

想对现在的搜索进行提速,但是不清楚该从哪些角度去分析问题。
项目场景:
i5 双核 8G内存 50万数据量
问题:
1. 查询条件的先后关系,是否影响查询速度?
我的思考:由于cache的机制,是不是所有的查询条件都会逐一进行,从而不会区分查询条件的先后。
2. 50万的数据量, 进行排序查询, 现在采用的是5个主分片,如果我减少主分片数量,会不会提高速度?
我的思考:想法是减少合并时间,但是考虑到减少主分片数又会减少并发的排序,不清楚该怎么衡量,是否有一套方法论
3. 是否有一些好的方法或书籍文章去检验或有助于分析性能问题
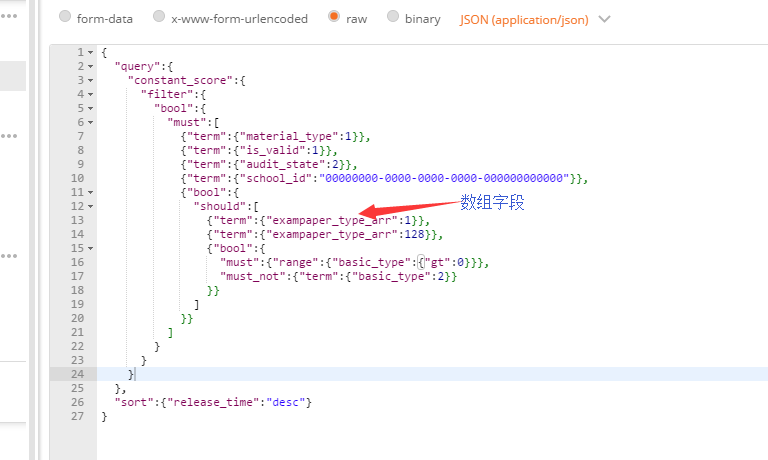
另:我上传了一个项目中普通的查询语句,针对这个查询,我应该怎么进行分析呢(现在这个查询在45万数据量,5主分片的情况下,速度稳定在220ms),希望这个图能帮助您更好得描述
先在这儿谢谢您的帮助!
项目场景:
i5 双核 8G内存 50万数据量
问题:
1. 查询条件的先后关系,是否影响查询速度?
我的思考:由于cache的机制,是不是所有的查询条件都会逐一进行,从而不会区分查询条件的先后。
2. 50万的数据量, 进行排序查询, 现在采用的是5个主分片,如果我减少主分片数量,会不会提高速度?
我的思考:想法是减少合并时间,但是考虑到减少主分片数又会减少并发的排序,不清楚该怎么衡量,是否有一套方法论
3. 是否有一些好的方法或书籍文章去检验或有助于分析性能问题
另:我上传了一个项目中普通的查询语句,针对这个查询,我应该怎么进行分析呢(现在这个查询在45万数据量,5主分片的情况下,速度稳定在220ms),希望这个图能帮助您更好得描述
先在这儿谢谢您的帮助!

3 个回复
rockybean - Elastic Certified Engineer, ElasticStack Fans,公众号:ElasticTalk
赞同来自: Ricky_Lau 、piggyci
https://www.elastic.co/guide/e ... .html
有几个建议:
1)可以用 profile 来查看具体是哪里执行慢
https://www.elastic.co/guide/e ... .html
2)能用 filter 的都用 filter,减少打分的查询,比如你 must 里面的很多都是可以用 filter 来做的
3)根据上面的文档来优化,另外,50万文档的话,我觉得1个分片足够了
piggyci
赞同来自:
1.是不是只有对analyzed的字段进行聚合(即不使用raw,而是对分词后的多个token聚合),fielddata,全局序数才对我有意义?
我的思考:fielddata是弥补doc-values不能记录analyzed字段与多个token之间关系的不足,全局序数是为了更好的压缩空间,他们处理的领域只是 对analyzed字段进行多token聚合的操作,我的理解对吗?
2.图片中,箭头指向的部分是我现在的问题所在,next_doc和match是速度的主要部分,我读过了profile的文档,其中讲述了这两个属性是什么,但是并没有给出具体的分析或调优建议,这个地方的速度我应该如何优化?这方面有好的文档或书籍推荐吗?(另这个profile 对应于 我问题的图片)
piggyci
赞同来自:
很感谢您的回复!
之所以写成constant score,是考虑到https://www.elastic.co/guide/c ... .html
这篇文章,最下面关于constant score的部分。
当然这篇文章可能有些老了,我依照您的建议,自己测试了一下,将查询改成了图中的形式,并且连续做了8次不使用cache的手工查询,平均的查询时间是251.875ms,使用constant_score的8次平均时间是258.125ms,在结果上看确实提高了7ms左右。
但是我仍然怀疑是否现在的版本确实修改了原来的逻辑,毕竟7毫秒的误差,很难让我相信文章中的说法有问题,您真的确定,修改constant_score会提高速度吗?(不知道是否是我对文章理解得有问题)
另外上一个回复的2个问题,您了解吗?