

版本:2.3.4
集群情况:6个节点 3个节点分配26G内存,3个节点16G
共50个indices 770shards 1.5亿docs 400GB+
优化过的措施:
threadpool.search.type: fixed
threadpool.search.size: 100
threadpool.search.queue_size: 5000
indices.fielddata.cache.size: 40%
discovery.zen.fd.ping_timeout: 120s
discovery.zen.fd.ping_retries: 3
discovery.zen.fd.ping_interval: 30s
index.refresh_interval: 60s
transport.tcp.compress: true
bootstrap.mlockall: true
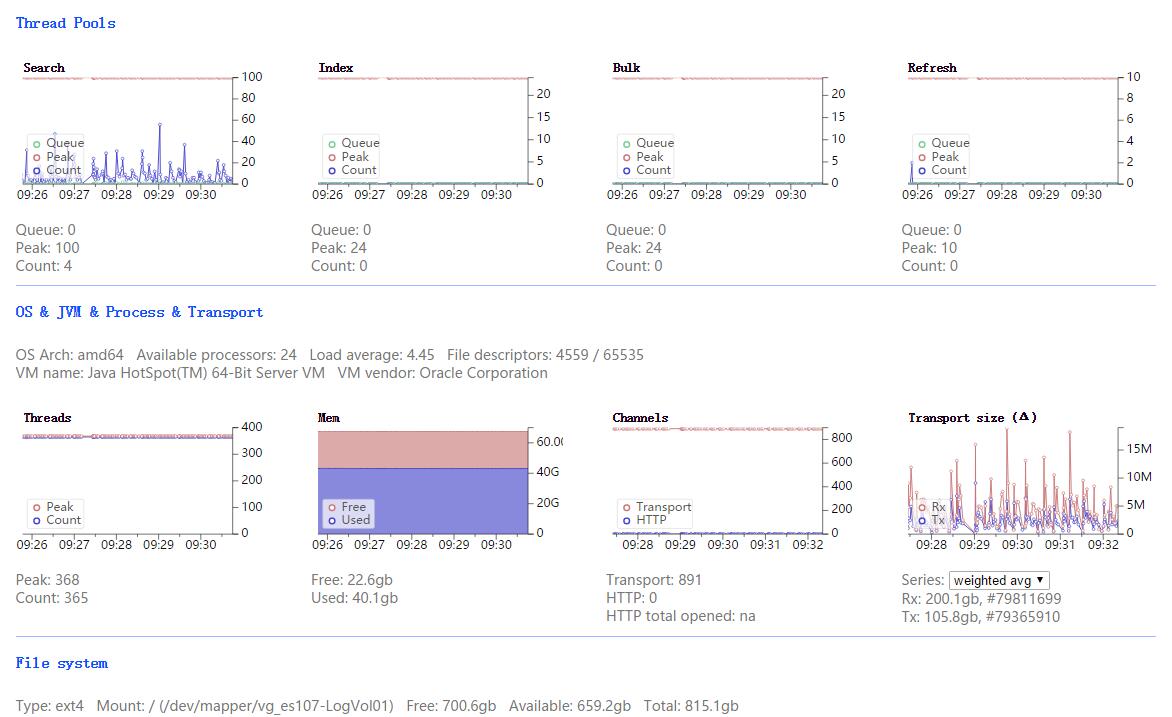
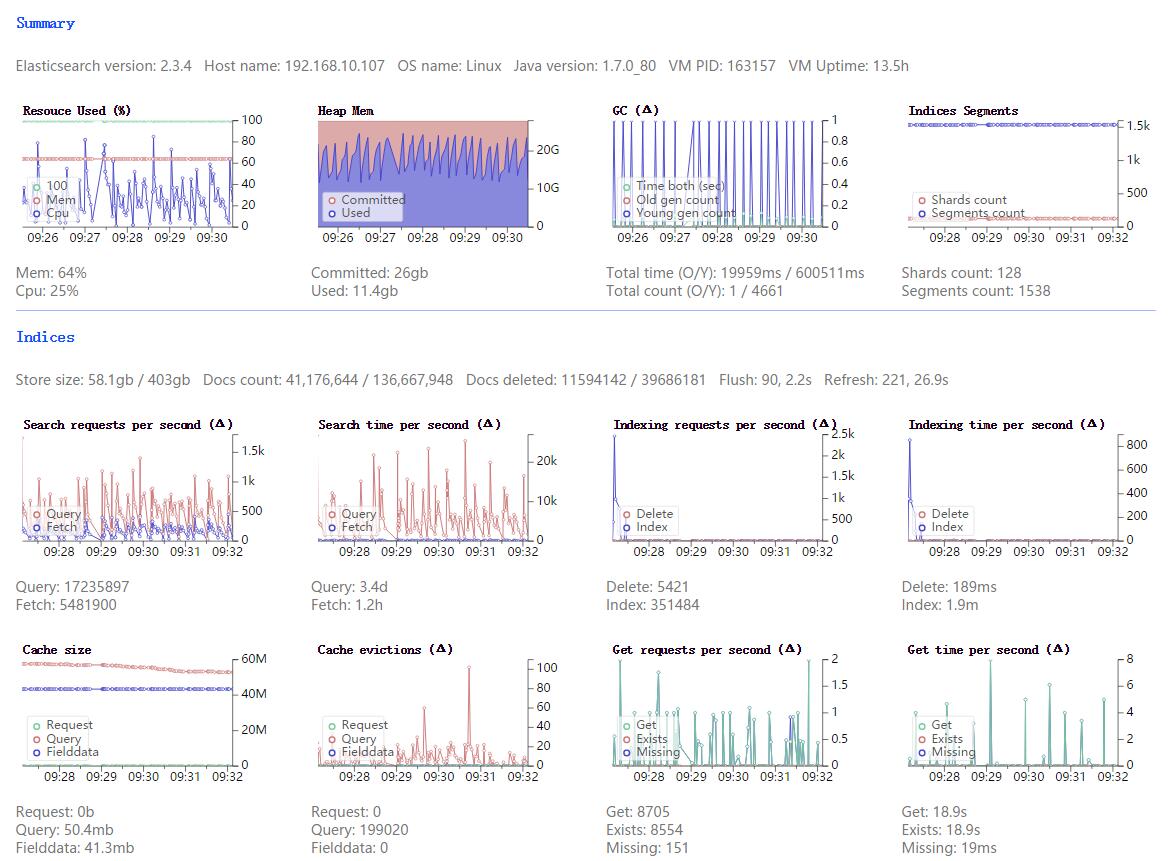
问题:最近es集群总是会挂掉,查看日志发现gc过于频繁,很多gc都是几十秒甚至几分钟,监控情况请查看附件!
请问M大大,会有哪些原因会造成这种情况呢?
集群情况:6个节点 3个节点分配26G内存,3个节点16G
共50个indices 770shards 1.5亿docs 400GB+
优化过的措施:
threadpool.search.type: fixed
threadpool.search.size: 100
threadpool.search.queue_size: 5000
indices.fielddata.cache.size: 40%
discovery.zen.fd.ping_timeout: 120s
discovery.zen.fd.ping_retries: 3
discovery.zen.fd.ping_interval: 30s
index.refresh_interval: 60s
transport.tcp.compress: true
bootstrap.mlockall: true
问题:最近es集群总是会挂掉,查看日志发现gc过于频繁,很多gc都是几十秒甚至几分钟,监控情况请查看附件!
请问M大大,会有哪些原因会造成这种情况呢?

9 个回复
code4j - coder github: https://github.com/rpgmakervx
赞同来自: lz8086
观察到您设置的threadpool.search.size 有100,也就是说业务高峰期,线程池中可能会滞留100个search线程,如果你的查询都是大查询,而线程并不释放(这个是fixed线程池决定的),就可能导致内存占用很大,特别是协调节点因为要汇总所有分片的结果,压力会更大。
建议把这个值放小点,最大不要超过核数1.5倍
novia - 1&0
赞同来自:
yang009ww
赞同来自:
novia - 1&0
赞同来自:
升级成2.1.1后,我们增加了路由,合理的设置了doc_value(所有需要aggs的全部设置),现在是一个片1500万,20G左右数据,一次最多访问4个片。就没有在出现频繁GC的情况,你可以参考下
yang009ww
赞同来自:
现在我们的单index最大不超过30G,分片5-8个!请问你们当初出现GC是通过一些什么样的手段来定位到具体的问题的呢?
medcl - 今晚打老虎。
赞同来自:
yang009ww
赞同来自:
这是一组es集群,3个节点配置一样,都是数据节点,也可以被选为主节点。但是发现节点1的搜索请求一直在堆积,而节点2和节点3的搜索请求并不多,这样导致节点1的请求队列超过设置的2000容量,则后续请求都被拒绝了。
为什么会出现这种情况?节点间不是会负载均衡吗?我该怎么处理这个问题呢?
Jokers - hi
赞同来自:
我有ES 集群也是频繁出现GC,一共有14个数据节点。每个节点都会频繁的出现GC,一分钟大概出现4次。
Jokers - hi
赞同来自: