


插件开发
Easysearch 正式支持插件开发:让你的搜索系统真正"为你所用"
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 17426 次浏览 • 2026-04-27 22:02
从"用搜索"到"造搜索"
搜索系统的需求千差万别。标准功能覆盖不了所有场景——行业特定的分词规则、定制化的业务逻辑、与外部系统的深度集成……
以往,这类定制需求需要依赖厂商支持。从 Easysearch 2.1.2 开始,你可以自己动手了。
随着构建依赖库正式发布到 Maven 中央仓库,Easysearch 的插件开发能力正式对外开放。这意味着 Easysearch 不再是一个黑盒产品,而是一个可扩展、可定制的搜索平台。你可以基于官方接口开发自定义插件,像使用原生功能一样使用它们。
插件能做什么
Easysearch 提供三类核心扩展点,覆盖搜索系统的关键环节:
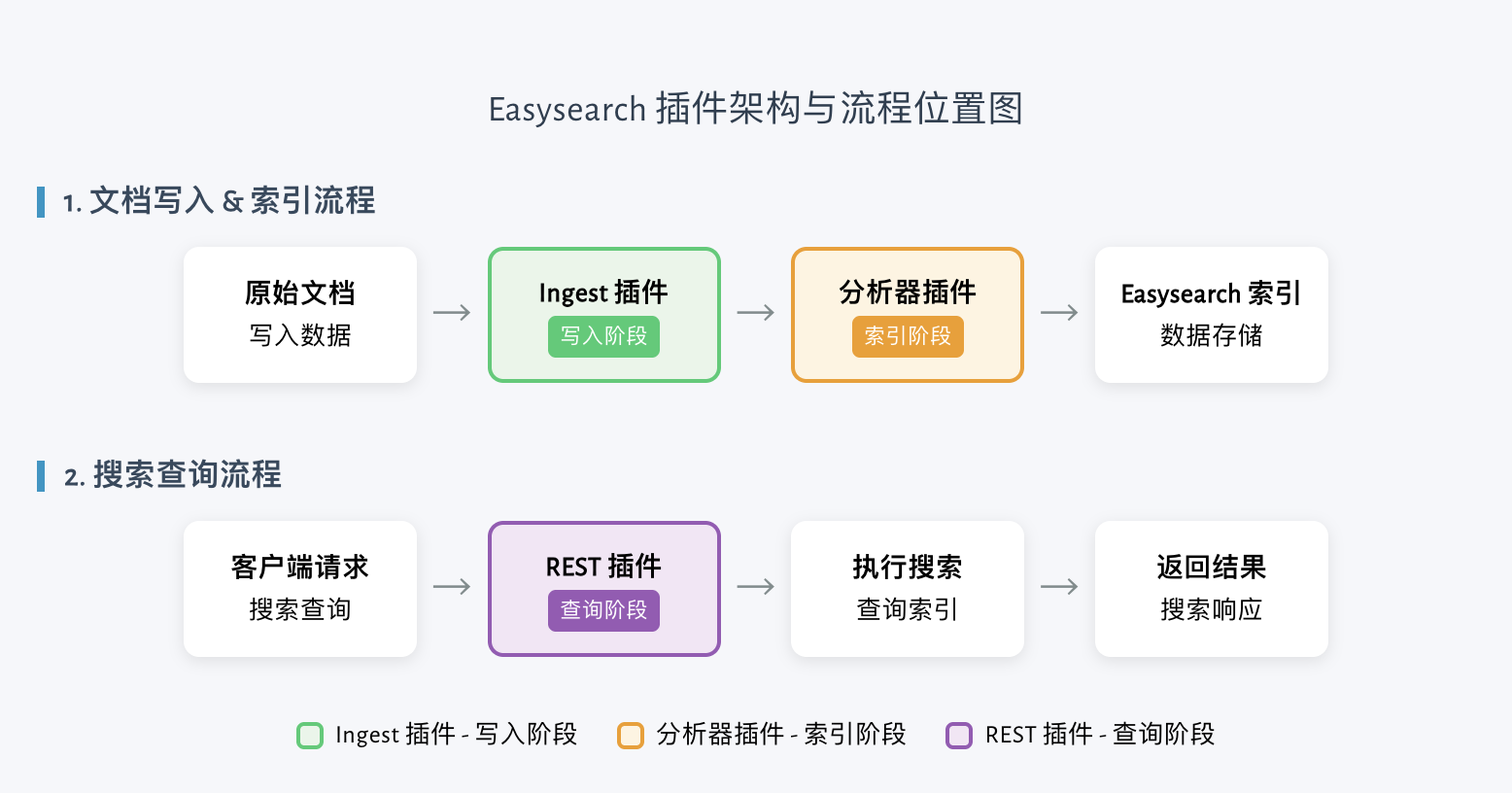
1. 分析器插件(AnalysisPlugin)
自定义分词器、Token 过滤器、字符过滤器。适用于:
- 电商 SKU 的型号规格解析
- 医疗、法律等领域的专业术语分词
- 特殊符号或空格的规范化处理
注册后直接在索引设置中使用,与原生分析器完全等同。

2. REST/API 插件(ActionPlugin)
新增自定义 HTTP 接口。适用于:
- 封装业务查询逻辑,对外暴露简化 API
- 对接企业内部权限中心或监控系统
- 暴露插件自身的管理接口(如状态检查)

3. Ingest 插件(IngestPlugin)
在文档写入前进行字段转换。适用于:
- 自定义业务字段转换(如根据业务规则计算衍生字段)
- 数据标准化(统一日期格式、大小写转换)
- 富文本提取或元数据生成

5 分钟上手
我们准备了官方模板仓库,让你从克隆到运行只需几条命令:
# 克隆模板
git clone https://github.com/infinilabs/easysearch-plugin-template.git my-plugin
cd my-plugin
# 修改包名和类名,编写你的逻辑
# ...方式一:开发调试——直接运行
# 构建插件并运行
./gradlew run
# 验证插件
curl -s "http://localhost:9200/_cat/plugins?v" | grep my-plugin方式二:构建后安装到外部集群
# 构建插件
./gradlew build
# 安装到 Easysearch
bin/easysearch-plugin install file:///$(pwd)/build/distributions/my-plugin-0.1.0.zip
# 启动验证
bin/easysearch
curl -s "http://localhost:9200/_cat/plugins?v" | grep my-plugin完整的开发指南请参考插件开发文档。
设计哲学
Easysearch 插件系统的设计遵循三个原则:
渐进式扩展——从最简单的 Plugin 类开始,按需实现 AnalysisPlugin、ActionPlugin 等接口,不必一次性掌握全部 API。
与原生同等——插件注册的分析器、处理器与系统原生组件在使用方式上完全一致,用户无需关心实现来源。
版本安全——插件加载时校验 easysearch.version,版本不匹配会拒绝加载,避免运行时异常。
从插件到生态
插件开发不只是技术能力的开放,更是产品理念的转变。
你可以将开发的插件发布到 GitHub Releases,通过 URL 直接安装:

bin/easysearch-plugin install https://github.com/yourname/my-plugin/releases/download/v0.1.0/my-plugin-0.1.0.zip我们也欢迎社区贡献。如果你有通用的插件想法,欢迎与我们交流。
结语
搜索系统的最后一公里,只有业务开发者最清楚该怎么走。
Easysearch 2.1.2 的插件开发能力,让你能够自主掌控搜索系统的"最后一公里"。从"用搜索"到"造搜索",现在你可以让你的搜索系统真正"为你所用"。
关于 Easysearch

INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
elasticsearch 支持 yara吗?elasticsearch 插件 elasticsearch-yara
回复开源项目 • 15210602359znn 回复了问题 • 2 人关注 • 2 个回复 • 4372 次浏览 • 2021-04-07 17:20
Day 23 - 基于 HanLP 的 ES 中文分词插件
Advent • rochy 发表了文章 • 0 个评论 • 9618 次浏览 • 2018-12-23 11:51
一、分词插件
1、分词器概念
在 ES 中,分词器的作用是从文本中提取出若干词元(token)来支持索引的存储和搜索,分词器(Analyzer)由一个分解器(Tokenizer)、零个或多个词元过滤器(TokenFilter)组成。
分解器用于将字符串分解成一系列词元,词元过滤器的作用是对分词器提取出来的词元做进一步处理,比如转成小写,增加同义词等。处理后的结果称为索引词(Term),引擎会建立 Term 和原文档的倒排索引(Inverted Index),这样就能根据 Term 很快到找到源文档了。

2、选择分词器
目前 ES 分词插件的选择性还是很多的,分词插件的核心就是提供各种分词器(Analyzer)、分解器(Tokenizer)、词元过滤器(TokenFilter);根据依赖的核心分词包(分词算法)的不同显现出不同的差异性,除了分词算法之外,是否支持用户自定义词典,是否支持词典热更新等其他附加功能也是选择分词插件时需要参考的。
下面列出选择分词插件需要考虑的因素(仅供参考):
- 分词准确性:大家都希望分词结果能够尽可能准确,与分词准确性直接相关的就是用户词典了,此外才是分词算法;
- 分词算法:个人认为无需纠结于分词算法,大多数分词包提供的分词算法都比较类似,选择时不需要过于纠结;
- 分词速度:这个与分词算法直接相关,基于词典的分词算法一般比基于模型的分词算法要快;基于词典如果考虑词频、命名实体识别、词性标注则会慢一些;
- 启动速度:当词典较大时,初始化词典会比较慢,某些分词器会对词典进行缓存,第二次启动会非常速度;
- 内存占用:与分词算法、词典大小、模型大小均有关系,设计精巧的算法对内存占用较小;
- 易用性:分词器是否开箱即用,是否可以直接使用在线链接或者压缩包进行安装,是否需要复杂的配置;
- 扩展性:是否支持用户自定义词典、是否支持自定义分词算法、是否支持热更新等;
- 是否开源:开源的分词器在遇到问题的时候可以自己进行深度调试,甚至可以进行二次开发;
- 社区活跃度:这个看一下 github 的 star 数或者依赖的分词包的 star 数和 issue 数目即可判定;
- 更新频率:是否能够与最新版的 ES 同步更新。
二、HanLP 简介
HanLP 是一系列模型与算法组成的 NLP 工具包,具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点,详情可参考 github 介绍:https://github.com/hankcs/HanLP。
选择 HanLP 作为核心的分词包开发 ES 分词插件,主要考虑以下因素:
- HanLP 是 Java 分词包中最为流行的;
- HanLP 提供了多种分词器,既可以基于词典也可以基于模型(在一亿字的大型综合语料库上训练的分词模型);
- HanLP 坚持使用明文词典,这样可以借助社区的力量对词典不断进行完善;
- 完善的开发文档和代码样例,较为活跃的用户群体;
- 个人参与了部分功能的开发,对代码结构较为熟悉。
三、开发分词插件
1、代码结构
conf:插件的配置文件、HanLP 的配置文件、Java 安全策略文件;scr.main.java.assemby:插件打包(maven-assembly-plugin)配置文件;org.elasticsearch.plugin.hanlp.analysis:分词插件核心构建器;org.elasticsearch.plugin.hanlp.conf:管理插件配置、分词器配置以及 HanLP 配置;org.elasticsearch.plugin.hanlp.lucene:HanLP 中文分词 Lucene 插件,对 Lucune 分词进行实现;scr.main.resources:插件属性文件所在目录

2、TokenStream
Analyzer 类是一个抽象类,是所有分词器的基类,它通过 TokenStream 类将文本转换为词汇单元流;TokenStream 有两种实现 Tokenizer(输入为 Reader) 和 TokenFilter(输入为另一个 TokenStream)。

TokenStream 基本使用流程:
- 实例化 TokenStream,向 AttributeSource 添加/获取属性(词汇单元文本、位置增量、偏移量、词汇类型等);
- 调用
reset()方法,将流(stream)重置到原始(clean)状态; - 循环调用
incrementToken()方法,并处理 Attribute 属性信息,直到它返回 false 表示流处理结束; - 调用
end()方法,确保流结束(end-of-stream)的操作可以被执行; - 调用
close()方法释放资源。
// 实例化 TokenStream
TokenStream tokenStream = new IKAnalyzer().tokenStream("keywords",new StringReader("思想者"));
// 向 AttributeSource 添加/获取属性
CharTermAttribute attribute = tokenStream.addAttribute(CharTermAttribute.class);
// 将流(stream)重置到原始(clean)状态
tokenStream.reset();
// 判断是否还有下一个 Token
while(tokenStream.incrementToken()) {
System.out.println(attribute);
}
tokenStream.end();
tokenStream.close();综上,开发 Tokenizer 或者 TokenFilter 时,需要重点关注
reset、incrementToken、end、close四个方法的实现。
3、开发中的小技巧
获取插件目录或文件目录
//获取插件根目录
private static Path getPluginPath() {
return env.pluginsFile().resolve("analysis-hanlp");
}
//获取插件目录下的文件
private static Path getDefDicConfigPath() {
return env.pluginsFile().resolve("analysis-hanlp/hanlp.properties").toAbsolutePath();
}插件属性文件
如果希望插件属性文件(plugin-descriptor.properties)能够自动根据 pom.xml 中的属性进行赋值,则需要将文件防止到 resources 文件夹下。
插件版本兼容性
从实际测试来看:
- ES5.X 及其以上的代码是完全复用的,也就是说代码逻辑不需要调整;
- ES5.X 到 ES6.2.X 的插件是可以通用的,其特征是打包的时候需要将插件的文件全部打包到
elasticsearch文件夹下; - ES6.3.X 以上的插件是可以通用的,打包的时候插件的文件全部打包到根目录即可。
也就是说,如果你升级了新版本 ES,对于插件升级,大多数情况只需要修改下
plugin-descriptor.properties文件中 ES 的版本号即可。
4、安全策略文件
在插件开发中经常会使用到文件读取、属性读取、网络链接等功能,如果不提前注册安全策略,在调用这些功能的时候会报以下错误java.security.AccessControlException: access denied。
官方给出的解决方案就是新建一个 plugin-security.policy 文件,然后在文件中声明需要的权限信息,最后在打包的时候将文件放置到插件的根目录,这样在使用 zip 包进行安装的时候,ES 会提示用户插件所需的权限信息,需要用户确认后插件才能正常安装。
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: plugin requires additional permissions @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
* java.io.FilePermission <<ALL FILES>> read,write,delete
* java.lang.RuntimePermission createClassLoader
* java.lang.RuntimePermission getClassLoader
* java.lang.RuntimePermission setContextClassLoader
* java.net.SocketPermission * connect,resolve
* java.util.PropertyPermission * read,write
See http://docs.oracle.com/javase/8/docs/technotes/guides/security/permissions.html
for descriptions of what these permissions allow and the associated risks.
Continue with installation? [y/N]y
-> Installed analysis-hanlp5、安全策略的坑
最开始认为只需要添加了 policy 文件,且打包到正确的位置即可解决插件的权限问题,因为在插件安装的时候 ES 已经提示了所需权限,但是代码在实际执行的时候依旧报 AccessControlException 的错误。
参考了多个 HanLP 的 ES 分词插件,都没有获得较好的方法,后来考虑到 IK 分词器远程加载词典时,需要网络连接权限,就去看了下其远程词典加载的代码,最终找到了正确的使用方法。
// 需要特殊权限的代码
AccessController.doPrivileged((PrivilegedAction<Segment>) () -> {
Segment segment;
if (config.getAlgorithm().equals("extend")) {
segment = new ViterbiSegment();
} else {
segment = HanLP.newSegment(config.getAlgorithm());
}
// 在此处显示调用一下分词,使得加载词典、缓存词典的操作可以正确执行
System.out.println( segment.seg("HanLP中文分词工具包!"));
return segment;
});四、插件特色
简单介绍一下插件的特点:
- 内置多种分词模式,适合不同场景;
- 内置词典,无需额外配置即可使用;
- 支持外置词典,用户可自定义分词算法,基于词典或是模型;
- 支持分词器级别的自定义词典,便于用于多租户场景;
- 支持远程词典热更新(待开发);
- 拼音过滤器、繁简体过滤器(待开发);
- 基于词语或单字的 ngram 切分分词(待开发)。
Github 地址:https://github.com/AnyListen/elasticsearch-analysis-hanlp
es插件开发,运行时报错
Elasticsearch • shiyuan 回复了问题 • 2 人关注 • 1 个回复 • 6620 次浏览 • 2018-02-28 21:27

elasticsearch java原生打分插件开发
Elasticsearch • JiaShiwen 发表了文章 • 1 个评论 • 10036 次浏览 • 2018-01-10 16:34
能有影响elasticsearch score的方法有很多,官方推荐的是使用内置的painless脚本语言结合function_score来重新定义score。由于本人开发的项目其算法是由java语言开发的,于是决定尝试原生脚本开发。 elasticsearch脚本由plugin-descriptor.properties文件以及运行jar包组成,plugin-descriptor.properties主要用来定义版本信息、对应es的版本信息等属性。
官方的例子
public class ExpertScriptPlugin extends Plugin implements ScriptPlugin {
@Override
public ScriptEngineService getScriptEngineService(Settings settings) {
return new MyExpertScriptEngine();
}
/** An example {@link ScriptEngineService} that uses Lucene segment details to implement pure document frequency scoring. */
// tag::expert_engine
private static class MyExpertScriptEngine implements ScriptEngineService {
@Override
public String getType() {
return "expert_scripts";
}
@Override
public Function<Map<String,Object>,SearchScript> compile(String scriptName, String scriptSource, Map<String, String> params) {
// we use the script "source" as the script identifier
if ("pure_df".equals(scriptSource)) {
return p -> new SearchScript() {
final String field;
final String term;
{
if (p.containsKey("field") == false) {
throw new IllegalArgumentException("Missing parameter [field]");
}
if (p.containsKey("term") == false) {
throw new IllegalArgumentException("Missing parameter [term]");
}
field = p.get("field").toString();
term = p.get("term").toString();
}
@Override
public LeafSearchScript getLeafSearchScript(LeafReaderContext context) throws IOException {
PostingsEnum postings = context.reader().postings(new Term(field, term));
if (postings == null) {
// the field and/or term don't exist in this segment, so always return 0
return () -> 0.0d;
}
return new LeafSearchScript() {
int currentDocid = -1;
@Override
public void setDocument(int docid) {
// advance has undefined behavior calling with a docid <= its current docid
if (postings.docID() < docid) {
try {
postings.advance(docid);
} catch (IOException e) {
throw new UncheckedIOException(e);
}
}
currentDocid = docid;
}
@Override
public double runAsDouble() {
if (postings.docID() != currentDocid) {
// advance moved past the current doc, so this doc has no occurrences of the term
return 0.0d;
}
try {
return postings.freq();
} catch (IOException e) {
throw new UncheckedIOException(e);
}
}
};
}
@Override
public boolean needsScores() {
return false;
}
};
}
throw new IllegalArgumentException("Unknown script name " + scriptSource);
}
@Override
@SuppressWarnings("unchecked")
public SearchScript search(CompiledScript compiledScript, SearchLookup lookup, @Nullable Map<String, Object> params) {
Function<Map<String,Object>,SearchScript> scriptFactory = (Function<Map<String,Object>,SearchScript>) compiledScript.compiled();
return scriptFactory.apply(params);
}
@Override
public ExecutableScript executable(CompiledScript compiledScript, @Nullable Map<String, Object> params) {
throw new UnsupportedOperationException();
}
@Override
public boolean isInlineScriptEnabled() {
return true;
}
@Override
public void close() {}
}
}代码解读: 本例在elasticsearch源码中,https://github.com/elastic/elasticsearch/tree/master/plugins/examples/script-expert-scoring
MyExpertScriptEngine类是其中最重要的类,用于实现脚本参数定义,编译,以及打分机制的实现。其中compile方法返回我们定义好打分逻辑的java function。search方法用于我们在搜索过程中实施定义好的打分逻辑。 怎奈笔者对于函数式编程知道的不多(后续需要补课),其实评分逻辑也可以在search方法中实现,于是有了下面的一段代码。
public class fieldaddScriptPlugin extends Plugin implements ScriptPlugin {
@Override
public ScriptEngineService getScriptEngineService(Settings settings) {
return new MyExpertScriptEngine();
}
private static class MyExpertScriptEngine implements ScriptEngineService {
@Override
public String getType() {
return "expert_scripts";
}
@Override
public Object compile(String scriptName, String scriptSource, Map<String, String> params) {
if ("example_add".equals(scriptSource)) {
return scriptSource;
}
throw new IllegalArgumentException("Unknown script name " + scriptSource);
}
@Override
@SuppressWarnings("unchecked")
public SearchScript search(CompiledScript compiledScript, SearchLookup lookup, @Nullable Map<String, Object> vars) {
/**
* 校验输入参数,DSL中params 参数列表
*/
final long inc;
final String fieldname;
if (vars == null || vars.containsKey("inc") == false) {
inc = 0;
} else {
inc = ((Number) vars.get("inc")).longValue();
}
if (vars == null || vars.containsKey("fieldname") == false) {
throw new IllegalArgumentException("Missing parameter [fieldname]");
} else {
fieldname = (String) vars.get("fieldname");
}
return new SearchScript() {
@Override
public LeafSearchScript getLeafSearchScript(LeafReaderContext context) throws IOException {
final LeafSearchLookup leafLookup = lookup.getLeafSearchLookup(context);
return new LeafSearchScript() {
@Override
public void setDocument(int doc) {
if (leafLookup != null) {
leafLookup.setDocument(doc);
}
}
@Override
public double runAsDouble() {
long values = 0;
/**
* 获取document中字段内容
*/
for (Object v : (List<?>) leafLookup.doc().get(fieldname)) {
values = ((Number) v).longValue() + values;
}
return values + inc;
}
};
}
@Override
public boolean needsScores() {
return false;
}
};
} 这段代码的逻辑是把给定的字段(字段类型long)的每个元素相加后再加上给定的增量参数最后形成score分值。为了实现上述逻辑需要实现参数获取、根据给定的字段名获取内容列表量的关键件。下面结合代码说说这两个步骤如何实现的。search方法中Map<String, Object> vars参数对应DSL中"params"参数,用于接受实际给定的运行时参数。SearchLookup lookup参数由系统传入,通过lookup.getLeafSearchLookup(context)获取LeafSearchLookup通过该对象可以获取给定字段的值。
对于elasticsearch 2.x以前的版本可以通过NativeScriptFactory实现原生脚本。
public class MyNativeScriptPlugin extends Plugin implements ScriptPlugin {
private final static Logger LOGGER = LogManager.getLogger(MyFirstPlugin.class);
public MyNativeScriptPlugin() {
super();
LOGGER.warn("This is MyNativeScriptPlugin");
}
@Override
public List<NativeScriptFactory> getNativeScripts() {
return Collections.singletonList(new MyNativeScriptFactory());
}
public static class MyNativeScriptFactory implements NativeScriptFactory {
@Override
public ExecutableScript newScript(@Nullable Map<String, Object> params) {
// return new MyNativeScript();
return new AbstractDoubleSearchScript(){
@Override
public double runAsDouble() {
int b=0;
if(params.get("add")!=null){
b= (int) params.get("add");
}
String s = source().get("last").toString();
double a = s.length()+b;
return a; }
};
}
@Override
public boolean needsScores() {
return false;
}
@Override
public String getName() {
return "my_script";
}
}
}工程组织 elasticsearch工程使用gradle进行依赖管理和生命周期管理,为此es项目自己也开发了esplugin的gradle插件,但不兼容gradle4.2以上的版本。参考github中的成熟插件,使用maven组织工程。
主要涉及两个文件 pom.xml plugin.xml 工程利用maven-assembly-plugin打包jar。
本例github地址:https://github.com/jiashiwen/elasticsearchpluginsample 欢迎点赞或拍砖
elasticsearch 支持 yara吗?elasticsearch 插件 elasticsearch-yara
回复开源项目 • 15210602359znn 回复了问题 • 2 人关注 • 2 个回复 • 4372 次浏览 • 2021-04-07 17:20
Easysearch 正式支持插件开发:让你的搜索系统真正"为你所用"
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 17426 次浏览 • 2026-04-27 22:02
从"用搜索"到"造搜索"
搜索系统的需求千差万别。标准功能覆盖不了所有场景——行业特定的分词规则、定制化的业务逻辑、与外部系统的深度集成……
以往,这类定制需求需要依赖厂商支持。从 Easysearch 2.1.2 开始,你可以自己动手了。
随着构建依赖库正式发布到 Maven 中央仓库,Easysearch 的插件开发能力正式对外开放。这意味着 Easysearch 不再是一个黑盒产品,而是一个可扩展、可定制的搜索平台。你可以基于官方接口开发自定义插件,像使用原生功能一样使用它们。
插件能做什么
Easysearch 提供三类核心扩展点,覆盖搜索系统的关键环节:
1. 分析器插件(AnalysisPlugin)
自定义分词器、Token 过滤器、字符过滤器。适用于:
- 电商 SKU 的型号规格解析
- 医疗、法律等领域的专业术语分词
- 特殊符号或空格的规范化处理
注册后直接在索引设置中使用,与原生分析器完全等同。
2. REST/API 插件(ActionPlugin)
新增自定义 HTTP 接口。适用于:
- 封装业务查询逻辑,对外暴露简化 API
- 对接企业内部权限中心或监控系统
- 暴露插件自身的管理接口(如状态检查)
3. Ingest 插件(IngestPlugin)
在文档写入前进行字段转换。适用于:
- 自定义业务字段转换(如根据业务规则计算衍生字段)
- 数据标准化(统一日期格式、大小写转换)
- 富文本提取或元数据生成
5 分钟上手
我们准备了官方模板仓库,让你从克隆到运行只需几条命令:
# 克隆模板
git clone https://github.com/infinilabs/easysearch-plugin-template.git my-plugin
cd my-plugin
# 修改包名和类名,编写你的逻辑
# ...方式一:开发调试——直接运行
# 构建插件并运行
./gradlew run
# 验证插件
curl -s "http://localhost:9200/_cat/plugins?v" | grep my-plugin方式二:构建后安装到外部集群
# 构建插件
./gradlew build
# 安装到 Easysearch
bin/easysearch-plugin install file:///$(pwd)/build/distributions/my-plugin-0.1.0.zip
# 启动验证
bin/easysearch
curl -s "http://localhost:9200/_cat/plugins?v" | grep my-plugin完整的开发指南请参考插件开发文档。
设计哲学
Easysearch 插件系统的设计遵循三个原则:
渐进式扩展——从最简单的 Plugin 类开始,按需实现 AnalysisPlugin、ActionPlugin 等接口,不必一次性掌握全部 API。
与原生同等——插件注册的分析器、处理器与系统原生组件在使用方式上完全一致,用户无需关心实现来源。
版本安全——插件加载时校验 easysearch.version,版本不匹配会拒绝加载,避免运行时异常。
从插件到生态
插件开发不只是技术能力的开放,更是产品理念的转变。
你可以将开发的插件发布到 GitHub Releases,通过 URL 直接安装:
bin/easysearch-plugin install https://github.com/yourname/my-plugin/releases/download/v0.1.0/my-plugin-0.1.0.zip我们也欢迎社区贡献。如果你有通用的插件想法,欢迎与我们交流。
结语
搜索系统的最后一公里,只有业务开发者最清楚该怎么走。
Easysearch 2.1.2 的插件开发能力,让你能够自主掌控搜索系统的"最后一公里"。从"用搜索"到"造搜索",现在你可以让你的搜索系统真正"为你所用"。
关于 Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
Day 23 - 基于 HanLP 的 ES 中文分词插件
Advent • rochy 发表了文章 • 0 个评论 • 9618 次浏览 • 2018-12-23 11:51
一、分词插件
1、分词器概念
在 ES 中,分词器的作用是从文本中提取出若干词元(token)来支持索引的存储和搜索,分词器(Analyzer)由一个分解器(Tokenizer)、零个或多个词元过滤器(TokenFilter)组成。
分解器用于将字符串分解成一系列词元,词元过滤器的作用是对分词器提取出来的词元做进一步处理,比如转成小写,增加同义词等。处理后的结果称为索引词(Term),引擎会建立 Term 和原文档的倒排索引(Inverted Index),这样就能根据 Term 很快到找到源文档了。
2、选择分词器
目前 ES 分词插件的选择性还是很多的,分词插件的核心就是提供各种分词器(Analyzer)、分解器(Tokenizer)、词元过滤器(TokenFilter);根据依赖的核心分词包(分词算法)的不同显现出不同的差异性,除了分词算法之外,是否支持用户自定义词典,是否支持词典热更新等其他附加功能也是选择分词插件时需要参考的。
下面列出选择分词插件需要考虑的因素(仅供参考):
- 分词准确性:大家都希望分词结果能够尽可能准确,与分词准确性直接相关的就是用户词典了,此外才是分词算法;
- 分词算法:个人认为无需纠结于分词算法,大多数分词包提供的分词算法都比较类似,选择时不需要过于纠结;
- 分词速度:这个与分词算法直接相关,基于词典的分词算法一般比基于模型的分词算法要快;基于词典如果考虑词频、命名实体识别、词性标注则会慢一些;
- 启动速度:当词典较大时,初始化词典会比较慢,某些分词器会对词典进行缓存,第二次启动会非常速度;
- 内存占用:与分词算法、词典大小、模型大小均有关系,设计精巧的算法对内存占用较小;
- 易用性:分词器是否开箱即用,是否可以直接使用在线链接或者压缩包进行安装,是否需要复杂的配置;
- 扩展性:是否支持用户自定义词典、是否支持自定义分词算法、是否支持热更新等;
- 是否开源:开源的分词器在遇到问题的时候可以自己进行深度调试,甚至可以进行二次开发;
- 社区活跃度:这个看一下 github 的 star 数或者依赖的分词包的 star 数和 issue 数目即可判定;
- 更新频率:是否能够与最新版的 ES 同步更新。
二、HanLP 简介
HanLP 是一系列模型与算法组成的 NLP 工具包,具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点,详情可参考 github 介绍:https://github.com/hankcs/HanLP。
选择 HanLP 作为核心的分词包开发 ES 分词插件,主要考虑以下因素:
- HanLP 是 Java 分词包中最为流行的;
- HanLP 提供了多种分词器,既可以基于词典也可以基于模型(在一亿字的大型综合语料库上训练的分词模型);
- HanLP 坚持使用明文词典,这样可以借助社区的力量对词典不断进行完善;
- 完善的开发文档和代码样例,较为活跃的用户群体;
- 个人参与了部分功能的开发,对代码结构较为熟悉。
三、开发分词插件
1、代码结构
conf:插件的配置文件、HanLP 的配置文件、Java 安全策略文件;scr.main.java.assemby:插件打包(maven-assembly-plugin)配置文件;org.elasticsearch.plugin.hanlp.analysis:分词插件核心构建器;org.elasticsearch.plugin.hanlp.conf:管理插件配置、分词器配置以及 HanLP 配置;org.elasticsearch.plugin.hanlp.lucene:HanLP 中文分词 Lucene 插件,对 Lucune 分词进行实现;scr.main.resources:插件属性文件所在目录
2、TokenStream
Analyzer 类是一个抽象类,是所有分词器的基类,它通过 TokenStream 类将文本转换为词汇单元流;TokenStream 有两种实现 Tokenizer(输入为 Reader) 和 TokenFilter(输入为另一个 TokenStream)。
TokenStream 基本使用流程:
- 实例化 TokenStream,向 AttributeSource 添加/获取属性(词汇单元文本、位置增量、偏移量、词汇类型等);
- 调用
reset()方法,将流(stream)重置到原始(clean)状态; - 循环调用
incrementToken()方法,并处理 Attribute 属性信息,直到它返回 false 表示流处理结束; - 调用
end()方法,确保流结束(end-of-stream)的操作可以被执行; - 调用
close()方法释放资源。
// 实例化 TokenStream
TokenStream tokenStream = new IKAnalyzer().tokenStream("keywords",new StringReader("思想者"));
// 向 AttributeSource 添加/获取属性
CharTermAttribute attribute = tokenStream.addAttribute(CharTermAttribute.class);
// 将流(stream)重置到原始(clean)状态
tokenStream.reset();
// 判断是否还有下一个 Token
while(tokenStream.incrementToken()) {
System.out.println(attribute);
}
tokenStream.end();
tokenStream.close();综上,开发 Tokenizer 或者 TokenFilter 时,需要重点关注
reset、incrementToken、end、close四个方法的实现。
3、开发中的小技巧
获取插件目录或文件目录
//获取插件根目录
private static Path getPluginPath() {
return env.pluginsFile().resolve("analysis-hanlp");
}
//获取插件目录下的文件
private static Path getDefDicConfigPath() {
return env.pluginsFile().resolve("analysis-hanlp/hanlp.properties").toAbsolutePath();
}插件属性文件
如果希望插件属性文件(plugin-descriptor.properties)能够自动根据 pom.xml 中的属性进行赋值,则需要将文件防止到 resources 文件夹下。
插件版本兼容性
从实际测试来看:
- ES5.X 及其以上的代码是完全复用的,也就是说代码逻辑不需要调整;
- ES5.X 到 ES6.2.X 的插件是可以通用的,其特征是打包的时候需要将插件的文件全部打包到
elasticsearch文件夹下; - ES6.3.X 以上的插件是可以通用的,打包的时候插件的文件全部打包到根目录即可。
也就是说,如果你升级了新版本 ES,对于插件升级,大多数情况只需要修改下
plugin-descriptor.properties文件中 ES 的版本号即可。
4、安全策略文件
在插件开发中经常会使用到文件读取、属性读取、网络链接等功能,如果不提前注册安全策略,在调用这些功能的时候会报以下错误java.security.AccessControlException: access denied。
官方给出的解决方案就是新建一个 plugin-security.policy 文件,然后在文件中声明需要的权限信息,最后在打包的时候将文件放置到插件的根目录,这样在使用 zip 包进行安装的时候,ES 会提示用户插件所需的权限信息,需要用户确认后插件才能正常安装。
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: plugin requires additional permissions @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
* java.io.FilePermission <<ALL FILES>> read,write,delete
* java.lang.RuntimePermission createClassLoader
* java.lang.RuntimePermission getClassLoader
* java.lang.RuntimePermission setContextClassLoader
* java.net.SocketPermission * connect,resolve
* java.util.PropertyPermission * read,write
See http://docs.oracle.com/javase/8/docs/technotes/guides/security/permissions.html
for descriptions of what these permissions allow and the associated risks.
Continue with installation? [y/N]y
-> Installed analysis-hanlp5、安全策略的坑
最开始认为只需要添加了 policy 文件,且打包到正确的位置即可解决插件的权限问题,因为在插件安装的时候 ES 已经提示了所需权限,但是代码在实际执行的时候依旧报 AccessControlException 的错误。
参考了多个 HanLP 的 ES 分词插件,都没有获得较好的方法,后来考虑到 IK 分词器远程加载词典时,需要网络连接权限,就去看了下其远程词典加载的代码,最终找到了正确的使用方法。
// 需要特殊权限的代码
AccessController.doPrivileged((PrivilegedAction<Segment>) () -> {
Segment segment;
if (config.getAlgorithm().equals("extend")) {
segment = new ViterbiSegment();
} else {
segment = HanLP.newSegment(config.getAlgorithm());
}
// 在此处显示调用一下分词,使得加载词典、缓存词典的操作可以正确执行
System.out.println( segment.seg("HanLP中文分词工具包!"));
return segment;
});四、插件特色
简单介绍一下插件的特点:
- 内置多种分词模式,适合不同场景;
- 内置词典,无需额外配置即可使用;
- 支持外置词典,用户可自定义分词算法,基于词典或是模型;
- 支持分词器级别的自定义词典,便于用于多租户场景;
- 支持远程词典热更新(待开发);
- 拼音过滤器、繁简体过滤器(待开发);
- 基于词语或单字的 ngram 切分分词(待开发)。
Github 地址:https://github.com/AnyListen/elasticsearch-analysis-hanlp
elasticsearch java原生打分插件开发
Elasticsearch • JiaShiwen 发表了文章 • 1 个评论 • 10036 次浏览 • 2018-01-10 16:34
能有影响elasticsearch score的方法有很多,官方推荐的是使用内置的painless脚本语言结合function_score来重新定义score。由于本人开发的项目其算法是由java语言开发的,于是决定尝试原生脚本开发。 elasticsearch脚本由plugin-descriptor.properties文件以及运行jar包组成,plugin-descriptor.properties主要用来定义版本信息、对应es的版本信息等属性。
官方的例子
public class ExpertScriptPlugin extends Plugin implements ScriptPlugin {
@Override
public ScriptEngineService getScriptEngineService(Settings settings) {
return new MyExpertScriptEngine();
}
/** An example {@link ScriptEngineService} that uses Lucene segment details to implement pure document frequency scoring. */
// tag::expert_engine
private static class MyExpertScriptEngine implements ScriptEngineService {
@Override
public String getType() {
return "expert_scripts";
}
@Override
public Function<Map<String,Object>,SearchScript> compile(String scriptName, String scriptSource, Map<String, String> params) {
// we use the script "source" as the script identifier
if ("pure_df".equals(scriptSource)) {
return p -> new SearchScript() {
final String field;
final String term;
{
if (p.containsKey("field") == false) {
throw new IllegalArgumentException("Missing parameter [field]");
}
if (p.containsKey("term") == false) {
throw new IllegalArgumentException("Missing parameter [term]");
}
field = p.get("field").toString();
term = p.get("term").toString();
}
@Override
public LeafSearchScript getLeafSearchScript(LeafReaderContext context) throws IOException {
PostingsEnum postings = context.reader().postings(new Term(field, term));
if (postings == null) {
// the field and/or term don't exist in this segment, so always return 0
return () -> 0.0d;
}
return new LeafSearchScript() {
int currentDocid = -1;
@Override
public void setDocument(int docid) {
// advance has undefined behavior calling with a docid <= its current docid
if (postings.docID() < docid) {
try {
postings.advance(docid);
} catch (IOException e) {
throw new UncheckedIOException(e);
}
}
currentDocid = docid;
}
@Override
public double runAsDouble() {
if (postings.docID() != currentDocid) {
// advance moved past the current doc, so this doc has no occurrences of the term
return 0.0d;
}
try {
return postings.freq();
} catch (IOException e) {
throw new UncheckedIOException(e);
}
}
};
}
@Override
public boolean needsScores() {
return false;
}
};
}
throw new IllegalArgumentException("Unknown script name " + scriptSource);
}
@Override
@SuppressWarnings("unchecked")
public SearchScript search(CompiledScript compiledScript, SearchLookup lookup, @Nullable Map<String, Object> params) {
Function<Map<String,Object>,SearchScript> scriptFactory = (Function<Map<String,Object>,SearchScript>) compiledScript.compiled();
return scriptFactory.apply(params);
}
@Override
public ExecutableScript executable(CompiledScript compiledScript, @Nullable Map<String, Object> params) {
throw new UnsupportedOperationException();
}
@Override
public boolean isInlineScriptEnabled() {
return true;
}
@Override
public void close() {}
}
}代码解读: 本例在elasticsearch源码中,https://github.com/elastic/elasticsearch/tree/master/plugins/examples/script-expert-scoring
MyExpertScriptEngine类是其中最重要的类,用于实现脚本参数定义,编译,以及打分机制的实现。其中compile方法返回我们定义好打分逻辑的java function。search方法用于我们在搜索过程中实施定义好的打分逻辑。 怎奈笔者对于函数式编程知道的不多(后续需要补课),其实评分逻辑也可以在search方法中实现,于是有了下面的一段代码。
public class fieldaddScriptPlugin extends Plugin implements ScriptPlugin {
@Override
public ScriptEngineService getScriptEngineService(Settings settings) {
return new MyExpertScriptEngine();
}
private static class MyExpertScriptEngine implements ScriptEngineService {
@Override
public String getType() {
return "expert_scripts";
}
@Override
public Object compile(String scriptName, String scriptSource, Map<String, String> params) {
if ("example_add".equals(scriptSource)) {
return scriptSource;
}
throw new IllegalArgumentException("Unknown script name " + scriptSource);
}
@Override
@SuppressWarnings("unchecked")
public SearchScript search(CompiledScript compiledScript, SearchLookup lookup, @Nullable Map<String, Object> vars) {
/**
* 校验输入参数,DSL中params 参数列表
*/
final long inc;
final String fieldname;
if (vars == null || vars.containsKey("inc") == false) {
inc = 0;
} else {
inc = ((Number) vars.get("inc")).longValue();
}
if (vars == null || vars.containsKey("fieldname") == false) {
throw new IllegalArgumentException("Missing parameter [fieldname]");
} else {
fieldname = (String) vars.get("fieldname");
}
return new SearchScript() {
@Override
public LeafSearchScript getLeafSearchScript(LeafReaderContext context) throws IOException {
final LeafSearchLookup leafLookup = lookup.getLeafSearchLookup(context);
return new LeafSearchScript() {
@Override
public void setDocument(int doc) {
if (leafLookup != null) {
leafLookup.setDocument(doc);
}
}
@Override
public double runAsDouble() {
long values = 0;
/**
* 获取document中字段内容
*/
for (Object v : (List<?>) leafLookup.doc().get(fieldname)) {
values = ((Number) v).longValue() + values;
}
return values + inc;
}
};
}
@Override
public boolean needsScores() {
return false;
}
};
} 这段代码的逻辑是把给定的字段(字段类型long)的每个元素相加后再加上给定的增量参数最后形成score分值。为了实现上述逻辑需要实现参数获取、根据给定的字段名获取内容列表量的关键件。下面结合代码说说这两个步骤如何实现的。search方法中Map<String, Object> vars参数对应DSL中"params"参数,用于接受实际给定的运行时参数。SearchLookup lookup参数由系统传入,通过lookup.getLeafSearchLookup(context)获取LeafSearchLookup通过该对象可以获取给定字段的值。
对于elasticsearch 2.x以前的版本可以通过NativeScriptFactory实现原生脚本。
public class MyNativeScriptPlugin extends Plugin implements ScriptPlugin {
private final static Logger LOGGER = LogManager.getLogger(MyFirstPlugin.class);
public MyNativeScriptPlugin() {
super();
LOGGER.warn("This is MyNativeScriptPlugin");
}
@Override
public List<NativeScriptFactory> getNativeScripts() {
return Collections.singletonList(new MyNativeScriptFactory());
}
public static class MyNativeScriptFactory implements NativeScriptFactory {
@Override
public ExecutableScript newScript(@Nullable Map<String, Object> params) {
// return new MyNativeScript();
return new AbstractDoubleSearchScript(){
@Override
public double runAsDouble() {
int b=0;
if(params.get("add")!=null){
b= (int) params.get("add");
}
String s = source().get("last").toString();
double a = s.length()+b;
return a; }
};
}
@Override
public boolean needsScores() {
return false;
}
@Override
public String getName() {
return "my_script";
}
}
}工程组织 elasticsearch工程使用gradle进行依赖管理和生命周期管理,为此es项目自己也开发了esplugin的gradle插件,但不兼容gradle4.2以上的版本。参考github中的成熟插件,使用maven组织工程。
主要涉及两个文件 pom.xml plugin.xml 工程利用maven-assembly-plugin打包jar。
本例github地址:https://github.com/jiashiwen/elasticsearchpluginsample 欢迎点赞或拍砖
