

官方文档说索引时存储IDF,但IDF是根据文档总量得出来的,后面是需要不断更新这个值吗
Elasticsearch | 作者 stephen_qu | 发布于2019年12月25日 | 阅读数:2334
Q1:
文档中说:
但是IDF是根据索引中文档数量去计算的,那随着索引中的文档数量增减,这个数值要不断变化吗?
Q2:
这个2,5是根据TF-IDF计算出来的吗?那每个文档的“happy”,“hippopotamus”对应的 权重应该都是不同的吧?这里只是为了演示吧?
https://www.elastic.co/guide/c ... -docs
文档中说:
以下三个因素——词频(term frequency)、逆向文档频率(inverse document frequency)和字段长度归一值(field-length norm)——是在索引时计算并存储的。最后将它们结合在一起计算单个词在特定文档中的 权重 。
但是IDF是根据索引中文档数量去计算的,那随着索引中的文档数量增减,这个数值要不断变化吗?
Q2:
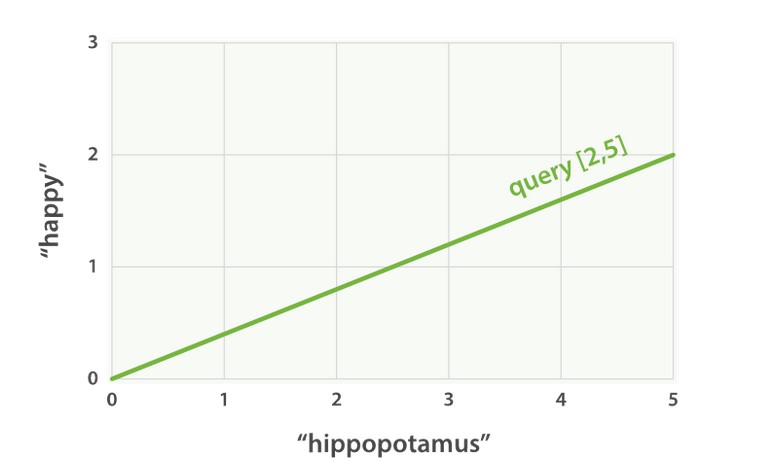
设想如果查询 “happy hippopotamus” ,常见词 happy 的权重较低,不常见词 hippopotamus 权重较高,假设 happy 的权重是 2 , hippopotamus 的权重是 5 ,可以将这个二维向量—— [2,5] ——在坐标系下作条直线,线的起点是 (0,0) 终点是 (2,5)
这个2,5是根据TF-IDF计算出来的吗?那每个文档的“happy”,“hippopotamus”对应的 权重应该都是不同的吧?这里只是为了演示吧?
https://www.elastic.co/guide/c ... -docs

2 个回复
stephen_qu - 多学,多动手,少说废话
赞同来自:
trycatchfinal
赞同来自:
elasticsearch的每个分片是由segment组成的。索引文档,会生成新的segment;删除文档,会记录在del文件中。
segment文件都是不可变的。IDF计算设计的文档数,应该会分别获取segment的文档数求和。