


redis
换掉ES? Redis官方搜索引擎,效率大幅提升
默认分类 • Fred2000 发表了文章 • 2 个评论 • 5425 次浏览 • 2024-05-30 10:08
RediSearch是一个Redis模块,为Redis提供查询、二次索引和全文搜索。要使用RediSearch,首先要在Redis数据上声明索引。然后可以使用重新搜索查询语言来查询该数据。
RedSearch使用压缩的反向索引进行快速索引,占用内存少。RedSearch索引通过提供精确的短语匹配、模糊搜索和数字过滤等功能增强了
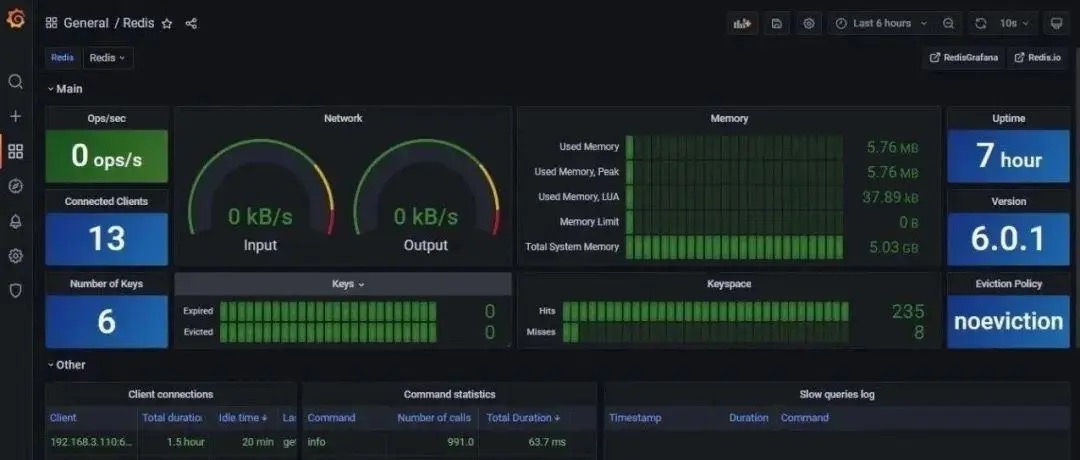
实现特性
- 基于文档的多个字段全文索引
- 高性能增量索引
- 文档排序(由用户在索引时手动提供)
- 在子查询之间使用 AND 或 NOT 操作符的复杂布尔查询
- 可选的查询子句
- 基于前缀的搜索
- 支持字段权重设置
- 自动完成建议(带有模糊前缀建议)
- 精确的短语搜索
- 在许多语言中基于词干分析的查询扩展
- 支持用于查询扩展和评分的自定义函数
- 将搜索限制到特定的文档字段
- 数字过滤器和范围
- 使用 Redis 自己的地理命令进行地理过滤
- Unicode 支持(需要 UTF-8 字符集)
- 检索完整的文档内容或只是ID 的检索
- 支持文档删除和更新与索引垃圾收集
- 支持部分更新和条件文档更新
对比 Elasticsearch
如下图所示,RediSearch 构建索引的时间为 221 秒,而 Elasticsearch 为 349 秒,快了 58%。
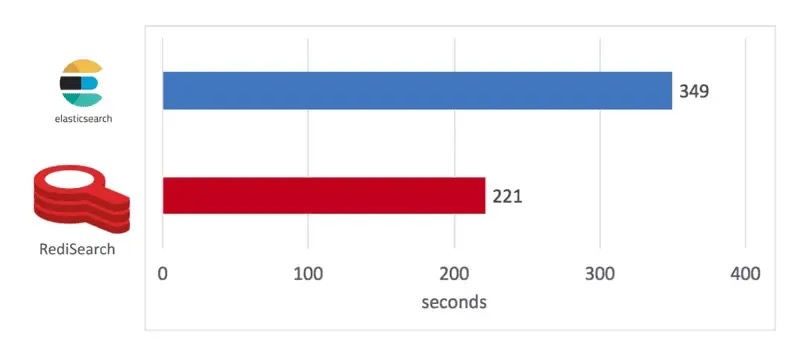
索引构建测试
我们模拟了一个多租户电子商务应用程序,其中每个租户代表一个产品类别并维护自己的索引。对于此基准测试,我们构建了 50K 个索引(或产品),每个索引最多存储 500 个文档(或项目),总共 2500 万个文档。
RediSearch 仅用了 201 秒就构建了索引,平均每秒运行 125K 个索引。然而,Elasticsearch 在 921 个索引后崩溃了,显然它不是为应对这种负载而设计的。
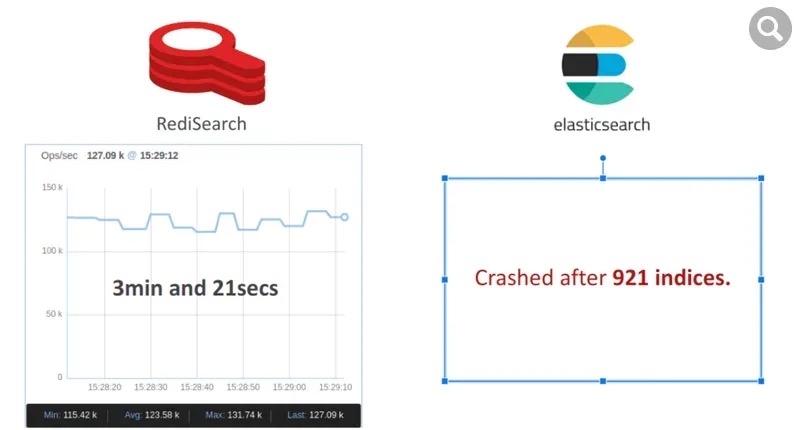
查询性能测试
一旦数据集被索引,我们就使用在专用负载生成器服务器上运行的 32 个客户端启动两个单词的搜索查询。如下图所示,RediSearch 吞吐量达到了 12.5K 操作/秒,而 Elasticsearch 为 3.1K 操作/秒,速度提高了 4 倍。
此外,RediSearch 延迟稍好一些,平均为 8 毫秒,而 Elasticsearch 为 10 毫秒。
安装
安装目前分为源码和docker安装两种方式。
源码安装
git clone https://github.com/RediSearch/RediSearch.git
cd RediSearch # 进入模块目录
make setup
make installdocker安装
note: RediSearch的安装比较复杂原包无法进行编译操作所以我们使用docker安装
docker run -p 6379:6379 redislabs/redisearch:latest判断是否安装成功
127.0.0.1:0>module list
1) 1) "name"
2) "ReJSON"
3) "ver"
4) "20007"
2) 1) "name"
2) "search"
3) "ver"
4) "20209"返回数组存在“ft”或 “search”(不同版本),表明 RediSearch 模块已经成功加载。
命令行操作
1、创建
1.1 创建索引
创建索引不妨想象成创建表结构,表一般基本属性有表名、字段和字段类别等,所以我们可以考虑将索引名代表表名,字段代表字段,属性即表示属性。
xxx.xxx.xxx.xxx:0>ft.create "student" schema "name" text weight 5.0 "sex" text "desc" text "class" tag
"OK"student 表示索引名,name、sex、desc表示字段,text表示类型(这样表示只是为了便于理解)
“weight”为权重,默认值为 1.0
type student
"none"我们创建的索引redis是不认识的,这证明使用的是插件。
1.2 创建文档
创建文档上下文的过程不妨想想成向表中插入数据,这里请注意字段名可以使用双引号但切记一定要用英文,这里之所以着重提出是因为有些编译器中文双引号和英文双引号用肉眼实在难以辨认否则会出现 “Fields must be specified in FIELD VALUE pairs”(其实是将“ 当作内容处理了以至于缺少了字段)
ft.add student 001 1.0 language "chinese" fields name "张三" sex "男" desc "这是一个学生" class "一班"
"OK"其中001为文档ID,"1.0"为评分缺少此值会报"Could not parse document score"异常,language 指明使用的语言默认是英文编码 如果没有此标记存储是没有问题的但不可以通过中文字符查询
1.3 查询
1.3.1 基本查询
1.3.1.1 全量查询
xxx.xxx.xxx.xxx:0>FT.SEARCH student * SORTBY sex desc RETURN 3 name sex desc
1) "2"
2) "001"
3) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
4) "002"
5) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"1.3.1.2 匹配查询
xxx.xxx.xxx.xxx:0>ft.search student "张三" limit 0 10 RETURN 3 name sex desc
1) "2"
2) "001"
3) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
4) "002"
5) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
limit 与mysql相识主要用于分页,此处是全量匹配,如果没有设置language “chinese” 此处查询为0,
1.3.2 模糊匹配
1.3.2.1 后置匹配
ft.search student "李*" SORTBY sex desc RETURN 3 name sex desc
1) "1"
2) "003"
3) 1) "name"
2) "李四"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"1.3.2.2 模糊搜索
xxx.xxx.xxx.xxx:0>FT.SEARCH beers "%%张店%%"
1) "1"
2) "beer:1"
3) 1) "name"
2) "集团本部已发布【文明就餐公约】,2号楼办公人员午餐的就餐时间是11:45~13:00,现经行政服务部进行抽查,发现我们部门有员工违规就餐现象。请大家务必遵守,相互转告,对于外地回到集团办公的同事,亦请遵守,谢谢!"
3) "org"
4) "山东省淄博市张店区"
5) "school"
6) "山东理工大学"别高兴太早全量模糊匹配是由很大限制的,他基于Levenshtein距离(LD)进行模糊匹配。术语的模糊匹配是通过在术语周围加“%”来实现的,模糊匹配的最大LD为3,确切的说这只是一种相识度查询,并非一般意义上的模糊搜索,但是如果仔细观察会发现通过精确匹配时不仅能够将完整value值查询出来而且还查询出其他处于文档某个位置的key请看官方提供的一个例子:
FT.CREATE idx SCHEMA txt TEXT
FT.ADD idx docCn 1.0 LANGUAGE chinese FIELDS txtRedis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。从盘可以有意无意的对数据进行写操作。
由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。
FT.CREATE idx SCHEMA txt TEXT
FT.ADD idx docCn 1.0 LANGUAGE chinese FIELDS txt "Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。从盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。[8]"
FT.SEARCH idx "数据" LANGUAGE chinese HIGHLIGHT SUMMARIZE
# Outputs:
# <b>数据</b>?... <b>数据</b>进行写操作。由于完全实现了发布... <b>数据</b>冗余很有帮助。[8...之所以会出现这样的效果是因为redisearch对文本进行了分词,其使用的工具是friso相比es的ik还是弱一些前者主要是对中文分词,体积小可移植性强。
从而我们可以结合后后置匹配算法
xxx.xxx.xxx.xxx:0>FT.SEARCH idx "数*" LANGUAGE chinese HIGHLIGHT
1) "1"
2) "docCn"
3) 1) "txt"
2) "Redis支持主从同步。<b>数据</b>可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。从盘可以有意无意的对<b>数据</b>进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和<b>数据</b>冗余很有帮助。[8]"
或者结合Levenshtein算法这样基本上能够满足业务查询需求
xxx.xxx.xxx.xxx:0>FT.SEARCH idx "%%单的树%%" LANGUAGE chinese HIGHLIGHT
1) "1"
2) "docCn"
3) 1) "txt"
2) "Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层<b>树</b>复制。从盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步<b>树</b>时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。[8]"1.3.2.3 字段查询
通过字段查询也可以实现模糊搜索,直接给例子,后面跟着官网上给的sql 和 redisearch的对照表
ft.search student *
1) "2"
2) "doudou"
3) 1) "name"
2) "豆豆"
3) "jtzz"
4) "“检索”是很多产品中"
5) "phone"
6) "18563717107"
4) "ttao"
5) 1) "name"
2) "姚元涛"
3) "jtzz"
4) "一个生病的人只"
5) "phone"
6) "18563717107"
ft.search student '@phone:185* @name:豆豆'
1) "1"
2) "doudou"
3) 1) "name"
2) "豆豆"
3) "jtzz"
4) "“检索”是很多产品中"
5) "phone"
6) "18563717107"1.4 删除
1.4.1 删除文档
xxx.xxx.xxx.xxx:0>ft.del student 002
"1"1.4.3 删除索引
xxx.xxx.xxx.xxx:0>ft.drop student
"OK"1.5 查看
1.5.1 查看所有索引
xxx.xxx.xxx.xxx:0>FT._LIST
1) "student1"
2) "ttao"
3) "idx"
4) "student"
5) "myidx"
6) "123"
7) "myIndex"
8) "testung"
9) "student2"1.5.2 查看索引文档中的数据
1.5.2.1 获取单条数据
xxx.xxx.xxx.xxx:0>ft.get student 001
1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
7) "class"
8) "一班"1.5.2.2 获取多条数据
xxx.xxx.xxx.xxx:0>ft.mget student 001 002
1) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
7) "class"
8) "一班"
2) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
7) "class"
8) "一班"1.6 索引别名操作
1.6.1 添加别名
123.232.112.84:0>FT.ALIASADD xs student
"OK"给索引student起个xs的别名,一个索引可以起多个别名
1.6.2 修改别名
1.6.3 删除别名
123.232.112.84:0>FT.ALIASDEL xs
"OK"作者:架构师公众号
来源:https://mp.weixin.qq.com/s/TmCXx3rLjLPggvOFjGqS9w
版权申明:内容来源网络,仅供学习研究,版权归原创者所有。如有侵权烦请告知,我们会立即删除并表示歉意。谢谢!
从 Redis 开源协议变更到 ES 国产化:一次技术自主的机遇
Easysearch • Muses 发表了文章 • 0 个评论 • 7004 次浏览 • 2024-04-11 16:05
引言
近日,Redis Labs 宣布其主导的开源项目 Redis 将采用双重源代码可用许可证(RSALv2)和服务器端公共许可证(SSPLv1)。这一重大决策标志着 Redis 从传统的 BSD 许可证向更加严格的控制权转变,同时也引发了广泛的社区和行业讨论。这不仅是一个关于许可证变更的故事,更是关于开源社区如何响应,以及这一变化如何激发对国产技术探索和发展的深刻思考。Redis,作为最受欢迎的开源键值存储数据库之一,其开源协议的变更反映了开源软件在商业化道路上的挑战和压力。Redis Labs 的 CEO Rowan Trollope 指出,这一变化旨在防止云服务提供商免费使用 Redis 代码,同时促进 Redis 社区的可持续发展和创新。

Redis 协议变更的深远影响
Redis 决定放弃 BSD 协议,转而采用双重源代码可用许可证(RSALv2 和 SSPLv1),标志着开源界的一个重要转折点。这一变化不仅影响了 Redis 本身,更引发了社区成员和技术行业的激烈讨论,许多人担心这将限制 Redis 的开源精神和广泛应用。然而,也有声音认为,这为其他开源项目,如 KeyDB、Dragonfly 和 Garnet 等,提供了发展的机遇,尤其是在提供与 Redis 兼容的替代解决方案方面。尽管 Redis 的这一变更在技术和法律上引发了争议,它也激发了开源社区对于如何在维护开源精神和寻求商业可持续性之间找到平衡的探索。此外,Redis 团队对于保持客户端库的开源许可和继续支持开源社区版的承诺,展示了一种尝试在新的许可模式下保持开放性和可接入性的方法。由于 Redis 的广泛应用,其协议变更对云服务商、Linux 发行版,甚至整个开源软件生态都产生了不小的冲击。一方面,云服务提供商需要重新评估其服务模型;另一方面,一些 Linux 发行版可能需要考虑将 Redis 从其软件仓库中移除。
ES 国产化的契机
Redis 开源协议的变更同时也让人们重新审视其他关键技术,特别是 Elasticsearch(ES)的依赖和发展。ES 作为一个强大的搜索和数据分析引擎,在全球范围内被广泛使用。随着对开源项目商业化模式的重新考量,中国开发者和企业开始寻求国产化的 ES 替代品,旨在减少对外部技术的依赖,同时推动国内技术生态的多元化和自主创新。但是国产化的探索并非没有挑战。从技术兼容性、性能优化到社区生态建设,每一步都需要深思熟虑和持续的努力。然而,Redis 的许可证变更为国内技术自主提供了一个独特的视角,鼓励开发者、企业乃至政府机构更加积极地参与到开源技术的本土化和创新中来。Redis 开源协议的变更引发的讨论和行动,凸显了开源社区对于自身未来发展方向的深刻反思。这一变革不仅关乎一个项目的许可模式转变,更触及到开源项目如何在保持开放和自由的同时,寻找到可持续发展的道路。此外,它也促使更多的开源项目和企业思考如何在全球化的技术生态中保持竞争力和影响力。
Easysearch:国产化的新选择
针对这一需求,极限科技 隆重推出了 Easysearch 搜索引擎软件,旨在提供一个与 Elasticsearch 兼容的国产化解决方案。Easysearch 不仅支持原生 Elasticsearch 的 DSL 查询语法,还提供了诸多企业级功能的增强,如更高的性能、稳定性和扩展性,以及更加丰富的安全管理和数据压缩功能。这表明,国产化技术的发展不仅是为了替代,更是在原有基础上进行创新和优化。ES 国产化解决方案 Easysearch 的推出,是响应国家对信创、自主可控战略布局的具体行动。通过提供兼容性强、功能丰富且稳定的国产技术替代品,不仅有助于减少对外部技术的依赖,也为国内技术生态的繁荣和创新贡献力量。这一过程中,既涵盖了对现有技术的深入理解和应用,也包含了对新技术、新方法的探索和实践。

结语
Redis 开源协议的变更和 Elasticsearch 国产化解决方案的兴起,共同反映了当前技术世界中开源与商业、国际与国产之间复杂而微妙的关系。这一趋势不仅仅是技术领域的变化,更是全球化背景下,各国在技术自主、安全与发展方面所做出的战略性调整。随着更多开源项目和技术面临类似的挑战,我们或许可以预见,技术自主和开源创新将成为推动未来技术发展的两大关键力量。
参考
- https://redis.com/blog/redis-adopts-dual-source-available-licensing
- https://www.elastic.co/cn/blog/licensing-change
- https://infinilabs.cn/products/easysearch
- https://infinilabs.cn/blog/2024/elasticsearch-alternative
- https://infinilabs.cn/blog/2023/the-first-to-complete-the-evaluation-of-search-database-products
关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
把日志输出到redis后,还能使用filebeat读取吗?
Beats • kennywu76 回复了问题 • 2 人关注 • 1 个回复 • 4113 次浏览 • 2017-12-22 14:31

logstash+redis cluster如何配置shipper与indexer
回复Logstash • LilCodeMan 发起了问题 • 1 人关注 • 0 个回复 • 6547 次浏览 • 2017-09-19 11:19

filebeat如何把日志日志内容输入redis,又如何取出呢?我的日志无法输入到redis
回复Logstash • ktpktr0 发起了问题 • 1 人关注 • 0 个回复 • 9071 次浏览 • 2017-08-18 09:04

filebeat如何根据document type 映射到redis的多个key中
Beats • 谭雁宏 回复了问题 • 2 人关注 • 2 个回复 • 10312 次浏览 • 2017-06-26 16:38

elasticsearch检索redis数据库

Elasticsearch • nightwish 回复了问题 • 2 人关注 • 1 个回复 • 9397 次浏览 • 2016-06-23 17:48
把日志输出到redis后,还能使用filebeat读取吗?
回复Beats • kennywu76 回复了问题 • 2 人关注 • 1 个回复 • 4113 次浏览 • 2017-12-22 14:31
logstash+redis cluster如何配置shipper与indexer
回复Logstash • LilCodeMan 发起了问题 • 1 人关注 • 0 个回复 • 6547 次浏览 • 2017-09-19 11:19
filebeat如何把日志日志内容输入redis,又如何取出呢?我的日志无法输入到redis
回复Logstash • ktpktr0 发起了问题 • 1 人关注 • 0 个回复 • 9071 次浏览 • 2017-08-18 09:04
filebeat如何根据document type 映射到redis的多个key中
回复Beats • 谭雁宏 回复了问题 • 2 人关注 • 2 个回复 • 10312 次浏览 • 2017-06-26 16:38
elasticsearch检索redis数据库
回复Elasticsearch • nightwish 回复了问题 • 2 人关注 • 1 个回复 • 9397 次浏览 • 2016-06-23 17:48
换掉ES? Redis官方搜索引擎,效率大幅提升
默认分类 • Fred2000 发表了文章 • 2 个评论 • 5425 次浏览 • 2024-05-30 10:08
RediSearch是一个Redis模块,为Redis提供查询、二次索引和全文搜索。要使用RediSearch,首先要在Redis数据上声明索引。然后可以使用重新搜索查询语言来查询该数据。
RedSearch使用压缩的反向索引进行快速索引,占用内存少。RedSearch索引通过提供精确的短语匹配、模糊搜索和数字过滤等功能增强了
实现特性
- 基于文档的多个字段全文索引
- 高性能增量索引
- 文档排序(由用户在索引时手动提供)
- 在子查询之间使用 AND 或 NOT 操作符的复杂布尔查询
- 可选的查询子句
- 基于前缀的搜索
- 支持字段权重设置
- 自动完成建议(带有模糊前缀建议)
- 精确的短语搜索
- 在许多语言中基于词干分析的查询扩展
- 支持用于查询扩展和评分的自定义函数
- 将搜索限制到特定的文档字段
- 数字过滤器和范围
- 使用 Redis 自己的地理命令进行地理过滤
- Unicode 支持(需要 UTF-8 字符集)
- 检索完整的文档内容或只是ID 的检索
- 支持文档删除和更新与索引垃圾收集
- 支持部分更新和条件文档更新
对比 Elasticsearch
如下图所示,RediSearch 构建索引的时间为 221 秒,而 Elasticsearch 为 349 秒,快了 58%。
索引构建测试
我们模拟了一个多租户电子商务应用程序,其中每个租户代表一个产品类别并维护自己的索引。对于此基准测试,我们构建了 50K 个索引(或产品),每个索引最多存储 500 个文档(或项目),总共 2500 万个文档。
RediSearch 仅用了 201 秒就构建了索引,平均每秒运行 125K 个索引。然而,Elasticsearch 在 921 个索引后崩溃了,显然它不是为应对这种负载而设计的。
查询性能测试
一旦数据集被索引,我们就使用在专用负载生成器服务器上运行的 32 个客户端启动两个单词的搜索查询。如下图所示,RediSearch 吞吐量达到了 12.5K 操作/秒,而 Elasticsearch 为 3.1K 操作/秒,速度提高了 4 倍。
此外,RediSearch 延迟稍好一些,平均为 8 毫秒,而 Elasticsearch 为 10 毫秒。
安装
安装目前分为源码和docker安装两种方式。
源码安装
git clone https://github.com/RediSearch/RediSearch.git
cd RediSearch # 进入模块目录
make setup
make installdocker安装
note: RediSearch的安装比较复杂原包无法进行编译操作所以我们使用docker安装
docker run -p 6379:6379 redislabs/redisearch:latest判断是否安装成功
127.0.0.1:0>module list
1) 1) "name"
2) "ReJSON"
3) "ver"
4) "20007"
2) 1) "name"
2) "search"
3) "ver"
4) "20209"返回数组存在“ft”或 “search”(不同版本),表明 RediSearch 模块已经成功加载。
命令行操作
1、创建
1.1 创建索引
创建索引不妨想象成创建表结构,表一般基本属性有表名、字段和字段类别等,所以我们可以考虑将索引名代表表名,字段代表字段,属性即表示属性。
xxx.xxx.xxx.xxx:0>ft.create "student" schema "name" text weight 5.0 "sex" text "desc" text "class" tag
"OK"student 表示索引名,name、sex、desc表示字段,text表示类型(这样表示只是为了便于理解)
“weight”为权重,默认值为 1.0
type student
"none"我们创建的索引redis是不认识的,这证明使用的是插件。
1.2 创建文档
创建文档上下文的过程不妨想想成向表中插入数据,这里请注意字段名可以使用双引号但切记一定要用英文,这里之所以着重提出是因为有些编译器中文双引号和英文双引号用肉眼实在难以辨认否则会出现 “Fields must be specified in FIELD VALUE pairs”(其实是将“ 当作内容处理了以至于缺少了字段)
ft.add student 001 1.0 language "chinese" fields name "张三" sex "男" desc "这是一个学生" class "一班"
"OK"其中001为文档ID,"1.0"为评分缺少此值会报"Could not parse document score"异常,language 指明使用的语言默认是英文编码 如果没有此标记存储是没有问题的但不可以通过中文字符查询
1.3 查询
1.3.1 基本查询
1.3.1.1 全量查询
xxx.xxx.xxx.xxx:0>FT.SEARCH student * SORTBY sex desc RETURN 3 name sex desc
1) "2"
2) "001"
3) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
4) "002"
5) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"1.3.1.2 匹配查询
xxx.xxx.xxx.xxx:0>ft.search student "张三" limit 0 10 RETURN 3 name sex desc
1) "2"
2) "001"
3) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
4) "002"
5) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
limit 与mysql相识主要用于分页,此处是全量匹配,如果没有设置language “chinese” 此处查询为0,
1.3.2 模糊匹配
1.3.2.1 后置匹配
ft.search student "李*" SORTBY sex desc RETURN 3 name sex desc
1) "1"
2) "003"
3) 1) "name"
2) "李四"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"1.3.2.2 模糊搜索
xxx.xxx.xxx.xxx:0>FT.SEARCH beers "%%张店%%"
1) "1"
2) "beer:1"
3) 1) "name"
2) "集团本部已发布【文明就餐公约】,2号楼办公人员午餐的就餐时间是11:45~13:00,现经行政服务部进行抽查,发现我们部门有员工违规就餐现象。请大家务必遵守,相互转告,对于外地回到集团办公的同事,亦请遵守,谢谢!"
3) "org"
4) "山东省淄博市张店区"
5) "school"
6) "山东理工大学"别高兴太早全量模糊匹配是由很大限制的,他基于Levenshtein距离(LD)进行模糊匹配。术语的模糊匹配是通过在术语周围加“%”来实现的,模糊匹配的最大LD为3,确切的说这只是一种相识度查询,并非一般意义上的模糊搜索,但是如果仔细观察会发现通过精确匹配时不仅能够将完整value值查询出来而且还查询出其他处于文档某个位置的key请看官方提供的一个例子:
FT.CREATE idx SCHEMA txt TEXT
FT.ADD idx docCn 1.0 LANGUAGE chinese FIELDS txtRedis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。从盘可以有意无意的对数据进行写操作。
由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。
FT.CREATE idx SCHEMA txt TEXT
FT.ADD idx docCn 1.0 LANGUAGE chinese FIELDS txt "Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。从盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。[8]"
FT.SEARCH idx "数据" LANGUAGE chinese HIGHLIGHT SUMMARIZE
# Outputs:
# <b>数据</b>?... <b>数据</b>进行写操作。由于完全实现了发布... <b>数据</b>冗余很有帮助。[8...之所以会出现这样的效果是因为redisearch对文本进行了分词,其使用的工具是friso相比es的ik还是弱一些前者主要是对中文分词,体积小可移植性强。
从而我们可以结合后后置匹配算法
xxx.xxx.xxx.xxx:0>FT.SEARCH idx "数*" LANGUAGE chinese HIGHLIGHT
1) "1"
2) "docCn"
3) 1) "txt"
2) "Redis支持主从同步。<b>数据</b>可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。从盘可以有意无意的对<b>数据</b>进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和<b>数据</b>冗余很有帮助。[8]"
或者结合Levenshtein算法这样基本上能够满足业务查询需求
xxx.xxx.xxx.xxx:0>FT.SEARCH idx "%%单的树%%" LANGUAGE chinese HIGHLIGHT
1) "1"
2) "docCn"
3) 1) "txt"
2) "Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层<b>树</b>复制。从盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步<b>树</b>时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。[8]"1.3.2.3 字段查询
通过字段查询也可以实现模糊搜索,直接给例子,后面跟着官网上给的sql 和 redisearch的对照表
ft.search student *
1) "2"
2) "doudou"
3) 1) "name"
2) "豆豆"
3) "jtzz"
4) "“检索”是很多产品中"
5) "phone"
6) "18563717107"
4) "ttao"
5) 1) "name"
2) "姚元涛"
3) "jtzz"
4) "一个生病的人只"
5) "phone"
6) "18563717107"
ft.search student '@phone:185* @name:豆豆'
1) "1"
2) "doudou"
3) 1) "name"
2) "豆豆"
3) "jtzz"
4) "“检索”是很多产品中"
5) "phone"
6) "18563717107"1.4 删除
1.4.1 删除文档
xxx.xxx.xxx.xxx:0>ft.del student 002
"1"1.4.3 删除索引
xxx.xxx.xxx.xxx:0>ft.drop student
"OK"1.5 查看
1.5.1 查看所有索引
xxx.xxx.xxx.xxx:0>FT._LIST
1) "student1"
2) "ttao"
3) "idx"
4) "student"
5) "myidx"
6) "123"
7) "myIndex"
8) "testung"
9) "student2"1.5.2 查看索引文档中的数据
1.5.2.1 获取单条数据
xxx.xxx.xxx.xxx:0>ft.get student 001
1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
7) "class"
8) "一班"1.5.2.2 获取多条数据
xxx.xxx.xxx.xxx:0>ft.mget student 001 002
1) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
7) "class"
8) "一班"
2) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
7) "class"
8) "一班"1.6 索引别名操作
1.6.1 添加别名
123.232.112.84:0>FT.ALIASADD xs student
"OK"给索引student起个xs的别名,一个索引可以起多个别名
1.6.2 修改别名
1.6.3 删除别名
123.232.112.84:0>FT.ALIASDEL xs
"OK"作者:架构师公众号
来源:https://mp.weixin.qq.com/s/TmCXx3rLjLPggvOFjGqS9w
版权申明:内容来源网络,仅供学习研究,版权归原创者所有。如有侵权烦请告知,我们会立即删除并表示歉意。谢谢!
从 Redis 开源协议变更到 ES 国产化:一次技术自主的机遇
Easysearch • Muses 发表了文章 • 0 个评论 • 7004 次浏览 • 2024-04-11 16:05
引言
近日,Redis Labs 宣布其主导的开源项目 Redis 将采用双重源代码可用许可证(RSALv2)和服务器端公共许可证(SSPLv1)。这一重大决策标志着 Redis 从传统的 BSD 许可证向更加严格的控制权转变,同时也引发了广泛的社区和行业讨论。这不仅是一个关于许可证变更的故事,更是关于开源社区如何响应,以及这一变化如何激发对国产技术探索和发展的深刻思考。Redis,作为最受欢迎的开源键值存储数据库之一,其开源协议的变更反映了开源软件在商业化道路上的挑战和压力。Redis Labs 的 CEO Rowan Trollope 指出,这一变化旨在防止云服务提供商免费使用 Redis 代码,同时促进 Redis 社区的可持续发展和创新。
Redis 协议变更的深远影响
Redis 决定放弃 BSD 协议,转而采用双重源代码可用许可证(RSALv2 和 SSPLv1),标志着开源界的一个重要转折点。这一变化不仅影响了 Redis 本身,更引发了社区成员和技术行业的激烈讨论,许多人担心这将限制 Redis 的开源精神和广泛应用。然而,也有声音认为,这为其他开源项目,如 KeyDB、Dragonfly 和 Garnet 等,提供了发展的机遇,尤其是在提供与 Redis 兼容的替代解决方案方面。尽管 Redis 的这一变更在技术和法律上引发了争议,它也激发了开源社区对于如何在维护开源精神和寻求商业可持续性之间找到平衡的探索。此外,Redis 团队对于保持客户端库的开源许可和继续支持开源社区版的承诺,展示了一种尝试在新的许可模式下保持开放性和可接入性的方法。由于 Redis 的广泛应用,其协议变更对云服务商、Linux 发行版,甚至整个开源软件生态都产生了不小的冲击。一方面,云服务提供商需要重新评估其服务模型;另一方面,一些 Linux 发行版可能需要考虑将 Redis 从其软件仓库中移除。
ES 国产化的契机
Redis 开源协议的变更同时也让人们重新审视其他关键技术,特别是 Elasticsearch(ES)的依赖和发展。ES 作为一个强大的搜索和数据分析引擎,在全球范围内被广泛使用。随着对开源项目商业化模式的重新考量,中国开发者和企业开始寻求国产化的 ES 替代品,旨在减少对外部技术的依赖,同时推动国内技术生态的多元化和自主创新。但是国产化的探索并非没有挑战。从技术兼容性、性能优化到社区生态建设,每一步都需要深思熟虑和持续的努力。然而,Redis 的许可证变更为国内技术自主提供了一个独特的视角,鼓励开发者、企业乃至政府机构更加积极地参与到开源技术的本土化和创新中来。Redis 开源协议的变更引发的讨论和行动,凸显了开源社区对于自身未来发展方向的深刻反思。这一变革不仅关乎一个项目的许可模式转变,更触及到开源项目如何在保持开放和自由的同时,寻找到可持续发展的道路。此外,它也促使更多的开源项目和企业思考如何在全球化的技术生态中保持竞争力和影响力。
Easysearch:国产化的新选择
针对这一需求,极限科技 隆重推出了 Easysearch 搜索引擎软件,旨在提供一个与 Elasticsearch 兼容的国产化解决方案。Easysearch 不仅支持原生 Elasticsearch 的 DSL 查询语法,还提供了诸多企业级功能的增强,如更高的性能、稳定性和扩展性,以及更加丰富的安全管理和数据压缩功能。这表明,国产化技术的发展不仅是为了替代,更是在原有基础上进行创新和优化。ES 国产化解决方案 Easysearch 的推出,是响应国家对信创、自主可控战略布局的具体行动。通过提供兼容性强、功能丰富且稳定的国产技术替代品,不仅有助于减少对外部技术的依赖,也为国内技术生态的繁荣和创新贡献力量。这一过程中,既涵盖了对现有技术的深入理解和应用,也包含了对新技术、新方法的探索和实践。
结语
Redis 开源协议的变更和 Elasticsearch 国产化解决方案的兴起,共同反映了当前技术世界中开源与商业、国际与国产之间复杂而微妙的关系。这一趋势不仅仅是技术领域的变化,更是全球化背景下,各国在技术自主、安全与发展方面所做出的战略性调整。随着更多开源项目和技术面临类似的挑战,我们或许可以预见,技术自主和开源创新将成为推动未来技术发展的两大关键力量。
参考
- https://redis.com/blog/redis-adopts-dual-source-available-licensing
- https://www.elastic.co/cn/blog/licensing-change
- https://infinilabs.cn/products/easysearch
- https://infinilabs.cn/blog/2024/elasticsearch-alternative
- https://infinilabs.cn/blog/2023/the-first-to-complete-the-evaluation-of-search-database-products
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
