

业务日志分布在其中的6个data节点中,每个节点只起一个分片,从磁盘空间使用看出是均匀写入到6个节点中,如图中磁盘空间为2.7T/2.8T的那6个节点。
但是发现只有其中一台的负载特别高,查看thead_pool也只有负载高的那台有堆积,其他是基本不用的状态!!!求解!!!
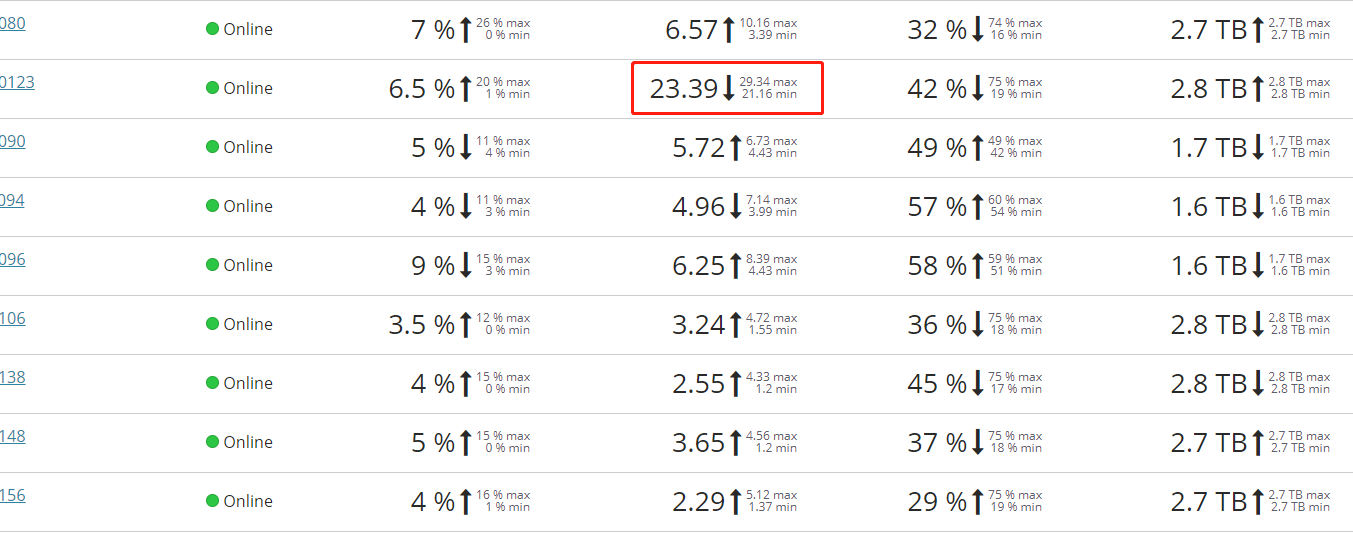
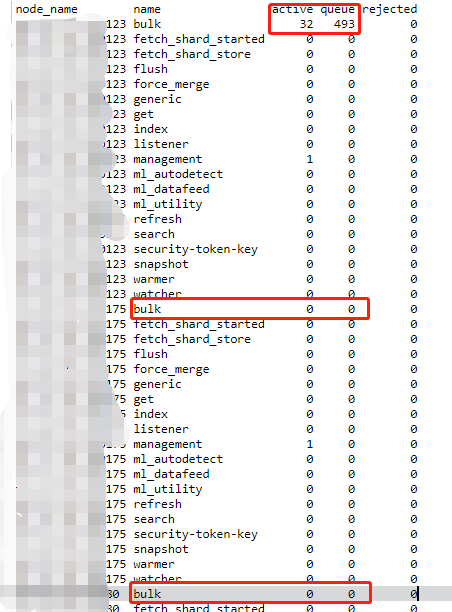
但是发现只有其中一台的负载特别高,查看thead_pool也只有负载高的那台有堆积,其他是基本不用的状态!!!求解!!!

8 个回复
kennywu76 - Wood
赞同来自:
paLog
赞同来自:
laoyang360 - 《一本书讲透Elasticsearch》作者,Elastic认证工程师 [死磕Elasitcsearch]知识星球地址:http://t.cn/RmwM3N9;微信公众号:铭毅天下; 博客:https://elastic.blog.csdn.net
赞同来自:
zqc0512 - andy zhou
赞同来自:
移动下数据。
yanlei
赞同来自:
God_lockin
赞同来自:
是不是你所有的client的都直连的是这个节点?
你有没有在这个节点上单独部署或者运行什么其他的服务?
可以从这些方面去考虑一下
fanmo3yuan
赞同来自:
2. 在看看这个节点上的shard和其它节点上的shard分布是否相同,确认是否是某些热shard引起的,可以试着reroute 相关到其它节点验证
3. 看看机器,硬件的信息,确认是否是机器问题
puyunjiafly
赞同来自:
2.还有就是bulk的routing 是不是录入数据大量倾斜导致绝大数数据是只往这一个分片录入,如指定routing=北京(地域) bulk中地域数据百分之90都是北京,可以从分片对应文档数量查看数据是否倾斜严重,然后想修改策略。
3.查看该机器,看是否是硬件或配置导致的原因。
找到原因可以分享下原因。