

INFINI Labs 产品更新 | Gateway 支持基于 Kafka 的复制能力,发布 Helm Charts 部署方式

INFINI Labs 产品又更新啦~。本次更新概要如下:Easysearch 新增了索引字段相关统计 API,优化了 source_reuse 提升压缩效率;Gateway 新增诸多新特性,如:支持基于 Kafka 的复制能力,添加可插拔的分布式锁实现,新增 CPU 资源限制等功能;Console 本次主要优化了数据迁移功能,迁移任务详情页新增了若干指标图和日志查看等功能。
欢迎大家下载使用和反馈。
INFINI Helm Charts v0.1.0
INFINI Helm Charts 是一组 Kubernetes 部署包管理工具。基于 Helm Charts,我们将 INFINI Labs 旗下相关产品预先配置好程序资源包,大大简化了部署流程。Github 仓库地址:https://github.com/infinilabs/helm-charts。
Helm Charts 本次更新如下:
Features
- 添加 Console Chart
- 添加 Easysearch Chart,支持单节点以及多节点(节点角色可配置)部署
部署视频演示:
博客文章:
INFINI Easysearch v1.6.0
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。
Easysearch 本次更新如下:
Features
- 新增 _field_usage_stats API,统计索引每个字段的访问次数
- 新增 _disk_usage API,可以分析指定索引每个字段的磁盘占用大小
- 增加 flattened 类型,将 JSON 对象作为字符串处理,可以减少嵌套 JSON 型的文档的大小
Improvements
- source_reuse 增加对 _source 中数字类型的值进行复用压缩,可进一步降低 _source 磁盘占用
- 改进 source_reuse 筛选字段的逻辑
INFINI Gateway v1.18.0
INFINI Gateway 是一个面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway 可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
Gateway 本次更新如下:
Breaking changes
- 彻底移除了 request_body_truncate 和 response_body_truncate 过滤器
Features
- 支持基于 Kafka 的复制能力
- 在请求上下文中添加 _util.generate_uuid
- 在请求上下文中添加 _util.increment_id.BUCKET_NAME
- 在 Pipeline 配置中添加 singleton,防止多个 Pipeline 同时运行
- 添加可插拔的分布式锁实现
- 添加通用应用程序的 preference 配置
- 泛化队列抽象,重构磁盘队列,完善 Kafka 实现
- 添加 merge_to_bulk 处理器, 废弃 indexing_merge 处理器
- 添加 flow_replay 处理器,废弃 flow_runner 处理器
- 为复制场景添加 replication_correlation
- 添加 hash_mod 过滤器
- 在 bulk_response_process 过滤器中添加新参数
- 添加 request_reshuffle 过滤器
- 添加资源限制,允许设置最大 CPU 数或绑定亲和性
- 支持模板中的嵌套变量
- 添加 rewrite_to_bulk 过滤器
Bug fix
- 修复了 Pipeline 中重试延迟未生效的问题
- 修复了模板中不支持数字的问题
- 修复了队列选择器通过标签的问题,如果指定了多个标签,它们都应该一起匹配
Improvements
- 将所有模块名称转换为小写
- 在启动期间预取 Elasticsearch 元数据
- 添加应用程序范围的关闭信号
- 重构队列 API,支持 Kafka 管理
- 在 Badger 模块中添加 enabled
- 允许使用优先级注册模块/插件
- 统一队列的使用和初始化
- 优化 bulk_reshuffle 过滤器的性能,添加响应头 X-Bulk-Reshuffled
- 支持在 queue 过滤器中使用变量,允许输出最后生成的消息偏移量
INFINI Console v1.8.0
INFINI Console 是一款非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管, 企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 在线体验: http://demo.infini.cloud (用户名/密码:readonly/readonly)。
Console 本次更新如下:
Features
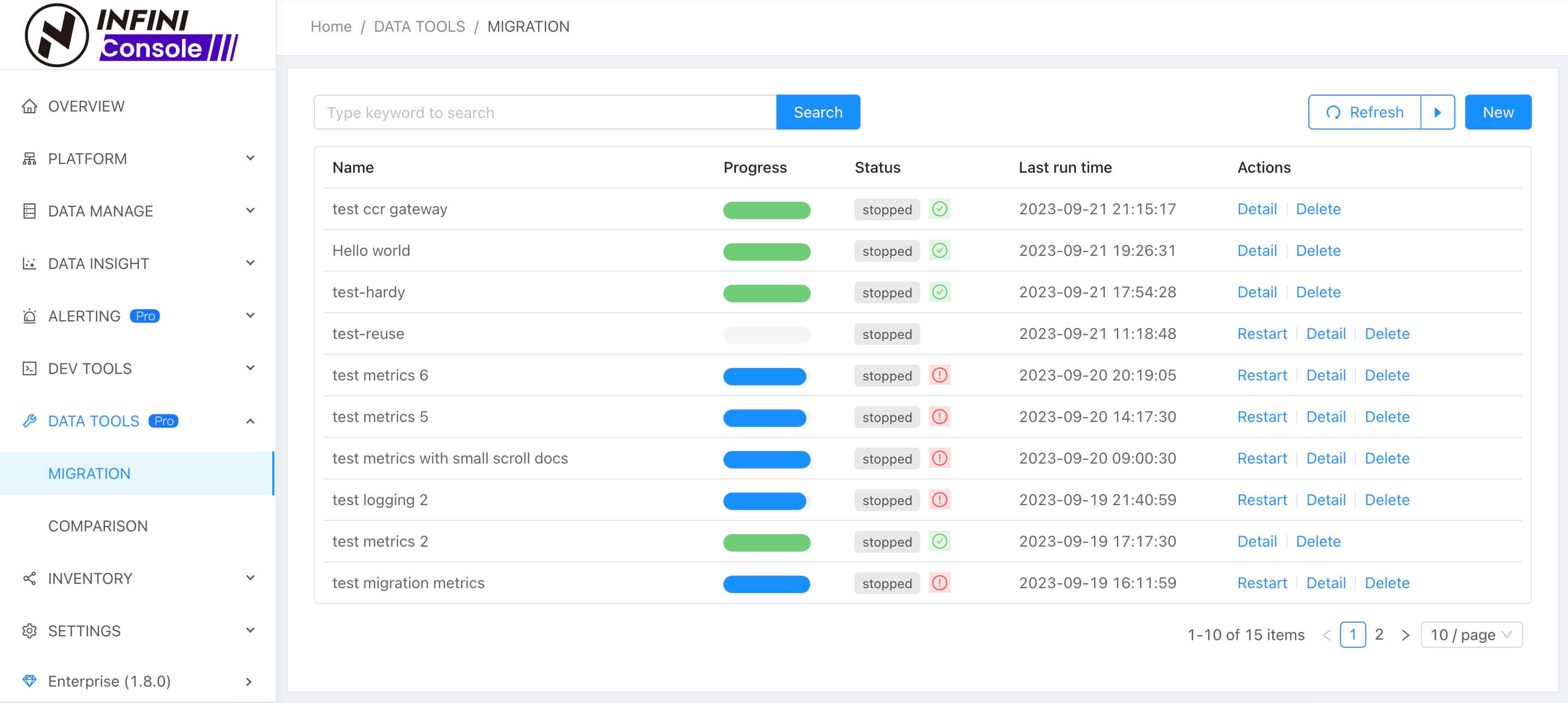
- 数据迁移任务支持自定义名称和添加标签
- 数据迁移任务详情页新增若干指标
- 数据迁移任务详情页新增查看日志
Improvements
- 数据迁移 UI 优化
- 优化监控报表、数据看板、数据探索的时间控件 UI

期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
- INFINI Gateway: https://github.com/infinilabs/gateway/issues
- INFINI Console: https://github.com/infinilabs/console/issues
- 下载地址: https://www.infinilabs.com/download
您还可以通过邮件联系我们:hello@infini.ltd
或者拨打我们的热线电话:(+86) 400-139-9200
欢迎加入 Discord 聊天室:https://discord.com/invite/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。

关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
INFINI Labs 产品又更新啦~。本次更新概要如下:Easysearch 新增了索引字段相关统计 API,优化了 source_reuse 提升压缩效率;Gateway 新增诸多新特性,如:支持基于 Kafka 的复制能力,添加可插拔的分布式锁实现,新增 CPU 资源限制等功能;Console 本次主要优化了数据迁移功能,迁移任务详情页新增了若干指标图和日志查看等功能。
欢迎大家下载使用和反馈。
INFINI Helm Charts v0.1.0
INFINI Helm Charts 是一组 Kubernetes 部署包管理工具。基于 Helm Charts,我们将 INFINI Labs 旗下相关产品预先配置好程序资源包,大大简化了部署流程。Github 仓库地址:https://github.com/infinilabs/helm-charts。
Helm Charts 本次更新如下:
Features
- 添加 Console Chart
- 添加 Easysearch Chart,支持单节点以及多节点(节点角色可配置)部署
部署视频演示:
博客文章:
INFINI Easysearch v1.6.0
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。
Easysearch 本次更新如下:
Features
- 新增 _field_usage_stats API,统计索引每个字段的访问次数
- 新增 _disk_usage API,可以分析指定索引每个字段的磁盘占用大小
- 增加 flattened 类型,将 JSON 对象作为字符串处理,可以减少嵌套 JSON 型的文档的大小
Improvements
- source_reuse 增加对 _source 中数字类型的值进行复用压缩,可进一步降低 _source 磁盘占用
- 改进 source_reuse 筛选字段的逻辑
INFINI Gateway v1.18.0
INFINI Gateway 是一个面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway 可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
Gateway 本次更新如下:
Breaking changes
- 彻底移除了 request_body_truncate 和 response_body_truncate 过滤器
Features
- 支持基于 Kafka 的复制能力
- 在请求上下文中添加 _util.generate_uuid
- 在请求上下文中添加 _util.increment_id.BUCKET_NAME
- 在 Pipeline 配置中添加 singleton,防止多个 Pipeline 同时运行
- 添加可插拔的分布式锁实现
- 添加通用应用程序的 preference 配置
- 泛化队列抽象,重构磁盘队列,完善 Kafka 实现
- 添加 merge_to_bulk 处理器, 废弃 indexing_merge 处理器
- 添加 flow_replay 处理器,废弃 flow_runner 处理器
- 为复制场景添加 replication_correlation
- 添加 hash_mod 过滤器
- 在 bulk_response_process 过滤器中添加新参数
- 添加 request_reshuffle 过滤器
- 添加资源限制,允许设置最大 CPU 数或绑定亲和性
- 支持模板中的嵌套变量
- 添加 rewrite_to_bulk 过滤器
Bug fix
- 修复了 Pipeline 中重试延迟未生效的问题
- 修复了模板中不支持数字的问题
- 修复了队列选择器通过标签的问题,如果指定了多个标签,它们都应该一起匹配
Improvements
- 将所有模块名称转换为小写
- 在启动期间预取 Elasticsearch 元数据
- 添加应用程序范围的关闭信号
- 重构队列 API,支持 Kafka 管理
- 在 Badger 模块中添加 enabled
- 允许使用优先级注册模块/插件
- 统一队列的使用和初始化
- 优化 bulk_reshuffle 过滤器的性能,添加响应头 X-Bulk-Reshuffled
- 支持在 queue 过滤器中使用变量,允许输出最后生成的消息偏移量
INFINI Console v1.8.0
INFINI Console 是一款非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管, 企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 在线体验: http://demo.infini.cloud (用户名/密码:readonly/readonly)。
Console 本次更新如下:
Features
- 数据迁移任务支持自定义名称和添加标签
- 数据迁移任务详情页新增若干指标
- 数据迁移任务详情页新增查看日志
Improvements
- 数据迁移 UI 优化
- 优化监控报表、数据看板、数据探索的时间控件 UI
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
- INFINI Gateway: https://github.com/infinilabs/gateway/issues
- INFINI Console: https://github.com/infinilabs/console/issues
- 下载地址: https://www.infinilabs.com/download
您还可以通过邮件联系我们:hello@infini.ltd
或者拨打我们的热线电话:(+86) 400-139-9200
欢迎加入 Discord 聊天室:https://discord.com/invite/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »社区日报 第1707期 (2023-09-21)
https://dev.to/jainec/ingest-d ... -3af4
2.Elasticsearch 集成 Slack 发送告警(需要梯子)
https://medium.com/%40kulekci/ ... cf126
3.了解并解决文档更新后 Elasticsearch 分数变化的问题(需要梯子)
https://kulekci.medium.com/und ... 76e38
编辑:Se7en
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
https://dev.to/jainec/ingest-d ... -3af4
2.Elasticsearch 集成 Slack 发送告警(需要梯子)
https://medium.com/%40kulekci/ ... cf126
3.了解并解决文档更新后 Elasticsearch 分数变化的问题(需要梯子)
https://kulekci.medium.com/und ... 76e38
编辑:Se7en
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili 收起阅读 »
社区日报 第1706期 (2023-09-20)
https://mp.weixin.qq.com/s/mFD-W2_D4PDscsoO3SDbIQ
2. Elasticsearch:为具有许多 and/or 高频术语的 top-k 查询带来加速
https://blog.csdn.net/UbuntuTo ... 54687
3.ES 字段设计的建议(需要梯子)
https://medium.com/elasticsear ... 2991d
编辑:kin122
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili
https://mp.weixin.qq.com/s/mFD-W2_D4PDscsoO3SDbIQ
2. Elasticsearch:为具有许多 and/or 高频术语的 top-k 查询带来加速
https://blog.csdn.net/UbuntuTo ... 54687
3.ES 字段设计的建议(需要梯子)
https://medium.com/elasticsear ... 2991d
编辑:kin122
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili 收起阅读 »
社区日报 第1705期 (2023-09-19)
1. 最简学习 + 测试 ES,java + docker本地搞起来
https://medium.com/%40dfalcone ... efc46
1. M1 芯片的Mac里怎么用docker玩ES?(需要梯子)
https://medium.com/%40guillem. ... c7ad2
1. es 8 + spring boot3 不完全手册(需要梯子)
https://medium.com/%40truongbu ... 15197
编辑:斯蒂文
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
1. 最简学习 + 测试 ES,java + docker本地搞起来
https://medium.com/%40dfalcone ... efc46
1. M1 芯片的Mac里怎么用docker玩ES?(需要梯子)
https://medium.com/%40guillem. ... c7ad2
1. es 8 + spring boot3 不完全手册(需要梯子)
https://medium.com/%40truongbu ... 15197
编辑:斯蒂文
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
收起阅读 »
社区日报 第1704期 (2023-09-18)
1. Function Score Query 优化算分和Term&PhraseSuggester
https://blog.csdn.net/zhougube ... 98402
2. Elasticsearch 中字段类型(Field Type)详解
https://blog.csdn.net/aben_sky ... 15175
3. Elasticsearch 从搜索中获取选定的字段 fields
https://blog.csdn.net/UbuntuTo ... 53365
编辑:yuebancanghai
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili
1. Function Score Query 优化算分和Term&PhraseSuggester
https://blog.csdn.net/zhougube ... 98402
2. Elasticsearch 中字段类型(Field Type)详解
https://blog.csdn.net/aben_sky ... 15175
3. Elasticsearch 从搜索中获取选定的字段 fields
https://blog.csdn.net/UbuntuTo ... 53365
编辑:yuebancanghai
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili 收起阅读 »
社区日报 第1703期 (2023-09-15)
https://www.elastic.co/es/blog ... -data
2、【视频】如何计算 Elasticsearch 或 Kibana 中的时差?(梯子)
https://www.youtube.com/watch?v=JD08pJsx27w
3、使用 E5 嵌入模型进行多语言矢量搜索
https://search-labs.elastic.co ... model
编辑:铭毅天下
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
https://www.elastic.co/es/blog ... -data
2、【视频】如何计算 Elasticsearch 或 Kibana 中的时差?(梯子)
https://www.youtube.com/watch?v=JD08pJsx27w
3、使用 E5 嵌入模型进行多语言矢量搜索
https://search-labs.elastic.co ... model
编辑:铭毅天下
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili 收起阅读 »
社区日报 第1702期 (2023-09-14)
https://levelup.gitconnected.c ... 3ce63
2.可观测性故事:Elasticsearch 性能杀手(需要梯子)
https://medium.com/adyen/tales ... fc0bc
3.使用 Elasticsearch 和 Neo4j 实现可观测性(需要梯子)
https://medium.com/%40alex.pui ... c9e88
编辑:Se7en
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
https://levelup.gitconnected.c ... 3ce63
2.可观测性故事:Elasticsearch 性能杀手(需要梯子)
https://medium.com/adyen/tales ... fc0bc
3.使用 Elasticsearch 和 Neo4j 实现可观测性(需要梯子)
https://medium.com/%40alex.pui ... c9e88
编辑:Se7en
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili 收起阅读 »
INFINI Easysearch 在墨天轮搜索型数据库排名中荣登榜首
近日,2023 年 9 月的 墨天轮中国数据库流行度排行 火热出炉,本月共有 287 个数据库参与排名,中国数据库行业竞争日益激烈。其中,极限科技旗下软件产品 INFINI Easysearch 在 搜索型数据库 分类排名中脱颖而出,荣登榜首,获得了第一名的好成绩。
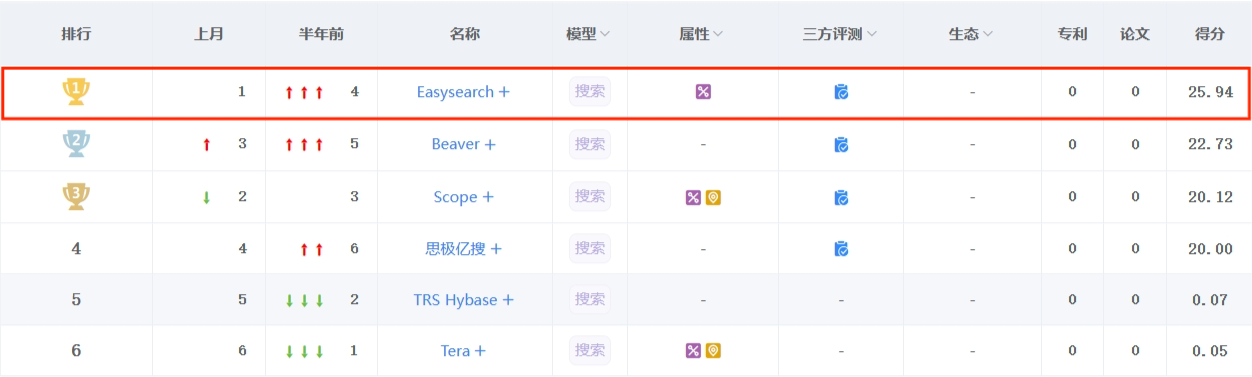
同时在国内整个数据库排行中进入了前 50 的行列。
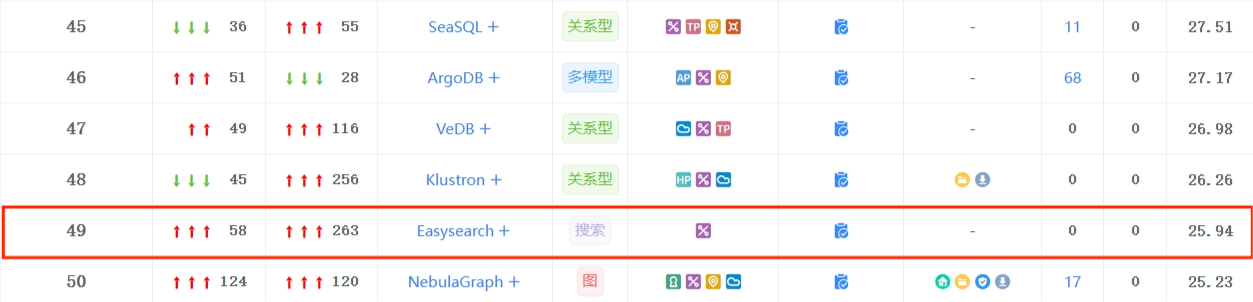
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,同时也是一款具备自主可控的分布式近实时搜索型数据库产品,具备高性能、高可用、弹性伸缩、高安全性等特性,具备支持丰富的个性化搜索及聚合分析能力,可部署在物理机、虚拟机、容器、私有云和公有云,能承载 PB 级别的海量业务数据,为金融核心系统、运营商、制造业和政企业务系统提供安全、稳定、可靠的快速检索和实时数据探索分析能力,可满足不同业务场景的各项复杂需求。

Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。 与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
国内搜索型数据库最近几年发展迅速,关键技术逐渐突破,应用场景和数据规模也逐年上升,已经成为企业必不可少的核心基础设施,产业生态也日益繁荣。极限科技作为国内搜索型数据库产品厂商第一梯队的杰出代表,同时也是行业标准的起草单位之一,此次在墨天轮中国数据库流行度排行搜索型数据库分类中荣登榜首,不仅代表着对 INFINI Easysearch 搜索型数据库的肯定,更代表着极限科技在“搜索数据库”产品的研究与创新上,取得了新的里程碑。
未来,极限科技将持续专注于打造国产搜索型数据库产品,致力于为用户提供更加优质、稳定、高效、安全的数据搜索服务和分析体验。
关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
近日,2023 年 9 月的 墨天轮中国数据库流行度排行 火热出炉,本月共有 287 个数据库参与排名,中国数据库行业竞争日益激烈。其中,极限科技旗下软件产品 INFINI Easysearch 在 搜索型数据库 分类排名中脱颖而出,荣登榜首,获得了第一名的好成绩。
同时在国内整个数据库排行中进入了前 50 的行列。
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,同时也是一款具备自主可控的分布式近实时搜索型数据库产品,具备高性能、高可用、弹性伸缩、高安全性等特性,具备支持丰富的个性化搜索及聚合分析能力,可部署在物理机、虚拟机、容器、私有云和公有云,能承载 PB 级别的海量业务数据,为金融核心系统、运营商、制造业和政企业务系统提供安全、稳定、可靠的快速检索和实时数据探索分析能力,可满足不同业务场景的各项复杂需求。
Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。 与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
国内搜索型数据库最近几年发展迅速,关键技术逐渐突破,应用场景和数据规模也逐年上升,已经成为企业必不可少的核心基础设施,产业生态也日益繁荣。极限科技作为国内搜索型数据库产品厂商第一梯队的杰出代表,同时也是行业标准的起草单位之一,此次在墨天轮中国数据库流行度排行搜索型数据库分类中荣登榜首,不仅代表着对 INFINI Easysearch 搜索型数据库的肯定,更代表着极限科技在“搜索数据库”产品的研究与创新上,取得了新的里程碑。
未来,极限科技将持续专注于打造国产搜索型数据库产品,致力于为用户提供更加优质、稳定、高效、安全的数据搜索服务和分析体验。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »社区日报 第1701期 (2023-09-13)
https://blog.csdn.net/UbuntuTo ... 23323
2. 为什么 Elasticsearch 中高基数字段上的聚合是一个坏主意以及如何优化它
https://blog.csdn.net/UbuntuTo ... 22848
3.ES 的缓存设计(需要梯子)
https://andreibaptista.medium. ... ad9a1
编辑:kin122
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili
https://blog.csdn.net/UbuntuTo ... 23323
2. 为什么 Elasticsearch 中高基数字段上的聚合是一个坏主意以及如何优化它
https://blog.csdn.net/UbuntuTo ... 22848
3.ES 的缓存设计(需要梯子)
https://andreibaptista.medium. ... ad9a1
编辑:kin122
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili 收起阅读 »
社区日报 第1700期 (2023-09-12)
https://martinfowler.com/bliki/CQRS.html
2. 我们在同步CQRS的时候为啥失败了?(需要梯子)
https://medium.com/trendyol-te ... 5c8f4
3. 我们在同步CQRS的时候为啥最终又成功了?(需要梯子)
https://medium.com/trendyol-te ... dcacd
编辑:斯蒂文
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
https://martinfowler.com/bliki/CQRS.html
2. 我们在同步CQRS的时候为啥失败了?(需要梯子)
https://medium.com/trendyol-te ... 5c8f4
3. 我们在同步CQRS的时候为啥最终又成功了?(需要梯子)
https://medium.com/trendyol-te ... dcacd
编辑:斯蒂文
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili 收起阅读 »
让 Easysearch 运行在 LoongArch(3C5000L) 上
简介
在上一次,我介绍了在国产操作系统 Kylin V10 (Lance)-aarch64 上安装单机版 Easysearch/Console/Agent/Gateway/Loadgen,小伙伴们可查看原文。今天我重点介绍下在 Loongnix-Server Linux release 8.4.1 (3C5000L)上安装 Easysearch。
系统配置
在安装之前,需要先进行系统参数调整并创建操作用户,以下命令均需要使用 root 用户操作。
#配置nofile和memlock
tee /etc/security/limits.d/21-infini.conf <<-'EOF'
* soft nofile 1048576
* hard nofile 1048576
* soft memlock unlimited
* hard memlock unlimited
root soft nofile 1048576
root hard nofile 1048576
root soft memlock unlimited
root hard memlock unlimited
EOF
#关闭THP
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo never > /sys/kernel/mm/transparent_hugepage/defrag
grep -i HugePages_Total /proc/meminfo
grep -wq transparent_hugepage /etc/rc.local || cat <<-'EOF' >> /etc/rc.local
if test -f /sys/kernel/mm/transparent_hugepage/enabled; then
echo never > /sys/kernel/mm/transparent_hugepage/enabled
fi
if test -f /sys/kernel/mm/transparent_hugepage/defrag; then
echo never > /sys/kernel/mm/transparent_hugepage/defrag
fi
EOF
chmod 755 /etc/rc.local
#内核调优
tee /etc/sysctl.d/70-infini.conf <<-'EOF'
vm.max_map_count = 262145
net.core.somaxconn = 65535
net.core.netdev_max_backlog = 65535
net.ipv4.tcp_max_syn_backlog = 65535
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_timestamps=1
net.ipv4.tcp_fin_timeout = 10
net.ipv4.tcp_keepalive_time = 900
net.ipv4.tcp_max_tw_buckets = 2000000
net.ipv4.ip_local_port_range = 1024 65535
EOF
sysctl -p /etc/sysctl.d/70-infini.conf用户配置
#创建Easysearch操作用户
groupadd -g 602 es
useradd -u 602 -g es -m -d /home/es -c 'easysearch' -s /bin/bash es配置 JDK
#在各个节点上分别操作
wget -N http://ftp.loongnix.cn/Java/openjdk17/loongson17.4.0-fx-jdk17.0.6_10-linux-loongarch64.tar.gz -P /usr/src
mkdir -p /usr/local/jdk
tar -zxf /usr/src/loongson*.tar.gz -C /usr/local/jdk --strip-components 1
tee /etc/profile.d/java.sh <<-'EOF'
# set java environment
JAVA_HOME=/usr/local/jdk
CLASSPATH=$CLASSPATH:$JAVA_HOME/lib
PATH=$JAVA_HOME/bin:$PATH
export PATH JAVA_HOME CLASSPATH
EOF
source /etc/profile
java -versionEasysearch 部署
部署及密码配置
#在线安装
curl -sSL http://get.infini.sh | bash -s -- -p easysearch -d /data/easysearch
#初始化证书(若不采用默认证书,如需要调整证书可修改证书生成文件)
cd /data/easysearch
#默认会生成随机密码
bin/initialize.sh
ll /data/easysearch/config/{*.crt,*.key,*.pem}配置文件及 JVM 调整
cat <<EOF > /data/easysearch/config/easysearch.yml
cluster.name: infinilabs
node.name: node-1
network.host: 0.0.0.0
http.port: 9200
transport.port: 9300
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
cluster.initial_master_nodes: ["node-1"]
path.home: /data/easysearch
path.data: /data/easysearch/data
path.logs: /data/easysearch/logs
http.compression: true
security.enabled: true
security.audit.type: noop
security.ssl.transport.cert_file: instance.crt
security.ssl.transport.key_file: instance.key
security.ssl.transport.ca_file: ca.crt
security.ssl.transport.skip_domain_verify: true
security.ssl.http.enabled: true
security.ssl.http.cert_file: instance.crt
security.ssl.http.key_file: instance.key
security.ssl.http.ca_file: ca.crt
security.allow_default_init_securityindex: true
security.nodes_dn:
- 'CN=infini.cloud,OU=UNIT,O=ORG,L=NI,ST=FI,C=IN'
security.restapi.roles_enabled: [ "superuser", "security_rest_api_access" ]
security.system_indices.enabled: true
security.ssl.http.clientauth_mode: OPTIONAL
security.system_indices.indices: [".infini-*"]
#for admin dn
## specify admin certs to operate against system indices, basic_auth is not required
## curl -k --cert config/admin.crt --key config/admin.key -XDELETE 'https://localhost:9200/.infini-*/'
security.authcz.admin_dn:
- 'CN=admin.infini.cloud,OU=UNIT,O=ORG,L=NI,ST=FI,C=IN'
EOF
#根据实际机器内存的大小进行配置,推荐配置为机器内存一半,且不超过31G
sed -i "s/1g/4g/g" $ES_HOME/config/jvm.options备份目录及权限调整
#创建备份目录
mkdir -p /data/easysearch/backup
#更新目录权限
chown -R es.es /data/easysearch环境变量及启动服务
su - es
grep -wq easysearch ~/.bashrc || cat<<EOF >> ~/.bashrc
export ES_HOME=/data/easysearch
EOF
source ~/.bashrc
#jna替换<龙芯平台有独立的jna实现>
rm -rvf $ES_HOME/lib/jna*.jar
wget -N https://release.infinilabs.com/easysearch/archive/jna/loongarch64/jna-5.12.1.jar -P $ES_HOME/lib
#以后台方式启动服务
$ES_HOME/bin/easysearch -dEasysearch 验证
curl -ku "admin:$pass" https://127.0.0.1:9200
curl -ku "admin:$pass" https://127.0.0.1:9200/_cluster/health?pretty
curl -ku "admin:$pass" https://127.0.0.1:9200/_cat/nodes?v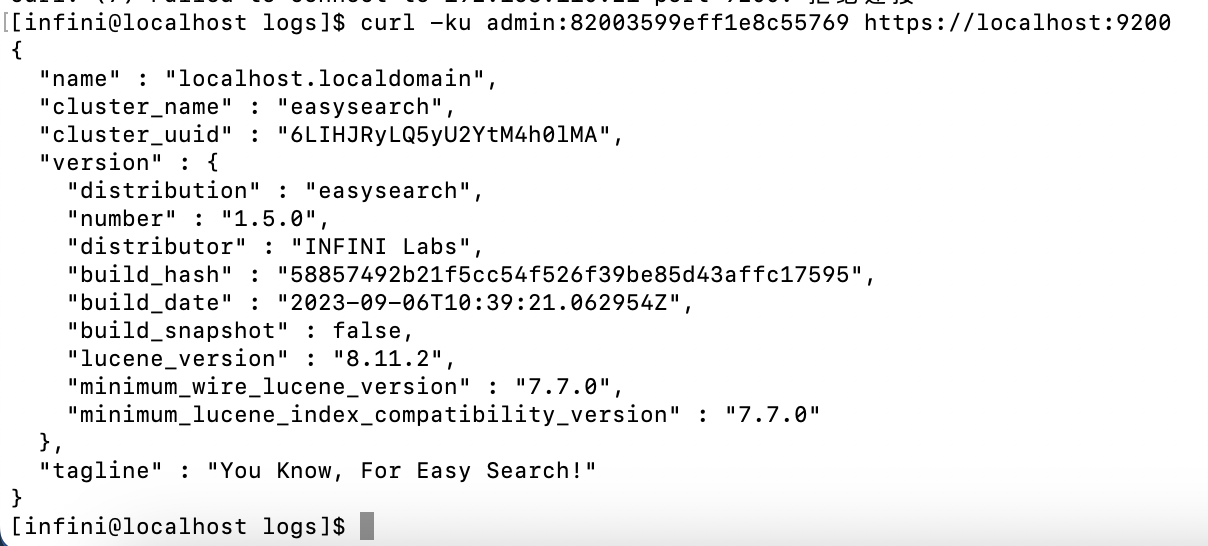
部署 Console
curl -sSL http://get.infini.sh | bash -s -- -p console
#安装服务并启动
cd /opt/console
./console-linux-loong64 -service install
./console-linux-loong64 -service start
#验证
systemctl status console部署 Agent
curl -sSL http://get.infini.sh | bash -s -- -p agent
#修改Agent配置文件
cd /opt/agent
sed -i "/ES_ENDPOINT:/ s|\(.*\: \).*|\1$https://localhost:9200|" agent.yml
sed -i "/ES_USER:/ s|\(.*\: \).*|\1admin|" agent.yml
sed -i "/ES_PASS:/ s|\(.*\: \).*|\1$pass|" gateway.yml
sed -i "/API_BINDING:/ s|\(.*\: \).*|\1\"0.0.0.0:8080\"|" agent.yml
head -n 5 agent.yml
#安装服务并启动
./agent-linux-loong64 -service install
./agent-linux-loong64 -service start
#验证
systemctl status agent部署 Gateway
curl -sSL http://get.infini.sh | bash -s -- -p gateway
cd /opt/gateway
#修改Gateway配置文件
sed -i "/ES_PASS:/ s|\(.*\: \).*|\1$pass|" gateway.yml
head -n 10 gateway.yml
#安装服务并启动
./gateway-linux-loong64 -service install
./gateway-linux-loong64 -service start
#检查服务
systemctl status gateway
curl -u "admin:$pass" http://127.0.0.1:8000部署 Loadgen
curl -sSL http://get.infini.sh | bash -s -- -p loadgen
#写入数据测试
cd /opt/loadgen
mkdir -p mock
cat <<EOF > mock/nginx.log
175.10.75.216 - - [28/Jul/2020:21:20:26 +0800] "GET / HTTP/1.1" 200 8676 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"
175.10.75.216 - - [28/Jul/2020:21:20:26 +0800] "GET /vendor/bootstrap/css/bootstrap.css HTTP/1.1" 200 17235 "http://dl-console.elasticsearch.cn/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"
175.10.75.216 - - [28/Jul/2020:21:20:26 +0800] "GET /vendor/daterangepicker/daterangepicker.css HTTP/1.1" 200 1700 "http://dl-console.elasticsearch.cn/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"
175.10.75.216 - - [28/Jul/2020:21:20:26 +0800] "GET /vendor/fork-awesome/css/v5-compat.css HTTP/1.1" 200 2091 "http://dl-console.elasticsearch.cn/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"
175.10.75.216 - - [28/Jul/2020:21:20:26 +0800] "GET /assets/font/raleway.css HTTP/1.1" 200 145 "http://dl-console.elasticsearch.cn/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"
175.10.75.216 - - [28/Jul/2020:21:20:26 +0800] "GET /vendor/fork-awesome/css/fork-awesome.css HTTP/1.1" 200 8401 "http://dl-console.elasticsearch.cn/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"
175.10.75.216 - - [28/Jul/2020:21:20:26 +0800] "GET /assets/css/overrides.css HTTP/1.1" 200 2524 "http://dl-console.elasticsearch.cn/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"
175.10.75.216 - - [28/Jul/2020:21:20:26 +0800] "GET /assets/css/theme.css HTTP/1.1" 200 306 "http://dl-console.elasticsearch.cn/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"
175.10.75.216 - - [28/Jul/2020:21:20:26 +0800] "GET /vendor/fancytree/css/ui.fancytree.css HTTP/1.1" 200 3456 "http://dl-console.elasticsearch.cn/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"
175.10.75.216 - - [28/Jul/2020:21:20:26 +0800] "GET /syncthing/development/logbar.js HTTP/1.1" 200 486 "http://dl-console.elasticsearch.cn/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"
EOF
cat <<EOF > loadgen.yml
env:
ES_USERNAME: admin
ES_PASSWORD: $pass
ES_ENDPOINT: http://localhost:8000
runner:
# total_rounds: 1
no_warm: false
# Whether to log all requests
log_requests: false
# Whether to log all requests with the specified response status
log_status_codes:
- 0
- 500
assert_invalid: false
assert_error: false
variables:
- name: ip
type: file
path: dict/ip.txt
- name: message
type: file
path: mock/nginx.log
replace: # replace special characters in the value
'"': '\"'
'\': '\\'
- name: user
type: file
path: dict/user.txt
- name: id
type: sequence
- name: uuid
type: uuid
- name: now_local
type: now_local
- name: now_utc
type: now_utc
- name: now_unix
type: now_unix
- name: suffix
type: range
from: 10
to: 13
requests:
- request:
method: POST
runtime_variables:
batch_no: uuid
runtime_body_line_variables:
routing_no: uuid
basic_auth:
username: $[[env.ES_USERNAME]]
password: $[[env.ES_PASSWORD]]
url: $[[env.ES_ENDPOINT]]/_bulk
body_repeat_times: 5000
body: |
{ "index" : { "_index" : "test-$[[suffix]]", "_id" : "$[[uuid]]" } }
{ "id" : "$[[uuid]]","routing_no" : "$[[routing_no]]","batch_number" : "$[[batch_no]]","message" : "$[[message]]","random_no" : "$[[suffix]]","ip" : "$[[ip]]","now_local" : "$[[now_local]]","now_unix" : "$[[now_unix]]" }
EOF
#执行测试
./loadgen-linux-loong64 -c 6 -d 6 --compress
#检查测试索引文档
curl -u "admin:$pass" http://127.0.0.1:8000/_cat/indices/test*?v至此,完成在 LoongArch(3C5000L)上安装单机版 Easysearch/Console/Agent/Gateway/Loadgen。通过浏览器 http://机器域名:9000/ 即可访问 Console,对 Easysearch 进行配置管理。
可能遇到的问题

检查下配置文件中监听的地址是否正确,防火墙是否有关闭。

关于 Easysearch

INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。 与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
简介
在上一次,我介绍了在国产操作系统 Kylin V10 (Lance)-aarch64 上安装单机版 Easysearch/Console/Agent/Gateway/Loadgen,小伙伴们可查看原文。今天我重点介绍下在 Loongnix-Server Linux release 8.4.1 (3C5000L)上安装 Easysearch。
系统配置
在安装之前,需要先进行系统参数调整并创建操作用户,以下命令均需要使用 root 用户操作。
#配置nofile和memlock
tee /etc/security/limits.d/21-infini.conf <<-'EOF'
* soft nofile 1048576
* hard nofile 1048576
* soft memlock unlimited
* hard memlock unlimited
root soft nofile 1048576
root hard nofile 1048576
root soft memlock unlimited
root hard memlock unlimited
EOF
#关闭THP
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo never > /sys/kernel/mm/transparent_hugepage/defrag
grep -i HugePages_Total /proc/meminfo
grep -wq transparent_hugepage /etc/rc.local || cat <<-'EOF' >> /etc/rc.local
if test -f /sys/kernel/mm/transparent_hugepage/enabled; then
echo never > /sys/kernel/mm/transparent_hugepage/enabled
fi
if test -f /sys/kernel/mm/transparent_hugepage/defrag; then
echo never > /sys/kernel/mm/transparent_hugepage/defrag
fi
EOF
chmod 755 /etc/rc.local
#内核调优
tee /etc/sysctl.d/70-infini.conf <<-'EOF'
vm.max_map_count = 262145
net.core.somaxconn = 65535
net.core.netdev_max_backlog = 65535
net.ipv4.tcp_max_syn_backlog = 65535
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_timestamps=1
net.ipv4.tcp_fin_timeout = 10
net.ipv4.tcp_keepalive_time = 900
net.ipv4.tcp_max_tw_buckets = 2000000
net.ipv4.ip_local_port_range = 1024 65535
EOF
sysctl -p /etc/sysctl.d/70-infini.conf用户配置
#创建Easysearch操作用户
groupadd -g 602 es
useradd -u 602 -g es -m -d /home/es -c 'easysearch' -s /bin/bash es配置 JDK
#在各个节点上分别操作
wget -N http://ftp.loongnix.cn/Java/openjdk17/loongson17.4.0-fx-jdk17.0.6_10-linux-loongarch64.tar.gz -P /usr/src
mkdir -p /usr/local/jdk
tar -zxf /usr/src/loongson*.tar.gz -C /usr/local/jdk --strip-components 1
tee /etc/profile.d/java.sh <<-'EOF'
# set java environment
JAVA_HOME=/usr/local/jdk
CLASSPATH=$CLASSPATH:$JAVA_HOME/lib
PATH=$JAVA_HOME/bin:$PATH
export PATH JAVA_HOME CLASSPATH
EOF
source /etc/profile
java -versionEasysearch 部署
部署及密码配置
#在线安装
curl -sSL http://get.infini.sh | bash -s -- -p easysearch -d /data/easysearch
#初始化证书(若不采用默认证书,如需要调整证书可修改证书生成文件)
cd /data/easysearch
#默认会生成随机密码
bin/initialize.sh
ll /data/easysearch/config/{*.crt,*.key,*.pem}配置文件及 JVM 调整
cat <<EOF > /data/easysearch/config/easysearch.yml
cluster.name: infinilabs
node.name: node-1
network.host: 0.0.0.0
http.port: 9200
transport.port: 9300
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
cluster.initial_master_nodes: ["node-1"]
path.home: /data/easysearch
path.data: /data/easysearch/data
path.logs: /data/easysearch/logs
http.compression: true
security.enabled: true
security.audit.type: noop
security.ssl.transport.cert_file: instance.crt
security.ssl.transport.key_file: instance.key
security.ssl.transport.ca_file: ca.crt
security.ssl.transport.skip_domain_verify: true
security.ssl.http.enabled: true
security.ssl.http.cert_file: instance.crt
security.ssl.http.key_file: instance.key
security.ssl.http.ca_file: ca.crt
security.allow_default_init_securityindex: true
security.nodes_dn:
- 'CN=infini.cloud,OU=UNIT,O=ORG,L=NI,ST=FI,C=IN'
security.restapi.roles_enabled: [ "superuser", "security_rest_api_access" ]
security.system_indices.enabled: true
security.ssl.http.clientauth_mode: OPTIONAL
security.system_indices.indices: [".infini-*"]
#for admin dn
## specify admin certs to operate against system indices, basic_auth is not required
## curl -k --cert config/admin.crt --key config/admin.key -XDELETE 'https://localhost:9200/.infini-*/'
security.authcz.admin_dn:
- 'CN=admin.infini.cloud,OU=UNIT,O=ORG,L=NI,ST=FI,C=IN'
EOF
#根据实际机器内存的大小进行配置,推荐配置为机器内存一半,且不超过31G
sed -i "s/1g/4g/g" $ES_HOME/config/jvm.options备份目录及权限调整
#创建备份目录
mkdir -p /data/easysearch/backup
#更新目录权限
chown -R es.es /data/easysearch环境变量及启动服务
su - es
grep -wq easysearch ~/.bashrc || cat<<EOF >> ~/.bashrc
export ES_HOME=/data/easysearch
EOF
source ~/.bashrc
#jna替换<龙芯平台有独立的jna实现>
rm -rvf $ES_HOME/lib/jna*.jar
wget -N https://release.infinilabs.com/easysearch/archive/jna/loongarch64/jna-5.12.1.jar -P $ES_HOME/lib
#以后台方式启动服务
$ES_HOME/bin/easysearch -dEasysearch 验证
curl -ku "admin:$pass" https://127.0.0.1:9200
curl -ku "admin:$pass" https://127.0.0.1:9200/_cluster/health?pretty
curl -ku "admin:$pass" https://127.0.0.1:9200/_cat/nodes?v部署 Console
curl -sSL http://get.infini.sh | bash -s -- -p console
#安装服务并启动
cd /opt/console
./console-linux-loong64 -service install
./console-linux-loong64 -service start
#验证
systemctl status console部署 Agent
curl -sSL http://get.infini.sh | bash -s -- -p agent
#修改Agent配置文件
cd /opt/agent
sed -i "/ES_ENDPOINT:/ s|\(.*\: \).*|\1$https://localhost:9200|" agent.yml
sed -i "/ES_USER:/ s|\(.*\: \).*|\1admin|" agent.yml
sed -i "/ES_PASS:/ s|\(.*\: \).*|\1$pass|" gateway.yml
sed -i "/API_BINDING:/ s|\(.*\: \).*|\1\"0.0.0.0:8080\"|" agent.yml
head -n 5 agent.yml
#安装服务并启动
./agent-linux-loong64 -service install
./agent-linux-loong64 -service start
#验证
systemctl status agent部署 Gateway
curl -sSL http://get.infini.sh | bash -s -- -p gateway
cd /opt/gateway
#修改Gateway配置文件
sed -i "/ES_PASS:/ s|\(.*\: \).*|\1$pass|" gateway.yml
head -n 10 gateway.yml
#安装服务并启动
./gateway-linux-loong64 -service install
./gateway-linux-loong64 -service start
#检查服务
systemctl status gateway
curl -u "admin:$pass" http://127.0.0.1:8000部署 Loadgen
curl -sSL http://get.infini.sh | bash -s -- -p loadgen
#写入数据测试
cd /opt/loadgen
mkdir -p mock
cat <<EOF > mock/nginx.log
175.10.75.216 - - [28/Jul/2020:21:20:26 +0800] "GET / HTTP/1.1" 200 8676 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"
175.10.75.216 - - [28/Jul/2020:21:20:26 +0800] "GET /vendor/bootstrap/css/bootstrap.css HTTP/1.1" 200 17235 "http://dl-console.elasticsearch.cn/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"
175.10.75.216 - - [28/Jul/2020:21:20:26 +0800] "GET /vendor/daterangepicker/daterangepicker.css HTTP/1.1" 200 1700 "http://dl-console.elasticsearch.cn/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"
175.10.75.216 - - [28/Jul/2020:21:20:26 +0800] "GET /vendor/fork-awesome/css/v5-compat.css HTTP/1.1" 200 2091 "http://dl-console.elasticsearch.cn/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"
175.10.75.216 - - [28/Jul/2020:21:20:26 +0800] "GET /assets/font/raleway.css HTTP/1.1" 200 145 "http://dl-console.elasticsearch.cn/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"
175.10.75.216 - - [28/Jul/2020:21:20:26 +0800] "GET /vendor/fork-awesome/css/fork-awesome.css HTTP/1.1" 200 8401 "http://dl-console.elasticsearch.cn/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"
175.10.75.216 - - [28/Jul/2020:21:20:26 +0800] "GET /assets/css/overrides.css HTTP/1.1" 200 2524 "http://dl-console.elasticsearch.cn/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"
175.10.75.216 - - [28/Jul/2020:21:20:26 +0800] "GET /assets/css/theme.css HTTP/1.1" 200 306 "http://dl-console.elasticsearch.cn/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"
175.10.75.216 - - [28/Jul/2020:21:20:26 +0800] "GET /vendor/fancytree/css/ui.fancytree.css HTTP/1.1" 200 3456 "http://dl-console.elasticsearch.cn/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"
175.10.75.216 - - [28/Jul/2020:21:20:26 +0800] "GET /syncthing/development/logbar.js HTTP/1.1" 200 486 "http://dl-console.elasticsearch.cn/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"
EOF
cat <<EOF > loadgen.yml
env:
ES_USERNAME: admin
ES_PASSWORD: $pass
ES_ENDPOINT: http://localhost:8000
runner:
# total_rounds: 1
no_warm: false
# Whether to log all requests
log_requests: false
# Whether to log all requests with the specified response status
log_status_codes:
- 0
- 500
assert_invalid: false
assert_error: false
variables:
- name: ip
type: file
path: dict/ip.txt
- name: message
type: file
path: mock/nginx.log
replace: # replace special characters in the value
'"': '\"'
'\': '\\'
- name: user
type: file
path: dict/user.txt
- name: id
type: sequence
- name: uuid
type: uuid
- name: now_local
type: now_local
- name: now_utc
type: now_utc
- name: now_unix
type: now_unix
- name: suffix
type: range
from: 10
to: 13
requests:
- request:
method: POST
runtime_variables:
batch_no: uuid
runtime_body_line_variables:
routing_no: uuid
basic_auth:
username: $[[env.ES_USERNAME]]
password: $[[env.ES_PASSWORD]]
url: $[[env.ES_ENDPOINT]]/_bulk
body_repeat_times: 5000
body: |
{ "index" : { "_index" : "test-$[[suffix]]", "_id" : "$[[uuid]]" } }
{ "id" : "$[[uuid]]","routing_no" : "$[[routing_no]]","batch_number" : "$[[batch_no]]","message" : "$[[message]]","random_no" : "$[[suffix]]","ip" : "$[[ip]]","now_local" : "$[[now_local]]","now_unix" : "$[[now_unix]]" }
EOF
#执行测试
./loadgen-linux-loong64 -c 6 -d 6 --compress
#检查测试索引文档
curl -u "admin:$pass" http://127.0.0.1:8000/_cat/indices/test*?v至此,完成在 LoongArch(3C5000L)上安装单机版 Easysearch/Console/Agent/Gateway/Loadgen。通过浏览器 http://机器域名:9000/ 即可访问 Console,对 Easysearch 进行配置管理。
可能遇到的问题
检查下配置文件中监听的地址是否正确,防火墙是否有关闭。
关于 Easysearch
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。 与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
官网文档:https://www.infinilabs.com/docs/latest/easysearch
下载地址:https://www.infinilabs.com/download
收起阅读 »社区日报 第1699期 (2023-09-11)
https://mp.weixin.qq.com/s/mFD-W2_D4PDscsoO3SDbIQ
2. 腾讯云 ES Serverless 初体验
https://mp.weixin.qq.com/s/1P6jW3sAisPCtSPwnJH5Cw
3. 源码剖析:Elasticsearch 段合并调度及优化手段
https://mp.weixin.qq.com/s/N-rtgaoyQAPJ0e44ljDS7Q
编辑:yuebancanghai
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili
https://mp.weixin.qq.com/s/mFD-W2_D4PDscsoO3SDbIQ
2. 腾讯云 ES Serverless 初体验
https://mp.weixin.qq.com/s/1P6jW3sAisPCtSPwnJH5Cw
3. 源码剖析:Elasticsearch 段合并调度及优化手段
https://mp.weixin.qq.com/s/N-rtgaoyQAPJ0e44ljDS7Q
编辑:yuebancanghai
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili 收起阅读 »
社区日报 第1698期 (2023-09-07)
https://medium.com/%40ivangfr/ ... 0aa27
2.Elasticsearch:使用 ESRE 和生成式 AI 了解 TLS 日志错误
https://elasticstack.blog.csdn ... 97222
3.近期碰到的Elasticsearch相关问题总结
https://mp.weixin.qq.com/s/MBUs4CJQ5TnvarCDORCZTQ
编辑:Se7en
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
https://medium.com/%40ivangfr/ ... 0aa27
2.Elasticsearch:使用 ESRE 和生成式 AI 了解 TLS 日志错误
https://elasticstack.blog.csdn ... 97222
3.近期碰到的Elasticsearch相关问题总结
https://mp.weixin.qq.com/s/MBUs4CJQ5TnvarCDORCZTQ
编辑:Se7en
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili 收起阅读 »
社区日报 第1697期 (2023-09-05)
1. 大佬,我该怎么规划我的集群配置?(需要梯子)
https://medium.com/%40sureshku ... 591d4
2. 在Windows系统上装ES全家你会吗?我也不会(需要梯子)
https://blog.devops.dev/instal ... 247b6
3. ES加持,让我们的数据分析系统变得贼厉害(需要梯子)
https://medium.com/oyindonesia ... 19e60
编辑:斯蒂文
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
1. 大佬,我该怎么规划我的集群配置?(需要梯子)
https://medium.com/%40sureshku ... 591d4
2. 在Windows系统上装ES全家你会吗?我也不会(需要梯子)
https://blog.devops.dev/instal ... 247b6
3. ES加持,让我们的数据分析系统变得贼厉害(需要梯子)
https://medium.com/oyindonesia ... 19e60
编辑:斯蒂文
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
收起阅读 »
INFINI Labs 产品更新 | Console 告警中心 UI 全新改版,新增 Dashboard 全屏模式等功能
本次 INFINI Labs 产品更新主要发布 Console v1.7.0,重点优化了 Console 告警中心和数据看板 Dashboard 可视化功能。详细介绍如下:
优化告警中心 UI
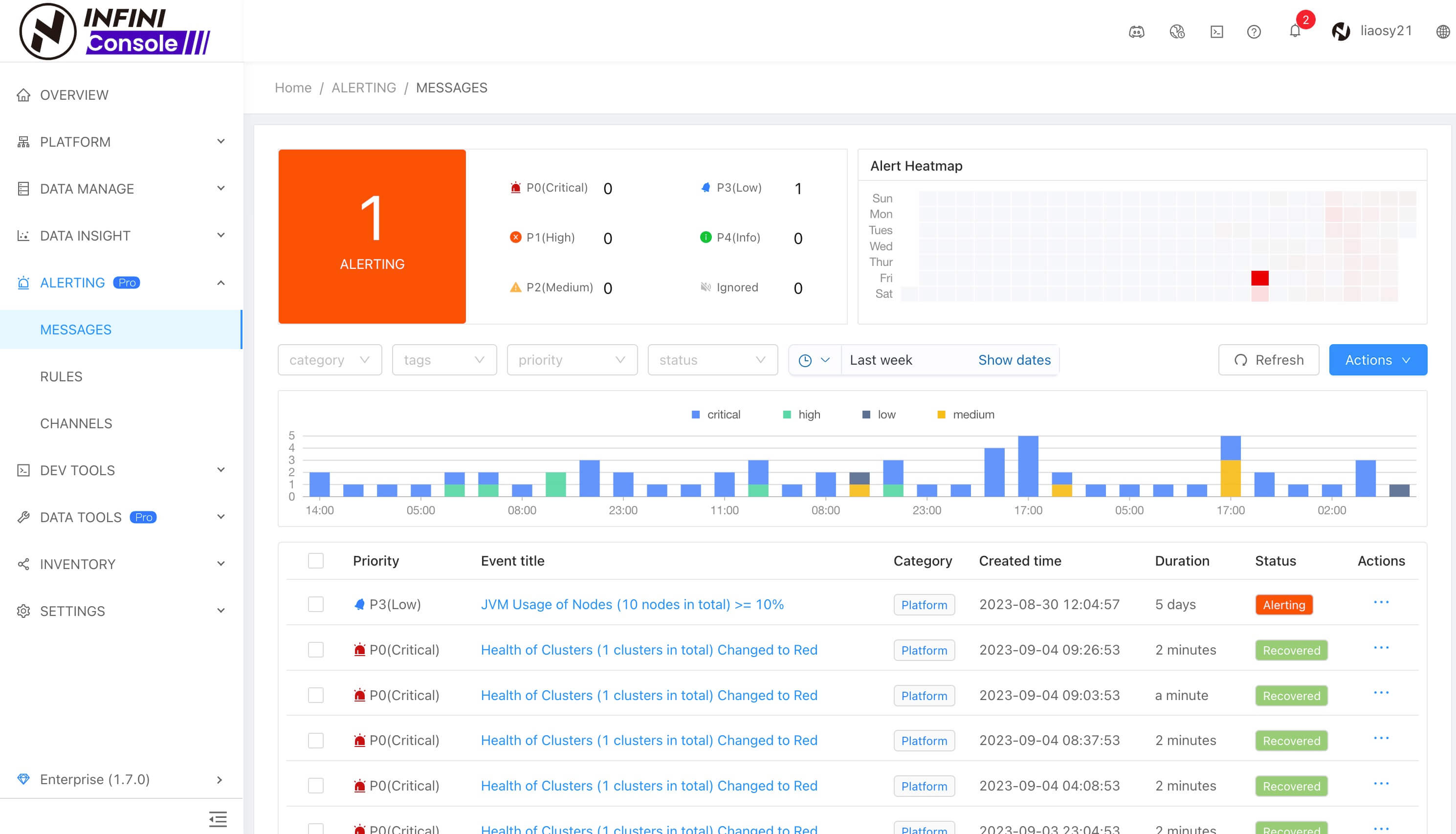
上个版本优化了告警渠道和通知,本版本主要对告警中心做了重点优化,重新设计了新的 UI 界面。进入告警中心,可以快速了解整个系统各集群告警状态,主要包括:
1、告警事件分类统计,支持点击过滤查询对应时间段的具体告警事件,便于管理员重点关注和处理高级别的告警事件;
2、告警事件数热力图,不同的色块表示当天告警数的密集程度,可以帮助我们快速发现告警数据的趋势规律以及不同时期的数据变化情况,进一步可帮助我们分析出集群的总体健康状态变化趋势。
3、告警事件列表,通过列表可以了解单个告警事件的信息,如事件级别、事件标题、告警持续时长、事件状态、触发时间等内容,如果你不想处理某个具体告警事件,可以进行忽略操作,避免再次收到告警通知。
告警中心 UI 界面如下所示:
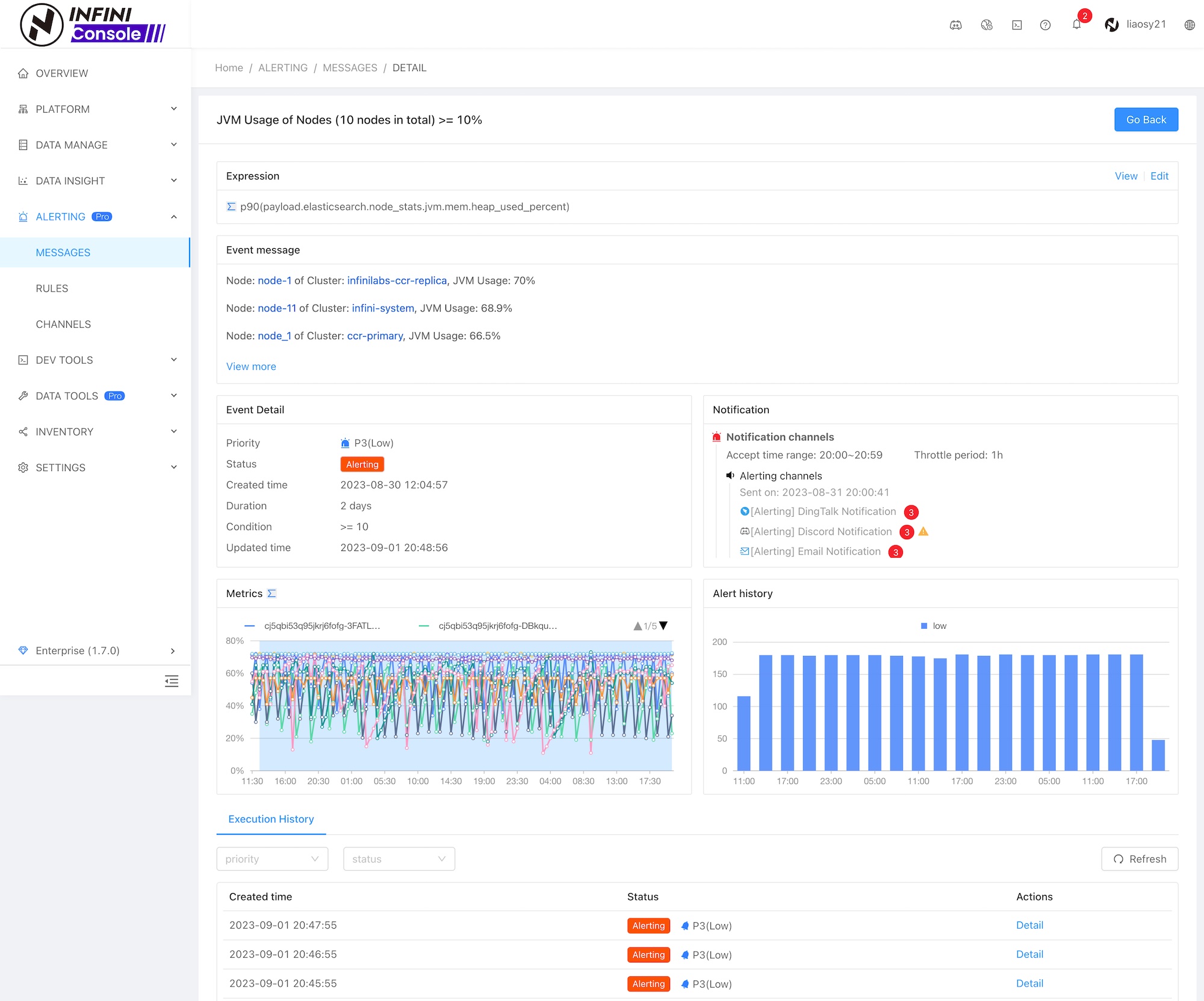
通过告警中心进入告警事件详情,可以查看更多告警信息,包括:告警规则、告警内容(支持 Markdown)、告警规则执行记录、告警通知发送情况、事件触发统计图等,界面如下所示:
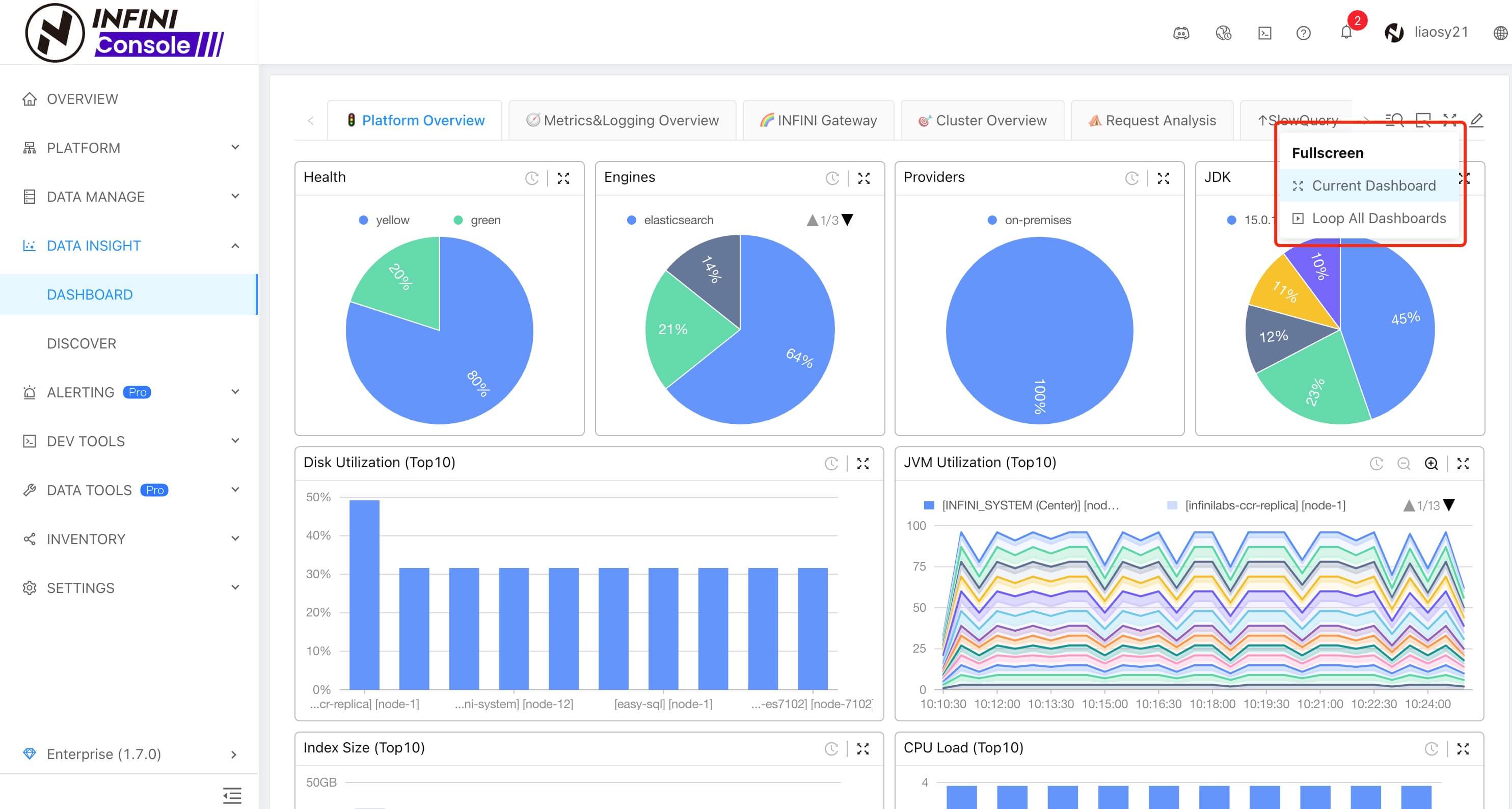
数据看板新增全屏功能
为了方便将数据看板 Dashboard 投影展示到电视墙或者 LED 大屏幕,我们新增了全屏功能,包含全屏展示当前 Dashboard,如果配置了多个 Dashboard,也支持全屏时自动滚动 Dashboard,无手动切换。效果如下所示:
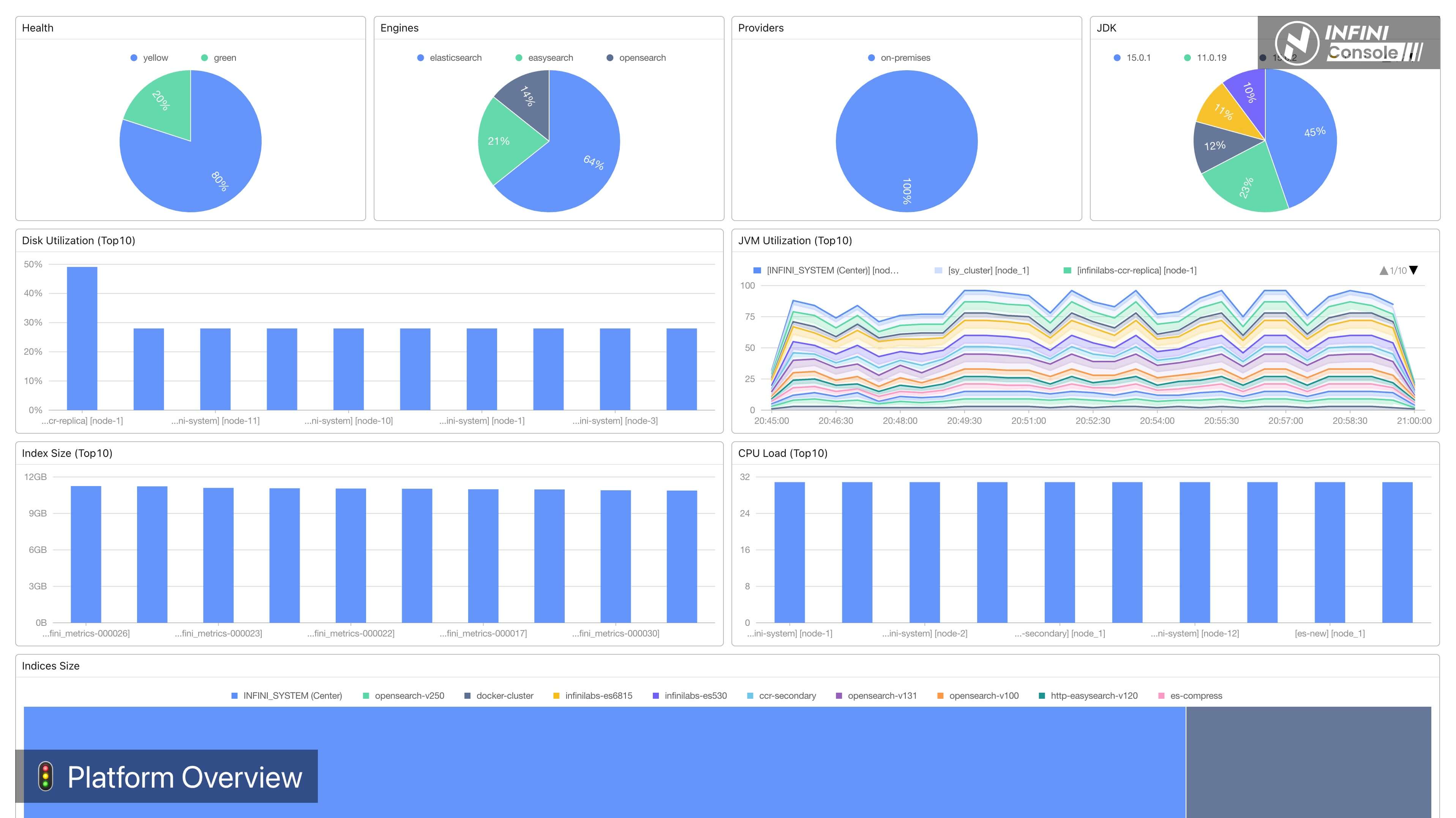
全屏模式显示效果如下:
其他更新
除了以上主要功能优化,Console 本次更新其他功能清单如下:
Features
- 告警规则新增分类和标签属性
- 告警 UI 操作增加批量操作
- 数据看板新增全屏功能
- 数据看板新增日历热力图
- 数据看板组件多分组支持分层显示
Bug fix
- 修复数据迁移任务在大量子任务场景下,统计进度不对的问题
- 修复某些场景下集群重复注册的问题
Improvements
- 告警中心页面 UI 优化
- 告警详情页面 UI 优化
- 数据看板组件配置 UI 优化
- 数据看板组件数据源配置优化
- 网关管理-队列管理支持批量删除队列和消费者
关于 INFINI Console
INFINI Console 是一款非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管, 企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 在线体验: http://demo.infini.cloud (用户名/密码:readonly/readonly)。
也欢迎下载本地安装体验!(附:Easysearch 与 Console 快速安装演示视频)
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
- INFINI Gateway: https://github.com/infinilabs/gateway/issues
- INFINI Console: https://github.com/infinilabs/console/issues
- 下载地址: https://www.infinilabs.com/download
您还可以通过邮件联系我们:hello@infini.ltd
或者拨打我们的热线电话:(+86) 400-139-9200
欢迎加入 Discord 聊天室:https://discord.gg/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。

关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
本次 INFINI Labs 产品更新主要发布 Console v1.7.0,重点优化了 Console 告警中心和数据看板 Dashboard 可视化功能。详细介绍如下:
优化告警中心 UI
上个版本优化了告警渠道和通知,本版本主要对告警中心做了重点优化,重新设计了新的 UI 界面。进入告警中心,可以快速了解整个系统各集群告警状态,主要包括:
1、告警事件分类统计,支持点击过滤查询对应时间段的具体告警事件,便于管理员重点关注和处理高级别的告警事件;
2、告警事件数热力图,不同的色块表示当天告警数的密集程度,可以帮助我们快速发现告警数据的趋势规律以及不同时期的数据变化情况,进一步可帮助我们分析出集群的总体健康状态变化趋势。
3、告警事件列表,通过列表可以了解单个告警事件的信息,如事件级别、事件标题、告警持续时长、事件状态、触发时间等内容,如果你不想处理某个具体告警事件,可以进行忽略操作,避免再次收到告警通知。
告警中心 UI 界面如下所示:
通过告警中心进入告警事件详情,可以查看更多告警信息,包括:告警规则、告警内容(支持 Markdown)、告警规则执行记录、告警通知发送情况、事件触发统计图等,界面如下所示:
数据看板新增全屏功能
为了方便将数据看板 Dashboard 投影展示到电视墙或者 LED 大屏幕,我们新增了全屏功能,包含全屏展示当前 Dashboard,如果配置了多个 Dashboard,也支持全屏时自动滚动 Dashboard,无手动切换。效果如下所示:
全屏模式显示效果如下:
其他更新
除了以上主要功能优化,Console 本次更新其他功能清单如下:
Features
- 告警规则新增分类和标签属性
- 告警 UI 操作增加批量操作
- 数据看板新增全屏功能
- 数据看板新增日历热力图
- 数据看板组件多分组支持分层显示
Bug fix
- 修复数据迁移任务在大量子任务场景下,统计进度不对的问题
- 修复某些场景下集群重复注册的问题
Improvements
- 告警中心页面 UI 优化
- 告警详情页面 UI 优化
- 数据看板组件配置 UI 优化
- 数据看板组件数据源配置优化
- 网关管理-队列管理支持批量删除队列和消费者
关于 INFINI Console
INFINI Console 是一款非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管, 企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 在线体验: http://demo.infini.cloud (用户名/密码:readonly/readonly)。
也欢迎下载本地安装体验!(附:Easysearch 与 Console 快速安装演示视频)
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
- INFINI Gateway: https://github.com/infinilabs/gateway/issues
- INFINI Console: https://github.com/infinilabs/console/issues
- 下载地址: https://www.infinilabs.com/download
您还可以通过邮件联系我们:hello@infini.ltd
或者拨打我们的热线电话:(+86) 400-139-9200
欢迎加入 Discord 聊天室:https://discord.gg/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »
