

如何用 Scrapy 爬取网站数据并在 Easysearch 中进行存储检索分析
Easysearch | 作者 INFINI Labs 小助手 | 发布于2024年09月13日 | | 阅读数:6839
做过数据分析和爬虫程序的小伙伴想必对 Scrapy 这个爬虫框架已经很熟悉了。今天给大家介绍下,如何基于 Scrapy 快速编写一个爬虫程序并利用 Easysearch 储存、检索、分析爬取的数据。我们以极限科技的官网 Blog 为数据源(https://infinilabs.cn/blog) ,做下实操演示。
1、安装 scrapy
使用 Scrapy 可以快速构建一个爬虫项目,从目标网站中获取所需的数据,并进行后续的处理和分析。
pip install scrapy
# 新建项目 infini_spiders
scrapy startproject infini_spiders
# 初始化爬虫
cd infini_spiders/spiders
scrapy genspider blog infinilabs.cn2、爬虫编写
编写一个爬虫文件 blog.py ,它会首先访问 start_urls 指定的地址,将结果发给 parse 函数解析。通过这一步解析,我们得到了每一篇博客的地址。然后我们对每个博客的地址发送请求,将结果发给 parse_blog 函数进行解析,在这里才会真正提取每篇博客的 title、tag、url、date、content 内容。
from typing import Any, Iterable
import scrapy
from bs4 import BeautifulSoup
from scrapy.http import Response
class BlogSpider(scrapy.Spider):
name = "blog"
allowed_domains = ["infinilabs.cn"]
start_urls = ["https://infinilabs.cn/blog/"]
def parse(self, response):
links = response.css("div.blogs a")
yield from response.follow_all(links, self.parse_blog)
def parse_blog(self, response):
title = response.xpath('//div[@class="title"]/text()').extract_first()
tags = response.xpath('//div[@class="tags"]/div[@class="tag"]/text()').extract()
url = response.url
author = response.xpath('//div[@class="logo"]/div[@class="name"]//text()').extract_first()
date = response.xpath('//div[@class="date"]/text()').extract_first()
all_text = response.xpath('//p//text() | //h3/text() | //h2/text() | //h4/text() | //ol/li//text()').extract()
content = '\n'.join(all_text)
yield {
'title': title,
'tags': tags,
'url': url,
'author': author,
'date': date,
'content': content
}提取完我们想要的内容后,接下来就要考虑存储了。考虑到要对内容进行检索、分析,接下来我们将内容直接存放到 Easysearch 当中。
3、安装插件
通过安装 ScrapyElasticsearch pipeline 可将 scrapy 爬取的内容存入到 Easysearch 中。
pip install ScrapyElasticSearch修改 scrapy 自带的配置文件 settings.py ,添加以下内容。
ITEM_PIPELINES = {
'scrapyelasticsearch.scrapyelasticsearch.ElasticSearchPipeline': 10
}
ELASTICSEARCH_SERVERS = ['http://192.168.56.3:9210']
ELASTICSEARCH_INDEX = 'scrapy'
ELASTICSEARCH_INDEX_DATE_FORMAT = '%Y-%m-%d'
ELASTICSEARCH_TYPE = '_doc'
ELASTICSEARCH_USERNAME = 'admin'
ELASTICSEARCH_PASSWORD = '9423d1d5345ed6d0db19'ScrapyElasticSearch 会以 bulk 方式写入 Easysearch,每次批量的大小由 scrapyelasticsearch.scrapyelasticsearch.ElasticSearchPipeline 参数控制,大家可自行修改。
在上述配置中,我们会将爬到的数据存放到 scrapy-yyyy-mm-dd 索引中。
4、启动爬虫
在 infini_spiders/spiders 目录下,使用命令启动爬虫。
scrapy crawl blogblog 就是爬虫的名字,对应到 blog.py 里面的 name 变量。运行完成后,就可以去 Easysearch 里查看数据了,当然我们还是使用 Console 进行查看。
5、查看数据
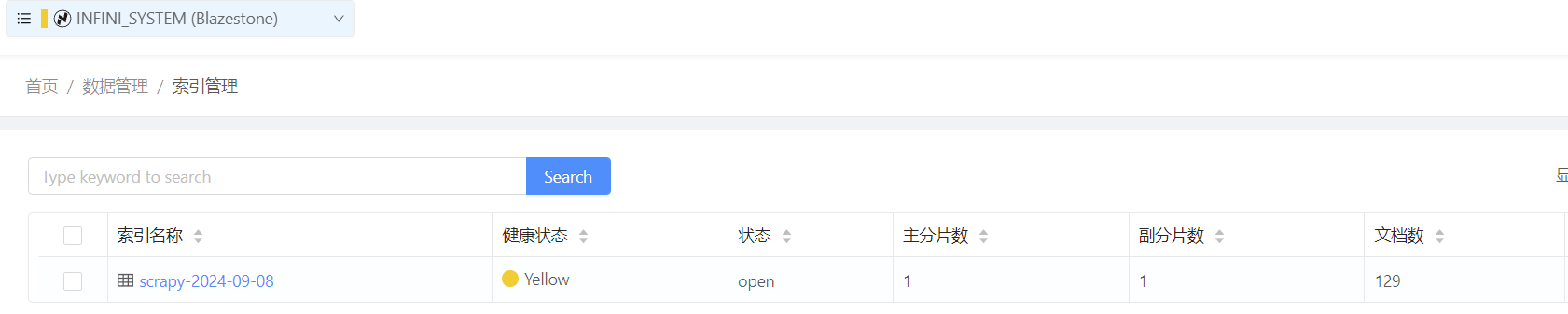
先查看下索引情况,scrapy 索引已经生成,里面有 129 篇博客。
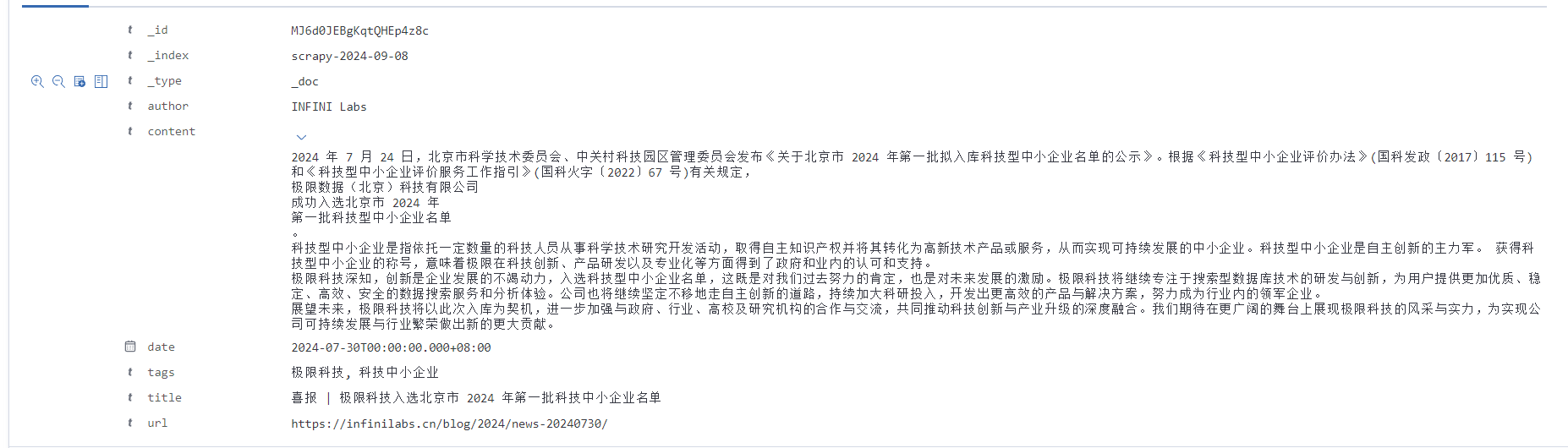
查看详细内容,确保博客正文已经保存。
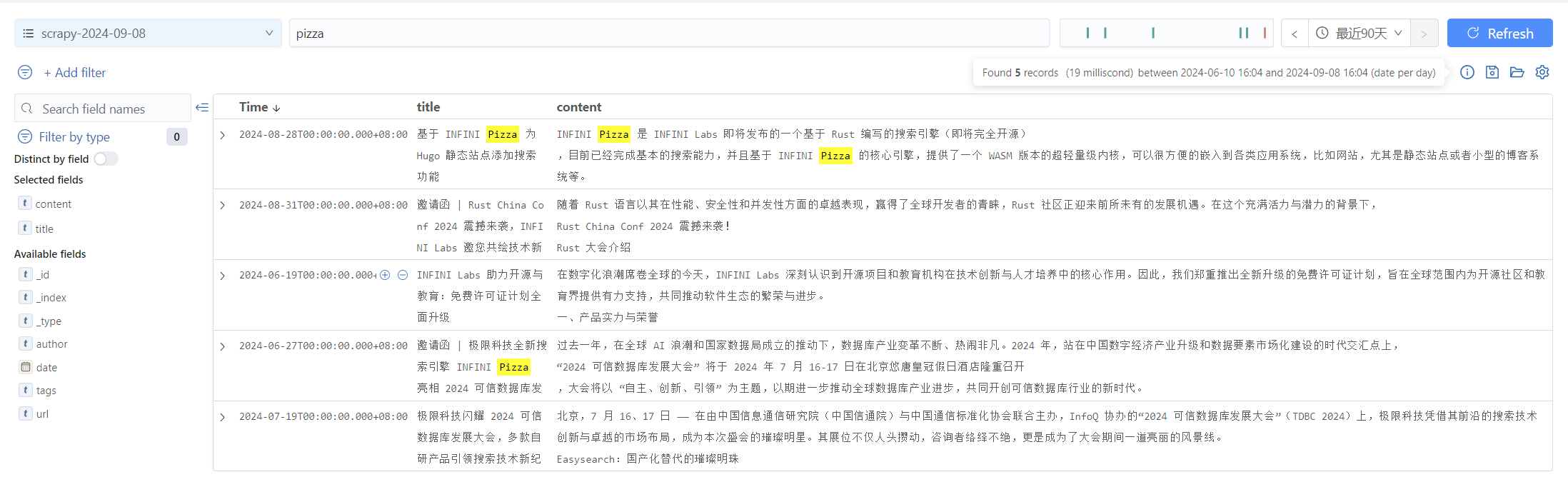
到了这一步,我们就能使用 Console 对博客进行搜索、分析了。
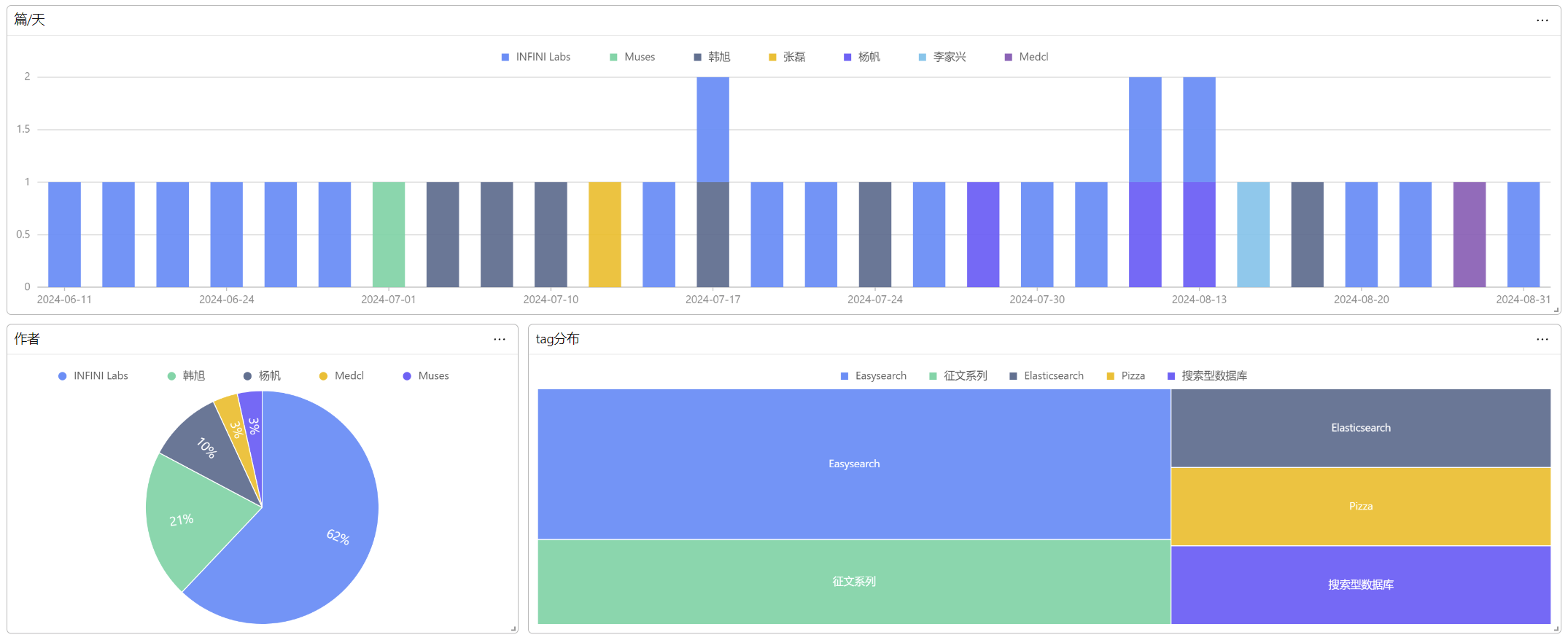
6、结语
这次的分享就到这里了。欢迎与我一起交流 ES 的各种问题和解决方案。

关于 Easysearch

INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。 与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
官网文档:https://infinilabs.cn/docs/latest/easysearch
本文地址:http://elasticsearch.cn/article/15260
