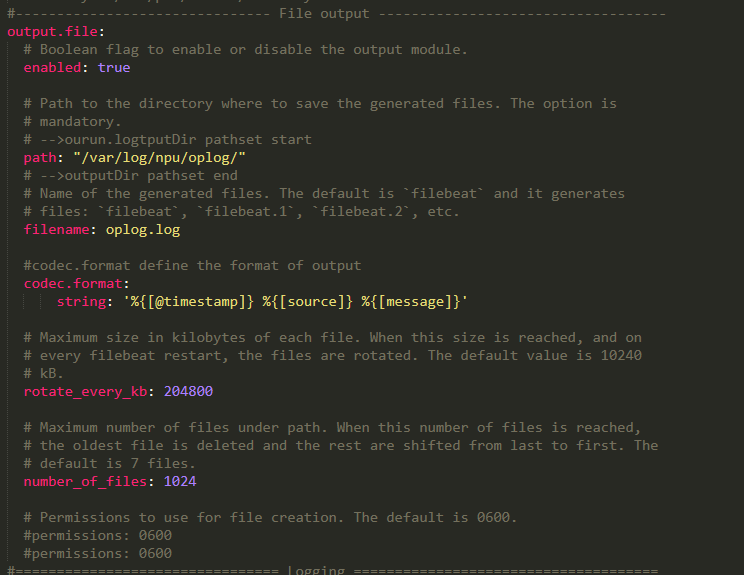
目前我使用的filebeat版本是6.2.4,测试场景采集的日志的生成速度大约是16M/S(约100000条/S),输出日志采用的是output.file的模块机制,注意不是es或者kafka,输出配置项在附件中可看到,目前发现在这样的规格下相应输出与输入的日志条数对不上,丢失率大约是百万分之一到千万分之一,想问下大神有没有人能帮忙定位一下到底是什么原因或者是filebeat哪一块有缺陷。


本站服务器及带宽由 ![]() 提供赞助 · 网站程序: WeCenter · 湘ICP备17007482号 · 湘公网安备43010402002319号
提供赞助 · 网站程序: WeCenter · 湘ICP备17007482号 · 湘公网安备43010402002319号

1 个回复
zqc0512 - andy zhou
赞同来自: