


搜索引擎
INFINI Easysearch 向量搜索实战(一)
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 578 次浏览 • 1 天前

Easysearch 提供了强大的向量搜索能力,打破传统关键词匹配的局限,实现真正的“懂你”的语义搜索。助力企业快速构建智能推荐、图像识别和内容理解等 AI 应用,释放数据深层价值。
核心能力
| 能力 | 说明 |
|---|---|
| 两种向量类型 | 稠密浮点向量(knn_dense_float_vector)和稀疏布尔向量(knn_sparse_bool_vector) |
| 多种索引模型 | lsh(局部敏感哈希,近似搜索)、permutation_lsh(置换 LSH)、sparse_indexed(倒排索引)、exact(精确搜索) |
| 多种相似度 | cosine(余弦)、l1(曼哈顿距离)、l2(欧氏距离)、jaccard、hamming |
| 与全文搜索融合 | 向量字段与文本字段存储在同一索引,支持 Hybrid 混合检索 |
| function_score 集成 | 向量相似度可作为 function_score 的评分函数 |
典型应用场景
- 语义搜索:文本通过 Embedding 模型转为向量,按语义相似度检索
- RAG 检索增强生成:为大语言模型提供知识库检索能力
- 推荐系统:用户/商品特征向量的相似推荐
- 图像/多模态搜索:图像特征向量的相似检索
- 去重与异常检测:通过向量距离判断内容相似度
Embedding 服务
在使用向量搜索前,先要准备一个 Embedding 模型,支持与 OpenAI API 兼容的 embedding 接口和 Ollama embedding 接口。本文使用阿里云上的 Embedding 模型进行演示。
写入方法
方法一:写入链路嵌入(推荐)
在数据写入 Easysearch 时,通过 Ingest Pipeline 自动调用 Embedding 服务:
应用写数据 → Easysearch → Ingest Pipeline → 调用 Embedding API → 写入向量字段
优势是写入后即可搜索,无需维护外部向量化流程。需要确保集群应至少有一个节点拥有 ingest 角色。
方法二:离线批处理
在应用侧完成向量化,再将向量字段直接写入 Easysearch:
原始数据 → 应用 → 调用模型 Embedding API → 写入 Easysearch(含向量字段)
参考文档。
实战
我们实战演示模式一,分为以下几个步骤:
- 建立带有向量字段的索引
- 创建对应的 Ingest Pipeline
- 写入数据到索引
1. 建立带有向量字段的索引
先建立一个带向量字段的索引,注意 dims 要与向量模型的输出匹配。
PUT /my-index
{
"mappings": {
"properties": {
"text_vector": {
"type": "knn_dense_float_vector",
"knn": {
"dims": 1024,
"model": "lsh",
"similarity": "cosine",
"L": 99,
"k": 1
}
}
}
}
}
2. 创建对应的 Ingest Pipeline
写入数据前先建立 Ingest Pipeline,注意 vendor 必须根据使用的模型来指定,比如本文使用的是阿里云 text-embedding-v4 模型,该模型提供了 OpenAI 格式的 API 接口,这里 vendor 我们就写 openai。
PUT _ingest/pipeline/text-embedding-pipeline
{
"description": "用于生成文本嵌入向量的管道",
"processors": [
{
"text_embedding": {
"url": "https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings",
"vendor": "openai",
"api_key": "xxxxxx",
"text_field": "input_text",
"vector_field": "text_vector",
"model_id": "text-embedding-v4",
"dims": 1024,
"ignore_missing": false,
"ignore_failure": false
}
}
]
}
text_field:指定原始文本字段,Pipeline 会将该字段的内容转换成向量。
vector_field:指定向量存储的字段,保存上面转换的向量。
3. 写入数据
POST /_bulk?pipeline=text-embedding-pipeline&pretty
{"index": {"_index": "my-index", "_id": "1"}}
{"input_text": "苹果发布了新款iPhone 15 Pro手机,搭载A17芯片"}
{"index": {"_index": "my-index", "_id": "2"}}
{"input_text": "特斯拉宣布将在上海建第二座超级工厂"}
{"index": {"_index": "my-index", "_id": "3"}}
{"input_text": "今天天气真好,阳光明媚适合去公园散步"}
{"index": {"_index": "my-index", "_id": "4"}}
{"input_text": "程序员用Python写了一个自动化数据清洗脚本"}
{"index": {"_index": "my-index", "_id": "5"}}
{"input_text": "故宫博物院推出了夏季特展,展出珍贵文物"}
{"index": {"_index": "my-index", "_id": "6"}}
{"input_text": "小明每天坚持跑步五公里,身体越来越健康"}
{"index": {"_index": "my-index", "_id": "7"}}
{"input_text": "人工智能大模型在自然语言处理领域取得突破"}
{"index": {"_index": "my-index", "_id": "8"}}
{"input_text": "这家咖啡店的拿铁口感丝滑,推荐给咖啡爱好者"}
{"index": {"_index": "my-index", "_id": "9"}}
{"input_text": "量子计算机有望在药物研发中发挥重要作用"}
{"index": {"_index": "my-index", "_id": "10"}}
{"input_text": "周末和朋友一起去爬山,山顶的风景美极了"}
4. 检查数据
搜索索引数据,看看是否成功转换成了向量。可以看到原始数据保存在 input_text 字段中,其向量保存到了 text_vector。

OK,下一步我们看看怎么方便地实现向量搜索。

关于 Easysearch

INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
官网文档:https://docs.infinilabs.com/easysearch
相关文章:
国产统信 UOS 部署 Coco Server 全指南:从零搭建企业级 AI 搜索服务端
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 9830 次浏览 • 2026-06-09 14:19
一、引言
在上一篇文章《从零到跑起来:Easysearch 信创环境安装全流程》中,我们成功在信创平台上安装并运行起了 Easysearch。但 Easysearch 是一个底层搜索引擎,直接操作有一定门槛。如果我们想让团队里的每个人都能方便地“搜文件、聊文档、问知识”,就需要一个更贴近日常使用、又能把 AI 能力融入进来的上层应用——这就是 Coco AI 。
本文将继续手把手带你从零开始,在国产统信 UOS 服务器操作系统上部署 Coco Server,并与已安装的 Easysearch 进行对接。全文依然零基础可读,跟着步骤一步步来即可。
二、Coco Server 是什么?它和 Easysearch 什么关系?
先对我们的产品进行一个简单的介绍:
- Easysearch 是底层引擎,负责存储和检索数据,像汽车的发动机和底盘;
- Coco Server 是基于 Easysearch 之上的服务端应用程序,提供 Web 管理界面、统一搜索、AI 聊天、知识库管理等高级功能,类似车身和智能驾驶系统;
- Coco AI 桌面客户端则是连接 Coco Server 的终端软件,安装在个人电脑上使用。
而在本文中部署的 Coco Server,是整个 Coco AI 体系的“大脑”:
- 它负责连接各类数据源(飞书、语雀、GitHub、本地文件等);
- 它管理大模型提供商(Deepseek、通义千问、OpenAI 等);
- 它提供 Web 管理后台,让管理员可以可视化地完成所有配置。
部署完成之后,团队成员只需通过客户端或浏览器,就能享受统一搜索与 AI 智能问答带来的便利。Coco AI 的整体架构图如下:

三、部署前置条件
1. 进行服务器相关优化
#内核参数优化
cat << SETTINGS | sudo tee /etc/sysctl.d/70-infini.conf
fs.file-max = 10485760
fs.nr_open = 10485760
vm.max_map_count = 262145
net.core.somaxconn = 65535
net.core.netdev_max_backlog = 65535
net.core.rmem_default = 262144
net.core.wmem_default = 262144
net.core.rmem_max = 4194304
net.core.wmem_max = 4194304
net.ipv4.ip_forward = 1
net.ipv4.ip_nonlocal_bind = 1
net.ipv4.ip_local_port_range = 1024 65535
net.ipv4.conf.default.accept_redirects = 0
net.ipv4.conf.default.rp_filter = 1
net.ipv4.conf.all.accept_redirects = 0
net.ipv4.conf.all.send_redirects = 0
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_max_tw_buckets = 300000
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 65535
net.ipv4.tcp_synack_retries = 0
net.ipv4.tcp_keepalive_intvl = 30
net.ipv4.tcp_keepalive_time = 900
net.ipv4.tcp_keepalive_probes = 3
net.ipv4.tcp_fin_timeout = 10
net.ipv4.tcp_max_orphans = 131072
net.ipv4.tcp_rmem = 4096 4096 16777216
net.ipv4.tcp_wmem = 4096 4096 16777216
net.ipv4.tcp_mem = 786432 3145728 4194304
SETTINGS
sysctl -p /etc/sysctl.d/70-infini.conf
2. 环境前提:Easysearch 已经运行好
Coco Server 运行强依赖 Easysearch,所以在继续之前,请确保你的信创服务器上已经安装并成功启动了 Easysearch。如果不确定,可以执行下面的命令验证:
curl -k -u admin:你的密码 https://localhost:9200运行命令后,看到正常的 JSON 响应即可。
如果还没有安装,可以参考上一篇文章《从零到跑起来:Easysearch 信创环境安装全流程》先行完成。
3. 信创平台信息确认
和 Easysearch 一样,你需要明确当前服务器的 CPU 架构和操作系统版本。在终端执行:
# 查看 CPU 架构
uname -m
# 查看操作系统信息
cat /etc/os-release根据输出,确认 CPU 架构和操作系统,后续下载时选择对应版本。
部署环境如下表中所示:
4. 软件环境
| 名称 | 版本 | 备注 |
|---|---|---|
| Coco AI 智能搜索软件 | V1.0.0 | Coco Server |
| 统信服务器操作系统 A 版 | V20 | |
| Easysearch 搜索型数据库 | V2.2.0 | 用于 Coco 数据存储 |
| 360安全浏览器 | V13 |
5. Coco AI 大语言模型 推荐配置
| 模型名称 | 上下文长度 | 最大输出长度 | 描述 |
|---|---|---|---|
| deepseek-r1 | 128K | 16K | 数学、代码、自然语言推理等任务上,性能较高,能力较强 |
| qwen3-max | 256K | 32K | 配场景复杂的智能体需求 |
| tongyi-intent-detect-v3 | 8K | 8K | 用于意图识别和槽位填充,负责对话系统中的基础任务 |
5. 网络端口配置
| 服务名 | 端口 | 配置文件 | 说明 |
|---|---|---|---|
| Coco Server | 9000(默认) | coco.yml | |
| INFINI Easysearch | 9200(默认) | config/easysearch.yml | 默认仅监控 127.0.0.0,可通过配置 network.host: 0.0.0.0 调整 |
| 9300(默认) | config/easysearch.yml |
四、部署步骤
步骤 1:下载 Coco Server
# 调整为 Coco 实际要安装的路径
cd /opt
#下载Coco v1.0.0压缩包
curl -O https://release.infinilabs.com/.testing/coco-1.0.0.zip
#解压到当前文件夹
unzip coco-1.0.0.zip
#选择对应的版本解压tar.gz文件
tar -xzf coco-1.0.0-2002-linux-arm64.tar.gz
#解压后在对应文件夹下得到可执行程序coco-linux-arm64(arm64版本)和配置文件coco.yml步骤 2:配置 Easysearch 连接信息
Coco Server 需要得到 Easysearch 的地址和登录凭证才能进行工作。
在 安装路径的目录下,找到配置文件 进行配置,比如监听的端口地址 WEB_BINDING, 将 Easysearch 的服务地址环境变量 ES_ENDPOINT 和用户名 ES_USERNAME 设置为实际的,参考如下:
env:
# 调整为实际可以访问的 Easysearch 访问地址
ES_ENDPOINT: https://localhost:9200
# 调整为实际可以访问的 Easysearch 的用户
ES_USERNAME: admin
# 使用 keystore 存储的密码
ES_PASSWORD: $[[keystore.ES_PASSWORD]]
# Coco Server 对外提供服务的端口(默认9000端口)
WEB_BINDING: 0.0.0.0:9000步骤 3:使用keystore对密码进行加密处理
Easysearch 的服务密码通过 Keystore 进行加密存放,避免明文存放到配置文件,减少数据泄露风险
# 调整为 Coco 实际安装路径进行配置
cd /opt
# 创建 coco 软链接,可不区分 amd64/arm64 平台进行操作
ln -s coco-linux-`arch | grep -q "x86_64" && echo "amd64" || echo "arm64"` coco
# 根据之前拿到的 Easysearch 密码进行初始化 ES_PASSWORD 变量
ES_PASSWORD=xxx
# 将 ES_PASSWORD 变量的值存储到 keystore(./coco-linux-arm64替换为对应版本名,下同)
echo "$ES_PASSWORD" | ./coco-linux-arm64 keystore add --stdin ES_PASSWORD
# 检查 keystore 存储列表,确认 ES_PASSWORD 添加成功
./coco-linux-arm64 keystore list步骤 4:启动服务
以上配置完成后,设置 Coco Server 以服务方式启动
#安装系统服务(./coco-linux-arm64替换为对应版本名,下同)
./coco-linux-arm64 -service install
#启动服务
./coco-linux-arm64 -service start
步骤 5:初始化设置
服务启动后,在信创服务器的桌面环境下,打开浏览器,访问 UI 界面:
http://localhost:9000/#/\_guide/
你将看到 Coco Server 的 Web 引导界面。因为是首次访问,所以需要创建管理员账号,按页面引导填写即可。

创建完管理员账户后,下一步
设置一个模型提供商,Coco Server 支持:
- Deepseek
- Ollama
- 任何和 OpenAI 格式兼容的模型提供商
如果设置的模型是推理模型,需要打开“推理模式”。我们推荐使用参数较大的模型,来获得更好的使用体验。同时请注意:Endpoint 地址的配置要准确。

Coco Server 默认配置了一些小助手,建议在初始化向导的时候直接配置一个可用的模型,这样进入系统之后就可以直接使用,避免一个个的手动配置。
向导设置完成后,就会跳转到登录页面,输入刚才创建的账户和密码,就可以进行登录了,如下图:

管理员首次登录之后的第一件事是确认服务器的地址是否正确,如果 Coco server 前面增加了负载均衡或者配置了域名,需要在这里设置一下正确的 Coco Server 对外服务地址,如下图:

五、总结
到这里,你已经完成了 Coco Server 在信创平台上的部署与初始化。我们回顾一下整个部署流程:
- 确认环境 — Easysearch 已部署成功,并明确 CPU 架构;
- 下载安装 — 下载 Coco Server 的压缩包进行解压;
- 配置连接 — 编辑
coco.yml,填入 Easysearch 端点和密码; - 启动服务 — 将 Coco Server 以服务方式启动;
- 初始化 — 浏览器打开 http://localhost:9000/#/\_guide/ 进行管理员账户的创建; 添加大模型、连接数据源、创建助手。
Coco Server 部署完成后,你就拥有了一个完全私有化、自主可控的企业级统一搜索与 AI 智能助手服务端。下一步可以安装 Coco AI 桌面客户端,让团队成员真正体验“一个搜索框搜遍全公司”的高效便捷。
如果在部署过程中遇到任何困难,欢迎查阅官方文档,祝你部署顺利!
Easysearch 正式支持插件开发:让你的搜索系统真正"为你所用"
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 17422 次浏览 • 2026-04-27 22:02
从"用搜索"到"造搜索"
搜索系统的需求千差万别。标准功能覆盖不了所有场景——行业特定的分词规则、定制化的业务逻辑、与外部系统的深度集成……
以往,这类定制需求需要依赖厂商支持。从 Easysearch 2.1.2 开始,你可以自己动手了。
随着构建依赖库正式发布到 Maven 中央仓库,Easysearch 的插件开发能力正式对外开放。这意味着 Easysearch 不再是一个黑盒产品,而是一个可扩展、可定制的搜索平台。你可以基于官方接口开发自定义插件,像使用原生功能一样使用它们。
插件能做什么
Easysearch 提供三类核心扩展点,覆盖搜索系统的关键环节:
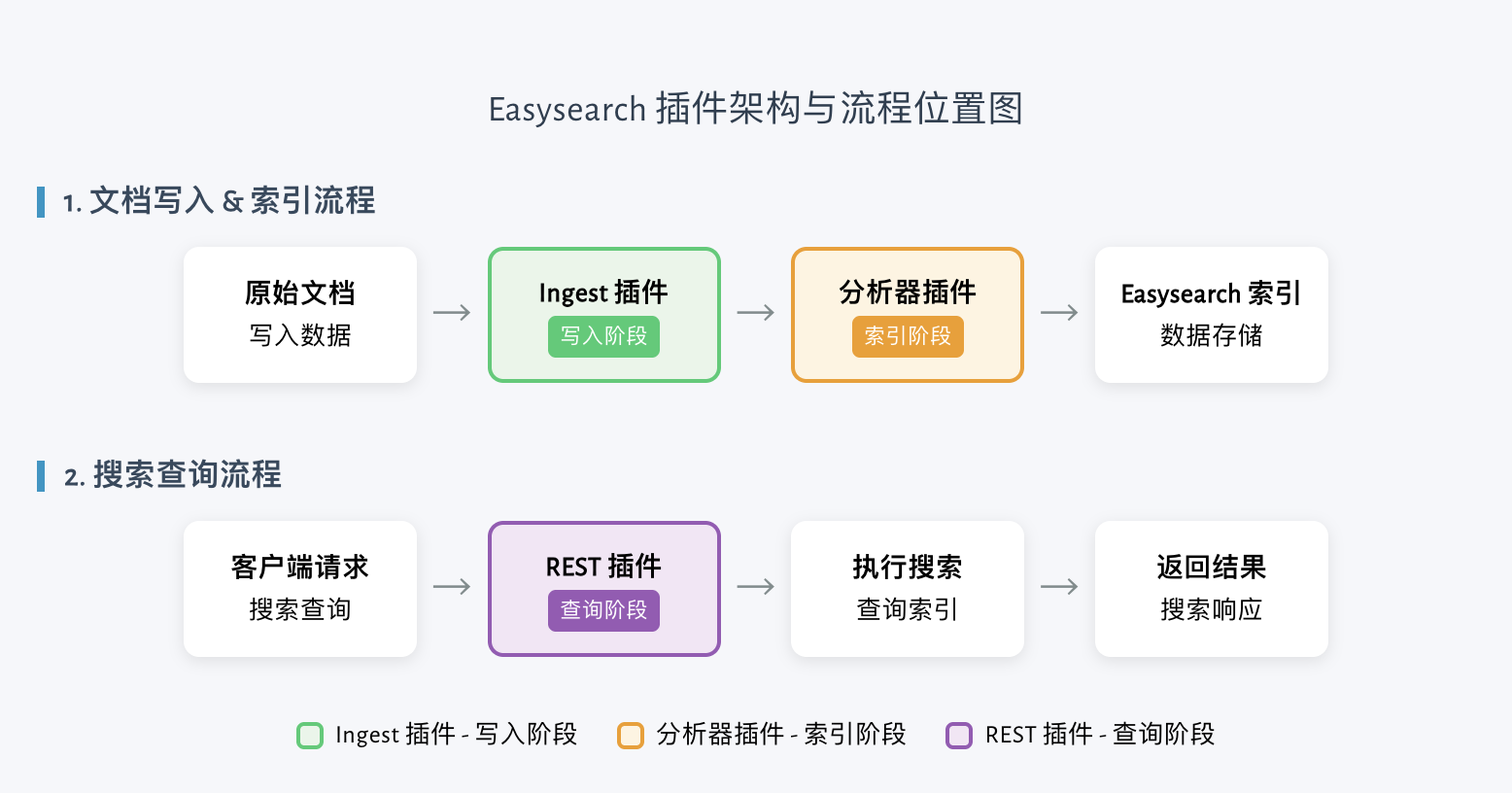
1. 分析器插件(AnalysisPlugin)
自定义分词器、Token 过滤器、字符过滤器。适用于:
- 电商 SKU 的型号规格解析
- 医疗、法律等领域的专业术语分词
- 特殊符号或空格的规范化处理
注册后直接在索引设置中使用,与原生分析器完全等同。

2. REST/API 插件(ActionPlugin)
新增自定义 HTTP 接口。适用于:
- 封装业务查询逻辑,对外暴露简化 API
- 对接企业内部权限中心或监控系统
- 暴露插件自身的管理接口(如状态检查)

3. Ingest 插件(IngestPlugin)
在文档写入前进行字段转换。适用于:
- 自定义业务字段转换(如根据业务规则计算衍生字段)
- 数据标准化(统一日期格式、大小写转换)
- 富文本提取或元数据生成

5 分钟上手
我们准备了官方模板仓库,让你从克隆到运行只需几条命令:
# 克隆模板
git clone https://github.com/infinilabs/easysearch-plugin-template.git my-plugin
cd my-plugin
# 修改包名和类名,编写你的逻辑
# ...方式一:开发调试——直接运行
# 构建插件并运行
./gradlew run
# 验证插件
curl -s "http://localhost:9200/_cat/plugins?v" | grep my-plugin方式二:构建后安装到外部集群
# 构建插件
./gradlew build
# 安装到 Easysearch
bin/easysearch-plugin install file:///$(pwd)/build/distributions/my-plugin-0.1.0.zip
# 启动验证
bin/easysearch
curl -s "http://localhost:9200/_cat/plugins?v" | grep my-plugin完整的开发指南请参考插件开发文档。
设计哲学
Easysearch 插件系统的设计遵循三个原则:
渐进式扩展——从最简单的 Plugin 类开始,按需实现 AnalysisPlugin、ActionPlugin 等接口,不必一次性掌握全部 API。
与原生同等——插件注册的分析器、处理器与系统原生组件在使用方式上完全一致,用户无需关心实现来源。
版本安全——插件加载时校验 easysearch.version,版本不匹配会拒绝加载,避免运行时异常。
从插件到生态
插件开发不只是技术能力的开放,更是产品理念的转变。
你可以将开发的插件发布到 GitHub Releases,通过 URL 直接安装:

bin/easysearch-plugin install https://github.com/yourname/my-plugin/releases/download/v0.1.0/my-plugin-0.1.0.zip我们也欢迎社区贡献。如果你有通用的插件想法,欢迎与我们交流。
结语
搜索系统的最后一公里,只有业务开发者最清楚该怎么走。
Easysearch 2.1.2 的插件开发能力,让你能够自主掌控搜索系统的"最后一公里"。从"用搜索"到"造搜索",现在你可以让你的搜索系统真正"为你所用"。
关于 Easysearch

INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
Easysearch ZSTD 基准测试:高压缩率下实现近 5 倍查询吞吐
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 5025 次浏览 • 2026-03-17 12:41
在搜索引擎领域,压缩算法的选择一直是一个经典的权衡难题:
- 选择高压缩率(如
best_compression/ DEFLATE),磁盘省了,但查询解压慢; - 选择高速编码(如默认 LZ4),查询快了,但磁盘占用大。
Easysearch 引入了基于 JDK 21 FFM(Foreign Function & Memory API) 直连本地 ZSTD 动态库的加速方案,试图打破这一困局。为了验证效果,我们在完全对等的环境下,对 Easysearch(ZSTD)和 Elasticsearch 7.10.2(best_compression)进行了一次严格的查询吞吐对比测试。
结果令人振奋——即使在系统明显背景负载下,Easysearch 也没有因为高压缩而变慢,反而在查询吞吐上实现了近 5 倍提升。
测试环境
为确保对比公平,两套集群的硬件资源、JVM 配置、数据规模、索引结构完全对齐:
| 配置项 | Easysearch | Elasticsearch 7.10.2 |
|---|---|---|
| 节点数 | 3 | 3 |
| JVM 堆内存 | 12GB × 3 | 12GB × 3 |
| node.processors | 16 × 3 | 16 × 3 |
| 文档数 | 10,000,000 | 10,000,000 |
| 主分片 / 副本 | 3 / 0 | 3 / 0 |
| 数据类型 | nginx 访问日志 | nginx 访问日志 |
| 字段数 | 17 | 17 |
| mapping | 完全一致(MD5 校验) | 完全一致(MD5 校验) |
| Stored fields 压缩模式 | ZSTD (JDK21 FFM/native, level=3) | best_compression (DEFLATE) |
压缩机制对比:
best_compression映射到 LuceneBEST_COMPRESSION;在 stored fields 路径上,压缩实现为DeflateWithPresetDictCompressionMode,内部使用java.util.zip.Deflater/Inflater(即 DEFLATE)。 Easysearch ZSTD 当前走 JDK 21 FFM 绑定本地 zstd 库(java.lang.foreign);index.compression.zstd.jni=true为当前这套实现的启用方式。
查询模型:JMeter 随机 match 查询,随机命中 service_name、method、error_code、url 四个字段,每次返回 10 条文档。
压测起始负载(_cat/nodes 快照):
| 负载项 | Easysearch run | Elasticsearch run |
|---|---|---|
| load_1m | 29.74 | 25.27 |
| load_5m | 27.10 | 28.15 |
| load_15m | 26.09 | 36.96 |
| ram.percent | 99 | 99 |
说明:压测并非在空闲机上进行,而是在已有明显背景负载的生产式环境下完成。
核心结果
1. 查询吞吐量(QPS):在高背景负载下,Easysearch 仍领先 372%
稳态阶段(3 轮平均),Easysearch 的查询吞吐是 Elasticsearch 的 4.7 倍:
| 指标 | Elasticsearch (DEFLATE) | Easysearch (ZSTD) | 差异 |
|---|---|---|---|
| 稳态 QPS | 532.8 | 2,518.0 | +372.6% |
| 平均响应时间 | 779.0 ms | 164.3 ms | -78.9% |
| 稳态 CPU 占用(系统总占用) | 92.43% | 89.59% | 仅作背景参考 |
注:压测期间服务器存在明显背景负载(其他进程占用较高),该 CPU 指标是系统总占用,不等价于“仅搜索进程”的纯业务 CPU 对比。
在系统总 CPU 均接近 90% 的背景下,Easysearch 仍达到接近 5 倍吞吐。
查询吞吐量 QPS 对比(稳态均值)
2. 响应时间:从近 1 秒降到 164 毫秒
平均响应时间对比(ms,越低越好)
用户体感上,这意味着:同样一个搜索请求,Elasticsearch 还在等解压,Easysearch 已经把结果送到了客户端。
3. 各轮次详细数据
各轮次 QPS 趋势
各轮次平均响应时间趋势(ms)
4. CPU 使用效率:每 1% CPU 产出的 QPS 差距惊人
单看 CPU 占用率,两者似乎差不多(89.59% vs 92.43%)。但如果换一个视角——每消耗 1% CPU 能产出多少 QPS,差距就一目了然了:
| 指标 | Elasticsearch (DEFLATE) | Easysearch (ZSTD) | 倍数 |
|---|---|---|---|
| 稳态 QPS | 532.8 | 2,518.0 | — |
| 稳态 CPU | 92.43% | 89.59% | — |
| QPS / 1% CPU | 5.76 | 28.10 | 4.88× |
CPU 使用效率:每 1% CPU 产出的 QPS
这意味着什么?
- ES 使用 DEFLATE(best_compression)时,解压路径更可能成为 CPU 热点;结合 ES 的高 CPU(92.43%)与较低 QPS,说明单位 CPU 产出偏低;
- Easysearch 使用 ZSTD(JDK21 FFM/native)时,解压开销更小;在相近 CPU 水位(89.59%)下获得更高 QPS,单位 CPU 产出明显更高。
换句话说,当前这组实测更支持“ZSTD 在该查询模型下单位 CPU 产出更高”。
5. 存储空间:ZSTD 并未膨胀
| 索引 | 压缩算法 | 磁盘占用 |
|---|---|---|
| nginx_best_10m (ES) | best_compression (DEFLATE) | 1.8 GB |
| nginx_zstd3 (Easysearch) | ZSTD (level=3, JDK21 FFM/native) | 1.9 GB |
两者存储空间接近。若按 _cat/indices 的 1 位小数展示是 1.8GB vs 1.9GB;若按 _stats/store 字节值计算,差异约 2.5%。因此可以认为 ZSTD 在 level=3 下与 DEFLATE best_compression 压缩率接近。
磁盘占用对比(GB)
为什么 ZSTD 能做到"又小又快"?
传统认知中,压缩率和解压速度是一对矛盾。但 ZSTD 算法天然具备非对称压缩的特性:
压缩算法特性对比
在搜索引擎场景中,查询会触发存储字段(_source)读取与解压路径,命中文件系统页缓存时,可能不发生实际磁盘 I/O,但仍需进行 _source 解压。
当查询涉及较多 _source 读取时:
- DEFLATE 的解压开销成为 CPU 瓶颈,拖慢了整体吞吐;
- ZSTD(JDK21 FFM/native) 的解压速度在该场景下明显更优,单次请求的解压 CPU 成本更低,从而释放出更多 CPU 资源用于并发查询处理。
这就是为什么 Easysearch 在 CPU 占用更低(89.59% vs 92.43%)的情况下,反而能处理近 5 倍的查询量。
一张图总结
Easysearch ZSTD vs Elasticsearch DEFLATE — 全维度对比
结论
Easysearch 的 ZSTD 压缩方案证明了一个事实:即使在高背景负载下,高压缩率和高查询性能依然可以兼得。
在 1000 万条 nginx 日志、且系统存在明显背景负载的实测中:
- 查询吞吐提升 372%,从 533 QPS 跃升至 2518 QPS
- 平均响应时间下降 79%,从 779ms 降至 164ms
- CPU 使用效率提升 388%,每 1% CPU 产出 28.10 QPS vs 5.76 QPS
- CPU 占用绝对值下降 2.84 个百分点(相对下降约 3.07%)
- 磁盘占用与 DEFLATE best_compression 接近(按字节口径约 +2.5%)
对于日志分析、可观测性、安全审计等需要兼顾存储成本和查询性能的场景,Easysearch ZSTD 是一个不需要妥协的选择。
ZSTD 使用方法
1) 新建索引时启用 ZSTD
curl -k -u 'admin:<password>' -X PUT 'https://127.0.0.1:9200/<index-name>' \
-H 'Content-Type: application/json' -d '{
"settings": {
"index.codec": "ZSTD",
"index.compression.zstd.jni": true
}
}'可选参数:
index.compression.zstd.level(默认3)
说明:
index.compression.zstd.dict固定为true,无需单独配置index.compression.zstd.dict不作为独立开关来调整
2) 老索引切换到 ZSTD(推荐 reindex)
index.codec 是静态设置(打开状态不可动态改;可在关闭索引后调整)。
index.compression.zstd.jni 是 final 设置(关闭索引后也不可修改)。
如果老索引要启用 index.compression.zstd.jni=true,建议新建目标索引后 reindex 迁移:
如果对已有索引执行 PUT /<index-name>/_settings 直接修改,会报错:final <index-name> setting [index.compression.zstd.jni], not updateable。
# 先创建目标索引(启用 ZSTD)
curl -k -u 'admin:<password>' -X PUT 'https://127.0.0.1:9200/<target-index>' \
-H 'Content-Type: application/json' -d '{
"settings": {
"index.codec": "ZSTD",
"index.compression.zstd.jni": true
}
}'
# 再迁移数据
curl -k -u 'admin:<password>' -X POST 'https://127.0.0.1:9200/_reindex' \
-H 'Content-Type: application/json' -d '{
"source": { "index": "<source-index>" },
"dest": { "index": "<target-index>" }
}'3) 校验是否生效
curl -k -u 'admin:<password>' \
'https://127.0.0.1:9200/<index-name>/_settings?include_defaults=true&pretty'重点确认:
index.codec = ZSTDindex.compression.zstd.jni = true
关于 Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
官网文档:https://docs.infinilabs.com/easysearch
作者:张磊,极限科技(INFINI Labs)搜索引擎研发负责人,对 Elasticsearch 和 Lucene 源码比较熟悉,目前主要负责公司的 Easysearch 产品的研发以及客户服务工作。
相关文章:
极限科技荣膺 2025 金猿奖 — “年度国产化优秀代表厂商”,自主可控搜索方案 Easysearch 获行业高度认可
资讯动态 • INFINI Labs 小助手 发表了文章 • 0 个评论 • 25128 次浏览 • 2026-01-16 17:41
近日于上海明捷万丽酒店成功举办的 “2025 第八届金猿大数据产业发展论坛 — 暨 AI Infra & Data Agent 趋势论坛” 大会上,极限数据(北京)科技有限公司(以下简称“极限科技”) 凭借其在分布式搜索型数据库领域的技术突破与卓越的国产化实践,成功入选《2025 中国大数据产业「年度国产化优秀代表厂商」》榜单,并获颁这一行业重磅奖项。

本届论坛由金猿组委会、数据猿、上海市数商协会及上海大数据联盟联合主办,以“数据有猿·智见十年”为主题,吸引了近千家企业参与申报。经过严格的初审、公审与终审交叉验证机制,极限科技最终从众多竞争者中脱颖而出,荣登榜单。

深耕核心搜索技术,填补国产化空白
极限科技成立于 2021 年 12 月,是一家专注于大数据搜索与分析的基础软件公司。公司总部位于北京,在长沙设立研发中心,并在上海、广州设立办事处或服务中心。其核心团队均来自 Elasticsearch 原厂及中文社区,拥有多年 ES 源码开发经验,致力于“让搜索更简单”,打造极致易用的数据探索与分析体验。
公司自主研发的核心产品 Easysearch 搜索型数据库,是我国在分布式搜索型数据库领域实现关键国产化替代的代表性成果。该产品精准填补了国内在轻量化、高性能、自主可控搜索引擎方面的市场空白。
产品性能卓越,实现无缝迁移与超越
Easysearch 支持结构化与非结构化数据检索、全文检索、向量检索、空间地理位置信息检索、多模态混合检索、组合查询、多语种支持、语义分析、聚合分析等多种核心功能。测试表明,其性能已达到甚至优于国外领先产品。
在产品能力上,Easysearch 不仅完全兼容 Elasticsearch 的生态接口,保障了用户业务的无缝平滑迁移,更在性能优化、存储效率、企业级安全及原生中文处理等方面实现了显著超越。其内置的 Web 管理控制台、全面的数据加密与权限管控功能,提供了开箱即用的企业级体验。
构建完整信创生态
尤为关键的是,Easysearch 率先完成了与国产主流 CPU(如鲲鹏、飞腾、海光、龙芯、申威、兆芯等)和操作系统(如统信 UOS、银河麒麟、开源欧拉等)的深度适配与互认证,构建了完整的信创技术栈支持能力,彻底解决了国外产品在国产化环境下兼容性差、维护困难、更新受限等长期存在的痛点。
在核心技术国产化意义上,Easysearch 通过完全自主可控的分布式搜索技术体系,突破了关键基础软件依赖国外企业的局面,满足了政府、金融、能源、运营商等行业对“可控、安全、可替代”的战略需求。同时,其向量搜索和 AI 检索能力填补了国内在智能搜索与大模型结合领域的技术缺口。
获权威资质认可,落地众多头部客户
极限科技及 Easysearch 已获得多项权威资质认证,包括国家高新技术企业、ISO 三大管理体系认证,并荣获 2023 年星河案例数据库标杆案例。产品亦通过了信通院基础能力专项测评及中国泰尔实验室检验测试。
目前,Easysearch 已在金融、运营商、制造、政企等多领域实现规模化落地,服务客户包括移动云、中国一汽、中国人保、东莞证券、航天信息等头部企业,累计下载部署量已超过 500 万次。其中,公司开发的中文分词器(IK、Pinyin)、压测工具(Loadgen)、数据迁移工具(ESM)已被 85% 的中国 Elasticsearch 用户部署在生产环境中。
荣获行业大奖,彰显标杆价值
此次荣获 “年度国产化优秀代表厂商” 奖项,不仅是行业对极限科技技术实力与国产化贡献的高度认可,更彰显了公司在推动大数据产业自主创新进程中的标杆作用。
极限科技创始人表示:
“我们坚信‘追求极致,无限可能’。获得这份荣誉,是对我们团队多年来坚持自主创新、深耕搜索技术的最好鼓励。未来,极限科技将持续加大研发投入,以技术创新驱动产业升级,为各行业客户提供更高效、更安全、更智能的数据探索与分析能力,助力中国大数据产业在智能时代实现高质量、自主可控的发展。”
相关链接:
Easy-Es 2.1.0-easysearch 版本发布
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 9670 次浏览 • 2025-12-15 17:42

01 | 版本更新概述
经过极限科技与 Dromara 开源社区下 Easy-Es 项目的紧密合作与共同努力,我们很荣幸地联合推出 Easy-Es 2.1.0-easysearch 版本!
作为双方携手打造的第一个合作成果,本版本已正式发布:
- 源码仓库:https://gitee.com/dromara/easy-es/tree/easy-es4easySearch/
- Maven 依赖:https://mvnrepository.com/artifact/org.dromara.easy-es/easy-es-boot-starter/2.1.0-easysearch
本次更新的核心内容是将 Easy-Es 框架底层增加兼容极限科技自主研发的 Easysearch 搜索引擎,这标志着国产搜索引擎与国内优秀开源项目深度融合的重要里程碑,是极限科技与 Dromara 社区携手共建国产技术生态的创新实践。
02 | 迁移至 Easysearch 的背景与优势
随着国内对自主可控技术需求的日益增长,特别是在基础设施软件领域,企业对于信创合规的要求不断提升。极限科技自主研发的 Easysearch 搜索引擎具备以下显著优势:
- 国产化自主可控:完全自主研发,符合信创要求,无许可证风险,为企业提供安全可靠的技术保障
- 轻量级架构:相比传统搜索引擎,资源占用更少,启动更快速,显著降低企业运维成本
- 卓越性能表现:查询性能优异,能够满足大部分业务场景需求,用户体验流畅
- 良好兼容性:与 Elasticsearch 的 API 接口基本兼容,迁移成本较低,保护用户现有投资
基于以上优势,双方决定共同将 Easy-Es 框架底层迁移至 Easysearch,这不仅为用户提供更多选择,更是双方携手推动国产搜索引擎生态建设的重要举措。
03 | Easy-Es 框架优势
Easy-Es 框架在搜索开发领域具备以下核心优势:
- 极简代码开发:相比原生 API 可减少 50%-80% 的代码量,大幅提升开发效率。
// 使用 Easy-Es 仅需一行代码完成查询
List<Document> documents = documentMapper.selectList(
EsWrappers.lambdaQuery(Document.class).eq(Document::getTitle, "测试")
);-
自动索引管理: 框架提供全自动智能索引托管功能,开发者无需关心索引的创建、更新及数据迁移等复杂操作,索引全生命周期由框架自动管理,过程零停机。
-
SQL 语法兼容: 支持使用 MySQL 语法完成搜索查询操作,无需学习复杂的 DSL 语句。支持 and、or、like、in 等常用 SQL 语法。
-
Lambda 表达式支持: 采用 Lambda 风格编程,提供类型安全的字段访问,避免手动输入字段名可能产生的错误,提升代码可读性和开发效率。
-
无缝 Spring Boot 集成: 与 Spring Boot 生态深度集成,提供开箱即用的自动配置,无需复杂的手动配置,支持 Spring Boot Actuator 监控,完美融入企业级应用架构。
-
丰富的查询功能: 支持复杂的嵌套查询、聚合查询、范围查询、高亮显示等高级搜索功能,同时保持 API 的简洁易用,满足各种业务场景需求。
-
分布式架构支持: 完美适配 Easysearch 的分布式特性,支持集群模式部署,具备高可用性和横向扩展能力,满足企业级大规模数据处理需求。
- 成熟稳定的国产 ORM 框架: 作为 Dromara 开源社区下的顶级开源项目,Easy-Es 已在国内众多企业和项目中得到广泛应用和验证,拥有活跃的中文社区和完善的文档支持,为企业级应用提供了可靠的技术保障。
04 | 快速上手示例
1. 添加依赖
根据您使用的构建工具,选择对应的配置方式:
Maven 项目
pom.xml 配置:
<properties>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<spring-boot.version>2.7.0</spring-boot.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.dromara.easy-es</groupId>
<artifactId>easy-es-boot-starter</artifactId>
<version>2.1.0-easysearch</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>${spring-boot.version}</version>
<executions>
<execution>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>Maven 启动命令:
# 运行应用
mvn spring-boot:run
# 编译打包
mvn clean packageGradle 项目
build.gradle 配置:
plugins {
id 'java'
id 'org.springframework.boot' version '2.7.0'
id 'io.spring.dependency-management' version '1.0.11.RELEASE'
}
group = 'org.easysearch'
version = '1.0-SNAPSHOT'
sourceCompatibility = '11'
repositories {
mavenLocal()
mavenCentral()
}
dependencies {
implementation 'org.dromara.easy-es:easy-es-boot-starter:2.1.0-easysearch'
implementation 'org.springframework.boot:spring-boot-starter-web'
}Gradle 启动命令:
# 运行应用
./gradlew bootRun
# 编译打包
./gradlew clean build2. 配置文件设置
application.yml(根据实际 Easysearch 部署情况修改):
easy-es:
enable: true
# Easysearch 服务地址
address: localhost:9200
# 协议:http 或 https
schema: https
# Easysearch 用户名
username: admin
# Easysearch 密码
password: your_password_here
# 连接保持时间(毫秒)
keep-alive-millis: 18000
global-config:
# 开启彩蛋模式(启动时显示 ASCII 艺术图案)
i-kun-mode: true
# 索引处理模式:smoothly 表示平滑模式(零停机更新索引)
process-index-mode: smoothly
# 异步处理索引时是否阻塞
async-process-index-blocking: true
# 是否打印 DSL 语句(开发调试时可设为 true)
print-dsl: false
db-config:
# 下划线转驼峰
map-underscore-to-camel-case: true
# 索引前缀
index-prefix: dev_
# 主键类型:customize 表示自定义
id-type: customize
# 字段更新策略:not_empty 表示非空时才更新
field-strategy: not_empty
# 刷新策略:immediate 表示立即刷新
refresh-policy: immediate
# 开启追踪总命中数
enable-track-total-hits: true3. 实体类定义
package org.dromara.easyes.sample.entity;
import lombok.Data;
import lombok.experimental.Accessors;
import org.dromara.easyes.annotation.HighLight;
import org.dromara.easyes.annotation.IndexField;
import org.dromara.easyes.annotation.IndexId;
import org.dromara.easyes.annotation.IndexName;
import org.dromara.easyes.annotation.Settings;
import org.dromara.easyes.annotation.rely.Analyzer;
import org.dromara.easyes.annotation.rely.FieldStrategy;
import org.dromara.easyes.annotation.rely.FieldType;
import org.dromara.easyes.annotation.rely.IdType;
import java.time.LocalDateTime;
/**
* es 数据模型
*/
@Data
@Accessors(chain = true)
@Settings(shardsNum = 3, replicasNum = 2)
@IndexName(value = "easyes_document", keepGlobalPrefix = true)
public class Document {
/**
* es 中的唯一 id
*/
@IndexId(type = IdType.CUSTOMIZE)
private String id;
/**
* 文档标题,默认为 keyword 类型,可进行精确查询
*/
private String title;
/**
* 文档内容,指定为 TEXT 类型,使用 IK 分词器
* 支持高亮显示,高亮结果映射到 highlightContent 字段
*/
@HighLight(mappingField = "highlightContent")
@IndexField(fieldType = FieldType.TEXT, analyzer = Analyzer.IK_SMART)
private String content;
/**
* 创建者,字段策略为非空时才更新
*/
@IndexField(strategy = FieldStrategy.NOT_EMPTY)
private String creator;
/**
* 创建时间
*/
@IndexField(fieldType = FieldType.DATE, dateFormat = "yyyy-MM-dd HH:mm:ss")
private LocalDateTime gmtCreate;
/**
* 高亮返回值被映射的字段
*/
private String highlightContent;
/**
* 文档点赞数
*/
private Integer starNum;
/**
* 地理位置经纬度坐标,例如: "40.13933715136454,116.63441990026217"
*/
@IndexField(fieldType = FieldType.GEO_POINT)
private String location;
}4. Mapper 接口
package org.dromara.easyes.sample.mapper;
import org.dromara.easyes.core.kernel.BaseEsMapper;
import org.dromara.easyes.sample.entity.Document;
/**
* Mapper 接口,继承 BaseEsMapper 即可获得所有 CRUD 方法
*/
public interface DocumentMapper extends BaseEsMapper<Document> {
}5. 启动类配置
package org.dromara.easyes.sample;
import org.dromara.easyes.spring.annotation.EsMapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* 启动类
*/
@SpringBootApplication
@EsMapperScan("org.dromara.easyes.sample.mapper")
public class EasyEsApplication {
public static void main(String[] args) {
SpringApplication.run(EasyEsApplication.class, args);
}
}6. 业务使用示例
package org.dromara.easyes.sample.controller;
import org.dromara.easyes.core.conditions.select.LambdaEsQueryWrapper;
import org.dromara.easyes.sample.entity.Document;
import org.dromara.easyes.sample.mapper.DocumentMapper;
import org.easysearch.action.search.SearchResponse;
import org.easysearch.search.aggregations.Aggregations;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
import java.time.LocalDateTime;
import java.util.List;
@RestController
public class SampleController {
@Resource
private DocumentMapper documentMapper;
/**
* 初始化插入数据
*/
@GetMapping("/insert")
public Integer insert() {
int count = 0;
// 插入 5 条测试数据
for (int i = 1; i <= 5; i++) {
Document document = new Document();
document.setId(String.valueOf(i));
document.setTitle("测试" + i);
document.setContent("测试内容" + i);
document.setCreator("创建者" + i);
document.setGmtCreate(LocalDateTime.now());
document.setStarNum(i * 10);
count += documentMapper.insert(document);
}
return count;
}
/**
* 根据标题精确查询
*/
@GetMapping("/listDocumentByTitle")
public List<Document> listDocumentByTitle(@RequestParam String title) {
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
wrapper.eq(Document::getTitle, title);
return documentMapper.selectList(wrapper);
}
/**
* 高亮搜索
*/
@GetMapping("/highlightSearch")
public List<Document> highlightSearch(@RequestParam String content) {
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
wrapper.match(Document::getContent, content);
return documentMapper.selectList(wrapper);
}
/**
* 查询所有数据
*/
@GetMapping("/selectAll")
public List<Document> selectAll() {
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
return documentMapper.selectList(wrapper);
}
/**
* 聚合查询 - 按创建时间和点赞数分组统计
*/
@GetMapping("/aggByDateAndStar")
public Aggregations aggByDateAndStar() {
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
wrapper.groupBy(Document::getGmtCreate)
.max(Document::getStarNum)
.min(Document::getStarNum);
SearchResponse response = documentMapper.search(wrapper);
return response.getAggregations();
}
/**
* 使用 SQL 语句查询文档
*/
@GetMapping("/queryBySQL")
public String queryBySQL(@RequestParam(required = false) String title) {
String sql;
if (title != null && !title.isEmpty()) {
sql = String.format("SELECT * FROM dev_easyes_document WHERE title = '%s'", title);
} else {
sql = "SELECT * FROM dev_easyes_document LIMIT 10";
}
return documentMapper.executeSQL(sql);
}
}7. 快速测试
启动应用后,可以通过以下接口测试:
# 1. 插入测试数据
curl http://localhost:8080/insert
# 2. 查询所有数据
curl http://localhost:8080/selectAll
# 3. 根据标题精确查询
curl "http://localhost:8080/listDocumentByTitle?title=测试1"
# 4. 高亮搜索
curl "http://localhost:8080/highlightSearch?content=测试"
# 5. SQL 查询
curl "http://localhost:8080/queryBySQL?title=测试1"
# 6. 聚合查询
curl http://localhost:8080/aggByDateAndStar05 | 相关链接
- Easy-Es 官方网站:https://easy-es.cn
- Gitee 仓库:https://gitee.com/dromara/easy-es
- GitHub 仓库:https://github.com/dromara/easy-es
- Easysearch 官方网站:https://infinilabs.cn/products/easysearch
06 | 特别致谢
在此,极限科技要特别感谢 Easy-Es 项目的核心开发者“老汉”和各位贡献者和维护者们。正是因为有了你们的辛勤付出、专业精神以及对开源事业的热忱奉献,Easy-Es 项目才能在国内外获得如此广泛的认可和应用。
也感谢你们对国产技术生态建设的信任与支持。此次 Easy-Es 与 Easysearch 的深度整合,正是双方通力合作、互利共赢的最佳体现。
我们相信,在 Easy-Es 项目团队的持续推动下,国产开源软件必将迎来更加辉煌的明天。极限科技将继续致力于提供优质的国产技术解决方案,与 Easy-Es 项目团队携手共进,为中国开源生态的发展贡献更多力量!
关于 Easy-Es
Easy-Es(简称 EE)是一款基于 Elasticsearch(简称 ES)官方提供的 ElasticsearchClient 打造的 ORM 开发框架,在 ElasticsearchClient 的基础上,只做增强不做改变,为简化开发、提高效率而生,您如果有用过 Mybatis-Plus(简称 MP),那么您基本可以零学习成本直接上手 EE,EE 是 MP 的 ES 平替版,在有些方面甚至比 MP 更简单,同时也融入了更多 ES 独有的功能,助力您快速实现各种场景的开发。
Easy-Es for Easysearch 是一款简化 Easysearch 国产化搜索引擎操作的开源框架,全自动智能索引托管。同时也是国内首家专门针对 Easysearch 客户端简化的工具。它简化 CRUD 及其它高阶操作,可以更好的帮助开发者减轻开发负担。底层采用 Easysearch Java Client,保证其原生性能及拓展性。
项目地址:https://gitee.com/dromara/easy-es/tree/easy-es4easySearch
关于极限科技
极限科技(全称:极限数据(北京)科技有限公司)是一家专注于实时搜索与数据分析的软件公司。
旗下品牌:极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验,为用户提供安全、稳定、高性能的国产搜索解决方案。
作者:张磊,极限科技(INFINI Labs)搜索引擎研发负责人,对 Elasticsearch 和 Lucene 源码比较熟悉,目前主要负责公司的 Easysearch 产品的研发以及客户服务工作。
使用 Docker Compose 轻松实现 INFINI Console 离线部署与持久化管理
开源项目 • INFINI Labs 小助手 发表了文章 • 0 个评论 • 11226 次浏览 • 2025-10-31 18:04
系列回顾与引言
在我们的 INFINI 本地环境搭建系列博客中:
- 第一篇《搭建持久化的 INFINI Console 与 Easysearch 容器环境》,我们深入探讨了如何使用基础的
docker run命令,一步步构建起 Console 和 Easysearch 服务,并重点解决了数据持久化的问题。 - 第二篇《使用 Docker Compose 简化 INFINI Console 与 Easysearch 环境搭建》,我们学习了如何利用 Docker Compose 的声明式配置,将多容器应用的定义和管理变得更加简洁高效。
- 第三篇《一键启动:使用 start-local 脚本轻松管理 INFINI Console 与 Easysearch 本地环境》,我们介绍了如何在联网环境下,一键安装 INFINI Console。
接下来,我们将聚焦于离线环境,详细讲解如何使用 Docker Compose 部署 INFINI Console 和 Easysearch。

简介
INFINI Console 是一款强大的集群管理与可观测性平台,而 INFINI Easysearch 则是一个轻量级、高性能的搜索与分析引擎。官方提供的离线部署包将两者整合,非常适合在无外网或需要快速搭建演示环境的场景下使用。
本文将详细介绍如何下载资源、正确加载镜像、以及最关键的——如何根据您的需求修改 docker-compose.yml 中的各项配置。
1. 准备工作
请确保您的环境中已安装以下软件:
- Docker
- Docker Compose
2. 下载离线资源
从官方地址下载两个核心文件:
infini-console.tar.gz: 包含docker-compose.yml和相关脚本。infini-console-easysearch-1.14.2.tar: 包含infinilabs/console和infinilabs/easysearch的 Docker 镜像。
wget https://release.infinilabs.com/easysearch/archive/offline/amd64/infini-console.tar.gz
wget https://release.infinilabs.com/easysearch/archive/offline/amd64/infini-console-easysearch-1.14.2.tar3. 正确加载 Docker 镜像
注意:infini-console-easysearch-1.14.2.tar 是一个包含多个镜像的归档包,不能直接使用 docker load 加载。
正确的加载步骤如下:
-
创建目录并解压镜像归档包:
mkdir -p images tar -xvf infini-console-easysearch-1.14.2.tar -C images这会将
console.tar和easysearch.tar等文件解压到images/目录中。 -
批量加载所有镜像:
cd images ls *.tar | xargs -I {} docker load -i {}该命令会自动为目录下的每个
.tar文件执行docker load操作。 - 验证镜像加载结果:
docker images您应该能看到
infinilabs/console:1.29.8和infinilabs/easysearch:1.14.2等镜像。
4. 修改配置文件
解压 infini-console.tar.gz 后,找到 .env 文件。所有自定义配置都应在此文件中修改。
以下是各项配置的详细说明和修改建议:
核心路径配置
WORK_DIR_ABS=/data/infini-console- 作用: 定义所有持久化数据(日志、配置、索引)的根目录。
- 修改建议: (必改) 强烈建议修改为您服务器上一个有足够空间的路径,例如
/opt/infini-console。确保该目录存在且 Docker 拥有写入权限。
网络配置
APP_NETWORK_NAME=infini-local-net- 作用: 定义 Docker 内部网络的名称。
- 修改建议: 通常无需修改。
Console 配置
CONSOLE_IMAGE=infinilabs/console
CONSOLE_VERSION_TAG=1.29.8
CONSOLE_CONTAINER_NAME=infini-console
CONSOLE_PORT_HOST=9000
CONSOLE_PORT_CONTAINER=9000- 作用: 定义 Console 的镜像、版本、容器名及端口映射。
- 修改建议:
CONSOLE_PORT_HOST: 如果宿主机的9000端口已被占用,请修改为其他可用端口(如8080)。
Easysearch 配置
EASYSEARCH_IMAGE=infinilabs/easysearch
EASYSEARCH_VERSION_TAG=1.14.2
EASYSEARCH_NODES=1
EASYSEARCH_CLUSTER_NAME=infini-console- 作用: 定义 Easysearch 的镜像、版本、节点数和集群名。
- 修改建议:
EASYSEARCH_NODES: 单机部署保持1即可。
访问与安全配置
EASYSEARCH_INITIAL_ADMIN_PASSWORD=ShouldChangeme123.- 作用: 设置 Easysearch
admin用户的初始密码。 - 修改建议: (必改) 请务必将其替换为一个强密码。登录 Console 时需要使用此密码。
EASYSEARCH_HTTP_PORT_HOST=9200
EASYSEARCH_TRANSPORT_PORT_HOST=9300- 作用: 定义 Easysearch HTTP 和 Transport 接口在宿主机上的映射端口。
- 修改建议: 如果
9200或9300端口冲突,请修改。
JVM 参数配置
ES_JAVA_OPTS_DEFAULT="-Xms8g -Xmx8g"- 作用: 设置 Easysearch 的 JVM 堆内存大小。
- 修改建议: (必改) 请根据服务器物理内存进行调整,避免超过物理内存的 50%。
- 8GB 内存服务器: 建议设为
-Xms2g -Xmx2g。 - 16GB 内存服务器: 建议设为
-Xms4g -Xmx4g。
- 8GB 内存服务器: 建议设为
数据持久化路径
CONSOLE_HOST_DATA_SUBPATH_REL=console/data
CONSOLE_HOST_LOGS_SUBPATH_REL=console/logs
EASYSEARCH_HOST_NODES_BASE_SUBPATH_REL=easysearch- 作用: 定义数据和日志在
WORK_DIR_ABS下的相对子路径。 - 修改建议: 通常无需修改。
5. 启动服务
完成配置修改后,在 docker-compose.yml 所在目录下执行:
docker-compose up -d等待服务完全启动。
6. 访问控制台
打开浏览器,访问 http://<你的服务器IP>:9000。
使用默认用户名 admin 和您在 EASYSEARCH_INITIAL_ADMIN_PASSWORD 中设置的密码进行初始化。
总结
通过以上步骤,您可以灵活地部署一套功能完整的 INFINI Console + Easysearch 环境。关键在于理解并根据实际情况修改 .env 文件中的参数,特别是 WORK_DIR_ABS、EASYSEARCH_INITIAL_ADMIN_PASSWORD 和 ES_JAVA_OPTS_DEFAULT,这能确保部署的稳定性和安全性。
希望这篇详细的指南能帮助您顺利完成部署!
作者:罗厚付,极限科技(INFINI Labs)云上产品设计与研发负责人,拥有多年安全风控及大数据系统架构经验,主导过多个核心产品的设计与落地,日常负责运维超大规模 ES 集群(800+节点/1PB+数据)。
原文:https://infinilabs.cn/blog/2025/console-easysearch-with-docker-compose-offline/
搜索百科(6):Meilisearch — Rust 打造的轻量级搜索新锐
开源项目 • liaosy 发表了文章 • 0 个评论 • 10340 次浏览 • 2025-10-31 18:00
大家好,我是 INFINI Labs 的石阳。
欢迎关注 《搜索百科》 专栏!每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
在之前的几期中,我们认识了搜索技术的基石 Lucene、企业级搜索先锋 Solr、搜索界的“流量明星” Elasticsearch 以及它的分叉兄弟 OpenSearch 和 ES 国产替代方案 Easysearch。它们大多基于 Lucene 构建,形成了庞大且功能丰富的生态。
今天,我们将介绍一位“非主流”选手:一款基于 Rust 编写、主打“快”和“简单”的现代搜索引擎——Meilisearch。它以全新的姿态,为开发者带来了不同的搜索体验。

Meilisearch 概述
Meilisearch 是一款开源的、用 Rust 编写的即时搜索引擎。它提供了一个快速、轻量且可定制的搜索 API,旨在为用户提供毫秒级的搜索体验。
它的核心优势在于为应用内搜索和电商搜索等对延迟敏感的场景提供了出色的用户体验。
- 首次发布:2020 年
- 最新版本:1.24.0(截止 2025 年 10 月)
- 核心语言:Rust
- 开源协议:MIT License
- 官方网址:https://www.meilisearch.com/
- GitHub 仓库:https://github.com/meilisearch/meilisearch
诞生故事
Meilisearch 的故事始于 2018 年,当时法国工程师 Quentin de Quelen 在开发一个电商项目时,发现现有的搜索引擎要么太重量级,要么配置太复杂。他想要一个"开箱即用"的搜索解决方案,能够快速集成到应用中,并提供优秀的搜索体验。
于是,他决定用 Rust 语言从头编写一个搜索引擎。选择 Rust 是因为其出色的性能、内存安全性和并发能力,非常适合构建高性能的搜索核心。
项目最初只是一个内部工具,但随着功能的完善和社区的反馈,Meilisearch 在 2019 年正式开源,并迅速获得了开发者的青睐。2020 年,团队获得了 150 万美元的种子轮融资,正式成立了 Meilisearch 公司。
核心特性
Meilisearch 在设计上做了大量的取舍,专注于核心的搜索功能,但做到了极致。
- 极速响应:核心目标是实现 50 毫秒以下的响应时间,即使在大型数据集中也能提供“所见即所得”的搜索体验。
- 零配置:开箱即用,部署和索引数据都非常简单,不需要预定义 Schema 或复杂的配置文件。
- 相关的默认值:内置一个强大的 相关性排名(Relevance Ranking) 算法,结合 Typos(拼写错误)、Word Proximity(词语距离)和 Attributes(字段权重)等因素,无需额外调优即可获得高质量的搜索结果。
- 语言无关性:支持多种语言的分词与搜索,能很好地处理中文、日文等非拉丁语系文本。
- 无分布式架构:为了追求极致的速度和简单性,Meilisearch 被设计为单机搜索引擎,不支持开箱即用的分布式集群,这简化了运维,但也限制了其 PB 级数据的处理能力。
对比优势:Meilisearch vs Lucene/ES 体系
Meilisearch 与基于 Lucene 的 Elasticsearch 体系,在设计哲学上有着本质区别:
| 特性 | Meilisearch | Elasticsearch |
|---|---|---|
| 核心目标 | 极速的应用内搜索体验 | 分布式搜索、日志分析、可观测性 |
| 基础架构 | 单机、轻量级 | 分布式集群(主从节点、分片) |
| 核心语言 | Rust | Java(基于 Lucene) |
| 性能瓶颈 | 单机 CPU / 内存限制 | 分布式协调开销 |
| 上手难度 | 简单,开箱即用,REST API | 相对复杂,需要了解集群、分片等概念 |
| 数据规模 | 适合中小型数据集(GB 级别) | 适合大型和超大型数据集(TB/PB 级别) |
| 全文检索 | 依赖内置的强相关性算法 | 依赖 Lucene 强大的分词、查询解析器 |
总结:
- 如果你的应用需要超低延迟、简单部署、数据量在 GB 级别,并且搜索是应用的核心功能,Meilisearch 是一个极佳的选择。
- 如果你的需求涉及日志分析、大规模数据存储、集群高可用和复杂的聚合分析,那么 Elasticsearch 仍然是更成熟和全面的解决方案。
快速上手:5 分钟体验 Meilisearch
部署 Meilisearch 非常简单,你甚至不需要 Docker,只需一个命令即可运行。
1. 运行 Meilisearch
# 安装 Meilisearch
curl -L https://install.meilisearch.com | sh
# 启动 Meilisearch
meilisearch --master-key 'aStrongMasterKey'
# 或使用 Docker
docker run -it --rm -p 7700:7700 getmeili/meilisearch:latest --master-key 'aStrongMasterKey'2. 添加索引(创建 Index)
Meilisearch 不需要预先定义索引结构(Schema-less)。
curl -X POST 'http://localhost:7700/indexes' \
-H 'Authorization: Bearer aStrongMasterKey' \
-H 'Content-Type: application/json' \
--data-binary '{
"uid": "movies",
"primaryKey": "id"
}'3. 索引文档(添加 Documents)
curl -X POST 'http://localhost:7700/indexes/movies/documents' \
-H 'Authorization: Bearer aStrongMasterKey' \
-H 'Content-Type: application/json' \
--data-binary '[
{"id": 1, "title": "泰坦尼克号", "genres": ["剧情", "爱情"]},
{"id": 2, "title": "黑客帝国", "genres": ["科幻", "动作"]}
]'4. 执行搜索
# 搜索关键词 "泰坦"
curl -X GET 'http://localhost:7700/indexes/movies/search?q=泰坦'返回结果:
{
"hits": [
{
"id": 1,
"title": "泰坦尼克号",
"genres": ["剧情", "爱情"]
}
],
"offset": 0,
"limit": 20,
"estimatedTotalHits": 1,
"processingTimeMs": 1,
"query": "泰坦"
}注意 processingTimeMs: 1,这是 Meilisearch 速度的最好证明!
5. 场景演示
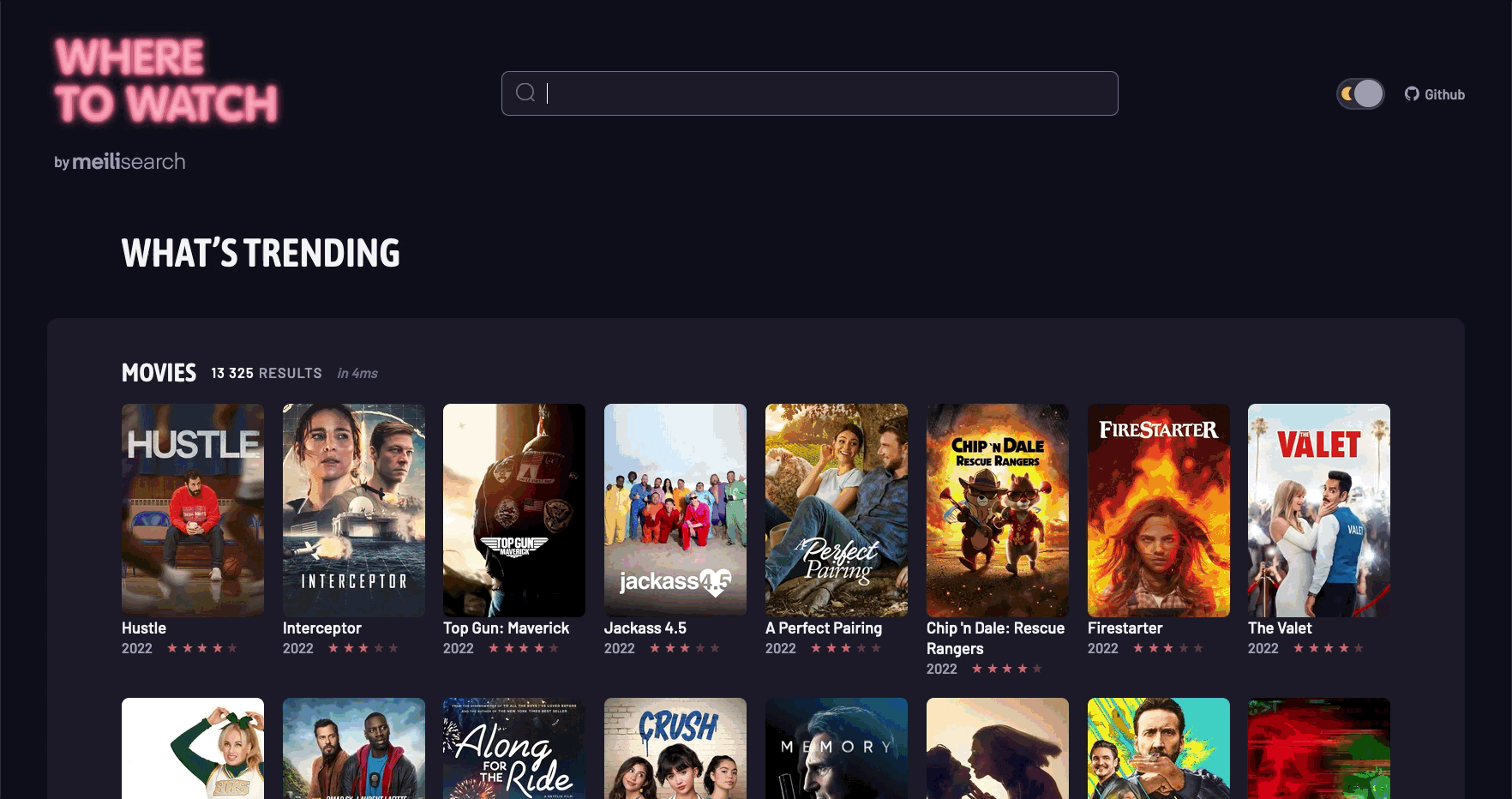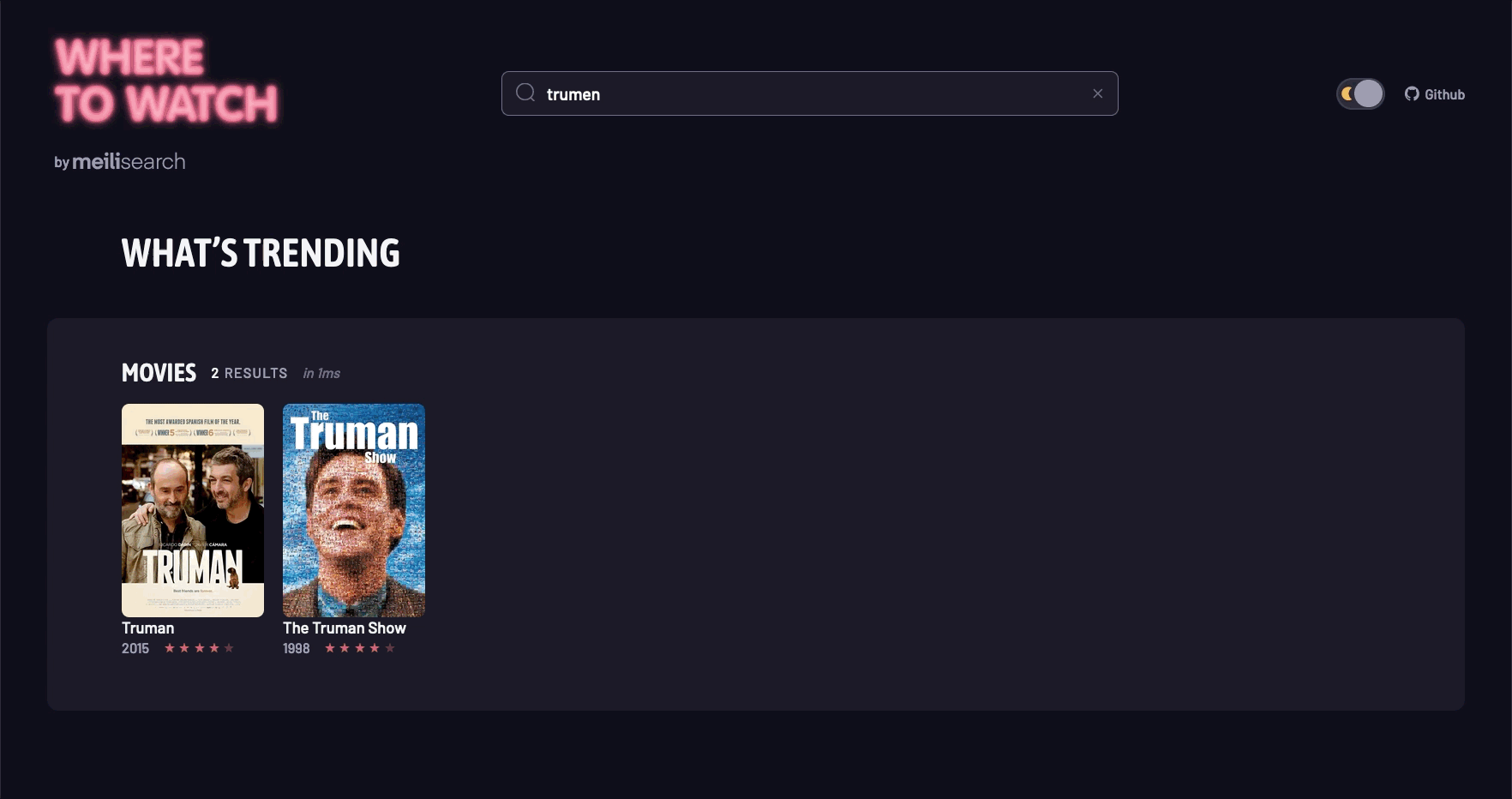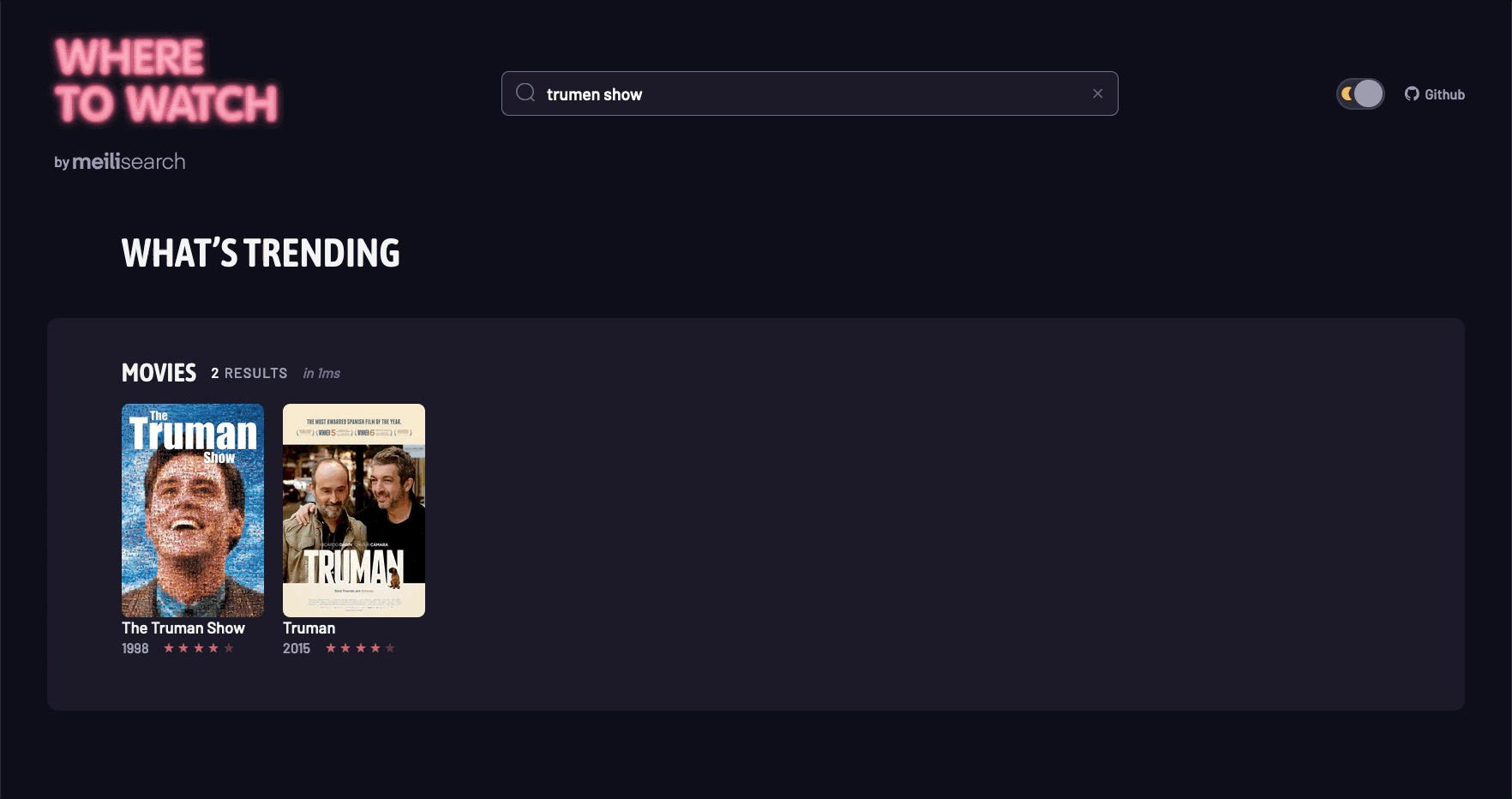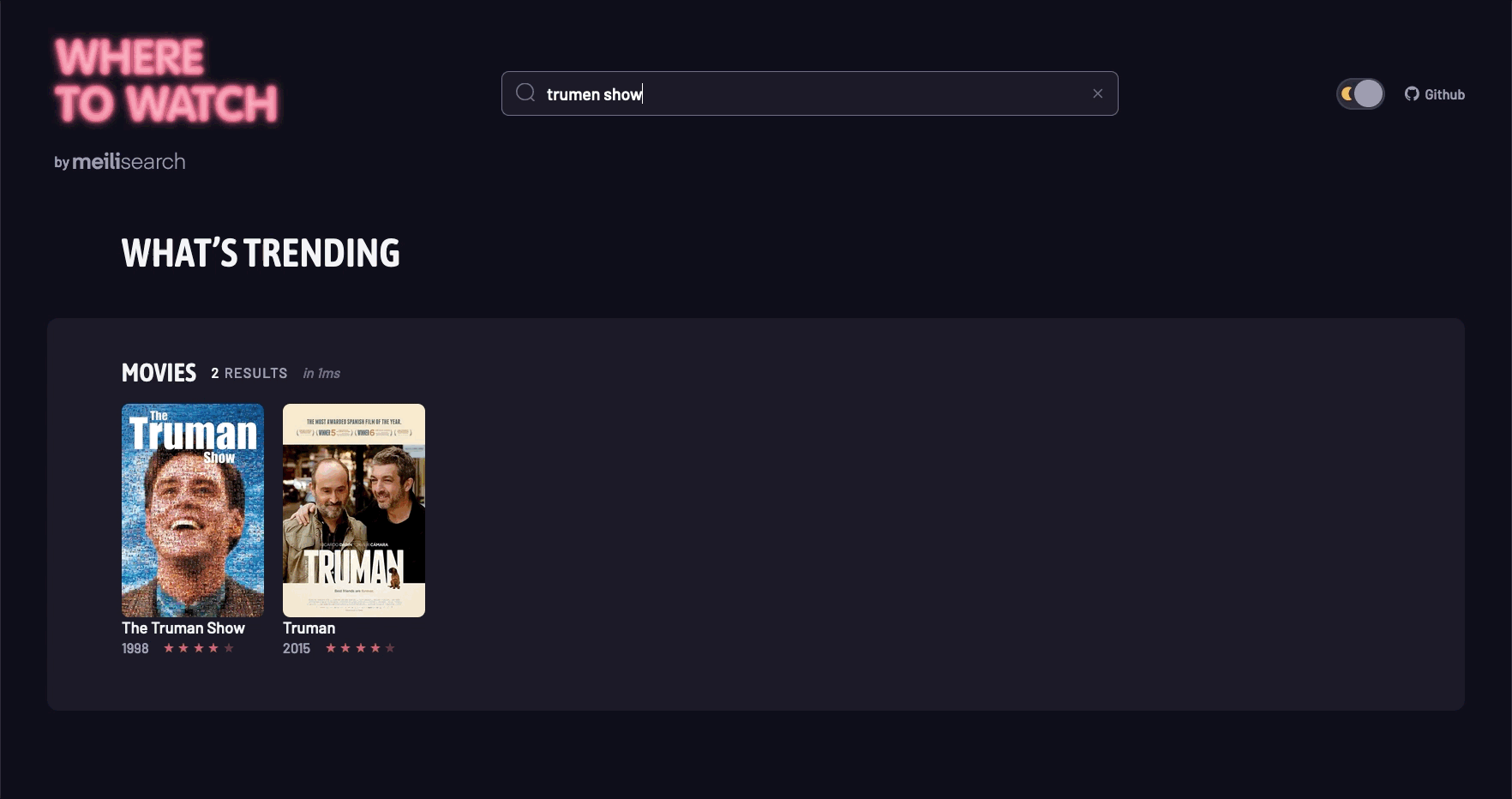
结语
Meilisearch 的出现,代表了新一代搜索引擎对于开发者体验和即时性的追求。它在应用内搜索领域展现了强大的竞争力,证明了不必依赖 Lucene 的庞大体系,也能打造出极致性能的搜索产品。
虽然它还无法完全取代 Elasticsearch 在日志分析、可观测性等大型分布式场景的地位,但在许多新兴应用和对搜索速度有极高要求的场景中,它无疑是一个值得尝试的开源新星。
🚀 下期预告
下一篇我们将把目光转向搜索领域的云端先锋 —— Algolia。作为搜索即服务(Search-as-a-Service)的开创者,Algolia 如何以其卓越的 API 设计、惊人的搜索速度和精准的相关性排序,重新定义云端搜索体验?
💬 三连互动
- 你会把 ES/Solr 换成 Meilisearch 吗?
- 在你的应用中,搜索延迟达到多少毫秒你会觉得无法接受?
- 在什么场景下你会考虑使用 Meilisearch 而不是 Elasticsearch?
对搜索技术感兴趣的朋友,也欢迎加我微信(ID:lsy965145175)备注“搜索百科”,拉你进 搜索技术交流群,一起探讨与学习!
✨ 推荐阅读
- 搜索百科(5):Easysearch — 自主可控的国产分布式搜索引擎
- 搜索百科(4):OpenSearch — 开源搜索的新选择
- 搜索百科(3):Elasticsearch — 搜索界的"流量明星"
- 搜索百科(2):Apache Solr — 企业级搜索的开源先锋
- 搜索百科(1):Lucene — 打开现代搜索世界的第一扇门
🔗 参考资源
搜索百科(5):Easysearch — 自主可控的国产分布式搜索引擎
Easysearch • liaosy 发表了文章 • 0 个评论 • 8437 次浏览 • 2025-10-20 15:54
大家好,我是 INFINI Labs 的石阳。
欢迎关注 《搜索百科》 专栏!每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
在上一篇我们介绍了 OpenSearch —— 那个因协议争议而诞生的开源搜索分支。今天,我们把目光转向国内,聊聊极限科技研发的一款轻量级搜索引擎:Easysearch。
引言
在搜索技术的世界里,从 Lucene 的出现到 Solr、Elasticsearch 的崛起,搜索引擎技术已经发展了二十余年。然而,随着开源协议的变更与国际形势的变化,国产自主搜索引擎的需求愈发迫切。在这样的背景下,Easysearch 作为一款自主可控、轻量高效、兼容 Elasticsearch 的分布式搜索引擎应运而生,为国内企业带来了全新的选择。
Easysearch 概述
Easysearch 是一款分布式搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析、AI 集成等。Easysearch 衍生自开源协议 Apache 2.0 的 Elasticsearch 7.10 版本,并不断往前迭代更新,紧跟 Lucene 最新版本的更新。Easysearch 可以替代 Elasticsearch,同时添加和完善多项企业级功能。
- 首次发布:2023 年 4 月
- 最新版本:1.15.4(截止 2025 年 10 月)
- 主导企业:极限科技 (INFINI Labs)
- 官方网址:https://easysearch.cn
诞生背景:为什么要有 Easysearch?
Easysearch 由极限科技(INFINI Labs)团队推出。项目的起点源于团队长期在搜索引擎和大数据领域的深厚实践积累,团队深刻认识到国内企业在使用 Elasticsearch 时普遍面临以下痛点:
- 开源协议变化带来的商业风险 —— Elastic 于 2021 年将许可更改为 SSPL,导致社区分裂,增加了企业在合规和商用上的不确定性;
- 高并发与高可靠性场景下对稳定可控方案的需求 —— 企业级应用亟需一个性能可靠、可深度优化的搜索基础设施;
- 技术栈自主可控的迫切需求 —— 随着国产化进程加快,国内生态中缺乏轻量化、易部署、且完全可控的搜索引擎产品;
- 本地化服务与快速响应能力的缺口 —— 国内企业更需要本地团队提供高效的技术支持与服务,对本土化、个性化功能需求能得到及时响应与反馈。
基于这些考虑,Easysearch 在设计之初就明确了目标:构建一款兼容 Elasticsearch API、简洁易用、性能出众且完全自主可控的国产搜索引擎。
核心特性
- 轻量级:安装包大小不到 60 MB,安装部署简洁,资源占用低,开箱即用;
- 跨平台:支持主流操作系统和 CPU 架构,支持国产信创运行环境;
- 高性能:针对不同场景进行的极致优化,可用更少硬件成本获得更高服务性能,降本增效。
- 稳定可靠:修复大量内核问题,解决内存泄露,集群卡顿、查询缓慢等问题,久经严苛业务环境考验。
- 安全增强:默认就提供完整的企业级安全功能,支持 LDAP/AD 集成,支持索引、文档、字段粒度细权管控。
- 兼容性强:兼容 Elasticsearch 7.x 的 REST API 和数据格式,迁移成本低;
- 可视化运维:无需 Kibana 即可通过内置 Web UI 插件界面管理索引、节点与监控指标等。
对比优势
| 对比维度 | Easysearch | Elasticsearch | OpenSearch |
|---|---|---|---|
| 用户协议 | 社区免费+商业授权 | SSPL/AGPL v3 | Apache 2.0 |
| API 兼容性 | 高度兼容 ES | 原生 | 高度兼容 ES |
| 最小安装体积 | 57MB | 482MB | 682MB |
| 部署复杂度 | 简单 | 中等 | 相对复杂 |
| 信创环境支持 | 全面兼容 | 无 | 无 |
| 可视化管理 | 开箱即用管理后台 | 需独立部署 Kibana | 需独立部署 OpenSearch Dashboards |
| 本地化与中文支持 | 强 | 弱 | 弱 |
| AI 插件支持 | 较弱 | 强 | 较强 |
| 社区与生态 | 快速成长中 | 成熟广泛 | 活跃增长 |
快速开始:5 分钟体验 Easysearch
1. 使用 Docker 启动
# 直接运行镜像使用随机密码(数据及配置未持久化)
docker run --name easysearch \
--ulimit memlock=-1:-1 \
-p 9200:9200 \
infinilabs/easysearch:1.15.42. 验证集群状态
curl -ku "username:password" -X GET "https://localhost:9200/"返回结果示例:
{
"name": "easysearch-node",
"cluster_name": "easysearch-6yhwn91v80gf",
"cluster_uuid": "Gfu_fuF1QViJfeUWVbiFCA",
"version": {
"distribution": "easysearch",
"number": "1.15.4",
"distributor": "INFINI Labs",
"build_hash": "9110128946b0af3de639966cfa74b5498346949d",
"build_date": "2025-10-14T03:30:41.948590Z",
"build_snapshot": false,
"lucene_version": "8.11.4",
"minimum_wire_lucene_version": "7.7.0",
"minimum_lucene_index_compatibility_version": "7.7.0"
},
"tagline": "You Know, For Easy Search!"
}3. 索引与搜索示例
# 写入文档
curl -ku "username:password" -X POST "https://localhost:9200/my_index/_doc" -H 'Content-Type: application/json' -d'
{
"title": "Easysearch 入门",
"content": "这是一个轻量级搜索引擎的示例文档。",
"tags": ["搜索", "国产", "轻量级"]
}'
# 搜索文档
curl -ku "username:password" -X GET "https://localhost:9200/my_index/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"content": "搜索引擎"
}
}
}'4. 使用 Easysearch UI
Easysearch 提供了轻量级界面化管理功能,不再依赖第三方组件即可对集群进行管理,真正做到开箱即用。如果你安装了 Easysearch UI 插件或者下载捆绑包,可通过 https://localhost:9200/\_ui/ 访问,进行节点、索引、分片、查询调试和监控查看等管理。
图 1:系统登录
图 2:集群概览
图 3:节点列表
图 4:节点概览
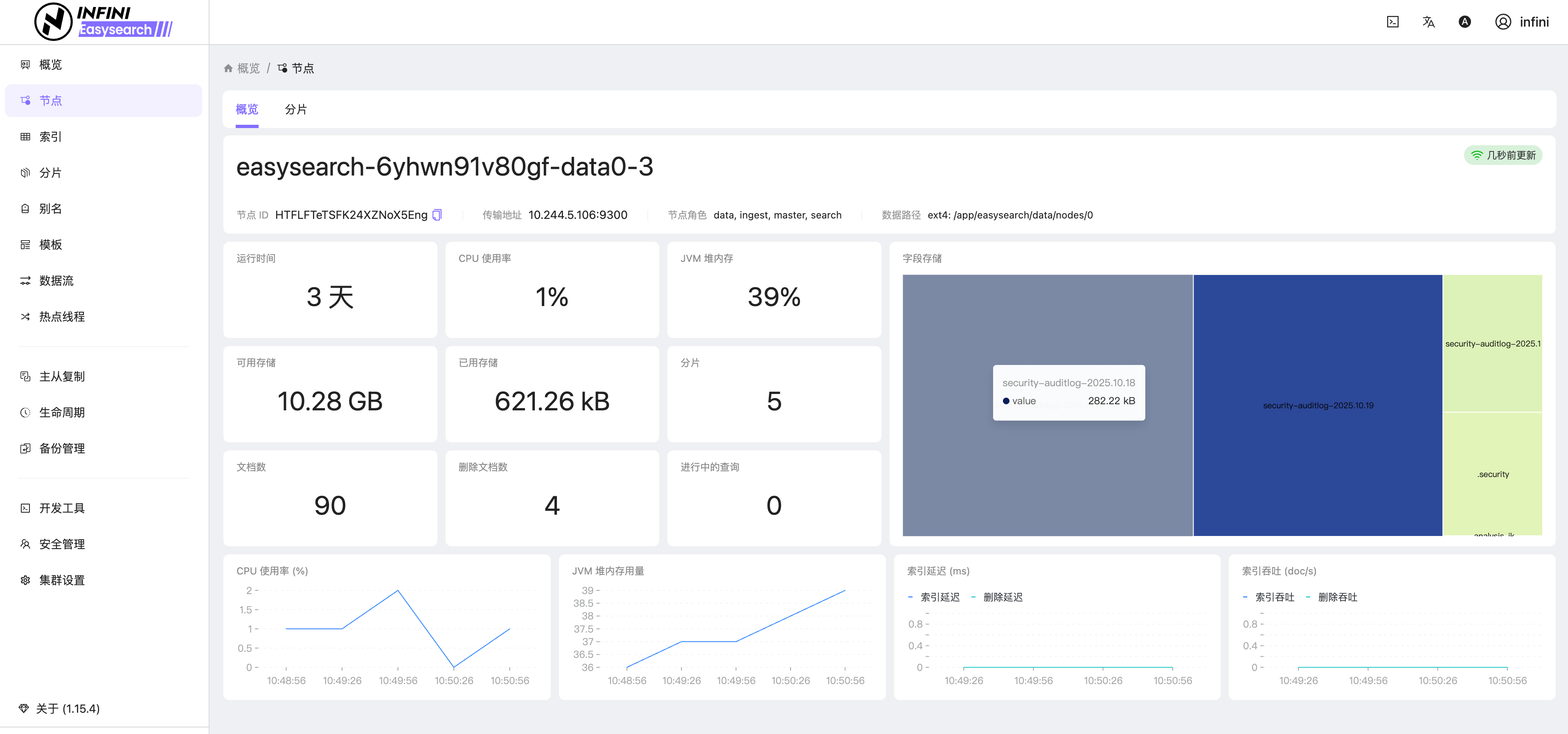
图 5:索引列表
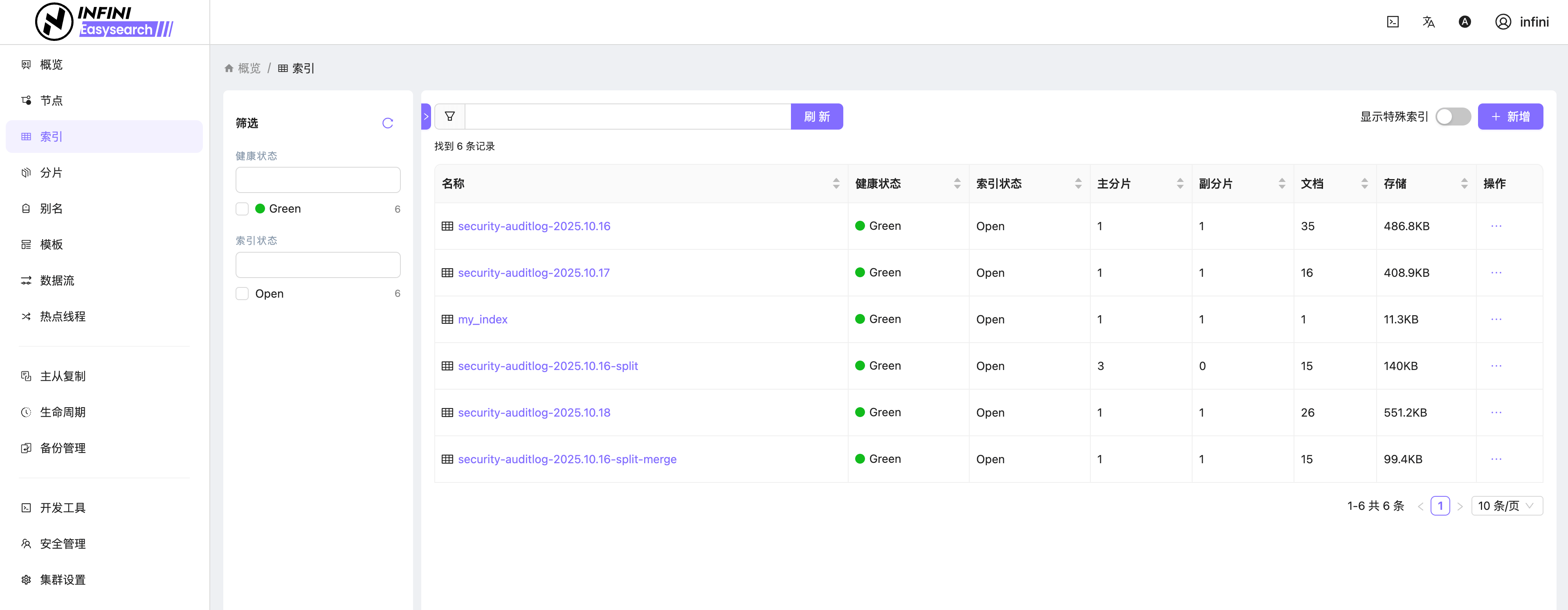
图 6:索引概览
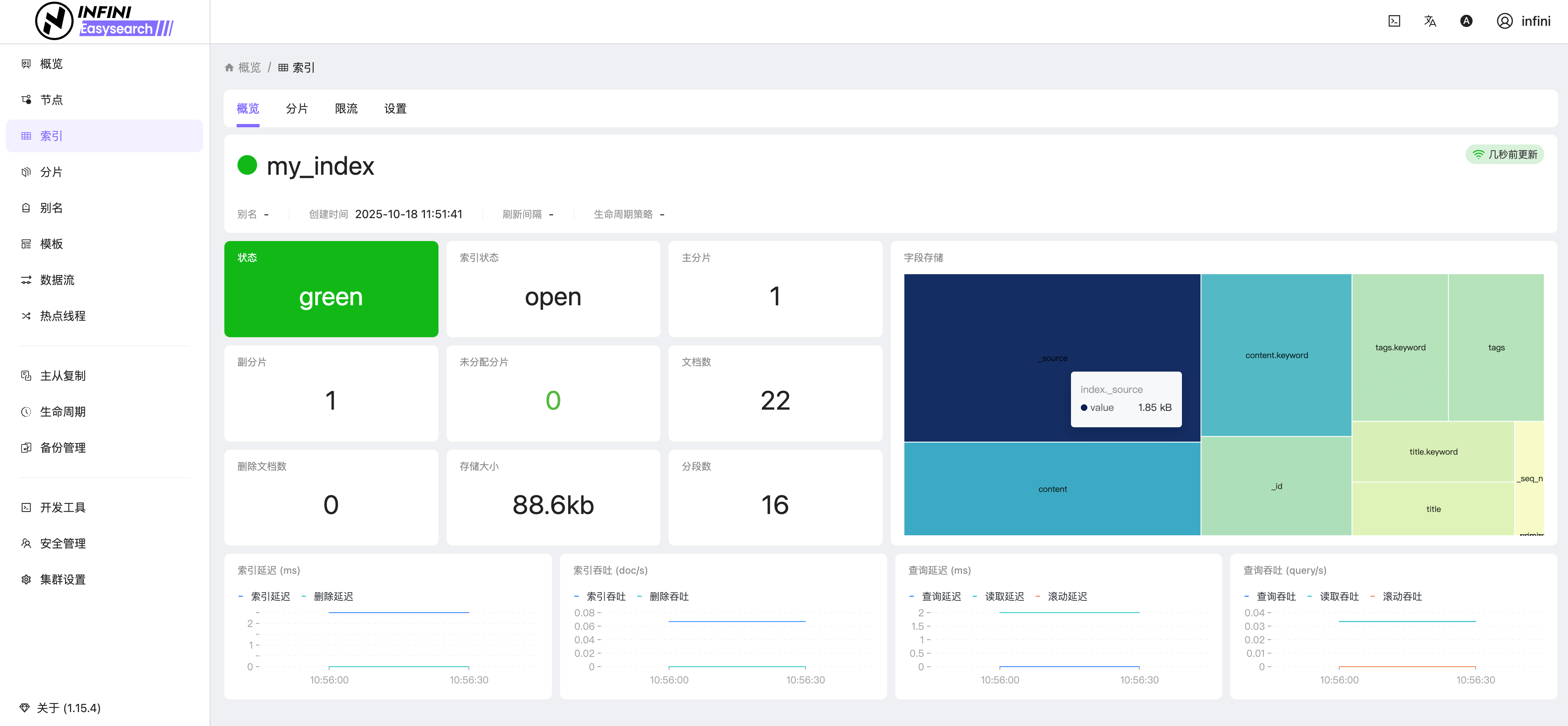
图 7:分片管理
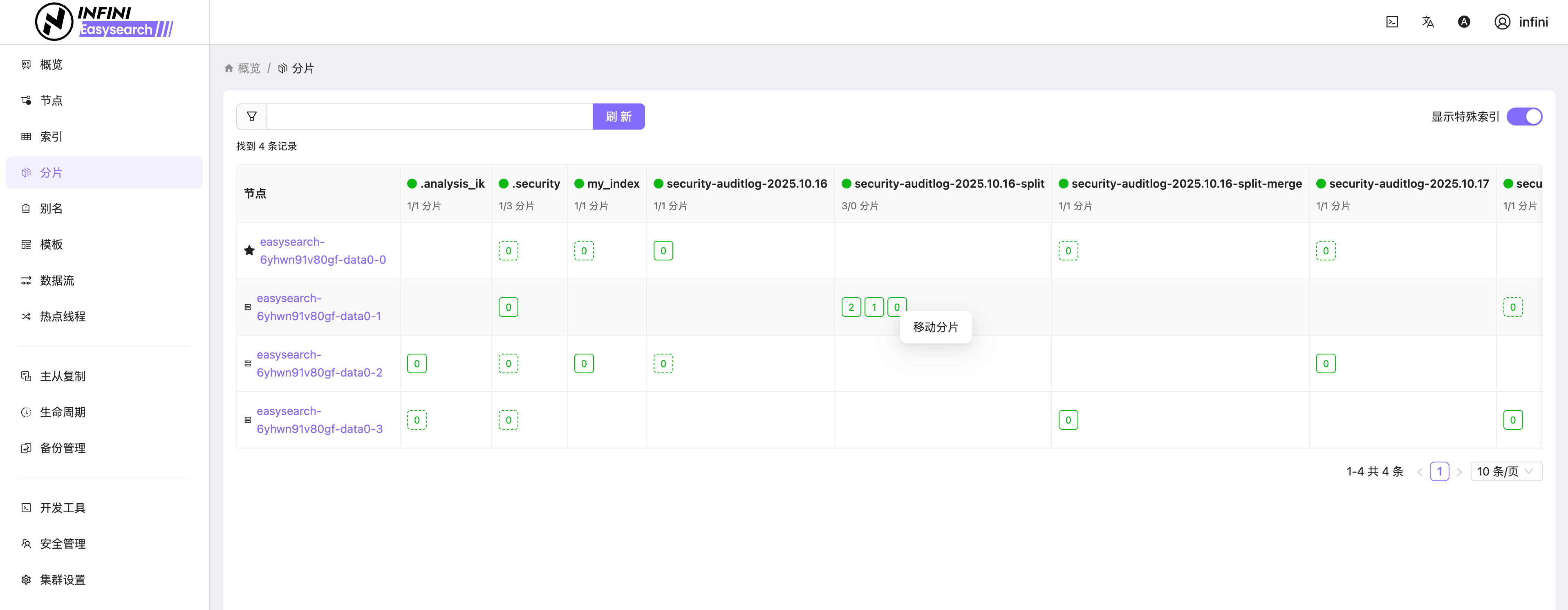
图 8:开发工具
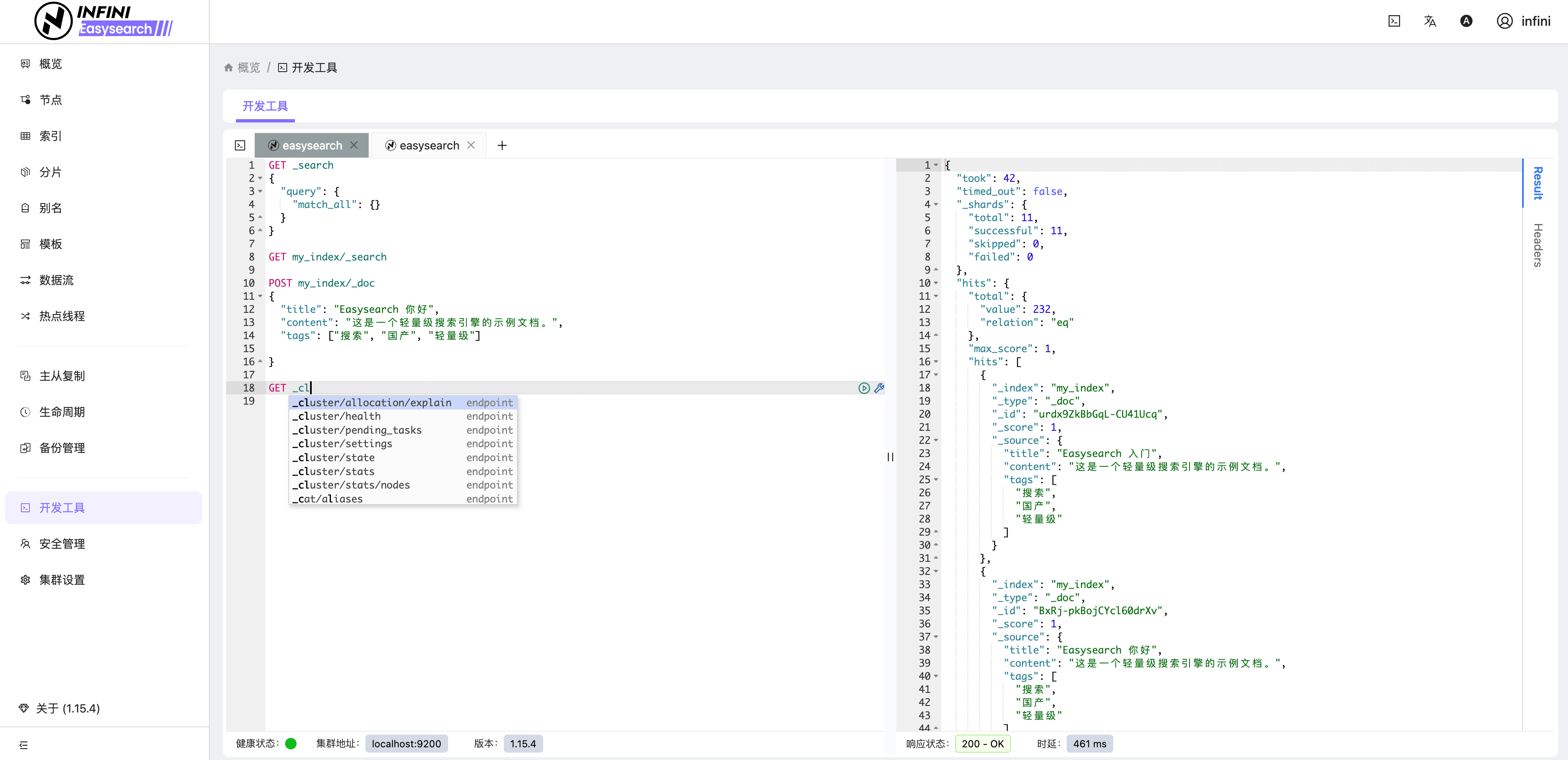
以上仅列出了一些基本功能,其他如安全管理、主从复制、备份管理、生命周期管理等更多高级功能由于篇幅限制不一一展示,有兴趣的朋友可自行部署探索。
结语
Easysearch 的诞生,不仅填补了国产搜索引擎在分布式与轻量化领域的空白,也让更多企业在面对开源协议变动与外部技术依赖时,拥有了更加安全、灵活、可控的选择。
它既是国产替代方案的有力代表,更是新一代搜索技术生态的积极探索者,为企业级实时搜索与分析带来新的可能。
🚀 下期预告
下一篇我们将介绍 一款 AI 驱动的现代搜索引擎 - Meilisearch,基于 Rust 构建的开源搜索引擎,性能高、部署简单。号称比 Elasticsearch 快 10 倍,真的这么牛吗?
💬 三连互动
- 你是否在使用或考虑国产搜索替代方案?
- 在实际项目中,你最看重搜索引擎的哪些特性?(性能、兼容性、运维、成本)
- 对 Easysearch 有什么功能上的期待?
对搜索技术感兴趣的朋友,也欢迎加我微信(ID:lsy965145175)备注“搜索百科”,拉你进 搜索技术交流群,一起探讨与学习!
✨ 推荐阅读
- 搜索百科(4):OpenSearch — 开源搜索的新选择
- 搜索百科(3):Elasticsearch — 搜索界的"流量明星"
- 搜索百科(2):Apache Solr — 企业级搜索的开源先锋
- 搜索百科(1):Lucene — 打开现代搜索世界的第一扇门
🔗 参考资源
原文:https://infinilabs.cn/blog/2025/search-wiki-5-easysearch/
搜索百科(4):OpenSearch — 开源搜索的新选择
OpenSearch • liaosy 发表了文章 • 0 个评论 • 9832 次浏览 • 2025-09-21 14:31
大家好,我是 INFINI Labs 的石阳。
欢迎关注 《搜索百科》 专栏!每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
上一篇我们围观了 “流量明星” Elasticsearch — 从食谱搜索到 PB 级明星产品,从 Apache 2.0 到 SSPL 协议风波;今天我们来聊聊它的“分叉兄弟” OpenSearch。

引言
2021 年,当 Elasticsearch 宣布将其许可证从 Apache 2.0 变更为 SSPL/Elastic License 时,整个搜索社区为之震动。这一变更直接催生了一个新的开源分支 — OpenSearch。这个由 AWS 主导的项目不仅在短短几年内迅速发展成熟,更成为了许多企业在云原生环境下搜索解决方案的新选择。
OpenSearch 概述
OpenSearch 是从 Elasticsearch 7.10.2 分支而来的开源搜索与分析套件,由 AWS 主导开发并贡献给开源社区。OpenSearch 包括 OpenSearch(搜索引擎)和 OpenSearch Dashboards(可视化界面),完全兼容 Apache 2.0 协议,旨在为用户提供一个真正开源、社区驱动的搜索与分析解决方案。
- 首次发布:2021 年 4 月
- 最新版本:3.2.0(截止 2025 年 9 月)
- 开源协议:Apache License 2.0
- 主导企业:Amazon Web Services (AWS)
- 官方网址:https://opensearch.org/
- GitHub 仓库:https://github.com/opensearch-project
诞生故事:开源协议争议的产物
时间回到 2021 年 1 月,Elastic 公司宣布 Elasticsearch 从 7.11 版本起不再使用 Apache 2.0 协议,而改为 Elastic License 与 SSPL。这一决定立刻在社区和产业界引发巨大争议。

AWS(亚马逊云)作为 Elasticsearch 的重要用户与云服务提供商,不愿意被 Elastic 的商业条款所限制,随即牵头将 Elasticsearch 7.10 版本 fork 出来,并与 Kibana 一起重命名为 OpenSearch 与 OpenSearch Dashboards。
从此,开源世界分裂成了两条路线:
- Elastic 官方的 Elasticsearch + Kibana(带有商业许可)。
- 社区驱动的 OpenSearch + OpenSearch Dashboards(继续遵循 Apache 2.0 协议)。
这个分叉,既是开源协议之争的产物,也是云厂商与开源公司之间博弈的缩影。虽然初期被质疑过“是否真开源”,但经过数年的迭代,OpenSearch 已形成了相对独立的开发节奏和用户群体,插件和生态也逐渐丰富。
技术架构与特性
OpenSearch 是一个基于 Apache Lucene 的分布式搜索与分析引擎。在将数据添加到 OpenSearch 后,可以对其执行各种功能完备的全文搜索操作:按字段搜索、跨多个索引搜索、提升字段权重、按得分排序结果、按字段排序结果以及对结果进行聚合。
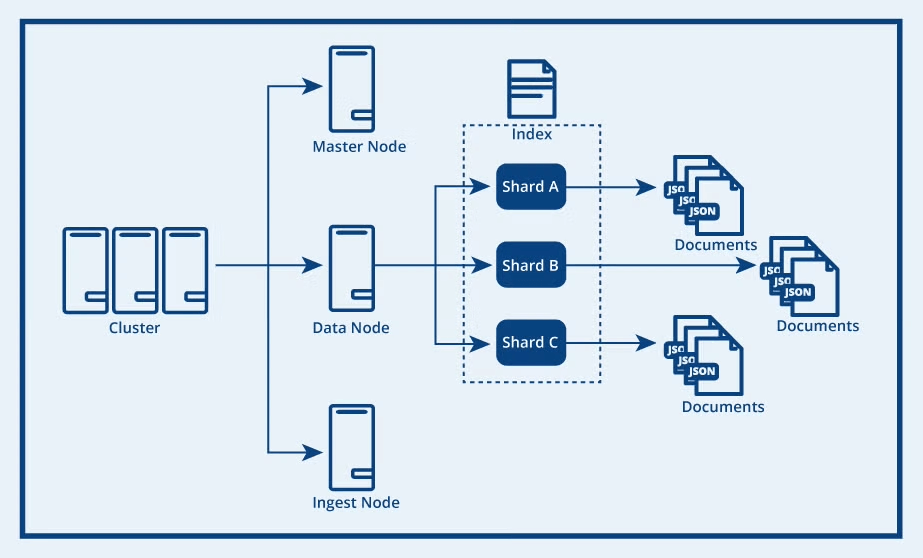
OpenSearch 的核心架构由集群、节点、索引、分片和文档组成。最高层是 OpenSearch 集群,它是由多个节点组成的分布式网络,每个节点会根据其类型负责不同的集群操作。数据节点负责存储索引(即文档的逻辑分组),并处理数据写入、搜索和聚合等任务。
每个索引会被划分为多个分片,分片包含主数据和副本数据。分片会分布在多台机器上,从而实现水平扩展,提升性能并高效利用存储资源。
OpenSearch vs Elasticsearch:详细对比
| 特性 | OpenSearch | Elasticsearch |
|---|---|---|
| 许可证 | Apache 2.0(完全开源) | SSPL/Elastic License/AGPLv3 |
| 起始版本 | 基于 Elasticsearch 7.10.2 | 从 7.11 开始协议变更 |
| 社区治理 | 开放治理模式,由社区驱动 | 由 Elastic NV 公司主导 |
| 安全性 | 所有安全功能默认开源 | 部分高级安全功能需要付费 |
| AI/向量检索 | 近年快速跟进,兼容性较好 | 原生支持,功能逐步增强 |
| 部署选择 | AWS OpenSearch Service / 自建 | Elastic Cloud / 自建 |
| 升级路径 | 从 Elasticsearch 7.x 平滑迁移 | 原生升级路径 |
| 社区活跃度 | 社区逐渐壮大,受到纯开源拥护者欢迎 | 用户基础庞大,但分裂带来争议 |
快速开始:5 分钟部署 OpenSearch
1. 使用 Docker 部署
# 拉取 OpenSearch 镜像
docker pull opensearchproject/opensearch:3.2.0
# 启动 OpenSearch 节点
docker run -d --name opensearch-node \
-p 9200:9200 -p 9600:9600 \
-e "discovery.type=single-node" \
-e "plugins.security.disabled=true" \
opensearchproject/opensearch:3.2.0
# 拉取 OpenSearch Dashboards
docker pull opensearchproject/opensearch-dashboards:3.2.0
# 启动 Dashboards
docker run -d --name opensearch-dashboards \
-p 5601:5601 \
-e "OPENSEARCH_HOSTS=http://opensearch-node:9200" \
opensearchproject/opensearch-dashboards:3.2.02. 验证安装
# 检查集群状态
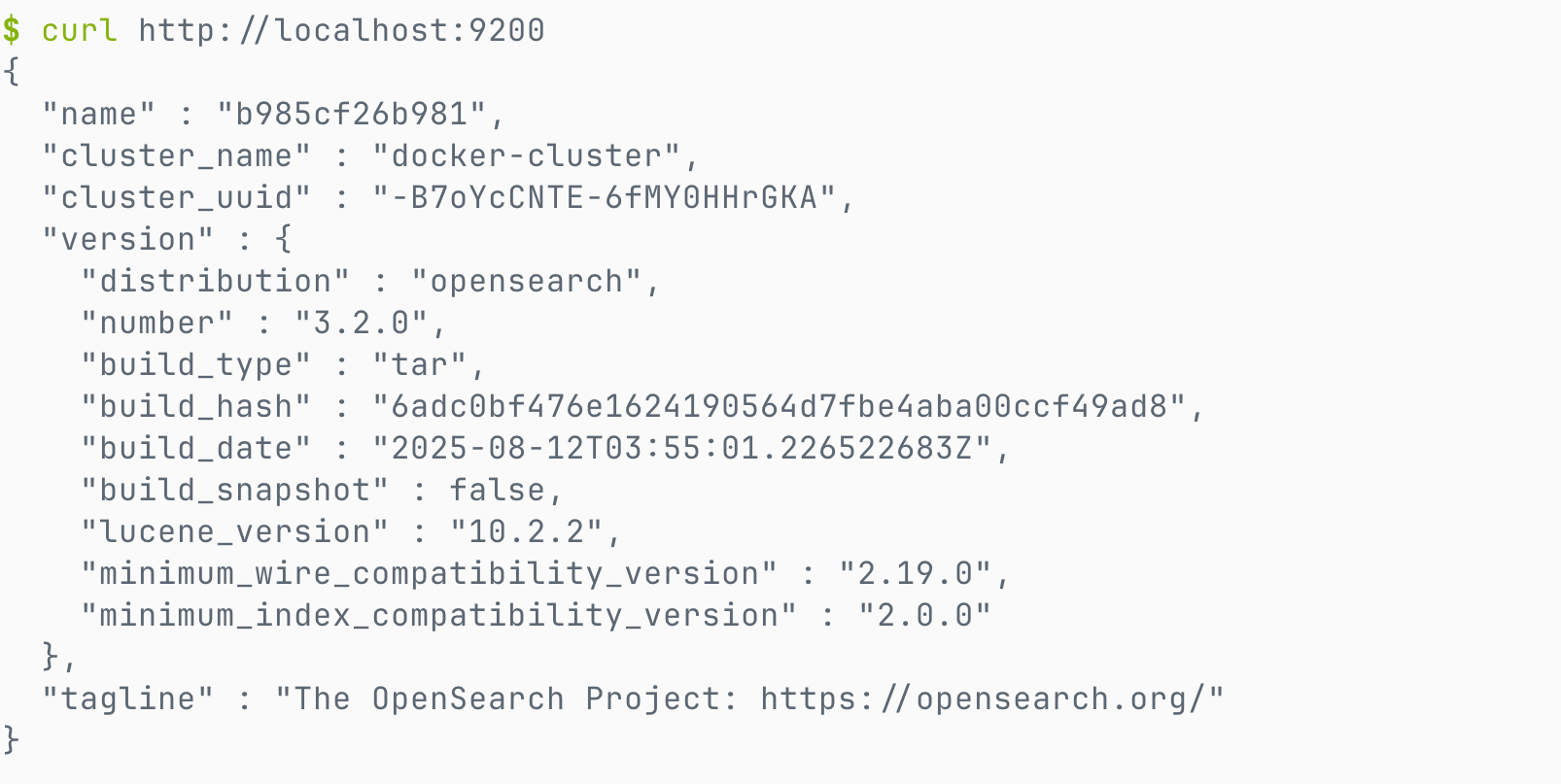
curl -X GET "http://localhost:9200/"出现如下结果说明安装成功。
3. 创建索引和搜索
# 索引文档
curl -X POST "http://localhost:9200/my-first-index/_doc" -H 'Content-Type: application/json' -d'
{
"title": "OpenSearch 入门指南",
"content": "这是我在 OpenSearch 中的第一个文档",
"timestamp": "2025-09-18T10:00:00"
}'
# 执行搜索
curl -X GET "http://localhost:9200/my-first-index/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"content": "第一个文档"
}
}
}'4. 访问控制台
打开浏览器访问 http://localhost:5601 即可使用 OpenSearch Dashboards 界面。
结语
OpenSearch 的出现,是开源社区的一次“自救”。它不仅延续了 Elasticsearch 的核心功能,还代表了另一种治理模式:由云厂商和社区共同维护,保证了开源协议的延续。
在搜索技术的版图里,Elasticsearch 与 OpenSearch 的分叉,注定会成为一个重要的历史节点。未来,两者可能会继续竞争,也可能各自发展出独特的生态。
🚀 下期预告
下一篇我们将介绍 OpenSearch 的另一个兄弟 Easysearch,一个衍生自开源协议 Apache 2.0 的 Elasticsearch 7.10.2 版本的轻量级搜索引擎,作为一个 ES 国产替代方案,看看它如何以其极致的速度和易用性在国内搜索领域占据一席之地。
💬 三连互动
- 您是否考虑过从 Elasticsearch 迁移到 OpenSearch?
- 在开源协议方面,您更倾向于哪种模式?Apache 2.0 还是 Elastic 的多重许可?
- 对于云厂商与开源项目之间的关系,您有什么看法?
对搜索技术感兴趣的朋友,也欢迎加我微信(ID:lsy965145175)备注“搜索百科”,拉你进 搜索技术交流群,一起探讨与学习!
✨ 推荐阅读
🔗 参考资源
原文:https://infinilabs.cn/blog/2025/search-wiki-4-opensearch/
Easysearch 国产替代 Elasticsearch:8 大核心问题解读
Easysearch • liaosy 发表了文章 • 0 个评论 • 14537 次浏览 • 2025-09-18 09:43
近年来,随着数据安全与自主可控需求的不断提升,越来越多的企业开始关注国产化的搜索与日志分析解决方案。作为极限科技推出的国产 Elasticsearch 替代产品,Easysearch 凭借其对搜索场景的深入优化、轻量级架构设计以及对 ES 生态的高度兼容,成为众多企业替代 Elasticsearch 的新选择。

我们在近期与用户的交流中,整理出了大家最关心的八大问题,并将它们浓缩为一篇技术解读,希望帮助你快速了解 Easysearch 的优势与定位。
用户最关心的八大问题
- Easysearch 对数据量的支撑能力如何,能应对 PB 级数据存储吗?
答:完全可以。Easysearch 支持水平扩展,通过增加节点即可线性提升存储与计算能力。在实际应用中,已成功支撑 PB 级日志与检索数据。同时,其存储压缩率相比 Elasticsearch 7.10.2 平均高出 2.5~3 倍,显著节省硬件成本。
- 在高并发写入场景下,Easysearch 和 ES 的性能差异有多大?
答:在相同硬件配置下,使用 Nginx 日志进行 bulk 写入压测,Easysearch 在多种分片配置下的写入性能相比 Elasticsearch 7.10.2 提升 40%-70%,更适合高并发写入场景。
- 是否支持中文分词?需要额外插件吗?
答:中文分词一直是 Elasticsearch 用户的「必装插件」。而在 Easysearch 中,中文分词是开箱即用的,同时支持 ik、pinyin 等主流分词器,还能自定义词典,方便电商、内容平台等场景。
- 从 ES 迁移到 Easysearch 是否复杂?会影响业务吗?
答:迁移往往是国产替代的最大顾虑。为此,Easysearch 提供了 极限网关 工具,支持全量同步和实时增量同步。迁移过程中业务可继续读写,只需短暂切换连接地址,几乎无感知。
- 监控与运维工具是否完善?是否支持 Kibana?
答:Easysearch 提供完整的监控与运维体系。从 Easysearch 1.15.x 版本起自带 Web UI 管理控制台(类似简化版 Kibana),支持索引管理、查询调试、权限控制等功能。同时还提供 INFINI Console 实现多集群管理与深度监控等。也可以通过配置让 Kibana 连接 Easysearch(部分高级功能可能受限)。
- 小型团队技术能力有限,用 Easysearch 运维难度高吗?
答:Easysearch 的一大设计理念就是降低运维门槛。Easysearch 提供一键部署脚本,减少手动配置参数,支持自动分片均衡与故障节点恢复,无需专职运维人员也能稳定运行,非常适合技术资源有限的团队。
- Easysearch 是否支持数据备份与恢复?操作复杂吗?
答:支持快照(Snapshot),可备份到本地磁盘或对象存储(S3、OSS 等)。恢复时仅需执行快照恢复命令,满足企业级数据安全需求。
- 对比 ES,Easysearch 在使用体验上最大的不同是什么?
答:Easysearch 保持与 Elasticsearch 类似的接口与查询 DSL,用户几乎无学习成本即可上手。同时,它针对国产化环境和搜索场景做了优化,运维更轻量,成本更可控。
结语:Easysearch,国产化搜索的新选择
作为一款国产自主可控的搜索与日志分析引擎,Easysearch 不仅继承了 Elasticsearch 的核心能力,更在性能、易用性、资源效率和中文支持等方面进行了深度优化。对于希望实现国产化替代、降低运维成本、提升系统性能的企业来说,Easysearch 是一个值得认真考虑的新选择。
如果你正在评估 Elasticsearch 的替代方案,不妨从 Easysearch 开始,体验更轻量、更高效的搜索新架构。
如需了解更多技术细节与使用案例,欢迎访问官方文档与社区资源:
- Easysearch 官网文档
- Elasticsearch VS Easysearch 性能测试
- 使用 Easysearch,日志存储少一半
- Kibana OSS 7.10.2 连接 Easysearch
- 自建 ES 集群通过极限网关无缝迁移到云上
- INFINI Console 一站式的数据搜索分析与管理平台

搜索百科(3):Elasticsearch — 搜索界的“流量明星”
Elasticsearch • liaosy 发表了文章 • 0 个评论 • 30446 次浏览 • 2025-09-16 11:20
大家好,我是 INFINI Labs 的石阳。
欢迎关注 《搜索百科》 专栏!每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
前两篇我们探讨了搜索技术的基石 Apache Lucene 和企业级搜索解决方案 Apache Solr。今天,我们来聊聊一个真正改变搜索游戏规则,但也充满争议的产品 — Elasticsearch。

引言
如果说 Lucene 是幕后英雄,那么 Elasticsearch 就是舞台中央的明星。借助 REST API、分布式架构、强大的生态系统,它让搜索 + 分析成为“马上可用”的服务形式。
在日志平台、可观察性、安全监控、AI 与语义检索等领域,Elasticsearch 的名字几乎成了默认选项。
Elasticsearch 概述
Elasticsearch 是一个开源的分布式搜索和分析引擎,构建于 Apache Lucene 之上。作为一个检索平台,它可以实时存储结构化、非结构化和向量数据,提供快速的混合和向量搜索,支持可观测性与安全分析,并以高性能、高准确性和高相关性实现 AI 驱动的应用。
- 首次发布:2010 年 2 月
- 最新版本:9.1.3(截止 2025 年 9 月)
- 核心依赖:Apache Lucene
- 开源协议:AGPL v3
- 官方网址:https://www.elastic.co/elasticsearch/
- GitHub 仓库:https://github.com/elastic/elasticsearch
起源:从食谱搜索到全球“流量明星”
Elasticsearch 的故事始于以色列开发者 Shay Banon。2010 年,当时他在学习厨师课程的妻子需要一款能够快速搜索食谱的工具。虽然当时已经有 Solr 这样的搜索解决方案,但 Shay 认为它们对于分布式场景的支持不够完善。

基于之前开发 Compass(一个基于 Lucene 的搜索库)的经验,Shay 开始构建一个完全分布式的、基于 JSON 的搜索引擎。2010 年 2 月,Elasticsearch 的第一个版本发布。
随着用户日益增多、企业级需求增强,Shay 在 2012 年创立了 Elastic 公司,把 Elasticsearch 不仅作为开源项目,也逐渐商业化运营起来,包括提供托管服务、企业支持,加入 Logstash 日志处理、Kibana 可视化工具等,Elastic 公司也逐渐从一个纯搜索引擎项目演变为一个更广泛的“数据搜索与分析”平台。
协议变更:开源和商业化的博弈
Elasticsearch 的发展并非一帆风顺。其历史上最具转折性的事件当属与 AWS 的冲突及随之而来的开源协议变更。

- 早期:Apache 2.0 协议
2010 年 Shay Banon 开源 Elasticsearch 时,最初采用的是 Apache 2.0 协议。Apache 2.0 属于宽松的自由协议,允许任何人免费使用、修改和商用(包括 SaaS 模式)。这帮助 Elasticsearch 快速壮大,成为事实上的“搜索引擎标准”。
- 协议变更:应对云厂商“白嫖”
随着 Elasticsearch 的流行,像 AWS(Amazon Web Services) 等云厂商直接将 Elasticsearch 做成托管服务,并从中获利。Elastic 公司认为这损害了他们的商业利益,因为云厂商“用开源赚钱,却没有回馈社区”。2021 年 1 月,Elastic 宣布 Elasticsearch 和 Kibana 不再采用 Apache 2.0,改为 双重协议:SSPL + Elastic License。这一步导致社区巨大分裂,AWS 带头将 Elasticsearch 分叉为 OpenSearch,并继续以 Apache 2.0 协议维护。
- 再次转向开源:AGPL v3
2024 年 3 月,Elastic 宣布新的版本(Elasticsearch 8.13 起)又新增 AGPL v3 作为一个开源许可选项。AGPL v3 既符合 OSI 真正开源标准,又能约束云厂商闭源托管服务,同时修复社区关系,Elastic 希望通过重新拥抱开源,减少分裂,吸引开发者回归。
Elasticsearch 从宽松到收紧,再到回归开源,是在社区生态与商业利益间寻找平衡的过程。
基本概念
要学习 Elasticsearch,得先了解其五大基本概览:集群、节点、分片、索引和文档。
- 集群(Cluster)
由一个或多个节点组成的整体,提供统一的搜索与存储服务。对外看起来像一个单一系统。
- 节点(Node)
集群中的一台服务器实例。节点有不同角色:
- Master 节点:负责集群管理(分片分配、元数据维护)。
- Data 节点:存储数据、处理搜索和聚合。
- Coordinating 节点:接收请求并调度任务。
- Ingest 节点:负责数据写入前的预处理。
- 索引(Index)
类似于传统数据库的“库”,按逻辑组织数据。一个索引往往对应一个业务场景(如日志、商品信息)。
- 分片(Shard)
为了让索引能水平扩展,Elasticsearch 会把索引拆分为多个 主分片,并为每个主分片创建 副本分片,提升高可用和查询性能。
- 文档(Document)
Elasticsearch 存储和检索的最小数据单元,通常是 JSON 格式。多个文档组成一个索引。
集群架构
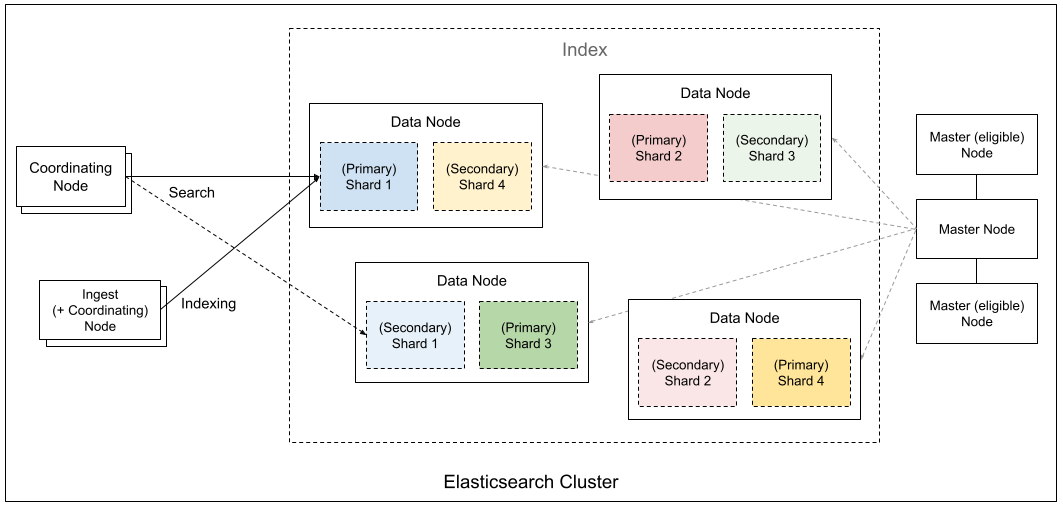
Elasticsearch 通过 Master、Data、Coordinating、Ingest 等不同角色节点的协作,将数据切分成分片并分布式存储,实现了高可用、可扩展的搜索与分析引擎架构。
快速开始:5 分钟体验 Elasticsearch
1. 使用 Docker 启动
# 拉取最新镜像
docker pull docker.elastic.co/elasticsearch/elasticsearch:9.1.3
# 启动单节点集群
docker run -d --name elasticsearch \
-p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e "xpack.security.enabled=false" \
docker.elastic.co/elasticsearch/elasticsearch:9.1.32. 验证安装
# 检查集群状态
curl -X GET "http://localhost:9200/"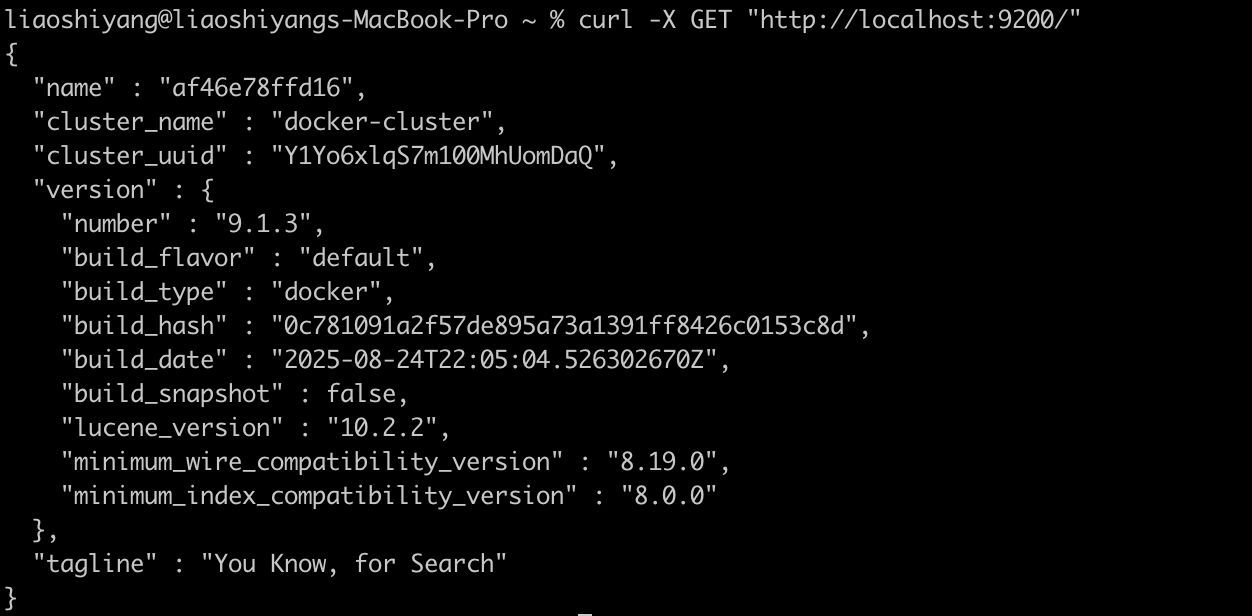
3. 索引文档
# 索引文档
curl -X POST "http://localhost:9200/myindex/_doc" -H 'Content-Type: application/json' -d'
{
"title": "Hello Elasticsearch",
"description": "An example document"
}'
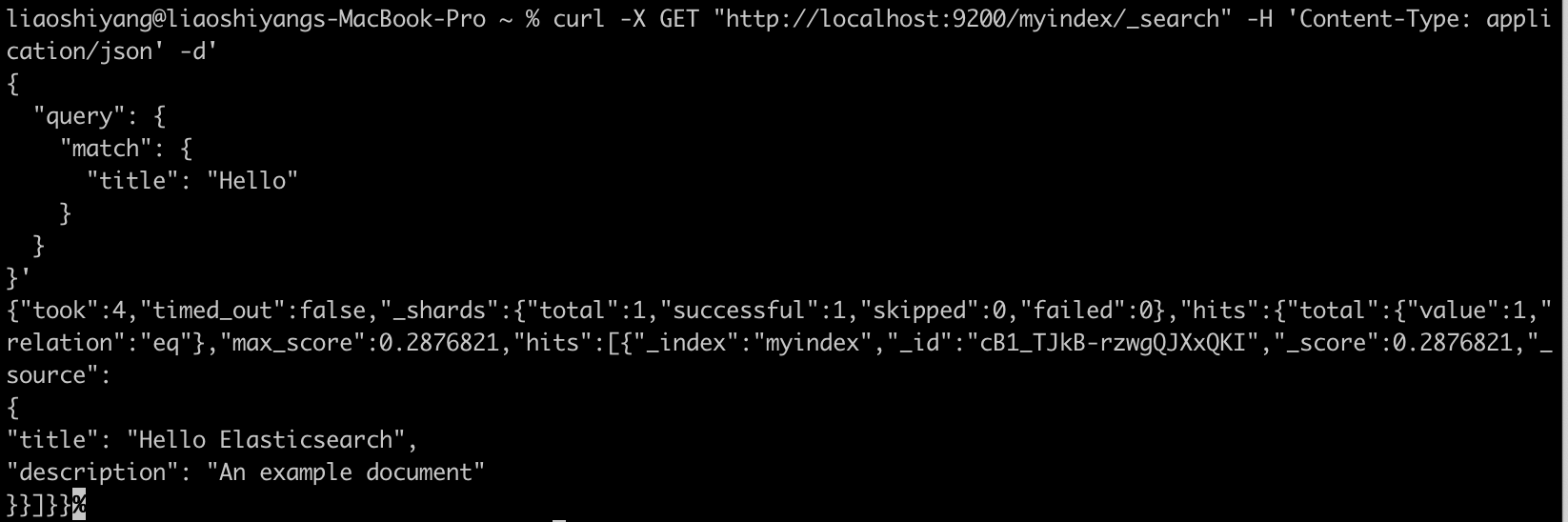
3. 搜索文档
# 搜索文档
curl -X GET "http://localhost:9200/myindex/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"title": "Hello"
}
}
}'
结语
Elasticsearch 是搜索与分析领域标杆性的产品。它将 Lucene 的能力包装起来,加上分布式、易用以及与数据可视化、安全监控等功能的整合,使搜索引擎从专业技术逐渐变为“随手可用”的基础设施。
虽然协议变动、与 OpenSearch 的分叉引发争议,但它在企业与开发者群体中的实际应用价值依然难以替代。
🚀 下期预告
下一篇我们将介绍 OpenSearch,探讨这个 Elasticsearch 分支项目的发展现状、技术特点以及与 Elasticsearch 的详细对比。如果您有特别关注的问题,欢迎提前提出!
💬 三连互动
- 你或公司最近在用 Elasticsearch 吗?拿来做了什么场景?
- 在 Elasticsearch 和 OpenSearch 之间做过技术选型?
- 对 Elasticsearch 的许可证变化有什么看法?
对搜索技术感兴趣的朋友,也欢迎加我微信(ID:lsy965145175)备注“搜索百科”,拉你进 搜索技术交流群,一起探讨与学习!
✨ 推荐阅读
🔗 参考
原文:https://infinilabs.cn/blog/2025/search-wiki-3-elasticsearch/
搜索百科(1):Lucene —— 打开现代搜索世界的第一扇门
Lucene • liaosy 发表了文章 • 0 个评论 • 5931 次浏览 • 2025-09-10 14:52
大家好,我是 INFINI Labs 的石阳。
这是《搜索百科》系列文章,每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
搜索技术看似专业,但它早已深度融入我们的日常生活。无论是电商搜索、知识检索,还是 AI 语义搜索、RAG、向量检索,背后都有经典与新兴技术的结合。希望这个系列能帮大家建立更清晰的认知,也欢迎留言交流。
引言:为什么先写 Lucene?

如果你曾用 GitHub 搜代码、用电商网站搜商品,或者在日志平台里“捞”报错,你就已经享受了 Lucene 的红利——只是自己还不知道。今天,让我们认识下这位“幕后大佬”,看看它如何以一己之力,孵化了整个现代搜索江湖。没有它,就没有 Elasticsearch 的锋芒,也没有 Solr 的稳健。讲搜索,不从 Lucene 开始,就像讲武侠不提《易筋经》——根基都丢了。
诞生故事:一个程序员的“副业”成果
Lucene 的诞生颇具传奇色彩。它的创造者 Doug Cutting(后来也是 Hadoop 的创始人之一)在 1997 年开始开发 Lucene,最初是为了给他的个人项目——一个网络爬虫和搜索引擎——提供搜索能力。

当时,市面上并没有成熟的开源搜索库可用,Doug 决定自己写一个。他在业余时间一点点打磨,最终在 1999 年发布了第一个版本。2001 年,Lucene 加入了 Apache 软件基金会,成为 Apache 的第一个开源搜索项目。
有趣的是,Lucene 的名字并不是来自什么技术术语,而是取自 Doug Cutting 妻子的中间名——Lucene。这也让这个项目多了一丝浪漫的色彩。
Lucene 概述
Apache Lucene,是一个用 Java 编写的高性能、全文搜索引擎库。它不是那种你下载下来就能直接用的“搜索软件”,而是一个底层库,就像乐高积木里的基础砖块,虽然不起眼,但没有它,很多搜索产品根本搭不起来。
Lucene 提供了强大的索引和查询能力,支持分词、倒排索引、相关性评分、模糊查询、布尔查询等一系列功能。它是 Elasticsearch、Solr、Easysearch、OpenSearch 等现代搜索引擎的核心引擎。
- 首次发布:1999 年
- 最新版本:截至 2025 年 9 月,Lucene 已更新至
10.2.x系列 - 开源协议:Apache License 2.0(商业友好)
- 官网:https://lucene.apache.org/
- GitHub:https://github.com/apache/lucene
社区生态
虽然已经 25 岁"高龄",Lucene 的社区却依然活力满满。作为 Apache 软件基金会的顶级项目,它拥有:
- 100+ 活跃贡献者
- 每月都有新的 commit 和 issue 处理
- 每年发布 2-4 个主要版本
- 完善的文档和活跃的邮件列表
虽然不像 Elasticsearch 那样“出圈”,但在开发者和企业内部系统中仍有广泛使用。
功能亮点:为什么大家都爱它?
- 高性能全文检索内核:倒排索引、短语/布尔/通配符/模糊查询、相关性打分。
- 面向工程的可扩展分析链:分词器、过滤器、同义词、停用词、高亮、排序等。
- 近邻向量检索(KNN):原生支持高维向量的最近邻搜索,为语义检索/RAG 奠基。 
- 嵌入式 & 纯 Java:作为库嵌入任意 Java 应用,掌控细粒度行为与性能。
- 成熟稳定的版本线:9.x 与 10.x 并行演进,兼顾稳定与新特性。
对比优势:Lucene vs 世界
| 产品 | 类型 | 与 Lucene 的关系 |
|---|---|---|
| Elasticsearch | 分布式引擎 | 基于 Lucene,提供分布式、RESTful 接口 |
| Apache Solr | 搜索平台 | 基于 Lucene,提供 Web 管理界面和更多功能 |
| Meilisearch | 轻量引擎 | 不基于 Lucene,用 Rust 编写,主打易用性 |
Lucene 是底层引擎,而其他产品是在它之上构建的完整解决方案。如果你想要完全控制搜索逻辑,Lucene 是最佳选择;如果你想要开箱即用的搜索服务,可以考虑 Elasticsearch 或 Solr。
快速上手:10 分钟体验 Lucene
虽然 Lucene 需要写一些 Java 代码,但其实入门并不复杂。
1. 环境准备
// Maven 依赖
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>10.xx.xx</version>
</dependency>2. 创建你的第一个索引
// 创建分析器(支持中文)
Analyzer analyzer = new StandardAnalyzer();
// 创建索引
Directory directory = FSDirectory.open(Paths.get("index"));
IndexWriterConfig config = new IndexWriterConfig(analyzer);
IndexWriter writer = new IndexWriter(directory, config);
Document doc = new Document();
doc.add(new TextField("content", "欢迎来到 Lucene 的世界", Field.Store.YES));
writer.addDocument(doc);
writer.close();3. 执行搜索
// 搜索 "Lucene"
Query query = new TermQuery(new Term("content", "lucene"));
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
TopDocs results = searcher.search(query, 10);
System.out.println("找到 " + results.totalHits + " 条结果");几行 Java 代码,就能完成一个迷你搜索引擎。
结语
Apache Lucene 虽然不是面向最终用户的产品,但它是搜索技术的基石。几乎所有现代搜索引擎都离不开它。如果你对搜索技术有兴趣,学习 Lucene 是理解搜索引擎工作原理的最佳途径。
🚀 下期预告
下一篇,我将介绍 Lucene 的第一个"孩子"—— Apache Solr,看看这个基于 Lucene 的企业级搜索平台如何让搜索变得更简单。
💬 三连互动
- 你或公司最近在用 Lucene 吗?拿来做了什么场景?
- 你觉得 Lucene 最香 / 最坑的点是什么?
- 下一期想先看 Solr 还是 Elasticsearch ?留言告诉我,我来插队!
对搜索技术感兴趣的朋友,也欢迎加我微信(ID:lsy965145175)备注“搜索百科”,拉你进 搜索技术交流群,一起探讨与学习!
如何用 Scrapy 爬取网站数据并在 Easysearch 中进行存储检索分析
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 6825 次浏览 • 2024-09-13 12:28

做过数据分析和爬虫程序的小伙伴想必对 Scrapy 这个爬虫框架已经很熟悉了。今天给大家介绍下,如何基于 Scrapy 快速编写一个爬虫程序并利用 Easysearch 储存、检索、分析爬取的数据。我们以极限科技的官网 Blog 为数据源(https://infinilabs.cn/blog) ,做下实操演示。
1、安装 scrapy
使用 Scrapy 可以快速构建一个爬虫项目,从目标网站中获取所需的数据,并进行后续的处理和分析。
pip install scrapy
# 新建项目 infini_spiders
scrapy startproject infini_spiders
# 初始化爬虫
cd infini_spiders/spiders
scrapy genspider blog infinilabs.cn2、爬虫编写
编写一个爬虫文件 blog.py ,它会首先访问 start_urls 指定的地址,将结果发给 parse 函数解析。通过这一步解析,我们得到了每一篇博客的地址。然后我们对每个博客的地址发送请求,将结果发给 parse_blog 函数进行解析,在这里才会真正提取每篇博客的 title、tag、url、date、content 内容。
from typing import Any, Iterable
import scrapy
from bs4 import BeautifulSoup
from scrapy.http import Response
class BlogSpider(scrapy.Spider):
name = "blog"
allowed_domains = ["infinilabs.cn"]
start_urls = ["https://infinilabs.cn/blog/"]
def parse(self, response):
links = response.css("div.blogs a")
yield from response.follow_all(links, self.parse_blog)
def parse_blog(self, response):
title = response.xpath('//div[@class="title"]/text()').extract_first()
tags = response.xpath('//div[@class="tags"]/div[@class="tag"]/text()').extract()
url = response.url
author = response.xpath('//div[@class="logo"]/div[@class="name"]//text()').extract_first()
date = response.xpath('//div[@class="date"]/text()').extract_first()
all_text = response.xpath('//p//text() | //h3/text() | //h2/text() | //h4/text() | //ol/li//text()').extract()
content = '\n'.join(all_text)
yield {
'title': title,
'tags': tags,
'url': url,
'author': author,
'date': date,
'content': content
}提取完我们想要的内容后,接下来就要考虑存储了。考虑到要对内容进行检索、分析,接下来我们将内容直接存放到 Easysearch 当中。
3、安装插件
通过安装 ScrapyElasticsearch pipeline 可将 scrapy 爬取的内容存入到 Easysearch 中。
pip install ScrapyElasticSearch修改 scrapy 自带的配置文件 settings.py ,添加以下内容。
ITEM_PIPELINES = {
'scrapyelasticsearch.scrapyelasticsearch.ElasticSearchPipeline': 10
}
ELASTICSEARCH_SERVERS = ['http://192.168.56.3:9210']
ELASTICSEARCH_INDEX = 'scrapy'
ELASTICSEARCH_INDEX_DATE_FORMAT = '%Y-%m-%d'
ELASTICSEARCH_TYPE = '_doc'
ELASTICSEARCH_USERNAME = 'admin'
ELASTICSEARCH_PASSWORD = '9423d1d5345ed6d0db19'ScrapyElasticSearch 会以 bulk 方式写入 Easysearch,每次批量的大小由 scrapyelasticsearch.scrapyelasticsearch.ElasticSearchPipeline 参数控制,大家可自行修改。
在上述配置中,我们会将爬到的数据存放到 scrapy-yyyy-mm-dd 索引中。
4、启动爬虫
在 infini_spiders/spiders 目录下,使用命令启动爬虫。
scrapy crawl blogblog 就是爬虫的名字,对应到 blog.py 里面的 name 变量。运行完成后,就可以去 Easysearch 里查看数据了,当然我们还是使用 Console 进行查看。
5、查看数据
先查看下索引情况,scrapy 索引已经生成,里面有 129 篇博客。
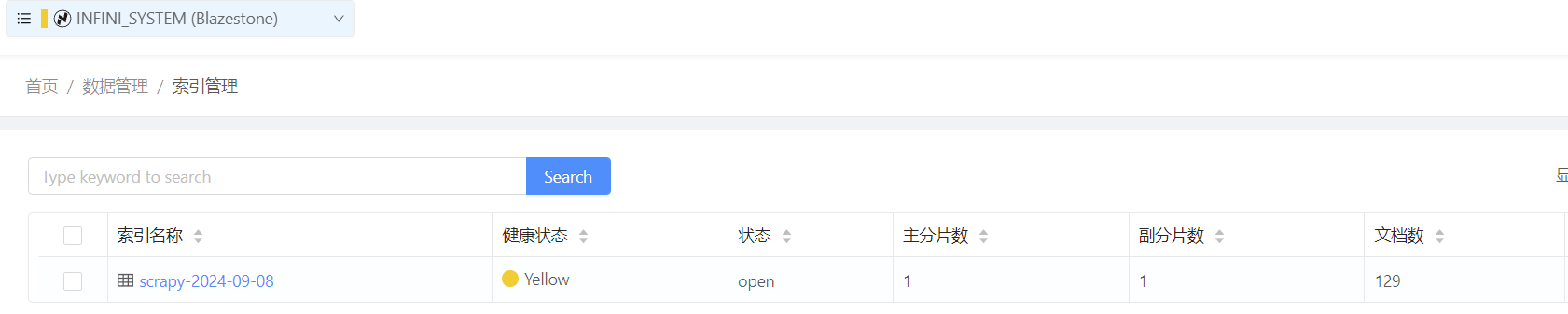
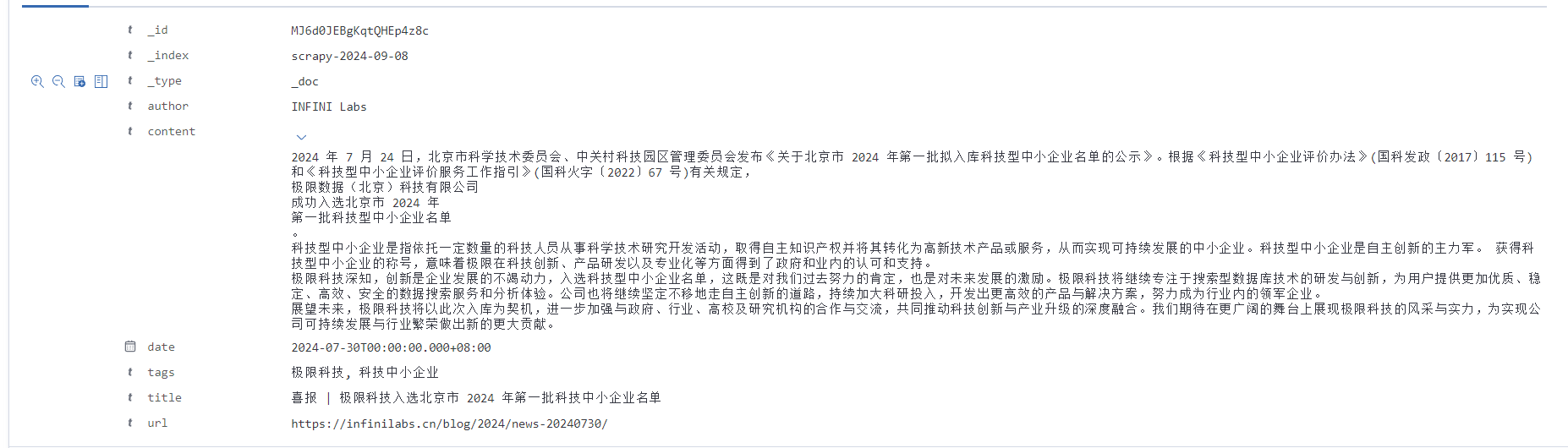
查看详细内容,确保博客正文已经保存。
到了这一步,我们就能使用 Console 对博客进行搜索、分析了。
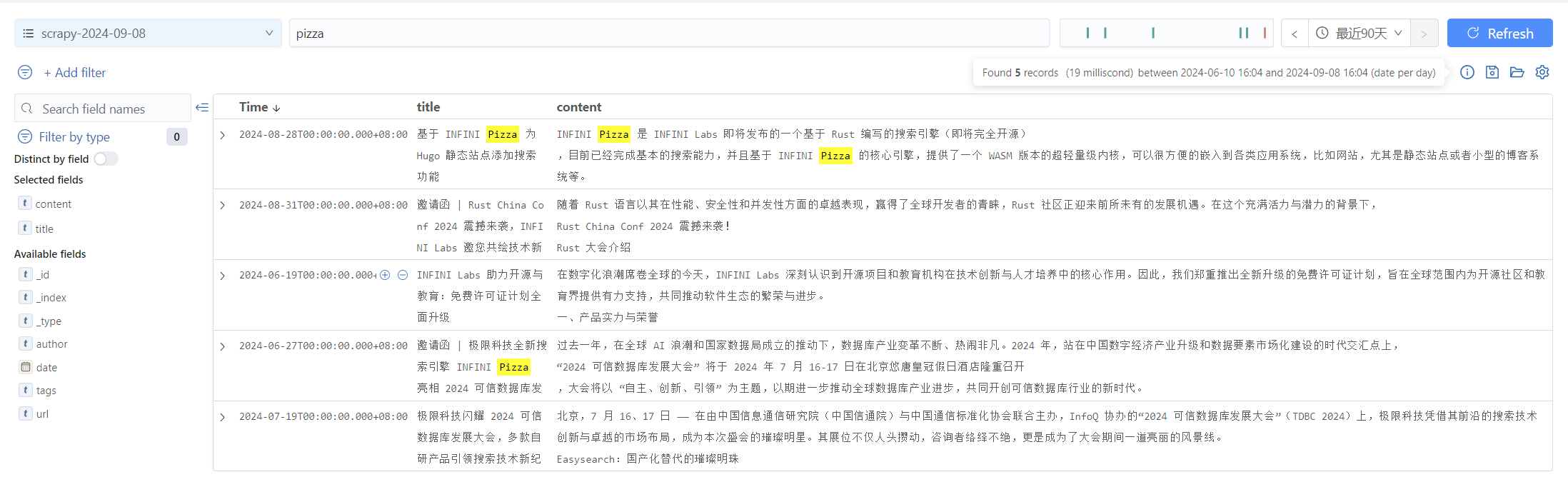
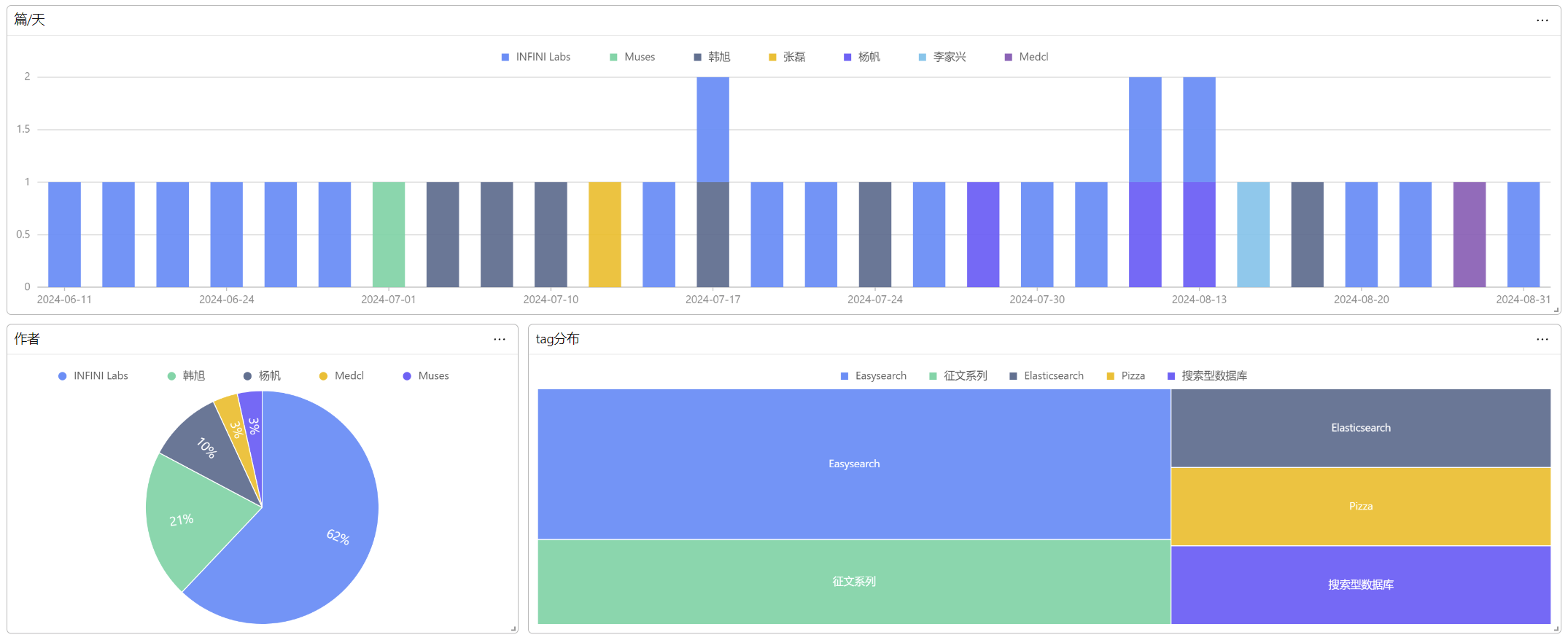
6、结语
这次的分享就到这里了。欢迎与我一起交流 ES 的各种问题和解决方案。
关于 Easysearch
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。 与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
官网文档:https://infinilabs.cn/docs/latest/easysearch
🔥 Rust China Conf 2024 震撼来袭,INFINI Pizza 搜索引擎重磅亮相!
活动 • INFINI Labs 小助手 发表了文章 • 0 个评论 • 5696 次浏览 • 2024-08-31 17:10
随着 Rust 语言以其在性能、安全性和并发性方面的卓越表现,赢得了全球开发者的青睐,Rust 社区正迎来前所未有的发展机遇。在这个充满活力与潜力的背景下,Rust China Conf 2024 震撼来袭!
Rust 大会介绍
Rust 大会即将于 9 月 7 日 - 8 日在上海盛大举办。作为年度国内规模最大并唯一的 Rust 线下大型会议,它由 Rust 中文社区发起主办、知名企业和开源组织联合协办,深受开发者与相关企业的喜爱与推崇。自 2020 年起,已连续举办四年,今年预计将吸引超过 400 名一线程序员和企业用户,他们已在个人或公司项目中实践 Rust,期待在此交流心得、共享经验,共同推动 Rust 生态的繁荣与发展。

INFINI Labs 亮相 Rust 大会
作为本次大会的重要赞助商之一,INFINI Labs 将携手蚂蚁集团、字节跳动、JetBrains、亚马逊云科技、华为、Greptime 等知名企业,为与会者带来创新的灵感和实践的洞见。INFINI Labs 的创始人 & CEO 曾勇先生将分享《基于 Rust 编写下一代实时搜索引擎》—— INFINI Pizza 的故事,这款搜索引擎旨在解决海量数据的实时搜索需求,释放现代硬件的潜力,为企业打造高效、准确的搜索解决方案。

大会部分议题亮点抢先看
《人人可用的 Rust》
讲师简介: Rebecca Rumbul,Rust 基金会执行董事兼首席执行官, OpenUK 董事会成员, OpenSSF 管理委员会成员。
议题介绍: 本次分享将介绍 Rust 基金会如何投资于工程和推广工作,以确保 Rust 对所有人来说都是有用、高效且安全的。
《携手共建繁荣的 Rust OS 内核软件生态》
讲师简介: 田洪亮,田洪亮博士是蚂蚁研究院操作系统方向的负责人, 在 Rust 编程和内核开发方面有丰富的经验,荣获 OS2ATC'24 颁发的开源创新先锋奖。他发起的 Occlum 项目,是业界最早的 Rust OS 开源项目, 已发展成可信执行环境中最流行的 library OS,荣登中科协发布的"科创中国"开源创新榜单。曾就职于 Intel Labs China,博士毕业于清华大学。
议题介绍: Rust 语言以其高效、安全和生产力被视为系统编程,尤其是 OS 编程的未来。但在开发 OS 内核时,存在频繁使用 unsafe、缺乏 Cargo 支持、以及可重用的 no_std crates 不足等痛点。星绽开源社区提出了星绽 Framework 和星绽 OSDK,提供强大的 safe API 和开发工具链, 使得 Rust 内核开发更加安全、高效,并促进了 no_std crates 的复用与组合,旨在提升开发者生产力并推动 Rust 生态的繁荣。
《用 Rust 构建高性能的生成式 AI 应用》
讲师简介: 王宇博,现任亚马逊云科技大中华区开发者关系总监、首席布道师,致力于新一代信息技术与创新在开发者中的布道推广,以及开发者生态体系的建设。
议题介绍: 生成式 AI 技术在自然语言处理和图像生成领域快速发展。对于 Rust 开发者来说,利用 Rust 的高性能特性构建高效、可靠的生成式 AI 应用至关重要。本次演讲将深入探讨在 Rust 中开发生成式 AI 应用的实践方法,分析其在数值计算和并发编程中的优势,并分享确保应用可靠性和安全性的最佳实践,帮助开发者掌握构建高性能生成式 AI 应用的技巧。
《字节跳动在 Rust 服务端方向的实践与思考》
讲师简介: 吴迪,字节跳动服务框架 Rust 负责人,负责字节跳动 Rust 生态建设与推广落地。
议题介绍: 字节跳动三年前开始投资 Rust 服务端开发,构建了内部生态并开源核心框架 Volo。现在已在多个业务线成功落地,规模国内最大,收益超预期。本次分享将介绍选择 Rust 的原因、落地心得及未来技术趋势的思考。
《Async Rust 维测&定位的探索和思考》
讲师简介:
陈明煜:毕业于加州大学圣地亚哥分校,现就职于华为,OpenHarmony Ylong Rust 异步框架的开发者,致力于推动 OH 应用的 Rust 异步化。
楼智豪:毕业于浙江大学,现就职于华为,参与过 Rust 与 Cangjie 语言的开源贡献,现从事 Rust 在 OpenHarmony 中的应用。
议题介绍: 本议题将介绍我们在 OpenHarmony 中遇到的一些异步框架使用问题,以及我们在 Rust 异步调测与定位方面的探索。内容包括对业界常见异步框架的维测能力调研,以及对 Rust 无栈协程的推栈处理和跨 FFI 的 C++ exception 问题解决方法,旨在提升 Rust 异步的可商用性。
《Rust HashMap:比看起来更复杂》
讲师简介: 曹瑞秋,蚂蚁集团高级开发工程师,Apache HoraeDB/CeresDB 核心开发者,Apache HoraeDB PPMC member,长期专注于时序数据库领域。
议题介绍: Rust HashMap 看似简单,实际使用中存在诸多"坑点",尤其在 CPU 消耗和内存占用方面。分段 HashMap 设计中的伪共享和内存访问局部性差会影响性能。HashMap 的 capacity 通常远大于指定值,加之内存访问特性,会占据大量物理内存。此外,with_capacity方法和 allocator 内存池的使用不当可能导致内存释放问题。因此,使用 Rust HashMap 需要细心设计。
《Rust 和 C++ 互操作及交叉编译》
讲师简介: 朱树磊,北京大学物理学士,德国 TUM 硕士,现任浙江大华技术股份有限公司高级算法专家。从事人工智能算法研发工作 10 余年,擅长机器学习、深度学习和大数据智能等技术领域,具备丰富的人工智能算法系统设计和开发经验。
议题介绍: Rust 和 C++ 经常需要共存,但 C++ 的交叉编译复杂性是一个挑战。本次分享将介绍如何使用 cxx 让 Rust 和 C++ 代码共存,并通过 LLVM 工具链补齐 C++ 交叉编译的短板,让 C++ 和 Rust 的互操作简单可移植。
《超大规模:抖音直播的 Rust 技术落地实践》
讲师简介: 赵鹏,抖音直播架构师,Rust 技术负责人。
议题介绍: 抖音直播从 2022 年开始引入 Rust 技术栈,用于应对直播业务中的超低延时、超高性能挑战,取得了远超预期巨大的收益。两年时间里我们有 20+ 个头部服务完成了 Rust 重构,吞吐平均提升超 100%,节省了 16w 核 CPU 资源,多个服务 SLA 提升至 6 个 9,目前我们的 Rust 服务在线上承担着超 4000w qps 的请求。Rust 技术在抖音直播研发团队二级部门实现了 100% 覆盖,每个子业务团队都有 Rust 服务在线上运行。我们还成立了专门的 Rust 技术组帮助解决业务公共问题,沉淀了完整的 Rust 研发流水线,基本实现了 Rust 新人两周即可上手开发,两个月完成一个 Rust 服务上线的速度。综合 Rust 服务类型覆盖、数量、资源占用、开发人员、生态、基建完善程度,抖音直播已经是国内规模最大的 Rust 技术生产环境落地团队,本次分享将给大家介绍我们从选型、验证、落地、推广到维护过程中的真实实践经验,希望能够帮助到其他同行朋友。
大会报名
本次大会致力于成为中国 Rustaceans 面对面交流的盛宴,为国内的 Rust 开发者和企业提供一次充分的成果展示、技术分享、能力提升、行业资讯交流、企业人才储备建设的机会。欢迎购票参与现场交流。
🔗 报名链接 / 扫二维码:
https://4292817522623.huodongxing.com/event/5757822319111

关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
【INFINI Workshop 上海站】7 月 27 日一起动手实验玩转 Easysearch
资讯动态 • liaosy 发表了文章 • 1 个评论 • 4387 次浏览 • 2023-07-07 16:30

招聘搜索引擎内核研发工程师(Rust方向)
求职招聘 • medcl 发表了文章 • 0 个评论 • 7705 次浏览 • 2023-01-28 17:33
- 设计并开发下一代实时搜索引擎 ;
- 持续优化实现方案,改进组件性能 ;
- 保证工程质量和开发效率 。
- 3 年以上搜索引擎开发经验,计算机相关专业,本科及以上学历 ;
- 熟练掌握 Rust/C/C++/Golang 中的一种或多种语言,有 Rust 实际开发经验者优先 ;
- 熟悉 Linux 操作系统,了解Linux系统常用操作命令, 能基于shell编写脚本 ;
- 熟悉 Linux 下内存管理机制,低延迟、高并发无锁化编程 ;
- 熟悉 TCP/IP、Socket、HTTP 等网络协议 ;
- 具有良好的沟通、团队协作能力;
- 熟悉常见分布式算法,有大规模分布式系统开发经验优先;
- 较好的英文阅读和写作能力,具备比较强的逻辑思维能力;
- 良好的编码习惯和技术文档能力,具备持续输出的能力;
- 工作地点不限 。
- 有自己的博客、Github、开源项目优先 ;
- 具有相关搜索引擎开发工作经验者优先 ;
- 熟悉各类索引结构;
- 熟悉 LSM-Tree、B+Tree、RocksDB、LevelDB 优先 ;
- 有较强的学习能力,愿意致力于新技术的研究 。
INFINI Easysearch 向量搜索实战(一)
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 578 次浏览 • 1 天前
Easysearch 提供了强大的向量搜索能力,打破传统关键词匹配的局限,实现真正的“懂你”的语义搜索。助力企业快速构建智能推荐、图像识别和内容理解等 AI 应用,释放数据深层价值。
核心能力
| 能力 | 说明 |
|---|---|
| 两种向量类型 | 稠密浮点向量(knn_dense_float_vector)和稀疏布尔向量(knn_sparse_bool_vector) |
| 多种索引模型 | lsh(局部敏感哈希,近似搜索)、permutation_lsh(置换 LSH)、sparse_indexed(倒排索引)、exact(精确搜索) |
| 多种相似度 | cosine(余弦)、l1(曼哈顿距离)、l2(欧氏距离)、jaccard、hamming |
| 与全文搜索融合 | 向量字段与文本字段存储在同一索引,支持 Hybrid 混合检索 |
| function_score 集成 | 向量相似度可作为 function_score 的评分函数 |
典型应用场景
- 语义搜索:文本通过 Embedding 模型转为向量,按语义相似度检索
- RAG 检索增强生成:为大语言模型提供知识库检索能力
- 推荐系统:用户/商品特征向量的相似推荐
- 图像/多模态搜索:图像特征向量的相似检索
- 去重与异常检测:通过向量距离判断内容相似度
Embedding 服务
在使用向量搜索前,先要准备一个 Embedding 模型,支持与 OpenAI API 兼容的 embedding 接口和 Ollama embedding 接口。本文使用阿里云上的 Embedding 模型进行演示。
写入方法
方法一:写入链路嵌入(推荐)
在数据写入 Easysearch 时,通过 Ingest Pipeline 自动调用 Embedding 服务:
应用写数据 → Easysearch → Ingest Pipeline → 调用 Embedding API → 写入向量字段
优势是写入后即可搜索,无需维护外部向量化流程。需要确保集群应至少有一个节点拥有 ingest 角色。
方法二:离线批处理
在应用侧完成向量化,再将向量字段直接写入 Easysearch:
原始数据 → 应用 → 调用模型 Embedding API → 写入 Easysearch(含向量字段)
参考文档。
实战
我们实战演示模式一,分为以下几个步骤:
- 建立带有向量字段的索引
- 创建对应的 Ingest Pipeline
- 写入数据到索引
1. 建立带有向量字段的索引
先建立一个带向量字段的索引,注意 dims 要与向量模型的输出匹配。
PUT /my-index
{
"mappings": {
"properties": {
"text_vector": {
"type": "knn_dense_float_vector",
"knn": {
"dims": 1024,
"model": "lsh",
"similarity": "cosine",
"L": 99,
"k": 1
}
}
}
}
}
2. 创建对应的 Ingest Pipeline
写入数据前先建立 Ingest Pipeline,注意 vendor 必须根据使用的模型来指定,比如本文使用的是阿里云 text-embedding-v4 模型,该模型提供了 OpenAI 格式的 API 接口,这里 vendor 我们就写 openai。
PUT _ingest/pipeline/text-embedding-pipeline
{
"description": "用于生成文本嵌入向量的管道",
"processors": [
{
"text_embedding": {
"url": "https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings",
"vendor": "openai",
"api_key": "xxxxxx",
"text_field": "input_text",
"vector_field": "text_vector",
"model_id": "text-embedding-v4",
"dims": 1024,
"ignore_missing": false,
"ignore_failure": false
}
}
]
}
text_field:指定原始文本字段,Pipeline 会将该字段的内容转换成向量。
vector_field:指定向量存储的字段,保存上面转换的向量。
3. 写入数据
POST /_bulk?pipeline=text-embedding-pipeline&pretty
{"index": {"_index": "my-index", "_id": "1"}}
{"input_text": "苹果发布了新款iPhone 15 Pro手机,搭载A17芯片"}
{"index": {"_index": "my-index", "_id": "2"}}
{"input_text": "特斯拉宣布将在上海建第二座超级工厂"}
{"index": {"_index": "my-index", "_id": "3"}}
{"input_text": "今天天气真好,阳光明媚适合去公园散步"}
{"index": {"_index": "my-index", "_id": "4"}}
{"input_text": "程序员用Python写了一个自动化数据清洗脚本"}
{"index": {"_index": "my-index", "_id": "5"}}
{"input_text": "故宫博物院推出了夏季特展,展出珍贵文物"}
{"index": {"_index": "my-index", "_id": "6"}}
{"input_text": "小明每天坚持跑步五公里,身体越来越健康"}
{"index": {"_index": "my-index", "_id": "7"}}
{"input_text": "人工智能大模型在自然语言处理领域取得突破"}
{"index": {"_index": "my-index", "_id": "8"}}
{"input_text": "这家咖啡店的拿铁口感丝滑,推荐给咖啡爱好者"}
{"index": {"_index": "my-index", "_id": "9"}}
{"input_text": "量子计算机有望在药物研发中发挥重要作用"}
{"index": {"_index": "my-index", "_id": "10"}}
{"input_text": "周末和朋友一起去爬山,山顶的风景美极了"}
4. 检查数据
搜索索引数据,看看是否成功转换成了向量。可以看到原始数据保存在 input_text 字段中,其向量保存到了 text_vector。
OK,下一步我们看看怎么方便地实现向量搜索。
关于 Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
官网文档:https://docs.infinilabs.com/easysearch
相关文章:
国产统信 UOS 部署 Coco Server 全指南:从零搭建企业级 AI 搜索服务端
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 9830 次浏览 • 2026-06-09 14:19
一、引言
在上一篇文章《从零到跑起来:Easysearch 信创环境安装全流程》中,我们成功在信创平台上安装并运行起了 Easysearch。但 Easysearch 是一个底层搜索引擎,直接操作有一定门槛。如果我们想让团队里的每个人都能方便地“搜文件、聊文档、问知识”,就需要一个更贴近日常使用、又能把 AI 能力融入进来的上层应用——这就是 Coco AI 。
本文将继续手把手带你从零开始,在国产统信 UOS 服务器操作系统上部署 Coco Server,并与已安装的 Easysearch 进行对接。全文依然零基础可读,跟着步骤一步步来即可。
二、Coco Server 是什么?它和 Easysearch 什么关系?
先对我们的产品进行一个简单的介绍:
- Easysearch 是底层引擎,负责存储和检索数据,像汽车的发动机和底盘;
- Coco Server 是基于 Easysearch 之上的服务端应用程序,提供 Web 管理界面、统一搜索、AI 聊天、知识库管理等高级功能,类似车身和智能驾驶系统;
- Coco AI 桌面客户端则是连接 Coco Server 的终端软件,安装在个人电脑上使用。
而在本文中部署的 Coco Server,是整个 Coco AI 体系的“大脑”:
- 它负责连接各类数据源(飞书、语雀、GitHub、本地文件等);
- 它管理大模型提供商(Deepseek、通义千问、OpenAI 等);
- 它提供 Web 管理后台,让管理员可以可视化地完成所有配置。
部署完成之后,团队成员只需通过客户端或浏览器,就能享受统一搜索与 AI 智能问答带来的便利。Coco AI 的整体架构图如下:
三、部署前置条件
1. 进行服务器相关优化
#内核参数优化
cat << SETTINGS | sudo tee /etc/sysctl.d/70-infini.conf
fs.file-max = 10485760
fs.nr_open = 10485760
vm.max_map_count = 262145
net.core.somaxconn = 65535
net.core.netdev_max_backlog = 65535
net.core.rmem_default = 262144
net.core.wmem_default = 262144
net.core.rmem_max = 4194304
net.core.wmem_max = 4194304
net.ipv4.ip_forward = 1
net.ipv4.ip_nonlocal_bind = 1
net.ipv4.ip_local_port_range = 1024 65535
net.ipv4.conf.default.accept_redirects = 0
net.ipv4.conf.default.rp_filter = 1
net.ipv4.conf.all.accept_redirects = 0
net.ipv4.conf.all.send_redirects = 0
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_max_tw_buckets = 300000
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 65535
net.ipv4.tcp_synack_retries = 0
net.ipv4.tcp_keepalive_intvl = 30
net.ipv4.tcp_keepalive_time = 900
net.ipv4.tcp_keepalive_probes = 3
net.ipv4.tcp_fin_timeout = 10
net.ipv4.tcp_max_orphans = 131072
net.ipv4.tcp_rmem = 4096 4096 16777216
net.ipv4.tcp_wmem = 4096 4096 16777216
net.ipv4.tcp_mem = 786432 3145728 4194304
SETTINGS
sysctl -p /etc/sysctl.d/70-infini.conf
2. 环境前提:Easysearch 已经运行好
Coco Server 运行强依赖 Easysearch,所以在继续之前,请确保你的信创服务器上已经安装并成功启动了 Easysearch。如果不确定,可以执行下面的命令验证:
curl -k -u admin:你的密码 https://localhost:9200运行命令后,看到正常的 JSON 响应即可。
如果还没有安装,可以参考上一篇文章《从零到跑起来:Easysearch 信创环境安装全流程》先行完成。
3. 信创平台信息确认
和 Easysearch 一样,你需要明确当前服务器的 CPU 架构和操作系统版本。在终端执行:
# 查看 CPU 架构
uname -m
# 查看操作系统信息
cat /etc/os-release根据输出,确认 CPU 架构和操作系统,后续下载时选择对应版本。
部署环境如下表中所示:
4. 软件环境
| 名称 | 版本 | 备注 |
|---|---|---|
| Coco AI 智能搜索软件 | V1.0.0 | Coco Server |
| 统信服务器操作系统 A 版 | V20 | |
| Easysearch 搜索型数据库 | V2.2.0 | 用于 Coco 数据存储 |
| 360安全浏览器 | V13 |
5. Coco AI 大语言模型 推荐配置
| 模型名称 | 上下文长度 | 最大输出长度 | 描述 |
|---|---|---|---|
| deepseek-r1 | 128K | 16K | 数学、代码、自然语言推理等任务上,性能较高,能力较强 |
| qwen3-max | 256K | 32K | 配场景复杂的智能体需求 |
| tongyi-intent-detect-v3 | 8K | 8K | 用于意图识别和槽位填充,负责对话系统中的基础任务 |
5. 网络端口配置
| 服务名 | 端口 | 配置文件 | 说明 |
|---|---|---|---|
| Coco Server | 9000(默认) | coco.yml | |
| INFINI Easysearch | 9200(默认) | config/easysearch.yml | 默认仅监控 127.0.0.0,可通过配置 network.host: 0.0.0.0 调整 |
| 9300(默认) | config/easysearch.yml |
四、部署步骤
步骤 1:下载 Coco Server
# 调整为 Coco 实际要安装的路径
cd /opt
#下载Coco v1.0.0压缩包
curl -O https://release.infinilabs.com/.testing/coco-1.0.0.zip
#解压到当前文件夹
unzip coco-1.0.0.zip
#选择对应的版本解压tar.gz文件
tar -xzf coco-1.0.0-2002-linux-arm64.tar.gz
#解压后在对应文件夹下得到可执行程序coco-linux-arm64(arm64版本)和配置文件coco.yml步骤 2:配置 Easysearch 连接信息
Coco Server 需要得到 Easysearch 的地址和登录凭证才能进行工作。
在 安装路径的目录下,找到配置文件 进行配置,比如监听的端口地址 WEB_BINDING, 将 Easysearch 的服务地址环境变量 ES_ENDPOINT 和用户名 ES_USERNAME 设置为实际的,参考如下:
env:
# 调整为实际可以访问的 Easysearch 访问地址
ES_ENDPOINT: https://localhost:9200
# 调整为实际可以访问的 Easysearch 的用户
ES_USERNAME: admin
# 使用 keystore 存储的密码
ES_PASSWORD: $[[keystore.ES_PASSWORD]]
# Coco Server 对外提供服务的端口(默认9000端口)
WEB_BINDING: 0.0.0.0:9000步骤 3:使用keystore对密码进行加密处理
Easysearch 的服务密码通过 Keystore 进行加密存放,避免明文存放到配置文件,减少数据泄露风险
# 调整为 Coco 实际安装路径进行配置
cd /opt
# 创建 coco 软链接,可不区分 amd64/arm64 平台进行操作
ln -s coco-linux-`arch | grep -q "x86_64" && echo "amd64" || echo "arm64"` coco
# 根据之前拿到的 Easysearch 密码进行初始化 ES_PASSWORD 变量
ES_PASSWORD=xxx
# 将 ES_PASSWORD 变量的值存储到 keystore(./coco-linux-arm64替换为对应版本名,下同)
echo "$ES_PASSWORD" | ./coco-linux-arm64 keystore add --stdin ES_PASSWORD
# 检查 keystore 存储列表,确认 ES_PASSWORD 添加成功
./coco-linux-arm64 keystore list步骤 4:启动服务
以上配置完成后,设置 Coco Server 以服务方式启动
#安装系统服务(./coco-linux-arm64替换为对应版本名,下同)
./coco-linux-arm64 -service install
#启动服务
./coco-linux-arm64 -service start
步骤 5:初始化设置
服务启动后,在信创服务器的桌面环境下,打开浏览器,访问 UI 界面:
http://localhost:9000/#/\_guide/
你将看到 Coco Server 的 Web 引导界面。因为是首次访问,所以需要创建管理员账号,按页面引导填写即可。
创建完管理员账户后,下一步
设置一个模型提供商,Coco Server 支持:
- Deepseek
- Ollama
- 任何和 OpenAI 格式兼容的模型提供商
如果设置的模型是推理模型,需要打开“推理模式”。我们推荐使用参数较大的模型,来获得更好的使用体验。同时请注意:Endpoint 地址的配置要准确。
Coco Server 默认配置了一些小助手,建议在初始化向导的时候直接配置一个可用的模型,这样进入系统之后就可以直接使用,避免一个个的手动配置。
向导设置完成后,就会跳转到登录页面,输入刚才创建的账户和密码,就可以进行登录了,如下图:
管理员首次登录之后的第一件事是确认服务器的地址是否正确,如果 Coco server 前面增加了负载均衡或者配置了域名,需要在这里设置一下正确的 Coco Server 对外服务地址,如下图:
五、总结
到这里,你已经完成了 Coco Server 在信创平台上的部署与初始化。我们回顾一下整个部署流程:
- 确认环境 — Easysearch 已部署成功,并明确 CPU 架构;
- 下载安装 — 下载 Coco Server 的压缩包进行解压;
- 配置连接 — 编辑
coco.yml,填入 Easysearch 端点和密码; - 启动服务 — 将 Coco Server 以服务方式启动;
- 初始化 — 浏览器打开 http://localhost:9000/#/\_guide/ 进行管理员账户的创建; 添加大模型、连接数据源、创建助手。
Coco Server 部署完成后,你就拥有了一个完全私有化、自主可控的企业级统一搜索与 AI 智能助手服务端。下一步可以安装 Coco AI 桌面客户端,让团队成员真正体验“一个搜索框搜遍全公司”的高效便捷。
如果在部署过程中遇到任何困难,欢迎查阅官方文档,祝你部署顺利!
Easysearch 正式支持插件开发:让你的搜索系统真正"为你所用"
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 17422 次浏览 • 2026-04-27 22:02
从"用搜索"到"造搜索"
搜索系统的需求千差万别。标准功能覆盖不了所有场景——行业特定的分词规则、定制化的业务逻辑、与外部系统的深度集成……
以往,这类定制需求需要依赖厂商支持。从 Easysearch 2.1.2 开始,你可以自己动手了。
随着构建依赖库正式发布到 Maven 中央仓库,Easysearch 的插件开发能力正式对外开放。这意味着 Easysearch 不再是一个黑盒产品,而是一个可扩展、可定制的搜索平台。你可以基于官方接口开发自定义插件,像使用原生功能一样使用它们。
插件能做什么
Easysearch 提供三类核心扩展点,覆盖搜索系统的关键环节:
1. 分析器插件(AnalysisPlugin)
自定义分词器、Token 过滤器、字符过滤器。适用于:
- 电商 SKU 的型号规格解析
- 医疗、法律等领域的专业术语分词
- 特殊符号或空格的规范化处理
注册后直接在索引设置中使用,与原生分析器完全等同。
2. REST/API 插件(ActionPlugin)
新增自定义 HTTP 接口。适用于:
- 封装业务查询逻辑,对外暴露简化 API
- 对接企业内部权限中心或监控系统
- 暴露插件自身的管理接口(如状态检查)
3. Ingest 插件(IngestPlugin)
在文档写入前进行字段转换。适用于:
- 自定义业务字段转换(如根据业务规则计算衍生字段)
- 数据标准化(统一日期格式、大小写转换)
- 富文本提取或元数据生成
5 分钟上手
我们准备了官方模板仓库,让你从克隆到运行只需几条命令:
# 克隆模板
git clone https://github.com/infinilabs/easysearch-plugin-template.git my-plugin
cd my-plugin
# 修改包名和类名,编写你的逻辑
# ...方式一:开发调试——直接运行
# 构建插件并运行
./gradlew run
# 验证插件
curl -s "http://localhost:9200/_cat/plugins?v" | grep my-plugin方式二:构建后安装到外部集群
# 构建插件
./gradlew build
# 安装到 Easysearch
bin/easysearch-plugin install file:///$(pwd)/build/distributions/my-plugin-0.1.0.zip
# 启动验证
bin/easysearch
curl -s "http://localhost:9200/_cat/plugins?v" | grep my-plugin完整的开发指南请参考插件开发文档。
设计哲学
Easysearch 插件系统的设计遵循三个原则:
渐进式扩展——从最简单的 Plugin 类开始,按需实现 AnalysisPlugin、ActionPlugin 等接口,不必一次性掌握全部 API。
与原生同等——插件注册的分析器、处理器与系统原生组件在使用方式上完全一致,用户无需关心实现来源。
版本安全——插件加载时校验 easysearch.version,版本不匹配会拒绝加载,避免运行时异常。
从插件到生态
插件开发不只是技术能力的开放,更是产品理念的转变。
你可以将开发的插件发布到 GitHub Releases,通过 URL 直接安装:
bin/easysearch-plugin install https://github.com/yourname/my-plugin/releases/download/v0.1.0/my-plugin-0.1.0.zip我们也欢迎社区贡献。如果你有通用的插件想法,欢迎与我们交流。
结语
搜索系统的最后一公里,只有业务开发者最清楚该怎么走。
Easysearch 2.1.2 的插件开发能力,让你能够自主掌控搜索系统的"最后一公里"。从"用搜索"到"造搜索",现在你可以让你的搜索系统真正"为你所用"。
关于 Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
Easysearch ZSTD 基准测试:高压缩率下实现近 5 倍查询吞吐
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 5025 次浏览 • 2026-03-17 12:41
在搜索引擎领域,压缩算法的选择一直是一个经典的权衡难题:
- 选择高压缩率(如
best_compression/ DEFLATE),磁盘省了,但查询解压慢; - 选择高速编码(如默认 LZ4),查询快了,但磁盘占用大。
Easysearch 引入了基于 JDK 21 FFM(Foreign Function & Memory API) 直连本地 ZSTD 动态库的加速方案,试图打破这一困局。为了验证效果,我们在完全对等的环境下,对 Easysearch(ZSTD)和 Elasticsearch 7.10.2(best_compression)进行了一次严格的查询吞吐对比测试。
结果令人振奋——即使在系统明显背景负载下,Easysearch 也没有因为高压缩而变慢,反而在查询吞吐上实现了近 5 倍提升。
测试环境
为确保对比公平,两套集群的硬件资源、JVM 配置、数据规模、索引结构完全对齐:
| 配置项 | Easysearch | Elasticsearch 7.10.2 |
|---|---|---|
| 节点数 | 3 | 3 |
| JVM 堆内存 | 12GB × 3 | 12GB × 3 |
| node.processors | 16 × 3 | 16 × 3 |
| 文档数 | 10,000,000 | 10,000,000 |
| 主分片 / 副本 | 3 / 0 | 3 / 0 |
| 数据类型 | nginx 访问日志 | nginx 访问日志 |
| 字段数 | 17 | 17 |
| mapping | 完全一致(MD5 校验) | 完全一致(MD5 校验) |
| Stored fields 压缩模式 | ZSTD (JDK21 FFM/native, level=3) | best_compression (DEFLATE) |
压缩机制对比:
best_compression映射到 LuceneBEST_COMPRESSION;在 stored fields 路径上,压缩实现为DeflateWithPresetDictCompressionMode,内部使用java.util.zip.Deflater/Inflater(即 DEFLATE)。 Easysearch ZSTD 当前走 JDK 21 FFM 绑定本地 zstd 库(java.lang.foreign);index.compression.zstd.jni=true为当前这套实现的启用方式。
查询模型:JMeter 随机 match 查询,随机命中 service_name、method、error_code、url 四个字段,每次返回 10 条文档。
压测起始负载(_cat/nodes 快照):
| 负载项 | Easysearch run | Elasticsearch run |
|---|---|---|
| load_1m | 29.74 | 25.27 |
| load_5m | 27.10 | 28.15 |
| load_15m | 26.09 | 36.96 |
| ram.percent | 99 | 99 |
说明:压测并非在空闲机上进行,而是在已有明显背景负载的生产式环境下完成。
核心结果
1. 查询吞吐量(QPS):在高背景负载下,Easysearch 仍领先 372%
稳态阶段(3 轮平均),Easysearch 的查询吞吐是 Elasticsearch 的 4.7 倍:
| 指标 | Elasticsearch (DEFLATE) | Easysearch (ZSTD) | 差异 |
|---|---|---|---|
| 稳态 QPS | 532.8 | 2,518.0 | +372.6% |
| 平均响应时间 | 779.0 ms | 164.3 ms | -78.9% |
| 稳态 CPU 占用(系统总占用) | 92.43% | 89.59% | 仅作背景参考 |
注:压测期间服务器存在明显背景负载(其他进程占用较高),该 CPU 指标是系统总占用,不等价于“仅搜索进程”的纯业务 CPU 对比。
在系统总 CPU 均接近 90% 的背景下,Easysearch 仍达到接近 5 倍吞吐。
查询吞吐量 QPS 对比(稳态均值)
2. 响应时间:从近 1 秒降到 164 毫秒
平均响应时间对比(ms,越低越好)
用户体感上,这意味着:同样一个搜索请求,Elasticsearch 还在等解压,Easysearch 已经把结果送到了客户端。
3. 各轮次详细数据
各轮次 QPS 趋势
各轮次平均响应时间趋势(ms)
4. CPU 使用效率:每 1% CPU 产出的 QPS 差距惊人
单看 CPU 占用率,两者似乎差不多(89.59% vs 92.43%)。但如果换一个视角——每消耗 1% CPU 能产出多少 QPS,差距就一目了然了:
| 指标 | Elasticsearch (DEFLATE) | Easysearch (ZSTD) | 倍数 |
|---|---|---|---|
| 稳态 QPS | 532.8 | 2,518.0 | — |
| 稳态 CPU | 92.43% | 89.59% | — |
| QPS / 1% CPU | 5.76 | 28.10 | 4.88× |
CPU 使用效率:每 1% CPU 产出的 QPS
这意味着什么?
- ES 使用 DEFLATE(best_compression)时,解压路径更可能成为 CPU 热点;结合 ES 的高 CPU(92.43%)与较低 QPS,说明单位 CPU 产出偏低;
- Easysearch 使用 ZSTD(JDK21 FFM/native)时,解压开销更小;在相近 CPU 水位(89.59%)下获得更高 QPS,单位 CPU 产出明显更高。
换句话说,当前这组实测更支持“ZSTD 在该查询模型下单位 CPU 产出更高”。
5. 存储空间:ZSTD 并未膨胀
| 索引 | 压缩算法 | 磁盘占用 |
|---|---|---|
| nginx_best_10m (ES) | best_compression (DEFLATE) | 1.8 GB |
| nginx_zstd3 (Easysearch) | ZSTD (level=3, JDK21 FFM/native) | 1.9 GB |
两者存储空间接近。若按 _cat/indices 的 1 位小数展示是 1.8GB vs 1.9GB;若按 _stats/store 字节值计算,差异约 2.5%。因此可以认为 ZSTD 在 level=3 下与 DEFLATE best_compression 压缩率接近。
磁盘占用对比(GB)
为什么 ZSTD 能做到"又小又快"?
传统认知中,压缩率和解压速度是一对矛盾。但 ZSTD 算法天然具备非对称压缩的特性:
压缩算法特性对比
在搜索引擎场景中,查询会触发存储字段(_source)读取与解压路径,命中文件系统页缓存时,可能不发生实际磁盘 I/O,但仍需进行 _source 解压。
当查询涉及较多 _source 读取时:
- DEFLATE 的解压开销成为 CPU 瓶颈,拖慢了整体吞吐;
- ZSTD(JDK21 FFM/native) 的解压速度在该场景下明显更优,单次请求的解压 CPU 成本更低,从而释放出更多 CPU 资源用于并发查询处理。
这就是为什么 Easysearch 在 CPU 占用更低(89.59% vs 92.43%)的情况下,反而能处理近 5 倍的查询量。
一张图总结
Easysearch ZSTD vs Elasticsearch DEFLATE — 全维度对比
结论
Easysearch 的 ZSTD 压缩方案证明了一个事实:即使在高背景负载下,高压缩率和高查询性能依然可以兼得。
在 1000 万条 nginx 日志、且系统存在明显背景负载的实测中:
- 查询吞吐提升 372%,从 533 QPS 跃升至 2518 QPS
- 平均响应时间下降 79%,从 779ms 降至 164ms
- CPU 使用效率提升 388%,每 1% CPU 产出 28.10 QPS vs 5.76 QPS
- CPU 占用绝对值下降 2.84 个百分点(相对下降约 3.07%)
- 磁盘占用与 DEFLATE best_compression 接近(按字节口径约 +2.5%)
对于日志分析、可观测性、安全审计等需要兼顾存储成本和查询性能的场景,Easysearch ZSTD 是一个不需要妥协的选择。
ZSTD 使用方法
1) 新建索引时启用 ZSTD
curl -k -u 'admin:<password>' -X PUT 'https://127.0.0.1:9200/<index-name>' \
-H 'Content-Type: application/json' -d '{
"settings": {
"index.codec": "ZSTD",
"index.compression.zstd.jni": true
}
}'可选参数:
index.compression.zstd.level(默认3)
说明:
index.compression.zstd.dict固定为true,无需单独配置index.compression.zstd.dict不作为独立开关来调整
2) 老索引切换到 ZSTD(推荐 reindex)
index.codec 是静态设置(打开状态不可动态改;可在关闭索引后调整)。
index.compression.zstd.jni 是 final 设置(关闭索引后也不可修改)。
如果老索引要启用 index.compression.zstd.jni=true,建议新建目标索引后 reindex 迁移:
如果对已有索引执行 PUT /<index-name>/_settings 直接修改,会报错:final <index-name> setting [index.compression.zstd.jni], not updateable。
# 先创建目标索引(启用 ZSTD)
curl -k -u 'admin:<password>' -X PUT 'https://127.0.0.1:9200/<target-index>' \
-H 'Content-Type: application/json' -d '{
"settings": {
"index.codec": "ZSTD",
"index.compression.zstd.jni": true
}
}'
# 再迁移数据
curl -k -u 'admin:<password>' -X POST 'https://127.0.0.1:9200/_reindex' \
-H 'Content-Type: application/json' -d '{
"source": { "index": "<source-index>" },
"dest": { "index": "<target-index>" }
}'3) 校验是否生效
curl -k -u 'admin:<password>' \
'https://127.0.0.1:9200/<index-name>/_settings?include_defaults=true&pretty'重点确认:
index.codec = ZSTDindex.compression.zstd.jni = true
关于 Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
官网文档:https://docs.infinilabs.com/easysearch
作者:张磊,极限科技(INFINI Labs)搜索引擎研发负责人,对 Elasticsearch 和 Lucene 源码比较熟悉,目前主要负责公司的 Easysearch 产品的研发以及客户服务工作。
相关文章:
极限科技荣膺 2025 金猿奖 — “年度国产化优秀代表厂商”,自主可控搜索方案 Easysearch 获行业高度认可
资讯动态 • INFINI Labs 小助手 发表了文章 • 0 个评论 • 25128 次浏览 • 2026-01-16 17:41
近日于上海明捷万丽酒店成功举办的 “2025 第八届金猿大数据产业发展论坛 — 暨 AI Infra & Data Agent 趋势论坛” 大会上,极限数据(北京)科技有限公司(以下简称“极限科技”) 凭借其在分布式搜索型数据库领域的技术突破与卓越的国产化实践,成功入选《2025 中国大数据产业「年度国产化优秀代表厂商」》榜单,并获颁这一行业重磅奖项。
本届论坛由金猿组委会、数据猿、上海市数商协会及上海大数据联盟联合主办,以“数据有猿·智见十年”为主题,吸引了近千家企业参与申报。经过严格的初审、公审与终审交叉验证机制,极限科技最终从众多竞争者中脱颖而出,荣登榜单。
深耕核心搜索技术,填补国产化空白
极限科技成立于 2021 年 12 月,是一家专注于大数据搜索与分析的基础软件公司。公司总部位于北京,在长沙设立研发中心,并在上海、广州设立办事处或服务中心。其核心团队均来自 Elasticsearch 原厂及中文社区,拥有多年 ES 源码开发经验,致力于“让搜索更简单”,打造极致易用的数据探索与分析体验。
公司自主研发的核心产品 Easysearch 搜索型数据库,是我国在分布式搜索型数据库领域实现关键国产化替代的代表性成果。该产品精准填补了国内在轻量化、高性能、自主可控搜索引擎方面的市场空白。
产品性能卓越,实现无缝迁移与超越
Easysearch 支持结构化与非结构化数据检索、全文检索、向量检索、空间地理位置信息检索、多模态混合检索、组合查询、多语种支持、语义分析、聚合分析等多种核心功能。测试表明,其性能已达到甚至优于国外领先产品。
在产品能力上,Easysearch 不仅完全兼容 Elasticsearch 的生态接口,保障了用户业务的无缝平滑迁移,更在性能优化、存储效率、企业级安全及原生中文处理等方面实现了显著超越。其内置的 Web 管理控制台、全面的数据加密与权限管控功能,提供了开箱即用的企业级体验。
构建完整信创生态
尤为关键的是,Easysearch 率先完成了与国产主流 CPU(如鲲鹏、飞腾、海光、龙芯、申威、兆芯等)和操作系统(如统信 UOS、银河麒麟、开源欧拉等)的深度适配与互认证,构建了完整的信创技术栈支持能力,彻底解决了国外产品在国产化环境下兼容性差、维护困难、更新受限等长期存在的痛点。
在核心技术国产化意义上,Easysearch 通过完全自主可控的分布式搜索技术体系,突破了关键基础软件依赖国外企业的局面,满足了政府、金融、能源、运营商等行业对“可控、安全、可替代”的战略需求。同时,其向量搜索和 AI 检索能力填补了国内在智能搜索与大模型结合领域的技术缺口。
获权威资质认可,落地众多头部客户
极限科技及 Easysearch 已获得多项权威资质认证,包括国家高新技术企业、ISO 三大管理体系认证,并荣获 2023 年星河案例数据库标杆案例。产品亦通过了信通院基础能力专项测评及中国泰尔实验室检验测试。
目前,Easysearch 已在金融、运营商、制造、政企等多领域实现规模化落地,服务客户包括移动云、中国一汽、中国人保、东莞证券、航天信息等头部企业,累计下载部署量已超过 500 万次。其中,公司开发的中文分词器(IK、Pinyin)、压测工具(Loadgen)、数据迁移工具(ESM)已被 85% 的中国 Elasticsearch 用户部署在生产环境中。
荣获行业大奖,彰显标杆价值
此次荣获 “年度国产化优秀代表厂商” 奖项,不仅是行业对极限科技技术实力与国产化贡献的高度认可,更彰显了公司在推动大数据产业自主创新进程中的标杆作用。
极限科技创始人表示:
“我们坚信‘追求极致,无限可能’。获得这份荣誉,是对我们团队多年来坚持自主创新、深耕搜索技术的最好鼓励。未来,极限科技将持续加大研发投入,以技术创新驱动产业升级,为各行业客户提供更高效、更安全、更智能的数据探索与分析能力,助力中国大数据产业在智能时代实现高质量、自主可控的发展。”
相关链接:
Easy-Es 2.1.0-easysearch 版本发布
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 9670 次浏览 • 2025-12-15 17:42
01 | 版本更新概述
经过极限科技与 Dromara 开源社区下 Easy-Es 项目的紧密合作与共同努力,我们很荣幸地联合推出 Easy-Es 2.1.0-easysearch 版本!
作为双方携手打造的第一个合作成果,本版本已正式发布:
- 源码仓库:https://gitee.com/dromara/easy-es/tree/easy-es4easySearch/
- Maven 依赖:https://mvnrepository.com/artifact/org.dromara.easy-es/easy-es-boot-starter/2.1.0-easysearch
本次更新的核心内容是将 Easy-Es 框架底层增加兼容极限科技自主研发的 Easysearch 搜索引擎,这标志着国产搜索引擎与国内优秀开源项目深度融合的重要里程碑,是极限科技与 Dromara 社区携手共建国产技术生态的创新实践。
02 | 迁移至 Easysearch 的背景与优势
随着国内对自主可控技术需求的日益增长,特别是在基础设施软件领域,企业对于信创合规的要求不断提升。极限科技自主研发的 Easysearch 搜索引擎具备以下显著优势:
- 国产化自主可控:完全自主研发,符合信创要求,无许可证风险,为企业提供安全可靠的技术保障
- 轻量级架构:相比传统搜索引擎,资源占用更少,启动更快速,显著降低企业运维成本
- 卓越性能表现:查询性能优异,能够满足大部分业务场景需求,用户体验流畅
- 良好兼容性:与 Elasticsearch 的 API 接口基本兼容,迁移成本较低,保护用户现有投资
基于以上优势,双方决定共同将 Easy-Es 框架底层迁移至 Easysearch,这不仅为用户提供更多选择,更是双方携手推动国产搜索引擎生态建设的重要举措。
03 | Easy-Es 框架优势
Easy-Es 框架在搜索开发领域具备以下核心优势:
- 极简代码开发:相比原生 API 可减少 50%-80% 的代码量,大幅提升开发效率。
// 使用 Easy-Es 仅需一行代码完成查询
List<Document> documents = documentMapper.selectList(
EsWrappers.lambdaQuery(Document.class).eq(Document::getTitle, "测试")
);-
自动索引管理: 框架提供全自动智能索引托管功能,开发者无需关心索引的创建、更新及数据迁移等复杂操作,索引全生命周期由框架自动管理,过程零停机。
-
SQL 语法兼容: 支持使用 MySQL 语法完成搜索查询操作,无需学习复杂的 DSL 语句。支持 and、or、like、in 等常用 SQL 语法。
-
Lambda 表达式支持: 采用 Lambda 风格编程,提供类型安全的字段访问,避免手动输入字段名可能产生的错误,提升代码可读性和开发效率。
-
无缝 Spring Boot 集成: 与 Spring Boot 生态深度集成,提供开箱即用的自动配置,无需复杂的手动配置,支持 Spring Boot Actuator 监控,完美融入企业级应用架构。
-
丰富的查询功能: 支持复杂的嵌套查询、聚合查询、范围查询、高亮显示等高级搜索功能,同时保持 API 的简洁易用,满足各种业务场景需求。
-
分布式架构支持: 完美适配 Easysearch 的分布式特性,支持集群模式部署,具备高可用性和横向扩展能力,满足企业级大规模数据处理需求。
- 成熟稳定的国产 ORM 框架: 作为 Dromara 开源社区下的顶级开源项目,Easy-Es 已在国内众多企业和项目中得到广泛应用和验证,拥有活跃的中文社区和完善的文档支持,为企业级应用提供了可靠的技术保障。
04 | 快速上手示例
1. 添加依赖
根据您使用的构建工具,选择对应的配置方式:
Maven 项目
pom.xml 配置:
<properties>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<spring-boot.version>2.7.0</spring-boot.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.dromara.easy-es</groupId>
<artifactId>easy-es-boot-starter</artifactId>
<version>2.1.0-easysearch</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>${spring-boot.version}</version>
<executions>
<execution>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>Maven 启动命令:
# 运行应用
mvn spring-boot:run
# 编译打包
mvn clean packageGradle 项目
build.gradle 配置:
plugins {
id 'java'
id 'org.springframework.boot' version '2.7.0'
id 'io.spring.dependency-management' version '1.0.11.RELEASE'
}
group = 'org.easysearch'
version = '1.0-SNAPSHOT'
sourceCompatibility = '11'
repositories {
mavenLocal()
mavenCentral()
}
dependencies {
implementation 'org.dromara.easy-es:easy-es-boot-starter:2.1.0-easysearch'
implementation 'org.springframework.boot:spring-boot-starter-web'
}Gradle 启动命令:
# 运行应用
./gradlew bootRun
# 编译打包
./gradlew clean build2. 配置文件设置
application.yml(根据实际 Easysearch 部署情况修改):
easy-es:
enable: true
# Easysearch 服务地址
address: localhost:9200
# 协议:http 或 https
schema: https
# Easysearch 用户名
username: admin
# Easysearch 密码
password: your_password_here
# 连接保持时间(毫秒)
keep-alive-millis: 18000
global-config:
# 开启彩蛋模式(启动时显示 ASCII 艺术图案)
i-kun-mode: true
# 索引处理模式:smoothly 表示平滑模式(零停机更新索引)
process-index-mode: smoothly
# 异步处理索引时是否阻塞
async-process-index-blocking: true
# 是否打印 DSL 语句(开发调试时可设为 true)
print-dsl: false
db-config:
# 下划线转驼峰
map-underscore-to-camel-case: true
# 索引前缀
index-prefix: dev_
# 主键类型:customize 表示自定义
id-type: customize
# 字段更新策略:not_empty 表示非空时才更新
field-strategy: not_empty
# 刷新策略:immediate 表示立即刷新
refresh-policy: immediate
# 开启追踪总命中数
enable-track-total-hits: true3. 实体类定义
package org.dromara.easyes.sample.entity;
import lombok.Data;
import lombok.experimental.Accessors;
import org.dromara.easyes.annotation.HighLight;
import org.dromara.easyes.annotation.IndexField;
import org.dromara.easyes.annotation.IndexId;
import org.dromara.easyes.annotation.IndexName;
import org.dromara.easyes.annotation.Settings;
import org.dromara.easyes.annotation.rely.Analyzer;
import org.dromara.easyes.annotation.rely.FieldStrategy;
import org.dromara.easyes.annotation.rely.FieldType;
import org.dromara.easyes.annotation.rely.IdType;
import java.time.LocalDateTime;
/**
* es 数据模型
*/
@Data
@Accessors(chain = true)
@Settings(shardsNum = 3, replicasNum = 2)
@IndexName(value = "easyes_document", keepGlobalPrefix = true)
public class Document {
/**
* es 中的唯一 id
*/
@IndexId(type = IdType.CUSTOMIZE)
private String id;
/**
* 文档标题,默认为 keyword 类型,可进行精确查询
*/
private String title;
/**
* 文档内容,指定为 TEXT 类型,使用 IK 分词器
* 支持高亮显示,高亮结果映射到 highlightContent 字段
*/
@HighLight(mappingField = "highlightContent")
@IndexField(fieldType = FieldType.TEXT, analyzer = Analyzer.IK_SMART)
private String content;
/**
* 创建者,字段策略为非空时才更新
*/
@IndexField(strategy = FieldStrategy.NOT_EMPTY)
private String creator;
/**
* 创建时间
*/
@IndexField(fieldType = FieldType.DATE, dateFormat = "yyyy-MM-dd HH:mm:ss")
private LocalDateTime gmtCreate;
/**
* 高亮返回值被映射的字段
*/
private String highlightContent;
/**
* 文档点赞数
*/
private Integer starNum;
/**
* 地理位置经纬度坐标,例如: "40.13933715136454,116.63441990026217"
*/
@IndexField(fieldType = FieldType.GEO_POINT)
private String location;
}4. Mapper 接口
package org.dromara.easyes.sample.mapper;
import org.dromara.easyes.core.kernel.BaseEsMapper;
import org.dromara.easyes.sample.entity.Document;
/**
* Mapper 接口,继承 BaseEsMapper 即可获得所有 CRUD 方法
*/
public interface DocumentMapper extends BaseEsMapper<Document> {
}5. 启动类配置
package org.dromara.easyes.sample;
import org.dromara.easyes.spring.annotation.EsMapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* 启动类
*/
@SpringBootApplication
@EsMapperScan("org.dromara.easyes.sample.mapper")
public class EasyEsApplication {
public static void main(String[] args) {
SpringApplication.run(EasyEsApplication.class, args);
}
}6. 业务使用示例
package org.dromara.easyes.sample.controller;
import org.dromara.easyes.core.conditions.select.LambdaEsQueryWrapper;
import org.dromara.easyes.sample.entity.Document;
import org.dromara.easyes.sample.mapper.DocumentMapper;
import org.easysearch.action.search.SearchResponse;
import org.easysearch.search.aggregations.Aggregations;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
import java.time.LocalDateTime;
import java.util.List;
@RestController
public class SampleController {
@Resource
private DocumentMapper documentMapper;
/**
* 初始化插入数据
*/
@GetMapping("/insert")
public Integer insert() {
int count = 0;
// 插入 5 条测试数据
for (int i = 1; i <= 5; i++) {
Document document = new Document();
document.setId(String.valueOf(i));
document.setTitle("测试" + i);
document.setContent("测试内容" + i);
document.setCreator("创建者" + i);
document.setGmtCreate(LocalDateTime.now());
document.setStarNum(i * 10);
count += documentMapper.insert(document);
}
return count;
}
/**
* 根据标题精确查询
*/
@GetMapping("/listDocumentByTitle")
public List<Document> listDocumentByTitle(@RequestParam String title) {
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
wrapper.eq(Document::getTitle, title);
return documentMapper.selectList(wrapper);
}
/**
* 高亮搜索
*/
@GetMapping("/highlightSearch")
public List<Document> highlightSearch(@RequestParam String content) {
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
wrapper.match(Document::getContent, content);
return documentMapper.selectList(wrapper);
}
/**
* 查询所有数据
*/
@GetMapping("/selectAll")
public List<Document> selectAll() {
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
return documentMapper.selectList(wrapper);
}
/**
* 聚合查询 - 按创建时间和点赞数分组统计
*/
@GetMapping("/aggByDateAndStar")
public Aggregations aggByDateAndStar() {
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
wrapper.groupBy(Document::getGmtCreate)
.max(Document::getStarNum)
.min(Document::getStarNum);
SearchResponse response = documentMapper.search(wrapper);
return response.getAggregations();
}
/**
* 使用 SQL 语句查询文档
*/
@GetMapping("/queryBySQL")
public String queryBySQL(@RequestParam(required = false) String title) {
String sql;
if (title != null && !title.isEmpty()) {
sql = String.format("SELECT * FROM dev_easyes_document WHERE title = '%s'", title);
} else {
sql = "SELECT * FROM dev_easyes_document LIMIT 10";
}
return documentMapper.executeSQL(sql);
}
}7. 快速测试
启动应用后,可以通过以下接口测试:
# 1. 插入测试数据
curl http://localhost:8080/insert
# 2. 查询所有数据
curl http://localhost:8080/selectAll
# 3. 根据标题精确查询
curl "http://localhost:8080/listDocumentByTitle?title=测试1"
# 4. 高亮搜索
curl "http://localhost:8080/highlightSearch?content=测试"
# 5. SQL 查询
curl "http://localhost:8080/queryBySQL?title=测试1"
# 6. 聚合查询
curl http://localhost:8080/aggByDateAndStar05 | 相关链接
- Easy-Es 官方网站:https://easy-es.cn
- Gitee 仓库:https://gitee.com/dromara/easy-es
- GitHub 仓库:https://github.com/dromara/easy-es
- Easysearch 官方网站:https://infinilabs.cn/products/easysearch
06 | 特别致谢
在此,极限科技要特别感谢 Easy-Es 项目的核心开发者“老汉”和各位贡献者和维护者们。正是因为有了你们的辛勤付出、专业精神以及对开源事业的热忱奉献,Easy-Es 项目才能在国内外获得如此广泛的认可和应用。
也感谢你们对国产技术生态建设的信任与支持。此次 Easy-Es 与 Easysearch 的深度整合,正是双方通力合作、互利共赢的最佳体现。
我们相信,在 Easy-Es 项目团队的持续推动下,国产开源软件必将迎来更加辉煌的明天。极限科技将继续致力于提供优质的国产技术解决方案,与 Easy-Es 项目团队携手共进,为中国开源生态的发展贡献更多力量!
关于 Easy-Es
Easy-Es(简称 EE)是一款基于 Elasticsearch(简称 ES)官方提供的 ElasticsearchClient 打造的 ORM 开发框架,在 ElasticsearchClient 的基础上,只做增强不做改变,为简化开发、提高效率而生,您如果有用过 Mybatis-Plus(简称 MP),那么您基本可以零学习成本直接上手 EE,EE 是 MP 的 ES 平替版,在有些方面甚至比 MP 更简单,同时也融入了更多 ES 独有的功能,助力您快速实现各种场景的开发。
Easy-Es for Easysearch 是一款简化 Easysearch 国产化搜索引擎操作的开源框架,全自动智能索引托管。同时也是国内首家专门针对 Easysearch 客户端简化的工具。它简化 CRUD 及其它高阶操作,可以更好的帮助开发者减轻开发负担。底层采用 Easysearch Java Client,保证其原生性能及拓展性。
项目地址:https://gitee.com/dromara/easy-es/tree/easy-es4easySearch
关于极限科技
极限科技(全称:极限数据(北京)科技有限公司)是一家专注于实时搜索与数据分析的软件公司。
旗下品牌:极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验,为用户提供安全、稳定、高性能的国产搜索解决方案。
作者:张磊,极限科技(INFINI Labs)搜索引擎研发负责人,对 Elasticsearch 和 Lucene 源码比较熟悉,目前主要负责公司的 Easysearch 产品的研发以及客户服务工作。
使用 Docker Compose 轻松实现 INFINI Console 离线部署与持久化管理
开源项目 • INFINI Labs 小助手 发表了文章 • 0 个评论 • 11226 次浏览 • 2025-10-31 18:04
系列回顾与引言
在我们的 INFINI 本地环境搭建系列博客中:
- 第一篇《搭建持久化的 INFINI Console 与 Easysearch 容器环境》,我们深入探讨了如何使用基础的
docker run命令,一步步构建起 Console 和 Easysearch 服务,并重点解决了数据持久化的问题。 - 第二篇《使用 Docker Compose 简化 INFINI Console 与 Easysearch 环境搭建》,我们学习了如何利用 Docker Compose 的声明式配置,将多容器应用的定义和管理变得更加简洁高效。
- 第三篇《一键启动:使用 start-local 脚本轻松管理 INFINI Console 与 Easysearch 本地环境》,我们介绍了如何在联网环境下,一键安装 INFINI Console。
接下来,我们将聚焦于离线环境,详细讲解如何使用 Docker Compose 部署 INFINI Console 和 Easysearch。
简介
INFINI Console 是一款强大的集群管理与可观测性平台,而 INFINI Easysearch 则是一个轻量级、高性能的搜索与分析引擎。官方提供的离线部署包将两者整合,非常适合在无外网或需要快速搭建演示环境的场景下使用。
本文将详细介绍如何下载资源、正确加载镜像、以及最关键的——如何根据您的需求修改 docker-compose.yml 中的各项配置。
1. 准备工作
请确保您的环境中已安装以下软件:
- Docker
- Docker Compose
2. 下载离线资源
从官方地址下载两个核心文件:
infini-console.tar.gz: 包含docker-compose.yml和相关脚本。infini-console-easysearch-1.14.2.tar: 包含infinilabs/console和infinilabs/easysearch的 Docker 镜像。
wget https://release.infinilabs.com/easysearch/archive/offline/amd64/infini-console.tar.gz
wget https://release.infinilabs.com/easysearch/archive/offline/amd64/infini-console-easysearch-1.14.2.tar3. 正确加载 Docker 镜像
注意:infini-console-easysearch-1.14.2.tar 是一个包含多个镜像的归档包,不能直接使用 docker load 加载。
正确的加载步骤如下:
-
创建目录并解压镜像归档包:
mkdir -p images tar -xvf infini-console-easysearch-1.14.2.tar -C images这会将
console.tar和easysearch.tar等文件解压到images/目录中。 -
批量加载所有镜像:
cd images ls *.tar | xargs -I {} docker load -i {}该命令会自动为目录下的每个
.tar文件执行docker load操作。 - 验证镜像加载结果:
docker images您应该能看到
infinilabs/console:1.29.8和infinilabs/easysearch:1.14.2等镜像。
4. 修改配置文件
解压 infini-console.tar.gz 后,找到 .env 文件。所有自定义配置都应在此文件中修改。
以下是各项配置的详细说明和修改建议:
核心路径配置
WORK_DIR_ABS=/data/infini-console- 作用: 定义所有持久化数据(日志、配置、索引)的根目录。
- 修改建议: (必改) 强烈建议修改为您服务器上一个有足够空间的路径,例如
/opt/infini-console。确保该目录存在且 Docker 拥有写入权限。
网络配置
APP_NETWORK_NAME=infini-local-net- 作用: 定义 Docker 内部网络的名称。
- 修改建议: 通常无需修改。
Console 配置
CONSOLE_IMAGE=infinilabs/console
CONSOLE_VERSION_TAG=1.29.8
CONSOLE_CONTAINER_NAME=infini-console
CONSOLE_PORT_HOST=9000
CONSOLE_PORT_CONTAINER=9000- 作用: 定义 Console 的镜像、版本、容器名及端口映射。
- 修改建议:
CONSOLE_PORT_HOST: 如果宿主机的9000端口已被占用,请修改为其他可用端口(如8080)。
Easysearch 配置
EASYSEARCH_IMAGE=infinilabs/easysearch
EASYSEARCH_VERSION_TAG=1.14.2
EASYSEARCH_NODES=1
EASYSEARCH_CLUSTER_NAME=infini-console- 作用: 定义 Easysearch 的镜像、版本、节点数和集群名。
- 修改建议:
EASYSEARCH_NODES: 单机部署保持1即可。
访问与安全配置
EASYSEARCH_INITIAL_ADMIN_PASSWORD=ShouldChangeme123.- 作用: 设置 Easysearch
admin用户的初始密码。 - 修改建议: (必改) 请务必将其替换为一个强密码。登录 Console 时需要使用此密码。
EASYSEARCH_HTTP_PORT_HOST=9200
EASYSEARCH_TRANSPORT_PORT_HOST=9300- 作用: 定义 Easysearch HTTP 和 Transport 接口在宿主机上的映射端口。
- 修改建议: 如果
9200或9300端口冲突,请修改。
JVM 参数配置
ES_JAVA_OPTS_DEFAULT="-Xms8g -Xmx8g"- 作用: 设置 Easysearch 的 JVM 堆内存大小。
- 修改建议: (必改) 请根据服务器物理内存进行调整,避免超过物理内存的 50%。
- 8GB 内存服务器: 建议设为
-Xms2g -Xmx2g。 - 16GB 内存服务器: 建议设为
-Xms4g -Xmx4g。
- 8GB 内存服务器: 建议设为
数据持久化路径
CONSOLE_HOST_DATA_SUBPATH_REL=console/data
CONSOLE_HOST_LOGS_SUBPATH_REL=console/logs
EASYSEARCH_HOST_NODES_BASE_SUBPATH_REL=easysearch- 作用: 定义数据和日志在
WORK_DIR_ABS下的相对子路径。 - 修改建议: 通常无需修改。
5. 启动服务
完成配置修改后,在 docker-compose.yml 所在目录下执行:
docker-compose up -d等待服务完全启动。
6. 访问控制台
打开浏览器,访问 http://<你的服务器IP>:9000。
使用默认用户名 admin 和您在 EASYSEARCH_INITIAL_ADMIN_PASSWORD 中设置的密码进行初始化。
总结
通过以上步骤,您可以灵活地部署一套功能完整的 INFINI Console + Easysearch 环境。关键在于理解并根据实际情况修改 .env 文件中的参数,特别是 WORK_DIR_ABS、EASYSEARCH_INITIAL_ADMIN_PASSWORD 和 ES_JAVA_OPTS_DEFAULT,这能确保部署的稳定性和安全性。
希望这篇详细的指南能帮助您顺利完成部署!
作者:罗厚付,极限科技(INFINI Labs)云上产品设计与研发负责人,拥有多年安全风控及大数据系统架构经验,主导过多个核心产品的设计与落地,日常负责运维超大规模 ES 集群(800+节点/1PB+数据)。
原文:https://infinilabs.cn/blog/2025/console-easysearch-with-docker-compose-offline/
搜索百科(6):Meilisearch — Rust 打造的轻量级搜索新锐
开源项目 • liaosy 发表了文章 • 0 个评论 • 10340 次浏览 • 2025-10-31 18:00
大家好,我是 INFINI Labs 的石阳。
欢迎关注 《搜索百科》 专栏!每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
在之前的几期中,我们认识了搜索技术的基石 Lucene、企业级搜索先锋 Solr、搜索界的“流量明星” Elasticsearch 以及它的分叉兄弟 OpenSearch 和 ES 国产替代方案 Easysearch。它们大多基于 Lucene 构建,形成了庞大且功能丰富的生态。
今天,我们将介绍一位“非主流”选手:一款基于 Rust 编写、主打“快”和“简单”的现代搜索引擎——Meilisearch。它以全新的姿态,为开发者带来了不同的搜索体验。
Meilisearch 概述
Meilisearch 是一款开源的、用 Rust 编写的即时搜索引擎。它提供了一个快速、轻量且可定制的搜索 API,旨在为用户提供毫秒级的搜索体验。
它的核心优势在于为应用内搜索和电商搜索等对延迟敏感的场景提供了出色的用户体验。
- 首次发布:2020 年
- 最新版本:1.24.0(截止 2025 年 10 月)
- 核心语言:Rust
- 开源协议:MIT License
- 官方网址:https://www.meilisearch.com/
- GitHub 仓库:https://github.com/meilisearch/meilisearch
诞生故事
Meilisearch 的故事始于 2018 年,当时法国工程师 Quentin de Quelen 在开发一个电商项目时,发现现有的搜索引擎要么太重量级,要么配置太复杂。他想要一个"开箱即用"的搜索解决方案,能够快速集成到应用中,并提供优秀的搜索体验。
于是,他决定用 Rust 语言从头编写一个搜索引擎。选择 Rust 是因为其出色的性能、内存安全性和并发能力,非常适合构建高性能的搜索核心。
项目最初只是一个内部工具,但随着功能的完善和社区的反馈,Meilisearch 在 2019 年正式开源,并迅速获得了开发者的青睐。2020 年,团队获得了 150 万美元的种子轮融资,正式成立了 Meilisearch 公司。
核心特性
Meilisearch 在设计上做了大量的取舍,专注于核心的搜索功能,但做到了极致。
- 极速响应:核心目标是实现 50 毫秒以下的响应时间,即使在大型数据集中也能提供“所见即所得”的搜索体验。
- 零配置:开箱即用,部署和索引数据都非常简单,不需要预定义 Schema 或复杂的配置文件。
- 相关的默认值:内置一个强大的 相关性排名(Relevance Ranking) 算法,结合 Typos(拼写错误)、Word Proximity(词语距离)和 Attributes(字段权重)等因素,无需额外调优即可获得高质量的搜索结果。
- 语言无关性:支持多种语言的分词与搜索,能很好地处理中文、日文等非拉丁语系文本。
- 无分布式架构:为了追求极致的速度和简单性,Meilisearch 被设计为单机搜索引擎,不支持开箱即用的分布式集群,这简化了运维,但也限制了其 PB 级数据的处理能力。
对比优势:Meilisearch vs Lucene/ES 体系
Meilisearch 与基于 Lucene 的 Elasticsearch 体系,在设计哲学上有着本质区别:
| 特性 | Meilisearch | Elasticsearch |
|---|---|---|
| 核心目标 | 极速的应用内搜索体验 | 分布式搜索、日志分析、可观测性 |
| 基础架构 | 单机、轻量级 | 分布式集群(主从节点、分片) |
| 核心语言 | Rust | Java(基于 Lucene) |
| 性能瓶颈 | 单机 CPU / 内存限制 | 分布式协调开销 |
| 上手难度 | 简单,开箱即用,REST API | 相对复杂,需要了解集群、分片等概念 |
| 数据规模 | 适合中小型数据集(GB 级别) | 适合大型和超大型数据集(TB/PB 级别) |
| 全文检索 | 依赖内置的强相关性算法 | 依赖 Lucene 强大的分词、查询解析器 |
总结:
- 如果你的应用需要超低延迟、简单部署、数据量在 GB 级别,并且搜索是应用的核心功能,Meilisearch 是一个极佳的选择。
- 如果你的需求涉及日志分析、大规模数据存储、集群高可用和复杂的聚合分析,那么 Elasticsearch 仍然是更成熟和全面的解决方案。
快速上手:5 分钟体验 Meilisearch
部署 Meilisearch 非常简单,你甚至不需要 Docker,只需一个命令即可运行。
1. 运行 Meilisearch
# 安装 Meilisearch
curl -L https://install.meilisearch.com | sh
# 启动 Meilisearch
meilisearch --master-key 'aStrongMasterKey'
# 或使用 Docker
docker run -it --rm -p 7700:7700 getmeili/meilisearch:latest --master-key 'aStrongMasterKey'2. 添加索引(创建 Index)
Meilisearch 不需要预先定义索引结构(Schema-less)。
curl -X POST 'http://localhost:7700/indexes' \
-H 'Authorization: Bearer aStrongMasterKey' \
-H 'Content-Type: application/json' \
--data-binary '{
"uid": "movies",
"primaryKey": "id"
}'3. 索引文档(添加 Documents)
curl -X POST 'http://localhost:7700/indexes/movies/documents' \
-H 'Authorization: Bearer aStrongMasterKey' \
-H 'Content-Type: application/json' \
--data-binary '[
{"id": 1, "title": "泰坦尼克号", "genres": ["剧情", "爱情"]},
{"id": 2, "title": "黑客帝国", "genres": ["科幻", "动作"]}
]'4. 执行搜索
# 搜索关键词 "泰坦"
curl -X GET 'http://localhost:7700/indexes/movies/search?q=泰坦'返回结果:
{
"hits": [
{
"id": 1,
"title": "泰坦尼克号",
"genres": ["剧情", "爱情"]
}
],
"offset": 0,
"limit": 20,
"estimatedTotalHits": 1,
"processingTimeMs": 1,
"query": "泰坦"
}注意 processingTimeMs: 1,这是 Meilisearch 速度的最好证明!
5. 场景演示
结语
Meilisearch 的出现,代表了新一代搜索引擎对于开发者体验和即时性的追求。它在应用内搜索领域展现了强大的竞争力,证明了不必依赖 Lucene 的庞大体系,也能打造出极致性能的搜索产品。
虽然它还无法完全取代 Elasticsearch 在日志分析、可观测性等大型分布式场景的地位,但在许多新兴应用和对搜索速度有极高要求的场景中,它无疑是一个值得尝试的开源新星。
🚀 下期预告
下一篇我们将把目光转向搜索领域的云端先锋 —— Algolia。作为搜索即服务(Search-as-a-Service)的开创者,Algolia 如何以其卓越的 API 设计、惊人的搜索速度和精准的相关性排序,重新定义云端搜索体验?
💬 三连互动
- 你会把 ES/Solr 换成 Meilisearch 吗?
- 在你的应用中,搜索延迟达到多少毫秒你会觉得无法接受?
- 在什么场景下你会考虑使用 Meilisearch 而不是 Elasticsearch?
对搜索技术感兴趣的朋友,也欢迎加我微信(ID:lsy965145175)备注“搜索百科”,拉你进 搜索技术交流群,一起探讨与学习!
✨ 推荐阅读
- 搜索百科(5):Easysearch — 自主可控的国产分布式搜索引擎
- 搜索百科(4):OpenSearch — 开源搜索的新选择
- 搜索百科(3):Elasticsearch — 搜索界的"流量明星"
- 搜索百科(2):Apache Solr — 企业级搜索的开源先锋
- 搜索百科(1):Lucene — 打开现代搜索世界的第一扇门
🔗 参考资源
搜索百科(5):Easysearch — 自主可控的国产分布式搜索引擎
Easysearch • liaosy 发表了文章 • 0 个评论 • 8437 次浏览 • 2025-10-20 15:54
大家好,我是 INFINI Labs 的石阳。
欢迎关注 《搜索百科》 专栏!每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
在上一篇我们介绍了 OpenSearch —— 那个因协议争议而诞生的开源搜索分支。今天,我们把目光转向国内,聊聊极限科技研发的一款轻量级搜索引擎:Easysearch。
引言
在搜索技术的世界里,从 Lucene 的出现到 Solr、Elasticsearch 的崛起,搜索引擎技术已经发展了二十余年。然而,随着开源协议的变更与国际形势的变化,国产自主搜索引擎的需求愈发迫切。在这样的背景下,Easysearch 作为一款自主可控、轻量高效、兼容 Elasticsearch 的分布式搜索引擎应运而生,为国内企业带来了全新的选择。
Easysearch 概述
Easysearch 是一款分布式搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析、AI 集成等。Easysearch 衍生自开源协议 Apache 2.0 的 Elasticsearch 7.10 版本,并不断往前迭代更新,紧跟 Lucene 最新版本的更新。Easysearch 可以替代 Elasticsearch,同时添加和完善多项企业级功能。
- 首次发布:2023 年 4 月
- 最新版本:1.15.4(截止 2025 年 10 月)
- 主导企业:极限科技 (INFINI Labs)
- 官方网址:https://easysearch.cn
诞生背景:为什么要有 Easysearch?
Easysearch 由极限科技(INFINI Labs)团队推出。项目的起点源于团队长期在搜索引擎和大数据领域的深厚实践积累,团队深刻认识到国内企业在使用 Elasticsearch 时普遍面临以下痛点:
- 开源协议变化带来的商业风险 —— Elastic 于 2021 年将许可更改为 SSPL,导致社区分裂,增加了企业在合规和商用上的不确定性;
- 高并发与高可靠性场景下对稳定可控方案的需求 —— 企业级应用亟需一个性能可靠、可深度优化的搜索基础设施;
- 技术栈自主可控的迫切需求 —— 随着国产化进程加快,国内生态中缺乏轻量化、易部署、且完全可控的搜索引擎产品;
- 本地化服务与快速响应能力的缺口 —— 国内企业更需要本地团队提供高效的技术支持与服务,对本土化、个性化功能需求能得到及时响应与反馈。
基于这些考虑,Easysearch 在设计之初就明确了目标:构建一款兼容 Elasticsearch API、简洁易用、性能出众且完全自主可控的国产搜索引擎。
核心特性
- 轻量级:安装包大小不到 60 MB,安装部署简洁,资源占用低,开箱即用;
- 跨平台:支持主流操作系统和 CPU 架构,支持国产信创运行环境;
- 高性能:针对不同场景进行的极致优化,可用更少硬件成本获得更高服务性能,降本增效。
- 稳定可靠:修复大量内核问题,解决内存泄露,集群卡顿、查询缓慢等问题,久经严苛业务环境考验。
- 安全增强:默认就提供完整的企业级安全功能,支持 LDAP/AD 集成,支持索引、文档、字段粒度细权管控。
- 兼容性强:兼容 Elasticsearch 7.x 的 REST API 和数据格式,迁移成本低;
- 可视化运维:无需 Kibana 即可通过内置 Web UI 插件界面管理索引、节点与监控指标等。
对比优势
| 对比维度 | Easysearch | Elasticsearch | OpenSearch |
|---|---|---|---|
| 用户协议 | 社区免费+商业授权 | SSPL/AGPL v3 | Apache 2.0 |
| API 兼容性 | 高度兼容 ES | 原生 | 高度兼容 ES |
| 最小安装体积 | 57MB | 482MB | 682MB |
| 部署复杂度 | 简单 | 中等 | 相对复杂 |
| 信创环境支持 | 全面兼容 | 无 | 无 |
| 可视化管理 | 开箱即用管理后台 | 需独立部署 Kibana | 需独立部署 OpenSearch Dashboards |
| 本地化与中文支持 | 强 | 弱 | 弱 |
| AI 插件支持 | 较弱 | 强 | 较强 |
| 社区与生态 | 快速成长中 | 成熟广泛 | 活跃增长 |
快速开始:5 分钟体验 Easysearch
1. 使用 Docker 启动
# 直接运行镜像使用随机密码(数据及配置未持久化)
docker run --name easysearch \
--ulimit memlock=-1:-1 \
-p 9200:9200 \
infinilabs/easysearch:1.15.42. 验证集群状态
curl -ku "username:password" -X GET "https://localhost:9200/"返回结果示例:
{
"name": "easysearch-node",
"cluster_name": "easysearch-6yhwn91v80gf",
"cluster_uuid": "Gfu_fuF1QViJfeUWVbiFCA",
"version": {
"distribution": "easysearch",
"number": "1.15.4",
"distributor": "INFINI Labs",
"build_hash": "9110128946b0af3de639966cfa74b5498346949d",
"build_date": "2025-10-14T03:30:41.948590Z",
"build_snapshot": false,
"lucene_version": "8.11.4",
"minimum_wire_lucene_version": "7.7.0",
"minimum_lucene_index_compatibility_version": "7.7.0"
},
"tagline": "You Know, For Easy Search!"
}3. 索引与搜索示例
# 写入文档
curl -ku "username:password" -X POST "https://localhost:9200/my_index/_doc" -H 'Content-Type: application/json' -d'
{
"title": "Easysearch 入门",
"content": "这是一个轻量级搜索引擎的示例文档。",
"tags": ["搜索", "国产", "轻量级"]
}'
# 搜索文档
curl -ku "username:password" -X GET "https://localhost:9200/my_index/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"content": "搜索引擎"
}
}
}'4. 使用 Easysearch UI
Easysearch 提供了轻量级界面化管理功能,不再依赖第三方组件即可对集群进行管理,真正做到开箱即用。如果你安装了 Easysearch UI 插件或者下载捆绑包,可通过 https://localhost:9200/\_ui/ 访问,进行节点、索引、分片、查询调试和监控查看等管理。
图 1:系统登录
图 2:集群概览
图 3:节点列表
图 4:节点概览
图 5:索引列表
图 6:索引概览
图 7:分片管理
图 8:开发工具
以上仅列出了一些基本功能,其他如安全管理、主从复制、备份管理、生命周期管理等更多高级功能由于篇幅限制不一一展示,有兴趣的朋友可自行部署探索。
结语
Easysearch 的诞生,不仅填补了国产搜索引擎在分布式与轻量化领域的空白,也让更多企业在面对开源协议变动与外部技术依赖时,拥有了更加安全、灵活、可控的选择。
它既是国产替代方案的有力代表,更是新一代搜索技术生态的积极探索者,为企业级实时搜索与分析带来新的可能。
🚀 下期预告
下一篇我们将介绍 一款 AI 驱动的现代搜索引擎 - Meilisearch,基于 Rust 构建的开源搜索引擎,性能高、部署简单。号称比 Elasticsearch 快 10 倍,真的这么牛吗?
💬 三连互动
- 你是否在使用或考虑国产搜索替代方案?
- 在实际项目中,你最看重搜索引擎的哪些特性?(性能、兼容性、运维、成本)
- 对 Easysearch 有什么功能上的期待?
对搜索技术感兴趣的朋友,也欢迎加我微信(ID:lsy965145175)备注“搜索百科”,拉你进 搜索技术交流群,一起探讨与学习!
✨ 推荐阅读
- 搜索百科(4):OpenSearch — 开源搜索的新选择
- 搜索百科(3):Elasticsearch — 搜索界的"流量明星"
- 搜索百科(2):Apache Solr — 企业级搜索的开源先锋
- 搜索百科(1):Lucene — 打开现代搜索世界的第一扇门
🔗 参考资源
原文:https://infinilabs.cn/blog/2025/search-wiki-5-easysearch/
搜索百科(4):OpenSearch — 开源搜索的新选择
OpenSearch • liaosy 发表了文章 • 0 个评论 • 9832 次浏览 • 2025-09-21 14:31
大家好,我是 INFINI Labs 的石阳。
欢迎关注 《搜索百科》 专栏!每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
上一篇我们围观了 “流量明星” Elasticsearch — 从食谱搜索到 PB 级明星产品,从 Apache 2.0 到 SSPL 协议风波;今天我们来聊聊它的“分叉兄弟” OpenSearch。
引言
2021 年,当 Elasticsearch 宣布将其许可证从 Apache 2.0 变更为 SSPL/Elastic License 时,整个搜索社区为之震动。这一变更直接催生了一个新的开源分支 — OpenSearch。这个由 AWS 主导的项目不仅在短短几年内迅速发展成熟,更成为了许多企业在云原生环境下搜索解决方案的新选择。
OpenSearch 概述
OpenSearch 是从 Elasticsearch 7.10.2 分支而来的开源搜索与分析套件,由 AWS 主导开发并贡献给开源社区。OpenSearch 包括 OpenSearch(搜索引擎)和 OpenSearch Dashboards(可视化界面),完全兼容 Apache 2.0 协议,旨在为用户提供一个真正开源、社区驱动的搜索与分析解决方案。
- 首次发布:2021 年 4 月
- 最新版本:3.2.0(截止 2025 年 9 月)
- 开源协议:Apache License 2.0
- 主导企业:Amazon Web Services (AWS)
- 官方网址:https://opensearch.org/
- GitHub 仓库:https://github.com/opensearch-project
诞生故事:开源协议争议的产物
时间回到 2021 年 1 月,Elastic 公司宣布 Elasticsearch 从 7.11 版本起不再使用 Apache 2.0 协议,而改为 Elastic License 与 SSPL。这一决定立刻在社区和产业界引发巨大争议。
AWS(亚马逊云)作为 Elasticsearch 的重要用户与云服务提供商,不愿意被 Elastic 的商业条款所限制,随即牵头将 Elasticsearch 7.10 版本 fork 出来,并与 Kibana 一起重命名为 OpenSearch 与 OpenSearch Dashboards。
从此,开源世界分裂成了两条路线:
- Elastic 官方的 Elasticsearch + Kibana(带有商业许可)。
- 社区驱动的 OpenSearch + OpenSearch Dashboards(继续遵循 Apache 2.0 协议)。
这个分叉,既是开源协议之争的产物,也是云厂商与开源公司之间博弈的缩影。虽然初期被质疑过“是否真开源”,但经过数年的迭代,OpenSearch 已形成了相对独立的开发节奏和用户群体,插件和生态也逐渐丰富。
技术架构与特性
OpenSearch 是一个基于 Apache Lucene 的分布式搜索与分析引擎。在将数据添加到 OpenSearch 后,可以对其执行各种功能完备的全文搜索操作:按字段搜索、跨多个索引搜索、提升字段权重、按得分排序结果、按字段排序结果以及对结果进行聚合。
OpenSearch 的核心架构由集群、节点、索引、分片和文档组成。最高层是 OpenSearch 集群,它是由多个节点组成的分布式网络,每个节点会根据其类型负责不同的集群操作。数据节点负责存储索引(即文档的逻辑分组),并处理数据写入、搜索和聚合等任务。
每个索引会被划分为多个分片,分片包含主数据和副本数据。分片会分布在多台机器上,从而实现水平扩展,提升性能并高效利用存储资源。
OpenSearch vs Elasticsearch:详细对比
| 特性 | OpenSearch | Elasticsearch |
|---|---|---|
| 许可证 | Apache 2.0(完全开源) | SSPL/Elastic License/AGPLv3 |
| 起始版本 | 基于 Elasticsearch 7.10.2 | 从 7.11 开始协议变更 |
| 社区治理 | 开放治理模式,由社区驱动 | 由 Elastic NV 公司主导 |
| 安全性 | 所有安全功能默认开源 | 部分高级安全功能需要付费 |
| AI/向量检索 | 近年快速跟进,兼容性较好 | 原生支持,功能逐步增强 |
| 部署选择 | AWS OpenSearch Service / 自建 | Elastic Cloud / 自建 |
| 升级路径 | 从 Elasticsearch 7.x 平滑迁移 | 原生升级路径 |
| 社区活跃度 | 社区逐渐壮大,受到纯开源拥护者欢迎 | 用户基础庞大,但分裂带来争议 |
快速开始:5 分钟部署 OpenSearch
1. 使用 Docker 部署
# 拉取 OpenSearch 镜像
docker pull opensearchproject/opensearch:3.2.0
# 启动 OpenSearch 节点
docker run -d --name opensearch-node \
-p 9200:9200 -p 9600:9600 \
-e "discovery.type=single-node" \
-e "plugins.security.disabled=true" \
opensearchproject/opensearch:3.2.0
# 拉取 OpenSearch Dashboards
docker pull opensearchproject/opensearch-dashboards:3.2.0
# 启动 Dashboards
docker run -d --name opensearch-dashboards \
-p 5601:5601 \
-e "OPENSEARCH_HOSTS=http://opensearch-node:9200" \
opensearchproject/opensearch-dashboards:3.2.02. 验证安装
# 检查集群状态
curl -X GET "http://localhost:9200/"出现如下结果说明安装成功。
3. 创建索引和搜索
# 索引文档
curl -X POST "http://localhost:9200/my-first-index/_doc" -H 'Content-Type: application/json' -d'
{
"title": "OpenSearch 入门指南",
"content": "这是我在 OpenSearch 中的第一个文档",
"timestamp": "2025-09-18T10:00:00"
}'
# 执行搜索
curl -X GET "http://localhost:9200/my-first-index/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"content": "第一个文档"
}
}
}'4. 访问控制台
打开浏览器访问 http://localhost:5601 即可使用 OpenSearch Dashboards 界面。
结语
OpenSearch 的出现,是开源社区的一次“自救”。它不仅延续了 Elasticsearch 的核心功能,还代表了另一种治理模式:由云厂商和社区共同维护,保证了开源协议的延续。
在搜索技术的版图里,Elasticsearch 与 OpenSearch 的分叉,注定会成为一个重要的历史节点。未来,两者可能会继续竞争,也可能各自发展出独特的生态。
🚀 下期预告
下一篇我们将介绍 OpenSearch 的另一个兄弟 Easysearch,一个衍生自开源协议 Apache 2.0 的 Elasticsearch 7.10.2 版本的轻量级搜索引擎,作为一个 ES 国产替代方案,看看它如何以其极致的速度和易用性在国内搜索领域占据一席之地。
💬 三连互动
- 您是否考虑过从 Elasticsearch 迁移到 OpenSearch?
- 在开源协议方面,您更倾向于哪种模式?Apache 2.0 还是 Elastic 的多重许可?
- 对于云厂商与开源项目之间的关系,您有什么看法?
对搜索技术感兴趣的朋友,也欢迎加我微信(ID:lsy965145175)备注“搜索百科”,拉你进 搜索技术交流群,一起探讨与学习!
✨ 推荐阅读
🔗 参考资源
原文:https://infinilabs.cn/blog/2025/search-wiki-4-opensearch/
Easysearch 国产替代 Elasticsearch:8 大核心问题解读
Easysearch • liaosy 发表了文章 • 0 个评论 • 14537 次浏览 • 2025-09-18 09:43
近年来,随着数据安全与自主可控需求的不断提升,越来越多的企业开始关注国产化的搜索与日志分析解决方案。作为极限科技推出的国产 Elasticsearch 替代产品,Easysearch 凭借其对搜索场景的深入优化、轻量级架构设计以及对 ES 生态的高度兼容,成为众多企业替代 Elasticsearch 的新选择。
我们在近期与用户的交流中,整理出了大家最关心的八大问题,并将它们浓缩为一篇技术解读,希望帮助你快速了解 Easysearch 的优势与定位。
用户最关心的八大问题
- Easysearch 对数据量的支撑能力如何,能应对 PB 级数据存储吗?
答:完全可以。Easysearch 支持水平扩展,通过增加节点即可线性提升存储与计算能力。在实际应用中,已成功支撑 PB 级日志与检索数据。同时,其存储压缩率相比 Elasticsearch 7.10.2 平均高出 2.5~3 倍,显著节省硬件成本。
- 在高并发写入场景下,Easysearch 和 ES 的性能差异有多大?
答:在相同硬件配置下,使用 Nginx 日志进行 bulk 写入压测,Easysearch 在多种分片配置下的写入性能相比 Elasticsearch 7.10.2 提升 40%-70%,更适合高并发写入场景。
- 是否支持中文分词?需要额外插件吗?
答:中文分词一直是 Elasticsearch 用户的「必装插件」。而在 Easysearch 中,中文分词是开箱即用的,同时支持 ik、pinyin 等主流分词器,还能自定义词典,方便电商、内容平台等场景。
- 从 ES 迁移到 Easysearch 是否复杂?会影响业务吗?
答:迁移往往是国产替代的最大顾虑。为此,Easysearch 提供了 极限网关 工具,支持全量同步和实时增量同步。迁移过程中业务可继续读写,只需短暂切换连接地址,几乎无感知。
- 监控与运维工具是否完善?是否支持 Kibana?
答:Easysearch 提供完整的监控与运维体系。从 Easysearch 1.15.x 版本起自带 Web UI 管理控制台(类似简化版 Kibana),支持索引管理、查询调试、权限控制等功能。同时还提供 INFINI Console 实现多集群管理与深度监控等。也可以通过配置让 Kibana 连接 Easysearch(部分高级功能可能受限)。
- 小型团队技术能力有限,用 Easysearch 运维难度高吗?
答:Easysearch 的一大设计理念就是降低运维门槛。Easysearch 提供一键部署脚本,减少手动配置参数,支持自动分片均衡与故障节点恢复,无需专职运维人员也能稳定运行,非常适合技术资源有限的团队。
- Easysearch 是否支持数据备份与恢复?操作复杂吗?
答:支持快照(Snapshot),可备份到本地磁盘或对象存储(S3、OSS 等)。恢复时仅需执行快照恢复命令,满足企业级数据安全需求。
- 对比 ES,Easysearch 在使用体验上最大的不同是什么?
答:Easysearch 保持与 Elasticsearch 类似的接口与查询 DSL,用户几乎无学习成本即可上手。同时,它针对国产化环境和搜索场景做了优化,运维更轻量,成本更可控。
结语:Easysearch,国产化搜索的新选择
作为一款国产自主可控的搜索与日志分析引擎,Easysearch 不仅继承了 Elasticsearch 的核心能力,更在性能、易用性、资源效率和中文支持等方面进行了深度优化。对于希望实现国产化替代、降低运维成本、提升系统性能的企业来说,Easysearch 是一个值得认真考虑的新选择。
如果你正在评估 Elasticsearch 的替代方案,不妨从 Easysearch 开始,体验更轻量、更高效的搜索新架构。
如需了解更多技术细节与使用案例,欢迎访问官方文档与社区资源:
- Easysearch 官网文档
- Elasticsearch VS Easysearch 性能测试
- 使用 Easysearch,日志存储少一半
- Kibana OSS 7.10.2 连接 Easysearch
- 自建 ES 集群通过极限网关无缝迁移到云上
- INFINI Console 一站式的数据搜索分析与管理平台
搜索百科(3):Elasticsearch — 搜索界的“流量明星”
Elasticsearch • liaosy 发表了文章 • 0 个评论 • 30446 次浏览 • 2025-09-16 11:20
大家好,我是 INFINI Labs 的石阳。
欢迎关注 《搜索百科》 专栏!每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
前两篇我们探讨了搜索技术的基石 Apache Lucene 和企业级搜索解决方案 Apache Solr。今天,我们来聊聊一个真正改变搜索游戏规则,但也充满争议的产品 — Elasticsearch。
引言
如果说 Lucene 是幕后英雄,那么 Elasticsearch 就是舞台中央的明星。借助 REST API、分布式架构、强大的生态系统,它让搜索 + 分析成为“马上可用”的服务形式。
在日志平台、可观察性、安全监控、AI 与语义检索等领域,Elasticsearch 的名字几乎成了默认选项。
Elasticsearch 概述
Elasticsearch 是一个开源的分布式搜索和分析引擎,构建于 Apache Lucene 之上。作为一个检索平台,它可以实时存储结构化、非结构化和向量数据,提供快速的混合和向量搜索,支持可观测性与安全分析,并以高性能、高准确性和高相关性实现 AI 驱动的应用。
- 首次发布:2010 年 2 月
- 最新版本:9.1.3(截止 2025 年 9 月)
- 核心依赖:Apache Lucene
- 开源协议:AGPL v3
- 官方网址:https://www.elastic.co/elasticsearch/
- GitHub 仓库:https://github.com/elastic/elasticsearch
起源:从食谱搜索到全球“流量明星”
Elasticsearch 的故事始于以色列开发者 Shay Banon。2010 年,当时他在学习厨师课程的妻子需要一款能够快速搜索食谱的工具。虽然当时已经有 Solr 这样的搜索解决方案,但 Shay 认为它们对于分布式场景的支持不够完善。
基于之前开发 Compass(一个基于 Lucene 的搜索库)的经验,Shay 开始构建一个完全分布式的、基于 JSON 的搜索引擎。2010 年 2 月,Elasticsearch 的第一个版本发布。
随着用户日益增多、企业级需求增强,Shay 在 2012 年创立了 Elastic 公司,把 Elasticsearch 不仅作为开源项目,也逐渐商业化运营起来,包括提供托管服务、企业支持,加入 Logstash 日志处理、Kibana 可视化工具等,Elastic 公司也逐渐从一个纯搜索引擎项目演变为一个更广泛的“数据搜索与分析”平台。
协议变更:开源和商业化的博弈
Elasticsearch 的发展并非一帆风顺。其历史上最具转折性的事件当属与 AWS 的冲突及随之而来的开源协议变更。
- 早期:Apache 2.0 协议
2010 年 Shay Banon 开源 Elasticsearch 时,最初采用的是 Apache 2.0 协议。Apache 2.0 属于宽松的自由协议,允许任何人免费使用、修改和商用(包括 SaaS 模式)。这帮助 Elasticsearch 快速壮大,成为事实上的“搜索引擎标准”。
- 协议变更:应对云厂商“白嫖”
随着 Elasticsearch 的流行,像 AWS(Amazon Web Services) 等云厂商直接将 Elasticsearch 做成托管服务,并从中获利。Elastic 公司认为这损害了他们的商业利益,因为云厂商“用开源赚钱,却没有回馈社区”。2021 年 1 月,Elastic 宣布 Elasticsearch 和 Kibana 不再采用 Apache 2.0,改为 双重协议:SSPL + Elastic License。这一步导致社区巨大分裂,AWS 带头将 Elasticsearch 分叉为 OpenSearch,并继续以 Apache 2.0 协议维护。
- 再次转向开源:AGPL v3
2024 年 3 月,Elastic 宣布新的版本(Elasticsearch 8.13 起)又新增 AGPL v3 作为一个开源许可选项。AGPL v3 既符合 OSI 真正开源标准,又能约束云厂商闭源托管服务,同时修复社区关系,Elastic 希望通过重新拥抱开源,减少分裂,吸引开发者回归。
Elasticsearch 从宽松到收紧,再到回归开源,是在社区生态与商业利益间寻找平衡的过程。
基本概念
要学习 Elasticsearch,得先了解其五大基本概览:集群、节点、分片、索引和文档。
- 集群(Cluster)
由一个或多个节点组成的整体,提供统一的搜索与存储服务。对外看起来像一个单一系统。
- 节点(Node)
集群中的一台服务器实例。节点有不同角色:
- Master 节点:负责集群管理(分片分配、元数据维护)。
- Data 节点:存储数据、处理搜索和聚合。
- Coordinating 节点:接收请求并调度任务。
- Ingest 节点:负责数据写入前的预处理。
- 索引(Index)
类似于传统数据库的“库”,按逻辑组织数据。一个索引往往对应一个业务场景(如日志、商品信息)。
- 分片(Shard)
为了让索引能水平扩展,Elasticsearch 会把索引拆分为多个 主分片,并为每个主分片创建 副本分片,提升高可用和查询性能。
- 文档(Document)
Elasticsearch 存储和检索的最小数据单元,通常是 JSON 格式。多个文档组成一个索引。
集群架构
Elasticsearch 通过 Master、Data、Coordinating、Ingest 等不同角色节点的协作,将数据切分成分片并分布式存储,实现了高可用、可扩展的搜索与分析引擎架构。
快速开始:5 分钟体验 Elasticsearch
1. 使用 Docker 启动
# 拉取最新镜像
docker pull docker.elastic.co/elasticsearch/elasticsearch:9.1.3
# 启动单节点集群
docker run -d --name elasticsearch \
-p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e "xpack.security.enabled=false" \
docker.elastic.co/elasticsearch/elasticsearch:9.1.32. 验证安装
# 检查集群状态
curl -X GET "http://localhost:9200/"
3. 索引文档
# 索引文档
curl -X POST "http://localhost:9200/myindex/_doc" -H 'Content-Type: application/json' -d'
{
"title": "Hello Elasticsearch",
"description": "An example document"
}'
3. 搜索文档
# 搜索文档
curl -X GET "http://localhost:9200/myindex/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"title": "Hello"
}
}
}'
结语
Elasticsearch 是搜索与分析领域标杆性的产品。它将 Lucene 的能力包装起来,加上分布式、易用以及与数据可视化、安全监控等功能的整合,使搜索引擎从专业技术逐渐变为“随手可用”的基础设施。
虽然协议变动、与 OpenSearch 的分叉引发争议,但它在企业与开发者群体中的实际应用价值依然难以替代。
🚀 下期预告
下一篇我们将介绍 OpenSearch,探讨这个 Elasticsearch 分支项目的发展现状、技术特点以及与 Elasticsearch 的详细对比。如果您有特别关注的问题,欢迎提前提出!
💬 三连互动
- 你或公司最近在用 Elasticsearch 吗?拿来做了什么场景?
- 在 Elasticsearch 和 OpenSearch 之间做过技术选型?
- 对 Elasticsearch 的许可证变化有什么看法?
对搜索技术感兴趣的朋友,也欢迎加我微信(ID:lsy965145175)备注“搜索百科”,拉你进 搜索技术交流群,一起探讨与学习!
✨ 推荐阅读
🔗 参考
原文:https://infinilabs.cn/blog/2025/search-wiki-3-elasticsearch/
搜索百科(1):Lucene —— 打开现代搜索世界的第一扇门
Lucene • liaosy 发表了文章 • 0 个评论 • 5931 次浏览 • 2025-09-10 14:52
大家好,我是 INFINI Labs 的石阳。
这是《搜索百科》系列文章,每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
搜索技术看似专业,但它早已深度融入我们的日常生活。无论是电商搜索、知识检索,还是 AI 语义搜索、RAG、向量检索,背后都有经典与新兴技术的结合。希望这个系列能帮大家建立更清晰的认知,也欢迎留言交流。
引言:为什么先写 Lucene?
如果你曾用 GitHub 搜代码、用电商网站搜商品,或者在日志平台里“捞”报错,你就已经享受了 Lucene 的红利——只是自己还不知道。今天,让我们认识下这位“幕后大佬”,看看它如何以一己之力,孵化了整个现代搜索江湖。没有它,就没有 Elasticsearch 的锋芒,也没有 Solr 的稳健。讲搜索,不从 Lucene 开始,就像讲武侠不提《易筋经》——根基都丢了。
诞生故事:一个程序员的“副业”成果
Lucene 的诞生颇具传奇色彩。它的创造者 Doug Cutting(后来也是 Hadoop 的创始人之一)在 1997 年开始开发 Lucene,最初是为了给他的个人项目——一个网络爬虫和搜索引擎——提供搜索能力。
当时,市面上并没有成熟的开源搜索库可用,Doug 决定自己写一个。他在业余时间一点点打磨,最终在 1999 年发布了第一个版本。2001 年,Lucene 加入了 Apache 软件基金会,成为 Apache 的第一个开源搜索项目。
有趣的是,Lucene 的名字并不是来自什么技术术语,而是取自 Doug Cutting 妻子的中间名——Lucene。这也让这个项目多了一丝浪漫的色彩。
Lucene 概述
Apache Lucene,是一个用 Java 编写的高性能、全文搜索引擎库。它不是那种你下载下来就能直接用的“搜索软件”,而是一个底层库,就像乐高积木里的基础砖块,虽然不起眼,但没有它,很多搜索产品根本搭不起来。
Lucene 提供了强大的索引和查询能力,支持分词、倒排索引、相关性评分、模糊查询、布尔查询等一系列功能。它是 Elasticsearch、Solr、Easysearch、OpenSearch 等现代搜索引擎的核心引擎。
- 首次发布:1999 年
- 最新版本:截至 2025 年 9 月,Lucene 已更新至
10.2.x系列 - 开源协议:Apache License 2.0(商业友好)
- 官网:https://lucene.apache.org/
- GitHub:https://github.com/apache/lucene
社区生态
虽然已经 25 岁"高龄",Lucene 的社区却依然活力满满。作为 Apache 软件基金会的顶级项目,它拥有:
- 100+ 活跃贡献者
- 每月都有新的 commit 和 issue 处理
- 每年发布 2-4 个主要版本
- 完善的文档和活跃的邮件列表
虽然不像 Elasticsearch 那样“出圈”,但在开发者和企业内部系统中仍有广泛使用。
功能亮点:为什么大家都爱它?
- 高性能全文检索内核:倒排索引、短语/布尔/通配符/模糊查询、相关性打分。
- 面向工程的可扩展分析链:分词器、过滤器、同义词、停用词、高亮、排序等。
- 近邻向量检索(KNN):原生支持高维向量的最近邻搜索,为语义检索/RAG 奠基。 
- 嵌入式 & 纯 Java:作为库嵌入任意 Java 应用,掌控细粒度行为与性能。
- 成熟稳定的版本线:9.x 与 10.x 并行演进,兼顾稳定与新特性。
对比优势:Lucene vs 世界
| 产品 | 类型 | 与 Lucene 的关系 |
|---|---|---|
| Elasticsearch | 分布式引擎 | 基于 Lucene,提供分布式、RESTful 接口 |
| Apache Solr | 搜索平台 | 基于 Lucene,提供 Web 管理界面和更多功能 |
| Meilisearch | 轻量引擎 | 不基于 Lucene,用 Rust 编写,主打易用性 |
Lucene 是底层引擎,而其他产品是在它之上构建的完整解决方案。如果你想要完全控制搜索逻辑,Lucene 是最佳选择;如果你想要开箱即用的搜索服务,可以考虑 Elasticsearch 或 Solr。
快速上手:10 分钟体验 Lucene
虽然 Lucene 需要写一些 Java 代码,但其实入门并不复杂。
1. 环境准备
// Maven 依赖
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>10.xx.xx</version>
</dependency>2. 创建你的第一个索引
// 创建分析器(支持中文)
Analyzer analyzer = new StandardAnalyzer();
// 创建索引
Directory directory = FSDirectory.open(Paths.get("index"));
IndexWriterConfig config = new IndexWriterConfig(analyzer);
IndexWriter writer = new IndexWriter(directory, config);
Document doc = new Document();
doc.add(new TextField("content", "欢迎来到 Lucene 的世界", Field.Store.YES));
writer.addDocument(doc);
writer.close();3. 执行搜索
// 搜索 "Lucene"
Query query = new TermQuery(new Term("content", "lucene"));
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
TopDocs results = searcher.search(query, 10);
System.out.println("找到 " + results.totalHits + " 条结果");几行 Java 代码,就能完成一个迷你搜索引擎。
结语
Apache Lucene 虽然不是面向最终用户的产品,但它是搜索技术的基石。几乎所有现代搜索引擎都离不开它。如果你对搜索技术有兴趣,学习 Lucene 是理解搜索引擎工作原理的最佳途径。
🚀 下期预告
下一篇,我将介绍 Lucene 的第一个"孩子"—— Apache Solr,看看这个基于 Lucene 的企业级搜索平台如何让搜索变得更简单。
💬 三连互动
- 你或公司最近在用 Lucene 吗?拿来做了什么场景?
- 你觉得 Lucene 最香 / 最坑的点是什么?
- 下一期想先看 Solr 还是 Elasticsearch ?留言告诉我,我来插队!
对搜索技术感兴趣的朋友,也欢迎加我微信(ID:lsy965145175)备注“搜索百科”,拉你进 搜索技术交流群,一起探讨与学习!
如何用 Scrapy 爬取网站数据并在 Easysearch 中进行存储检索分析
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 6825 次浏览 • 2024-09-13 12:28
做过数据分析和爬虫程序的小伙伴想必对 Scrapy 这个爬虫框架已经很熟悉了。今天给大家介绍下,如何基于 Scrapy 快速编写一个爬虫程序并利用 Easysearch 储存、检索、分析爬取的数据。我们以极限科技的官网 Blog 为数据源(https://infinilabs.cn/blog) ,做下实操演示。
1、安装 scrapy
使用 Scrapy 可以快速构建一个爬虫项目,从目标网站中获取所需的数据,并进行后续的处理和分析。
pip install scrapy
# 新建项目 infini_spiders
scrapy startproject infini_spiders
# 初始化爬虫
cd infini_spiders/spiders
scrapy genspider blog infinilabs.cn2、爬虫编写
编写一个爬虫文件 blog.py ,它会首先访问 start_urls 指定的地址,将结果发给 parse 函数解析。通过这一步解析,我们得到了每一篇博客的地址。然后我们对每个博客的地址发送请求,将结果发给 parse_blog 函数进行解析,在这里才会真正提取每篇博客的 title、tag、url、date、content 内容。
from typing import Any, Iterable
import scrapy
from bs4 import BeautifulSoup
from scrapy.http import Response
class BlogSpider(scrapy.Spider):
name = "blog"
allowed_domains = ["infinilabs.cn"]
start_urls = ["https://infinilabs.cn/blog/"]
def parse(self, response):
links = response.css("div.blogs a")
yield from response.follow_all(links, self.parse_blog)
def parse_blog(self, response):
title = response.xpath('//div[@class="title"]/text()').extract_first()
tags = response.xpath('//div[@class="tags"]/div[@class="tag"]/text()').extract()
url = response.url
author = response.xpath('//div[@class="logo"]/div[@class="name"]//text()').extract_first()
date = response.xpath('//div[@class="date"]/text()').extract_first()
all_text = response.xpath('//p//text() | //h3/text() | //h2/text() | //h4/text() | //ol/li//text()').extract()
content = '\n'.join(all_text)
yield {
'title': title,
'tags': tags,
'url': url,
'author': author,
'date': date,
'content': content
}提取完我们想要的内容后,接下来就要考虑存储了。考虑到要对内容进行检索、分析,接下来我们将内容直接存放到 Easysearch 当中。
3、安装插件
通过安装 ScrapyElasticsearch pipeline 可将 scrapy 爬取的内容存入到 Easysearch 中。
pip install ScrapyElasticSearch修改 scrapy 自带的配置文件 settings.py ,添加以下内容。
ITEM_PIPELINES = {
'scrapyelasticsearch.scrapyelasticsearch.ElasticSearchPipeline': 10
}
ELASTICSEARCH_SERVERS = ['http://192.168.56.3:9210']
ELASTICSEARCH_INDEX = 'scrapy'
ELASTICSEARCH_INDEX_DATE_FORMAT = '%Y-%m-%d'
ELASTICSEARCH_TYPE = '_doc'
ELASTICSEARCH_USERNAME = 'admin'
ELASTICSEARCH_PASSWORD = '9423d1d5345ed6d0db19'ScrapyElasticSearch 会以 bulk 方式写入 Easysearch,每次批量的大小由 scrapyelasticsearch.scrapyelasticsearch.ElasticSearchPipeline 参数控制,大家可自行修改。
在上述配置中,我们会将爬到的数据存放到 scrapy-yyyy-mm-dd 索引中。
4、启动爬虫
在 infini_spiders/spiders 目录下,使用命令启动爬虫。
scrapy crawl blogblog 就是爬虫的名字,对应到 blog.py 里面的 name 变量。运行完成后,就可以去 Easysearch 里查看数据了,当然我们还是使用 Console 进行查看。
5、查看数据
先查看下索引情况,scrapy 索引已经生成,里面有 129 篇博客。
查看详细内容,确保博客正文已经保存。
到了这一步,我们就能使用 Console 对博客进行搜索、分析了。
6、结语
这次的分享就到这里了。欢迎与我一起交流 ES 的各种问题和解决方案。
关于 Easysearch
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。 与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
官网文档:https://infinilabs.cn/docs/latest/easysearch
🔥 Rust China Conf 2024 震撼来袭,INFINI Pizza 搜索引擎重磅亮相!
活动 • INFINI Labs 小助手 发表了文章 • 0 个评论 • 5696 次浏览 • 2024-08-31 17:10
随着 Rust 语言以其在性能、安全性和并发性方面的卓越表现,赢得了全球开发者的青睐,Rust 社区正迎来前所未有的发展机遇。在这个充满活力与潜力的背景下,Rust China Conf 2024 震撼来袭!
Rust 大会介绍
Rust 大会即将于 9 月 7 日 - 8 日在上海盛大举办。作为年度国内规模最大并唯一的 Rust 线下大型会议,它由 Rust 中文社区发起主办、知名企业和开源组织联合协办,深受开发者与相关企业的喜爱与推崇。自 2020 年起,已连续举办四年,今年预计将吸引超过 400 名一线程序员和企业用户,他们已在个人或公司项目中实践 Rust,期待在此交流心得、共享经验,共同推动 Rust 生态的繁荣与发展。
INFINI Labs 亮相 Rust 大会
作为本次大会的重要赞助商之一,INFINI Labs 将携手蚂蚁集团、字节跳动、JetBrains、亚马逊云科技、华为、Greptime 等知名企业,为与会者带来创新的灵感和实践的洞见。INFINI Labs 的创始人 & CEO 曾勇先生将分享《基于 Rust 编写下一代实时搜索引擎》—— INFINI Pizza 的故事,这款搜索引擎旨在解决海量数据的实时搜索需求,释放现代硬件的潜力,为企业打造高效、准确的搜索解决方案。
大会部分议题亮点抢先看
《人人可用的 Rust》
讲师简介: Rebecca Rumbul,Rust 基金会执行董事兼首席执行官, OpenUK 董事会成员, OpenSSF 管理委员会成员。
议题介绍: 本次分享将介绍 Rust 基金会如何投资于工程和推广工作,以确保 Rust 对所有人来说都是有用、高效且安全的。
《携手共建繁荣的 Rust OS 内核软件生态》
讲师简介: 田洪亮,田洪亮博士是蚂蚁研究院操作系统方向的负责人, 在 Rust 编程和内核开发方面有丰富的经验,荣获 OS2ATC'24 颁发的开源创新先锋奖。他发起的 Occlum 项目,是业界最早的 Rust OS 开源项目, 已发展成可信执行环境中最流行的 library OS,荣登中科协发布的"科创中国"开源创新榜单。曾就职于 Intel Labs China,博士毕业于清华大学。
议题介绍: Rust 语言以其高效、安全和生产力被视为系统编程,尤其是 OS 编程的未来。但在开发 OS 内核时,存在频繁使用 unsafe、缺乏 Cargo 支持、以及可重用的 no_std crates 不足等痛点。星绽开源社区提出了星绽 Framework 和星绽 OSDK,提供强大的 safe API 和开发工具链, 使得 Rust 内核开发更加安全、高效,并促进了 no_std crates 的复用与组合,旨在提升开发者生产力并推动 Rust 生态的繁荣。
《用 Rust 构建高性能的生成式 AI 应用》
讲师简介: 王宇博,现任亚马逊云科技大中华区开发者关系总监、首席布道师,致力于新一代信息技术与创新在开发者中的布道推广,以及开发者生态体系的建设。
议题介绍: 生成式 AI 技术在自然语言处理和图像生成领域快速发展。对于 Rust 开发者来说,利用 Rust 的高性能特性构建高效、可靠的生成式 AI 应用至关重要。本次演讲将深入探讨在 Rust 中开发生成式 AI 应用的实践方法,分析其在数值计算和并发编程中的优势,并分享确保应用可靠性和安全性的最佳实践,帮助开发者掌握构建高性能生成式 AI 应用的技巧。
《字节跳动在 Rust 服务端方向的实践与思考》
讲师简介: 吴迪,字节跳动服务框架 Rust 负责人,负责字节跳动 Rust 生态建设与推广落地。
议题介绍: 字节跳动三年前开始投资 Rust 服务端开发,构建了内部生态并开源核心框架 Volo。现在已在多个业务线成功落地,规模国内最大,收益超预期。本次分享将介绍选择 Rust 的原因、落地心得及未来技术趋势的思考。
《Async Rust 维测&定位的探索和思考》
讲师简介:
陈明煜:毕业于加州大学圣地亚哥分校,现就职于华为,OpenHarmony Ylong Rust 异步框架的开发者,致力于推动 OH 应用的 Rust 异步化。
楼智豪:毕业于浙江大学,现就职于华为,参与过 Rust 与 Cangjie 语言的开源贡献,现从事 Rust 在 OpenHarmony 中的应用。
议题介绍: 本议题将介绍我们在 OpenHarmony 中遇到的一些异步框架使用问题,以及我们在 Rust 异步调测与定位方面的探索。内容包括对业界常见异步框架的维测能力调研,以及对 Rust 无栈协程的推栈处理和跨 FFI 的 C++ exception 问题解决方法,旨在提升 Rust 异步的可商用性。
《Rust HashMap:比看起来更复杂》
讲师简介: 曹瑞秋,蚂蚁集团高级开发工程师,Apache HoraeDB/CeresDB 核心开发者,Apache HoraeDB PPMC member,长期专注于时序数据库领域。
议题介绍: Rust HashMap 看似简单,实际使用中存在诸多"坑点",尤其在 CPU 消耗和内存占用方面。分段 HashMap 设计中的伪共享和内存访问局部性差会影响性能。HashMap 的 capacity 通常远大于指定值,加之内存访问特性,会占据大量物理内存。此外,with_capacity方法和 allocator 内存池的使用不当可能导致内存释放问题。因此,使用 Rust HashMap 需要细心设计。
《Rust 和 C++ 互操作及交叉编译》
讲师简介: 朱树磊,北京大学物理学士,德国 TUM 硕士,现任浙江大华技术股份有限公司高级算法专家。从事人工智能算法研发工作 10 余年,擅长机器学习、深度学习和大数据智能等技术领域,具备丰富的人工智能算法系统设计和开发经验。
议题介绍: Rust 和 C++ 经常需要共存,但 C++ 的交叉编译复杂性是一个挑战。本次分享将介绍如何使用 cxx 让 Rust 和 C++ 代码共存,并通过 LLVM 工具链补齐 C++ 交叉编译的短板,让 C++ 和 Rust 的互操作简单可移植。
《超大规模:抖音直播的 Rust 技术落地实践》
讲师简介: 赵鹏,抖音直播架构师,Rust 技术负责人。
议题介绍: 抖音直播从 2022 年开始引入 Rust 技术栈,用于应对直播业务中的超低延时、超高性能挑战,取得了远超预期巨大的收益。两年时间里我们有 20+ 个头部服务完成了 Rust 重构,吞吐平均提升超 100%,节省了 16w 核 CPU 资源,多个服务 SLA 提升至 6 个 9,目前我们的 Rust 服务在线上承担着超 4000w qps 的请求。Rust 技术在抖音直播研发团队二级部门实现了 100% 覆盖,每个子业务团队都有 Rust 服务在线上运行。我们还成立了专门的 Rust 技术组帮助解决业务公共问题,沉淀了完整的 Rust 研发流水线,基本实现了 Rust 新人两周即可上手开发,两个月完成一个 Rust 服务上线的速度。综合 Rust 服务类型覆盖、数量、资源占用、开发人员、生态、基建完善程度,抖音直播已经是国内规模最大的 Rust 技术生产环境落地团队,本次分享将给大家介绍我们从选型、验证、落地、推广到维护过程中的真实实践经验,希望能够帮助到其他同行朋友。
大会报名
本次大会致力于成为中国 Rustaceans 面对面交流的盛宴,为国内的 Rust 开发者和企业提供一次充分的成果展示、技术分享、能力提升、行业资讯交流、企业人才储备建设的机会。欢迎购票参与现场交流。
🔗 报名链接 / 扫二维码:
https://4292817522623.huodongxing.com/event/5757822319111
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
