

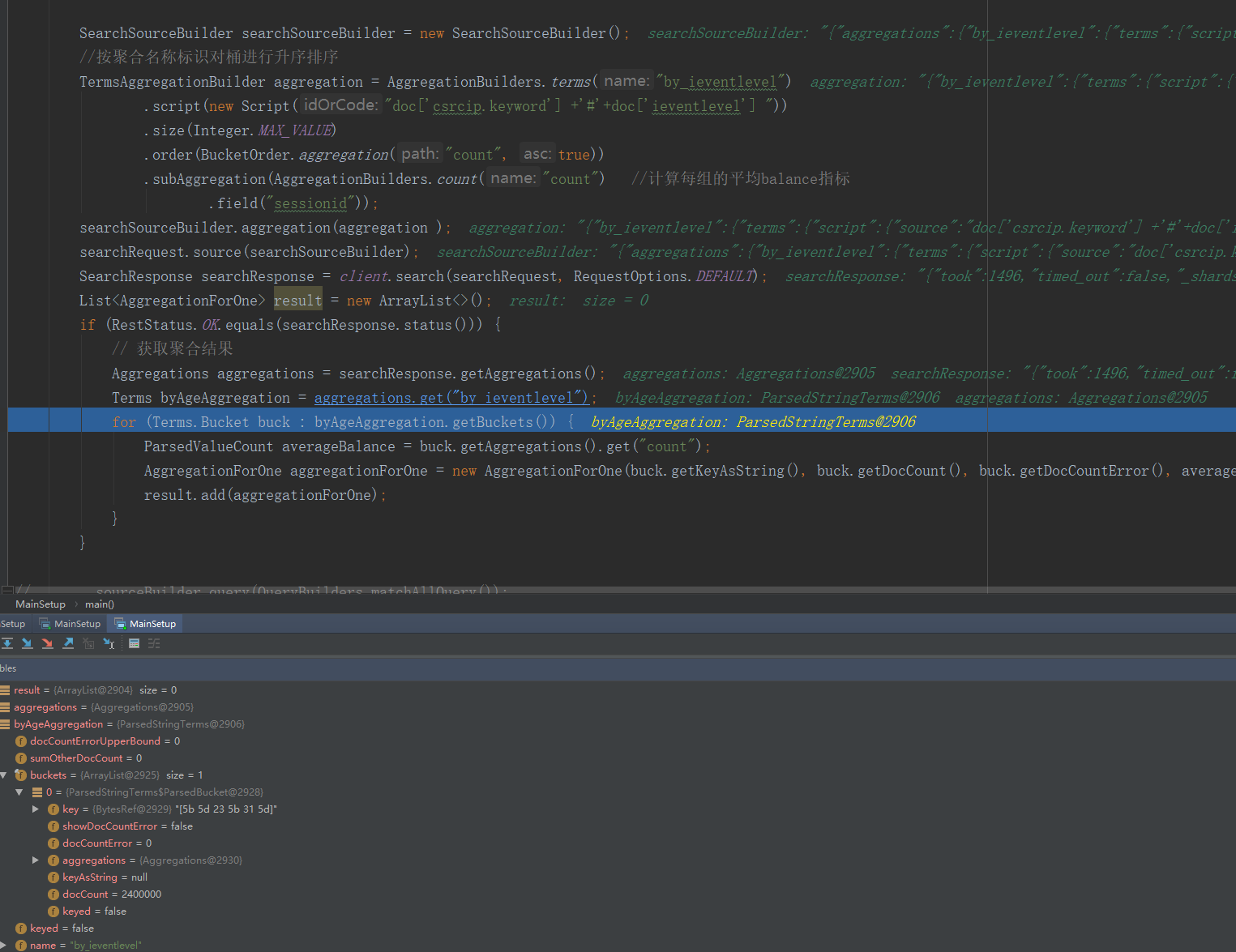
我带了两个字段 但是分组查出来得结果doccount是全部得 没有按照我给得字段分组
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //按聚合名称标识对桶进行升序排序 TermsAggregationBuilder aggregation = AggregationBuilders.terms("by_ieventlevel") .script(new Script("doc['csrcip.keyword'] +'#'+doc['ieventlevel'] ")) .size(Integer.MAX_VALUE) .order(BucketOrder.aggregation("count", true)) .subAggregation(AggregationBuilders.count("count") //计算每组的平均balance指标 .field("sessionid")); searchSourceBuilder.aggregation(aggregation ); searchRequest.source(searchSourceBuilder); SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT); List<AggregationForOne> result = new ArrayList<>(); if (RestStatus.OK.equals(searchResponse.status())) { // 获取聚合结果 Aggregations aggregations = searchResponse.getAggregations(); Terms byAgeAggregation = aggregations.get("by_ieventlevel"); for (Terms.Bucket buck : byAgeAggregation.getBuckets()) { ParsedValueCount averageBalance = buck.getAggregations().get("count"); AggregationForOne aggregationForOne = new AggregationForOne(buck.getKeyAsString(), buck.getDocCount(), buck.getDocCountError(), averageBalance.getValue()); result.add(aggregationForOne); } }

2 个回复
liu_lanyu - 出言便作狮子鸣
赞同来自:
"csrctip": {
"type": "string",
"fielddata": {
"format": "doc_values"
},
"index": "not_analyzed"
},
"isrcp
FFFrp
赞同来自:
csrcip.keyword这个子字段你有吗