


OpenSearch
【搜索客社区日报】第2231期 (2026-05-15)
社区日报 • Fred2000 发表了文章 • 0 个评论 • 13125 次浏览 • 2026-05-15 10:19
【搜索客社区日报】第2119期 (2025-09-22)
社区日报 • Muses 发表了文章 • 0 个评论 • 12443 次浏览 • 2025-09-22 13:44
招聘!搜索运维工程师(Elasticsearch/Easysearch)-全职/北京/12-20K
求职招聘 • INFINI Labs 小助手 发表了文章 • 0 个评论 • 11015 次浏览 • 2025-09-22 12:33
极限科技诚招全职搜索运维工程师(Elasticsearch/Easysearch)!
欢迎搜索技术热爱者加入我们,共同打造高效、智能的搜索解决方案!
在招岗位介绍
岗位名称
搜索运维工程师(Elasticsearch/Easysearch)
Base:北京
薪资待遇:12-20K,五险一金,双休等
岗位职责
- 负责客户现场的 Elasticsearch/Easysearch/OpenSearch 搜索引擎集群的日常维护、监控和优化,确保集群的高可用性和性能稳定;
- 协助客户进行搜索引擎集群的部署、配置及版本升级;
- 排查和解决 Elasticsearch/Easysearch/OpenSearch 集群中的各种技术问题,及时响应并处理集群异常;
- 根据业务需求设计和实施搜索索引的调优、数据迁移和扩展方案;
- 负责与客户沟通,提供技术支持及相关培训,确保客户需求得到有效满足;
- 制定并实施搜索引擎的备份、恢复和安全策略,保障数据安全;
- 与内部研发团队和外部客户进行协作,推动集群性能改进和功能优化。
岗位要求
- 全日制本科及以上学历,2 年以上运维工作经验;
- 拥有 Elasticsearch/Easysearch/OpenSearch 使用经验,熟悉搜索引擎的原理、架构和相关生态工具(如 Logstash、Kibana 等);
- 熟悉 Linux 操作系统的使用及常见性能调优方法;
- 熟练掌握 Shell 或 Python 等至少一种脚本语言,能够编写自动化运维脚本;
- 具有优秀的问题分析与解决能力,能够快速应对突发情况;
- 具备良好的沟通能力和团队合作精神,能够接受客户驻场工作;
- 提供 五险一金,享有带薪年假及法定节假日。
加分项
- 计算机科学、信息技术或相关专业;
- 具备丰富的大规模分布式系统运维经验;
- 熟悉 Elasticsearch/Easysearch/OpenSearch 分片、路由、查询优化等高级功能;
- 拥有 Elastic Certified Engineer 认证;
- 具备大规模搜索引擎集群设计、扩展和调优经验;
- 熟悉其他搜索引擎技术(如 Solr、Lucene)者优先;
- 熟悉大数据处理相关技术(比如: Kafka 、Flink 等)者优先。
简历投递
- 邮件:hello@infini.ltd(邮件标题请备注姓名 求职岗位)
- 微信:INFINI-Labs (加微请备注求职岗位)

关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
我们在做什么
极限科技(INFINI Labs)正在致力于以下几个核心方向:
1、开发近实时搜索引擎 INFINI Easysearch INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。详情参见:https://infinilabs.cn
2、打造下一代实时搜索引擎 INFINI Pizza INFINI Pizza 是一个分布式混合搜索数据库系统。我们的使命是充分利用现代硬件和人工智能的潜力,为企业提供量身定制的实时智能搜索体验。我们致力于满足具有挑战性的环境中高并发和高吞吐量的需求,同时提供无缝高效的搜索功能。详情参见:https://pizza.rs
3、为现代团队打造的统一搜索与 AI 智能助手 Coco AI Coco AI 是一款完全开源的统一搜索与 AI 助手平台,它通过统一搜索入口,连接企业内外部的异构数据源,融合大模型能力,帮助团队高效访问知识,智能决策协作。详情参见:https://coco.rs
4、积极参与全球开源生态建设 通过开源 Coco AI、Console、Gateway、Agent、Loadgen 等搜索领域产品和社区贡献,推动全球开源技术的发展,提升中国在全球开源领域的影响力。INFINI Labs Github 主页:https://github.com/infinilabs
5、提供专业服务 为客户提供包括搜索技术支持、迁移服务、定制解决方案和培训在内的全方位服务。
6、提供国产化搜索解决方案 针对中国市场的特殊需求,提供符合国产化标准的搜索产品和解决方案,帮助客户解决使用 Elasticsearch 时遇到的挑战。
极限科技(INFINI Labs)通过这些努力,旨在成为全球领先的实时搜索和数据分析解决方案提供商。
搜索百科(4):OpenSearch — 开源搜索的新选择
OpenSearch • liaosy 发表了文章 • 0 个评论 • 9831 次浏览 • 2025-09-21 14:31
大家好,我是 INFINI Labs 的石阳。
欢迎关注 《搜索百科》 专栏!每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
上一篇我们围观了 “流量明星” Elasticsearch — 从食谱搜索到 PB 级明星产品,从 Apache 2.0 到 SSPL 协议风波;今天我们来聊聊它的“分叉兄弟” OpenSearch。

引言
2021 年,当 Elasticsearch 宣布将其许可证从 Apache 2.0 变更为 SSPL/Elastic License 时,整个搜索社区为之震动。这一变更直接催生了一个新的开源分支 — OpenSearch。这个由 AWS 主导的项目不仅在短短几年内迅速发展成熟,更成为了许多企业在云原生环境下搜索解决方案的新选择。
OpenSearch 概述
OpenSearch 是从 Elasticsearch 7.10.2 分支而来的开源搜索与分析套件,由 AWS 主导开发并贡献给开源社区。OpenSearch 包括 OpenSearch(搜索引擎)和 OpenSearch Dashboards(可视化界面),完全兼容 Apache 2.0 协议,旨在为用户提供一个真正开源、社区驱动的搜索与分析解决方案。
- 首次发布:2021 年 4 月
- 最新版本:3.2.0(截止 2025 年 9 月)
- 开源协议:Apache License 2.0
- 主导企业:Amazon Web Services (AWS)
- 官方网址:https://opensearch.org/
- GitHub 仓库:https://github.com/opensearch-project
诞生故事:开源协议争议的产物
时间回到 2021 年 1 月,Elastic 公司宣布 Elasticsearch 从 7.11 版本起不再使用 Apache 2.0 协议,而改为 Elastic License 与 SSPL。这一决定立刻在社区和产业界引发巨大争议。

AWS(亚马逊云)作为 Elasticsearch 的重要用户与云服务提供商,不愿意被 Elastic 的商业条款所限制,随即牵头将 Elasticsearch 7.10 版本 fork 出来,并与 Kibana 一起重命名为 OpenSearch 与 OpenSearch Dashboards。
从此,开源世界分裂成了两条路线:
- Elastic 官方的 Elasticsearch + Kibana(带有商业许可)。
- 社区驱动的 OpenSearch + OpenSearch Dashboards(继续遵循 Apache 2.0 协议)。
这个分叉,既是开源协议之争的产物,也是云厂商与开源公司之间博弈的缩影。虽然初期被质疑过“是否真开源”,但经过数年的迭代,OpenSearch 已形成了相对独立的开发节奏和用户群体,插件和生态也逐渐丰富。
技术架构与特性
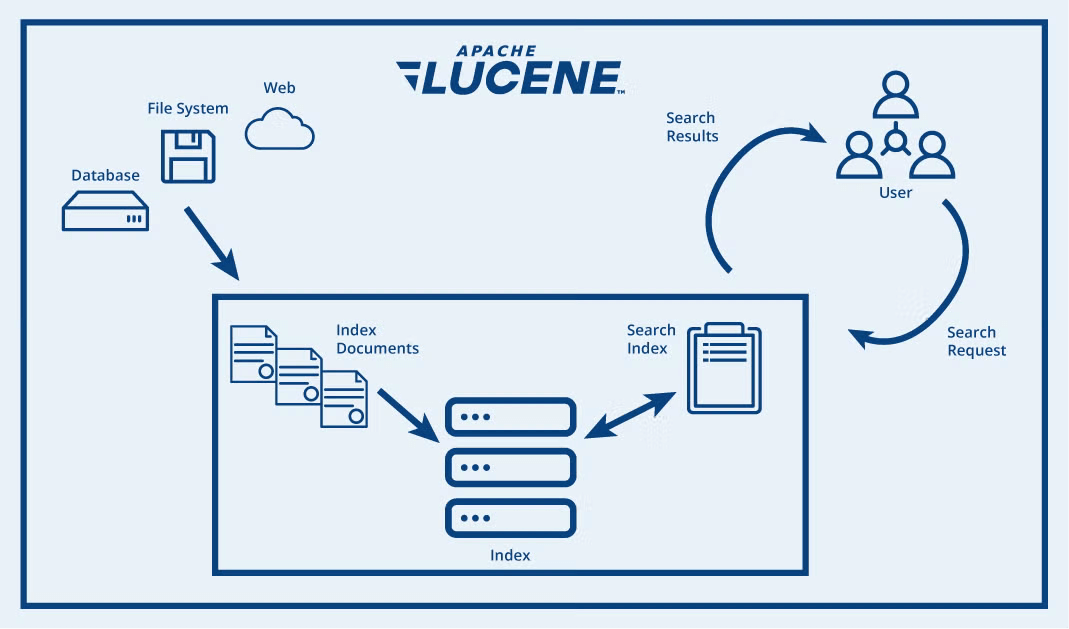
OpenSearch 是一个基于 Apache Lucene 的分布式搜索与分析引擎。在将数据添加到 OpenSearch 后,可以对其执行各种功能完备的全文搜索操作:按字段搜索、跨多个索引搜索、提升字段权重、按得分排序结果、按字段排序结果以及对结果进行聚合。
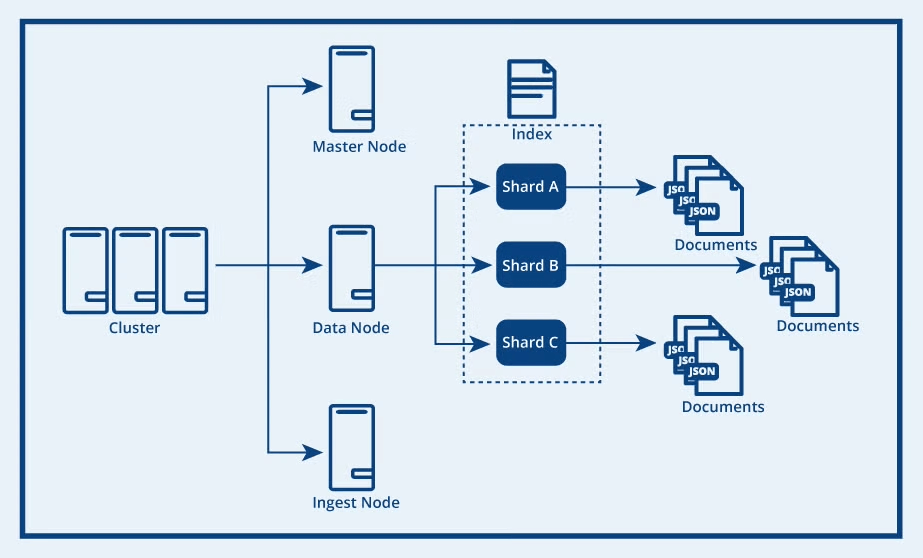
OpenSearch 的核心架构由集群、节点、索引、分片和文档组成。最高层是 OpenSearch 集群,它是由多个节点组成的分布式网络,每个节点会根据其类型负责不同的集群操作。数据节点负责存储索引(即文档的逻辑分组),并处理数据写入、搜索和聚合等任务。
每个索引会被划分为多个分片,分片包含主数据和副本数据。分片会分布在多台机器上,从而实现水平扩展,提升性能并高效利用存储资源。
OpenSearch vs Elasticsearch:详细对比
| 特性 | OpenSearch | Elasticsearch |
|---|---|---|
| 许可证 | Apache 2.0(完全开源) | SSPL/Elastic License/AGPLv3 |
| 起始版本 | 基于 Elasticsearch 7.10.2 | 从 7.11 开始协议变更 |
| 社区治理 | 开放治理模式,由社区驱动 | 由 Elastic NV 公司主导 |
| 安全性 | 所有安全功能默认开源 | 部分高级安全功能需要付费 |
| AI/向量检索 | 近年快速跟进,兼容性较好 | 原生支持,功能逐步增强 |
| 部署选择 | AWS OpenSearch Service / 自建 | Elastic Cloud / 自建 |
| 升级路径 | 从 Elasticsearch 7.x 平滑迁移 | 原生升级路径 |
| 社区活跃度 | 社区逐渐壮大,受到纯开源拥护者欢迎 | 用户基础庞大,但分裂带来争议 |
快速开始:5 分钟部署 OpenSearch
1. 使用 Docker 部署
# 拉取 OpenSearch 镜像
docker pull opensearchproject/opensearch:3.2.0
# 启动 OpenSearch 节点
docker run -d --name opensearch-node \
-p 9200:9200 -p 9600:9600 \
-e "discovery.type=single-node" \
-e "plugins.security.disabled=true" \
opensearchproject/opensearch:3.2.0
# 拉取 OpenSearch Dashboards
docker pull opensearchproject/opensearch-dashboards:3.2.0
# 启动 Dashboards
docker run -d --name opensearch-dashboards \
-p 5601:5601 \
-e "OPENSEARCH_HOSTS=http://opensearch-node:9200" \
opensearchproject/opensearch-dashboards:3.2.02. 验证安装
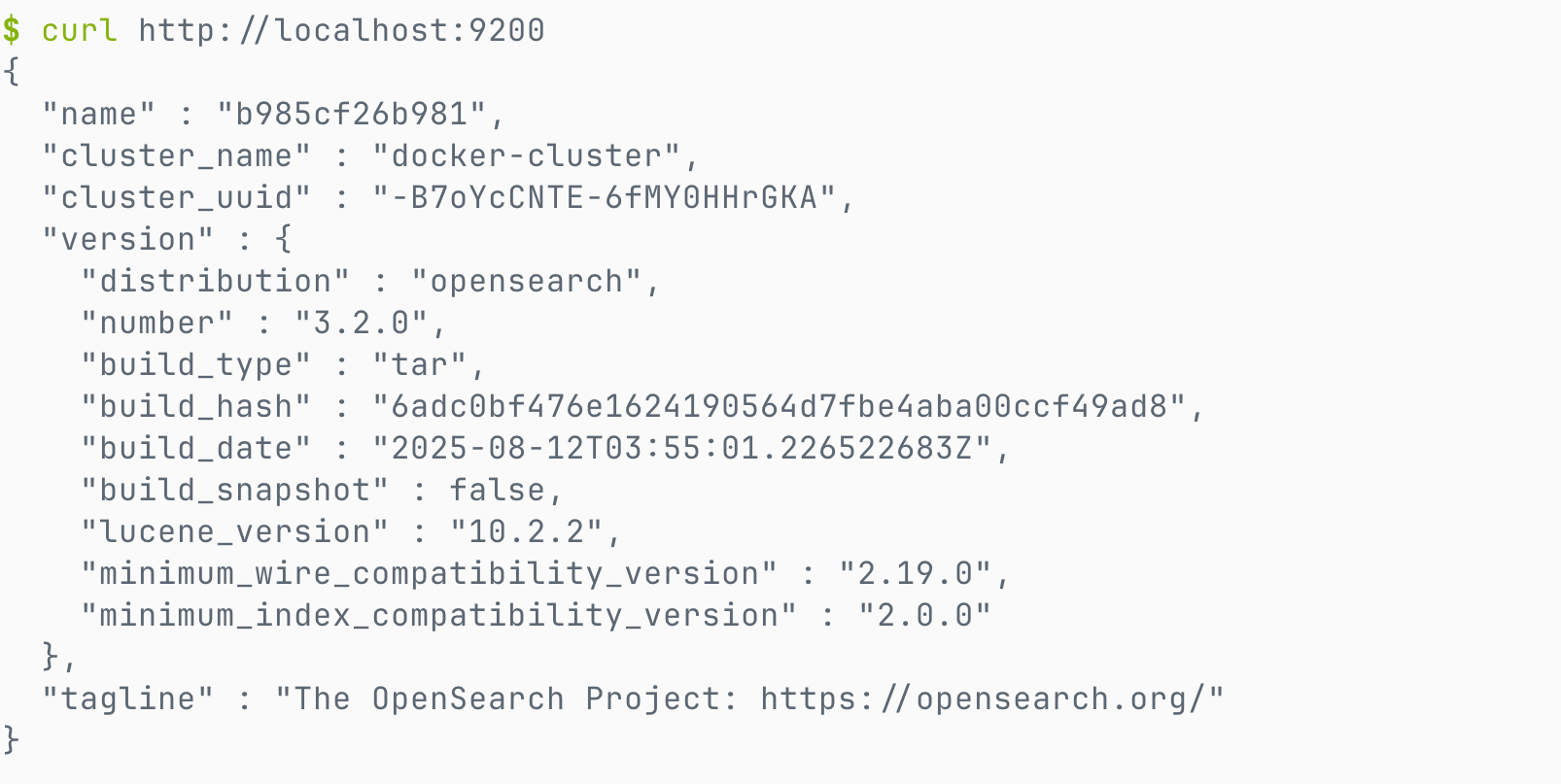
# 检查集群状态
curl -X GET "http://localhost:9200/"出现如下结果说明安装成功。
3. 创建索引和搜索
# 索引文档
curl -X POST "http://localhost:9200/my-first-index/_doc" -H 'Content-Type: application/json' -d'
{
"title": "OpenSearch 入门指南",
"content": "这是我在 OpenSearch 中的第一个文档",
"timestamp": "2025-09-18T10:00:00"
}'
# 执行搜索
curl -X GET "http://localhost:9200/my-first-index/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"content": "第一个文档"
}
}
}'4. 访问控制台
打开浏览器访问 http://localhost:5601 即可使用 OpenSearch Dashboards 界面。
结语
OpenSearch 的出现,是开源社区的一次“自救”。它不仅延续了 Elasticsearch 的核心功能,还代表了另一种治理模式:由云厂商和社区共同维护,保证了开源协议的延续。
在搜索技术的版图里,Elasticsearch 与 OpenSearch 的分叉,注定会成为一个重要的历史节点。未来,两者可能会继续竞争,也可能各自发展出独特的生态。
🚀 下期预告
下一篇我们将介绍 OpenSearch 的另一个兄弟 Easysearch,一个衍生自开源协议 Apache 2.0 的 Elasticsearch 7.10.2 版本的轻量级搜索引擎,作为一个 ES 国产替代方案,看看它如何以其极致的速度和易用性在国内搜索领域占据一席之地。
💬 三连互动
- 您是否考虑过从 Elasticsearch 迁移到 OpenSearch?
- 在开源协议方面,您更倾向于哪种模式?Apache 2.0 还是 Elastic 的多重许可?
- 对于云厂商与开源项目之间的关系,您有什么看法?
对搜索技术感兴趣的朋友,也欢迎加我微信(ID:lsy965145175)备注“搜索百科”,拉你进 搜索技术交流群,一起探讨与学习!
✨ 推荐阅读
🔗 参考资源
原文:https://infinilabs.cn/blog/2025/search-wiki-4-opensearch/
搜索百科(3):Elasticsearch — 搜索界的“流量明星”
Elasticsearch • liaosy 发表了文章 • 0 个评论 • 30444 次浏览 • 2025-09-16 11:20
大家好,我是 INFINI Labs 的石阳。
欢迎关注 《搜索百科》 专栏!每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
前两篇我们探讨了搜索技术的基石 Apache Lucene 和企业级搜索解决方案 Apache Solr。今天,我们来聊聊一个真正改变搜索游戏规则,但也充满争议的产品 — Elasticsearch。

引言
如果说 Lucene 是幕后英雄,那么 Elasticsearch 就是舞台中央的明星。借助 REST API、分布式架构、强大的生态系统,它让搜索 + 分析成为“马上可用”的服务形式。
在日志平台、可观察性、安全监控、AI 与语义检索等领域,Elasticsearch 的名字几乎成了默认选项。
Elasticsearch 概述
Elasticsearch 是一个开源的分布式搜索和分析引擎,构建于 Apache Lucene 之上。作为一个检索平台,它可以实时存储结构化、非结构化和向量数据,提供快速的混合和向量搜索,支持可观测性与安全分析,并以高性能、高准确性和高相关性实现 AI 驱动的应用。
- 首次发布:2010 年 2 月
- 最新版本:9.1.3(截止 2025 年 9 月)
- 核心依赖:Apache Lucene
- 开源协议:AGPL v3
- 官方网址:https://www.elastic.co/elasticsearch/
- GitHub 仓库:https://github.com/elastic/elasticsearch
起源:从食谱搜索到全球“流量明星”
Elasticsearch 的故事始于以色列开发者 Shay Banon。2010 年,当时他在学习厨师课程的妻子需要一款能够快速搜索食谱的工具。虽然当时已经有 Solr 这样的搜索解决方案,但 Shay 认为它们对于分布式场景的支持不够完善。

基于之前开发 Compass(一个基于 Lucene 的搜索库)的经验,Shay 开始构建一个完全分布式的、基于 JSON 的搜索引擎。2010 年 2 月,Elasticsearch 的第一个版本发布。
随着用户日益增多、企业级需求增强,Shay 在 2012 年创立了 Elastic 公司,把 Elasticsearch 不仅作为开源项目,也逐渐商业化运营起来,包括提供托管服务、企业支持,加入 Logstash 日志处理、Kibana 可视化工具等,Elastic 公司也逐渐从一个纯搜索引擎项目演变为一个更广泛的“数据搜索与分析”平台。
协议变更:开源和商业化的博弈
Elasticsearch 的发展并非一帆风顺。其历史上最具转折性的事件当属与 AWS 的冲突及随之而来的开源协议变更。

- 早期:Apache 2.0 协议
2010 年 Shay Banon 开源 Elasticsearch 时,最初采用的是 Apache 2.0 协议。Apache 2.0 属于宽松的自由协议,允许任何人免费使用、修改和商用(包括 SaaS 模式)。这帮助 Elasticsearch 快速壮大,成为事实上的“搜索引擎标准”。
- 协议变更:应对云厂商“白嫖”
随着 Elasticsearch 的流行,像 AWS(Amazon Web Services) 等云厂商直接将 Elasticsearch 做成托管服务,并从中获利。Elastic 公司认为这损害了他们的商业利益,因为云厂商“用开源赚钱,却没有回馈社区”。2021 年 1 月,Elastic 宣布 Elasticsearch 和 Kibana 不再采用 Apache 2.0,改为 双重协议:SSPL + Elastic License。这一步导致社区巨大分裂,AWS 带头将 Elasticsearch 分叉为 OpenSearch,并继续以 Apache 2.0 协议维护。
- 再次转向开源:AGPL v3
2024 年 3 月,Elastic 宣布新的版本(Elasticsearch 8.13 起)又新增 AGPL v3 作为一个开源许可选项。AGPL v3 既符合 OSI 真正开源标准,又能约束云厂商闭源托管服务,同时修复社区关系,Elastic 希望通过重新拥抱开源,减少分裂,吸引开发者回归。
Elasticsearch 从宽松到收紧,再到回归开源,是在社区生态与商业利益间寻找平衡的过程。
基本概念
要学习 Elasticsearch,得先了解其五大基本概览:集群、节点、分片、索引和文档。
- 集群(Cluster)
由一个或多个节点组成的整体,提供统一的搜索与存储服务。对外看起来像一个单一系统。
- 节点(Node)
集群中的一台服务器实例。节点有不同角色:
- Master 节点:负责集群管理(分片分配、元数据维护)。
- Data 节点:存储数据、处理搜索和聚合。
- Coordinating 节点:接收请求并调度任务。
- Ingest 节点:负责数据写入前的预处理。
- 索引(Index)
类似于传统数据库的“库”,按逻辑组织数据。一个索引往往对应一个业务场景(如日志、商品信息)。
- 分片(Shard)
为了让索引能水平扩展,Elasticsearch 会把索引拆分为多个 主分片,并为每个主分片创建 副本分片,提升高可用和查询性能。
- 文档(Document)
Elasticsearch 存储和检索的最小数据单元,通常是 JSON 格式。多个文档组成一个索引。
集群架构
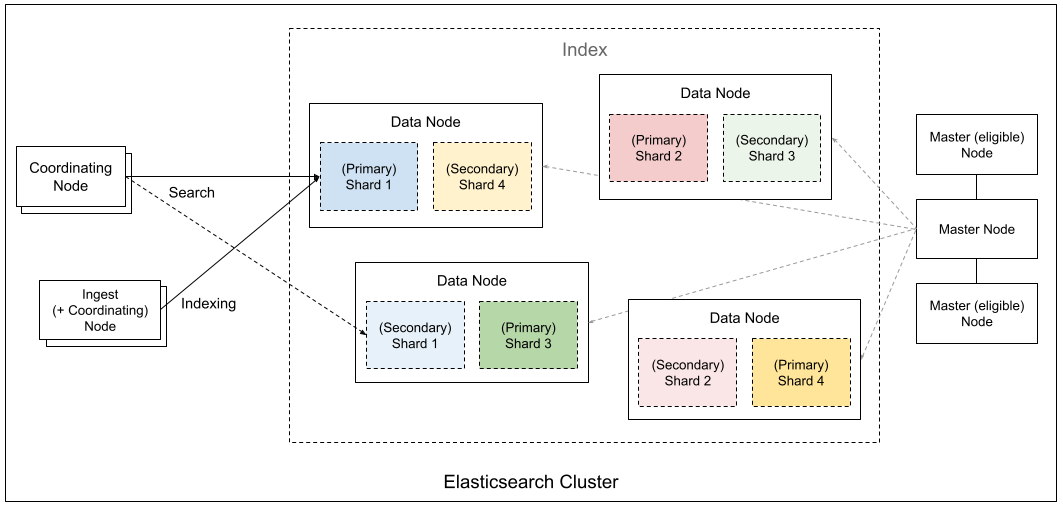
Elasticsearch 通过 Master、Data、Coordinating、Ingest 等不同角色节点的协作,将数据切分成分片并分布式存储,实现了高可用、可扩展的搜索与分析引擎架构。
快速开始:5 分钟体验 Elasticsearch
1. 使用 Docker 启动
# 拉取最新镜像
docker pull docker.elastic.co/elasticsearch/elasticsearch:9.1.3
# 启动单节点集群
docker run -d --name elasticsearch \
-p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e "xpack.security.enabled=false" \
docker.elastic.co/elasticsearch/elasticsearch:9.1.32. 验证安装
# 检查集群状态
curl -X GET "http://localhost:9200/"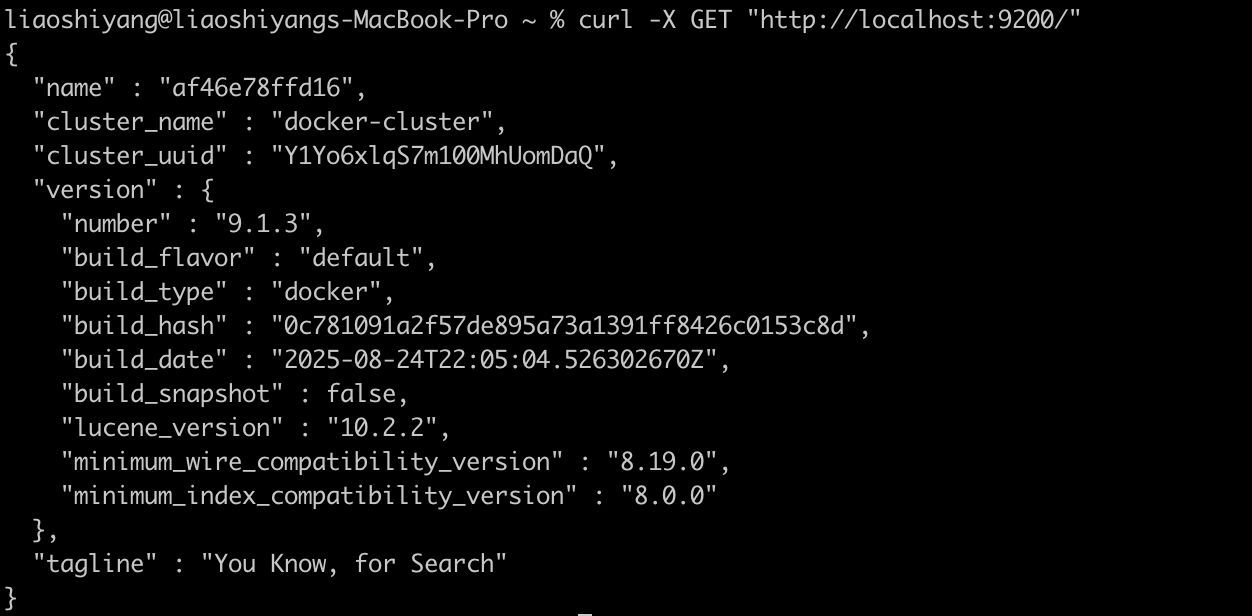
3. 索引文档
# 索引文档
curl -X POST "http://localhost:9200/myindex/_doc" -H 'Content-Type: application/json' -d'
{
"title": "Hello Elasticsearch",
"description": "An example document"
}'
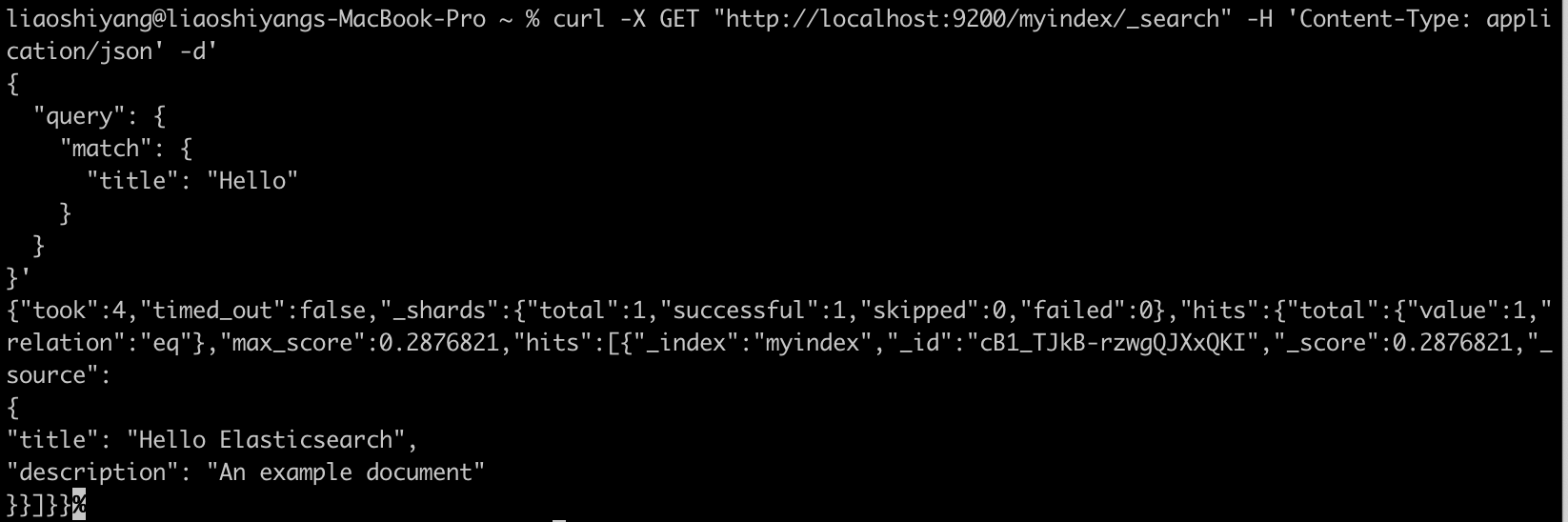
3. 搜索文档
# 搜索文档
curl -X GET "http://localhost:9200/myindex/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"title": "Hello"
}
}
}'
结语
Elasticsearch 是搜索与分析领域标杆性的产品。它将 Lucene 的能力包装起来,加上分布式、易用以及与数据可视化、安全监控等功能的整合,使搜索引擎从专业技术逐渐变为“随手可用”的基础设施。
虽然协议变动、与 OpenSearch 的分叉引发争议,但它在企业与开发者群体中的实际应用价值依然难以替代。
🚀 下期预告
下一篇我们将介绍 OpenSearch,探讨这个 Elasticsearch 分支项目的发展现状、技术特点以及与 Elasticsearch 的详细对比。如果您有特别关注的问题,欢迎提前提出!
💬 三连互动
- 你或公司最近在用 Elasticsearch 吗?拿来做了什么场景?
- 在 Elasticsearch 和 OpenSearch 之间做过技术选型?
- 对 Elasticsearch 的许可证变化有什么看法?
对搜索技术感兴趣的朋友,也欢迎加我微信(ID:lsy965145175)备注“搜索百科”,拉你进 搜索技术交流群,一起探讨与学习!
✨ 推荐阅读
🔗 参考
原文:https://infinilabs.cn/blog/2025/search-wiki-3-elasticsearch/
【搜索客社区日报】第2007期 (2025-03-21)
社区日报 • Fred2000 发表了文章 • 0 个评论 • 4345 次浏览 • 2025-03-21 09:04
Easysearch、Elasticsearch、Amazon OpenSearch 快照兼容对比
Easysearch • INFINI Labs 小助手 发表了文章 • 2 个评论 • 5715 次浏览 • 2024-07-29 11:54
在当今的数据驱动时代,搜索引擎的快照功能在数据保护和灾难恢复中至关重要。本文将对 Easysearch、Elasticsearch 和 Amazon OpenSearch 的快照兼容性进行比较,分析它们在快照创建、恢复、存储格式和跨平台兼容性等方面的特点,帮助大家更好地理解这些搜索引擎的差异,从而选择最适合自己需求的解决方案。
启动集群
Easysearch
服务器一般情况下默认参数都是很低的,而 Easysearch/Elasticsearch 是内存大户,所以就需要进行系统调优。
sysctl -w vm.max_map_count=262144vm.max_map_count 是一个 Linux 内核参数,用于控制单个进程可以拥有的最大内存映射区域(VMA,Virtual Memory Areas)的数量。内存映射区域是指通过内存映射文件或匿名内存映射创建的虚拟内存区域。
这个参数在一些应用程序中非常重要,尤其是那些需要大量内存映射的应用程序,比如 Elasticsearch。Elasticsearch 使用内存映射文件来索引和搜索数据,这可能需要大量的内存映射区域。如果 vm.max_map_count 设置得太低,Elasticsearch 可能无法正常工作,并会出现错误信息。
调整 vm.max_map_count 参数的一些常见原因:
-
支持大型数据集: 应用程序(如 Elasticsearch)在处理大型数据集时可能需要大量内存映射区域。增加
vm.max_map_count可以确保这些应用程序有足够的内存映射区域来处理数据。 -
防止内存错误: 如果
vm.max_map_count设置得太低,当应用程序尝试创建超过限制的内存映射时,会出现错误,导致应用程序崩溃或无法正常工作。 - 优化性能:
适当地设置
vm.max_map_count可以优化应用程序的性能,确保内存映射操作顺利进行。
检查当前的 vm.max_map_count 值:
sysctl vm.max_map_count或者查看 /proc/sys/vm/max_map_count 文件:
cat /proc/sys/vm/max_map_countElasticsearch 官方建议将 vm.max_map_count 设置为至少 262144。对于其他应用程序。
Easysearch 具体安装步骤见 INFINI Easysearch 尝鲜 Hands on
Amazon OpenSearch
使用 Amazon Web Services 控制台进行创建。
Elasticsearch
使用如下 docker compose 部署一个三节点的 ES 集群:
version: "2.2"
services:
es01:
image: docker.elastic.co/elasticsearch/elasticsearch:7.10.2
container_name: es01
environment:
- node.name=es01
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es02,es03
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data01:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- elastic
es02:
image: docker.elastic.co/elasticsearch/elasticsearch:7.10.2
container_name: es02
environment:
- node.name=es02
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es03
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data02:/usr/share/elasticsearch/data
networks:
- elastic
es03:
image: docker.elastic.co/elasticsearch/elasticsearch:7.10.2
container_name: es03
environment:
- node.name=es03
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es02
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data03:/usr/share/elasticsearch/data
networks:
- elastic
volumes:
data01:
driver: local
data02:
driver: local
data03:
driver: local
networks:
elastic:
driver: bridge由于这个 docker compose 没有关于 kibana 的配置,所以我们还是用 Console 添加原生的 Elasticsearch 集群!

集群信息

快照还原的步骤
快照前的准备
插件安装
本次测试选择把索引快照备份到 Amazon S3,所以需要使用 S3 repository plugin,这个插件添加了对使用 Amazon S3 作为快照/恢复存储库的支持。
Easysearch 和 OpenSearch 集群自带了这个插件,所以无需额外安装。
对于自己部署的三节点 Elasticsearch 则需要进入每一个节点运行安装命令然后再重启集群,建议使用自动化运维工具来做这步,安装命令如下:
sudo bin/elasticsearch-plugin install repository-s3如果不再需要这个插件,可以这样删除。
sudo bin/elasticsearch-plugin remove repository-s3由于需要和 Amazon Web Services 打交道,所以我们需要设置 IAM 凭证,这个插件可以从 EC2 IAM instance profile,ECS task role 以及 EKS 的 Service account 读取相应的凭证。
对于托管的 Amazon OpenSearch 来说,我们无法在托管的 EC2 上绑定我们的凭证,所以需要新建一个 OpenSearchSnapshotRole,然后通过当前的用户把这个角色传递给服务,也就是我们说的 IAM:PassRole。
创建 OpenSearchSnapshotRole,策略如下:
{
"Version": "2012-10-17",
"Statement": [{
"Action": [
"s3:ListBucket"
],
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::bucket-name"
]
},
{
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject"
],
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::bucket-name/*"
]
}
]
}信任关系如下:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "es.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}然后在我们的 IAM user 上加上 PassRole 的权限,这样我们就可以把 OpenSearchSnapshotRole 传递给 OpenSearch 集群。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::123456789012:role/OpenSearchSnapshotRole"
}
]
}注册存储库
在源集群执行注册
PUT /_snapshot/snapshot-repo-name
{
"type": "s3",
"settings": {
"bucket": "<bucket-name>",
"base_path": "<bucket-prefix>",在目标集群同样执行这个语句,为了防止覆盖源集群存储库的数据,将 "readonly": true 添加到"settings" PUT 请求中,这样就只有一个集群具有对存储库的写入权限。
PUT /_snapshot/snapshot-repo-name
{
"type": "s3",
"settings": {
"bucket": "<bucket-name>",
"base_path": "<bucket-prefix>",
"readonly": true,对于 OpenSearch 来说,还需要执行 passrole,所以还需要添加role_arn这个字段,由于 IAM:PassRole 需要对 HTTP 请求做 signV4 日签名,所以这部常常使用 Postman 来完成。把角色传递过去之后,接下来的快照还原操作就可以在 OpenSearch Dashboard 中进行操作了。

需要注意的是,需要在 auth 这里输入 AccessKey,SecretKey,AWS Region,Service Name(es)来做 SignV4 的签名。

请求体如下:
{
"type": "s3",
"settings": {
"bucket": "<bucket-name>",
"base_path": "<bucket-prefix>",
"readonly": true,
"role_arn": "arn:aws:iam::123456789012:role/OpenSearchSnapshotRole"
}
}- 查看所有注册的存储库:
GET _snapshot:这个命令返回所有已注册的快照存储库列表及其基本信息。
GET _snapshot{
"es_repository": {
"type": "s3",
"settings": {
"bucket": "your-s3-bucket-name",
"region": "your-s3-bucket-region"
}
}
}- 查看特定存储库的详细信息:
GET _snapshot/es_repository:这个命令返回名为es_repository的存储库的详细配置信息,包括存储桶名称、区域和其他设置。
GET _snapshot/es_repository{
"es_repository": {
"type": "s3",
"settings": {
"bucket": "your-s3-bucket-name",
"region": "your-s3-bucket-region",
"access_key": "your-access-key",
"secret_key": "your-secret-key"
}
}
}- 查看特定存储库中的快照:
GET _cat/snapshots/es_repository?v:这个命令返回es_repository存储库中的所有快照及其详细信息,包括快照 ID、状态、开始时间、结束时间、持续时间、包含的索引数量、成功和失败的分片数量等。
GET _cat/snapshots/es_repository?vid status start_epoch start_time end_epoch end_time duration indices successful_shards failed_shards total_shards
snapshot_1 SUCCESS 1628884800 08:00:00 1628888400 09:00:00 1h 3 10 0 10
snapshot_2 SUCCESS 1628971200 08:00:00 1628974800 09:00:00 1h 3 10 0 10创建索引快照
# PUT _snapshot/my_repository/<my_snapshot_{now/d}>
PUT _snapshot/my_repository/my_snapshot
{
"indices": "my-index,logs-my_app-default",
}根据快照的大小不同,完成快照可能需要一些时间。默认情况下,create snapshot API 只会异步启动快照过程,该过程在后台运行。要更改为同步调用,可以将 wait_for_completion 查询参数设置为 true。
PUT _snapshot/my_repository/my_snapshot?wait_for_completion=true另外还可以使用 clone snapshot API 克隆现有的快照。要监控当前正在运行的快照,可以使用带有 _current 请求路径参数的 get snapshot API。
GET _snapshot/my_repository/_current如果要获取参与当前运行快照的每个分片的完整详细信息,可以使用 get snapshot status API。
GET _snapshot/_status成功创建快照之后,就可以在 S3 上看到备份的数据块文件,这个是正确的快照层级结构:

需要注意的是, "base_path": "

所以在 Open Search 中还原 Elasticsearch 就遇到了这个问题:
{
"error": {
"root_cause": [
{
"type": "snapshot_missing_exception",
"reason": "[easy_repository:2/-jOQ0oucQDGF3hJMNz-vKQ] is missing"
}
],
"type": "snapshot_missing_exception",
"reason": "[easy_repository:2/-jOQ0oucQDGF3hJMNz-vKQ] is missing",
"caused_by": {
"type": "no_such_file_exception",
"reason": "Blob object [11111/indices/7fv2zAi4Rt203JfsczUrBg/meta-YGnzxZABRBxW-2vqcmci.dat] not found: The specified key does not exist. (Service: S3, Status Code: 404, Request ID: R71DDHX4XXM0434T, Extended Request ID: d9M/HWvPvMFdPhB6KX+wYCW3ZFqeFo9EoscWPkulOXWa+TnovAE5PlemtuVzKXjlC+rrgskXAus=)"
}
},
"status": 404
}恢复索引快照
POST _snapshot/my_repository/my_snapshot_2099.05.06/_restore
{
"indices": "my-index,logs-my_app-default",
}各个集群的还原
-
Elasticsearch 7.10.2 的快照可以还原到 Easysearch 和 Amazon OpenSearch
- 从 Easysearch 1.8.2 还原到 Elasticsearch 7.10.2 报错如下:
{
"error": {
"root_cause": [
{
"type": "snapshot_restore_exception",
"reason": "[s3_repository:1/a2qV4NYIReqvgW6BX_nxxw] cannot restore index [my_indexs] because it cannot be upgraded"
}
],
"type": "snapshot_restore_exception",
"reason": "[s3_repository:1/a2qV4NYIReqvgW6BX_nxxw] cannot restore index [my_indexs] because it cannot be upgraded",
"caused_by": {
"type": "illegal_state_exception",
"reason": "The index [[my_indexs/ALlTCIr0RJqtP06ouQmf0g]] was created with version [1.8.2] but the minimum compatible version is [6.0.0-beta1]. It should be re-indexed in Elasticsearch 6.x before upgrading to 7.10.2."
}
},
"status": 500
}- 从 Amazon OpenSearch 2.1.3 还原到 Elasticsearch 7.10.2 报错如下(无论是否开启兼容模式):
{
"error": {
"root_cause": [
{
"type": "snapshot_restore_exception",
"reason": "[aos:2/D-oyYSscSdCbZFcmPZa_yg] the snapshot was created with Elasticsearch version [36.34.78-beta2] which is higher than the version of this node [7.10.2]"
}
],
"type": "snapshot_restore_exception",
"reason": "[aos:2/D-oyYSscSdCbZFcmPZa_yg] the snapshot was created with Elasticsearch version [36.34.78-beta2] which is higher than the version of this node [7.10.2]"
},
"status": 500
}- 从 Easysearch 1.8.2 还原到 Amazon OpenSearch2.13 报错如下(无论是否开启兼容模式):
{
"error": {
"root_cause": [
{
"type": "snapshot_restore_exception",
"reason": "[easy_repository:2/LE18AWHlRJu9rpz9BJatUQ] cannot restore index [my_indexs] because it cannot be upgraded"
}
],
"type": "snapshot_restore_exception",
"reason": "[easy_repository:2/LE18AWHlRJu9rpz9BJatUQ] cannot restore index [my_indexs] because it cannot be upgraded",
"caused_by": {
"type": "illegal_state_exception",
"reason": "The index [[my_indexs/VHOo7yfDTRa48uhQvquFzQ]] was created with version [1.8.2] but the minimum compatible version is OpenSearch 1.0.0 (or Elasticsearch 7.0.0). It should be re-indexed in OpenSearch 1.x (or Elasticsearch 7.x) before upgrading to 2.13.0."
}
},
"status": 500
}- Amazon OpenSearch 还原到 Easysearch 同样失败
{
"error": {
"root_cause": [
{
"type": "snapshot_restore_exception",
"reason": "[aoss:2/D-oyYSscSdCbZFcmPZa_yg] cannot restore index [aos] because it cannot be upgraded"
}
],
"type": "snapshot_restore_exception",
"reason": "[aoss:2/D-oyYSscSdCbZFcmPZa_yg] cannot restore index [aos] because it cannot be upgraded",
"caused_by": {
"type": "illegal_state_exception",
"reason": "The index [[aos/864WjTAXQCaxJ829V5ktaw]] was created with version [36.34.78-beta2] but the minimum compatible version is [6.0.0]. It should be re-indexed in Easysearch 6.x before upgrading to 1.8.2."
}
},
"status": 500
}- Elasticsearch 8.14.3 迁移到 Amazon OpenSearch 或者 Elasticsearch 都是有这个报错:
{
"error": {
"root_cause": [
{
"type": "parsing_exception",
"reason": "Failed to parse object: unknown field [uuid] found",
"line": 1,
"col": 25
}
],
"type": "repository_exception",
"reason": "[snap] Unexpected exception when loading repository data",
"caused_by": {
"type": "parsing_exception",
"reason": "Failed to parse object: unknown field [uuid] found",
"line": 1,
"col": 25
}
},
"status": 500
}这是由于 Elasticsearch 8 在创建快照的时候会默认加上一个 UUID 的字段,所以我们低版本的 Easysearch、Amazon OpenSearch 中会找不到这个字段,在执行GET _cat/snapshots/snap?v的时候就报错,及时在注册存储库的时候显示加上 UUID 的字段也无事无补。
{
"snapshot-repo-name": {
"type": "s3",
"uuid": "qlJ0uqErRmW6aww2Fyt4Fg",
"settings": {
"bucket": "<bucket-name>",
"base_path": "<bucket-prefix>",
}
},以下是兼容性对比,每行第一列代表源集群,第一行代表目标集群:
| 快照兼容对比 | Easysearch 1.8.2 | Elasticsearch 7.10.2 | OpenSearch 2.13 |
|---|---|---|---|
| Easysearch 1.8.2 | 兼容 | 不兼容 | 不兼容 |
| Elasticsearch 7.10.2 | 兼容 | 兼容 | 兼容 |
| OpenSearch 2.13 | 不兼容 | 不兼容 | 兼容 |
Elasticsearch 的兼容列表官方的列表如下:

参考文献
-
开始使用 Elastic Stack 和 Docker Compose:第 1 部分
https://www.elastic.co/cn/blog/getting-started-with-the-elastic-stack-and-docker-compose -
Docker Compose 部署多节点 Elasticsearch
https://www.elastic.co/guide/en/elasticsearch/reference/7.10/docker.html#docker-compose-file -
repository-s3 教程
https://www.elastic.co/guide/en/elasticsearch/reference/8.14/repository-s3.html
https://www.elastic.co/guide/en/elasticsearch/plugins/7.10/repository-s3.html -
snapshot-restore
https://www.elastic.co/guide/en/elasticsearch/reference/7.10/snapshot-restore.html -
在亚马逊 OpenSearch 服务中创建索引快照
https://docs.amazonaws.cn/zh_cn/opensearch-service/latest/developerguide/managedomains-snapshots.html#managedomains-snapshot-restore - 教程:迁移至 Amazon OpenSearch Service
https://docs.amazonaws.cn/zh_cn/opensearch-service/latest/developerguide/migration.html
关于 Easysearch 有奖征文活动

无论你是 Easysearch 的老用户,还是第一次听说这个名字,只要你对 INFINI Labs 旗下的 Easysearch 产品感兴趣,或者是希望了解 Easysearch,都可以参加这次活动。
详情查看:Easysearch 征文活动
作者:韩旭,亚马逊云技术支持,亚马逊云科技技领云博主,目前专注于云计算开发和大数据领域。
【搜索客社区日报】第1863期 (2024-07-19)
社区日报 • Fred2000 发表了文章 • 0 个评论 • 3693 次浏览 • 2024-07-19 11:32
搜索型数据库的技术发展历程与趋势前瞻
资讯动态 • INFINI Labs 小助手 发表了文章 • 0 个评论 • 4873 次浏览 • 2024-06-26 13:13
概述
随着数字科技的飞速发展和信息量的爆炸性增长,搜索引擎已成为我们获取信息的首选途径之一,典型的代表厂商如 Google。然而,随着用户需求的不断演变,传统的搜索技术已经无法满足人们对信息的实时性、个性化和多样性的需求。
在企业内部,这种需求更加显著。随着企业数字化转型的持续深化,非结构化数据正日益成为各类组织数据增长的主要来源,也是数据体系中至关重要的组成部分,蕴含着巨大的价值。如何高效地存储和利用非结构化数据的重要性也日益凸显。企业需要更高效地管理和检索内部的海量数据,以支持业务决策和运营需求。

据 IDC 数据预计,到 2025 年,80%的数据将是非结构化数据;而根据 Gartner 的数据显示,从 2019 年到 2024 年,非结构化数据容量预计将增加两倍。然而,目前非结构化数据面临着表现形式多样、管理复杂性高、价值挖掘难度大等诸多挑战。传统的数据库系统往往无法满足企业对实时性和多样性的搜索需求,为了解决这些挑战,以自动分词、倒排索引、相关度计算、向量检索引擎等技术为核心构建的搜索型数据库应运而生。这些数据库自上世纪 90 年代诞生以来不断发展演进,正在成为数据库领域中不可或缺的一个重要分支。
什么是搜索型数据库?
搜索型数据库早期又称全文数据库,或者企业搜索引擎,是一种专门用于存储和管理大规模文本数据,并支持高效的文本搜索和信息检索的数据库系统,不过随着技术不断发展和应用场景日益丰富,目前搜索型数据库不仅仅可以处理长文本数据,也可以处理常见的数值、日期等结构化数据,IP、地理位置信息、图片、音视频等非结构化数据,搜索型数据库的应用范畴不断拓展,正在由支撑业务系统检索加速、IT 运维可观测性、聚合查询分析等向多场景、多模态数据搜索方向发展。

典型的搜索数据库一般具有以下特点:
- 灵活的索引能力:搜索数据库能够处理多种类型的数据,包括文本、图像、音频、视频等非结构化数据。它们采用自动分词、倒排索引等技术,能够高效地处理不同格式和类型的数据,提供灵活的搜索和检索功能。
- 高效的查询性能:搜索数据库具有高效的查询处理能力,能够快速索引和检索大规模的数据。借助优化的索引结构和查询算法,搜索数据库能够在短时间内准确地返回与查询相关的结果,提高用户的搜索效率,常用于解决关系型数据库的高并发检索需求。
- 支持复杂的搜索功能:搜索数据库提供多样化的搜索功能,包括全文检索、模糊搜索、精确搜索、范围搜索、向量搜索、地理信息检索等。用户可以根据不同的需求和场景,灵活地选择和组合不同的搜索功能,以获取符合期望的搜索结果。
- 高性能和可扩展性:搜索数据库具有高性能和可扩展性的特点,能够处理大规模数据和高并发访问。它们采用分布式架构和并行计算技术,实现了水平扩展,能够满足不断增长的数据量和用户访问量的需求。
综上所述,搜索数据库具有处理非结构化数据、实时搜索和更新、多样化的搜索功能、个性化推荐和智能搜索、高性能和可扩展性、全面的搜索结果展示等特点,是处理大规模数据和提供高效搜索服务的重要工具。
搜索型数据库的应用场景
搜索型数据库在各行各业都有广泛的应用,以下是一些典型的应用场景:
- 零售和电商:在零售和电商行业,搜索型数据库被广泛应用于产品搜索和推荐系统中。通过搜索功能,顾客可以轻松查找所需商品,而个性化推荐系统则可以根据用户的搜索历史和行为习惯推荐相关的产品,提高购物体验和交易转化率。
- 医疗保健:在医疗保健行业,搜索型数据库被用于医学文献检索、疾病诊断和药物搜索等方面。医生和研究人员可以利用搜索功能找到相关的医学文献和研究成果,帮助诊断疾病和制定治疗方案。
- 金融服务:在金融服务行业,搜索型数据库被用于金融数据检索、市场分析和投资决策等方面。投资者可以通过搜索功能查找相关的金融数据和市场资讯,帮助他们做出更加准确的投资决策。
- 制造业:在制造业中,搜索型数据库被用于生产过程监控、质量控制和故障诊断等方面。工程师可以利用搜索功能查找相关的生产数据和技术资料,帮助他们解决生产中的问题和挑战。
- 媒体和娱乐:在媒体和娱乐行业,搜索型数据库被用于内容检索、版权管理和用户推荐等方面。用户可以通过搜索功能查找感兴趣的新闻、音乐和视频等内容,而个性化推荐系统则可以根据用户的搜索历史和偏好推荐相关的内容。
- 教育和培训:在教育和培训行业,搜索型数据库被用于学习资源检索、课程管理和学习分析等方面。学生和教师可以利用搜索功能查找相关的学习资源和课程内容,而学习分析系统则可以分析学生的搜索行为和学习表现,为教学提供参考和支持。
- IT 运维可观测性:通过搜索型数据库,可以实时监控系统的运行状况、性能指标和日志数据,帮助运维团队及时发现和解决系统故障、性能问题和异常情况,确保系统的稳定运行。
- 安全监测和威胁检测:利用搜索型数据库对系统的安全日志进行审计和监控,监测用户的访问行为和系统操作,及时发现异常行为和安全事件。同时,搜索型数据库还可以与威胁情报数据集成,对内部日志数据进行关联分析,快速识别并应对各种安全威胁和攻击行为,保障系统和数据的安全。
综上所述,搜索型数据库在各行各业都发挥着重要作用,数据规模从 GB 到 PB 不等,体现在生活中的方方面面,为用户提供了高效、准确和个性化的信息搜索和检索服务,推动了各行业的发展和进步。随着搜索技术的不断创新和发展,搜索型数据库在各行业中的应用将会越来越广泛,并持续为用户带来更加便捷和智能的搜索体验。
搜索型数据库的发展历程
搜索型数据库的发展历程可以概括如下四个阶段:
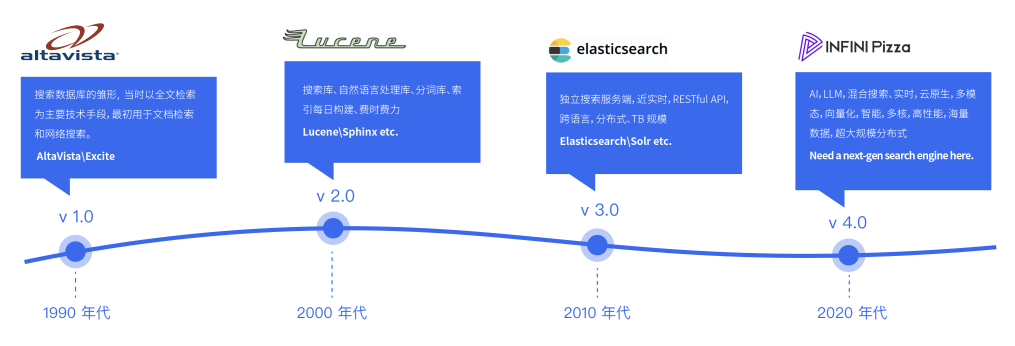
- 起步阶段(1990 年代):搜索数据库的雏形开始于上世纪 90 年代,当时以全文检索为主要技术手段,最初用于文档检索和网络搜索。典型代表包括 AltaVista、Excite 等。
- 技术突破(2000 年代):随着互联网的快速发展,搜索数据库开始应用于更多领域,如电子商务、社交网络等。Lucene、Sphinx 等开源搜索引擎的出现推动了搜索技术的进步。
- 商业化发展(2010 年代):搜索数据库进入商业化阶段,以 Elasticsearch 等为代表的商业搜索引擎崭露头角。企业开始大规模应用搜索数据库来管理和检索大量数据。
-
智能化转型(2020 年代):随着人工智能技术的发展,搜索数据库逐渐向智能化转型,开始引入机器学习、自然语言处理等技术,提供个性化推荐和智能搜索服务。同时,搜索数据库也在更多领域得到应用,如医疗保健、金融服务等。
综上所述,搜索数据库经历了从起步阶段到技术突破、商业化发展再到智能化转型的发展历程,表明了其在信息检索领域的重要性和不断演进的趋势,不并断推动着搜索技术的进步和应用范围的扩展。随着人工智能技术的不断成熟,搜索数据库将会在智能化、个性化等方面取得更大的进步,为用户提供更加优质的搜索体验。
搜索型数据库的发展情况
搜索型数据库市场上已经有不少成熟的产品和厂商,但是总的来说,搜索型数据库的界限范围有点模糊,当然其他数据库也有同样的问题,有很多数据库既是文档数据库,又是多模态数据库,还是向量数据库等等,而常见的搜索型数据库主要诞生于:
- 由搜索引擎内核库发展而来的搜索数据库,如 Elasticsearch
- 由其他数据库扩展而来的搜索数据库,如 Postgres Full-Text Search
- 从零开始整体设计的搜索数据库:如 INFINI Pizza
通过流行的 DB-Engines 的搜索引擎排行榜,可以初探国外主流的搜索型数据库的流行趋势,如下图:

可以看到 Elastic 公司的 Elasticsearch 还是依旧保持强悍,自从 Elasticsearch 十多年前掀翻了 Splunk 的桌子,硬生生的在日志领域杀出一条新路,随后大杀四方,碾压整个搜索行业,霸榜至今。Elastic 商业化增长稳健,2023 年收入超过 10 亿美金。

OpenSearch 是由 AWS 发起的 Elasticsearch 开源分支,起因是由于 Elastic 针对云厂商采取的协议变更为 Elastic+SSPL,OpenSearch 基于 Apache 2.0 协议的 Elasticsearch 7.10 版本衍生而来,目前也具备了一定的用户基础。

Splunk 是一款用于搜索、监控和分析大规模机器生成的数据的软件平台,主要用于日志和安全分析领域,属于商业闭源产品。2023 年中被思科(Cisco) 以 230 亿美元现金收购,瞬间刷爆朋友圈。另外有意思的是,前四名除了 Splunk,底层都是 Lucene 内核。
MarkLogic 成立于 2001 年,自我定位是一个 NoSQL 多模态数据库厂商,也是商业闭源软件,生态成熟但是系统过于复杂,学习曲线较陡, 2023 年初被 Progress Software 以 3.55 亿美元收购算是一个比较好的结局。

当然了,除了榜上的这些产品,还有很多优秀的挑战者正摩拳擦掌,跃跃欲试。如下面的这些项目: vespa、Rockset、Doris,Clickhouse、quickwit、Pinot、SingleStore、qdrant、milvus、algolia、meilisearch、typesense、Manticore Search 等等。这些项目不一定都是自己定位是搜索型数据库,有侧重在 AI 领域的,有侧重在实时分析领域的等等,可谓各有千秋,不过都具备一定的搜索和分析能力,不出意外,基本上每家都要号称吊打 Elasticsearch 一番。
国内搜索型数据库的发展情况
搜索型数据库已经成为企业事实上的重要基础设施,而国内搜索型数据库的发展近些年也是开始得到重视,2023 年初,由中国信通院云计算与大数据研究所牵头,依托中国通信标准化协会大数据技术标准推进委员会,联合拓尔思、极限科技、星环科技等 30 余家企业编制的《搜索型数据库技术要求》正式出炉,该标准已成为行业内搜索型数据库技术选型和产品开发的风向标,极限科技的 INFINI Easysearch 率先通过了该标准。
墨天轮社区也开辟了搜索型数据库的排行榜,共有 6 家企业的产品上榜:

国内搜索型数据库的市场还在起步阶段,厂商和可选的产品也还比较少,不过随着市场的成熟,相信未来将迎来一波高速的发展。
搜索型数据库的趋势前瞻
技术在演变,场景在演变,数据也在演变,搜索数据库领域的发展也呈现出多个显著的趋势,这些趋势将进一步推动搜索技术的演进和应用范围的扩展。笔者观测到的主要的发展趋势包括以下方向供参考:
1. 趋势一:实时搜索与分析
-
实时搜索是搜索数据库领域的一个重要发展趋势,业务应用都在朝实时方向演进,用户对信息的即时性需求不断增加,要求搜索结果能够及时反映最新的数据和内容。
-
实时搜索技术通过实时索引和实时更新机制,能够实现快速的数据检索和更新,提供与时俱进的搜索结果,满足用户对信息的即时性需求。
- 目前以 Lucene 为内核的搜索型数据库基本上都只能做到 NRT(近实时)搜索,并且频繁更新带来的挑战和资源的浪费比较高,如果能做到更高效的实时性,可以大大提升用户的搜索体验和实时决策能力。
2. 趋势二:多模态混合搜索
-
多模态搜索是指在搜索过程中同时考虑多种信息形式,如文本、图像、视频等,以提高搜索结果的准确性和全面性。
-
这种技术能够通过分析和理解多种信息形式之间的关联性,为用户提供更加全面、丰富的搜索结果,适用于需要综合不同媒体形式的搜索场景。
- 现实世界的数据越来越复杂化,非结构化数据的利用的场景也越来越多,多模态可以为业务提供更加灵活的分析和探索能力,混合搜索的能力非常具有吸引力。
3. 趋势三:AI 智能语义搜索
-
大模型、AI 智能搜索技术的探索可谓是一日千里,通过利用人工智能技术来实现搜索过程中的智能化、语义化和个性化,结合自然语言处理、机器学习等技术分析用户意图,提供更加智能、个性化的搜索服务。
-
随着大模型的兴起,搜索数据库开始采用像 RAG(Retriever-Reader for Generative Question Answering)这样的大型预训练模型来提升搜索的效果。RAG 模型结合了检索器和阅读器的功能,能够实现更加准确和全面的搜索结果,为用户提供更加智能和个性化的搜索服务。
- 搜索型数据库可谓是 AI 落地最好的是试验田,Elasticsearch 通过拥抱 AI 和大模型,目前股价又重回巅峰,可喜可贺。
4. 趋势四:云原生、存算分离、Serverless
-
随着云计算技术的发展,搜索数据库正逐渐向云原生架构转变。云原生搜索数据库利用容器化、微服务架构等技术,实现了更高的灵活性、可扩展性和容错性,为企业提供了更加稳定和高效的搜索服务,并且成本更低,更加弹性。
-
存算分离是搜索数据库发展的另一重要趋势。通过将存储与计算分离,搜索数据库可以更好地适应数据存储和计算需求的变化,提高系统的性能和效率。存算分离技术使得搜索数据库能够实现更高的并发访问和更快的数据处理速度,为用户提供更加流畅和稳定的搜索体验。
- Serverless 提供开箱即用的体验,成本更低,使用更加灵活,也是目前很多搜索服务提供商正在积极探索的方向。
5. 趋势五:增强现实搜索
- 随着增强现实技术的发展,尤其是 Apple 发布的头戴式 Vision Pro,一部革命性的空间运算设备,将数位内容无缝融入实体世界,而搜索技术也将逐渐与增强现实相结合,为用户提供更加直观和沉浸式的搜索体验。增强现实搜索能够将搜索结果与现实世界相结合,结合 AI 技术为用户提供更加个性化和便捷的搜索服务,这是一个全新的领域,也意味着巨大的机会。
6. 趋势六:现代硬件的高效利用
-
现代硬件及软件运行环境已发生翻天覆地的变化, 片上计算,边缘计算,FPGA,DPU,GPU,一台设备几百核上 TB 内存已经成为现实,可运行之上的软件却还是停留在几十年前的架构。 如 Elasticsearch 其核心 Lucene(及类似实现) 是在 1997 建立的,距今已有 27 年了,虽然也在与时俱进,但是部分架构和设计理念已不具备先进性。
- 在现代的硬件上采用更先进的算法,更新的数据结构、更新的设计理论,利用最新的 CPU 指令集,向量化,批处理,充分发挥多核、大内存和 SSD 的优势,从而达到更高的效率,更低的成本,去解决之前不可能实现的问题,大有可为,也是下一代引擎需要关注的方向。

随着各类数据库功能的边界越来越模糊,应用场景高度交叉重叠,市场竞争也变得白热化,不过笔者认为垂直领域的搜索型数据库机会还是很大,而想做大而全的数据库产品已经没有太多的市场生存空间,一定要在垂直领域有特别专注的地方,我们 INFINI Labs 正在基于 Rust 研发的下一代搜索引擎 INFINI Pizza,就侧重于面向终端用户场景,解决海量数据更新情况下,同时满足高并发和低延迟的核心业务实时检索需求。
总结
综上所述,搜索数据库领域正处于快速发展的阶段。随着互联网数据量的不断增长和用户需求的不断变化,搜索数据库技术将不断创新和进步,以满足用户对信息获取的更加即时、个性化和多样化的需求。未来,随着人工智能技术的进一步发展和应用,搜索数据库将会变得更加智能化、普及化和多样化,为用户提供更加高效、准确和个性化的搜索服务,推动互联网信息的更加便捷获取和利用。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。

【搜索客社区日报】第1838期 (2024-06-14)
社区日报 • Fred2000 发表了文章 • 0 个评论 • 3145 次浏览 • 2024-06-14 09:18
【搜索客社区日报】第1834期 (2024-06-07)
社区日报 • Fred2000 发表了文章 • 0 个评论 • 3123 次浏览 • 2024-06-09 12:34
4月13日 OpenSearch Meetup:探索大模型时代下的 VectorDB
OpenSearch • liaosy 发表了文章 • 0 个评论 • 5314 次浏览 • 2024-04-10 10:08

在大模型席卷全球的行业背景下,基于检索结果增强的文本生成(RAG)备受关注。而作为 RAG 关键技术的向量数据库(VectorDB)正处在发展的十字路口。作为全球头部的 VectorDB 解决方案,OpenSearch 社区一直致力于前沿向量检索技术的研发。为了探讨 VectorDB 的发展趋势、应用场景、上下游技术生态,我们策划了这一场技术分享与线下见面会。希望可以给 VectorDB 玩家提供一个学习知识、结交朋友的平台。
在这场见面会中,我们会邀请来自于头部企业的向量检索技术研发专家、OpenSearch 社区的活跃贡献者以及一线人工智能科学家,来分享 VectorDB、大模型以及上下游相关技术的最新发展,以及对这个行业的未来的走向的见解。您将在这场会议中看到各个 VectorDB 头部企业的最新向量检索技术和产品,甚至有机会亲自作为用户去尝试。同时,我们还将举行圆桌讨论,您可以和各个相关行业的资深人士深入探讨 VectorDB 的未来,以及在这个行业中可能把握的机会。
时间:2024/04/13(周六) 14:00-18:30
地点:上海市长宁区新华路345弄4号楼 STOP SHOP(社友咖啡)
INIFINI Labs 议题推荐
《向量搜索基础设施 OpenSearch - 多集群管理的挑战与实践》By 曾嘉毅| INFINI Labs 联合创始人
摘要:数据规模不断增长和业务需求的多样化,推动了向量搜索技术的兴起。本次介绍聚焦于向量搜索的崛起和 OpenSearch 平台的能力,同时探讨业务数据集群发展趋势和常见挑战,包括管理多套集群、容量规划、监控、告警、治理、安全、开发、流量和排障等问题,提供解决方案和最佳实践。
活动整体议程

关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。

3月26日 OpenSearch Community Meeting 视频回放
OpenSearch • Charele 回复了问题 • 2 人关注 • 1 个回复 • 6391 次浏览 • 2024-04-05 16:58
OpenSearch 与 Elasticsearch:哪个开源搜索引擎适合您?
OpenSearch • Hansoph 发表了文章 • 1 个评论 • 4242 次浏览 • 2024-03-15 10:49
当谈论到搜索引擎产品时,Elasticsearch 和 OpenSearch 是两个备受关注的选择。它们都以其出色的功能和灵活性而闻名,但在一些方面存在一些差异。在本文中,我们将从功能和延展性、工具与资源、价格和许可这三个角度对这两个产品进行论述。通过深入研究它们的特点和优势,您将能够更好地了解它们,从而为您的搜索需求做出明智的选择。让我们开始探索 Elasticsearch 和 OpenSearch 的世界,以便您能够为自己的项目或业务找到最佳的搜索解决方案。
功能和延展性
Elasticsearch 是一个功能强大的搜索引擎,它支持全文搜索、实时数据分析、数据聚合和可视化等功能。
- 分布式架构:它使用分布式架构,可以处理大规模数据集,并以快速的速度返回查询结果。
- 多种查询类型和过滤器:提供多种查询类型和过滤器,使用户能够进行复杂的数据分析和检索。
- 高可用性和容错性:提供高可用性和容错性,通过复制和分片机制来确保数据的安全性和可靠性。
- 强大的插件生态系统:帮助用户处理映射、分析、脚本引擎和发现等任务。通过使用这些插件,用户可以根据其特定的数据处理和分析需求进行功能扩展和定制。
OpenSearch 是从 Elasticsearch 分叉出来的版本,因此在许多方面与 Elasticsearch 相似。它保留了 Elasticsearch 的核心功能,并加入了一些新的功能和扩展性。下面主要讨论一些差异点:
- 开源性和社区参与:OpenSearch 更注重开源性和社区参与,鼓励用户共同开发和改进系统。
- 功能差异:OpenSearch 提供了一些额外的免费功能,如集中用户账户/访问控制、交叉集群复制、IP 过滤、可配置的数据保留期、异常检测、Tableau 连接器、JDBC 驱动程序、ODBC 驱动程序以及回归和分类等机器学习功能。
- 插件生态系统差异:OpenSearch 中的某些功能作为插件捆绑在一起,需要用户额外学习和适应新工具。
服务与支持
Elasticsearch 拥有丰富的工具和资源,使用户能够更好地使用和管理搜索引擎。
- 配套工具:丰富的生态系统,Logstash 用于数据摄取和转换,可以帮助用户为非结构化数据添加结构,进行字段匿名处理,并解析 IP 地址以获取位置信息。Beats 是一个专注于数据传输的工具,可以将数据从数千台机器发送到 Logstash 或 Elasticsearch。
-
完善的文档资料和培训资源:
a. 官方网站提供了产品指南、教程视频、博客文章、讨论论坛等丰富的学习材料。
b. Elastic 还提供了 Slack 频道、YouTube 频道、以及定期举办的在线研讨会和培训活动,为用户提供即时的答疑和学习机会。
c. 广泛的支持服务,包括社区支持、商业支持和培训服务。
OpenSearch 配套工具延展性更好,但是在学习资料和用户培训方面存在大部分空白,目前的服务与支持模式主要依赖于社区。
-
配套工具:除去支持 Logstash 和 Beats 外,还有其他工具如 Fluentd、Fluent Bit、OpenTelemetry Collector 和 Data Prepper,来支持数据处理和传输。
-
文档资料和培训资源:
a. 文档资源:积极填补文档中的空白,并且每月举行两次社区会议,鼓励用户通过 GitHub 提交拉取请求、报告问题和提供反馈。
b. 合作伙伴:提供 OpenSearch 的咨询支持和托管服务,其中就包括 INFINI Labs 在内,通过这些合作伙伴,用户可以获取与 OpenSearch 相关的专业服务和咨询,以满足其特定需求。
OpenSearch 的学习资源和培训材料相对较少,相比之下,Elasticsearch 的学习资料更加丰富和全面。然而,OpenSearch 社区积极发展中,未来可能会有更多的学习资源和支持服务可用。
价格和许可
Elasticsearch 和 OpenSearch 在价格和许可方面也存在差异。本文将从紧急支持和许可限制两个角度进行分析。
Elasticsearch:
- 紧急支持:Elasticsearch 的高级许可证提供紧急支持,这意味着当出现集群崩溃、数据丢失或安全漏洞等问题时,公司能够提供即时的支持。
- 许可限制:Elasticsearch 提供基于订阅模型的商业许可,其中包括从免费的基本许可到高级许可的多个层次。高级许可提供了额外的功能和支持,适合对性能和功能有更高要求的企业。
Opensearch:
- 紧急支持:当前可以通过过第三方咨询公司或 AWS OpenSearch 等免费工具获得同样水平的支持,OpenSearch 有一个合作伙伴页面,列出了许多咨询公司,包括 INFINI Labs 的 OpenSearch 支持页面,他们提供 24 x 7 的支持。
- 许可限制:OpenSearch 是基于 Apache 2.0 许可的开源软件,允许用户自由使用、修改和分发。它提供了免费的功能和灵活的定制,使用户能够根据自己的需求进行自定义和扩展。
总结
Elasticsearch 和 OpenSearch 都是强大而灵活的搜索引擎产品,但是存在一些差异。
总体来说,Elasticsearch 是一个成熟、功能强大的搜索引擎,拥有广泛的插件生态系统和丰富的学习资源。商业版本提供额外的功能和支持服务,适合需要高级功能和专业支持的企业。
OpenSearch 是从 Elasticsearch 分叉出来的版本,保留了核心功能,并添加了一些额外的功能。它更注重开源性和社区参与,适合更倾向于自主开发和定制的用户。
作者的话
希望这些信息能为您提供有价值的帮助,并使您更好地了解 Elasticsearch 和 OpenSearch。无论您选择哪个搜索引擎,都希望它能满足您的需求并取得成功。
INFINI Labs 产品更新 | Easysearch 新增快照搜索功能,Console 支持 OpenSearch 存储
Easysearch • liaosy 发表了文章 • 0 个评论 • 3874 次浏览 • 2023-12-15 23:14

INFINI Labs 产品又更新啦~,包括 Easysearch v1.7.0、Console v1.13.0。本次各产品更新了 Easysearch 快照搜索功能;Console 支持 OpenSearch 集群存储系统数据、优化了初始化安装向导流程等。
以下是本次更新的详细说明。
INFINI Easysearch v1.7.0
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。
Easysearch 本次更新如下:
Features
发布快照搜索功能 Beta 版本,此功能旨在提高对已备份数据的使用效率。让用户利用对象存储(如 AWS S3、MinIO、Microsoft Azure Storage、Google Cloud Storage 等)技术来大幅降低存储成本。
Bug fix
- 修复单个节点场景下,从快照恢复多个 shard 的索引时,恢复不完整的问题
- 修复无法删除索引已关联的 ILM 策略问题
Improvements
- 初始化脚本优化,新增重复执行判断
INFINI Console v1.12.0
INFINI Console 是一款非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管, 企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 在线体验: http://demo.infini.cloud (用户名/密码:readonly/readonly)。
Console 本次更新如下:
Features
支持 OpenSearch 集群存储系统数据
Bug fix
- 优化初始化安装流程
- 新增探针初始化配置
- 安装向导,新增凭据检查功能
- 安装向导,新增管理员密码重置功能
- 探针管理,支持自动关联 Auto Enroll
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
您还可以通过邮件联系我们:hello@infini.ltd
或者拨打我们的热线电话:(+86) 400-139-9200
欢迎加入 Discord 聊天室:https://discord.gg/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。

关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
3月26日 OpenSearch Community Meeting 视频回放
回复OpenSearch • Charele 回复了问题 • 2 人关注 • 1 个回复 • 6391 次浏览 • 2024-04-05 16:58
【搜索客社区日报】第2231期 (2026-05-15)
社区日报 • Fred2000 发表了文章 • 0 个评论 • 13125 次浏览 • 2026-05-15 10:19
【搜索客社区日报】第2119期 (2025-09-22)
社区日报 • Muses 发表了文章 • 0 个评论 • 12443 次浏览 • 2025-09-22 13:44
招聘!搜索运维工程师(Elasticsearch/Easysearch)-全职/北京/12-20K
求职招聘 • INFINI Labs 小助手 发表了文章 • 0 个评论 • 11015 次浏览 • 2025-09-22 12:33
极限科技诚招全职搜索运维工程师(Elasticsearch/Easysearch)!
欢迎搜索技术热爱者加入我们,共同打造高效、智能的搜索解决方案!
在招岗位介绍
岗位名称
搜索运维工程师(Elasticsearch/Easysearch)
Base:北京
薪资待遇:12-20K,五险一金,双休等
岗位职责
- 负责客户现场的 Elasticsearch/Easysearch/OpenSearch 搜索引擎集群的日常维护、监控和优化,确保集群的高可用性和性能稳定;
- 协助客户进行搜索引擎集群的部署、配置及版本升级;
- 排查和解决 Elasticsearch/Easysearch/OpenSearch 集群中的各种技术问题,及时响应并处理集群异常;
- 根据业务需求设计和实施搜索索引的调优、数据迁移和扩展方案;
- 负责与客户沟通,提供技术支持及相关培训,确保客户需求得到有效满足;
- 制定并实施搜索引擎的备份、恢复和安全策略,保障数据安全;
- 与内部研发团队和外部客户进行协作,推动集群性能改进和功能优化。
岗位要求
- 全日制本科及以上学历,2 年以上运维工作经验;
- 拥有 Elasticsearch/Easysearch/OpenSearch 使用经验,熟悉搜索引擎的原理、架构和相关生态工具(如 Logstash、Kibana 等);
- 熟悉 Linux 操作系统的使用及常见性能调优方法;
- 熟练掌握 Shell 或 Python 等至少一种脚本语言,能够编写自动化运维脚本;
- 具有优秀的问题分析与解决能力,能够快速应对突发情况;
- 具备良好的沟通能力和团队合作精神,能够接受客户驻场工作;
- 提供 五险一金,享有带薪年假及法定节假日。
加分项
- 计算机科学、信息技术或相关专业;
- 具备丰富的大规模分布式系统运维经验;
- 熟悉 Elasticsearch/Easysearch/OpenSearch 分片、路由、查询优化等高级功能;
- 拥有 Elastic Certified Engineer 认证;
- 具备大规模搜索引擎集群设计、扩展和调优经验;
- 熟悉其他搜索引擎技术(如 Solr、Lucene)者优先;
- 熟悉大数据处理相关技术(比如: Kafka 、Flink 等)者优先。
简历投递
- 邮件:hello@infini.ltd(邮件标题请备注姓名 求职岗位)
- 微信:INFINI-Labs (加微请备注求职岗位)
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
我们在做什么
极限科技(INFINI Labs)正在致力于以下几个核心方向:
1、开发近实时搜索引擎 INFINI Easysearch INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。详情参见:https://infinilabs.cn
2、打造下一代实时搜索引擎 INFINI Pizza INFINI Pizza 是一个分布式混合搜索数据库系统。我们的使命是充分利用现代硬件和人工智能的潜力,为企业提供量身定制的实时智能搜索体验。我们致力于满足具有挑战性的环境中高并发和高吞吐量的需求,同时提供无缝高效的搜索功能。详情参见:https://pizza.rs
3、为现代团队打造的统一搜索与 AI 智能助手 Coco AI Coco AI 是一款完全开源的统一搜索与 AI 助手平台,它通过统一搜索入口,连接企业内外部的异构数据源,融合大模型能力,帮助团队高效访问知识,智能决策协作。详情参见:https://coco.rs
4、积极参与全球开源生态建设 通过开源 Coco AI、Console、Gateway、Agent、Loadgen 等搜索领域产品和社区贡献,推动全球开源技术的发展,提升中国在全球开源领域的影响力。INFINI Labs Github 主页:https://github.com/infinilabs
5、提供专业服务 为客户提供包括搜索技术支持、迁移服务、定制解决方案和培训在内的全方位服务。
6、提供国产化搜索解决方案 针对中国市场的特殊需求,提供符合国产化标准的搜索产品和解决方案,帮助客户解决使用 Elasticsearch 时遇到的挑战。
极限科技(INFINI Labs)通过这些努力,旨在成为全球领先的实时搜索和数据分析解决方案提供商。
搜索百科(4):OpenSearch — 开源搜索的新选择
OpenSearch • liaosy 发表了文章 • 0 个评论 • 9831 次浏览 • 2025-09-21 14:31
大家好,我是 INFINI Labs 的石阳。
欢迎关注 《搜索百科》 专栏!每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
上一篇我们围观了 “流量明星” Elasticsearch — 从食谱搜索到 PB 级明星产品,从 Apache 2.0 到 SSPL 协议风波;今天我们来聊聊它的“分叉兄弟” OpenSearch。
引言
2021 年,当 Elasticsearch 宣布将其许可证从 Apache 2.0 变更为 SSPL/Elastic License 时,整个搜索社区为之震动。这一变更直接催生了一个新的开源分支 — OpenSearch。这个由 AWS 主导的项目不仅在短短几年内迅速发展成熟,更成为了许多企业在云原生环境下搜索解决方案的新选择。
OpenSearch 概述
OpenSearch 是从 Elasticsearch 7.10.2 分支而来的开源搜索与分析套件,由 AWS 主导开发并贡献给开源社区。OpenSearch 包括 OpenSearch(搜索引擎)和 OpenSearch Dashboards(可视化界面),完全兼容 Apache 2.0 协议,旨在为用户提供一个真正开源、社区驱动的搜索与分析解决方案。
- 首次发布:2021 年 4 月
- 最新版本:3.2.0(截止 2025 年 9 月)
- 开源协议:Apache License 2.0
- 主导企业:Amazon Web Services (AWS)
- 官方网址:https://opensearch.org/
- GitHub 仓库:https://github.com/opensearch-project
诞生故事:开源协议争议的产物
时间回到 2021 年 1 月,Elastic 公司宣布 Elasticsearch 从 7.11 版本起不再使用 Apache 2.0 协议,而改为 Elastic License 与 SSPL。这一决定立刻在社区和产业界引发巨大争议。
AWS(亚马逊云)作为 Elasticsearch 的重要用户与云服务提供商,不愿意被 Elastic 的商业条款所限制,随即牵头将 Elasticsearch 7.10 版本 fork 出来,并与 Kibana 一起重命名为 OpenSearch 与 OpenSearch Dashboards。
从此,开源世界分裂成了两条路线:
- Elastic 官方的 Elasticsearch + Kibana(带有商业许可)。
- 社区驱动的 OpenSearch + OpenSearch Dashboards(继续遵循 Apache 2.0 协议)。
这个分叉,既是开源协议之争的产物,也是云厂商与开源公司之间博弈的缩影。虽然初期被质疑过“是否真开源”,但经过数年的迭代,OpenSearch 已形成了相对独立的开发节奏和用户群体,插件和生态也逐渐丰富。
技术架构与特性
OpenSearch 是一个基于 Apache Lucene 的分布式搜索与分析引擎。在将数据添加到 OpenSearch 后,可以对其执行各种功能完备的全文搜索操作:按字段搜索、跨多个索引搜索、提升字段权重、按得分排序结果、按字段排序结果以及对结果进行聚合。
OpenSearch 的核心架构由集群、节点、索引、分片和文档组成。最高层是 OpenSearch 集群,它是由多个节点组成的分布式网络,每个节点会根据其类型负责不同的集群操作。数据节点负责存储索引(即文档的逻辑分组),并处理数据写入、搜索和聚合等任务。
每个索引会被划分为多个分片,分片包含主数据和副本数据。分片会分布在多台机器上,从而实现水平扩展,提升性能并高效利用存储资源。
OpenSearch vs Elasticsearch:详细对比
| 特性 | OpenSearch | Elasticsearch |
|---|---|---|
| 许可证 | Apache 2.0(完全开源) | SSPL/Elastic License/AGPLv3 |
| 起始版本 | 基于 Elasticsearch 7.10.2 | 从 7.11 开始协议变更 |
| 社区治理 | 开放治理模式,由社区驱动 | 由 Elastic NV 公司主导 |
| 安全性 | 所有安全功能默认开源 | 部分高级安全功能需要付费 |
| AI/向量检索 | 近年快速跟进,兼容性较好 | 原生支持,功能逐步增强 |
| 部署选择 | AWS OpenSearch Service / 自建 | Elastic Cloud / 自建 |
| 升级路径 | 从 Elasticsearch 7.x 平滑迁移 | 原生升级路径 |
| 社区活跃度 | 社区逐渐壮大,受到纯开源拥护者欢迎 | 用户基础庞大,但分裂带来争议 |
快速开始:5 分钟部署 OpenSearch
1. 使用 Docker 部署
# 拉取 OpenSearch 镜像
docker pull opensearchproject/opensearch:3.2.0
# 启动 OpenSearch 节点
docker run -d --name opensearch-node \
-p 9200:9200 -p 9600:9600 \
-e "discovery.type=single-node" \
-e "plugins.security.disabled=true" \
opensearchproject/opensearch:3.2.0
# 拉取 OpenSearch Dashboards
docker pull opensearchproject/opensearch-dashboards:3.2.0
# 启动 Dashboards
docker run -d --name opensearch-dashboards \
-p 5601:5601 \
-e "OPENSEARCH_HOSTS=http://opensearch-node:9200" \
opensearchproject/opensearch-dashboards:3.2.02. 验证安装
# 检查集群状态
curl -X GET "http://localhost:9200/"出现如下结果说明安装成功。
3. 创建索引和搜索
# 索引文档
curl -X POST "http://localhost:9200/my-first-index/_doc" -H 'Content-Type: application/json' -d'
{
"title": "OpenSearch 入门指南",
"content": "这是我在 OpenSearch 中的第一个文档",
"timestamp": "2025-09-18T10:00:00"
}'
# 执行搜索
curl -X GET "http://localhost:9200/my-first-index/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"content": "第一个文档"
}
}
}'4. 访问控制台
打开浏览器访问 http://localhost:5601 即可使用 OpenSearch Dashboards 界面。
结语
OpenSearch 的出现,是开源社区的一次“自救”。它不仅延续了 Elasticsearch 的核心功能,还代表了另一种治理模式:由云厂商和社区共同维护,保证了开源协议的延续。
在搜索技术的版图里,Elasticsearch 与 OpenSearch 的分叉,注定会成为一个重要的历史节点。未来,两者可能会继续竞争,也可能各自发展出独特的生态。
🚀 下期预告
下一篇我们将介绍 OpenSearch 的另一个兄弟 Easysearch,一个衍生自开源协议 Apache 2.0 的 Elasticsearch 7.10.2 版本的轻量级搜索引擎,作为一个 ES 国产替代方案,看看它如何以其极致的速度和易用性在国内搜索领域占据一席之地。
💬 三连互动
- 您是否考虑过从 Elasticsearch 迁移到 OpenSearch?
- 在开源协议方面,您更倾向于哪种模式?Apache 2.0 还是 Elastic 的多重许可?
- 对于云厂商与开源项目之间的关系,您有什么看法?
对搜索技术感兴趣的朋友,也欢迎加我微信(ID:lsy965145175)备注“搜索百科”,拉你进 搜索技术交流群,一起探讨与学习!
✨ 推荐阅读
🔗 参考资源
原文:https://infinilabs.cn/blog/2025/search-wiki-4-opensearch/
搜索百科(3):Elasticsearch — 搜索界的“流量明星”
Elasticsearch • liaosy 发表了文章 • 0 个评论 • 30444 次浏览 • 2025-09-16 11:20
大家好,我是 INFINI Labs 的石阳。
欢迎关注 《搜索百科》 专栏!每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
前两篇我们探讨了搜索技术的基石 Apache Lucene 和企业级搜索解决方案 Apache Solr。今天,我们来聊聊一个真正改变搜索游戏规则,但也充满争议的产品 — Elasticsearch。
引言
如果说 Lucene 是幕后英雄,那么 Elasticsearch 就是舞台中央的明星。借助 REST API、分布式架构、强大的生态系统,它让搜索 + 分析成为“马上可用”的服务形式。
在日志平台、可观察性、安全监控、AI 与语义检索等领域,Elasticsearch 的名字几乎成了默认选项。
Elasticsearch 概述
Elasticsearch 是一个开源的分布式搜索和分析引擎,构建于 Apache Lucene 之上。作为一个检索平台,它可以实时存储结构化、非结构化和向量数据,提供快速的混合和向量搜索,支持可观测性与安全分析,并以高性能、高准确性和高相关性实现 AI 驱动的应用。
- 首次发布:2010 年 2 月
- 最新版本:9.1.3(截止 2025 年 9 月)
- 核心依赖:Apache Lucene
- 开源协议:AGPL v3
- 官方网址:https://www.elastic.co/elasticsearch/
- GitHub 仓库:https://github.com/elastic/elasticsearch
起源:从食谱搜索到全球“流量明星”
Elasticsearch 的故事始于以色列开发者 Shay Banon。2010 年,当时他在学习厨师课程的妻子需要一款能够快速搜索食谱的工具。虽然当时已经有 Solr 这样的搜索解决方案,但 Shay 认为它们对于分布式场景的支持不够完善。
基于之前开发 Compass(一个基于 Lucene 的搜索库)的经验,Shay 开始构建一个完全分布式的、基于 JSON 的搜索引擎。2010 年 2 月,Elasticsearch 的第一个版本发布。
随着用户日益增多、企业级需求增强,Shay 在 2012 年创立了 Elastic 公司,把 Elasticsearch 不仅作为开源项目,也逐渐商业化运营起来,包括提供托管服务、企业支持,加入 Logstash 日志处理、Kibana 可视化工具等,Elastic 公司也逐渐从一个纯搜索引擎项目演变为一个更广泛的“数据搜索与分析”平台。
协议变更:开源和商业化的博弈
Elasticsearch 的发展并非一帆风顺。其历史上最具转折性的事件当属与 AWS 的冲突及随之而来的开源协议变更。
- 早期:Apache 2.0 协议
2010 年 Shay Banon 开源 Elasticsearch 时,最初采用的是 Apache 2.0 协议。Apache 2.0 属于宽松的自由协议,允许任何人免费使用、修改和商用(包括 SaaS 模式)。这帮助 Elasticsearch 快速壮大,成为事实上的“搜索引擎标准”。
- 协议变更:应对云厂商“白嫖”
随着 Elasticsearch 的流行,像 AWS(Amazon Web Services) 等云厂商直接将 Elasticsearch 做成托管服务,并从中获利。Elastic 公司认为这损害了他们的商业利益,因为云厂商“用开源赚钱,却没有回馈社区”。2021 年 1 月,Elastic 宣布 Elasticsearch 和 Kibana 不再采用 Apache 2.0,改为 双重协议:SSPL + Elastic License。这一步导致社区巨大分裂,AWS 带头将 Elasticsearch 分叉为 OpenSearch,并继续以 Apache 2.0 协议维护。
- 再次转向开源:AGPL v3
2024 年 3 月,Elastic 宣布新的版本(Elasticsearch 8.13 起)又新增 AGPL v3 作为一个开源许可选项。AGPL v3 既符合 OSI 真正开源标准,又能约束云厂商闭源托管服务,同时修复社区关系,Elastic 希望通过重新拥抱开源,减少分裂,吸引开发者回归。
Elasticsearch 从宽松到收紧,再到回归开源,是在社区生态与商业利益间寻找平衡的过程。
基本概念
要学习 Elasticsearch,得先了解其五大基本概览:集群、节点、分片、索引和文档。
- 集群(Cluster)
由一个或多个节点组成的整体,提供统一的搜索与存储服务。对外看起来像一个单一系统。
- 节点(Node)
集群中的一台服务器实例。节点有不同角色:
- Master 节点:负责集群管理(分片分配、元数据维护)。
- Data 节点:存储数据、处理搜索和聚合。
- Coordinating 节点:接收请求并调度任务。
- Ingest 节点:负责数据写入前的预处理。
- 索引(Index)
类似于传统数据库的“库”,按逻辑组织数据。一个索引往往对应一个业务场景(如日志、商品信息)。
- 分片(Shard)
为了让索引能水平扩展,Elasticsearch 会把索引拆分为多个 主分片,并为每个主分片创建 副本分片,提升高可用和查询性能。
- 文档(Document)
Elasticsearch 存储和检索的最小数据单元,通常是 JSON 格式。多个文档组成一个索引。
集群架构
Elasticsearch 通过 Master、Data、Coordinating、Ingest 等不同角色节点的协作,将数据切分成分片并分布式存储,实现了高可用、可扩展的搜索与分析引擎架构。
快速开始:5 分钟体验 Elasticsearch
1. 使用 Docker 启动
# 拉取最新镜像
docker pull docker.elastic.co/elasticsearch/elasticsearch:9.1.3
# 启动单节点集群
docker run -d --name elasticsearch \
-p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e "xpack.security.enabled=false" \
docker.elastic.co/elasticsearch/elasticsearch:9.1.32. 验证安装
# 检查集群状态
curl -X GET "http://localhost:9200/"
3. 索引文档
# 索引文档
curl -X POST "http://localhost:9200/myindex/_doc" -H 'Content-Type: application/json' -d'
{
"title": "Hello Elasticsearch",
"description": "An example document"
}'
3. 搜索文档
# 搜索文档
curl -X GET "http://localhost:9200/myindex/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"title": "Hello"
}
}
}'
结语
Elasticsearch 是搜索与分析领域标杆性的产品。它将 Lucene 的能力包装起来,加上分布式、易用以及与数据可视化、安全监控等功能的整合,使搜索引擎从专业技术逐渐变为“随手可用”的基础设施。
虽然协议变动、与 OpenSearch 的分叉引发争议,但它在企业与开发者群体中的实际应用价值依然难以替代。
🚀 下期预告
下一篇我们将介绍 OpenSearch,探讨这个 Elasticsearch 分支项目的发展现状、技术特点以及与 Elasticsearch 的详细对比。如果您有特别关注的问题,欢迎提前提出!
💬 三连互动
- 你或公司最近在用 Elasticsearch 吗?拿来做了什么场景?
- 在 Elasticsearch 和 OpenSearch 之间做过技术选型?
- 对 Elasticsearch 的许可证变化有什么看法?
对搜索技术感兴趣的朋友,也欢迎加我微信(ID:lsy965145175)备注“搜索百科”,拉你进 搜索技术交流群,一起探讨与学习!
✨ 推荐阅读
🔗 参考
原文:https://infinilabs.cn/blog/2025/search-wiki-3-elasticsearch/
【搜索客社区日报】第2007期 (2025-03-21)
社区日报 • Fred2000 发表了文章 • 0 个评论 • 4345 次浏览 • 2025-03-21 09:04
Easysearch、Elasticsearch、Amazon OpenSearch 快照兼容对比
Easysearch • INFINI Labs 小助手 发表了文章 • 2 个评论 • 5715 次浏览 • 2024-07-29 11:54
在当今的数据驱动时代,搜索引擎的快照功能在数据保护和灾难恢复中至关重要。本文将对 Easysearch、Elasticsearch 和 Amazon OpenSearch 的快照兼容性进行比较,分析它们在快照创建、恢复、存储格式和跨平台兼容性等方面的特点,帮助大家更好地理解这些搜索引擎的差异,从而选择最适合自己需求的解决方案。
启动集群
Easysearch
服务器一般情况下默认参数都是很低的,而 Easysearch/Elasticsearch 是内存大户,所以就需要进行系统调优。
sysctl -w vm.max_map_count=262144vm.max_map_count 是一个 Linux 内核参数,用于控制单个进程可以拥有的最大内存映射区域(VMA,Virtual Memory Areas)的数量。内存映射区域是指通过内存映射文件或匿名内存映射创建的虚拟内存区域。
这个参数在一些应用程序中非常重要,尤其是那些需要大量内存映射的应用程序,比如 Elasticsearch。Elasticsearch 使用内存映射文件来索引和搜索数据,这可能需要大量的内存映射区域。如果 vm.max_map_count 设置得太低,Elasticsearch 可能无法正常工作,并会出现错误信息。
调整 vm.max_map_count 参数的一些常见原因:
-
支持大型数据集: 应用程序(如 Elasticsearch)在处理大型数据集时可能需要大量内存映射区域。增加
vm.max_map_count可以确保这些应用程序有足够的内存映射区域来处理数据。 -
防止内存错误: 如果
vm.max_map_count设置得太低,当应用程序尝试创建超过限制的内存映射时,会出现错误,导致应用程序崩溃或无法正常工作。 - 优化性能:
适当地设置
vm.max_map_count可以优化应用程序的性能,确保内存映射操作顺利进行。
检查当前的 vm.max_map_count 值:
sysctl vm.max_map_count或者查看 /proc/sys/vm/max_map_count 文件:
cat /proc/sys/vm/max_map_countElasticsearch 官方建议将 vm.max_map_count 设置为至少 262144。对于其他应用程序。
Easysearch 具体安装步骤见 INFINI Easysearch 尝鲜 Hands on
Amazon OpenSearch
使用 Amazon Web Services 控制台进行创建。
Elasticsearch
使用如下 docker compose 部署一个三节点的 ES 集群:
version: "2.2"
services:
es01:
image: docker.elastic.co/elasticsearch/elasticsearch:7.10.2
container_name: es01
environment:
- node.name=es01
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es02,es03
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data01:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- elastic
es02:
image: docker.elastic.co/elasticsearch/elasticsearch:7.10.2
container_name: es02
environment:
- node.name=es02
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es03
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data02:/usr/share/elasticsearch/data
networks:
- elastic
es03:
image: docker.elastic.co/elasticsearch/elasticsearch:7.10.2
container_name: es03
environment:
- node.name=es03
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es02
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data03:/usr/share/elasticsearch/data
networks:
- elastic
volumes:
data01:
driver: local
data02:
driver: local
data03:
driver: local
networks:
elastic:
driver: bridge由于这个 docker compose 没有关于 kibana 的配置,所以我们还是用 Console 添加原生的 Elasticsearch 集群!
集群信息
快照还原的步骤
快照前的准备
插件安装
本次测试选择把索引快照备份到 Amazon S3,所以需要使用 S3 repository plugin,这个插件添加了对使用 Amazon S3 作为快照/恢复存储库的支持。
Easysearch 和 OpenSearch 集群自带了这个插件,所以无需额外安装。
对于自己部署的三节点 Elasticsearch 则需要进入每一个节点运行安装命令然后再重启集群,建议使用自动化运维工具来做这步,安装命令如下:
sudo bin/elasticsearch-plugin install repository-s3如果不再需要这个插件,可以这样删除。
sudo bin/elasticsearch-plugin remove repository-s3由于需要和 Amazon Web Services 打交道,所以我们需要设置 IAM 凭证,这个插件可以从 EC2 IAM instance profile,ECS task role 以及 EKS 的 Service account 读取相应的凭证。
对于托管的 Amazon OpenSearch 来说,我们无法在托管的 EC2 上绑定我们的凭证,所以需要新建一个 OpenSearchSnapshotRole,然后通过当前的用户把这个角色传递给服务,也就是我们说的 IAM:PassRole。
创建 OpenSearchSnapshotRole,策略如下:
{
"Version": "2012-10-17",
"Statement": [{
"Action": [
"s3:ListBucket"
],
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::bucket-name"
]
},
{
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject"
],
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::bucket-name/*"
]
}
]
}信任关系如下:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "es.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}然后在我们的 IAM user 上加上 PassRole 的权限,这样我们就可以把 OpenSearchSnapshotRole 传递给 OpenSearch 集群。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::123456789012:role/OpenSearchSnapshotRole"
}
]
}注册存储库
在源集群执行注册
PUT /_snapshot/snapshot-repo-name
{
"type": "s3",
"settings": {
"bucket": "<bucket-name>",
"base_path": "<bucket-prefix>",在目标集群同样执行这个语句,为了防止覆盖源集群存储库的数据,将 "readonly": true 添加到"settings" PUT 请求中,这样就只有一个集群具有对存储库的写入权限。
PUT /_snapshot/snapshot-repo-name
{
"type": "s3",
"settings": {
"bucket": "<bucket-name>",
"base_path": "<bucket-prefix>",
"readonly": true,对于 OpenSearch 来说,还需要执行 passrole,所以还需要添加role_arn这个字段,由于 IAM:PassRole 需要对 HTTP 请求做 signV4 日签名,所以这部常常使用 Postman 来完成。把角色传递过去之后,接下来的快照还原操作就可以在 OpenSearch Dashboard 中进行操作了。
需要注意的是,需要在 auth 这里输入 AccessKey,SecretKey,AWS Region,Service Name(es)来做 SignV4 的签名。
请求体如下:
{
"type": "s3",
"settings": {
"bucket": "<bucket-name>",
"base_path": "<bucket-prefix>",
"readonly": true,
"role_arn": "arn:aws:iam::123456789012:role/OpenSearchSnapshotRole"
}
}- 查看所有注册的存储库:
GET _snapshot:这个命令返回所有已注册的快照存储库列表及其基本信息。
GET _snapshot{
"es_repository": {
"type": "s3",
"settings": {
"bucket": "your-s3-bucket-name",
"region": "your-s3-bucket-region"
}
}
}- 查看特定存储库的详细信息:
GET _snapshot/es_repository:这个命令返回名为es_repository的存储库的详细配置信息,包括存储桶名称、区域和其他设置。
GET _snapshot/es_repository{
"es_repository": {
"type": "s3",
"settings": {
"bucket": "your-s3-bucket-name",
"region": "your-s3-bucket-region",
"access_key": "your-access-key",
"secret_key": "your-secret-key"
}
}
}- 查看特定存储库中的快照:
GET _cat/snapshots/es_repository?v:这个命令返回es_repository存储库中的所有快照及其详细信息,包括快照 ID、状态、开始时间、结束时间、持续时间、包含的索引数量、成功和失败的分片数量等。
GET _cat/snapshots/es_repository?vid status start_epoch start_time end_epoch end_time duration indices successful_shards failed_shards total_shards
snapshot_1 SUCCESS 1628884800 08:00:00 1628888400 09:00:00 1h 3 10 0 10
snapshot_2 SUCCESS 1628971200 08:00:00 1628974800 09:00:00 1h 3 10 0 10创建索引快照
# PUT _snapshot/my_repository/<my_snapshot_{now/d}>
PUT _snapshot/my_repository/my_snapshot
{
"indices": "my-index,logs-my_app-default",
}根据快照的大小不同,完成快照可能需要一些时间。默认情况下,create snapshot API 只会异步启动快照过程,该过程在后台运行。要更改为同步调用,可以将 wait_for_completion 查询参数设置为 true。
PUT _snapshot/my_repository/my_snapshot?wait_for_completion=true另外还可以使用 clone snapshot API 克隆现有的快照。要监控当前正在运行的快照,可以使用带有 _current 请求路径参数的 get snapshot API。
GET _snapshot/my_repository/_current如果要获取参与当前运行快照的每个分片的完整详细信息,可以使用 get snapshot status API。
GET _snapshot/_status成功创建快照之后,就可以在 S3 上看到备份的数据块文件,这个是正确的快照层级结构:
需要注意的是, "base_path": "
所以在 Open Search 中还原 Elasticsearch 就遇到了这个问题:
{
"error": {
"root_cause": [
{
"type": "snapshot_missing_exception",
"reason": "[easy_repository:2/-jOQ0oucQDGF3hJMNz-vKQ] is missing"
}
],
"type": "snapshot_missing_exception",
"reason": "[easy_repository:2/-jOQ0oucQDGF3hJMNz-vKQ] is missing",
"caused_by": {
"type": "no_such_file_exception",
"reason": "Blob object [11111/indices/7fv2zAi4Rt203JfsczUrBg/meta-YGnzxZABRBxW-2vqcmci.dat] not found: The specified key does not exist. (Service: S3, Status Code: 404, Request ID: R71DDHX4XXM0434T, Extended Request ID: d9M/HWvPvMFdPhB6KX+wYCW3ZFqeFo9EoscWPkulOXWa+TnovAE5PlemtuVzKXjlC+rrgskXAus=)"
}
},
"status": 404
}恢复索引快照
POST _snapshot/my_repository/my_snapshot_2099.05.06/_restore
{
"indices": "my-index,logs-my_app-default",
}各个集群的还原
-
Elasticsearch 7.10.2 的快照可以还原到 Easysearch 和 Amazon OpenSearch
- 从 Easysearch 1.8.2 还原到 Elasticsearch 7.10.2 报错如下:
{
"error": {
"root_cause": [
{
"type": "snapshot_restore_exception",
"reason": "[s3_repository:1/a2qV4NYIReqvgW6BX_nxxw] cannot restore index [my_indexs] because it cannot be upgraded"
}
],
"type": "snapshot_restore_exception",
"reason": "[s3_repository:1/a2qV4NYIReqvgW6BX_nxxw] cannot restore index [my_indexs] because it cannot be upgraded",
"caused_by": {
"type": "illegal_state_exception",
"reason": "The index [[my_indexs/ALlTCIr0RJqtP06ouQmf0g]] was created with version [1.8.2] but the minimum compatible version is [6.0.0-beta1]. It should be re-indexed in Elasticsearch 6.x before upgrading to 7.10.2."
}
},
"status": 500
}- 从 Amazon OpenSearch 2.1.3 还原到 Elasticsearch 7.10.2 报错如下(无论是否开启兼容模式):
{
"error": {
"root_cause": [
{
"type": "snapshot_restore_exception",
"reason": "[aos:2/D-oyYSscSdCbZFcmPZa_yg] the snapshot was created with Elasticsearch version [36.34.78-beta2] which is higher than the version of this node [7.10.2]"
}
],
"type": "snapshot_restore_exception",
"reason": "[aos:2/D-oyYSscSdCbZFcmPZa_yg] the snapshot was created with Elasticsearch version [36.34.78-beta2] which is higher than the version of this node [7.10.2]"
},
"status": 500
}- 从 Easysearch 1.8.2 还原到 Amazon OpenSearch2.13 报错如下(无论是否开启兼容模式):
{
"error": {
"root_cause": [
{
"type": "snapshot_restore_exception",
"reason": "[easy_repository:2/LE18AWHlRJu9rpz9BJatUQ] cannot restore index [my_indexs] because it cannot be upgraded"
}
],
"type": "snapshot_restore_exception",
"reason": "[easy_repository:2/LE18AWHlRJu9rpz9BJatUQ] cannot restore index [my_indexs] because it cannot be upgraded",
"caused_by": {
"type": "illegal_state_exception",
"reason": "The index [[my_indexs/VHOo7yfDTRa48uhQvquFzQ]] was created with version [1.8.2] but the minimum compatible version is OpenSearch 1.0.0 (or Elasticsearch 7.0.0). It should be re-indexed in OpenSearch 1.x (or Elasticsearch 7.x) before upgrading to 2.13.0."
}
},
"status": 500
}- Amazon OpenSearch 还原到 Easysearch 同样失败
{
"error": {
"root_cause": [
{
"type": "snapshot_restore_exception",
"reason": "[aoss:2/D-oyYSscSdCbZFcmPZa_yg] cannot restore index [aos] because it cannot be upgraded"
}
],
"type": "snapshot_restore_exception",
"reason": "[aoss:2/D-oyYSscSdCbZFcmPZa_yg] cannot restore index [aos] because it cannot be upgraded",
"caused_by": {
"type": "illegal_state_exception",
"reason": "The index [[aos/864WjTAXQCaxJ829V5ktaw]] was created with version [36.34.78-beta2] but the minimum compatible version is [6.0.0]. It should be re-indexed in Easysearch 6.x before upgrading to 1.8.2."
}
},
"status": 500
}- Elasticsearch 8.14.3 迁移到 Amazon OpenSearch 或者 Elasticsearch 都是有这个报错:
{
"error": {
"root_cause": [
{
"type": "parsing_exception",
"reason": "Failed to parse object: unknown field [uuid] found",
"line": 1,
"col": 25
}
],
"type": "repository_exception",
"reason": "[snap] Unexpected exception when loading repository data",
"caused_by": {
"type": "parsing_exception",
"reason": "Failed to parse object: unknown field [uuid] found",
"line": 1,
"col": 25
}
},
"status": 500
}这是由于 Elasticsearch 8 在创建快照的时候会默认加上一个 UUID 的字段,所以我们低版本的 Easysearch、Amazon OpenSearch 中会找不到这个字段,在执行GET _cat/snapshots/snap?v的时候就报错,及时在注册存储库的时候显示加上 UUID 的字段也无事无补。
{
"snapshot-repo-name": {
"type": "s3",
"uuid": "qlJ0uqErRmW6aww2Fyt4Fg",
"settings": {
"bucket": "<bucket-name>",
"base_path": "<bucket-prefix>",
}
},以下是兼容性对比,每行第一列代表源集群,第一行代表目标集群:
| 快照兼容对比 | Easysearch 1.8.2 | Elasticsearch 7.10.2 | OpenSearch 2.13 |
|---|---|---|---|
| Easysearch 1.8.2 | 兼容 | 不兼容 | 不兼容 |
| Elasticsearch 7.10.2 | 兼容 | 兼容 | 兼容 |
| OpenSearch 2.13 | 不兼容 | 不兼容 | 兼容 |
Elasticsearch 的兼容列表官方的列表如下:
参考文献
-
开始使用 Elastic Stack 和 Docker Compose:第 1 部分
https://www.elastic.co/cn/blog/getting-started-with-the-elastic-stack-and-docker-compose -
Docker Compose 部署多节点 Elasticsearch
https://www.elastic.co/guide/en/elasticsearch/reference/7.10/docker.html#docker-compose-file -
repository-s3 教程
https://www.elastic.co/guide/en/elasticsearch/reference/8.14/repository-s3.html
https://www.elastic.co/guide/en/elasticsearch/plugins/7.10/repository-s3.html -
snapshot-restore
https://www.elastic.co/guide/en/elasticsearch/reference/7.10/snapshot-restore.html -
在亚马逊 OpenSearch 服务中创建索引快照
https://docs.amazonaws.cn/zh_cn/opensearch-service/latest/developerguide/managedomains-snapshots.html#managedomains-snapshot-restore - 教程:迁移至 Amazon OpenSearch Service
https://docs.amazonaws.cn/zh_cn/opensearch-service/latest/developerguide/migration.html
关于 Easysearch 有奖征文活动
无论你是 Easysearch 的老用户,还是第一次听说这个名字,只要你对 INFINI Labs 旗下的 Easysearch 产品感兴趣,或者是希望了解 Easysearch,都可以参加这次活动。
详情查看:Easysearch 征文活动
作者:韩旭,亚马逊云技术支持,亚马逊云科技技领云博主,目前专注于云计算开发和大数据领域。
【搜索客社区日报】第1863期 (2024-07-19)
社区日报 • Fred2000 发表了文章 • 0 个评论 • 3693 次浏览 • 2024-07-19 11:32
搜索型数据库的技术发展历程与趋势前瞻
资讯动态 • INFINI Labs 小助手 发表了文章 • 0 个评论 • 4873 次浏览 • 2024-06-26 13:13
概述
随着数字科技的飞速发展和信息量的爆炸性增长,搜索引擎已成为我们获取信息的首选途径之一,典型的代表厂商如 Google。然而,随着用户需求的不断演变,传统的搜索技术已经无法满足人们对信息的实时性、个性化和多样性的需求。
在企业内部,这种需求更加显著。随着企业数字化转型的持续深化,非结构化数据正日益成为各类组织数据增长的主要来源,也是数据体系中至关重要的组成部分,蕴含着巨大的价值。如何高效地存储和利用非结构化数据的重要性也日益凸显。企业需要更高效地管理和检索内部的海量数据,以支持业务决策和运营需求。
据 IDC 数据预计,到 2025 年,80%的数据将是非结构化数据;而根据 Gartner 的数据显示,从 2019 年到 2024 年,非结构化数据容量预计将增加两倍。然而,目前非结构化数据面临着表现形式多样、管理复杂性高、价值挖掘难度大等诸多挑战。传统的数据库系统往往无法满足企业对实时性和多样性的搜索需求,为了解决这些挑战,以自动分词、倒排索引、相关度计算、向量检索引擎等技术为核心构建的搜索型数据库应运而生。这些数据库自上世纪 90 年代诞生以来不断发展演进,正在成为数据库领域中不可或缺的一个重要分支。
什么是搜索型数据库?
搜索型数据库早期又称全文数据库,或者企业搜索引擎,是一种专门用于存储和管理大规模文本数据,并支持高效的文本搜索和信息检索的数据库系统,不过随着技术不断发展和应用场景日益丰富,目前搜索型数据库不仅仅可以处理长文本数据,也可以处理常见的数值、日期等结构化数据,IP、地理位置信息、图片、音视频等非结构化数据,搜索型数据库的应用范畴不断拓展,正在由支撑业务系统检索加速、IT 运维可观测性、聚合查询分析等向多场景、多模态数据搜索方向发展。
典型的搜索数据库一般具有以下特点:
- 灵活的索引能力:搜索数据库能够处理多种类型的数据,包括文本、图像、音频、视频等非结构化数据。它们采用自动分词、倒排索引等技术,能够高效地处理不同格式和类型的数据,提供灵活的搜索和检索功能。
- 高效的查询性能:搜索数据库具有高效的查询处理能力,能够快速索引和检索大规模的数据。借助优化的索引结构和查询算法,搜索数据库能够在短时间内准确地返回与查询相关的结果,提高用户的搜索效率,常用于解决关系型数据库的高并发检索需求。
- 支持复杂的搜索功能:搜索数据库提供多样化的搜索功能,包括全文检索、模糊搜索、精确搜索、范围搜索、向量搜索、地理信息检索等。用户可以根据不同的需求和场景,灵活地选择和组合不同的搜索功能,以获取符合期望的搜索结果。
- 高性能和可扩展性:搜索数据库具有高性能和可扩展性的特点,能够处理大规模数据和高并发访问。它们采用分布式架构和并行计算技术,实现了水平扩展,能够满足不断增长的数据量和用户访问量的需求。
综上所述,搜索数据库具有处理非结构化数据、实时搜索和更新、多样化的搜索功能、个性化推荐和智能搜索、高性能和可扩展性、全面的搜索结果展示等特点,是处理大规模数据和提供高效搜索服务的重要工具。
搜索型数据库的应用场景
搜索型数据库在各行各业都有广泛的应用,以下是一些典型的应用场景:
- 零售和电商:在零售和电商行业,搜索型数据库被广泛应用于产品搜索和推荐系统中。通过搜索功能,顾客可以轻松查找所需商品,而个性化推荐系统则可以根据用户的搜索历史和行为习惯推荐相关的产品,提高购物体验和交易转化率。
- 医疗保健:在医疗保健行业,搜索型数据库被用于医学文献检索、疾病诊断和药物搜索等方面。医生和研究人员可以利用搜索功能找到相关的医学文献和研究成果,帮助诊断疾病和制定治疗方案。
- 金融服务:在金融服务行业,搜索型数据库被用于金融数据检索、市场分析和投资决策等方面。投资者可以通过搜索功能查找相关的金融数据和市场资讯,帮助他们做出更加准确的投资决策。
- 制造业:在制造业中,搜索型数据库被用于生产过程监控、质量控制和故障诊断等方面。工程师可以利用搜索功能查找相关的生产数据和技术资料,帮助他们解决生产中的问题和挑战。
- 媒体和娱乐:在媒体和娱乐行业,搜索型数据库被用于内容检索、版权管理和用户推荐等方面。用户可以通过搜索功能查找感兴趣的新闻、音乐和视频等内容,而个性化推荐系统则可以根据用户的搜索历史和偏好推荐相关的内容。
- 教育和培训:在教育和培训行业,搜索型数据库被用于学习资源检索、课程管理和学习分析等方面。学生和教师可以利用搜索功能查找相关的学习资源和课程内容,而学习分析系统则可以分析学生的搜索行为和学习表现,为教学提供参考和支持。
- IT 运维可观测性:通过搜索型数据库,可以实时监控系统的运行状况、性能指标和日志数据,帮助运维团队及时发现和解决系统故障、性能问题和异常情况,确保系统的稳定运行。
- 安全监测和威胁检测:利用搜索型数据库对系统的安全日志进行审计和监控,监测用户的访问行为和系统操作,及时发现异常行为和安全事件。同时,搜索型数据库还可以与威胁情报数据集成,对内部日志数据进行关联分析,快速识别并应对各种安全威胁和攻击行为,保障系统和数据的安全。
综上所述,搜索型数据库在各行各业都发挥着重要作用,数据规模从 GB 到 PB 不等,体现在生活中的方方面面,为用户提供了高效、准确和个性化的信息搜索和检索服务,推动了各行业的发展和进步。随着搜索技术的不断创新和发展,搜索型数据库在各行业中的应用将会越来越广泛,并持续为用户带来更加便捷和智能的搜索体验。
搜索型数据库的发展历程
搜索型数据库的发展历程可以概括如下四个阶段:
- 起步阶段(1990 年代):搜索数据库的雏形开始于上世纪 90 年代,当时以全文检索为主要技术手段,最初用于文档检索和网络搜索。典型代表包括 AltaVista、Excite 等。
- 技术突破(2000 年代):随着互联网的快速发展,搜索数据库开始应用于更多领域,如电子商务、社交网络等。Lucene、Sphinx 等开源搜索引擎的出现推动了搜索技术的进步。
- 商业化发展(2010 年代):搜索数据库进入商业化阶段,以 Elasticsearch 等为代表的商业搜索引擎崭露头角。企业开始大规模应用搜索数据库来管理和检索大量数据。
-
智能化转型(2020 年代):随着人工智能技术的发展,搜索数据库逐渐向智能化转型,开始引入机器学习、自然语言处理等技术,提供个性化推荐和智能搜索服务。同时,搜索数据库也在更多领域得到应用,如医疗保健、金融服务等。
综上所述,搜索数据库经历了从起步阶段到技术突破、商业化发展再到智能化转型的发展历程,表明了其在信息检索领域的重要性和不断演进的趋势,不并断推动着搜索技术的进步和应用范围的扩展。随着人工智能技术的不断成熟,搜索数据库将会在智能化、个性化等方面取得更大的进步,为用户提供更加优质的搜索体验。
搜索型数据库的发展情况
搜索型数据库市场上已经有不少成熟的产品和厂商,但是总的来说,搜索型数据库的界限范围有点模糊,当然其他数据库也有同样的问题,有很多数据库既是文档数据库,又是多模态数据库,还是向量数据库等等,而常见的搜索型数据库主要诞生于:
- 由搜索引擎内核库发展而来的搜索数据库,如 Elasticsearch
- 由其他数据库扩展而来的搜索数据库,如 Postgres Full-Text Search
- 从零开始整体设计的搜索数据库:如 INFINI Pizza
通过流行的 DB-Engines 的搜索引擎排行榜,可以初探国外主流的搜索型数据库的流行趋势,如下图:
可以看到 Elastic 公司的 Elasticsearch 还是依旧保持强悍,自从 Elasticsearch 十多年前掀翻了 Splunk 的桌子,硬生生的在日志领域杀出一条新路,随后大杀四方,碾压整个搜索行业,霸榜至今。Elastic 商业化增长稳健,2023 年收入超过 10 亿美金。
OpenSearch 是由 AWS 发起的 Elasticsearch 开源分支,起因是由于 Elastic 针对云厂商采取的协议变更为 Elastic+SSPL,OpenSearch 基于 Apache 2.0 协议的 Elasticsearch 7.10 版本衍生而来,目前也具备了一定的用户基础。
Splunk 是一款用于搜索、监控和分析大规模机器生成的数据的软件平台,主要用于日志和安全分析领域,属于商业闭源产品。2023 年中被思科(Cisco) 以 230 亿美元现金收购,瞬间刷爆朋友圈。另外有意思的是,前四名除了 Splunk,底层都是 Lucene 内核。
MarkLogic 成立于 2001 年,自我定位是一个 NoSQL 多模态数据库厂商,也是商业闭源软件,生态成熟但是系统过于复杂,学习曲线较陡, 2023 年初被 Progress Software 以 3.55 亿美元收购算是一个比较好的结局。
当然了,除了榜上的这些产品,还有很多优秀的挑战者正摩拳擦掌,跃跃欲试。如下面的这些项目: vespa、Rockset、Doris,Clickhouse、quickwit、Pinot、SingleStore、qdrant、milvus、algolia、meilisearch、typesense、Manticore Search 等等。这些项目不一定都是自己定位是搜索型数据库,有侧重在 AI 领域的,有侧重在实时分析领域的等等,可谓各有千秋,不过都具备一定的搜索和分析能力,不出意外,基本上每家都要号称吊打 Elasticsearch 一番。
国内搜索型数据库的发展情况
搜索型数据库已经成为企业事实上的重要基础设施,而国内搜索型数据库的发展近些年也是开始得到重视,2023 年初,由中国信通院云计算与大数据研究所牵头,依托中国通信标准化协会大数据技术标准推进委员会,联合拓尔思、极限科技、星环科技等 30 余家企业编制的《搜索型数据库技术要求》正式出炉,该标准已成为行业内搜索型数据库技术选型和产品开发的风向标,极限科技的 INFINI Easysearch 率先通过了该标准。
墨天轮社区也开辟了搜索型数据库的排行榜,共有 6 家企业的产品上榜:
国内搜索型数据库的市场还在起步阶段,厂商和可选的产品也还比较少,不过随着市场的成熟,相信未来将迎来一波高速的发展。
搜索型数据库的趋势前瞻
技术在演变,场景在演变,数据也在演变,搜索数据库领域的发展也呈现出多个显著的趋势,这些趋势将进一步推动搜索技术的演进和应用范围的扩展。笔者观测到的主要的发展趋势包括以下方向供参考:
1. 趋势一:实时搜索与分析
-
实时搜索是搜索数据库领域的一个重要发展趋势,业务应用都在朝实时方向演进,用户对信息的即时性需求不断增加,要求搜索结果能够及时反映最新的数据和内容。
-
实时搜索技术通过实时索引和实时更新机制,能够实现快速的数据检索和更新,提供与时俱进的搜索结果,满足用户对信息的即时性需求。
- 目前以 Lucene 为内核的搜索型数据库基本上都只能做到 NRT(近实时)搜索,并且频繁更新带来的挑战和资源的浪费比较高,如果能做到更高效的实时性,可以大大提升用户的搜索体验和实时决策能力。
2. 趋势二:多模态混合搜索
-
多模态搜索是指在搜索过程中同时考虑多种信息形式,如文本、图像、视频等,以提高搜索结果的准确性和全面性。
-
这种技术能够通过分析和理解多种信息形式之间的关联性,为用户提供更加全面、丰富的搜索结果,适用于需要综合不同媒体形式的搜索场景。
- 现实世界的数据越来越复杂化,非结构化数据的利用的场景也越来越多,多模态可以为业务提供更加灵活的分析和探索能力,混合搜索的能力非常具有吸引力。
3. 趋势三:AI 智能语义搜索
-
大模型、AI 智能搜索技术的探索可谓是一日千里,通过利用人工智能技术来实现搜索过程中的智能化、语义化和个性化,结合自然语言处理、机器学习等技术分析用户意图,提供更加智能、个性化的搜索服务。
-
随着大模型的兴起,搜索数据库开始采用像 RAG(Retriever-Reader for Generative Question Answering)这样的大型预训练模型来提升搜索的效果。RAG 模型结合了检索器和阅读器的功能,能够实现更加准确和全面的搜索结果,为用户提供更加智能和个性化的搜索服务。
- 搜索型数据库可谓是 AI 落地最好的是试验田,Elasticsearch 通过拥抱 AI 和大模型,目前股价又重回巅峰,可喜可贺。
4. 趋势四:云原生、存算分离、Serverless
-
随着云计算技术的发展,搜索数据库正逐渐向云原生架构转变。云原生搜索数据库利用容器化、微服务架构等技术,实现了更高的灵活性、可扩展性和容错性,为企业提供了更加稳定和高效的搜索服务,并且成本更低,更加弹性。
-
存算分离是搜索数据库发展的另一重要趋势。通过将存储与计算分离,搜索数据库可以更好地适应数据存储和计算需求的变化,提高系统的性能和效率。存算分离技术使得搜索数据库能够实现更高的并发访问和更快的数据处理速度,为用户提供更加流畅和稳定的搜索体验。
- Serverless 提供开箱即用的体验,成本更低,使用更加灵活,也是目前很多搜索服务提供商正在积极探索的方向。
5. 趋势五:增强现实搜索
- 随着增强现实技术的发展,尤其是 Apple 发布的头戴式 Vision Pro,一部革命性的空间运算设备,将数位内容无缝融入实体世界,而搜索技术也将逐渐与增强现实相结合,为用户提供更加直观和沉浸式的搜索体验。增强现实搜索能够将搜索结果与现实世界相结合,结合 AI 技术为用户提供更加个性化和便捷的搜索服务,这是一个全新的领域,也意味着巨大的机会。
6. 趋势六:现代硬件的高效利用
-
现代硬件及软件运行环境已发生翻天覆地的变化, 片上计算,边缘计算,FPGA,DPU,GPU,一台设备几百核上 TB 内存已经成为现实,可运行之上的软件却还是停留在几十年前的架构。 如 Elasticsearch 其核心 Lucene(及类似实现) 是在 1997 建立的,距今已有 27 年了,虽然也在与时俱进,但是部分架构和设计理念已不具备先进性。
- 在现代的硬件上采用更先进的算法,更新的数据结构、更新的设计理论,利用最新的 CPU 指令集,向量化,批处理,充分发挥多核、大内存和 SSD 的优势,从而达到更高的效率,更低的成本,去解决之前不可能实现的问题,大有可为,也是下一代引擎需要关注的方向。
随着各类数据库功能的边界越来越模糊,应用场景高度交叉重叠,市场竞争也变得白热化,不过笔者认为垂直领域的搜索型数据库机会还是很大,而想做大而全的数据库产品已经没有太多的市场生存空间,一定要在垂直领域有特别专注的地方,我们 INFINI Labs 正在基于 Rust 研发的下一代搜索引擎 INFINI Pizza,就侧重于面向终端用户场景,解决海量数据更新情况下,同时满足高并发和低延迟的核心业务实时检索需求。
总结
综上所述,搜索数据库领域正处于快速发展的阶段。随着互联网数据量的不断增长和用户需求的不断变化,搜索数据库技术将不断创新和进步,以满足用户对信息获取的更加即时、个性化和多样化的需求。未来,随着人工智能技术的进一步发展和应用,搜索数据库将会变得更加智能化、普及化和多样化,为用户提供更加高效、准确和个性化的搜索服务,推动互联网信息的更加便捷获取和利用。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
【搜索客社区日报】第1838期 (2024-06-14)
社区日报 • Fred2000 发表了文章 • 0 个评论 • 3145 次浏览 • 2024-06-14 09:18
【搜索客社区日报】第1834期 (2024-06-07)
社区日报 • Fred2000 发表了文章 • 0 个评论 • 3123 次浏览 • 2024-06-09 12:34
4月13日 OpenSearch Meetup:探索大模型时代下的 VectorDB
OpenSearch • liaosy 发表了文章 • 0 个评论 • 5314 次浏览 • 2024-04-10 10:08
在大模型席卷全球的行业背景下,基于检索结果增强的文本生成(RAG)备受关注。而作为 RAG 关键技术的向量数据库(VectorDB)正处在发展的十字路口。作为全球头部的 VectorDB 解决方案,OpenSearch 社区一直致力于前沿向量检索技术的研发。为了探讨 VectorDB 的发展趋势、应用场景、上下游技术生态,我们策划了这一场技术分享与线下见面会。希望可以给 VectorDB 玩家提供一个学习知识、结交朋友的平台。
在这场见面会中,我们会邀请来自于头部企业的向量检索技术研发专家、OpenSearch 社区的活跃贡献者以及一线人工智能科学家,来分享 VectorDB、大模型以及上下游相关技术的最新发展,以及对这个行业的未来的走向的见解。您将在这场会议中看到各个 VectorDB 头部企业的最新向量检索技术和产品,甚至有机会亲自作为用户去尝试。同时,我们还将举行圆桌讨论,您可以和各个相关行业的资深人士深入探讨 VectorDB 的未来,以及在这个行业中可能把握的机会。
时间:2024/04/13(周六) 14:00-18:30
地点:上海市长宁区新华路345弄4号楼 STOP SHOP(社友咖啡)
INIFINI Labs 议题推荐
《向量搜索基础设施 OpenSearch - 多集群管理的挑战与实践》By 曾嘉毅| INFINI Labs 联合创始人
摘要:数据规模不断增长和业务需求的多样化,推动了向量搜索技术的兴起。本次介绍聚焦于向量搜索的崛起和 OpenSearch 平台的能力,同时探讨业务数据集群发展趋势和常见挑战,包括管理多套集群、容量规划、监控、告警、治理、安全、开发、流量和排障等问题,提供解决方案和最佳实践。
活动整体议程
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。
OpenSearch 与 Elasticsearch:哪个开源搜索引擎适合您?
OpenSearch • Hansoph 发表了文章 • 1 个评论 • 4242 次浏览 • 2024-03-15 10:49
当谈论到搜索引擎产品时,Elasticsearch 和 OpenSearch 是两个备受关注的选择。它们都以其出色的功能和灵活性而闻名,但在一些方面存在一些差异。在本文中,我们将从功能和延展性、工具与资源、价格和许可这三个角度对这两个产品进行论述。通过深入研究它们的特点和优势,您将能够更好地了解它们,从而为您的搜索需求做出明智的选择。让我们开始探索 Elasticsearch 和 OpenSearch 的世界,以便您能够为自己的项目或业务找到最佳的搜索解决方案。
功能和延展性
Elasticsearch 是一个功能强大的搜索引擎,它支持全文搜索、实时数据分析、数据聚合和可视化等功能。
- 分布式架构:它使用分布式架构,可以处理大规模数据集,并以快速的速度返回查询结果。
- 多种查询类型和过滤器:提供多种查询类型和过滤器,使用户能够进行复杂的数据分析和检索。
- 高可用性和容错性:提供高可用性和容错性,通过复制和分片机制来确保数据的安全性和可靠性。
- 强大的插件生态系统:帮助用户处理映射、分析、脚本引擎和发现等任务。通过使用这些插件,用户可以根据其特定的数据处理和分析需求进行功能扩展和定制。
OpenSearch 是从 Elasticsearch 分叉出来的版本,因此在许多方面与 Elasticsearch 相似。它保留了 Elasticsearch 的核心功能,并加入了一些新的功能和扩展性。下面主要讨论一些差异点:
- 开源性和社区参与:OpenSearch 更注重开源性和社区参与,鼓励用户共同开发和改进系统。
- 功能差异:OpenSearch 提供了一些额外的免费功能,如集中用户账户/访问控制、交叉集群复制、IP 过滤、可配置的数据保留期、异常检测、Tableau 连接器、JDBC 驱动程序、ODBC 驱动程序以及回归和分类等机器学习功能。
- 插件生态系统差异:OpenSearch 中的某些功能作为插件捆绑在一起,需要用户额外学习和适应新工具。
服务与支持
Elasticsearch 拥有丰富的工具和资源,使用户能够更好地使用和管理搜索引擎。
- 配套工具:丰富的生态系统,Logstash 用于数据摄取和转换,可以帮助用户为非结构化数据添加结构,进行字段匿名处理,并解析 IP 地址以获取位置信息。Beats 是一个专注于数据传输的工具,可以将数据从数千台机器发送到 Logstash 或 Elasticsearch。
-
完善的文档资料和培训资源:
a. 官方网站提供了产品指南、教程视频、博客文章、讨论论坛等丰富的学习材料。
b. Elastic 还提供了 Slack 频道、YouTube 频道、以及定期举办的在线研讨会和培训活动,为用户提供即时的答疑和学习机会。
c. 广泛的支持服务,包括社区支持、商业支持和培训服务。
OpenSearch 配套工具延展性更好,但是在学习资料和用户培训方面存在大部分空白,目前的服务与支持模式主要依赖于社区。
-
配套工具:除去支持 Logstash 和 Beats 外,还有其他工具如 Fluentd、Fluent Bit、OpenTelemetry Collector 和 Data Prepper,来支持数据处理和传输。
-
文档资料和培训资源:
a. 文档资源:积极填补文档中的空白,并且每月举行两次社区会议,鼓励用户通过 GitHub 提交拉取请求、报告问题和提供反馈。
b. 合作伙伴:提供 OpenSearch 的咨询支持和托管服务,其中就包括 INFINI Labs 在内,通过这些合作伙伴,用户可以获取与 OpenSearch 相关的专业服务和咨询,以满足其特定需求。
OpenSearch 的学习资源和培训材料相对较少,相比之下,Elasticsearch 的学习资料更加丰富和全面。然而,OpenSearch 社区积极发展中,未来可能会有更多的学习资源和支持服务可用。
价格和许可
Elasticsearch 和 OpenSearch 在价格和许可方面也存在差异。本文将从紧急支持和许可限制两个角度进行分析。
Elasticsearch:
- 紧急支持:Elasticsearch 的高级许可证提供紧急支持,这意味着当出现集群崩溃、数据丢失或安全漏洞等问题时,公司能够提供即时的支持。
- 许可限制:Elasticsearch 提供基于订阅模型的商业许可,其中包括从免费的基本许可到高级许可的多个层次。高级许可提供了额外的功能和支持,适合对性能和功能有更高要求的企业。
Opensearch:
- 紧急支持:当前可以通过过第三方咨询公司或 AWS OpenSearch 等免费工具获得同样水平的支持,OpenSearch 有一个合作伙伴页面,列出了许多咨询公司,包括 INFINI Labs 的 OpenSearch 支持页面,他们提供 24 x 7 的支持。
- 许可限制:OpenSearch 是基于 Apache 2.0 许可的开源软件,允许用户自由使用、修改和分发。它提供了免费的功能和灵活的定制,使用户能够根据自己的需求进行自定义和扩展。
总结
Elasticsearch 和 OpenSearch 都是强大而灵活的搜索引擎产品,但是存在一些差异。
总体来说,Elasticsearch 是一个成熟、功能强大的搜索引擎,拥有广泛的插件生态系统和丰富的学习资源。商业版本提供额外的功能和支持服务,适合需要高级功能和专业支持的企业。
OpenSearch 是从 Elasticsearch 分叉出来的版本,保留了核心功能,并添加了一些额外的功能。它更注重开源性和社区参与,适合更倾向于自主开发和定制的用户。
作者的话
希望这些信息能为您提供有价值的帮助,并使您更好地了解 Elasticsearch 和 OpenSearch。无论您选择哪个搜索引擎,都希望它能满足您的需求并取得成功。
INFINI Labs 产品更新 | Easysearch 新增快照搜索功能,Console 支持 OpenSearch 存储
Easysearch • liaosy 发表了文章 • 0 个评论 • 3874 次浏览 • 2023-12-15 23:14
INFINI Labs 产品又更新啦~,包括 Easysearch v1.7.0、Console v1.13.0。本次各产品更新了 Easysearch 快照搜索功能;Console 支持 OpenSearch 集群存储系统数据、优化了初始化安装向导流程等。
以下是本次更新的详细说明。
INFINI Easysearch v1.7.0
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。
Easysearch 本次更新如下:
Features
发布快照搜索功能 Beta 版本,此功能旨在提高对已备份数据的使用效率。让用户利用对象存储(如 AWS S3、MinIO、Microsoft Azure Storage、Google Cloud Storage 等)技术来大幅降低存储成本。
Bug fix
- 修复单个节点场景下,从快照恢复多个 shard 的索引时,恢复不完整的问题
- 修复无法删除索引已关联的 ILM 策略问题
Improvements
- 初始化脚本优化,新增重复执行判断
INFINI Console v1.12.0
INFINI Console 是一款非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管, 企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 在线体验: http://demo.infini.cloud (用户名/密码:readonly/readonly)。
Console 本次更新如下:
Features
支持 OpenSearch 集群存储系统数据
Bug fix
- 优化初始化安装流程
- 新增探针初始化配置
- 安装向导,新增凭据检查功能
- 安装向导,新增管理员密码重置功能
- 探针管理,支持自动关联 Auto Enroll
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
您还可以通过邮件联系我们:hello@infini.ltd
或者拨打我们的热线电话:(+86) 400-139-9200
欢迎加入 Discord 聊天室:https://discord.gg/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
