


极限网关
信创环境下部署 INFINI Gateway:为 Easysearch 构建高性能安全入口
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 11718 次浏览 • 2026-06-11 17:17
引言
上一篇文章里,我们已经完成了 Easysearch 在信创环境下的部署。搜索服务能跑起来只是第一步,要让它真正用于生产,还需要补上“入口治理”这一环。
例如,下面这些问题在生产环境中非常常见:
- 如何防止某个应用或用户发出超大查询请求,把 Easysearch 集群拖垮?
- 如果 Easysearch 某个节点突然宕机,请求能不能自动切换到健康节点,让业务无感知?
- 如何知道每天有多少次查询、哪些查询慢、哪些请求不合法,有没有办法对请求进行审计?
这些正是 INFINI Gateway(极限网关) 擅长解决的问题。本文延续“小白友好”风格,带你完成 Gateway 的安装与验证,为 Easysearch 增加一层高性能、安全、可观测的入口防护。

一、INFINI Gateway 是什么?和 Easysearch 是什么关系?
如果把 Easysearch 比作大型图书馆,那么 INFINI Gateway 就像门口的 “前台总台”。过去读者(应用程序)直接进入书库检索;现在所有请求先经过前台,再转发到书库。这样做的好处很直接:可以缓存热门请求,减少后端压力;可以限制流量,避免集群被突发请求冲垮;还可以记录访问日志,方便审计与分析。
从技术层面讲,INFINI Gateway 的定位如下:
- 高性能数据网关:面向搜索场景设计,请求先在网关完成处理,再转发到后端 Easysearch 集群。
- 代理 + 增强:位于客户端与 Easysearch 之间,可在转发链路中叠加限流、缓存加速、请求审计、结果改写等能力。
- 兼容原生 API:对外接口兼容 Elasticsearch / Easysearch 原生 API,应用只需把连接地址从直连 Easysearch 改为指向网关,无需改业务代码。
- 轻量易部署:基于 Golang 开发,安装包约 10MB,无额外外部依赖。
- 信创兼容认证:已通过华为鲲鹏 Kunpeng 920 兼容性认证,并获得 KUNPENG COMPATIBLE 证书。
整个系列的组件关系如下:
应用程序 → INFINI Gateway(流量入口) → Easysearch(数据存储与检索)
有了 Gateway,你就可以更放心地将搜索服务开放给更多应用和用户,而不必过度担心安全与性能失控问题。
二、部署前置条件
1. 信创环境
- CPU :鲲鹏 Kunpeng-920、aarch64
- 操作系统:统信服务器操作系统A版 V20
2. 确保 Easysearch 已正常运行
Gateway 本身不存储数据,核心职责是代理与增强 Easysearch。因此部署前请先确认 Easysearch 已启动,并且网络可达:
curl -ku admin:你的密码 https://localhost:9200三、部署步骤
步骤 1:下载 INFINI Gateway
下面脚本会自动下载对应平台的 Gateway 最新版本,并解压到 /opt/gateway:
# 一键下载并安装到 /opt/gateway
curl -sSL http://get.infini.cloud | bash -s -- -p gateway -d /opt/gateway
步骤 2:编写 Gateway 配置文件
Gateway 启动依赖 YAML 配置文件,用来声明监听端口、后端 Easysearch 地址和认证信息。进入安装目录后,找到 gateway.yml 并按实际环境修改:
# 按实际情况填写可访问的 Easysearch 地址
LOGGING_ES_ENDPOINT:https://localhost:9200/
LOGGING_ES_USER:admin
LOGGING_ES_PASS:"你的 Easysearch 密码"
# 按实际情况填写可访问的 Easysearch 地址
PROD_ES_ENDPOINT:https://localhost:9200/
PROD_ES_USER:admin
PROD_ES_PASS:"你的 Easysearch 密码"
# 按需设置 Gateway 对外监听端口
GW_BINDING:"0.0.0.0:8000"步骤 3:启动 Gateway
进入 Gateway 安装目录,执行下面命令启动程序:
# 进入安装目录
cd /opt/gateway
# 运行程序(gateway-linux-arm64 为可执行文件名)
./gateway-linux-arm64

程序启动后,即可通过配置端口访问 Easysearch 服务。

在前台运行模式下,如需停止 Gateway,按 Ctrl+C 即可。

如果希望将 Gateway 作为后台服务运行,可执行:
# 命令中的 gateway-linux-arm64 为可执行文件名
./gateway-linux-arm64 -service install && ./gateway-linux-arm64 -service start如需卸载服务,执行以下命令:
./gateway-linux-arm64 -service stop
./gateway-linux-arm64 -service uninstall步骤 4:验证 Gateway 是否正常工作
通过 Gateway 间接访问 Easysearch,确认转发通路正常:
# 通过 Gateway(8000 端口)访问 Easysearch
curl http://0.0.0.0:8000
# 对比直连 Easysearch 的结果
curl -ku admin:你的密码 https://localhost:9200两条命令返回的 JSON 结果应基本一致。若都能正常响应,说明 Gateway 已成功接管 Easysearch 的访问入口。
如果你的生产环境需要将搜索服务开放给大量应用和用户,建议将 Gateway 纳入标准部署方案。借助 Gateway,你可以更好地保护后端 Easysearch 集群,并获得限流限速、缓存加速、安全防护、审计日志等增强能力,让整体架构更健壮、更安全、更可观测。
如果在部署过程中遇到问题,欢迎查阅官方文档。祝你部署顺利!
作者:小袁
原文:https://infinilabs.cn/blog/2026/gateway-install-at-xc-platform/
如何使用极限网关实现 Elasticsearch 集群迁移至 Easysearch
Elasticsearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 21233 次浏览 • 2025-09-21 14:50
之前有博客介绍过通过 Reindex 的方法将 Elasticsearch 的数据迁移到 Easysearch 集群,今天再介绍一个方法,通过 极限网关(INFINI Gateway) 来进行数据迁移。
测试环境
| 软件 | 版本 |
|---|---|
| Easysearch | 1.12.0 |
| Elasticsearch | 7.17.29 |
| INFINI Gateway | 1.29.2 |
迁移步骤
- 选定要迁移的索引
- 在目标集群建立索引的 mapping 和 setting
- 准备 INFINI Gateway 迁移配置
- 运行 INFINI Gateway 进行数据迁移
迁移实战
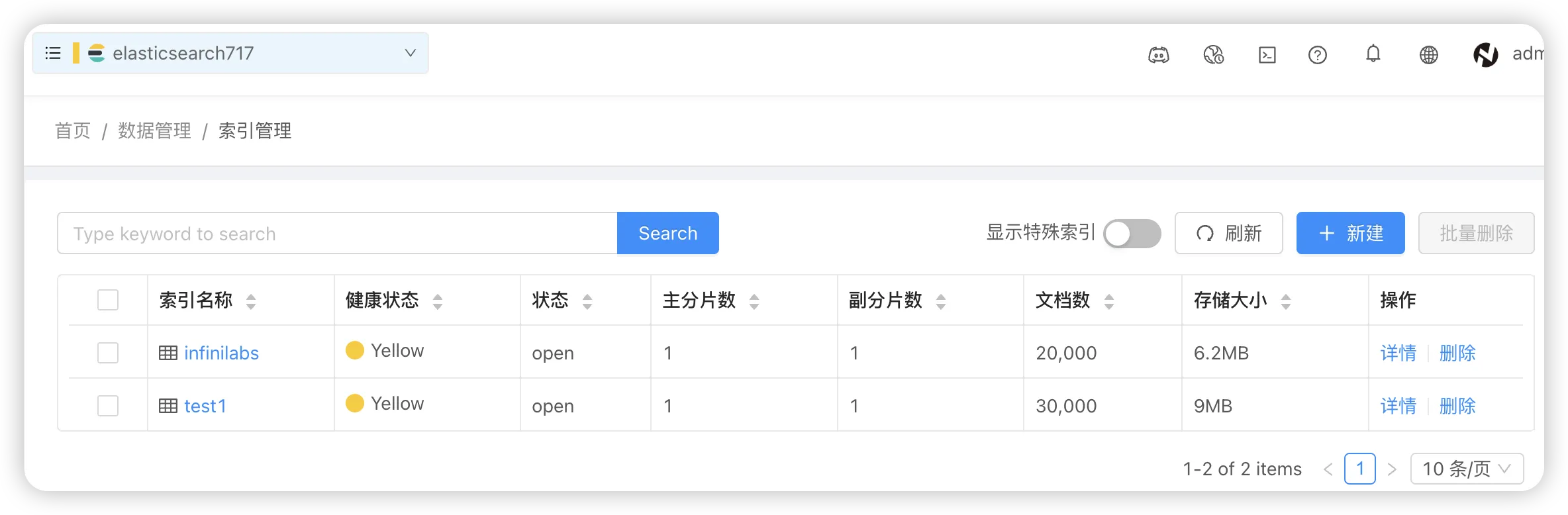
- 选定要迁移的索引
在 Elasticsearch 集群中选择目标索引:infinilabs 和 test1,没错,我们一次可以迁移多个。
- 在 Easysearch 集群使用源索引的 setting 和 mapping 建立目标索引。(略)
- INFINI Gateway 迁移配置准备
去 github 下载配置,修改下面的连接集群的部分
1 env:
2 LR_GATEWAY_API_HOST: 127.0.0.1:2900
3 SRC_ELASTICSEARCH_ENDPOINT: http://127.0.0.1:9200
4 DST_ELASTICSEARCH_ENDPOINT: http://127.0.0.1:9201
5 path.data: data
6 path.logs: log
7 progress_bar.enabled: true
8 configs.auto_reload: true
9
10 api:
11 enabled: true
12 network:
13 binding: $[[env.LR_GATEWAY_API_HOST]]
14
15 elasticsearch:
16 - name: source
17 enabled: true
18 endpoint: $[[env.SRC_ELASTICSEARCH_ENDPOINT]]
19 basic_auth:
20 username: elastic
21 password: goodgoodstudy
22
23 - name: target
24 enabled: true
25 endpoint: $[[env.DST_ELASTICSEARCH_ENDPOINT]]
26 basic_auth:
27 username: admin
28 password: 14da41c79ad2d744b90cpipeline 部分修改要迁移的索引名称,我们迁移 infinilabs 和 test1 两个索引。
31 pipeline:
32 - name: source_scroll
33 auto_start: true
34 keep_running: false
35 processor:
36 - es_scroll:
37 slice_size: 1
38 batch_size: 5000
39 indices: "infinilabs,test1"
40 elasticsearch: source
41 output_queue: source_index_dump
42 partition_size: 1
43 scroll_time: "5m"- 迁移数据
./gateway-mac-arm64
#如果你保存的配置文件名称不叫 gateway.yml,则需要加参数 -config 文件名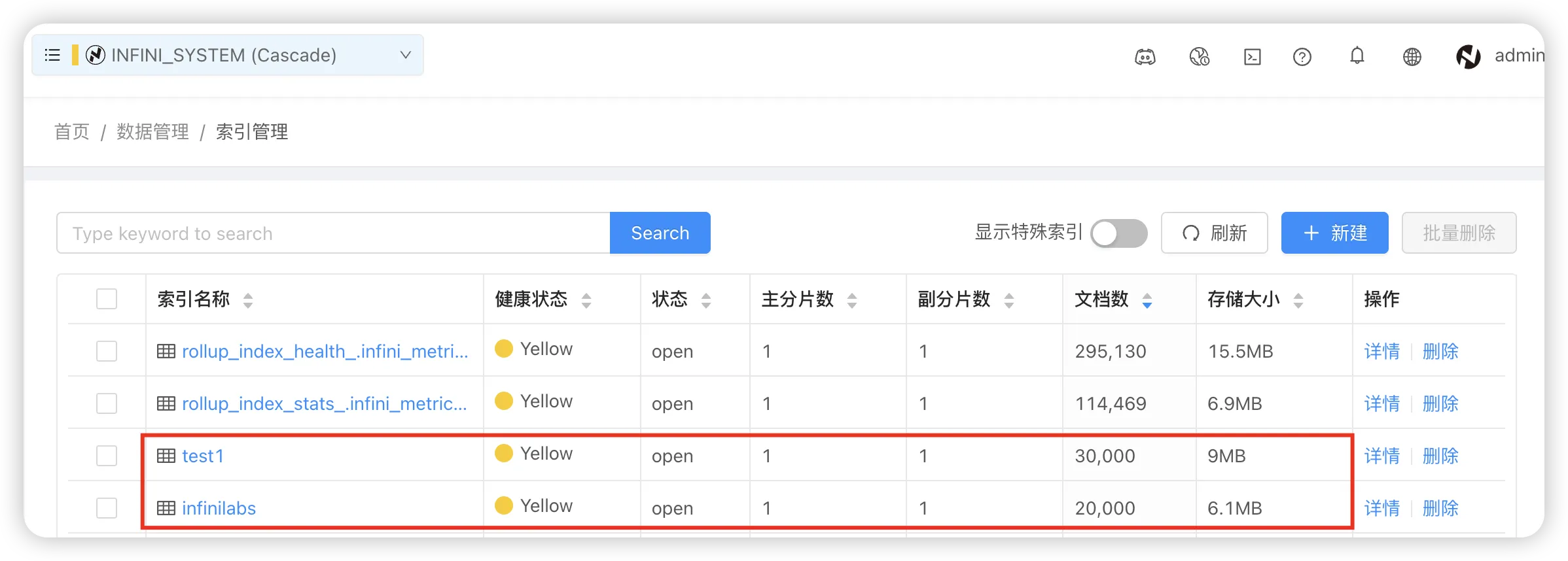
数据导入完成后,网关 ctrl+c 退出。
至此,数据迁移就完成了。下一篇我们来介绍 INFINI Gateway 的数据比对功能。
有任何问题,欢迎加我微信沟通。

关于极限网关(INFINI Gateway)

INFINI Gateway 是一个开源的面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway,可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
官网文档:https://docs.infinilabs.com/gateway
开源地址:https://github.com/infinilabs/gateway
ES 调优帖:Gateway 批量写入性能优化实践
Elasticsearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 19087 次浏览 • 2025-08-06 17:32
背景:bulk 优化的应用
在 ES 的写入优化里,bulk 操作被广泛地用于批量处理数据。bulk 操作允许用户一次提交多个数据操作,如索引、更新、删除等,从而提高数据处理效率。bulk 操作的实现原理是,将数据操作请求打包成 HTTP 请求,并批量提交给 Elasticsearch 服务器。这样,Elasticsearch 服务器就可以一次处理多个数据操作,从而提高处理效率。
这种优化的核心价值在于减少了网络往返的次数和连接建立的开销。每一次单独的写入操作都需要经历完整的请求-响应周期,而批量写入则是将多个操作打包在一起,用一次通信完成原本需要多次交互的工作。这不仅仅节省了时间,更重要的是释放了系统资源,让服务器能够专注于真正的数据处理,而不是频繁的协议握手和状态维护。
这样的批量请求的确是可以优化写入请求的效率,让 ES 集群获得更多的资源去做写入请求的集中处理。但是除了客户端与 ES 集群的通讯效率优化,还有其他中间过程能优化么?
Gateway 的优化点
bulk 的优化理念是将日常零散的写入需求做集中化的处理,尽量减低日常请求的损耗,完成资源最大化的利用。简而言之就是“好钢用在刀刃上”。
但是 ES 在收到 bulk 写入请求后,也是需要协调节点根据文档的 id 计算所属的分片来将数据分发到对应的数据节点的。这个过程也是有一定损耗的,如果 bulk 请求中数据分布的很散,每个分片都需要进行写入,原本 bulk 集中写入的需求优势则还是没有得到最理想化的提升。
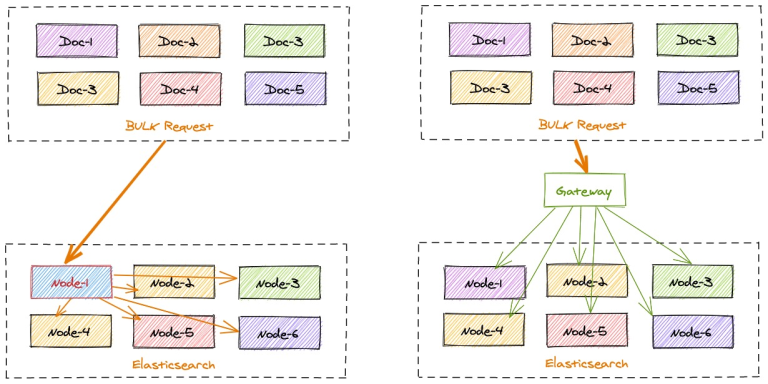
gateway 的写入加速则对 bulk 的优化理念的最大化补全。
gateway 可以本地计算每个索引文档对应后端 Elasticsearch 集群的目标存放位置,从而能够精准的进行写入请求定位。
在一批 bulk 请求中,可能存在多个后端节点的数据,bulk_reshuffle 过滤器用来将正常的 bulk 请求打散,按照目标节点或者分片进行拆分重新组装,避免 Elasticsearch 节点收到请求之后再次进行请求分发, 从而降低 Elasticsearch 集群间的流量和负载,也能避免单个节点成为热点瓶颈,确保各个数据节点的处理均衡,从而提升集群总体的索引吞吐能力。
整理的优化思路如下图:
优化实践
那我们来实践一下,看看 gateway 能提升多少的写入。
这里我们分 2 个测试场景:
- 基础集中写入测试,不带文档 id,直接批量写入。这个场景更像是日志或者监控数据采集的场景。
- 带文档 id 的写入测试,更偏向搜索场景或者大数据批同步的场景。
2 个场景都进行直接写入 ES 和 gateway 转发 ES 的效率比对。
测试材料除了需要备一个网关和一套 es 外,其余的内容如下:
测试索引 mapping 一致,名称区分:
PUT gateway_bulk_test
{
"settings": {
"number_of_shards": 6,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"timestamp": {
"type": "date",
"format": "strict_date_optional_time"
},
"field1": {
"type": "keyword"
},
"field2": {
"type": "keyword"
},
"field3": {
"type": "keyword"
},
"field4": {
"type": "integer"
},
"field5": {
"type": "keyword"
},
"field6": {
"type": "float"
}
}
}
}
PUT bulk_test
{
"settings": {
"number_of_shards": 6,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"timestamp": {
"type": "date",
"format": "strict_date_optional_time"
},
"field1": {
"type": "keyword"
},
"field2": {
"type": "keyword"
},
"field3": {
"type": "keyword"
},
"field4": {
"type": "integer"
},
"field5": {
"type": "keyword"
},
"field6": {
"type": "float"
}
}
}
}gateway 的配置文件如下:
path.data: data
path.logs: log
entry:
- name: my_es_entry
enabled: true
router: my_router
max_concurrency: 200000
network:
binding: 0.0.0.0:8000
flow:
- name: async_bulk
filter:
- bulk_reshuffle:
when:
contains:
_ctx.request.path: /_bulk
elasticsearch: prod
level: node
partition_size: 1
fix_null_id: true
- elasticsearch:
elasticsearch: prod #elasticsearch configure reference name
max_connection_per_node: 1000 #max tcp connection to upstream, default for all nodes
max_response_size: -1 #default for all nodes
balancer: weight
refresh: # refresh upstream nodes list, need to enable this feature to use elasticsearch nodes auto discovery
enabled: true
interval: 60s
filter:
roles:
exclude:
- master
router:
- name: my_router
default_flow: async_bulk
elasticsearch:
- name: prod
enabled: true
endpoints:
- https://127.0.0.1:9221
- https://127.0.0.1:9222
- https://127.0.0.1:9223
basic_auth:
username: admin
password: admin
pipeline:
- name: bulk_request_ingest
auto_start: true
keep_running: true
retry_delay_in_ms: 1000
processor:
- bulk_indexing:
max_connection_per_node: 100
num_of_slices: 3
max_worker_size: 30
idle_timeout_in_seconds: 10
bulk:
compress: false
batch_size_in_mb: 10
batch_size_in_docs: 10000
consumer:
fetch_max_messages: 100
queue_selector:
labels:
type: bulk_reshuffle测试脚本如下:
#!/usr/bin/env python3
"""
ES Bulk写入性能测试脚本
"""
import hashlib
import json
import random
import string
import time
from typing import List, Dict, Any
import requests
from concurrent.futures import ThreadPoolExecutor
from datetime import datetime
import urllib3
# 禁用SSL警告
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
class ESBulkTester:
def __init__(self):
# 配置变量 - 可修改
self.es_configs = [
{
"name": "ES直连",
"url": "https://127.0.0.1:9221",
"index": "bulk_test",
"username": "admin", # 修改为实际用户名
"password": "admin", # 修改为实际密码
"verify_ssl": False # HTTPS需要SSL验证
},
{
"name": "Gateway代理",
"url": "http://localhost:8000",
"index": "gateway_bulk_test",
"username": None, # 无需认证
"password": None,
"verify_ssl": False
}
]
self.batch_size = 10000 # 每次bulk写入条数
self.log_interval = 100000 # 每多少次bulk写入输出日志
# ID生成规则配置 - 前2位后5位
self.id_prefix_start = 1
self.id_prefix_end = 999 # 前3位: 01-999
self.id_suffix_start = 1
self.id_suffix_end = 9999 # 后4位: 0001-9999
# 当前ID计数器
self.current_prefix = self.id_prefix_start
self.current_suffix = self.id_suffix_start
def generate_id(self) -> str:
"""生成固定规则的ID - 前2位后5位"""
id_str = f"{self.current_prefix:02d}{self.current_suffix:05d}"
# 更新计数器
self.current_suffix += 1
if self.current_suffix > self.id_suffix_end:
self.current_suffix = self.id_suffix_start
self.current_prefix += 1
if self.current_prefix > self.id_prefix_end:
self.current_prefix = self.id_prefix_start
return id_str
def generate_random_hash(self, length: int = 32) -> str:
"""生成随机hash值"""
random_string = ''.join(random.choices(string.ascii_letters + string.digits, k=length))
return hashlib.md5(random_string.encode()).hexdigest()
def generate_document(self) -> Dict[str, Any]:
"""生成随机文档内容"""
return {
"timestamp": datetime.now().isoformat(),
"field1": self.generate_random_hash(),
"field2": self.generate_random_hash(),
"field3": self.generate_random_hash(),
"field4": random.randint(1, 1000),
"field5": random.choice(["A", "B", "C", "D"]),
"field6": random.uniform(0.1, 100.0)
}
def create_bulk_payload(self, index_name: str) -> str:
"""创建bulk写入payload"""
bulk_data = []
for _ in range(self.batch_size):
#doc_id = self.generate_id()
doc = self.generate_document()
# 添加index操作
bulk_data.append(json.dumps({
"index": {
"_index": index_name,
# "_id": doc_id
}
}))
bulk_data.append(json.dumps(doc))
return "\n".join(bulk_data) + "\n"
def bulk_index(self, config: Dict[str, Any], payload: str) -> bool:
"""执行bulk写入"""
url = f"{config['url']}/_bulk"
headers = {
"Content-Type": "application/x-ndjson"
}
# 设置认证信息
auth = None
if config.get('username') and config.get('password'):
auth = (config['username'], config['password'])
try:
response = requests.post(
url,
data=payload,
headers=headers,
auth=auth,
verify=config.get('verify_ssl', True),
timeout=30
)
return response.status_code == 200
except Exception as e:
print(f"Bulk写入失败: {e}")
return False
def refresh_index(self, config: Dict[str, Any]) -> bool:
"""刷新索引"""
url = f"{config['url']}/{config['index']}/_refresh"
# 设置认证信息
auth = None
if config.get('username') and config.get('password'):
auth = (config['username'], config['password'])
try:
response = requests.post(
url,
auth=auth,
verify=config.get('verify_ssl', True),
timeout=10
)
success = response.status_code == 200
print(f"索引刷新{'成功' if success else '失败'}: {config['index']}")
return success
except Exception as e:
print(f"索引刷新失败: {e}")
return False
def run_test(self, config: Dict[str, Any], round_num: int, total_iterations: int = 100000):
"""运行性能测试"""
test_name = f"{config['name']}-第{round_num}轮"
print(f"\n开始测试: {test_name}")
print(f"ES地址: {config['url']}")
print(f"索引名称: {config['index']}")
print(f"认证: {'是' if config.get('username') else '否'}")
print(f"每次bulk写入: {self.batch_size}条")
print(f"总计划写入: {total_iterations * self.batch_size}条")
print("-" * 50)
start_time = time.time()
success_count = 0
error_count = 0
for i in range(1, total_iterations + 1):
payload = self.create_bulk_payload(config['index'])
if self.bulk_index(config, payload):
success_count += 1
else:
error_count += 1
# 每N次输出日志
if i % self.log_interval == 0:
elapsed_time = time.time() - start_time
rate = i / elapsed_time if elapsed_time > 0 else 0
print(f"已完成 {i:,} 次bulk写入, 耗时: {elapsed_time:.2f}秒, 速率: {rate:.2f} bulk/秒")
end_time = time.time()
total_time = end_time - start_time
total_docs = total_iterations * self.batch_size
print(f"\n{test_name} 测试完成!")
print(f"总耗时: {total_time:.2f}秒")
print(f"成功bulk写入: {success_count:,}次")
print(f"失败bulk写入: {error_count:,}次")
print(f"总文档数: {total_docs:,}条")
print(f"平均速率: {success_count/total_time:.2f} bulk/秒")
print(f"文档写入速率: {total_docs/total_time:.2f} docs/秒")
print("=" * 60)
return {
"test_name": test_name,
"config_name": config['name'],
"round": round_num,
"es_url": config['url'],
"index": config['index'],
"total_time": total_time,
"success_count": success_count,
"error_count": error_count,
"total_docs": total_docs,
"bulk_rate": success_count/total_time,
"doc_rate": total_docs/total_time
}
def run_comparison_test(self, total_iterations: int = 10000):
"""运行双地址对比测试"""
print("ES Bulk写入性能测试开始")
print(f"测试时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
print("=" * 60)
results = []
rounds = 2 # 每个地址测试2轮
# 循环测试所有配置
for config in self.es_configs:
print(f"\n开始测试配置: {config['name']}")
print("*" * 40)
for round_num in range(1, rounds + 1):
# 运行测试
result = self.run_test(config, round_num, total_iterations)
results.append(result)
# 每轮结束后刷新索引
print(f"\n第{round_num}轮测试完成,执行索引刷新...")
self.refresh_index(config)
# 重置ID计数器
if round_num == 1:
# 第1轮:使用初始ID范围(新增数据)
print("第1轮:新增数据模式")
else:
# 第2轮:重复使用相同ID(更新数据模式)
print("第2轮:数据更新模式,复用第1轮ID")
self.current_prefix = self.id_prefix_start
self.current_suffix = self.id_suffix_start
print(f"{config['name']} 第{round_num}轮测试结束\n")
# 输出对比结果
print("\n性能对比结果:")
print("=" * 80)
# 按配置分组显示结果
config_results = {}
for result in results:
config_name = result['config_name']
if config_name not in config_results:
config_results[config_name] = []
config_results[config_name].append(result)
for config_name, rounds_data in config_results.items():
print(f"\n{config_name}:")
total_time = 0
total_bulk_rate = 0
total_doc_rate = 0
for round_data in rounds_data:
print(f" 第{round_data['round']}轮:")
print(f" 耗时: {round_data['total_time']:.2f}秒")
print(f" Bulk速率: {round_data['bulk_rate']:.2f} bulk/秒")
print(f" 文档速率: {round_data['doc_rate']:.2f} docs/秒")
print(f" 成功率: {round_data['success_count']/(round_data['success_count']+round_data['error_count'])*100:.2f}%")
total_time += round_data['total_time']
total_bulk_rate += round_data['bulk_rate']
total_doc_rate += round_data['doc_rate']
avg_bulk_rate = total_bulk_rate / len(rounds_data)
avg_doc_rate = total_doc_rate / len(rounds_data)
print(f" 平均性能:")
print(f" 总耗时: {total_time:.2f}秒")
print(f" 平均Bulk速率: {avg_bulk_rate:.2f} bulk/秒")
print(f" 平均文档速率: {avg_doc_rate:.2f} docs/秒")
# 整体对比
if len(config_results) >= 2:
config_names = list(config_results.keys())
config1_avg = sum([r['bulk_rate'] for r in config_results[config_names[0]]]) / len(config_results[config_names[0]])
config2_avg = sum([r['bulk_rate'] for r in config_results[config_names[1]]]) / len(config_results[config_names[1]])
if config1_avg > config2_avg:
faster = config_names[0]
rate_diff = config1_avg - config2_avg
else:
faster = config_names[1]
rate_diff = config2_avg - config1_avg
print(f"\n整体性能对比:")
print(f"{faster} 平均性能更好,bulk速率高 {rate_diff:.2f} bulk/秒")
print(f"性能提升: {(rate_diff/min(config1_avg, config2_avg)*100):.1f}%")
def main():
"""主函数"""
tester = ESBulkTester()
# 运行测试(每次bulk 1万条,300次bulk = 300万条文档)
tester.run_comparison_test(total_iterations=300)
if __name__ == "__main__":
main()1. 日志场景:不带 id 写入
测试条件:
- bulk 写入数据不带文档 id
- 每批次 bulk 10000 条数据,总共写入 30w 数据
这里把
反馈结果:
性能对比结果:
================================================================================
ES直连:
第1轮:
耗时: 152.29秒
Bulk速率: 1.97 bulk/秒
文档速率: 19699.59 docs/秒
成功率: 100.00%
平均性能:
总耗时: 152.29秒
平均Bulk速率: 1.97 bulk/秒
平均文档速率: 19699.59 docs/秒
Gateway代理:
第1轮:
耗时: 115.63秒
Bulk速率: 2.59 bulk/秒
文档速率: 25944.35 docs/秒
成功率: 100.00%
平均性能:
总耗时: 115.63秒
平均Bulk速率: 2.59 bulk/秒
平均文档速率: 25944.35 docs/秒
整体性能对比:
Gateway代理 平均性能更好,bulk速率高 0.62 bulk/秒
性能提升: 31.7%2. 业务场景:带文档 id 的写入
测试条件:
- bulk 写入数据带有文档 id,两次测试写入的文档 id 生成规则一致且重复。
- 每批次 bulk 10000 条数据,总共写入 30w 数据
这里把 py 脚本中 第 99 行 和 第 107 行的注释打开。
反馈结果:
性能对比结果:
================================================================================
ES直连:
第1轮:
耗时: 155.30秒
Bulk速率: 1.93 bulk/秒
文档速率: 19317.39 docs/秒
成功率: 100.00%
平均性能:
总耗时: 155.30秒
平均Bulk速率: 1.93 bulk/秒
平均文档速率: 19317.39 docs/秒
Gateway代理:
第1轮:
耗时: 116.73秒
Bulk速率: 2.57 bulk/秒
文档速率: 25700.06 docs/秒
成功率: 100.00%
平均性能:
总耗时: 116.73秒
平均Bulk速率: 2.57 bulk/秒
平均文档速率: 25700.06 docs/秒
整体性能对比:
Gateway代理 平均性能更好,bulk速率高 0.64 bulk/秒
性能提升: 33.0%小结
不管是日志场景还是业务价值更重要的大数据或者搜索数据同步场景, gateway 的写入加速都能平稳的节省 25%-30% 的写入耗时。
关于极限网关(INFINI Gateway)
INFINI Gateway 是一个开源的面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway,可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
官网文档:https://docs.infinilabs.com/gateway
开源地址:https://github.com/infinilabs/gateway
作者:金多安,极限科技(INFINI Labs)搜索运维专家,Elastic 认证专家,搜索客社区日报责任编辑。一直从事与搜索运维相关的工作,日常会去挖掘 ES / Lucene 方向的搜索技术原理,保持搜索相关技术发展的关注。
原文:https://infinilabs.cn/blog/2025/gateway-bulk-write-performance-optimization/
【搜索客社区日报】第1838期 (2024-06-14)
社区日报 • Fred2000 发表了文章 • 0 个评论 • 3185 次浏览 • 2024-06-14 09:18
极限网关助力好未来 Elasticsearch 容器化升级
Elasticsearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 5423 次浏览 • 2024-06-12 15:01
极限网关在好未来的最佳实践案例,轻松扛住日增百 TB 数据的流量,助力 ES 从物理机到云原生架构的改造,实现了流控、请求分析、安全管理、无缝迁移等场景。一次完美的客户体验~
背景
物理机架构时代
2022 年,好未来整个日志 Elasticsearch 拥有数十套服务集群,几百台物理机。这么多台机器耗费成本非常高,而且还要花费很大精力去维护。在人力资源有限情况下,存在非常多的弊端,运行成本高,不仅是机器折旧还有机柜等费用。
流量特征
这是来自某个业务线,如下图 1,真实流量,潮汐性非常明显。好未来有很多条业务线,几乎跟这个趋势都一致的,除了个别业务有“续报”、“开课”等活动特殊情况。潮汐性带来的问题就是高峰期 CPU、内存资源是可以消耗很高;低峰期资源使用量非常低,由于是物理架构,这些资源无法给其他业务线共享。
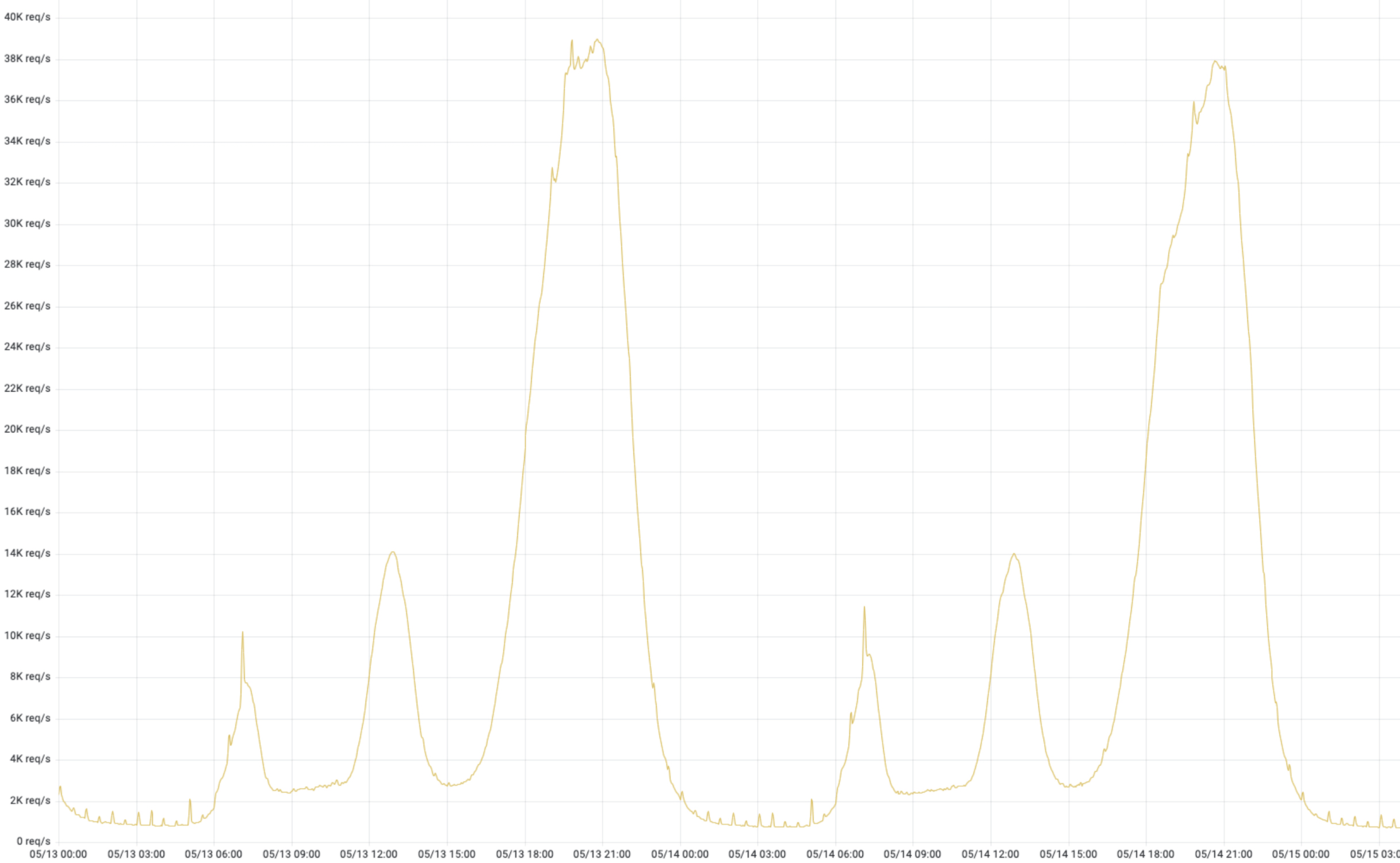
降本增效-容器化改造原动力
日志服务对成本的空前的压力促使我们推进 Elasticsearch 进行架构改造;如何改造,改造成什么样子,这两个问题一直是推进改造原动力。业界能够同时对水平扩展和垂直扩展就是 K8S,我们开始对 Elasticsearch 改造成能在 K8S 上运行进行探索,从而提升 CPU、内存利用率。
物理机时代,没办法把资源动态的扩缩,动态调配,资源隔离,单靠人力操作调度成本太高,几乎无法完成;集群对内存资源需求要比 CPU 资源大很多,由于机器型号配置是固定的,无法“定制”,这也会导致成本居高不下。所以,无论从那个方面来讲,容器化优势非常明显,既能够优化成本,也能够降低运维复杂度。
ES 容器化改造
进行架构升级重点难点- API 服务
改造过程,我们遇到了很多问题,比如容器 ES 版本和物理机 ES 版本不一致,如何让 ES API 能够兼容不同的 ES 版本,由于版本的不兼容,导致无法直接使用原有的 tribenode 进行服务,怎么提供一个高可用的 Elasticsearch API 服务。我们考虑到多个方面,比如使用官方推荐的 proxy 模式、第三方服务等进行选择,经过多方面对比,选择了极限网关 进行 tribenode 替换。
原始 ES API 服务痛点
- API 访问没有流量控制
- 可观测性差,而且稳定性一般
- 版本兼容性差
物理机时代 API 架构
在物理机时代 ES 集群,API 架构如图 2,可以明显看到 tribe node 对所有 ES 集群的“侵入性”是非常大的,这就带来了很多问题,比较严重的就是单个集群对 ES tribenode 的影响和版本升级带来的不兼容问题。

混合时代 API 架构
通过图 3,我们可以看到,极限网关对于版本兼容性很好,能够适配不同的版本。因此,最终选择极限网关作为下一代 ES API 服务方。

里程碑:全部 ES 集群容器化
在 2023 年 3 月份,通过 Elastic 官方 ECK 模式,完成全部日志 ES 集群容器化改造,拥有数百节点,1PB+ 数据存储,每日新增数据 100T 左右。紧接着,除了日志服务外,同时支持了好未来多条业务线。

极限网关实践
下面主要讲述了,为什么选择极限网关,以及极限网关在好未来落地、应用这些内容。
为什么选择极限网关?
学习成本低
我们可以从文档中看到极限网关,其架构简洁,语法简单,直观易懂。学习成本比较低,上手非常快,对新手友好。
性能强悍
经过压测,发现极限网关速度非常快,且针对 Elasticsearch 做了非常细致的优化,能成倍提升写入和查询的速度。
安全性高
支持多种认证方式,最简单的账号密码认证,可以给自定义多个账户密码,大大简化了 Elasticsearch 的安全设置,同时,还可以支持 LDAP 安全验证。
跨版本支持
我们容器化改造过程需要兼容不同版本的 Elasticsrearch,极限网关针对不同的 Elasticsearch 版本做了兼容和针对性处理,能够让业务代码无缝的进行适配,后端 Elasticsearch 集群版本升级能够做到无缝过渡,降低版本升级和数据迁移的复杂度,非常匹配我们的业务场景。
灵活可扩展
可灵活对每个请求进行干预和路由,支持路由的智能学习,内置丰富的过滤器,通过配置动态修改每个请求的处理逻辑,也支持通过插件来进行扩展,满足我们对流量的控制,尤其是限流、用户、IP 等这些功能非常实用。
启用安全策略-为 API 服务保驾护航
痛点
在升级之前使用 tribe 作为 API 服务提供后端,几乎相当于裸奔,没有任何认证策略;另外,tribe 本身的稳定性也有问题,官方在新版本逐渐废弃这种 CCS(跨集群搜索),期间出现多次服务崩溃。
极限网关解决问题
极限网关通过,“basic_auth” 插件,提供最基本的安全校验,使用起来非常方便;同时,极限网关提供 LDAP 插件,可以接入公共的 LDAP 服务,对所有的访问用户进行校验,安全策略对所有的用户生效,不用担心因为 IP 问题泄漏数据等。
强大的过滤功能
在使用 ES 集群过程中,许多场景,需要对请求进行控制、限制等操作。在这方便,感受到了极限网关强大的产品力。比如下面的两个场景
对异常流量进行限流
- 支持对 IP 限流
- 支持对 hostname 限流
- 支持 header 限流
对异常用户进行封禁
当 Elasticsearch 是通过 Basic Auth 或者 LDAP 方式来进行身份认证的时候,request_user_filter 过滤器可用来按请求的用户名信息来进行过滤。操作起来也非常简单,只需要 request_user_filter 这一个过滤器。
- request_user_filter:
include:
- "elastic"
exclude:
- "Ryan"总结来讲,主要有这些方面的功能:

优秀的可观测性
痛点
改造前经常为看不到直观的数据指标感到头疼,查看指标需要多个地方同时打开,去筛选,查找,非常繁琐,付出的成本非常大。为此,大家都再考虑如何优化这种情况,无奈优先级比较低,一直没有真正的投入时间去优化这块。
完美解决
使用了极限网关,通过收集请求日志,非常清晰的收集到想要的数据,具体如下:
- 总体方面:
- 流量曲线
- 状态码占比
- 缓存统计
- 每台网关请求流量
- 细节方面:
- 打印每次请求语句
- 可以查看请求到具体 ES 节点流量
- 可以查看过滤器的列表
通过下图,我们可以从管理视角直观的看到各种信息,这对于管理员来讲,省时省力,方便快捷。

意外收获:无缝迁移业务 Elasticsearch 上云
由于前期日志业务上云,受到非常好的反馈,多个业务线期望能够上云上服务,达到降本增效的目的。
支持双写
数据可以通过极限网关同时写入两个 ES 集群,能够保障数据完全一致,安全可靠。
无缝切换
切换很丝滑,影响非常小,能够让外界几乎感受不到服务波动。

通过使用极限网关,自建 ES 集群可以无缝的迁移上云,在整个迁移的过程中,两套集群通过网关进行了解耦,在迁移的过程中还能实现版本的无缝升级,极大降低了迁移成本,提高迁移效率,多次验证服务稳定可靠。
极限网关流量概览
这是其中一套极限网关的流量统计。用这部分数据进行巡检,一目了然,做到全局的掌控,提高感知力度。


极限网关使用总结
极限网关提供一系列高性能和高可靠性的网关服务。使用这样的服务给我们带来以下好处:
- 可观测性好:极限网关可以动态的对 Elasticsearch 运行过程中请求进行拦截和分析,通过指标和日志来了解集群运行状态,这些指标可以用于提升性能和业务优化。
- 增强安全性:包含先进的安全机制,如 basicauth、LDAP 等支持,保护用户数据不受未授权访问和各种网络威胁的侵害。
- 高稳定性:通过冗余设计和故障转移机制,极限网关能够确保网络服务的高可用性,即使在某些组件发生故障时也能保持服务不中断,单版本最长服务超过 15 个月。
- 易于管理:通过提供 INFINI Console 简洁直观的管理界面,让用户能够轻松配置和监控网络状态,提升管理效率。
- 客户支持:良好的客户服务支持可以帮助用户快速解决使用过程中遇到的问题,提供专业的技术指导。
综上所述,极限网关为用户提供了一个高速、安全、稳定且易于管理的 ES 网关,适合对网络性能有较高要求的个人和企业用户。
未来规划
第一阶段,完成了日志 ES 集群,所有集群的容器化改造,合并,成功的把成本降低了 60%以上。这期间积累了丰富容器化经验,为业务 ES 集群上容器做了良好的铺垫;成本优势和运维优势吸引越来越多的业务接入到容器化 ES 集群。
提升 ES 集群效能--新技术应用&&版本升级
- 极限科技官方推荐的 Easysearch 在压缩率,查询速度等等方面有很多的优势,通过长时间的测试稳定性,新特性,对比云原生的 ES 集群,根据测试结果,给“客户”提供多种选择,这也是工作重点之一。
- 我们当前使用的 ES 版本是 6.8,已经远远落后于官方版本,今年我们计划在选择合适的集群升级 ES 版本,拥抱更多官方提供的特性。
混合(多)云架构支持
随着越来越多的 ES 集群在机房的 K8S 集群部署,这里资源出现了紧张局面。 我们尝试在云上部署自建 ES 集群,弥补机房资源有限,无法大规模扩容,同时能够支持多活场景,满足更多客户的不同需求。混合云主要实现以下几种能力:
1、扩缩容:满足不同业务灵活适配
混合(多)云部署,可以让负载内部私有云 ES,同时部署到公有云,提升扩展 IT 基础设施不仅局限于 CPU、内存,还有存储。比如某一个业务要做活动,预估流量“大爆发”,需要提前准备大规模资源,在机房内根本来不及采购扩容支持,然而在公有云上就能很方便扩容、缩容。在云上搭建 ES 集群,设置满足需求的数量、容量、配置,配合极限网关路由策略,精准的把控流量流向。

2、灾备:紧急情况快速部署,恢复 ES 集群读写
当机房级别大规模故障,部分业务实现了多活,单一的机房故障不会影响其服务能力,而此时比如日志查看等仍有需求,为了满足这部分“客户”需求,可以在云上 K8S 集群,快速搭建 ES 集群,恢复日志读写功能。

参考文档:
- https://infinilabs.cn/docs/latest/gateway
- https://www.elastic.co/guide/en/cloud-on-K8S/current/K8S-overview.html
作者:张华勋,前新浪 CDN 研发,工作主要涉及 Mysql、MongoDB、Redis、Elasticsearch、流量调度等组件和系统,以及运维自动化、平台化等工作。现就职于好未来。
关于好未来
好未来(NYSE:TAL)是一家以内容能力与科技能力为基础,以科教、科创、科普为战略方向,助力人的终身成长,并持续探索创新的科技公司。 好未来的前身学而思成立于 2003 年,2010 年在美国纽交所正式挂牌交易。好未来以“爱与科技助力终身成长”为使命,致力成为持续创新的组织。更多参见:https://www.100tal.com/
关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。

【搜索客社区日报】 第1824期 (2024-05-24)
社区日报 • searchkit 发表了文章 • 0 个评论 • 3753 次浏览 • 2024-05-24 13:17
INFINI Labs 产品更新 | Console 1.24.0 操作日志审计功能发布
资讯动态 • liaosy 发表了文章 • 0 个评论 • 4659 次浏览 • 2024-04-28 12:51

INFINI Labs 产品又更新啦~,包括 Console,Gateway 1.24.0。本次各产品更新了很多亮点功能,如 Console 增加操作日志审计功能,优化数据探索字段统计,修复 Gateway 增加认证后添加实例失败等问题。以下是本次更新的详细说明。
INFINI Console v1.24.0
INFINI Console 是一款非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管, 企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 在线体验: http://demo.infini.cloud (用户名/密码:readonly/readonly)。
Console 本次更新如下:
Features
- 用户操作审计日志功能
- 新增告警规则克隆一键克隆功能,简化重复类型告警的创建
Bug fix
- 修复普通用户权限 403 问题
- 修复探针管理表格展开显示错位问题
Improvements
- 优化开发工具集群选择控件显示位置
- 优化数据探索查询控件显示宽度
- 优化数据探索字段统计功能
- 优化告警规则列表页搜索,支持远程搜索
- Discover 左侧字段聚合支持开关控制拉取本地或远程统计值
INFINI Gateway v1.24.0
INFINI Gateway 是一个面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway 可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
Gateway 本次更新如下:
Improvements
- Refactoring http client tls config
- Write field routing to bulk metadata when field _routing exists in scrolled doc
Bug fix
- Fix(reshuffle filter): make sure queue config always have label type
- Fix rotate config usage
INFINI Framework
Improvements
- feat: allow to use default auth for agent’s auto enroll
- refactor: refactor func GetFieldCaps
- feat: register background job to clean up badger LSM tree
- fix: skip load missing wal
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
您还可以通过邮件联系我们:hello@infini.ltd
或者拨打我们的热线电话:(+86) 400-139-9200
欢迎加入 Discord 聊天室:https://discord.gg/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。

关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
记某客户的一次 Elasticsearch 无缝数据迁移
Elasticsearch • yangmf2040 发表了文章 • 0 个评论 • 7484 次浏览 • 2024-04-02 14:16
背景
客户需要将 Elasticsearch 集群无缝迁移到移动云,迁移过程要保证业务的最小停机时间。
实现方式
通过采用成熟的 INFINI 网关来进行数据的双写,在集群的切换恢复过程中来记录数据变更,待全量数据恢复之后再追平后面增量数据,追平增量之后,进行校验确保数据一致再进行流量的切换。
总体流程
总体迁移流程如下:
- 客户业务代码,切流量,双写。(新增的变更都会记录在网关本地,但是暂停消费到移动云)
- 暂停网关移动云这边的增量数据消费。
- 迁移 11 月的数据,快照,快照上传到 S3;
- 下载 S3 的文件到移动云。
- 恢复快照到移动云的 11 月份的索引。
- 开启网关移动云这边的增量消费。
- 等待增量追平(接近追平)。
- 按照时间条件(如:时间 A,当前时间往前 30 分钟),验证文档数据量,Hash 校验等等。
- 停业务的写入,网关,腾讯云的写入(10 分钟)。
- 等待剩余的增量追完。
- 对时间 A 之后的,增量进行校验。
- 切换所有流量到移动云,业务端直接访问移动云 ES。
总体的迁移时间:
- 11 月备份时间(30 分钟)19 号开始
- 备份下载到移动云的时间(2-3 天)
- 备份恢复到移动云集群的时间(30 分钟)
- 11 月份增量备份(20 分钟)(双写开始)(21 号)
- 11 月份增量下载到移动云(6 小时)
- 11 月份增量恢复时间(20 分钟)
- 追增量数据(8 个小时产生的数据,需要 1 个小时)
- 校验比对(存量 1 个小时)
- 流量暂停,增量的校验(10 分钟)
- 切换(1 分钟)
总体流程如下示意图:

ES 集群信息
- ES 版本 7.10.1
- 2个热节点 3个温节点 总数 1.9 TB
- 索引 1041, 分片2085
- 无自定义插件
- 有 update_bu_query 使用
- 有 delete_by_query 使用
- 吞吐量没有测试过,当前日增文档数 1 千多万,目标日增加上亿
迁移操作手册(参考)
环境
- 自建 ES 5.4.2
- 自建 ES 5.6.8
- 自建 ES 7.5.0
- 极限网关服务器 1
- 极限网关服务器 2
- 云端负载均衡 1 (监听 9200 端口,指向极限网关服务器 1/2 的 8000 端口)
- 云端负载均衡 2 (监听 9200 端口,指向极限网关服务器 1/2 的 8001 端口)
场景描述
若干个自建 Elasticsearch 集群需要平滑迁移到移动云,业务不停写、不做代码改动。
数据架构
通过将应用端流量走网关的方式,请求同步转发给自建 ES,网关记录所有的写入请求,并确保顺序在云端 ES 上重放请求,两侧集群的各种故障都妥善进行了处理,从而实现透明的集群双写,实现安全无缝的数据迁移。
 业务端如果已经部署在云上,可以使用云上的 SLB 服务来访问网关,确保后端网关的高可用,如果业务端和极限网关还在企业内网,可以使用极限网关自带的 4 层浮动 IP 来确保网关的高可用。
业务端如果已经部署在云上,可以使用云上的 SLB 服务来访问网关,确保后端网关的高可用,如果业务端和极限网关还在企业内网,可以使用极限网关自带的 4 层浮动 IP 来确保网关的高可用。
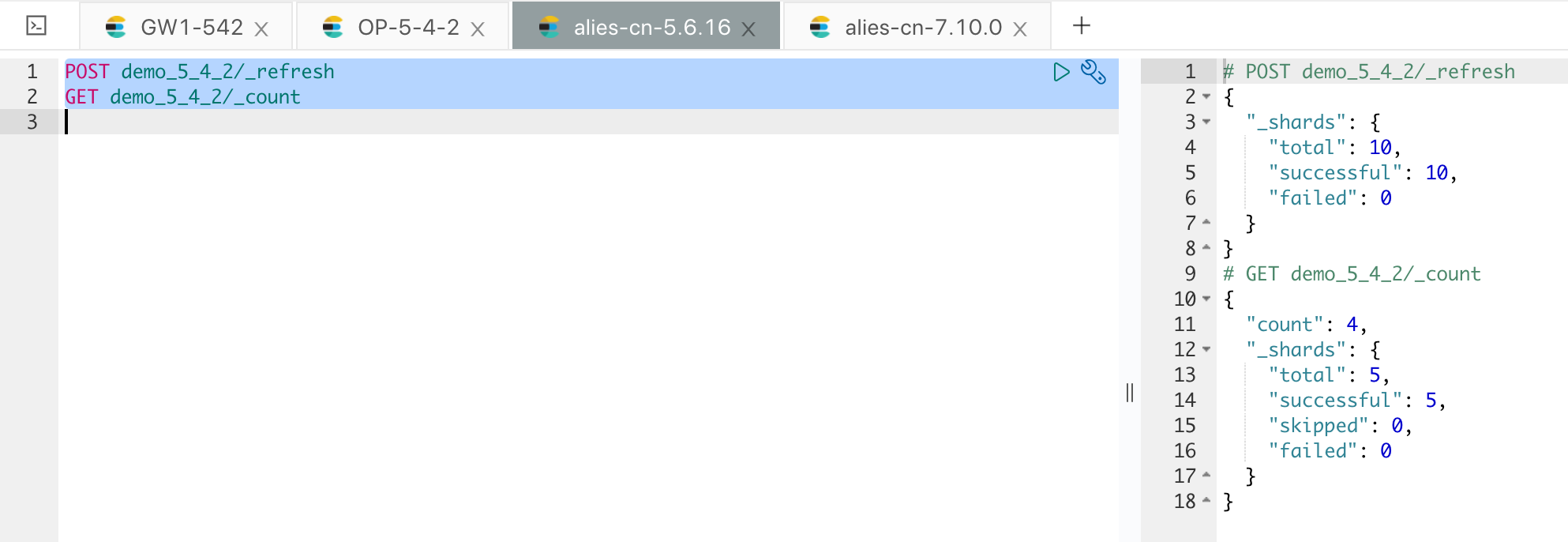
数据描述
以数据从自建集群 5.4.2 迁移到云上的 5.6.16 为例进行说明,执行步骤依次说明。
执行步骤
部署 INFINI Gateway
为了保证数据的无缝透明迁移,通过 INFINI Gateway 来进行双写。
-
系统调优
参考此文档。
- 下载程序
[root@iZbp1gxkifg8uetb33pvcoZ ~]# mkdir /opt/gateway [root@iZbp1gxkifg8uetb33pvcoZ ~]# cd /opt/gateway/ [root@iZbp1gxkifg8uetb33pvcoZ gateway]# wget http://release.infinilabs.com/gateway/snapshot/gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz --2022-05-19 10:16:25-- http://release.infinilabs.com/gateway/snapshot/gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz 正在解析主机 release.infinilabs.com (release.infinilabs.com)... 120.79.205.193 正在连接 release.infinilabs.com (release.infinilabs.com)|120.79.205.193|:80... 已连接。 已发出 HTTP 请求,正在等待回应... 200 OK 长度:7430568 (7.1M) [application/octet-stream] 正在保存至: “gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz”
100%[==============================================================================================================================================>] 7,430,568 22.8MB/s 用时 0.3s
2022-05-19 10:16:25 (22.8 MB/s) - 已保存 “gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz” [7430568/7430568])
[root@iZbp1gxkifg8uetb33pvcoZ gateway]# tar vxzf gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz gateway-linux-amd64 gateway.yml sample-configs/ sample-configs/elasticsearch-with-ldap.yml sample-configs/indices-replace.yml sample-configs/record_and_play.yml sample-configs/cross-cluster-search.yml sample-configs/kibana-proxy.yml sample-configs/elasticsearch-proxy.yml sample-configs/v8-bulk-indexing-compatibility.yml sample-configs/use_old_style_search_response.yml sample-configs/context-update.yml sample-configs/elasticsearch-route-by-index.yml sample-configs/hello_world.yml sample-configs/entry-with-tls.yml sample-configs/javascript.yml sample-configs/log4j-request-filter.yml sample-configs/request-filter.yml sample-configs/condition.yml sample-configs/cross-cluster-replication.yml sample-configs/secured-elasticsearch-proxy.yml sample-configs/fast-bulk-indexing.yml sample-configs/es_migration.yml sample-configs/index-docs-diff.yml sample-configs/rate-limiter.yml sample-configs/async-bulk-indexing.yml sample-configs/elasticssearch-request-logging.yml sample-configs/router_rules.yml sample-configs/auth.yml sample-configs/index-backup.yml
3. 修改配置
将网关提供的示例配置拷贝,并根据实际集群的信息进行相应的修改,如下:[root@iZbp1gxkifg8uetb33pvcoZ gateway]# cp sample-configs/cross-cluster-replication.yml 5.4.2TO5.6.16.yml
首先修改集群的身份信息,如下:

然后修改集群的注册信息,如下:

根据需要修改网关监听的端口,以及是否开启 TLS (如果应用客户端通过 http 协议访问 ES,请将entry.tls.enabled 值改为 false),如下:

不同的集群可以使用不同的配置,分别监听不同的端口,用于业务的分开访问。
4. 启动网关
启动网关并指定刚刚创建的配置,如下:[root@iZbp1gxkifg8uetb33pvcoZ gateway]# ./gateway-linux-amd64 -config 5.4.2TO5.6.16.yml
/ \ /\ / \/\/ / /\ \ \/\ /_/\ / /\///\ / /\/\ \ \/ \/ //\_ / / /\/ \/ / // \ /\ / \/ \ ___/\/ \/\/ \/ \/ \/_/ _/_/
[GATEWAY] A light-weight, powerful and high-performance elasticsearch gateway. [GATEWAY] 1.6.0_SNAPSHOT, 2022-05-18 11:09:54, 2023-12-31 10:10:10, 73408e82a0f96352075f4c7d2974fd274eeafe11 [05-19 13:35:43] [INF] [app.go:174] initializing gateway. [05-19 13:35:43] [INF] [app.go:175] using config: /opt/gateway/5.4.2TO5.6.16.yml. [05-19 13:35:43] [INF] [instance.go:72] workspace: /opt/gateway/data1/gateway/nodes/ca2tc22j7ad0gneois80 [05-19 13:35:43] [INF] [app.go:283] gateway is up and running now. [05-19 13:35:50] [INF] [actions.go:358] elasticsearch [primary] is available [05-19 13:35:50] [INF] [api.go:262] api listen at: http://0.0.0.0:2900 [05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [primary] hosts: [] => [192.168.0.19:9200] [05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [backup] hosts: [] => [es-cn-tl32p9fkk0006m56k.elasticsearch.aliyuncs.com:9200] [05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [primary] hosts: [] => [192.168.0.19:9200] [05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [backup] hosts: [] => [es-cn-tl32p9fkk0006m56k.elasticsearch.aliyuncs.com:9200] [05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [primary] hosts: [] => [192.168.0.19:9200] [05-19 13:35:50] [INF] [entry.go:322] entry [my_es_entry/] listen at: https://0.0.0.0:8000 [05-19 13:35:50] [INF] [module.go:116] all modules are started
5. 后台运行[root@iZbp1gxkifg8uetb33pvcoZ gateway]# nohup ./gateway-linux-amd64 -config 5.4.2TO5.6.16.yml &
6. 应用授权curl -XPOST http://localhost:2900/_license/apply -d' { "license": "XXXXXXXXXXXXXXXXXXXXXXXXX" }'
#### 部署 INFINI Console
为了方便在多个集群之间快速切换,使用 INFINI [Console](https://infinilabs.cn/products/console/) 来进行管理。
1. 下载安装[root@iZbp1gxkifg8uetb33pvcpZ console]# wget http://release.infinilabs.com/console/snapshot/console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz --2022-05-19 10:57:24-- http://release.infinilabs.com/console/snapshot/console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz 正在解析主机 release.infinilabs.com (release.infinilabs.com)... 120.79.205.193 正在连接 release.infinilabs.com (release.infinilabs.com)|120.79.205.193|:80... 已连接。 已发出 HTTP 请求,正在等待回应... 200 OK 长度:13576234 (13M) [application/octet-stream] 正在保存至: “console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz”
100%[==============================================================================================================================================>] 13,576,234 33.2MB/s 用时 0.4s
2022-05-19 10:57:25 (33.2 MB/s) - 已保存 “console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz” [13576234/13576234])
[root@iZbp1gxkifg8uetb33pvcpZ console]# tar vxzf console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz console-linux-amd64 console.yml
2. 修改配置[root@iZbp1gxkifg8uetb33pvcpZ console]# cat console.yml
for the system cluster, please use Elasticsearch v7.3+
elasticsearch:
- name: default
enabled: true
monitored: false
endpoint: http://es-cn-7mz2p9fty0007frx0.elasticsearch.aliyuncs.com:9200
basic_auth:
username: elastic
password: XXXXXX
discovery:
enabled: false
...
-
启动服务
[root@iZbp1gxkifg8uetb33pvcpZ console]# ./console-linux-amd64 -service install Success [root@iZbp1gxkifg8uetb33pvcpZ console]# ./console-linux-amd64 -service start Success - 访问后台
访问该主机的 9000 端口,即可打开 Console 后台,http://x.x.x.x:9000/
打开菜单 [System][Cluster] ,注册当前需要管理的 Elasticsearch 集群和网关地址,用来快速管理,如下:

测试 INFINI Gateway
为了验证网关是否正常工作,我们通过 INFINI Console 来快速验证一下。
首先通过走网关的接口来创建一个索引,并写入一个文档,如下:
 查看 5.4.2 集群的数据情况,如下:
查看 5.4.2 集群的数据情况,如下:
 查看集群 5.6.16 的数据情况,如下:
查看集群 5.6.16 的数据情况,如下:
 说明网关配置都正常,验证结束。
说明网关配置都正常,验证结束。
调整网关的消费策略
因为我们需要在全量数据迁移之后,才能进行增量数据的追加,在全量数据迁移完成之前,我们应该暂停增量数据的消费。修改网关配置里面 Pipeline consume-queue_backup-to-backup和 consume-queue_primary-failure-to-backup的参数 auto_start为 false,表示不自动启动该任务,具体配置方法如下:

 修改完配置之后,需要重新启动网关。
为了方便管理,可以使用 INFINI Console 来注册和管理网关,如下:
修改完配置之后,需要重新启动网关。
为了方便管理,可以使用 INFINI Console 来注册和管理网关,如下:

 待全量迁移完成之后,可以通过后台的 Task 管理来进行后续的任务启动、停止,如下:
待全量迁移完成之后,可以通过后台的 Task 管理来进行后续的任务启动、停止,如下:

切换流量
接下来,将业务正常写的流量切换到网关,也就是需要把之前指向 ES 5.4.2 的地址指向网关的地址,如果 5.4.2 集群开启了身份验证,业务端代码同样需要传递身份信息,和 5.4.2 之前的用法保持不变。
 切换流量到网关之后,用户的请求还是以同步的方式正常访问自建集群,网关记录到的请求会按顺序记录到 MQ 里面,但是消费是暂停状态。
如果业务端代码使用的 ES 的 SDK 支持 Sniff,并且业务代码开启了 Sniff,那么应该关闭 Sniff,避免业务端通过 Sniff 直接链接到后端的 ES 节点,所有的流量现在应该都只通过网关来进行访问。
切换流量到网关之后,用户的请求还是以同步的方式正常访问自建集群,网关记录到的请求会按顺序记录到 MQ 里面,但是消费是暂停状态。
如果业务端代码使用的 ES 的 SDK 支持 Sniff,并且业务代码开启了 Sniff,那么应该关闭 Sniff,避免业务端通过 Sniff 直接链接到后端的 ES 节点,所有的流量现在应该都只通过网关来进行访问。
全量数据迁移
在流量迁移到网关之后,我们开始对自建 Elasticsearch 集群的数据进行全量迁移到云端 Elasticsearch 集群。
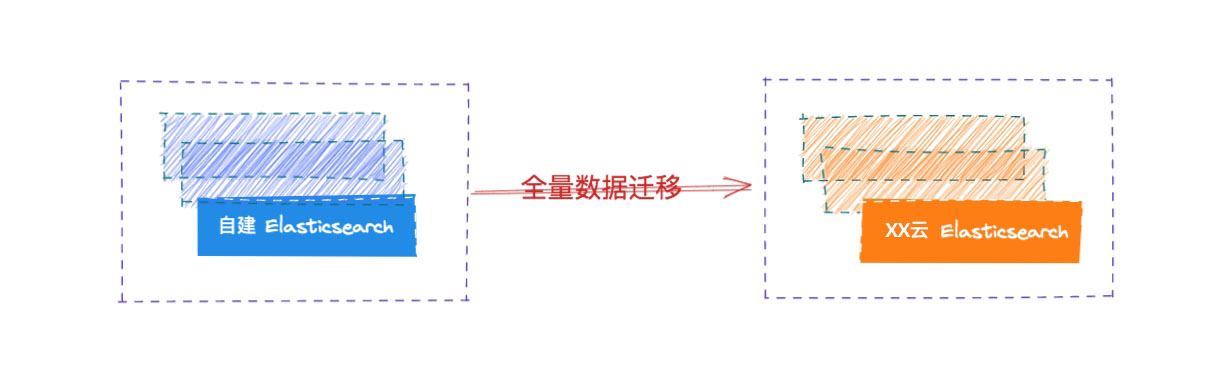 全量迁移已有的数据的方式有很多种:
全量迁移已有的数据的方式有很多种:
- 通过快照的方式进行恢复
- 使用工具来导出导入,如: ESM
如果索引数量很多的话,可以按照索引依次进行导入,同时需要注意将 Mapping 和 Setting 提前导入。
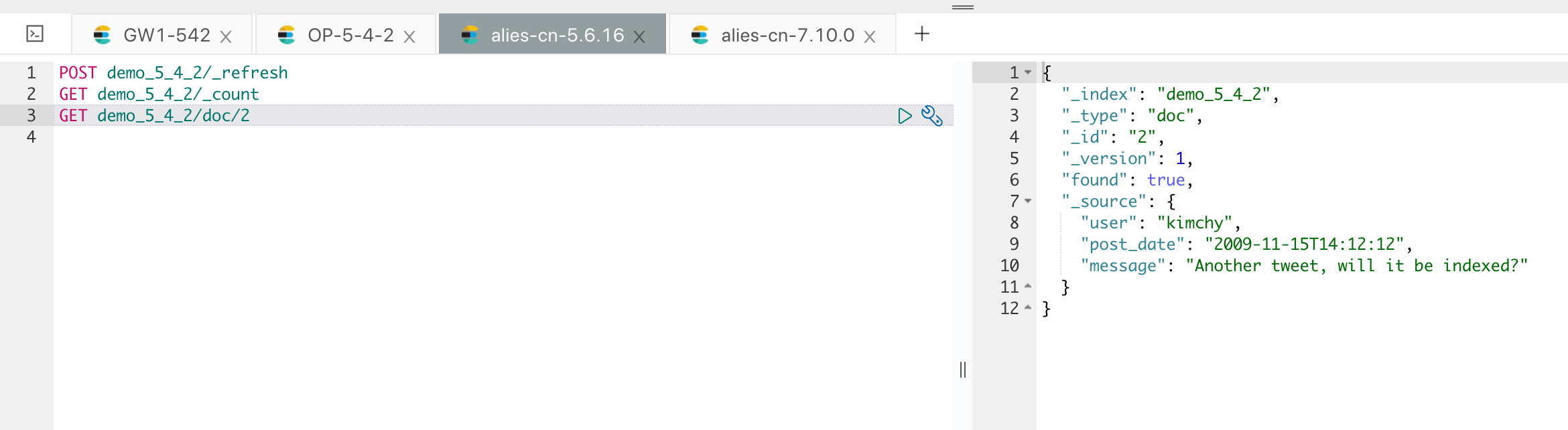
以现在 5.4 集群的索引来为例,目前的待迁移索引为 demo_5_4_2,只有4 个文档:
 我们使用网关自带的迁移功能来进行数据迁移,拷贝自带的样例文件,如下:
我们使用网关自带的迁移功能来进行数据迁移,拷贝自带的样例文件,如下:
[root@iZbp1gxkifg8uetb33pvcpZ gateway]# cp sample-configs/es_migration.yml 5.4TO5.6.yml修改其中代表集群和索引的相关配置,可以根据需要配置是否需要重命名索引和统一 Type( 用于跨版本统一 Type),如下图红框位置:
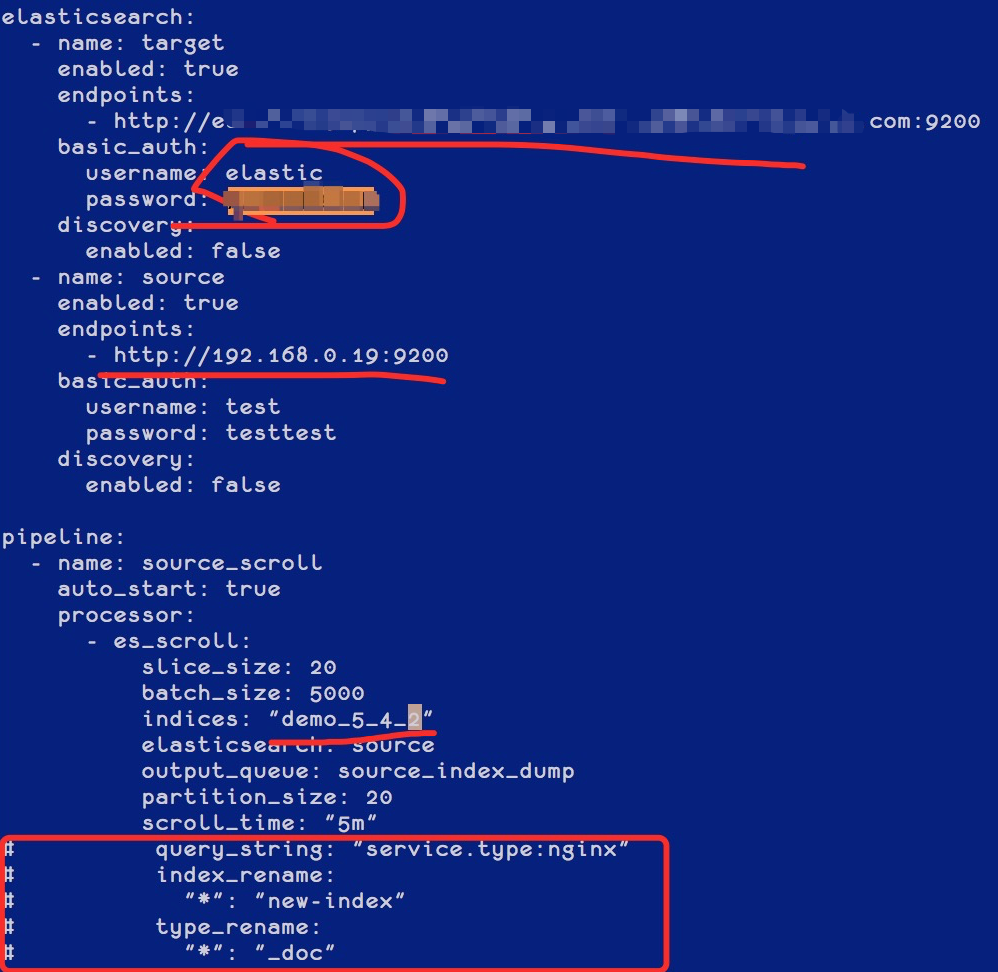 创建好模板和索引,如果目标集群不允许动态创建文档,需要提前创建好索引,如下图:
创建好模板和索引,如果目标集群不允许动态创建文档,需要提前创建好索引,如下图:
 然后就可以开始数据的迁移了,执行网关程序并指定刚刚定义的配置,如下:
然后就可以开始数据的迁移了,执行网关程序并指定刚刚定义的配置,如下:
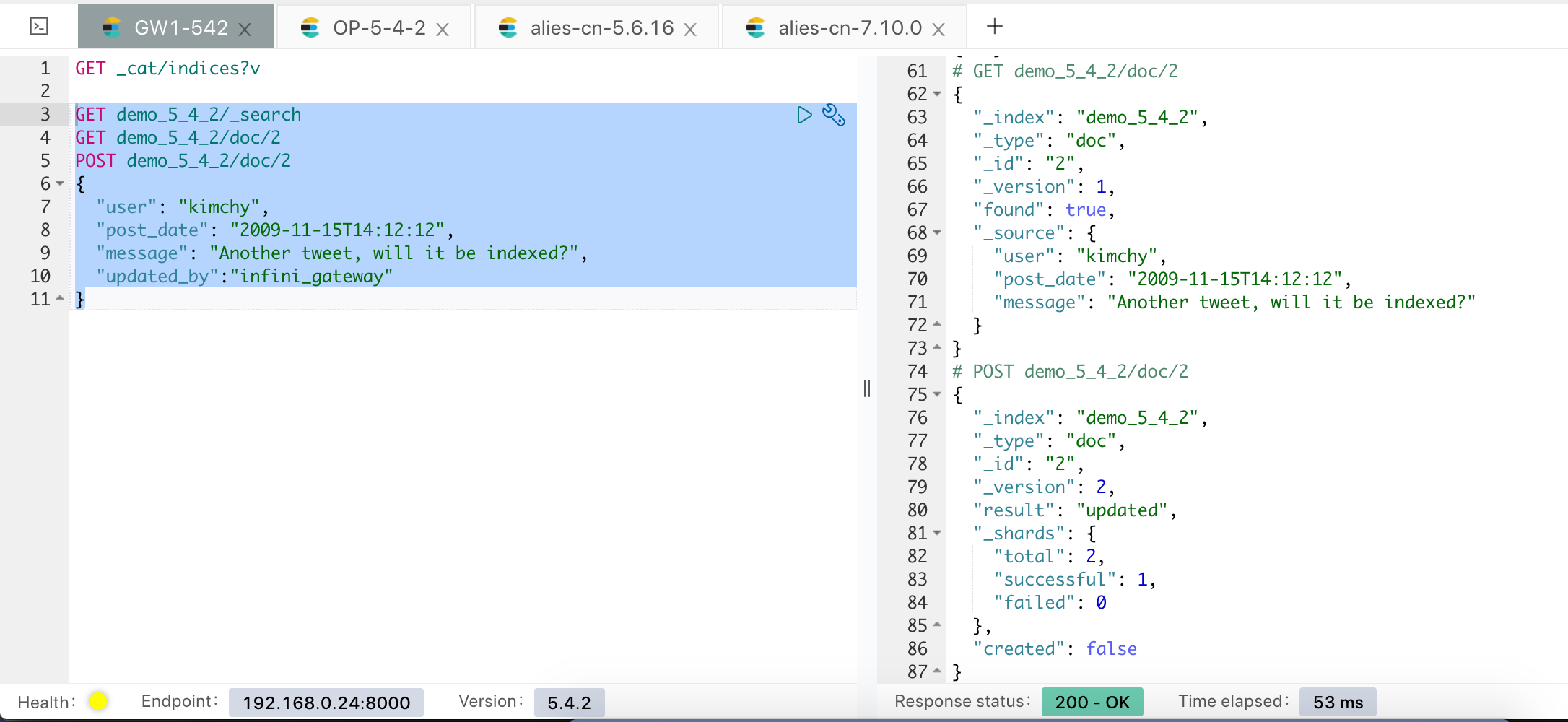
 执行完成后,可以确认下数据的情况,如下图:
执行完成后,可以确认下数据的情况,如下图:
 全量数据至此导入完成。
全量数据至此导入完成。
增量数据迁移
在全量导入的过程中,可能存在数据的增量修改,不过这部分请求都已经完整记录下来了,我们只需要开启网关的消费任务即可将挤压的请求应用到云端的 Elasticsearch 集群。
 示例操作如下:
示例操作如下:
 如果从 5.6 的集群来看的话,这部分的修改还没同步过来,如下:
如果从 5.6 的集群来看的话,这部分的修改还没同步过来,如下:
 这部分增量的数据变更,在网关层面都进行了完整记录,我们只需要开启网关的增量消费任务,如下:
这部分增量的数据变更,在网关层面都进行了完整记录,我们只需要开启网关的增量消费任务,如下:
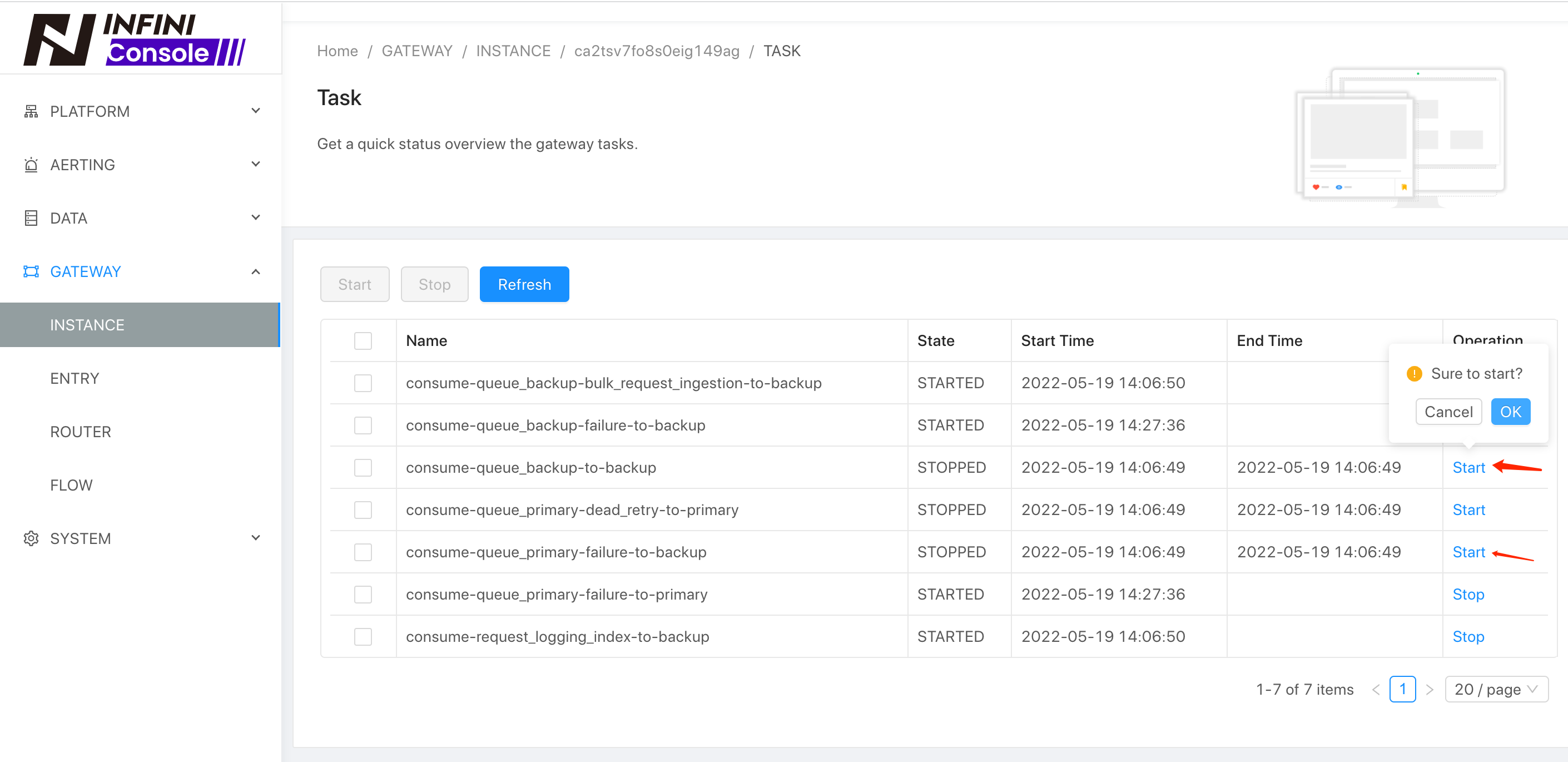 通过观察队列是否消费完成来判断增量数据是否做完,如下:
通过观察队列是否消费完成来判断增量数据是否做完,如下:
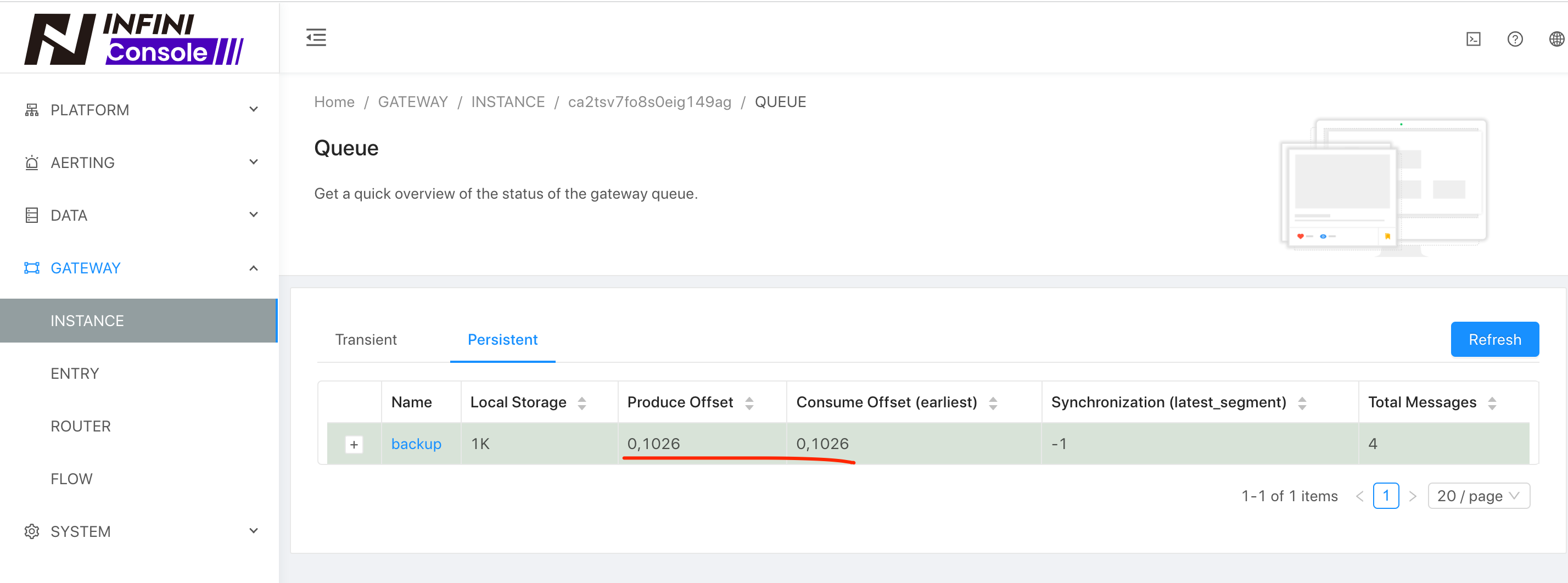 现在我们再看一下 5.6 集群的数据情况,如下:
现在我们再看一下 5.6 集群的数据情况,如下:
 数据的增量更新就过来了。
数据的增量更新就过来了。
执行数据比对
由于集群内部的数据可能比较多,我们需要进行一个完整的比对才能确保数据的完整性,可以通过网关自带的数据比对工具来进行,将样例自带的文件拷贝一份,如下:
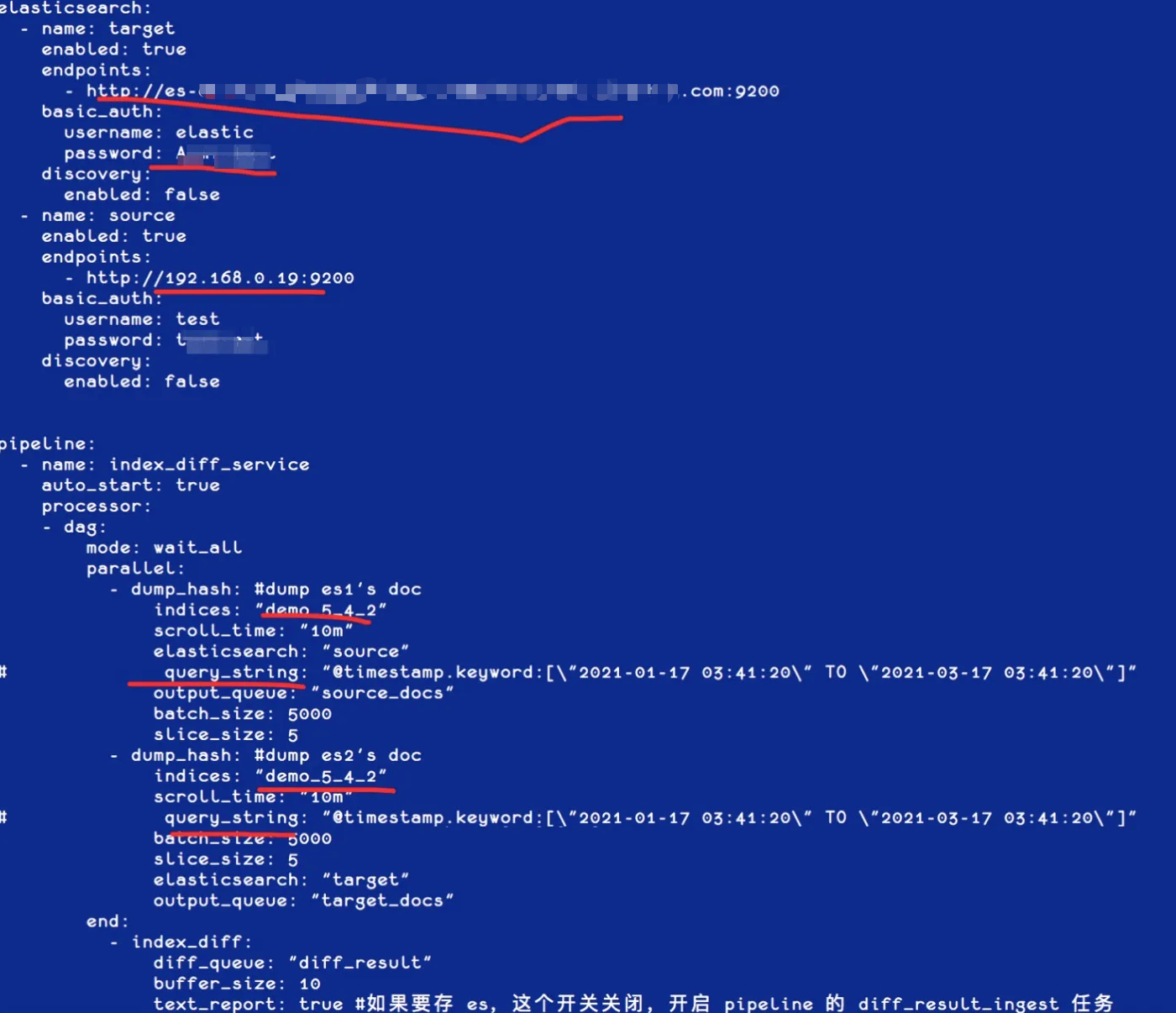
[root@iZbp1gxkifg8uetb33pvcpZ gateway]# cp sample-configs/index-docs-diff.yml 5.4DIFF5.6.yml修改需要比对的集群和索引信息,可以加上过滤条件,如时间范围窗口来进行增量 Diff,如下图:
执行网关程序,并指定该配置文件,如下图:
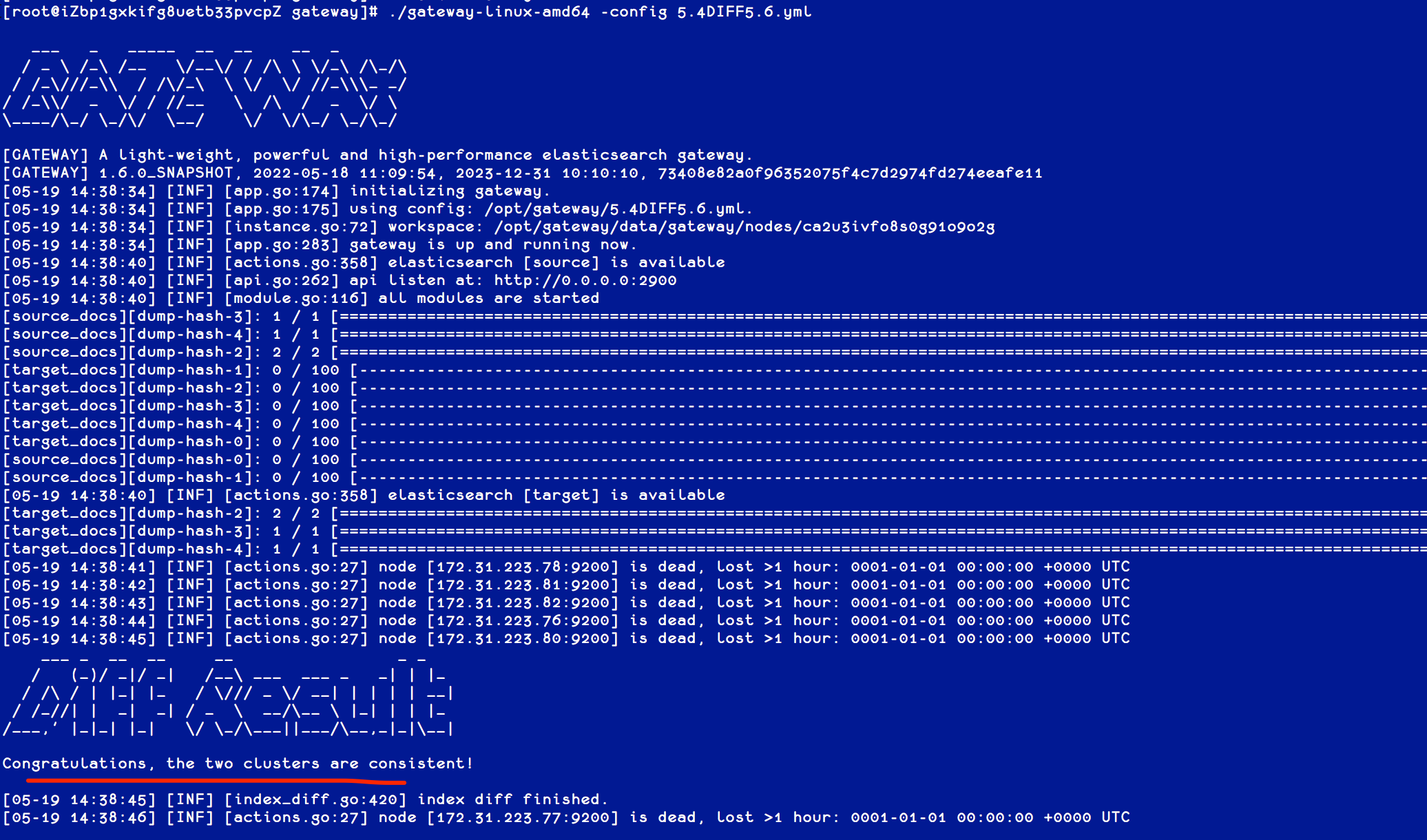 如图,两个集群完全一致。
如图,两个集群完全一致。
切换集群
如果验证完之后,两个集群的数据已经完全一致了,可以将程序切换到新集群,或者将网关的配置里面的主备进行互换,同步写 5.6 集群。
 双集群在线运行一段时间,待业务完全验证之后,再安全下线旧集群,如遇到问题,也可以随时回切到老集群。
双集群在线运行一段时间,待业务完全验证之后,再安全下线旧集群,如遇到问题,也可以随时回切到老集群。
小结
通过使用极限网关,自建 ES 集群可以安全无缝的迁移到移动云 ES,在迁移的过程中,两套集群通过网关进行了解耦,两套集群的版本也可以不一样,在迁移的过程中还能实现版本的无缝升级。
如有任何问题,请随时联系我,期待与您交流!
如何防止 Elasticsearch 服务 OOM?
Easysearch • yangmf2040 发表了文章 • 0 个评论 • 3963 次浏览 • 2024-02-26 10:12
Elasticsearch(简称:ES) 和传统关系型数据库有很多区别, 比如传统数据中普遍都有一个叫“最大连接数”的设置。目的是使数据库系统工作在可控的负载下,避免出现负载过高,资源耗尽,谁也无法登录的局面。
那 ES 在这方面有类似参数吗?答案是没有,这也是为何 ES 会被流量打爆的原因之一。
针对大并发访问 ES 服务,造成 ES 节点 OOM,服务中断的情况,极限科技旗下的 INFINI Gateway 产品(以下简称 “极限网关”)可从两个方面入手,保障 ES 服务的可用性。
- 限制最大并发访问连接数。
- 限制非重要索引的请求速度,保障重要业务索引的访问速度。
下面我们来详细聊聊。
架构图
 所有访问 ES 的请求都发给网关,可部署多个网关。
所有访问 ES 的请求都发给网关,可部署多个网关。
限制最大连接数
在网关配置文件中,默认有最大并发连接数限制,默认最大 10000。
entry:
- name: my_es_entry
enabled: true
router: my_router
max_concurrency: 10000
network:
binding: $[[env.GW_BINDING]]
# See `gateway.disable_reuse_port_by_default` for more information.
reuse_port: true使用压测程序测试,看看到达10000个连接后,能否限制新的连接。
 超过的连接请求,被丢弃。更多信息参考官方文档。
超过的连接请求,被丢弃。更多信息参考官方文档。
限制索引写入速度
我们先看看不做限制的时候,测试环境的写入速度,在 9w - 15w docs/s 之间波动。虽然峰值很高,但不稳定。
 接下来,我们通过网关把写入速度控制在最大 1w docs/s 。
对网关的配置文件 gateway.yml ,做以下修改。
接下来,我们通过网关把写入速度控制在最大 1w docs/s 。
对网关的配置文件 gateway.yml ,做以下修改。
env: # env 下添加
THROTTLE_BULK_INDEXING_MAX_BYTES: 40485760 #40MB/s
THROTTLE_BULK_INDEXING_MAX_REQUESTS: 10000 #10k docs/s
THROTTLE_BULK_INDEXING_ACTION: retry #retry,drop
THROTTLE_BULK_INDEXING_MAX_RETRY_TIMES: 10 #1000
THROTTLE_BULK_INDEXING_RETRY_DELAY_IN_MS: 100 #10
router: # route 部分修改 flow
- name: my_router
default_flow: default_flow
tracing_flow: logging_flow
rules:
- method:
- "*"
pattern:
- "/_bulk"
- "/{any_index}/_bulk"
flow:
- write_flow
flow: #flow 部分增加下面两段
- name: write_flow
filter:
- flow:
flows:
- bulking_indexing_limit
- elasticsearch:
elasticsearch: prod
max_connection_per_node: 1000
- name: bulking_indexing_limit
filter:
- bulk_request_throttle:
indices:
"test-index":
max_bytes: $[[env.THROTTLE_BULK_INDEXING_MAX_BYTES]]
max_requests: $[[env.THROTTLE_BULK_INDEXING_MAX_REQUESTS]]
action: $[[env.THROTTLE_BULK_INDEXING_ACTION]]
retry_delay_in_ms: $[[env.THROTTLE_BULK_INDEXING_RETRY_DELAY_IN_MS]]
max_retry_times: $[[env.THROTTLE_BULK_INDEXING_MAX_RETRY_TIMES]]
message: "bulk writing too fast" #触发限流告警message自定义
log_warn_message: true
再次压测,test-index 索引写入速度被限制在了 1w docs/s 。

限制多个索引写入速度
上面的配置是针对 test-index 索引的写入速度控制。如果想添加其他的索引,新增一段配置即可。 比如,我允许 abc 索引写入达到 2w docs/s,test-index 索引最多不超过 1w docs/s ,可配置如下。
- name: bulking_indexing_limit
filter:
- bulk_request_throttle:
indices:
"abc":
max_requests: 20000
action: drop
message: "abc doc写入超阈值" #触发限流告警message自定义
log_warn_message: true
"test-index":
max_bytes: $[[env.THROTTLE_BULK_INDEXING_MAX_BYTES]]
max_requests: $[[env.THROTTLE_BULK_INDEXING_MAX_REQUESTS]]
action: $[[env.THROTTLE_BULK_INDEXING_ACTION]]
retry_delay_in_ms: $[[env.THROTTLE_BULK_INDEXING_RETRY_DELAY_IN_MS]]
max_retry_times: $[[env.THROTTLE_BULK_INDEXING_MAX_RETRY_TIMES]]
message: "bulk writing too fast" #触发限流告警message自定义
log_warn_message: true限速效果如下

限制读请求速度
我们先看看不做限制的时候,测试环境的读取速度,7w qps 。
 接下来我们通过网关把读取速度控制在最大 1w qps 。
继续对网关的配置文件 gateway.yml 做以下修改。
接下来我们通过网关把读取速度控制在最大 1w qps 。
继续对网关的配置文件 gateway.yml 做以下修改。
- name: default_flow
filter:
- request_path_limiter:
message: "Hey, You just reached our request limit!" rules:
- pattern: "/(?P<index_name>abc)/_search"
max_qps: 10000
group: index_name
- elasticsearch:
elasticsearch: prod
max_connection_per_node: 1000再次进行测试,读取速度被限制在了 1w qps 。

限制多个索引读取速度
上面的配置是针对 abc 索引的写入速度控制。如果想添加其他的索引,新增一段配置即可。 比如,我允许 abc 索引读取达到 1w qps,test-index 索引最多不超过 2w qps ,可配置如下。
- name: default_flow
filter:
- request_path_limiter:
message: "Hey, You just reached our request limit!"
rules:
- pattern: "/(?P<index_name>abc)/_search"
max_qps: 10000
group: index_name
- pattern: "/(?P<index_name>test-index)/_search"
max_qps: 20000
group: index_name
- elasticsearch:
elasticsearch: prod
max_connection_per_node: 1000
多个网关限速
限速是每个网关自身的控制,如果有多个网关,那么后端 ES 集群收到的请求数等于多个网关限速的总和。
 本次介绍就到这里了。相信大家在使用 ES 的过程中也遇到过各种各样的问题。欢迎大家来我们这个平台分享自己的问题、解决方案等。如有任何问题,请随时联系我,期待与您交流!
本次介绍就到这里了。相信大家在使用 ES 的过程中也遇到过各种各样的问题。欢迎大家来我们这个平台分享自己的问题、解决方案等。如有任何问题,请随时联系我,期待与您交流!

开启安全功能 ES 集群就安全了吗?
Easysearch • yangmf2040 发表了文章 • 0 个评论 • 4956 次浏览 • 2023-12-27 10:38
背景
经常跟 ES 打交道的朋友都知道,现在主流的 ES 集群安全方案是:RBAC + TLS for Internal + HTTPS 。

作为终端用户一般只需要关心用户名和密码就行了。作为管理和运维 ES 的人员来说,可能希望 ES 能提供密码策略来强制密码强度和密码使用周期。遗憾的是 ES 对密码强度和密码使用周期没有任何强制要求。如果不注意,可能我们天天都在使用“弱密码”或从不修改的密码(直到无法登录)。而且 ES 对连续的认证失败,不会做任何处理,这让 ES 很容易遭受暴力破解的入侵。
那还有没有别的办法,进一步提高安全呢? 其实,网关可以来帮忙。
虽然网关无法强制提高密码复杂度,但可以提高 ES 集群被暴力破解的难度。
大家都知道,暴力破解--本质就是不停的“猜”你的密码。以现在的 CPU 算力,一秒钟“猜”个几千上万次不过是洒洒水,而且 CPU 监控都不带波动的,很难发现异常。从这里入手,一方面,网关可以延长认证失败的过程--延迟返回结果,让破解不再暴力。另一方面,网关可以记录认证失败的情况,做到实时监控,有条件的告警。一旦出现苗头,可以使用网关阻断该 IP 或用户发来的任何请求。
场景模拟
首先,用网关代理 ES 集群,并在 default_flow 中增加一段 response_status_filter 过滤器配置,对返回码是 401 的请求,跳转到 rate_limit_flow 进行降速,延迟 5 秒返回。
- name: default_flow
filter:
- elasticsearch:
elasticsearch: prod
max_connection_per_node: 1000
- response_status_filter:
exclude:
- 401
action: redirect_flow
flow: rate_limit_flow
- name: rate_limit_flow
filter:
- sleep:
sleep_in_million_seconds: 5000
其次,对于失败的认证,我们可以通过 Console 来做个看板实时分析,展示。
折线图、饼图图、柱状图等,多种展示方式,大家可充分发挥。
最后,可在 Console 的告警中心,配置对应的告警规则,实时监控该类事件,方便及时跟进处置。
效果测试
先带上正确的用户名密码测试,看看返回速度。
.png)
0.011 秒返回。再使用错误的密码测试。
.png)
整整 5 秒多后,才回返结果。如果要暴力破解,每 5 秒钟甚至更久才尝试一个密码,这还叫暴力吗?
看板示例
此处仅仅是抛砖引玉,欢迎大家发挥想象。
.png)
告警示例
建立告警规则,用户 1 分钟内超过 3 次登录失败,就产生告警。
.png)
可在告警中心查看详情,也可将告警推送至微信、钉钉、飞书、邮件等。
.png)
查看告警详情,是 es 用户触发了告警。
.png)
最后,剩下的工作就是对该账号的处置了。如果有需要可以考虑阻止该用户或 IP 的请求,对应的过滤器文档在这里,老规矩加到 default_flow 里就行了。
如果小伙伴有其他办法提升 ES 集群安全,欢迎和我们一起讨论、交流。我们的宗旨是:让搜索更简单!
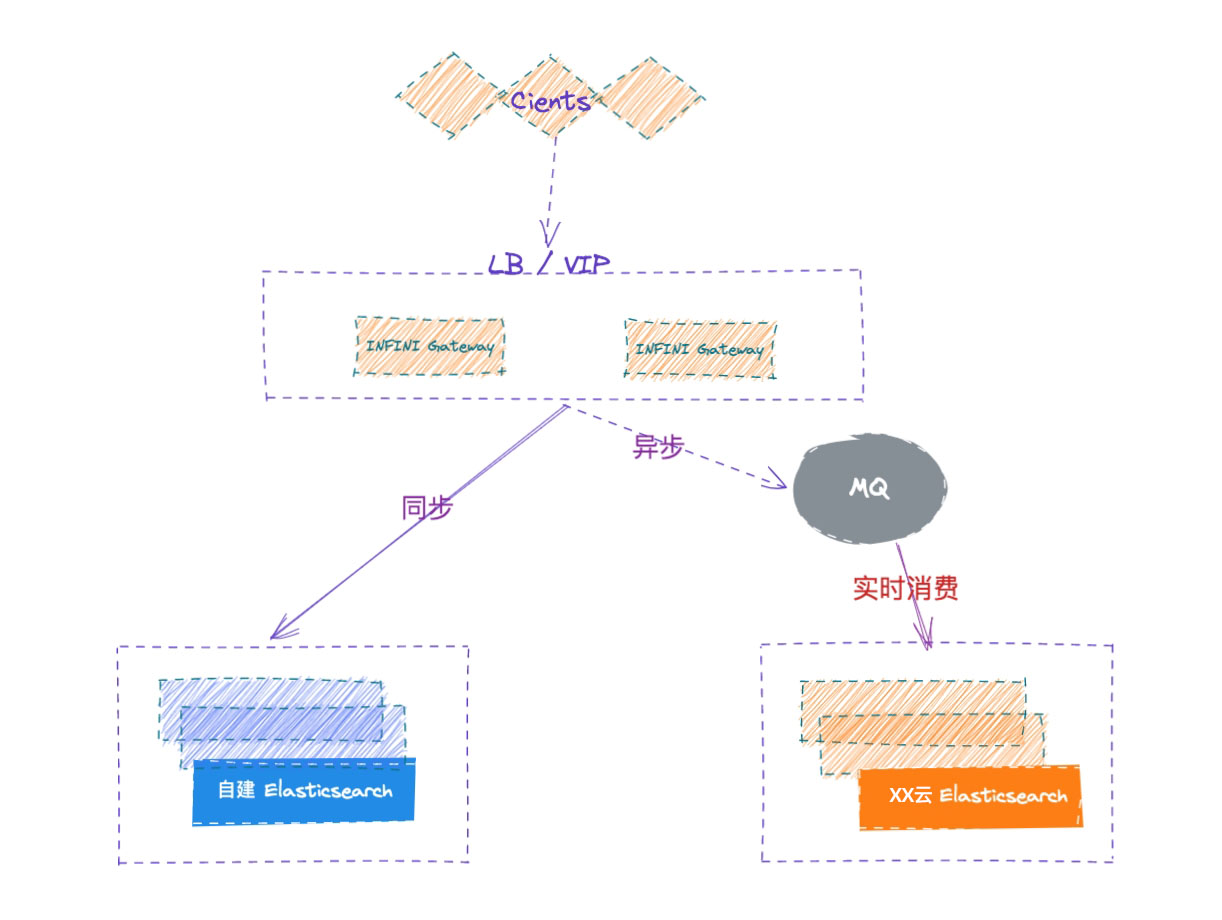
用极限网关实现ES容灾,简单!
Elasticsearch • yangmf2040 发表了文章 • 0 个评论 • 4274 次浏览 • 2023-07-20 10:33
身为 IT 人士,大伙身边的各种系统肯定不少吧。系统虽多,但最最最重要的那套、那几套,大伙肯定是捧在手心,关怀备至。如此重要的系统,万一发生故障了且短期无法恢复,该如何保障业务持续运行? 有过这方面思考或经验的同学,肯定脱口而出--切灾备啊。 是的,接下来我来介绍下我们的 ES 灾备方案。当然如果你有更好的,请使用各种可用的渠道联系我们。
总体设计
通过极限网关将应用对主集群的写操作,复制到灾备集群。应用发送的读请求则直接转发到主集群,并将响应结果转发给应用。应用对网关无感知,访问方式与访问 ES 集群一样。
方案优势
- 轻量级
极限网关使用 Golang 编写,安装包很小,只有 10MB 左右,没有任何外部环境依赖,部署安装都非常简单,只需要下载对应平台的二进制可执行文件,启动网关程序的二进制程序文件执行即可。
- 跨版本支持
极限网关针对不同的 Elasticsearch 版本做了兼容和针对性处理,能够让业务代码无缝的进行适配,后端 Elasticsearch 集群版本升级能够做到无缝过渡,降低版本升级和数据迁移的复杂度。
- 高可用
极限网关内置多种高可用解决方案,前端请求入口支持基于虚拟 IP 的双机热备,后端集群支持集群拓扑的自动感知,节点上下线能自动发现,自动处理后端故障,自动进行请求的重试和迁移。
- 灵活性
主备集群都是可读可写,切换迅速,只需切换网关到另一套配置即可。回切灵活,恢复使用原配置即可。
架构图

网关程序部署
下载
根据操作系统和平台选择下面相应的安装包: 解压到指定目录:
mkdir gateway
tar -zxf xxx.gz -C gateway修改网关配置
在此 下载 网关配置,默认网关会加载配置文件 gateway.yml ,如果要指定其他配置文件使用 -config 选项指定。 网关配置文件内容较多,下面展示必要部分。
#primary
PRIMARY_ENDPOINT: http://192.168.56.3:7171
PRIMARY_USERNAME: elastic
PRIMARY_PASSWORD: password
PRIMARY_MAX_QPS_PER_NODE: 10000
PRIMARY_MAX_BYTES_PER_NODE: 104857600 #100MB/s
PRIMARY_MAX_CONNECTION_PER_NODE: 200
PRIMARY_DISCOVERY_ENABLED: false
PRIMARY_DISCOVERY_REFRESH_ENABLED: false
#backup
BACKUP_ENDPOINT: http://192.168.56.3:9200
BACKUP_USERNAME: admin
BACKUP_PASSWORD: admin
BACKUP_MAX_QPS_PER_NODE: 10000
BACKUP_MAX_BYTES_PER_NODE: 104857600 #100MB/s
BACKUP_MAX_CONNECTION_PER_NODE: 200
BACKUP_DISCOVERY_ENABLED: false
BACKUP_DISCOVERY_REFRESH_ENABLED: falsePRIMARY_ENDPOINT:配置主集群地址和端口
PRIMARY_USERNAME、PRIMARY_PASSWORD: 访问主集群的用户信息
BACKUP_ENDPOINT:配置备集群地址和端口
BACKUP_USERNAME、BACKUP_PASSWORD: 访问备集群的用户信息
运行网关
前台运行 直接运行网关程序即可启动极限网关了,如下:
./gateway-linux-amd64后台运行
./gateway-linux-amd64 -service install
Success
./gateway-linux-amd64 -service start
Success卸载服务
./gateway-linux-amd64 -service stop
Success
./gateway-linux-amd64 -service uninstall
Success灾备功能测试
在灾备场景下,为保证数据一致性,对集群的访问操作都通过网关进行。注意只有 bulk API 的操作才会被复制到备集群。 在此次测试中,网关灾备配置功能为:
- 主备集群正常时
读写请求正常执行; 写请求被记录到队列,备集群实时消费队列数据。
- 当主集群故障时
写入请求报错,主备集群都不写入数据; 查询请求转到备集群执行,并返回结果给客户端。
- 当备集群故障时
读写请求都正常执行; 写操作记录到磁盘队列,待备集群恢复后,自动消费队列数据直到两个集群一致。
主备集群正常时写入、查询测试
写入数据
# 通过网关写入数据
curl -X POST "localhost:18000/_bulk?pretty" -H 'Content-Type: application/json' -uelastic:password -d'
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "create" : { "_index" : "test", "_id" : "2" } }
{ "field2" : "value2" }
'
查询数据
# 查询主集群
curl 192.168.56.3:7171/test/_search?pretty -uelastic:password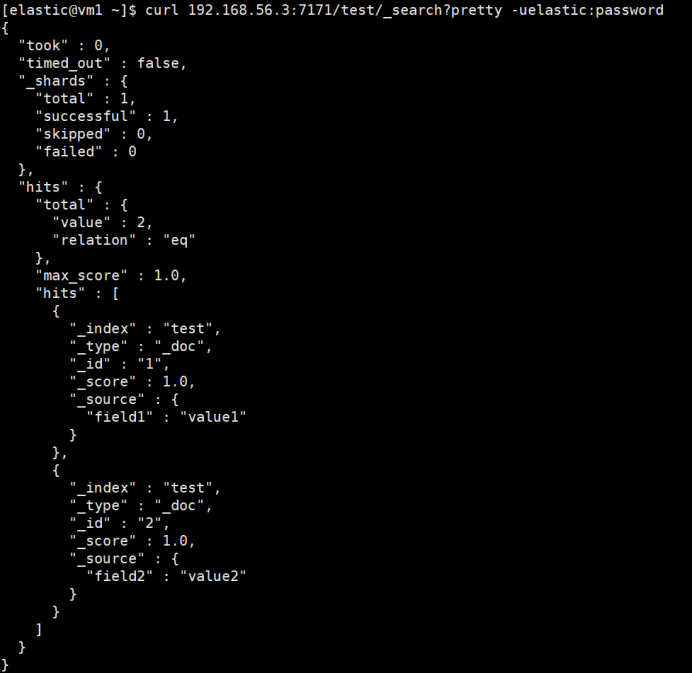
# 查询备集群
curl 192.168.56.3:9200/test/_search?pretty -uadmin:admin
# 查询网关,网关转发给主集群执行
curl 192.168.56.3:18000/test/_search?pretty -uelastic:password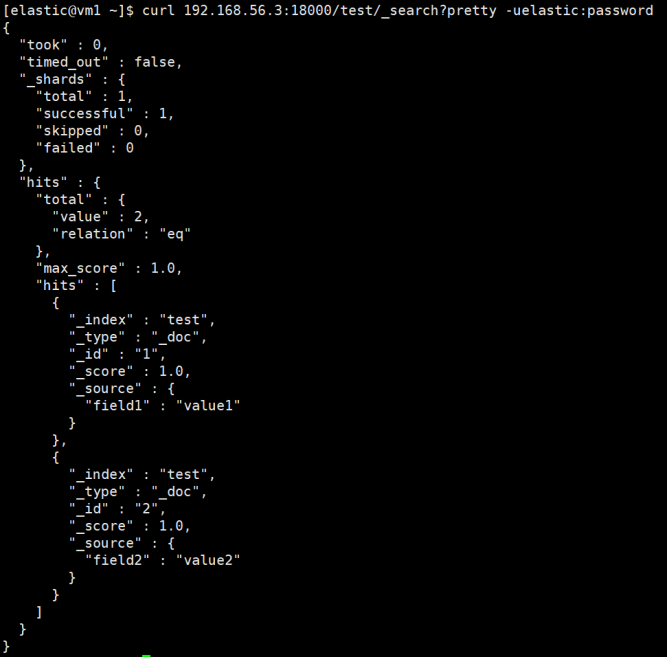
主备集群都已写入数据,且数据一致。通过网关查询,也正常返回。
删除和更新文档
# 通过网关删除和更新文档
curl -X POST "192.168.56.3:18000/_bulk?pretty" -H 'Content-Type: application/json' -uelastic:password -d'
{ "delete" : { "_index" : "test", "_id" : "1" } }
{ "update" : {"_id" : "2", "_index" : "test"} }
{ "doc" : {"field2" : "value2-updated"} }
'
查询数据
# 查询主集群
curl 192.168.56.3:7171/test/_search?pretty -uelastic:password
# 查询备集群
curl 192.168.56.3:9200/test/_search?pretty -uadmin:admin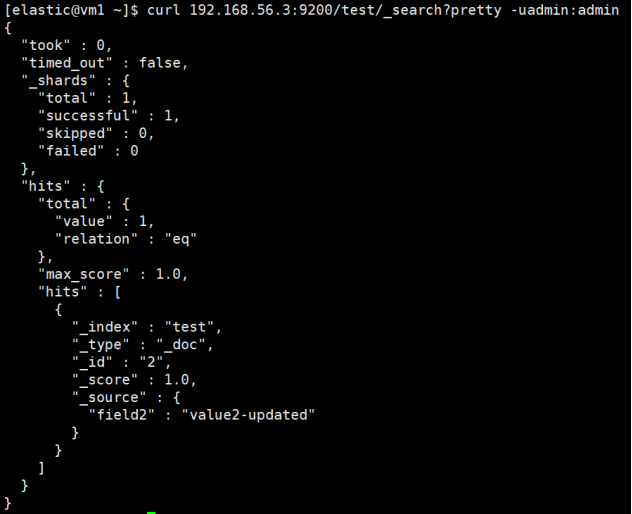
两个集群都已执行删除和更新操作,数据一致。
主集群故障时写入、查询测试
为模拟主集群故障,直接关闭主集群。
写入数据
# 通过网关写入数据
curl -X POST "192.168.56.3:18000/_bulk?pretty" -H 'Content-Type: application/json' -uelastic:password -d'
{ "index" : { "_index" : "test", "_id" : "3" } }
{ "field3" : "value3" }
{ "create" : { "_index" : "test", "_id" : "4" } }
{ "field4" : "value4" }
'写入数据报错

查询数据
# 通过网关查询,因为主集群不可用,网关将查询转发到备集群执行
curl 192.168.56.3:18000/test/_search?pretty -uelastic:password
正常查询到数据,说明请求被转发到了备集群执行。
备集群故障时写入、查询测试
为模拟备集群故障,直接关闭备集群。
写入数据
# 通过网关写入数据
curl -X POST "192.168.56.3:18000/_bulk?pretty" -H 'Content-Type: application/json' -uelastic:password -d'
{ "index" : { "_index" : "test", "_id" : "5" } }
{ "field5" : "value5" }
{ "create" : { "_index" : "test", "_id" : "6" } }
{ "field6" : "value6" }
'
数据正常写入。
查询数据
# 通过网关查询
curl 192.168.56.3:18000/test/_search?pretty -uelastic:password
查询成功返回。主集群成功写入了两条新数据。同时此数据会被记录到备集群的队列中,待备集群恢复后,会消费此队列追数据。
恢复备集群
启动备集群。
查询数据
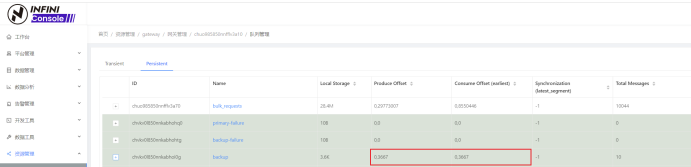
等待片刻或通过 INFINI Console 确定网关队列消费完毕后,查询备集群的数据。
(生产和消费 offset 相同,说明消费完毕。)
# 查询备集群的数据
curl 192.168.56.3:9200/test/_search?pretty -uadmin:admin
备集群启动后自动消费队列数据,消费完后备集群数据达到与主集群数据一致。
灾备切换
测试了这么多,终于到切换的时刻了。切换前我们判断下主系统是否短期无法修复。

如果我们判断主用系统无法短时间恢复,要执行切换。非常简单,我们直接将配置文件中定义的主备集群互换,然后重启网关程序就行了。但我们推荐在相同主机上另部署一套网关程序--网关B,先前那套用网关A指代。网关B中的配置文件把原备集群定义为主集群,原主集群定义为备集群。若要执行切换,我们先停止网关A,然后启动网关B,此时应用连接到网关(端口不变),就把原备系统当作主系统使用,把原主系统当作备系统,也就完成了主备系统的切换。
灾备回切
当原主集群修复后,正常启动,就会从消费队列追写修复期间产生数据直到主备数据一致,同样我们可通过 INFINI Console 查看消费的进度。如果大家还是担心数据的一致性,INFINI Console 还能帮大家做[校验数据]()任务,做到数据完全一致后(文档数量及文档内容一致),才进行回切。

回切也非常简单,停止网关B,启动网关A即可。
网关高可用
网关自带浮动 IP 模块,可进行双机热备。客户端通过 VIP 连接网关,网关出现故障时,VIP 漂移到备网关。
视频教程戳这里。

这样的优点是简单,不足是只有一个网关在线提供服务。如果想多个网关在线提供服务,则需搭配分布式消息系统一起工作,架构如下。

前端通过负载均衡将流量分散到多个在线网关,网关将消息存入分布式消息系统。此时,网关可看作无状态应用,可根据需要扩缩规模。
以上就是我介绍的ES灾备方案,是不是相当灵活了。有问题还是那句话 Call me 。
关于极限网关
INFINI Gateway 是一个面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway,可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
在 Kibana 里统一访问来自不同集群的索引
资料分享 • medcl 发表了文章 • 0 个评论 • 6575 次浏览 • 2022-04-21 15:29
在 Kibana 里统一访问来自不同集群的索引
现在有这么一个需求,客户根据需要将数据按照业务维度划分,将索引分别存放在了不同的三个集群, 将一个大集群拆分成多个小集群有很多好处,比如降低了耦合,带来了集群可用性和稳定性方面的好处,也避免了单个业务的热点访问造成其他业务的影响, 尽管拆分集群是很常见的玩法,但是管理起来不是那么方便了,尤其是在查询的时候,可能要分别访问三套集群各自的 API,甚至要切换三套不同的 Kibana 来访问集群的数据, 那么有没有办法将他们无缝的联合在一起呢?
极限网关!
答案自然是有的,通过将 Kibana 访问 Elasticsearch 的地址切换为极限网关的地址,我们可以将请求按照索引来进行智能的路由, 也就是当访问不同的业务索引时会智能的路由到不同的集群,如下图:

上图,我们分别有 3 个不同的索引:
- apm-*
- erp-*
- mall-*
分别对应不同的三套 Elasticsearch 集群:
- ES1-APM
- ES2-ERP
- ES3-MALL
接下来我们来看如何在极限网关里面进行相应的配置来满足这个业务需求。
配置集群信息
首先配置 3 个集群的连接信息。
elasticsearch:
- name: es1-apm
enabled: true
endpoints:
- http://192.168.3.188:9206
- name: es2-erp
enabled: true
endpoints:
- http://192.168.3.188:9207
- name: es3-mall
enabled: true
endpoints:
- http://192.168.3.188:9208配置服务 Flow
然后,我们定义 3 个 Flow,分别对应用来访问 3 个不同的 Elasticsearch 集群,如下:
flow:
- name: es1-flow
filter:
- elasticsearch:
elasticsearch: es1-apm
- name: es2-flow
filter:
- elasticsearch:
elasticsearch: es2-erp
- name: es3-flow
filter:
- elasticsearch:
elasticsearch: es3-mall然后再定义一个 flow 用来进行路径的判断和转发,如下:
- name: default-flow
filter:
- switch:
remove_prefix: false
path_rules:
- prefix: apm-
flow: es1-flow
- prefix: erp-
flow: es2-flow
- prefix: mall-
flow: es3-flow
- flow: #default flow
flows:
- es1-flow根据请求路径里面的索引前缀来匹配不同的索引,并转发到不同的 Flow。
配置路由信息
接下来,我们定义路由信息,具体配置如下:
router:
- name: my_router
default_flow: default-flow指向上面定义的默认 flow 来统一请求的处理。
定义服务及关联路由
最后,我们定义一个监听为 8000 端口的服务,用来提供给 Kibana 来进行统一的入口访问,如下:
entry:
- name: es_entry
enabled: true
router: my_router
max_concurrency: 10000
network:
binding: 0.0.0.0:8000完整配置
最后的完整配置如下:
path.data: data
path.logs: log
entry:
- name: es_entry
enabled: true
router: my_router
max_concurrency: 10000
network:
binding: 0.0.0.0:8000
flow:
- name: default-flow
filter:
- switch:
remove_prefix: false
path_rules:
- prefix: apm-
flow: es1-flow
- prefix: erp-
flow: es2-flow
- prefix: mall-
flow: es3-flow
- flow: #default flow
flows:
- es1-flow
- name: es1-flow
filter:
- elasticsearch:
elasticsearch: es1-apm
- name: es2-flow
filter:
- elasticsearch:
elasticsearch: es2-erp
- name: es3-flow
filter:
- elasticsearch:
elasticsearch: es3-mall
router:
- name: my_router
default_flow: default-flow
elasticsearch:
- name: es1-apm
enabled: true
endpoints:
- http://192.168.3.188:9206
- name: es2-erp
enabled: true
endpoints:
- http://192.168.3.188:9207
- name: es3-mall
enabled: true
endpoints:
- http://192.168.3.188:9208启动网关
直接启动网关,如下:
➜ gateway git:(master) ✗ ./bin/gateway -config sample-configs/elasticsearch-route-by-index.yml
___ _ _____ __ __ __ _
/ _ \ /_\ /__ \/__\/ / /\ \ \/_\ /\_/\
/ /_\///_\\ / /\/_\ \ \/ \/ //_\\\_ _/
/ /_\\/ _ \/ / //__ \ /\ / _ \/ \
\____/\_/ \_/\/ \__/ \/ \/\_/ \_/\_/
[GATEWAY] A light-weight, powerful and high-performance elasticsearch gateway.
[GATEWAY] 1.0.0_SNAPSHOT, 2022-04-20 08:23:56, 2023-12-31 10:10:10, 51650a5c3d6aaa436f3c8a8828ea74894c3524b9
[04-21 13:41:21] [INF] [app.go:174] initializing gateway.
[04-21 13:41:21] [INF] [app.go:175] using config: /Users/medcl/go/src/infini.sh/gateway/sample-configs/elasticsearch-route-by-index.yml.
[04-21 13:41:21] [INF] [instance.go:72] workspace: /Users/medcl/go/src/infini.sh/gateway/data/gateway/nodes/c9bpg0ai4h931o4ngs3g
[04-21 13:41:21] [INF] [app.go:283] gateway is up and running now.
[04-21 13:41:21] [INF] [api.go:262] api listen at: http://0.0.0.0:2900
[04-21 13:41:21] [INF] [reverseproxy.go:255] elasticsearch [es1-apm] hosts: [] => [192.168.3.188:9206]
[04-21 13:41:21] [INF] [reverseproxy.go:255] elasticsearch [es2-erp] hosts: [] => [192.168.3.188:9207]
[04-21 13:41:21] [INF] [reverseproxy.go:255] elasticsearch [es3-mall] hosts: [] => [192.168.3.188:9208]
[04-21 13:41:21] [INF] [actions.go:349] elasticsearch [es2-erp] is available
[04-21 13:41:21] [INF] [actions.go:349] elasticsearch [es1-apm] is available
[04-21 13:41:21] [INF] [entry.go:312] entry [es_entry] listen at: http://0.0.0.0:8000
[04-21 13:41:21] [INF] [module.go:116] all modules are started
[04-21 13:41:21] [INF] [actions.go:349] elasticsearch [es3-mall] is available
[04-21 13:41:55] [INF] [reverseproxy.go:255] elasticsearch [es1-apm] hosts: [] => [192.168.3.188:9206]网关启动成功之后,就可以通过网关的 IP+8000 端口来访问目标 Elasticsearch 集群了。
测试访问
首先通过 API 来访问测试一下,如下:
➜ ~ curl http://localhost:8000/apm-2022/_search -v
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to localhost (127.0.0.1) port 8000 (#0)
> GET /apm-2022/_search HTTP/1.1
> Host: localhost:8000
> User-Agent: curl/7.54.0
> Accept: */*
>
< HTTP/1.1 200 OK
< Date: Thu, 21 Apr 2022 05:45:44 GMT
< content-type: application/json; charset=UTF-8
< Content-Length: 162
< X-elastic-product: Elasticsearch
< X-Backend-Cluster: es1-apm
< X-Backend-Server: 192.168.3.188:9206
< X-Filters: filters->elasticsearch
<
* Connection #0 to host localhost left intact
{"took":142,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":0,"relation":"eq"},"max_score":null,"hits":[]}}% 可以看到 apm-2022 指向了后端的 es1-apm 集群。
继续测试,erp 索引的访问,如下:
➜ ~ curl http://localhost:8000/erp-2022/_search -v
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to localhost (127.0.0.1) port 8000 (#0)
> GET /erp-2022/_search HTTP/1.1
> Host: localhost:8000
> User-Agent: curl/7.54.0
> Accept: */*
>
< HTTP/1.1 200 OK
< Date: Thu, 21 Apr 2022 06:24:46 GMT
< content-type: application/json; charset=UTF-8
< Content-Length: 161
< X-Backend-Cluster: es2-erp
< X-Backend-Server: 192.168.3.188:9207
< X-Filters: filters->switch->filters->elasticsearch->skipped
<
* Connection #0 to host localhost left intact
{"took":12,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":0,"relation":"eq"},"max_score":null,"hits":[]}}%继续测试,mall 索引的访问,如下:
➜ ~ curl http://localhost:8000/mall-2022/_search -v
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to localhost (127.0.0.1) port 8000 (#0)
> GET /mall-2022/_search HTTP/1.1
> Host: localhost:8000
> User-Agent: curl/7.54.0
> Accept: */*
>
< HTTP/1.1 200 OK
< Date: Thu, 21 Apr 2022 06:25:08 GMT
< content-type: application/json; charset=UTF-8
< Content-Length: 134
< X-Backend-Cluster: es3-mall
< X-Backend-Server: 192.168.3.188:9208
< X-Filters: filters->switch->filters->elasticsearch->skipped
<
* Connection #0 to host localhost left intact
{"took":8,"timed_out":false,"_shards":{"total":5,"successful":5,"skipped":0,"failed":0},"hits":{"total":0,"max_score":null,"hits":[]}}% 完美转发。
修改 Kibana 配置
修改 Kibana 的配置文件: kibana.yml,替换 Elasticsearch 的地址为网关地址(http://192.168.3.200:8000),如下:
elasticsearch.hosts: ["http://192.168.3.200:8000"]重启 Kibana 让配置生效。
效果如下

可以看到,在一个 Kibana 的开发者工具里面,我们已经可以像操作一个集群一样来同时读写实际上来自三个不同集群的索引数据了。
展望
通过极限网关,我们还可以非常灵活的进行在线请求的流量编辑,动态组合不同集群的操作。
在极限网关里面使用 JavaScript 脚本来进行复杂的查询改写
资料分享 • medcl 发表了文章 • 1 个评论 • 5290 次浏览 • 2022-04-19 11:55
使用 JavaScript 脚本来进行复杂的查询改写
有这么一个需求:
网关里怎样对跨集群搜索进行支持的呢?我想实现: 输入的搜索请求是 lp:9200/index1/_search 这个索引在3个集群上,需要跨集群检索,也就是网关能否改成 lp:9200/cluster01:index1,cluster02,index1,cluster03:index1/_search 呢? 索引有一百多个,名称不一定是 app, 还可能多个索引一起的。
极限网关自带的过滤器 content_regex_replace 虽然可以实现字符正则替换,但是这个需求是带参数的变量替换,稍微复杂一点,没有办法直接用这个正则替换实现,有什么其他办法实现么?
使用脚本过滤器
当然有的,上面的这个需求,理论上我们只需要将其中的索引 index1 匹配之后,替换为 cluster01:index1,cluster02,index1,cluster03:index1 就行了。
答案就是使用自定义脚本来做,再复杂的业务逻辑都不是问题,都能通过自定义脚本来实现,一行脚本不行,那就两行。
使用极限网关提供的 JavaScript 过滤器可以很灵活的实现这个功能,具体继续看。
定义过滤器
首先创建一个脚本文件,放在网关数据目录的 scripts 子目录下面,如下:
➜ gateway ✗ tree data
data
└── gateway
└── nodes
└── c9bpg0ai4h931o4ngs3g
├── kvdb
├── queue
├── scripts
│ └── index_path_rewrite.js
└── stats这个脚本的内容如下:
function process(context) {
var originalPath = context.Get("_ctx.request.path");
var matches = originalPath.match(/\/?(.*?)\/_search/)
var indexNames = [];
if(matches && matches.length > 1) {
indexNames = matches[1].split(",")
}
var resultNames = []
var clusterNames = ["cluster01", "cluster02"]
if(indexNames.length > 0) {
for(var i=0; i<indexNames.length; i++){
if(indexNames[i].length > 0) {
for(var j=0; j<clusterNames.length; j++){
resultNames.push(clusterNames[j]+":"+indexNames[i])
}
}
}
}
if (resultNames.length>0){
var newPath="/"+resultNames.join(",")+"/_search";
context.Put("_ctx.request.path",newPath);
}
}和普通的 JavaScript 一样,定义一个特定的函数 process 来处理请求里面的上下文信息,_ctx.request.path 是网关内置上下文的一个变量,用来获取请求的路径,通过 context.Get("_ctx.request.path") 在脚本里面进行访问。
中间我们使用了 JavaScript 的正则匹配和字符处理,做了一些字符拼接,得到新的路径 newPath 变量,最后使用 context.Put("_ctx.request.path",newPath) 更新网关请求的路径信息,从而实现查询条件里面的参数替换。
有关网关内置上下文的变量列表,请访问 Request Context
接下来,创建一个网关配置,并使用 javascript 过滤器调用该脚本,如下:
entry:
- name: my_es_entry
enabled: true
router: my_router
max_concurrency: 10000
network:
binding: 0.0.0.0:8000
flow:
- name: default_flow
filter:
- dump:
context:
- _ctx.request.path
- javascript:
file: index_path_rewrite.js
- dump:
context:
- _ctx.request.path
- elasticsearch:
elasticsearch: dev
router:
- name: my_router
default_flow: default_flow
elasticsearch:
- name: dev
enabled: true
schema: http
hosts:
- 192.168.3.188:9206上面的例子中,使用了一个 javascript 过滤器,并且指定了加载的脚本文件为 index_path_rewrite.js,并使用了两个 dump 过滤器来输出脚本运行前后的路径信息,最后再使用一个 elasticsearch 过滤器来转发请求给 Elasticsearch 进行查询。
我们启动网关测试一下,如下:
➜ gateway ✗ ./bin/gateway
___ _ _____ __ __ __ _
/ _ \ /_\ /__ \/__\/ / /\ \ \/_\ /\_/\
/ /_\///_\\ / /\/_\ \ \/ \/ //_\\\_ _/
/ /_\\/ _ \/ / //__ \ /\ / _ \/ \
\____/\_/ \_/\/ \__/ \/ \/\_/ \_/\_/
[GATEWAY] A light-weight, powerful and high-performance elasticsearch gateway.
[GATEWAY] 1.0.0_SNAPSHOT, 2022-04-18 07:11:09, 2023-12-31 10:10:10, 8062c4bc6e57a3fefcce71c0628d2d4141e46953
[04-19 11:41:29] [INF] [app.go:174] initializing gateway.
[04-19 11:41:29] [INF] [app.go:175] using config: /Users/medcl/go/src/infini.sh/gateway/gateway.yml.
[04-19 11:41:29] [INF] [instance.go:72] workspace: /Users/medcl/go/src/infini.sh/gateway/data/gateway/nodes/c9bpg0ai4h931o4ngs3g
[04-19 11:41:29] [INF] [app.go:283] gateway is up and running now.
[04-19 11:41:30] [INF] [api.go:262] api listen at: http://0.0.0.0:2900
[04-19 11:41:30] [INF] [entry.go:312] entry [my_es_entry] listen at: http://0.0.0.0:8000
[04-19 11:41:30] [INF] [module.go:116] all modules are started
[04-19 11:41:30] [INF] [actions.go:349] elasticsearch [dev] is available运行下面的查询来验证查询结果,如下:
curl localhost:8000/abc,efg/_search可以看到网关通过 dump 过滤器输出的调试信息:
---- DUMPING CONTEXT ----
_ctx.request.path : /abc,efg/_search
---- DUMPING CONTEXT ----
_ctx.request.path : /cluster01:abc,cluster02:abc,cluster01:efg,cluster02:efg/_search查询条件按照我们的需求进行了改写,Nice!
重写 DSL 查询语句
好吧,我们刚刚只是修改了查询的索引而已,那么查询请求的 DSL 呢?行不行?
那自然是可以的嘛,瞧下面的例子:
function process(context) {
var originalDSL = context.Get("_ctx.request.body");
if (originalDSL.length >0){
var jsonObj=JSON.parse(originalDSL);
jsonObj.size=123;
jsonObj.aggs= {
"test1": {
"terms": {
"field": "abc",
"size": 10
}
}
}
context.Put("_ctx.request.body",JSON.stringify(jsonObj));
}
}先是获取查询请求,然后转换成 JSON 对象,之后任意修改查询对象就行了,保存回去,搞掂。
测试一下:
curl -XPOST localhost:8000/abc,efg/_search -d'{"query":{}}'输出:
---- DUMPING CONTEXT ----
_ctx.request.path : /abc,efg/_search
_ctx.request.body : {"query":{}}
[04-19 18:14:24] [INF] [reverseproxy.go:255] elasticsearch [dev] hosts: [] => [192.168.3.188:9206]
---- DUMPING CONTEXT ----
_ctx.request.path : /abc,efg/_search
_ctx.request.body : {"query":{},"size":123,"aggs":{"test1":{"terms":{"field":"abc","size":10}}}}是不是感觉解锁了新的世界?
结论
通过使用 Javascript 脚本过滤器,我们可以非常灵活的进行复杂逻辑的操作来满足我们的业务需求。

极限网关初探(2)配置
Elasticsearch • xushuhui 发表了文章 • 0 个评论 • 3924 次浏览 • 2022-04-06 17:03
配置
上一篇我们先学习了极限网关的安装和启动,今天学习配置。
读写分离
现在我们遇到读写分离的需求,用网关该怎么做呢? 假设服务端现在从 http://127.0.0.1:8000 写入数据,从 http://127.0.0.1:9000 读取数据,怎么设计呢?
首先查看文档配置文档
我们在 gateway.yml 中定义两个 entry,分别绑定不同的端口,配置不同的 router
entry:
- name: write_es
enabled: true
router: write_router
network:
binding: 0.0.0.0:8000
- name: read_es
enabled: true
router: read_router
network:
binding: 0.0.0.0:9000
router:
- name: write_router
default_flow: default_flow
tracing_flow: logging
- name: read_router
default_flow: default_flow
tracing_flow: logging为了演示效果,只配置一个 Elasticsearch
elasticsearch:
- name: dev
enabled: true
schema: http
hosts:
- 192.168.3.188:9206启动项目

我们从 http://127.0.0.1:8000 写入一条数据,再从 http://127.0.0.1:9000 读取该条数据


添加接口
返回字符串
我们想自定义添加一个接口,怎么在不写代码的情况下通过配置实现返回字符串
flow:
- name: hello_flow
filter:
- echo:
message: "hello flow"
router:
- name: read_router
default_flow: hello_flow修改配置后启动

返回 json 数据
返回字符串不符合标准的 restful 接口规范,怎么返回给调用方标准 json 数据?
filter:
- set_response:
content_type: application/json
body: '{"message":"hello world"}'修改配置后启动

修改路由
我们已经新加了接口,返回 json 数据,但是接口是直接定义在 http://127.0.0.1:9000 中,之前网关的接口就无法使用,所以我们需要单独为自定义的接口指定单独的路由
router:
- name: read_router
default_flow: default_flow
tracing_flow: logging
rules:
- method:
- GET
pattern:
- "/hello"
flow:
- hello_flowdefault_flow: 默认的处理流,也就是业务处理的主流程,请求转发、过滤、缓存等操作都在这里面进行
tracing_flow:用于追踪请求状态的流,用于记录请求日志、统计等
如果我们有过开发经验,了解 MVC 模式,flow 就类似 MVC 中的 Controller,rules 中类似路由规则,当请求匹配到配置中的路由规则时,由配置的 flow 处理业务逻辑。
数据整体流向,从服务端发到网关,网关为每个 Elasticsearch 绑定不同的 IP 地址,每个 Elasticsearch 都有唯一一个 router 和它对应,根据请求的 method 和 path 匹配到 router 中的一个 flow,flow 中包含多个 filter 处理对数据进行流式处理。
如下图所示

流式处理是什么,假设水从一个管子里面流出来,管子旁边每一段依次站了几个人,第一个人往水里放点鱼,鱼和水到了第二个人,第二个人往水里放点草,鱼、水和草到了第三人等等,每个人对水做一定的操作,水经过这些操作后最后到达水池里。
我们可以把数据当成水,filter 是管子旁边的人,水池就是 Elasticsearch
总结
在学习了router/flow/filter后,我们已经对极限网关的配置有了初步的了解,后续开发的时候直接查阅文档。
极限网关初探(1) 安装启动
Elasticsearch • xushuhui 发表了文章 • 0 个评论 • 3939 次浏览 • 2022-04-06 16:54
产品介绍
极限网关(INFINI Gateway)是一个面向 Elasticsearch 的高性能应用网关。特性丰富,使用简单。
它和其他业务型网关最大的区别是业务网关把请求转发给各个底层微服务,而它把请求转发给 Elasticsearch,更多是类似 Mycat 的中间件的作用。
没有使用网关之前,服务端请求多个节点

使用网关后

下载地址
打开 下载地址,根据操作系统版本选择。
Windows 安装和启动
安装
下载 gateway-1.6.0_SNAPSHOT-597-windows-amd64.zip,解压如下。

启动失败
当 gateway.yml 的 elasticsearch 选项中的 hosts 不能正常响应请求的时候,启动界面如下。

为什么 elasticsearch 不能访问的时候,网关还要继续提供服务呢,为什么不像业务接口启动时在基础业务组件如 MySQL/Redis 不能正常响应就直接 panic?
一方面网关作为 elasticsearch 抵挡流量冲击的城墙,在 elasticsearch 不能提供服务的时候,对之前成功的请求缓存结果,继续提供有限度的服务,为 elasticsearch 修复后上线争取时间。
另一方面业务接口和基础组件是强耦合关系,没有基础组件就完全无法对外提供数据读写服务,而网关与 elasticsearch 是松耦合关系,网关在没有 elasticsearch 的情况下也能对外提供有限度的服务。
在 gateway.yml 的 elasticsearch 选项中的 hosts 改成能够正常响应的 elasticsearch 请求地址。
启动成功
双击 gateway-windows-amd64.exe 文件,启动成功界面如下

访问
API 访问
由启动后终端显示可知,网关的 API 接口地址是 http://localhost:2900
[api.go:262] api listen at: http://0.0.0.0:2900打开浏览器输入 http://localhost:2900,显示所有可以对外提供的 API 接口

我们选择其中一个,在浏览器中输入 http://localhost:2900/_framework/api/_version 从路由上看该接口是查询产品的版本信息,显示如下

gateway.yml 中可以看到有被注释掉的一段配置,看起来应该是配置 api 地址的地方。
#api:
# enabled: true
# network:
# binding: 127.0.0.1:2900把注释去掉后尝试把端口改成 2901。
api:
enabled: true
network:
binding: 127.0.0.1:2901改完后启动

Elasticsearch 访问
启动日志中显示监听 8000 端口,猜测应该是 elasticsearch 请求地址,打开浏览器输入 http://127.0.0.1:8000/
entry [my_es_entry] listen at: http://0.0.0.0:8000
entry:
- name: my_es_entry
enabled: true
router: my_router
max_concurrency: 10000
network:
binding: 0.0.0.0:8000总结
我们成功安装和启动极限网关,接下来我们学习怎么根据需求修改配置。
极限网关初探(2)配置
Elasticsearch • xushuhui 发表了文章 • 0 个评论 • 3924 次浏览 • 2022-04-06 17:03
配置
上一篇我们先学习了极限网关的安装和启动,今天学习配置。
读写分离
现在我们遇到读写分离的需求,用网关该怎么做呢? 假设服务端现在从 http://127.0.0.1:8000 写入数据,从 http://127.0.0.1:9000 读取数据,怎么设计呢?
首先查看文档配置文档
我们在 gateway.yml 中定义两个 entry,分别绑定不同的端口,配置不同的 router
entry:
- name: write_es
enabled: true
router: write_router
network:
binding: 0.0.0.0:8000
- name: read_es
enabled: true
router: read_router
network:
binding: 0.0.0.0:9000
router:
- name: write_router
default_flow: default_flow
tracing_flow: logging
- name: read_router
default_flow: default_flow
tracing_flow: logging为了演示效果,只配置一个 Elasticsearch
elasticsearch:
- name: dev
enabled: true
schema: http
hosts:
- 192.168.3.188:9206启动项目
我们从 http://127.0.0.1:8000 写入一条数据,再从 http://127.0.0.1:9000 读取该条数据
添加接口
返回字符串
我们想自定义添加一个接口,怎么在不写代码的情况下通过配置实现返回字符串
flow:
- name: hello_flow
filter:
- echo:
message: "hello flow"
router:
- name: read_router
default_flow: hello_flow修改配置后启动
返回 json 数据
返回字符串不符合标准的 restful 接口规范,怎么返回给调用方标准 json 数据?
filter:
- set_response:
content_type: application/json
body: '{"message":"hello world"}'修改配置后启动
修改路由
我们已经新加了接口,返回 json 数据,但是接口是直接定义在 http://127.0.0.1:9000 中,之前网关的接口就无法使用,所以我们需要单独为自定义的接口指定单独的路由
router:
- name: read_router
default_flow: default_flow
tracing_flow: logging
rules:
- method:
- GET
pattern:
- "/hello"
flow:
- hello_flowdefault_flow: 默认的处理流,也就是业务处理的主流程,请求转发、过滤、缓存等操作都在这里面进行
tracing_flow:用于追踪请求状态的流,用于记录请求日志、统计等
如果我们有过开发经验,了解 MVC 模式,flow 就类似 MVC 中的 Controller,rules 中类似路由规则,当请求匹配到配置中的路由规则时,由配置的 flow 处理业务逻辑。
数据整体流向,从服务端发到网关,网关为每个 Elasticsearch 绑定不同的 IP 地址,每个 Elasticsearch 都有唯一一个 router 和它对应,根据请求的 method 和 path 匹配到 router 中的一个 flow,flow 中包含多个 filter 处理对数据进行流式处理。
如下图所示
流式处理是什么,假设水从一个管子里面流出来,管子旁边每一段依次站了几个人,第一个人往水里放点鱼,鱼和水到了第二个人,第二个人往水里放点草,鱼、水和草到了第三人等等,每个人对水做一定的操作,水经过这些操作后最后到达水池里。
我们可以把数据当成水,filter 是管子旁边的人,水池就是 Elasticsearch
总结
在学习了router/flow/filter后,我们已经对极限网关的配置有了初步的了解,后续开发的时候直接查阅文档。
极限网关初探(1) 安装启动
Elasticsearch • xushuhui 发表了文章 • 0 个评论 • 3939 次浏览 • 2022-04-06 16:54
产品介绍
极限网关(INFINI Gateway)是一个面向 Elasticsearch 的高性能应用网关。特性丰富,使用简单。
它和其他业务型网关最大的区别是业务网关把请求转发给各个底层微服务,而它把请求转发给 Elasticsearch,更多是类似 Mycat 的中间件的作用。
没有使用网关之前,服务端请求多个节点
使用网关后
下载地址
打开 下载地址,根据操作系统版本选择。
Windows 安装和启动
安装
下载 gateway-1.6.0_SNAPSHOT-597-windows-amd64.zip,解压如下。
启动失败
当 gateway.yml 的 elasticsearch 选项中的 hosts 不能正常响应请求的时候,启动界面如下。
为什么 elasticsearch 不能访问的时候,网关还要继续提供服务呢,为什么不像业务接口启动时在基础业务组件如 MySQL/Redis 不能正常响应就直接 panic?
一方面网关作为 elasticsearch 抵挡流量冲击的城墙,在 elasticsearch 不能提供服务的时候,对之前成功的请求缓存结果,继续提供有限度的服务,为 elasticsearch 修复后上线争取时间。
另一方面业务接口和基础组件是强耦合关系,没有基础组件就完全无法对外提供数据读写服务,而网关与 elasticsearch 是松耦合关系,网关在没有 elasticsearch 的情况下也能对外提供有限度的服务。
在 gateway.yml 的 elasticsearch 选项中的 hosts 改成能够正常响应的 elasticsearch 请求地址。
启动成功
双击 gateway-windows-amd64.exe 文件,启动成功界面如下
访问
API 访问
由启动后终端显示可知,网关的 API 接口地址是 http://localhost:2900
[api.go:262] api listen at: http://0.0.0.0:2900打开浏览器输入 http://localhost:2900,显示所有可以对外提供的 API 接口
我们选择其中一个,在浏览器中输入 http://localhost:2900/_framework/api/_version 从路由上看该接口是查询产品的版本信息,显示如下
gateway.yml 中可以看到有被注释掉的一段配置,看起来应该是配置 api 地址的地方。
#api:
# enabled: true
# network:
# binding: 127.0.0.1:2900把注释去掉后尝试把端口改成 2901。
api:
enabled: true
network:
binding: 127.0.0.1:2901改完后启动
Elasticsearch 访问
启动日志中显示监听 8000 端口,猜测应该是 elasticsearch 请求地址,打开浏览器输入 http://127.0.0.1:8000/
entry [my_es_entry] listen at: http://0.0.0.0:8000
entry:
- name: my_es_entry
enabled: true
router: my_router
max_concurrency: 10000
network:
binding: 0.0.0.0:8000总结
我们成功安装和启动极限网关,接下来我们学习怎么根据需求修改配置。
使用极限网关来处置 Elasticsearch 的 Apache Log4j 漏洞
Elasticsearch • medcl 发表了文章 • 2 个评论 • 9701 次浏览 • 2021-12-11 03:57
昨日爆出的 Log4j 安全漏洞,业界一片哗然,今天给大家介绍一下,如何使用极限网关来快速处置 Elasticsearch 的 Apache Log4j 漏洞。
【CVE 地址】
https://github.com/advisories/GHSA-jfh8-c2jp-5v3q
【漏洞描述】
Apache Log4j 是一款非常流行的开源的用于 Java 运行环境的日志记录工具包,大量的 Java 框架包括 Elasticsearch 的最新版本都使用了该组件,故影响范围非常之大。
近日, 随着 Apache Log4j 的远程代码执行最新漏洞细节被公开,攻击者可通过构造恶意请求利用该漏洞实现在目标服务器上执行任意代码。可导致服务器被黑客控制,从而进行页面篡改、数据窃取、挖矿、勒索等行为。建议使用该组件的用户第一时间启动应急响应进行修复。
简单总结一下就是,在使用 Log4j 打印输出的日志中,如果发现日志内容中包含关键词 ${,那么这个里面包含的内容会当做变量来进行替换和执行,导致攻击者可以通过恶意构造日志内容来让 Java 进程来执行任意命令,达到攻击的效果。
【漏洞等级】:非常紧急
此次漏洞是用于 Log4j2 提供的 lookup 功能造成的,该功能允许开发者通过一些协议去读取相应环境中的配置。但在实现的过程中,并未对输入进行严格的判断,从而造成漏洞的发生。
【影响范围】:Java 类产品:Apache Log4j 2.x < 2.15.0-rc2,Elasticsearch 当前所有版本。
【攻击检测】
可以通过检查日志中是否存在 jndi:ldap://、jndi:rmi 等字符来发现可能的攻击行为。
处理办法
最简单的办法是通过修改 config/jvm.options,新增以下参数,重启集群所有节点即可。
-Dlog4j2.formatMsgNoLookups=true不过,如果集群规模较大,数据较多,业务不能中断,不能通过修改 Elasticsearch 配置、或者替换 Log4j 的最新 jar 包来重启集群的情况,可以考虑使用极限网关来进行拦截或者参数替换甚至是直接阻断请求。
通过在网关层对发往 Elasticsearch 的请求统一进行参数检测,将包含的敏感关键词 ${ 进行替换或者直接拒绝,
可以防止带攻击的请求到达 Elasticsearch 服务端而被 Log4j 打印相关日志的时候执行恶意攻击命令,从而避免被攻击。
极限网关是透明代理,只需要在应用端,将以往配置指向 Elasticsearch 的地址替换为现在网关的地址即可,其他都不用动。
参考配置
下载最新的 1.5.0-SNAPSHOT 版本http://release.elasticsearch.cn/gateway/snapshot/
使用极限网关的 context_filter 过滤器,对请求上下文 _ctx.request.to_string 进行关键字检测,过滤掉恶意流量,从而阻断攻击。
新增一个配置文件 gateway.yml
path.data: data
path.logs: log
entry:
- name: es_entrypoint
enabled: true
router: default
max_concurrency: 20000
network:
binding: 0.0.0.0:8000
router:
- name: default
default_flow: main_flow
flow:
- name: main_flow
filter:
- context_filter:
context: _ctx.request.to_string
action: redirect_flow
status: 403
flow: log4j_matched_flow
must_not: # any match will be filtered
regex:
- \$\{.*?\}
- "%24%7B.*?%7D" #urlencode
contain:
- "jndi:"
- "jndi:ldap:"
- "jndi:rmi:"
- "jndi%3A" #urlencode
- "jndi%3Aldap%3A" #urlencode
- "jndi%3Armi%3A" #urlencode
- elasticsearch:
elasticsearch: es-server
- name: log4j_matched_flow
filter:
- echo:
message: 'Apache Log4j 2, Boom!'
elasticsearch:
- name: es-server
enabled: true
endpoints:
- http://localhost:9200启动网关:
➜ ./bin/gateway -config /tmp/gateway.yml
___ _ _____ __ __ __ _
/ _ \ /_\ /__ \/__\/ / /\ \ \/_\ /\_/\
/ /_\///_\\ / /\/_\ \ \/ \/ //_\\\_ _/
/ /_\\/ _ \/ / //__ \ /\ / _ \/ \
\____/\_/ \_/\/ \__/ \/ \/\_/ \_/\_/
[GATEWAY] A light-weight, powerful and high-performance elasticsearch gateway.
[GATEWAY] 1.0.0_SNAPSHOT, 2021-12-10 23:55:34, 2212aff
[12-11 01:55:49] [INF] [app.go:250] initializing gateway.
[12-11 01:55:49] [INF] [instance.go:26] workspace: /Users/medcl/go/src/infini.sh/gateway/data/gateway/nodes/0
[12-11 01:55:49] [INF] [api.go:261] api listen at: http://0.0.0.0:2900
[12-11 01:55:49] [INF] [reverseproxy.go:253] elasticsearch [es-server] hosts: [] => [localhost:9200]
[12-11 01:55:49] [INF] [entry.go:296] entry [es_entrypoint] listen at: http://0.0.0.0:8000
[12-11 01:55:49] [INF] [module.go:116] all modules started
[12-11 01:55:49] [INF] [app.go:357] gateway is running now.
[12-11 01:55:49] [INF] [actions.go:236] elasticsearch [es-server] is available将要使用的测试命令 ${java:os} 使用 urlencode 转码为 %24%7Bjava%3Aos%7D,构造查询语句,分别测试。
不走网关:
~% curl 'http://localhost:9200/index1/_search?q=%24%7Bjava%3Aos%7D'
{"error":{"root_cause":[{"type":"index_not_found_exception","reason":"no such index","resource.type":"index_or_alias","resource.id":"index1","index_uuid":"_na_","index":"index1"}],"type":"index_not_found_exception","reason":"no such index","resource.type":"index_or_alias","resource.id":"index1","index_uuid":"_na_","index":"index1"},"status":404}% 查看 Elasticsearch 端日志为:
[2021-12-11T01:49:50,303][DEBUG][r.suppressed ] path: /index1/_search, params: {q=Mac OS X 10.13.4 unknown, architecture: x86_64-64, index=index1}
org.elasticsearch.index.IndexNotFoundException: no such index
at org.elasticsearch.cluster.metadata.IndexNameExpressionResolver$WildcardExpressionResolver.infe(IndexNameExpressionResolver.java:678) ~[elasticsearch-5.6.15.jar:5.6.15]
at org.elasticsearch.cluster.metadata.IndexNameExpressionResolver$WildcardExpressionResolver.innerResolve(IndexNameExpressionResolver.java:632) ~[elasticsearch-5.6.15.jar:5.6.15]
at org.elasticsearch.cluster.metadata.IndexNameExpressionResolver$WildcardExpressionResolver.resolve(IndexNameExpressionResolver.java:580) ~[elasticsearch-5.6.15.jar:5.6.15]
可以看到查询条件里面的 q=${java:os} 被执行了,变成了 q=Mac OS X 10.13.4 unknown, architecture: x86_64-64, index=index1,说明变量被解析且执行,存在漏洞利用的风险。
那走网关之后呢:
~% curl 'http://localhost:8000/index1/_search?q=%24%7Bjava%3Aos%7D'
Apache Log4j 2, Boom!% 可以看到请求被过滤掉了,返回了自定义的信息。
还有一些其他测试命令,大家也可以试试:
#{java:vm}
~% curl 'http://localhost:9200/index/_search?q=%24%7Bjava%3Avm%7D'
[2021-12-11T02:36:04,764][DEBUG][r.suppressed ] [INFINI-2.local] path: /index/_search, params: {q=OpenJDK 64-Bit Server VM (build 25.72-b15, mixed mode), index=index}
~% curl 'http://localhost:8000/index/_search?q=%24%7Bjava%3Avm%7D'
Apache Log4j 2, Boom!%
#{jndi:rmi://localhost:1099/api}
~% curl 'http://localhost:9200/index/_search?q=%24%7Bjndi%3Armi%3A%2F%2Flocalhost%3A1099%2Fapi%7D'
2021-12-11 03:35:06,493 elasticsearch[YOmFJsW][search][T#3] ERROR An exception occurred processing Appender console java.lang.SecurityException: attempt to add a Permission to a readonly Permissions object
~% curl 'http://localhost:8000/index/_search?q=%24%7Bjndi%3Armi%3A%2F%2Flocalhost%3A1099%2Fapi%7D'
Apache Log4j 2, Boom!% 另外不同版本的 Elasticsearch 对于攻击的复现程度参差不齐,因为 es 不同版本是否有 Java Security Manager 、不同版本 JDK 、以及默认配置也不相同,新一点的 es 其实同样可以触发恶意请求,只不过网络调用被默认的网络策略给拒绝了,相对安全,当然如果设置不当同样存在风险,见过很多用户一上来就关默认安全配置的,甚至还放开很多暂时用不上的权限,另外未知的攻击方式也一定有,比如大量日志产生的系统调用可能会拖垮机器造成服务不可用,所以要么还是尽快改配置换 log4j 包重启集群,或者走网关来过滤阻断请求吧。
使用极限网关处置类似安全事件的好处是,Elasticsearch 服务器不用做任何变动,尤其是大规模集群的场景,可以节省大量的工作,提升效率,非常灵活,缩短安全处置的时间,降低企业风险。
使用极限网关来进行 Elasticsearch 跨集群跨版本查询及所有其它请求
Elasticsearch • medcl 发表了文章 • 9 个评论 • 9329 次浏览 • 2021-10-16 11:31
使用场景
如果你的业务需要用到有多个集群,并且版本还不一样,是不是管理起来很麻烦,如果能够通过一个 API 来进行查询就方便了,聪明的你相信已经想到了 CCS,没错用 CCS 可以实现跨集群的查询,不过 Elasticsearch 提供的 CCS 对版本有一点的限制,并且需要提前做好 mTLS,也就是需要提前配置好两个集群之间的证书互信,这个免不了要重启维护,好像有点麻烦,那么问题来咯,有没有更好的方案呢?
😁 有办法,今天我就给大家介绍一个基于极限网关的方案,极限网关的网址:http://极限网关.com/。
假设现在有两个集群,一个集群是 v2.4.6,有不少业务数据,舍不得删,里面有很多好东西 :)还有一个集群是 v7.14.0,版本还算比较新,业务正在做的一个新的试点,没什么好东西,但是也得用 :(,现在老板们的的需求是希望通过在一个统一的接口就能访问这些数据,程序员懒得很,懂得都懂。
集群信息
- v2.4.6 集群的访问入口地址:192.168.3.188:9202
- v7.14.0 集群的访问入口地址:192.168.3.188:9206
这两个集群都是 http 协议的。
实现步骤
今天用到的是极限网关的 switch 过滤器:https://极限网关.com/docs/references/filters/switch/
网关下载下来就两个文件,一个主程序,一个配置文件,记得下载对应操作系统的包。
定义两个集群资源
elasticsearch:
- name: v2
enabled: true
endpoint: http://192.168.3.188:9202
- name: v7
enabled: true
endpoint: http://192.168.3.188:9206上面定义了两个集群,分别命名为 v2 和 v7,待会会用到这些资源。
定义一个服务入口
entry:
- name: my_es_entry
enabled: true
router: my_router
max_concurrency: 1000
network:
binding: 0.0.0.0:8000
tls:
enabled: true这里定义了一个名为 my_es_entry 的资源入口,并引用了一个名为 my_router 的请求转发路由,同时绑定了网卡的 0.0.0.0:8000 也就是所有本地网卡监听 IP 的 8000 端口,访问任意 IP 的 8000 端口就能访问到这个网关了。
另外老板也说了,Elasticsearch 用 HTTP 协议简直就是裸奔,通过这里开启 tls,可以让网关对外提供的是 HTTPS 协议,这样用户连接的 Elasticsearch 服务就自带 buffer 了,后端的 es 集群和网关直接可以做好网络流量隔离,集群不用动,简直完美。
为什么定义 TLS 不用指定证书,好用的软件不需要这么麻烦,就这样,不解释。
最后,通过设置 max_concurrency 为 1000,限制下并发数,避免野猴子把我们的后端的 Elasticsearch 给压挂了。
定义一个请求路由
router:
- name: my_router
default_flow: cross-cluster-search这里的名称 my_router 就是表示上面的服务入口的router 参数指定的值。
另外设置一个 default_flow 来将所有的请求都转发给一个名为 cross-cluster-search 的请求处理流程,还没定义,别急,马上。
定义请求处理流程
来啦,来啦,先定义两个 flow,如下,分别名为 v2-flow 和 v7-flow,每节配置的 filter 定义了一系列过滤器,用来对请求进行处理,这里就用了一个 elasticsearch 过滤器,也就是转发请求给指定的 Elasticsearch 后端服务器,了否?
flow:
- name: v2-flow
filter:
- elasticsearch:
elasticsearch: v2
- name: v7-flow
filter:
- elasticsearch:
elasticsearch: v7然后,在定义额外一个名为 cross-cluster-search 的 flow,如下:
- name: cross-cluster-search
filter:
- switch:
path_rules:
- prefix: "v2:"
flow: v2-flow
- prefix: "v7:"
flow: v7-flow这个 flow 就是通过请求的路径的前缀来进行路由的过滤器,如果是 v2:开头的请求,则转发给 v2-flow 继续处理,如果是 v7: 开头的请求,则转发给 v7-flow 来处理,使用的用法和 CCS 是一样的。so easy!
对了,那是不是每个请求都需要加前缀啊,费事啊,没事,在这个 cross-cluster-search 的 filter 最后再加上一个 elasticsearch filter,前面前缀匹配不上的都会走它,假设默认都走 v7,最后完整的 flow 配置如下:
flow:
- name: v2-flow
filter:
- elasticsearch:
elasticsearch: v2
- name: v7-flow
filter:
- elasticsearch:
elasticsearch: v7
- name: cross-cluster-search
filter:
- switch:
path_rules:
- prefix: "v2:"
flow: v2-flow
- prefix: "v7:"
flow: v7-flow
- elasticsearch:
elasticsearch: v7 然后就没有然后了,因为就配置这些就行了。
启动网关
假设配置文件的路径为 sample-configs/cross-cluster-search.yml,运行如下命令:
➜ gateway git:(master) ✗ ./bin/gateway -config sample-configs/cross-cluster-search.yml
___ _ _____ __ __ __ _
/ _ \ /_\ /__ \/__\/ / /\ \ \/_\ /\_/\
/ /_\///_\\ / /\/_\ \ \/ \/ //_\\\_ _/
/ /_\\/ _ \/ / //__ \ /\ / _ \/ \
\____/\_/ \_/\/ \__/ \/ \/\_/ \_/\_/
[GATEWAY] A light-weight, powerful and high-performance elasticsearch gateway.
[GATEWAY] 1.0.0_SNAPSHOT, 2021-10-15 16:25:56, 3d0a1cd
[10-16 11:00:52] [INF] [app.go:228] initializing gateway.
[10-16 11:00:52] [INF] [instance.go:24] workspace: data/gateway/nodes/0
[10-16 11:00:52] [INF] [api.go:260] api listen at: http://0.0.0.0:2900
[10-16 11:00:52] [INF] [reverseproxy.go:257] elasticsearch [v7] hosts: [] => [192.168.3.188:9206]
[10-16 11:00:52] [INF] [entry.go:225] auto generating cert files
[10-16 11:00:52] [INF] [actions.go:223] elasticsearch [v2] is available
[10-16 11:00:52] [INF] [actions.go:223] elasticsearch [v7] is available
[10-16 11:00:53] [INF] [entry.go:296] entry [my_es_entry] listen at: https://0.0.0.0:8000
[10-16 11:00:53] [INF] [app.go:309] gateway is running now.可以看到网关输出了启动成功的日志,网关服务监听在 https://0.0.0.0:8000 。
试试访问网关
直接访问网关的 8000 端口,因为是网关自签的证书,加上 -k 来跳过证书的校验,如下:
➜ loadgen git:(master) ✗ curl -k https://localhost:8000
{
"name" : "LENOVO",
"cluster_name" : "es-v7140",
"cluster_uuid" : "npWjpIZmS8iP_p3GK01-xg",
"version" : {
"number" : "7.14.0",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "dd5a0a2acaa2045ff9624f3729fc8a6f40835aa1",
"build_date" : "2021-07-29T20:49:32.864135063Z",
"build_snapshot" : false,
"lucene_version" : "8.9.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}正如前面配置所配置的一样,默认请求访问的就是 v7 集群。
访问 v2 集群
➜ loadgen git:(master) ✗ curl -k https://localhost:8000/v2:/
{
"name" : "Solomon O'Sullivan",
"cluster_name" : "es-v246",
"cluster_uuid" : "cqlpjByvQVWDAv6VvRwPAw",
"version" : {
"number" : "2.4.6",
"build_hash" : "5376dca9f70f3abef96a77f4bb22720ace8240fd",
"build_timestamp" : "2017-07-18T12:17:44Z",
"build_snapshot" : false,
"lucene_version" : "5.5.4"
},
"tagline" : "You Know, for Search"
}查看集群信息:
➜ loadgen git:(master) ✗ curl -k https://localhost:8000/v2:_cluster/health\?pretty
{
"cluster_name" : "es-v246",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 5,
"active_shards" : 5,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 5,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 50.0
}插入一条文档:
➜ loadgen git:(master) ✗ curl-json -k https://localhost:8000/v2:medcl/doc/1 -d '{"name":"hello world"}'
{"_index":"medcl","_type":"doc","_id":"1","_version":1,"_shards":{"total":2,"successful":1,"failed":0},"created":true}% 执行一个查询
➜ loadgen git:(master) ✗ curl -k https://localhost:8000/v2:medcl/_search\?q\=name:hello
{"took":78,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":1,"max_score":0.19178301,"hits":[{"_index":"medcl","_type":"doc","_id":"1","_score":0.19178301,"_source":{"name":"hello world"}}]}}% 可以看到,所有的请求,不管是集群的操作,还是索引的增删改查都可以,而 Elasticsearch 自带的 CCS 是只读的,只能进行查询。
访问 v7 集群
➜ loadgen git:(master) ✗ curl -k https://localhost:8000/v7:/
{
"name" : "LENOVO",
"cluster_name" : "es-v7140",
"cluster_uuid" : "npWjpIZmS8iP_p3GK01-xg",
"version" : {
"number" : "7.14.0",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "dd5a0a2acaa2045ff9624f3729fc8a6f40835aa1",
"build_date" : "2021-07-29T20:49:32.864135063Z",
"build_snapshot" : false,
"lucene_version" : "8.9.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}Kibana 里面访问
完全没问题,有图有真相:

其他操作也类似,就不重复了。
完整的配置
path.data: data
path.logs: log
entry:
- name: my_es_entry
enabled: true
router: my_router
max_concurrency: 10000
network:
binding: 0.0.0.0:8000
tls:
enabled: true
flow:
- name: v2-flow
filter:
- elasticsearch:
elasticsearch: v2
- name: v7-flow
filter:
- elasticsearch:
elasticsearch: v7
- name: cross-cluster-search
filter:
- switch:
path_rules:
- prefix: "v2:"
flow: v2-flow
- prefix: "v7:"
flow: v7-flow
- elasticsearch:
elasticsearch: v7
router:
- name: my_router
default_flow: cross-cluster-search
elasticsearch:
- name: v2
enabled: true
endpoint: http://192.168.3.188:9202
- name: v7
enabled: true
endpoint: http://192.168.3.188:9206小结
好了,今天给大家分享的如何使用极限网关来进行 Elasticsearch 跨集群跨版本的操作就到这里了,希望大家周末玩的开心。😁
求教极限网关的endpoins如何配置多个es节点的ip
回复Elasticsearch • zqc0512 回复了问题 • 2 人关注 • 1 个回复 • 5694 次浏览 • 2021-11-25 11:27
信创环境下部署 INFINI Gateway:为 Easysearch 构建高性能安全入口
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 11718 次浏览 • 2026-06-11 17:17
引言
上一篇文章里,我们已经完成了 Easysearch 在信创环境下的部署。搜索服务能跑起来只是第一步,要让它真正用于生产,还需要补上“入口治理”这一环。
例如,下面这些问题在生产环境中非常常见:
- 如何防止某个应用或用户发出超大查询请求,把 Easysearch 集群拖垮?
- 如果 Easysearch 某个节点突然宕机,请求能不能自动切换到健康节点,让业务无感知?
- 如何知道每天有多少次查询、哪些查询慢、哪些请求不合法,有没有办法对请求进行审计?
这些正是 INFINI Gateway(极限网关) 擅长解决的问题。本文延续“小白友好”风格,带你完成 Gateway 的安装与验证,为 Easysearch 增加一层高性能、安全、可观测的入口防护。
一、INFINI Gateway 是什么?和 Easysearch 是什么关系?
如果把 Easysearch 比作大型图书馆,那么 INFINI Gateway 就像门口的 “前台总台”。过去读者(应用程序)直接进入书库检索;现在所有请求先经过前台,再转发到书库。这样做的好处很直接:可以缓存热门请求,减少后端压力;可以限制流量,避免集群被突发请求冲垮;还可以记录访问日志,方便审计与分析。
从技术层面讲,INFINI Gateway 的定位如下:
- 高性能数据网关:面向搜索场景设计,请求先在网关完成处理,再转发到后端 Easysearch 集群。
- 代理 + 增强:位于客户端与 Easysearch 之间,可在转发链路中叠加限流、缓存加速、请求审计、结果改写等能力。
- 兼容原生 API:对外接口兼容 Elasticsearch / Easysearch 原生 API,应用只需把连接地址从直连 Easysearch 改为指向网关,无需改业务代码。
- 轻量易部署:基于 Golang 开发,安装包约 10MB,无额外外部依赖。
- 信创兼容认证:已通过华为鲲鹏 Kunpeng 920 兼容性认证,并获得 KUNPENG COMPATIBLE 证书。
整个系列的组件关系如下:
应用程序 → INFINI Gateway(流量入口) → Easysearch(数据存储与检索)
有了 Gateway,你就可以更放心地将搜索服务开放给更多应用和用户,而不必过度担心安全与性能失控问题。
二、部署前置条件
1. 信创环境
- CPU :鲲鹏 Kunpeng-920、aarch64
- 操作系统:统信服务器操作系统A版 V20
2. 确保 Easysearch 已正常运行
Gateway 本身不存储数据,核心职责是代理与增强 Easysearch。因此部署前请先确认 Easysearch 已启动,并且网络可达:
curl -ku admin:你的密码 https://localhost:9200三、部署步骤
步骤 1:下载 INFINI Gateway
下面脚本会自动下载对应平台的 Gateway 最新版本,并解压到 /opt/gateway:
# 一键下载并安装到 /opt/gateway
curl -sSL http://get.infini.cloud | bash -s -- -p gateway -d /opt/gateway
步骤 2:编写 Gateway 配置文件
Gateway 启动依赖 YAML 配置文件,用来声明监听端口、后端 Easysearch 地址和认证信息。进入安装目录后,找到 gateway.yml 并按实际环境修改:
# 按实际情况填写可访问的 Easysearch 地址
LOGGING_ES_ENDPOINT:https://localhost:9200/
LOGGING_ES_USER:admin
LOGGING_ES_PASS:"你的 Easysearch 密码"
# 按实际情况填写可访问的 Easysearch 地址
PROD_ES_ENDPOINT:https://localhost:9200/
PROD_ES_USER:admin
PROD_ES_PASS:"你的 Easysearch 密码"
# 按需设置 Gateway 对外监听端口
GW_BINDING:"0.0.0.0:8000"步骤 3:启动 Gateway
进入 Gateway 安装目录,执行下面命令启动程序:
# 进入安装目录
cd /opt/gateway
# 运行程序(gateway-linux-arm64 为可执行文件名)
./gateway-linux-arm64
程序启动后,即可通过配置端口访问 Easysearch 服务。
在前台运行模式下,如需停止 Gateway,按 Ctrl+C 即可。
如果希望将 Gateway 作为后台服务运行,可执行:
# 命令中的 gateway-linux-arm64 为可执行文件名
./gateway-linux-arm64 -service install && ./gateway-linux-arm64 -service start如需卸载服务,执行以下命令:
./gateway-linux-arm64 -service stop
./gateway-linux-arm64 -service uninstall步骤 4:验证 Gateway 是否正常工作
通过 Gateway 间接访问 Easysearch,确认转发通路正常:
# 通过 Gateway(8000 端口)访问 Easysearch
curl http://0.0.0.0:8000
# 对比直连 Easysearch 的结果
curl -ku admin:你的密码 https://localhost:9200两条命令返回的 JSON 结果应基本一致。若都能正常响应,说明 Gateway 已成功接管 Easysearch 的访问入口。
如果你的生产环境需要将搜索服务开放给大量应用和用户,建议将 Gateway 纳入标准部署方案。借助 Gateway,你可以更好地保护后端 Easysearch 集群,并获得限流限速、缓存加速、安全防护、审计日志等增强能力,让整体架构更健壮、更安全、更可观测。
如果在部署过程中遇到问题,欢迎查阅官方文档。祝你部署顺利!
作者:小袁
原文:https://infinilabs.cn/blog/2026/gateway-install-at-xc-platform/
如何使用极限网关实现 Elasticsearch 集群迁移至 Easysearch
Elasticsearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 21233 次浏览 • 2025-09-21 14:50
之前有博客介绍过通过 Reindex 的方法将 Elasticsearch 的数据迁移到 Easysearch 集群,今天再介绍一个方法,通过 极限网关(INFINI Gateway) 来进行数据迁移。
测试环境
| 软件 | 版本 |
|---|---|
| Easysearch | 1.12.0 |
| Elasticsearch | 7.17.29 |
| INFINI Gateway | 1.29.2 |
迁移步骤
- 选定要迁移的索引
- 在目标集群建立索引的 mapping 和 setting
- 准备 INFINI Gateway 迁移配置
- 运行 INFINI Gateway 进行数据迁移
迁移实战
- 选定要迁移的索引
在 Elasticsearch 集群中选择目标索引:infinilabs 和 test1,没错,我们一次可以迁移多个。
- 在 Easysearch 集群使用源索引的 setting 和 mapping 建立目标索引。(略)
- INFINI Gateway 迁移配置准备
去 github 下载配置,修改下面的连接集群的部分
1 env:
2 LR_GATEWAY_API_HOST: 127.0.0.1:2900
3 SRC_ELASTICSEARCH_ENDPOINT: http://127.0.0.1:9200
4 DST_ELASTICSEARCH_ENDPOINT: http://127.0.0.1:9201
5 path.data: data
6 path.logs: log
7 progress_bar.enabled: true
8 configs.auto_reload: true
9
10 api:
11 enabled: true
12 network:
13 binding: $[[env.LR_GATEWAY_API_HOST]]
14
15 elasticsearch:
16 - name: source
17 enabled: true
18 endpoint: $[[env.SRC_ELASTICSEARCH_ENDPOINT]]
19 basic_auth:
20 username: elastic
21 password: goodgoodstudy
22
23 - name: target
24 enabled: true
25 endpoint: $[[env.DST_ELASTICSEARCH_ENDPOINT]]
26 basic_auth:
27 username: admin
28 password: 14da41c79ad2d744b90cpipeline 部分修改要迁移的索引名称,我们迁移 infinilabs 和 test1 两个索引。
31 pipeline:
32 - name: source_scroll
33 auto_start: true
34 keep_running: false
35 processor:
36 - es_scroll:
37 slice_size: 1
38 batch_size: 5000
39 indices: "infinilabs,test1"
40 elasticsearch: source
41 output_queue: source_index_dump
42 partition_size: 1
43 scroll_time: "5m"- 迁移数据
./gateway-mac-arm64
#如果你保存的配置文件名称不叫 gateway.yml,则需要加参数 -config 文件名
数据导入完成后,网关 ctrl+c 退出。
至此,数据迁移就完成了。下一篇我们来介绍 INFINI Gateway 的数据比对功能。
有任何问题,欢迎加我微信沟通。
关于极限网关(INFINI Gateway)
INFINI Gateway 是一个开源的面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway,可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
官网文档:https://docs.infinilabs.com/gateway
开源地址:https://github.com/infinilabs/gateway
ES 调优帖:Gateway 批量写入性能优化实践
Elasticsearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 19087 次浏览 • 2025-08-06 17:32
背景:bulk 优化的应用
在 ES 的写入优化里,bulk 操作被广泛地用于批量处理数据。bulk 操作允许用户一次提交多个数据操作,如索引、更新、删除等,从而提高数据处理效率。bulk 操作的实现原理是,将数据操作请求打包成 HTTP 请求,并批量提交给 Elasticsearch 服务器。这样,Elasticsearch 服务器就可以一次处理多个数据操作,从而提高处理效率。
这种优化的核心价值在于减少了网络往返的次数和连接建立的开销。每一次单独的写入操作都需要经历完整的请求-响应周期,而批量写入则是将多个操作打包在一起,用一次通信完成原本需要多次交互的工作。这不仅仅节省了时间,更重要的是释放了系统资源,让服务器能够专注于真正的数据处理,而不是频繁的协议握手和状态维护。
这样的批量请求的确是可以优化写入请求的效率,让 ES 集群获得更多的资源去做写入请求的集中处理。但是除了客户端与 ES 集群的通讯效率优化,还有其他中间过程能优化么?
Gateway 的优化点
bulk 的优化理念是将日常零散的写入需求做集中化的处理,尽量减低日常请求的损耗,完成资源最大化的利用。简而言之就是“好钢用在刀刃上”。
但是 ES 在收到 bulk 写入请求后,也是需要协调节点根据文档的 id 计算所属的分片来将数据分发到对应的数据节点的。这个过程也是有一定损耗的,如果 bulk 请求中数据分布的很散,每个分片都需要进行写入,原本 bulk 集中写入的需求优势则还是没有得到最理想化的提升。
gateway 的写入加速则对 bulk 的优化理念的最大化补全。
gateway 可以本地计算每个索引文档对应后端 Elasticsearch 集群的目标存放位置,从而能够精准的进行写入请求定位。
在一批 bulk 请求中,可能存在多个后端节点的数据,bulk_reshuffle 过滤器用来将正常的 bulk 请求打散,按照目标节点或者分片进行拆分重新组装,避免 Elasticsearch 节点收到请求之后再次进行请求分发, 从而降低 Elasticsearch 集群间的流量和负载,也能避免单个节点成为热点瓶颈,确保各个数据节点的处理均衡,从而提升集群总体的索引吞吐能力。
整理的优化思路如下图:
优化实践
那我们来实践一下,看看 gateway 能提升多少的写入。
这里我们分 2 个测试场景:
- 基础集中写入测试,不带文档 id,直接批量写入。这个场景更像是日志或者监控数据采集的场景。
- 带文档 id 的写入测试,更偏向搜索场景或者大数据批同步的场景。
2 个场景都进行直接写入 ES 和 gateway 转发 ES 的效率比对。
测试材料除了需要备一个网关和一套 es 外,其余的内容如下:
测试索引 mapping 一致,名称区分:
PUT gateway_bulk_test
{
"settings": {
"number_of_shards": 6,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"timestamp": {
"type": "date",
"format": "strict_date_optional_time"
},
"field1": {
"type": "keyword"
},
"field2": {
"type": "keyword"
},
"field3": {
"type": "keyword"
},
"field4": {
"type": "integer"
},
"field5": {
"type": "keyword"
},
"field6": {
"type": "float"
}
}
}
}
PUT bulk_test
{
"settings": {
"number_of_shards": 6,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"timestamp": {
"type": "date",
"format": "strict_date_optional_time"
},
"field1": {
"type": "keyword"
},
"field2": {
"type": "keyword"
},
"field3": {
"type": "keyword"
},
"field4": {
"type": "integer"
},
"field5": {
"type": "keyword"
},
"field6": {
"type": "float"
}
}
}
}gateway 的配置文件如下:
path.data: data
path.logs: log
entry:
- name: my_es_entry
enabled: true
router: my_router
max_concurrency: 200000
network:
binding: 0.0.0.0:8000
flow:
- name: async_bulk
filter:
- bulk_reshuffle:
when:
contains:
_ctx.request.path: /_bulk
elasticsearch: prod
level: node
partition_size: 1
fix_null_id: true
- elasticsearch:
elasticsearch: prod #elasticsearch configure reference name
max_connection_per_node: 1000 #max tcp connection to upstream, default for all nodes
max_response_size: -1 #default for all nodes
balancer: weight
refresh: # refresh upstream nodes list, need to enable this feature to use elasticsearch nodes auto discovery
enabled: true
interval: 60s
filter:
roles:
exclude:
- master
router:
- name: my_router
default_flow: async_bulk
elasticsearch:
- name: prod
enabled: true
endpoints:
- https://127.0.0.1:9221
- https://127.0.0.1:9222
- https://127.0.0.1:9223
basic_auth:
username: admin
password: admin
pipeline:
- name: bulk_request_ingest
auto_start: true
keep_running: true
retry_delay_in_ms: 1000
processor:
- bulk_indexing:
max_connection_per_node: 100
num_of_slices: 3
max_worker_size: 30
idle_timeout_in_seconds: 10
bulk:
compress: false
batch_size_in_mb: 10
batch_size_in_docs: 10000
consumer:
fetch_max_messages: 100
queue_selector:
labels:
type: bulk_reshuffle测试脚本如下:
#!/usr/bin/env python3
"""
ES Bulk写入性能测试脚本
"""
import hashlib
import json
import random
import string
import time
from typing import List, Dict, Any
import requests
from concurrent.futures import ThreadPoolExecutor
from datetime import datetime
import urllib3
# 禁用SSL警告
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
class ESBulkTester:
def __init__(self):
# 配置变量 - 可修改
self.es_configs = [
{
"name": "ES直连",
"url": "https://127.0.0.1:9221",
"index": "bulk_test",
"username": "admin", # 修改为实际用户名
"password": "admin", # 修改为实际密码
"verify_ssl": False # HTTPS需要SSL验证
},
{
"name": "Gateway代理",
"url": "http://localhost:8000",
"index": "gateway_bulk_test",
"username": None, # 无需认证
"password": None,
"verify_ssl": False
}
]
self.batch_size = 10000 # 每次bulk写入条数
self.log_interval = 100000 # 每多少次bulk写入输出日志
# ID生成规则配置 - 前2位后5位
self.id_prefix_start = 1
self.id_prefix_end = 999 # 前3位: 01-999
self.id_suffix_start = 1
self.id_suffix_end = 9999 # 后4位: 0001-9999
# 当前ID计数器
self.current_prefix = self.id_prefix_start
self.current_suffix = self.id_suffix_start
def generate_id(self) -> str:
"""生成固定规则的ID - 前2位后5位"""
id_str = f"{self.current_prefix:02d}{self.current_suffix:05d}"
# 更新计数器
self.current_suffix += 1
if self.current_suffix > self.id_suffix_end:
self.current_suffix = self.id_suffix_start
self.current_prefix += 1
if self.current_prefix > self.id_prefix_end:
self.current_prefix = self.id_prefix_start
return id_str
def generate_random_hash(self, length: int = 32) -> str:
"""生成随机hash值"""
random_string = ''.join(random.choices(string.ascii_letters + string.digits, k=length))
return hashlib.md5(random_string.encode()).hexdigest()
def generate_document(self) -> Dict[str, Any]:
"""生成随机文档内容"""
return {
"timestamp": datetime.now().isoformat(),
"field1": self.generate_random_hash(),
"field2": self.generate_random_hash(),
"field3": self.generate_random_hash(),
"field4": random.randint(1, 1000),
"field5": random.choice(["A", "B", "C", "D"]),
"field6": random.uniform(0.1, 100.0)
}
def create_bulk_payload(self, index_name: str) -> str:
"""创建bulk写入payload"""
bulk_data = []
for _ in range(self.batch_size):
#doc_id = self.generate_id()
doc = self.generate_document()
# 添加index操作
bulk_data.append(json.dumps({
"index": {
"_index": index_name,
# "_id": doc_id
}
}))
bulk_data.append(json.dumps(doc))
return "\n".join(bulk_data) + "\n"
def bulk_index(self, config: Dict[str, Any], payload: str) -> bool:
"""执行bulk写入"""
url = f"{config['url']}/_bulk"
headers = {
"Content-Type": "application/x-ndjson"
}
# 设置认证信息
auth = None
if config.get('username') and config.get('password'):
auth = (config['username'], config['password'])
try:
response = requests.post(
url,
data=payload,
headers=headers,
auth=auth,
verify=config.get('verify_ssl', True),
timeout=30
)
return response.status_code == 200
except Exception as e:
print(f"Bulk写入失败: {e}")
return False
def refresh_index(self, config: Dict[str, Any]) -> bool:
"""刷新索引"""
url = f"{config['url']}/{config['index']}/_refresh"
# 设置认证信息
auth = None
if config.get('username') and config.get('password'):
auth = (config['username'], config['password'])
try:
response = requests.post(
url,
auth=auth,
verify=config.get('verify_ssl', True),
timeout=10
)
success = response.status_code == 200
print(f"索引刷新{'成功' if success else '失败'}: {config['index']}")
return success
except Exception as e:
print(f"索引刷新失败: {e}")
return False
def run_test(self, config: Dict[str, Any], round_num: int, total_iterations: int = 100000):
"""运行性能测试"""
test_name = f"{config['name']}-第{round_num}轮"
print(f"\n开始测试: {test_name}")
print(f"ES地址: {config['url']}")
print(f"索引名称: {config['index']}")
print(f"认证: {'是' if config.get('username') else '否'}")
print(f"每次bulk写入: {self.batch_size}条")
print(f"总计划写入: {total_iterations * self.batch_size}条")
print("-" * 50)
start_time = time.time()
success_count = 0
error_count = 0
for i in range(1, total_iterations + 1):
payload = self.create_bulk_payload(config['index'])
if self.bulk_index(config, payload):
success_count += 1
else:
error_count += 1
# 每N次输出日志
if i % self.log_interval == 0:
elapsed_time = time.time() - start_time
rate = i / elapsed_time if elapsed_time > 0 else 0
print(f"已完成 {i:,} 次bulk写入, 耗时: {elapsed_time:.2f}秒, 速率: {rate:.2f} bulk/秒")
end_time = time.time()
total_time = end_time - start_time
total_docs = total_iterations * self.batch_size
print(f"\n{test_name} 测试完成!")
print(f"总耗时: {total_time:.2f}秒")
print(f"成功bulk写入: {success_count:,}次")
print(f"失败bulk写入: {error_count:,}次")
print(f"总文档数: {total_docs:,}条")
print(f"平均速率: {success_count/total_time:.2f} bulk/秒")
print(f"文档写入速率: {total_docs/total_time:.2f} docs/秒")
print("=" * 60)
return {
"test_name": test_name,
"config_name": config['name'],
"round": round_num,
"es_url": config['url'],
"index": config['index'],
"total_time": total_time,
"success_count": success_count,
"error_count": error_count,
"total_docs": total_docs,
"bulk_rate": success_count/total_time,
"doc_rate": total_docs/total_time
}
def run_comparison_test(self, total_iterations: int = 10000):
"""运行双地址对比测试"""
print("ES Bulk写入性能测试开始")
print(f"测试时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
print("=" * 60)
results = []
rounds = 2 # 每个地址测试2轮
# 循环测试所有配置
for config in self.es_configs:
print(f"\n开始测试配置: {config['name']}")
print("*" * 40)
for round_num in range(1, rounds + 1):
# 运行测试
result = self.run_test(config, round_num, total_iterations)
results.append(result)
# 每轮结束后刷新索引
print(f"\n第{round_num}轮测试完成,执行索引刷新...")
self.refresh_index(config)
# 重置ID计数器
if round_num == 1:
# 第1轮:使用初始ID范围(新增数据)
print("第1轮:新增数据模式")
else:
# 第2轮:重复使用相同ID(更新数据模式)
print("第2轮:数据更新模式,复用第1轮ID")
self.current_prefix = self.id_prefix_start
self.current_suffix = self.id_suffix_start
print(f"{config['name']} 第{round_num}轮测试结束\n")
# 输出对比结果
print("\n性能对比结果:")
print("=" * 80)
# 按配置分组显示结果
config_results = {}
for result in results:
config_name = result['config_name']
if config_name not in config_results:
config_results[config_name] = []
config_results[config_name].append(result)
for config_name, rounds_data in config_results.items():
print(f"\n{config_name}:")
total_time = 0
total_bulk_rate = 0
total_doc_rate = 0
for round_data in rounds_data:
print(f" 第{round_data['round']}轮:")
print(f" 耗时: {round_data['total_time']:.2f}秒")
print(f" Bulk速率: {round_data['bulk_rate']:.2f} bulk/秒")
print(f" 文档速率: {round_data['doc_rate']:.2f} docs/秒")
print(f" 成功率: {round_data['success_count']/(round_data['success_count']+round_data['error_count'])*100:.2f}%")
total_time += round_data['total_time']
total_bulk_rate += round_data['bulk_rate']
total_doc_rate += round_data['doc_rate']
avg_bulk_rate = total_bulk_rate / len(rounds_data)
avg_doc_rate = total_doc_rate / len(rounds_data)
print(f" 平均性能:")
print(f" 总耗时: {total_time:.2f}秒")
print(f" 平均Bulk速率: {avg_bulk_rate:.2f} bulk/秒")
print(f" 平均文档速率: {avg_doc_rate:.2f} docs/秒")
# 整体对比
if len(config_results) >= 2:
config_names = list(config_results.keys())
config1_avg = sum([r['bulk_rate'] for r in config_results[config_names[0]]]) / len(config_results[config_names[0]])
config2_avg = sum([r['bulk_rate'] for r in config_results[config_names[1]]]) / len(config_results[config_names[1]])
if config1_avg > config2_avg:
faster = config_names[0]
rate_diff = config1_avg - config2_avg
else:
faster = config_names[1]
rate_diff = config2_avg - config1_avg
print(f"\n整体性能对比:")
print(f"{faster} 平均性能更好,bulk速率高 {rate_diff:.2f} bulk/秒")
print(f"性能提升: {(rate_diff/min(config1_avg, config2_avg)*100):.1f}%")
def main():
"""主函数"""
tester = ESBulkTester()
# 运行测试(每次bulk 1万条,300次bulk = 300万条文档)
tester.run_comparison_test(total_iterations=300)
if __name__ == "__main__":
main()1. 日志场景:不带 id 写入
测试条件:
- bulk 写入数据不带文档 id
- 每批次 bulk 10000 条数据,总共写入 30w 数据
这里把
反馈结果:
性能对比结果:
================================================================================
ES直连:
第1轮:
耗时: 152.29秒
Bulk速率: 1.97 bulk/秒
文档速率: 19699.59 docs/秒
成功率: 100.00%
平均性能:
总耗时: 152.29秒
平均Bulk速率: 1.97 bulk/秒
平均文档速率: 19699.59 docs/秒
Gateway代理:
第1轮:
耗时: 115.63秒
Bulk速率: 2.59 bulk/秒
文档速率: 25944.35 docs/秒
成功率: 100.00%
平均性能:
总耗时: 115.63秒
平均Bulk速率: 2.59 bulk/秒
平均文档速率: 25944.35 docs/秒
整体性能对比:
Gateway代理 平均性能更好,bulk速率高 0.62 bulk/秒
性能提升: 31.7%2. 业务场景:带文档 id 的写入
测试条件:
- bulk 写入数据带有文档 id,两次测试写入的文档 id 生成规则一致且重复。
- 每批次 bulk 10000 条数据,总共写入 30w 数据
这里把 py 脚本中 第 99 行 和 第 107 行的注释打开。
反馈结果:
性能对比结果:
================================================================================
ES直连:
第1轮:
耗时: 155.30秒
Bulk速率: 1.93 bulk/秒
文档速率: 19317.39 docs/秒
成功率: 100.00%
平均性能:
总耗时: 155.30秒
平均Bulk速率: 1.93 bulk/秒
平均文档速率: 19317.39 docs/秒
Gateway代理:
第1轮:
耗时: 116.73秒
Bulk速率: 2.57 bulk/秒
文档速率: 25700.06 docs/秒
成功率: 100.00%
平均性能:
总耗时: 116.73秒
平均Bulk速率: 2.57 bulk/秒
平均文档速率: 25700.06 docs/秒
整体性能对比:
Gateway代理 平均性能更好,bulk速率高 0.64 bulk/秒
性能提升: 33.0%小结
不管是日志场景还是业务价值更重要的大数据或者搜索数据同步场景, gateway 的写入加速都能平稳的节省 25%-30% 的写入耗时。
关于极限网关(INFINI Gateway)
INFINI Gateway 是一个开源的面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway,可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
官网文档:https://docs.infinilabs.com/gateway
开源地址:https://github.com/infinilabs/gateway
作者:金多安,极限科技(INFINI Labs)搜索运维专家,Elastic 认证专家,搜索客社区日报责任编辑。一直从事与搜索运维相关的工作,日常会去挖掘 ES / Lucene 方向的搜索技术原理,保持搜索相关技术发展的关注。
原文:https://infinilabs.cn/blog/2025/gateway-bulk-write-performance-optimization/
【搜索客社区日报】第1838期 (2024-06-14)
社区日报 • Fred2000 发表了文章 • 0 个评论 • 3185 次浏览 • 2024-06-14 09:18
极限网关助力好未来 Elasticsearch 容器化升级
Elasticsearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 5423 次浏览 • 2024-06-12 15:01
极限网关在好未来的最佳实践案例,轻松扛住日增百 TB 数据的流量,助力 ES 从物理机到云原生架构的改造,实现了流控、请求分析、安全管理、无缝迁移等场景。一次完美的客户体验~
背景
物理机架构时代
2022 年,好未来整个日志 Elasticsearch 拥有数十套服务集群,几百台物理机。这么多台机器耗费成本非常高,而且还要花费很大精力去维护。在人力资源有限情况下,存在非常多的弊端,运行成本高,不仅是机器折旧还有机柜等费用。
流量特征
这是来自某个业务线,如下图 1,真实流量,潮汐性非常明显。好未来有很多条业务线,几乎跟这个趋势都一致的,除了个别业务有“续报”、“开课”等活动特殊情况。潮汐性带来的问题就是高峰期 CPU、内存资源是可以消耗很高;低峰期资源使用量非常低,由于是物理架构,这些资源无法给其他业务线共享。
降本增效-容器化改造原动力
日志服务对成本的空前的压力促使我们推进 Elasticsearch 进行架构改造;如何改造,改造成什么样子,这两个问题一直是推进改造原动力。业界能够同时对水平扩展和垂直扩展就是 K8S,我们开始对 Elasticsearch 改造成能在 K8S 上运行进行探索,从而提升 CPU、内存利用率。
物理机时代,没办法把资源动态的扩缩,动态调配,资源隔离,单靠人力操作调度成本太高,几乎无法完成;集群对内存资源需求要比 CPU 资源大很多,由于机器型号配置是固定的,无法“定制”,这也会导致成本居高不下。所以,无论从那个方面来讲,容器化优势非常明显,既能够优化成本,也能够降低运维复杂度。
ES 容器化改造
进行架构升级重点难点- API 服务
改造过程,我们遇到了很多问题,比如容器 ES 版本和物理机 ES 版本不一致,如何让 ES API 能够兼容不同的 ES 版本,由于版本的不兼容,导致无法直接使用原有的 tribenode 进行服务,怎么提供一个高可用的 Elasticsearch API 服务。我们考虑到多个方面,比如使用官方推荐的 proxy 模式、第三方服务等进行选择,经过多方面对比,选择了极限网关 进行 tribenode 替换。
原始 ES API 服务痛点
- API 访问没有流量控制
- 可观测性差,而且稳定性一般
- 版本兼容性差
物理机时代 API 架构
在物理机时代 ES 集群,API 架构如图 2,可以明显看到 tribe node 对所有 ES 集群的“侵入性”是非常大的,这就带来了很多问题,比较严重的就是单个集群对 ES tribenode 的影响和版本升级带来的不兼容问题。
混合时代 API 架构
通过图 3,我们可以看到,极限网关对于版本兼容性很好,能够适配不同的版本。因此,最终选择极限网关作为下一代 ES API 服务方。
里程碑:全部 ES 集群容器化
在 2023 年 3 月份,通过 Elastic 官方 ECK 模式,完成全部日志 ES 集群容器化改造,拥有数百节点,1PB+ 数据存储,每日新增数据 100T 左右。紧接着,除了日志服务外,同时支持了好未来多条业务线。
极限网关实践
下面主要讲述了,为什么选择极限网关,以及极限网关在好未来落地、应用这些内容。
为什么选择极限网关?
学习成本低
我们可以从文档中看到极限网关,其架构简洁,语法简单,直观易懂。学习成本比较低,上手非常快,对新手友好。
性能强悍
经过压测,发现极限网关速度非常快,且针对 Elasticsearch 做了非常细致的优化,能成倍提升写入和查询的速度。
安全性高
支持多种认证方式,最简单的账号密码认证,可以给自定义多个账户密码,大大简化了 Elasticsearch 的安全设置,同时,还可以支持 LDAP 安全验证。
跨版本支持
我们容器化改造过程需要兼容不同版本的 Elasticsrearch,极限网关针对不同的 Elasticsearch 版本做了兼容和针对性处理,能够让业务代码无缝的进行适配,后端 Elasticsearch 集群版本升级能够做到无缝过渡,降低版本升级和数据迁移的复杂度,非常匹配我们的业务场景。
灵活可扩展
可灵活对每个请求进行干预和路由,支持路由的智能学习,内置丰富的过滤器,通过配置动态修改每个请求的处理逻辑,也支持通过插件来进行扩展,满足我们对流量的控制,尤其是限流、用户、IP 等这些功能非常实用。
启用安全策略-为 API 服务保驾护航
痛点
在升级之前使用 tribe 作为 API 服务提供后端,几乎相当于裸奔,没有任何认证策略;另外,tribe 本身的稳定性也有问题,官方在新版本逐渐废弃这种 CCS(跨集群搜索),期间出现多次服务崩溃。
极限网关解决问题
极限网关通过,“basic_auth” 插件,提供最基本的安全校验,使用起来非常方便;同时,极限网关提供 LDAP 插件,可以接入公共的 LDAP 服务,对所有的访问用户进行校验,安全策略对所有的用户生效,不用担心因为 IP 问题泄漏数据等。
强大的过滤功能
在使用 ES 集群过程中,许多场景,需要对请求进行控制、限制等操作。在这方便,感受到了极限网关强大的产品力。比如下面的两个场景
对异常流量进行限流
- 支持对 IP 限流
- 支持对 hostname 限流
- 支持 header 限流
对异常用户进行封禁
当 Elasticsearch 是通过 Basic Auth 或者 LDAP 方式来进行身份认证的时候,request_user_filter 过滤器可用来按请求的用户名信息来进行过滤。操作起来也非常简单,只需要 request_user_filter 这一个过滤器。
- request_user_filter:
include:
- "elastic"
exclude:
- "Ryan"总结来讲,主要有这些方面的功能:
优秀的可观测性
痛点
改造前经常为看不到直观的数据指标感到头疼,查看指标需要多个地方同时打开,去筛选,查找,非常繁琐,付出的成本非常大。为此,大家都再考虑如何优化这种情况,无奈优先级比较低,一直没有真正的投入时间去优化这块。
完美解决
使用了极限网关,通过收集请求日志,非常清晰的收集到想要的数据,具体如下:
- 总体方面:
- 流量曲线
- 状态码占比
- 缓存统计
- 每台网关请求流量
- 细节方面:
- 打印每次请求语句
- 可以查看请求到具体 ES 节点流量
- 可以查看过滤器的列表
通过下图,我们可以从管理视角直观的看到各种信息,这对于管理员来讲,省时省力,方便快捷。
意外收获:无缝迁移业务 Elasticsearch 上云
由于前期日志业务上云,受到非常好的反馈,多个业务线期望能够上云上服务,达到降本增效的目的。
支持双写
数据可以通过极限网关同时写入两个 ES 集群,能够保障数据完全一致,安全可靠。
无缝切换
切换很丝滑,影响非常小,能够让外界几乎感受不到服务波动。
通过使用极限网关,自建 ES 集群可以无缝的迁移上云,在整个迁移的过程中,两套集群通过网关进行了解耦,在迁移的过程中还能实现版本的无缝升级,极大降低了迁移成本,提高迁移效率,多次验证服务稳定可靠。
极限网关流量概览
这是其中一套极限网关的流量统计。用这部分数据进行巡检,一目了然,做到全局的掌控,提高感知力度。
极限网关使用总结
极限网关提供一系列高性能和高可靠性的网关服务。使用这样的服务给我们带来以下好处:
- 可观测性好:极限网关可以动态的对 Elasticsearch 运行过程中请求进行拦截和分析,通过指标和日志来了解集群运行状态,这些指标可以用于提升性能和业务优化。
- 增强安全性:包含先进的安全机制,如 basicauth、LDAP 等支持,保护用户数据不受未授权访问和各种网络威胁的侵害。
- 高稳定性:通过冗余设计和故障转移机制,极限网关能够确保网络服务的高可用性,即使在某些组件发生故障时也能保持服务不中断,单版本最长服务超过 15 个月。
- 易于管理:通过提供 INFINI Console 简洁直观的管理界面,让用户能够轻松配置和监控网络状态,提升管理效率。
- 客户支持:良好的客户服务支持可以帮助用户快速解决使用过程中遇到的问题,提供专业的技术指导。
综上所述,极限网关为用户提供了一个高速、安全、稳定且易于管理的 ES 网关,适合对网络性能有较高要求的个人和企业用户。
未来规划
第一阶段,完成了日志 ES 集群,所有集群的容器化改造,合并,成功的把成本降低了 60%以上。这期间积累了丰富容器化经验,为业务 ES 集群上容器做了良好的铺垫;成本优势和运维优势吸引越来越多的业务接入到容器化 ES 集群。
提升 ES 集群效能--新技术应用&&版本升级
- 极限科技官方推荐的 Easysearch 在压缩率,查询速度等等方面有很多的优势,通过长时间的测试稳定性,新特性,对比云原生的 ES 集群,根据测试结果,给“客户”提供多种选择,这也是工作重点之一。
- 我们当前使用的 ES 版本是 6.8,已经远远落后于官方版本,今年我们计划在选择合适的集群升级 ES 版本,拥抱更多官方提供的特性。
混合(多)云架构支持
随着越来越多的 ES 集群在机房的 K8S 集群部署,这里资源出现了紧张局面。 我们尝试在云上部署自建 ES 集群,弥补机房资源有限,无法大规模扩容,同时能够支持多活场景,满足更多客户的不同需求。混合云主要实现以下几种能力:
1、扩缩容:满足不同业务灵活适配
混合(多)云部署,可以让负载内部私有云 ES,同时部署到公有云,提升扩展 IT 基础设施不仅局限于 CPU、内存,还有存储。比如某一个业务要做活动,预估流量“大爆发”,需要提前准备大规模资源,在机房内根本来不及采购扩容支持,然而在公有云上就能很方便扩容、缩容。在云上搭建 ES 集群,设置满足需求的数量、容量、配置,配合极限网关路由策略,精准的把控流量流向。
2、灾备:紧急情况快速部署,恢复 ES 集群读写
当机房级别大规模故障,部分业务实现了多活,单一的机房故障不会影响其服务能力,而此时比如日志查看等仍有需求,为了满足这部分“客户”需求,可以在云上 K8S 集群,快速搭建 ES 集群,恢复日志读写功能。
参考文档:
- https://infinilabs.cn/docs/latest/gateway
- https://www.elastic.co/guide/en/cloud-on-K8S/current/K8S-overview.html
作者:张华勋,前新浪 CDN 研发,工作主要涉及 Mysql、MongoDB、Redis、Elasticsearch、流量调度等组件和系统,以及运维自动化、平台化等工作。现就职于好未来。
关于好未来
好未来(NYSE:TAL)是一家以内容能力与科技能力为基础,以科教、科创、科普为战略方向,助力人的终身成长,并持续探索创新的科技公司。 好未来的前身学而思成立于 2003 年,2010 年在美国纽交所正式挂牌交易。好未来以“爱与科技助力终身成长”为使命,致力成为持续创新的组织。更多参见:https://www.100tal.com/
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
【搜索客社区日报】 第1824期 (2024-05-24)
社区日报 • searchkit 发表了文章 • 0 个评论 • 3753 次浏览 • 2024-05-24 13:17
INFINI Labs 产品更新 | Console 1.24.0 操作日志审计功能发布
资讯动态 • liaosy 发表了文章 • 0 个评论 • 4659 次浏览 • 2024-04-28 12:51
INFINI Labs 产品又更新啦~,包括 Console,Gateway 1.24.0。本次各产品更新了很多亮点功能,如 Console 增加操作日志审计功能,优化数据探索字段统计,修复 Gateway 增加认证后添加实例失败等问题。以下是本次更新的详细说明。
INFINI Console v1.24.0
INFINI Console 是一款非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管, 企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 在线体验: http://demo.infini.cloud (用户名/密码:readonly/readonly)。
Console 本次更新如下:
Features
- 用户操作审计日志功能
- 新增告警规则克隆一键克隆功能,简化重复类型告警的创建
Bug fix
- 修复普通用户权限 403 问题
- 修复探针管理表格展开显示错位问题
Improvements
- 优化开发工具集群选择控件显示位置
- 优化数据探索查询控件显示宽度
- 优化数据探索字段统计功能
- 优化告警规则列表页搜索,支持远程搜索
- Discover 左侧字段聚合支持开关控制拉取本地或远程统计值
INFINI Gateway v1.24.0
INFINI Gateway 是一个面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway 可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
Gateway 本次更新如下:
Improvements
- Refactoring http client tls config
- Write field routing to bulk metadata when field _routing exists in scrolled doc
Bug fix
- Fix(reshuffle filter): make sure queue config always have label type
- Fix rotate config usage
INFINI Framework
Improvements
- feat: allow to use default auth for agent’s auto enroll
- refactor: refactor func GetFieldCaps
- feat: register background job to clean up badger LSM tree
- fix: skip load missing wal
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
您还可以通过邮件联系我们:hello@infini.ltd
或者拨打我们的热线电话:(+86) 400-139-9200
欢迎加入 Discord 聊天室:https://discord.gg/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
记某客户的一次 Elasticsearch 无缝数据迁移
Elasticsearch • yangmf2040 发表了文章 • 0 个评论 • 7484 次浏览 • 2024-04-02 14:16
背景
客户需要将 Elasticsearch 集群无缝迁移到移动云,迁移过程要保证业务的最小停机时间。
实现方式
通过采用成熟的 INFINI 网关来进行数据的双写,在集群的切换恢复过程中来记录数据变更,待全量数据恢复之后再追平后面增量数据,追平增量之后,进行校验确保数据一致再进行流量的切换。
总体流程
总体迁移流程如下:
- 客户业务代码,切流量,双写。(新增的变更都会记录在网关本地,但是暂停消费到移动云)
- 暂停网关移动云这边的增量数据消费。
- 迁移 11 月的数据,快照,快照上传到 S3;
- 下载 S3 的文件到移动云。
- 恢复快照到移动云的 11 月份的索引。
- 开启网关移动云这边的增量消费。
- 等待增量追平(接近追平)。
- 按照时间条件(如:时间 A,当前时间往前 30 分钟),验证文档数据量,Hash 校验等等。
- 停业务的写入,网关,腾讯云的写入(10 分钟)。
- 等待剩余的增量追完。
- 对时间 A 之后的,增量进行校验。
- 切换所有流量到移动云,业务端直接访问移动云 ES。
总体的迁移时间:
- 11 月备份时间(30 分钟)19 号开始
- 备份下载到移动云的时间(2-3 天)
- 备份恢复到移动云集群的时间(30 分钟)
- 11 月份增量备份(20 分钟)(双写开始)(21 号)
- 11 月份增量下载到移动云(6 小时)
- 11 月份增量恢复时间(20 分钟)
- 追增量数据(8 个小时产生的数据,需要 1 个小时)
- 校验比对(存量 1 个小时)
- 流量暂停,增量的校验(10 分钟)
- 切换(1 分钟)
总体流程如下示意图:
ES 集群信息
- ES 版本 7.10.1
- 2个热节点 3个温节点 总数 1.9 TB
- 索引 1041, 分片2085
- 无自定义插件
- 有 update_bu_query 使用
- 有 delete_by_query 使用
- 吞吐量没有测试过,当前日增文档数 1 千多万,目标日增加上亿
迁移操作手册(参考)
环境
- 自建 ES 5.4.2
- 自建 ES 5.6.8
- 自建 ES 7.5.0
- 极限网关服务器 1
- 极限网关服务器 2
- 云端负载均衡 1 (监听 9200 端口,指向极限网关服务器 1/2 的 8000 端口)
- 云端负载均衡 2 (监听 9200 端口,指向极限网关服务器 1/2 的 8001 端口)
场景描述
若干个自建 Elasticsearch 集群需要平滑迁移到移动云,业务不停写、不做代码改动。
数据架构
通过将应用端流量走网关的方式,请求同步转发给自建 ES,网关记录所有的写入请求,并确保顺序在云端 ES 上重放请求,两侧集群的各种故障都妥善进行了处理,从而实现透明的集群双写,实现安全无缝的数据迁移。
业务端如果已经部署在云上,可以使用云上的 SLB 服务来访问网关,确保后端网关的高可用,如果业务端和极限网关还在企业内网,可以使用极限网关自带的 4 层浮动 IP 来确保网关的高可用。
数据描述
以数据从自建集群 5.4.2 迁移到云上的 5.6.16 为例进行说明,执行步骤依次说明。
执行步骤
部署 INFINI Gateway
为了保证数据的无缝透明迁移,通过 INFINI Gateway 来进行双写。
-
系统调优
参考此文档。
- 下载程序
[root@iZbp1gxkifg8uetb33pvcoZ ~]# mkdir /opt/gateway [root@iZbp1gxkifg8uetb33pvcoZ ~]# cd /opt/gateway/ [root@iZbp1gxkifg8uetb33pvcoZ gateway]# wget http://release.infinilabs.com/gateway/snapshot/gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz --2022-05-19 10:16:25-- http://release.infinilabs.com/gateway/snapshot/gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz 正在解析主机 release.infinilabs.com (release.infinilabs.com)... 120.79.205.193 正在连接 release.infinilabs.com (release.infinilabs.com)|120.79.205.193|:80... 已连接。 已发出 HTTP 请求,正在等待回应... 200 OK 长度:7430568 (7.1M) [application/octet-stream] 正在保存至: “gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz”
100%[==============================================================================================================================================>] 7,430,568 22.8MB/s 用时 0.3s
2022-05-19 10:16:25 (22.8 MB/s) - 已保存 “gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz” [7430568/7430568])
[root@iZbp1gxkifg8uetb33pvcoZ gateway]# tar vxzf gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz gateway-linux-amd64 gateway.yml sample-configs/ sample-configs/elasticsearch-with-ldap.yml sample-configs/indices-replace.yml sample-configs/record_and_play.yml sample-configs/cross-cluster-search.yml sample-configs/kibana-proxy.yml sample-configs/elasticsearch-proxy.yml sample-configs/v8-bulk-indexing-compatibility.yml sample-configs/use_old_style_search_response.yml sample-configs/context-update.yml sample-configs/elasticsearch-route-by-index.yml sample-configs/hello_world.yml sample-configs/entry-with-tls.yml sample-configs/javascript.yml sample-configs/log4j-request-filter.yml sample-configs/request-filter.yml sample-configs/condition.yml sample-configs/cross-cluster-replication.yml sample-configs/secured-elasticsearch-proxy.yml sample-configs/fast-bulk-indexing.yml sample-configs/es_migration.yml sample-configs/index-docs-diff.yml sample-configs/rate-limiter.yml sample-configs/async-bulk-indexing.yml sample-configs/elasticssearch-request-logging.yml sample-configs/router_rules.yml sample-configs/auth.yml sample-configs/index-backup.yml
3. 修改配置
将网关提供的示例配置拷贝,并根据实际集群的信息进行相应的修改,如下:[root@iZbp1gxkifg8uetb33pvcoZ gateway]# cp sample-configs/cross-cluster-replication.yml 5.4.2TO5.6.16.yml
首先修改集群的身份信息,如下:

然后修改集群的注册信息,如下:

根据需要修改网关监听的端口,以及是否开启 TLS (如果应用客户端通过 http 协议访问 ES,请将entry.tls.enabled 值改为 false),如下:

不同的集群可以使用不同的配置,分别监听不同的端口,用于业务的分开访问。
4. 启动网关
启动网关并指定刚刚创建的配置,如下:[root@iZbp1gxkifg8uetb33pvcoZ gateway]# ./gateway-linux-amd64 -config 5.4.2TO5.6.16.yml
/ \ /\ / \/\/ / /\ \ \/\ /_/\ / /\///\ / /\/\ \ \/ \/ //\_ / / /\/ \/ / // \ /\ / \/ \ ___/\/ \/\/ \/ \/ \/_/ _/_/
[GATEWAY] A light-weight, powerful and high-performance elasticsearch gateway. [GATEWAY] 1.6.0_SNAPSHOT, 2022-05-18 11:09:54, 2023-12-31 10:10:10, 73408e82a0f96352075f4c7d2974fd274eeafe11 [05-19 13:35:43] [INF] [app.go:174] initializing gateway. [05-19 13:35:43] [INF] [app.go:175] using config: /opt/gateway/5.4.2TO5.6.16.yml. [05-19 13:35:43] [INF] [instance.go:72] workspace: /opt/gateway/data1/gateway/nodes/ca2tc22j7ad0gneois80 [05-19 13:35:43] [INF] [app.go:283] gateway is up and running now. [05-19 13:35:50] [INF] [actions.go:358] elasticsearch [primary] is available [05-19 13:35:50] [INF] [api.go:262] api listen at: http://0.0.0.0:2900 [05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [primary] hosts: [] => [192.168.0.19:9200] [05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [backup] hosts: [] => [es-cn-tl32p9fkk0006m56k.elasticsearch.aliyuncs.com:9200] [05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [primary] hosts: [] => [192.168.0.19:9200] [05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [backup] hosts: [] => [es-cn-tl32p9fkk0006m56k.elasticsearch.aliyuncs.com:9200] [05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [primary] hosts: [] => [192.168.0.19:9200] [05-19 13:35:50] [INF] [entry.go:322] entry [my_es_entry/] listen at: https://0.0.0.0:8000 [05-19 13:35:50] [INF] [module.go:116] all modules are started
5. 后台运行[root@iZbp1gxkifg8uetb33pvcoZ gateway]# nohup ./gateway-linux-amd64 -config 5.4.2TO5.6.16.yml &
6. 应用授权curl -XPOST http://localhost:2900/_license/apply -d' { "license": "XXXXXXXXXXXXXXXXXXXXXXXXX" }'
#### 部署 INFINI Console
为了方便在多个集群之间快速切换,使用 INFINI [Console](https://infinilabs.cn/products/console/) 来进行管理。
1. 下载安装[root@iZbp1gxkifg8uetb33pvcpZ console]# wget http://release.infinilabs.com/console/snapshot/console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz --2022-05-19 10:57:24-- http://release.infinilabs.com/console/snapshot/console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz 正在解析主机 release.infinilabs.com (release.infinilabs.com)... 120.79.205.193 正在连接 release.infinilabs.com (release.infinilabs.com)|120.79.205.193|:80... 已连接。 已发出 HTTP 请求,正在等待回应... 200 OK 长度:13576234 (13M) [application/octet-stream] 正在保存至: “console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz”
100%[==============================================================================================================================================>] 13,576,234 33.2MB/s 用时 0.4s
2022-05-19 10:57:25 (33.2 MB/s) - 已保存 “console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz” [13576234/13576234])
[root@iZbp1gxkifg8uetb33pvcpZ console]# tar vxzf console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz console-linux-amd64 console.yml
2. 修改配置[root@iZbp1gxkifg8uetb33pvcpZ console]# cat console.yml
for the system cluster, please use Elasticsearch v7.3+
elasticsearch:
- name: default
enabled: true
monitored: false
endpoint: http://es-cn-7mz2p9fty0007frx0.elasticsearch.aliyuncs.com:9200
basic_auth:
username: elastic
password: XXXXXX
discovery:
enabled: false
...
-
启动服务
[root@iZbp1gxkifg8uetb33pvcpZ console]# ./console-linux-amd64 -service install Success [root@iZbp1gxkifg8uetb33pvcpZ console]# ./console-linux-amd64 -service start Success - 访问后台
访问该主机的 9000 端口,即可打开 Console 后台,http://x.x.x.x:9000/
打开菜单 [System][Cluster] ,注册当前需要管理的 Elasticsearch 集群和网关地址,用来快速管理,如下:
测试 INFINI Gateway
为了验证网关是否正常工作,我们通过 INFINI Console 来快速验证一下。
首先通过走网关的接口来创建一个索引,并写入一个文档,如下:
查看 5.4.2 集群的数据情况,如下:
查看集群 5.6.16 的数据情况,如下:
说明网关配置都正常,验证结束。
调整网关的消费策略
因为我们需要在全量数据迁移之后,才能进行增量数据的追加,在全量数据迁移完成之前,我们应该暂停增量数据的消费。修改网关配置里面 Pipeline consume-queue_backup-to-backup和 consume-queue_primary-failure-to-backup的参数 auto_start为 false,表示不自动启动该任务,具体配置方法如下:
修改完配置之后,需要重新启动网关。
为了方便管理,可以使用 INFINI Console 来注册和管理网关,如下:
待全量迁移完成之后,可以通过后台的 Task 管理来进行后续的任务启动、停止,如下:
切换流量
接下来,将业务正常写的流量切换到网关,也就是需要把之前指向 ES 5.4.2 的地址指向网关的地址,如果 5.4.2 集群开启了身份验证,业务端代码同样需要传递身份信息,和 5.4.2 之前的用法保持不变。
切换流量到网关之后,用户的请求还是以同步的方式正常访问自建集群,网关记录到的请求会按顺序记录到 MQ 里面,但是消费是暂停状态。
如果业务端代码使用的 ES 的 SDK 支持 Sniff,并且业务代码开启了 Sniff,那么应该关闭 Sniff,避免业务端通过 Sniff 直接链接到后端的 ES 节点,所有的流量现在应该都只通过网关来进行访问。
全量数据迁移
在流量迁移到网关之后,我们开始对自建 Elasticsearch 集群的数据进行全量迁移到云端 Elasticsearch 集群。
全量迁移已有的数据的方式有很多种:
- 通过快照的方式进行恢复
- 使用工具来导出导入,如: ESM
如果索引数量很多的话,可以按照索引依次进行导入,同时需要注意将 Mapping 和 Setting 提前导入。
以现在 5.4 集群的索引来为例,目前的待迁移索引为 demo_5_4_2,只有4 个文档:
我们使用网关自带的迁移功能来进行数据迁移,拷贝自带的样例文件,如下:
[root@iZbp1gxkifg8uetb33pvcpZ gateway]# cp sample-configs/es_migration.yml 5.4TO5.6.yml修改其中代表集群和索引的相关配置,可以根据需要配置是否需要重命名索引和统一 Type( 用于跨版本统一 Type),如下图红框位置:
创建好模板和索引,如果目标集群不允许动态创建文档,需要提前创建好索引,如下图:
然后就可以开始数据的迁移了,执行网关程序并指定刚刚定义的配置,如下:
执行完成后,可以确认下数据的情况,如下图:
全量数据至此导入完成。
增量数据迁移
在全量导入的过程中,可能存在数据的增量修改,不过这部分请求都已经完整记录下来了,我们只需要开启网关的消费任务即可将挤压的请求应用到云端的 Elasticsearch 集群。
示例操作如下:
如果从 5.6 的集群来看的话,这部分的修改还没同步过来,如下:
这部分增量的数据变更,在网关层面都进行了完整记录,我们只需要开启网关的增量消费任务,如下:
通过观察队列是否消费完成来判断增量数据是否做完,如下:
现在我们再看一下 5.6 集群的数据情况,如下:
数据的增量更新就过来了。
执行数据比对
由于集群内部的数据可能比较多,我们需要进行一个完整的比对才能确保数据的完整性,可以通过网关自带的数据比对工具来进行,将样例自带的文件拷贝一份,如下:
[root@iZbp1gxkifg8uetb33pvcpZ gateway]# cp sample-configs/index-docs-diff.yml 5.4DIFF5.6.yml修改需要比对的集群和索引信息,可以加上过滤条件,如时间范围窗口来进行增量 Diff,如下图:
执行网关程序,并指定该配置文件,如下图:
如图,两个集群完全一致。
切换集群
如果验证完之后,两个集群的数据已经完全一致了,可以将程序切换到新集群,或者将网关的配置里面的主备进行互换,同步写 5.6 集群。
双集群在线运行一段时间,待业务完全验证之后,再安全下线旧集群,如遇到问题,也可以随时回切到老集群。
小结
通过使用极限网关,自建 ES 集群可以安全无缝的迁移到移动云 ES,在迁移的过程中,两套集群通过网关进行了解耦,两套集群的版本也可以不一样,在迁移的过程中还能实现版本的无缝升级。
如有任何问题,请随时联系我,期待与您交流!
如何防止 Elasticsearch 服务 OOM?
Easysearch • yangmf2040 发表了文章 • 0 个评论 • 3963 次浏览 • 2024-02-26 10:12
Elasticsearch(简称:ES) 和传统关系型数据库有很多区别, 比如传统数据中普遍都有一个叫“最大连接数”的设置。目的是使数据库系统工作在可控的负载下,避免出现负载过高,资源耗尽,谁也无法登录的局面。
那 ES 在这方面有类似参数吗?答案是没有,这也是为何 ES 会被流量打爆的原因之一。
针对大并发访问 ES 服务,造成 ES 节点 OOM,服务中断的情况,极限科技旗下的 INFINI Gateway 产品(以下简称 “极限网关”)可从两个方面入手,保障 ES 服务的可用性。
- 限制最大并发访问连接数。
- 限制非重要索引的请求速度,保障重要业务索引的访问速度。
下面我们来详细聊聊。
架构图
所有访问 ES 的请求都发给网关,可部署多个网关。
限制最大连接数
在网关配置文件中,默认有最大并发连接数限制,默认最大 10000。
entry:
- name: my_es_entry
enabled: true
router: my_router
max_concurrency: 10000
network:
binding: $[[env.GW_BINDING]]
# See `gateway.disable_reuse_port_by_default` for more information.
reuse_port: true使用压测程序测试,看看到达10000个连接后,能否限制新的连接。
超过的连接请求,被丢弃。更多信息参考官方文档。
限制索引写入速度
我们先看看不做限制的时候,测试环境的写入速度,在 9w - 15w docs/s 之间波动。虽然峰值很高,但不稳定。
接下来,我们通过网关把写入速度控制在最大 1w docs/s 。
对网关的配置文件 gateway.yml ,做以下修改。
env: # env 下添加
THROTTLE_BULK_INDEXING_MAX_BYTES: 40485760 #40MB/s
THROTTLE_BULK_INDEXING_MAX_REQUESTS: 10000 #10k docs/s
THROTTLE_BULK_INDEXING_ACTION: retry #retry,drop
THROTTLE_BULK_INDEXING_MAX_RETRY_TIMES: 10 #1000
THROTTLE_BULK_INDEXING_RETRY_DELAY_IN_MS: 100 #10
router: # route 部分修改 flow
- name: my_router
default_flow: default_flow
tracing_flow: logging_flow
rules:
- method:
- "*"
pattern:
- "/_bulk"
- "/{any_index}/_bulk"
flow:
- write_flow
flow: #flow 部分增加下面两段
- name: write_flow
filter:
- flow:
flows:
- bulking_indexing_limit
- elasticsearch:
elasticsearch: prod
max_connection_per_node: 1000
- name: bulking_indexing_limit
filter:
- bulk_request_throttle:
indices:
"test-index":
max_bytes: $[[env.THROTTLE_BULK_INDEXING_MAX_BYTES]]
max_requests: $[[env.THROTTLE_BULK_INDEXING_MAX_REQUESTS]]
action: $[[env.THROTTLE_BULK_INDEXING_ACTION]]
retry_delay_in_ms: $[[env.THROTTLE_BULK_INDEXING_RETRY_DELAY_IN_MS]]
max_retry_times: $[[env.THROTTLE_BULK_INDEXING_MAX_RETRY_TIMES]]
message: "bulk writing too fast" #触发限流告警message自定义
log_warn_message: true
再次压测,test-index 索引写入速度被限制在了 1w docs/s 。
限制多个索引写入速度
上面的配置是针对 test-index 索引的写入速度控制。如果想添加其他的索引,新增一段配置即可。 比如,我允许 abc 索引写入达到 2w docs/s,test-index 索引最多不超过 1w docs/s ,可配置如下。
- name: bulking_indexing_limit
filter:
- bulk_request_throttle:
indices:
"abc":
max_requests: 20000
action: drop
message: "abc doc写入超阈值" #触发限流告警message自定义
log_warn_message: true
"test-index":
max_bytes: $[[env.THROTTLE_BULK_INDEXING_MAX_BYTES]]
max_requests: $[[env.THROTTLE_BULK_INDEXING_MAX_REQUESTS]]
action: $[[env.THROTTLE_BULK_INDEXING_ACTION]]
retry_delay_in_ms: $[[env.THROTTLE_BULK_INDEXING_RETRY_DELAY_IN_MS]]
max_retry_times: $[[env.THROTTLE_BULK_INDEXING_MAX_RETRY_TIMES]]
message: "bulk writing too fast" #触发限流告警message自定义
log_warn_message: true限速效果如下
限制读请求速度
我们先看看不做限制的时候,测试环境的读取速度,7w qps 。
接下来我们通过网关把读取速度控制在最大 1w qps 。
继续对网关的配置文件 gateway.yml 做以下修改。
- name: default_flow
filter:
- request_path_limiter:
message: "Hey, You just reached our request limit!" rules:
- pattern: "/(?P<index_name>abc)/_search"
max_qps: 10000
group: index_name
- elasticsearch:
elasticsearch: prod
max_connection_per_node: 1000再次进行测试,读取速度被限制在了 1w qps 。
限制多个索引读取速度
上面的配置是针对 abc 索引的写入速度控制。如果想添加其他的索引,新增一段配置即可。 比如,我允许 abc 索引读取达到 1w qps,test-index 索引最多不超过 2w qps ,可配置如下。
- name: default_flow
filter:
- request_path_limiter:
message: "Hey, You just reached our request limit!"
rules:
- pattern: "/(?P<index_name>abc)/_search"
max_qps: 10000
group: index_name
- pattern: "/(?P<index_name>test-index)/_search"
max_qps: 20000
group: index_name
- elasticsearch:
elasticsearch: prod
max_connection_per_node: 1000
多个网关限速
限速是每个网关自身的控制,如果有多个网关,那么后端 ES 集群收到的请求数等于多个网关限速的总和。
本次介绍就到这里了。相信大家在使用 ES 的过程中也遇到过各种各样的问题。欢迎大家来我们这个平台分享自己的问题、解决方案等。如有任何问题,请随时联系我,期待与您交流!
开启安全功能 ES 集群就安全了吗?
Easysearch • yangmf2040 发表了文章 • 0 个评论 • 4956 次浏览 • 2023-12-27 10:38
背景
经常跟 ES 打交道的朋友都知道,现在主流的 ES 集群安全方案是:RBAC + TLS for Internal + HTTPS 。
作为终端用户一般只需要关心用户名和密码就行了。作为管理和运维 ES 的人员来说,可能希望 ES 能提供密码策略来强制密码强度和密码使用周期。遗憾的是 ES 对密码强度和密码使用周期没有任何强制要求。如果不注意,可能我们天天都在使用“弱密码”或从不修改的密码(直到无法登录)。而且 ES 对连续的认证失败,不会做任何处理,这让 ES 很容易遭受暴力破解的入侵。
那还有没有别的办法,进一步提高安全呢? 其实,网关可以来帮忙。
虽然网关无法强制提高密码复杂度,但可以提高 ES 集群被暴力破解的难度。
大家都知道,暴力破解--本质就是不停的“猜”你的密码。以现在的 CPU 算力,一秒钟“猜”个几千上万次不过是洒洒水,而且 CPU 监控都不带波动的,很难发现异常。从这里入手,一方面,网关可以延长认证失败的过程--延迟返回结果,让破解不再暴力。另一方面,网关可以记录认证失败的情况,做到实时监控,有条件的告警。一旦出现苗头,可以使用网关阻断该 IP 或用户发来的任何请求。
场景模拟
首先,用网关代理 ES 集群,并在 default_flow 中增加一段 response_status_filter 过滤器配置,对返回码是 401 的请求,跳转到 rate_limit_flow 进行降速,延迟 5 秒返回。
- name: default_flow
filter:
- elasticsearch:
elasticsearch: prod
max_connection_per_node: 1000
- response_status_filter:
exclude:
- 401
action: redirect_flow
flow: rate_limit_flow
- name: rate_limit_flow
filter:
- sleep:
sleep_in_million_seconds: 5000
其次,对于失败的认证,我们可以通过 Console 来做个看板实时分析,展示。
折线图、饼图图、柱状图等,多种展示方式,大家可充分发挥。
最后,可在 Console 的告警中心,配置对应的告警规则,实时监控该类事件,方便及时跟进处置。
效果测试
先带上正确的用户名密码测试,看看返回速度。
0.011 秒返回。再使用错误的密码测试。
整整 5 秒多后,才回返结果。如果要暴力破解,每 5 秒钟甚至更久才尝试一个密码,这还叫暴力吗?
看板示例
此处仅仅是抛砖引玉,欢迎大家发挥想象。
告警示例
建立告警规则,用户 1 分钟内超过 3 次登录失败,就产生告警。
可在告警中心查看详情,也可将告警推送至微信、钉钉、飞书、邮件等。
查看告警详情,是 es 用户触发了告警。
最后,剩下的工作就是对该账号的处置了。如果有需要可以考虑阻止该用户或 IP 的请求,对应的过滤器文档在这里,老规矩加到 default_flow 里就行了。
如果小伙伴有其他办法提升 ES 集群安全,欢迎和我们一起讨论、交流。我们的宗旨是:让搜索更简单!
用极限网关实现ES容灾,简单!
Elasticsearch • yangmf2040 发表了文章 • 0 个评论 • 4274 次浏览 • 2023-07-20 10:33
身为 IT 人士,大伙身边的各种系统肯定不少吧。系统虽多,但最最最重要的那套、那几套,大伙肯定是捧在手心,关怀备至。如此重要的系统,万一发生故障了且短期无法恢复,该如何保障业务持续运行? 有过这方面思考或经验的同学,肯定脱口而出--切灾备啊。 是的,接下来我来介绍下我们的 ES 灾备方案。当然如果你有更好的,请使用各种可用的渠道联系我们。
总体设计
通过极限网关将应用对主集群的写操作,复制到灾备集群。应用发送的读请求则直接转发到主集群,并将响应结果转发给应用。应用对网关无感知,访问方式与访问 ES 集群一样。
方案优势
- 轻量级
极限网关使用 Golang 编写,安装包很小,只有 10MB 左右,没有任何外部环境依赖,部署安装都非常简单,只需要下载对应平台的二进制可执行文件,启动网关程序的二进制程序文件执行即可。
- 跨版本支持
极限网关针对不同的 Elasticsearch 版本做了兼容和针对性处理,能够让业务代码无缝的进行适配,后端 Elasticsearch 集群版本升级能够做到无缝过渡,降低版本升级和数据迁移的复杂度。
- 高可用
极限网关内置多种高可用解决方案,前端请求入口支持基于虚拟 IP 的双机热备,后端集群支持集群拓扑的自动感知,节点上下线能自动发现,自动处理后端故障,自动进行请求的重试和迁移。
- 灵活性
主备集群都是可读可写,切换迅速,只需切换网关到另一套配置即可。回切灵活,恢复使用原配置即可。
架构图
网关程序部署
下载
根据操作系统和平台选择下面相应的安装包: 解压到指定目录:
mkdir gateway
tar -zxf xxx.gz -C gateway修改网关配置
在此 下载 网关配置,默认网关会加载配置文件 gateway.yml ,如果要指定其他配置文件使用 -config 选项指定。 网关配置文件内容较多,下面展示必要部分。
#primary
PRIMARY_ENDPOINT: http://192.168.56.3:7171
PRIMARY_USERNAME: elastic
PRIMARY_PASSWORD: password
PRIMARY_MAX_QPS_PER_NODE: 10000
PRIMARY_MAX_BYTES_PER_NODE: 104857600 #100MB/s
PRIMARY_MAX_CONNECTION_PER_NODE: 200
PRIMARY_DISCOVERY_ENABLED: false
PRIMARY_DISCOVERY_REFRESH_ENABLED: false
#backup
BACKUP_ENDPOINT: http://192.168.56.3:9200
BACKUP_USERNAME: admin
BACKUP_PASSWORD: admin
BACKUP_MAX_QPS_PER_NODE: 10000
BACKUP_MAX_BYTES_PER_NODE: 104857600 #100MB/s
BACKUP_MAX_CONNECTION_PER_NODE: 200
BACKUP_DISCOVERY_ENABLED: false
BACKUP_DISCOVERY_REFRESH_ENABLED: falsePRIMARY_ENDPOINT:配置主集群地址和端口
PRIMARY_USERNAME、PRIMARY_PASSWORD: 访问主集群的用户信息
BACKUP_ENDPOINT:配置备集群地址和端口
BACKUP_USERNAME、BACKUP_PASSWORD: 访问备集群的用户信息
运行网关
前台运行 直接运行网关程序即可启动极限网关了,如下:
./gateway-linux-amd64后台运行
./gateway-linux-amd64 -service install
Success
./gateway-linux-amd64 -service start
Success卸载服务
./gateway-linux-amd64 -service stop
Success
./gateway-linux-amd64 -service uninstall
Success灾备功能测试
在灾备场景下,为保证数据一致性,对集群的访问操作都通过网关进行。注意只有 bulk API 的操作才会被复制到备集群。 在此次测试中,网关灾备配置功能为:
- 主备集群正常时
读写请求正常执行; 写请求被记录到队列,备集群实时消费队列数据。
- 当主集群故障时
写入请求报错,主备集群都不写入数据; 查询请求转到备集群执行,并返回结果给客户端。
- 当备集群故障时
读写请求都正常执行; 写操作记录到磁盘队列,待备集群恢复后,自动消费队列数据直到两个集群一致。
主备集群正常时写入、查询测试
写入数据
# 通过网关写入数据
curl -X POST "localhost:18000/_bulk?pretty" -H 'Content-Type: application/json' -uelastic:password -d'
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "create" : { "_index" : "test", "_id" : "2" } }
{ "field2" : "value2" }
'
查询数据
# 查询主集群
curl 192.168.56.3:7171/test/_search?pretty -uelastic:password
# 查询备集群
curl 192.168.56.3:9200/test/_search?pretty -uadmin:admin
# 查询网关,网关转发给主集群执行
curl 192.168.56.3:18000/test/_search?pretty -uelastic:password
主备集群都已写入数据,且数据一致。通过网关查询,也正常返回。
删除和更新文档
# 通过网关删除和更新文档
curl -X POST "192.168.56.3:18000/_bulk?pretty" -H 'Content-Type: application/json' -uelastic:password -d'
{ "delete" : { "_index" : "test", "_id" : "1" } }
{ "update" : {"_id" : "2", "_index" : "test"} }
{ "doc" : {"field2" : "value2-updated"} }
'
查询数据
# 查询主集群
curl 192.168.56.3:7171/test/_search?pretty -uelastic:password
# 查询备集群
curl 192.168.56.3:9200/test/_search?pretty -uadmin:admin
两个集群都已执行删除和更新操作,数据一致。
主集群故障时写入、查询测试
为模拟主集群故障,直接关闭主集群。
写入数据
# 通过网关写入数据
curl -X POST "192.168.56.3:18000/_bulk?pretty" -H 'Content-Type: application/json' -uelastic:password -d'
{ "index" : { "_index" : "test", "_id" : "3" } }
{ "field3" : "value3" }
{ "create" : { "_index" : "test", "_id" : "4" } }
{ "field4" : "value4" }
'写入数据报错
查询数据
# 通过网关查询,因为主集群不可用,网关将查询转发到备集群执行
curl 192.168.56.3:18000/test/_search?pretty -uelastic:password
正常查询到数据,说明请求被转发到了备集群执行。
备集群故障时写入、查询测试
为模拟备集群故障,直接关闭备集群。
写入数据
# 通过网关写入数据
curl -X POST "192.168.56.3:18000/_bulk?pretty" -H 'Content-Type: application/json' -uelastic:password -d'
{ "index" : { "_index" : "test", "_id" : "5" } }
{ "field5" : "value5" }
{ "create" : { "_index" : "test", "_id" : "6" } }
{ "field6" : "value6" }
'
数据正常写入。
查询数据
# 通过网关查询
curl 192.168.56.3:18000/test/_search?pretty -uelastic:password
查询成功返回。主集群成功写入了两条新数据。同时此数据会被记录到备集群的队列中,待备集群恢复后,会消费此队列追数据。
恢复备集群
启动备集群。
查询数据
等待片刻或通过 INFINI Console 确定网关队列消费完毕后,查询备集群的数据。
(生产和消费 offset 相同,说明消费完毕。)
# 查询备集群的数据
curl 192.168.56.3:9200/test/_search?pretty -uadmin:admin
备集群启动后自动消费队列数据,消费完后备集群数据达到与主集群数据一致。
灾备切换
测试了这么多,终于到切换的时刻了。切换前我们判断下主系统是否短期无法修复。
如果我们判断主用系统无法短时间恢复,要执行切换。非常简单,我们直接将配置文件中定义的主备集群互换,然后重启网关程序就行了。但我们推荐在相同主机上另部署一套网关程序--网关B,先前那套用网关A指代。网关B中的配置文件把原备集群定义为主集群,原主集群定义为备集群。若要执行切换,我们先停止网关A,然后启动网关B,此时应用连接到网关(端口不变),就把原备系统当作主系统使用,把原主系统当作备系统,也就完成了主备系统的切换。
灾备回切
当原主集群修复后,正常启动,就会从消费队列追写修复期间产生数据直到主备数据一致,同样我们可通过 INFINI Console 查看消费的进度。如果大家还是担心数据的一致性,INFINI Console 还能帮大家做[校验数据]()任务,做到数据完全一致后(文档数量及文档内容一致),才进行回切。
回切也非常简单,停止网关B,启动网关A即可。
网关高可用
网关自带浮动 IP 模块,可进行双机热备。客户端通过 VIP 连接网关,网关出现故障时,VIP 漂移到备网关。
视频教程戳这里。
这样的优点是简单,不足是只有一个网关在线提供服务。如果想多个网关在线提供服务,则需搭配分布式消息系统一起工作,架构如下。
前端通过负载均衡将流量分散到多个在线网关,网关将消息存入分布式消息系统。此时,网关可看作无状态应用,可根据需要扩缩规模。
以上就是我介绍的ES灾备方案,是不是相当灵活了。有问题还是那句话 Call me 。
关于极限网关
INFINI Gateway 是一个面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway,可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
在 Kibana 里统一访问来自不同集群的索引
资料分享 • medcl 发表了文章 • 0 个评论 • 6575 次浏览 • 2022-04-21 15:29
在 Kibana 里统一访问来自不同集群的索引
现在有这么一个需求,客户根据需要将数据按照业务维度划分,将索引分别存放在了不同的三个集群, 将一个大集群拆分成多个小集群有很多好处,比如降低了耦合,带来了集群可用性和稳定性方面的好处,也避免了单个业务的热点访问造成其他业务的影响, 尽管拆分集群是很常见的玩法,但是管理起来不是那么方便了,尤其是在查询的时候,可能要分别访问三套集群各自的 API,甚至要切换三套不同的 Kibana 来访问集群的数据, 那么有没有办法将他们无缝的联合在一起呢?
极限网关!
答案自然是有的,通过将 Kibana 访问 Elasticsearch 的地址切换为极限网关的地址,我们可以将请求按照索引来进行智能的路由, 也就是当访问不同的业务索引时会智能的路由到不同的集群,如下图:
上图,我们分别有 3 个不同的索引:
- apm-*
- erp-*
- mall-*
分别对应不同的三套 Elasticsearch 集群:
- ES1-APM
- ES2-ERP
- ES3-MALL
接下来我们来看如何在极限网关里面进行相应的配置来满足这个业务需求。
配置集群信息
首先配置 3 个集群的连接信息。
elasticsearch:
- name: es1-apm
enabled: true
endpoints:
- http://192.168.3.188:9206
- name: es2-erp
enabled: true
endpoints:
- http://192.168.3.188:9207
- name: es3-mall
enabled: true
endpoints:
- http://192.168.3.188:9208配置服务 Flow
然后,我们定义 3 个 Flow,分别对应用来访问 3 个不同的 Elasticsearch 集群,如下:
flow:
- name: es1-flow
filter:
- elasticsearch:
elasticsearch: es1-apm
- name: es2-flow
filter:
- elasticsearch:
elasticsearch: es2-erp
- name: es3-flow
filter:
- elasticsearch:
elasticsearch: es3-mall然后再定义一个 flow 用来进行路径的判断和转发,如下:
- name: default-flow
filter:
- switch:
remove_prefix: false
path_rules:
- prefix: apm-
flow: es1-flow
- prefix: erp-
flow: es2-flow
- prefix: mall-
flow: es3-flow
- flow: #default flow
flows:
- es1-flow根据请求路径里面的索引前缀来匹配不同的索引,并转发到不同的 Flow。
配置路由信息
接下来,我们定义路由信息,具体配置如下:
router:
- name: my_router
default_flow: default-flow指向上面定义的默认 flow 来统一请求的处理。
定义服务及关联路由
最后,我们定义一个监听为 8000 端口的服务,用来提供给 Kibana 来进行统一的入口访问,如下:
entry:
- name: es_entry
enabled: true
router: my_router
max_concurrency: 10000
network:
binding: 0.0.0.0:8000完整配置
最后的完整配置如下:
path.data: data
path.logs: log
entry:
- name: es_entry
enabled: true
router: my_router
max_concurrency: 10000
network:
binding: 0.0.0.0:8000
flow:
- name: default-flow
filter:
- switch:
remove_prefix: false
path_rules:
- prefix: apm-
flow: es1-flow
- prefix: erp-
flow: es2-flow
- prefix: mall-
flow: es3-flow
- flow: #default flow
flows:
- es1-flow
- name: es1-flow
filter:
- elasticsearch:
elasticsearch: es1-apm
- name: es2-flow
filter:
- elasticsearch:
elasticsearch: es2-erp
- name: es3-flow
filter:
- elasticsearch:
elasticsearch: es3-mall
router:
- name: my_router
default_flow: default-flow
elasticsearch:
- name: es1-apm
enabled: true
endpoints:
- http://192.168.3.188:9206
- name: es2-erp
enabled: true
endpoints:
- http://192.168.3.188:9207
- name: es3-mall
enabled: true
endpoints:
- http://192.168.3.188:9208启动网关
直接启动网关,如下:
➜ gateway git:(master) ✗ ./bin/gateway -config sample-configs/elasticsearch-route-by-index.yml
___ _ _____ __ __ __ _
/ _ \ /_\ /__ \/__\/ / /\ \ \/_\ /\_/\
/ /_\///_\\ / /\/_\ \ \/ \/ //_\\\_ _/
/ /_\\/ _ \/ / //__ \ /\ / _ \/ \
\____/\_/ \_/\/ \__/ \/ \/\_/ \_/\_/
[GATEWAY] A light-weight, powerful and high-performance elasticsearch gateway.
[GATEWAY] 1.0.0_SNAPSHOT, 2022-04-20 08:23:56, 2023-12-31 10:10:10, 51650a5c3d6aaa436f3c8a8828ea74894c3524b9
[04-21 13:41:21] [INF] [app.go:174] initializing gateway.
[04-21 13:41:21] [INF] [app.go:175] using config: /Users/medcl/go/src/infini.sh/gateway/sample-configs/elasticsearch-route-by-index.yml.
[04-21 13:41:21] [INF] [instance.go:72] workspace: /Users/medcl/go/src/infini.sh/gateway/data/gateway/nodes/c9bpg0ai4h931o4ngs3g
[04-21 13:41:21] [INF] [app.go:283] gateway is up and running now.
[04-21 13:41:21] [INF] [api.go:262] api listen at: http://0.0.0.0:2900
[04-21 13:41:21] [INF] [reverseproxy.go:255] elasticsearch [es1-apm] hosts: [] => [192.168.3.188:9206]
[04-21 13:41:21] [INF] [reverseproxy.go:255] elasticsearch [es2-erp] hosts: [] => [192.168.3.188:9207]
[04-21 13:41:21] [INF] [reverseproxy.go:255] elasticsearch [es3-mall] hosts: [] => [192.168.3.188:9208]
[04-21 13:41:21] [INF] [actions.go:349] elasticsearch [es2-erp] is available
[04-21 13:41:21] [INF] [actions.go:349] elasticsearch [es1-apm] is available
[04-21 13:41:21] [INF] [entry.go:312] entry [es_entry] listen at: http://0.0.0.0:8000
[04-21 13:41:21] [INF] [module.go:116] all modules are started
[04-21 13:41:21] [INF] [actions.go:349] elasticsearch [es3-mall] is available
[04-21 13:41:55] [INF] [reverseproxy.go:255] elasticsearch [es1-apm] hosts: [] => [192.168.3.188:9206]网关启动成功之后,就可以通过网关的 IP+8000 端口来访问目标 Elasticsearch 集群了。
测试访问
首先通过 API 来访问测试一下,如下:
➜ ~ curl http://localhost:8000/apm-2022/_search -v
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to localhost (127.0.0.1) port 8000 (#0)
> GET /apm-2022/_search HTTP/1.1
> Host: localhost:8000
> User-Agent: curl/7.54.0
> Accept: */*
>
< HTTP/1.1 200 OK
< Date: Thu, 21 Apr 2022 05:45:44 GMT
< content-type: application/json; charset=UTF-8
< Content-Length: 162
< X-elastic-product: Elasticsearch
< X-Backend-Cluster: es1-apm
< X-Backend-Server: 192.168.3.188:9206
< X-Filters: filters->elasticsearch
<
* Connection #0 to host localhost left intact
{"took":142,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":0,"relation":"eq"},"max_score":null,"hits":[]}}% 可以看到 apm-2022 指向了后端的 es1-apm 集群。
继续测试,erp 索引的访问,如下:
➜ ~ curl http://localhost:8000/erp-2022/_search -v
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to localhost (127.0.0.1) port 8000 (#0)
> GET /erp-2022/_search HTTP/1.1
> Host: localhost:8000
> User-Agent: curl/7.54.0
> Accept: */*
>
< HTTP/1.1 200 OK
< Date: Thu, 21 Apr 2022 06:24:46 GMT
< content-type: application/json; charset=UTF-8
< Content-Length: 161
< X-Backend-Cluster: es2-erp
< X-Backend-Server: 192.168.3.188:9207
< X-Filters: filters->switch->filters->elasticsearch->skipped
<
* Connection #0 to host localhost left intact
{"took":12,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":0,"relation":"eq"},"max_score":null,"hits":[]}}%继续测试,mall 索引的访问,如下:
➜ ~ curl http://localhost:8000/mall-2022/_search -v
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to localhost (127.0.0.1) port 8000 (#0)
> GET /mall-2022/_search HTTP/1.1
> Host: localhost:8000
> User-Agent: curl/7.54.0
> Accept: */*
>
< HTTP/1.1 200 OK
< Date: Thu, 21 Apr 2022 06:25:08 GMT
< content-type: application/json; charset=UTF-8
< Content-Length: 134
< X-Backend-Cluster: es3-mall
< X-Backend-Server: 192.168.3.188:9208
< X-Filters: filters->switch->filters->elasticsearch->skipped
<
* Connection #0 to host localhost left intact
{"took":8,"timed_out":false,"_shards":{"total":5,"successful":5,"skipped":0,"failed":0},"hits":{"total":0,"max_score":null,"hits":[]}}% 完美转发。
修改 Kibana 配置
修改 Kibana 的配置文件: kibana.yml,替换 Elasticsearch 的地址为网关地址(http://192.168.3.200:8000),如下:
elasticsearch.hosts: ["http://192.168.3.200:8000"]重启 Kibana 让配置生效。
效果如下
可以看到,在一个 Kibana 的开发者工具里面,我们已经可以像操作一个集群一样来同时读写实际上来自三个不同集群的索引数据了。
展望
通过极限网关,我们还可以非常灵活的进行在线请求的流量编辑,动态组合不同集群的操作。
在极限网关里面使用 JavaScript 脚本来进行复杂的查询改写
资料分享 • medcl 发表了文章 • 1 个评论 • 5290 次浏览 • 2022-04-19 11:55
使用 JavaScript 脚本来进行复杂的查询改写
有这么一个需求:
网关里怎样对跨集群搜索进行支持的呢?我想实现: 输入的搜索请求是 lp:9200/index1/_search 这个索引在3个集群上,需要跨集群检索,也就是网关能否改成 lp:9200/cluster01:index1,cluster02,index1,cluster03:index1/_search 呢? 索引有一百多个,名称不一定是 app, 还可能多个索引一起的。
极限网关自带的过滤器 content_regex_replace 虽然可以实现字符正则替换,但是这个需求是带参数的变量替换,稍微复杂一点,没有办法直接用这个正则替换实现,有什么其他办法实现么?
使用脚本过滤器
当然有的,上面的这个需求,理论上我们只需要将其中的索引 index1 匹配之后,替换为 cluster01:index1,cluster02,index1,cluster03:index1 就行了。
答案就是使用自定义脚本来做,再复杂的业务逻辑都不是问题,都能通过自定义脚本来实现,一行脚本不行,那就两行。
使用极限网关提供的 JavaScript 过滤器可以很灵活的实现这个功能,具体继续看。
定义过滤器
首先创建一个脚本文件,放在网关数据目录的 scripts 子目录下面,如下:
➜ gateway ✗ tree data
data
└── gateway
└── nodes
└── c9bpg0ai4h931o4ngs3g
├── kvdb
├── queue
├── scripts
│ └── index_path_rewrite.js
└── stats这个脚本的内容如下:
function process(context) {
var originalPath = context.Get("_ctx.request.path");
var matches = originalPath.match(/\/?(.*?)\/_search/)
var indexNames = [];
if(matches && matches.length > 1) {
indexNames = matches[1].split(",")
}
var resultNames = []
var clusterNames = ["cluster01", "cluster02"]
if(indexNames.length > 0) {
for(var i=0; i<indexNames.length; i++){
if(indexNames[i].length > 0) {
for(var j=0; j<clusterNames.length; j++){
resultNames.push(clusterNames[j]+":"+indexNames[i])
}
}
}
}
if (resultNames.length>0){
var newPath="/"+resultNames.join(",")+"/_search";
context.Put("_ctx.request.path",newPath);
}
}和普通的 JavaScript 一样,定义一个特定的函数 process 来处理请求里面的上下文信息,_ctx.request.path 是网关内置上下文的一个变量,用来获取请求的路径,通过 context.Get("_ctx.request.path") 在脚本里面进行访问。
中间我们使用了 JavaScript 的正则匹配和字符处理,做了一些字符拼接,得到新的路径 newPath 变量,最后使用 context.Put("_ctx.request.path",newPath) 更新网关请求的路径信息,从而实现查询条件里面的参数替换。
有关网关内置上下文的变量列表,请访问 Request Context
接下来,创建一个网关配置,并使用 javascript 过滤器调用该脚本,如下:
entry:
- name: my_es_entry
enabled: true
router: my_router
max_concurrency: 10000
network:
binding: 0.0.0.0:8000
flow:
- name: default_flow
filter:
- dump:
context:
- _ctx.request.path
- javascript:
file: index_path_rewrite.js
- dump:
context:
- _ctx.request.path
- elasticsearch:
elasticsearch: dev
router:
- name: my_router
default_flow: default_flow
elasticsearch:
- name: dev
enabled: true
schema: http
hosts:
- 192.168.3.188:9206上面的例子中,使用了一个 javascript 过滤器,并且指定了加载的脚本文件为 index_path_rewrite.js,并使用了两个 dump 过滤器来输出脚本运行前后的路径信息,最后再使用一个 elasticsearch 过滤器来转发请求给 Elasticsearch 进行查询。
我们启动网关测试一下,如下:
➜ gateway ✗ ./bin/gateway
___ _ _____ __ __ __ _
/ _ \ /_\ /__ \/__\/ / /\ \ \/_\ /\_/\
/ /_\///_\\ / /\/_\ \ \/ \/ //_\\\_ _/
/ /_\\/ _ \/ / //__ \ /\ / _ \/ \
\____/\_/ \_/\/ \__/ \/ \/\_/ \_/\_/
[GATEWAY] A light-weight, powerful and high-performance elasticsearch gateway.
[GATEWAY] 1.0.0_SNAPSHOT, 2022-04-18 07:11:09, 2023-12-31 10:10:10, 8062c4bc6e57a3fefcce71c0628d2d4141e46953
[04-19 11:41:29] [INF] [app.go:174] initializing gateway.
[04-19 11:41:29] [INF] [app.go:175] using config: /Users/medcl/go/src/infini.sh/gateway/gateway.yml.
[04-19 11:41:29] [INF] [instance.go:72] workspace: /Users/medcl/go/src/infini.sh/gateway/data/gateway/nodes/c9bpg0ai4h931o4ngs3g
[04-19 11:41:29] [INF] [app.go:283] gateway is up and running now.
[04-19 11:41:30] [INF] [api.go:262] api listen at: http://0.0.0.0:2900
[04-19 11:41:30] [INF] [entry.go:312] entry [my_es_entry] listen at: http://0.0.0.0:8000
[04-19 11:41:30] [INF] [module.go:116] all modules are started
[04-19 11:41:30] [INF] [actions.go:349] elasticsearch [dev] is available运行下面的查询来验证查询结果,如下:
curl localhost:8000/abc,efg/_search可以看到网关通过 dump 过滤器输出的调试信息:
---- DUMPING CONTEXT ----
_ctx.request.path : /abc,efg/_search
---- DUMPING CONTEXT ----
_ctx.request.path : /cluster01:abc,cluster02:abc,cluster01:efg,cluster02:efg/_search查询条件按照我们的需求进行了改写,Nice!
重写 DSL 查询语句
好吧,我们刚刚只是修改了查询的索引而已,那么查询请求的 DSL 呢?行不行?
那自然是可以的嘛,瞧下面的例子:
function process(context) {
var originalDSL = context.Get("_ctx.request.body");
if (originalDSL.length >0){
var jsonObj=JSON.parse(originalDSL);
jsonObj.size=123;
jsonObj.aggs= {
"test1": {
"terms": {
"field": "abc",
"size": 10
}
}
}
context.Put("_ctx.request.body",JSON.stringify(jsonObj));
}
}先是获取查询请求,然后转换成 JSON 对象,之后任意修改查询对象就行了,保存回去,搞掂。
测试一下:
curl -XPOST localhost:8000/abc,efg/_search -d'{"query":{}}'输出:
---- DUMPING CONTEXT ----
_ctx.request.path : /abc,efg/_search
_ctx.request.body : {"query":{}}
[04-19 18:14:24] [INF] [reverseproxy.go:255] elasticsearch [dev] hosts: [] => [192.168.3.188:9206]
---- DUMPING CONTEXT ----
_ctx.request.path : /abc,efg/_search
_ctx.request.body : {"query":{},"size":123,"aggs":{"test1":{"terms":{"field":"abc","size":10}}}}是不是感觉解锁了新的世界?
结论
通过使用 Javascript 脚本过滤器,我们可以非常灵活的进行复杂逻辑的操作来满足我们的业务需求。
极限网关初探(2)配置
Elasticsearch • xushuhui 发表了文章 • 0 个评论 • 3924 次浏览 • 2022-04-06 17:03
配置
上一篇我们先学习了极限网关的安装和启动,今天学习配置。
读写分离
现在我们遇到读写分离的需求,用网关该怎么做呢? 假设服务端现在从 http://127.0.0.1:8000 写入数据,从 http://127.0.0.1:9000 读取数据,怎么设计呢?
首先查看文档配置文档
我们在 gateway.yml 中定义两个 entry,分别绑定不同的端口,配置不同的 router
entry:
- name: write_es
enabled: true
router: write_router
network:
binding: 0.0.0.0:8000
- name: read_es
enabled: true
router: read_router
network:
binding: 0.0.0.0:9000
router:
- name: write_router
default_flow: default_flow
tracing_flow: logging
- name: read_router
default_flow: default_flow
tracing_flow: logging为了演示效果,只配置一个 Elasticsearch
elasticsearch:
- name: dev
enabled: true
schema: http
hosts:
- 192.168.3.188:9206启动项目
我们从 http://127.0.0.1:8000 写入一条数据,再从 http://127.0.0.1:9000 读取该条数据
添加接口
返回字符串
我们想自定义添加一个接口,怎么在不写代码的情况下通过配置实现返回字符串
flow:
- name: hello_flow
filter:
- echo:
message: "hello flow"
router:
- name: read_router
default_flow: hello_flow修改配置后启动
返回 json 数据
返回字符串不符合标准的 restful 接口规范,怎么返回给调用方标准 json 数据?
filter:
- set_response:
content_type: application/json
body: '{"message":"hello world"}'修改配置后启动
修改路由
我们已经新加了接口,返回 json 数据,但是接口是直接定义在 http://127.0.0.1:9000 中,之前网关的接口就无法使用,所以我们需要单独为自定义的接口指定单独的路由
router:
- name: read_router
default_flow: default_flow
tracing_flow: logging
rules:
- method:
- GET
pattern:
- "/hello"
flow:
- hello_flowdefault_flow: 默认的处理流,也就是业务处理的主流程,请求转发、过滤、缓存等操作都在这里面进行
tracing_flow:用于追踪请求状态的流,用于记录请求日志、统计等
如果我们有过开发经验,了解 MVC 模式,flow 就类似 MVC 中的 Controller,rules 中类似路由规则,当请求匹配到配置中的路由规则时,由配置的 flow 处理业务逻辑。
数据整体流向,从服务端发到网关,网关为每个 Elasticsearch 绑定不同的 IP 地址,每个 Elasticsearch 都有唯一一个 router 和它对应,根据请求的 method 和 path 匹配到 router 中的一个 flow,flow 中包含多个 filter 处理对数据进行流式处理。
如下图所示
流式处理是什么,假设水从一个管子里面流出来,管子旁边每一段依次站了几个人,第一个人往水里放点鱼,鱼和水到了第二个人,第二个人往水里放点草,鱼、水和草到了第三人等等,每个人对水做一定的操作,水经过这些操作后最后到达水池里。
我们可以把数据当成水,filter 是管子旁边的人,水池就是 Elasticsearch
总结
在学习了router/flow/filter后,我们已经对极限网关的配置有了初步的了解,后续开发的时候直接查阅文档。
极限网关初探(1) 安装启动
Elasticsearch • xushuhui 发表了文章 • 0 个评论 • 3939 次浏览 • 2022-04-06 16:54
产品介绍
极限网关(INFINI Gateway)是一个面向 Elasticsearch 的高性能应用网关。特性丰富,使用简单。
它和其他业务型网关最大的区别是业务网关把请求转发给各个底层微服务,而它把请求转发给 Elasticsearch,更多是类似 Mycat 的中间件的作用。
没有使用网关之前,服务端请求多个节点
使用网关后
下载地址
打开 下载地址,根据操作系统版本选择。
Windows 安装和启动
安装
下载 gateway-1.6.0_SNAPSHOT-597-windows-amd64.zip,解压如下。
启动失败
当 gateway.yml 的 elasticsearch 选项中的 hosts 不能正常响应请求的时候,启动界面如下。
为什么 elasticsearch 不能访问的时候,网关还要继续提供服务呢,为什么不像业务接口启动时在基础业务组件如 MySQL/Redis 不能正常响应就直接 panic?
一方面网关作为 elasticsearch 抵挡流量冲击的城墙,在 elasticsearch 不能提供服务的时候,对之前成功的请求缓存结果,继续提供有限度的服务,为 elasticsearch 修复后上线争取时间。
另一方面业务接口和基础组件是强耦合关系,没有基础组件就完全无法对外提供数据读写服务,而网关与 elasticsearch 是松耦合关系,网关在没有 elasticsearch 的情况下也能对外提供有限度的服务。
在 gateway.yml 的 elasticsearch 选项中的 hosts 改成能够正常响应的 elasticsearch 请求地址。
启动成功
双击 gateway-windows-amd64.exe 文件,启动成功界面如下
访问
API 访问
由启动后终端显示可知,网关的 API 接口地址是 http://localhost:2900
[api.go:262] api listen at: http://0.0.0.0:2900打开浏览器输入 http://localhost:2900,显示所有可以对外提供的 API 接口
我们选择其中一个,在浏览器中输入 http://localhost:2900/_framework/api/_version 从路由上看该接口是查询产品的版本信息,显示如下
gateway.yml 中可以看到有被注释掉的一段配置,看起来应该是配置 api 地址的地方。
#api:
# enabled: true
# network:
# binding: 127.0.0.1:2900把注释去掉后尝试把端口改成 2901。
api:
enabled: true
network:
binding: 127.0.0.1:2901改完后启动
Elasticsearch 访问
启动日志中显示监听 8000 端口,猜测应该是 elasticsearch 请求地址,打开浏览器输入 http://127.0.0.1:8000/
entry [my_es_entry] listen at: http://0.0.0.0:8000
entry:
- name: my_es_entry
enabled: true
router: my_router
max_concurrency: 10000
network:
binding: 0.0.0.0:8000总结
我们成功安装和启动极限网关,接下来我们学习怎么根据需求修改配置。

