

社区日报 第1736期 (2023-11-13)
https://mp.weixin.qq.com/s/GCcmBixIvOjblkHZiAGXCw
2. Elasticsearch 性能监控
https://blog.csdn.net/mingongg ... 98538
3. Elasticsearch分片数量选择及如何保证数据一致性
https://blog.csdn.net/github_3 ... 83971
编辑:yuebancanghai
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili
https://mp.weixin.qq.com/s/GCcmBixIvOjblkHZiAGXCw
2. Elasticsearch 性能监控
https://blog.csdn.net/mingongg ... 98538
3. Elasticsearch分片数量选择及如何保证数据一致性
https://blog.csdn.net/github_3 ... 83971
编辑:yuebancanghai
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili 收起阅读 »
社区日报 第1735期 (2023-11-10)
https://www.elastic.co/fr/blog ... -11-0
2、Elasticsearch ES|QL 牛在哪里
https://www.elastic.co/cn/blog ... guage
3、Elasticsearch 向量检索视频解读(梯子)
https://www.elastic.co/cn/vide ... earch
编辑:铭毅天下
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
https://www.elastic.co/fr/blog ... -11-0
2、Elasticsearch ES|QL 牛在哪里
https://www.elastic.co/cn/blog ... guage
3、Elasticsearch 向量检索视频解读(梯子)
https://www.elastic.co/cn/vide ... earch
编辑:铭毅天下
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili 收起阅读 »
社区日报 第1734期 (2023-11-09)
https://mp.weixin.qq.com/s/tU9nN7AOFJs13QazPLfKJA
2.使用 Elastic Beat 采集 Prometheus 数据(需要梯子)
https://thomasdecaux.medium.co ... 1fedd
3.ES|QL(Elasticsearch 查询语言)入门
https://www.elastic.co/blog/ge ... guage
编辑:Se7en
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
https://mp.weixin.qq.com/s/tU9nN7AOFJs13QazPLfKJA
2.使用 Elastic Beat 采集 Prometheus 数据(需要梯子)
https://thomasdecaux.medium.co ... 1fedd
3.ES|QL(Elasticsearch 查询语言)入门
https://www.elastic.co/blog/ge ... guage
编辑:Se7en
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili 收起阅读 »
社区日报 第1733期 (2023-11-08)
https://medium.com/%40andre.lu ... 0c055
2.Elasticsearch:搜索架构
https://elasticstack.blog.csdn ... 44073
3.Elasticsearch:处理 Elasticsearch 中的字段名称不一致
https://elasticstack.blog.csdn ... 75664
编辑:kin122
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili
https://medium.com/%40andre.lu ... 0c055
2.Elasticsearch:搜索架构
https://elasticstack.blog.csdn ... 44073
3.Elasticsearch:处理 Elasticsearch 中的字段名称不一致
https://elasticstack.blog.csdn ... 75664
编辑:kin122
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili 收起阅读 »
从白日梦到现实:推出 Elastic 的管道查询语言 ES|QL
!(https://img-blog.csdnimg.cn/a5 ... 63.png)
今天,我们很高兴地宣布 Elastic® 的新管道查询语言 [ES|QL](https://www.elastic.co/guide/e ... .html "ES|QL")(Elasticsearch 查询语言)的技术预览版,它可以转换、丰富和简化数据调查。 ES|QL 由新的查询引擎提供支持,通过并发处理提供高级搜索功能,无论数据源和结构如何,都可以提高速度和效率。 通过在单个屏幕上创建聚合和可视化来快速解决问题,以实现迭代和流畅的工作流程。
ES|QL 介绍
Elasticsearch 的演变
-----------------
在过去 13 年中,[Elasticsearch®](https://www.elastic.co/elasticsearch/ "Elasticsearch®") 取得了显着发展,适应了用户需求和不断变化的数字环境。 Elasticsearch 最初用于全文搜索,后来根据用户反馈扩展到支持更广泛的用例。 在整个过程中,Elasticsearch [Query DSL](https://www.elastic.co/guide/e ... .html "Query DSL")(我们第一个采用的搜索语言)为过滤器、聚合和其他操作提供了丰富的查询集。 这种基于 JSON 的 DSL 最终成为我们 [_search](https://www.elastic.co/guide/e ... .html "_search") API 端点的基础。
随着时间的推移和需求的多样化,逐渐显现出用户需要的不仅仅是查询 DSL 所提供的功能。我们开始在查询 DSL 下引入和融合了其他 DSL,用于[脚本编写](https://www.elastic.co/guide/e ... .html "脚本编写")、安全调查中的[事件](https://www.elastic.co/guide/e ... .html "事件")等等。然而,尽管这些扩展功能非常多才多艺,它们并没有完全满足用户的一些需求。
用户想要一种能够:
* 简化威胁和安全调查,同时通过提供全面和迭代方法的单个查询观察和解决生产问题
* 通过单一界面搜索、丰富、聚合和可视化更多内容来简化数据调查
* 使用高级搜索功能(例如带有并发处理的查找)提高查询大量数据的速度和效率,无论来源和结构如何
更多阅读,请点击 https://elasticstack.blog.csdn ... 86439
!(https://img-blog.csdnimg.cn/a5 ... 63.png)
今天,我们很高兴地宣布 Elastic® 的新管道查询语言 [ES|QL](https://www.elastic.co/guide/e ... .html "ES|QL")(Elasticsearch 查询语言)的技术预览版,它可以转换、丰富和简化数据调查。 ES|QL 由新的查询引擎提供支持,通过并发处理提供高级搜索功能,无论数据源和结构如何,都可以提高速度和效率。 通过在单个屏幕上创建聚合和可视化来快速解决问题,以实现迭代和流畅的工作流程。
ES|QL 介绍
Elasticsearch 的演变
-----------------
在过去 13 年中,[Elasticsearch®](https://www.elastic.co/elasticsearch/ "Elasticsearch®") 取得了显着发展,适应了用户需求和不断变化的数字环境。 Elasticsearch 最初用于全文搜索,后来根据用户反馈扩展到支持更广泛的用例。 在整个过程中,Elasticsearch [Query DSL](https://www.elastic.co/guide/e ... .html "Query DSL")(我们第一个采用的搜索语言)为过滤器、聚合和其他操作提供了丰富的查询集。 这种基于 JSON 的 DSL 最终成为我们 [_search](https://www.elastic.co/guide/e ... .html "_search") API 端点的基础。
随着时间的推移和需求的多样化,逐渐显现出用户需要的不仅仅是查询 DSL 所提供的功能。我们开始在查询 DSL 下引入和融合了其他 DSL,用于[脚本编写](https://www.elastic.co/guide/e ... .html "脚本编写")、安全调查中的[事件](https://www.elastic.co/guide/e ... .html "事件")等等。然而,尽管这些扩展功能非常多才多艺,它们并没有完全满足用户的一些需求。
用户想要一种能够:
* 简化威胁和安全调查,同时通过提供全面和迭代方法的单个查询观察和解决生产问题
* 通过单一界面搜索、丰富、聚合和可视化更多内容来简化数据调查
* 使用高级搜索功能(例如带有并发处理的查找)提高查询大量数据的速度和效率,无论来源和结构如何
更多阅读,请点击 https://elasticstack.blog.csdn ... 86439 收起阅读 »
社区日报 第1732期 (2023-11-07)
1. K8S里的日志处理,这次我想试试EFK(需要梯子)
https://medium.com/%40kishorch ... c5e84
2. 你看到的相关性分数,你看不到的核心库 —— lucene(需要梯子)
https://medium.com/%40josemamg ... 95a09
3. prometheus VS ES 全家监控和日志分析的巅峰对决(需要梯子)
https://medium.com/cloud-nativ ... 791cd
编辑:斯蒂文
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
1. K8S里的日志处理,这次我想试试EFK(需要梯子)
https://medium.com/%40kishorch ... c5e84
2. 你看到的相关性分数,你看不到的核心库 —— lucene(需要梯子)
https://medium.com/%40josemamg ... 95a09
3. prometheus VS ES 全家监控和日志分析的巅峰对决(需要梯子)
https://medium.com/cloud-nativ ... 791cd
编辑:斯蒂文
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili 收起阅读 »
社区日报 第1731期 (2023-11-06)
https://mp.weixin.qq.com/s/_WSMVB6fj8-89nRbBb8ELw
2. Elasticsearch高性能优化实践
https://blog.csdn.net/fanshuku ... 39803
3. ElasticSearch线程池设置以及EsRejectedExcutionException排查
https://blog.51cto.com/u_14014612/6004450
编辑:yuebancanghai
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili
https://mp.weixin.qq.com/s/_WSMVB6fj8-89nRbBb8ELw
2. Elasticsearch高性能优化实践
https://blog.csdn.net/fanshuku ... 39803
3. ElasticSearch线程池设置以及EsRejectedExcutionException排查
https://blog.51cto.com/u_14014612/6004450
编辑:yuebancanghai
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili 收起阅读 »
社区日报 第1730期 (2023-11-03)
1、Elasticsearch 实现语义搜索
https://heidloff.net/article/s ... arch/
2、Elasticsearch 实现相似文档检索
https://www.prakashbhandari.co ... arch/
3、Elasticsearch 实现混合搜索
https://heidloff.net/article/h ... ctor/
编辑:铭毅天下
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
1、Elasticsearch 实现语义搜索
https://heidloff.net/article/s ... arch/
2、Elasticsearch 实现相似文档检索
https://www.prakashbhandari.co ... arch/
3、Elasticsearch 实现混合搜索
https://heidloff.net/article/h ... ctor/
编辑:铭毅天下
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili 收起阅读 »
INFINI Labs 产品更新 | Agent 全新重构,优化指标采集,支持集中配置管理,支持动态下发等功能

INFINI Labs 产品又更新啦~
本次更新主要有 Agent、Console、Loadgen 等产品,其中 Agent 进行全新重构升级,新版限制了 CPU 资源消耗,优化了内存,相比旧版内存使用率降低 10 倍,极大的降低了对宿主服务器资源占用的压力。同时 Agent 还优化了指标采集,支持集中配置管理,支持动态下发,支持一键安装和自动注册到 Console,可通过 Console 集中管理,并进行关联集群和节点。
以下是本次更新的详细说明。
INFINI Agent v0.7.0
INFINI Agent 是 INFINI Console 的一个可选探针组件,负责采集和上传集群指标和日志等信息,并可通过 Console 管理。Agent 支持主流操作系统和平台,安装包轻量且无任何外部依赖,可以快速方便地安装。
探针 Agent 本次更新如下:
Features
- 限制探针资源消耗,限制 CPU 的使用
- 优化探针内存使用,10 倍降低
- 支持集中配置管理,支持动态下发
- 支持探针一键安装和自动注册
- 优化节点指标采集,仅采集本节点指标
Improvements
- 重构节点统计信息
- 删除未使用的文件
- 添加发现未知节点的 API
- 重构节点发现
- 重构新的 API
INFINI Console v1.10.0
INFINI Console 是一款非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管, 企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 在线体验: http://demo.infini.cloud (用户名/密码:readonly/readonly)。
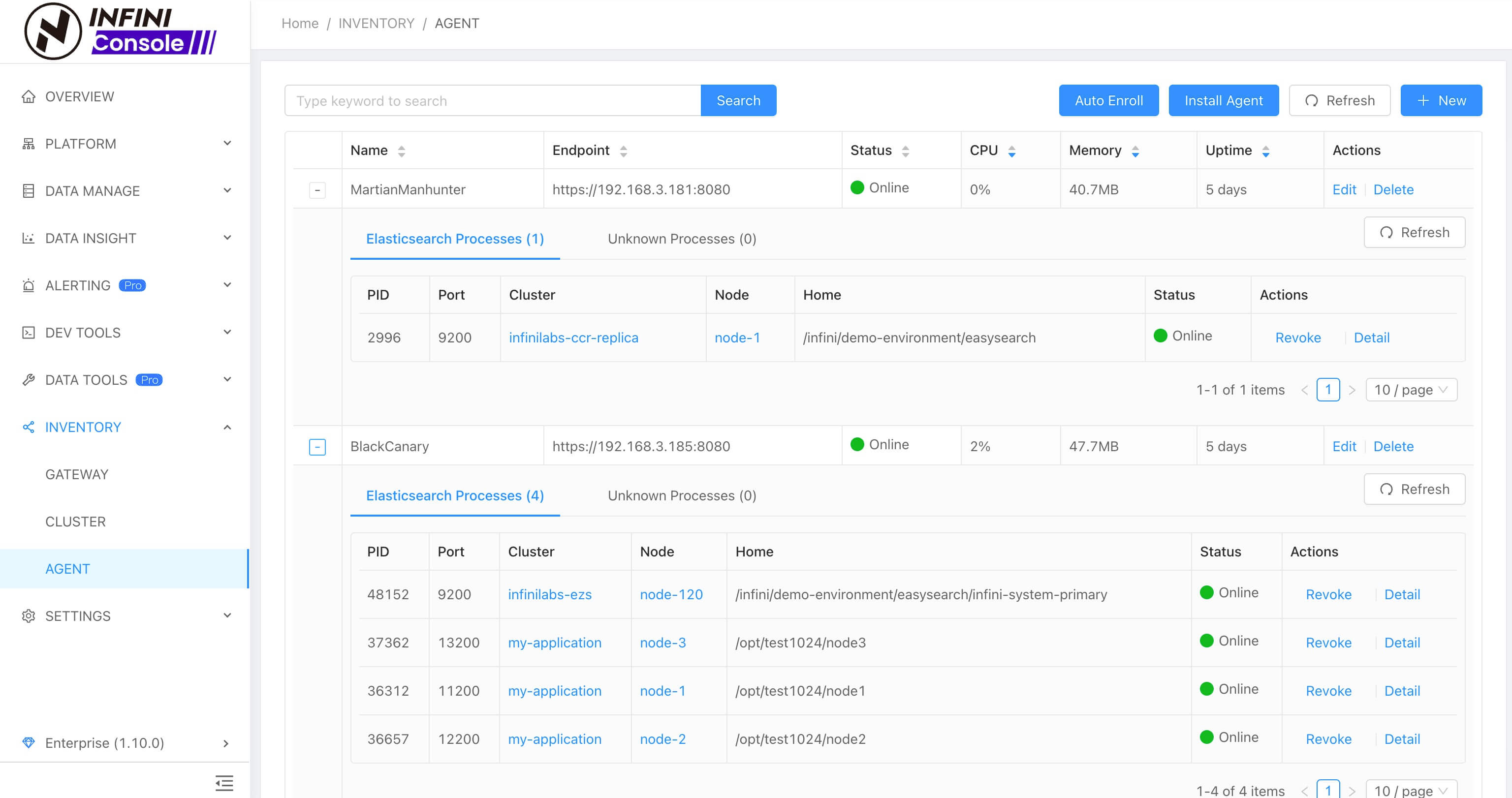
探针管理
新版 Agent 安装好之后可在 Console 探针管理界面集中纳管,支持发现 ES 进程 和 疑似 ES 进程,并支持手动和自动批量关联到集群。如下图所示:
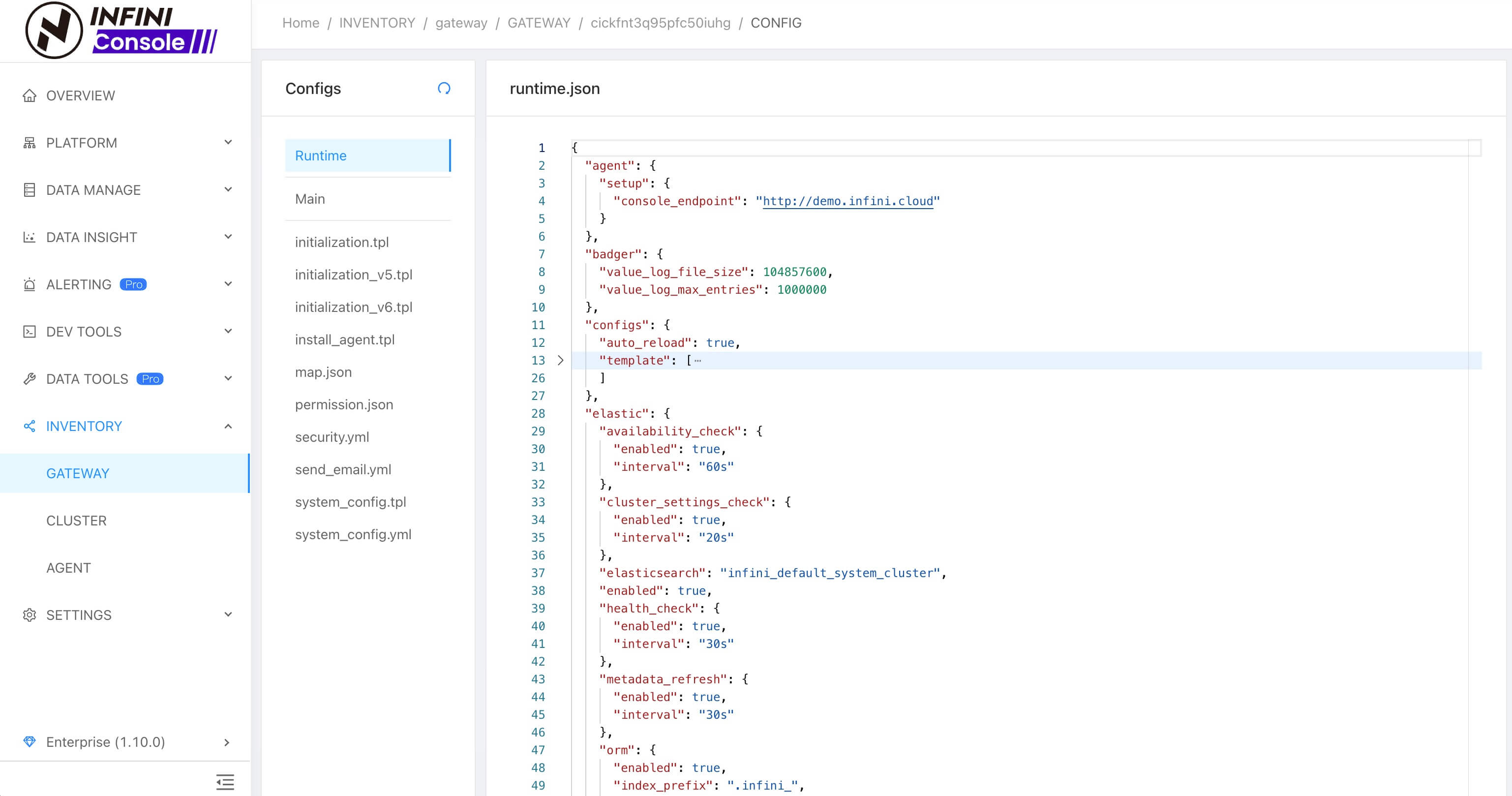
实例动态配置
Console 网关实例模块新增配置管理功能,支持实例配置内容查看和修改,修改后的配置支持自动加载生效,无需再去手动重启实例。如下图所示:
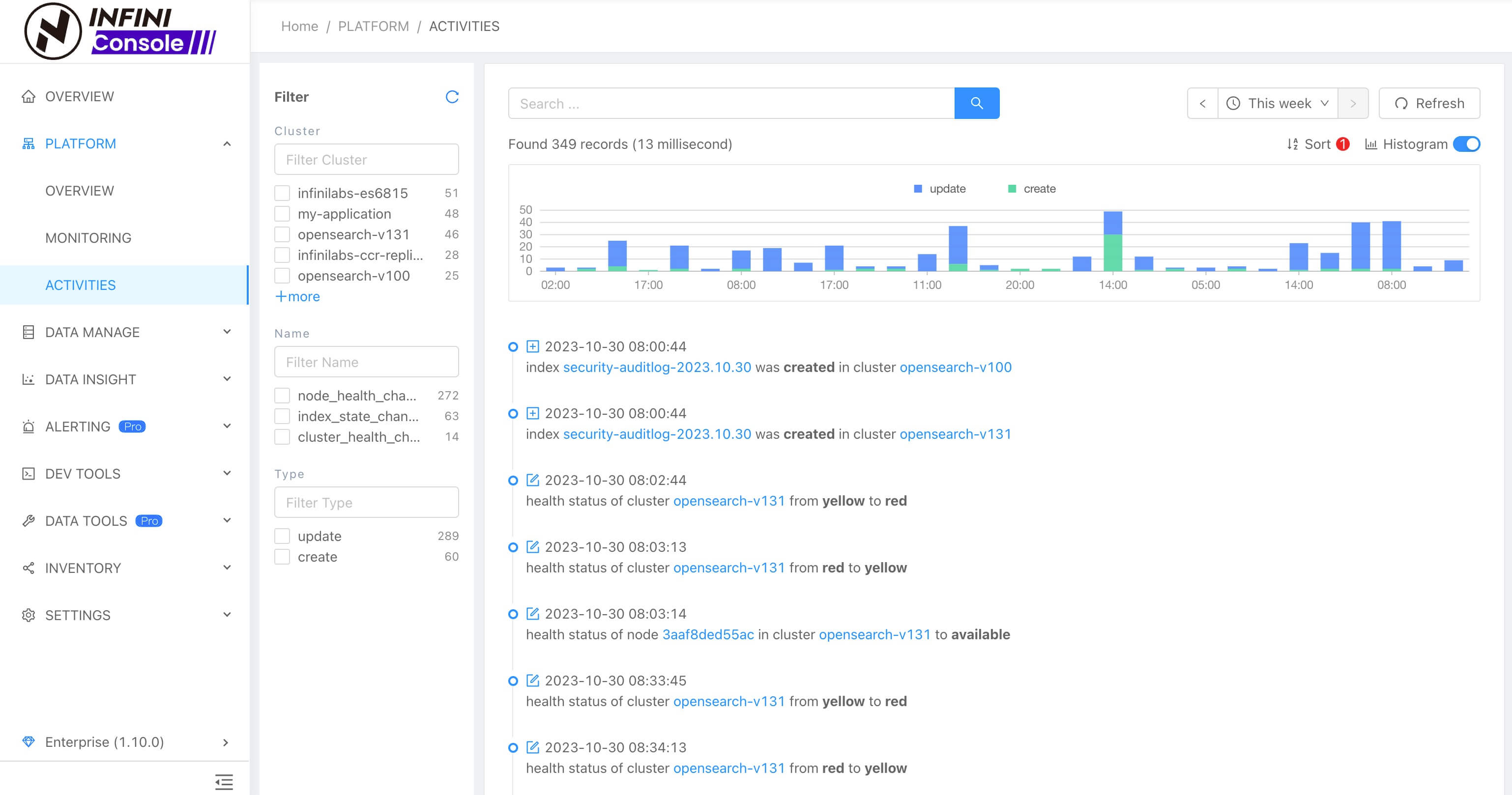
集群动态
集群动态界面进行了优化,新增了筛选过滤、时序图等。如下图所示:
Console 本次更新详细清单如下:
Features
- 重构探针注册流程
- 合并精简冗余接口
- 支持实例的配置查看和动态修改
- 允许准入和移除探针
- 监控新增分片级别指标
- 节点级别添加线程池相关指标
Bug fix
- 修复数据迁移/校验任务列表状态显示异常的问题
- 修复数据探索索引选择列表数据不完整的问题
- 修复开发工具集群列表找不到集群的问题
- 修复监控告警详情点击后查询的数据未包含告警时间点产生的数据问题
Improvements
- 优化数据迁移/校验任务剩余时间显示
- 数据探索查询数据支持自定超时时间
- 数据探索字段 TOP5 统计的总数调整为当前时间范围内的文档数
- 监控指标支持自定义时间桶的大小
- 数据检验任务添加导出文档数提示信息
- 优化集群,网关注册输入框,自动去除两边空格
- 完善探针探测未知 ES 节点的流程
- 优化探针安装脚本,新增远程配置服务器参数
- 优化集群动态界面,新增筛选过滤、时序图等
- 优化集群管理界面,新增筛选过滤
INFINI Loadgen v1.8.0
INFINI Loadgen 是一款支持 Easysearch、Elasticsearch 等搜索引擎压测工具,其特点轻量级无依赖、性能强劲、支持高并发、支持模板化参数随机、支持压测端均衡流量控制等。
Loadgen 本次更新如下:
Breaking changes
- 原 Loadrun 功能并入 Loadgen
- 测试请求、断言等使用新的 Loadgen DSL 语法来配置
下载地址:https://release.infinilabs.com/loadgen
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
- INFINI Gateway: https://github.com/infinilabs/gateway/issues
- INFINI Console: https://github.com/infinilabs/console/issues
- 下载地址: https://www.infinilabs.com/download
您还可以通过邮件联系我们:hello@infini.ltd
或者拨打我们的热线电话:(+86) 400-139-9200
欢迎加入 Discord 聊天室:https://discord.com/invite/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。

关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
INFINI Labs 产品又更新啦~
本次更新主要有 Agent、Console、Loadgen 等产品,其中 Agent 进行全新重构升级,新版限制了 CPU 资源消耗,优化了内存,相比旧版内存使用率降低 10 倍,极大的降低了对宿主服务器资源占用的压力。同时 Agent 还优化了指标采集,支持集中配置管理,支持动态下发,支持一键安装和自动注册到 Console,可通过 Console 集中管理,并进行关联集群和节点。
以下是本次更新的详细说明。
INFINI Agent v0.7.0
INFINI Agent 是 INFINI Console 的一个可选探针组件,负责采集和上传集群指标和日志等信息,并可通过 Console 管理。Agent 支持主流操作系统和平台,安装包轻量且无任何外部依赖,可以快速方便地安装。
探针 Agent 本次更新如下:
Features
- 限制探针资源消耗,限制 CPU 的使用
- 优化探针内存使用,10 倍降低
- 支持集中配置管理,支持动态下发
- 支持探针一键安装和自动注册
- 优化节点指标采集,仅采集本节点指标
Improvements
- 重构节点统计信息
- 删除未使用的文件
- 添加发现未知节点的 API
- 重构节点发现
- 重构新的 API
INFINI Console v1.10.0
INFINI Console 是一款非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管, 企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 在线体验: http://demo.infini.cloud (用户名/密码:readonly/readonly)。
探针管理
新版 Agent 安装好之后可在 Console 探针管理界面集中纳管,支持发现 ES 进程 和 疑似 ES 进程,并支持手动和自动批量关联到集群。如下图所示:
实例动态配置
Console 网关实例模块新增配置管理功能,支持实例配置内容查看和修改,修改后的配置支持自动加载生效,无需再去手动重启实例。如下图所示:
集群动态
集群动态界面进行了优化,新增了筛选过滤、时序图等。如下图所示:
Console 本次更新详细清单如下:
Features
- 重构探针注册流程
- 合并精简冗余接口
- 支持实例的配置查看和动态修改
- 允许准入和移除探针
- 监控新增分片级别指标
- 节点级别添加线程池相关指标
Bug fix
- 修复数据迁移/校验任务列表状态显示异常的问题
- 修复数据探索索引选择列表数据不完整的问题
- 修复开发工具集群列表找不到集群的问题
- 修复监控告警详情点击后查询的数据未包含告警时间点产生的数据问题
Improvements
- 优化数据迁移/校验任务剩余时间显示
- 数据探索查询数据支持自定超时时间
- 数据探索字段 TOP5 统计的总数调整为当前时间范围内的文档数
- 监控指标支持自定义时间桶的大小
- 数据检验任务添加导出文档数提示信息
- 优化集群,网关注册输入框,自动去除两边空格
- 完善探针探测未知 ES 节点的流程
- 优化探针安装脚本,新增远程配置服务器参数
- 优化集群动态界面,新增筛选过滤、时序图等
- 优化集群管理界面,新增筛选过滤
INFINI Loadgen v1.8.0
INFINI Loadgen 是一款支持 Easysearch、Elasticsearch 等搜索引擎压测工具,其特点轻量级无依赖、性能强劲、支持高并发、支持模板化参数随机、支持压测端均衡流量控制等。
Loadgen 本次更新如下:
Breaking changes
- 原 Loadrun 功能并入 Loadgen
- 测试请求、断言等使用新的 Loadgen DSL 语法来配置
下载地址:https://release.infinilabs.com/loadgen
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
- INFINI Gateway: https://github.com/infinilabs/gateway/issues
- INFINI Console: https://github.com/infinilabs/console/issues
- 下载地址: https://www.infinilabs.com/download
您还可以通过邮件联系我们:hello@infini.ltd
或者拨打我们的热线电话:(+86) 400-139-9200
欢迎加入 Discord 聊天室:https://discord.com/invite/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »社区日报 第1729期 (2023-11-02)
https://cloud.tencent.com/deve ... 51489
2.Elasticsearch最佳实践:通过调优来节省日志和指标存储成本
https://cloud.tencent.com/deve ... 51952
3.系统设计系列:Elasticsearch 搜索架构(需要梯子)
https://betterprogramming.pub/ ... 60463
编辑:Se7en
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
https://cloud.tencent.com/deve ... 51489
2.Elasticsearch最佳实践:通过调优来节省日志和指标存储成本
https://cloud.tencent.com/deve ... 51952
3.系统设计系列:Elasticsearch 搜索架构(需要梯子)
https://betterprogramming.pub/ ... 60463
编辑:Se7en
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili 收起阅读 »
社区日报 第1728期 (2023-11-01)
https://mp.weixin.qq.com/s/qZaQfQq4Rwq5kmKKVGwOAQ
2.Elasticsearch:使用 Elasticsearch 进行词汇和语义搜索
https://blog.csdn.net/UbuntuTo ... 11585
3.Elasticsearch线程池
https://zhuanlan.zhihu.com/p/397436075
编辑:kin122
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili
https://mp.weixin.qq.com/s/qZaQfQq4Rwq5kmKKVGwOAQ
2.Elasticsearch:使用 Elasticsearch 进行词汇和语义搜索
https://blog.csdn.net/UbuntuTo ... 11585
3.Elasticsearch线程池
https://zhuanlan.zhihu.com/p/397436075
编辑:kin122
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili 收起阅读 »
Easysearch 容量规划建议
你是否还在纠结怎么规划 Easysearch 集群存储容量,这篇文章将从容量估算、搜索吞吐量估算等场景为你提供详细的规划建议。
基于容量估算
主要问题:
- 每天将索引多少原始数据(GB)?保留数据多少天?
- 原始数据膨胀率
- 您将强制执行多少个副本分片?
- 您将为每个数据节点分配多少内存?
- 您的内存:数据比例是多少?
原则
- 保留 +15% 以保持在磁盘水位以下。
- 保留 +5% 用于误差和后台活动的余量。
- 保留相当于一个数据节点的资源来处理故障。
公式:
总数据量 GB = 原始数据 GB/天 * 保留天数 * 膨胀率 * (副本数 + 1)
总存储 GB = 总数据 GB * 1.15(包括磁盘 watermark threshold 和误差范围)
总数据节点数 = ROUNDUP(总存储 GB / (每个数据节点的内存 * 内存/数据比例)) + 1(用于故障转移)
举例:
假设 需要存储的源数据 50TB 大小
膨胀率 10% 副本数 1
每个节点 256G 内存
计算出:
总数据量 TB
= 50TB * (1 + 0.10) * (1 + 1)
= 110TB
总存储 TB
= 110TB * 1.15(考虑磁盘 watermark threshold 和误差范围)
= 126.5TB
如果有 256GB 的物理内存,128GB 会用于 JVM 堆,剩下的 128GB 将用于操作系统、文件缓存和其他系统进程。
按照常见的 1:30 的 RAM 到磁盘比例来计算,那么每个节点能处理的数据存储大约是:
256GB 内存 * 30 = 7680GB,大约等于 7.68TB
总数据节点数
= ROUNDUP(126.5TB / 7.68TB) + 1(用于故障转移)
= ROUNDUP(16.47) + 1
= 18
基于搜索吞吐量估算
在存储容量层面之外,还要考虑搜索响应时间和搜索吞吐量的目标,这些目标可能需要更多的内存和计算资源。
搜索响应时间受太多变量的影响,无法预测任何给定容量计划会如何影响它。但通过经验性测试搜索响应时间并估计预期的搜索吞吐量,我们可以估算出满足这些需求所需的集群资源。
主要问题:
- 你每秒的最高搜索次数是多少?
- 你的平均搜索响应时间(毫秒)是多少?
- 你的数据节点上有多少个核心和每个核心有多少个线程
经验方法:
与其确定资源将如何影响搜索速度,不如将搜索速度视为一个常数,通过在计划的硬件上进行测量来处理。然后确定集群需要多少个核心来处理预期的搜索吞吐量峰值。最终目标是防止线程池队列增长速度超过它们被消耗的速度。如果计算资源不足,搜索请求有被丢弃的风险。
公式:
峰值线程数 = 向上取整(每秒的峰值搜索次数 * 平均搜索响应时间(毫秒) / 1000 毫秒)
线程池大小 = 向上取整((每个节点的物理核心数 * 每个核心的线程数 * 3 / 2) + 1)
总数据节点数 = 向上取整(峰值线程数 / 线程池大小)
举例:
假设每秒 2 万搜索请求,平均响应时间 50 毫秒,每个节点有 16 个线程数,计算需要多少节点
峰值线程数 = 20000 * 50 /1000 = 1000
线程池大小 = (16 * 1 * 3/2) + 1 = 25
总数据节点数 = 1000 / 25 = 40
大概需要 40 个数据节点来处理每秒 2 万的搜索请求,平均响应时间为 50 毫秒,每个节点有 16 个线程。这是一个粗略的估计,实际需求可能会因多种因素而有所不同。建议进行实际测试以确认这些数字。
Hot, Warm, Frozen
根据索引使用情况不同,通常分为种存储。 这是一种经济高效的方法,用于存储大量数据,同时优化了对较新数据的性能。在容量规划期间,每个层次必须独立进行规模确定,然后进行合并。
| 层面 | 目标 | 示例存储 | 示例内存:存储比 |
|---|---|---|---|
| Hot | 搜索为主 | SSD DAS/SAN (>200Gb/s) | 1:30 |
| Warm | 存储为主 | HDD DAS/SAN (~100Gb/s) | 1:100 |
| Frozen | 存档为主 | Cheapest DAS/SAN (<100Gb/s) | 1:500 |
实际情况要把搜索吞吐量估算和容量估算结合考虑。
关于 Easysearch

INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。 与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
官网文档:https://www.infinilabs.com/docs/latest/easysearch
下载地址:https://www.infinilabs.com/download
原文:https://www.infinilabs.com/blog/2023/capacity-planning-recommendations-for-easysearch/
你是否还在纠结怎么规划 Easysearch 集群存储容量,这篇文章将从容量估算、搜索吞吐量估算等场景为你提供详细的规划建议。
基于容量估算
主要问题:
- 每天将索引多少原始数据(GB)?保留数据多少天?
- 原始数据膨胀率
- 您将强制执行多少个副本分片?
- 您将为每个数据节点分配多少内存?
- 您的内存:数据比例是多少?
原则
- 保留 +15% 以保持在磁盘水位以下。
- 保留 +5% 用于误差和后台活动的余量。
- 保留相当于一个数据节点的资源来处理故障。
公式:
总数据量 GB = 原始数据 GB/天 * 保留天数 * 膨胀率 * (副本数 + 1)
总存储 GB = 总数据 GB * 1.15(包括磁盘 watermark threshold 和误差范围)
总数据节点数 = ROUNDUP(总存储 GB / (每个数据节点的内存 * 内存/数据比例)) + 1(用于故障转移)
举例:
假设 需要存储的源数据 50TB 大小
膨胀率 10% 副本数 1
每个节点 256G 内存
计算出:
总数据量 TB
= 50TB * (1 + 0.10) * (1 + 1)
= 110TB
总存储 TB
= 110TB * 1.15(考虑磁盘 watermark threshold 和误差范围)
= 126.5TB
如果有 256GB 的物理内存,128GB 会用于 JVM 堆,剩下的 128GB 将用于操作系统、文件缓存和其他系统进程。
按照常见的 1:30 的 RAM 到磁盘比例来计算,那么每个节点能处理的数据存储大约是:
256GB 内存 * 30 = 7680GB,大约等于 7.68TB
总数据节点数
= ROUNDUP(126.5TB / 7.68TB) + 1(用于故障转移)
= ROUNDUP(16.47) + 1
= 18
基于搜索吞吐量估算
在存储容量层面之外,还要考虑搜索响应时间和搜索吞吐量的目标,这些目标可能需要更多的内存和计算资源。
搜索响应时间受太多变量的影响,无法预测任何给定容量计划会如何影响它。但通过经验性测试搜索响应时间并估计预期的搜索吞吐量,我们可以估算出满足这些需求所需的集群资源。
主要问题:
- 你每秒的最高搜索次数是多少?
- 你的平均搜索响应时间(毫秒)是多少?
- 你的数据节点上有多少个核心和每个核心有多少个线程
经验方法:
与其确定资源将如何影响搜索速度,不如将搜索速度视为一个常数,通过在计划的硬件上进行测量来处理。然后确定集群需要多少个核心来处理预期的搜索吞吐量峰值。最终目标是防止线程池队列增长速度超过它们被消耗的速度。如果计算资源不足,搜索请求有被丢弃的风险。
公式:
峰值线程数 = 向上取整(每秒的峰值搜索次数 * 平均搜索响应时间(毫秒) / 1000 毫秒)
线程池大小 = 向上取整((每个节点的物理核心数 * 每个核心的线程数 * 3 / 2) + 1)
总数据节点数 = 向上取整(峰值线程数 / 线程池大小)
举例:
假设每秒 2 万搜索请求,平均响应时间 50 毫秒,每个节点有 16 个线程数,计算需要多少节点
峰值线程数 = 20000 * 50 /1000 = 1000
线程池大小 = (16 * 1 * 3/2) + 1 = 25
总数据节点数 = 1000 / 25 = 40
大概需要 40 个数据节点来处理每秒 2 万的搜索请求,平均响应时间为 50 毫秒,每个节点有 16 个线程。这是一个粗略的估计,实际需求可能会因多种因素而有所不同。建议进行实际测试以确认这些数字。
Hot, Warm, Frozen
根据索引使用情况不同,通常分为种存储。 这是一种经济高效的方法,用于存储大量数据,同时优化了对较新数据的性能。在容量规划期间,每个层次必须独立进行规模确定,然后进行合并。
| 层面 | 目标 | 示例存储 | 示例内存:存储比 |
|---|---|---|---|
| Hot | 搜索为主 | SSD DAS/SAN (>200Gb/s) | 1:30 |
| Warm | 存储为主 | HDD DAS/SAN (~100Gb/s) | 1:100 |
| Frozen | 存档为主 | Cheapest DAS/SAN (<100Gb/s) | 1:500 |
实际情况要把搜索吞吐量估算和容量估算结合考虑。
关于 Easysearch
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。 与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
官网文档:https://www.infinilabs.com/docs/latest/easysearch
下载地址:https://www.infinilabs.com/download
收起阅读 »原文:https://www.infinilabs.com/blog/2023/capacity-planning-recommendations-for-easysearch/
社区日报 第1727期 (2023-10-31)
https://zhuanlan.zhihu.com/p/620260383
2. Elasticsearch跨集群复制(CCR)介绍
https://blog.csdn.net/sinat_32 ... 43366
3. 重构实践:基于腾讯云Elasticsearch搭建QQ邮箱全文检索
https://zhuanlan.zhihu.com/p/272209132
编辑:yuebancanghai
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili
https://zhuanlan.zhihu.com/p/620260383
2. Elasticsearch跨集群复制(CCR)介绍
https://blog.csdn.net/sinat_32 ... 43366
3. 重构实践:基于腾讯云Elasticsearch搭建QQ邮箱全文检索
https://zhuanlan.zhihu.com/p/272209132
编辑:yuebancanghai
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili 收起阅读 »
社区日报 第1726期 (2023-10-30)
https://medium.com/%40lopchann ... 4c0ad
2. 在ES中通过向量嵌入做语义搜索(需要梯子)
https://medium.com/%40mickey.l ... fac92
3. 微服务架构中的缓存设计思路(需要梯子)
https://medium.com/hexaworks-p ... 8655d
编辑:斯蒂文
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
https://medium.com/%40lopchann ... 4c0ad
2. 在ES中通过向量嵌入做语义搜索(需要梯子)
https://medium.com/%40mickey.l ... fac92
3. 微服务架构中的缓存设计思路(需要梯子)
https://medium.com/hexaworks-p ... 8655d
编辑:斯蒂文
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili 收起阅读 »
社区日报 第1725 期 (2023-10-27)
https://betterprogramming.pub/ ... 60463
2、将 10 亿条日志行从 OpenSearch 迁移到 Elasticsearch
https://www.elastic.co/cn/blog ... earch
3、Elasticsearch索引创建和通过Postman访问API
https://medium.com/%40toimrank ... eddc9
编辑:铭毅天下
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
https://betterprogramming.pub/ ... 60463
2、将 10 亿条日志行从 OpenSearch 迁移到 Elasticsearch
https://www.elastic.co/cn/blog ... earch
3、Elasticsearch索引创建和通过Postman访问API
https://medium.com/%40toimrank ... eddc9
编辑:铭毅天下
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
收起阅读 »


