对象, 一次listobject最大支持1000
@listObjectsRequest.setMaxKeys(1000)
@listObjectsRequest.setMarker(@markerConfig.getMarker)示例代码中设置了@cosclient和@listObjectRequest为全局变量, 因为在run方法中会用到这两个变量。
注意在ruby中调用java代码的方式:没有变量描述符;不能直接new Object(),而只能Object.new().
实现run方法
run方法获取数据并将数据流转换成event事件
最简单的run方法为:
def run(queue)
Stud.interval(@interval) do
event = LogStash::Event.new("message" => @message, "host" => @host)
decorate(event)
queue << event
end # loop
end # def run代码说明:
- 通过Stud ruby模块执行定时任务,interval可自定义,从配置文件中读取
- 生成event, 示例代码生成了一个包含两个字段数据的event
- 调用decorate()方法, 给该event打上tag,如果配置的话
- queue<<event, 将event插入到数据管道中,发送给filter处理
logstash-input-cos的run方法实现为:
def run(queue)
@current_thread = Thread.current
Stud.interval(@interval) do
process(queue)
end
end
def process(queue)
@logger.info('Marker from: ' + @markerConfig.getMarker)
objectListing = @cosclient.listObjects(@listObjectsRequest)
nextMarker = objectListing.getNextMarker()
cosObjectSummaries = objectListing.getObjectSummaries()
cosObjectSummaries.each do |obj|
# 文件的路径key
key = obj.getKey()
if stop?
@logger.info("stop while attempting to read log file")
break
end
# 根据key获取内容
getObject(key) { |log|
# 发送消息
@codec.decode(log) do |event|
decorate(event)
queue << event
end
}
#记录 marker
@markerConfig.setMarker(key)
@logger.info('Marker end: ' + @markerConfig.getMarker)
end
end
# 获取下载输入流
def getObject(key, &block)
getObjectRequest = com.qcloud.cos.model.GetObjectRequest.new(@bucketName, key)
cosObject = @cosclient.getObject(getObjectRequest)
cosObjectInput = cosObject.getObjectContent()
buffered =BufferedReader.new(InputStreamReader.new(cosObjectInput))
while (line = buffered.readLine())
block.call(line)
end
end测试代码
在spec/inputs/cos_spec.rb中增加如下测试代码:
# encoding: utf-8
require "logstash/devutils/rspec/spec_helper"
require "logstash/inputs/cos"
describe LogStash::Inputs::Cos do
it_behaves_like "an interruptible input plugin" do
let(:config) { {
"endpoint" => 'cos.ap-guangzhou.myqcloud.com',
"access_key_id" => '*',
"access_key_secret" => '*',
"bucket" => '*',
"region" => 'ap-guangzhou',
"appId" => '*',
"interval" => 60 } }
end
end
rspec是一个ruby测试库,通过bundle命令执行rspec:
bundle exec rspec如果cos.rb中的代码没有语法或运行时错误,则会出现如果信息表明测试成功:
Finished in 0.8022 seconds (files took 3.45 seconds to load)
1 example, 0 failures构建并测试input-plugin-cos
build
使用gem对input-plugin-cos插件源码进行build:
gem build logstash-input-cos.gemspec构建完成后会生成一个名为logstash-input-cos-0.0.1-java.gem的文件
test
在logstash的解压目录下,执行一下命令安装logstash-input-cos plugin:
./bin/logstash-plugin install /usr/local/githome/logstash-input-cos/logstash-input-cos-0.0.1-java.gem执行结果为:
Validating /usr/local/githome/logstash-input-cos/logstash-input-cos-0.0.1-java.gem
Installing logstash-input-cos
Installation successful另外,可以通过./bin/logstash-plugin list命令查看logstash已经安装的所有input/output/filter/codec插件。
生成配置文件cos.logstash.conf,内容为:
input {
cos {
"endpoint" => "cos.ap-guangzhou.myqcloud.com"
"access_key_id" => "*****"
"access_key_secret" => "****"
"bucket" => "******"
"region" => "ap-guangzhou"
"appId" => "**********"
"interval" => 60
}
}
output {
stdout {
codec=>rubydebug
}
}该配置文件使用腾讯云官网账号的secret_id和secret_key进行权限验证,拉取指定bucket里的数据,为了测试,将output设置为标准输出。
执行logstash:
./bin/logstash -f cos.logstash.conf输出结果为:
Sending Logstash's logs to /root/logstash-5.6.4/logs which is now configured via log4j2.properties
[2018-07-30T19:26:17,039][WARN ][logstash.runner ] --config.debug was specified, but log.level was not set to 'debug'! No config info will be logged.
[2018-07-30T19:26:17,048][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"netflow", :directory=>"/root/logstash-5.6.4/modules/netflow/configuration"}
[2018-07-30T19:26:17,049][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"fb_apache", :directory=>"/root/logstash-5.6.4/modules/fb_apache/configuration"}
[2018-07-30T19:26:17,252][INFO ][logstash.inputs.cos ] Using version 0.1.x input plugin 'cos'. This plugin isn't well supported by the community and likely has no maintainer.
[2018-07-30T19:26:17,341][INFO ][logstash.pipeline ] Starting pipeline {"id"=>"main", "pipeline.workers"=>4, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>5, "pipeline.max_inflight"=>500}
[2018-07-30T19:26:17,362][INFO ][logstash.inputs.cos ] Registering cos input {:bucket=>"bellengao", :region=>"ap-guangzhou"}
[2018-07-30T19:26:17,528][INFO ][logstash.pipeline ] Pipeline main started
[2018-07-30T19:26:17,530][INFO ][logstash.inputs.cos ] Marker from:
log4j:WARN No appenders could be found for logger (org.apache.http.client.protocol.RequestAddCookies).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
[2018-07-30T19:26:17,574][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
[2018-07-30T19:26:17,714][INFO ][logstash.inputs.cos ] Marker end: access.log
{
"message" => "77.179.66.156 - - [25/Oct/2016:14:49:33 +0200] \"GET / HTTP/1.1\" 200 612 \"-\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.59 Safari/537.36\"",
"@version" => "1",
"@timestamp" => 2018-07-30T11:26:17.710Z
}
{
"message" => "77.179.66.156 - - [25/Oct/2016:14:49:34 +0200] \"GET /favicon.ico HTTP/1.1\" 404 571 \"http://localhost:8080/\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.59 Safari/537.36\"",
"@version" => "1",
"@timestamp" => 2018-07-30T11:26:17.711Z
}在cos中的bucket里上传了名为access.log的nginx日志,上述输出结果中最后打印出来的每个json结构体构成一个event, 其中message消息即为access.log中每一条日志。
收起阅读 »一文快速上手Logstash
本文同步发布在腾讯云+社区Elasticsearch专栏:https://cloud.tencent.com/developer/column/4008
Elasticsearch是当前主流的分布式大数据存储和搜索引擎,可以为用户提供强大的全文本检索能力,广泛应用于日志检索,全站搜索等领域。Logstash作为Elasicsearch常用的实时数据采集引擎,可以采集来自不同数据源的数据,并对数据进行处理后输出到多种输出源,是Elastic Stack 的重要组成部分。本文从Logstash的工作原理,使用示例,部署方式及性能调优等方面入手,为大家提供一个快速入门Logstash的方式。文章最后也给出了一些深入了解Logstash的的链接,以方便大家根据需要详细了解。
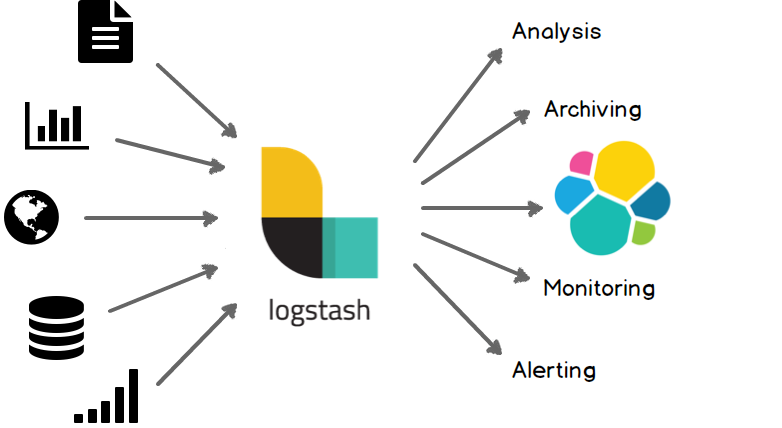
1 Logstash工作原理
1.1 处理过程
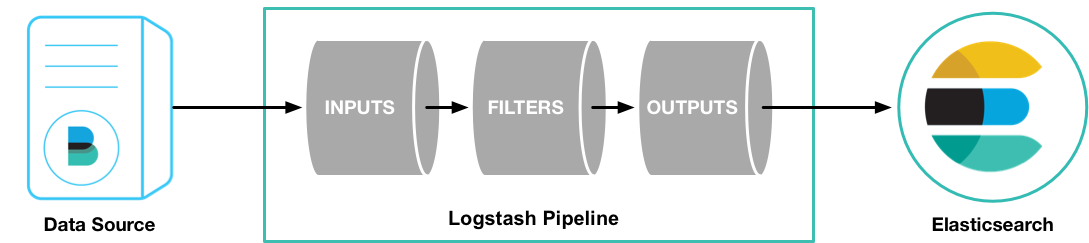
如上图,Logstash的数据处理过程主要包括:Inputs, Filters, Outputs 三部分, 另外在Inputs和Outputs中可以使用Codecs对数据格式进行处理。这四个部分均以插件形式存在,用户通过定义pipeline配置文件,设置需要使用的input,filter,output, codec插件,以实现特定的数据采集,数据处理,数据输出等功能
- (1)Inputs:用于从数据源获取数据,常见的插件如file, syslog, redis, beats 等[详细参考]
- (2)Filters:用于处理数据如格式转换,数据派生等,常见的插件如grok, mutate, drop, clone, geoip等[详细参考]
- (3)Outputs:用于数据输出,常见的插件如elastcisearch,file, graphite, statsd等[详细参考]
- (4)Codecs:Codecs不是一个单独的流程,而是在输入和输出等插件中用于数据转换的模块,用于对数据进行编码处理,常见的插件如json,multiline[详细参考]
可以点击每个模块后面的_详细参考_链接了解该模块的插件列表及对应功能
1.2 执行模型:
- (1)每个Input启动一个线程,从对应数据源获取数据
- (2)Input会将数据写入一个队列:默认为内存中的有界队列(意外停止会导致数据丢失)。为了防止数丢失Logstash提供了两个特性: Persistent Queues:通过磁盘上的queue来防止数据丢失 Dead Letter Queues:保存无法处理的event(仅支持Elasticsearch作为输出源)
- (3)Logstash会有多个pipeline worker, 每一个pipeline worker会从队列中取一批数据,然后执行filter和output(worker数目及每次处理的数据量均由配置确定)
2 Logstash使用示例
2.1 Logstash Hello world
第一个示例Logstash将采用标准输入和标准输出作为input和output,并且不指定filter
- (1)下载Logstash并解压(需要预先安装JDK8)
- (2)cd到Logstash的根目录,并执行启动命令如下:
cd logstash-6.4.0
bin/logstash -e 'input { stdin { } } output { stdout {} }'- (3)此时Logstash已经启动成功,-e表示在启动时直接指定pipeline配置,当然也可以将该配置写入一个配置文件中,然后通过指定配置文件来启动
- (4)在控制台输入:hello world,可以看到如下输出:
{
"@version" => "1",
"host" => "localhost",
"@timestamp" => 2018-09-18T12:39:38.514Z,
"message" => "hello world"
} Logstash会自动为数据添加@version, host, @timestamp等字段
在这个示例中Logstash从标准输入中获得数据,仅在数据中添加一些简单字段后将其输出到标准输出。
2.2 日志采集
这个示例将采用Filebeat input插件(Elastic Stack中的轻量级数据采集程序)采集本地日志,然后将结果输出到标准输出
filebeat.yml配置如下(paths改为日志实际位置,不同版本beats配置可能略有变化,请根据情况调整)
filebeat.prospectors:
- input\_type: log
paths:
- /path/to/file/logstash-tutorial.log
output.logstash:
hosts: "localhost:5044"启动命令:
./filebeat -e -c filebeat.yml -d "publish"- (3)配置logstash并启动
1)创建first-pipeline.conf文件内容如下(该文件为pipeline配置文件,用于指定input,filter, output等):
input {
beats {
port => "5044"
}
}
#filter {
#}
output {
stdout { codec => rubydebug }
}codec => rubydebug用于美化输出[参考]
2)验证配置(注意指定配置文件的路径):
./bin/logstash -f first-pipeline.conf --config.test_and_exit3)启动命令:
./bin/logstash -f first-pipeline.conf --config.reload.automatic--config.reload.automatic选项启用动态重载配置功能
4)预期结果:
可以在Logstash的终端显示中看到,日志文件被读取并处理为如下格式的多条数据
{
"@timestamp" => 2018-10-09T12:22:39.742Z,
"offset" => 24464,
"@version" => "1",
"input_type" => "log",
"beat" => {
"name" => "VM_136_9_centos",
"hostname" => "VM_136_9_centos",
"version" => "5.6.10"
},
"host" => "VM_136_9_centos",
"source" => "/data/home/michelmu/workspace/logstash-tutorial.log",
"message" => "86.1.76.62 - - [04/Jan/2015:05:30:37 +0000] \"GET /style2.css HTTP/1.1\" 200 4877 \"http://www.semicomplete.com/projects/xdotool/\" \"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"type" => "log",
"tags" => [
[0] "beats_input_codec_plain_applied"
]
}相对于示例2.1,该示例使用了filebeat input插件从日志中获取一行记录,这也是Elastic stack获取日志数据最常见的一种方式。另外该示例还采用了rubydebug codec 对输出的数据进行显示美化。
2.3 日志格式处理
可以看到虽然示例2.2使用filebeat从日志中读取数据,并将数据输出到标准输出,但是日志内容作为一个整体被存放在message字段中,这样对后续存储及查询都极为不便。可以为该pipeline指定一个grok filter来对日志格式进行处理
- (1)在first-pipeline.conf中增加filter配置如下
input {
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
}
output {
stdout { codec => rubydebug }
}- (2)到filebeat的根目录下删除之前上报的数据历史(以便重新上报数据),并重启filebeat
sudo rm data/registry
sudo ./filebeat -e -c filebeat.yml -d "publish"- (3)由于之前启动Logstash设置了自动更新配置,因此Logstash不需要重新启动,这个时候可以获取到的日志数据如下:
{
"request" => "/style2.css",
"agent" => "\"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"offset" => 24464,
"auth" => "-",
"ident" => "-",
"input_type" => "log",
"verb" => "GET",
"source" => "/data/home/michelmu/workspace/logstash-tutorial.log",
"message" => "86.1.76.62 - - [04/Jan/2015:05:30:37 +0000] \"GET /style2.css HTTP/1.1\" 200 4877 \"http://www.semicomplete.com/projects/xdotool/\" \"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"type" => "log",
"tags" => [
[0] "beats_input_codec_plain_applied"
],
"referrer" => "\"http://www.semicomplete.com/projects/xdotool/\"",
"@timestamp" => 2018-10-09T12:24:21.276Z,
"response" => "200",
"bytes" => "4877",
"clientip" => "86.1.76.62",
"@version" => "1",
"beat" => {
"name" => "VM_136_9_centos",
"hostname" => "VM_136_9_centos",
"version" => "5.6.10"
},
"host" => "VM_136_9_centos",
"httpversion" => "1.1",
"timestamp" => "04/Jan/2015:05:30:37 +0000"
}可以看到message中的数据被详细解析出来了
2.4 数据派生和增强
Logstash中的一些filter可以根据现有数据生成一些新的数据,如geoip可以根据ip生成经纬度信息
- (1)在first-pipeline.conf中增加geoip配置如下
input {
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
geoip {
source => "clientip"
}
}
output {
stdout { codec => rubydebug }
}- (2)如2.3一样清空filebeat历史数据,并重启
- (3)当然Logstash仍然不需要重启,可以看到输出变为如下:
{
"request" => "/style2.css",
"agent" => "\"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"geoip" => {
"timezone" => "Europe/London",
"ip" => "86.1.76.62",
"latitude" => 51.5333,
"continent_code" => "EU",
"city_name" => "Willesden",
"country_name" => "United Kingdom",
"country_code2" => "GB",
"country_code3" => "GB",
"region_name" => "Brent",
"location" => {
"lon" => -0.2333,
"lat" => 51.5333
},
"postal_code" => "NW10",
"region_code" => "BEN",
"longitude" => -0.2333
},
"offset" => 24464,
"auth" => "-",
"ident" => "-",
"input_type" => "log",
"verb" => "GET",
"source" => "/data/home/michelmu/workspace/logstash-tutorial.log",
"message" => "86.1.76.62 - - [04/Jan/2015:05:30:37 +0000] \"GET /style2.css HTTP/1.1\" 200 4877 \"http://www.semicomplete.com/projects/xdotool/\" \"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"type" => "log",
"tags" => [
[0] "beats_input_codec_plain_applied"
],
"referrer" => "\"http://www.semicomplete.com/projects/xdotool/\"",
"@timestamp" => 2018-10-09T12:37:46.686Z,
"response" => "200",
"bytes" => "4877",
"clientip" => "86.1.76.62",
"@version" => "1",
"beat" => {
"name" => "VM_136_9_centos",
"hostname" => "VM_136_9_centos",
"version" => "5.6.10"
},
"host" => "VM_136_9_centos",
"httpversion" => "1.1",
"timestamp" => "04/Jan/2015:05:30:37 +0000"
}可以看到根据ip派生出了许多地理位置信息数据
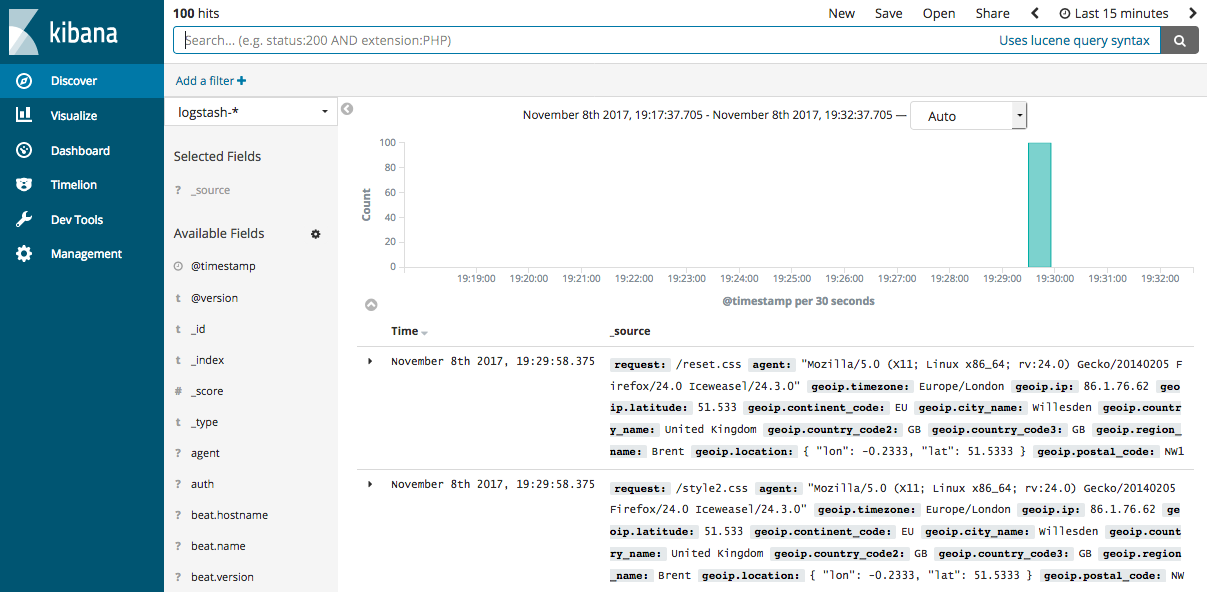
2.5 将数据导入Elasticsearch
Logstash作为Elastic stack的重要组成部分,其最常用的功能是将数据导入到Elasticssearch中。将Logstash中的数据导入到Elasticsearch中操作也非常的方便,只需要在pipeline配置文件中增加Elasticsearch的output即可。
- (1)首先要有一个已经部署好的Logstash,当然可以使用腾讯云快速创建一个Elasticsearch创建地址
- (2)在first-pipeline.conf中增加Elasticsearch的配置,如下
input {
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
geoip {
source => "clientip"
}
}
output {
elasticsearch {
hosts => [ "localhost:9200" ]
}
}- (3)清理filebeat历史数据,并重启
- (4)查询Elasticsearch确认数据是否正常上传(注意替换查询语句中的日期)
curl -XGET 'http://172.16.16.17:9200/logstash-2018.10.09/_search?pretty&q=response=200'- (5)如果Elasticsearch关联了Kibana也可以使用kibana查看数据是否正常上报
Logstash提供了大量的Input, filter, output, codec的插件,用户可以根据自己的需要,使用一个或多个组件实现自己的功能,当然用户也可以自定义插件以实现更为定制化的功能。自定义插件可以参考[logstash input插件开发]
3 部署Logstash
演示过如何快速使用Logstash后,现在详细讲述一下Logstash的部署方式。
3.1 安装
- 安装JDK:Logstash采用JRuby编写,运行需要JDK环境,因此安装Logstash前需要先安装JDK。(当前6.4仅支持JDK8)
- 安装Logstash:可以采用直接下载压缩包方式安装,也通过APT或YUM安装,另外Logstash支持安装到Docker中。[Logstash安装参考]
- 安装X-PACK:在6.3及之后版本X-PACK会随Logstash安装,在此之前需要手动安装[参考链接]
3.2 目录结构
logstash的目录主要包括:根目录、bin目录、配置目录、日志目录、插件目录、数据目录
不同安装方式各目录的默认位置参考[此处]
3.3 配置文件
- Pipeline配置文件,名称可以自定义,在启动Logstash时显式指定,编写方式可以参考前面示例,对于具体插件的配置方式参见具体插件的说明(使用Logstash时必须配置): 用于定义一个pipeline,数据处理方式和输出源
- Settings配置文件(可以使用默认配置): 在使用Logstash时可以不用设置,用于性能调优,日志记录等
- 为了保证敏感配置的安全性,logstash提供了配置加密功能[参考链接]
3.4 启动关闭方式
3.4.1 启动
- 命令行启动
- 在debian和rpm上以服务形式启动
- 在docker中启动3.4.2 关闭
- 关闭Logstash
- Logstash的关闭时会先关闭input停止输入,然后处理完所有进行中的事件,然后才完全停止,以防止数据丢失,但这也导致停止过程出现延迟或失败的情况。
3.5 扩展Logstash
当单个Logstash无法满足性能需求时,可以采用横向扩展的方式来提高Logstash的处理能力。横向扩展的多个Logstash相互独立,采用相同的pipeline配置,另外可以在这多个Logstash前增加一个LoadBalance,以实现多个Logstash的负载均衡。
4 性能调优
[详细调优参考]
- (1)Inputs和Outputs的性能:当输入输出源的性能已经达到上限,那么性能瓶颈不在Logstash,应优先对输入输出源的性能进行调优。
- (2)系统性能指标:
- CPU:确定CPU使用率是否过高,如果CPU过高则先查看JVM堆空间使用率部分,确认是否为GC频繁导致,如果GC正常,则可以通过调节Logstash worker相关配置来解决。
- 内存:由于Logstash运行在JVM上,因此注意调整JVM堆空间上限,以便其有足够的运行空间。另外注意Logstash所在机器上是否有其他应用占用了大量内存,导致Logstash内存磁盘交换频繁。
- I/O使用率: 1)磁盘IO: 磁盘IO饱和可能是因为使用了会导致磁盘IO饱和的创建(如file output),另外Logstash中出现错误产生大量错误日志时也会导致磁盘IO饱和。Linux下可以通过iostat, dstat等查看磁盘IO情况 2)网络IO: 网络IO饱和一般发生在使用有大量网络操作的插件时。linux下可以使用dstat或iftop等查看网络IO情况
- (3)JVM堆检查:
- 如果JVM堆大小设置过小会导致GC频繁,从而导致CPU使用率过高
- 快速验证这个问题的方法是double堆大小,看性能是否有提升。注意要给系统至少预留1GB的空间。
- 为了精确查找问题可以使用jmap或VisualVM。[参考]
- 设置Xms和Xmx为相同值,防止堆大小在运行时调整,这个过程非常消耗性能。
- (4)Logstash worker设置:
worker相关配置在logstash.yml中,主要包括如下三个:
- pipeline.workers: 该参数用以指定Logstash中执行filter和output的线程数,当如果发现CPU使用率尚未达到上限,可以通过调整该参数,为Logstash提供更高的性能。建议将Worker数设置适当超过CPU核数可以减少IO等待时间对处理过程的影响。实际调优中可以先通过-w指定该参数,当确定好数值后再写入配置文件中。
- pipeline.batch.size: 该指标用于指定单个worker线程一次性执行flilter和output的event批量数。增大该值可以减少IO次数,提高处理速度,但是也以为这增加内存等资源的消耗。当与Elasticsearch联用时,该值可以用于指定Elasticsearch一次bluck操作的大小。
- pipeline.batch.delay: 该指标用于指定worker等待时间的超时时间,如果worker在该时间内没有等到pipeline.batch.size个事件,那么将直接开始执行filter和output而不再等待。
结束语
Logstash作为Elastic Stack的重要组成部分,在Elasticsearch数据采集和处理过程中扮演着重要的角色。本文通过简单示例的演示和Logstash基础知识的铺陈,希望可以帮助初次接触Logstash的用户对Logstash有一个整体认识,并能较为快速上手。对于Logstash的高阶使用,仍需要用户在使用过程中结合实际情况查阅相关资源深入研究。当然也欢迎大家积极交流,并对文中的错误提出宝贵意见。
MORE:
本文同步发布在腾讯云+社区Elasticsearch专栏:https://cloud.tencent.com/developer/column/4008
Elasticsearch是当前主流的分布式大数据存储和搜索引擎,可以为用户提供强大的全文本检索能力,广泛应用于日志检索,全站搜索等领域。Logstash作为Elasicsearch常用的实时数据采集引擎,可以采集来自不同数据源的数据,并对数据进行处理后输出到多种输出源,是Elastic Stack 的重要组成部分。本文从Logstash的工作原理,使用示例,部署方式及性能调优等方面入手,为大家提供一个快速入门Logstash的方式。文章最后也给出了一些深入了解Logstash的的链接,以方便大家根据需要详细了解。
1 Logstash工作原理
1.1 处理过程
如上图,Logstash的数据处理过程主要包括:Inputs, Filters, Outputs 三部分, 另外在Inputs和Outputs中可以使用Codecs对数据格式进行处理。这四个部分均以插件形式存在,用户通过定义pipeline配置文件,设置需要使用的input,filter,output, codec插件,以实现特定的数据采集,数据处理,数据输出等功能
- (1)Inputs:用于从数据源获取数据,常见的插件如file, syslog, redis, beats 等[详细参考]
- (2)Filters:用于处理数据如格式转换,数据派生等,常见的插件如grok, mutate, drop, clone, geoip等[详细参考]
- (3)Outputs:用于数据输出,常见的插件如elastcisearch,file, graphite, statsd等[详细参考]
- (4)Codecs:Codecs不是一个单独的流程,而是在输入和输出等插件中用于数据转换的模块,用于对数据进行编码处理,常见的插件如json,multiline[详细参考]
可以点击每个模块后面的_详细参考_链接了解该模块的插件列表及对应功能
1.2 执行模型:
- (1)每个Input启动一个线程,从对应数据源获取数据
- (2)Input会将数据写入一个队列:默认为内存中的有界队列(意外停止会导致数据丢失)。为了防止数丢失Logstash提供了两个特性: Persistent Queues:通过磁盘上的queue来防止数据丢失 Dead Letter Queues:保存无法处理的event(仅支持Elasticsearch作为输出源)
- (3)Logstash会有多个pipeline worker, 每一个pipeline worker会从队列中取一批数据,然后执行filter和output(worker数目及每次处理的数据量均由配置确定)
2 Logstash使用示例
2.1 Logstash Hello world
第一个示例Logstash将采用标准输入和标准输出作为input和output,并且不指定filter
- (1)下载Logstash并解压(需要预先安装JDK8)
- (2)cd到Logstash的根目录,并执行启动命令如下:
cd logstash-6.4.0
bin/logstash -e 'input { stdin { } } output { stdout {} }'- (3)此时Logstash已经启动成功,-e表示在启动时直接指定pipeline配置,当然也可以将该配置写入一个配置文件中,然后通过指定配置文件来启动
- (4)在控制台输入:hello world,可以看到如下输出:
{
"@version" => "1",
"host" => "localhost",
"@timestamp" => 2018-09-18T12:39:38.514Z,
"message" => "hello world"
} Logstash会自动为数据添加@version, host, @timestamp等字段
在这个示例中Logstash从标准输入中获得数据,仅在数据中添加一些简单字段后将其输出到标准输出。
2.2 日志采集
这个示例将采用Filebeat input插件(Elastic Stack中的轻量级数据采集程序)采集本地日志,然后将结果输出到标准输出
filebeat.yml配置如下(paths改为日志实际位置,不同版本beats配置可能略有变化,请根据情况调整)
filebeat.prospectors:
- input\_type: log
paths:
- /path/to/file/logstash-tutorial.log
output.logstash:
hosts: "localhost:5044"启动命令:
./filebeat -e -c filebeat.yml -d "publish"- (3)配置logstash并启动
1)创建first-pipeline.conf文件内容如下(该文件为pipeline配置文件,用于指定input,filter, output等):
input {
beats {
port => "5044"
}
}
#filter {
#}
output {
stdout { codec => rubydebug }
}codec => rubydebug用于美化输出[参考]
2)验证配置(注意指定配置文件的路径):
./bin/logstash -f first-pipeline.conf --config.test_and_exit3)启动命令:
./bin/logstash -f first-pipeline.conf --config.reload.automatic--config.reload.automatic选项启用动态重载配置功能
4)预期结果:
可以在Logstash的终端显示中看到,日志文件被读取并处理为如下格式的多条数据
{
"@timestamp" => 2018-10-09T12:22:39.742Z,
"offset" => 24464,
"@version" => "1",
"input_type" => "log",
"beat" => {
"name" => "VM_136_9_centos",
"hostname" => "VM_136_9_centos",
"version" => "5.6.10"
},
"host" => "VM_136_9_centos",
"source" => "/data/home/michelmu/workspace/logstash-tutorial.log",
"message" => "86.1.76.62 - - [04/Jan/2015:05:30:37 +0000] \"GET /style2.css HTTP/1.1\" 200 4877 \"http://www.semicomplete.com/projects/xdotool/\" \"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"type" => "log",
"tags" => [
[0] "beats_input_codec_plain_applied"
]
}相对于示例2.1,该示例使用了filebeat input插件从日志中获取一行记录,这也是Elastic stack获取日志数据最常见的一种方式。另外该示例还采用了rubydebug codec 对输出的数据进行显示美化。
2.3 日志格式处理
可以看到虽然示例2.2使用filebeat从日志中读取数据,并将数据输出到标准输出,但是日志内容作为一个整体被存放在message字段中,这样对后续存储及查询都极为不便。可以为该pipeline指定一个grok filter来对日志格式进行处理
- (1)在first-pipeline.conf中增加filter配置如下
input {
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
}
output {
stdout { codec => rubydebug }
}- (2)到filebeat的根目录下删除之前上报的数据历史(以便重新上报数据),并重启filebeat
sudo rm data/registry
sudo ./filebeat -e -c filebeat.yml -d "publish"- (3)由于之前启动Logstash设置了自动更新配置,因此Logstash不需要重新启动,这个时候可以获取到的日志数据如下:
{
"request" => "/style2.css",
"agent" => "\"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"offset" => 24464,
"auth" => "-",
"ident" => "-",
"input_type" => "log",
"verb" => "GET",
"source" => "/data/home/michelmu/workspace/logstash-tutorial.log",
"message" => "86.1.76.62 - - [04/Jan/2015:05:30:37 +0000] \"GET /style2.css HTTP/1.1\" 200 4877 \"http://www.semicomplete.com/projects/xdotool/\" \"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"type" => "log",
"tags" => [
[0] "beats_input_codec_plain_applied"
],
"referrer" => "\"http://www.semicomplete.com/projects/xdotool/\"",
"@timestamp" => 2018-10-09T12:24:21.276Z,
"response" => "200",
"bytes" => "4877",
"clientip" => "86.1.76.62",
"@version" => "1",
"beat" => {
"name" => "VM_136_9_centos",
"hostname" => "VM_136_9_centos",
"version" => "5.6.10"
},
"host" => "VM_136_9_centos",
"httpversion" => "1.1",
"timestamp" => "04/Jan/2015:05:30:37 +0000"
}可以看到message中的数据被详细解析出来了
2.4 数据派生和增强
Logstash中的一些filter可以根据现有数据生成一些新的数据,如geoip可以根据ip生成经纬度信息
- (1)在first-pipeline.conf中增加geoip配置如下
input {
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
geoip {
source => "clientip"
}
}
output {
stdout { codec => rubydebug }
}- (2)如2.3一样清空filebeat历史数据,并重启
- (3)当然Logstash仍然不需要重启,可以看到输出变为如下:
{
"request" => "/style2.css",
"agent" => "\"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"geoip" => {
"timezone" => "Europe/London",
"ip" => "86.1.76.62",
"latitude" => 51.5333,
"continent_code" => "EU",
"city_name" => "Willesden",
"country_name" => "United Kingdom",
"country_code2" => "GB",
"country_code3" => "GB",
"region_name" => "Brent",
"location" => {
"lon" => -0.2333,
"lat" => 51.5333
},
"postal_code" => "NW10",
"region_code" => "BEN",
"longitude" => -0.2333
},
"offset" => 24464,
"auth" => "-",
"ident" => "-",
"input_type" => "log",
"verb" => "GET",
"source" => "/data/home/michelmu/workspace/logstash-tutorial.log",
"message" => "86.1.76.62 - - [04/Jan/2015:05:30:37 +0000] \"GET /style2.css HTTP/1.1\" 200 4877 \"http://www.semicomplete.com/projects/xdotool/\" \"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"type" => "log",
"tags" => [
[0] "beats_input_codec_plain_applied"
],
"referrer" => "\"http://www.semicomplete.com/projects/xdotool/\"",
"@timestamp" => 2018-10-09T12:37:46.686Z,
"response" => "200",
"bytes" => "4877",
"clientip" => "86.1.76.62",
"@version" => "1",
"beat" => {
"name" => "VM_136_9_centos",
"hostname" => "VM_136_9_centos",
"version" => "5.6.10"
},
"host" => "VM_136_9_centos",
"httpversion" => "1.1",
"timestamp" => "04/Jan/2015:05:30:37 +0000"
}可以看到根据ip派生出了许多地理位置信息数据
2.5 将数据导入Elasticsearch
Logstash作为Elastic stack的重要组成部分,其最常用的功能是将数据导入到Elasticssearch中。将Logstash中的数据导入到Elasticsearch中操作也非常的方便,只需要在pipeline配置文件中增加Elasticsearch的output即可。
- (1)首先要有一个已经部署好的Logstash,当然可以使用腾讯云快速创建一个Elasticsearch创建地址
- (2)在first-pipeline.conf中增加Elasticsearch的配置,如下
input {
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
geoip {
source => "clientip"
}
}
output {
elasticsearch {
hosts => [ "localhost:9200" ]
}
}- (3)清理filebeat历史数据,并重启
- (4)查询Elasticsearch确认数据是否正常上传(注意替换查询语句中的日期)
curl -XGET 'http://172.16.16.17:9200/logstash-2018.10.09/_search?pretty&q=response=200'- (5)如果Elasticsearch关联了Kibana也可以使用kibana查看数据是否正常上报
Logstash提供了大量的Input, filter, output, codec的插件,用户可以根据自己的需要,使用一个或多个组件实现自己的功能,当然用户也可以自定义插件以实现更为定制化的功能。自定义插件可以参考[logstash input插件开发]
3 部署Logstash
演示过如何快速使用Logstash后,现在详细讲述一下Logstash的部署方式。
3.1 安装
- 安装JDK:Logstash采用JRuby编写,运行需要JDK环境,因此安装Logstash前需要先安装JDK。(当前6.4仅支持JDK8)
- 安装Logstash:可以采用直接下载压缩包方式安装,也通过APT或YUM安装,另外Logstash支持安装到Docker中。[Logstash安装参考]
- 安装X-PACK:在6.3及之后版本X-PACK会随Logstash安装,在此之前需要手动安装[参考链接]
3.2 目录结构
logstash的目录主要包括:根目录、bin目录、配置目录、日志目录、插件目录、数据目录
不同安装方式各目录的默认位置参考[此处]
3.3 配置文件
- Pipeline配置文件,名称可以自定义,在启动Logstash时显式指定,编写方式可以参考前面示例,对于具体插件的配置方式参见具体插件的说明(使用Logstash时必须配置): 用于定义一个pipeline,数据处理方式和输出源
- Settings配置文件(可以使用默认配置): 在使用Logstash时可以不用设置,用于性能调优,日志记录等
- 为了保证敏感配置的安全性,logstash提供了配置加密功能[参考链接]
3.4 启动关闭方式
3.4.1 启动
- 命令行启动
- 在debian和rpm上以服务形式启动
- 在docker中启动3.4.2 关闭
- 关闭Logstash
- Logstash的关闭时会先关闭input停止输入,然后处理完所有进行中的事件,然后才完全停止,以防止数据丢失,但这也导致停止过程出现延迟或失败的情况。
3.5 扩展Logstash
当单个Logstash无法满足性能需求时,可以采用横向扩展的方式来提高Logstash的处理能力。横向扩展的多个Logstash相互独立,采用相同的pipeline配置,另外可以在这多个Logstash前增加一个LoadBalance,以实现多个Logstash的负载均衡。
4 性能调优
[详细调优参考]
- (1)Inputs和Outputs的性能:当输入输出源的性能已经达到上限,那么性能瓶颈不在Logstash,应优先对输入输出源的性能进行调优。
- (2)系统性能指标:
- CPU:确定CPU使用率是否过高,如果CPU过高则先查看JVM堆空间使用率部分,确认是否为GC频繁导致,如果GC正常,则可以通过调节Logstash worker相关配置来解决。
- 内存:由于Logstash运行在JVM上,因此注意调整JVM堆空间上限,以便其有足够的运行空间。另外注意Logstash所在机器上是否有其他应用占用了大量内存,导致Logstash内存磁盘交换频繁。
- I/O使用率: 1)磁盘IO: 磁盘IO饱和可能是因为使用了会导致磁盘IO饱和的创建(如file output),另外Logstash中出现错误产生大量错误日志时也会导致磁盘IO饱和。Linux下可以通过iostat, dstat等查看磁盘IO情况 2)网络IO: 网络IO饱和一般发生在使用有大量网络操作的插件时。linux下可以使用dstat或iftop等查看网络IO情况
- (3)JVM堆检查:
- 如果JVM堆大小设置过小会导致GC频繁,从而导致CPU使用率过高
- 快速验证这个问题的方法是double堆大小,看性能是否有提升。注意要给系统至少预留1GB的空间。
- 为了精确查找问题可以使用jmap或VisualVM。[参考]
- 设置Xms和Xmx为相同值,防止堆大小在运行时调整,这个过程非常消耗性能。
- (4)Logstash worker设置:
worker相关配置在logstash.yml中,主要包括如下三个:
- pipeline.workers: 该参数用以指定Logstash中执行filter和output的线程数,当如果发现CPU使用率尚未达到上限,可以通过调整该参数,为Logstash提供更高的性能。建议将Worker数设置适当超过CPU核数可以减少IO等待时间对处理过程的影响。实际调优中可以先通过-w指定该参数,当确定好数值后再写入配置文件中。
- pipeline.batch.size: 该指标用于指定单个worker线程一次性执行flilter和output的event批量数。增大该值可以减少IO次数,提高处理速度,但是也以为这增加内存等资源的消耗。当与Elasticsearch联用时,该值可以用于指定Elasticsearch一次bluck操作的大小。
- pipeline.batch.delay: 该指标用于指定worker等待时间的超时时间,如果worker在该时间内没有等到pipeline.batch.size个事件,那么将直接开始执行filter和output而不再等待。
结束语
Logstash作为Elastic Stack的重要组成部分,在Elasticsearch数据采集和处理过程中扮演着重要的角色。本文通过简单示例的演示和Logstash基础知识的铺陈,希望可以帮助初次接触Logstash的用户对Logstash有一个整体认识,并能较为快速上手。对于Logstash的高阶使用,仍需要用户在使用过程中结合实际情况查阅相关资源深入研究。当然也欢迎大家积极交流,并对文中的错误提出宝贵意见。
MORE:
收起阅读 »logstash怎么把csv文件中的x列和y列编程geo_shape的point导入es集群中
filter {
mutate {
add_field => {"location" => "%{y},%{x}"} --把x,y变为location属性,类型为geohash
remove_field => ["@version","@timestamp","qsdwmc","gldwmc","bz","sjly","rksj","guid","clsj"," czsj","x","y","mjzrq","gxsj"]
}
}
但是我看了官网上的例子:
PUT /example
{
"mappings": {
"doc": {
"properties": {
"location": {
"type": "geo_shape"
}
}
}
}
}
POST /example/doc?refresh
{
"name": "Wind & Wetter, Berlin, Germany",
"location": {
"type": "point",
"coordinates": [13.400544, 52.530286]
}
}
请问各位大佬通过logstash怎么添加这样子的location的属性,type为point,然后还有个coordinates数组
filter {
mutate {
add_field => {"location" => "%{y},%{x}"} --把x,y变为location属性,类型为geohash
remove_field => ["@version","@timestamp","qsdwmc","gldwmc","bz","sjly","rksj","guid","clsj"," czsj","x","y","mjzrq","gxsj"]
}
}
但是我看了官网上的例子:
PUT /example
{
"mappings": {
"doc": {
"properties": {
"location": {
"type": "geo_shape"
}
}
}
}
}
POST /example/doc?refresh
{
"name": "Wind & Wetter, Berlin, Germany",
"location": {
"type": "point",
"coordinates": [13.400544, 52.530286]
}
}
请问各位大佬通过logstash怎么添加这样子的location的属性,type为point,然后还有个coordinates数组 收起阅读 »
通过 metadata 使logstash配置更简洁
从Logstash 1.5开始,我们可以在logstash配置中使用metadata。metadata不会在output中被序列化输出,这样我们便可以在metadata中添加一些临时的中间数据,而不需要去删除它。
我们可以通过以下方式来访问metadata:
[@metadata][foo]用例
假设我们有这样一条日志:
[2017-04-01 22:21:21] production.INFO: this is a test log message by leon我们可以在filter中使用grok来做解析:
grok {
match => { "message" => "\[%{TIMESTAMP_ISO8601:timestamp}\] %{DATA:env}\.%{DATA:log_level}: %{DATA:content}" }
}解析的结果为
{
"env" => "production",
"timestamp" => "2017-04-01 22:21:21",
"log_level" => "INFO",
"content" => "{\"message\":\"[2017-04-01 22:21:21] production.INFO: this is a test log message by leon\"}"
}假设我们希望
- 能把log_level为INFO的日志丢弃掉,但又不想让该字段出现在最终的输出中
- 输出的索引名中能体现出env,但也不想让该字段出现在输出结果里
对于1,一种方案是在输出之前通过mutate插件把不需要的字段删除掉,但是一旦这样的处理多了,会让配置文件变得“不干净”。
通过 metadata,我们可以轻松地处理这些问题:
grok {
match => { "message" => "\[%{TIMESTAMP_ISO8601:timestamp}\] %{DATA:[@metadata][env]}\.%{DATA:[@metadata][log_level]}: %{DATA:content}" }
}
if [@metadata][log_level] == "INFO"{
drop{}
}
output{
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "%{[@metadata][env]}-log-%{+YYYY.MM}"
document_type => "_doc"
}
}除了简化我们的配置文件、减少冗余字段意外,同时也能提高logstash的处理速度。
Elasticsearch input插件
有些插件会用到metadata这个特性,比如elasticsearch input插件:
input {
elasticsearch {
host => "127.0.0.1"
# 把 ES document metadata (_index, _type, _id) 包存到 @metadata 中
docinfo_in_metadata => true
}
}
filter{
......
}
output {
elasticsearch {
document_id => "%{[@metadata][_id]}"
index => "transformed-%{[@metadata][_index]}"
type => "%{[@metadata][_type]}"
}
}调试
一般来说metadata是不会出现在输出中的,除非使用 rubydebug codec 的方式输出:
output {
stdout {
codec => rubydebug {
metadata => true
}
}
}日志经过处理后输出中会包含:
{
....,
"@metadata" => {
"env" => "production",
"log_level" => "INFO"
}
}总结
由上可见,metadata提供了一种简单、方便的方式来保存中间数据。这样一方面减少了logstash配置文件的复杂性:避免调用remove_field,另一方面也减少了输出中的一些不必要的数据。通过这篇对metadata的介绍,希望能对大家有所帮助。

从Logstash 1.5开始,我们可以在logstash配置中使用metadata。metadata不会在output中被序列化输出,这样我们便可以在metadata中添加一些临时的中间数据,而不需要去删除它。
我们可以通过以下方式来访问metadata:
[@metadata][foo]用例
假设我们有这样一条日志:
[2017-04-01 22:21:21] production.INFO: this is a test log message by leon我们可以在filter中使用grok来做解析:
grok {
match => { "message" => "\[%{TIMESTAMP_ISO8601:timestamp}\] %{DATA:env}\.%{DATA:log_level}: %{DATA:content}" }
}解析的结果为
{
"env" => "production",
"timestamp" => "2017-04-01 22:21:21",
"log_level" => "INFO",
"content" => "{\"message\":\"[2017-04-01 22:21:21] production.INFO: this is a test log message by leon\"}"
}假设我们希望
- 能把log_level为INFO的日志丢弃掉,但又不想让该字段出现在最终的输出中
- 输出的索引名中能体现出env,但也不想让该字段出现在输出结果里
对于1,一种方案是在输出之前通过mutate插件把不需要的字段删除掉,但是一旦这样的处理多了,会让配置文件变得“不干净”。
通过 metadata,我们可以轻松地处理这些问题:
grok {
match => { "message" => "\[%{TIMESTAMP_ISO8601:timestamp}\] %{DATA:[@metadata][env]}\.%{DATA:[@metadata][log_level]}: %{DATA:content}" }
}
if [@metadata][log_level] == "INFO"{
drop{}
}
output{
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "%{[@metadata][env]}-log-%{+YYYY.MM}"
document_type => "_doc"
}
}除了简化我们的配置文件、减少冗余字段意外,同时也能提高logstash的处理速度。
Elasticsearch input插件
有些插件会用到metadata这个特性,比如elasticsearch input插件:
input {
elasticsearch {
host => "127.0.0.1"
# 把 ES document metadata (_index, _type, _id) 包存到 @metadata 中
docinfo_in_metadata => true
}
}
filter{
......
}
output {
elasticsearch {
document_id => "%{[@metadata][_id]}"
index => "transformed-%{[@metadata][_index]}"
type => "%{[@metadata][_type]}"
}
}调试
一般来说metadata是不会出现在输出中的,除非使用 rubydebug codec 的方式输出:
output {
stdout {
codec => rubydebug {
metadata => true
}
}
}日志经过处理后输出中会包含:
{
....,
"@metadata" => {
"env" => "production",
"log_level" => "INFO"
}
}总结
由上可见,metadata提供了一种简单、方便的方式来保存中间数据。这样一方面减少了logstash配置文件的复杂性:避免调用remove_field,另一方面也减少了输出中的一些不必要的数据。通过这篇对metadata的介绍,希望能对大家有所帮助。
ET001 不可不掌握的 Logstash 使用技巧
Logstash 是 Elastic Stack 中功能最强大的 ETL 工具,相较于 beats 家族,虽然它略显臃肿,但是强在功能丰富、处理能力强大。大家在使用的过程中肯定也体验过其启动时的慢吞吞,那么有什么办法可以减少等待 Logstash 的启动时间,提高编写其处理配置文件的效率呢?本文给大家推荐一个小技巧,帮助大家解决如下两个问题,让大家更好地与这个笨重的大家伙相处。
- 减少 Logstash 重启的次数,也就节省宝贵的时间
- 方便快捷地向 Logstash 输入需要处理的内容
1. 打开 reload 配置开关
Logstash 启动的时候可以加上 -r 的参数来做到配置文件热加载,效果是:
- 当你修改了配置文件后,无需重启 Logstash 即可让新配置文件生效。
它的含义如下:

当你写好配置文件,比如 test.conf ,启动命令如下:
bin/logstash -f test.conf -r
启动完毕,修改 test.conf 的内容并保存后,过 1 秒钟,你会发现 Logstash 端有类似如下日志输出(注意红色框标记的部分),此时说明 reload 的成功。

如果你修改的配置文件有错误,会看到报错的日志,你可以根据错误提示修改。

至此,第一个问题解决!
2. 使用 HTTP INPUT
编写配置文件的另一个痛点是需要针对不同格式的输入内容进行详细的测试,以防解析报错的情况出现。此时大家常用标准输入来解决这个问题(stdin input),但是标准输入对于文字编辑支持不太友好,而且配置文件热更新的功能也不支持标准输入。
在这里向大家推荐使用 http input 插件,配置如下:
input{
http{
port => 7474
codec => "json"
}
}然后大家再用自己喜欢的 http 请求工具,比如 POSTMan、Insomnia 等向 http://loclahost:7474发送待测试内容即可,如下是 Insomnia 的截图。

至此,第二个问题也解决了。
3. 总结
相信看到这里,大家一定是跃跃欲试了,赶紧打开电脑,找到 Logstash,然后编辑 test.conf,输入如下内容:
input{
http{
port => 7474
codec => "json"
}
}
filter{
}
output{
stdout{
codec => rubydebug{
metadata => true
}
}
}然后执行启动命令:
bin/logstash -f test.conf -r
打开 Insomnia ,输入要测试的内容,点击发送,开始舒爽流畅的配置文件编写之旅吧!
Logstash 是 Elastic Stack 中功能最强大的 ETL 工具,相较于 beats 家族,虽然它略显臃肿,但是强在功能丰富、处理能力强大。大家在使用的过程中肯定也体验过其启动时的慢吞吞,那么有什么办法可以减少等待 Logstash 的启动时间,提高编写其处理配置文件的效率呢?本文给大家推荐一个小技巧,帮助大家解决如下两个问题,让大家更好地与这个笨重的大家伙相处。
- 减少 Logstash 重启的次数,也就节省宝贵的时间
- 方便快捷地向 Logstash 输入需要处理的内容
1. 打开 reload 配置开关
Logstash 启动的时候可以加上 -r 的参数来做到配置文件热加载,效果是:
- 当你修改了配置文件后,无需重启 Logstash 即可让新配置文件生效。
它的含义如下:
当你写好配置文件,比如 test.conf ,启动命令如下:
bin/logstash -f test.conf -r
启动完毕,修改 test.conf 的内容并保存后,过 1 秒钟,你会发现 Logstash 端有类似如下日志输出(注意红色框标记的部分),此时说明 reload 的成功。
如果你修改的配置文件有错误,会看到报错的日志,你可以根据错误提示修改。
至此,第一个问题解决!
2. 使用 HTTP INPUT
编写配置文件的另一个痛点是需要针对不同格式的输入内容进行详细的测试,以防解析报错的情况出现。此时大家常用标准输入来解决这个问题(stdin input),但是标准输入对于文字编辑支持不太友好,而且配置文件热更新的功能也不支持标准输入。
在这里向大家推荐使用 http input 插件,配置如下:
input{
http{
port => 7474
codec => "json"
}
}然后大家再用自己喜欢的 http 请求工具,比如 POSTMan、Insomnia 等向 http://loclahost:7474发送待测试内容即可,如下是 Insomnia 的截图。
至此,第二个问题也解决了。
3. 总结
相信看到这里,大家一定是跃跃欲试了,赶紧打开电脑,找到 Logstash,然后编辑 test.conf,输入如下内容:
input{
http{
port => 7474
codec => "json"
}
}
filter{
}
output{
stdout{
codec => rubydebug{
metadata => true
}
}
}然后执行启动命令:
bin/logstash -f test.conf -r
打开 Insomnia ,输入要测试的内容,点击发送,开始舒爽流畅的配置文件编写之旅吧!
logstash5.X 时差8小时问题
ruby {
code => "event.set('timestamp', event.get('@timestamp').time.localtime + 8*60*60)"
}
ruby {
code => "event.set('@timestamp',event.get('timestamp'))"
}
mutate {
remove_field => ["timestamp"]
}
ruby {
code => "event.set('timestamp', event.get('@timestamp').time.localtime + 8*60*60)"
}
ruby {
code => "event.set('@timestamp',event.get('timestamp'))"
}
mutate {
remove_field => ["timestamp"]
} 收起阅读 »
logstash-filter-elasticsearch的简易安装
官方提供的方法因为需要联网,并且需要调整插件管理源,比较麻烦,针对logstash-filter-elasticsearch插件,使用下面这种方式安装。
logstash-filter-elasticsearch插件安装
1、在git上下载logstash-filter-elasticsearch压缩包,logstash-filter-elasticsearch.zip,
2、在logstash的目录下新建plugins目录,解压logstash-filter-elasticsearch.zip到此目录下。
3、在logstash目录下的Gemfile中添加一行:
gem "logstash-filter-elasticsearch", :path => "./plugins/logstash-filter-elasticsearch"4、重启logstash即可。
此方法适用logstash-filter-elasticsearch,但不适用全部logstash插件。
官方提供的方法因为需要联网,并且需要调整插件管理源,比较麻烦,针对logstash-filter-elasticsearch插件,使用下面这种方式安装。
logstash-filter-elasticsearch插件安装
1、在git上下载logstash-filter-elasticsearch压缩包,logstash-filter-elasticsearch.zip,
2、在logstash的目录下新建plugins目录,解压logstash-filter-elasticsearch.zip到此目录下。
3、在logstash目录下的Gemfile中添加一行:
gem "logstash-filter-elasticsearch", :path => "./plugins/logstash-filter-elasticsearch"4、重启logstash即可。
此方法适用logstash-filter-elasticsearch,但不适用全部logstash插件。 收起阅读 »
