

社区日报 第1695期 (2023-08-31)
https://medium.com/people-ai-e ... 9d6df
2.使用 Elasticsearch、OpenAI 和 LangChain 进行语义搜索
https://dylancastillo.co/seman ... hain/
3.使用 Opster Management Console 在 Kubernetes 集群中管理 OpenSearch
https://opster.com/docs/omc/ov ... sole/
编辑:Se7en
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
https://medium.com/people-ai-e ... 9d6df
2.使用 Elasticsearch、OpenAI 和 LangChain 进行语义搜索
https://dylancastillo.co/seman ... hain/
3.使用 Opster Management Console 在 Kubernetes 集群中管理 OpenSearch
https://opster.com/docs/omc/ov ... sole/
编辑:Se7en
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili 收起阅读 »
社区日报 第1694期 (2023-08-29)
1. 在EKBS上怎么部署ES,你学废了吗?(需要梯子)
https://medium.com/appscode/de ... 1652f
2. EXFO大量数据写入优化实战,90%速度的提升,我们最对了什么(需要梯子)
https://medium.com/%40yannvds/ ... ee574
3. ES8在.Net平台上的api使用教程(需要梯子)
https://medium.com/%40abdulwar ... 7df21
编辑:斯蒂文
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
1. 在EKBS上怎么部署ES,你学废了吗?(需要梯子)
https://medium.com/appscode/de ... 1652f
2. EXFO大量数据写入优化实战,90%速度的提升,我们最对了什么(需要梯子)
https://medium.com/%40yannvds/ ... ee574
3. ES8在.Net平台上的api使用教程(需要梯子)
https://medium.com/%40abdulwar ... 7df21
编辑:斯蒂文
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
收起阅读 »
社区日报 第1693期 (2023-08-28)
https://blog.csdn.net/weixin_4 ... 14092
2. ElasticSearch 在大数据场景的应用与实践
http://www.360doc.com/content/ ... shtml
3. Elasticsearch 5.x 字段折叠的使用
https://blog.csdn.net/qq_41455 ... 06886
编辑:yuebancanghai
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili
https://blog.csdn.net/weixin_4 ... 14092
2. ElasticSearch 在大数据场景的应用与实践
http://www.360doc.com/content/ ... shtml
3. Elasticsearch 5.x 字段折叠的使用
https://blog.csdn.net/qq_41455 ... 06886
编辑:yuebancanghai
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili 收起阅读 »
社区日报 第1692期 (2023-08-25)
1、增强搜索功能:部署、优化和扩展 Elasticsearch 的 DevOps 之旅
https://itgix.com/case-studies ... Dpost
2、[视频]如何使用 Docker Secrets 保护 Elasticsearch 8.9 集群 - 第 1 部分(梯子)
https://www.youtube.com/watch?v=NnmeXCjPpaM
3、文本搜索与矢量搜索:一起使用效果更好?(梯子)
https://towardsdatascience.com ... 6132a
编辑:铭毅天下
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
1、增强搜索功能:部署、优化和扩展 Elasticsearch 的 DevOps 之旅
https://itgix.com/case-studies ... Dpost
2、[视频]如何使用 Docker Secrets 保护 Elasticsearch 8.9 集群 - 第 1 部分(梯子)
https://www.youtube.com/watch?v=NnmeXCjPpaM
3、文本搜索与矢量搜索:一起使用效果更好?(梯子)
https://towardsdatascience.com ... 6132a
编辑:铭毅天下
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili 收起阅读 »
社区日报 第1691期 (2023-08-24)
https://medium.com/%40learnrep ... f80db
2.Shopify 是如何在 Kubernetes 上管理 Elasticsearch 的(需要梯子)
https://www.youtube.com/watch% ... D792s
3.介绍 Elasticsearch Rust client(需要梯子)
https://www.youtube.com/watch?v=U_P27x-gYKc
编辑:Se7en
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
https://medium.com/%40learnrep ... f80db
2.Shopify 是如何在 Kubernetes 上管理 Elasticsearch 的(需要梯子)
https://www.youtube.com/watch% ... D792s
3.介绍 Elasticsearch Rust client(需要梯子)
https://www.youtube.com/watch?v=U_P27x-gYKc
编辑:Se7en
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili 收起阅读 »
社区日报 第1690期 (2023-08-23)
https://blog.csdn.net/UbuntuTo ... 32809
2. ES 查询概念大全(需要梯子)
https://medium.com/%40abhirup. ... 0b097
3.ES 查询语句概念梳理(需要梯子)
https://medium.com/elasticsear ... bf455
编辑:kin122
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili
https://blog.csdn.net/UbuntuTo ... 32809
2. ES 查询概念大全(需要梯子)
https://medium.com/%40abhirup. ... 0b097
3.ES 查询语句概念梳理(需要梯子)
https://medium.com/elasticsear ... bf455
编辑:kin122
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili 收起阅读 »
Easysearch 跨集群复制实战
在之前的文章中,有通过极限网关实现容灾的案例。今天给大家介绍 Easysearch 的跨集群复制功能。该功能可在集群之间复制数据,应用场景包括但不限于以下举例:
- 灾备同步:将数据同步到灾备中心,灾备中心可对外提供查询服务。
- 读写分离:单一集群读写压力都较大时,为了避免读写互相干扰造成性能降级,可将读压力分流到另外的集群。
- 就近查询:在多地中心之间复制数据,应用只需连接本地 ES 集群读取数据,避免网络延时和干扰。
跨集群复制使用 active-passive 模型,由目标集群主动拉取数据变化到本地,因此对源集群影响很小。
先决条件
- 源集群和目标集群都必须安装 cross-cluster-replication 和 index-management 插件。安装插件参考这里。
- 如果目标集群的 easysearch.yml 文件中覆盖了 node.roles,确保它也包括 remote_cluster_client 角色,默认已启用。
演示环境
- 源集群( leader 集群 ): 192.168.3.45:9200
- 目标集群( follower 集群 ): 192.168.3.39:9200
- 两个集群都已启用 security 功能。
设置集群间证书互信
将两个集群的证书合并到一个文件,将文件放到 config 目录下。
cat ca-A.crt ca-B.crt > trust-chain.pem更新 easysearch.yml 文件,变化如下。
#security.ssl.transport.ca_file: ca.crt
security.ssl.transport.ca_file: trust-chain.pem设置跨群集连接
在目标集群建立源集群的连接信息。在 INFINI console 的开发工具中,选中目标集群,执行以下命令。
PUT /_cluster/settings?pretty
{
"persistent": {
"cluster": {
"remote": {
"primary": {
"seeds": ["192.168.3.45:9300"]
}
}
}
}
}开始复制
首先在源集群创建测试索引 test , 并向索引写入数据。如果有测试索引,此步可省略。
POST /_bulk?pretty
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "create" : { "_index" : "test", "_id" : "2" } }
{ "field2" : "value2" }然后在目标集群,创建一个名为 follower-test 的索引来复制源集群中 test 索引的内容。follower-test 可更换成自己想要的名字。
PUT /_replication/follower-test/_start?pretty
{
"leader_alias": "primary",
"leader_index": "test",
"use_roles":{
"leader_cluster_role": "cross_cluster_replication_leader_full_access",
"follower_cluster_role": "cross_cluster_replication_follower_full_access"
}
}- leader_alias 指定之前创建的连接名称 primary 。
- leader_index 指定想要复制的索引名称 test 。
- use_roles 指定用什么角色访问对应的集群,为了安全使用最小权限,命令中的角色是系统自带的。
命令执行完后,会在目标集群建立名为 follower-test 的索引,其内容来自源集群的 test 索引。 我们可以看到,其内容就是之前插入的两个文档。
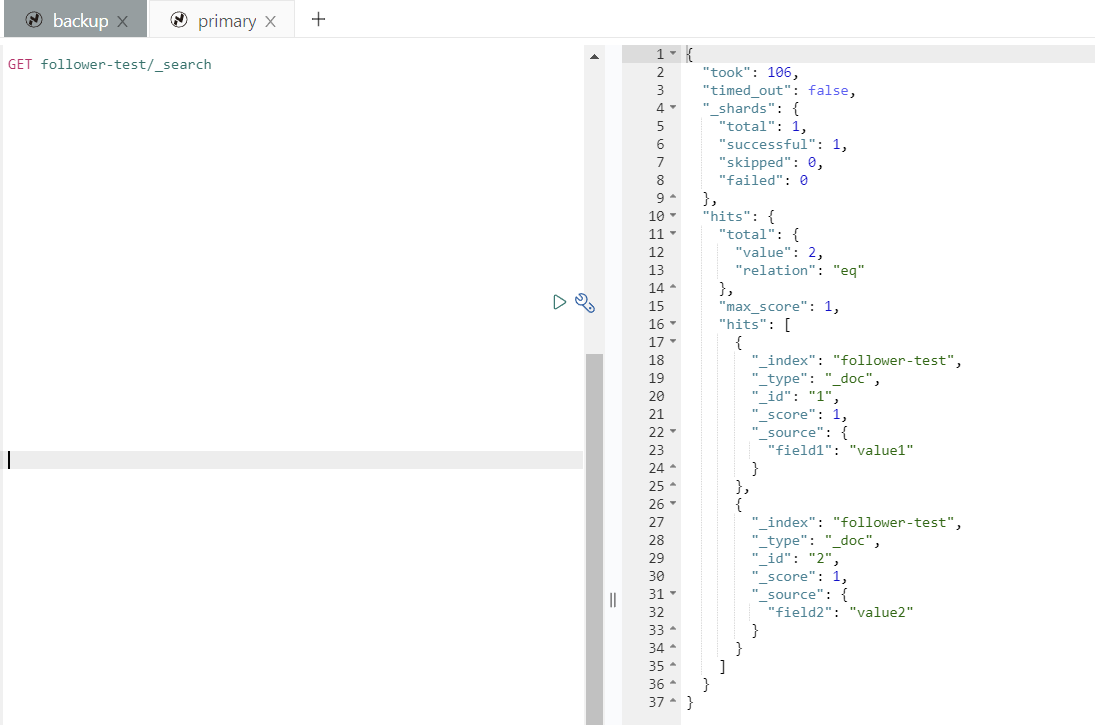
确认复制状态
可以看到 follow-test 处于同步的状态会实时同步远端的数据。
GET /_replication/follower-test/_status?pretty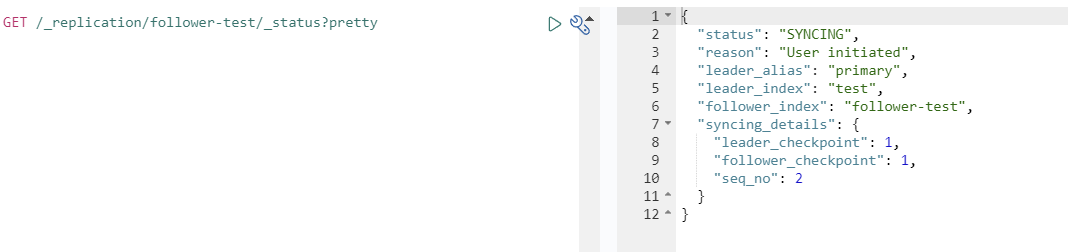 在源集群再插入数据,看是否会同步。
在源集群再插入数据,看是否会同步。
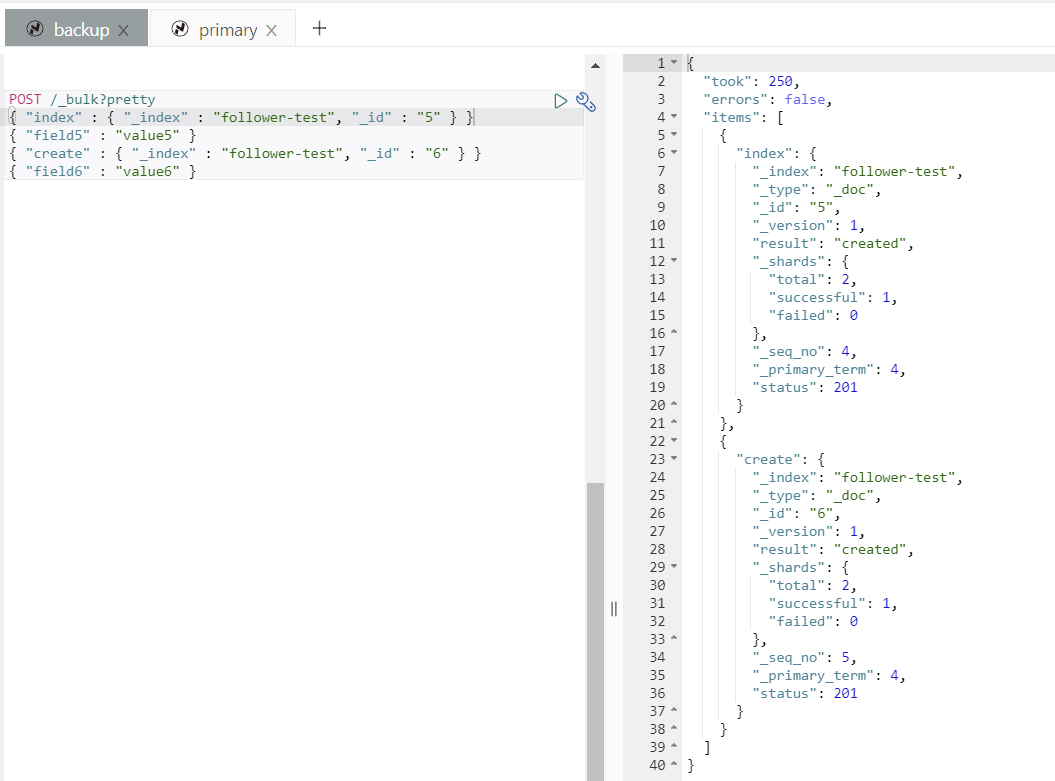
POST /_bulk?pretty
{ "index" : { "_index" : "test", "_id" : "3" } }
{ "field3" : "value3" }
{ "create" : { "_index" : "test", "_id" : "4" } }
{ "field4" : "value4" }目标集群查询索引,文档 3 和 4 已同步。
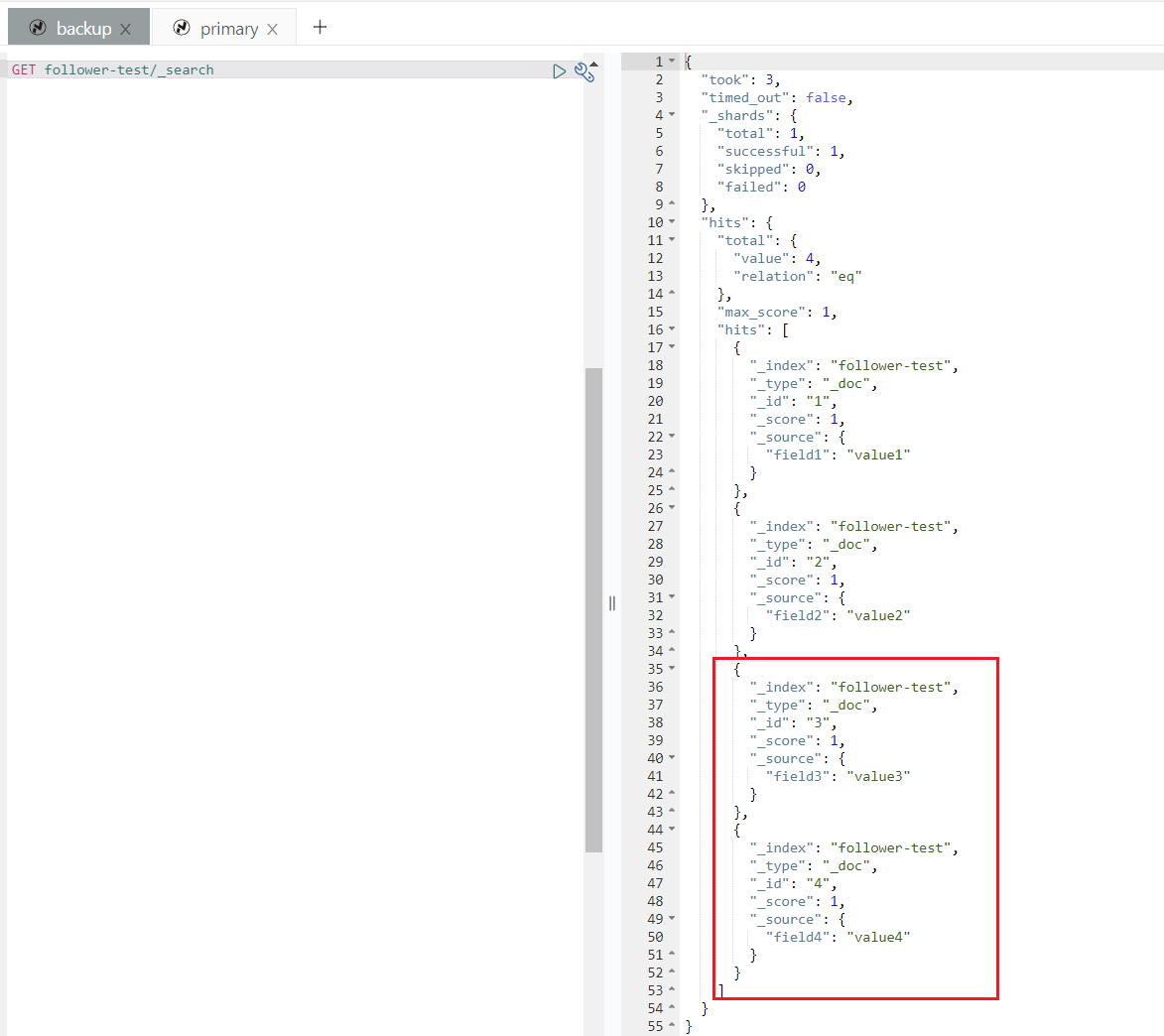
暂停和恢复复制
如果需要停机维护或其他原因想暂停复制功能,可使用暂停和恢复索引复制。
暂停
暂停目标集群上的索引复制。源集群索引再有新的变化,不会进行同步。
POST /_replication/follower-test/_pause?pretty
{}暂停后查看索引复制状态为 PAUSED 。
GET /_replication/follower-test/_status?pretty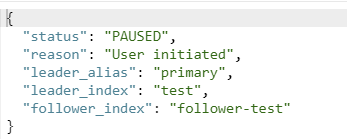
恢复
恢复目标集群上的索引复制。
POST /_replication/follower-test/_resume?pretty
{}停止复制
为了保证数据的一致性,目标集群上的 follower 索引都是只读的。如果要切换到可读写的状态,需要先停止复制。我们先直接写入数据,会报禁止该操作。
 停止复制
停止复制
执行停止复制命令,索引变为可读写状态,一个独立状态,不再会从源端复制内容。想要删除索引之前,也要先停止复制。
POST /_replication/follower-test/_stop?pretty
{}再次写入数据测试,成功。
自动跟随
前面给大家演示了单个索引的复制操作,对于每天自动创建一个索引的场景(日期后缀),这样的操作不免太麻烦了。跨集群复制的自动跟随功能,可以在目标集群建立一个复制模式,如果源集群新建索引名称匹配该模式,目标集群会自动创建一个索引来复制它。
创建复制模式
先在目标集群建立一个复制模式,模式名叫 nginx-index ,会自动复制源集群上 nginx 开头的索引。
POST /_replication/_autofollow?pretty
{
"leader_alias" : "primary",
"name": "nginx-index",
"pattern": "nginx*",
"use_roles":{
"leader_cluster_role": "cross_cluster_replication_leader_full_access",
"follower_cluster_role": "cross_cluster_replication_follower_full_access"
}
}
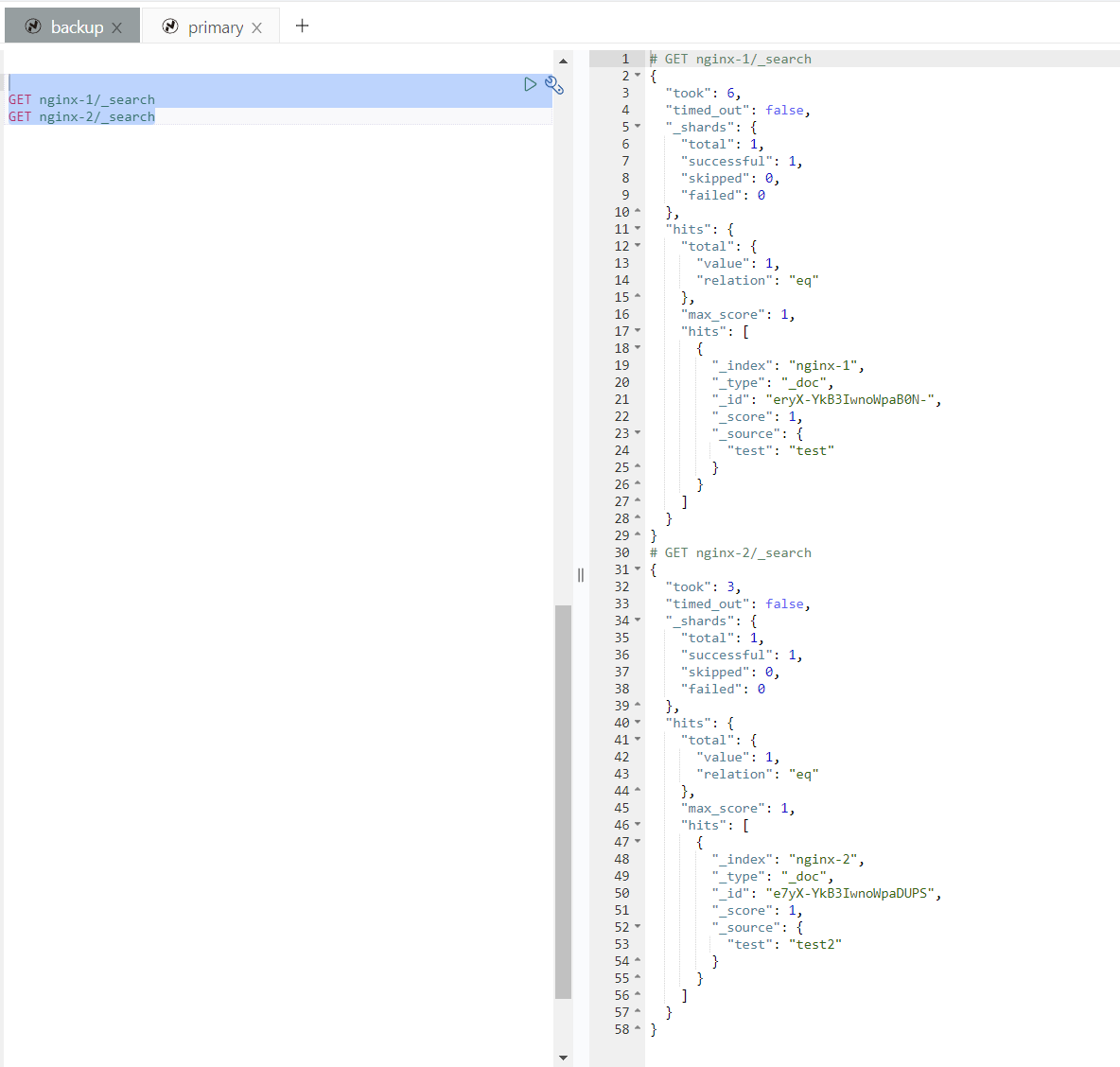
源集群创建 nginx 开头的索引。
POST /nginx-1/_doc/
{
"test":"test"
}
POST /nginx-2/_doc/
{
"test":"test2"
}目标集群查看复制结果。
停止自动跟随
如果不想复制新创建 nginx 开头的索引,可以使用停止跟随。停止自动跟随仅仅停止任何新的自动跟随活动,不会停止现存自动跟随启动的复制。
DELETE /_replication/_autofollow?pretty
{
"leader_alias" : "primary",
"name": "nginx-index"
}
上述命令不会影响目标集群上 nginx-1 和 nginx-2 索引的复制。而且 nginx-1 和 nginx-2 索引是只读的,如果要切换到读写状态,先停止复制。
POST /_replication/nginx-1/_stop?pretty
{}小结
这次实战主要演示了跨集群复制的操作过程:
- 建立证书互信
- 目标集群创建跨集群连接
- 开始复制:单索引或自动跟随复制
- 管理复制:暂停、查看状态、恢复、停止、删除自动跟随
好的,这次跨集群复制实战就到这里了,更多的内容大家可参考官方文档。如遇到问题,可以通过微信群、Discord 联系我们。
关于 Easysearch

INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。 与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
在之前的文章中,有通过极限网关实现容灾的案例。今天给大家介绍 Easysearch 的跨集群复制功能。该功能可在集群之间复制数据,应用场景包括但不限于以下举例:
- 灾备同步:将数据同步到灾备中心,灾备中心可对外提供查询服务。
- 读写分离:单一集群读写压力都较大时,为了避免读写互相干扰造成性能降级,可将读压力分流到另外的集群。
- 就近查询:在多地中心之间复制数据,应用只需连接本地 ES 集群读取数据,避免网络延时和干扰。
跨集群复制使用 active-passive 模型,由目标集群主动拉取数据变化到本地,因此对源集群影响很小。
先决条件
- 源集群和目标集群都必须安装 cross-cluster-replication 和 index-management 插件。安装插件参考这里。
- 如果目标集群的 easysearch.yml 文件中覆盖了 node.roles,确保它也包括 remote_cluster_client 角色,默认已启用。
演示环境
- 源集群( leader 集群 ): 192.168.3.45:9200
- 目标集群( follower 集群 ): 192.168.3.39:9200
- 两个集群都已启用 security 功能。
设置集群间证书互信
将两个集群的证书合并到一个文件,将文件放到 config 目录下。
cat ca-A.crt ca-B.crt > trust-chain.pem更新 easysearch.yml 文件,变化如下。
#security.ssl.transport.ca_file: ca.crt
security.ssl.transport.ca_file: trust-chain.pem设置跨群集连接
在目标集群建立源集群的连接信息。在 INFINI console 的开发工具中,选中目标集群,执行以下命令。
PUT /_cluster/settings?pretty
{
"persistent": {
"cluster": {
"remote": {
"primary": {
"seeds": ["192.168.3.45:9300"]
}
}
}
}
}开始复制
首先在源集群创建测试索引 test , 并向索引写入数据。如果有测试索引,此步可省略。
POST /_bulk?pretty
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "create" : { "_index" : "test", "_id" : "2" } }
{ "field2" : "value2" }然后在目标集群,创建一个名为 follower-test 的索引来复制源集群中 test 索引的内容。follower-test 可更换成自己想要的名字。
PUT /_replication/follower-test/_start?pretty
{
"leader_alias": "primary",
"leader_index": "test",
"use_roles":{
"leader_cluster_role": "cross_cluster_replication_leader_full_access",
"follower_cluster_role": "cross_cluster_replication_follower_full_access"
}
}- leader_alias 指定之前创建的连接名称 primary 。
- leader_index 指定想要复制的索引名称 test 。
- use_roles 指定用什么角色访问对应的集群,为了安全使用最小权限,命令中的角色是系统自带的。
命令执行完后,会在目标集群建立名为 follower-test 的索引,其内容来自源集群的 test 索引。 我们可以看到,其内容就是之前插入的两个文档。
确认复制状态
可以看到 follow-test 处于同步的状态会实时同步远端的数据。
GET /_replication/follower-test/_status?pretty
在源集群再插入数据,看是否会同步。
POST /_bulk?pretty
{ "index" : { "_index" : "test", "_id" : "3" } }
{ "field3" : "value3" }
{ "create" : { "_index" : "test", "_id" : "4" } }
{ "field4" : "value4" }目标集群查询索引,文档 3 和 4 已同步。
暂停和恢复复制
如果需要停机维护或其他原因想暂停复制功能,可使用暂停和恢复索引复制。
暂停
暂停目标集群上的索引复制。源集群索引再有新的变化,不会进行同步。
POST /_replication/follower-test/_pause?pretty
{}暂停后查看索引复制状态为 PAUSED 。
GET /_replication/follower-test/_status?pretty
恢复
恢复目标集群上的索引复制。
POST /_replication/follower-test/_resume?pretty
{}停止复制
为了保证数据的一致性,目标集群上的 follower 索引都是只读的。如果要切换到可读写的状态,需要先停止复制。我们先直接写入数据,会报禁止该操作。
停止复制
执行停止复制命令,索引变为可读写状态,一个独立状态,不再会从源端复制内容。想要删除索引之前,也要先停止复制。
POST /_replication/follower-test/_stop?pretty
{}再次写入数据测试,成功。
自动跟随
前面给大家演示了单个索引的复制操作,对于每天自动创建一个索引的场景(日期后缀),这样的操作不免太麻烦了。跨集群复制的自动跟随功能,可以在目标集群建立一个复制模式,如果源集群新建索引名称匹配该模式,目标集群会自动创建一个索引来复制它。
创建复制模式
先在目标集群建立一个复制模式,模式名叫 nginx-index ,会自动复制源集群上 nginx 开头的索引。
POST /_replication/_autofollow?pretty
{
"leader_alias" : "primary",
"name": "nginx-index",
"pattern": "nginx*",
"use_roles":{
"leader_cluster_role": "cross_cluster_replication_leader_full_access",
"follower_cluster_role": "cross_cluster_replication_follower_full_access"
}
}
源集群创建 nginx 开头的索引。
POST /nginx-1/_doc/
{
"test":"test"
}
POST /nginx-2/_doc/
{
"test":"test2"
}目标集群查看复制结果。
停止自动跟随
如果不想复制新创建 nginx 开头的索引,可以使用停止跟随。停止自动跟随仅仅停止任何新的自动跟随活动,不会停止现存自动跟随启动的复制。
DELETE /_replication/_autofollow?pretty
{
"leader_alias" : "primary",
"name": "nginx-index"
}
上述命令不会影响目标集群上 nginx-1 和 nginx-2 索引的复制。而且 nginx-1 和 nginx-2 索引是只读的,如果要切换到读写状态,先停止复制。
POST /_replication/nginx-1/_stop?pretty
{}小结
这次实战主要演示了跨集群复制的操作过程:
- 建立证书互信
- 目标集群创建跨集群连接
- 开始复制:单索引或自动跟随复制
- 管理复制:暂停、查看状态、恢复、停止、删除自动跟随
好的,这次跨集群复制实战就到这里了,更多的内容大家可参考官方文档。如遇到问题,可以通过微信群、Discord 联系我们。
关于 Easysearch
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。 与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
官网文档:https://www.infinilabs.com/docs/latest/easysearch
下载地址:https://www.infinilabs.com/download
收起阅读 »社区日报 第1689期 (2023-08-22)
1. 拿向量引擎配合ES做过滤了吗(需要梯子)
https://medium.com/%40fatihsat ... 8d179
2. 在K8S里部署ES全家(需要梯子)
https://medium.com/%40KushanJa ... d6531
3. 通过dump json的方式做ES合mongodb的备份方案(需要梯子)
https://medium.com/%40aivinsol ... a5d65
编辑:斯蒂文
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
1. 拿向量引擎配合ES做过滤了吗(需要梯子)
https://medium.com/%40fatihsat ... 8d179
2. 在K8S里部署ES全家(需要梯子)
https://medium.com/%40KushanJa ... d6531
3. 通过dump json的方式做ES合mongodb的备份方案(需要梯子)
https://medium.com/%40aivinsol ... a5d65
编辑:斯蒂文
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
收起阅读 »
社区日报 第1688期 (2023-08-21)
https://blog.csdn.net/fengxian ... 15858
2. ElasticSearch分片不均匀,集群负载不均衡
https://blog.csdn.net/qq_20545 ... 49335
3. 如何用 Elasticsearch 实现“图搜图”
https://mp.weixin.qq.com/s/PgY035gC_BfU-AG4cO6NtQ
编辑:yuebancanghai
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili
https://blog.csdn.net/fengxian ... 15858
2. ElasticSearch分片不均匀,集群负载不均衡
https://blog.csdn.net/qq_20545 ... 49335
3. 如何用 Elasticsearch 实现“图搜图”
https://mp.weixin.qq.com/s/PgY035gC_BfU-AG4cO6NtQ
编辑:yuebancanghai
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili 收起阅读 »
社区日报 第1687期 (2023-08-18)
1、Elasticsearch ESQL解读
https://www.elastic.co/cn/blog ... -esql
2、Elasticsearch vs OpenSearch 对比视频解读
https://www.elastic.co/cn/blog ... e-gap
3、Elasticsearch 预先加载数据的多种方案
https://www.elastic.co/cn/blog ... taset
编辑:铭毅天下
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
1、Elasticsearch ESQL解读
https://www.elastic.co/cn/blog ... -esql
2、Elasticsearch vs OpenSearch 对比视频解读
https://www.elastic.co/cn/blog ... e-gap
3、Elasticsearch 预先加载数据的多种方案
https://www.elastic.co/cn/blog ... taset
编辑:铭毅天下
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili 收起阅读 »
社区日报 第1686期 (2023-08-17)
https://medium.com/%40fatihsat ... 8d179
2.Elasticsearch 通过路由提升聚合性能(需要梯子)
https://medium.com/%40kulekci/ ... 1e12d
3.优化 Elasticsearch 以实现大容量数据摄取(需要梯子)
https://medium.com/%40yannvds/ ... ee574
编辑:Se7en
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
https://medium.com/%40fatihsat ... 8d179
2.Elasticsearch 通过路由提升聚合性能(需要梯子)
https://medium.com/%40kulekci/ ... 1e12d
3.优化 Elasticsearch 以实现大容量数据摄取(需要梯子)
https://medium.com/%40yannvds/ ... ee574
编辑:Se7en
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili 收起阅读 »
使用 Logstash 同步 MySQL 到 Easysearch
从 MySQL 同步数据到 ES 有多种方案,这次我们使用 ELK 技术栈中的 Logstash 来将数据从 MySQL 同步到 Easysearch 。
方案前提
- MySQL 表记录必须有主键,比如 id 字段。通过该字段,可将 Easysearch 索引数据与 MySQL 表数据形成一对一映射关系,支持修改。
- MySQL 表记录必须有时间字段,以支持增量同步。
如果上述条件具备,便可使用 logstash 定期同步新写入或修改后的数据到 Easysearch 中。
方案演示
版本信息
MySQL: 5.7
Logstash: 7.10.2
Easysearch: 1.5.0
MySQL 设置
创建演示用的表。
CREATE DATABASE es_db;
USE es_db;
DROP TABLE IF EXISTS es_table;
CREATE TABLE es_table (
id BIGINT(20) UNSIGNED NOT NULL,
PRIMARY KEY (id),
UNIQUE KEY unique_id (id),
client_name VARCHAR(32) NOT NULL,
modification_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
insertion_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);说明
- id 字段: 主键、唯一键,将作为 Easysearch 索引中的 doc id 字段。
- modification_time 字段: 表记录的插入和修改都会记录在此。
- client_name: 代表用户数据。
- insertion_time: 可省略,用来记录数据插入到 MySQL 数据的时间。
插入数据
INSERT INTO es_table (id, client_name) VALUES (1, 'test 1'); INSERT INTO es_table (id, client_name) VALUES (2, 'test 2'); INSERT INTO es_table (id, client_name) VALUES (3, 'test 3');Logstash
配置文件
input { jdbc { jdbc_driver_library => "./mysql-connector-j-8.1.0/mysql-connector-j-8.1.0.jar" jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_connection_string => "jdbc:mysql://192.168.56.3:3306/es_db" jdbc_user => "root" jdbc_password => "password" jdbc_paging_enabled => true tracking_column => "unix_ts_in_secs" use_column_value => true tracking_column_type => "numeric" last_run_metadata_path => "./.mysql-es_table-sql_last_value.yml" schedule => "*/5 * * * * *" statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW()) ORDER BY modification_time ASC" } jdbc { jdbc_driver_library => "./mysql-connector-j-8.1.0/mysql-connector-j-8.1.0.jar" jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_connection_string => "jdbc:mysql://192.168.56.3:3306/es_db" jdbc_user => "root" jdbc_password => "password" schedule => "*/5 * * * * *" statement => "SELECT count(*) AS count,'es_table' AS table_name from es_table" } } filter { if ![table_name] { mutate { copy => { "id" => "[@metadata][_id]"} remove_field => ["@version", "unix_ts_in_secs","@timestamp"] add_field => { "[@metadata][target_index]" => "mysql_es_table" } } } else { mutate { add_field => { "[@metadata][target_index]" => "table_counts" } remove_field => ["@version"] } uuid { target => "[@metadata][_id]" overwrite => true } } } output { elasticsearch { hosts => ["https://localhost:9200"] user => "admin" password => "f0c6fc61fe5f7b084c00" ssl_certificate_verification => "false" index => "%{[@metadata][target_index]}" manage_template => "false" document_id => "%{[@metadata][_id]}" } } - 每 5 秒钟同步一次 es_table 表的数据到 mysql_sync_idx 索引。
- 每 5 秒统计一次 es_table 表的记录条数到 table_counts 索引,用于监控。
启动 logstash
./bin/logstash -f sync_es_table.conf查看同步结果, 3 条数据都已同步到索引。
 Mysql 数据库新增记录
Mysql 数据库新增记录INSERT INTO es_table (id, client_name) VALUES (4, 'test 4');Easysearch 确认新增

Mysql 数据库修改记录
UPDATE es_table SET client_name = 'test 0001' WHERE id=1;Easysearch 确认修改

删除数据
Logstash 无法直接删除操作到 ES ,有两个方案:
- 在表中增加 is_deleted 字段,实现软删除,可达到同步的目的。查询过滤掉 is_deleted : true 的记录,后续通过脚本等方式定期清理 is_deleted : true 的数据。
- 执行删除操作的程序,删除完 MySQL 中的记录后,继续删除 Easysearch 中的记录。
同步监控
数据已经在 ES 中了,我们可利用 INFINI Console 的数据看板来监控数据是否同步,展示表记录数、索引记录数及其变化。

从 MySQL 同步数据到 ES 有多种方案,这次我们使用 ELK 技术栈中的 Logstash 来将数据从 MySQL 同步到 Easysearch 。
方案前提
- MySQL 表记录必须有主键,比如 id 字段。通过该字段,可将 Easysearch 索引数据与 MySQL 表数据形成一对一映射关系,支持修改。
- MySQL 表记录必须有时间字段,以支持增量同步。
如果上述条件具备,便可使用 logstash 定期同步新写入或修改后的数据到 Easysearch 中。
方案演示
版本信息
MySQL: 5.7
Logstash: 7.10.2
Easysearch: 1.5.0
MySQL 设置
创建演示用的表。
CREATE DATABASE es_db;
USE es_db;
DROP TABLE IF EXISTS es_table;
CREATE TABLE es_table (
id BIGINT(20) UNSIGNED NOT NULL,
PRIMARY KEY (id),
UNIQUE KEY unique_id (id),
client_name VARCHAR(32) NOT NULL,
modification_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
insertion_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);说明
- id 字段: 主键、唯一键,将作为 Easysearch 索引中的 doc id 字段。
- modification_time 字段: 表记录的插入和修改都会记录在此。
- client_name: 代表用户数据。
- insertion_time: 可省略,用来记录数据插入到 MySQL 数据的时间。
插入数据
INSERT INTO es_table (id, client_name) VALUES (1, 'test 1'); INSERT INTO es_table (id, client_name) VALUES (2, 'test 2'); INSERT INTO es_table (id, client_name) VALUES (3, 'test 3');Logstash
配置文件
input { jdbc { jdbc_driver_library => "./mysql-connector-j-8.1.0/mysql-connector-j-8.1.0.jar" jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_connection_string => "jdbc:mysql://192.168.56.3:3306/es_db" jdbc_user => "root" jdbc_password => "password" jdbc_paging_enabled => true tracking_column => "unix_ts_in_secs" use_column_value => true tracking_column_type => "numeric" last_run_metadata_path => "./.mysql-es_table-sql_last_value.yml" schedule => "*/5 * * * * *" statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW()) ORDER BY modification_time ASC" } jdbc { jdbc_driver_library => "./mysql-connector-j-8.1.0/mysql-connector-j-8.1.0.jar" jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_connection_string => "jdbc:mysql://192.168.56.3:3306/es_db" jdbc_user => "root" jdbc_password => "password" schedule => "*/5 * * * * *" statement => "SELECT count(*) AS count,'es_table' AS table_name from es_table" } } filter { if ![table_name] { mutate { copy => { "id" => "[@metadata][_id]"} remove_field => ["@version", "unix_ts_in_secs","@timestamp"] add_field => { "[@metadata][target_index]" => "mysql_es_table" } } } else { mutate { add_field => { "[@metadata][target_index]" => "table_counts" } remove_field => ["@version"] } uuid { target => "[@metadata][_id]" overwrite => true } } } output { elasticsearch { hosts => ["https://localhost:9200"] user => "admin" password => "f0c6fc61fe5f7b084c00" ssl_certificate_verification => "false" index => "%{[@metadata][target_index]}" manage_template => "false" document_id => "%{[@metadata][_id]}" } } - 每 5 秒钟同步一次 es_table 表的数据到 mysql_sync_idx 索引。
- 每 5 秒统计一次 es_table 表的记录条数到 table_counts 索引,用于监控。
启动 logstash
./bin/logstash -f sync_es_table.conf查看同步结果, 3 条数据都已同步到索引。
Mysql 数据库新增记录INSERT INTO es_table (id, client_name) VALUES (4, 'test 4');Easysearch 确认新增
Mysql 数据库修改记录
UPDATE es_table SET client_name = 'test 0001' WHERE id=1;Easysearch 确认修改
删除数据
Logstash 无法直接删除操作到 ES ,有两个方案:
- 在表中增加 is_deleted 字段,实现软删除,可达到同步的目的。查询过滤掉 is_deleted : true 的记录,后续通过脚本等方式定期清理 is_deleted : true 的数据。
- 执行删除操作的程序,删除完 MySQL 中的记录后,继续删除 Easysearch 中的记录。
同步监控
数据已经在 ES 中了,我们可利用 INFINI Console 的数据看板来监控数据是否同步,展示表记录数、索引记录数及其变化。
社区日报 第1685期 (2023-08-16)
https://medium.com/%40_niteshs ... 74004
2.‘Cycle detected for pipeline: main-pipeline’报错探究(需要梯子)
https://medium.com/%40musabdog ... f993d
3.搜文本搜位置搜图片,1小时玩转阿里云 Elasticsearch
https://blog.csdn.net/UbuntuTo ... 89544
编辑:kin122
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili
https://medium.com/%40_niteshs ... 74004
2.‘Cycle detected for pipeline: main-pipeline’报错探究(需要梯子)
https://medium.com/%40musabdog ... f993d
3.搜文本搜位置搜图片,1小时玩转阿里云 Elasticsearch
https://blog.csdn.net/UbuntuTo ... 89544
编辑:kin122
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili 收起阅读 »
社区日报 第1684期 (2023-08-15)
1. python接入ES利器之又一个 Django(需要梯子)
https://awstip.com/mastering-e ... a861a
2. 在Admina,我们这样存数据(需要梯子)
https://mfi.engineering/how-do ... 37551
3. 同一网络里的俩节点,咋用ES agent采日志?(需要梯子)
https://medium.com/%40bytaskin ... e9194
编辑:斯蒂文
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili
1. python接入ES利器之又一个 Django(需要梯子)
https://awstip.com/mastering-e ... a861a
2. 在Admina,我们这样存数据(需要梯子)
https://mfi.engineering/how-do ... 37551
3. 同一网络里的俩节点,咋用ES agent采日志?(需要梯子)
https://medium.com/%40bytaskin ... e9194
编辑:斯蒂文
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站: https://ela.st/bilibili 收起阅读 »
社区日报 第1683期 (2023-08-14)
https://elasticstack.blog.csdn ... .5502
2. 使用 Elasticsearch 进行地理位置搜索
https://zhuanlan.zhihu.com/p/315931530
3. 如何让主分片(shards)均匀分布
https://blog.csdn.net/myhes/ar ... 22966
编辑:yuebancanghai
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili
https://elasticstack.blog.csdn ... .5502
2. 使用 Elasticsearch 进行地理位置搜索
https://zhuanlan.zhihu.com/p/315931530
3. 如何让主分片(shards)均匀分布
https://blog.csdn.net/myhes/ar ... 22966
编辑:yuebancanghai
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
B站:https://ela.st/bilibili 收起阅读 »


