

上个礼拜将现有的ES集群进行了扩容,将ES集群节点数量由3个提升到了9个,3个master,6个data node,在扩容完成后恢复分片过程中恢复了2000多个分片,还有1000多个无法分配,通过使用 Cluster Allocation Explain API去查看不能分片原因如下:
同时也去查看了不能分片所在的数据存储目录,是有数据的。
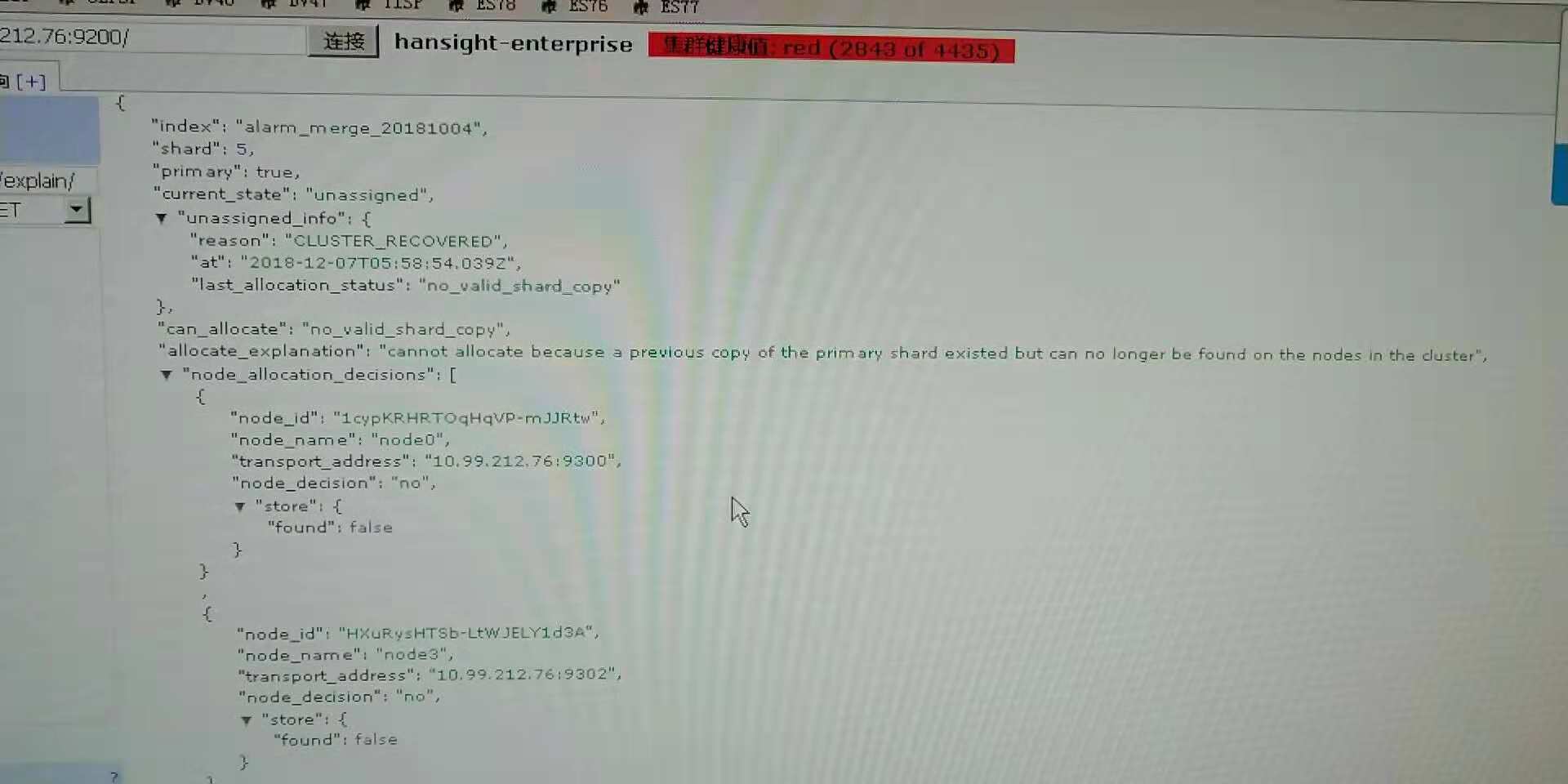
同时也去查看了不能分片所在的数据存储目录,是有数据的。

6 个回复
kennywu76 - Wood
赞同来自:
zqc0512 - andy zhou
赞同来自:
一般都是discovery.zen.ping.unicast.hosts: 这玩意的问题。
OnePunchMan - 人间有味是清欢。
赞同来自:
zqc0512 - andy zhou
赞同来自:
zqc0512 - andy zhou
赞同来自:
zqc0512 - andy zhou
赞同来自: