

信创环境下部署 INFINI Console:一站式搭建搜索基础设施统一管控平台
引言
在前面的文章中,我们分别进行了 Easysearch 在信创环境下的部署 以及 INFINI Gateway 数据网关的部署。到目前为止,整套搜索服务体系的核心组件已经就位 —— Easysearch 负责存储和检索,Gateway 负责进行流量管控。
但你可能注意到一个问题:Easysearch 虽然有着自己的管理界面。但随着集群数量增多、业务变得更加复杂,管理者不得不在多个系统之间切换,效率低下且容易遗漏告警。有没有一个 “管理中枢” ,将所有搜索集群统一纳管,一站式完成监控、告警、安全审计和数据探索?
这正是 INFINI Console 要解决的问题。本文将延续“小白友好”风格,带你完成系列第四篇——部署 INFINI Console,用它为整个搜索服务体系装上统一的“指挥中心”。
一、INFINI Console 是什么?为什么需要它?
1. 精准定位
INFINI Console 是一款 轻量级、跨版本、多集群的搜索基础设施统一管控平台,也是整个极限科技产品体系中承担“可观测性与集中管理”角色的核心组件。它可以将不同业务、不同版本的多个 Easysearch 或 Elasticsearch 集群集中纳管,让管理者和运维人员在一个平台上完成日常运维工作。

2. 它能做什么?
INFINI Console 的核心能力可以概括为以下五大板块:
- 平台管理:在一个平台内统一纳管任意多套 Easysearch / Elasticsearch 集群,支持跨版本(5.x 到 8.x)、跨云混合部署,新集群动态注册接入,目标集群无需安装任何插件。
- 可观察性监控:一键开启对目标集群的全维度监控,覆盖集群、节点、索引等级的详细指标,慢查询、异常日志、集群动态一览无余,帮你快速定位问题、缩短故障时间。
- 主动告警:支持灵活的告警规则配置,7×24 小时自动巡检集群关键指标和业务数据,一旦触发阈值立即通知,让你从“被动等故障”变成“主动防问题”。
- 安全审计:支持企业级 LDAP、AD、SSO 对接,提供集群、索引、字段、文档级别的统一访问控制,支持查询请求审计与分析,可智能识别和阻断异常查询。
- 开发者工具与数据探索:内置智能语法提示、多集群工作区、常用指令快捷加载,支持索引管理、数据浏览、文档编辑、时序数据快速查看等功能。
3. 轻量级特性
INFINI Console 使用 Golang 编写,安装包非常小,只有约 11MB,没有任何外部环境依赖(除了需要一个 Easysearch 或 Elasticsearch 集群作为存储后端),部署安装非常简单,只需下载对应平台的二进制可执行文件,启动即可。
此外,INFINI Console 已经通过了华为鲲鹏 Kunpeng 920 兼容性认证和统信 UOS 适配认证,并获得了 KUNPENG COMPATIBLE 证书,在信创环境下的稳定性和兼容性得到了官方验证.
二、部署前提
1. 环境前提:需要一个 Easysearch 集群作为“系统集群”
Console 本身不存储业务数据,但它需要将自身的配置信息(用户、角色、告警规则、监控数据等)存储到一个 Easysearch 集群中,这个集群被称为 “系统集群” 。
如果你已经按照本系列前面的文章Easysearch 在信创环境下的部署 安装了 Easysearch ,可以直接用它作为系统集群。而在部署 Console 之前,请确保该集群已正常启动:
curl -ku admin:你的密码 https://localhost:92002. 确认 CPU 架构
先确认你的信创服务器架构:
uname -m本文示例使用的信创环境为:
- CPU :鲲鹏 Kunpeng-920、aarch64
- 操作系统:统信服务器操作系统A版 V20
三、部署流程
步骤 1:下载 INFINI Console
使用命令下载
#创建文件安装目录
mkdir -p /opt/console
# 一键下载并安装到 /opt/console
curl -sSL http://get.infini.cloud | bash -s -- -p console -d /opt/console
步骤 2:修改配置文件
安装好后在安装目录下得到可执行程序 console-linux-arm64 与配置文件 console.yml,修改配置文件
network:
#找到 network 下的 binding 项,修改为想要放置服务的端点(默认为 9000)
bingding:9001步骤 3:启动程序
进入程序安装路径,运行可执行程序,首次运行建议直接运行程序启动,方便查看运行日志
#进入程序安装目录下
cd /opt/console
#运行可执行程序(console-linux-arm64 为可执行程序名)
./console-linux-arm64
从上述启动信息来看,意味着程序已经成功运行并监听了 9001 端口
如果想要关闭程序,按住 :Ctrl+C
如果想将 Console 作为后台任务运行,请执行以下命令:
./console-linux-arm64 -service install
./console-linux-arm64 -service start若是想要卸载服务的话,执行下列命令即可:
./console-linux-arm64 -service stop
./console-linux-arm64 -service uninstall步骤 4:程序初始化
在浏览器中输入地址:http://0.0.0.0:9001,首次访问会自动进入初始化流程
连接已安装的集群

进行初始化系统索引和模板

设置用户,可以选择重置管理员账户

初始化完成,请妥善保存账号数据避免遗失

初始化流程结束后会回到登录界面,此时就可以使用设置好的账号信息进行登录

登陆后进入工作台页面

总结
到这里,你已经完成了 INFINI Console 在信创平台上的部署与初步上手。我们回顾一下整个流程:
- 确认环境 — Easysearch 已启动,明确 CPU 架构;
- 下载安装 — 执行命令一键下载与安装;
- 编写配置 — 修改配置文件
console.yml,指定服务监听地址; - 启动服务 — 先前台验证,再以后台模式运行;
- 初始化 — 浏览器访问服务端口,创建管理员账号;
- 注册集群 — 将 Easysearch 集群接入 Console,开启监控和管理。
部署完成后,你就拥有了一个统一的搜索服务管理中枢,可以在一个界面内完成多集群的监控、告警、安全审计和数据探索。
如果在部署过程中遇到困难,欢迎查阅官方文档。祝你部署顺利!
引言
在前面的文章中,我们分别进行了 Easysearch 在信创环境下的部署 以及 INFINI Gateway 数据网关的部署。到目前为止,整套搜索服务体系的核心组件已经就位 —— Easysearch 负责存储和检索,Gateway 负责进行流量管控。
但你可能注意到一个问题:Easysearch 虽然有着自己的管理界面。但随着集群数量增多、业务变得更加复杂,管理者不得不在多个系统之间切换,效率低下且容易遗漏告警。有没有一个 “管理中枢” ,将所有搜索集群统一纳管,一站式完成监控、告警、安全审计和数据探索?
这正是 INFINI Console 要解决的问题。本文将延续“小白友好”风格,带你完成系列第四篇——部署 INFINI Console,用它为整个搜索服务体系装上统一的“指挥中心”。
一、INFINI Console 是什么?为什么需要它?
1. 精准定位
INFINI Console 是一款 轻量级、跨版本、多集群的搜索基础设施统一管控平台,也是整个极限科技产品体系中承担“可观测性与集中管理”角色的核心组件。它可以将不同业务、不同版本的多个 Easysearch 或 Elasticsearch 集群集中纳管,让管理者和运维人员在一个平台上完成日常运维工作。
2. 它能做什么?
INFINI Console 的核心能力可以概括为以下五大板块:
- 平台管理:在一个平台内统一纳管任意多套 Easysearch / Elasticsearch 集群,支持跨版本(5.x 到 8.x)、跨云混合部署,新集群动态注册接入,目标集群无需安装任何插件。
- 可观察性监控:一键开启对目标集群的全维度监控,覆盖集群、节点、索引等级的详细指标,慢查询、异常日志、集群动态一览无余,帮你快速定位问题、缩短故障时间。
- 主动告警:支持灵活的告警规则配置,7×24 小时自动巡检集群关键指标和业务数据,一旦触发阈值立即通知,让你从“被动等故障”变成“主动防问题”。
- 安全审计:支持企业级 LDAP、AD、SSO 对接,提供集群、索引、字段、文档级别的统一访问控制,支持查询请求审计与分析,可智能识别和阻断异常查询。
- 开发者工具与数据探索:内置智能语法提示、多集群工作区、常用指令快捷加载,支持索引管理、数据浏览、文档编辑、时序数据快速查看等功能。
3. 轻量级特性
INFINI Console 使用 Golang 编写,安装包非常小,只有约 11MB,没有任何外部环境依赖(除了需要一个 Easysearch 或 Elasticsearch 集群作为存储后端),部署安装非常简单,只需下载对应平台的二进制可执行文件,启动即可。
此外,INFINI Console 已经通过了华为鲲鹏 Kunpeng 920 兼容性认证和统信 UOS 适配认证,并获得了 KUNPENG COMPATIBLE 证书,在信创环境下的稳定性和兼容性得到了官方验证.
二、部署前提
1. 环境前提:需要一个 Easysearch 集群作为“系统集群”
Console 本身不存储业务数据,但它需要将自身的配置信息(用户、角色、告警规则、监控数据等)存储到一个 Easysearch 集群中,这个集群被称为 “系统集群” 。
如果你已经按照本系列前面的文章Easysearch 在信创环境下的部署 安装了 Easysearch ,可以直接用它作为系统集群。而在部署 Console 之前,请确保该集群已正常启动:
curl -ku admin:你的密码 https://localhost:92002. 确认 CPU 架构
先确认你的信创服务器架构:
uname -m本文示例使用的信创环境为:
- CPU :鲲鹏 Kunpeng-920、aarch64
- 操作系统:统信服务器操作系统A版 V20
三、部署流程
步骤 1:下载 INFINI Console
使用命令下载
#创建文件安装目录
mkdir -p /opt/console
# 一键下载并安装到 /opt/console
curl -sSL http://get.infini.cloud | bash -s -- -p console -d /opt/console
步骤 2:修改配置文件
安装好后在安装目录下得到可执行程序 console-linux-arm64 与配置文件 console.yml,修改配置文件
network:
#找到 network 下的 binding 项,修改为想要放置服务的端点(默认为 9000)
bingding:9001步骤 3:启动程序
进入程序安装路径,运行可执行程序,首次运行建议直接运行程序启动,方便查看运行日志
#进入程序安装目录下
cd /opt/console
#运行可执行程序(console-linux-arm64 为可执行程序名)
./console-linux-arm64
从上述启动信息来看,意味着程序已经成功运行并监听了 9001 端口
如果想要关闭程序,按住 :Ctrl+C
如果想将 Console 作为后台任务运行,请执行以下命令:
./console-linux-arm64 -service install
./console-linux-arm64 -service start若是想要卸载服务的话,执行下列命令即可:
./console-linux-arm64 -service stop
./console-linux-arm64 -service uninstall步骤 4:程序初始化
在浏览器中输入地址:http://0.0.0.0:9001,首次访问会自动进入初始化流程
连接已安装的集群
进行初始化系统索引和模板
设置用户,可以选择重置管理员账户
初始化完成,请妥善保存账号数据避免遗失
初始化流程结束后会回到登录界面,此时就可以使用设置好的账号信息进行登录
登陆后进入工作台页面
总结
到这里,你已经完成了 INFINI Console 在信创平台上的部署与初步上手。我们回顾一下整个流程:
- 确认环境 — Easysearch 已启动,明确 CPU 架构;
- 下载安装 — 执行命令一键下载与安装;
- 编写配置 — 修改配置文件
console.yml,指定服务监听地址; - 启动服务 — 先前台验证,再以后台模式运行;
- 初始化 — 浏览器访问服务端口,创建管理员账号;
- 注册集群 — 将 Easysearch 集群接入 Console,开启监控和管理。
部署完成后,你就拥有了一个统一的搜索服务管理中枢,可以在一个界面内完成多集群的监控、告警、安全审计和数据探索。
如果在部署过程中遇到困难,欢迎查阅官方文档。祝你部署顺利!
收起阅读 »Wayland 的架构之困:当合成器与窗口管理器解耦之后
Linux 桌面生态正在经历一场静默的架构革命。
过去十年,Wayland 作为 X11 的继任者被寄予厚望,却迟迟未能完全接管桌面市场。其中一个被忽视的原因,或许藏在它的架构设计里——传统 Wayland 合成器(Compositor)采用了与 X11 时代截然不同的单体架构,将显示服务器、合成器和窗口管理器三个角色强行捆绑在一起。
这种设计解决了 X11 的延迟问题,却制造了新的麻烦:如果你想换一个窗口管理器,就必须重写整个 Wayland 合成器。
被忽视的架构债务
让我们先看看 X11 时代的分工:
- X Server 负责与内核交互,处理输入事件和缓冲区
- Compositor 负责将多个窗口的缓冲区合成为一帧画面
- Window Manager 负责窗口布局、快捷键、用户交互策略
这种分离架构的问题很明显:当用户点击一个按钮时,输入事件要在 X Server、Compositor、Window Manager 之间来回传递,每一次跨进程通信都在增加延迟。
Wayland 的解决方案是"一刀切"——把三个角色合并到一个进程里。这确实消除了延迟,但也带来了意想不到的副作用。
单体架构的隐性成本
想象一下这个场景:你喜欢 i3wm 的平铺布局,却看中了 Hyprland 的动画效果。在 X11 时代,你可以自由组合:用 i3wm 管理窗口,用 picom 做合成。但在 Wayland 世界里,这是不可能的。
每一个 Wayland 合成器都在重复造轮子:
- Sway 实现了 i3 的平铺逻辑,但必须从头写一套 Wayland 合成代码
- Hyprland 做出了漂亮的动画,却无法被其他窗口管理器复用
- 开发者想要自定义窗口管理策略,必须 fork 整个合成器
这种架构的隐性成本是:创新被锁定在单体边界内,无法像 X11 时代那样自由组合最佳组件。
River 的解耦实验
River 项目正在尝试一条不同的路。
它的核心洞察是:Wayland 解决的是 X11 的延迟问题,但并不意味着窗口管理器必须与合成器绑定。真正需要合并的只有显示服务器和合成器——这两个角色决定了帧延迟。窗口管理器完全可以作为独立进程存在。
River 0.4.0 版本引入的 river-window-management-v1 协议,正是这种思路的体现:
- River 专注于帧完美渲染、性能优化、底层基础设施
- Window Manager 作为独立程序,通过协议控制窗口位置、快捷键、布局策略
这种分离不是简单的进程拆分,而是重新定义了协议边界。窗口管理器拥有完整的控制权,却不必关心缓冲区合成、DRM/KMS 交互这些底层细节。
对搜索技术的启示
这个架构实验对搜索领域有有趣的映射。
现代搜索引擎的架构演进,其实也经历了类似的"合久必分,分久必合":
早期分离架构:爬虫、索引、查询处理、排序各自独立,通过消息队列通信。灵活但延迟高。
单体优化阶段:为了降低延迟,很多系统开始将组件合并到同一进程,甚至同一台机器。性能提升,但灵活性下降。
现在的微服务趋势:随着硬件性能提升和网络优化,又开始在灵活性和性能之间寻找新平衡。
River 的探索提醒我们:架构选择的权衡不是一成不变的。当底层基础设施(Wayland 协议、硬件性能)发生变化时,上层的组件边界也值得重新审视。
未来展望
River 的窗口管理协议已经吸引了多个独立窗口管理器的实现。这种生态的多样性,正是 X11 时代的魅力所在。
如果这种模式被更广泛地接受,我们可能会看到:
- 专注于特定交互范式(平铺、浮动、标签页)的窗口管理器百花齐放
- 合成器专注于渲染性能和视觉效果,不必重复实现窗口管理逻辑
- 用户可以自由组合最佳组件,而不是被迫接受单体合成器的全部设计
当然,这种架构也有代价:进程间通信的延迟、协议标准化的复杂性、生态碎片化的风险。River 能否证明这些代价是值得的,还有待时间检验。
但无论如何,这种敢于质疑"既定架构"的探索精神,本身就值得尊重。
技术架构的演进,从来不是寻找唯一正确的答案,而是在不同约束条件下寻找最优的权衡。
或许 Wayland 的下一个十年,会从 River 这样的实验中找到新的方向。
来源: HackerNews (232 points, 107 comments)
原文: Separating the Wayland Compositor and Window Manager
相关: FOSDEM 2026 Talk
Linux 桌面生态正在经历一场静默的架构革命。
过去十年,Wayland 作为 X11 的继任者被寄予厚望,却迟迟未能完全接管桌面市场。其中一个被忽视的原因,或许藏在它的架构设计里——传统 Wayland 合成器(Compositor)采用了与 X11 时代截然不同的单体架构,将显示服务器、合成器和窗口管理器三个角色强行捆绑在一起。
这种设计解决了 X11 的延迟问题,却制造了新的麻烦:如果你想换一个窗口管理器,就必须重写整个 Wayland 合成器。
被忽视的架构债务
让我们先看看 X11 时代的分工:
- X Server 负责与内核交互,处理输入事件和缓冲区
- Compositor 负责将多个窗口的缓冲区合成为一帧画面
- Window Manager 负责窗口布局、快捷键、用户交互策略
这种分离架构的问题很明显:当用户点击一个按钮时,输入事件要在 X Server、Compositor、Window Manager 之间来回传递,每一次跨进程通信都在增加延迟。
Wayland 的解决方案是"一刀切"——把三个角色合并到一个进程里。这确实消除了延迟,但也带来了意想不到的副作用。
单体架构的隐性成本
想象一下这个场景:你喜欢 i3wm 的平铺布局,却看中了 Hyprland 的动画效果。在 X11 时代,你可以自由组合:用 i3wm 管理窗口,用 picom 做合成。但在 Wayland 世界里,这是不可能的。
每一个 Wayland 合成器都在重复造轮子:
- Sway 实现了 i3 的平铺逻辑,但必须从头写一套 Wayland 合成代码
- Hyprland 做出了漂亮的动画,却无法被其他窗口管理器复用
- 开发者想要自定义窗口管理策略,必须 fork 整个合成器
这种架构的隐性成本是:创新被锁定在单体边界内,无法像 X11 时代那样自由组合最佳组件。
River 的解耦实验
River 项目正在尝试一条不同的路。
它的核心洞察是:Wayland 解决的是 X11 的延迟问题,但并不意味着窗口管理器必须与合成器绑定。真正需要合并的只有显示服务器和合成器——这两个角色决定了帧延迟。窗口管理器完全可以作为独立进程存在。
River 0.4.0 版本引入的 river-window-management-v1 协议,正是这种思路的体现:
- River 专注于帧完美渲染、性能优化、底层基础设施
- Window Manager 作为独立程序,通过协议控制窗口位置、快捷键、布局策略
这种分离不是简单的进程拆分,而是重新定义了协议边界。窗口管理器拥有完整的控制权,却不必关心缓冲区合成、DRM/KMS 交互这些底层细节。
对搜索技术的启示
这个架构实验对搜索领域有有趣的映射。
现代搜索引擎的架构演进,其实也经历了类似的"合久必分,分久必合":
早期分离架构:爬虫、索引、查询处理、排序各自独立,通过消息队列通信。灵活但延迟高。
单体优化阶段:为了降低延迟,很多系统开始将组件合并到同一进程,甚至同一台机器。性能提升,但灵活性下降。
现在的微服务趋势:随着硬件性能提升和网络优化,又开始在灵活性和性能之间寻找新平衡。
River 的探索提醒我们:架构选择的权衡不是一成不变的。当底层基础设施(Wayland 协议、硬件性能)发生变化时,上层的组件边界也值得重新审视。
未来展望
River 的窗口管理协议已经吸引了多个独立窗口管理器的实现。这种生态的多样性,正是 X11 时代的魅力所在。
如果这种模式被更广泛地接受,我们可能会看到:
- 专注于特定交互范式(平铺、浮动、标签页)的窗口管理器百花齐放
- 合成器专注于渲染性能和视觉效果,不必重复实现窗口管理逻辑
- 用户可以自由组合最佳组件,而不是被迫接受单体合成器的全部设计
当然,这种架构也有代价:进程间通信的延迟、协议标准化的复杂性、生态碎片化的风险。River 能否证明这些代价是值得的,还有待时间检验。
但无论如何,这种敢于质疑"既定架构"的探索精神,本身就值得尊重。
技术架构的演进,从来不是寻找唯一正确的答案,而是在不同约束条件下寻找最优的权衡。
或许 Wayland 的下一个十年,会从 River 这样的实验中找到新的方向。
来源: HackerNews (232 points, 107 comments)
原文: Separating the Wayland Compositor and Window Manager
相关: FOSDEM 2026 Talk
使用 Docker Compose 轻松实现 INFINI Console 离线部署与持久化管理
系列回顾与引言
在我们的 INFINI 本地环境搭建系列博客中:
- 第一篇《搭建持久化的 INFINI Console 与 Easysearch 容器环境》,我们深入探讨了如何使用基础的
docker run命令,一步步构建起 Console 和 Easysearch 服务,并重点解决了数据持久化的问题。 - 第二篇《使用 Docker Compose 简化 INFINI Console 与 Easysearch 环境搭建》,我们学习了如何利用 Docker Compose 的声明式配置,将多容器应用的定义和管理变得更加简洁高效。
- 第三篇《一键启动:使用 start-local 脚本轻松管理 INFINI Console 与 Easysearch 本地环境》,我们介绍了如何在联网环境下,一键安装 INFINI Console。
接下来,我们将聚焦于离线环境,详细讲解如何使用 Docker Compose 部署 INFINI Console 和 Easysearch。

简介
INFINI Console 是一款强大的集群管理与可观测性平台,而 INFINI Easysearch 则是一个轻量级、高性能的搜索与分析引擎。官方提供的离线部署包将两者整合,非常适合在无外网或需要快速搭建演示环境的场景下使用。

本文将详细介绍如何下载资源、正确加载镜像、以及最关键的——如何根据您的需求修改 docker-compose.yml 中的各项配置。
1. 准备工作
请确保您的环境中已安装以下软件:
- Docker
- Docker Compose
2. 下载离线资源
从官方地址下载两个核心文件:
infini-console.tar.gz: 包含docker-compose.yml和相关脚本。infini-console-easysearch-1.14.2.tar: 包含infinilabs/console和infinilabs/easysearch的 Docker 镜像。
wget https://release.infinilabs.com/easysearch/archive/offline/amd64/infini-console.tar.gz
wget https://release.infinilabs.com/easysearch/archive/offline/amd64/infini-console-easysearch-1.14.2.tar3. 正确加载 Docker 镜像
注意:infini-console-easysearch-1.14.2.tar 是一个包含多个镜像的归档包,不能直接使用 docker load 加载。
正确的加载步骤如下:
-
创建目录并解压镜像归档包:
mkdir -p images tar -xvf infini-console-easysearch-1.14.2.tar -C images这会将
console.tar和easysearch.tar等文件解压到images/目录中。 -
批量加载所有镜像:
cd images ls *.tar | xargs -I {} docker load -i {}该命令会自动为目录下的每个
.tar文件执行docker load操作。 - 验证镜像加载结果:
docker images您应该能看到
infinilabs/console:1.29.8和infinilabs/easysearch:1.14.2等镜像。
4. 修改配置文件
解压 infini-console.tar.gz 后,找到 .env 文件。所有自定义配置都应在此文件中修改。
以下是各项配置的详细说明和修改建议:
核心路径配置
WORK_DIR_ABS=/data/infini-console- 作用: 定义所有持久化数据(日志、配置、索引)的根目录。
- 修改建议: (必改) 强烈建议修改为您服务器上一个有足够空间的路径,例如
/opt/infini-console。确保该目录存在且 Docker 拥有写入权限。
网络配置
APP_NETWORK_NAME=infini-local-net- 作用: 定义 Docker 内部网络的名称。
- 修改建议: 通常无需修改。
Console 配置
CONSOLE_IMAGE=infinilabs/console
CONSOLE_VERSION_TAG=1.29.8
CONSOLE_CONTAINER_NAME=infini-console
CONSOLE_PORT_HOST=9000
CONSOLE_PORT_CONTAINER=9000- 作用: 定义 Console 的镜像、版本、容器名及端口映射。
- 修改建议:
CONSOLE_PORT_HOST: 如果宿主机的9000端口已被占用,请修改为其他可用端口(如8080)。
Easysearch 配置
EASYSEARCH_IMAGE=infinilabs/easysearch
EASYSEARCH_VERSION_TAG=1.14.2
EASYSEARCH_NODES=1
EASYSEARCH_CLUSTER_NAME=infini-console- 作用: 定义 Easysearch 的镜像、版本、节点数和集群名。
- 修改建议:
EASYSEARCH_NODES: 单机部署保持1即可。
访问与安全配置
EASYSEARCH_INITIAL_ADMIN_PASSWORD=ShouldChangeme123.- 作用: 设置 Easysearch
admin用户的初始密码。 - 修改建议: (必改) 请务必将其替换为一个强密码。登录 Console 时需要使用此密码。
EASYSEARCH_HTTP_PORT_HOST=9200
EASYSEARCH_TRANSPORT_PORT_HOST=9300- 作用: 定义 Easysearch HTTP 和 Transport 接口在宿主机上的映射端口。
- 修改建议: 如果
9200或9300端口冲突,请修改。
JVM 参数配置
ES_JAVA_OPTS_DEFAULT="-Xms8g -Xmx8g"- 作用: 设置 Easysearch 的 JVM 堆内存大小。
- 修改建议: (必改) 请根据服务器物理内存进行调整,避免超过物理内存的 50%。
- 8GB 内存服务器: 建议设为
-Xms2g -Xmx2g。 - 16GB 内存服务器: 建议设为
-Xms4g -Xmx4g。
- 8GB 内存服务器: 建议设为
数据持久化路径
CONSOLE_HOST_DATA_SUBPATH_REL=console/data
CONSOLE_HOST_LOGS_SUBPATH_REL=console/logs
EASYSEARCH_HOST_NODES_BASE_SUBPATH_REL=easysearch- 作用: 定义数据和日志在
WORK_DIR_ABS下的相对子路径。 - 修改建议: 通常无需修改。
5. 启动服务
完成配置修改后,在 docker-compose.yml 所在目录下执行:
docker-compose up -d等待服务完全启动。
6. 访问控制台
打开浏览器,访问 http://<你的服务器IP>:9000。
使用默认用户名 admin 和您在 EASYSEARCH_INITIAL_ADMIN_PASSWORD 中设置的密码进行初始化。
总结
通过以上步骤,您可以灵活地部署一套功能完整的 INFINI Console + Easysearch 环境。关键在于理解并根据实际情况修改 .env 文件中的参数,特别是 WORK_DIR_ABS、EASYSEARCH_INITIAL_ADMIN_PASSWORD 和 ES_JAVA_OPTS_DEFAULT,这能确保部署的稳定性和安全性。
希望这篇详细的指南能帮助您顺利完成部署!
作者:罗厚付,极限科技(INFINI Labs)云上产品设计与研发负责人,拥有多年安全风控及大数据系统架构经验,主导过多个核心产品的设计与落地,日常负责运维超大规模 ES 集群(800+节点/1PB+数据)。
原文:https://infinilabs.cn/blog/2025/console-easysearch-with-docker-compose-offline/
系列回顾与引言
在我们的 INFINI 本地环境搭建系列博客中:
- 第一篇《搭建持久化的 INFINI Console 与 Easysearch 容器环境》,我们深入探讨了如何使用基础的
docker run命令,一步步构建起 Console 和 Easysearch 服务,并重点解决了数据持久化的问题。 - 第二篇《使用 Docker Compose 简化 INFINI Console 与 Easysearch 环境搭建》,我们学习了如何利用 Docker Compose 的声明式配置,将多容器应用的定义和管理变得更加简洁高效。
- 第三篇《一键启动:使用 start-local 脚本轻松管理 INFINI Console 与 Easysearch 本地环境》,我们介绍了如何在联网环境下,一键安装 INFINI Console。
接下来,我们将聚焦于离线环境,详细讲解如何使用 Docker Compose 部署 INFINI Console 和 Easysearch。
简介
INFINI Console 是一款强大的集群管理与可观测性平台,而 INFINI Easysearch 则是一个轻量级、高性能的搜索与分析引擎。官方提供的离线部署包将两者整合,非常适合在无外网或需要快速搭建演示环境的场景下使用。
本文将详细介绍如何下载资源、正确加载镜像、以及最关键的——如何根据您的需求修改 docker-compose.yml 中的各项配置。
1. 准备工作
请确保您的环境中已安装以下软件:
- Docker
- Docker Compose
2. 下载离线资源
从官方地址下载两个核心文件:
infini-console.tar.gz: 包含docker-compose.yml和相关脚本。infini-console-easysearch-1.14.2.tar: 包含infinilabs/console和infinilabs/easysearch的 Docker 镜像。
wget https://release.infinilabs.com/easysearch/archive/offline/amd64/infini-console.tar.gz
wget https://release.infinilabs.com/easysearch/archive/offline/amd64/infini-console-easysearch-1.14.2.tar3. 正确加载 Docker 镜像
注意:infini-console-easysearch-1.14.2.tar 是一个包含多个镜像的归档包,不能直接使用 docker load 加载。
正确的加载步骤如下:
-
创建目录并解压镜像归档包:
mkdir -p images tar -xvf infini-console-easysearch-1.14.2.tar -C images这会将
console.tar和easysearch.tar等文件解压到images/目录中。 -
批量加载所有镜像:
cd images ls *.tar | xargs -I {} docker load -i {}该命令会自动为目录下的每个
.tar文件执行docker load操作。 - 验证镜像加载结果:
docker images您应该能看到
infinilabs/console:1.29.8和infinilabs/easysearch:1.14.2等镜像。
4. 修改配置文件
解压 infini-console.tar.gz 后,找到 .env 文件。所有自定义配置都应在此文件中修改。
以下是各项配置的详细说明和修改建议:
核心路径配置
WORK_DIR_ABS=/data/infini-console- 作用: 定义所有持久化数据(日志、配置、索引)的根目录。
- 修改建议: (必改) 强烈建议修改为您服务器上一个有足够空间的路径,例如
/opt/infini-console。确保该目录存在且 Docker 拥有写入权限。
网络配置
APP_NETWORK_NAME=infini-local-net- 作用: 定义 Docker 内部网络的名称。
- 修改建议: 通常无需修改。
Console 配置
CONSOLE_IMAGE=infinilabs/console
CONSOLE_VERSION_TAG=1.29.8
CONSOLE_CONTAINER_NAME=infini-console
CONSOLE_PORT_HOST=9000
CONSOLE_PORT_CONTAINER=9000- 作用: 定义 Console 的镜像、版本、容器名及端口映射。
- 修改建议:
CONSOLE_PORT_HOST: 如果宿主机的9000端口已被占用,请修改为其他可用端口(如8080)。
Easysearch 配置
EASYSEARCH_IMAGE=infinilabs/easysearch
EASYSEARCH_VERSION_TAG=1.14.2
EASYSEARCH_NODES=1
EASYSEARCH_CLUSTER_NAME=infini-console- 作用: 定义 Easysearch 的镜像、版本、节点数和集群名。
- 修改建议:
EASYSEARCH_NODES: 单机部署保持1即可。
访问与安全配置
EASYSEARCH_INITIAL_ADMIN_PASSWORD=ShouldChangeme123.- 作用: 设置 Easysearch
admin用户的初始密码。 - 修改建议: (必改) 请务必将其替换为一个强密码。登录 Console 时需要使用此密码。
EASYSEARCH_HTTP_PORT_HOST=9200
EASYSEARCH_TRANSPORT_PORT_HOST=9300- 作用: 定义 Easysearch HTTP 和 Transport 接口在宿主机上的映射端口。
- 修改建议: 如果
9200或9300端口冲突,请修改。
JVM 参数配置
ES_JAVA_OPTS_DEFAULT="-Xms8g -Xmx8g"- 作用: 设置 Easysearch 的 JVM 堆内存大小。
- 修改建议: (必改) 请根据服务器物理内存进行调整,避免超过物理内存的 50%。
- 8GB 内存服务器: 建议设为
-Xms2g -Xmx2g。 - 16GB 内存服务器: 建议设为
-Xms4g -Xmx4g。
- 8GB 内存服务器: 建议设为
数据持久化路径
CONSOLE_HOST_DATA_SUBPATH_REL=console/data
CONSOLE_HOST_LOGS_SUBPATH_REL=console/logs
EASYSEARCH_HOST_NODES_BASE_SUBPATH_REL=easysearch- 作用: 定义数据和日志在
WORK_DIR_ABS下的相对子路径。 - 修改建议: 通常无需修改。
5. 启动服务
完成配置修改后,在 docker-compose.yml 所在目录下执行:
docker-compose up -d等待服务完全启动。
6. 访问控制台
打开浏览器,访问 http://<你的服务器IP>:9000。
使用默认用户名 admin 和您在 EASYSEARCH_INITIAL_ADMIN_PASSWORD 中设置的密码进行初始化。
总结
通过以上步骤,您可以灵活地部署一套功能完整的 INFINI Console + Easysearch 环境。关键在于理解并根据实际情况修改 .env 文件中的参数,特别是 WORK_DIR_ABS、EASYSEARCH_INITIAL_ADMIN_PASSWORD 和 ES_JAVA_OPTS_DEFAULT,这能确保部署的稳定性和安全性。
希望这篇详细的指南能帮助您顺利完成部署!
收起阅读 »作者:罗厚付,极限科技(INFINI Labs)云上产品设计与研发负责人,拥有多年安全风控及大数据系统架构经验,主导过多个核心产品的设计与落地,日常负责运维超大规模 ES 集群(800+节点/1PB+数据)。
原文:https://infinilabs.cn/blog/2025/console-easysearch-with-docker-compose-offline/
搜索百科(6):Meilisearch — Rust 打造的轻量级搜索新锐
大家好,我是 INFINI Labs 的石阳。
欢迎关注 《搜索百科》 专栏!每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
在之前的几期中,我们认识了搜索技术的基石 Lucene、企业级搜索先锋 Solr、搜索界的“流量明星” Elasticsearch 以及它的分叉兄弟 OpenSearch 和 ES 国产替代方案 Easysearch。它们大多基于 Lucene 构建,形成了庞大且功能丰富的生态。
今天,我们将介绍一位“非主流”选手:一款基于 Rust 编写、主打“快”和“简单”的现代搜索引擎——Meilisearch。它以全新的姿态,为开发者带来了不同的搜索体验。

Meilisearch 概述
Meilisearch 是一款开源的、用 Rust 编写的即时搜索引擎。它提供了一个快速、轻量且可定制的搜索 API,旨在为用户提供毫秒级的搜索体验。
它的核心优势在于为应用内搜索和电商搜索等对延迟敏感的场景提供了出色的用户体验。
- 首次发布:2020 年
- 最新版本:1.24.0(截止 2025 年 10 月)
- 核心语言:Rust
- 开源协议:MIT License
- 官方网址:https://www.meilisearch.com/
- GitHub 仓库:https://github.com/meilisearch/meilisearch
诞生故事
Meilisearch 的故事始于 2018 年,当时法国工程师 Quentin de Quelen 在开发一个电商项目时,发现现有的搜索引擎要么太重量级,要么配置太复杂。他想要一个"开箱即用"的搜索解决方案,能够快速集成到应用中,并提供优秀的搜索体验。
于是,他决定用 Rust 语言从头编写一个搜索引擎。选择 Rust 是因为其出色的性能、内存安全性和并发能力,非常适合构建高性能的搜索核心。
项目最初只是一个内部工具,但随着功能的完善和社区的反馈,Meilisearch 在 2019 年正式开源,并迅速获得了开发者的青睐。2020 年,团队获得了 150 万美元的种子轮融资,正式成立了 Meilisearch 公司。
核心特性
Meilisearch 在设计上做了大量的取舍,专注于核心的搜索功能,但做到了极致。
- 极速响应:核心目标是实现 50 毫秒以下的响应时间,即使在大型数据集中也能提供“所见即所得”的搜索体验。
- 零配置:开箱即用,部署和索引数据都非常简单,不需要预定义 Schema 或复杂的配置文件。
- 相关的默认值:内置一个强大的 相关性排名(Relevance Ranking) 算法,结合 Typos(拼写错误)、Word Proximity(词语距离)和 Attributes(字段权重)等因素,无需额外调优即可获得高质量的搜索结果。
- 语言无关性:支持多种语言的分词与搜索,能很好地处理中文、日文等非拉丁语系文本。
- 无分布式架构:为了追求极致的速度和简单性,Meilisearch 被设计为单机搜索引擎,不支持开箱即用的分布式集群,这简化了运维,但也限制了其 PB 级数据的处理能力。
对比优势:Meilisearch vs Lucene/ES 体系
Meilisearch 与基于 Lucene 的 Elasticsearch 体系,在设计哲学上有着本质区别:
| 特性 | Meilisearch | Elasticsearch |
|---|---|---|
| 核心目标 | 极速的应用内搜索体验 | 分布式搜索、日志分析、可观测性 |
| 基础架构 | 单机、轻量级 | 分布式集群(主从节点、分片) |
| 核心语言 | Rust | Java(基于 Lucene) |
| 性能瓶颈 | 单机 CPU / 内存限制 | 分布式协调开销 |
| 上手难度 | 简单,开箱即用,REST API | 相对复杂,需要了解集群、分片等概念 |
| 数据规模 | 适合中小型数据集(GB 级别) | 适合大型和超大型数据集(TB/PB 级别) |
| 全文检索 | 依赖内置的强相关性算法 | 依赖 Lucene 强大的分词、查询解析器 |
总结:
- 如果你的应用需要超低延迟、简单部署、数据量在 GB 级别,并且搜索是应用的核心功能,Meilisearch 是一个极佳的选择。
- 如果你的需求涉及日志分析、大规模数据存储、集群高可用和复杂的聚合分析,那么 Elasticsearch 仍然是更成熟和全面的解决方案。
快速上手:5 分钟体验 Meilisearch
部署 Meilisearch 非常简单,你甚至不需要 Docker,只需一个命令即可运行。
1. 运行 Meilisearch
# 安装 Meilisearch
curl -L https://install.meilisearch.com | sh
# 启动 Meilisearch
meilisearch --master-key 'aStrongMasterKey'
# 或使用 Docker
docker run -it --rm -p 7700:7700 getmeili/meilisearch:latest --master-key 'aStrongMasterKey'2. 添加索引(创建 Index)
Meilisearch 不需要预先定义索引结构(Schema-less)。
curl -X POST 'http://localhost:7700/indexes' \
-H 'Authorization: Bearer aStrongMasterKey' \
-H 'Content-Type: application/json' \
--data-binary '{
"uid": "movies",
"primaryKey": "id"
}'3. 索引文档(添加 Documents)
curl -X POST 'http://localhost:7700/indexes/movies/documents' \
-H 'Authorization: Bearer aStrongMasterKey' \
-H 'Content-Type: application/json' \
--data-binary '[
{"id": 1, "title": "泰坦尼克号", "genres": ["剧情", "爱情"]},
{"id": 2, "title": "黑客帝国", "genres": ["科幻", "动作"]}
]'4. 执行搜索
# 搜索关键词 "泰坦"
curl -X GET 'http://localhost:7700/indexes/movies/search?q=泰坦'返回结果:
{
"hits": [
{
"id": 1,
"title": "泰坦尼克号",
"genres": ["剧情", "爱情"]
}
],
"offset": 0,
"limit": 20,
"estimatedTotalHits": 1,
"processingTimeMs": 1,
"query": "泰坦"
}注意 processingTimeMs: 1,这是 Meilisearch 速度的最好证明!
5. 场景演示
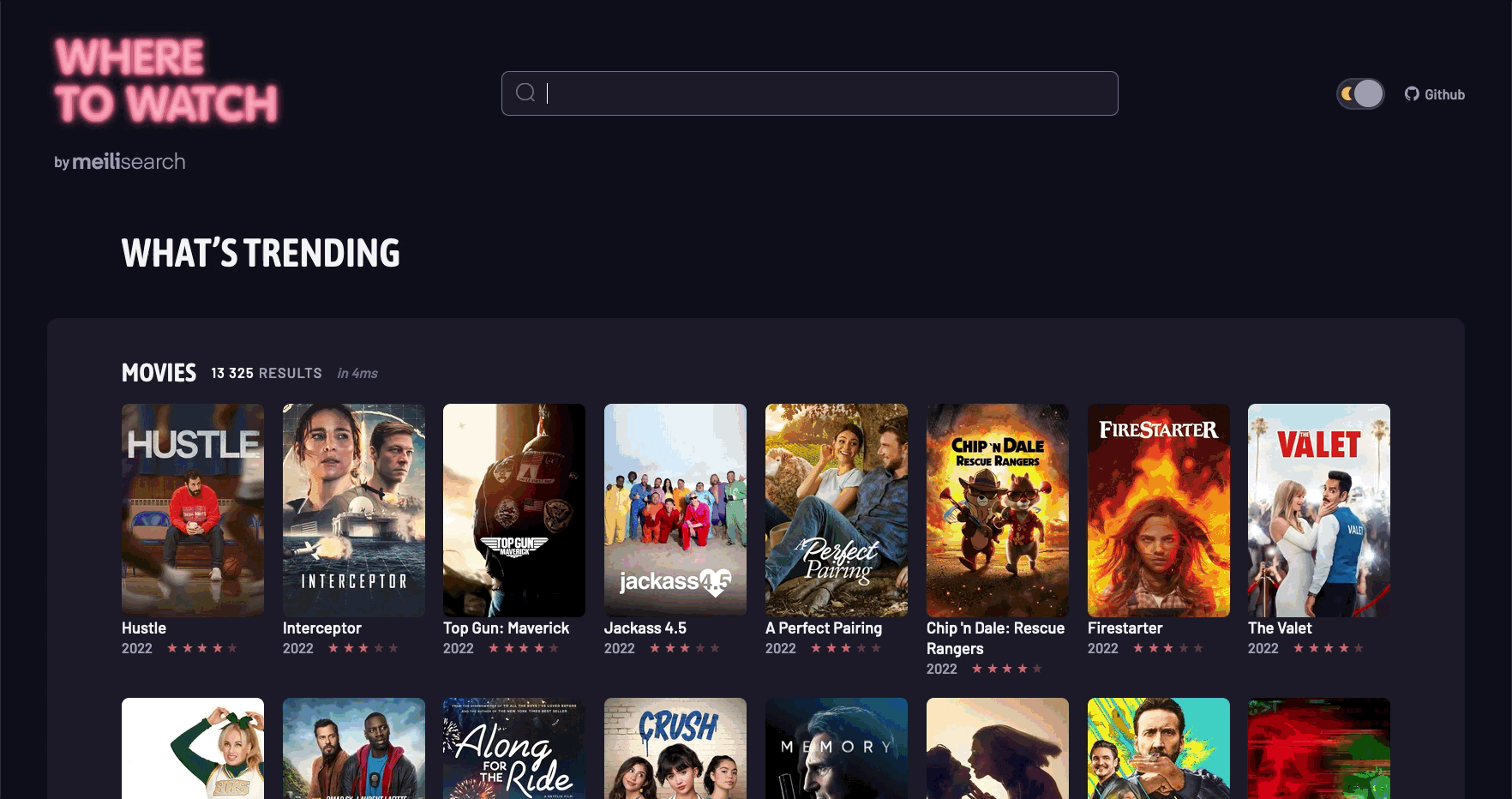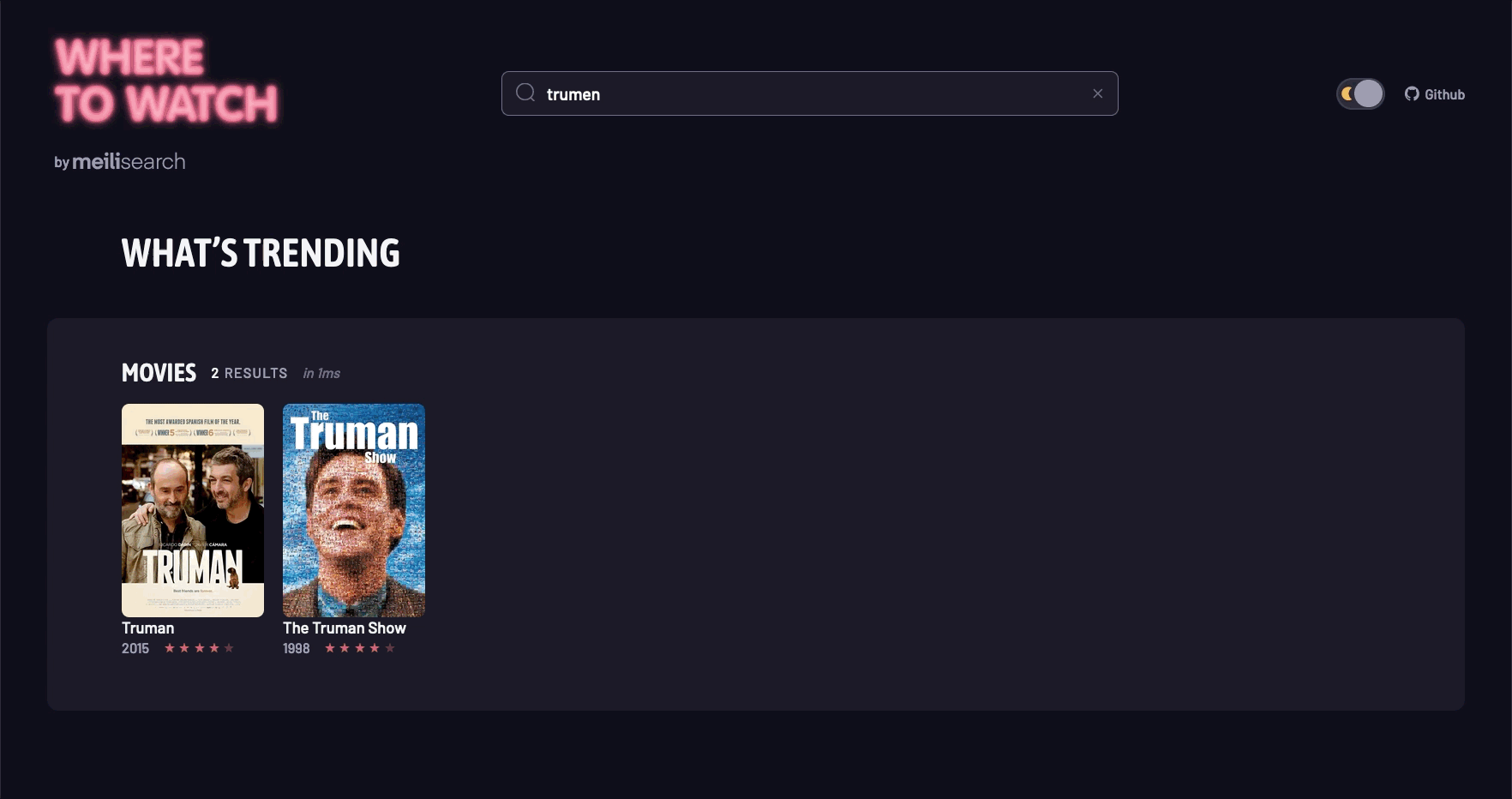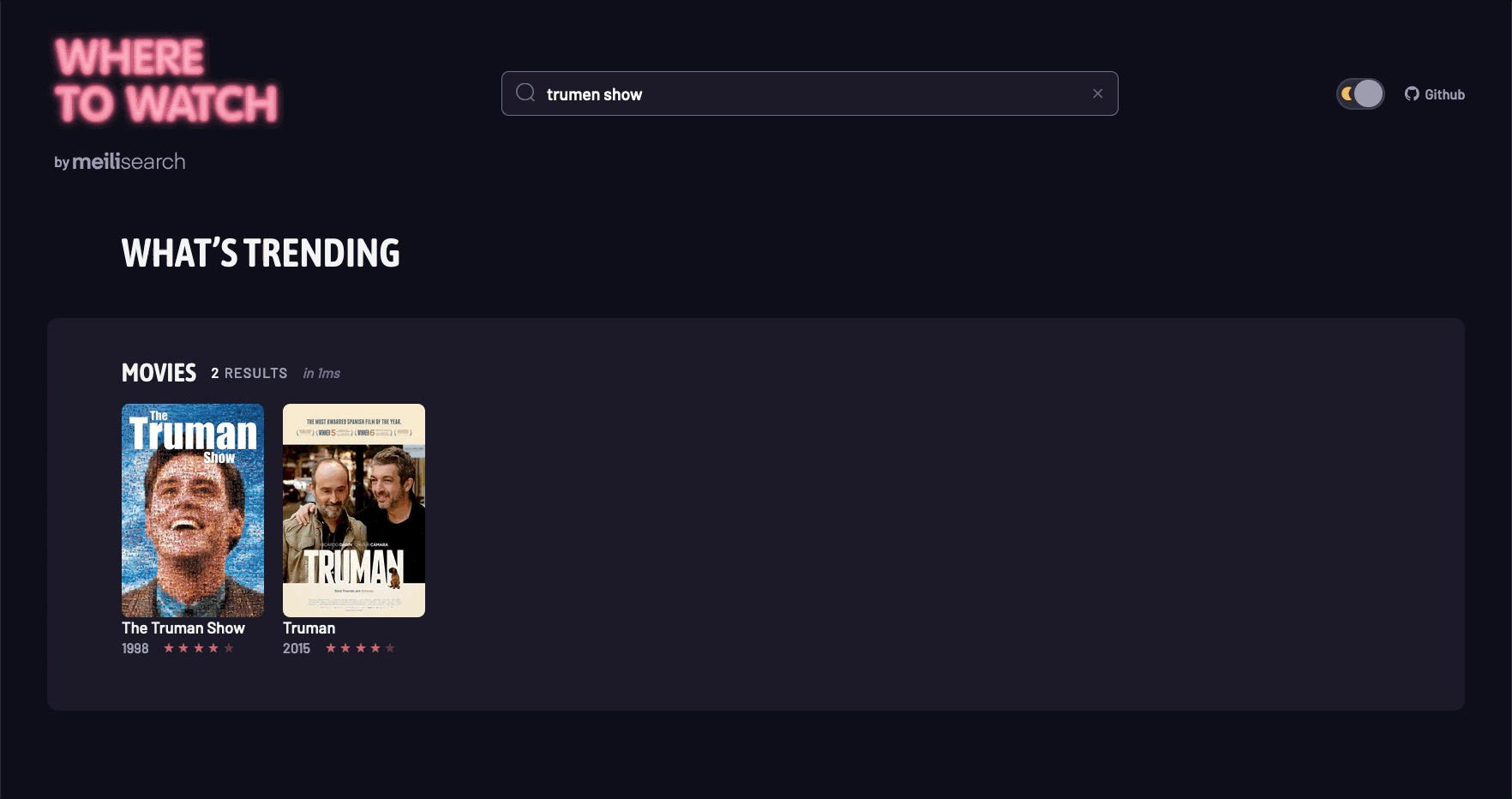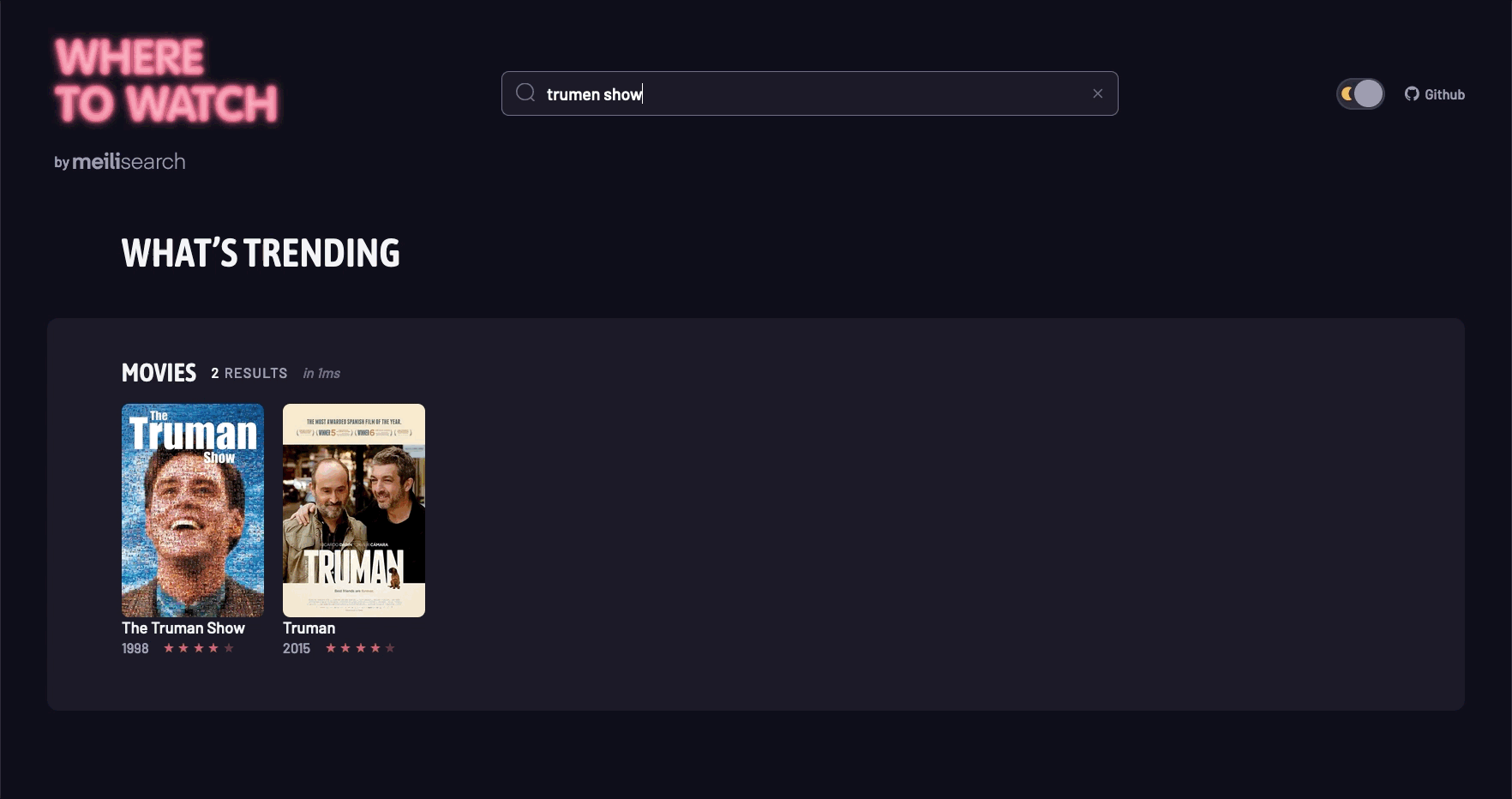
结语
Meilisearch 的出现,代表了新一代搜索引擎对于开发者体验和即时性的追求。它在应用内搜索领域展现了强大的竞争力,证明了不必依赖 Lucene 的庞大体系,也能打造出极致性能的搜索产品。
虽然它还无法完全取代 Elasticsearch 在日志分析、可观测性等大型分布式场景的地位,但在许多新兴应用和对搜索速度有极高要求的场景中,它无疑是一个值得尝试的开源新星。
🚀 下期预告
下一篇我们将把目光转向搜索领域的云端先锋 —— Algolia。作为搜索即服务(Search-as-a-Service)的开创者,Algolia 如何以其卓越的 API 设计、惊人的搜索速度和精准的相关性排序,重新定义云端搜索体验?
💬 三连互动
- 你会把 ES/Solr 换成 Meilisearch 吗?
- 在你的应用中,搜索延迟达到多少毫秒你会觉得无法接受?
- 在什么场景下你会考虑使用 Meilisearch 而不是 Elasticsearch?
对搜索技术感兴趣的朋友,也欢迎加我微信(ID:lsy965145175)备注“搜索百科”,拉你进 搜索技术交流群,一起探讨与学习!
✨ 推荐阅读
- 搜索百科(5):Easysearch — 自主可控的国产分布式搜索引擎
- 搜索百科(4):OpenSearch — 开源搜索的新选择
- 搜索百科(3):Elasticsearch — 搜索界的"流量明星"
- 搜索百科(2):Apache Solr — 企业级搜索的开源先锋
- 搜索百科(1):Lucene — 打开现代搜索世界的第一扇门
🔗 参考资源
大家好,我是 INFINI Labs 的石阳。
欢迎关注 《搜索百科》 专栏!每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
在之前的几期中,我们认识了搜索技术的基石 Lucene、企业级搜索先锋 Solr、搜索界的“流量明星” Elasticsearch 以及它的分叉兄弟 OpenSearch 和 ES 国产替代方案 Easysearch。它们大多基于 Lucene 构建,形成了庞大且功能丰富的生态。
今天,我们将介绍一位“非主流”选手:一款基于 Rust 编写、主打“快”和“简单”的现代搜索引擎——Meilisearch。它以全新的姿态,为开发者带来了不同的搜索体验。
Meilisearch 概述
Meilisearch 是一款开源的、用 Rust 编写的即时搜索引擎。它提供了一个快速、轻量且可定制的搜索 API,旨在为用户提供毫秒级的搜索体验。
它的核心优势在于为应用内搜索和电商搜索等对延迟敏感的场景提供了出色的用户体验。
- 首次发布:2020 年
- 最新版本:1.24.0(截止 2025 年 10 月)
- 核心语言:Rust
- 开源协议:MIT License
- 官方网址:https://www.meilisearch.com/
- GitHub 仓库:https://github.com/meilisearch/meilisearch
诞生故事
Meilisearch 的故事始于 2018 年,当时法国工程师 Quentin de Quelen 在开发一个电商项目时,发现现有的搜索引擎要么太重量级,要么配置太复杂。他想要一个"开箱即用"的搜索解决方案,能够快速集成到应用中,并提供优秀的搜索体验。
于是,他决定用 Rust 语言从头编写一个搜索引擎。选择 Rust 是因为其出色的性能、内存安全性和并发能力,非常适合构建高性能的搜索核心。
项目最初只是一个内部工具,但随着功能的完善和社区的反馈,Meilisearch 在 2019 年正式开源,并迅速获得了开发者的青睐。2020 年,团队获得了 150 万美元的种子轮融资,正式成立了 Meilisearch 公司。
核心特性
Meilisearch 在设计上做了大量的取舍,专注于核心的搜索功能,但做到了极致。
- 极速响应:核心目标是实现 50 毫秒以下的响应时间,即使在大型数据集中也能提供“所见即所得”的搜索体验。
- 零配置:开箱即用,部署和索引数据都非常简单,不需要预定义 Schema 或复杂的配置文件。
- 相关的默认值:内置一个强大的 相关性排名(Relevance Ranking) 算法,结合 Typos(拼写错误)、Word Proximity(词语距离)和 Attributes(字段权重)等因素,无需额外调优即可获得高质量的搜索结果。
- 语言无关性:支持多种语言的分词与搜索,能很好地处理中文、日文等非拉丁语系文本。
- 无分布式架构:为了追求极致的速度和简单性,Meilisearch 被设计为单机搜索引擎,不支持开箱即用的分布式集群,这简化了运维,但也限制了其 PB 级数据的处理能力。
对比优势:Meilisearch vs Lucene/ES 体系
Meilisearch 与基于 Lucene 的 Elasticsearch 体系,在设计哲学上有着本质区别:
| 特性 | Meilisearch | Elasticsearch |
|---|---|---|
| 核心目标 | 极速的应用内搜索体验 | 分布式搜索、日志分析、可观测性 |
| 基础架构 | 单机、轻量级 | 分布式集群(主从节点、分片) |
| 核心语言 | Rust | Java(基于 Lucene) |
| 性能瓶颈 | 单机 CPU / 内存限制 | 分布式协调开销 |
| 上手难度 | 简单,开箱即用,REST API | 相对复杂,需要了解集群、分片等概念 |
| 数据规模 | 适合中小型数据集(GB 级别) | 适合大型和超大型数据集(TB/PB 级别) |
| 全文检索 | 依赖内置的强相关性算法 | 依赖 Lucene 强大的分词、查询解析器 |
总结:
- 如果你的应用需要超低延迟、简单部署、数据量在 GB 级别,并且搜索是应用的核心功能,Meilisearch 是一个极佳的选择。
- 如果你的需求涉及日志分析、大规模数据存储、集群高可用和复杂的聚合分析,那么 Elasticsearch 仍然是更成熟和全面的解决方案。
快速上手:5 分钟体验 Meilisearch
部署 Meilisearch 非常简单,你甚至不需要 Docker,只需一个命令即可运行。
1. 运行 Meilisearch
# 安装 Meilisearch
curl -L https://install.meilisearch.com | sh
# 启动 Meilisearch
meilisearch --master-key 'aStrongMasterKey'
# 或使用 Docker
docker run -it --rm -p 7700:7700 getmeili/meilisearch:latest --master-key 'aStrongMasterKey'2. 添加索引(创建 Index)
Meilisearch 不需要预先定义索引结构(Schema-less)。
curl -X POST 'http://localhost:7700/indexes' \
-H 'Authorization: Bearer aStrongMasterKey' \
-H 'Content-Type: application/json' \
--data-binary '{
"uid": "movies",
"primaryKey": "id"
}'3. 索引文档(添加 Documents)
curl -X POST 'http://localhost:7700/indexes/movies/documents' \
-H 'Authorization: Bearer aStrongMasterKey' \
-H 'Content-Type: application/json' \
--data-binary '[
{"id": 1, "title": "泰坦尼克号", "genres": ["剧情", "爱情"]},
{"id": 2, "title": "黑客帝国", "genres": ["科幻", "动作"]}
]'4. 执行搜索
# 搜索关键词 "泰坦"
curl -X GET 'http://localhost:7700/indexes/movies/search?q=泰坦'返回结果:
{
"hits": [
{
"id": 1,
"title": "泰坦尼克号",
"genres": ["剧情", "爱情"]
}
],
"offset": 0,
"limit": 20,
"estimatedTotalHits": 1,
"processingTimeMs": 1,
"query": "泰坦"
}注意 processingTimeMs: 1,这是 Meilisearch 速度的最好证明!
5. 场景演示
结语
Meilisearch 的出现,代表了新一代搜索引擎对于开发者体验和即时性的追求。它在应用内搜索领域展现了强大的竞争力,证明了不必依赖 Lucene 的庞大体系,也能打造出极致性能的搜索产品。
虽然它还无法完全取代 Elasticsearch 在日志分析、可观测性等大型分布式场景的地位,但在许多新兴应用和对搜索速度有极高要求的场景中,它无疑是一个值得尝试的开源新星。
🚀 下期预告
下一篇我们将把目光转向搜索领域的云端先锋 —— Algolia。作为搜索即服务(Search-as-a-Service)的开创者,Algolia 如何以其卓越的 API 设计、惊人的搜索速度和精准的相关性排序,重新定义云端搜索体验?
💬 三连互动
- 你会把 ES/Solr 换成 Meilisearch 吗?
- 在你的应用中,搜索延迟达到多少毫秒你会觉得无法接受?
- 在什么场景下你会考虑使用 Meilisearch 而不是 Elasticsearch?
对搜索技术感兴趣的朋友,也欢迎加我微信(ID:lsy965145175)备注“搜索百科”,拉你进 搜索技术交流群,一起探讨与学习!
✨ 推荐阅读
- 搜索百科(5):Easysearch — 自主可控的国产分布式搜索引擎
- 搜索百科(4):OpenSearch — 开源搜索的新选择
- 搜索百科(3):Elasticsearch — 搜索界的"流量明星"
- 搜索百科(2):Apache Solr — 企业级搜索的开源先锋
- 搜索百科(1):Lucene — 打开现代搜索世界的第一扇门
🔗 参考资源
收起阅读 »搜索百科(2):Apache Solr — 企业级搜索的开源先锋
大家好,我是 INFINI Labs 的石阳。
欢迎回到 《搜索百科》 专栏!每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
上一篇我们认识了搜索技术的基石 Apache Lucene,今天我们将继续这个旅程,了解基于 Lucene 构建的第一个成功商业级搜索平台 —— Apache Solr。

Solr 是什么?
Solr 是一款极速的开源多模态搜索平台,基于 Apache Lucene 的全文、向量和地理空间搜索能力构建而成。Solr 具备高可靠性、可扩展性和容错性,支持分布式索引、复制与负载均衡查询,提供自动故障转移与恢复、集中化配置等功能。如今,Solr 为全球众多大型互联网网站提供搜索和导航功能。
- 首次发布:2004 年,2006 年进入 Apache
- 最新版本:截至 2025 年,已更新至 9.x 系列
- 核心依赖:Apache Lucene
- 开源协议:Apache License 2.0
- 官方网址:https://solr.apache.org
- GitHub 仓库:https://github.com/apache/solr
它的定位是:把 Lucene 打造成独立的企业级搜索服务。相比 Lucene 需要写代码调用,Solr 提供了 Web 管理界面、REST API 和配置文件,让开发者更容易上手。
起源:从网站搜索到 Apache 顶级项目
Solr(读作"solar")的故事始于 2004 年,当时 CNET 公司的开发人员 Yonik Seeley 需要为其新闻网站构建一个搜索功能。虽然 Lucene 提供了强大的核心搜索能力,但直接使用 Lucene 需要编写大量 Java 代码,缺乏开箱即用的功能。
Seeley 决定在 Lucene 之上构建一个更易用的搜索服务器,于是 Solr 诞生了。最初的目标很明确:通过 HTTP/XML 接口提供搜索服务,让任何编程语言都能轻松集成搜索功能。
2006 年,Solr 捐赠给 Apache 基金会,2007 年成为顶级项目。2010 年,Solr 与 Lucene 项目合并,形成了今天我们所知的 Apache Lucene/Solr 项目。
技术架构
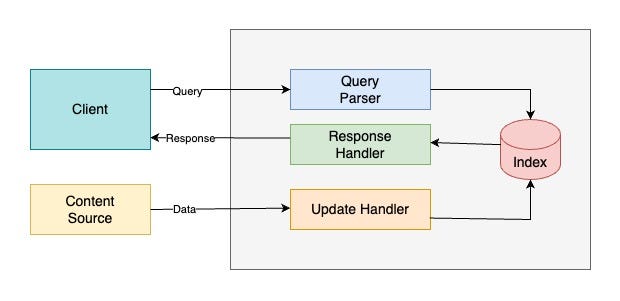
Index(索引)
Apache Solr 的索引就像是用于管理结构化 / 非结构化数据的“数据库”。它以便于分析和全文检索的方式存储数据。
Query Parser(查询解析器)
所有由客户端提交的查询都会由查询解析器处理。
Response Handler(响应处理器)
响应处理器负责为客户端生成合适格式的响应(如 JSON/XML/CSV)。
Update Handler(更新处理器)
更新处理器用于索引操作,即对索引中的数据进行插入、更新和删除。例如,如果我们希望 MySQL 数据与 Apache Solr 保持同步,就需要创建一个负责同步的更新处理器。
功能亮点
- 全文检索:高效支持关键词搜索、布尔查询、短语匹配等。
- 分面搜索(Faceted Search):可以对搜索结果进行分类和聚合统计。
- 分布式架构(SolrCloud):支持集群部署、自动分片、副本和容错。
- 丰富的数据接口:提供 RESTful API,支持 JSON、XML、CSV 等多种格式的数据交互。
- 扩展性与可定制性:通过插件机制支持多语言分词、排序、评分模型等个性化定制。
- 地理位置搜索:内置空间搜索能力,支持基于经纬度的范围查询和排序。
对比: Solr vs Elasticsearch 如何选择?
虽然两者都基于 Lucene,但在设计哲学上有所不同:
| 特性 | Apache Solr | Elasticsearch |
|---|---|---|
| 定位 | 企业级搜索服务器 | 分布式搜索和分析引擎 |
| API | 更标准化,遵循传统 REST | 更灵活,JSON 原生 |
| 分布式 | 需要 ZooKeeper 协调 | 内置分布式协调 |
| 上手难度 | 相对简单,开箱即用 | 学习曲线较陡峭 |
| 生态系统 | 搜索功能更丰富 | 分析和可视化更强 |
| 适用场景 | 传统企业搜索、电商 | 日志分析、实时监控 |
简单来说:Solr 更像"精装房",开箱即用;Elasticsearch 更像"毛坯房",需要更多自定义但更灵活。
快速开始:5 分钟搭建 Solr 服务
1. 下载和安装
# 下载 8.x 版 Solr
wget https://dlcdn.apache.org/solr/solr/8.11.4/solr-8.11.4.tgz
# 解压
tar -xzf solr-8.11.4.tgz
# 启动 Solr(单机模式)
cd solr-8.11.4
bin/solr start2. 创建 Core
# 创建测试 Core
bin/solr create -c test_core
# 查看 Core 状态
bin/solr status3. 索引文档
# 使用 curl 索引 JSON 文档
curl http://localhost:8983/solr/test_core/update -d '
[
{"id": "1", "title": "Solr 入门指南", "content": "Apache Solr 是企业级搜索平台"},
{"id": "2", "title": "搜索技术演进", "content": "从 Lucene 到 Solr 的技术发展"}
]' -H 'Content-type:application/json'
# 提交更改
curl http://localhost:8983/solr/test_core/update -d '<commit/>' -H 'Content-type:application/xml'4. 执行搜索
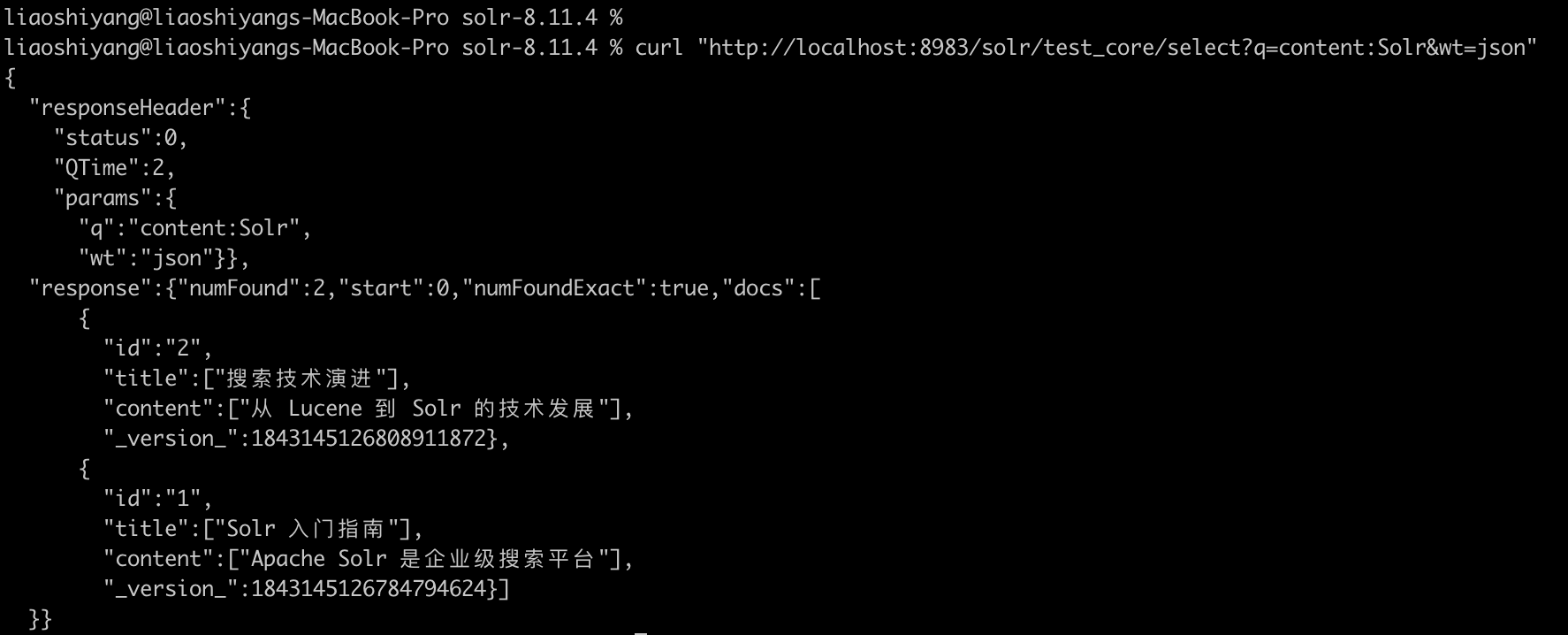
# 搜索"Solr"
curl "http://localhost:8983/solr/test_core/select?q=content:Solr"
# 使用 JSON 格式返回
curl "http://localhost:8983/solr/test_core/select?q=content:Solr&wt=json"执行搜索返回结果:
访问 http://localhost:8983/solr 即可使用 Solr 的管理界面。
Dashboard:
Core Admin:
结语
从最初的公司内部工具,到成为全球范围内广泛使用的开源搜索引擎,Apache Solr 见证并推动了搜索技术的进化。尽管近年来 Elasticsearch、向量数据库和 AI 驱动的搜索技术逐渐崛起,但 Solr 依然是许多企业可靠且成熟的选择。它的故事不仅属于开源社区,也代表了搜索技术发展的一个重要阶段。
🚀 下期预告
在下一篇「搜索百科」中,我们将介绍它的明星兄弟 —— Elasticsearch。
💬 三连互动
- 你现在还在用 Solr 吗?
- 在 Solr 和 Elasticsearch 之间做过技术选型?
- 遇到过有趣的 Solr 使用案例或挑战?
对搜索技术感兴趣的朋友,也欢迎加我微信(ID:lsy965145175)备注“搜索百科”,拉你进 搜索技术交流群,一起探讨与学习!
✨ 推荐阅读
🔗 参考
大家好,我是 INFINI Labs 的石阳。
欢迎回到 《搜索百科》 专栏!每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
上一篇我们认识了搜索技术的基石 Apache Lucene,今天我们将继续这个旅程,了解基于 Lucene 构建的第一个成功商业级搜索平台 —— Apache Solr。
Solr 是什么?
Solr 是一款极速的开源多模态搜索平台,基于 Apache Lucene 的全文、向量和地理空间搜索能力构建而成。Solr 具备高可靠性、可扩展性和容错性,支持分布式索引、复制与负载均衡查询,提供自动故障转移与恢复、集中化配置等功能。如今,Solr 为全球众多大型互联网网站提供搜索和导航功能。
- 首次发布:2004 年,2006 年进入 Apache
- 最新版本:截至 2025 年,已更新至 9.x 系列
- 核心依赖:Apache Lucene
- 开源协议:Apache License 2.0
- 官方网址:https://solr.apache.org
- GitHub 仓库:https://github.com/apache/solr
它的定位是:把 Lucene 打造成独立的企业级搜索服务。相比 Lucene 需要写代码调用,Solr 提供了 Web 管理界面、REST API 和配置文件,让开发者更容易上手。
起源:从网站搜索到 Apache 顶级项目
Solr(读作"solar")的故事始于 2004 年,当时 CNET 公司的开发人员 Yonik Seeley 需要为其新闻网站构建一个搜索功能。虽然 Lucene 提供了强大的核心搜索能力,但直接使用 Lucene 需要编写大量 Java 代码,缺乏开箱即用的功能。
Seeley 决定在 Lucene 之上构建一个更易用的搜索服务器,于是 Solr 诞生了。最初的目标很明确:通过 HTTP/XML 接口提供搜索服务,让任何编程语言都能轻松集成搜索功能。
2006 年,Solr 捐赠给 Apache 基金会,2007 年成为顶级项目。2010 年,Solr 与 Lucene 项目合并,形成了今天我们所知的 Apache Lucene/Solr 项目。
技术架构
Index(索引)
Apache Solr 的索引就像是用于管理结构化 / 非结构化数据的“数据库”。它以便于分析和全文检索的方式存储数据。
Query Parser(查询解析器)
所有由客户端提交的查询都会由查询解析器处理。
Response Handler(响应处理器)
响应处理器负责为客户端生成合适格式的响应(如 JSON/XML/CSV)。
Update Handler(更新处理器)
更新处理器用于索引操作,即对索引中的数据进行插入、更新和删除。例如,如果我们希望 MySQL 数据与 Apache Solr 保持同步,就需要创建一个负责同步的更新处理器。
功能亮点
- 全文检索:高效支持关键词搜索、布尔查询、短语匹配等。
- 分面搜索(Faceted Search):可以对搜索结果进行分类和聚合统计。
- 分布式架构(SolrCloud):支持集群部署、自动分片、副本和容错。
- 丰富的数据接口:提供 RESTful API,支持 JSON、XML、CSV 等多种格式的数据交互。
- 扩展性与可定制性:通过插件机制支持多语言分词、排序、评分模型等个性化定制。
- 地理位置搜索:内置空间搜索能力,支持基于经纬度的范围查询和排序。
对比: Solr vs Elasticsearch 如何选择?
虽然两者都基于 Lucene,但在设计哲学上有所不同:
| 特性 | Apache Solr | Elasticsearch |
|---|---|---|
| 定位 | 企业级搜索服务器 | 分布式搜索和分析引擎 |
| API | 更标准化,遵循传统 REST | 更灵活,JSON 原生 |
| 分布式 | 需要 ZooKeeper 协调 | 内置分布式协调 |
| 上手难度 | 相对简单,开箱即用 | 学习曲线较陡峭 |
| 生态系统 | 搜索功能更丰富 | 分析和可视化更强 |
| 适用场景 | 传统企业搜索、电商 | 日志分析、实时监控 |
简单来说:Solr 更像"精装房",开箱即用;Elasticsearch 更像"毛坯房",需要更多自定义但更灵活。
快速开始:5 分钟搭建 Solr 服务
1. 下载和安装
# 下载 8.x 版 Solr
wget https://dlcdn.apache.org/solr/solr/8.11.4/solr-8.11.4.tgz
# 解压
tar -xzf solr-8.11.4.tgz
# 启动 Solr(单机模式)
cd solr-8.11.4
bin/solr start2. 创建 Core
# 创建测试 Core
bin/solr create -c test_core
# 查看 Core 状态
bin/solr status3. 索引文档
# 使用 curl 索引 JSON 文档
curl http://localhost:8983/solr/test_core/update -d '
[
{"id": "1", "title": "Solr 入门指南", "content": "Apache Solr 是企业级搜索平台"},
{"id": "2", "title": "搜索技术演进", "content": "从 Lucene 到 Solr 的技术发展"}
]' -H 'Content-type:application/json'
# 提交更改
curl http://localhost:8983/solr/test_core/update -d '<commit/>' -H 'Content-type:application/xml'4. 执行搜索
# 搜索"Solr"
curl "http://localhost:8983/solr/test_core/select?q=content:Solr"
# 使用 JSON 格式返回
curl "http://localhost:8983/solr/test_core/select?q=content:Solr&wt=json"执行搜索返回结果:
访问 http://localhost:8983/solr 即可使用 Solr 的管理界面。
Dashboard:
Core Admin:
结语
从最初的公司内部工具,到成为全球范围内广泛使用的开源搜索引擎,Apache Solr 见证并推动了搜索技术的进化。尽管近年来 Elasticsearch、向量数据库和 AI 驱动的搜索技术逐渐崛起,但 Solr 依然是许多企业可靠且成熟的选择。它的故事不仅属于开源社区,也代表了搜索技术发展的一个重要阶段。
🚀 下期预告
在下一篇「搜索百科」中,我们将介绍它的明星兄弟 —— Elasticsearch。
💬 三连互动
- 你现在还在用 Solr 吗?
- 在 Solr 和 Elasticsearch 之间做过技术选型?
- 遇到过有趣的 Solr 使用案例或挑战?
对搜索技术感兴趣的朋友,也欢迎加我微信(ID:lsy965145175)备注“搜索百科”,拉你进 搜索技术交流群,一起探讨与学习!
✨ 推荐阅读
🔗 参考
收起阅读 »
Coco AI 入驻 GitCode:打破数据孤岛,解锁智能协作新可能
在信息爆炸时代,企业正面临前所未有的挑战:
- 企业数据和信息分散,数据孤岛现象严重,员工往往浪费大量时间跨平台检索;
- 跨部门协作困难,团队因信息隔阂导致项目延期;
- 数据安全问题严峻,迫使企业对数据管理提出高要求;
- 传统搜索准确率不足,无法满足用户深层次需求;
这正是 Coco AI 诞生的契机——一款重新定义企业效率的智能中枢。
Coco AI 是一个完全开源、跨平台的统一搜索与效率工具,深度融合大语言模型技术,实现从"人找信息"到"信息追人"的范式革命。目前已加入 GitCode 平台成为 G-Star 优秀毕业项目。通过连接 Google Workspace、Notion、语雀等 200+ 数据源,接入 DeepSeek 等大模型,构建企业级智能知识图谱,让数据真正流动起来,帮助企业高效管理和利用内外部数据资源。

多种功能 一次集合
全域智能搜索
- Coco AI 支持整合企业内部和外部的多种数据源,包括 Google Workspace、Dropbox、GitHub、本地文件系统等。
- 提供统一的搜索界面,用户无需切换多个平台即可快速检索所需信息。
AI 知识管家
- 内置基于生成式 AI 的聊天助手,能够理解企业内部的文档、对话记录和工作流程。
- 支持从互联网、内部知识库和指定数据源中提取信息,提供与组织相关的智能回答。
- 支持在搜索模式和聊天模式之间快速切换。
企业安全中枢
- 遵循企业级权限管理规范,确保数据访问的安全性。
- 支持私有化部署,满足企业对数据隐私的高要求。
- 允许开发者根据需求进行定制和扩展,支持企业自行部署,确保数据隐私和安全。
协作生态集成
- 用户可以直接与单个文件或数据源进行交互,例如对文档内容提问或生成摘要。
- 通过整合团队常用的工具和数据源,提升团队协作效率。
- 支持基于上下文的多轮对话,帮助团队成员快速获取所需信息。
- 在 1 分钟内轻松将 Coco AI 功能嵌入到您的网站中。
架构设计图
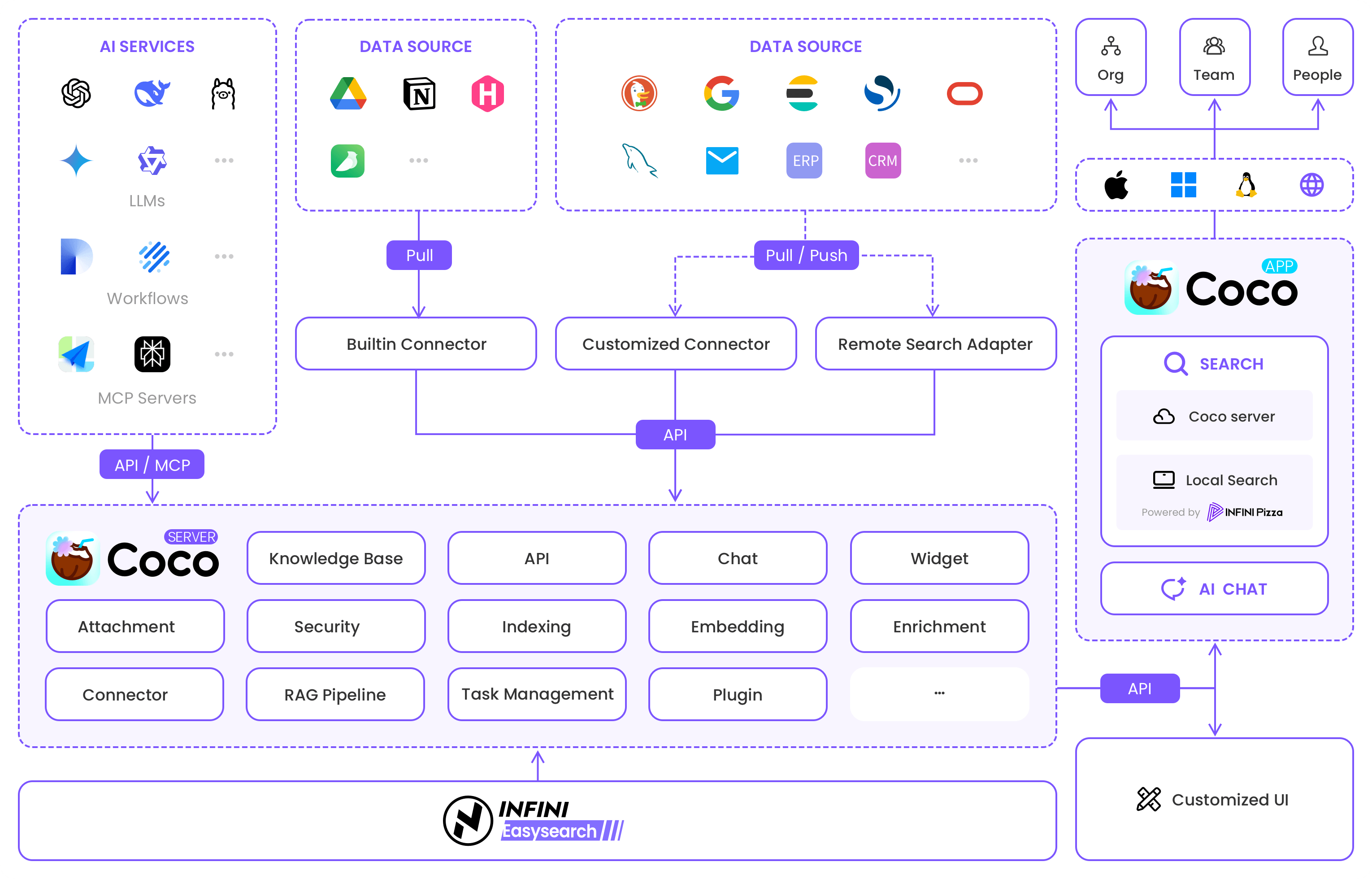
核心模块 “Coco Server” 提供搜索、聊天、附件管理、索引、嵌入、安全等功能,并通过 API 实现与外部系统的交互。同时,系统支持自定义 UI,为用户提供个性化的搜索和任务管理体验,并通过 AI 助手提供智能化的信息交互体验。
从 V0.3 到行业标准,Coco AI 持续进化,致力于推动知识管理和信息检索的变革,加速企业数字化转型。
立即访问
来 GitCode 了解 Coco AI,让您的企业获得:
- 每年节省百万级人力成本
- 打造永不遗忘的组织和大脑
- 激活数据资产的复合价值
开源可许:
MIT License
项目地址:
https://gitcode.com/infinilabs/coco-app
快来 ⭐️ Star 支持 Coco AI 吧 ~
直播预告
4 月 28 日 星期一 19:00 极限科技(INFINI Labs)团队带您全面解析 Coco AI,探索其核心功能、技术架构及实际应用场景,领略智能搜索与知识管理的革新。

CSDN 直播间地址 👇
https://live.csdn.net/room/csdnedu/q6BD0Kui
关于 Gitcode

GitCode 新一代由 AI 驱动的开源开发者平台,依托 CSDN 开发者社区,通过集成代码托管服务、代码仓库和可信赖的开源组件库,使开发者能够在云端进行代码托管和开发,平台提供了丰富的功能支持和完善的生态体系,帮助开发者轻松管理和分享代码,为开源项目提供强有力的支持。
作者:GitCode
原文:https://mp.weixin.qq.com/s/03VTrmVXzflO6QTcZaCLTA
在信息爆炸时代,企业正面临前所未有的挑战:
- 企业数据和信息分散,数据孤岛现象严重,员工往往浪费大量时间跨平台检索;
- 跨部门协作困难,团队因信息隔阂导致项目延期;
- 数据安全问题严峻,迫使企业对数据管理提出高要求;
- 传统搜索准确率不足,无法满足用户深层次需求;
这正是 Coco AI 诞生的契机——一款重新定义企业效率的智能中枢。
Coco AI 是一个完全开源、跨平台的统一搜索与效率工具,深度融合大语言模型技术,实现从"人找信息"到"信息追人"的范式革命。目前已加入 GitCode 平台成为 G-Star 优秀毕业项目。通过连接 Google Workspace、Notion、语雀等 200+ 数据源,接入 DeepSeek 等大模型,构建企业级智能知识图谱,让数据真正流动起来,帮助企业高效管理和利用内外部数据资源。
多种功能 一次集合
全域智能搜索
- Coco AI 支持整合企业内部和外部的多种数据源,包括 Google Workspace、Dropbox、GitHub、本地文件系统等。
- 提供统一的搜索界面,用户无需切换多个平台即可快速检索所需信息。
AI 知识管家
- 内置基于生成式 AI 的聊天助手,能够理解企业内部的文档、对话记录和工作流程。
- 支持从互联网、内部知识库和指定数据源中提取信息,提供与组织相关的智能回答。
- 支持在搜索模式和聊天模式之间快速切换。
企业安全中枢
- 遵循企业级权限管理规范,确保数据访问的安全性。
- 支持私有化部署,满足企业对数据隐私的高要求。
- 允许开发者根据需求进行定制和扩展,支持企业自行部署,确保数据隐私和安全。
协作生态集成
- 用户可以直接与单个文件或数据源进行交互,例如对文档内容提问或生成摘要。
- 通过整合团队常用的工具和数据源,提升团队协作效率。
- 支持基于上下文的多轮对话,帮助团队成员快速获取所需信息。
- 在 1 分钟内轻松将 Coco AI 功能嵌入到您的网站中。
架构设计图
核心模块 “Coco Server” 提供搜索、聊天、附件管理、索引、嵌入、安全等功能,并通过 API 实现与外部系统的交互。同时,系统支持自定义 UI,为用户提供个性化的搜索和任务管理体验,并通过 AI 助手提供智能化的信息交互体验。
从 V0.3 到行业标准,Coco AI 持续进化,致力于推动知识管理和信息检索的变革,加速企业数字化转型。
立即访问
来 GitCode 了解 Coco AI,让您的企业获得:
- 每年节省百万级人力成本
- 打造永不遗忘的组织和大脑
- 激活数据资产的复合价值
开源可许:
MIT License
项目地址:
https://gitcode.com/infinilabs/coco-app
快来 ⭐️ Star 支持 Coco AI 吧 ~
直播预告
4 月 28 日 星期一 19:00 极限科技(INFINI Labs)团队带您全面解析 Coco AI,探索其核心功能、技术架构及实际应用场景,领略智能搜索与知识管理的革新。
CSDN 直播间地址 👇
https://live.csdn.net/room/csdnedu/q6BD0Kui
关于 Gitcode
GitCode 新一代由 AI 驱动的开源开发者平台,依托 CSDN 开发者社区,通过集成代码托管服务、代码仓库和可信赖的开源组件库,使开发者能够在云端进行代码托管和开发,平台提供了丰富的功能支持和完善的生态体系,帮助开发者轻松管理和分享代码,为开源项目提供强有力的支持。
收起阅读 »作者:GitCode
原文:https://mp.weixin.qq.com/s/03VTrmVXzflO6QTcZaCLTA
INFINI Labs 助力开源与教育:免费许可证计划全面升级

在数字化浪潮席卷全球的今天,INFINI Labs 深刻认识到开源项目和教育机构在技术创新与人才培养中的核心作用。因此,我们郑重推出全新升级的免费许可证计划,旨在全球范围内为开源社区和教育界提供有力支持,共同推动软件生态的繁荣与进步。
一、产品实力与荣誉
1.INFINI Pizza:实时搜索的新纪元

- 在第十三届“数据技术嘉年华”(DTC2024)上,INFINI Labs 发布了划时代的搜索引擎——INFINI Pizza,标志着搜索型数据库迈入实时搜索的新纪元。
- INFINI Pizza 凭借先进的设计理念与架构,以及独有的专利技术,实现了对海量数据的无限伸缩,提供高效、准确的实时数据搜索能力
2.行业标杆案例
- INFINI Labs 荣获中国信通院大数据“星河”标杆案例,其中移动云搜索数据库案例更是荣选为数据库标杆案例。
- 该案例基于移动云 Easysearch 数据库,通过创新的多集群协同模式,实现了数据高性能存取,展现出极高的经济价值与社会价值。
3.国家发明专利认可
- INFINI Labs 的多项自主研发技术获得国家发明专利授权,这些成果彰显了公司在大数据领域的技术实力与创新精神。
二、品牌与行业地位
-
INFINI Labs 作为搜索型数据库产品领域的领军企业,积极参与行业标准的制定与推动。
- 其核心产品 INFINI Easysearch 荣获信通院首批可信搜索型数据库产品证书,再次印证了公司在行业中的领先地位。
三、产品介绍

-
INFINI Easysearch:作为 Elasticsearch 的国产化替代方案,提供高度兼容性与卓越性能,满足企业级需求。
-
INFINI Console:轻量级多集群、跨版本搜索基础设施统一管控平台,助力企业高效管理搜索集群。
-
INFINI Gateway:专为 Elasticsearch 打造的高性能应用网关,提供丰富的功能特性与卓越性能。
-
INFINI Loadgen:支持多种搜索引擎的轻量级压测工具,为企业提供强大的数据加载与测试能力。
- INFINI Pizza:引领实时搜索时代的新星,为企业提供高效、准确的实时数据搜索解决方案。
四、免费许可证计划
1.教育机构学术许可证
-
面向全球公立或私立学校、职业学校、大学等教育机构,提供非商业用途的软件使用许可。
- 有效期一年,符合条件的教育机构可继续申请。
2.开源项目许可证
-
面向非商业开源项目开发者,要求项目拥有活跃社区并在其官网添加 INFINI Labs 的链接。
- 许可证免费,有效期一年,符合条件的项目可继续申请。
五、申请方式
符合条件的开源项目和教育机构可通过访问 INFINI Labs 官方网站,轻松提交申请,我们将尽快审核并回复。
申请链接:https://infinilabs.cn/community
六、结语
INFINI Labs 以全新升级的免费许可证计划为契机,与全球开源社区和教育界携手合作,共同推动软件生态的创新与发展。让我们共同迎接更加美好的未来!
七、关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。

在数字化浪潮席卷全球的今天,INFINI Labs 深刻认识到开源项目和教育机构在技术创新与人才培养中的核心作用。因此,我们郑重推出全新升级的免费许可证计划,旨在全球范围内为开源社区和教育界提供有力支持,共同推动软件生态的繁荣与进步。
一、产品实力与荣誉
1.INFINI Pizza:实时搜索的新纪元
- 在第十三届“数据技术嘉年华”(DTC2024)上,INFINI Labs 发布了划时代的搜索引擎——INFINI Pizza,标志着搜索型数据库迈入实时搜索的新纪元。
- INFINI Pizza 凭借先进的设计理念与架构,以及独有的专利技术,实现了对海量数据的无限伸缩,提供高效、准确的实时数据搜索能力
2.行业标杆案例
- INFINI Labs 荣获中国信通院大数据“星河”标杆案例,其中移动云搜索数据库案例更是荣选为数据库标杆案例。
- 该案例基于移动云 Easysearch 数据库,通过创新的多集群协同模式,实现了数据高性能存取,展现出极高的经济价值与社会价值。
3.国家发明专利认可
- INFINI Labs 的多项自主研发技术获得国家发明专利授权,这些成果彰显了公司在大数据领域的技术实力与创新精神。
二、品牌与行业地位
-
INFINI Labs 作为搜索型数据库产品领域的领军企业,积极参与行业标准的制定与推动。
- 其核心产品 INFINI Easysearch 荣获信通院首批可信搜索型数据库产品证书,再次印证了公司在行业中的领先地位。
三、产品介绍
-
INFINI Easysearch:作为 Elasticsearch 的国产化替代方案,提供高度兼容性与卓越性能,满足企业级需求。
-
INFINI Console:轻量级多集群、跨版本搜索基础设施统一管控平台,助力企业高效管理搜索集群。
-
INFINI Gateway:专为 Elasticsearch 打造的高性能应用网关,提供丰富的功能特性与卓越性能。
-
INFINI Loadgen:支持多种搜索引擎的轻量级压测工具,为企业提供强大的数据加载与测试能力。
- INFINI Pizza:引领实时搜索时代的新星,为企业提供高效、准确的实时数据搜索解决方案。
四、免费许可证计划
1.教育机构学术许可证
-
面向全球公立或私立学校、职业学校、大学等教育机构,提供非商业用途的软件使用许可。
- 有效期一年,符合条件的教育机构可继续申请。
2.开源项目许可证
-
面向非商业开源项目开发者,要求项目拥有活跃社区并在其官网添加 INFINI Labs 的链接。
- 许可证免费,有效期一年,符合条件的项目可继续申请。
五、申请方式
符合条件的开源项目和教育机构可通过访问 INFINI Labs 官方网站,轻松提交申请,我们将尽快审核并回复。
申请链接:https://infinilabs.cn/community
六、结语
INFINI Labs 以全新升级的免费许可证计划为契机,与全球开源社区和教育界携手合作,共同推动软件生态的创新与发展。让我们共同迎接更加美好的未来!
七、关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »
开源中国专访 TJ:开源许可证,欢迎来到云时代
Elastic日报 第1077期 (2020-10-15)
https://mp.weixin.qq.com/s%3F_ ... ab24f
2、Cerebro
https://github.com/lmenezes/cerebro
3、esquery
https://github.com/aquasecurity/esquery
编辑:江水
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
https://mp.weixin.qq.com/s%3F_ ... ab24f
2、Cerebro
https://github.com/lmenezes/cerebro
3、esquery
https://github.com/aquasecurity/esquery
编辑:江水
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
收起阅读 »
一个仿Linux 控制台的ES的_cat的插件

- 简化_cat使用,可以直接输入 cat 命令 ,可以滚动查看历史结果
- 支持字体放大缩小
- 支持命令历史记录(通过上下方向键来切换 )
- 支持鼠标划取的复制粘贴(暂不复制到剪贴板)
- 安装后在 http://127.0.0.1:9200/_console 使用,也可本地使用:直接访问html文件
GIT 地址
欢迎加 576037940 这个群讨论哈
- 简化_cat使用,可以直接输入 cat 命令 ,可以滚动查看历史结果
- 支持字体放大缩小
- 支持命令历史记录(通过上下方向键来切换 )
- 支持鼠标划取的复制粘贴(暂不复制到剪贴板)
- 安装后在 http://127.0.0.1:9200/_console 使用,也可本地使用:直接访问html文件
GIT 地址
欢迎加 576037940 这个群讨论哈
收起阅读 »
Kibana 新的可视化插件:Vega
https://vega.github.io/vega/examples/
Vega是什么?
相比其他第三方可视化库,Vega的目的是让你更快将数据进行展现,vega通过声明的方式可以快速将你的数据进行各种格式化,而不用纠结于具体的调用细节,和SQL这种通用式交互语言类似,数据的输入是JSON。

Vega的Kibana插件下载地址:
https://github.com/nyurik/kibana-vega-vis/releases
安装之后,就能在可视化类型里面选择Vega了,使用起来很简单,输入相应的描叙语言,如:
{
"$schema": "https://vega.github.io/schema/ ... ot%3B,
"description": "A simple bar chart with embedded data.",
"width": 300, "height": 200, "padding": 5,
"data": {
"values": [
{"a": "A","b": 28}, {"a": "B","b": 55}, {"a": "C","b": 43},
{"a": "D","b": 91}, {"a": "E","b": 81}, {"a": "F","b": 53},
{"a": "G","b": 19}, {"a": "H","b": 87}, {"a": "I","b": 52}
]
},
"mark": "bar",
"encoding": {
"x": {"field": "a", "type": "ordinal"},
"y": {"field": "b", "type": "quantitative"}
}
}https://vega.github.io/vega-li ... k-def
https://vega.github.io/vega/examples/
https://github.com/nyurik/kiba ... -demo
https://vega.github.io/vega/examples/
Vega是什么?
相比其他第三方可视化库,Vega的目的是让你更快将数据进行展现,vega通过声明的方式可以快速将你的数据进行各种格式化,而不用纠结于具体的调用细节,和SQL这种通用式交互语言类似,数据的输入是JSON。
Vega的Kibana插件下载地址:
https://github.com/nyurik/kibana-vega-vis/releases
安装之后,就能在可视化类型里面选择Vega了,使用起来很简单,输入相应的描叙语言,如:
{
"$schema": "https://vega.github.io/schema/ ... ot%3B,
"description": "A simple bar chart with embedded data.",
"width": 300, "height": 200, "padding": 5,
"data": {
"values": [
{"a": "A","b": 28}, {"a": "B","b": 55}, {"a": "C","b": 43},
{"a": "D","b": 91}, {"a": "E","b": 81}, {"a": "F","b": 53},
{"a": "G","b": 19}, {"a": "H","b": 87}, {"a": "I","b": 52}
]
},
"mark": "bar",
"encoding": {
"x": {"field": "a", "type": "ordinal"},
"y": {"field": "b", "type": "quantitative"}
}
}https://vega.github.io/vega-li ... k-def
https://vega.github.io/vega/examples/
https://github.com/nyurik/kiba ... -demo 收起阅读 »
