

使用logstash增量拉去数据指定ID为增量记录列,可以正常拉去到数据,代码如下:
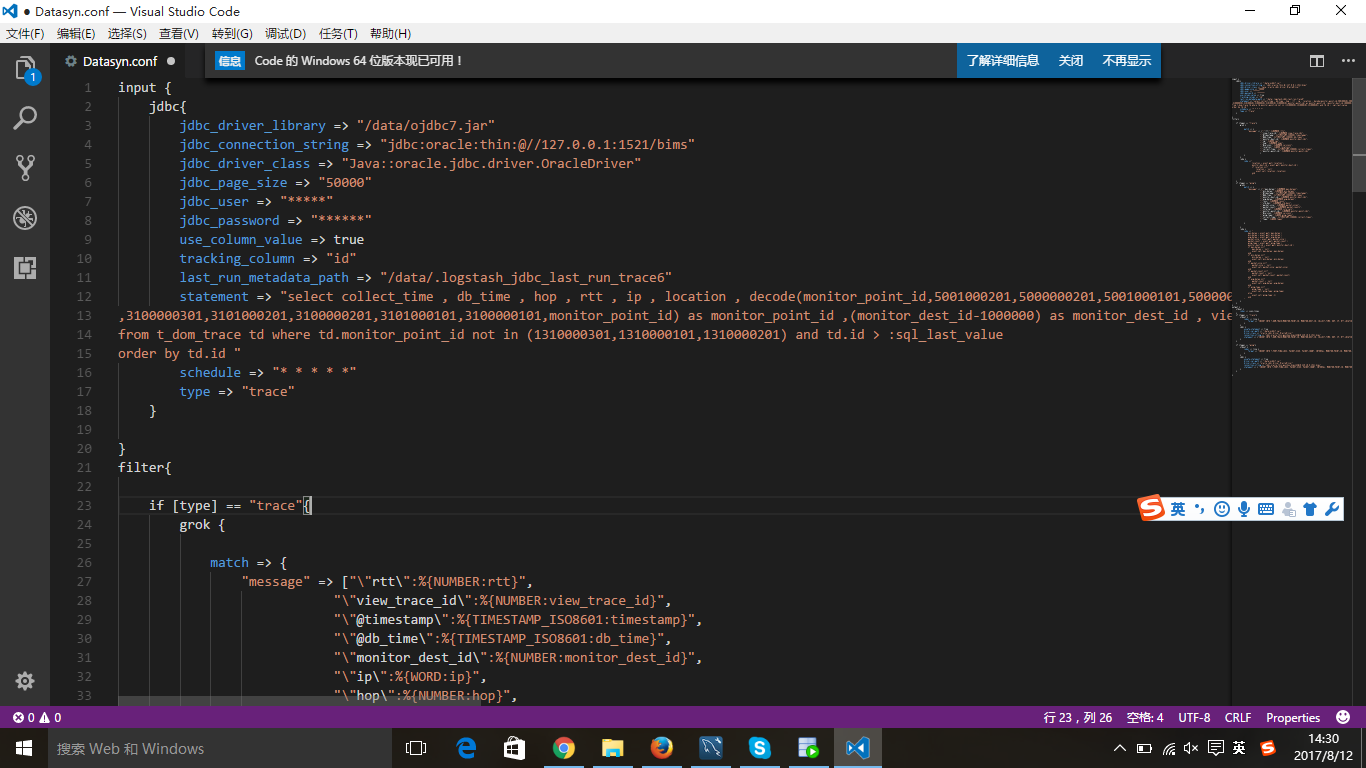
input {
jdbc{
jdbc_driver_library => "/data/ojdbc7.jar"
jdbc_connection_string => "jdbc:oracle:thin:@//127.0.0.1:1521/bims"
jdbc_driver_class => "Java::oracle.jdbc.driver.OracleDriver"
jdbc_page_size => "50000"
jdbc_user => "*****"
jdbc_password => "******"
use_column_value => true
tracking_column => "id"
last_run_metadata_path => "/data/.logstash_jdbc_last_run_trace6"
statement => "select collect_time , db_time , hop , rtt , ip , location , decode(monitor_point_id,5001000201,5000000201,5001000101,5000000101,5001000301,5000000301,3101000301
,3100000301,3101000201,3100000201,3101000101,3100000101,monitor_point_id) as monitor_point_id ,(monitor_dest_id-1000000) as monitor_dest_id , view_trace_id
from t_dom_trace td where td.monitor_point_id not in (1310000301,1310000101,1310000201) and td.id > :sql_last_value
order by td.id "
schedule => "* * * * *"
type => "trace"
}
}
但是不生成增量记录文件/data/.logstash_jdbc_last_run_trace6,每次导入时:sql_last_value为0,求帮助
input {
jdbc{
jdbc_driver_library => "/data/ojdbc7.jar"
jdbc_connection_string => "jdbc:oracle:thin:@//127.0.0.1:1521/bims"
jdbc_driver_class => "Java::oracle.jdbc.driver.OracleDriver"
jdbc_page_size => "50000"
jdbc_user => "*****"
jdbc_password => "******"
use_column_value => true
tracking_column => "id"
last_run_metadata_path => "/data/.logstash_jdbc_last_run_trace6"
statement => "select collect_time , db_time , hop , rtt , ip , location , decode(monitor_point_id,5001000201,5000000201,5001000101,5000000101,5001000301,5000000301,3101000301
,3100000301,3101000201,3100000201,3101000101,3100000101,monitor_point_id) as monitor_point_id ,(monitor_dest_id-1000000) as monitor_dest_id , view_trace_id
from t_dom_trace td where td.monitor_point_id not in (1310000301,1310000101,1310000201) and td.id > :sql_last_value
order by td.id "
schedule => "* * * * *"
type => "trace"
}
}
但是不生成增量记录文件/data/.logstash_jdbc_last_run_trace6,每次导入时:sql_last_value为0,求帮助

1 个回复
a1043244426
赞同来自: