


elasicsearch

multi_match+term的组合查询,能否提高term匹配的得分权重,让其排序在前面

Elasticsearch • laoyang360 回复了问题 • 3 人关注 • 2 个回复 • 6051 次浏览 • 2024-01-26 20:59

求助,ES对查询结果进行后置处理
Elasticsearch • laoyang360 回复了问题 • 3 人关注 • 2 个回复 • 4545 次浏览 • 2024-01-07 22:22

span_containing和span_with查询到底是什么意思?两者什么区别?
Elasticsearch • kennywu76 回复了问题 • 5 人关注 • 2 个回复 • 5014 次浏览 • 2023-09-08 16:14
es局部更新文档字段
Elasticsearch • duanxiaobiao 回复了问题 • 2 人关注 • 1 个回复 • 7300 次浏览 • 2023-04-02 15:39
ES 使用Join父子文档的方式能否一次查询,同时返回父文档和子文档的结果
Elasticsearch • laoyang360 回复了问题 • 2 人关注 • 1 个回复 • 8060 次浏览 • 2023-02-08 10:31

keyword类型的数字的大于小于查询
Elasticsearch • laoyang360 回复了问题 • 3 人关注 • 3 个回复 • 4320 次浏览 • 2022-05-29 15:02

elasticsearch疯狂的读磁盘是怎么回事?
Elasticsearch • pony_maggie 回复了问题 • 7 人关注 • 6 个回复 • 4720 次浏览 • 2020-12-03 12:35

索引某个shard无法恢复的问题

Elasticsearch • shwtz 回复了问题 • 15 人关注 • 5 个回复 • 27324 次浏览 • 2020-08-31 11:20

elasticsearch-6.2.2启动后CURL请求后报 master_not_discovered_exception错误
Elasticsearch • opewhgori 回复了问题 • 4 人关注 • 3 个回复 • 20414 次浏览 • 2020-08-16 11:45

删除index下type的mapping

Elasticsearch • dadaball 回复了问题 • 2 人关注 • 1 个回复 • 4396 次浏览 • 2020-05-26 16:16

关于数字.字母的匹配问题

Elasticsearch • sxwinter 回复了问题 • 5 人关注 • 6 个回复 • 6460 次浏览 • 2020-03-07 14:31

Elasticsearch安装报错:max size virtual memory is too low, increase to [unlimited]
Elasticsearch • damon10244201 回复了问题 • 3 人关注 • 2 个回复 • 11661 次浏览 • 2020-03-04 17:56

long类型的时间字段date_histogram,extended_bounds,min无效?

Elasticsearch • yetao 回复了问题 • 5 人关注 • 2 个回复 • 9638 次浏览 • 2020-01-01 14:38

修改Lucene源码,重新打包,替换elasticsearch中原有的Lucene-core.jar包,出现问题

Elasticsearch • Kalasearch 回复了问题 • 2 人关注 • 1 个回复 • 9625 次浏览 • 2019-12-29 04:06

elasticsearch索引生命周期管理
回复Elasticsearch • shaoyuwu 发起了问题 • 1 人关注 • 0 个回复 • 4096 次浏览 • 2019-12-24 20:48
2.查询条件加引号,查询处理的时候,会将引号内的查询关键字作为一个整体,重写为 phrase 查询;
索引:中国人民银行 -> 中国人民银行 中国人... 显示全部 »
2.查询条件加引号,查询处理的时候,会将引号内的查询关键字作为一个整体,重写为 phrase 查询;
索引:中国人民银行 -> 中国人民银行 中国人民 中国人 中国 国人人民银行 人民 银行 银 行
查询:"\"中国人 中国\""-> "中国人 中国 国人 中国" ,是一个Phrase查询。
关键点在于查询展开之后,附加了一个“中国”,这个中国是带有位置属性的(phrase),而在索引里面,是没有两个“中国”的,即需要保证先出现一个“中国人”,然后“中国”,再出现一个“国人”,再出现一个“中国”,所以命中不了,有 4 个term要出现,且满足一个大概的位置,当然,可以通过 slop 设置位置的跳跃。
你要是把索引数据改成:“中国人民银行 中国”,就能查出来。
50x75=[doc40,doc41,doc53,doc78... 显示全部 »
50x75=[doc40,doc41,doc53,doc78,doc99,...]", 表示50-75这个范围的数值包含在后面哪些文档列表里。由此“
50 OR 51 OR 52 ... OR 100”这样的范围查找,被优化成类似“50x75 OR 76x99 OR 100"这样的形式。 对于该算法的详细解释参考: https://blog.parse.ly/post/1691/lucene/
从ES5.0版本(Lucene 6.0)开始,对于数值型字段,改用了k-d tree这种数据结构编码。 改用这种数据结构以后,数值型数据的索引以及范围查找效率比之前用倒排编码的方式提高很多。参考: https://www.elastic.co/blog/lucene-points-6.0
POST /type/1/_update
{
"script" : "ctx._source.remove(\"name\")"
}
批量删除
[code]POST /type/... 显示全部 »
POST /type/1/_update
{
"script" : "ctx._source.remove(\"name\")"
}
批量删除
[code]POST /type/_update_by_query
{
"script" : "ctx._source.remove(\"name\")",
"query": {
"bool": {
"must":
}
}
}
删除mapping 里面的字段,目前还不支持,只能建立新的mapping了
20w每秒的写入量不算小,自己剋模拟不同量级的id重复情... 显示全部 »
20w每秒的写入量不算小,自己剋模拟不同量级的id重复情况,测试一下写入吞吐量,据此规划硬件资源。
如果retry_failed无法解决问题,可以尝试一下allocate_stale_primary,前提是需要知道这个shard的primary在哪个结点上。实在解决不了,又不想丢数据,还可以重启一下该结点,内存锁应该可以释放。
我们生产环境discovery.zen.ping_timeout用的默认的3s, 而discovery.zen.fd相关的几个参数设置如下:
ping_interval: 10s (默认1s)
ping_timeout: 60s (默认30)
ping_retries: 3 (等于默认值)
这些参数在我们的环境长期运行后验证基本是比较理想的。 只有负载最重的日志集群,在夜间做force merge的时候,因为某些shard过大(300 - 400GB), 大量的IO操作因为机器load过高,偶尔出现结点被误判脱离,然后马上又加回的现象。 虽然继续增大上面的几个参数可以减少误判的机会,但是如果真的有结点故障,将其剔除掉的周期又太长。 所以我们还是通过增加shard数量,限制shard的size来缓解forcemerge带来的压力,降低高负载结点被误判脱离的几率。
当cluster.routing.allocation.enable设置为"none"的时候,不会allocate任何UNASSIGNED状态的shard,但是有一个特例:
本地的因为重启而变成UNASSIGNED... 显示全部 »
当cluster.routing.allocation.enable设置为"none"的时候,不会allocate任何UNASSIGNED状态的shard,但是有一个特例:
本地的因为重启而变成UNASSIGNED状态的primary shard不受这个参数约束
怎么理解这个规则呢?举个例子吧。
假设集群索引都有设置复制片,然后重启了某一个结点,该结点上的shard会经历下面这个过程:
replica变成UNASSIGNED
primary在其他结点上对应的replica被推举为primary,而本地的这些primary变成replica,并且状态变成UNASSIGNED
由于cluster.routing.allocation.enable设置为none, 这些replica不会再其他结点上复制恢复,保持在UNASSIGNED状态
因此集群状态应该是yellow,意味着所有索引的primary都存在可用,只是部分复制片因为上述参数设置的原因,没有立即进行恢复。
重启的结点加入集群,通过master恢复状态信息以后,可以得知那些UNASSIGNED的shard,在这个结点上存在数据。
重新设置cluster.routing.allocation.enable" : "all" ,master得到指令,开始恢复那些UNASSIGNED的shard
对于不再更新的冷shard,由于synced_flush, master知道这些数据在重启的结点上存在并且和primary一致,只需要更新一下集群的状态,将他们allocate到刚启动的结点,并且状态置为started。所以这个过程非常快,看起来瞬间可以完成。
由于集群持续有数据写入,部分primary由于新写入了数据,重启结点上对应的replica已经out of sync,因此需要进入数据的recovery过程,这个过程可能需要在主副片之间拷贝数据,或者利用translog重放热数据。 该过程取决于shard大小,以及实时数据写入量的大小,需要一些时间,可能几分钟到几个小时,直到primary -replica完全in-sync,才会将replica置为started。
如果同时重启2个或者更多结点,会是怎样的?
这种情况下,有可能某个shard的primary和replica同时变成UNASSIGNED了,集群状态变成red。 如果结点重启好全部加入集群,即使cluster.routing.allocation.enable设置为none,本地的primary shard因为不受这个参数约束,会立即开始做existing_store类别的恢复。 等全部primary恢复好以后,集群状态变成yellow,然后不再继续恢复replica,直到重新设置cluster.routing.allocation.enable为all。
所以,cluster.routing.allocation.enable: "none",实际上影响的是已有索引(local存在)的replica,以及新创建索引的primary和replica。
至于停掉结点后,集群查询延迟增加,是因为重启结点上的查询会由剩余的结点分担,多少延迟会增加一些。
multi_match+term的组合查询,能否提高term匹配的得分权重,让其排序在前面
回复Elasticsearch • laoyang360 回复了问题 • 3 人关注 • 2 个回复 • 6051 次浏览 • 2024-01-26 20:59
span_containing和span_with查询到底是什么意思?两者什么区别?
回复Elasticsearch • kennywu76 回复了问题 • 5 人关注 • 2 个回复 • 5014 次浏览 • 2023-09-08 16:14
ES 使用Join父子文档的方式能否一次查询,同时返回父文档和子文档的结果
回复Elasticsearch • laoyang360 回复了问题 • 2 人关注 • 1 个回复 • 8060 次浏览 • 2023-02-08 10:31
keyword类型的数字的大于小于查询
回复Elasticsearch • laoyang360 回复了问题 • 3 人关注 • 3 个回复 • 4320 次浏览 • 2022-05-29 15:02
elasticsearch疯狂的读磁盘是怎么回事?
回复Elasticsearch • pony_maggie 回复了问题 • 7 人关注 • 6 个回复 • 4720 次浏览 • 2020-12-03 12:35
elasticsearch-6.2.2启动后CURL请求后报 master_not_discovered_exception错误
回复Elasticsearch • opewhgori 回复了问题 • 4 人关注 • 3 个回复 • 20414 次浏览 • 2020-08-16 11:45
删除index下type的mapping
回复Elasticsearch • dadaball 回复了问题 • 2 人关注 • 1 个回复 • 4396 次浏览 • 2020-05-26 16:16
Elasticsearch安装报错:max size virtual memory is too low, increase to [unlimited]
回复Elasticsearch • damon10244201 回复了问题 • 3 人关注 • 2 个回复 • 11661 次浏览 • 2020-03-04 17:56
long类型的时间字段date_histogram,extended_bounds,min无效?
回复Elasticsearch • yetao 回复了问题 • 5 人关注 • 2 个回复 • 9638 次浏览 • 2020-01-01 14:38
修改Lucene源码,重新打包,替换elasticsearch中原有的Lucene-core.jar包,出现问题
回复Elasticsearch • Kalasearch 回复了问题 • 2 人关注 • 1 个回复 • 9625 次浏览 • 2019-12-29 04:06
elasticsearch索引生命周期管理
回复Elasticsearch • shaoyuwu 发起了问题 • 1 人关注 • 0 个回复 • 4096 次浏览 • 2019-12-24 20:48
如何解决ES的性能问题
Elasticsearch • sterne vencel 发表了文章 • 0 个评论 • 18014 次浏览 • 2018-07-10 21:56




[TIMESTAMP] ... Cluster health status changed from [GREEN] to [RED]
curl -XPUT "localhost:9200/blog_index" -d '
{
"mappings": {
"blogger": {
"_routing": {
"required": true
}
}
}
}'curl -XPUT "localhost:9200/blog_index/blogger/1?routing=blogger1" -d '
{
"comment": "blogger1 made this cool comment"
}'curl -XGET "localhost:9200/blog_index/_search?routing=blogger1" -d '
{
"query": {
"match": {
"comment": {
"query": "cool comment"
}
}
}
}'
社区日报 第323期 (2018-07-05)
社区日报 • sterne vencel 发表了文章 • 0 个评论 • 2803 次浏览 • 2018-07-05 09:34

_validate/query?explain解释
Elasticsearch • hnj1575565068 发表了文章 • 0 个评论 • 3430 次浏览 • 2018-04-24 10:33

php的操作类库,通过写sql来转化dsl来查询elasticsearch
Elasticsearch • qieangel2013 发表了文章 • 1 个评论 • 6930 次浏览 • 2018-03-21 15:44
EsParser
php的操作类库,通过写sql来转化dsl来查询elasticsearch
composer使用
{
"require": {
"qieangel2013/esparser": "dev-master"
}
}
composer install
require __DIR__.'/vendor/autoload.php';
$sql = 'select * from alp_dish_sales_saas where sid in(994,290) limit 1,10';
//$sql='update alp_dish_sales_saas set mid=3 where adsid=15125110';
//$sql='delete from alp_dish_sales_saas where adsid=15546509';
$es_config=array(
'index' =>"alp_dish_sales_saas",
'type' =>"alp_dish_sales_saas",
'url' =>"http://127.0.0.1:9200",
'version' =>"5.x" //1.x 2.x 5.x 6.x,可以不配置,系统会请求获取版本,这样会多一次请求,建议配置一下
);
$parser = new EsParser($sql, true,$es_config);//第三个参数是es的配置参数,一定要配置
print_r($parser->result);//打印结果
//print_r($parser->explain());//打印dsl普通调用
require_once dirname(__FILE__) . '/src/library/EsParser.php';
$sql = 'select * from alp_dish_sales_saas where sid in(994,290) limit 1,10';
//$sql='update alp_dish_sales_saas set mid=3 where adsid=15125110';
//$sql='delete from alp_dish_sales_saas where adsid=15546509';
$es_config=array(
'index' =>"alp_dish_sales_saas",
'type' =>"alp_dish_sales_saas",
'url' =>"http://127.0.0.1:9200",
'version' =>"5.x" //1.x 2.x 5.x 6.x,可以不配置,系统会请求获取版本,这样会多一次请求,建议配置一下
);
$parser = new EsParser($sql, true,$es_config);//第三个参数是es的配置参数,一定要配置
print_r($parser->result);//打印结果
//print_r($parser->explain()); //打印dsl目前支持的sql函数
* SQL Select
* SQL Delete
* SQL Update
* SQL Where
* SQL Order By
* SQL Group By
* SQL AND & OR
* SQL Like
* SQL COUNT distinct
* SQL In
* SQL avg()
* SQL count()
* SQL max()
* SQL min()
* SQL sum()
* SQL Between
* SQL Aliases使用注意事项
请在配置项填写es的版本,这样系统不会请求获取版本,这样不会多一次请求,建议配置一下交流使用
qq群:578276199项目地址
github:https://github.com/qieangel2013/EsParser
oschina:https://gitee.com/qieangel2013/EsParserelasticsearch参考手册 (译文)
Elasticsearch • code4j 发表了文章 • 2 个评论 • 7648 次浏览 • 2018-03-14 00:29

java 客户端 获取 termvectors
Elasticsearch • JiaShiwen 发表了文章 • 0 个评论 • 6057 次浏览 • 2018-01-19 15:56
elasticsearch的termvectors包括了term的位置、词频等信息。这些信息用于相应的数据统计或开发其他功能,本文介绍termvecters如何使用,如何通过java客户端获取termvectors相关信息。
要使用termvctor首先要配置mapping中field的"term_vector"属性,默认状态es不开启termvector,因为这样会增加索引的体积,毕竟多存了不少元数据。
PUT test
{
"mappings": {
"qa_test": {
"dynamic": "strict",
"_all": {
"enabled": false
},
"properties": {
"question": {
"properties": {
"cate": {
"type": "keyword"
},
"desc": {
"type": "text",
"store": true,
"term_vector": "with_positions_offsets_payloads",
"analyzer": "ik_smart"
},
"time": {
"type": "date",
"store": true,
"format": "strict_date_optional_time||epoch_millis||yyyy-MM-dd HH:mm:ss"
},
"title": {
"type": "text",
"store": true,
"term_vector": "with_positions_offsets_payloads",
"analyzer": "ik_smart"
}
}
},
"updatetime": {
"type": "date",
"store": true,
"format": "strict_date_optional_time||epoch_millis||yyyy-MM-dd HH:mm:ss"
}
}
}
},
"settings": {
"index": {
"number_of_shards": "1",
"requests": {
"cache": {
"enable": "true"
}
},
"number_of_replicas": "1"
}
}
}注意示例中的"title"的"term_vector"属性。
接下来为索引创建一条数据
PUT qa_test_02/qa_test/1
{
"question": {
"cate": [
"装修流程",
"其它"
],
"desc": "筒灯,大洋和索正这两个牌子,哪个好?希望内行的朋友告知一下,谢谢!",
"time": "2016-07-02 19:59:00",
"title": "筒灯大洋和索正这两个牌子哪个好"
},
"updatetime": 1467503940000
}下面我们看看这条数据上question.title字段的termvector信息
GET qa_test_02/qa_test/1/_termvectors
{
"fields": [
"question.title"
],
"offsets": true,
"payloads": true,
"positions": true,
"term_statistics": true,
"field_statistics": true
}结果大概这个样子
{
"_index": "qa_test_02",
"_type": "qa_test",
"_id": "1",
"_version": 1,
"found": true,
"took": 0,
"term_vectors": {
"question.title": {
"field_statistics": {
"sum_doc_freq": 9,
"doc_count": 1,
"sum_ttf": 9
},
"terms": {
"和": {
"doc_freq": 1,
"ttf": 1,
"term_freq": 1,
"tokens": [
{
"position": 2,
"start_offset": 4,
"end_offset": 5
}
]
},
"哪个": {
"doc_freq": 1,
"ttf": 1,
"term_freq": 1,
"tokens": [
{
"position": 7,
"start_offset": 12,
"end_offset": 14
}
]
},
"大洋": {
"doc_freq": 1,
"ttf": 1,
"term_freq": 1,
"tokens": [
{
"position": 1,
"start_offset": 2,
"end_offset": 4
}
]
},
"好": {
"doc_freq": 1,
"ttf": 1,
"term_freq": 1,
"tokens": [
{
"position": 8,
"start_offset": 14,
"end_offset": 15
}
]
},
"正": {
"doc_freq": 1,
"ttf": 1,
"term_freq": 1,
"tokens": [
{
"position": 4,
"start_offset": 6,
"end_offset": 7
}
]
},
"牌子": {
"doc_freq": 1,
"ttf": 1,
"term_freq": 1,
"tokens": [
{
"position": 6,
"start_offset": 10,
"end_offset": 12
}
]
},
"筒灯": {
"doc_freq": 1,
"ttf": 1,
"term_freq": 1,
"tokens": [
{
"position": 0,
"start_offset": 0,
"end_offset": 2
}
]
},
"索": {
"doc_freq": 1,
"ttf": 1,
"term_freq": 1,
"tokens": [
{
"position": 3,
"start_offset": 5,
"end_offset": 6
}
]
},
"这两个": {
"doc_freq": 1,
"ttf": 1,
"term_freq": 1,
"tokens": [
{
"position": 5,
"start_offset": 7,
"end_offset": 10
}
]
}
}
}
}
}下面我们说说如何通过java代码实现termvector的获取,不说废话直接上代码
TermVectorsResponse termVectorResponse = client.prepareTermVectors().setIndex(sourceindexname).setType(sourceindextype)
.setId(id).setSelectedFields(fieldname).setTermStatistics(true).execute()
.actionGet();
XContentBuilder builder = XContentFactory.contentBuilder(XContentType.JSON);
termVectorResponse.toXContent(builder, null);
System.out.println(builder.string());
Fields fields = termVectorResponse.getFields();
Iterator<String> iterator = fields.iterator();
while (iterator.hasNext()) {
String field = iterator.next();
Terms terms = fields.terms(field);
TermsEnum termsEnum = terms.iterator();
while (termsEnum.next() != null) {
BytesRef term = termsEnum.term();
if (term != null) {
System.out.println(term.utf8ToString() + termsEnum.totalTermFreq());
}
}
}
获取TermVectorsResponse的代码很好理解,主要是设置索引名称、索引type、索引id以及需要展示的若干属性。
接下来是如何获取某一term的termvector,有两种方案第一种是通过TermVectorsResponse的toXContent方法直接生成XContentBuilder,这种方法可以直接获取和上面通过DSL查询一样的json结果;第二种是通过Fields的iterator遍历fields,获取TermsEnum,熟悉lucene的同学应会更熟悉第二种方法。

elasticsearch批量导入数据注意事项
Elasticsearch • wj86611199 发表了文章 • 0 个评论 • 12651 次浏览 • 2017-12-16 23:55

Elasticsearch 5.6 Java API 中文手册
Elasticsearch • quanke 发表了文章 • 1 个评论 • 27691 次浏览 • 2017-11-08 22:30


ElasticSearch 集群监控
Elasticsearch • zhisheng 发表了文章 • 3 个评论 • 11945 次浏览 • 2017-11-07 00:41
原文地址:http://www.54tianzhisheng.cn/2017/10/15/ElasticSearch-cluster-health-metrics/

最近在做 ElasticSearch 的信息(集群和节点)监控,特此稍微整理下学到的东西。这篇文章主要介绍集群的监控。
要监控哪些 ElasticSearch metrics
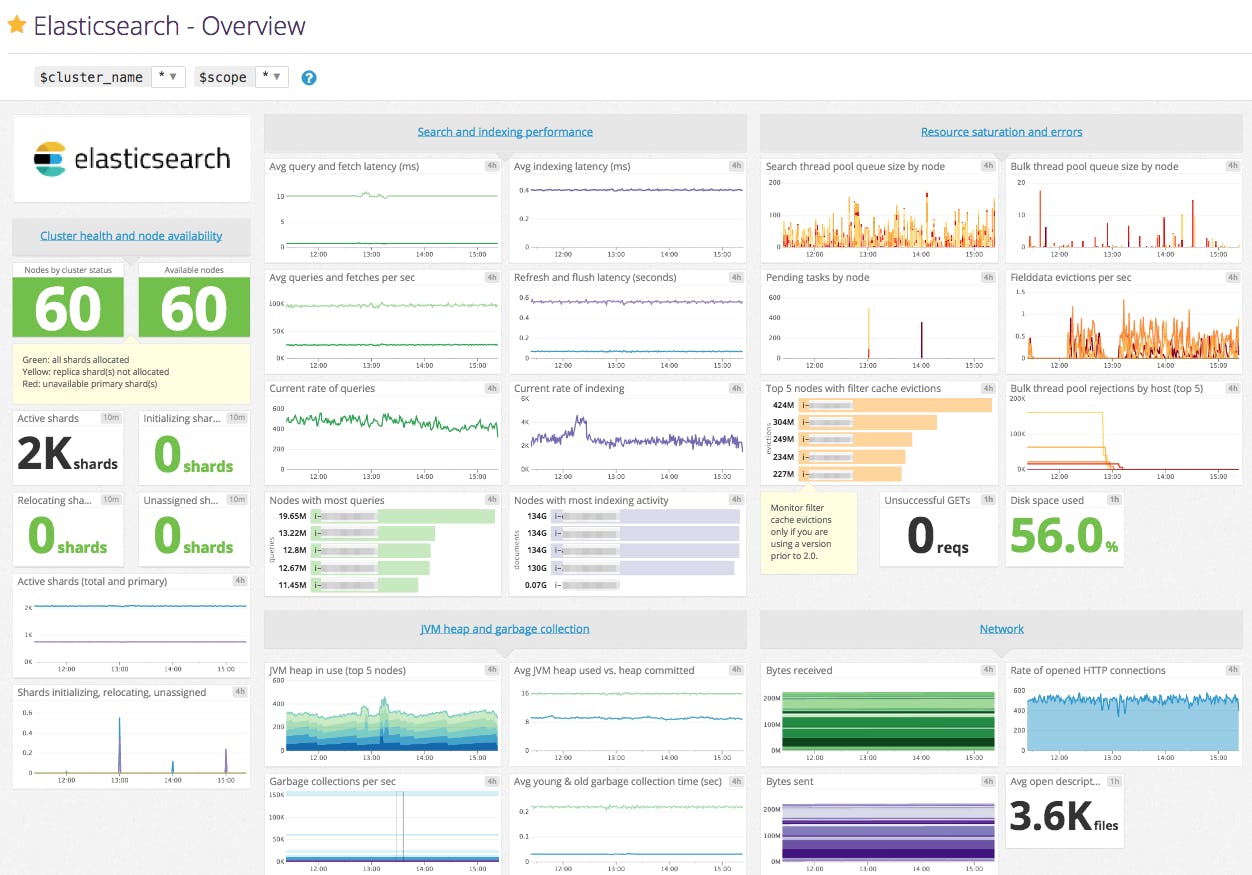
Elasticsearch 提供了大量的 Metric,可以帮助您检测到问题的迹象,在遇到节点不可用、out-of-memory、long garbage collection times 的时候采取相应措施。但是指标太多了,有时我们并不需要这么多,这就需要我们进行筛选。
集群健康
一个 Elasticsearch 集群至少包括一个节点和一个索引。或者它 可能有一百个数据节点、三个单独的主节点,以及一小打客户端节点——这些共同操作一千个索引(以及上万个分片)。
不管集群扩展到多大规模,你都会想要一个快速获取集群状态的途径。Cluster Health API 充当的就是这个角色。你可以把它想象成是在一万英尺的高度鸟瞰集群。它可以告诉你安心吧一切都好,或者警告你集群某个地方有问题。
让我们执行一下 cluster-health API 然后看看响应体是什么样子的:
GET _cluster/health和 Elasticsearch 里其他 API 一样,cluster-health 会返回一个 JSON 响应。这对自动化和告警系统来说,非常便于解析。响应中包含了和你集群有关的一些关键信息:
{
"cluster_name": "elasticsearch_zach",
"status": "green",
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 10,
"active_shards": 10,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0
}响应信息中最重要的一块就是 status 字段。状态可能是下列三个值之一 :
| status | 含义 |
|---|---|
| green | 所有的主分片和副本分片都已分配。你的集群是 100% 可用的。 |
| yellow | 所有的主分片已经分片了,但至少还有一个副本是缺失的。不会有数据丢失,所以搜索结果依然是完整的。不过,你的高可用性在某种程度上被弱化。如果 更多的 分片消失,你就会丢数据了。把 yellow 想象成一个需要及时调查的警告。 |
| red | 至少一个主分片(以及它的全部副本)都在缺失中。这意味着你在缺少数据:搜索只能返回部分数据,而分配到这个分片上的写入请求会返回一个异常。 |
number_of_nodes和number_of_data_nodes这个命名完全是自描述的。active_primary_shards指出你集群中的主分片数量。这是涵盖了所有索引的汇总值。active_shards是涵盖了所有索引的所有分片的汇总值,即包括副本分片。relocating_shards显示当前正在从一个节点迁往其他节点的分片的数量。通常来说应该是 0,不过在 Elasticsearch 发现集群不太均衡时,该值会上涨。比如说:添加了一个新节点,或者下线了一个节点。initializing_shards是刚刚创建的分片的个数。比如,当你刚创建第一个索引,分片都会短暂的处于initializing状态。这通常会是一个临时事件,分片不应该长期停留在initializing状态。你还可能在节点刚重启的时候看到initializing分片:当分片从磁盘上加载后,它们会从initializing状态开始。unassigned_shards是已经在集群状态中存在的分片,但是实际在集群里又找不着。通常未分配分片的来源是未分配的副本。比如,一个有 5 分片和 1 副本的索引,在单节点集群上,就会有 5 个未分配副本分片。如果你的集群是red状态,也会长期保有未分配分片(因为缺少主分片)。
集群统计
集群统计信息包含 集群的分片数,文档数,存储空间,缓存信息,内存作用率,插件内容,文件系统内容,JVM 作用状况,系统 CPU,OS 信息,段信息。
查看全部统计信息命令:
curl -XGET 'http://localhost:9200/_cluster/stats?human&pretty'返回 JSON 结果:
{
"timestamp": 1459427693515,
"cluster_name": "elasticsearch",
"status": "green",
"indices": {
"count": 2,
"shards": {
"total": 10,
"primaries": 10,
"replication": 0,
"index": {
"shards": {
"min": 5,
"max": 5,
"avg": 5
},
"primaries": {
"min": 5,
"max": 5,
"avg": 5
},
"replication": {
"min": 0,
"max": 0,
"avg": 0
}
}
},
"docs": {
"count": 10,
"deleted": 0
},
"store": {
"size": "16.2kb",
"size_in_bytes": 16684,
"throttle_time": "0s",
"throttle_time_in_millis": 0
},
"fielddata": {
"memory_size": "0b",
"memory_size_in_bytes": 0,
"evictions": 0
},
"query_cache": {
"memory_size": "0b",
"memory_size_in_bytes": 0,
"total_count": 0,
"hit_count": 0,
"miss_count": 0,
"cache_size": 0,
"cache_count": 0,
"evictions": 0
},
"completion": {
"size": "0b",
"size_in_bytes": 0
},
"segments": {
"count": 4,
"memory": "8.6kb",
"memory_in_bytes": 8898,
"terms_memory": "6.3kb",
"terms_memory_in_bytes": 6522,
"stored_fields_memory": "1.2kb",
"stored_fields_memory_in_bytes": 1248,
"term_vectors_memory": "0b",
"term_vectors_memory_in_bytes": 0,
"norms_memory": "384b",
"norms_memory_in_bytes": 384,
"doc_values_memory": "744b",
"doc_values_memory_in_bytes": 744,
"index_writer_memory": "0b",
"index_writer_memory_in_bytes": 0,
"version_map_memory": "0b",
"version_map_memory_in_bytes": 0,
"fixed_bit_set": "0b",
"fixed_bit_set_memory_in_bytes": 0,
"file_sizes": {}
},
"percolator": {
"num_queries": 0
}
},
"nodes": {
"count": {
"total": 1,
"data": 1,
"coordinating_only": 0,
"master": 1,
"ingest": 1
},
"versions": [
"5.6.3"
],
"os": {
"available_processors": 8,
"allocated_processors": 8,
"names": [
{
"name": "Mac OS X",
"count": 1
}
],
"mem" : {
"total" : "16gb",
"total_in_bytes" : 17179869184,
"free" : "78.1mb",
"free_in_bytes" : 81960960,
"used" : "15.9gb",
"used_in_bytes" : 17097908224,
"free_percent" : 0,
"used_percent" : 100
}
},
"process": {
"cpu": {
"percent": 9
},
"open_file_descriptors": {
"min": 268,
"max": 268,
"avg": 268
}
},
"jvm": {
"max_uptime": "13.7s",
"max_uptime_in_millis": 13737,
"versions": [
{
"version": "1.8.0_74",
"vm_name": "Java HotSpot(TM) 64-Bit Server VM",
"vm_version": "25.74-b02",
"vm_vendor": "Oracle Corporation",
"count": 1
}
],
"mem": {
"heap_used": "57.5mb",
"heap_used_in_bytes": 60312664,
"heap_max": "989.8mb",
"heap_max_in_bytes": 1037959168
},
"threads": 90
},
"fs": {
"total": "200.6gb",
"total_in_bytes": 215429193728,
"free": "32.6gb",
"free_in_bytes": 35064553472,
"available": "32.4gb",
"available_in_bytes": 34802409472
},
"plugins": [
{
"name": "analysis-icu",
"version": "5.6.3",
"description": "The ICU Analysis plugin integrates Lucene ICU module into elasticsearch, adding ICU relates analysis components.",
"classname": "org.elasticsearch.plugin.analysis.icu.AnalysisICUPlugin",
"has_native_controller": false
},
{
"name": "ingest-geoip",
"version": "5.6.3",
"description": "Ingest processor that uses looksup geo data based on ip adresses using the Maxmind geo database",
"classname": "org.elasticsearch.ingest.geoip.IngestGeoIpPlugin",
"has_native_controller": false
},
{
"name": "ingest-user-agent",
"version": "5.6.3",
"description": "Ingest processor that extracts information from a user agent",
"classname": "org.elasticsearch.ingest.useragent.IngestUserAgentPlugin",
"has_native_controller": false
}
]
}
}内存使用和 GC 指标
在运行 Elasticsearch 时,内存是您要密切监控的关键资源之一。 Elasticsearch 和 Lucene 以两种方式利用节点上的所有可用 RAM:JVM heap 和文件系统缓存。 Elasticsearch 运行在Java虚拟机(JVM)中,这意味着JVM垃圾回收的持续时间和频率将成为其他重要的监控领域。
上面返回的 JSON监控的指标有我个人觉得有这些:
- nodes.successful
- nodes.failed
- nodes.total
- nodes.mem.used_percent
- nodes.process.cpu.percent
- nodes.jvm.mem.heap_used
可以看到 JSON 文件是很复杂的,如果从这复杂的 JSON 中获取到对应的指标(key)的值呢,这里请看文章 :JsonPath —— JSON 解析神器
最后
这里主要讲下 ES 集群的一些监控信息,有些监控指标是个人觉得需要监控的,但是具体情况还是得看需求了。下篇文章主要讲节点的监控信息。转载请注明地址:http://www.54tianzhisheng.cn/2017/10/15/ElasticSearch-cluster-health-metrics/
参考资料
1、How to monitor Elasticsearch performance
相关阅读
ElasticSearch 单个节点监控
Elasticsearch • zhisheng 发表了文章 • 1 个评论 • 5229 次浏览 • 2017-11-07 00:39
原文地址:http://www.54tianzhisheng.cn/2017/10/18/ElasticSearch-nodes-metrics/

集群健康监控是对集群信息进行高度的概括,节点统计值 API 提供了集群中每个节点的统计值。节点统计值很多,在监控的时候仍需要我们清楚哪些指标是最值得关注的。
集群健康监控可以参考这篇文章:ElasticSearch 集群监控
节点信息 Node Info :
curl -XGET 'http://localhost:9200/_nodes'执行上述命令可以获取所有 node 的信息
_nodes: {
total: 2,
successful: 2,
failed: 0
},
cluster_name: "elasticsearch",
nodes: {
MSQ_CZ7mTNyOSlYIfrvHag: {
name: "node0",
transport_address: "192.168.180.110:9300",
host: "192.168.180.110",
ip: "192.168.180.110",
version: "5.5.0",
build_hash: "260387d",
total_indexing_buffer: 103887667,
roles:{...},
settings: {...},
os: {
refresh_interval_in_millis: 1000,
name: "Linux",
arch: "amd64",
version: "3.10.0-229.el7.x86_64",
available_processors: 4,
allocated_processors: 4
},
process: {
refresh_interval_in_millis: 1000,
id: 3022,
mlockall: false
},
jvm: {
pid: 3022,
version: "1.8.0_121",
vm_name: "Java HotSpot(TM) 64-Bit Server VM",
vm_version: "25.121-b13",
vm_vendor: "Oracle Corporation",
start_time_in_millis: 1507515225302,
mem: {
heap_init_in_bytes: 1073741824,
heap_max_in_bytes: 1038876672,
non_heap_init_in_bytes: 2555904,
non_heap_max_in_bytes: 0,
direct_max_in_bytes: 1038876672
},
gc_collectors: [],
memory_pools: [],
using_compressed_ordinary_object_pointers: "true",
input_arguments:{}
}
thread_pool:{
force_merge: {},
fetch_shard_started: {},
listener: {},
index: {},
refresh: {},
generic: {},
warmer: {},
search: {},
flush: {},
fetch_shard_store: {},
management: {},
get: {},
bulk: {},
snapshot: {}
}
transport: {...},
http: {...},
plugins: [],
modules: [],
ingest: {...}
}上面是我已经简写了很多数据之后的返回值,但是指标还是很多,有些是一些常规的指标,对于监控来说,没必要拿取。从上面我们可以主要关注以下这些指标:
os, process, jvm, thread_pool, transport, http, ingest and indices节点统计 nodes-statistics
节点统计值 API 可通过如下命令获取:
GET /_nodes/stats得到:
_nodes: {
total: 2,
successful: 2,
failed: 0
},
cluster_name: "elasticsearch",
nodes: {
MSQ_CZ7mTNyOSlYI0yvHag: {
timestamp: 1508312932354,
name: "node0",
transport_address: "192.168.180.110:9300",
host: "192.168.180.110",
ip: "192.168.180.110:9300",
roles: [],
indices: {
docs: {
count: 6163666,
deleted: 0
},
store: {
size_in_bytes: 2301398179,
throttle_time_in_millis: 122850
},
indexing: {},
get: {},
search: {},
merges: {},
refresh: {},
flush: {},
warmer: {},
query_cache: {},
fielddata: {},
completion: {},
segments: {},
translog: {},
request_cache: {},
recovery: {}
},
os: {
timestamp: 1508312932369,
cpu: {
percent: 0,
load_average: {
1m: 0.09,
5m: 0.12,
15m: 0.08
}
},
mem: {
total_in_bytes: 8358301696,
free_in_bytes: 1381613568,
used_in_bytes: 6976688128,
free_percent: 17,
used_percent: 83
},
swap: {
total_in_bytes: 8455712768,
free_in_bytes: 8455299072,
used_in_bytes: 413696
},
cgroup: {
cpuacct: {},
cpu: {
control_group: "/user.slice",
cfs_period_micros: 100000,
cfs_quota_micros: -1,
stat: {}
}
}
},
process: {
timestamp: 1508312932369,
open_file_descriptors: 228,
max_file_descriptors: 65536,
cpu: {
percent: 0,
total_in_millis: 2495040
},
mem: {
total_virtual_in_bytes: 5002465280
}
},
jvm: {
timestamp: 1508312932369,
uptime_in_millis: 797735804,
mem: {
heap_used_in_bytes: 318233768,
heap_used_percent: 30,
heap_committed_in_bytes: 1038876672,
heap_max_in_bytes: 1038876672,
non_heap_used_in_bytes: 102379784,
non_heap_committed_in_bytes: 108773376,
pools: {
young: {
used_in_bytes: 62375176,
max_in_bytes: 279183360,
peak_used_in_bytes: 279183360,
peak_max_in_bytes: 279183360
},
survivor: {
used_in_bytes: 175384,
max_in_bytes: 34865152,
peak_used_in_bytes: 34865152,
peak_max_in_bytes: 34865152
},
old: {
used_in_bytes: 255683208,
max_in_bytes: 724828160,
peak_used_in_bytes: 255683208,
peak_max_in_bytes: 724828160
}
}
},
threads: {},
gc: {},
buffer_pools: {},
classes: {}
},
thread_pool: {
bulk: {},
fetch_shard_started: {},
fetch_shard_store: {},
flush: {},
force_merge: {},
generic: {},
get: {},
index: {
threads: 1,
queue: 0,
active: 0,
rejected: 0,
largest: 1,
completed: 1
}
listener: {},
management: {},
refresh: {},
search: {},
snapshot: {},
warmer: {}
},
fs: {},
transport: {
server_open: 13,
rx_count: 11696,
rx_size_in_bytes: 1525774,
tx_count: 10282,
tx_size_in_bytes: 1440101928
},
http: {
current_open: 4,
total_opened: 23
},
breakers: {},
script: {},
discovery: {},
ingest: {}
}节点名是一个 UUID,上面列举了很多指标,下面讲解下:
索引部分 indices
这部分列出了这个节点上所有索引的聚合过的统计值 :
-
docs展示节点内存有多少文档,包括还没有从段里清除的已删除文档数量。 -
store部分显示节点耗用了多少物理存储。这个指标包括主分片和副本分片在内。如果限流时间很大,那可能表明你的磁盘限流设置得过低。 indexing显示已经索引了多少文档。这个值是一个累加计数器。在文档被删除的时候,数值不会下降。还要注意的是,在发生内部 索引操作的时候,这个值也会增加,比如说文档更新。
还列出了索引操作耗费的时间,正在索引的文档数量,以及删除操作的类似统计值。
-
get显示通过 ID 获取文档的接口相关的统计值。包括对单个文档的GET和HEAD请求。 search描述在活跃中的搜索(open_contexts)数量、查询的总数量、以及自节点启动以来在查询上消耗的总时间。用query_time_in_millis / query_total计算的比值,可以用来粗略的评价你的查询有多高效。比值越大,每个查询花费的时间越多,你应该要考虑调优了。
fetch 统计值展示了查询处理的后一半流程(query-then-fetch 里的 fetch )。如果 fetch 耗时比 query 还多,说明磁盘较慢,或者获取了太多文档,或者可能搜索请求设置了太大的分页(比如, size: 10000 )。
-
merges包括了 Lucene 段合并相关的信息。它会告诉你目前在运行几个合并,合并涉及的文档数量,正在合并的段的总大小,以及在合并操作上消耗的总时间。 filter_cache展示了已缓存的过滤器位集合所用的内存数量,以及过滤器被驱逐出内存的次数。过多的驱逐数 可能 说明你需要加大过滤器缓存的大小,或者你的过滤器不太适合缓存(比如它们因为高基数而在大量产生,就像是缓存一个now时间表达式)。
不过,驱逐数是一个很难评定的指标。过滤器是在每个段的基础上缓存的,而从一个小的段里驱逐过滤器,代价比从一个大的段里要廉价的多。有可能你有很大的驱逐数,但是它们都发生在小段上,也就意味着这些对查询性能只有很小的影响。
把驱逐数指标作为一个粗略的参考。如果你看到数字很大,检查一下你的过滤器,确保他们都是正常缓存的。不断驱逐着的过滤器,哪怕都发生在很小的段上,效果也比正确缓存住了的过滤器差很多。
-
field_data显示 fielddata 使用的内存, 用以聚合、排序等等。这里也有一个驱逐计数。和filter_cache不同的是,这里的驱逐计数是很有用的:这个数应该或者至少是接近于 0。因为 fielddata 不是缓存,任何驱逐都消耗巨大,应该避免掉。如果你在这里看到驱逐数,你需要重新评估你的内存情况,fielddata 限制,请求语句,或者这三者。 segments会展示这个节点目前正在服务中的 Lucene 段的数量。 这是一个重要的数字。大多数索引会有大概 50–150 个段,哪怕它们存有 TB 级别的数十亿条文档。段数量过大表明合并出现了问题(比如,合并速度跟不上段的创建)。注意这个统计值是节点上所有索引的汇聚总数。记住这点。
memory 统计值展示了 Lucene 段自己用掉的内存大小。 这里包括底层数据结构,比如倒排表,字典,和布隆过滤器等。太大的段数量会增加这些数据结构带来的开销,这个内存使用量就是一个方便用来衡量开销的度量值。
操作系统和进程部分
OS 和 Process 部分基本是自描述的,不会在细节中展开讲解。它们列出来基础的资源统计值,比如 CPU 和负载。OS 部分描述了整个操作系统,而 Process 部分只显示 Elasticsearch 的 JVM 进程使用的资源情况。
这些都是非常有用的指标,不过通常在你的监控技术栈里已经都测量好了。统计值包括下面这些:
- CPU
- 负载
- 内存使用率 (mem.used_percent)
- Swap 使用率
- 打开的文件描述符 (open_file_descriptors)
JVM 部分
jvm 部分包括了运行 Elasticsearch 的 JVM 进程一些很关键的信息。 最重要的,它包括了垃圾回收的细节,这对你的 Elasticsearch 集群的稳定性有着重大影响。
jvm: {
timestamp: 1508312932369,
uptime_in_millis: 797735804,
mem: {
heap_used_in_bytes: 318233768,
heap_used_percent: 30,
heap_committed_in_bytes: 1038876672,
heap_max_in_bytes: 1038876672,
non_heap_used_in_bytes: 102379784,
non_heap_committed_in_bytes: 108773376,
}
}jvm 部分首先列出一些和 heap 内存使用有关的常见统计值。你可以看到有多少 heap 被使用了,多少被指派了(当前被分配给进程的),以及 heap 被允许分配的最大值。理想情况下,heap_committed_in_bytes 应该等于 heap_max_in_bytes 。如果指派的大小更小,JVM 最终会被迫调整 heap 大小——这是一个非常昂贵的操作。如果你的数字不相等,阅读 堆内存:大小和交换 学习如何正确的配置它。
heap_used_percent 指标是值得关注的一个数字。Elasticsearch 被配置为当 heap 达到 75% 的时候开始 GC。如果你的节点一直 >= 75%,你的节点正处于 内存压力 状态。这是个危险信号,不远的未来可能就有慢 GC 要出现了。
如果 heap 使用率一直 >=85%,你就麻烦了。Heap 在 90–95% 之间,则面临可怕的性能风险,此时最好的情况是长达 10–30s 的 GC,最差的情况就是内存溢出(OOM)异常。
线程池部分
Elasticsearch 在内部维护了线程池。 这些线程池相互协作完成任务,有必要的话相互间还会传递任务。通常来说,你不需要配置或者调优线程池,不过查看它们的统计值有时候还是有用的,可以洞察你的集群表现如何。
每个线程池会列出已配置的线程数量( threads ),当前在处理任务的线程数量( active ),以及在队列中等待处理的任务单元数量( queue )。
如果队列中任务单元数达到了极限,新的任务单元会开始被拒绝,你会在 rejected 统计值上看到它反映出来。这通常是你的集群在某些资源上碰到瓶颈的信号。因为队列满意味着你的节点或集群在用最高速度运行,但依然跟不上工作的蜂拥而入。
这里的一系列的线程池,大多数你可以忽略,但是有一小部分还是值得关注的:
indexing普通的索引请求的线程池bulk批量请求,和单条的索引请求不同的线程池getGet-by-ID 操作search所有的搜索和查询请求merging专用于管理 Lucene 合并的线程池
网络部分
transport显示和 传输地址 相关的一些基础统计值。包括节点间的通信(通常是 9300 端口)以及任意传输客户端或者节点客户端的连接。如果看到这里有很多连接数不要担心;Elasticsearch 在节点之间维护了大量的连接。http显示 HTTP 端口(通常是 9200)的统计值。如果你看到total_opened数很大而且还在一直上涨,这是一个明确信号,说明你的 HTTP 客户端里有没启用 keep-alive 长连接的。持续的 keep-alive 长连接对性能很重要,因为连接、断开套接字是很昂贵的(而且浪费文件描述符)。请确认你的客户端都配置正确。
参考资料
3、ES监控指标
最后:
转载请注明地址:http://www.54tianzhisheng.cn/2017/10/18/ElasticSearch-nodes-metrics/

一个仿Linux 控制台的ES的_cat的插件
开源项目 • psfu 发表了文章 • 3 个评论 • 4715 次浏览 • 2017-10-16 10:31

- 简化_cat使用,可以直接输入 cat 命令 ,可以滚动查看历史结果
- 支持字体放大缩小
- 支持命令历史记录(通过上下方向键来切换 )
- 支持鼠标划取的复制粘贴(暂不复制到剪贴板)
- 安装后在 http://127.0.0.1:9200/_console 使用,也可本地使用:直接访问html文件
- 简化_cat使用,可以直接输入 cat 命令 ,可以滚动查看历史结果
- 支持字体放大缩小
- 支持命令历史记录(通过上下方向键来切换 )
- 支持鼠标划取的复制粘贴(暂不复制到剪贴板)
- 安装后在 http://127.0.0.1:9200/_console 使用,也可本地使用:直接访问html文件
