

Kibana 中的巨大控制台改进
作者:CJ Cenizal
更多阅读请参阅 Elastic 中国社区官方博客。

在过去的 9 个月里,我们的一位工程师 Muhammad Ibragimov 一直在悄悄地构建新功能、修复错误,并全面完善 Kibana Console。 从性能改进到在请求正文中留下评论的能力,他和团队在这个被很多人使用和喜爱的应用程序上做了一些令人难以置信的工作。 继续阅读以了解这些和其他改进如何在 Elastic Stack 的 8.1 至 8.4 版本中提高你的工作效率。
主要功能
我想与你分享五个甜蜜的新功能。
-
向 Kibana API 发送请求
在 8.3 中,我们通过在路径前加上 “kbn:” 来提供向 Kibana API 发送请求的能力。 例如,你可以通过以下方式向 Export Saved Objects API 发送请求:
POST kbn:api/saved_objects/_export如果你构建与这些 API 通信的软件或脚本,这将特别有用。 你现在可以快速测试请求,而无需使用第三方工具并为这些工具配置身份验证。
-
请求正文中的评论
曾经看过一个庞大的请求体并且很难回忆起为什么要这样配置它? 在 8.4 中,你可以在请求正文中编写注释并留下有关其配置的注释。 你甚至可以注释掉特定行以暂时禁用它们并尝试请求的其他变体!
1. # This request searches all of your indices.
2. GET /_search
3. {
4. // The query parameter indicates query context.
5. "query": {
6. // Matches all documents.
7. /*"match_all": {
8. "boost": 1.2
9. }*/
10. "match_none": {} // Matches no documents.
11. }
12. }
-
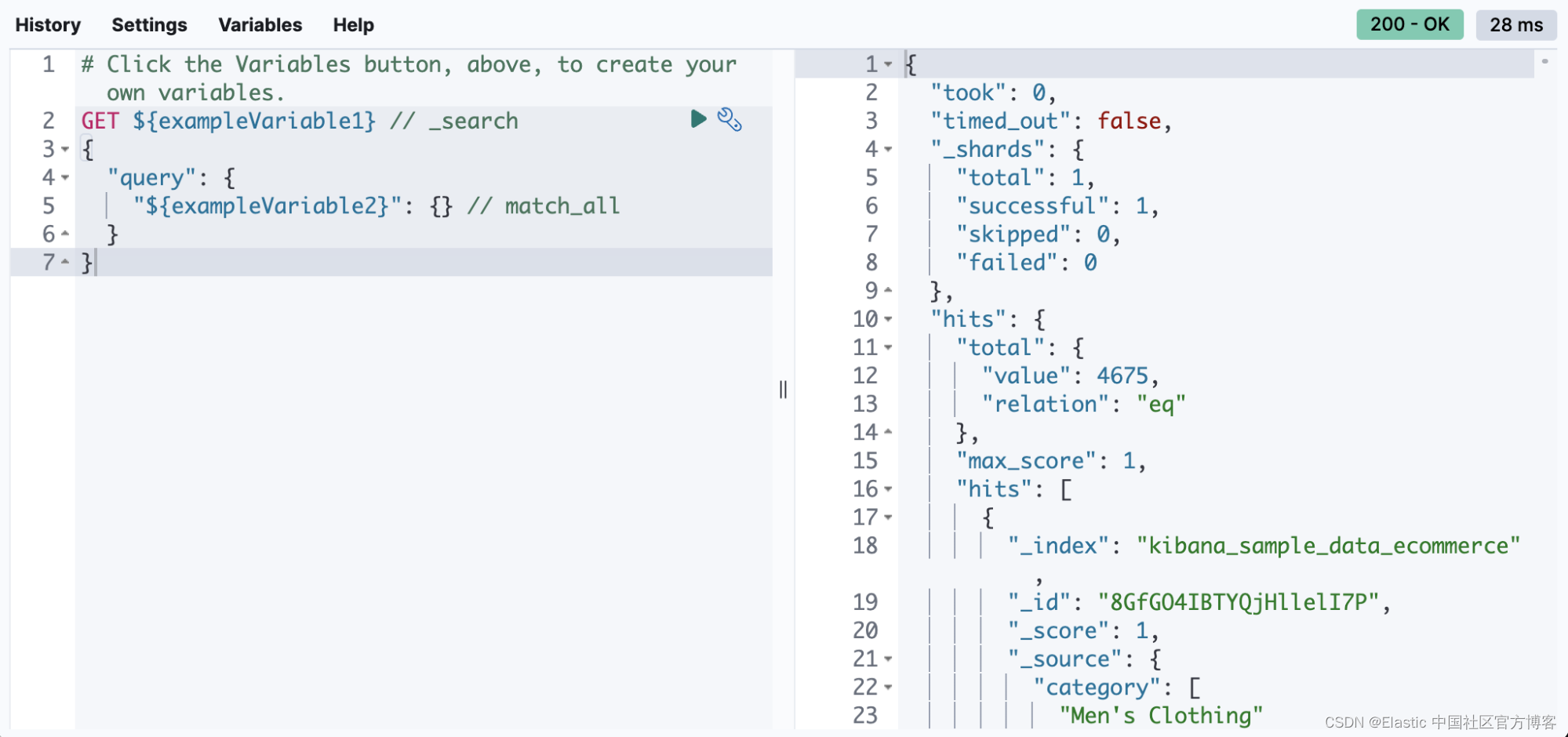
使用变量重用值
在 8.4 中,你可以在 Console 中定义变量并在你的请求中重用它们。 看起来是这样的:
你可以根据需要多次引用请求的路径和正文中的变量。
1. GET ${pathVariable}
2. {
3. "query": {
4. "match": {
5. "${bodyNameVariable}": "${bodyValueVariable}"
6. }
7. }
8. }
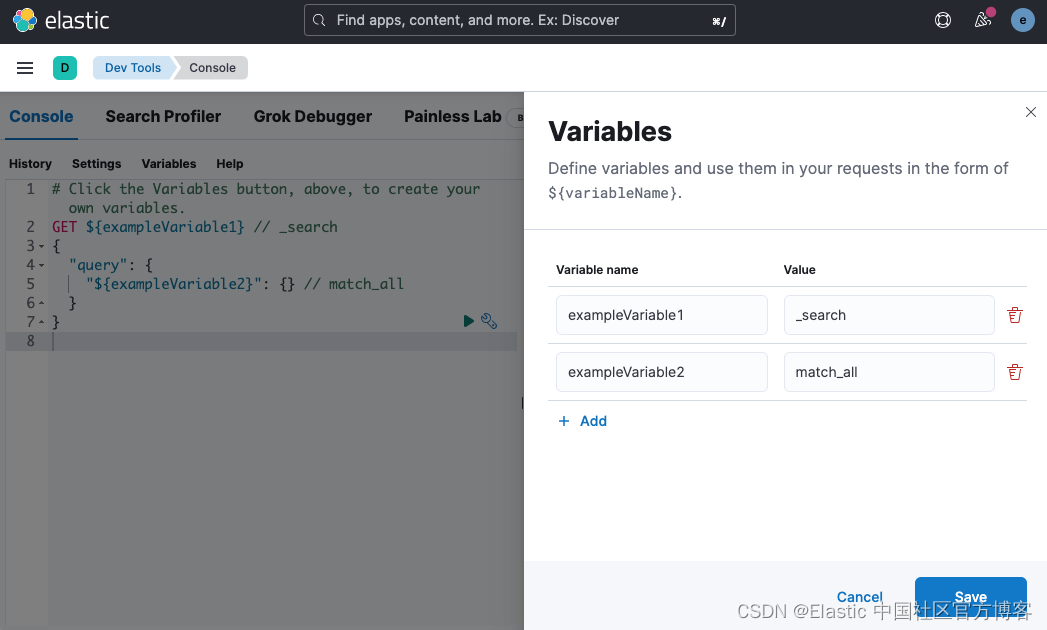
比如,我们可以创建如下的变量:
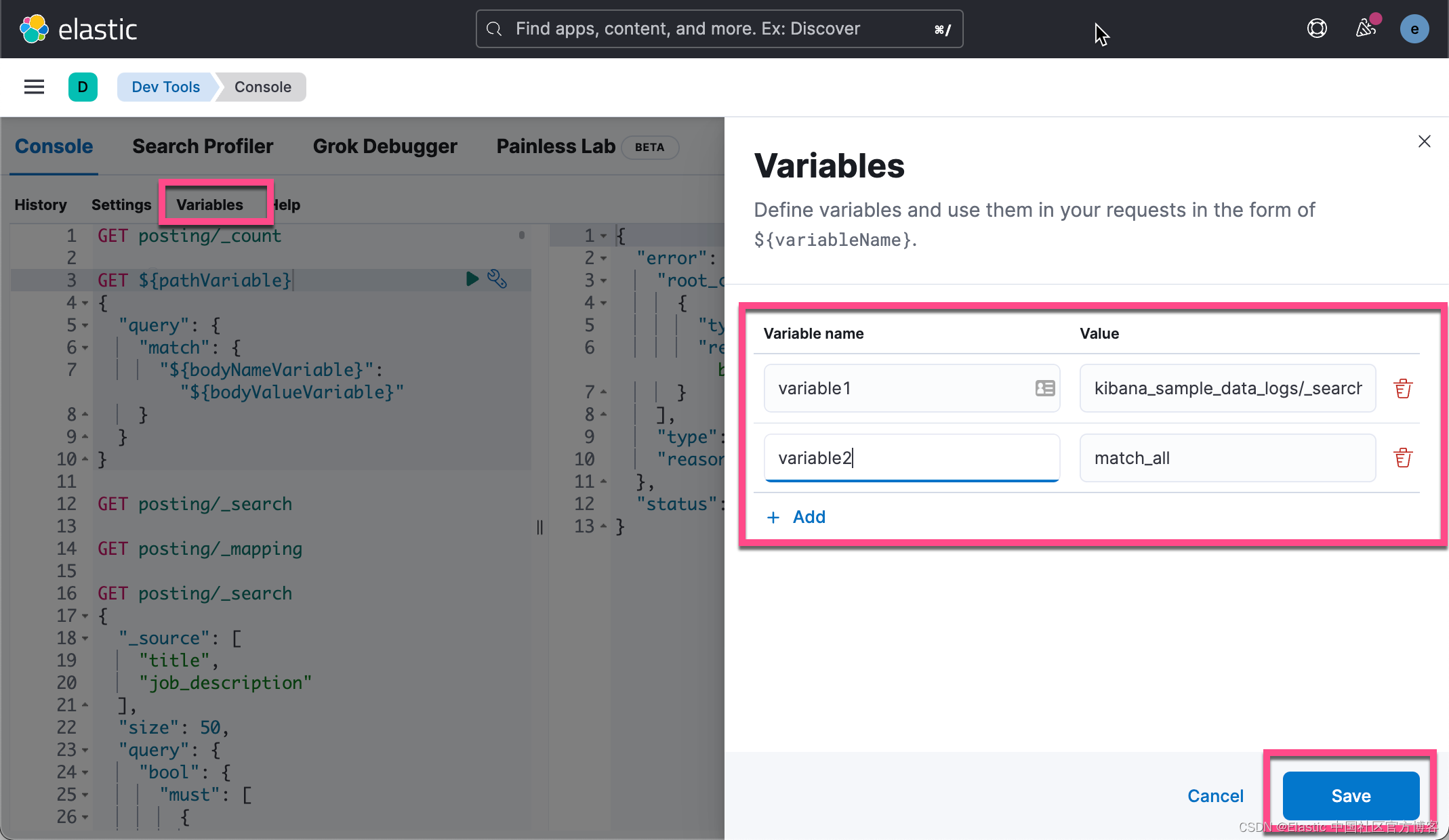
然后,我们可以使用这些变量进行如下的搜索:
1. GET ${variable1}
2. {
3. "query": {
4. "${variable2}": {}
5. }
6. }
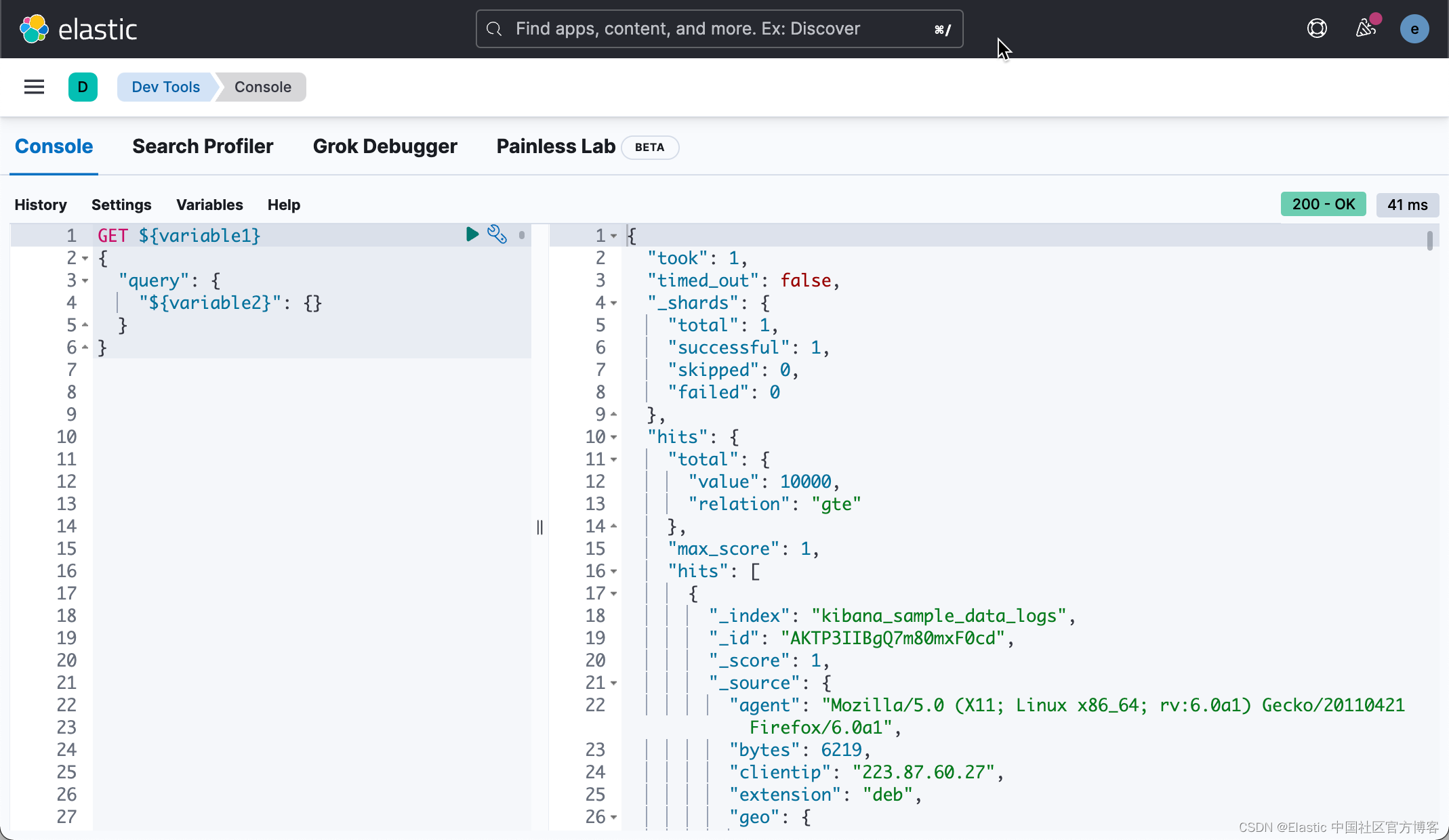
4.多个请求的多个状态
控制台长期以来一直支持同时发送多个请求。 但从历史上看,如果一个请求失败,那么成功的响应就会从 UI 中丢弃。 从 8.3 开始,你可以查看对请求的所有响应,无论它们是失败还是成功。 在 8.4 的基础上,我们在每个响应旁边添加了 HTTP 状态标记。 这使得判断哪个请求失败和哪个请求成功变得更加容易。 最严重的状态位于 UI 的顶部,因此您可以快速了解您的任何请求是否有问题。
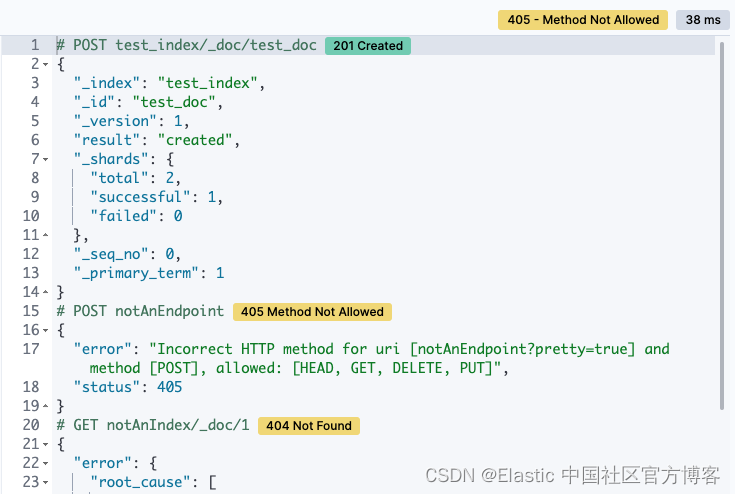
-
新 ES 实体的自动完成
自动完成是控制台的核心。 在 8.2 中,我们更新了自动完成功能,以建议部署中存在的特定可组合索引模板、组件模板和数据流的名称。
性能
控制台性能一直是大型部署的一个问题,尤其是对于经常使用控制台的人。 我们花了一些时间来处理这些案例。
优化映射检索
控制台在加载时从 ES 检索所有索引映射,以支持字段的自动完成。 对于具有许多映射的部署,此有效负载可能非常大,以至于可能导致集群不稳定。 在 8.1 和 7.17.3 中,我们通过压缩映射响应、减小其大小和响应时间来解决此问题。
控制台可以按时间间隔自动刷新这些映射,但如果你的映射不经常更改,这将是低效的。 从 8.1 开始,你将能够配置刷新映射的速率、完全禁用获取映射或将 Console 配置为仅在用户导航到 Console 时获取它们一次。
本地存储管理
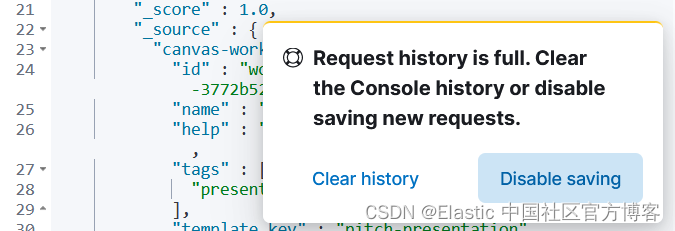
你的控制台历史记录当前存储在浏览器的本地存储中。 如果你经常使用控制台并用历史数据填满存储空间,那么用完这个本地存储空间是一个真正的问题。 从 8.1 开始,当你用尽本地存储空间并能够清除你的历史记录或完全禁用历史记录时,你将看到一条警告。
尽情享受这些新功能吧!
我们希望这些新功能和增强功能能让您从 Console 中获得更多价值! 如果你希望看到我们对 Console 进行任何进一步的具体更改,请告知我们。
作者:CJ Cenizal
更多阅读请参阅 Elastic 中国社区官方博客。
在过去的 9 个月里,我们的一位工程师 Muhammad Ibragimov 一直在悄悄地构建新功能、修复错误,并全面完善 Kibana Console。 从性能改进到在请求正文中留下评论的能力,他和团队在这个被很多人使用和喜爱的应用程序上做了一些令人难以置信的工作。 继续阅读以了解这些和其他改进如何在 Elastic Stack 的 8.1 至 8.4 版本中提高你的工作效率。
主要功能
我想与你分享五个甜蜜的新功能。
-
向 Kibana API 发送请求
在 8.3 中,我们通过在路径前加上 “kbn:” 来提供向 Kibana API 发送请求的能力。 例如,你可以通过以下方式向 Export Saved Objects API 发送请求:
POST kbn:api/saved_objects/_export如果你构建与这些 API 通信的软件或脚本,这将特别有用。 你现在可以快速测试请求,而无需使用第三方工具并为这些工具配置身份验证。
-
请求正文中的评论
曾经看过一个庞大的请求体并且很难回忆起为什么要这样配置它? 在 8.4 中,你可以在请求正文中编写注释并留下有关其配置的注释。 你甚至可以注释掉特定行以暂时禁用它们并尝试请求的其他变体!
1. # This request searches all of your indices.
2. GET /_search
3. {
4. // The query parameter indicates query context.
5. "query": {
6. // Matches all documents.
7. /*"match_all": {
8. "boost": 1.2
9. }*/
10. "match_none": {} // Matches no documents.
11. }
12. }
-
使用变量重用值
在 8.4 中,你可以在 Console 中定义变量并在你的请求中重用它们。 看起来是这样的:
你可以根据需要多次引用请求的路径和正文中的变量。
1. GET ${pathVariable}
2. {
3. "query": {
4. "match": {
5. "${bodyNameVariable}": "${bodyValueVariable}"
6. }
7. }
8. }
比如,我们可以创建如下的变量:
然后,我们可以使用这些变量进行如下的搜索:
1. GET ${variable1}
2. {
3. "query": {
4. "${variable2}": {}
5. }
6. }
4.多个请求的多个状态
控制台长期以来一直支持同时发送多个请求。 但从历史上看,如果一个请求失败,那么成功的响应就会从 UI 中丢弃。 从 8.3 开始,你可以查看对请求的所有响应,无论它们是失败还是成功。 在 8.4 的基础上,我们在每个响应旁边添加了 HTTP 状态标记。 这使得判断哪个请求失败和哪个请求成功变得更加容易。 最严重的状态位于 UI 的顶部,因此您可以快速了解您的任何请求是否有问题。
-
新 ES 实体的自动完成
自动完成是控制台的核心。 在 8.2 中,我们更新了自动完成功能,以建议部署中存在的特定可组合索引模板、组件模板和数据流的名称。
性能
控制台性能一直是大型部署的一个问题,尤其是对于经常使用控制台的人。 我们花了一些时间来处理这些案例。
优化映射检索
控制台在加载时从 ES 检索所有索引映射,以支持字段的自动完成。 对于具有许多映射的部署,此有效负载可能非常大,以至于可能导致集群不稳定。 在 8.1 和 7.17.3 中,我们通过压缩映射响应、减小其大小和响应时间来解决此问题。
控制台可以按时间间隔自动刷新这些映射,但如果你的映射不经常更改,这将是低效的。 从 8.1 开始,你将能够配置刷新映射的速率、完全禁用获取映射或将 Console 配置为仅在用户导航到 Console 时获取它们一次。
本地存储管理
你的控制台历史记录当前存储在浏览器的本地存储中。 如果你经常使用控制台并用历史数据填满存储空间,那么用完这个本地存储空间是一个真正的问题。 从 8.1 开始,当你用尽本地存储空间并能够清除你的历史记录或完全禁用历史记录时,你将看到一条警告。
尽情享受这些新功能吧!
我们希望这些新功能和增强功能能让您从 Console 中获得更多价值! 如果你希望看到我们对 Console 进行任何进一步的具体更改,请告知我们。
收起阅读 »使用极限网关来代理 Kibana
来来来,几个简单步骤告别不舒服的这几个问题,如下:
下载最新的 530 版本:http://release.elasticsearch.cn/gateway/snapshot/
找到配置:
entry:
- name: my_es_entry
enabled: true
router: my_router
max_concurrency: 10000
network:
binding: 0.0.0.0:8000
skip_occupied_port: true
tls:
enabled: true
flow:
- name: default_flow
filter:
- basic_auth:
valid_users:
medcl: passwd
- http:
schema: "http" #https or http
host: "192.168.3.98:5601"
router:
- name: my_router
default_flow: default_flowhttps://极限网关.com/docs/references/filters/http/
启动网关,因为自动开启了 https,访问网关的服务地址:https://localhost:8000,如下:

输入配置的用户名密码,即可。

来来来,几个简单步骤告别不舒服的这几个问题,如下:
下载最新的 530 版本:http://release.elasticsearch.cn/gateway/snapshot/
找到配置:
entry:
- name: my_es_entry
enabled: true
router: my_router
max_concurrency: 10000
network:
binding: 0.0.0.0:8000
skip_occupied_port: true
tls:
enabled: true
flow:
- name: default_flow
filter:
- basic_auth:
valid_users:
medcl: passwd
- http:
schema: "http" #https or http
host: "192.168.3.98:5601"
router:
- name: my_router
default_flow: default_flowhttps://极限网关.com/docs/references/filters/http/
启动网关,因为自动开启了 https,访问网关的服务地址:https://localhost:8000,如下:
输入配置的用户名密码,即可。
Kibana:Kibana 入门 (一)
Kibana 是你进入 Elastic Stack 的窗口。 Kibana 使你能够:
分析和可视化你的数据。搜索隐藏的见解,编制图表仪表板,仪表、地图和其他可视化显示您发现的内容,并与他人分享。
搜索、观察和保护你的数据。向你的应用或网站添加搜索框,分析日志,指标,并发现安全漏洞。
管理、监控和保护 Elastic Stack。管理您的索引和摄入管道,监控 Elastic Stack 集群的运行状况,并控制哪些用户可以访问哪些特征和数据。
在今天的练习中,你将学习如何在 Kibana 中探索数据,如何使用 Kibana 创建可视化镜头,并将它们组合在仪表板中。你将使用 Kibana 的示例数据集。一个数据集描述了过去 10 天的航班信息。第二个数据集代表电子商务平台的订单。你将使用不同的 Kibana可视化来探索数据。你将深入了解运营商的典型延误等主题,以及票价波动。
在今天的练习中,我们将使用最新的 Elastic Stack 7.17 来进行展示。针对之前的版本,界面可能有所不同,但是很多操作基本是一样的。
原文链接:https://elasticstack.blog.csdn ... 05096
Kibana 是你进入 Elastic Stack 的窗口。 Kibana 使你能够:
分析和可视化你的数据。搜索隐藏的见解,编制图表仪表板,仪表、地图和其他可视化显示您发现的内容,并与他人分享。
搜索、观察和保护你的数据。向你的应用或网站添加搜索框,分析日志,指标,并发现安全漏洞。
管理、监控和保护 Elastic Stack。管理您的索引和摄入管道,监控 Elastic Stack 集群的运行状况,并控制哪些用户可以访问哪些特征和数据。
在今天的练习中,你将学习如何在 Kibana 中探索数据,如何使用 Kibana 创建可视化镜头,并将它们组合在仪表板中。你将使用 Kibana 的示例数据集。一个数据集描述了过去 10 天的航班信息。第二个数据集代表电子商务平台的订单。你将使用不同的 Kibana可视化来探索数据。你将深入了解运营商的典型延误等主题,以及票价波动。
在今天的练习中,我们将使用最新的 Elastic Stack 7.17 来进行展示。针对之前的版本,界面可能有所不同,但是很多操作基本是一样的。
原文链接:https://elasticstack.blog.csdn ... 05096 收起阅读 »
Kibana 中用公式和时间旅行回答的 10 个常见问题
此外,在时间和空间中移动和重放数据是获取历史背景和了解关于现在的更多见解的有效方法。
在以下部分中,你将找到 10 个问题示例,你可以通过公式、时移和及时浏览数据,使用 Kibana 中的仪表板数据和地图可视化来回答这些问题。 尝试跟随你自己的数据或使用 Kibana 的示例数据集。 有问题吗? 前往我们的讨论论坛。
在名单上:
错误的比例在增加吗?
表现与上周相比如何?
这些数据与同行相比如何?
对我的平均水平影响最大的是什么?
与历史相比,原始收益/损失是多少?
收益/损失占过去业绩的百分比是多少?
数据是如何到达现在的位置的?
如何以交互方式探索空间中的仪表板?
这个指标的单位版本是什么?
我对上一时期的行业特定计算(例如“净推荐值”)是什么?
https://elasticstack.blog.csdn ... 83729
此外,在时间和空间中移动和重放数据是获取历史背景和了解关于现在的更多见解的有效方法。
在以下部分中,你将找到 10 个问题示例,你可以通过公式、时移和及时浏览数据,使用 Kibana 中的仪表板数据和地图可视化来回答这些问题。 尝试跟随你自己的数据或使用 Kibana 的示例数据集。 有问题吗? 前往我们的讨论论坛。
在名单上:
错误的比例在增加吗?
表现与上周相比如何?
这些数据与同行相比如何?
对我的平均水平影响最大的是什么?
与历史相比,原始收益/损失是多少?
收益/损失占过去业绩的百分比是多少?
数据是如何到达现在的位置的?
如何以交互方式探索空间中的仪表板?
这个指标的单位版本是什么?
我对上一时期的行业特定计算(例如“净推荐值”)是什么?
https://elasticstack.blog.csdn ... 83729 收起阅读 »
户匿名访问 Kibana 中的 Dashboard
原文链接:https://blog.csdn.net/UbuntuTo ... 52293
原文链接:https://blog.csdn.net/UbuntuTo ... 52293 收起阅读 »
Kibana:在 Lens 中轻松地创建运行时字段以分析数据 - 7.13 版本
运行时字段让分析师在探索和增强他们所用数据方面迈出了坚实的第一步。使用运行时字段编辑器,分析师可以从 Discover 和 Kibana Lens 实时创建字段,以对数据进行格式化、修改和转换,而无需导航到其他屏幕或联系 Elasticsearch 管理员。
在我之前的文档里,我介绍了 Scripted fields,它也可以轻松地实现相应的功能:
Kibana:使用 Scripted fields 来提高数据的可观测性
Kibana:运用 script fields 对数据进行清洗
在今天的练习中,我将展示如何在 Kibana Lens 中创建运行时字段(runtime fields)来分析数据。有关 runtime fields,你可以阅读我之前的文章:
Elasticsearch:使用 Runtime fields 对索引字段进行覆盖处理以修复错误 - 7.11 发布
Elasticsearch:创建 Runtime field 并在 Kibana 中使用它 - 7.11 发布
Elasticsearch:动态创建 Runtime fields - 7.11 发行版
在今天的练习中,我们必须记住的一点是我们必须使用 7.13 及以后的版本!
原文链接:https://blog.csdn.net/UbuntuTo ... 94318
运行时字段让分析师在探索和增强他们所用数据方面迈出了坚实的第一步。使用运行时字段编辑器,分析师可以从 Discover 和 Kibana Lens 实时创建字段,以对数据进行格式化、修改和转换,而无需导航到其他屏幕或联系 Elasticsearch 管理员。
在我之前的文档里,我介绍了 Scripted fields,它也可以轻松地实现相应的功能:
Kibana:使用 Scripted fields 来提高数据的可观测性
Kibana:运用 script fields 对数据进行清洗
在今天的练习中,我将展示如何在 Kibana Lens 中创建运行时字段(runtime fields)来分析数据。有关 runtime fields,你可以阅读我之前的文章:
Elasticsearch:使用 Runtime fields 对索引字段进行覆盖处理以修复错误 - 7.11 发布
Elasticsearch:创建 Runtime field 并在 Kibana 中使用它 - 7.11 发布
Elasticsearch:动态创建 Runtime fields - 7.11 发行版
在今天的练习中,我们必须记住的一点是我们必须使用 7.13 及以后的版本!
原文链接:https://blog.csdn.net/UbuntuTo ... 94318 收起阅读 »
Elastic Maps 基于位置的警报 - 7.10
在 Kibana 中的四种表格制作方式
- 在 Discover 界面中制作
- 使用 table 可视化进行制作
- 使用 TSVB 来制作
- 使用 Lens 进行制作
在这几种方式中,几种制作最后的结果是不一样的。我们在实际的使用中,需要根据自己的需求来分别进行选择。
详细阅读,请参阅 https://elasticstack.blog.csdn ... 88189
- 在 Discover 界面中制作
- 使用 table 可视化进行制作
- 使用 TSVB 来制作
- 使用 Lens 进行制作
在这几种方式中,几种制作最后的结果是不一样的。我们在实际的使用中,需要根据自己的需求来分别进行选择。
详细阅读,请参阅 https://elasticstack.blog.csdn ... 88189
收起阅读 »
Kibana:运用 TSVB 中的 Metric 生成两个指标的可视化
如何在canvas使用过滤功能?
还是这个需求上,我用的方法不对?求大神指点。
还是这个需求上,我用的方法不对?求大神指点。
如何修改kibana的默认主页
在6.0版本以前,登录kibana之后,默认会路由到app/kibana下的discover应用。
在6.3版本以后,新增了一个home路径/app/kibana#/home?_g=h@44136fa,访问根路径\会直接跳到以上路径。
希望在kibana上做更多定制化开发的同学,或许会有需求在登录kibana之后能够跳转到自己的页面。
要完成以上需求,只需要在kibana的配置文件里面增加一行:
server.defaultRoute: /app/system_portal以上例子,我让kibana登录之后直接跳到我自己的app插件system_portal
配置默认路由的文件, src/server/http/get_default_route.js:
import _ from 'lodash';
export default _.once(function (kbnServer) {
const {
config
} = kbnServer;
// 根目录basePath加上defaultRoute
return `${config.get('server.basePath')}${config.get('server.defaultRoute')}`;
});默认路由就是定义在server.defaultRoute中,默认值是app/kibana,可查看src/server/config/schema.js:
import Joi from 'joi';
import { constants as cryptoConstants } from 'crypto';
import os from 'os';
import { fromRoot } from '../../utils';
import { getData } from '../path';
export default async () => Joi.object({
pkg: Joi.object({
version: Joi.string().default(Joi.ref('$version')),
branch: Joi.string().default(Joi.ref('$branch')),
buildNum: Joi.number().default(Joi.ref('$buildNum')),
buildSha: Joi.string().default(Joi.ref('$buildSha')),
}).default(),
env: Joi.object({
name: Joi.string().default(Joi.ref('$env')),
dev: Joi.boolean().default(Joi.ref('$dev')),
prod: Joi.boolean().default(Joi.ref('$prod'))
}).default(),
dev: Joi.object({
basePathProxyTarget: Joi.number().default(5603),
}).default(),
pid: Joi.object({
file: Joi.string(),
exclusive: Joi.boolean().default(false)
}).default(),
cpu: Joi.object({
cgroup: Joi.object({
path: Joi.object({
override: Joi.string().default()
})
})
}),
cpuacct: Joi.object({
cgroup: Joi.object({
path: Joi.object({
override: Joi.string().default()
})
})
}),
server: Joi.object({
uuid: Joi.string().guid().default(),
name: Joi.string().default(os.hostname()),
host: Joi.string().hostname().default('localhost'),
port: Joi.number().default(5601),
maxPayloadBytes: Joi.number().default(1048576),
autoListen: Joi.boolean().default(true),
defaultRoute: Joi.string().default('/app/kibana').regex(/^\//, `start with a slash`),
basePath: Joi.string().default('').allow('').regex(/(^$|^\/.*[^\/]$)/, `start with a slash, don't end with one`),
rewriteBasePath: Joi.boolean().when('basePath', {
is: '',
then: Joi.default(false).valid(false),
otherwise: Joi.default(false),
}),
customResponseHeaders: Joi.object().unknown(true).default({}),
ssl: Joi.object({
enabled: Joi.boolean().default(false),
redirectHttpFromPort: Joi.number(),
certificate: Joi.string().when('enabled', {
is: true,
then: Joi.required(),
}),
key: Joi.string().when('enabled', {
is: true,
then: Joi.required()
}),
keyPassphrase: Joi.string(),
certificateAuthorities: Joi.array().single().items(Joi.string()).default(),
supportedProtocols: Joi.array().items(Joi.string().valid('TLSv1', 'TLSv1.1', 'TLSv1.2')),
cipherSuites: Joi.array().items(Joi.string()).default(cryptoConstants.defaultCoreCipherList.split(':'))
}).default(),
cors: Joi.when('$dev', {
is: true,
then: Joi.object().default({
origin: ['*://localhost:9876'] // karma test server
}),
otherwise: Joi.boolean().default(false)
}),
xsrf: Joi.object({
disableProtection: Joi.boolean().default(false),
whitelist: Joi.array().items(
Joi.string().regex(/^\//, 'start with a slash')
).default(),
token: Joi.string().optional().notes('Deprecated')
}).default(),
}).default(),
logging: Joi.object().keys({
silent: Joi.boolean().default(false),
quiet: Joi.boolean()
.when('silent', {
is: true,
then: Joi.default(true).valid(true),
otherwise: Joi.default(false)
}),
verbose: Joi.boolean()
.when('quiet', {
is: true,
then: Joi.valid(false).default(false),
otherwise: Joi.default(false)
}),
events: Joi.any().default({}),
dest: Joi.string().default('stdout'),
filter: Joi.any().default({}),
json: Joi.boolean()
.when('dest', {
is: 'stdout',
then: Joi.default(!process.stdout.isTTY),
otherwise: Joi.default(true)
}),
useUTC: Joi.boolean().default(true),
})
.default(),
ops: Joi.object({
interval: Joi.number().default(5000),
}).default(),
plugins: Joi.object({
paths: Joi.array().items(Joi.string()).default(),
scanDirs: Joi.array().items(Joi.string()).default(),
initialize: Joi.boolean().default(true)
}).default(),
path: Joi.object({
data: Joi.string().default(getData())
}).default(),
optimize: Joi.object({
enabled: Joi.boolean().default(true),
bundleFilter: Joi.string().default('!tests'),
bundleDir: Joi.string().default(fromRoot('optimize/bundles')),
viewCaching: Joi.boolean().default(Joi.ref('$prod')),
watch: Joi.boolean().default(false),
watchPort: Joi.number().default(5602),
watchHost: Joi.string().hostname().default('localhost'),
watchPrebuild: Joi.boolean().default(false),
watchProxyTimeout: Joi.number().default(5 * 60000),
useBundleCache: Joi.boolean().default(Joi.ref('$prod')),
unsafeCache: Joi.when('$prod', {
is: true,
then: Joi.boolean().valid(false),
otherwise: Joi
.alternatives()
.try(
Joi.boolean(),
Joi.string().regex(/^\/.+\/$/)
)
.default(true),
}),
sourceMaps: Joi.when('$prod', {
is: true,
then: Joi.boolean().valid(false),
otherwise: Joi
.alternatives()
.try(
Joi.string().required(),
Joi.boolean()
)
.default('#cheap-source-map'),
}),
profile: Joi.boolean().default(false)
}).default(),
status: Joi.object({
allowAnonymous: Joi.boolean().default(false)
}).default(),
map: Joi.object({
manifestServiceUrl: Joi.string().default(' https://catalogue.maps.elastic.co/v2/manifest'),
emsLandingPageUrl: Joi.string().default('https://maps.elastic.co/v2'),
includeElasticMapsService: Joi.boolean().default(true)
}).default(),
tilemap: Joi.object({
url: Joi.string(),
options: Joi.object({
attribution: Joi.string(),
minZoom: Joi.number().min(0, 'Must be 0 or higher').default(0),
maxZoom: Joi.number().default(10),
tileSize: Joi.number(),
subdomains: Joi.array().items(Joi.string()).single(),
errorTileUrl: Joi.string().uri(),
tms: Joi.boolean(),
reuseTiles: Joi.boolean(),
bounds: Joi.array().items(Joi.array().items(Joi.number()).min(2).required()).min(2)
}).default()
}).default(),
regionmap: Joi.object({
includeElasticMapsService: Joi.boolean().default(true),
layers: Joi.array().items(Joi.object({
url: Joi.string(),
format: Joi.object({
type: Joi.string().default('geojson')
}).default({
type: 'geojson'
}),
meta: Joi.object({
feature_collection_path: Joi.string().default('data')
}).default({
feature_collection_path: 'data'
}),
attribution: Joi.string(),
name: Joi.string(),
fields: Joi.array().items(Joi.object({
name: Joi.string(),
description: Joi.string()
}))
}))
}).default(),
i18n: Joi.object({
defaultLocale: Joi.string().default('en'),
}).default(),
// This is a configuration node that is specifically handled by the config system
// in the new platform, and that the current platform doesn't need to handle at all.
__newPlatform: Joi.any(),
}).default();在6.0版本以前,登录kibana之后,默认会路由到app/kibana下的discover应用。
在6.3版本以后,新增了一个home路径/app/kibana#/home?_g=h@44136fa,访问根路径\会直接跳到以上路径。
希望在kibana上做更多定制化开发的同学,或许会有需求在登录kibana之后能够跳转到自己的页面。
要完成以上需求,只需要在kibana的配置文件里面增加一行:
server.defaultRoute: /app/system_portal以上例子,我让kibana登录之后直接跳到我自己的app插件system_portal
配置默认路由的文件, src/server/http/get_default_route.js:
import _ from 'lodash';
export default _.once(function (kbnServer) {
const {
config
} = kbnServer;
// 根目录basePath加上defaultRoute
return `${config.get('server.basePath')}${config.get('server.defaultRoute')}`;
});默认路由就是定义在server.defaultRoute中,默认值是app/kibana,可查看src/server/config/schema.js:
import Joi from 'joi';
import { constants as cryptoConstants } from 'crypto';
import os from 'os';
import { fromRoot } from '../../utils';
import { getData } from '../path';
export default async () => Joi.object({
pkg: Joi.object({
version: Joi.string().default(Joi.ref('$version')),
branch: Joi.string().default(Joi.ref('$branch')),
buildNum: Joi.number().default(Joi.ref('$buildNum')),
buildSha: Joi.string().default(Joi.ref('$buildSha')),
}).default(),
env: Joi.object({
name: Joi.string().default(Joi.ref('$env')),
dev: Joi.boolean().default(Joi.ref('$dev')),
prod: Joi.boolean().default(Joi.ref('$prod'))
}).default(),
dev: Joi.object({
basePathProxyTarget: Joi.number().default(5603),
}).default(),
pid: Joi.object({
file: Joi.string(),
exclusive: Joi.boolean().default(false)
}).default(),
cpu: Joi.object({
cgroup: Joi.object({
path: Joi.object({
override: Joi.string().default()
})
})
}),
cpuacct: Joi.object({
cgroup: Joi.object({
path: Joi.object({
override: Joi.string().default()
})
})
}),
server: Joi.object({
uuid: Joi.string().guid().default(),
name: Joi.string().default(os.hostname()),
host: Joi.string().hostname().default('localhost'),
port: Joi.number().default(5601),
maxPayloadBytes: Joi.number().default(1048576),
autoListen: Joi.boolean().default(true),
defaultRoute: Joi.string().default('/app/kibana').regex(/^\//, `start with a slash`),
basePath: Joi.string().default('').allow('').regex(/(^$|^\/.*[^\/]$)/, `start with a slash, don't end with one`),
rewriteBasePath: Joi.boolean().when('basePath', {
is: '',
then: Joi.default(false).valid(false),
otherwise: Joi.default(false),
}),
customResponseHeaders: Joi.object().unknown(true).default({}),
ssl: Joi.object({
enabled: Joi.boolean().default(false),
redirectHttpFromPort: Joi.number(),
certificate: Joi.string().when('enabled', {
is: true,
then: Joi.required(),
}),
key: Joi.string().when('enabled', {
is: true,
then: Joi.required()
}),
keyPassphrase: Joi.string(),
certificateAuthorities: Joi.array().single().items(Joi.string()).default(),
supportedProtocols: Joi.array().items(Joi.string().valid('TLSv1', 'TLSv1.1', 'TLSv1.2')),
cipherSuites: Joi.array().items(Joi.string()).default(cryptoConstants.defaultCoreCipherList.split(':'))
}).default(),
cors: Joi.when('$dev', {
is: true,
then: Joi.object().default({
origin: ['*://localhost:9876'] // karma test server
}),
otherwise: Joi.boolean().default(false)
}),
xsrf: Joi.object({
disableProtection: Joi.boolean().default(false),
whitelist: Joi.array().items(
Joi.string().regex(/^\//, 'start with a slash')
).default(),
token: Joi.string().optional().notes('Deprecated')
}).default(),
}).default(),
logging: Joi.object().keys({
silent: Joi.boolean().default(false),
quiet: Joi.boolean()
.when('silent', {
is: true,
then: Joi.default(true).valid(true),
otherwise: Joi.default(false)
}),
verbose: Joi.boolean()
.when('quiet', {
is: true,
then: Joi.valid(false).default(false),
otherwise: Joi.default(false)
}),
events: Joi.any().default({}),
dest: Joi.string().default('stdout'),
filter: Joi.any().default({}),
json: Joi.boolean()
.when('dest', {
is: 'stdout',
then: Joi.default(!process.stdout.isTTY),
otherwise: Joi.default(true)
}),
useUTC: Joi.boolean().default(true),
})
.default(),
ops: Joi.object({
interval: Joi.number().default(5000),
}).default(),
plugins: Joi.object({
paths: Joi.array().items(Joi.string()).default(),
scanDirs: Joi.array().items(Joi.string()).default(),
initialize: Joi.boolean().default(true)
}).default(),
path: Joi.object({
data: Joi.string().default(getData())
}).default(),
optimize: Joi.object({
enabled: Joi.boolean().default(true),
bundleFilter: Joi.string().default('!tests'),
bundleDir: Joi.string().default(fromRoot('optimize/bundles')),
viewCaching: Joi.boolean().default(Joi.ref('$prod')),
watch: Joi.boolean().default(false),
watchPort: Joi.number().default(5602),
watchHost: Joi.string().hostname().default('localhost'),
watchPrebuild: Joi.boolean().default(false),
watchProxyTimeout: Joi.number().default(5 * 60000),
useBundleCache: Joi.boolean().default(Joi.ref('$prod')),
unsafeCache: Joi.when('$prod', {
is: true,
then: Joi.boolean().valid(false),
otherwise: Joi
.alternatives()
.try(
Joi.boolean(),
Joi.string().regex(/^\/.+\/$/)
)
.default(true),
}),
sourceMaps: Joi.when('$prod', {
is: true,
then: Joi.boolean().valid(false),
otherwise: Joi
.alternatives()
.try(
Joi.string().required(),
Joi.boolean()
)
.default('#cheap-source-map'),
}),
profile: Joi.boolean().default(false)
}).default(),
status: Joi.object({
allowAnonymous: Joi.boolean().default(false)
}).default(),
map: Joi.object({
manifestServiceUrl: Joi.string().default(' https://catalogue.maps.elastic.co/v2/manifest'),
emsLandingPageUrl: Joi.string().default('https://maps.elastic.co/v2'),
includeElasticMapsService: Joi.boolean().default(true)
}).default(),
tilemap: Joi.object({
url: Joi.string(),
options: Joi.object({
attribution: Joi.string(),
minZoom: Joi.number().min(0, 'Must be 0 or higher').default(0),
maxZoom: Joi.number().default(10),
tileSize: Joi.number(),
subdomains: Joi.array().items(Joi.string()).single(),
errorTileUrl: Joi.string().uri(),
tms: Joi.boolean(),
reuseTiles: Joi.boolean(),
bounds: Joi.array().items(Joi.array().items(Joi.number()).min(2).required()).min(2)
}).default()
}).default(),
regionmap: Joi.object({
includeElasticMapsService: Joi.boolean().default(true),
layers: Joi.array().items(Joi.object({
url: Joi.string(),
format: Joi.object({
type: Joi.string().default('geojson')
}).default({
type: 'geojson'
}),
meta: Joi.object({
feature_collection_path: Joi.string().default('data')
}).default({
feature_collection_path: 'data'
}),
attribution: Joi.string(),
name: Joi.string(),
fields: Joi.array().items(Joi.object({
name: Joi.string(),
description: Joi.string()
}))
}))
}).default(),
i18n: Joi.object({
defaultLocale: Joi.string().default('en'),
}).default(),
// This is a configuration node that is specifically handled by the config system
// in the new platform, and that the current platform doesn't need to handle at all.
__newPlatform: Joi.any(),
}).default();如何让kibana零等待时间升级插件(前后端分离的部署)
正如官方文档所自豪宣称的那样。Kibana更多的是一个平台,一个可以让插件独立开发,“独立部署”的可扩展性平台,可以让我们自由的发挥自己的想象力和能力,根据自己的需求往上添加原生Kibana所不提供的功能。你可以开发一个新的app,也可以只部署一个后台服务,也可以是一个隐藏的跳转页面,这些,都有赖于plugin的方式,自由的在kibana上install, update和remove。
问题描述
以上。看起来是比较美好的,但硬币的反面是kibana作为一个单页应用,任何都其他功能都是"/"路径下都一个子path,任何插件的安装(除非是一个纯后台的服务,但我没有测试)都需要和主页面、所有已安装都插件产生联系,即每次插件都变动,都需要将所有的页面和js重新bundle一次。这个捆绑不是简单的捆绑,而是经过优化后的打包操作,相当耗时。重点是,按照目前的方式,optimize(bundle)的过程必须是现场的,即必须在正在运行的kibana服务器上进行,因此在以下情况下你可能会遇到麻烦:
- 你的kibana服务作为一个生产服务,不能停
- 你没有给kibana做双活
- 因为只是一个前端,你给kibana分配的硬件资源很少(单核2G,双核4G)
- 你使用的是6.3之后的版本,kibana已经默认安装了xpack。或者你是之前的版本,自己手动安装了xpack
这时,你若是安装或者更新插件(包括remove插件),都可能会因为optimize过程占用大量的cpu和内存资源,而造成kibana停止服务响应。
这里有一个小tips,如果你开发了多个插件,需要同时更新当时候,安装当时候请使用命令
kibana-plugin install --no-optimize file:///path_to_your_file,当全部的插件都安装完了之后,再重启kibana,一次性的执行optimize流程,或者通过bin/kibana --optimize命令触发
Kibana架构简述
如果我们的目标是让kibana零等待时间升级插件,找到解决方案的前提是我们能够了解Kibana的软件架构和部署方式。
首先,我们需要知道的是Kibana是一个基于node的web应用,前端后端都主要使用的javascript。web后端使用的hapi作为web服务器应用程序。并且node无需安装,已经包含在了kibana目录下。(node目录)
以下是kibana的目录,所有的插件都安装在plugins目录,而所有打包后的内容都放在optimize目录。
├── LICENSE.txt
├── NOTICE.txt
├── README.txt
├── bin
├── config
├── data
├── node
├── node_modules
├── optimize
├── package.json
├── plugins
├── src
└── webpackShimsplugins目录(这里,我有两个插件):
.
├── kibana_auth_plugin
│ ├── index.js
│ ├── node_modules
│ ├── package.json
│ ├── public
│ ├── server
│ └── yarn.lock
└── system_portal
├── index.js
├── node_modules
├── package.json
├── public
├── server
└── yarn.lock每个插件都是类似的目录结构。public目录存放的是前端的页面和js,server目录存放的是后端的js。这里最终要的信息是,插件的开发其实也是一种 前后端分离的架构 。插件安装后后端主程序会调用server目录下的文件,而前端public目录下的文件会被压缩后打包到optimize目录,详见如下。
optimize目录:
├── bundles
│ ├── 176bcca991b07a6ec908fc4d36ac5ae0.svg
│ ├── 45c73723862c6fc5eb3d6961db2d71fb.eot
│ ├── 4b5a84aaf1c9485e060c503a0ff8cadb.woff2
│ ├── 69d89e51f62b6a582c311c35c0f778aa.svg
│ ├── 76a4f23c6be74fd309e0d0fd2c27a5de.svg
│ ├── 7c87870ab40d63cfb8870c1f183f9939.ttf
│ ├── apm.bundle.js
│ ├── apm.entry.js
│ ├── apm.style.css
│ ├── kibana-auth-plugin.bundle.js
│ ├── kibana-auth-plugin.entry.js
│ ├── kibana-auth-plugin.style.css
│ ├── canvas.bundle.js
│ ├── canvas.entry.js
│ ├── canvas.style.css
│ ├── cc17a3dbad9fc4557b4d5d47a38fcc56.svg
│ ├── commons.bundle.js
│ ├── commons.style.css
│ ├── dashboardViewer.bundle.js
│ ├── dashboardViewer.entry.js
│ ├── dashboardViewer.style.css
│ ├── dfb02f8f6d0cedc009ee5887cc68f1f3.woff
│ ├── fa0bbd682c66f1187d48f74b33b5bbd0.svg
│ ├── graph.bundle.js
│ ├── graph.entry.js
│ ├── graph.style.css
│ ├── infra.bundle.js
│ ├── infra.entry.js
│ ├── infra.style.css
│ ├── kibana.bundle.js
│ ├── kibana.entry.js
│ ├── kibana.style.css
│ ├── ml.bundle.js
│ ├── ml.entry.js
│ ├── ml.style.css
│ ├── monitoring.bundle.js
│ ├── monitoring.entry.js
│ ├── monitoring.style.css
│ ├── space_selector.bundle.js
│ ├── space_selector.entry.js
│ ├── space_selector.style.css
│ ├── src
│ ├── stateSessionStorageRedirect.bundle.js
│ ├── stateSessionStorageRedirect.entry.js
│ ├── stateSessionStorageRedirect.style.css
│ ├── status_page.bundle.js
│ ├── status_page.entry.js
│ ├── status_page.style.css
│ ├── system_portal.bundle.js
│ ├── system_portal.entry.js
│ ├── system_portal.style.css
│ ├── timelion.bundle.js
│ ├── timelion.entry.js
│ ├── timelion.style.css
│ ├── vendors.bundle.js
│ └── vendors.style.css前端浏览器在访问"/"目录的时候会最先获取到kibana.*.js相关的文件。我们看一下
kibana.entry.js, 里面是包含了所有插件的信息的,即,每次插件的变动,这些文件也会跟着跟新
/**
* Kibana entry file
*
* This is programmatically created and updated, do not modify
*
* context: ä
"env": "production",
"kbnVersion": "6.5.0",
"buildNum": 18730,
"plugins": Ä
"apm",
"apm_oss",
"beats_management",
"kibana_auth_plugin",
"canvas",
"cloud",
"console",
"console_extensions",
"dashboard_mode",
"elasticsearch",
"graph",
"grokdebugger",
"index_management",
"infra",
"input_control_vis",
"inspector_views",
"kbn_doc_views",
"kbn_vislib_vis_types",
"kibana",
"kuery_autocomplete",
"license_management",
"logstash",
"markdown_vis",
"metric_vis",
"metrics",
"ml",
"monitoring",
"notifications",
"region_map",
"reporting",
"rollup",
"searchprofiler",
"spaces",
"state_session_storage_redirect",
"status_page",
"system_portal",
"table_vis",
"tagcloud",
"tile_map",
"tilemap",
"timelion",
"vega",
"watcher",
"xpack_main"
Å
å
*/
// import global polyfills before everything else
import 'babel-polyfill';
import 'custom-event-polyfill';
import 'whatwg-fetch';
import 'abortcontroller-polyfill';
import 'childnode-remove-polyfill';
import ä i18n å from 'Ékbn/i18n';
import ä CoreSystem å from '__kibanaCore__'
const injectedMetadata = JSON.parse(document.querySelector('kbn-injected-metadata').getAttribute('data'));
i18n.init(injectedMetadata.legacyMetadata.translations);
new CoreSystem(ä
injectedMetadata,
rootDomElement: document.body,
requireLegacyFiles: () => ä
require('plugins/kibana/kibana');
å
å).start()优化部署的方案(前后端分离的部署)
我们已经初步了解了kibana和kibana plugins的架构。那kibana插件的安装方案是怎么样的呢?
kibana为了简化我们的工作,只需要我们将打包好的源码丢给kibana,然后执行命令:kibana-plugin install file:///path_to_your_file,这样貌似省事,但也把所有的工作都丢给了kibana服务器去完成。
在kibana服务器性能不佳的情况下,这部分工作可能会造成服务中断。因此,我们要代替kibana服务器完成这部分工作,做一个前后端分离的部署。
后端部署
后端部署的速度是极快的,只需要把文件解压缩到具体目录就可以:
`kibana-plugin install --no-optimize file:///path_to_your_file`这里特别要注意: --no-optimize参数是必须的,这时,插件的安装只是一个解压的过程,不会让kibana服务器去做繁重的optimize工作。
注意,执行这一步之后,不能重启kibana服务器,否则会自动做optimize
前端部署
这里说的前端,主要是指bundle之后的内容。在你的开发环境上,安装插件。当插件安装完成后,把bundles目录整体打包(bundles.zip)。将打包好之后的内容,上传到kibana服务器,删除旧的optimize/bundles目录,把打包好的bundles目录解压到optimize目录下
注意,这里开发环境上的kibana版本,和kibana安装的插件必须是和生产环境上是一致的,否则会造成无法启动或者自动重做optimize
重启kibana服务器
当以上两步完成之后,重启kibana service即可,你会发现,内容已经更新,但是不会触发任何的optimize过程。
参考示例
以下是该过程的一个ansible playbook供大家参考
---
- name: deploy bundles zip
copy: src=bundles.zip dest={{kibana_home}}/optimize force=yes mode={{file_mask}}
- name: deploy system plugins zip
copy: src=system_portal-0.0.0.zip dest={{kibana_home}}/ force=yes mode={{file_mask}}
- name: deploy auth zip
copy: src=kibana_auth_plugin-6.5.0.zip dest={{kibana_home}}/ force=yes mode={{file_mask}}
- name: remove system plugin
shell: "{{kibana_home}}/bin/kibana-plugin remove system_portal"
ignore_errors: True
- name: remove auth plugin
shell: "{{kibana_home}}/bin/kibana-plugin remove kibana_auth_plugin"
ignore_errors: True
- name: install system plugin
shell: "{{kibana_home}}/bin/kibana-plugin install --no-optimize file://{{kibana_home}}/system_portal-0.0.0.zip"
register: install_state
- name: install auth plugin
shell: "{{kibana_home}}/bin/kibana-plugin install --no-optimize file://{{kibana_home}}/kibana_auth_plugin-6.5.0.zip"
register: install_state
# failed_when: "'Extraction complete' in install_state.stdout_lines"
- name: delete old bundls
file: dest={{kibana_home}}/optimize/bundles state=absent
- name: delete old bundls
unarchive:
src: "{{kibana_home}}/optimize/bundles.zip"
dest: "{{kibana_home}}/optimize/"
copy: no
group: "kibana"
owner: "kibana"
mode: "{{file_mask}}"
- name: delete zip files
file: dest={{kibana_home}}/optimize/bundles.zip state=absent
- name: restart kibana
become: yes
service: name={{kibana_init_script | basename}} state=restarted enabled=yes
正如官方文档所自豪宣称的那样。Kibana更多的是一个平台,一个可以让插件独立开发,“独立部署”的可扩展性平台,可以让我们自由的发挥自己的想象力和能力,根据自己的需求往上添加原生Kibana所不提供的功能。你可以开发一个新的app,也可以只部署一个后台服务,也可以是一个隐藏的跳转页面,这些,都有赖于plugin的方式,自由的在kibana上install, update和remove。
问题描述
以上。看起来是比较美好的,但硬币的反面是kibana作为一个单页应用,任何都其他功能都是"/"路径下都一个子path,任何插件的安装(除非是一个纯后台的服务,但我没有测试)都需要和主页面、所有已安装都插件产生联系,即每次插件都变动,都需要将所有的页面和js重新bundle一次。这个捆绑不是简单的捆绑,而是经过优化后的打包操作,相当耗时。重点是,按照目前的方式,optimize(bundle)的过程必须是现场的,即必须在正在运行的kibana服务器上进行,因此在以下情况下你可能会遇到麻烦:
- 你的kibana服务作为一个生产服务,不能停
- 你没有给kibana做双活
- 因为只是一个前端,你给kibana分配的硬件资源很少(单核2G,双核4G)
- 你使用的是6.3之后的版本,kibana已经默认安装了xpack。或者你是之前的版本,自己手动安装了xpack
这时,你若是安装或者更新插件(包括remove插件),都可能会因为optimize过程占用大量的cpu和内存资源,而造成kibana停止服务响应。
这里有一个小tips,如果你开发了多个插件,需要同时更新当时候,安装当时候请使用命令
kibana-plugin install --no-optimize file:///path_to_your_file,当全部的插件都安装完了之后,再重启kibana,一次性的执行optimize流程,或者通过bin/kibana --optimize命令触发
Kibana架构简述
如果我们的目标是让kibana零等待时间升级插件,找到解决方案的前提是我们能够了解Kibana的软件架构和部署方式。
首先,我们需要知道的是Kibana是一个基于node的web应用,前端后端都主要使用的javascript。web后端使用的hapi作为web服务器应用程序。并且node无需安装,已经包含在了kibana目录下。(node目录)
以下是kibana的目录,所有的插件都安装在plugins目录,而所有打包后的内容都放在optimize目录。
├── LICENSE.txt
├── NOTICE.txt
├── README.txt
├── bin
├── config
├── data
├── node
├── node_modules
├── optimize
├── package.json
├── plugins
├── src
└── webpackShimsplugins目录(这里,我有两个插件):
.
├── kibana_auth_plugin
│ ├── index.js
│ ├── node_modules
│ ├── package.json
│ ├── public
│ ├── server
│ └── yarn.lock
└── system_portal
├── index.js
├── node_modules
├── package.json
├── public
├── server
└── yarn.lock每个插件都是类似的目录结构。public目录存放的是前端的页面和js,server目录存放的是后端的js。这里最终要的信息是,插件的开发其实也是一种 前后端分离的架构 。插件安装后后端主程序会调用server目录下的文件,而前端public目录下的文件会被压缩后打包到optimize目录,详见如下。
optimize目录:
├── bundles
│ ├── 176bcca991b07a6ec908fc4d36ac5ae0.svg
│ ├── 45c73723862c6fc5eb3d6961db2d71fb.eot
│ ├── 4b5a84aaf1c9485e060c503a0ff8cadb.woff2
│ ├── 69d89e51f62b6a582c311c35c0f778aa.svg
│ ├── 76a4f23c6be74fd309e0d0fd2c27a5de.svg
│ ├── 7c87870ab40d63cfb8870c1f183f9939.ttf
│ ├── apm.bundle.js
│ ├── apm.entry.js
│ ├── apm.style.css
│ ├── kibana-auth-plugin.bundle.js
│ ├── kibana-auth-plugin.entry.js
│ ├── kibana-auth-plugin.style.css
│ ├── canvas.bundle.js
│ ├── canvas.entry.js
│ ├── canvas.style.css
│ ├── cc17a3dbad9fc4557b4d5d47a38fcc56.svg
│ ├── commons.bundle.js
│ ├── commons.style.css
│ ├── dashboardViewer.bundle.js
│ ├── dashboardViewer.entry.js
│ ├── dashboardViewer.style.css
│ ├── dfb02f8f6d0cedc009ee5887cc68f1f3.woff
│ ├── fa0bbd682c66f1187d48f74b33b5bbd0.svg
│ ├── graph.bundle.js
│ ├── graph.entry.js
│ ├── graph.style.css
│ ├── infra.bundle.js
│ ├── infra.entry.js
│ ├── infra.style.css
│ ├── kibana.bundle.js
│ ├── kibana.entry.js
│ ├── kibana.style.css
│ ├── ml.bundle.js
│ ├── ml.entry.js
│ ├── ml.style.css
│ ├── monitoring.bundle.js
│ ├── monitoring.entry.js
│ ├── monitoring.style.css
│ ├── space_selector.bundle.js
│ ├── space_selector.entry.js
│ ├── space_selector.style.css
│ ├── src
│ ├── stateSessionStorageRedirect.bundle.js
│ ├── stateSessionStorageRedirect.entry.js
│ ├── stateSessionStorageRedirect.style.css
│ ├── status_page.bundle.js
│ ├── status_page.entry.js
│ ├── status_page.style.css
│ ├── system_portal.bundle.js
│ ├── system_portal.entry.js
│ ├── system_portal.style.css
│ ├── timelion.bundle.js
│ ├── timelion.entry.js
│ ├── timelion.style.css
│ ├── vendors.bundle.js
│ └── vendors.style.css前端浏览器在访问"/"目录的时候会最先获取到kibana.*.js相关的文件。我们看一下
kibana.entry.js, 里面是包含了所有插件的信息的,即,每次插件的变动,这些文件也会跟着跟新
/**
* Kibana entry file
*
* This is programmatically created and updated, do not modify
*
* context: ä
"env": "production",
"kbnVersion": "6.5.0",
"buildNum": 18730,
"plugins": Ä
"apm",
"apm_oss",
"beats_management",
"kibana_auth_plugin",
"canvas",
"cloud",
"console",
"console_extensions",
"dashboard_mode",
"elasticsearch",
"graph",
"grokdebugger",
"index_management",
"infra",
"input_control_vis",
"inspector_views",
"kbn_doc_views",
"kbn_vislib_vis_types",
"kibana",
"kuery_autocomplete",
"license_management",
"logstash",
"markdown_vis",
"metric_vis",
"metrics",
"ml",
"monitoring",
"notifications",
"region_map",
"reporting",
"rollup",
"searchprofiler",
"spaces",
"state_session_storage_redirect",
"status_page",
"system_portal",
"table_vis",
"tagcloud",
"tile_map",
"tilemap",
"timelion",
"vega",
"watcher",
"xpack_main"
Å
å
*/
// import global polyfills before everything else
import 'babel-polyfill';
import 'custom-event-polyfill';
import 'whatwg-fetch';
import 'abortcontroller-polyfill';
import 'childnode-remove-polyfill';
import ä i18n å from 'Ékbn/i18n';
import ä CoreSystem å from '__kibanaCore__'
const injectedMetadata = JSON.parse(document.querySelector('kbn-injected-metadata').getAttribute('data'));
i18n.init(injectedMetadata.legacyMetadata.translations);
new CoreSystem(ä
injectedMetadata,
rootDomElement: document.body,
requireLegacyFiles: () => ä
require('plugins/kibana/kibana');
å
å).start()优化部署的方案(前后端分离的部署)
我们已经初步了解了kibana和kibana plugins的架构。那kibana插件的安装方案是怎么样的呢?
kibana为了简化我们的工作,只需要我们将打包好的源码丢给kibana,然后执行命令:kibana-plugin install file:///path_to_your_file,这样貌似省事,但也把所有的工作都丢给了kibana服务器去完成。
在kibana服务器性能不佳的情况下,这部分工作可能会造成服务中断。因此,我们要代替kibana服务器完成这部分工作,做一个前后端分离的部署。
后端部署
后端部署的速度是极快的,只需要把文件解压缩到具体目录就可以:
`kibana-plugin install --no-optimize file:///path_to_your_file`这里特别要注意: --no-optimize参数是必须的,这时,插件的安装只是一个解压的过程,不会让kibana服务器去做繁重的optimize工作。
注意,执行这一步之后,不能重启kibana服务器,否则会自动做optimize
前端部署
这里说的前端,主要是指bundle之后的内容。在你的开发环境上,安装插件。当插件安装完成后,把bundles目录整体打包(bundles.zip)。将打包好之后的内容,上传到kibana服务器,删除旧的optimize/bundles目录,把打包好的bundles目录解压到optimize目录下
注意,这里开发环境上的kibana版本,和kibana安装的插件必须是和生产环境上是一致的,否则会造成无法启动或者自动重做optimize
重启kibana服务器
当以上两步完成之后,重启kibana service即可,你会发现,内容已经更新,但是不会触发任何的optimize过程。
参考示例
以下是该过程的一个ansible playbook供大家参考
---
- name: deploy bundles zip
copy: src=bundles.zip dest={{kibana_home}}/optimize force=yes mode={{file_mask}}
- name: deploy system plugins zip
copy: src=system_portal-0.0.0.zip dest={{kibana_home}}/ force=yes mode={{file_mask}}
- name: deploy auth zip
copy: src=kibana_auth_plugin-6.5.0.zip dest={{kibana_home}}/ force=yes mode={{file_mask}}
- name: remove system plugin
shell: "{{kibana_home}}/bin/kibana-plugin remove system_portal"
ignore_errors: True
- name: remove auth plugin
shell: "{{kibana_home}}/bin/kibana-plugin remove kibana_auth_plugin"
ignore_errors: True
- name: install system plugin
shell: "{{kibana_home}}/bin/kibana-plugin install --no-optimize file://{{kibana_home}}/system_portal-0.0.0.zip"
register: install_state
- name: install auth plugin
shell: "{{kibana_home}}/bin/kibana-plugin install --no-optimize file://{{kibana_home}}/kibana_auth_plugin-6.5.0.zip"
register: install_state
# failed_when: "'Extraction complete' in install_state.stdout_lines"
- name: delete old bundls
file: dest={{kibana_home}}/optimize/bundles state=absent
- name: delete old bundls
unarchive:
src: "{{kibana_home}}/optimize/bundles.zip"
dest: "{{kibana_home}}/optimize/"
copy: no
group: "kibana"
owner: "kibana"
mode: "{{file_mask}}"
- name: delete zip files
file: dest={{kibana_home}}/optimize/bundles.zip state=absent
- name: restart kibana
become: yes
service: name={{kibana_init_script | basename}} state=restarted enabled=yes
为何要通过Kibana展示promethues的数据以及如何去做
Elastic stack不停的迭代中狂奔。在最新的V6.5版本发布后,我们可以发现,其路线图已经越来越倾向于成为一个全栈的,全链路的,从下至上,从底层硬件资源数据一直到上层用户数据,从资源监控,到性能监控,直至安全审计的智能化运维系统了。这其中解决的一个痛点是:企业中存在各种各样的业务系统,每个系统又存在不同的数据源和存储数据的数据库;同时在运维管理层面上,又各种不同的监控系统(资源监控,性能监控,安全和审计)以及上层的可视化系统。这样,导致运维人员需要面对繁多的系统、入口和数据维度,在处理问题时,需要登录不同的平台,并且无法对数据进行有效的关联分析,因此,是迫切需要一个强大的平台,能够快速便捷的处理这些问题的。 我们可以看到,从不停发布的beats,以及beats里面不停添加的modules:

以及支持的各种数据指标模版:

elastic stack在加速将越来越多的数据需要汇聚到一起,并且提供一个统一的接口进入,这就是Kibana。这里,我不打算深入的比较Kibana和Grafana,简单说一句,就是grafana的主要场景只是dashboard,并不适合将其用作一个将所有数据集中到一起,需要做各种维度的查询,分析,安全检查等功能的portal。所以,这里我们讨论的是Kibana上如何展示其他数据源的数据。
为什么是prometheus而不是beats
在这个人人上云的时代,无论是open stack还是K8S,最流行的资源监控软件我看到的是prometheus,特别是以node_exporter为基础的一系列metric采集工具,为prometheus提供了各种维度的监控数据。而对应的,elastic stack也提供了类似filebeat, metricbeat, packatbeat等一系列工具和对应的数据template。
我没有深入使用过prometheus,但作为一个beats的资深用户,我还是感觉到beats还存在诸多的问题,特别是filebeat上幽灵般存在的内存占用过多的问题,导致大规模在所有的节点上安装beats成为一种风险。并且,最主要的一个点,我觉得是beats采集的数据,是依赖于整个elastic stack进行展示的,而作为云的运维人员,其关心的重点是每个虚拟机,容器的资源监控情况,metric和alart是其重心,而非query,search,security等功能。并且安装一个prometheus,比安装整个elastic stack简便得多,消耗的资源也小的多。所以,普遍的,从主机运维人员的角度,肯定首选安装prometheus的exporter来作资源的监控,而非安装beats。
为什么Kibana上需要集成prometheus的数据
正因为之前所讲的,我们试图使用elastic stack作为一个多维度的统一的数据入口和展示工具,要求我们必须能在Kibana看到硬件资源监控级别的指标,而elastic stack提供的beats等工具,却并不为云运维人员所待见(因为他们更喜欢prometheus,而非elastic stack,原因见以上)。因此,如果我们需要将elastic stack打造为一套全栈的智能运维系统,大多数情况下,prometheus成为必须跨越的一个槛。
将prometheus上的数据转移到elasticsearch
这是我想到的第一个解决方案。可惜logstash上没有prometheus的input plugins。所以,我们还是需要beats。注意,在metricbeat上有一个prometheus的module,号称可以 fetch metric from prometheus exporter,但实际上只是一个乌龙,这个module的并不能从成千上万的云主机或者容器中拉取数据,它能做的只是获取prometheus服务器节点prometheus这个进程的基本数据,然并卵。 这里给大家介绍的是两个社区提供prometheus相关的beats:
但建议大家还是自己写一个beat吧,代码可以参考prombeat。 不过如果你仔细观看prometheus里面的数据,都是num type的,将其转存到elasticsearch绝对不是一个经济的选择:

将grafana集成到kibana中
这是为什么我在一开始提到了grafana,虽然它不适合做portal,但是极其适合做dashboard,而kibana又是如此的开放,随便做个插件,可以轻松的跳转到grafana的dashboard上。而grafana与prometheus又是如此的登对,看看grafana上的各种专业而美丽的prometheus的dashboard吧:

我们要做的是做一个kibana的插件,然后将关键参数传递给grafana,并跳转:

虽然kibana和grafana是两个不同的工具,但并不妨碍我们将它们放在一起工作。而Kibana的开放性和基于插件的独立开发模式,让我们可以更方便的将各种好用的开源工具集成到一起,这里展示的Kibana与grafana和promethues的集成,希望能给到你一些微光。
Elastic stack不停的迭代中狂奔。在最新的V6.5版本发布后,我们可以发现,其路线图已经越来越倾向于成为一个全栈的,全链路的,从下至上,从底层硬件资源数据一直到上层用户数据,从资源监控,到性能监控,直至安全审计的智能化运维系统了。这其中解决的一个痛点是:企业中存在各种各样的业务系统,每个系统又存在不同的数据源和存储数据的数据库;同时在运维管理层面上,又各种不同的监控系统(资源监控,性能监控,安全和审计)以及上层的可视化系统。这样,导致运维人员需要面对繁多的系统、入口和数据维度,在处理问题时,需要登录不同的平台,并且无法对数据进行有效的关联分析,因此,是迫切需要一个强大的平台,能够快速便捷的处理这些问题的。 我们可以看到,从不停发布的beats,以及beats里面不停添加的modules:
以及支持的各种数据指标模版:
elastic stack在加速将越来越多的数据需要汇聚到一起,并且提供一个统一的接口进入,这就是Kibana。这里,我不打算深入的比较Kibana和Grafana,简单说一句,就是grafana的主要场景只是dashboard,并不适合将其用作一个将所有数据集中到一起,需要做各种维度的查询,分析,安全检查等功能的portal。所以,这里我们讨论的是Kibana上如何展示其他数据源的数据。
为什么是prometheus而不是beats
在这个人人上云的时代,无论是open stack还是K8S,最流行的资源监控软件我看到的是prometheus,特别是以node_exporter为基础的一系列metric采集工具,为prometheus提供了各种维度的监控数据。而对应的,elastic stack也提供了类似filebeat, metricbeat, packatbeat等一系列工具和对应的数据template。
我没有深入使用过prometheus,但作为一个beats的资深用户,我还是感觉到beats还存在诸多的问题,特别是filebeat上幽灵般存在的内存占用过多的问题,导致大规模在所有的节点上安装beats成为一种风险。并且,最主要的一个点,我觉得是beats采集的数据,是依赖于整个elastic stack进行展示的,而作为云的运维人员,其关心的重点是每个虚拟机,容器的资源监控情况,metric和alart是其重心,而非query,search,security等功能。并且安装一个prometheus,比安装整个elastic stack简便得多,消耗的资源也小的多。所以,普遍的,从主机运维人员的角度,肯定首选安装prometheus的exporter来作资源的监控,而非安装beats。
为什么Kibana上需要集成prometheus的数据
正因为之前所讲的,我们试图使用elastic stack作为一个多维度的统一的数据入口和展示工具,要求我们必须能在Kibana看到硬件资源监控级别的指标,而elastic stack提供的beats等工具,却并不为云运维人员所待见(因为他们更喜欢prometheus,而非elastic stack,原因见以上)。因此,如果我们需要将elastic stack打造为一套全栈的智能运维系统,大多数情况下,prometheus成为必须跨越的一个槛。
将prometheus上的数据转移到elasticsearch
这是我想到的第一个解决方案。可惜logstash上没有prometheus的input plugins。所以,我们还是需要beats。注意,在metricbeat上有一个prometheus的module,号称可以 fetch metric from prometheus exporter,但实际上只是一个乌龙,这个module的并不能从成千上万的云主机或者容器中拉取数据,它能做的只是获取prometheus服务器节点prometheus这个进程的基本数据,然并卵。 这里给大家介绍的是两个社区提供prometheus相关的beats:
但建议大家还是自己写一个beat吧,代码可以参考prombeat。 不过如果你仔细观看prometheus里面的数据,都是num type的,将其转存到elasticsearch绝对不是一个经济的选择:
将grafana集成到kibana中
这是为什么我在一开始提到了grafana,虽然它不适合做portal,但是极其适合做dashboard,而kibana又是如此的开放,随便做个插件,可以轻松的跳转到grafana的dashboard上。而grafana与prometheus又是如此的登对,看看grafana上的各种专业而美丽的prometheus的dashboard吧:
我们要做的是做一个kibana的插件,然后将关键参数传递给grafana,并跳转:
虽然kibana和grafana是两个不同的工具,但并不妨碍我们将它们放在一起工作。而Kibana的开放性和基于插件的独立开发模式,让我们可以更方便的将各种好用的开源工具集成到一起,这里展示的Kibana与grafana和promethues的集成,希望能给到你一些微光。
收起阅读 »用elasitc stack监控kafka
当我们搭建elasitc stack集群时,大多数时候会在我们的架构中加入kafka作为消息缓冲区,即从beats -> kafka -> logstash -> elasticsearch这样的一个消息流。使用kafka可以给我们带来很多便利,但是也让我们需要额外多维护一套组件,elasitc stack本身已经提供了monitoring的功能,我们可以方便的从kibana上监控各个组件中各节点的可用性,吞吐和性能等各种指标,但kafka作为架构中的组件之一却游离在监控之外,相当不合理。
幸而elastic真的是迭代的相当快,在metricbeat上很早就有了对kafka的监控,但一直没有一个直观的dashboard,终于在6.5版本上,上新了kafka dashboard。我们来看一下吧。
安装和配置metricbeat
安装包下载地址,下载后,自己安装。
然后,将/etc/metricbeat/modules.d/kafka.yml.disable文件重命名为/etc/metricbeat/modules.d/kafka.yml。(即打开kafka的监控)。稍微修改一下文件内容, 注意,这里需填入所有你需要监控的kafka服务器的地址:
# Module: kafka
# Docs: https://www.elastic.co/guide/en/beats/metricbeat/6.4/metricbeat-module-kafka.html
- module: kafka
metricsets:
- partition
- consumergroup
period: 20s
hosts: ["10.*.*.*:9092","10.*.*.*:9092","10.*.*.*:9092","10.*.*.*:9092"]
#client_id: metricbeat
#retries: 3
#backoff: 250ms
# List of Topics to query metadata for. If empty, all topics will be queried.
#topics: []
# Optional SSL. By default is off.
# List of root certificates for HTTPS server verifications
#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]
# Certificate for SSL client authentication
#ssl.certificate: "/etc/pki/client/cert.pem"
# Client Certificate Key
#ssl.key: "/etc/pki/client/cert.key"
# SASL authentication
#username: ""
#password: ""运行metricbeat,这里,一定要注意enable kibana dashboard。
然后就可以在kibana里面看到:


这样,我们就可以通过sentinl等类似的插件,自动做kafka的告警等功能了
当我们搭建elasitc stack集群时,大多数时候会在我们的架构中加入kafka作为消息缓冲区,即从beats -> kafka -> logstash -> elasticsearch这样的一个消息流。使用kafka可以给我们带来很多便利,但是也让我们需要额外多维护一套组件,elasitc stack本身已经提供了monitoring的功能,我们可以方便的从kibana上监控各个组件中各节点的可用性,吞吐和性能等各种指标,但kafka作为架构中的组件之一却游离在监控之外,相当不合理。
幸而elastic真的是迭代的相当快,在metricbeat上很早就有了对kafka的监控,但一直没有一个直观的dashboard,终于在6.5版本上,上新了kafka dashboard。我们来看一下吧。
安装和配置metricbeat
安装包下载地址,下载后,自己安装。
然后,将/etc/metricbeat/modules.d/kafka.yml.disable文件重命名为/etc/metricbeat/modules.d/kafka.yml。(即打开kafka的监控)。稍微修改一下文件内容, 注意,这里需填入所有你需要监控的kafka服务器的地址:
# Module: kafka
# Docs: https://www.elastic.co/guide/en/beats/metricbeat/6.4/metricbeat-module-kafka.html
- module: kafka
metricsets:
- partition
- consumergroup
period: 20s
hosts: ["10.*.*.*:9092","10.*.*.*:9092","10.*.*.*:9092","10.*.*.*:9092"]
#client_id: metricbeat
#retries: 3
#backoff: 250ms
# List of Topics to query metadata for. If empty, all topics will be queried.
#topics: []
# Optional SSL. By default is off.
# List of root certificates for HTTPS server verifications
#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]
# Certificate for SSL client authentication
#ssl.certificate: "/etc/pki/client/cert.pem"
# Client Certificate Key
#ssl.key: "/etc/pki/client/cert.key"
# SASL authentication
#username: ""
#password: ""运行metricbeat,这里,一定要注意enable kibana dashboard。
然后就可以在kibana里面看到:
这样,我们就可以通过sentinl等类似的插件,自动做kafka的告警等功能了
收起阅读 »Kibana优化过程(Optimize)过长或无法结束的解决方案
使用过Kibana的同学应该都知道,当我们在kibana的配置文件中打开或者关闭功能,或者安装、卸载额外的插件后,重启kibana会触发一个优化的过程(optimize),如下图:

这个过程或长或短,视你电脑的性能而定。这里简单介绍一下该过程所要完成的事情。
Kibana是一个单页Web应用
首先,Kibana是一个单页的web应用。何为单页web应用?即所有的页面的读取都是在浏览器上完成,而与后台服务器无关。与后台服务器的通信只关乎数据,而非页面。所以,应用上所有的UI都被打包在一起,一次性的发送到了浏览器端,而不是通过URL到后台进行获取。所以,我们看到kibana的首页是下面这样的:
http://localhost:5601/app/kibana#/
注意这里的#后,代表#后面的内容会被浏览器提取,不往服务器端进行url的情况,而是在浏览器上进行内部重新渲染。因为所有的页面都是存储在浏览器的,所有在初次访问的时候,会加载大量的代码到浏览器端,这些代码都是被压缩过的bundle文件:

而optimize的过程,就是把这些原本可读性的源代码压缩为bundle.js的过程。因此,每当你对Kibana进行裁剪之后重启,因为前端的部分是完全由浏览器负责的,所有bundle文件需要重新生成后再发给浏览器,所以会触发optimize的过程。
Kibana在6.2.0版本之后,常规版本已经默认自带了xpack(当然,你还是可以直接下载不带xpack的开源社区版),导致Kibana的size已经到了200M左右,而且越往后的版本,功能越多,代码量越大,每次optimize的过程都会耗费更多的时间。一般来说,我们会将Kibana部署在单独的机器上,因为这仅仅是一个web后端,通常我们不会分配比较优质的资源,(2C4G都算浪费的了),这种情况下面,每次我们裁剪后重启Kibana都会耗费半个小时~1个小时的时间,更有甚者直接hang住,查看系统日志才知道OOM了。
Nodejs的内存机制
Kibana是用Nodejs编写的程序,在一般的后端语言中,基本的内存使用上基本没有什么限制,但是在nodeJs中却只能使用部分内存。在64位系统下位约为1.4G,在32位系统下约为0.7G,造成这个问题的主要原因是因为nodeJs基于V8构建,V8使用自己的方式来管理和分配内存,这一套管理方式在浏览器端使用绰绰有余,但是在nodeJs中这却限制了开发者,在应用中如果碰到了这个限制,就会造成进程退出。
Nodejs内存机制对Kibana优化的影响
因为Kibana的代码体量越来越大,将所有的代码加载到内存之后,再解析语法树,进行bundle的转换所耗费的内存已经接近1.4G的限制了,当你安装更多插件,比如sentinl的时候,系统往往已经无法为继,导致Kibana无法启动
解决方案
这种情况下,我们需要在Kibana启动的时候,指定NodeJs使用更多的内存。这个可以通过设置Node的环境变量办到。
NODE_OPTIONS="--max-old-space-size=4096"当然,我的建议是直接指定在kibana的启动脚本当中,修改/usr/share/kibana/bin/kibana文件为:
#!/bin/sh
SCRIPT=$0
# SCRIPT may be an arbitrarily deep series of symlinks. Loop until we have the concrete path.
while [ -h "$SCRIPT" ] ; do
ls=$(ls -ld "$SCRIPT")
# Drop everything prior to ->
link=$(expr "$ls" : '.*-> \(.*\)$')
if expr "$link" : '/.*' > /dev/null; then
SCRIPT="$link"
else
SCRIPT=$(dirname "$SCRIPT")/"$link"
fi
done
DIR="$(dirname "${SCRIPT}")/.."
NODE="${DIR}/node/bin/node"
test -x "$NODE" || NODE=$(which node)
if [ ! -x "$NODE" ]; then
echo "unable to find usable node.js executable."
exit 1
fi
NODE_ENV=production exec "${NODE}" $NODE_OPTIONS --max_old_space_size=3072 --no-warnings "${DIR}/src/cli" ${@}
改动在最后一句:NODE_ENV=production exec "${NODE}" $NODE_OPTIONS --max_old_space_size=3072 --no-warnings "${DIR}/src/cli" ${@}
这样,我们可以保证Kibana能顺利的完成optimize的过程
使用过Kibana的同学应该都知道,当我们在kibana的配置文件中打开或者关闭功能,或者安装、卸载额外的插件后,重启kibana会触发一个优化的过程(optimize),如下图:
这个过程或长或短,视你电脑的性能而定。这里简单介绍一下该过程所要完成的事情。
Kibana是一个单页Web应用
首先,Kibana是一个单页的web应用。何为单页web应用?即所有的页面的读取都是在浏览器上完成,而与后台服务器无关。与后台服务器的通信只关乎数据,而非页面。所以,应用上所有的UI都被打包在一起,一次性的发送到了浏览器端,而不是通过URL到后台进行获取。所以,我们看到kibana的首页是下面这样的:
http://localhost:5601/app/kibana#/
注意这里的#后,代表#后面的内容会被浏览器提取,不往服务器端进行url的情况,而是在浏览器上进行内部重新渲染。因为所有的页面都是存储在浏览器的,所有在初次访问的时候,会加载大量的代码到浏览器端,这些代码都是被压缩过的bundle文件:
而optimize的过程,就是把这些原本可读性的源代码压缩为bundle.js的过程。因此,每当你对Kibana进行裁剪之后重启,因为前端的部分是完全由浏览器负责的,所有bundle文件需要重新生成后再发给浏览器,所以会触发optimize的过程。
Kibana在6.2.0版本之后,常规版本已经默认自带了xpack(当然,你还是可以直接下载不带xpack的开源社区版),导致Kibana的size已经到了200M左右,而且越往后的版本,功能越多,代码量越大,每次optimize的过程都会耗费更多的时间。一般来说,我们会将Kibana部署在单独的机器上,因为这仅仅是一个web后端,通常我们不会分配比较优质的资源,(2C4G都算浪费的了),这种情况下面,每次我们裁剪后重启Kibana都会耗费半个小时~1个小时的时间,更有甚者直接hang住,查看系统日志才知道OOM了。
Nodejs的内存机制
Kibana是用Nodejs编写的程序,在一般的后端语言中,基本的内存使用上基本没有什么限制,但是在nodeJs中却只能使用部分内存。在64位系统下位约为1.4G,在32位系统下约为0.7G,造成这个问题的主要原因是因为nodeJs基于V8构建,V8使用自己的方式来管理和分配内存,这一套管理方式在浏览器端使用绰绰有余,但是在nodeJs中这却限制了开发者,在应用中如果碰到了这个限制,就会造成进程退出。
Nodejs内存机制对Kibana优化的影响
因为Kibana的代码体量越来越大,将所有的代码加载到内存之后,再解析语法树,进行bundle的转换所耗费的内存已经接近1.4G的限制了,当你安装更多插件,比如sentinl的时候,系统往往已经无法为继,导致Kibana无法启动
解决方案
这种情况下,我们需要在Kibana启动的时候,指定NodeJs使用更多的内存。这个可以通过设置Node的环境变量办到。
NODE_OPTIONS="--max-old-space-size=4096"当然,我的建议是直接指定在kibana的启动脚本当中,修改/usr/share/kibana/bin/kibana文件为:
#!/bin/sh
SCRIPT=$0
# SCRIPT may be an arbitrarily deep series of symlinks. Loop until we have the concrete path.
while [ -h "$SCRIPT" ] ; do
ls=$(ls -ld "$SCRIPT")
# Drop everything prior to ->
link=$(expr "$ls" : '.*-> \(.*\)$')
if expr "$link" : '/.*' > /dev/null; then
SCRIPT="$link"
else
SCRIPT=$(dirname "$SCRIPT")/"$link"
fi
done
DIR="$(dirname "${SCRIPT}")/.."
NODE="${DIR}/node/bin/node"
test -x "$NODE" || NODE=$(which node)
if [ ! -x "$NODE" ]; then
echo "unable to find usable node.js executable."
exit 1
fi
NODE_ENV=production exec "${NODE}" $NODE_OPTIONS --max_old_space_size=3072 --no-warnings "${DIR}/src/cli" ${@}
改动在最后一句:NODE_ENV=production exec "${NODE}" $NODE_OPTIONS --max_old_space_size=3072 --no-warnings "${DIR}/src/cli" ${@}
这样,我们可以保证Kibana能顺利的完成optimize的过程
收起阅读 »