


join
Elasticsearch 与SQL-style Join 前篇
Elasticsearch • liaosy 发表了文章 • 1 个评论 • 4634 次浏览 • 2022-01-18 19:27
Elasticsearch 与SQL-style Join 前篇
1.上下文
Elasticsearch(后面简称ES)作为火热的开源&分布式&Json文档形式的搜索引擎在互联网行业被广泛应用. 作为一种NoSQL数据存储服务, ES的侧重点放在了扩展性(Scalability) 与可用性(Availability)上, 提供了极快的搜索与索引文档能力(省略各种对ES的赞美.....就如同你知道的.....主要提供搜索的能力!) 然而, 来自SQL世界的我们, 日常被各种关系性数据充斥着, 使用ES常常疑惑为什么大量MySql中适用的法则在ES中行不通: 不同于SQL的ES DSL语言风格, 搜到/搜不到想要的结果集, 复杂的聚合分析,众多正在不断演进的新功能与永远记不完的APIs....... 本文不会对ES的基本功能作太多的讲解, 侧重放在了对SQL中的join查询与ES提供的join方案的对比与分析上, 基于本人的实践经验, 提供了数种可行的跨索引关联查询方案
本文分为"前篇"与"后篇" ,分别覆盖了不同的ES中实现SQL-style join的技术方案
2.引子
2.1 建议
- 不要用Mysql上的规则去理解一款NoSql DB(Elastic search)
- Join查询与简单的"向多个索引查询数据"并不等价: join查询体现一个"数据关联",后文将重点描述
- 有时候, 为了达到某些效果, 可能意味着"pay some price" (e.g 空间换时间)
2.2 Join查询
开始正文前, 聊聊什么是join查询, join查询在绝大数情况下是SQL中的概念, SQL-style join查询是体现关系型数据库中"关系"的重要方式, 通过驱动表与被驱动表的字段关联, 表与表之间建立了联系方式, 并可以把多个表中的字段值一起返回到结果集:
- 表与表之间有关联性(由连接字段确定)
- 结果集中体现了这种关联性
看到这....或许你会疑惑为什么在解释join查询时反复强调"关联"二字, 相信你应该熟悉SQL中的笛卡尔积现象, 如果不通过连接字段对数据进行筛选, 那么表与表之间连接后产生的"宽表"的数据量会是一个很恐怖的数字(表A行数X表B行数X表C行数.....以此类推), 业务往往需要对产生的结果集进行二次数据筛选, 最后才能从大量的数据中找到少量感兴趣的信息. 而通过指定SQL-style中的join关联关系(e.g table A.字段1 =tableB.字段1)就能在SQL服务中就完成数据筛选, 并且返回的结果集中体现了这种关联性, 降低了业务上筛选相关的工作量.
作为一款 Nosql 且 Schemaless的数据存储, ElasticSearch没有对数据的结构进行强限制, 对客户端而言,返回的结果集都是由弱类型的json对象组成. ES没有像SQL DB那样做到对join查询的友好支持. 但是数据与数据之间的关联在ES中同样非常重要!(或许在任何数据存储服务中都重要). 本文前后篇通过对比讨论 "denormalization(反范式)" , "应用层join", "ES nested query" ,"ES has parent/child query", "ES服务层join(open distro开源生态下)"这些技术的方式(部分将在后篇描述), 探讨join查询在不同环境下的有效解决方案.
3. 方案
3.0 前言: 需解决的问题
如果需要在ES中实现一个SQL:
select * from tablea a join tableb b
on a.field1 =b.field1 order by a.create_time desc等价查询效果, 并且应用层能通过分页的方式滚动查询到所有数据
3.1 方案一: denormalization(反范式)
这可能是最"直接"的方案了, 通过修改数据模型来“flatten”数据,每个ES文档在被index时就已经有了所需要的全部关联数据.
如果是搭建异构索引场景(可理解为RDS从库), 根据关联关系的不同(1 to N, N to M)索引的文档量最高将会是 2乘以 tablea行数乘以 tableb行数(有点笛卡尔积的感觉). Denormalization通过建立"超级宽"的索引维系了1 to N 或 N to M的关联关系, 应用层与ES不需要做任何join处理, 因为一个文档已经拥有了客户端需要的全部数据(数据层面上已经做到了聚合)
对于平时与关系型数据库打交道的童鞋而言, 建 "超级宽表" 映射的索引与数据冗余可能是一件"非正常"的行为, 第一反应就是数据的冗余与空间资源浪费. 但是这种方案的确是目前广泛使用的建立数据关联关系的解决方案(如同前文说的------不要用Mysql上的规则去理解ES).
3.1.1 优势
- 应用端 & ES端都不需要做任何join操作(一个ES文档有全部客户端想要的数据)
- 分布式环境下因聚合结果集相关操作产生的延迟问题得到有效解决
- 在空间资源足够下, 方案可行性高(至少有信心吼一句"能做到")
3.1.2 挑战
- 数据的冗余与空间资源浪费(空间换时间)
- 如何梳理业务模型与flatten数据: 关系型数据中通过外键,schema约束, 查询语句(join)等方式建立的关联关系要被体现到ES的索引mapping中
- 应用层(访问ES的服务)需要的编码调整(有些工程会在dao层做统一适配处理)
- 更新操作涉及到的数据大幅度增加: 原本一个涉及单表单行update SQL可能会牵扯到多个文档中的某个字段, 且每个文档占用的空间资源更高
- 新增文档的频率会更高: 理由同上
总结: Denormation方案的通用性高, 并且能够满足快速搜索的需求(最快的查询关联数据的方式), 但是额外的存储资源使用带来的相应开销问题与数据模型梳理上的问题会带来挑战
3.2 方案二: ES SQL join(open distro开源生态)
xpack 增加了有限度的SQL支持
然而...不支持join语法....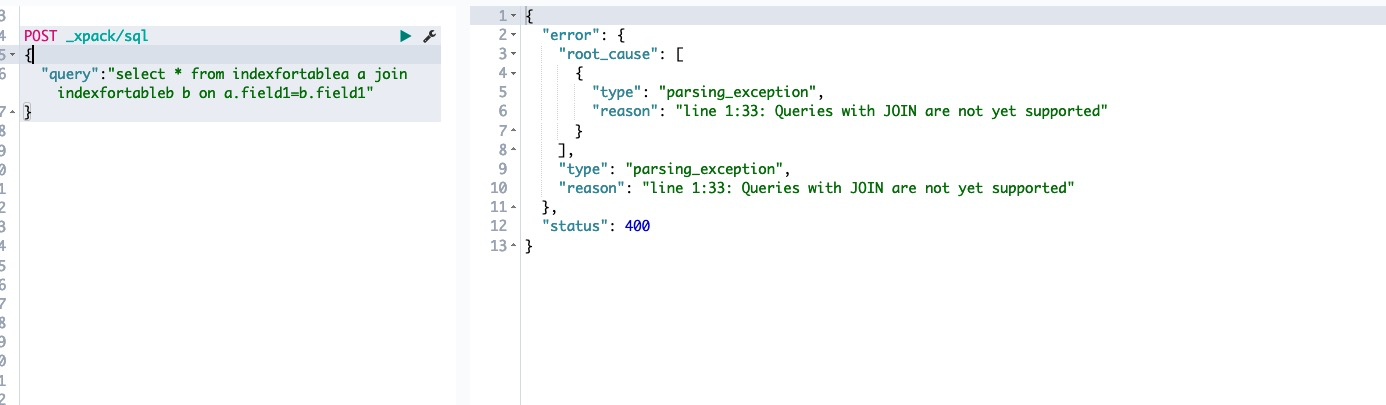
安装扩展插件获取更强的SQL支持能力(open distro)
LINK
更为强大的SQL支持(包括join语法)
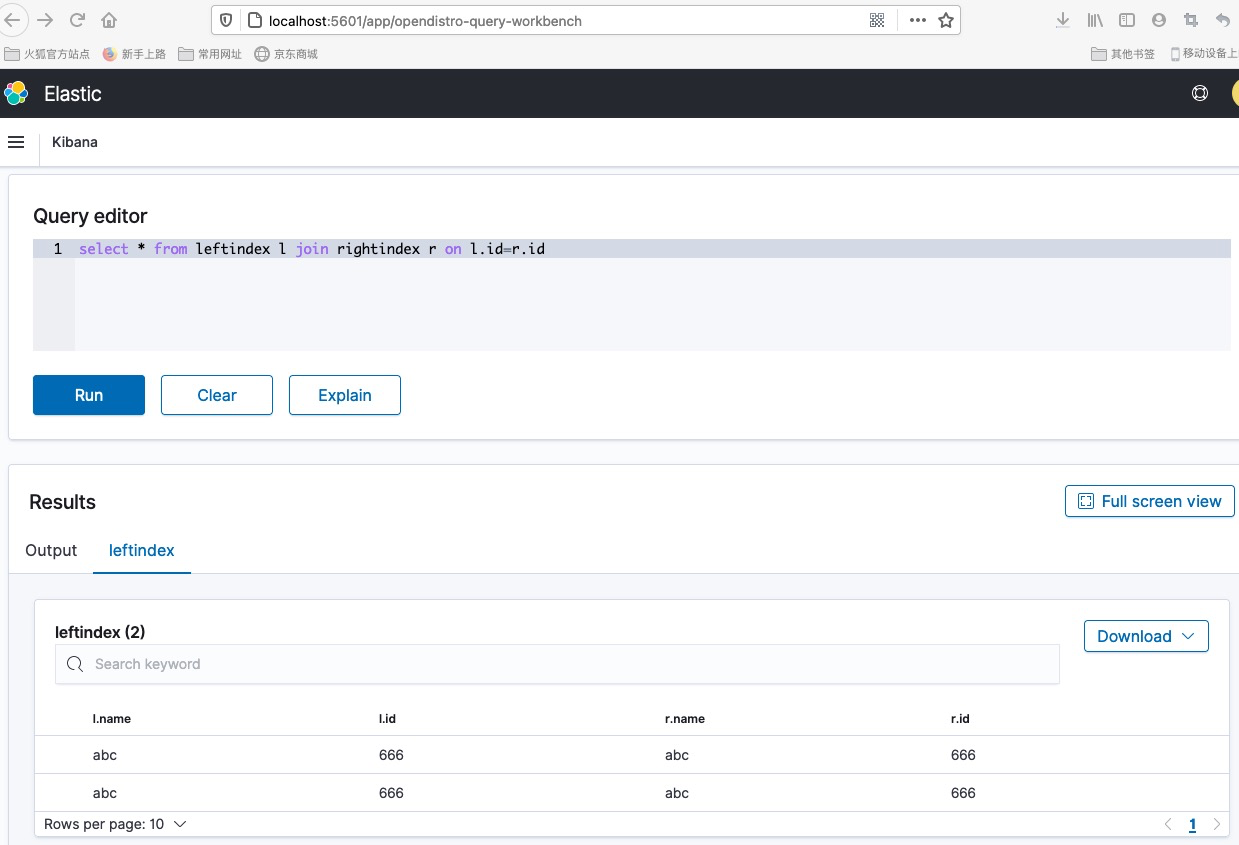 挑战:
挑战:
- 额外的ES插件(第三方插件对ES不同版本的兼容性?)
- 业务方调整(语句改为SQL-style, 且要使用open distro提供的JDBC相关依赖)
- open distro是一整套ES工具集(AWS上自带集成)
- 对该产品特性的学习LINK
3.3 方案三: 应用层join
通过应用工程对不同索引的多次访问,在组装结果集的过程中建立数据的关联关系
3.3.1 实现方式
可以仿照MySQL的join实现方式: 例如为了实现
select * from tablea a join tableb b
on a.field1 =b.field1 where a.field2 in ('value1','value2','value3') order by a.create_time desc这句SQL的等效查询
应用层可以:
- 1 选择 tablea 对应的异构索引作为驱动索引, 通过结构化查询, 获取field2 为'value1','value2','value3' 的文档中_id值(N个)
- 2 以文档field1作为连接条件, 从被驱动索引(tableb对应的异构索引)中找到字段field1满足条件( a.field1 =b.field1)的文档
- 3 用获取到的文档拼接结果集返回
如果配合ES terms-lookup 则为:
/**从tablea fetch符合条件的文档集**/
GET tablea/_search
{
"query": {
"terms": {
"field2": [
"value1",
"value2",
"value3"
]
}
}
}
/**假使仅获得一个文档且_id值为6666**/
GET tableb/_search
{
"query": {
"terms": {
"field1": {
"index" : "tablea",
"type" : "_doc",
"id" : "6666",
"path" : "field1"
}
}
}
}
/**利用ES terms-lookup进行连接查询**/
以上查询在应用层可用ES high-level-client实现, 数据的拼接,过滤, 循环查询等挑战都需要在应用层克服(难)
3.3.2 该方案面临几个挑战
- 如果文档数过多(被驱动表/驱动表中任意一张表获取的文档过多) -> 内存,网络等资源占用过高
- 应用层join引发的多次请求
- 应用层join引发的ES服务端压力
- 应用层代码的改动: 驱动表的选择, join的实现, 应用层缓存数据的压力...
- 一套稳定的join机制的实现会很复杂......
4. End
本文分为前篇与后篇, 我会在后篇文章中对这些技术进行进一步描述与对比, 并且引入可实践的方案.
原稿作者:Yukai糖在江湖
原稿链接:https://blog.csdn.net/fanduifandui/article/details/117264084

ES的父子文档中,如果有多个子文档,如何在子文档之间实现join?

Elasticsearch • a2dou 回复了问题 • 1 人关注 • 1 个回复 • 2890 次浏览 • 2021-03-19 17:43
es 6x版本, jointype查询 子文档聚合后如何再聚合出父文档的个数
回复Elasticsearch • Carpe 发起了问题 • 2 人关注 • 0 个回复 • 3074 次浏览 • 2019-10-14 18:17

join 类型如何查询子文档

Elasticsearch • aa1356889 回复了问题 • 3 人关注 • 2 个回复 • 3713 次浏览 • 2019-02-28 15:44

es 6.1版本jar包没有hasParentQueryBuilder和hasChildQueryBuilder
回复Elasticsearch • lizhan 发起了问题 • 1 人关注 • 0 个回复 • 3368 次浏览 • 2018-07-26 18:10

请问:has_parent的查询,在查出child记录的同时能不能也同时带出点parent的字段?

Elasticsearch • milu2003 回复了问题 • 3 人关注 • 2 个回复 • 3259 次浏览 • 2018-06-29 06:36
es-hadoop的es.mapping.join属性格式是什么样的?
回复Elasticsearch • linfq 发起了问题 • 1 人关注 • 0 个回复 • 4216 次浏览 • 2018-02-13 14:13


dsl能否实现sql的join功能?

Elasticsearch • novia 回复了问题 • 4 人关注 • 5 个回复 • 5485 次浏览 • 2017-06-15 11:44
ES的父子文档中,如果有多个子文档,如何在子文档之间实现join?
回复Elasticsearch • a2dou 回复了问题 • 1 人关注 • 1 个回复 • 2890 次浏览 • 2021-03-19 17:43
es 6x版本, jointype查询 子文档聚合后如何再聚合出父文档的个数
回复Elasticsearch • Carpe 发起了问题 • 2 人关注 • 0 个回复 • 3074 次浏览 • 2019-10-14 18:17
es 6.1版本jar包没有hasParentQueryBuilder和hasChildQueryBuilder
回复Elasticsearch • lizhan 发起了问题 • 1 人关注 • 0 个回复 • 3368 次浏览 • 2018-07-26 18:10
请问:has_parent的查询,在查出child记录的同时能不能也同时带出点parent的字段?
回复Elasticsearch • milu2003 回复了问题 • 3 人关注 • 2 个回复 • 3259 次浏览 • 2018-06-29 06:36
es-hadoop的es.mapping.join属性格式是什么样的?
回复Elasticsearch • linfq 发起了问题 • 1 人关注 • 0 个回复 • 4216 次浏览 • 2018-02-13 14:13
Elasticsearch 与SQL-style Join 前篇
Elasticsearch • liaosy 发表了文章 • 1 个评论 • 4634 次浏览 • 2022-01-18 19:27
Elasticsearch 与SQL-style Join 前篇
1.上下文
Elasticsearch(后面简称ES)作为火热的开源&分布式&Json文档形式的搜索引擎在互联网行业被广泛应用. 作为一种NoSQL数据存储服务, ES的侧重点放在了扩展性(Scalability) 与可用性(Availability)上, 提供了极快的搜索与索引文档能力(省略各种对ES的赞美.....就如同你知道的.....主要提供搜索的能力!) 然而, 来自SQL世界的我们, 日常被各种关系性数据充斥着, 使用ES常常疑惑为什么大量MySql中适用的法则在ES中行不通: 不同于SQL的ES DSL语言风格, 搜到/搜不到想要的结果集, 复杂的聚合分析,众多正在不断演进的新功能与永远记不完的APIs....... 本文不会对ES的基本功能作太多的讲解, 侧重放在了对SQL中的join查询与ES提供的join方案的对比与分析上, 基于本人的实践经验, 提供了数种可行的跨索引关联查询方案
本文分为"前篇"与"后篇" ,分别覆盖了不同的ES中实现SQL-style join的技术方案
2.引子
2.1 建议
- 不要用Mysql上的规则去理解一款NoSql DB(Elastic search)
- Join查询与简单的"向多个索引查询数据"并不等价: join查询体现一个"数据关联",后文将重点描述
- 有时候, 为了达到某些效果, 可能意味着"pay some price" (e.g 空间换时间)
2.2 Join查询
开始正文前, 聊聊什么是join查询, join查询在绝大数情况下是SQL中的概念, SQL-style join查询是体现关系型数据库中"关系"的重要方式, 通过驱动表与被驱动表的字段关联, 表与表之间建立了联系方式, 并可以把多个表中的字段值一起返回到结果集:
- 表与表之间有关联性(由连接字段确定)
- 结果集中体现了这种关联性
看到这....或许你会疑惑为什么在解释join查询时反复强调"关联"二字, 相信你应该熟悉SQL中的笛卡尔积现象, 如果不通过连接字段对数据进行筛选, 那么表与表之间连接后产生的"宽表"的数据量会是一个很恐怖的数字(表A行数X表B行数X表C行数.....以此类推), 业务往往需要对产生的结果集进行二次数据筛选, 最后才能从大量的数据中找到少量感兴趣的信息. 而通过指定SQL-style中的join关联关系(e.g table A.字段1 =tableB.字段1)就能在SQL服务中就完成数据筛选, 并且返回的结果集中体现了这种关联性, 降低了业务上筛选相关的工作量.
作为一款 Nosql 且 Schemaless的数据存储, ElasticSearch没有对数据的结构进行强限制, 对客户端而言,返回的结果集都是由弱类型的json对象组成. ES没有像SQL DB那样做到对join查询的友好支持. 但是数据与数据之间的关联在ES中同样非常重要!(或许在任何数据存储服务中都重要). 本文前后篇通过对比讨论 "denormalization(反范式)" , "应用层join", "ES nested query" ,"ES has parent/child query", "ES服务层join(open distro开源生态下)"这些技术的方式(部分将在后篇描述), 探讨join查询在不同环境下的有效解决方案.
3. 方案
3.0 前言: 需解决的问题
如果需要在ES中实现一个SQL:
select * from tablea a join tableb b
on a.field1 =b.field1 order by a.create_time desc等价查询效果, 并且应用层能通过分页的方式滚动查询到所有数据
3.1 方案一: denormalization(反范式)
这可能是最"直接"的方案了, 通过修改数据模型来“flatten”数据,每个ES文档在被index时就已经有了所需要的全部关联数据.
如果是搭建异构索引场景(可理解为RDS从库), 根据关联关系的不同(1 to N, N to M)索引的文档量最高将会是 2乘以 tablea行数乘以 tableb行数(有点笛卡尔积的感觉). Denormalization通过建立"超级宽"的索引维系了1 to N 或 N to M的关联关系, 应用层与ES不需要做任何join处理, 因为一个文档已经拥有了客户端需要的全部数据(数据层面上已经做到了聚合)
对于平时与关系型数据库打交道的童鞋而言, 建 "超级宽表" 映射的索引与数据冗余可能是一件"非正常"的行为, 第一反应就是数据的冗余与空间资源浪费. 但是这种方案的确是目前广泛使用的建立数据关联关系的解决方案(如同前文说的------不要用Mysql上的规则去理解ES).
3.1.1 优势
- 应用端 & ES端都不需要做任何join操作(一个ES文档有全部客户端想要的数据)
- 分布式环境下因聚合结果集相关操作产生的延迟问题得到有效解决
- 在空间资源足够下, 方案可行性高(至少有信心吼一句"能做到")
3.1.2 挑战
- 数据的冗余与空间资源浪费(空间换时间)
- 如何梳理业务模型与flatten数据: 关系型数据中通过外键,schema约束, 查询语句(join)等方式建立的关联关系要被体现到ES的索引mapping中
- 应用层(访问ES的服务)需要的编码调整(有些工程会在dao层做统一适配处理)
- 更新操作涉及到的数据大幅度增加: 原本一个涉及单表单行update SQL可能会牵扯到多个文档中的某个字段, 且每个文档占用的空间资源更高
- 新增文档的频率会更高: 理由同上
总结: Denormation方案的通用性高, 并且能够满足快速搜索的需求(最快的查询关联数据的方式), 但是额外的存储资源使用带来的相应开销问题与数据模型梳理上的问题会带来挑战
3.2 方案二: ES SQL join(open distro开源生态)
xpack 增加了有限度的SQL支持
然而...不支持join语法....
安装扩展插件获取更强的SQL支持能力(open distro)
LINK
更为强大的SQL支持(包括join语法)
挑战:
- 额外的ES插件(第三方插件对ES不同版本的兼容性?)
- 业务方调整(语句改为SQL-style, 且要使用open distro提供的JDBC相关依赖)
- open distro是一整套ES工具集(AWS上自带集成)
- 对该产品特性的学习LINK
3.3 方案三: 应用层join
通过应用工程对不同索引的多次访问,在组装结果集的过程中建立数据的关联关系
3.3.1 实现方式
可以仿照MySQL的join实现方式: 例如为了实现
select * from tablea a join tableb b
on a.field1 =b.field1 where a.field2 in ('value1','value2','value3') order by a.create_time desc这句SQL的等效查询
应用层可以:
- 1 选择 tablea 对应的异构索引作为驱动索引, 通过结构化查询, 获取field2 为'value1','value2','value3' 的文档中_id值(N个)
- 2 以文档field1作为连接条件, 从被驱动索引(tableb对应的异构索引)中找到字段field1满足条件( a.field1 =b.field1)的文档
- 3 用获取到的文档拼接结果集返回
如果配合ES terms-lookup 则为:
/**从tablea fetch符合条件的文档集**/
GET tablea/_search
{
"query": {
"terms": {
"field2": [
"value1",
"value2",
"value3"
]
}
}
}
/**假使仅获得一个文档且_id值为6666**/
GET tableb/_search
{
"query": {
"terms": {
"field1": {
"index" : "tablea",
"type" : "_doc",
"id" : "6666",
"path" : "field1"
}
}
}
}
/**利用ES terms-lookup进行连接查询**/
以上查询在应用层可用ES high-level-client实现, 数据的拼接,过滤, 循环查询等挑战都需要在应用层克服(难)
3.3.2 该方案面临几个挑战
- 如果文档数过多(被驱动表/驱动表中任意一张表获取的文档过多) -> 内存,网络等资源占用过高
- 应用层join引发的多次请求
- 应用层join引发的ES服务端压力
- 应用层代码的改动: 驱动表的选择, join的实现, 应用层缓存数据的压力...
- 一套稳定的join机制的实现会很复杂......
4. End
本文分为前篇与后篇, 我会在后篇文章中对这些技术进行进一步描述与对比, 并且引入可实践的方案.
原稿作者:Yukai糖在江湖
原稿链接:https://blog.csdn.net/fanduifandui/article/details/117264084
