


mysql
使用 Logstash 同步 MySQL 到 Easysearch
Easysearch • yangmf2040 发表了文章 • 0 个评论 • 2525 次浏览 • 2023-08-17 00:49
从 MySQL 同步数据到 ES 有多种方案,这次我们使用 ELK 技术栈中的 Logstash 来将数据从 MySQL 同步到 Easysearch 。
方案前提
- MySQL 表记录必须有主键,比如 id 字段。通过该字段,可将 Easysearch 索引数据与 MySQL 表数据形成一对一映射关系,支持修改。
- MySQL 表记录必须有时间字段,以支持增量同步。
如果上述条件具备,便可使用 logstash 定期同步新写入或修改后的数据到 Easysearch 中。
方案演示
版本信息
MySQL: 5.7
Logstash: 7.10.2
Easysearch: 1.5.0
MySQL 设置
创建演示用的表。
CREATE DATABASE es_db;
USE es_db;
DROP TABLE IF EXISTS es_table;
CREATE TABLE es_table (
id BIGINT(20) UNSIGNED NOT NULL,
PRIMARY KEY (id),
UNIQUE KEY unique_id (id),
client_name VARCHAR(32) NOT NULL,
modification_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
insertion_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);说明
- id 字段: 主键、唯一键,将作为 Easysearch 索引中的 doc id 字段。
- modification_time 字段: 表记录的插入和修改都会记录在此。
- client_name: 代表用户数据。
- insertion_time: 可省略,用来记录数据插入到 MySQL 数据的时间。
插入数据
INSERT INTO es_table (id, client_name) VALUES (1, 'test 1'); INSERT INTO es_table (id, client_name) VALUES (2, 'test 2'); INSERT INTO es_table (id, client_name) VALUES (3, 'test 3');Logstash
配置文件
input { jdbc { jdbc_driver_library => "./mysql-connector-j-8.1.0/mysql-connector-j-8.1.0.jar" jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_connection_string => "jdbc:mysql://192.168.56.3:3306/es_db" jdbc_user => "root" jdbc_password => "password" jdbc_paging_enabled => true tracking_column => "unix_ts_in_secs" use_column_value => true tracking_column_type => "numeric" last_run_metadata_path => "./.mysql-es_table-sql_last_value.yml" schedule => "*/5 * * * * *" statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW()) ORDER BY modification_time ASC" } jdbc { jdbc_driver_library => "./mysql-connector-j-8.1.0/mysql-connector-j-8.1.0.jar" jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_connection_string => "jdbc:mysql://192.168.56.3:3306/es_db" jdbc_user => "root" jdbc_password => "password" schedule => "*/5 * * * * *" statement => "SELECT count(*) AS count,'es_table' AS table_name from es_table" } } filter { if ![table_name] { mutate { copy => { "id" => "[@metadata][_id]"} remove_field => ["@version", "unix_ts_in_secs","@timestamp"] add_field => { "[@metadata][target_index]" => "mysql_es_table" } } } else { mutate { add_field => { "[@metadata][target_index]" => "table_counts" } remove_field => ["@version"] } uuid { target => "[@metadata][_id]" overwrite => true } } } output { elasticsearch { hosts => ["https://localhost:9200"] user => "admin" password => "f0c6fc61fe5f7b084c00" ssl_certificate_verification => "false" index => "%{[@metadata][target_index]}" manage_template => "false" document_id => "%{[@metadata][_id]}" } } - 每 5 秒钟同步一次 es_table 表的数据到 mysql_sync_idx 索引。
- 每 5 秒统计一次 es_table 表的记录条数到 table_counts 索引,用于监控。
启动 logstash
./bin/logstash -f sync_es_table.conf查看同步结果, 3 条数据都已同步到索引。
 Mysql 数据库新增记录
Mysql 数据库新增记录INSERT INTO es_table (id, client_name) VALUES (4, 'test 4');Easysearch 确认新增

Mysql 数据库修改记录
UPDATE es_table SET client_name = 'test 0001' WHERE id=1;Easysearch 确认修改

删除数据
Logstash 无法直接删除操作到 ES ,有两个方案:
- 在表中增加 is_deleted 字段,实现软删除,可达到同步的目的。查询过滤掉 is_deleted : true 的记录,后续通过脚本等方式定期清理 is_deleted : true 的数据。
- 执行删除操作的程序,删除完 MySQL 中的记录后,继续删除 Easysearch 中的记录。
同步监控
数据已经在 ES 中了,我们可利用 INFINI Console 的数据看板来监控数据是否同步,展示表记录数、索引记录数及其变化。

类比mysql查询,适合新手学习Elasticsearch的DSL查询语句
Elasticsearch • 森 发表了文章 • 0 个评论 • 9104 次浏览 • 2020-04-29 10:44
Mysql查询与Elasticsearch的DSL查询语句对照
作者:
小森同学,互联网公司搜索开发工程师。
前言
作为新入门的后端开发人员,一般对Mysql,SqlServer这类的关系型数据库或多或少都有了解。当入门Elasticsearch时,发现其DSL语句与关系型数据库的查询完全不一样,不再是那熟悉的语法,顿感门槛有点高。为了方便熟悉关系型数据库查询的同学,更加容易,快捷的理解并掌握DSL基础语法,本文将进行Mysql与DSL语句进行类比。
一、Mysql数据库与Elasticsearch的类比
| 关系型数据库(比如Mysql) | 非关系型数据库(Elasticsearch) |
|---|---|
| 数据库 Database | 索引 Index |
| 表 Table | 类型 Type |
| 数据行 Row | 文档 Document |
| 数据列 Column | 字段 Field |
| 约束 Schema | 映射 Mapping |
二、Mysql查询语句与DSL查询类比
Mysql查询语句与Elasticsearch的DSL查询类比,主要通过mysql库中的search_lexicon表和es中的search_lexicon_v1索引进行比较。
2.1 search_lexicon 表结构
CREATE TABLE `search_lexicon` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
`keyword` varchar(50) NOT NULL DEFAULT '' COMMENT '关键词',
`keyword_crc32` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '关键词校验',
`search_type` tinyint(1) NOT NULL DEFAULT '0' COMMENT '类型',
`consumer_id` varchar(50) NOT NULL DEFAULT '' COMMENT '消费者ID',
`num` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '文档数',
`views` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '搜索次数',
`state` tinyint(1) unsigned NOT NULL DEFAULT '1' COMMENT '状态 0 关闭 1 开启',
`is_del` tinyint(1) unsigned NOT NULL DEFAULT '0' COMMENT '是否删除 0 正常 1 删除',
`createtime` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '数据创建时间',
`updatetime` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '数据最后更新时间',
PRIMARY KEY (`id`),
KEY `idx_search_lexicon_views` (`views`),
KEY `idx_search_lexicon_updatetime` (`updatetime`) USING BTREE,
KEY `idx_search_lexicon_keyword_type` (`keyword_crc32`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='搜索词库';2.2 search_lexicon_v1 索引结构
{
"search_lexicon_v1" : {
"mappings" : {
"_doc" : {
"properties" : {
"@timestamp" : {
"type" : "date"
},
"@version" : {
"type" : "long"
},
"consumer_id" : {
"type" : "keyword"
},
"createtime" : {
"type" : "date",
"format" : "yyyy-MM-dd HH:mm:ss||strict_date_optional_time||epoch_millis"
},
"id" : {
"type" : "integer"
},
"is_del" : {
"type" : "integer"
},
"keyword" : {
"type" : "text",
"fields" : {
"standard" : {
"type" : "text",
"analyzer" : "by_standard_no_synonym"
}
},
"analyzer" : "by_max_word_pinyin_no_synonym"
},
"num" : {
"type" : "long"
},
"search_type" : {
"type" : "integer"
},
"state" : {
"type" : "integer"
},
"updatetime" : {
"type" : "date",
"format" : "yyyy-MM-dd HH:mm:ss||strict_date_optional_time||epoch_millis"
},
"views" : {
"type" : "long"
}
}
}
}
}
}2.3 查询语句对照
注意:dsl查询,每次默认展示10(size默认为10)条
以下的查询条件,是为了写查询而构造的,无任何实质性的意义,仅供mysql查询与dsl查询对比用
布尔查询支持的子查询类型共有四种,分别是:must,should,must_not和filter:
| 查询字句 | 说明 | 类型 |
|---|---|---|
| must | 文档必须符合must中所有的条件,会影响相关性得分 | 数组 |
| should | 文档应该匹配should子句查询的一个或多个 | 数组 |
| must_not | 文档必须不符合must_not 中的所有条件 | 数组 |
| filter | 过滤器,文档必须匹配该过滤条件,跟must子句的唯一区别是,filter不影响查询的score ,会缓存 | 字典 |
A、查询所有数据
mysql
SELECT * FROM search_lexicondsl
GET search_lexicon/_search
{
}
或
GET search_lexicon/_search
{
"query": {
"match_all": {}
}
}B、 查询一个条件且条件只有一个值(consumer_id=demo)的数据
mysql
SELECT * FROM search_lexicon WHERE consumer_id='demo'dsl
GET search_lexicon/_search
{
"query": {
"bool": {
"filter": {
"term": {
"consumer_id": "demo"
}
}
}
}
}
或
GET search_lexicon/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"consumer_id": "demo"
}
}
]
}
}
}
两者的区别在于前一个filter是一个对象,filter中只能放一个条件,后者filter是一个数组,里面可以放多个对象(多个查询条件),后续都将按照第二种方式查询C、 查询一个条件且条件有多个值(consumer_id的值为demo,demo2)的数据
mysql
SELECT * FROM search_lexicon WHERE consumer_id in('demo','demo2')dsl
GET search_lexicon/_search
{
"query": {
"bool": {
"filter": [
{
"terms": {
"consumer_id": [
"demo",
"demo2"
]
}
}
]
}
}
}D、 查询consumer_id=demo 且 state=1的数据
mysql
SELECT * FROM search_lexicon WHERE consumer_id ='demo' and state=1dsl
GET search_lexicon/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"consumer_id": "demo"
}
},
{
"term": {
"state": 1
}
}
]
}
}
}E、 查询consumer_id=demo , state=1 且 is_del<>1的数据
mysql
SELECT * FROM search_lexicon WHERE consumer_id ='demo' and state=1 and is_del <>1dsl
GET search_lexicon/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"consumer_id": "demo"
}
},
{
"term": {
"state": 1
}
}
],
"must_not": [
{
"term": {
"is_del": {
"value": 1
}
}
}
]
}
}
}F、查询Sconsumer_id ='demo' or (state=1 and is_del =0)的数据
mysql
SELECT * FROM search_lexicon WHERE consumer_id ='demo' or (state=1 and is_del =0)dsl
GET search_lexicon/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"consumer_id": {
"value": "demo"
}
}
},
{
"bool": {
"filter": [
{
"term": {
"state": 1
}
},
{
"term": {
"is_del": 0
}
}
]
}
}
]
}
}
}G、在F的基础上,查询指定字段
mysql
SELECT id,keyword,consumer_id,num,views,state,is_del FROM search_lexicon WHERE consumer_id ='demo' or (state=1 and is_del =0)dsl
GET search_lexicon/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"consumer_id": {
"value": "demo"
}
}
},
{
"bool": {
"filter": [
{
"term": {
"state": 1
}
},
{
"term": {
"is_del": 0
}
}
]
}
}
]
}
},
"_source": {
"includes": [
"id",
"keyword",
"num",
"is_del",
"state",
"consumer_id",
"views"
]
}
}H、在G的基础上,增加排序
mysql
SELECT id,keyword,consumer_id,num,views,state,is_del FROM search_lexicon WHERE consumer_id ='demo' or (state=1 and is_del =0) ORDER BY state DESC,id DESCdsl
GET search_lexicon/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"consumer_id": {
"value": "demo"
}
}
},
{
"bool": {
"filter": [
{
"term": {
"state": 1
}
},
{
"term": {
"is_del": 0
}
}
]
}
}
]
}
},
"_source": {
"includes": [
"id",
"keyword",
"num",
"is_del",
"state",
"consumer_id",
"views"
]
},
"sort": [
{
"state": {
"order": "desc"
}
},
{
"id": {
"order": "desc"
}
}
]
}I、在H的基础上,添加分页
mysql
SELECT id,keyword,consumer_id,num,views,state,is_del FROM search_lexicon WHERE consumer_id ='demo' or (state=1 and is_del =0) ORDER BY state DESC,id DESC LIMIT 0,20dsl
GET search_lexicon/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"consumer_id": {
"value": "demo"
}
}
},
{
"bool": {
"filter": [
{
"term": {
"state": 1
}
},
{
"term": {
"is_del": 0
}
}
]
}
}
]
}
},
"_source": {
"includes": [
"id",
"keyword",
"num",
"is_del",
"state",
"consumer_id",
"views"
]
},
"sort": [
{
"state": {
"order": "desc"
}
},
{
"id": {
"order": "desc"
}
}
],
"from": 0,
"size": 20
}
# from 是一个偏移量,size为每页显示条数J、去重查询
mysql
SELECT DISTINCT state FROM search_lexicon WHERE consumer_id = 'demo'dsl
# 通过折叠去重查询
GET search_lexicon/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"consumer_id": {
"value": "demo"
}
}
}
]
}
},
"collapse": {
"field": "state"
}
}K、分组查询
mysql
SELECT * FROM search_lexicon WHERE consumer_id = 'demo' GROUP BY statedsl
GET search_lexicon/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"consumer_id": {
"value": "demo"
}
}
}
]
}
},
"size": 0,
"aggs": {
"aaa": {
"terms": {
"field": "state",
"size": 10
}
}
}
}
L、模糊匹配
mysql
SELECT * FROM search_lexicon WHERE consumer_id="demo" and keyword LIKE '%渴望%'dsl
GET search_lexicon/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"consumer_id": {
"value": "demo"
}
}
}
],
"must": [
{
"match": {
"keyword": "渴望"
}
}
]
}
}
}三、总结
Mysql查询与DSL查询对照,用心体会二者之间,上下文之间,各查询条件的差异与相似,快速掌握DSL的语法结构,You can do it!
声明:
本文版权归作者所有,未经许可不得擅自转载或引用。 原文地址:https://elasticsearch.cn/article/13760
logstash同步多张相同表结构的数据表到同一个索引

Logstash • zm 回复了问题 • 4 人关注 • 4 个回复 • 6141 次浏览 • 2019-10-20 17:09
logstash向es中导入mysql数据,tinyint字段导入过程中抛出mapper_parsing_exception类型异常

Logstash • guotenv 回复了问题 • 3 人关注 • 3 个回复 • 10488 次浏览 • 2019-10-17 14:52
从MySQL建立Elasticsearch索引-索引
Elasticsearch • hufuman 发表了文章 • 0 个评论 • 5898 次浏览 • 2019-07-16 23:24
本文始发于知乎Elasticsearch专栏:从MySQL建立Elasticsearch索引-索引
接上文从MySQL建立Elasticsearch索引-引言,本文介绍一下我们实现索引创建时的一些思路。
目标
框架以Jar包的形式提供,通过配置(XML)提供规则,支持插件开发,支持全量、增量等。
因为希望尽量减少开发量,所以不要求使用方提供平表,因此需要考虑如何将平表
概念
- 全量:即使用全部数据创建一个新的索引
- 增量:按照时间范围或者给定的规则,把变化的数据同步到ES
- 插件:本框架内定义了一个插件接口,用于特定需求自行开发,并接入到现有的配置文件中
- 分批参数:SQL中由框架填充的参数,类似${id}等
配置
以用户(users)为例,配置有三种文件:
- users.mapping,保存了索引的配置,每次全量的时候会读取本文件进行索引创建
- rule,规则文件,里面主要定义了对应SQL和插件的配置
- users-all.rule,全量规则,规则中以主表为主体,支持以Top、Limit的形式对数据进行分批获取,分批参数在SQL里可以定义为${id},框架会自动填充该值,以保证能够拉取到全量的数据
- users-inc.rule,按照时间范围进行增量,分批参数支持在SQL中使用${startTime}和${endTime}
- users-spec.rule,按照指定的主表的主键,获取数据及更新索引的操作
- users-partial.rule,框架接入了阿里的Canal,本规则定义了各种表变化时,如果取到主表Id,以使用spec进行数据更新
- users.plugin,以上的rule主要提供了主表数据的获取方法,plugin文件则提供了各种关联表的信息获取方式,可以使用SQL,或者自定义的插件
全量索引实现关键点
为了保证索引的性能、监控、正确性等,实现时进行了以下设计。
(一)索引的维护
ES使用分布式、Replica、Snapshot机制保证索引的有效及集群稳定性。我们综合考虑后决定放弃Snapshot机制,通过定时/不定时创建全新全量索引,索引名字以${indexName}-{yyyy-MM-dd}的格式定义。正进行全量的索引关联上${indexName}_F的别名,正在使用的索引关联上${indexName}的别名,这样代码里可以不用关心应该读取或者使用哪个索引,合适的场景使用合适的别名即可。
(二)索引的性能
此处专指创建索引的性能,ES的性能是老话题了。
首先,为了保证全量的性能,创建索引时会调整mapping参数,类似refresh_interval改成-1,number_of_replicas改成0,添加默认slowlog设置。
索引过程中,控制bulk请求体的总大小,保证合适的分批大小的数据一并提交到ES。如果失败简单重试三次,如果三次都失败则认为失败,退出并删除当前索引,以保证线上ES数据干净准确。
(三)索引的变更
索引完成后,检查当前索引文档数和正使用索引文档数差异,如果大于配置的阈值,则认为此次索引创建有问题,删除索引并退出;做强制合并,减少segments数,提高搜索性能;恢复refresh_interval、number_of_replicas等设置;等待新索引状态变成GREEN后,将${indexName}切换到新的索引上,以使新索引生效。
最后,检查以${indexName}-{yyyy-MM-dd}格式命名的索引有几份,将多于指定个数的较老的索引删除,将多于指定个数的索引状态改为Close。这样可以尽可能提供磁盘内存利用率,减少不必要的损耗,又能在一定程度上保证数据可用。
以上,即完成了全量索引的创建。
增量索引实现关键点
增量索引因为场景比较多,所以规则也分了几种:
- inc,使用${startTime}和${endTime}在SQL中代替时间范围,框架会自动保存上次执行时间,以使整个增量整体不断滚动更新。实际使用时,因为有多个关联表导致SQL写起来比较复杂,以及部分增量数据过大,对DB有一定压力,因此不推荐使用此种方式。数据相对简单的场景可以使用。
- spec,在知道主表数据变化范围的时候使用,也是目前我们推荐的一种方式。使用主键查找数据,所有的表都是主键查询,影响范围也很明确。
- partial,针对canal做了单独封装的规则,用户获取canal的变化类型(更新、删除),变化的主表Id,用于使用spec的方式进行数据更新。
暂时没有使用部分更新的原因是,关联表与主表的映射关系比较复杂,有1:1,1:N,M:N;并且目前按照主键更新数据的方式,对DB等压力不大;加上spec的方式逻辑清晰,有利于维护和开发。
扩展性
SQL不是万能的,比方说我们部分数据需要从其他微服务取,或者SQL逻辑复杂建议代码实现,这时候就可以使用我们的插件机制了。默认框架提供了一个很强大的插件,支持Distinct、Merge、Mapping等功能,可以满足80%的关联数据的场景了。其他的场景以及需要微服务的场景,支持用户自己实现指定插件,通过配置文件,即可接入现有的框架体系中。以此能支持目前我们全部需求。
下一篇,我们将分享我们搜索模块的实现思路。
从MySQL建立Elasticsearch索引-引言
Elasticsearch • hufuman 发表了文章 • 0 个评论 • 3748 次浏览 • 2019-07-16 23:19
本文始发于知乎Elasticsearch专栏:从MySQL建立Elasticsearch索引-引言
日常工作里,因业务需要大量使用了Elasticsearch。为了简化索引的开发工作,我们需要一个易用可扩展的MySQL到ES的同步框架,在比较了可以找到的各种开源框架&工具后,我们还是选择自行研发了一个,名字简单粗暴:es-common。
背景
16年我接手了并负责了部门所有业务的搜索系统,旧搜索系统是基于Lucene自研实现的一个搜索框架,包含了平表创建、全量索引、增量索引、搜索引擎四个部分基础功能的封装;另有一个管理系统,用于配置索引、字典等信息。框架的实现思路是通过建立平表,简化索引创建的过程。
接手该系统以后,各业务出现井喷式发展,各种需求铺天盖地,同时该系统的不稳定性也开始作妖,最早三个人的小团队每天都疲于奔命。解决现有问题的同时,也在查找更好的解决方案。于是Elasticsearch进入视野。 基于JSON的交互、分布式、数据与逻辑隔离、开箱即用、稳定等特性,使我们确定了向ES转型的计划。每个点都是现有系统没有解决的问题,具体的点就不吐槽了。
选择
我们的需求有:
- 支持全量、增量建立索引,以使数据变更较快体现
- 支持更新指定文档,以处理突发问题
- 索引有版本控制,以防止出现问题无法快速回滚
- 尽量减少代码开发,减少出错概率,更专注业务
- 简单的出错处理,失败检测等
- 支持插件化开发,提供额外数据
- 支持简单的规则,类似合并同主键数据
- 域名、AUTH不可见,以满足安全要求
- 支持非MySQL来源的数据,因为微服务的存在,不是所有数据都能从DB获取到
当时的调用结果已经找不到了,那么按照现在可以搜索到的框架和工具来重新做调研好了。简单搜索了一下MySQL到ES的同步框架或者工具,有以下几个:
这几个工具通过简单的配置,即可建立索引,但分析我们的需求,有以下需求无法满足:
- 需要提供DB的URL、User和Password等,我们公司由于安全的考虑,是无法拿到这些参数的;
- 有部分数据是通过微服务获取的,单纯的SQL是无法访问微服务的;
- 有的表数据量比较大,需要分片多JOB同时处理,JDBC在这点上操作比较麻烦;
- 增量是需要按照主键进行更新的,按照时间扫描对表压力比较大;
- 类似工具无法走常规发布,有一定的发布风险
基于以上原因,我们选择了自己研发了一个框架,用来满足我们的需求。下篇文章讲介绍es-common的实现思路。

MySQL慢日志 制图去掉重复SQL 问题

Kibana • kkk 回复了问题 • 2 人关注 • 3 个回复 • 3325 次浏览 • 2019-04-23 16:28

logstash导入mysql上亿级别数据的效率问题


Logstash • Jea 回复了问题 • 14 人关注 • 7 个回复 • 23162 次浏览 • 2019-03-08 17:33

用go-mysql-elasticsearch同步mysql数据到es5.5.0的时候,字符串怎么转日期
Elasticsearch • bellengao 回复了问题 • 2 人关注 • 1 个回复 • 3694 次浏览 • 2018-12-15 11:05

filebeat只把系统日志发到ELK,没有发送mysql日志到ELK
Beats • sailershen 回复了问题 • 3 人关注 • 3 个回复 • 4926 次浏览 • 2018-11-05 01:15

应使用哪个beats同步mysql数据到es

Beats • chienx 回复了问题 • 4 人关注 • 2 个回复 • 6948 次浏览 • 2018-09-18 08:57
推荐一个同步Mysql数据到Elasticsearch的工具
Elasticsearch • MCTW 发表了文章 • 13 个评论 • 31974 次浏览 • 2018-08-14 15:47
把Mysql的数据同步到Elasticsearch是个很常见的需求,但在Github里找到的同步工具用起来或多或少都有些别扭。
例如:某记录内容为"aaa|bbb|ccc",将其按|分割成数组同步到es,这样的简单任务都难以实现,再加上配置繁琐,文档语焉不详...
所以我写了个同步工具MysqlsMom:力求用最简单的配置完成复杂的同步任务。目前除了我所在的部门,也有越来越多的互联网公司在生产环境中使用该工具了。
欢迎各位大佬进行试用并提出意见,任何建议、鼓励、批评都受到欢迎。
github: https://github.com/m358807551/mysqlsmom
简介:同步 Mysql 数据到 elasticsearch 的工具; QQ、微信:358807551
特点
- 纯 Python 编写;
- 支持基于 sql 语句的全量同步,基于 binlog 的增量同步,基于更新字段的增量同步三种同步方式;
- 全量更新只占用少量内存;支持通过sql语句同步数据;
- 增量更新自动断点续传;
- 取自 Mysql 的数据可经过一系列自定义函数的处理后再同步至 Elasticsearch;
- 能用非常简单的配置完成复杂的同步任务;
环境
- python2.7;
- 增量同步需开启 redis;
- 分析 binlog 的增量同步需要 Mysql 开启 binlog(binlog-format=row);
快速开始
全量同步MySql数据到es
-
clone 项目到本地;
-
安装依赖;
cd mysqlsmom pip install -r requirements.txt默认支持 elasticsearch-2.4版本,支持其它版本请运行(将5.4换成需要的elasticsearch版本)
pip install --upgrade elasticsearch==5.4 -
编辑 ./config/example_init.py,按注释提示修改配置;
# coding=utf-8 STREAM = "INIT" # 修改数据库连接 CONNECTION = { 'host': '127.0.0.1', 'port': 3306, 'user': 'root', 'passwd': '' } # 修改elasticsearch节点 NODES = [{"host": "127.0.0.1", "port": 9200}] TASKS = [ { "stream": { "database": "test_db", # 在此数据库执行sql语句 "sql": "select * from person" # 将该sql语句选中的数据同步到 elasticsearch }, "jobs": [ { "actions": ["insert", "update"], "pipeline": [ {"set_id": {"field": "id"}} # 默认设置 id字段的值 为elasticsearch中的文档id ], "dest": { "es": { "action": "upsert", "index": "test_index", # 设置 index "type": "test", # 设置 type "nodes": NODES } } } ] } ] -
运行
cd mysqlsmom python mysqlsmom.py ./config/example_init.py等待同步完成即可;
分析 binlog 的增量同步
-
确保要增量同步的MySql数据库开启binlog,且开启redis(为了存储最后一次读到的binlog文件名及读到的位置。未来可能支持本地文件存储该信息。)
-
下载项目到本地,且安装好依赖后,编辑 ./config/example_init.py,按注释提示修改配置;
# coding=utf-8 STREAM = "BINLOG" SERVER_ID = 99 # 确保每个用于binlog同步的配置文件的SERVER_ID不同; SLAVE_UUID = __name__ # 配置开启binlog权限的MySql连接 BINLOG_CONNECTION = { 'host': '127.0.0.1', 'port': 3306, 'user': 'root', 'passwd': '' } # 配置es节点 NODES = [{"host": "127.0.0.1", "port": 9200}] TASKS = [ { "stream": { "database": "test_db", # [table]所在的数据库 "table": "person" # 监控该表的binlog }, "jobs": [ { "actions": ["insert", "update"], "pipeline": [ {"only_fields": {"fields": ["id", "name", "age"]}}, # 只同步这些字段到es,注释掉该行则同步全部字段的值到es {"set_id": {"field": "id"}} # 设置es中文档_id的值取自 id(或根据需要更改)字段 ], "dest": { "es": { "action": "upsert", "index": "test_index", # 设置 index "type": "test", # 设置 type "nodes": NODES } } } ] } ] -
运行
cd mysqlsmom python mysqlsmom.py ./config/example_binlog.py该进程会一直运行,实时同步新增和更改后的数据到elasticsearch;
注意:第一次运行该进程时不会同步MySql中已存在的数据,从第二次运行开始,将接着上次同步停止时的位置继续同步;
同步旧数据请看全量同步MySql数据到es;
基于更新时间的增量同步
若 Mysql 表中有类似 update_time 的时间字段,且在每次插入、更新数据后将该字段的值设置为操作时间,则可在不用开启 binlog 的情况下进行增量同步。
-
下载项目到本地,且安装好依赖后,编辑 ./config/example_cron.py,按注释提示修改配置;
# coding=utf-8 STREAM = "CRON" # 修改数据库连接 CONNECTION = { 'host': '127.0.0.1', 'port': 3306, 'user': 'root', 'passwd': '' } # redis存储上次同步时间等信息 REDIS = { "host": "127.0.0.1", "port": 6379, "db": 0, "password": "password", # 不需要密码则注释或删掉该行 } # 一次同步 BULK_SIZE 条数据到elasticsearch,不设置该配置项默认为1 BULK_SIZE = 1 # 修改elasticsearch节点 NODES = [{"host": "127.0.0.1", "port": 9200}] TASKS = [ { "stream": { "database": "test_db", # 在此数据库执行sql语句 "sql": "select id, name from person where update_time >= ?", # 将该sql语句选中的数据同步到 elasticsearch "seconds": 10, # 每隔 seconds 秒同步一次, "init_time": "2018-08-15 18:05:47" # 只有第一次同步会加载 }, "jobs": [ { "pipeline": [ {"set_id": {"field": "id"}} # 默认设置 id字段的值 为 es 中的文档id ], "dest": { "es": { "action": "upsert", "index": "test_index", # 设置 index "type": "test" # 设置 type } } } ] } ] -
运行
cd mysqlsmom python mysqlsmom.py ./config/example_cron.py
组织架构
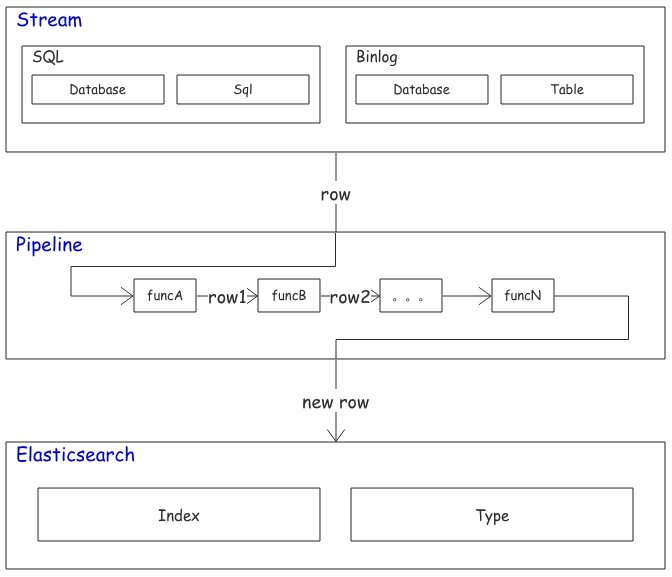
Mysqlsmom 使用实战
Mysqlsmom 的灵活性依赖于:
- 在 row_handlers.py 中添加自定义函数对取自Mysql的数据进行二次加工。
- 在 row_filters.py 中添加自定义函数决定是否要同步某一条数据。
- 在 config/ 目录下的任意配置文件应用上面的函数。
如果不了解 Python 也没关系,上述两个文件中自带的函数足以应付大多数种情况,遇到特殊的同步需求可以在 Github 发起 issue 或通过微信、QQ联系作者。
同步多张表
在一个配置文件中即可完成:
...
TASKS = [
# 同步表1
{
"stream": {
"database": "数据库名1",
"table": "表名1"
},
"jobs": [...]
}
# 同步表2
{
"stream": {
"database": "数据库名2",
"table": "表名2"
},
"jobs": [...]
}
]一个 Mysql Connection 对应一个配置文件。
一张表同步到多个索引
分为两种情况。
一种是把相同的数据同步到不同的索引,配置如下:
...
TASKS = [
{
"stream": {...},
"jobs": [
{
"actions": [...],
"pipeline": [...],
"dest": [
# 同步到索引1
{
"es": {"action": "upsert", "index": "索引1", "type": "类型1", "nodes": NODES},
},
# 同步到索引2
{
"es": {"action": "upsert", "index": "索引2", "type": "类型2", "nodes": NODES},
}
]
}
]
},
...
]另一种是把同一个表产生的数据经过不同的 pipeline 同步到不同的索引:
...
TASKS = [
{
"stream": {...},
"jobs": [
{
"actions": {...},
"pipeline": [...], # 对数据经过一系列处理
"dest": {"es": {"index": "索引1", ...}} # 同步到索引1
},
{
"actions": {...},
"pipeline": [...], # 与上面的pipeline不同
"dest": {"es": {"index": "索引2", ...}} # 同步到索引2
}
]
}
]- TASKS 中的每一项对应一张要同步的表。
- jobs 中的每一项对应对一条记录的一种处理方式。
- dest 中的每一项对应一个es索引类型。
只同步某些字段
对每条来自 Mysql 的 记录的处理都在 pipeline 中进行处理。
"pipeline": [
{"only_fields": {"fields": ["id", "name"]}}, # 只同步 id 和 name字段
{"set_id": {"field": "id"}} # 然后设置 id 字段为es中文档的_id
]字段重命名
对于 Mysql 中的字段名和 elasticsearch 中的域名不一致的情况:
"pipeline": [
# 将name重命名为name1,age 重命名为age1
{"replace_fields": {"name": ["name1"], "age": ["age1"]}},
{"set_id": {"field": "id"}}
]pipeline 会依次执行处理函数,上面的例子等价于:
"pipeline": [
# 先重命名 name 为 name1
{"replace_fields": {"name": ["name1"]}},
# 再重命名 age 为 age1
{"replace_fields": {"age": ["age1"]}},
{"set_id": {"field": "id"}}
]还有一种特殊情形,es 中两个字段存相同的数据,但是分词方式不同。
例如 name_default 的分析器为 default,name_raw 设置为不分词,需要将 name 的值同时同步到这两个域:
"pipeline": [
{"replace_fields": {"name": ["name_default", "name_raw"]}},
{"set_id": {"field": "id"}}
]当然上述问题有一个更好的解决方案,在 es 的 mappings 中配置 name 字段的 fields 属性即可,这超出了本文档的内容。
切分字符串为数组
有时 Mysql 存储字符串类似:"aaa|bbb|ccc",希望转化成数组: ["aaa", "bbb", "ccc"] 再进行同步
"pipeline": [
# tags 存储类似"aaa|bbb|ccc"的字符串,将 tags 字段的值按符号 `|` 切分成数组
{"split": {"field": "tags", "flag": "|"}},
{"set_id": {"field": "id"}}
] 同步删除文档
只有 binlog 同步 能实现删除 elasticsearch 中的文档,配置如下:
TASKS = [
{
"stream": {
"database": "test_db",
"table": "person"
},
"jobs": [
# 插入、更新
{
"actions": ["insert", "update"],
"pipeline": [
{"set_id": {"field": "id"}} # 设置 id 字段的值为 es 中文档 _id
],
"dest": {
"es": {
"action": "upsert",
...
}
}
},
# 重点在这里,配置删除
{
"actions": ["delete"], # 当读取到 binlog 中该表的删除操作时
"pipeline": [{"set_id": {"field": "id"}}], # 要删除的文档 _id
"dest": {
"es": {
"action": "delete", # 在 es 中执行删除操作
... # 与上面的 index 和 type 相同
}
}
}
]
},
...
]更多示例正在更新
常见问题
为什么我的增量同步不及时?
-
连接本地数据库增量同步不及时
该情况暂未收到过反馈,如能复现请联系作者。
-
连接线上数据库发现增量同步不及时
2.1 推荐使用内网IP连接数据库。连接线上数据库(如开启在阿里、腾讯服务器上的Mysql)时,推荐使用内网IP地址,因为外网IP会受到带宽等限制导致获取binlog数据速度受限,最终可能造成同步延时。
待改进
- 据部分用户反馈,全量同步百万级以上的数据性能不佳。
未完待续
文档近期会较频繁更新,任何问题、建议都收到欢迎,请在issues留言,会在24小时内回复;或联系QQ、微信: 358807551;

logstash的input和output的statement => 有个需求怎么设置
Logstash • heyddo 回复了问题 • 4 人关注 • 4 个回复 • 8574 次浏览 • 2018-08-08 14:12
请教各位大神,我的logstash提取数据后,是无限自循环的数据,怎么办呢?
Logstash • laoyang360 回复了问题 • 2 人关注 • 1 个回复 • 4779 次浏览 • 2018-08-06 22:14
我的logstash input jdbc 配置时间格式不一样怎么办
Logstash • medcl 回复了问题 • 4 人关注 • 2 个回复 • 7005 次浏览 • 2018-08-06 10:58
1.在业务系统里做双写
2.用elasticsearch-jdbc之类的工具来做全量和增量同步
3.用阿里的canal来做数据库binlog->kafka->es的同步,需要开发,而且依赖比较多,小公司选择还是慎重些... 显示全部 »
1.在业务系统里做双写
2.用elasticsearch-jdbc之类的工具来做全量和增量同步
3.用阿里的canal来做数据库binlog->kafka->es的同步,需要开发,而且依赖比较多,小公司选择还是慎重些吧
1.给updated_ts时间字段加上索引。
2.分批处理原则
(1)你的SQL:每批处理100000个
SELECT a.party_id AS id ,a.* FROM PARTY_ALL_1 a WHERE a.upd... 显示全部 »
1.给updated_ts时间字段加上索引。
2.分批处理原则
(1)你的SQL:每批处理100000个
SELECT a.party_id AS id ,a.* FROM PARTY_ALL_1 a WHERE a.updated_ts > '2011-11-17 13:23:58' order by a.updated_ts asc LIMIT 100000;
(2)logstash分页的时候每次处理50000个
SELECT * FROM (SELECT a.party_id AS id ,a.* FROM PARTY_ALL_1 a WHERE a.updated_ts > '2011-11-17 13:23:58' order by a.updated_ts asc LIMIT 100000) AS `t1` LIMIT 50000 OFFSET 0;
SELECT * FROM (SELECT a.party_id AS id ,a.* FROM PARTY_ALL_1 a WHERE a.updated_ts > '2011-11-17 13:23:58' order by a.updated_ts asc LIMIT 100000) AS `t1` LIMIT 50000 OFFSET 50000;
(3)处理两次就写一个最后一条记录的updated_ts时间到指定文件。下一个定时任务启动的时候进行循环处理就行,因为每批处理updated_ts都会改变
logstash向es中导入mysql数据,tinyint字段导入过程中抛出mapper_parsing_exception类型异常
回复Logstash • guotenv 回复了问题 • 3 人关注 • 3 个回复 • 10488 次浏览 • 2019-10-17 14:52
用go-mysql-elasticsearch同步mysql数据到es5.5.0的时候,字符串怎么转日期
回复Elasticsearch • bellengao 回复了问题 • 2 人关注 • 1 个回复 • 3694 次浏览 • 2018-12-15 11:05
filebeat只把系统日志发到ELK,没有发送mysql日志到ELK
回复Beats • sailershen 回复了问题 • 3 人关注 • 3 个回复 • 4926 次浏览 • 2018-11-05 01:15
logstash的input和output的statement => 有个需求怎么设置
回复Logstash • heyddo 回复了问题 • 4 人关注 • 4 个回复 • 8574 次浏览 • 2018-08-08 14:12
请教各位大神,我的logstash提取数据后,是无限自循环的数据,怎么办呢?
回复Logstash • laoyang360 回复了问题 • 2 人关注 • 1 个回复 • 4779 次浏览 • 2018-08-06 22:14
我的logstash input jdbc 配置时间格式不一样怎么办
回复Logstash • medcl 回复了问题 • 4 人关注 • 2 个回复 • 7005 次浏览 • 2018-08-06 10:58
logstash-input-jdbc 和 logstash-output-jdbc 中间如何过滤改变一下时间字段数据格式
回复默认分类 • ljx95315 发起了问题 • 1 人关注 • 0 个回复 • 4218 次浏览 • 2018-08-05 01:25
我的logstash配置文件input和output检索数据表字段和获取数据表字段如何配置??
回复Logstash • 匿名用户 发起了问题 • 1 人关注 • 0 个回复 • 1381 次浏览 • 2018-08-02 21:52
请教一个logstash简单的获取数据的问题,获取的数据错误
回复Logstash • medcl 回复了问题 • 2 人关注 • 2 个回复 • 4078 次浏览 • 2018-08-02 10:29


各位做过 将 mysql表导入到 kafka 中吗, 然后从kafka 中导入到es 中, 有什么方案吗?
回复Elasticsearch • clean 回复了问题 • 4 人关注 • 4 个回复 • 7044 次浏览 • 2018-04-04 10:10
使用 Logstash 同步 MySQL 到 Easysearch
Easysearch • yangmf2040 发表了文章 • 0 个评论 • 2525 次浏览 • 2023-08-17 00:49
从 MySQL 同步数据到 ES 有多种方案,这次我们使用 ELK 技术栈中的 Logstash 来将数据从 MySQL 同步到 Easysearch 。
方案前提
- MySQL 表记录必须有主键,比如 id 字段。通过该字段,可将 Easysearch 索引数据与 MySQL 表数据形成一对一映射关系,支持修改。
- MySQL 表记录必须有时间字段,以支持增量同步。
如果上述条件具备,便可使用 logstash 定期同步新写入或修改后的数据到 Easysearch 中。
方案演示
版本信息
MySQL: 5.7
Logstash: 7.10.2
Easysearch: 1.5.0
MySQL 设置
创建演示用的表。
CREATE DATABASE es_db;
USE es_db;
DROP TABLE IF EXISTS es_table;
CREATE TABLE es_table (
id BIGINT(20) UNSIGNED NOT NULL,
PRIMARY KEY (id),
UNIQUE KEY unique_id (id),
client_name VARCHAR(32) NOT NULL,
modification_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
insertion_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);说明
- id 字段: 主键、唯一键,将作为 Easysearch 索引中的 doc id 字段。
- modification_time 字段: 表记录的插入和修改都会记录在此。
- client_name: 代表用户数据。
- insertion_time: 可省略,用来记录数据插入到 MySQL 数据的时间。
插入数据
INSERT INTO es_table (id, client_name) VALUES (1, 'test 1'); INSERT INTO es_table (id, client_name) VALUES (2, 'test 2'); INSERT INTO es_table (id, client_name) VALUES (3, 'test 3');Logstash
配置文件
input { jdbc { jdbc_driver_library => "./mysql-connector-j-8.1.0/mysql-connector-j-8.1.0.jar" jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_connection_string => "jdbc:mysql://192.168.56.3:3306/es_db" jdbc_user => "root" jdbc_password => "password" jdbc_paging_enabled => true tracking_column => "unix_ts_in_secs" use_column_value => true tracking_column_type => "numeric" last_run_metadata_path => "./.mysql-es_table-sql_last_value.yml" schedule => "*/5 * * * * *" statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW()) ORDER BY modification_time ASC" } jdbc { jdbc_driver_library => "./mysql-connector-j-8.1.0/mysql-connector-j-8.1.0.jar" jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_connection_string => "jdbc:mysql://192.168.56.3:3306/es_db" jdbc_user => "root" jdbc_password => "password" schedule => "*/5 * * * * *" statement => "SELECT count(*) AS count,'es_table' AS table_name from es_table" } } filter { if ![table_name] { mutate { copy => { "id" => "[@metadata][_id]"} remove_field => ["@version", "unix_ts_in_secs","@timestamp"] add_field => { "[@metadata][target_index]" => "mysql_es_table" } } } else { mutate { add_field => { "[@metadata][target_index]" => "table_counts" } remove_field => ["@version"] } uuid { target => "[@metadata][_id]" overwrite => true } } } output { elasticsearch { hosts => ["https://localhost:9200"] user => "admin" password => "f0c6fc61fe5f7b084c00" ssl_certificate_verification => "false" index => "%{[@metadata][target_index]}" manage_template => "false" document_id => "%{[@metadata][_id]}" } } - 每 5 秒钟同步一次 es_table 表的数据到 mysql_sync_idx 索引。
- 每 5 秒统计一次 es_table 表的记录条数到 table_counts 索引,用于监控。
启动 logstash
./bin/logstash -f sync_es_table.conf查看同步结果, 3 条数据都已同步到索引。
Mysql 数据库新增记录INSERT INTO es_table (id, client_name) VALUES (4, 'test 4');Easysearch 确认新增
Mysql 数据库修改记录
UPDATE es_table SET client_name = 'test 0001' WHERE id=1;Easysearch 确认修改
删除数据
Logstash 无法直接删除操作到 ES ,有两个方案:
- 在表中增加 is_deleted 字段,实现软删除,可达到同步的目的。查询过滤掉 is_deleted : true 的记录,后续通过脚本等方式定期清理 is_deleted : true 的数据。
- 执行删除操作的程序,删除完 MySQL 中的记录后,继续删除 Easysearch 中的记录。
同步监控
数据已经在 ES 中了,我们可利用 INFINI Console 的数据看板来监控数据是否同步,展示表记录数、索引记录数及其变化。
类比mysql查询,适合新手学习Elasticsearch的DSL查询语句
Elasticsearch • 森 发表了文章 • 0 个评论 • 9104 次浏览 • 2020-04-29 10:44
Mysql查询与Elasticsearch的DSL查询语句对照
作者:
小森同学,互联网公司搜索开发工程师。
前言
作为新入门的后端开发人员,一般对Mysql,SqlServer这类的关系型数据库或多或少都有了解。当入门Elasticsearch时,发现其DSL语句与关系型数据库的查询完全不一样,不再是那熟悉的语法,顿感门槛有点高。为了方便熟悉关系型数据库查询的同学,更加容易,快捷的理解并掌握DSL基础语法,本文将进行Mysql与DSL语句进行类比。
一、Mysql数据库与Elasticsearch的类比
| 关系型数据库(比如Mysql) | 非关系型数据库(Elasticsearch) |
|---|---|
| 数据库 Database | 索引 Index |
| 表 Table | 类型 Type |
| 数据行 Row | 文档 Document |
| 数据列 Column | 字段 Field |
| 约束 Schema | 映射 Mapping |
二、Mysql查询语句与DSL查询类比
Mysql查询语句与Elasticsearch的DSL查询类比,主要通过mysql库中的search_lexicon表和es中的search_lexicon_v1索引进行比较。
2.1 search_lexicon 表结构
CREATE TABLE `search_lexicon` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
`keyword` varchar(50) NOT NULL DEFAULT '' COMMENT '关键词',
`keyword_crc32` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '关键词校验',
`search_type` tinyint(1) NOT NULL DEFAULT '0' COMMENT '类型',
`consumer_id` varchar(50) NOT NULL DEFAULT '' COMMENT '消费者ID',
`num` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '文档数',
`views` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '搜索次数',
`state` tinyint(1) unsigned NOT NULL DEFAULT '1' COMMENT '状态 0 关闭 1 开启',
`is_del` tinyint(1) unsigned NOT NULL DEFAULT '0' COMMENT '是否删除 0 正常 1 删除',
`createtime` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '数据创建时间',
`updatetime` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '数据最后更新时间',
PRIMARY KEY (`id`),
KEY `idx_search_lexicon_views` (`views`),
KEY `idx_search_lexicon_updatetime` (`updatetime`) USING BTREE,
KEY `idx_search_lexicon_keyword_type` (`keyword_crc32`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='搜索词库';2.2 search_lexicon_v1 索引结构
{
"search_lexicon_v1" : {
"mappings" : {
"_doc" : {
"properties" : {
"@timestamp" : {
"type" : "date"
},
"@version" : {
"type" : "long"
},
"consumer_id" : {
"type" : "keyword"
},
"createtime" : {
"type" : "date",
"format" : "yyyy-MM-dd HH:mm:ss||strict_date_optional_time||epoch_millis"
},
"id" : {
"type" : "integer"
},
"is_del" : {
"type" : "integer"
},
"keyword" : {
"type" : "text",
"fields" : {
"standard" : {
"type" : "text",
"analyzer" : "by_standard_no_synonym"
}
},
"analyzer" : "by_max_word_pinyin_no_synonym"
},
"num" : {
"type" : "long"
},
"search_type" : {
"type" : "integer"
},
"state" : {
"type" : "integer"
},
"updatetime" : {
"type" : "date",
"format" : "yyyy-MM-dd HH:mm:ss||strict_date_optional_time||epoch_millis"
},
"views" : {
"type" : "long"
}
}
}
}
}
}2.3 查询语句对照
注意:dsl查询,每次默认展示10(size默认为10)条
以下的查询条件,是为了写查询而构造的,无任何实质性的意义,仅供mysql查询与dsl查询对比用
布尔查询支持的子查询类型共有四种,分别是:must,should,must_not和filter:
| 查询字句 | 说明 | 类型 |
|---|---|---|
| must | 文档必须符合must中所有的条件,会影响相关性得分 | 数组 |
| should | 文档应该匹配should子句查询的一个或多个 | 数组 |
| must_not | 文档必须不符合must_not 中的所有条件 | 数组 |
| filter | 过滤器,文档必须匹配该过滤条件,跟must子句的唯一区别是,filter不影响查询的score ,会缓存 | 字典 |
A、查询所有数据
mysql
SELECT * FROM search_lexicondsl
GET search_lexicon/_search
{
}
或
GET search_lexicon/_search
{
"query": {
"match_all": {}
}
}B、 查询一个条件且条件只有一个值(consumer_id=demo)的数据
mysql
SELECT * FROM search_lexicon WHERE consumer_id='demo'dsl
GET search_lexicon/_search
{
"query": {
"bool": {
"filter": {
"term": {
"consumer_id": "demo"
}
}
}
}
}
或
GET search_lexicon/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"consumer_id": "demo"
}
}
]
}
}
}
两者的区别在于前一个filter是一个对象,filter中只能放一个条件,后者filter是一个数组,里面可以放多个对象(多个查询条件),后续都将按照第二种方式查询C、 查询一个条件且条件有多个值(consumer_id的值为demo,demo2)的数据
mysql
SELECT * FROM search_lexicon WHERE consumer_id in('demo','demo2')dsl
GET search_lexicon/_search
{
"query": {
"bool": {
"filter": [
{
"terms": {
"consumer_id": [
"demo",
"demo2"
]
}
}
]
}
}
}D、 查询consumer_id=demo 且 state=1的数据
mysql
SELECT * FROM search_lexicon WHERE consumer_id ='demo' and state=1dsl
GET search_lexicon/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"consumer_id": "demo"
}
},
{
"term": {
"state": 1
}
}
]
}
}
}E、 查询consumer_id=demo , state=1 且 is_del<>1的数据
mysql
SELECT * FROM search_lexicon WHERE consumer_id ='demo' and state=1 and is_del <>1dsl
GET search_lexicon/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"consumer_id": "demo"
}
},
{
"term": {
"state": 1
}
}
],
"must_not": [
{
"term": {
"is_del": {
"value": 1
}
}
}
]
}
}
}F、查询Sconsumer_id ='demo' or (state=1 and is_del =0)的数据
mysql
SELECT * FROM search_lexicon WHERE consumer_id ='demo' or (state=1 and is_del =0)dsl
GET search_lexicon/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"consumer_id": {
"value": "demo"
}
}
},
{
"bool": {
"filter": [
{
"term": {
"state": 1
}
},
{
"term": {
"is_del": 0
}
}
]
}
}
]
}
}
}G、在F的基础上,查询指定字段
mysql
SELECT id,keyword,consumer_id,num,views,state,is_del FROM search_lexicon WHERE consumer_id ='demo' or (state=1 and is_del =0)dsl
GET search_lexicon/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"consumer_id": {
"value": "demo"
}
}
},
{
"bool": {
"filter": [
{
"term": {
"state": 1
}
},
{
"term": {
"is_del": 0
}
}
]
}
}
]
}
},
"_source": {
"includes": [
"id",
"keyword",
"num",
"is_del",
"state",
"consumer_id",
"views"
]
}
}H、在G的基础上,增加排序
mysql
SELECT id,keyword,consumer_id,num,views,state,is_del FROM search_lexicon WHERE consumer_id ='demo' or (state=1 and is_del =0) ORDER BY state DESC,id DESCdsl
GET search_lexicon/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"consumer_id": {
"value": "demo"
}
}
},
{
"bool": {
"filter": [
{
"term": {
"state": 1
}
},
{
"term": {
"is_del": 0
}
}
]
}
}
]
}
},
"_source": {
"includes": [
"id",
"keyword",
"num",
"is_del",
"state",
"consumer_id",
"views"
]
},
"sort": [
{
"state": {
"order": "desc"
}
},
{
"id": {
"order": "desc"
}
}
]
}I、在H的基础上,添加分页
mysql
SELECT id,keyword,consumer_id,num,views,state,is_del FROM search_lexicon WHERE consumer_id ='demo' or (state=1 and is_del =0) ORDER BY state DESC,id DESC LIMIT 0,20dsl
GET search_lexicon/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"consumer_id": {
"value": "demo"
}
}
},
{
"bool": {
"filter": [
{
"term": {
"state": 1
}
},
{
"term": {
"is_del": 0
}
}
]
}
}
]
}
},
"_source": {
"includes": [
"id",
"keyword",
"num",
"is_del",
"state",
"consumer_id",
"views"
]
},
"sort": [
{
"state": {
"order": "desc"
}
},
{
"id": {
"order": "desc"
}
}
],
"from": 0,
"size": 20
}
# from 是一个偏移量,size为每页显示条数J、去重查询
mysql
SELECT DISTINCT state FROM search_lexicon WHERE consumer_id = 'demo'dsl
# 通过折叠去重查询
GET search_lexicon/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"consumer_id": {
"value": "demo"
}
}
}
]
}
},
"collapse": {
"field": "state"
}
}K、分组查询
mysql
SELECT * FROM search_lexicon WHERE consumer_id = 'demo' GROUP BY statedsl
GET search_lexicon/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"consumer_id": {
"value": "demo"
}
}
}
]
}
},
"size": 0,
"aggs": {
"aaa": {
"terms": {
"field": "state",
"size": 10
}
}
}
}
L、模糊匹配
mysql
SELECT * FROM search_lexicon WHERE consumer_id="demo" and keyword LIKE '%渴望%'dsl
GET search_lexicon/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"consumer_id": {
"value": "demo"
}
}
}
],
"must": [
{
"match": {
"keyword": "渴望"
}
}
]
}
}
}三、总结
Mysql查询与DSL查询对照,用心体会二者之间,上下文之间,各查询条件的差异与相似,快速掌握DSL的语法结构,You can do it!
声明:
本文版权归作者所有,未经许可不得擅自转载或引用。 原文地址:https://elasticsearch.cn/article/13760
从MySQL建立Elasticsearch索引-索引
Elasticsearch • hufuman 发表了文章 • 0 个评论 • 5898 次浏览 • 2019-07-16 23:24
本文始发于知乎Elasticsearch专栏:从MySQL建立Elasticsearch索引-索引
接上文从MySQL建立Elasticsearch索引-引言,本文介绍一下我们实现索引创建时的一些思路。
目标
框架以Jar包的形式提供,通过配置(XML)提供规则,支持插件开发,支持全量、增量等。
因为希望尽量减少开发量,所以不要求使用方提供平表,因此需要考虑如何将平表
概念
- 全量:即使用全部数据创建一个新的索引
- 增量:按照时间范围或者给定的规则,把变化的数据同步到ES
- 插件:本框架内定义了一个插件接口,用于特定需求自行开发,并接入到现有的配置文件中
- 分批参数:SQL中由框架填充的参数,类似${id}等
配置
以用户(users)为例,配置有三种文件:
- users.mapping,保存了索引的配置,每次全量的时候会读取本文件进行索引创建
- rule,规则文件,里面主要定义了对应SQL和插件的配置
- users-all.rule,全量规则,规则中以主表为主体,支持以Top、Limit的形式对数据进行分批获取,分批参数在SQL里可以定义为${id},框架会自动填充该值,以保证能够拉取到全量的数据
- users-inc.rule,按照时间范围进行增量,分批参数支持在SQL中使用${startTime}和${endTime}
- users-spec.rule,按照指定的主表的主键,获取数据及更新索引的操作
- users-partial.rule,框架接入了阿里的Canal,本规则定义了各种表变化时,如果取到主表Id,以使用spec进行数据更新
- users.plugin,以上的rule主要提供了主表数据的获取方法,plugin文件则提供了各种关联表的信息获取方式,可以使用SQL,或者自定义的插件
全量索引实现关键点
为了保证索引的性能、监控、正确性等,实现时进行了以下设计。
(一)索引的维护
ES使用分布式、Replica、Snapshot机制保证索引的有效及集群稳定性。我们综合考虑后决定放弃Snapshot机制,通过定时/不定时创建全新全量索引,索引名字以${indexName}-{yyyy-MM-dd}的格式定义。正进行全量的索引关联上${indexName}_F的别名,正在使用的索引关联上${indexName}的别名,这样代码里可以不用关心应该读取或者使用哪个索引,合适的场景使用合适的别名即可。
(二)索引的性能
此处专指创建索引的性能,ES的性能是老话题了。
首先,为了保证全量的性能,创建索引时会调整mapping参数,类似refresh_interval改成-1,number_of_replicas改成0,添加默认slowlog设置。
索引过程中,控制bulk请求体的总大小,保证合适的分批大小的数据一并提交到ES。如果失败简单重试三次,如果三次都失败则认为失败,退出并删除当前索引,以保证线上ES数据干净准确。
(三)索引的变更
索引完成后,检查当前索引文档数和正使用索引文档数差异,如果大于配置的阈值,则认为此次索引创建有问题,删除索引并退出;做强制合并,减少segments数,提高搜索性能;恢复refresh_interval、number_of_replicas等设置;等待新索引状态变成GREEN后,将${indexName}切换到新的索引上,以使新索引生效。
最后,检查以${indexName}-{yyyy-MM-dd}格式命名的索引有几份,将多于指定个数的较老的索引删除,将多于指定个数的索引状态改为Close。这样可以尽可能提供磁盘内存利用率,减少不必要的损耗,又能在一定程度上保证数据可用。
以上,即完成了全量索引的创建。
增量索引实现关键点
增量索引因为场景比较多,所以规则也分了几种:
- inc,使用${startTime}和${endTime}在SQL中代替时间范围,框架会自动保存上次执行时间,以使整个增量整体不断滚动更新。实际使用时,因为有多个关联表导致SQL写起来比较复杂,以及部分增量数据过大,对DB有一定压力,因此不推荐使用此种方式。数据相对简单的场景可以使用。
- spec,在知道主表数据变化范围的时候使用,也是目前我们推荐的一种方式。使用主键查找数据,所有的表都是主键查询,影响范围也很明确。
- partial,针对canal做了单独封装的规则,用户获取canal的变化类型(更新、删除),变化的主表Id,用于使用spec的方式进行数据更新。
暂时没有使用部分更新的原因是,关联表与主表的映射关系比较复杂,有1:1,1:N,M:N;并且目前按照主键更新数据的方式,对DB等压力不大;加上spec的方式逻辑清晰,有利于维护和开发。
扩展性
SQL不是万能的,比方说我们部分数据需要从其他微服务取,或者SQL逻辑复杂建议代码实现,这时候就可以使用我们的插件机制了。默认框架提供了一个很强大的插件,支持Distinct、Merge、Mapping等功能,可以满足80%的关联数据的场景了。其他的场景以及需要微服务的场景,支持用户自己实现指定插件,通过配置文件,即可接入现有的框架体系中。以此能支持目前我们全部需求。
下一篇,我们将分享我们搜索模块的实现思路。
从MySQL建立Elasticsearch索引-引言
Elasticsearch • hufuman 发表了文章 • 0 个评论 • 3748 次浏览 • 2019-07-16 23:19
本文始发于知乎Elasticsearch专栏:从MySQL建立Elasticsearch索引-引言
日常工作里,因业务需要大量使用了Elasticsearch。为了简化索引的开发工作,我们需要一个易用可扩展的MySQL到ES的同步框架,在比较了可以找到的各种开源框架&工具后,我们还是选择自行研发了一个,名字简单粗暴:es-common。
背景
16年我接手了并负责了部门所有业务的搜索系统,旧搜索系统是基于Lucene自研实现的一个搜索框架,包含了平表创建、全量索引、增量索引、搜索引擎四个部分基础功能的封装;另有一个管理系统,用于配置索引、字典等信息。框架的实现思路是通过建立平表,简化索引创建的过程。
接手该系统以后,各业务出现井喷式发展,各种需求铺天盖地,同时该系统的不稳定性也开始作妖,最早三个人的小团队每天都疲于奔命。解决现有问题的同时,也在查找更好的解决方案。于是Elasticsearch进入视野。 基于JSON的交互、分布式、数据与逻辑隔离、开箱即用、稳定等特性,使我们确定了向ES转型的计划。每个点都是现有系统没有解决的问题,具体的点就不吐槽了。
选择
我们的需求有:
- 支持全量、增量建立索引,以使数据变更较快体现
- 支持更新指定文档,以处理突发问题
- 索引有版本控制,以防止出现问题无法快速回滚
- 尽量减少代码开发,减少出错概率,更专注业务
- 简单的出错处理,失败检测等
- 支持插件化开发,提供额外数据
- 支持简单的规则,类似合并同主键数据
- 域名、AUTH不可见,以满足安全要求
- 支持非MySQL来源的数据,因为微服务的存在,不是所有数据都能从DB获取到
当时的调用结果已经找不到了,那么按照现在可以搜索到的框架和工具来重新做调研好了。简单搜索了一下MySQL到ES的同步框架或者工具,有以下几个:
这几个工具通过简单的配置,即可建立索引,但分析我们的需求,有以下需求无法满足:
- 需要提供DB的URL、User和Password等,我们公司由于安全的考虑,是无法拿到这些参数的;
- 有部分数据是通过微服务获取的,单纯的SQL是无法访问微服务的;
- 有的表数据量比较大,需要分片多JOB同时处理,JDBC在这点上操作比较麻烦;
- 增量是需要按照主键进行更新的,按照时间扫描对表压力比较大;
- 类似工具无法走常规发布,有一定的发布风险
基于以上原因,我们选择了自己研发了一个框架,用来满足我们的需求。下篇文章讲介绍es-common的实现思路。
推荐一个同步Mysql数据到Elasticsearch的工具
Elasticsearch • MCTW 发表了文章 • 13 个评论 • 31974 次浏览 • 2018-08-14 15:47
把Mysql的数据同步到Elasticsearch是个很常见的需求,但在Github里找到的同步工具用起来或多或少都有些别扭。
例如:某记录内容为"aaa|bbb|ccc",将其按|分割成数组同步到es,这样的简单任务都难以实现,再加上配置繁琐,文档语焉不详...
所以我写了个同步工具MysqlsMom:力求用最简单的配置完成复杂的同步任务。目前除了我所在的部门,也有越来越多的互联网公司在生产环境中使用该工具了。
欢迎各位大佬进行试用并提出意见,任何建议、鼓励、批评都受到欢迎。
github: https://github.com/m358807551/mysqlsmom
简介:同步 Mysql 数据到 elasticsearch 的工具; QQ、微信:358807551
特点
- 纯 Python 编写;
- 支持基于 sql 语句的全量同步,基于 binlog 的增量同步,基于更新字段的增量同步三种同步方式;
- 全量更新只占用少量内存;支持通过sql语句同步数据;
- 增量更新自动断点续传;
- 取自 Mysql 的数据可经过一系列自定义函数的处理后再同步至 Elasticsearch;
- 能用非常简单的配置完成复杂的同步任务;
环境
- python2.7;
- 增量同步需开启 redis;
- 分析 binlog 的增量同步需要 Mysql 开启 binlog(binlog-format=row);
快速开始
全量同步MySql数据到es
-
clone 项目到本地;
-
安装依赖;
cd mysqlsmom pip install -r requirements.txt默认支持 elasticsearch-2.4版本,支持其它版本请运行(将5.4换成需要的elasticsearch版本)
pip install --upgrade elasticsearch==5.4 -
编辑 ./config/example_init.py,按注释提示修改配置;
# coding=utf-8 STREAM = "INIT" # 修改数据库连接 CONNECTION = { 'host': '127.0.0.1', 'port': 3306, 'user': 'root', 'passwd': '' } # 修改elasticsearch节点 NODES = [{"host": "127.0.0.1", "port": 9200}] TASKS = [ { "stream": { "database": "test_db", # 在此数据库执行sql语句 "sql": "select * from person" # 将该sql语句选中的数据同步到 elasticsearch }, "jobs": [ { "actions": ["insert", "update"], "pipeline": [ {"set_id": {"field": "id"}} # 默认设置 id字段的值 为elasticsearch中的文档id ], "dest": { "es": { "action": "upsert", "index": "test_index", # 设置 index "type": "test", # 设置 type "nodes": NODES } } } ] } ] -
运行
cd mysqlsmom python mysqlsmom.py ./config/example_init.py等待同步完成即可;
分析 binlog 的增量同步
-
确保要增量同步的MySql数据库开启binlog,且开启redis(为了存储最后一次读到的binlog文件名及读到的位置。未来可能支持本地文件存储该信息。)
-
下载项目到本地,且安装好依赖后,编辑 ./config/example_init.py,按注释提示修改配置;
# coding=utf-8 STREAM = "BINLOG" SERVER_ID = 99 # 确保每个用于binlog同步的配置文件的SERVER_ID不同; SLAVE_UUID = __name__ # 配置开启binlog权限的MySql连接 BINLOG_CONNECTION = { 'host': '127.0.0.1', 'port': 3306, 'user': 'root', 'passwd': '' } # 配置es节点 NODES = [{"host": "127.0.0.1", "port": 9200}] TASKS = [ { "stream": { "database": "test_db", # [table]所在的数据库 "table": "person" # 监控该表的binlog }, "jobs": [ { "actions": ["insert", "update"], "pipeline": [ {"only_fields": {"fields": ["id", "name", "age"]}}, # 只同步这些字段到es,注释掉该行则同步全部字段的值到es {"set_id": {"field": "id"}} # 设置es中文档_id的值取自 id(或根据需要更改)字段 ], "dest": { "es": { "action": "upsert", "index": "test_index", # 设置 index "type": "test", # 设置 type "nodes": NODES } } } ] } ] -
运行
cd mysqlsmom python mysqlsmom.py ./config/example_binlog.py该进程会一直运行,实时同步新增和更改后的数据到elasticsearch;
注意:第一次运行该进程时不会同步MySql中已存在的数据,从第二次运行开始,将接着上次同步停止时的位置继续同步;
同步旧数据请看全量同步MySql数据到es;
基于更新时间的增量同步
若 Mysql 表中有类似 update_time 的时间字段,且在每次插入、更新数据后将该字段的值设置为操作时间,则可在不用开启 binlog 的情况下进行增量同步。
-
下载项目到本地,且安装好依赖后,编辑 ./config/example_cron.py,按注释提示修改配置;
# coding=utf-8 STREAM = "CRON" # 修改数据库连接 CONNECTION = { 'host': '127.0.0.1', 'port': 3306, 'user': 'root', 'passwd': '' } # redis存储上次同步时间等信息 REDIS = { "host": "127.0.0.1", "port": 6379, "db": 0, "password": "password", # 不需要密码则注释或删掉该行 } # 一次同步 BULK_SIZE 条数据到elasticsearch,不设置该配置项默认为1 BULK_SIZE = 1 # 修改elasticsearch节点 NODES = [{"host": "127.0.0.1", "port": 9200}] TASKS = [ { "stream": { "database": "test_db", # 在此数据库执行sql语句 "sql": "select id, name from person where update_time >= ?", # 将该sql语句选中的数据同步到 elasticsearch "seconds": 10, # 每隔 seconds 秒同步一次, "init_time": "2018-08-15 18:05:47" # 只有第一次同步会加载 }, "jobs": [ { "pipeline": [ {"set_id": {"field": "id"}} # 默认设置 id字段的值 为 es 中的文档id ], "dest": { "es": { "action": "upsert", "index": "test_index", # 设置 index "type": "test" # 设置 type } } } ] } ] -
运行
cd mysqlsmom python mysqlsmom.py ./config/example_cron.py
组织架构
Mysqlsmom 使用实战
Mysqlsmom 的灵活性依赖于:
- 在 row_handlers.py 中添加自定义函数对取自Mysql的数据进行二次加工。
- 在 row_filters.py 中添加自定义函数决定是否要同步某一条数据。
- 在 config/ 目录下的任意配置文件应用上面的函数。
如果不了解 Python 也没关系,上述两个文件中自带的函数足以应付大多数种情况,遇到特殊的同步需求可以在 Github 发起 issue 或通过微信、QQ联系作者。
同步多张表
在一个配置文件中即可完成:
...
TASKS = [
# 同步表1
{
"stream": {
"database": "数据库名1",
"table": "表名1"
},
"jobs": [...]
}
# 同步表2
{
"stream": {
"database": "数据库名2",
"table": "表名2"
},
"jobs": [...]
}
]一个 Mysql Connection 对应一个配置文件。
一张表同步到多个索引
分为两种情况。
一种是把相同的数据同步到不同的索引,配置如下:
...
TASKS = [
{
"stream": {...},
"jobs": [
{
"actions": [...],
"pipeline": [...],
"dest": [
# 同步到索引1
{
"es": {"action": "upsert", "index": "索引1", "type": "类型1", "nodes": NODES},
},
# 同步到索引2
{
"es": {"action": "upsert", "index": "索引2", "type": "类型2", "nodes": NODES},
}
]
}
]
},
...
]另一种是把同一个表产生的数据经过不同的 pipeline 同步到不同的索引:
...
TASKS = [
{
"stream": {...},
"jobs": [
{
"actions": {...},
"pipeline": [...], # 对数据经过一系列处理
"dest": {"es": {"index": "索引1", ...}} # 同步到索引1
},
{
"actions": {...},
"pipeline": [...], # 与上面的pipeline不同
"dest": {"es": {"index": "索引2", ...}} # 同步到索引2
}
]
}
]- TASKS 中的每一项对应一张要同步的表。
- jobs 中的每一项对应对一条记录的一种处理方式。
- dest 中的每一项对应一个es索引类型。
只同步某些字段
对每条来自 Mysql 的 记录的处理都在 pipeline 中进行处理。
"pipeline": [
{"only_fields": {"fields": ["id", "name"]}}, # 只同步 id 和 name字段
{"set_id": {"field": "id"}} # 然后设置 id 字段为es中文档的_id
]字段重命名
对于 Mysql 中的字段名和 elasticsearch 中的域名不一致的情况:
"pipeline": [
# 将name重命名为name1,age 重命名为age1
{"replace_fields": {"name": ["name1"], "age": ["age1"]}},
{"set_id": {"field": "id"}}
]pipeline 会依次执行处理函数,上面的例子等价于:
"pipeline": [
# 先重命名 name 为 name1
{"replace_fields": {"name": ["name1"]}},
# 再重命名 age 为 age1
{"replace_fields": {"age": ["age1"]}},
{"set_id": {"field": "id"}}
]还有一种特殊情形,es 中两个字段存相同的数据,但是分词方式不同。
例如 name_default 的分析器为 default,name_raw 设置为不分词,需要将 name 的值同时同步到这两个域:
"pipeline": [
{"replace_fields": {"name": ["name_default", "name_raw"]}},
{"set_id": {"field": "id"}}
]当然上述问题有一个更好的解决方案,在 es 的 mappings 中配置 name 字段的 fields 属性即可,这超出了本文档的内容。
切分字符串为数组
有时 Mysql 存储字符串类似:"aaa|bbb|ccc",希望转化成数组: ["aaa", "bbb", "ccc"] 再进行同步
"pipeline": [
# tags 存储类似"aaa|bbb|ccc"的字符串,将 tags 字段的值按符号 `|` 切分成数组
{"split": {"field": "tags", "flag": "|"}},
{"set_id": {"field": "id"}}
] 同步删除文档
只有 binlog 同步 能实现删除 elasticsearch 中的文档,配置如下:
TASKS = [
{
"stream": {
"database": "test_db",
"table": "person"
},
"jobs": [
# 插入、更新
{
"actions": ["insert", "update"],
"pipeline": [
{"set_id": {"field": "id"}} # 设置 id 字段的值为 es 中文档 _id
],
"dest": {
"es": {
"action": "upsert",
...
}
}
},
# 重点在这里,配置删除
{
"actions": ["delete"], # 当读取到 binlog 中该表的删除操作时
"pipeline": [{"set_id": {"field": "id"}}], # 要删除的文档 _id
"dest": {
"es": {
"action": "delete", # 在 es 中执行删除操作
... # 与上面的 index 和 type 相同
}
}
}
]
},
...
]更多示例正在更新
常见问题
为什么我的增量同步不及时?
-
连接本地数据库增量同步不及时
该情况暂未收到过反馈,如能复现请联系作者。
-
连接线上数据库发现增量同步不及时
2.1 推荐使用内网IP连接数据库。连接线上数据库(如开启在阿里、腾讯服务器上的Mysql)时,推荐使用内网IP地址,因为外网IP会受到带宽等限制导致获取binlog数据速度受限,最终可能造成同步延时。
待改进
- 据部分用户反馈,全量同步百万级以上的数据性能不佳。
未完待续
文档近期会较频繁更新,任何问题、建议都收到欢迎,请在issues留言,会在24小时内回复;或联系QQ、微信: 358807551;
mysql协议解析扩展
Beats • ggg 发表了文章 • 5 个评论 • 4200 次浏览 • 2018-05-08 15:40

一个把数据从MySQL同步到Elasticsearch的工具
Elasticsearch • windfarer 发表了文章 • 2 个评论 • 10789 次浏览 • 2016-01-13 16:34
