


es
Easysearch analysis-ik 多词典性能优化:从性能回退到分词性能提升 25%~30%
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 15790 次浏览 • 2026-05-08 14:34
Easysearch 版 analysis-ik 相比开源 IK 有一个重要的增强:支持多词典。简单说就是不同字段可以挂不同词库,可以叠加默认词典,也可以只用自定义词典。这是开源单词典 IK 做不到的。
功能实现初期,主要精力放在把能力跑通上。但在后来的一次写入压测中,我们发现 Easysearch 的写入吞吐和 Elasticsearch 有明显差距,最终定位到问题出在多词典的实现方式上——字段最终该用哪套词典,本来应该在分词前就算好,结果代码里把这个选择丢进了分词的热路径,每次分词都要反复切词典、重复扫同一段文本。
这篇文章记录的就是我们怎么一步步把性能拉回来、最终反超基线的过程。
问题怎么冒出来的
4 月 20 号,我们跑了一轮系统级写入压测。数据、mapping、settings、并发和 bulk 参数都一样,Elasticsearch 8.19.5 和 Easysearch 2.1.2 的写入吞吐差距大得有点不对劲:
| 时间 | 场景 | Elasticsearch | Easysearch | 说明 |
|---|---|---|---|---|
| 2026-04-20 第 2 次有效重跑 | 29900 docs / bulk=250 / concurrency=3 端到端写入压测 |
129.44 docs/s |
31.21 docs/s |
这是整条写入链路的 docs/s,不是单独分词吞吐 |
| 2026-04-20 诊断样本 | 5000 docs / bulk=250 / concurrency=3 |
156.25 docs/s |
30.67 docs/s |
Easysearch 的累计索引耗时约为 Elasticsearch 的 8.0x |

当时服务器上跑的就是早期多词典版本。后面修性能,追的就是这个版本和开源单词典 IK 基线之间的差距。
这一步还不能直接确定问题就在分词器。但差距摆在这儿了,得继续往下排。我们先排除了几个常见干扰因素:
refresh_interval- 动态同义词 HTTP 服务
- mapping / settings 不一致
- 网络层和 bulk 客户端本身
采样结果很快把范围收窄了。Elasticsearch 那边热点比较分散,Easysearch 这边呢,分词链路里出现了异常集中的开销——分词过程中反复做词典选择和字典查找。
瓶颈不在 Lucene 写入链路本身,就在 analysis-ik 的多词典实现上。
根因分析
第一类问题出在实现模型上。多词典想表达的是”这个字段最终用哪套词典”,这件事完全可以在分词前算好。但早期代码里,硬是把它变成了运行时的事:
- “字段用哪个词典”变成了”运行时多轮扫描”——同一段文本对着多套词典各来一遍。
- 全局字典切换的动作放进了每字符的热路径。
- 结果就是同一段文本的扫描和查找成本翻了好几倍。
所以问题不是多词典天然慢,是实现把本该提前算好的东西塞进了热路径反复做。
第二类问题是后续优化过程中留下的额外开销。后面加的跨边界、停用词、长文本等测试本身不是性能问题的来源,它们的作用是把正确性边界补齐,确保每次优化不会改变分词结果。
最后通过性能分析确认,残留开销主要来自两处:缓存命中前还在做不必要的数据复制;诊断逻辑在生产热路径上产生了额外开销。修完之后这两处热点都从火焰图上消失了,说明性能回退确实来自真实的代码路径成本,不是测试抖动。
修复过程
整个修复分四个阶段。
第一阶段:把多词典从”运行时分发”收敛为”最终有效词典视图”
多词典能力保留,但不再让分词器在热路径里反复切词典、重复扫文本。改成在分词前就把字段最终生效的词典算好,分词过程只面对一个已经收敛好的词典视图。
说白了就是把模型拉回正确方向——多词典管表达能力,热路径只管分词。
第二阶段:逐步打掉热路径上的常数开销
留下来的每一项优化,都经过正式性能测试和采样分析验证。原则就一条:不改分词语义,只减少热路径上反复发生的查找、分配和判断。
第三阶段:补齐正确性护栏
正确性测试必须先到位,不然吞吐提升没有意义——万一分词结果变了,跑得再快也白搭。
这一轮重点覆盖了这些容易出问题的场景:
- 真跨边界场景
- 数字和量词合并,如
1号 - 自定义词典里的含符号词
- 补充平面字符跨边界稳定性
- 停用词过滤后的偏移量
- 长文本样本的稳定性
- 正式性能测试数据集的分词结果对齐
后面所有的吞吐数字,前提都是分词结果一致,避免把分词行为的变化误当成性能提升。
第四阶段:清理最后的残留开销
到 4 月 28 号,最后一轮修复集中处理两个地方:
- 词典视图命中缓存时直接返回,不再多做一次数据复制
- 诊断逻辑默认关掉,不让线上请求为调试能力买单
这两处修完,Easysearch 版 IK 就不只是恢复到单词典版本附近了,在正式测试里已经明显领先。
用数据看恢复过程
为了不把系统级写入压测和分词器性能测试混在一起,下面只看几个关键节点。2026-04-20 的 docs/s 是系统级写入吞吐,后面的 tok/s 是单独的分词器吞吐。
这里说的”开源 IK 基线”就是开源 IK 的单词典实现对照版本。所有正式吞吐结论都建立在同一数据集、同一测试方法、分词结果一致的前提上。
| 时间 | 口径 | 关键结果 | 说明 |
|---|---|---|---|
| 2026-04-23 17:02 CST | 初期本地复现 | 服务器多词典版本 61.39 万 tok/s,单词典版本 114.48 万 tok/s |
单词典版本快 86.49%,性能差距被明确复现 |
| 2026-04-24 09:51:12~09:55:15 CST | 第一次正式追平 | smart 相对开源单词典基线 +7.26% |
从明显落后追到略微领先 |
| 2026-04-25 04:14~04:16 CST | 双模式阶段复核 | smart +16.88%,max_word +20.09% |
领先优势开始扩大 |
| 2026-04-28 12:30:56 CST | 最新正式复核 | smart +30.96%,max_word +21.31% |
当前最新结果 |
整个过程就是:
- 先暴露出明显的性能退化
- 逐步缩小差距
- 追平,然后开始领先
- 最终在分词结果完全一致的前提下,正式反超
最早的本地复现数据很关键:服务器当时跑的多词典版本只有 613896.67 tok/s,单词典版本 1144843.77 tok/s。后面所有修复就是冲着这个差距去的。


三张图分别对应问题暴露、分词复现和修复结果:第一张展示服务器 bulk 写入吞吐的系统级差距;第二张展示多词典版本和单词典版本的本地分词差距;第三张展示分词结果对齐后,Easysearch 版 IK 怎么一步步追上来,最终实现 25%~30% 的分词性能提升。
为什么说 Easysearch 版 IK 现在更好
这次修复的价值不只是消灭了几个热点,更重要的是把多词典能力、分词正确性和性能测试体系一起补齐了。
1. 功能更强,性能代价可控
开源单词典 IK 模型简单,但表达能力也弱。Easysearch 的多词典能力要解决的是字段级词库隔离、自定义词典叠加这些实际需求。
关键问题是:能不能把这些能力的性能开销压到足够低。修复后的结果证明,可以。
2. 正确性护栏更完整
这轮补上的测试不只是几个短样例,覆盖了更容易翻车的边界条件:
- 真跨边界场景
- 长文本稳定性
- 自定义词典和符号词
- 数字量词合并
- 停用词过滤后的偏移量
这意味着以后再做性能优化,必须同时保证分词结果不变。想靠改分词行为换吞吐,测试会先拦住。
3. 性能测试体系更严格
这轮之后,Easysearch 对 analysis-ik 的正式性能结论统一按一套标准出:
- 同一数据集
- 同一测试方法
smart和max_word双模式- 分词结果一致
- 有性能分析结果支撑
这套体系能避免两个常见坑:只看单轮吞吐波动就下结论,或者分词结果已经变了还在比性能。
小结
多词典能力在实现初期,主要精力放在功能补齐上——先把字段级词库隔离、自定义词典叠加这些能力跑通,性能优化是后面分阶段来的事,没办法一蹴而就。
这轮优化下来,核心思路其实就一条:把词典选择从分词热路径里挪出去,提前收敛好,让分词过程只面对最终的词典视图。再配合热点清理和正确性护栏,增强功能和更高性能完全可以兼得。
截至 2026 年 4 月 28 日,在本地 Mac 笔记本上的多轮 benchmark 中,Easysearch 版 IK 在 smart 模式大约领先开源单词典 IK 基线 25%~30%,max_word 模式大约领先 20% 左右,分词结果完全一致。具体数字每次跑会有波动,但趋势是稳定的。
这也是 Easysearch 版 IK 相对开源版更有价值的地方:不是多了几个配置项,而是在多词典能力、分词正确性和分词性能三个方面都给出了可验证的结果。
关于 Easysearch

INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
作者:张磊,极限科技(INFINI Labs)搜索引擎研发负责人,对 Elasticsearch 和 Lucene 源码比较熟悉,目前主要负责公司的 Easysearch 产品的研发以及客户服务工作。
相关文章:
【搜索客社区日报】第2105期 (2025-09-01)
社区日报 • Muses 发表了文章 • 0 个评论 • 5731 次浏览 • 2025-09-01 12:17
ES 调优帖:Gateway 批量写入性能优化实践
Elasticsearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 19030 次浏览 • 2025-08-06 17:32
背景:bulk 优化的应用
在 ES 的写入优化里,bulk 操作被广泛地用于批量处理数据。bulk 操作允许用户一次提交多个数据操作,如索引、更新、删除等,从而提高数据处理效率。bulk 操作的实现原理是,将数据操作请求打包成 HTTP 请求,并批量提交给 Elasticsearch 服务器。这样,Elasticsearch 服务器就可以一次处理多个数据操作,从而提高处理效率。
这种优化的核心价值在于减少了网络往返的次数和连接建立的开销。每一次单独的写入操作都需要经历完整的请求-响应周期,而批量写入则是将多个操作打包在一起,用一次通信完成原本需要多次交互的工作。这不仅仅节省了时间,更重要的是释放了系统资源,让服务器能够专注于真正的数据处理,而不是频繁的协议握手和状态维护。
这样的批量请求的确是可以优化写入请求的效率,让 ES 集群获得更多的资源去做写入请求的集中处理。但是除了客户端与 ES 集群的通讯效率优化,还有其他中间过程能优化么?
Gateway 的优化点
bulk 的优化理念是将日常零散的写入需求做集中化的处理,尽量减低日常请求的损耗,完成资源最大化的利用。简而言之就是“好钢用在刀刃上”。
但是 ES 在收到 bulk 写入请求后,也是需要协调节点根据文档的 id 计算所属的分片来将数据分发到对应的数据节点的。这个过程也是有一定损耗的,如果 bulk 请求中数据分布的很散,每个分片都需要进行写入,原本 bulk 集中写入的需求优势则还是没有得到最理想化的提升。
gateway 的写入加速则对 bulk 的优化理念的最大化补全。
gateway 可以本地计算每个索引文档对应后端 Elasticsearch 集群的目标存放位置,从而能够精准的进行写入请求定位。
在一批 bulk 请求中,可能存在多个后端节点的数据,bulk_reshuffle 过滤器用来将正常的 bulk 请求打散,按照目标节点或者分片进行拆分重新组装,避免 Elasticsearch 节点收到请求之后再次进行请求分发, 从而降低 Elasticsearch 集群间的流量和负载,也能避免单个节点成为热点瓶颈,确保各个数据节点的处理均衡,从而提升集群总体的索引吞吐能力。
整理的优化思路如下图:
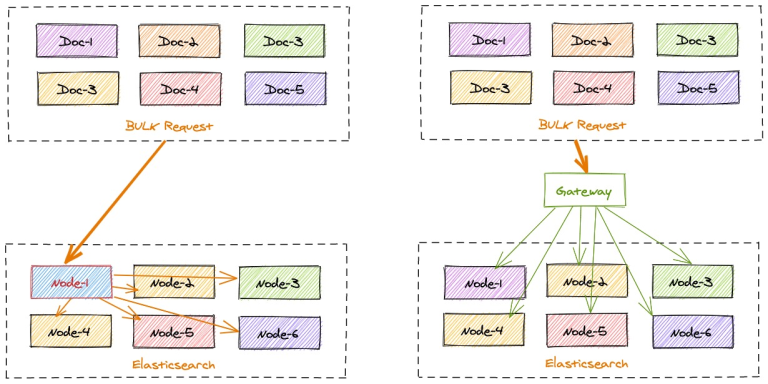
优化实践
那我们来实践一下,看看 gateway 能提升多少的写入。
这里我们分 2 个测试场景:
- 基础集中写入测试,不带文档 id,直接批量写入。这个场景更像是日志或者监控数据采集的场景。
- 带文档 id 的写入测试,更偏向搜索场景或者大数据批同步的场景。
2 个场景都进行直接写入 ES 和 gateway 转发 ES 的效率比对。
测试材料除了需要备一个网关和一套 es 外,其余的内容如下:
测试索引 mapping 一致,名称区分:
PUT gateway_bulk_test
{
"settings": {
"number_of_shards": 6,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"timestamp": {
"type": "date",
"format": "strict_date_optional_time"
},
"field1": {
"type": "keyword"
},
"field2": {
"type": "keyword"
},
"field3": {
"type": "keyword"
},
"field4": {
"type": "integer"
},
"field5": {
"type": "keyword"
},
"field6": {
"type": "float"
}
}
}
}
PUT bulk_test
{
"settings": {
"number_of_shards": 6,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"timestamp": {
"type": "date",
"format": "strict_date_optional_time"
},
"field1": {
"type": "keyword"
},
"field2": {
"type": "keyword"
},
"field3": {
"type": "keyword"
},
"field4": {
"type": "integer"
},
"field5": {
"type": "keyword"
},
"field6": {
"type": "float"
}
}
}
}gateway 的配置文件如下:
path.data: data
path.logs: log
entry:
- name: my_es_entry
enabled: true
router: my_router
max_concurrency: 200000
network:
binding: 0.0.0.0:8000
flow:
- name: async_bulk
filter:
- bulk_reshuffle:
when:
contains:
_ctx.request.path: /_bulk
elasticsearch: prod
level: node
partition_size: 1
fix_null_id: true
- elasticsearch:
elasticsearch: prod #elasticsearch configure reference name
max_connection_per_node: 1000 #max tcp connection to upstream, default for all nodes
max_response_size: -1 #default for all nodes
balancer: weight
refresh: # refresh upstream nodes list, need to enable this feature to use elasticsearch nodes auto discovery
enabled: true
interval: 60s
filter:
roles:
exclude:
- master
router:
- name: my_router
default_flow: async_bulk
elasticsearch:
- name: prod
enabled: true
endpoints:
- https://127.0.0.1:9221
- https://127.0.0.1:9222
- https://127.0.0.1:9223
basic_auth:
username: admin
password: admin
pipeline:
- name: bulk_request_ingest
auto_start: true
keep_running: true
retry_delay_in_ms: 1000
processor:
- bulk_indexing:
max_connection_per_node: 100
num_of_slices: 3
max_worker_size: 30
idle_timeout_in_seconds: 10
bulk:
compress: false
batch_size_in_mb: 10
batch_size_in_docs: 10000
consumer:
fetch_max_messages: 100
queue_selector:
labels:
type: bulk_reshuffle测试脚本如下:
#!/usr/bin/env python3
"""
ES Bulk写入性能测试脚本
"""
import hashlib
import json
import random
import string
import time
from typing import List, Dict, Any
import requests
from concurrent.futures import ThreadPoolExecutor
from datetime import datetime
import urllib3
# 禁用SSL警告
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
class ESBulkTester:
def __init__(self):
# 配置变量 - 可修改
self.es_configs = [
{
"name": "ES直连",
"url": "https://127.0.0.1:9221",
"index": "bulk_test",
"username": "admin", # 修改为实际用户名
"password": "admin", # 修改为实际密码
"verify_ssl": False # HTTPS需要SSL验证
},
{
"name": "Gateway代理",
"url": "http://localhost:8000",
"index": "gateway_bulk_test",
"username": None, # 无需认证
"password": None,
"verify_ssl": False
}
]
self.batch_size = 10000 # 每次bulk写入条数
self.log_interval = 100000 # 每多少次bulk写入输出日志
# ID生成规则配置 - 前2位后5位
self.id_prefix_start = 1
self.id_prefix_end = 999 # 前3位: 01-999
self.id_suffix_start = 1
self.id_suffix_end = 9999 # 后4位: 0001-9999
# 当前ID计数器
self.current_prefix = self.id_prefix_start
self.current_suffix = self.id_suffix_start
def generate_id(self) -> str:
"""生成固定规则的ID - 前2位后5位"""
id_str = f"{self.current_prefix:02d}{self.current_suffix:05d}"
# 更新计数器
self.current_suffix += 1
if self.current_suffix > self.id_suffix_end:
self.current_suffix = self.id_suffix_start
self.current_prefix += 1
if self.current_prefix > self.id_prefix_end:
self.current_prefix = self.id_prefix_start
return id_str
def generate_random_hash(self, length: int = 32) -> str:
"""生成随机hash值"""
random_string = ''.join(random.choices(string.ascii_letters + string.digits, k=length))
return hashlib.md5(random_string.encode()).hexdigest()
def generate_document(self) -> Dict[str, Any]:
"""生成随机文档内容"""
return {
"timestamp": datetime.now().isoformat(),
"field1": self.generate_random_hash(),
"field2": self.generate_random_hash(),
"field3": self.generate_random_hash(),
"field4": random.randint(1, 1000),
"field5": random.choice(["A", "B", "C", "D"]),
"field6": random.uniform(0.1, 100.0)
}
def create_bulk_payload(self, index_name: str) -> str:
"""创建bulk写入payload"""
bulk_data = []
for _ in range(self.batch_size):
#doc_id = self.generate_id()
doc = self.generate_document()
# 添加index操作
bulk_data.append(json.dumps({
"index": {
"_index": index_name,
# "_id": doc_id
}
}))
bulk_data.append(json.dumps(doc))
return "\n".join(bulk_data) + "\n"
def bulk_index(self, config: Dict[str, Any], payload: str) -> bool:
"""执行bulk写入"""
url = f"{config['url']}/_bulk"
headers = {
"Content-Type": "application/x-ndjson"
}
# 设置认证信息
auth = None
if config.get('username') and config.get('password'):
auth = (config['username'], config['password'])
try:
response = requests.post(
url,
data=payload,
headers=headers,
auth=auth,
verify=config.get('verify_ssl', True),
timeout=30
)
return response.status_code == 200
except Exception as e:
print(f"Bulk写入失败: {e}")
return False
def refresh_index(self, config: Dict[str, Any]) -> bool:
"""刷新索引"""
url = f"{config['url']}/{config['index']}/_refresh"
# 设置认证信息
auth = None
if config.get('username') and config.get('password'):
auth = (config['username'], config['password'])
try:
response = requests.post(
url,
auth=auth,
verify=config.get('verify_ssl', True),
timeout=10
)
success = response.status_code == 200
print(f"索引刷新{'成功' if success else '失败'}: {config['index']}")
return success
except Exception as e:
print(f"索引刷新失败: {e}")
return False
def run_test(self, config: Dict[str, Any], round_num: int, total_iterations: int = 100000):
"""运行性能测试"""
test_name = f"{config['name']}-第{round_num}轮"
print(f"\n开始测试: {test_name}")
print(f"ES地址: {config['url']}")
print(f"索引名称: {config['index']}")
print(f"认证: {'是' if config.get('username') else '否'}")
print(f"每次bulk写入: {self.batch_size}条")
print(f"总计划写入: {total_iterations * self.batch_size}条")
print("-" * 50)
start_time = time.time()
success_count = 0
error_count = 0
for i in range(1, total_iterations + 1):
payload = self.create_bulk_payload(config['index'])
if self.bulk_index(config, payload):
success_count += 1
else:
error_count += 1
# 每N次输出日志
if i % self.log_interval == 0:
elapsed_time = time.time() - start_time
rate = i / elapsed_time if elapsed_time > 0 else 0
print(f"已完成 {i:,} 次bulk写入, 耗时: {elapsed_time:.2f}秒, 速率: {rate:.2f} bulk/秒")
end_time = time.time()
total_time = end_time - start_time
total_docs = total_iterations * self.batch_size
print(f"\n{test_name} 测试完成!")
print(f"总耗时: {total_time:.2f}秒")
print(f"成功bulk写入: {success_count:,}次")
print(f"失败bulk写入: {error_count:,}次")
print(f"总文档数: {total_docs:,}条")
print(f"平均速率: {success_count/total_time:.2f} bulk/秒")
print(f"文档写入速率: {total_docs/total_time:.2f} docs/秒")
print("=" * 60)
return {
"test_name": test_name,
"config_name": config['name'],
"round": round_num,
"es_url": config['url'],
"index": config['index'],
"total_time": total_time,
"success_count": success_count,
"error_count": error_count,
"total_docs": total_docs,
"bulk_rate": success_count/total_time,
"doc_rate": total_docs/total_time
}
def run_comparison_test(self, total_iterations: int = 10000):
"""运行双地址对比测试"""
print("ES Bulk写入性能测试开始")
print(f"测试时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
print("=" * 60)
results = []
rounds = 2 # 每个地址测试2轮
# 循环测试所有配置
for config in self.es_configs:
print(f"\n开始测试配置: {config['name']}")
print("*" * 40)
for round_num in range(1, rounds + 1):
# 运行测试
result = self.run_test(config, round_num, total_iterations)
results.append(result)
# 每轮结束后刷新索引
print(f"\n第{round_num}轮测试完成,执行索引刷新...")
self.refresh_index(config)
# 重置ID计数器
if round_num == 1:
# 第1轮:使用初始ID范围(新增数据)
print("第1轮:新增数据模式")
else:
# 第2轮:重复使用相同ID(更新数据模式)
print("第2轮:数据更新模式,复用第1轮ID")
self.current_prefix = self.id_prefix_start
self.current_suffix = self.id_suffix_start
print(f"{config['name']} 第{round_num}轮测试结束\n")
# 输出对比结果
print("\n性能对比结果:")
print("=" * 80)
# 按配置分组显示结果
config_results = {}
for result in results:
config_name = result['config_name']
if config_name not in config_results:
config_results[config_name] = []
config_results[config_name].append(result)
for config_name, rounds_data in config_results.items():
print(f"\n{config_name}:")
total_time = 0
total_bulk_rate = 0
total_doc_rate = 0
for round_data in rounds_data:
print(f" 第{round_data['round']}轮:")
print(f" 耗时: {round_data['total_time']:.2f}秒")
print(f" Bulk速率: {round_data['bulk_rate']:.2f} bulk/秒")
print(f" 文档速率: {round_data['doc_rate']:.2f} docs/秒")
print(f" 成功率: {round_data['success_count']/(round_data['success_count']+round_data['error_count'])*100:.2f}%")
total_time += round_data['total_time']
total_bulk_rate += round_data['bulk_rate']
total_doc_rate += round_data['doc_rate']
avg_bulk_rate = total_bulk_rate / len(rounds_data)
avg_doc_rate = total_doc_rate / len(rounds_data)
print(f" 平均性能:")
print(f" 总耗时: {total_time:.2f}秒")
print(f" 平均Bulk速率: {avg_bulk_rate:.2f} bulk/秒")
print(f" 平均文档速率: {avg_doc_rate:.2f} docs/秒")
# 整体对比
if len(config_results) >= 2:
config_names = list(config_results.keys())
config1_avg = sum([r['bulk_rate'] for r in config_results[config_names[0]]]) / len(config_results[config_names[0]])
config2_avg = sum([r['bulk_rate'] for r in config_results[config_names[1]]]) / len(config_results[config_names[1]])
if config1_avg > config2_avg:
faster = config_names[0]
rate_diff = config1_avg - config2_avg
else:
faster = config_names[1]
rate_diff = config2_avg - config1_avg
print(f"\n整体性能对比:")
print(f"{faster} 平均性能更好,bulk速率高 {rate_diff:.2f} bulk/秒")
print(f"性能提升: {(rate_diff/min(config1_avg, config2_avg)*100):.1f}%")
def main():
"""主函数"""
tester = ESBulkTester()
# 运行测试(每次bulk 1万条,300次bulk = 300万条文档)
tester.run_comparison_test(total_iterations=300)
if __name__ == "__main__":
main()1. 日志场景:不带 id 写入
测试条件:
- bulk 写入数据不带文档 id
- 每批次 bulk 10000 条数据,总共写入 30w 数据
这里把
反馈结果:
性能对比结果:
================================================================================
ES直连:
第1轮:
耗时: 152.29秒
Bulk速率: 1.97 bulk/秒
文档速率: 19699.59 docs/秒
成功率: 100.00%
平均性能:
总耗时: 152.29秒
平均Bulk速率: 1.97 bulk/秒
平均文档速率: 19699.59 docs/秒
Gateway代理:
第1轮:
耗时: 115.63秒
Bulk速率: 2.59 bulk/秒
文档速率: 25944.35 docs/秒
成功率: 100.00%
平均性能:
总耗时: 115.63秒
平均Bulk速率: 2.59 bulk/秒
平均文档速率: 25944.35 docs/秒
整体性能对比:
Gateway代理 平均性能更好,bulk速率高 0.62 bulk/秒
性能提升: 31.7%2. 业务场景:带文档 id 的写入
测试条件:
- bulk 写入数据带有文档 id,两次测试写入的文档 id 生成规则一致且重复。
- 每批次 bulk 10000 条数据,总共写入 30w 数据
这里把 py 脚本中 第 99 行 和 第 107 行的注释打开。
反馈结果:
性能对比结果:
================================================================================
ES直连:
第1轮:
耗时: 155.30秒
Bulk速率: 1.93 bulk/秒
文档速率: 19317.39 docs/秒
成功率: 100.00%
平均性能:
总耗时: 155.30秒
平均Bulk速率: 1.93 bulk/秒
平均文档速率: 19317.39 docs/秒
Gateway代理:
第1轮:
耗时: 116.73秒
Bulk速率: 2.57 bulk/秒
文档速率: 25700.06 docs/秒
成功率: 100.00%
平均性能:
总耗时: 116.73秒
平均Bulk速率: 2.57 bulk/秒
平均文档速率: 25700.06 docs/秒
整体性能对比:
Gateway代理 平均性能更好,bulk速率高 0.64 bulk/秒
性能提升: 33.0%小结
不管是日志场景还是业务价值更重要的大数据或者搜索数据同步场景, gateway 的写入加速都能平稳的节省 25%-30% 的写入耗时。
关于极限网关(INFINI Gateway)

INFINI Gateway 是一个开源的面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway,可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
官网文档:https://docs.infinilabs.com/gateway
开源地址:https://github.com/infinilabs/gateway
作者:金多安,极限科技(INFINI Labs)搜索运维专家,Elastic 认证专家,搜索客社区日报责任编辑。一直从事与搜索运维相关的工作,日常会去挖掘 ES / Lucene 方向的搜索技术原理,保持搜索相关技术发展的关注。
原文:https://infinilabs.cn/blog/2025/gateway-bulk-write-performance-optimization/
Elasticsearch 磁盘空间异常:一次成功的故障排除案例分享
Elasticsearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 5832 次浏览 • 2024-08-09 00:18
故障现象
近日有客户找到我们,说有个 ES 集群节点,磁盘利用率达到了 82% ,而其节点才 63% ,想处理下这个节点,降低节点的磁盘利用率。
起初以为是没有打开自动平衡导致的,经查询,数据还是比较平衡的。
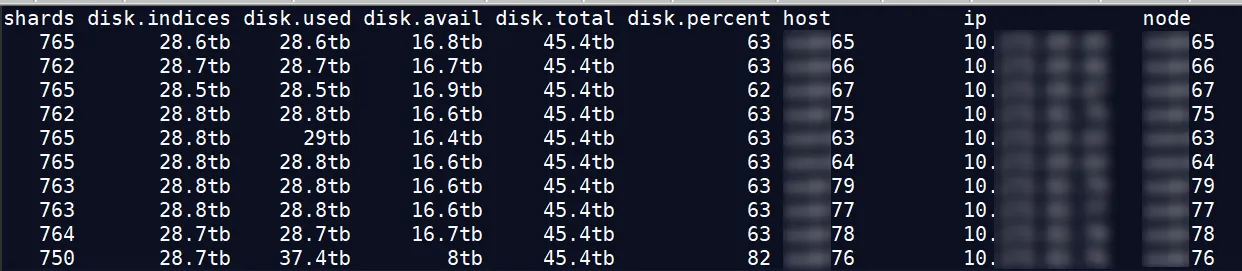 利用率较高的是 76 节点,如果 76 节点的分片比其他节点多,好像还比较合乎逻辑,但它反而比其他节点少了 12-15 个分片。那是 76 节点上的分片比较大?
利用率较高的是 76 节点,如果 76 节点的分片比其他节点多,好像还比较合乎逻辑,但它反而比其他节点少了 12-15 个分片。那是 76 节点上的分片比较大?
索引情况
 图中都是较大的索引,1 个索引 25TB 左右,共 160 个分片。
图中都是较大的索引,1 个索引 25TB 左右,共 160 个分片。
分片大小
节点 64
 节点 77
节点 77
 节点 75
节点 75
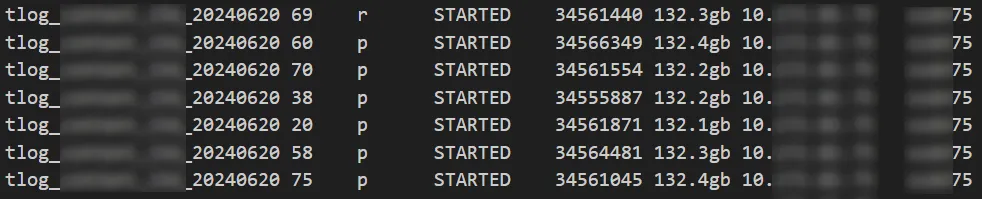 问题节点 76
问题节点 76
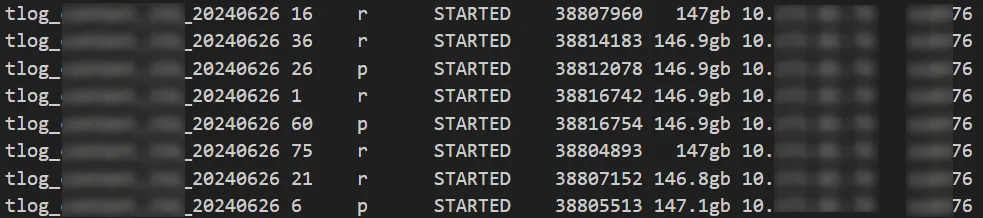 可以看出分片大小没有出现较大的倾斜,分片大小和数据平衡的原因都被排除。
可以看出分片大小没有出现较大的倾斜,分片大小和数据平衡的原因都被排除。
换个方向思考,节点 76 比其他节点多使用了磁盘空间 8 个 TB 左右,集群最大分片大小约 140GB ,8000/140=57 ,即节点 76 至少要比其他节点多 57 个分片才行,啊这...
会不会有其他的文件占用了磁盘空间?
我们登录到节点主机,排查是否有其他文件占用了磁盘空间。
结果:客户的数据路径是单独的数据磁盘,并没有其他文件,都是 ES 集群索引占用的空间。
现象总结
分片大小差不多的情况下,节点 76 的分片数还比别的节点还少 10 个左右,它的磁盘空间反而多占用了 8TB 。
这是不是太奇怪了?事出反常必有妖,继续往下查。
原因定位
通过进一步排查,我们发现节点 76 上有一批索引目录,在其他的节点上没有,而且也不在 GET \_cat/indices?v 命令的结果中。说明这些目录都是 dangling 索引占用的。
dangling 索引产生的原因
当 Elasticsearch 节点脱机时,如果删除的索引数量超过 Cluster.indes.tombstones.size,就会发生这种情况。
解决方案
通过命令删除 dangling 索引:
DELETE /\_dangling/<index-uuid>?accept_data_loss=true最后
这次的分享就到这里了,欢迎与我一起交流 ES 的各种问题和解决方案。

关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
极限网关助力好未来 Elasticsearch 容器化升级
Elasticsearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 5417 次浏览 • 2024-06-12 15:01
极限网关在好未来的最佳实践案例,轻松扛住日增百 TB 数据的流量,助力 ES 从物理机到云原生架构的改造,实现了流控、请求分析、安全管理、无缝迁移等场景。一次完美的客户体验~
背景
物理机架构时代
2022 年,好未来整个日志 Elasticsearch 拥有数十套服务集群,几百台物理机。这么多台机器耗费成本非常高,而且还要花费很大精力去维护。在人力资源有限情况下,存在非常多的弊端,运行成本高,不仅是机器折旧还有机柜等费用。
流量特征
这是来自某个业务线,如下图 1,真实流量,潮汐性非常明显。好未来有很多条业务线,几乎跟这个趋势都一致的,除了个别业务有“续报”、“开课”等活动特殊情况。潮汐性带来的问题就是高峰期 CPU、内存资源是可以消耗很高;低峰期资源使用量非常低,由于是物理架构,这些资源无法给其他业务线共享。
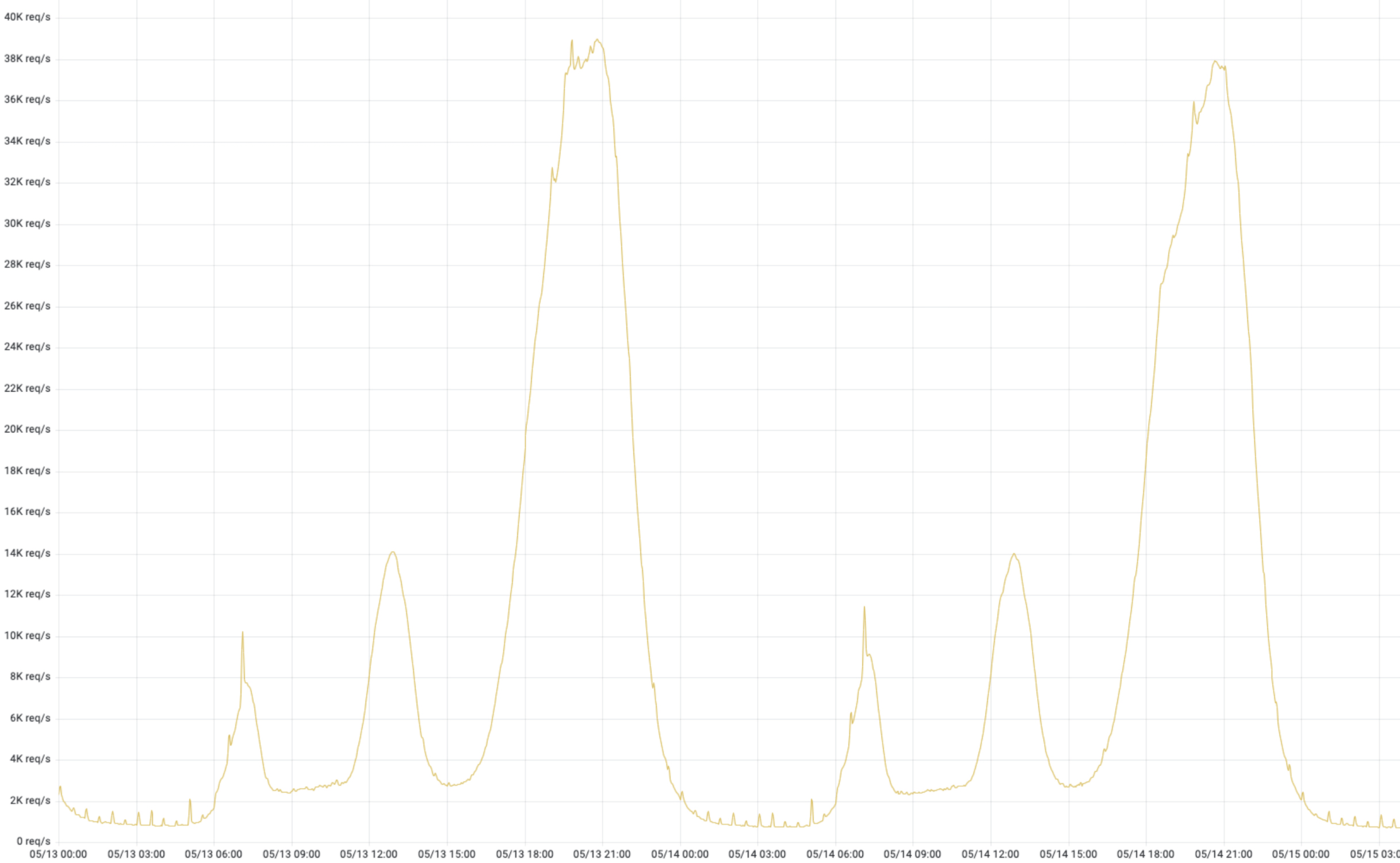
降本增效-容器化改造原动力
日志服务对成本的空前的压力促使我们推进 Elasticsearch 进行架构改造;如何改造,改造成什么样子,这两个问题一直是推进改造原动力。业界能够同时对水平扩展和垂直扩展就是 K8S,我们开始对 Elasticsearch 改造成能在 K8S 上运行进行探索,从而提升 CPU、内存利用率。
物理机时代,没办法把资源动态的扩缩,动态调配,资源隔离,单靠人力操作调度成本太高,几乎无法完成;集群对内存资源需求要比 CPU 资源大很多,由于机器型号配置是固定的,无法“定制”,这也会导致成本居高不下。所以,无论从那个方面来讲,容器化优势非常明显,既能够优化成本,也能够降低运维复杂度。
ES 容器化改造
进行架构升级重点难点- API 服务
改造过程,我们遇到了很多问题,比如容器 ES 版本和物理机 ES 版本不一致,如何让 ES API 能够兼容不同的 ES 版本,由于版本的不兼容,导致无法直接使用原有的 tribenode 进行服务,怎么提供一个高可用的 Elasticsearch API 服务。我们考虑到多个方面,比如使用官方推荐的 proxy 模式、第三方服务等进行选择,经过多方面对比,选择了极限网关 进行 tribenode 替换。
原始 ES API 服务痛点
- API 访问没有流量控制
- 可观测性差,而且稳定性一般
- 版本兼容性差
物理机时代 API 架构
在物理机时代 ES 集群,API 架构如图 2,可以明显看到 tribe node 对所有 ES 集群的“侵入性”是非常大的,这就带来了很多问题,比较严重的就是单个集群对 ES tribenode 的影响和版本升级带来的不兼容问题。

混合时代 API 架构
通过图 3,我们可以看到,极限网关对于版本兼容性很好,能够适配不同的版本。因此,最终选择极限网关作为下一代 ES API 服务方。

里程碑:全部 ES 集群容器化
在 2023 年 3 月份,通过 Elastic 官方 ECK 模式,完成全部日志 ES 集群容器化改造,拥有数百节点,1PB+ 数据存储,每日新增数据 100T 左右。紧接着,除了日志服务外,同时支持了好未来多条业务线。

极限网关实践
下面主要讲述了,为什么选择极限网关,以及极限网关在好未来落地、应用这些内容。
为什么选择极限网关?
学习成本低
我们可以从文档中看到极限网关,其架构简洁,语法简单,直观易懂。学习成本比较低,上手非常快,对新手友好。
性能强悍
经过压测,发现极限网关速度非常快,且针对 Elasticsearch 做了非常细致的优化,能成倍提升写入和查询的速度。
安全性高
支持多种认证方式,最简单的账号密码认证,可以给自定义多个账户密码,大大简化了 Elasticsearch 的安全设置,同时,还可以支持 LDAP 安全验证。
跨版本支持
我们容器化改造过程需要兼容不同版本的 Elasticsrearch,极限网关针对不同的 Elasticsearch 版本做了兼容和针对性处理,能够让业务代码无缝的进行适配,后端 Elasticsearch 集群版本升级能够做到无缝过渡,降低版本升级和数据迁移的复杂度,非常匹配我们的业务场景。
灵活可扩展
可灵活对每个请求进行干预和路由,支持路由的智能学习,内置丰富的过滤器,通过配置动态修改每个请求的处理逻辑,也支持通过插件来进行扩展,满足我们对流量的控制,尤其是限流、用户、IP 等这些功能非常实用。
启用安全策略-为 API 服务保驾护航
痛点
在升级之前使用 tribe 作为 API 服务提供后端,几乎相当于裸奔,没有任何认证策略;另外,tribe 本身的稳定性也有问题,官方在新版本逐渐废弃这种 CCS(跨集群搜索),期间出现多次服务崩溃。
极限网关解决问题
极限网关通过,“basic_auth” 插件,提供最基本的安全校验,使用起来非常方便;同时,极限网关提供 LDAP 插件,可以接入公共的 LDAP 服务,对所有的访问用户进行校验,安全策略对所有的用户生效,不用担心因为 IP 问题泄漏数据等。
强大的过滤功能
在使用 ES 集群过程中,许多场景,需要对请求进行控制、限制等操作。在这方便,感受到了极限网关强大的产品力。比如下面的两个场景
对异常流量进行限流
- 支持对 IP 限流
- 支持对 hostname 限流
- 支持 header 限流
对异常用户进行封禁
当 Elasticsearch 是通过 Basic Auth 或者 LDAP 方式来进行身份认证的时候,request_user_filter 过滤器可用来按请求的用户名信息来进行过滤。操作起来也非常简单,只需要 request_user_filter 这一个过滤器。
- request_user_filter:
include:
- "elastic"
exclude:
- "Ryan"总结来讲,主要有这些方面的功能:

优秀的可观测性
痛点
改造前经常为看不到直观的数据指标感到头疼,查看指标需要多个地方同时打开,去筛选,查找,非常繁琐,付出的成本非常大。为此,大家都再考虑如何优化这种情况,无奈优先级比较低,一直没有真正的投入时间去优化这块。
完美解决
使用了极限网关,通过收集请求日志,非常清晰的收集到想要的数据,具体如下:
- 总体方面:
- 流量曲线
- 状态码占比
- 缓存统计
- 每台网关请求流量
- 细节方面:
- 打印每次请求语句
- 可以查看请求到具体 ES 节点流量
- 可以查看过滤器的列表
通过下图,我们可以从管理视角直观的看到各种信息,这对于管理员来讲,省时省力,方便快捷。

意外收获:无缝迁移业务 Elasticsearch 上云
由于前期日志业务上云,受到非常好的反馈,多个业务线期望能够上云上服务,达到降本增效的目的。
支持双写
数据可以通过极限网关同时写入两个 ES 集群,能够保障数据完全一致,安全可靠。
无缝切换
切换很丝滑,影响非常小,能够让外界几乎感受不到服务波动。

通过使用极限网关,自建 ES 集群可以无缝的迁移上云,在整个迁移的过程中,两套集群通过网关进行了解耦,在迁移的过程中还能实现版本的无缝升级,极大降低了迁移成本,提高迁移效率,多次验证服务稳定可靠。
极限网关流量概览
这是其中一套极限网关的流量统计。用这部分数据进行巡检,一目了然,做到全局的掌控,提高感知力度。


极限网关使用总结
极限网关提供一系列高性能和高可靠性的网关服务。使用这样的服务给我们带来以下好处:
- 可观测性好:极限网关可以动态的对 Elasticsearch 运行过程中请求进行拦截和分析,通过指标和日志来了解集群运行状态,这些指标可以用于提升性能和业务优化。
- 增强安全性:包含先进的安全机制,如 basicauth、LDAP 等支持,保护用户数据不受未授权访问和各种网络威胁的侵害。
- 高稳定性:通过冗余设计和故障转移机制,极限网关能够确保网络服务的高可用性,即使在某些组件发生故障时也能保持服务不中断,单版本最长服务超过 15 个月。
- 易于管理:通过提供 INFINI Console 简洁直观的管理界面,让用户能够轻松配置和监控网络状态,提升管理效率。
- 客户支持:良好的客户服务支持可以帮助用户快速解决使用过程中遇到的问题,提供专业的技术指导。
综上所述,极限网关为用户提供了一个高速、安全、稳定且易于管理的 ES 网关,适合对网络性能有较高要求的个人和企业用户。
未来规划
第一阶段,完成了日志 ES 集群,所有集群的容器化改造,合并,成功的把成本降低了 60%以上。这期间积累了丰富容器化经验,为业务 ES 集群上容器做了良好的铺垫;成本优势和运维优势吸引越来越多的业务接入到容器化 ES 集群。
提升 ES 集群效能--新技术应用&&版本升级
- 极限科技官方推荐的 Easysearch 在压缩率,查询速度等等方面有很多的优势,通过长时间的测试稳定性,新特性,对比云原生的 ES 集群,根据测试结果,给“客户”提供多种选择,这也是工作重点之一。
- 我们当前使用的 ES 版本是 6.8,已经远远落后于官方版本,今年我们计划在选择合适的集群升级 ES 版本,拥抱更多官方提供的特性。
混合(多)云架构支持
随着越来越多的 ES 集群在机房的 K8S 集群部署,这里资源出现了紧张局面。 我们尝试在云上部署自建 ES 集群,弥补机房资源有限,无法大规模扩容,同时能够支持多活场景,满足更多客户的不同需求。混合云主要实现以下几种能力:
1、扩缩容:满足不同业务灵活适配
混合(多)云部署,可以让负载内部私有云 ES,同时部署到公有云,提升扩展 IT 基础设施不仅局限于 CPU、内存,还有存储。比如某一个业务要做活动,预估流量“大爆发”,需要提前准备大规模资源,在机房内根本来不及采购扩容支持,然而在公有云上就能很方便扩容、缩容。在云上搭建 ES 集群,设置满足需求的数量、容量、配置,配合极限网关路由策略,精准的把控流量流向。

2、灾备:紧急情况快速部署,恢复 ES 集群读写
当机房级别大规模故障,部分业务实现了多活,单一的机房故障不会影响其服务能力,而此时比如日志查看等仍有需求,为了满足这部分“客户”需求,可以在云上 K8S 集群,快速搭建 ES 集群,恢复日志读写功能。

参考文档:
- https://infinilabs.cn/docs/latest/gateway
- https://www.elastic.co/guide/en/cloud-on-K8S/current/K8S-overview.html
作者:张华勋,前新浪 CDN 研发,工作主要涉及 Mysql、MongoDB、Redis、Elasticsearch、流量调度等组件和系统,以及运维自动化、平台化等工作。现就职于好未来。
关于好未来
好未来(NYSE:TAL)是一家以内容能力与科技能力为基础,以科教、科创、科普为战略方向,助力人的终身成长,并持续探索创新的科技公司。 好未来的前身学而思成立于 2003 年,2010 年在美国纽交所正式挂牌交易。好未来以“爱与科技助力终身成长”为使命,致力成为持续创新的组织。更多参见:https://www.100tal.com/
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。

换掉ES? Redis官方搜索引擎,效率大幅提升
默认分类 • Fred2000 发表了文章 • 2 个评论 • 5458 次浏览 • 2024-05-30 10:08
RediSearch是一个Redis模块,为Redis提供查询、二次索引和全文搜索。要使用RediSearch,首先要在Redis数据上声明索引。然后可以使用重新搜索查询语言来查询该数据。
RedSearch使用压缩的反向索引进行快速索引,占用内存少。RedSearch索引通过提供精确的短语匹配、模糊搜索和数字过滤等功能增强了
实现特性
- 基于文档的多个字段全文索引
- 高性能增量索引
- 文档排序(由用户在索引时手动提供)
- 在子查询之间使用 AND 或 NOT 操作符的复杂布尔查询
- 可选的查询子句
- 基于前缀的搜索
- 支持字段权重设置
- 自动完成建议(带有模糊前缀建议)
- 精确的短语搜索
- 在许多语言中基于词干分析的查询扩展
- 支持用于查询扩展和评分的自定义函数
- 将搜索限制到特定的文档字段
- 数字过滤器和范围
- 使用 Redis 自己的地理命令进行地理过滤
- Unicode 支持(需要 UTF-8 字符集)
- 检索完整的文档内容或只是ID 的检索
- 支持文档删除和更新与索引垃圾收集
- 支持部分更新和条件文档更新
对比 Elasticsearch
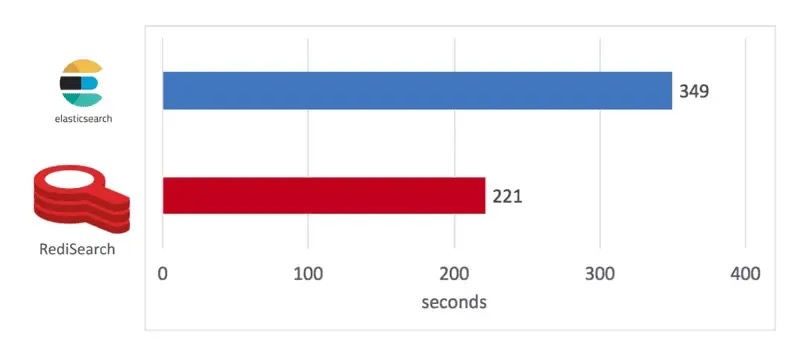
如下图所示,RediSearch 构建索引的时间为 221 秒,而 Elasticsearch 为 349 秒,快了 58%。
索引构建测试
我们模拟了一个多租户电子商务应用程序,其中每个租户代表一个产品类别并维护自己的索引。对于此基准测试,我们构建了 50K 个索引(或产品),每个索引最多存储 500 个文档(或项目),总共 2500 万个文档。
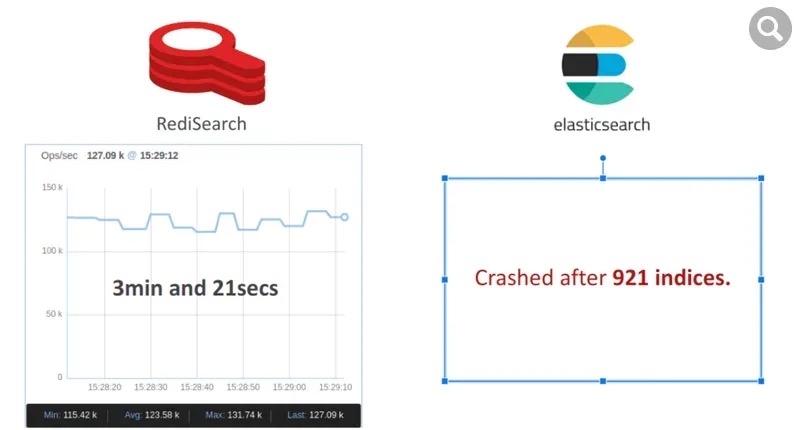
RediSearch 仅用了 201 秒就构建了索引,平均每秒运行 125K 个索引。然而,Elasticsearch 在 921 个索引后崩溃了,显然它不是为应对这种负载而设计的。
查询性能测试
一旦数据集被索引,我们就使用在专用负载生成器服务器上运行的 32 个客户端启动两个单词的搜索查询。如下图所示,RediSearch 吞吐量达到了 12.5K 操作/秒,而 Elasticsearch 为 3.1K 操作/秒,速度提高了 4 倍。
此外,RediSearch 延迟稍好一些,平均为 8 毫秒,而 Elasticsearch 为 10 毫秒。
安装
安装目前分为源码和docker安装两种方式。
源码安装
git clone https://github.com/RediSearch/RediSearch.git
cd RediSearch # 进入模块目录
make setup
make installdocker安装
note: RediSearch的安装比较复杂原包无法进行编译操作所以我们使用docker安装
docker run -p 6379:6379 redislabs/redisearch:latest判断是否安装成功
127.0.0.1:0>module list
1) 1) "name"
2) "ReJSON"
3) "ver"
4) "20007"
2) 1) "name"
2) "search"
3) "ver"
4) "20209"返回数组存在“ft”或 “search”(不同版本),表明 RediSearch 模块已经成功加载。
命令行操作
1、创建
1.1 创建索引
创建索引不妨想象成创建表结构,表一般基本属性有表名、字段和字段类别等,所以我们可以考虑将索引名代表表名,字段代表字段,属性即表示属性。
xxx.xxx.xxx.xxx:0>ft.create "student" schema "name" text weight 5.0 "sex" text "desc" text "class" tag
"OK"student 表示索引名,name、sex、desc表示字段,text表示类型(这样表示只是为了便于理解)
“weight”为权重,默认值为 1.0
type student
"none"我们创建的索引redis是不认识的,这证明使用的是插件。
1.2 创建文档
创建文档上下文的过程不妨想想成向表中插入数据,这里请注意字段名可以使用双引号但切记一定要用英文,这里之所以着重提出是因为有些编译器中文双引号和英文双引号用肉眼实在难以辨认否则会出现 “Fields must be specified in FIELD VALUE pairs”(其实是将“ 当作内容处理了以至于缺少了字段)
ft.add student 001 1.0 language "chinese" fields name "张三" sex "男" desc "这是一个学生" class "一班"
"OK"其中001为文档ID,"1.0"为评分缺少此值会报"Could not parse document score"异常,language 指明使用的语言默认是英文编码 如果没有此标记存储是没有问题的但不可以通过中文字符查询
1.3 查询
1.3.1 基本查询
1.3.1.1 全量查询
xxx.xxx.xxx.xxx:0>FT.SEARCH student * SORTBY sex desc RETURN 3 name sex desc
1) "2"
2) "001"
3) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
4) "002"
5) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"1.3.1.2 匹配查询
xxx.xxx.xxx.xxx:0>ft.search student "张三" limit 0 10 RETURN 3 name sex desc
1) "2"
2) "001"
3) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
4) "002"
5) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
limit 与mysql相识主要用于分页,此处是全量匹配,如果没有设置language “chinese” 此处查询为0,
1.3.2 模糊匹配
1.3.2.1 后置匹配
ft.search student "李*" SORTBY sex desc RETURN 3 name sex desc
1) "1"
2) "003"
3) 1) "name"
2) "李四"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"1.3.2.2 模糊搜索
xxx.xxx.xxx.xxx:0>FT.SEARCH beers "%%张店%%"
1) "1"
2) "beer:1"
3) 1) "name"
2) "集团本部已发布【文明就餐公约】,2号楼办公人员午餐的就餐时间是11:45~13:00,现经行政服务部进行抽查,发现我们部门有员工违规就餐现象。请大家务必遵守,相互转告,对于外地回到集团办公的同事,亦请遵守,谢谢!"
3) "org"
4) "山东省淄博市张店区"
5) "school"
6) "山东理工大学"别高兴太早全量模糊匹配是由很大限制的,他基于Levenshtein距离(LD)进行模糊匹配。术语的模糊匹配是通过在术语周围加“%”来实现的,模糊匹配的最大LD为3,确切的说这只是一种相识度查询,并非一般意义上的模糊搜索,但是如果仔细观察会发现通过精确匹配时不仅能够将完整value值查询出来而且还查询出其他处于文档某个位置的key请看官方提供的一个例子:
FT.CREATE idx SCHEMA txt TEXT
FT.ADD idx docCn 1.0 LANGUAGE chinese FIELDS txtRedis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。从盘可以有意无意的对数据进行写操作。
由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。
FT.CREATE idx SCHEMA txt TEXT
FT.ADD idx docCn 1.0 LANGUAGE chinese FIELDS txt "Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。从盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。[8]"
FT.SEARCH idx "数据" LANGUAGE chinese HIGHLIGHT SUMMARIZE
# Outputs:
# <b>数据</b>?... <b>数据</b>进行写操作。由于完全实现了发布... <b>数据</b>冗余很有帮助。[8...之所以会出现这样的效果是因为redisearch对文本进行了分词,其使用的工具是friso相比es的ik还是弱一些前者主要是对中文分词,体积小可移植性强。
从而我们可以结合后后置匹配算法
xxx.xxx.xxx.xxx:0>FT.SEARCH idx "数*" LANGUAGE chinese HIGHLIGHT
1) "1"
2) "docCn"
3) 1) "txt"
2) "Redis支持主从同步。<b>数据</b>可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。从盘可以有意无意的对<b>数据</b>进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和<b>数据</b>冗余很有帮助。[8]"
或者结合Levenshtein算法这样基本上能够满足业务查询需求
xxx.xxx.xxx.xxx:0>FT.SEARCH idx "%%单的树%%" LANGUAGE chinese HIGHLIGHT
1) "1"
2) "docCn"
3) 1) "txt"
2) "Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层<b>树</b>复制。从盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步<b>树</b>时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。[8]"1.3.2.3 字段查询
通过字段查询也可以实现模糊搜索,直接给例子,后面跟着官网上给的sql 和 redisearch的对照表
ft.search student *
1) "2"
2) "doudou"
3) 1) "name"
2) "豆豆"
3) "jtzz"
4) "“检索”是很多产品中"
5) "phone"
6) "18563717107"
4) "ttao"
5) 1) "name"
2) "姚元涛"
3) "jtzz"
4) "一个生病的人只"
5) "phone"
6) "18563717107"
ft.search student '@phone:185* @name:豆豆'
1) "1"
2) "doudou"
3) 1) "name"
2) "豆豆"
3) "jtzz"
4) "“检索”是很多产品中"
5) "phone"
6) "18563717107"1.4 删除
1.4.1 删除文档
xxx.xxx.xxx.xxx:0>ft.del student 002
"1"1.4.3 删除索引
xxx.xxx.xxx.xxx:0>ft.drop student
"OK"1.5 查看
1.5.1 查看所有索引
xxx.xxx.xxx.xxx:0>FT._LIST
1) "student1"
2) "ttao"
3) "idx"
4) "student"
5) "myidx"
6) "123"
7) "myIndex"
8) "testung"
9) "student2"1.5.2 查看索引文档中的数据
1.5.2.1 获取单条数据
xxx.xxx.xxx.xxx:0>ft.get student 001
1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
7) "class"
8) "一班"1.5.2.2 获取多条数据
xxx.xxx.xxx.xxx:0>ft.mget student 001 002
1) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
7) "class"
8) "一班"
2) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
7) "class"
8) "一班"1.6 索引别名操作
1.6.1 添加别名
123.232.112.84:0>FT.ALIASADD xs student
"OK"给索引student起个xs的别名,一个索引可以起多个别名
1.6.2 修改别名
1.6.3 删除别名
123.232.112.84:0>FT.ALIASDEL xs
"OK"作者:架构师公众号
来源:https://mp.weixin.qq.com/s/TmCXx3rLjLPggvOFjGqS9w
版权申明:内容来源网络,仅供学习研究,版权归原创者所有。如有侵权烦请告知,我们会立即删除并表示歉意。谢谢!
记某客户的一次 Elasticsearch 无缝数据迁移
Elasticsearch • yangmf2040 发表了文章 • 0 个评论 • 7465 次浏览 • 2024-04-02 14:16
背景
客户需要将 Elasticsearch 集群无缝迁移到移动云,迁移过程要保证业务的最小停机时间。
实现方式
通过采用成熟的 INFINI 网关来进行数据的双写,在集群的切换恢复过程中来记录数据变更,待全量数据恢复之后再追平后面增量数据,追平增量之后,进行校验确保数据一致再进行流量的切换。
总体流程
总体迁移流程如下:
- 客户业务代码,切流量,双写。(新增的变更都会记录在网关本地,但是暂停消费到移动云)
- 暂停网关移动云这边的增量数据消费。
- 迁移 11 月的数据,快照,快照上传到 S3;
- 下载 S3 的文件到移动云。
- 恢复快照到移动云的 11 月份的索引。
- 开启网关移动云这边的增量消费。
- 等待增量追平(接近追平)。
- 按照时间条件(如:时间 A,当前时间往前 30 分钟),验证文档数据量,Hash 校验等等。
- 停业务的写入,网关,腾讯云的写入(10 分钟)。
- 等待剩余的增量追完。
- 对时间 A 之后的,增量进行校验。
- 切换所有流量到移动云,业务端直接访问移动云 ES。
总体的迁移时间:
- 11 月备份时间(30 分钟)19 号开始
- 备份下载到移动云的时间(2-3 天)
- 备份恢复到移动云集群的时间(30 分钟)
- 11 月份增量备份(20 分钟)(双写开始)(21 号)
- 11 月份增量下载到移动云(6 小时)
- 11 月份增量恢复时间(20 分钟)
- 追增量数据(8 个小时产生的数据,需要 1 个小时)
- 校验比对(存量 1 个小时)
- 流量暂停,增量的校验(10 分钟)
- 切换(1 分钟)
总体流程如下示意图:

ES 集群信息
- ES 版本 7.10.1
- 2个热节点 3个温节点 总数 1.9 TB
- 索引 1041, 分片2085
- 无自定义插件
- 有 update_bu_query 使用
- 有 delete_by_query 使用
- 吞吐量没有测试过,当前日增文档数 1 千多万,目标日增加上亿
迁移操作手册(参考)
环境
- 自建 ES 5.4.2
- 自建 ES 5.6.8
- 自建 ES 7.5.0
- 极限网关服务器 1
- 极限网关服务器 2
- 云端负载均衡 1 (监听 9200 端口,指向极限网关服务器 1/2 的 8000 端口)
- 云端负载均衡 2 (监听 9200 端口,指向极限网关服务器 1/2 的 8001 端口)
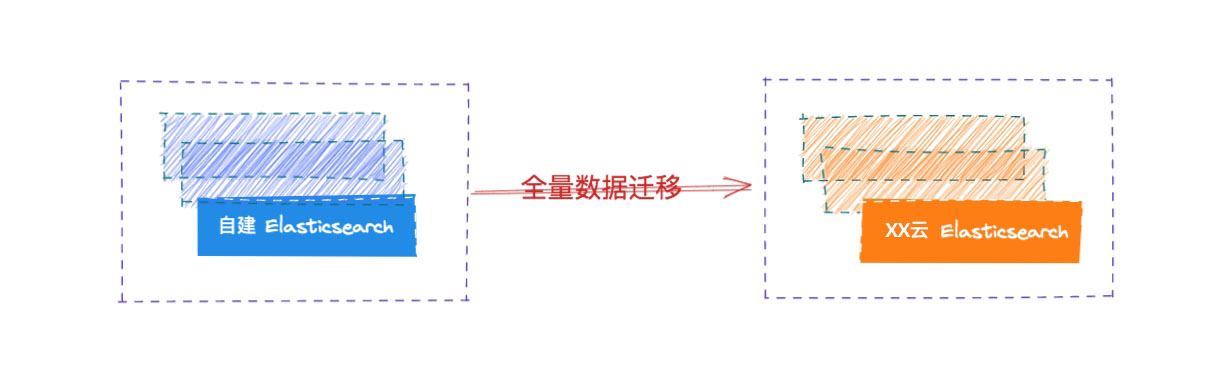
场景描述
若干个自建 Elasticsearch 集群需要平滑迁移到移动云,业务不停写、不做代码改动。
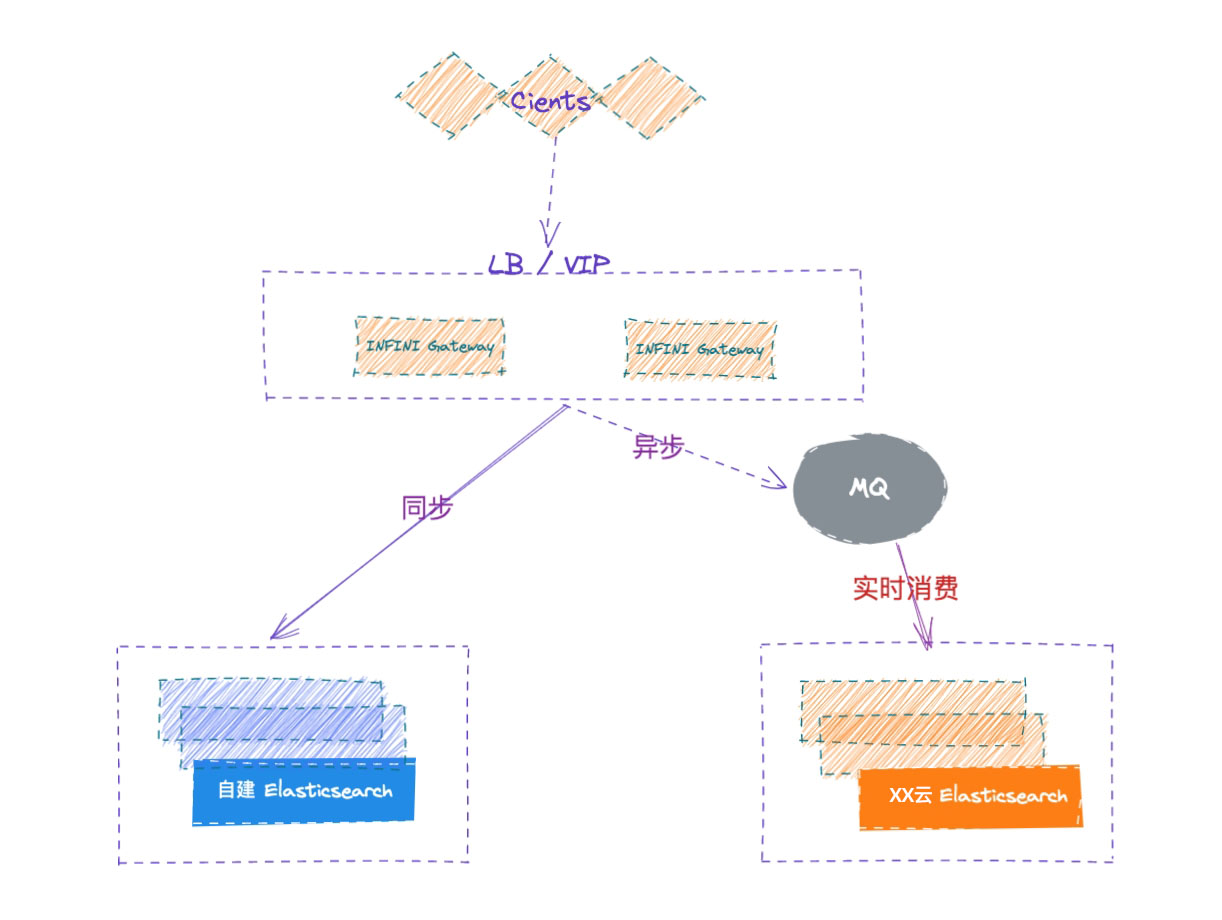
数据架构
通过将应用端流量走网关的方式,请求同步转发给自建 ES,网关记录所有的写入请求,并确保顺序在云端 ES 上重放请求,两侧集群的各种故障都妥善进行了处理,从而实现透明的集群双写,实现安全无缝的数据迁移。
 业务端如果已经部署在云上,可以使用云上的 SLB 服务来访问网关,确保后端网关的高可用,如果业务端和极限网关还在企业内网,可以使用极限网关自带的 4 层浮动 IP 来确保网关的高可用。
业务端如果已经部署在云上,可以使用云上的 SLB 服务来访问网关,确保后端网关的高可用,如果业务端和极限网关还在企业内网,可以使用极限网关自带的 4 层浮动 IP 来确保网关的高可用。
数据描述
以数据从自建集群 5.4.2 迁移到云上的 5.6.16 为例进行说明,执行步骤依次说明。
执行步骤
部署 INFINI Gateway
为了保证数据的无缝透明迁移,通过 INFINI Gateway 来进行双写。
-
系统调优
参考此文档。
- 下载程序
[root@iZbp1gxkifg8uetb33pvcoZ ~]# mkdir /opt/gateway [root@iZbp1gxkifg8uetb33pvcoZ ~]# cd /opt/gateway/ [root@iZbp1gxkifg8uetb33pvcoZ gateway]# wget http://release.infinilabs.com/gateway/snapshot/gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz --2022-05-19 10:16:25-- http://release.infinilabs.com/gateway/snapshot/gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz 正在解析主机 release.infinilabs.com (release.infinilabs.com)... 120.79.205.193 正在连接 release.infinilabs.com (release.infinilabs.com)|120.79.205.193|:80... 已连接。 已发出 HTTP 请求,正在等待回应... 200 OK 长度:7430568 (7.1M) [application/octet-stream] 正在保存至: “gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz”
100%[==============================================================================================================================================>] 7,430,568 22.8MB/s 用时 0.3s
2022-05-19 10:16:25 (22.8 MB/s) - 已保存 “gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz” [7430568/7430568])
[root@iZbp1gxkifg8uetb33pvcoZ gateway]# tar vxzf gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz gateway-linux-amd64 gateway.yml sample-configs/ sample-configs/elasticsearch-with-ldap.yml sample-configs/indices-replace.yml sample-configs/record_and_play.yml sample-configs/cross-cluster-search.yml sample-configs/kibana-proxy.yml sample-configs/elasticsearch-proxy.yml sample-configs/v8-bulk-indexing-compatibility.yml sample-configs/use_old_style_search_response.yml sample-configs/context-update.yml sample-configs/elasticsearch-route-by-index.yml sample-configs/hello_world.yml sample-configs/entry-with-tls.yml sample-configs/javascript.yml sample-configs/log4j-request-filter.yml sample-configs/request-filter.yml sample-configs/condition.yml sample-configs/cross-cluster-replication.yml sample-configs/secured-elasticsearch-proxy.yml sample-configs/fast-bulk-indexing.yml sample-configs/es_migration.yml sample-configs/index-docs-diff.yml sample-configs/rate-limiter.yml sample-configs/async-bulk-indexing.yml sample-configs/elasticssearch-request-logging.yml sample-configs/router_rules.yml sample-configs/auth.yml sample-configs/index-backup.yml
3. 修改配置
将网关提供的示例配置拷贝,并根据实际集群的信息进行相应的修改,如下:[root@iZbp1gxkifg8uetb33pvcoZ gateway]# cp sample-configs/cross-cluster-replication.yml 5.4.2TO5.6.16.yml
首先修改集群的身份信息,如下:

然后修改集群的注册信息,如下:

根据需要修改网关监听的端口,以及是否开启 TLS (如果应用客户端通过 http 协议访问 ES,请将entry.tls.enabled 值改为 false),如下:

不同的集群可以使用不同的配置,分别监听不同的端口,用于业务的分开访问。
4. 启动网关
启动网关并指定刚刚创建的配置,如下:[root@iZbp1gxkifg8uetb33pvcoZ gateway]# ./gateway-linux-amd64 -config 5.4.2TO5.6.16.yml
/ \ /\ / \/\/ / /\ \ \/\ /_/\ / /\///\ / /\/\ \ \/ \/ //\_ / / /\/ \/ / // \ /\ / \/ \ ___/\/ \/\/ \/ \/ \/_/ _/_/
[GATEWAY] A light-weight, powerful and high-performance elasticsearch gateway. [GATEWAY] 1.6.0_SNAPSHOT, 2022-05-18 11:09:54, 2023-12-31 10:10:10, 73408e82a0f96352075f4c7d2974fd274eeafe11 [05-19 13:35:43] [INF] [app.go:174] initializing gateway. [05-19 13:35:43] [INF] [app.go:175] using config: /opt/gateway/5.4.2TO5.6.16.yml. [05-19 13:35:43] [INF] [instance.go:72] workspace: /opt/gateway/data1/gateway/nodes/ca2tc22j7ad0gneois80 [05-19 13:35:43] [INF] [app.go:283] gateway is up and running now. [05-19 13:35:50] [INF] [actions.go:358] elasticsearch [primary] is available [05-19 13:35:50] [INF] [api.go:262] api listen at: http://0.0.0.0:2900 [05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [primary] hosts: [] => [192.168.0.19:9200] [05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [backup] hosts: [] => [es-cn-tl32p9fkk0006m56k.elasticsearch.aliyuncs.com:9200] [05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [primary] hosts: [] => [192.168.0.19:9200] [05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [backup] hosts: [] => [es-cn-tl32p9fkk0006m56k.elasticsearch.aliyuncs.com:9200] [05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [primary] hosts: [] => [192.168.0.19:9200] [05-19 13:35:50] [INF] [entry.go:322] entry [my_es_entry/] listen at: https://0.0.0.0:8000 [05-19 13:35:50] [INF] [module.go:116] all modules are started
5. 后台运行[root@iZbp1gxkifg8uetb33pvcoZ gateway]# nohup ./gateway-linux-amd64 -config 5.4.2TO5.6.16.yml &
6. 应用授权curl -XPOST http://localhost:2900/_license/apply -d' { "license": "XXXXXXXXXXXXXXXXXXXXXXXXX" }'
#### 部署 INFINI Console
为了方便在多个集群之间快速切换,使用 INFINI [Console](https://infinilabs.cn/products/console/) 来进行管理。
1. 下载安装[root@iZbp1gxkifg8uetb33pvcpZ console]# wget http://release.infinilabs.com/console/snapshot/console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz --2022-05-19 10:57:24-- http://release.infinilabs.com/console/snapshot/console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz 正在解析主机 release.infinilabs.com (release.infinilabs.com)... 120.79.205.193 正在连接 release.infinilabs.com (release.infinilabs.com)|120.79.205.193|:80... 已连接。 已发出 HTTP 请求,正在等待回应... 200 OK 长度:13576234 (13M) [application/octet-stream] 正在保存至: “console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz”
100%[==============================================================================================================================================>] 13,576,234 33.2MB/s 用时 0.4s
2022-05-19 10:57:25 (33.2 MB/s) - 已保存 “console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz” [13576234/13576234])
[root@iZbp1gxkifg8uetb33pvcpZ console]# tar vxzf console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz console-linux-amd64 console.yml
2. 修改配置[root@iZbp1gxkifg8uetb33pvcpZ console]# cat console.yml
for the system cluster, please use Elasticsearch v7.3+
elasticsearch:
- name: default
enabled: true
monitored: false
endpoint: http://es-cn-7mz2p9fty0007frx0.elasticsearch.aliyuncs.com:9200
basic_auth:
username: elastic
password: XXXXXX
discovery:
enabled: false
...
-
启动服务
[root@iZbp1gxkifg8uetb33pvcpZ console]# ./console-linux-amd64 -service install Success [root@iZbp1gxkifg8uetb33pvcpZ console]# ./console-linux-amd64 -service start Success - 访问后台
访问该主机的 9000 端口,即可打开 Console 后台,http://x.x.x.x:9000/
打开菜单 [System][Cluster] ,注册当前需要管理的 Elasticsearch 集群和网关地址,用来快速管理,如下:

测试 INFINI Gateway
为了验证网关是否正常工作,我们通过 INFINI Console 来快速验证一下。
首先通过走网关的接口来创建一个索引,并写入一个文档,如下:
 查看 5.4.2 集群的数据情况,如下:
查看 5.4.2 集群的数据情况,如下:
 查看集群 5.6.16 的数据情况,如下:
查看集群 5.6.16 的数据情况,如下:
 说明网关配置都正常,验证结束。
说明网关配置都正常,验证结束。
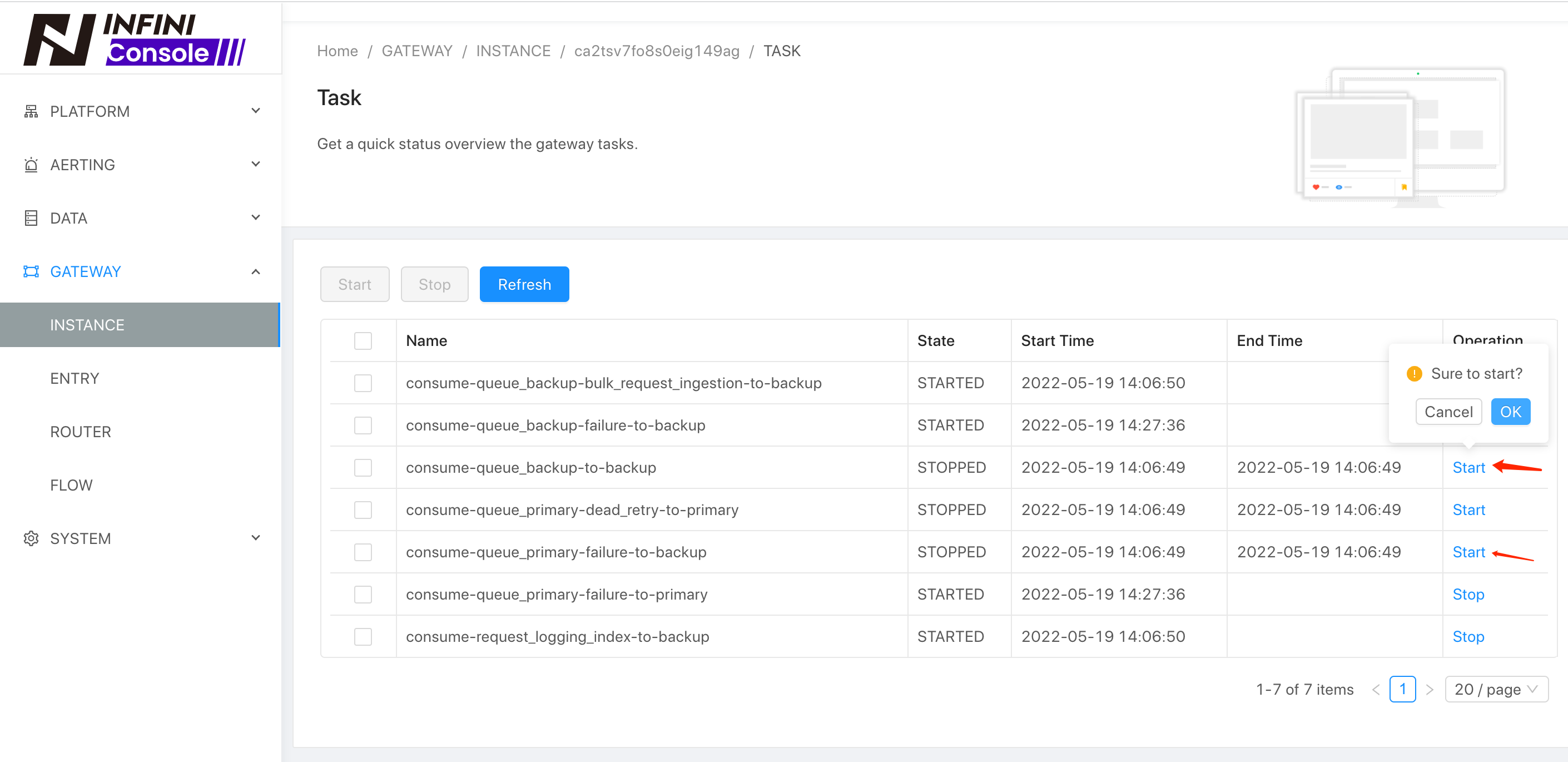
调整网关的消费策略
因为我们需要在全量数据迁移之后,才能进行增量数据的追加,在全量数据迁移完成之前,我们应该暂停增量数据的消费。修改网关配置里面 Pipeline consume-queue_backup-to-backup和 consume-queue_primary-failure-to-backup的参数 auto_start为 false,表示不自动启动该任务,具体配置方法如下:

 修改完配置之后,需要重新启动网关。
为了方便管理,可以使用 INFINI Console 来注册和管理网关,如下:
修改完配置之后,需要重新启动网关。
为了方便管理,可以使用 INFINI Console 来注册和管理网关,如下:

 待全量迁移完成之后,可以通过后台的 Task 管理来进行后续的任务启动、停止,如下:
待全量迁移完成之后,可以通过后台的 Task 管理来进行后续的任务启动、停止,如下:

切换流量
接下来,将业务正常写的流量切换到网关,也就是需要把之前指向 ES 5.4.2 的地址指向网关的地址,如果 5.4.2 集群开启了身份验证,业务端代码同样需要传递身份信息,和 5.4.2 之前的用法保持不变。
 切换流量到网关之后,用户的请求还是以同步的方式正常访问自建集群,网关记录到的请求会按顺序记录到 MQ 里面,但是消费是暂停状态。
如果业务端代码使用的 ES 的 SDK 支持 Sniff,并且业务代码开启了 Sniff,那么应该关闭 Sniff,避免业务端通过 Sniff 直接链接到后端的 ES 节点,所有的流量现在应该都只通过网关来进行访问。
切换流量到网关之后,用户的请求还是以同步的方式正常访问自建集群,网关记录到的请求会按顺序记录到 MQ 里面,但是消费是暂停状态。
如果业务端代码使用的 ES 的 SDK 支持 Sniff,并且业务代码开启了 Sniff,那么应该关闭 Sniff,避免业务端通过 Sniff 直接链接到后端的 ES 节点,所有的流量现在应该都只通过网关来进行访问。
全量数据迁移
在流量迁移到网关之后,我们开始对自建 Elasticsearch 集群的数据进行全量迁移到云端 Elasticsearch 集群。
 全量迁移已有的数据的方式有很多种:
全量迁移已有的数据的方式有很多种:
- 通过快照的方式进行恢复
- 使用工具来导出导入,如: ESM
如果索引数量很多的话,可以按照索引依次进行导入,同时需要注意将 Mapping 和 Setting 提前导入。
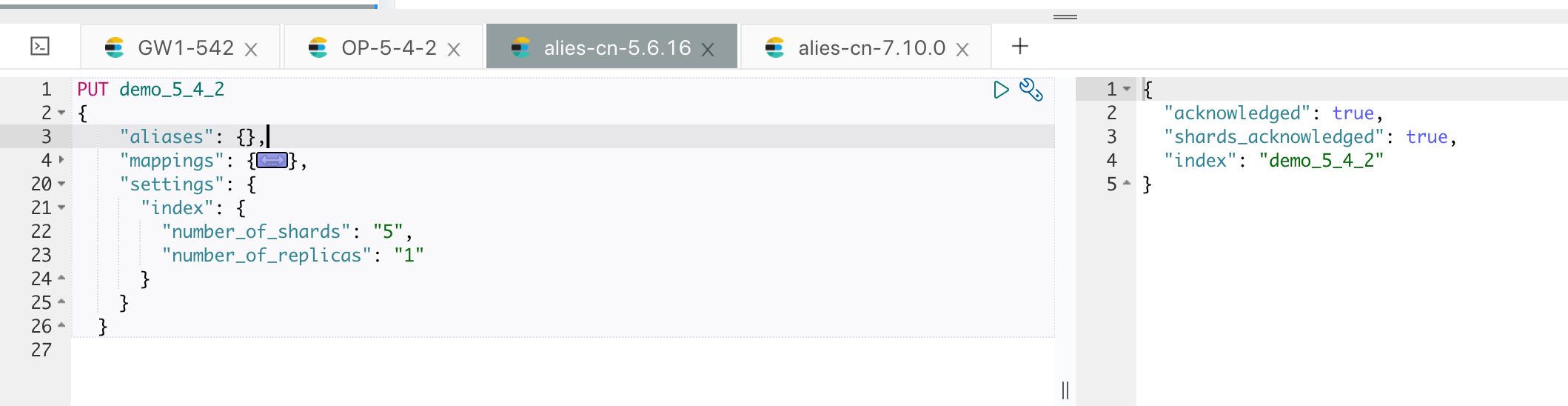
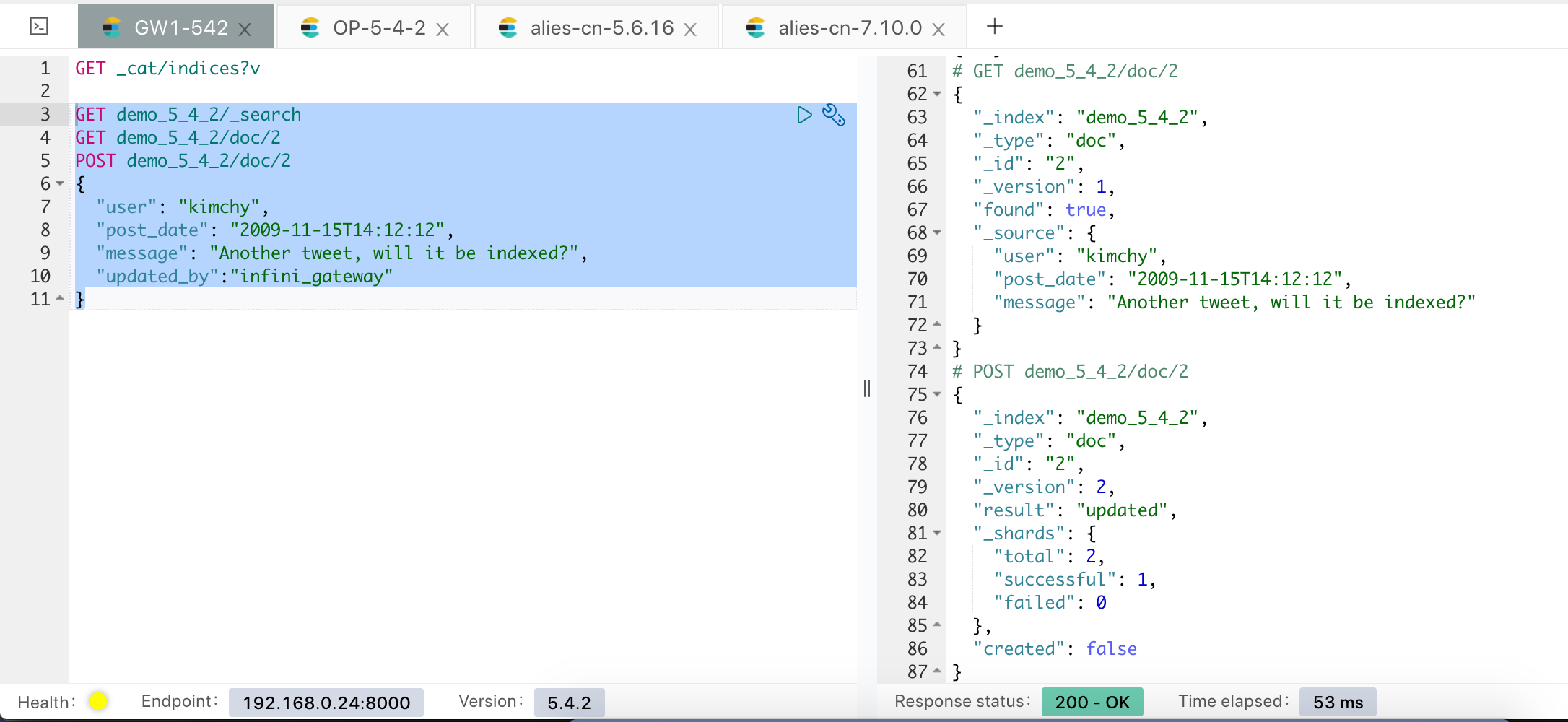
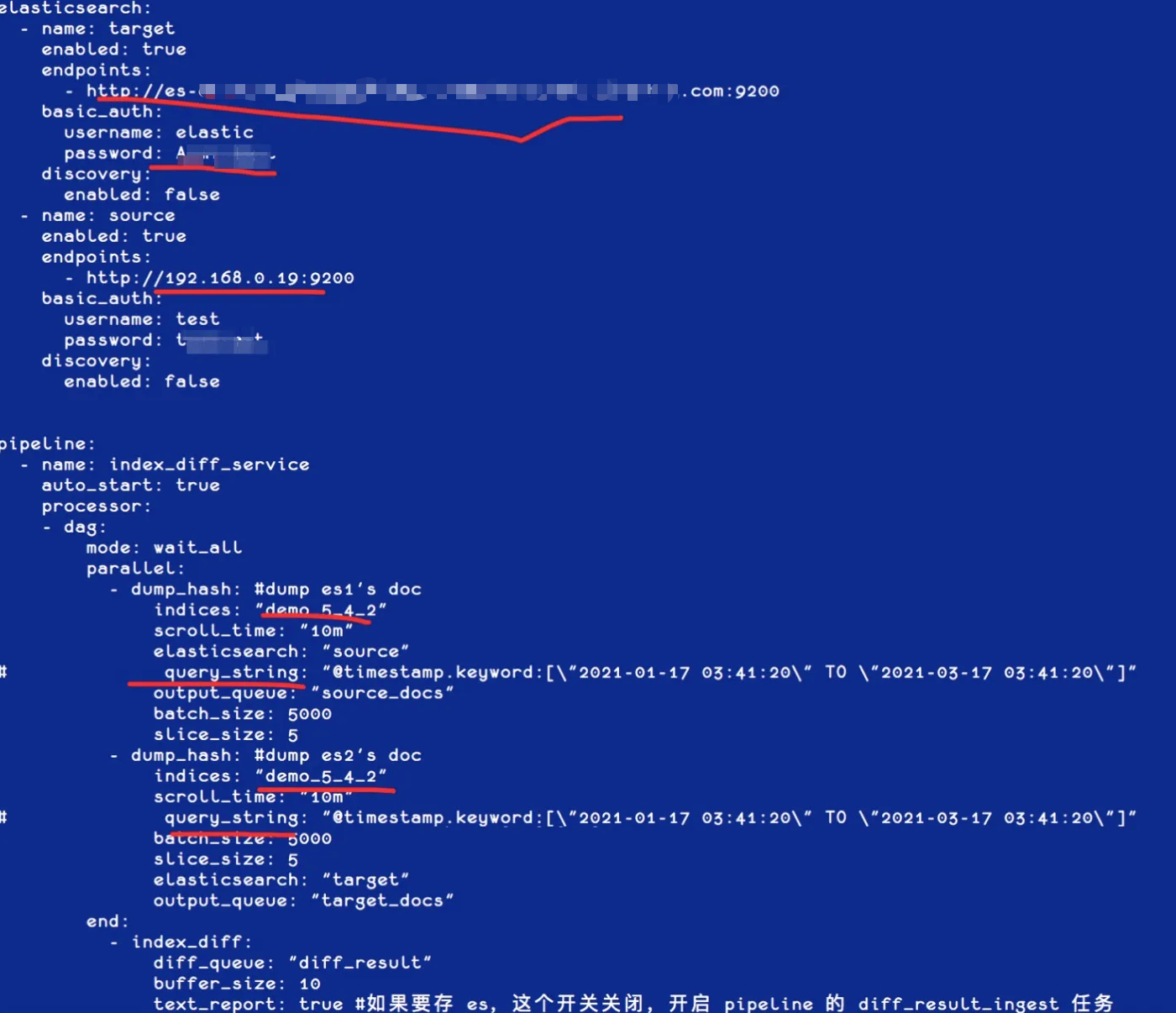
以现在 5.4 集群的索引来为例,目前的待迁移索引为 demo_5_4_2,只有4 个文档:
 我们使用网关自带的迁移功能来进行数据迁移,拷贝自带的样例文件,如下:
我们使用网关自带的迁移功能来进行数据迁移,拷贝自带的样例文件,如下:
[root@iZbp1gxkifg8uetb33pvcpZ gateway]# cp sample-configs/es_migration.yml 5.4TO5.6.yml修改其中代表集群和索引的相关配置,可以根据需要配置是否需要重命名索引和统一 Type( 用于跨版本统一 Type),如下图红框位置:
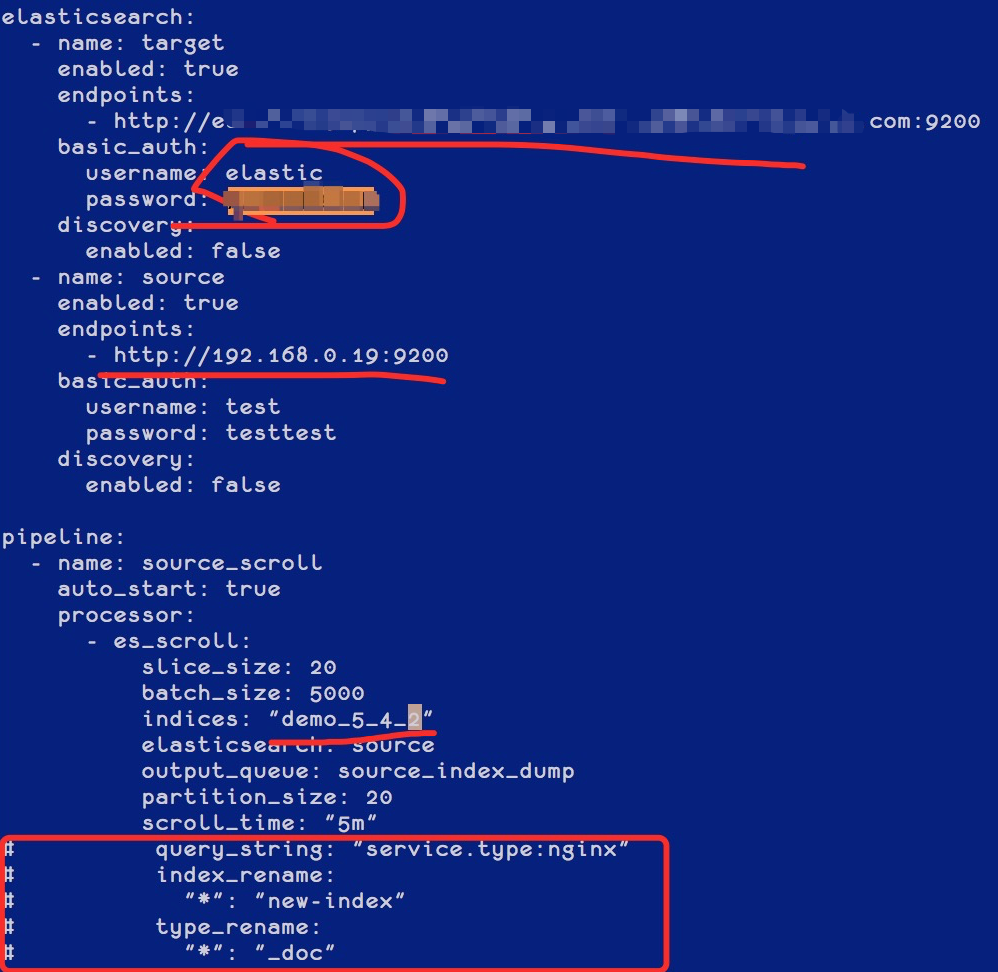 创建好模板和索引,如果目标集群不允许动态创建文档,需要提前创建好索引,如下图:
创建好模板和索引,如果目标集群不允许动态创建文档,需要提前创建好索引,如下图:
 然后就可以开始数据的迁移了,执行网关程序并指定刚刚定义的配置,如下:
然后就可以开始数据的迁移了,执行网关程序并指定刚刚定义的配置,如下:
 执行完成后,可以确认下数据的情况,如下图:
执行完成后,可以确认下数据的情况,如下图:
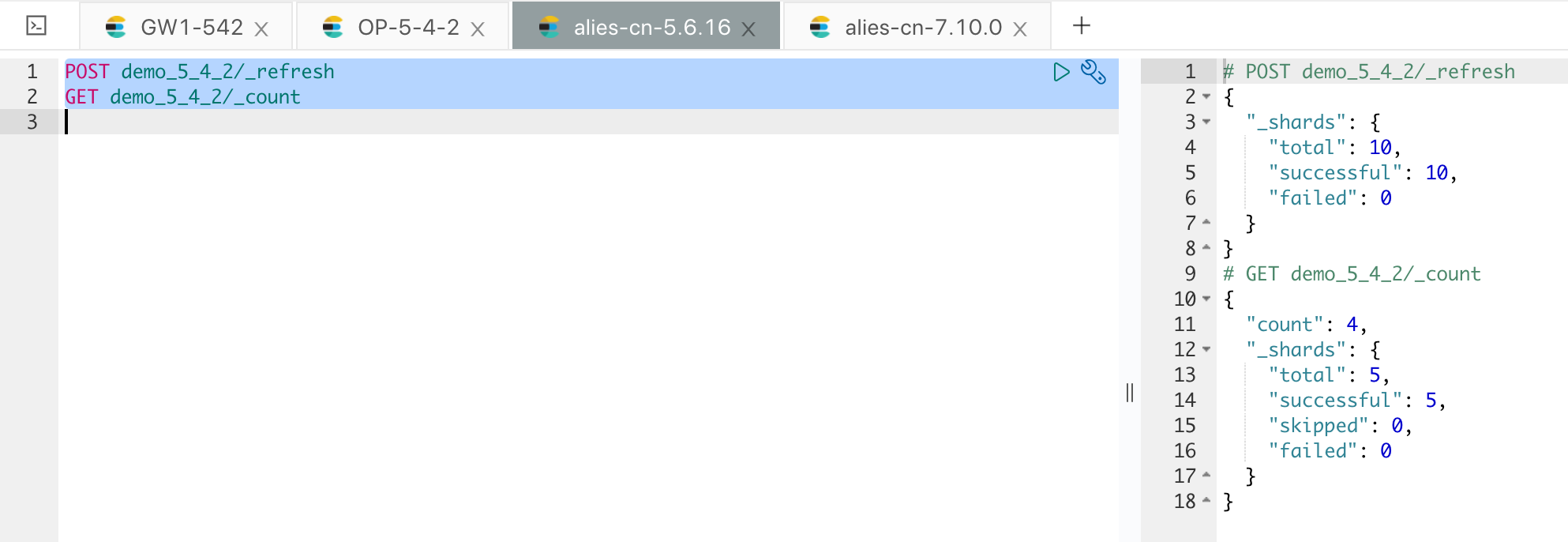 全量数据至此导入完成。
全量数据至此导入完成。
增量数据迁移
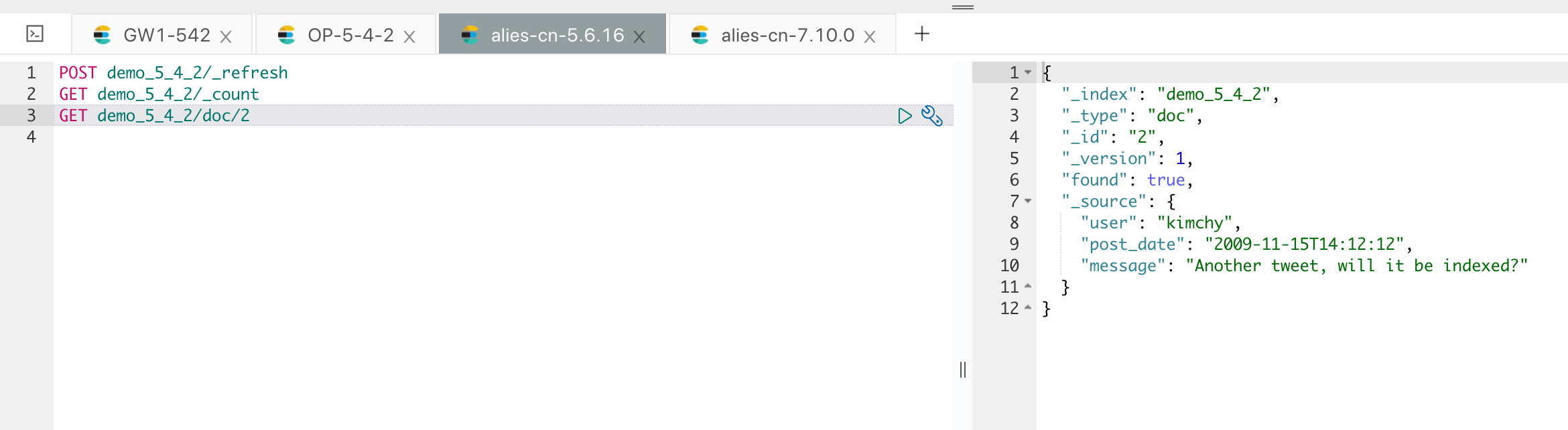
在全量导入的过程中,可能存在数据的增量修改,不过这部分请求都已经完整记录下来了,我们只需要开启网关的消费任务即可将挤压的请求应用到云端的 Elasticsearch 集群。
 示例操作如下:
示例操作如下:
 如果从 5.6 的集群来看的话,这部分的修改还没同步过来,如下:
如果从 5.6 的集群来看的话,这部分的修改还没同步过来,如下:
 这部分增量的数据变更,在网关层面都进行了完整记录,我们只需要开启网关的增量消费任务,如下:
这部分增量的数据变更,在网关层面都进行了完整记录,我们只需要开启网关的增量消费任务,如下:
 通过观察队列是否消费完成来判断增量数据是否做完,如下:
通过观察队列是否消费完成来判断增量数据是否做完,如下:
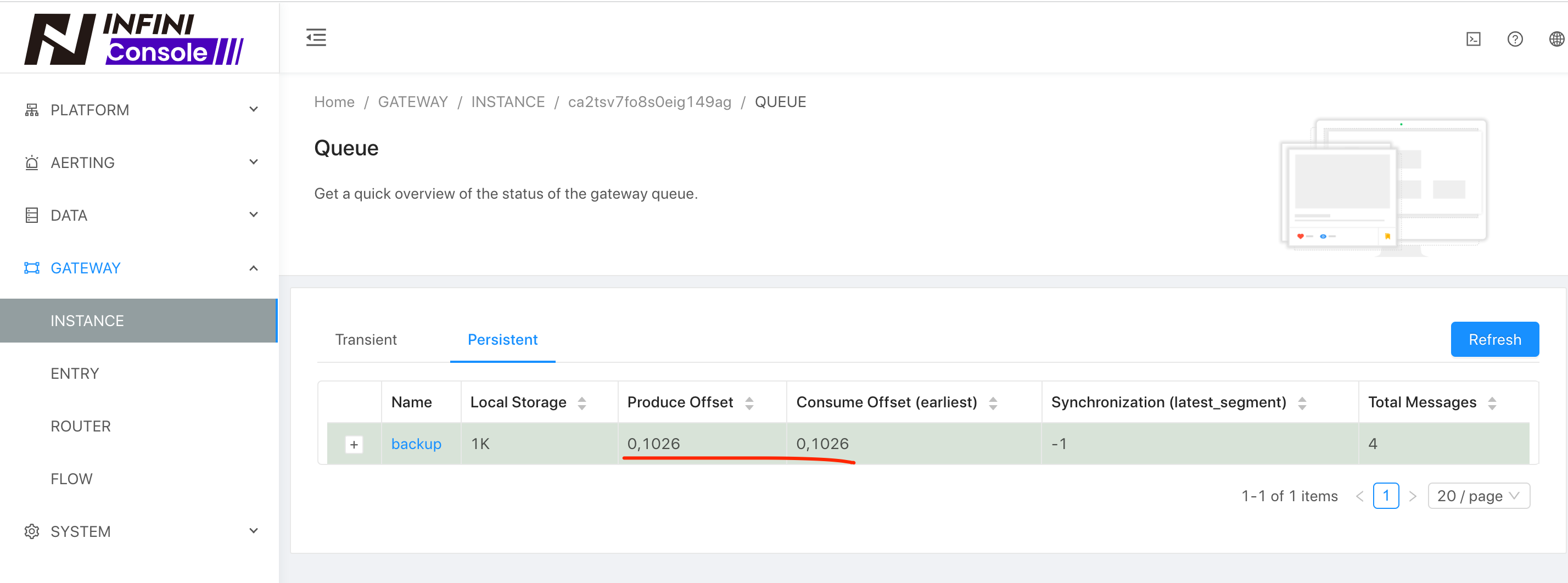 现在我们再看一下 5.6 集群的数据情况,如下:
现在我们再看一下 5.6 集群的数据情况,如下:
 数据的增量更新就过来了。
数据的增量更新就过来了。
执行数据比对
由于集群内部的数据可能比较多,我们需要进行一个完整的比对才能确保数据的完整性,可以通过网关自带的数据比对工具来进行,将样例自带的文件拷贝一份,如下:
[root@iZbp1gxkifg8uetb33pvcpZ gateway]# cp sample-configs/index-docs-diff.yml 5.4DIFF5.6.yml修改需要比对的集群和索引信息,可以加上过滤条件,如时间范围窗口来进行增量 Diff,如下图:
执行网关程序,并指定该配置文件,如下图:
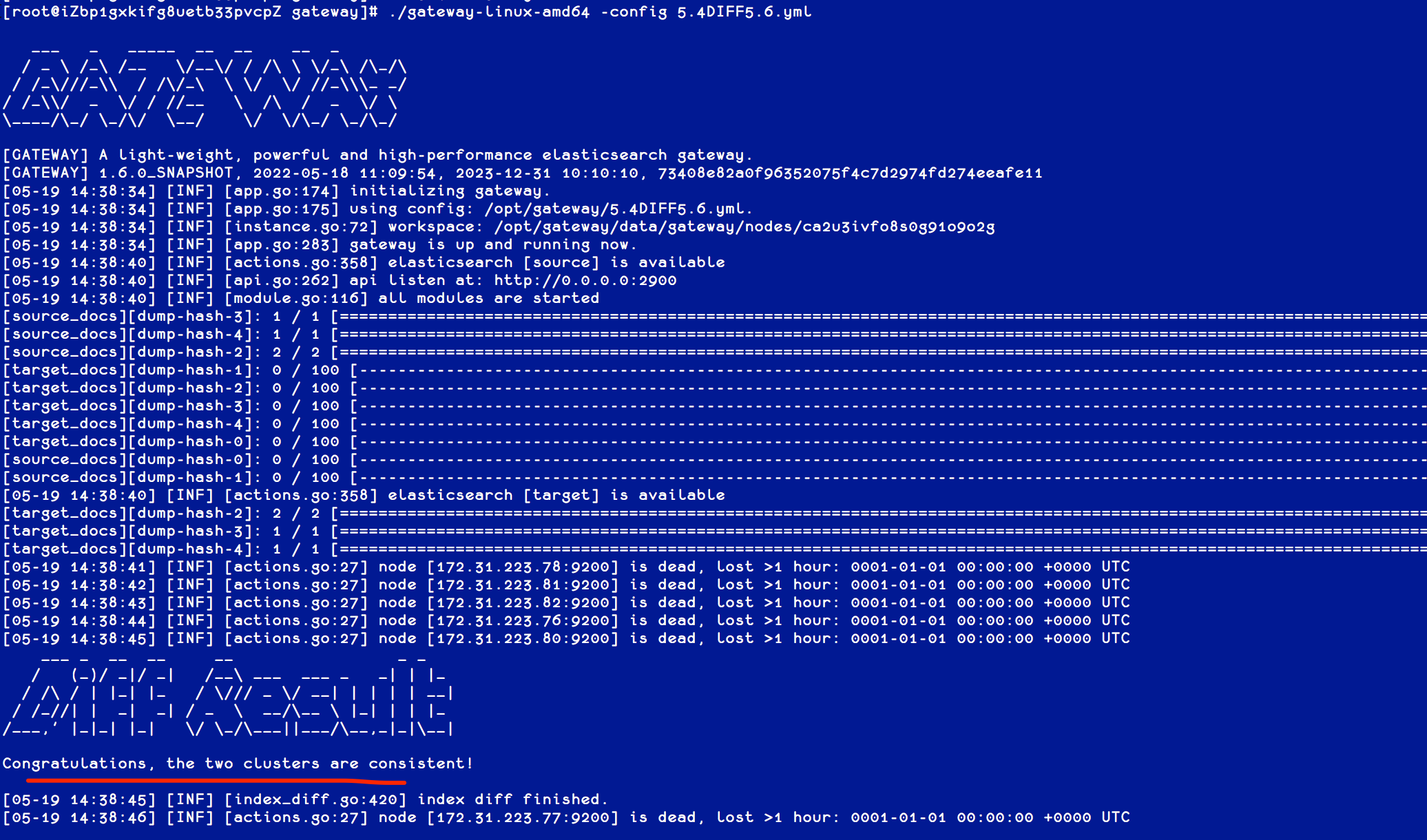 如图,两个集群完全一致。
如图,两个集群完全一致。
切换集群
如果验证完之后,两个集群的数据已经完全一致了,可以将程序切换到新集群,或者将网关的配置里面的主备进行互换,同步写 5.6 集群。
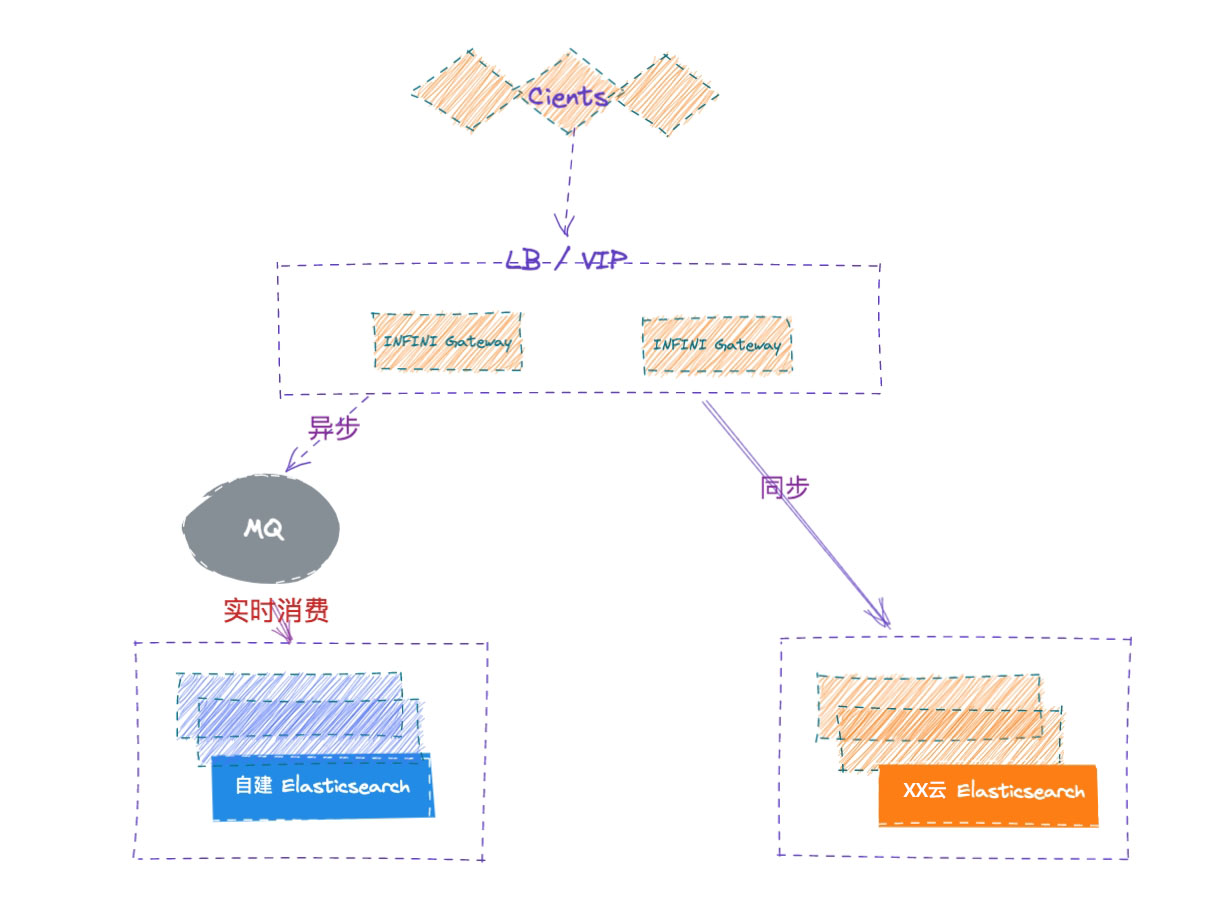 双集群在线运行一段时间,待业务完全验证之后,再安全下线旧集群,如遇到问题,也可以随时回切到老集群。
双集群在线运行一段时间,待业务完全验证之后,再安全下线旧集群,如遇到问题,也可以随时回切到老集群。
小结
通过使用极限网关,自建 ES 集群可以安全无缝的迁移到移动云 ES,在迁移的过程中,两套集群通过网关进行了解耦,两套集群的版本也可以不一样,在迁移的过程中还能实现版本的无缝升级。
如有任何问题,请随时联系我,期待与您交流!
Elasticsearch 国产化
Easysearch • yangmf2040 发表了文章 • 0 个评论 • 4957 次浏览 • 2024-03-16 16:36
背景
Elasticsearch 这些年来在搜索领域一直是领头羊。国内也有非常多的企业在使用 Elasticsearch 来做查询搜索、数据分析、安全分析等等。甚至一些很重要的行业、系统都在使用 Elasticsearch。在使用 Elasticsearch 的道路上狂飙的时候,我们也观察到了一些问题:
- Elasticsearch 不再是开源软件了。
- Elastic 公司退出了中国直销市场,不提供本土化支持了。
- 国家对信创、自主可控的战略化布局。
- 国际形势从合作共赢到自闭对垒。
- Elasticsearch 软件本身安全问题频发。
- Elasticsearch 软件在性能、稳定性和扩展性方面存在很大的提升空间。
基于以上这些问题,推出一个 Elasticsearch 国产化解决方案就很有必要了。我们的解决方案是推出一款名为 Easysearch 的软件,作为 Elasticsearch 国产化替代 。
出发点是在兼容原 Elasticsearch 软件的基础之上,完善更多的企业级功能,同时提高产品的性能、稳定性和扩展性。
下面我将从几个方面简单介绍下 Easysearch 软件。
兼容性
支持原生 Elasticsearch 的 DSL 查询语法,原业务代码无需调整。 支持 SQL ,方便熟悉 SQL 的开发人员上手分析数据。 兼容 Elasticsearch 的 SDK。 兼容现有索引存储格式。 支持冷热架构和索引生命周期,真正做到无缝衔接。
功能增强
提供企业级的安全管理,可对接 LDAP、AD 认证。 重构分布式架构,保持稳定的同时,能支持更大规模的数据。 在不降低性能的同时,实现更高压缩比的数据压缩,直接节省磁盘 40% 以上。 支持 KNN、异步搜索、数据脱敏、可搜索快照、审计等企业级功能。
容灾
支持基于 CDC 的集群复制技术,实现同版本间的容灾。
支持基于请求双写的复制技术,实现跨版本容灾。
信创
全面适配国产 CPU、操作系统,并获得厂家认证。

迁移方案
支持原索引存储格式,可通过快照备份直接恢复到 Easysearch 集群。
提供迁移工具,直接可视化操作迁移数据。
简单的介绍就到这里了,更多信息请访问:https://www.infinilabs.com/products/easysearch
最后
如有需要请联系我,让我们一起位祖国的信创事业添砖加瓦。

如何防止 Elasticsearch 服务 OOM?
Easysearch • yangmf2040 发表了文章 • 0 个评论 • 3951 次浏览 • 2024-02-26 10:12
Elasticsearch(简称:ES) 和传统关系型数据库有很多区别, 比如传统数据中普遍都有一个叫“最大连接数”的设置。目的是使数据库系统工作在可控的负载下,避免出现负载过高,资源耗尽,谁也无法登录的局面。
那 ES 在这方面有类似参数吗?答案是没有,这也是为何 ES 会被流量打爆的原因之一。
针对大并发访问 ES 服务,造成 ES 节点 OOM,服务中断的情况,极限科技旗下的 INFINI Gateway 产品(以下简称 “极限网关”)可从两个方面入手,保障 ES 服务的可用性。
- 限制最大并发访问连接数。
- 限制非重要索引的请求速度,保障重要业务索引的访问速度。
下面我们来详细聊聊。
架构图
 所有访问 ES 的请求都发给网关,可部署多个网关。
所有访问 ES 的请求都发给网关,可部署多个网关。
限制最大连接数
在网关配置文件中,默认有最大并发连接数限制,默认最大 10000。
entry:
- name: my_es_entry
enabled: true
router: my_router
max_concurrency: 10000
network:
binding: $[[env.GW_BINDING]]
# See `gateway.disable_reuse_port_by_default` for more information.
reuse_port: true使用压测程序测试,看看到达10000个连接后,能否限制新的连接。
 超过的连接请求,被丢弃。更多信息参考官方文档。
超过的连接请求,被丢弃。更多信息参考官方文档。
限制索引写入速度
我们先看看不做限制的时候,测试环境的写入速度,在 9w - 15w docs/s 之间波动。虽然峰值很高,但不稳定。
 接下来,我们通过网关把写入速度控制在最大 1w docs/s 。
对网关的配置文件 gateway.yml ,做以下修改。
接下来,我们通过网关把写入速度控制在最大 1w docs/s 。
对网关的配置文件 gateway.yml ,做以下修改。
env: # env 下添加
THROTTLE_BULK_INDEXING_MAX_BYTES: 40485760 #40MB/s
THROTTLE_BULK_INDEXING_MAX_REQUESTS: 10000 #10k docs/s
THROTTLE_BULK_INDEXING_ACTION: retry #retry,drop
THROTTLE_BULK_INDEXING_MAX_RETRY_TIMES: 10 #1000
THROTTLE_BULK_INDEXING_RETRY_DELAY_IN_MS: 100 #10
router: # route 部分修改 flow
- name: my_router
default_flow: default_flow
tracing_flow: logging_flow
rules:
- method:
- "*"
pattern:
- "/_bulk"
- "/{any_index}/_bulk"
flow:
- write_flow
flow: #flow 部分增加下面两段
- name: write_flow
filter:
- flow:
flows:
- bulking_indexing_limit
- elasticsearch:
elasticsearch: prod
max_connection_per_node: 1000
- name: bulking_indexing_limit
filter:
- bulk_request_throttle:
indices:
"test-index":
max_bytes: $[[env.THROTTLE_BULK_INDEXING_MAX_BYTES]]
max_requests: $[[env.THROTTLE_BULK_INDEXING_MAX_REQUESTS]]
action: $[[env.THROTTLE_BULK_INDEXING_ACTION]]
retry_delay_in_ms: $[[env.THROTTLE_BULK_INDEXING_RETRY_DELAY_IN_MS]]
max_retry_times: $[[env.THROTTLE_BULK_INDEXING_MAX_RETRY_TIMES]]
message: "bulk writing too fast" #触发限流告警message自定义
log_warn_message: true
再次压测,test-index 索引写入速度被限制在了 1w docs/s 。

限制多个索引写入速度
上面的配置是针对 test-index 索引的写入速度控制。如果想添加其他的索引,新增一段配置即可。 比如,我允许 abc 索引写入达到 2w docs/s,test-index 索引最多不超过 1w docs/s ,可配置如下。
- name: bulking_indexing_limit
filter:
- bulk_request_throttle:
indices:
"abc":
max_requests: 20000
action: drop
message: "abc doc写入超阈值" #触发限流告警message自定义
log_warn_message: true
"test-index":
max_bytes: $[[env.THROTTLE_BULK_INDEXING_MAX_BYTES]]
max_requests: $[[env.THROTTLE_BULK_INDEXING_MAX_REQUESTS]]
action: $[[env.THROTTLE_BULK_INDEXING_ACTION]]
retry_delay_in_ms: $[[env.THROTTLE_BULK_INDEXING_RETRY_DELAY_IN_MS]]
max_retry_times: $[[env.THROTTLE_BULK_INDEXING_MAX_RETRY_TIMES]]
message: "bulk writing too fast" #触发限流告警message自定义
log_warn_message: true限速效果如下

限制读请求速度
我们先看看不做限制的时候,测试环境的读取速度,7w qps 。
 接下来我们通过网关把读取速度控制在最大 1w qps 。
继续对网关的配置文件 gateway.yml 做以下修改。
接下来我们通过网关把读取速度控制在最大 1w qps 。
继续对网关的配置文件 gateway.yml 做以下修改。
- name: default_flow
filter:
- request_path_limiter:
message: "Hey, You just reached our request limit!" rules:
- pattern: "/(?P<index_name>abc)/_search"
max_qps: 10000
group: index_name
- elasticsearch:
elasticsearch: prod
max_connection_per_node: 1000再次进行测试,读取速度被限制在了 1w qps 。

限制多个索引读取速度
上面的配置是针对 abc 索引的写入速度控制。如果想添加其他的索引,新增一段配置即可。 比如,我允许 abc 索引读取达到 1w qps,test-index 索引最多不超过 2w qps ,可配置如下。
- name: default_flow
filter:
- request_path_limiter:
message: "Hey, You just reached our request limit!"
rules:
- pattern: "/(?P<index_name>abc)/_search"
max_qps: 10000
group: index_name
- pattern: "/(?P<index_name>test-index)/_search"
max_qps: 20000
group: index_name
- elasticsearch:
elasticsearch: prod
max_connection_per_node: 1000
多个网关限速
限速是每个网关自身的控制,如果有多个网关,那么后端 ES 集群收到的请求数等于多个网关限速的总和。
 本次介绍就到这里了。相信大家在使用 ES 的过程中也遇到过各种各样的问题。欢迎大家来我们这个平台分享自己的问题、解决方案等。如有任何问题,请随时联系我,期待与您交流!
本次介绍就到这里了。相信大家在使用 ES 的过程中也遇到过各种各样的问题。欢迎大家来我们这个平台分享自己的问题、解决方案等。如有任何问题,请随时联系我,期待与您交流!

用 Easysearch 帮助大型车企降本增效
Easysearch • yangmf2040 发表了文章 • 0 个评论 • 6017 次浏览 • 2024-02-02 15:15
最近某头部汽车集团需要针对当前 ES 集群进行优化,背景如下: ES 用于支撑包括核心营销系统、管理支持系统、财务类、IT 基础设施类、研发、自动驾驶等多个重要应用,合计超 50 余套集群,累计数据超 1.5PB 。 本文针对其中一个 ES 集群进行分享,该集群原本使用的是 ES 7.3.2 免费版,数据已经 130TB 了,14 个节点。写入数据时经常掉节点,写入性能也不稳定,当天的数据写不完。迫切需要新的解决方案。 分析业务场景后总结需求要点:主要是写,很少查。审计需求,数据需要长期保存。 这个需求比较普遍,处理起来也很简单:
- 使用 Easysearch 软件,只需少量节点存储近两天的数据。
- 索引设置开启 ZSTD 压缩功能,节省磁盘空间。
- 每天索引数据写完后,第二天执行快照备份存放到 S3 存储。
- 备份成功后,删除索引释放磁盘空间。
- 需要搜索数据时,直接从快照搜索。
 将近期的数据,存放到本地磁盘,保障写入速度。写入完毕的索引,在执行快照备份后,可删除索引,释放本地磁盘空间。
将近期的数据,存放到本地磁盘,保障写入速度。写入完毕的索引,在执行快照备份后,可删除索引,释放本地磁盘空间。
Easysearch 配置要点
path.repo: ["/S3-path"]
node.roles: ["data","search"]
node.search.cache.size: 500mb- path.repo : 指定 S3 存储路径,上传快照用。
- node.roles : 只有 search 角色的节点,才能去搜索快照中的数据。
- node.search.cache.size : 执行快照搜索时的,缓存大小。
更多信息请参考官方文档。
旧数据迁移
通过 Console 将原 ES 集群的数据,迁移到新 Easysearch 集群。迁移时,复制 mapping 和 setting,并在 setting 中添加如下设置。
"codec": "ZSTD",
"source_reuse": true,
 原索引数据量大,可拆分成多个小任务。
原索引数据量大,可拆分成多个小任务。
 迁移完,索引存储空间一般节省 50% 左右。
原索引 279GB ,迁移完后 138GB。
迁移完,索引存储空间一般节省 50% 左右。
原索引 279GB ,迁移完后 138GB。

搜索快照数据
挂载快照后,搜索快照里的索引和搜索本地的索引,语法完全一样。
 如何判断一个索引是在快照还是本地磁盘呢?可以查看索引设置里的 settings.index.store.type
如何判断一个索引是在快照还是本地磁盘呢?可以查看索引设置里的 settings.index.store.type
 如果是 remote_snapshot ,说明是快照中的数据。如果是空值,则是集群本地的数据。
如果是 remote_snapshot ,说明是快照中的数据。如果是空值,则是集群本地的数据。
这次迁移,节省了 6 台主机资源。更重要的是,用上对象存储后,主机磁盘空间压力骤减。
这次介绍就到这里了,有问题联系我。
关于 Easysearch

INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
【搜索客社区日报】第1769期 (2024-01-05)
社区日报 • laoyang360 发表了文章 • 0 个评论 • 4146 次浏览 • 2024-01-05 15:41
开启安全功能 ES 集群就安全了吗?
Easysearch • yangmf2040 发表了文章 • 0 个评论 • 4944 次浏览 • 2023-12-27 10:38
背景
经常跟 ES 打交道的朋友都知道,现在主流的 ES 集群安全方案是:RBAC + TLS for Internal + HTTPS 。

作为终端用户一般只需要关心用户名和密码就行了。作为管理和运维 ES 的人员来说,可能希望 ES 能提供密码策略来强制密码强度和密码使用周期。遗憾的是 ES 对密码强度和密码使用周期没有任何强制要求。如果不注意,可能我们天天都在使用“弱密码”或从不修改的密码(直到无法登录)。而且 ES 对连续的认证失败,不会做任何处理,这让 ES 很容易遭受暴力破解的入侵。
那还有没有别的办法,进一步提高安全呢? 其实,网关可以来帮忙。
虽然网关无法强制提高密码复杂度,但可以提高 ES 集群被暴力破解的难度。
大家都知道,暴力破解--本质就是不停的“猜”你的密码。以现在的 CPU 算力,一秒钟“猜”个几千上万次不过是洒洒水,而且 CPU 监控都不带波动的,很难发现异常。从这里入手,一方面,网关可以延长认证失败的过程--延迟返回结果,让破解不再暴力。另一方面,网关可以记录认证失败的情况,做到实时监控,有条件的告警。一旦出现苗头,可以使用网关阻断该 IP 或用户发来的任何请求。
场景模拟
首先,用网关代理 ES 集群,并在 default_flow 中增加一段 response_status_filter 过滤器配置,对返回码是 401 的请求,跳转到 rate_limit_flow 进行降速,延迟 5 秒返回。
- name: default_flow
filter:
- elasticsearch:
elasticsearch: prod
max_connection_per_node: 1000
- response_status_filter:
exclude:
- 401
action: redirect_flow
flow: rate_limit_flow
- name: rate_limit_flow
filter:
- sleep:
sleep_in_million_seconds: 5000
其次,对于失败的认证,我们可以通过 Console 来做个看板实时分析,展示。
折线图、饼图图、柱状图等,多种展示方式,大家可充分发挥。
最后,可在 Console 的告警中心,配置对应的告警规则,实时监控该类事件,方便及时跟进处置。
效果测试
先带上正确的用户名密码测试,看看返回速度。
.png)
0.011 秒返回。再使用错误的密码测试。
.png)
整整 5 秒多后,才回返结果。如果要暴力破解,每 5 秒钟甚至更久才尝试一个密码,这还叫暴力吗?
看板示例
此处仅仅是抛砖引玉,欢迎大家发挥想象。
.png)
告警示例
建立告警规则,用户 1 分钟内超过 3 次登录失败,就产生告警。
.png)
可在告警中心查看详情,也可将告警推送至微信、钉钉、飞书、邮件等。
.png)
查看告警详情,是 es 用户触发了告警。
.png)
最后,剩下的工作就是对该账号的处置了。如果有需要可以考虑阻止该用户或 IP 的请求,对应的过滤器文档在这里,老规矩加到 default_flow 里就行了。
如果小伙伴有其他办法提升 ES 集群安全,欢迎和我们一起讨论、交流。我们的宗旨是:让搜索更简单!
给 ES 插上向量检索的翅膀 | DataFunSummit 2023 峰会演讲内容速达
Elasticsearch • liaosy 发表了文章 • 0 个评论 • 3126 次浏览 • 2023-07-12 18:37
近日,由 DataFun 主办的 DataFunSummit 2023 数据基础架构峰会 圆满落下帷幕,本次峰会邀请了腾讯、百度、字节、极限科技、Zilliz 等众多企业技术专家为大家带来分布式存储以及向量数据库的架构原理、性能优化与实践解析分享。

在 向量数据库架构与实践论坛 中,极限科技搜索引擎研发工程师张磊受邀出席做了《给 ES 插上向量检索的翅膀》的主题演讲。据介绍,本次演讲主要介绍了 Elasticsearch(ES)与向量技术的融合,展示其在不同行业中的应用场景和优势,同时也对 ES 与向量的技术细节进行详细讨论,并通过具体案例演示如何利用向量提升搜索能力。
讲师介绍
张磊,极限科技 Easysearch 引擎研发工程师,2013 年开始接触 Elasticsearch,10 余年搜索相关经验,之前主要做一些围绕 Elasticsearch 在日志检索和公安大数据相关业务的开发,对 Elasticsearch 和 Lucene 源码比较熟悉,目前专注于公司内部搜索产品的开发。
《给 ES 插上向量检索的翅膀》PPT 内容








更多 PPT 内容参见 https://elasticsearch.cn/slides/322
关于 Easysearch
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 衍生自基于开源协议 Apache 2.0 的 Elasticsearch 7.10 版本。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。

集群分片数非常多的情况下,是否会造成master节点频繁gc


Elasticsearch • xiaohei 回复了问题 • 3 人关注 • 2 个回复 • 3969 次浏览 • 2023-07-07 16:23

ES的正排索引(field data)转为doc values存储后如何做到disk上实时搜索的

Elasticsearch • hapjin 回复了问题 • 4 人关注 • 2 个回复 • 8146 次浏览 • 2023-06-20 11:47
技术上来说elasticsearch-Hadoop实现了Hadoop的读写接口,翻译es的查询到Hadoop的map-reduce,job,这样可以通过es来直接查询Hadoop里面的数据。
HDFS之前可以作为elasticsearch的gateway,1.0之后也能当做snapshot的存储,用来做索引备份,方便恢复数据。
如果每天200gb日志估计用redis问题不大,但以后量会大很多,推荐用Kafka,主要原因是redis是单线程,一个实例的处理能力受限于一个cpu内核,而多个实例做lb会很麻烦。kafka是集群方式运作,扩容简单得多。另外Kafka的队列是构造在磁盘上的,相比Reidis可以容忍更长的消费端故障时间。我们目前是2台服务器做kafka集群,上面所说的量撑住毫无压力。


2. 禁用dynamic scripting.
3. Elasticsearch更新频繁, 务必跟上更新脚步至1.4.4
4. ... 显示全部 »
2. 禁用dynamic scripting.
3. Elasticsearch更新频繁, 务必跟上更新脚步至1.4.4
4. Elasticsearch并不依赖于Shield插件. Shield插件只是一个extra sugar, 并且是商业收费.

我猜你的size参数用的默认值10... 显示全部 »
我猜你的size参数用的默认值10
size – Number of hits to return (default: 10)
解决方法一个是更改这个第三方库,在异常的时候不要掉用system.exit,或者为这个库加一个白名单(有安全隐患,不建议这么做)。
参考:
https://www.elastic.co/guide/en/elasticsearch/reference/5.2/modules-scripting-security.html#java-security-manager
http://docs.oracle.com/javase/7/docs/technotes/guides/security/PolicyFiles.html
在5.0以后,官方文档没有明确说是否可以使用G1,但是ES启动过程中有一个针对G1 GC的J... 显示全部 »
在5.0以后,官方文档没有明确说是否可以使用G1,但是ES启动过程中有一个针对G1 GC的JVM版本校验
https://www.elastic.co/guide/en/elasticsearch/reference/5.5/_g1gc_check.html
其隐含的意思是说,使用 JDK 8u40以上版本,启用G1应该是安全的。
不过,根据经验,在使用ES过程中遇到长时间GC问题时,通常需要调整的不是JVM,而是Query本身。特别是,频繁OLD GC过后, 释放不了Heap空间的情况下,用CMS还是G1不会有什么分别。
20w每秒的写入量不算小,自己剋模拟不同量级的id重复情... 显示全部 »
20w每秒的写入量不算小,自己剋模拟不同量级的id重复情况,测试一下写入吞吐量,据此规划硬件资源。
参考: http... 显示全部 »
参考: https://www.elastic.co/guide/en/elasticsearch/reference/6.4/allocation-awareness.html
公司名称可以索引为multi-filed,即一个为keyword类型,一个为text类型。 查询的时候,使用bool Query,对两个字段分别查询后用should连接, 这样完全匹配的公司名称相关度比部分匹配的高,排在前面优先返回。... 显示全部 »
公司名称可以索引为multi-filed,即一个为keyword类型,一个为text类型。 查询的时候,使用bool Query,对两个字段分别查询后用should连接, 这样完全匹配的公司名称相关度比部分匹配的高,排在前面优先返回。
例如:
[code]{
"query": {
"bool": {
"should":
}
}
}
对于常用词的滤除,一个可以考虑在分词器中,将常用词定义为stop word, 从而在分词阶段就滤除掉。 另外也可以通过boosting Query,降低这类词的打分权重。 参考: not-quite-not.html
集群分片数非常多的情况下,是否会造成master节点频繁gc
回复Elasticsearch • xiaohei 回复了问题 • 3 人关注 • 2 个回复 • 3969 次浏览 • 2023-07-07 16:23
ES的正排索引(field data)转为doc values存储后如何做到disk上实时搜索的
回复Elasticsearch • hapjin 回复了问题 • 4 人关注 • 2 个回复 • 8146 次浏览 • 2023-06-20 11:47

es进程异常退出,es日志和系统日志都无相关信息,求助各位大大~
回复Elasticsearch • lemontree666 回复了问题 • 3 人关注 • 2 个回复 • 9640 次浏览 • 2023-06-02 16:20
关于es7中的节点失效探测(fault_detection)参数
回复Elasticsearch • shwtz 发起了问题 • 1 人关注 • 0 个回复 • 8590 次浏览 • 2023-01-17 14:56
elasticsearch 自定义id引发的负载均衡问题
回复Elasticsearch • amc 回复了问题 • 2 人关注 • 1 个回复 • 3710 次浏览 • 2022-12-12 15:04
es的bulk操做,相同的id,可以保证写入数据的顺序性吗?
回复Elasticsearch • 陈水鱼 回复了问题 • 3 人关注 • 3 个回复 • 4347 次浏览 • 2022-11-11 11:10
elasticsearch es如何统计用户文档数量范围内容聚合?
回复Elasticsearch • Charele 回复了问题 • 5 人关注 • 3 个回复 • 4789 次浏览 • 2022-06-01 13:42
elasticsearch 分索引后如何快速更新指定数据?
回复Elasticsearch • liujiacheng 回复了问题 • 2 人关注 • 1 个回复 • 3277 次浏览 • 2022-03-24 09:41
segments的version_map_memory指标具体表示什么
回复Elasticsearch • Charele 回复了问题 • 3 人关注 • 2 个回复 • 3422 次浏览 • 2022-02-21 16:43

match_phrase_prefix返回结果如何使越靠前的单词占有的权重越高,排序更靠前
回复Elasticsearch • xiaowuge 回复了问题 • 4 人关注 • 3 个回复 • 4215 次浏览 • 2022-01-25 09:01


es7.6副本越少检索速度越快
回复Elasticsearch • tongchuan1992 回复了问题 • 3 人关注 • 3 个回复 • 2642 次浏览 • 2021-09-28 16:48

ElasticSearch 同一个query查询响应时间差异大?
回复Elasticsearch • zmc 回复了问题 • 4 人关注 • 4 个回复 • 4697 次浏览 • 2021-07-21 19:33
search after取出全量数据会比scoll更快吗
回复Elasticsearch • guoyanbiao520 回复了问题 • 7 人关注 • 6 个回复 • 5821 次浏览 • 2021-06-11 18:05
Easysearch analysis-ik 多词典性能优化:从性能回退到分词性能提升 25%~30%
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 15790 次浏览 • 2026-05-08 14:34
Easysearch 版 analysis-ik 相比开源 IK 有一个重要的增强:支持多词典。简单说就是不同字段可以挂不同词库,可以叠加默认词典,也可以只用自定义词典。这是开源单词典 IK 做不到的。
功能实现初期,主要精力放在把能力跑通上。但在后来的一次写入压测中,我们发现 Easysearch 的写入吞吐和 Elasticsearch 有明显差距,最终定位到问题出在多词典的实现方式上——字段最终该用哪套词典,本来应该在分词前就算好,结果代码里把这个选择丢进了分词的热路径,每次分词都要反复切词典、重复扫同一段文本。
这篇文章记录的就是我们怎么一步步把性能拉回来、最终反超基线的过程。
问题怎么冒出来的
4 月 20 号,我们跑了一轮系统级写入压测。数据、mapping、settings、并发和 bulk 参数都一样,Elasticsearch 8.19.5 和 Easysearch 2.1.2 的写入吞吐差距大得有点不对劲:
| 时间 | 场景 | Elasticsearch | Easysearch | 说明 |
|---|---|---|---|---|
| 2026-04-20 第 2 次有效重跑 | 29900 docs / bulk=250 / concurrency=3 端到端写入压测 |
129.44 docs/s |
31.21 docs/s |
这是整条写入链路的 docs/s,不是单独分词吞吐 |
| 2026-04-20 诊断样本 | 5000 docs / bulk=250 / concurrency=3 |
156.25 docs/s |
30.67 docs/s |
Easysearch 的累计索引耗时约为 Elasticsearch 的 8.0x |
当时服务器上跑的就是早期多词典版本。后面修性能,追的就是这个版本和开源单词典 IK 基线之间的差距。
这一步还不能直接确定问题就在分词器。但差距摆在这儿了,得继续往下排。我们先排除了几个常见干扰因素:
refresh_interval- 动态同义词 HTTP 服务
- mapping / settings 不一致
- 网络层和 bulk 客户端本身
采样结果很快把范围收窄了。Elasticsearch 那边热点比较分散,Easysearch 这边呢,分词链路里出现了异常集中的开销——分词过程中反复做词典选择和字典查找。
瓶颈不在 Lucene 写入链路本身,就在 analysis-ik 的多词典实现上。
根因分析
第一类问题出在实现模型上。多词典想表达的是”这个字段最终用哪套词典”,这件事完全可以在分词前算好。但早期代码里,硬是把它变成了运行时的事:
- “字段用哪个词典”变成了”运行时多轮扫描”——同一段文本对着多套词典各来一遍。
- 全局字典切换的动作放进了每字符的热路径。
- 结果就是同一段文本的扫描和查找成本翻了好几倍。
所以问题不是多词典天然慢,是实现把本该提前算好的东西塞进了热路径反复做。
第二类问题是后续优化过程中留下的额外开销。后面加的跨边界、停用词、长文本等测试本身不是性能问题的来源,它们的作用是把正确性边界补齐,确保每次优化不会改变分词结果。
最后通过性能分析确认,残留开销主要来自两处:缓存命中前还在做不必要的数据复制;诊断逻辑在生产热路径上产生了额外开销。修完之后这两处热点都从火焰图上消失了,说明性能回退确实来自真实的代码路径成本,不是测试抖动。
修复过程
整个修复分四个阶段。
第一阶段:把多词典从”运行时分发”收敛为”最终有效词典视图”
多词典能力保留,但不再让分词器在热路径里反复切词典、重复扫文本。改成在分词前就把字段最终生效的词典算好,分词过程只面对一个已经收敛好的词典视图。
说白了就是把模型拉回正确方向——多词典管表达能力,热路径只管分词。
第二阶段:逐步打掉热路径上的常数开销
留下来的每一项优化,都经过正式性能测试和采样分析验证。原则就一条:不改分词语义,只减少热路径上反复发生的查找、分配和判断。
第三阶段:补齐正确性护栏
正确性测试必须先到位,不然吞吐提升没有意义——万一分词结果变了,跑得再快也白搭。
这一轮重点覆盖了这些容易出问题的场景:
- 真跨边界场景
- 数字和量词合并,如
1号 - 自定义词典里的含符号词
- 补充平面字符跨边界稳定性
- 停用词过滤后的偏移量
- 长文本样本的稳定性
- 正式性能测试数据集的分词结果对齐
后面所有的吞吐数字,前提都是分词结果一致,避免把分词行为的变化误当成性能提升。
第四阶段:清理最后的残留开销
到 4 月 28 号,最后一轮修复集中处理两个地方:
- 词典视图命中缓存时直接返回,不再多做一次数据复制
- 诊断逻辑默认关掉,不让线上请求为调试能力买单
这两处修完,Easysearch 版 IK 就不只是恢复到单词典版本附近了,在正式测试里已经明显领先。
用数据看恢复过程
为了不把系统级写入压测和分词器性能测试混在一起,下面只看几个关键节点。2026-04-20 的 docs/s 是系统级写入吞吐,后面的 tok/s 是单独的分词器吞吐。
这里说的”开源 IK 基线”就是开源 IK 的单词典实现对照版本。所有正式吞吐结论都建立在同一数据集、同一测试方法、分词结果一致的前提上。
| 时间 | 口径 | 关键结果 | 说明 |
|---|---|---|---|
| 2026-04-23 17:02 CST | 初期本地复现 | 服务器多词典版本 61.39 万 tok/s,单词典版本 114.48 万 tok/s |
单词典版本快 86.49%,性能差距被明确复现 |
| 2026-04-24 09:51:12~09:55:15 CST | 第一次正式追平 | smart 相对开源单词典基线 +7.26% |
从明显落后追到略微领先 |
| 2026-04-25 04:14~04:16 CST | 双模式阶段复核 | smart +16.88%,max_word +20.09% |
领先优势开始扩大 |
| 2026-04-28 12:30:56 CST | 最新正式复核 | smart +30.96%,max_word +21.31% |
当前最新结果 |
整个过程就是:
- 先暴露出明显的性能退化
- 逐步缩小差距
- 追平,然后开始领先
- 最终在分词结果完全一致的前提下,正式反超
最早的本地复现数据很关键:服务器当时跑的多词典版本只有 613896.67 tok/s,单词典版本 1144843.77 tok/s。后面所有修复就是冲着这个差距去的。
三张图分别对应问题暴露、分词复现和修复结果:第一张展示服务器 bulk 写入吞吐的系统级差距;第二张展示多词典版本和单词典版本的本地分词差距;第三张展示分词结果对齐后,Easysearch 版 IK 怎么一步步追上来,最终实现 25%~30% 的分词性能提升。
为什么说 Easysearch 版 IK 现在更好
这次修复的价值不只是消灭了几个热点,更重要的是把多词典能力、分词正确性和性能测试体系一起补齐了。
1. 功能更强,性能代价可控
开源单词典 IK 模型简单,但表达能力也弱。Easysearch 的多词典能力要解决的是字段级词库隔离、自定义词典叠加这些实际需求。
关键问题是:能不能把这些能力的性能开销压到足够低。修复后的结果证明,可以。
2. 正确性护栏更完整
这轮补上的测试不只是几个短样例,覆盖了更容易翻车的边界条件:
- 真跨边界场景
- 长文本稳定性
- 自定义词典和符号词
- 数字量词合并
- 停用词过滤后的偏移量
这意味着以后再做性能优化,必须同时保证分词结果不变。想靠改分词行为换吞吐,测试会先拦住。
3. 性能测试体系更严格
这轮之后,Easysearch 对 analysis-ik 的正式性能结论统一按一套标准出:
- 同一数据集
- 同一测试方法
smart和max_word双模式- 分词结果一致
- 有性能分析结果支撑
这套体系能避免两个常见坑:只看单轮吞吐波动就下结论,或者分词结果已经变了还在比性能。
小结
多词典能力在实现初期,主要精力放在功能补齐上——先把字段级词库隔离、自定义词典叠加这些能力跑通,性能优化是后面分阶段来的事,没办法一蹴而就。
这轮优化下来,核心思路其实就一条:把词典选择从分词热路径里挪出去,提前收敛好,让分词过程只面对最终的词典视图。再配合热点清理和正确性护栏,增强功能和更高性能完全可以兼得。
截至 2026 年 4 月 28 日,在本地 Mac 笔记本上的多轮 benchmark 中,Easysearch 版 IK 在 smart 模式大约领先开源单词典 IK 基线 25%~30%,max_word 模式大约领先 20% 左右,分词结果完全一致。具体数字每次跑会有波动,但趋势是稳定的。
这也是 Easysearch 版 IK 相对开源版更有价值的地方:不是多了几个配置项,而是在多词典能力、分词正确性和分词性能三个方面都给出了可验证的结果。
关于 Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
作者:张磊,极限科技(INFINI Labs)搜索引擎研发负责人,对 Elasticsearch 和 Lucene 源码比较熟悉,目前主要负责公司的 Easysearch 产品的研发以及客户服务工作。
相关文章:
【搜索客社区日报】第2105期 (2025-09-01)
社区日报 • Muses 发表了文章 • 0 个评论 • 5731 次浏览 • 2025-09-01 12:17
ES 调优帖:Gateway 批量写入性能优化实践
Elasticsearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 19030 次浏览 • 2025-08-06 17:32
背景:bulk 优化的应用
在 ES 的写入优化里,bulk 操作被广泛地用于批量处理数据。bulk 操作允许用户一次提交多个数据操作,如索引、更新、删除等,从而提高数据处理效率。bulk 操作的实现原理是,将数据操作请求打包成 HTTP 请求,并批量提交给 Elasticsearch 服务器。这样,Elasticsearch 服务器就可以一次处理多个数据操作,从而提高处理效率。
这种优化的核心价值在于减少了网络往返的次数和连接建立的开销。每一次单独的写入操作都需要经历完整的请求-响应周期,而批量写入则是将多个操作打包在一起,用一次通信完成原本需要多次交互的工作。这不仅仅节省了时间,更重要的是释放了系统资源,让服务器能够专注于真正的数据处理,而不是频繁的协议握手和状态维护。
这样的批量请求的确是可以优化写入请求的效率,让 ES 集群获得更多的资源去做写入请求的集中处理。但是除了客户端与 ES 集群的通讯效率优化,还有其他中间过程能优化么?
Gateway 的优化点
bulk 的优化理念是将日常零散的写入需求做集中化的处理,尽量减低日常请求的损耗,完成资源最大化的利用。简而言之就是“好钢用在刀刃上”。
但是 ES 在收到 bulk 写入请求后,也是需要协调节点根据文档的 id 计算所属的分片来将数据分发到对应的数据节点的。这个过程也是有一定损耗的,如果 bulk 请求中数据分布的很散,每个分片都需要进行写入,原本 bulk 集中写入的需求优势则还是没有得到最理想化的提升。
gateway 的写入加速则对 bulk 的优化理念的最大化补全。
gateway 可以本地计算每个索引文档对应后端 Elasticsearch 集群的目标存放位置,从而能够精准的进行写入请求定位。
在一批 bulk 请求中,可能存在多个后端节点的数据,bulk_reshuffle 过滤器用来将正常的 bulk 请求打散,按照目标节点或者分片进行拆分重新组装,避免 Elasticsearch 节点收到请求之后再次进行请求分发, 从而降低 Elasticsearch 集群间的流量和负载,也能避免单个节点成为热点瓶颈,确保各个数据节点的处理均衡,从而提升集群总体的索引吞吐能力。
整理的优化思路如下图:
优化实践
那我们来实践一下,看看 gateway 能提升多少的写入。
这里我们分 2 个测试场景:
- 基础集中写入测试,不带文档 id,直接批量写入。这个场景更像是日志或者监控数据采集的场景。
- 带文档 id 的写入测试,更偏向搜索场景或者大数据批同步的场景。
2 个场景都进行直接写入 ES 和 gateway 转发 ES 的效率比对。
测试材料除了需要备一个网关和一套 es 外,其余的内容如下:
测试索引 mapping 一致,名称区分:
PUT gateway_bulk_test
{
"settings": {
"number_of_shards": 6,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"timestamp": {
"type": "date",
"format": "strict_date_optional_time"
},
"field1": {
"type": "keyword"
},
"field2": {
"type": "keyword"
},
"field3": {
"type": "keyword"
},
"field4": {
"type": "integer"
},
"field5": {
"type": "keyword"
},
"field6": {
"type": "float"
}
}
}
}
PUT bulk_test
{
"settings": {
"number_of_shards": 6,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"timestamp": {
"type": "date",
"format": "strict_date_optional_time"
},
"field1": {
"type": "keyword"
},
"field2": {
"type": "keyword"
},
"field3": {
"type": "keyword"
},
"field4": {
"type": "integer"
},
"field5": {
"type": "keyword"
},
"field6": {
"type": "float"
}
}
}
}gateway 的配置文件如下:
path.data: data
path.logs: log
entry:
- name: my_es_entry
enabled: true
router: my_router
max_concurrency: 200000
network:
binding: 0.0.0.0:8000
flow:
- name: async_bulk
filter:
- bulk_reshuffle:
when:
contains:
_ctx.request.path: /_bulk
elasticsearch: prod
level: node
partition_size: 1
fix_null_id: true
- elasticsearch:
elasticsearch: prod #elasticsearch configure reference name
max_connection_per_node: 1000 #max tcp connection to upstream, default for all nodes
max_response_size: -1 #default for all nodes
balancer: weight
refresh: # refresh upstream nodes list, need to enable this feature to use elasticsearch nodes auto discovery
enabled: true
interval: 60s
filter:
roles:
exclude:
- master
router:
- name: my_router
default_flow: async_bulk
elasticsearch:
- name: prod
enabled: true
endpoints:
- https://127.0.0.1:9221
- https://127.0.0.1:9222
- https://127.0.0.1:9223
basic_auth:
username: admin
password: admin
pipeline:
- name: bulk_request_ingest
auto_start: true
keep_running: true
retry_delay_in_ms: 1000
processor:
- bulk_indexing:
max_connection_per_node: 100
num_of_slices: 3
max_worker_size: 30
idle_timeout_in_seconds: 10
bulk:
compress: false
batch_size_in_mb: 10
batch_size_in_docs: 10000
consumer:
fetch_max_messages: 100
queue_selector:
labels:
type: bulk_reshuffle测试脚本如下:
#!/usr/bin/env python3
"""
ES Bulk写入性能测试脚本
"""
import hashlib
import json
import random
import string
import time
from typing import List, Dict, Any
import requests
from concurrent.futures import ThreadPoolExecutor
from datetime import datetime
import urllib3
# 禁用SSL警告
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
class ESBulkTester:
def __init__(self):
# 配置变量 - 可修改
self.es_configs = [
{
"name": "ES直连",
"url": "https://127.0.0.1:9221",
"index": "bulk_test",
"username": "admin", # 修改为实际用户名
"password": "admin", # 修改为实际密码
"verify_ssl": False # HTTPS需要SSL验证
},
{
"name": "Gateway代理",
"url": "http://localhost:8000",
"index": "gateway_bulk_test",
"username": None, # 无需认证
"password": None,
"verify_ssl": False
}
]
self.batch_size = 10000 # 每次bulk写入条数
self.log_interval = 100000 # 每多少次bulk写入输出日志
# ID生成规则配置 - 前2位后5位
self.id_prefix_start = 1
self.id_prefix_end = 999 # 前3位: 01-999
self.id_suffix_start = 1
self.id_suffix_end = 9999 # 后4位: 0001-9999
# 当前ID计数器
self.current_prefix = self.id_prefix_start
self.current_suffix = self.id_suffix_start
def generate_id(self) -> str:
"""生成固定规则的ID - 前2位后5位"""
id_str = f"{self.current_prefix:02d}{self.current_suffix:05d}"
# 更新计数器
self.current_suffix += 1
if self.current_suffix > self.id_suffix_end:
self.current_suffix = self.id_suffix_start
self.current_prefix += 1
if self.current_prefix > self.id_prefix_end:
self.current_prefix = self.id_prefix_start
return id_str
def generate_random_hash(self, length: int = 32) -> str:
"""生成随机hash值"""
random_string = ''.join(random.choices(string.ascii_letters + string.digits, k=length))
return hashlib.md5(random_string.encode()).hexdigest()
def generate_document(self) -> Dict[str, Any]:
"""生成随机文档内容"""
return {
"timestamp": datetime.now().isoformat(),
"field1": self.generate_random_hash(),
"field2": self.generate_random_hash(),
"field3": self.generate_random_hash(),
"field4": random.randint(1, 1000),
"field5": random.choice(["A", "B", "C", "D"]),
"field6": random.uniform(0.1, 100.0)
}
def create_bulk_payload(self, index_name: str) -> str:
"""创建bulk写入payload"""
bulk_data = []
for _ in range(self.batch_size):
#doc_id = self.generate_id()
doc = self.generate_document()
# 添加index操作
bulk_data.append(json.dumps({
"index": {
"_index": index_name,
# "_id": doc_id
}
}))
bulk_data.append(json.dumps(doc))
return "\n".join(bulk_data) + "\n"
def bulk_index(self, config: Dict[str, Any], payload: str) -> bool:
"""执行bulk写入"""
url = f"{config['url']}/_bulk"
headers = {
"Content-Type": "application/x-ndjson"
}
# 设置认证信息
auth = None
if config.get('username') and config.get('password'):
auth = (config['username'], config['password'])
try:
response = requests.post(
url,
data=payload,
headers=headers,
auth=auth,
verify=config.get('verify_ssl', True),
timeout=30
)
return response.status_code == 200
except Exception as e:
print(f"Bulk写入失败: {e}")
return False
def refresh_index(self, config: Dict[str, Any]) -> bool:
"""刷新索引"""
url = f"{config['url']}/{config['index']}/_refresh"
# 设置认证信息
auth = None
if config.get('username') and config.get('password'):
auth = (config['username'], config['password'])
try:
response = requests.post(
url,
auth=auth,
verify=config.get('verify_ssl', True),
timeout=10
)
success = response.status_code == 200
print(f"索引刷新{'成功' if success else '失败'}: {config['index']}")
return success
except Exception as e:
print(f"索引刷新失败: {e}")
return False
def run_test(self, config: Dict[str, Any], round_num: int, total_iterations: int = 100000):
"""运行性能测试"""
test_name = f"{config['name']}-第{round_num}轮"
print(f"\n开始测试: {test_name}")
print(f"ES地址: {config['url']}")
print(f"索引名称: {config['index']}")
print(f"认证: {'是' if config.get('username') else '否'}")
print(f"每次bulk写入: {self.batch_size}条")
print(f"总计划写入: {total_iterations * self.batch_size}条")
print("-" * 50)
start_time = time.time()
success_count = 0
error_count = 0
for i in range(1, total_iterations + 1):
payload = self.create_bulk_payload(config['index'])
if self.bulk_index(config, payload):
success_count += 1
else:
error_count += 1
# 每N次输出日志
if i % self.log_interval == 0:
elapsed_time = time.time() - start_time
rate = i / elapsed_time if elapsed_time > 0 else 0
print(f"已完成 {i:,} 次bulk写入, 耗时: {elapsed_time:.2f}秒, 速率: {rate:.2f} bulk/秒")
end_time = time.time()
total_time = end_time - start_time
total_docs = total_iterations * self.batch_size
print(f"\n{test_name} 测试完成!")
print(f"总耗时: {total_time:.2f}秒")
print(f"成功bulk写入: {success_count:,}次")
print(f"失败bulk写入: {error_count:,}次")
print(f"总文档数: {total_docs:,}条")
print(f"平均速率: {success_count/total_time:.2f} bulk/秒")
print(f"文档写入速率: {total_docs/total_time:.2f} docs/秒")
print("=" * 60)
return {
"test_name": test_name,
"config_name": config['name'],
"round": round_num,
"es_url": config['url'],
"index": config['index'],
"total_time": total_time,
"success_count": success_count,
"error_count": error_count,
"total_docs": total_docs,
"bulk_rate": success_count/total_time,
"doc_rate": total_docs/total_time
}
def run_comparison_test(self, total_iterations: int = 10000):
"""运行双地址对比测试"""
print("ES Bulk写入性能测试开始")
print(f"测试时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
print("=" * 60)
results = []
rounds = 2 # 每个地址测试2轮
# 循环测试所有配置
for config in self.es_configs:
print(f"\n开始测试配置: {config['name']}")
print("*" * 40)
for round_num in range(1, rounds + 1):
# 运行测试
result = self.run_test(config, round_num, total_iterations)
results.append(result)
# 每轮结束后刷新索引
print(f"\n第{round_num}轮测试完成,执行索引刷新...")
self.refresh_index(config)
# 重置ID计数器
if round_num == 1:
# 第1轮:使用初始ID范围(新增数据)
print("第1轮:新增数据模式")
else:
# 第2轮:重复使用相同ID(更新数据模式)
print("第2轮:数据更新模式,复用第1轮ID")
self.current_prefix = self.id_prefix_start
self.current_suffix = self.id_suffix_start
print(f"{config['name']} 第{round_num}轮测试结束\n")
# 输出对比结果
print("\n性能对比结果:")
print("=" * 80)
# 按配置分组显示结果
config_results = {}
for result in results:
config_name = result['config_name']
if config_name not in config_results:
config_results[config_name] = []
config_results[config_name].append(result)
for config_name, rounds_data in config_results.items():
print(f"\n{config_name}:")
total_time = 0
total_bulk_rate = 0
total_doc_rate = 0
for round_data in rounds_data:
print(f" 第{round_data['round']}轮:")
print(f" 耗时: {round_data['total_time']:.2f}秒")
print(f" Bulk速率: {round_data['bulk_rate']:.2f} bulk/秒")
print(f" 文档速率: {round_data['doc_rate']:.2f} docs/秒")
print(f" 成功率: {round_data['success_count']/(round_data['success_count']+round_data['error_count'])*100:.2f}%")
total_time += round_data['total_time']
total_bulk_rate += round_data['bulk_rate']
total_doc_rate += round_data['doc_rate']
avg_bulk_rate = total_bulk_rate / len(rounds_data)
avg_doc_rate = total_doc_rate / len(rounds_data)
print(f" 平均性能:")
print(f" 总耗时: {total_time:.2f}秒")
print(f" 平均Bulk速率: {avg_bulk_rate:.2f} bulk/秒")
print(f" 平均文档速率: {avg_doc_rate:.2f} docs/秒")
# 整体对比
if len(config_results) >= 2:
config_names = list(config_results.keys())
config1_avg = sum([r['bulk_rate'] for r in config_results[config_names[0]]]) / len(config_results[config_names[0]])
config2_avg = sum([r['bulk_rate'] for r in config_results[config_names[1]]]) / len(config_results[config_names[1]])
if config1_avg > config2_avg:
faster = config_names[0]
rate_diff = config1_avg - config2_avg
else:
faster = config_names[1]
rate_diff = config2_avg - config1_avg
print(f"\n整体性能对比:")
print(f"{faster} 平均性能更好,bulk速率高 {rate_diff:.2f} bulk/秒")
print(f"性能提升: {(rate_diff/min(config1_avg, config2_avg)*100):.1f}%")
def main():
"""主函数"""
tester = ESBulkTester()
# 运行测试(每次bulk 1万条,300次bulk = 300万条文档)
tester.run_comparison_test(total_iterations=300)
if __name__ == "__main__":
main()1. 日志场景:不带 id 写入
测试条件:
- bulk 写入数据不带文档 id
- 每批次 bulk 10000 条数据,总共写入 30w 数据
这里把
反馈结果:
性能对比结果:
================================================================================
ES直连:
第1轮:
耗时: 152.29秒
Bulk速率: 1.97 bulk/秒
文档速率: 19699.59 docs/秒
成功率: 100.00%
平均性能:
总耗时: 152.29秒
平均Bulk速率: 1.97 bulk/秒
平均文档速率: 19699.59 docs/秒
Gateway代理:
第1轮:
耗时: 115.63秒
Bulk速率: 2.59 bulk/秒
文档速率: 25944.35 docs/秒
成功率: 100.00%
平均性能:
总耗时: 115.63秒
平均Bulk速率: 2.59 bulk/秒
平均文档速率: 25944.35 docs/秒
整体性能对比:
Gateway代理 平均性能更好,bulk速率高 0.62 bulk/秒
性能提升: 31.7%2. 业务场景:带文档 id 的写入
测试条件:
- bulk 写入数据带有文档 id,两次测试写入的文档 id 生成规则一致且重复。
- 每批次 bulk 10000 条数据,总共写入 30w 数据
这里把 py 脚本中 第 99 行 和 第 107 行的注释打开。
反馈结果:
性能对比结果:
================================================================================
ES直连:
第1轮:
耗时: 155.30秒
Bulk速率: 1.93 bulk/秒
文档速率: 19317.39 docs/秒
成功率: 100.00%
平均性能:
总耗时: 155.30秒
平均Bulk速率: 1.93 bulk/秒
平均文档速率: 19317.39 docs/秒
Gateway代理:
第1轮:
耗时: 116.73秒
Bulk速率: 2.57 bulk/秒
文档速率: 25700.06 docs/秒
成功率: 100.00%
平均性能:
总耗时: 116.73秒
平均Bulk速率: 2.57 bulk/秒
平均文档速率: 25700.06 docs/秒
整体性能对比:
Gateway代理 平均性能更好,bulk速率高 0.64 bulk/秒
性能提升: 33.0%小结
不管是日志场景还是业务价值更重要的大数据或者搜索数据同步场景, gateway 的写入加速都能平稳的节省 25%-30% 的写入耗时。
关于极限网关(INFINI Gateway)
INFINI Gateway 是一个开源的面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway,可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
官网文档:https://docs.infinilabs.com/gateway
开源地址:https://github.com/infinilabs/gateway
作者:金多安,极限科技(INFINI Labs)搜索运维专家,Elastic 认证专家,搜索客社区日报责任编辑。一直从事与搜索运维相关的工作,日常会去挖掘 ES / Lucene 方向的搜索技术原理,保持搜索相关技术发展的关注。
原文:https://infinilabs.cn/blog/2025/gateway-bulk-write-performance-optimization/
Elasticsearch 磁盘空间异常:一次成功的故障排除案例分享
Elasticsearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 5832 次浏览 • 2024-08-09 00:18
故障现象
近日有客户找到我们,说有个 ES 集群节点,磁盘利用率达到了 82% ,而其节点才 63% ,想处理下这个节点,降低节点的磁盘利用率。
起初以为是没有打开自动平衡导致的,经查询,数据还是比较平衡的。
利用率较高的是 76 节点,如果 76 节点的分片比其他节点多,好像还比较合乎逻辑,但它反而比其他节点少了 12-15 个分片。那是 76 节点上的分片比较大?
索引情况
图中都是较大的索引,1 个索引 25TB 左右,共 160 个分片。
分片大小
节点 64
节点 77
节点 75
问题节点 76
可以看出分片大小没有出现较大的倾斜,分片大小和数据平衡的原因都被排除。
换个方向思考,节点 76 比其他节点多使用了磁盘空间 8 个 TB 左右,集群最大分片大小约 140GB ,8000/140=57 ,即节点 76 至少要比其他节点多 57 个分片才行,啊这...
会不会有其他的文件占用了磁盘空间?
我们登录到节点主机,排查是否有其他文件占用了磁盘空间。
结果:客户的数据路径是单独的数据磁盘,并没有其他文件,都是 ES 集群索引占用的空间。
现象总结
分片大小差不多的情况下,节点 76 的分片数还比别的节点还少 10 个左右,它的磁盘空间反而多占用了 8TB 。
这是不是太奇怪了?事出反常必有妖,继续往下查。
原因定位
通过进一步排查,我们发现节点 76 上有一批索引目录,在其他的节点上没有,而且也不在 GET \_cat/indices?v 命令的结果中。说明这些目录都是 dangling 索引占用的。
dangling 索引产生的原因
当 Elasticsearch 节点脱机时,如果删除的索引数量超过 Cluster.indes.tombstones.size,就会发生这种情况。
解决方案
通过命令删除 dangling 索引:
DELETE /\_dangling/<index-uuid>?accept_data_loss=true最后
这次的分享就到这里了,欢迎与我一起交流 ES 的各种问题和解决方案。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
极限网关助力好未来 Elasticsearch 容器化升级
Elasticsearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 5417 次浏览 • 2024-06-12 15:01
极限网关在好未来的最佳实践案例,轻松扛住日增百 TB 数据的流量,助力 ES 从物理机到云原生架构的改造,实现了流控、请求分析、安全管理、无缝迁移等场景。一次完美的客户体验~
背景
物理机架构时代
2022 年,好未来整个日志 Elasticsearch 拥有数十套服务集群,几百台物理机。这么多台机器耗费成本非常高,而且还要花费很大精力去维护。在人力资源有限情况下,存在非常多的弊端,运行成本高,不仅是机器折旧还有机柜等费用。
流量特征
这是来自某个业务线,如下图 1,真实流量,潮汐性非常明显。好未来有很多条业务线,几乎跟这个趋势都一致的,除了个别业务有“续报”、“开课”等活动特殊情况。潮汐性带来的问题就是高峰期 CPU、内存资源是可以消耗很高;低峰期资源使用量非常低,由于是物理架构,这些资源无法给其他业务线共享。
降本增效-容器化改造原动力
日志服务对成本的空前的压力促使我们推进 Elasticsearch 进行架构改造;如何改造,改造成什么样子,这两个问题一直是推进改造原动力。业界能够同时对水平扩展和垂直扩展就是 K8S,我们开始对 Elasticsearch 改造成能在 K8S 上运行进行探索,从而提升 CPU、内存利用率。
物理机时代,没办法把资源动态的扩缩,动态调配,资源隔离,单靠人力操作调度成本太高,几乎无法完成;集群对内存资源需求要比 CPU 资源大很多,由于机器型号配置是固定的,无法“定制”,这也会导致成本居高不下。所以,无论从那个方面来讲,容器化优势非常明显,既能够优化成本,也能够降低运维复杂度。
ES 容器化改造
进行架构升级重点难点- API 服务
改造过程,我们遇到了很多问题,比如容器 ES 版本和物理机 ES 版本不一致,如何让 ES API 能够兼容不同的 ES 版本,由于版本的不兼容,导致无法直接使用原有的 tribenode 进行服务,怎么提供一个高可用的 Elasticsearch API 服务。我们考虑到多个方面,比如使用官方推荐的 proxy 模式、第三方服务等进行选择,经过多方面对比,选择了极限网关 进行 tribenode 替换。
原始 ES API 服务痛点
- API 访问没有流量控制
- 可观测性差,而且稳定性一般
- 版本兼容性差
物理机时代 API 架构
在物理机时代 ES 集群,API 架构如图 2,可以明显看到 tribe node 对所有 ES 集群的“侵入性”是非常大的,这就带来了很多问题,比较严重的就是单个集群对 ES tribenode 的影响和版本升级带来的不兼容问题。
混合时代 API 架构
通过图 3,我们可以看到,极限网关对于版本兼容性很好,能够适配不同的版本。因此,最终选择极限网关作为下一代 ES API 服务方。
里程碑:全部 ES 集群容器化
在 2023 年 3 月份,通过 Elastic 官方 ECK 模式,完成全部日志 ES 集群容器化改造,拥有数百节点,1PB+ 数据存储,每日新增数据 100T 左右。紧接着,除了日志服务外,同时支持了好未来多条业务线。
极限网关实践
下面主要讲述了,为什么选择极限网关,以及极限网关在好未来落地、应用这些内容。
为什么选择极限网关?
学习成本低
我们可以从文档中看到极限网关,其架构简洁,语法简单,直观易懂。学习成本比较低,上手非常快,对新手友好。
性能强悍
经过压测,发现极限网关速度非常快,且针对 Elasticsearch 做了非常细致的优化,能成倍提升写入和查询的速度。
安全性高
支持多种认证方式,最简单的账号密码认证,可以给自定义多个账户密码,大大简化了 Elasticsearch 的安全设置,同时,还可以支持 LDAP 安全验证。
跨版本支持
我们容器化改造过程需要兼容不同版本的 Elasticsrearch,极限网关针对不同的 Elasticsearch 版本做了兼容和针对性处理,能够让业务代码无缝的进行适配,后端 Elasticsearch 集群版本升级能够做到无缝过渡,降低版本升级和数据迁移的复杂度,非常匹配我们的业务场景。
灵活可扩展
可灵活对每个请求进行干预和路由,支持路由的智能学习,内置丰富的过滤器,通过配置动态修改每个请求的处理逻辑,也支持通过插件来进行扩展,满足我们对流量的控制,尤其是限流、用户、IP 等这些功能非常实用。
启用安全策略-为 API 服务保驾护航
痛点
在升级之前使用 tribe 作为 API 服务提供后端,几乎相当于裸奔,没有任何认证策略;另外,tribe 本身的稳定性也有问题,官方在新版本逐渐废弃这种 CCS(跨集群搜索),期间出现多次服务崩溃。
极限网关解决问题
极限网关通过,“basic_auth” 插件,提供最基本的安全校验,使用起来非常方便;同时,极限网关提供 LDAP 插件,可以接入公共的 LDAP 服务,对所有的访问用户进行校验,安全策略对所有的用户生效,不用担心因为 IP 问题泄漏数据等。
强大的过滤功能
在使用 ES 集群过程中,许多场景,需要对请求进行控制、限制等操作。在这方便,感受到了极限网关强大的产品力。比如下面的两个场景
对异常流量进行限流
- 支持对 IP 限流
- 支持对 hostname 限流
- 支持 header 限流
对异常用户进行封禁
当 Elasticsearch 是通过 Basic Auth 或者 LDAP 方式来进行身份认证的时候,request_user_filter 过滤器可用来按请求的用户名信息来进行过滤。操作起来也非常简单,只需要 request_user_filter 这一个过滤器。
- request_user_filter:
include:
- "elastic"
exclude:
- "Ryan"总结来讲,主要有这些方面的功能:
优秀的可观测性
痛点
改造前经常为看不到直观的数据指标感到头疼,查看指标需要多个地方同时打开,去筛选,查找,非常繁琐,付出的成本非常大。为此,大家都再考虑如何优化这种情况,无奈优先级比较低,一直没有真正的投入时间去优化这块。
完美解决
使用了极限网关,通过收集请求日志,非常清晰的收集到想要的数据,具体如下:
- 总体方面:
- 流量曲线
- 状态码占比
- 缓存统计
- 每台网关请求流量
- 细节方面:
- 打印每次请求语句
- 可以查看请求到具体 ES 节点流量
- 可以查看过滤器的列表
通过下图,我们可以从管理视角直观的看到各种信息,这对于管理员来讲,省时省力,方便快捷。
意外收获:无缝迁移业务 Elasticsearch 上云
由于前期日志业务上云,受到非常好的反馈,多个业务线期望能够上云上服务,达到降本增效的目的。
支持双写
数据可以通过极限网关同时写入两个 ES 集群,能够保障数据完全一致,安全可靠。
无缝切换
切换很丝滑,影响非常小,能够让外界几乎感受不到服务波动。
通过使用极限网关,自建 ES 集群可以无缝的迁移上云,在整个迁移的过程中,两套集群通过网关进行了解耦,在迁移的过程中还能实现版本的无缝升级,极大降低了迁移成本,提高迁移效率,多次验证服务稳定可靠。
极限网关流量概览
这是其中一套极限网关的流量统计。用这部分数据进行巡检,一目了然,做到全局的掌控,提高感知力度。
极限网关使用总结
极限网关提供一系列高性能和高可靠性的网关服务。使用这样的服务给我们带来以下好处:
- 可观测性好:极限网关可以动态的对 Elasticsearch 运行过程中请求进行拦截和分析,通过指标和日志来了解集群运行状态,这些指标可以用于提升性能和业务优化。
- 增强安全性:包含先进的安全机制,如 basicauth、LDAP 等支持,保护用户数据不受未授权访问和各种网络威胁的侵害。
- 高稳定性:通过冗余设计和故障转移机制,极限网关能够确保网络服务的高可用性,即使在某些组件发生故障时也能保持服务不中断,单版本最长服务超过 15 个月。
- 易于管理:通过提供 INFINI Console 简洁直观的管理界面,让用户能够轻松配置和监控网络状态,提升管理效率。
- 客户支持:良好的客户服务支持可以帮助用户快速解决使用过程中遇到的问题,提供专业的技术指导。
综上所述,极限网关为用户提供了一个高速、安全、稳定且易于管理的 ES 网关,适合对网络性能有较高要求的个人和企业用户。
未来规划
第一阶段,完成了日志 ES 集群,所有集群的容器化改造,合并,成功的把成本降低了 60%以上。这期间积累了丰富容器化经验,为业务 ES 集群上容器做了良好的铺垫;成本优势和运维优势吸引越来越多的业务接入到容器化 ES 集群。
提升 ES 集群效能--新技术应用&&版本升级
- 极限科技官方推荐的 Easysearch 在压缩率,查询速度等等方面有很多的优势,通过长时间的测试稳定性,新特性,对比云原生的 ES 集群,根据测试结果,给“客户”提供多种选择,这也是工作重点之一。
- 我们当前使用的 ES 版本是 6.8,已经远远落后于官方版本,今年我们计划在选择合适的集群升级 ES 版本,拥抱更多官方提供的特性。
混合(多)云架构支持
随着越来越多的 ES 集群在机房的 K8S 集群部署,这里资源出现了紧张局面。 我们尝试在云上部署自建 ES 集群,弥补机房资源有限,无法大规模扩容,同时能够支持多活场景,满足更多客户的不同需求。混合云主要实现以下几种能力:
1、扩缩容:满足不同业务灵活适配
混合(多)云部署,可以让负载内部私有云 ES,同时部署到公有云,提升扩展 IT 基础设施不仅局限于 CPU、内存,还有存储。比如某一个业务要做活动,预估流量“大爆发”,需要提前准备大规模资源,在机房内根本来不及采购扩容支持,然而在公有云上就能很方便扩容、缩容。在云上搭建 ES 集群,设置满足需求的数量、容量、配置,配合极限网关路由策略,精准的把控流量流向。
2、灾备:紧急情况快速部署,恢复 ES 集群读写
当机房级别大规模故障,部分业务实现了多活,单一的机房故障不会影响其服务能力,而此时比如日志查看等仍有需求,为了满足这部分“客户”需求,可以在云上 K8S 集群,快速搭建 ES 集群,恢复日志读写功能。
参考文档:
- https://infinilabs.cn/docs/latest/gateway
- https://www.elastic.co/guide/en/cloud-on-K8S/current/K8S-overview.html
作者:张华勋,前新浪 CDN 研发,工作主要涉及 Mysql、MongoDB、Redis、Elasticsearch、流量调度等组件和系统,以及运维自动化、平台化等工作。现就职于好未来。
关于好未来
好未来(NYSE:TAL)是一家以内容能力与科技能力为基础,以科教、科创、科普为战略方向,助力人的终身成长,并持续探索创新的科技公司。 好未来的前身学而思成立于 2003 年,2010 年在美国纽交所正式挂牌交易。好未来以“爱与科技助力终身成长”为使命,致力成为持续创新的组织。更多参见:https://www.100tal.com/
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
换掉ES? Redis官方搜索引擎,效率大幅提升
默认分类 • Fred2000 发表了文章 • 2 个评论 • 5458 次浏览 • 2024-05-30 10:08
RediSearch是一个Redis模块,为Redis提供查询、二次索引和全文搜索。要使用RediSearch,首先要在Redis数据上声明索引。然后可以使用重新搜索查询语言来查询该数据。
RedSearch使用压缩的反向索引进行快速索引,占用内存少。RedSearch索引通过提供精确的短语匹配、模糊搜索和数字过滤等功能增强了
实现特性
- 基于文档的多个字段全文索引
- 高性能增量索引
- 文档排序(由用户在索引时手动提供)
- 在子查询之间使用 AND 或 NOT 操作符的复杂布尔查询
- 可选的查询子句
- 基于前缀的搜索
- 支持字段权重设置
- 自动完成建议(带有模糊前缀建议)
- 精确的短语搜索
- 在许多语言中基于词干分析的查询扩展
- 支持用于查询扩展和评分的自定义函数
- 将搜索限制到特定的文档字段
- 数字过滤器和范围
- 使用 Redis 自己的地理命令进行地理过滤
- Unicode 支持(需要 UTF-8 字符集)
- 检索完整的文档内容或只是ID 的检索
- 支持文档删除和更新与索引垃圾收集
- 支持部分更新和条件文档更新
对比 Elasticsearch
如下图所示,RediSearch 构建索引的时间为 221 秒,而 Elasticsearch 为 349 秒,快了 58%。
索引构建测试
我们模拟了一个多租户电子商务应用程序,其中每个租户代表一个产品类别并维护自己的索引。对于此基准测试,我们构建了 50K 个索引(或产品),每个索引最多存储 500 个文档(或项目),总共 2500 万个文档。
RediSearch 仅用了 201 秒就构建了索引,平均每秒运行 125K 个索引。然而,Elasticsearch 在 921 个索引后崩溃了,显然它不是为应对这种负载而设计的。
查询性能测试
一旦数据集被索引,我们就使用在专用负载生成器服务器上运行的 32 个客户端启动两个单词的搜索查询。如下图所示,RediSearch 吞吐量达到了 12.5K 操作/秒,而 Elasticsearch 为 3.1K 操作/秒,速度提高了 4 倍。
此外,RediSearch 延迟稍好一些,平均为 8 毫秒,而 Elasticsearch 为 10 毫秒。
安装
安装目前分为源码和docker安装两种方式。
源码安装
git clone https://github.com/RediSearch/RediSearch.git
cd RediSearch # 进入模块目录
make setup
make installdocker安装
note: RediSearch的安装比较复杂原包无法进行编译操作所以我们使用docker安装
docker run -p 6379:6379 redislabs/redisearch:latest判断是否安装成功
127.0.0.1:0>module list
1) 1) "name"
2) "ReJSON"
3) "ver"
4) "20007"
2) 1) "name"
2) "search"
3) "ver"
4) "20209"返回数组存在“ft”或 “search”(不同版本),表明 RediSearch 模块已经成功加载。
命令行操作
1、创建
1.1 创建索引
创建索引不妨想象成创建表结构,表一般基本属性有表名、字段和字段类别等,所以我们可以考虑将索引名代表表名,字段代表字段,属性即表示属性。
xxx.xxx.xxx.xxx:0>ft.create "student" schema "name" text weight 5.0 "sex" text "desc" text "class" tag
"OK"student 表示索引名,name、sex、desc表示字段,text表示类型(这样表示只是为了便于理解)
“weight”为权重,默认值为 1.0
type student
"none"我们创建的索引redis是不认识的,这证明使用的是插件。
1.2 创建文档
创建文档上下文的过程不妨想想成向表中插入数据,这里请注意字段名可以使用双引号但切记一定要用英文,这里之所以着重提出是因为有些编译器中文双引号和英文双引号用肉眼实在难以辨认否则会出现 “Fields must be specified in FIELD VALUE pairs”(其实是将“ 当作内容处理了以至于缺少了字段)
ft.add student 001 1.0 language "chinese" fields name "张三" sex "男" desc "这是一个学生" class "一班"
"OK"其中001为文档ID,"1.0"为评分缺少此值会报"Could not parse document score"异常,language 指明使用的语言默认是英文编码 如果没有此标记存储是没有问题的但不可以通过中文字符查询
1.3 查询
1.3.1 基本查询
1.3.1.1 全量查询
xxx.xxx.xxx.xxx:0>FT.SEARCH student * SORTBY sex desc RETURN 3 name sex desc
1) "2"
2) "001"
3) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
4) "002"
5) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"1.3.1.2 匹配查询
xxx.xxx.xxx.xxx:0>ft.search student "张三" limit 0 10 RETURN 3 name sex desc
1) "2"
2) "001"
3) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
4) "002"
5) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
limit 与mysql相识主要用于分页,此处是全量匹配,如果没有设置language “chinese” 此处查询为0,
1.3.2 模糊匹配
1.3.2.1 后置匹配
ft.search student "李*" SORTBY sex desc RETURN 3 name sex desc
1) "1"
2) "003"
3) 1) "name"
2) "李四"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"1.3.2.2 模糊搜索
xxx.xxx.xxx.xxx:0>FT.SEARCH beers "%%张店%%"
1) "1"
2) "beer:1"
3) 1) "name"
2) "集团本部已发布【文明就餐公约】,2号楼办公人员午餐的就餐时间是11:45~13:00,现经行政服务部进行抽查,发现我们部门有员工违规就餐现象。请大家务必遵守,相互转告,对于外地回到集团办公的同事,亦请遵守,谢谢!"
3) "org"
4) "山东省淄博市张店区"
5) "school"
6) "山东理工大学"别高兴太早全量模糊匹配是由很大限制的,他基于Levenshtein距离(LD)进行模糊匹配。术语的模糊匹配是通过在术语周围加“%”来实现的,模糊匹配的最大LD为3,确切的说这只是一种相识度查询,并非一般意义上的模糊搜索,但是如果仔细观察会发现通过精确匹配时不仅能够将完整value值查询出来而且还查询出其他处于文档某个位置的key请看官方提供的一个例子:
FT.CREATE idx SCHEMA txt TEXT
FT.ADD idx docCn 1.0 LANGUAGE chinese FIELDS txtRedis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。从盘可以有意无意的对数据进行写操作。
由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。
FT.CREATE idx SCHEMA txt TEXT
FT.ADD idx docCn 1.0 LANGUAGE chinese FIELDS txt "Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。从盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。[8]"
FT.SEARCH idx "数据" LANGUAGE chinese HIGHLIGHT SUMMARIZE
# Outputs:
# <b>数据</b>?... <b>数据</b>进行写操作。由于完全实现了发布... <b>数据</b>冗余很有帮助。[8...之所以会出现这样的效果是因为redisearch对文本进行了分词,其使用的工具是friso相比es的ik还是弱一些前者主要是对中文分词,体积小可移植性强。
从而我们可以结合后后置匹配算法
xxx.xxx.xxx.xxx:0>FT.SEARCH idx "数*" LANGUAGE chinese HIGHLIGHT
1) "1"
2) "docCn"
3) 1) "txt"
2) "Redis支持主从同步。<b>数据</b>可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。从盘可以有意无意的对<b>数据</b>进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和<b>数据</b>冗余很有帮助。[8]"
或者结合Levenshtein算法这样基本上能够满足业务查询需求
xxx.xxx.xxx.xxx:0>FT.SEARCH idx "%%单的树%%" LANGUAGE chinese HIGHLIGHT
1) "1"
2) "docCn"
3) 1) "txt"
2) "Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层<b>树</b>复制。从盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步<b>树</b>时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。[8]"1.3.2.3 字段查询
通过字段查询也可以实现模糊搜索,直接给例子,后面跟着官网上给的sql 和 redisearch的对照表
ft.search student *
1) "2"
2) "doudou"
3) 1) "name"
2) "豆豆"
3) "jtzz"
4) "“检索”是很多产品中"
5) "phone"
6) "18563717107"
4) "ttao"
5) 1) "name"
2) "姚元涛"
3) "jtzz"
4) "一个生病的人只"
5) "phone"
6) "18563717107"
ft.search student '@phone:185* @name:豆豆'
1) "1"
2) "doudou"
3) 1) "name"
2) "豆豆"
3) "jtzz"
4) "“检索”是很多产品中"
5) "phone"
6) "18563717107"1.4 删除
1.4.1 删除文档
xxx.xxx.xxx.xxx:0>ft.del student 002
"1"1.4.3 删除索引
xxx.xxx.xxx.xxx:0>ft.drop student
"OK"1.5 查看
1.5.1 查看所有索引
xxx.xxx.xxx.xxx:0>FT._LIST
1) "student1"
2) "ttao"
3) "idx"
4) "student"
5) "myidx"
6) "123"
7) "myIndex"
8) "testung"
9) "student2"1.5.2 查看索引文档中的数据
1.5.2.1 获取单条数据
xxx.xxx.xxx.xxx:0>ft.get student 001
1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
7) "class"
8) "一班"1.5.2.2 获取多条数据
xxx.xxx.xxx.xxx:0>ft.mget student 001 002
1) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
7) "class"
8) "一班"
2) 1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
7) "class"
8) "一班"1.6 索引别名操作
1.6.1 添加别名
123.232.112.84:0>FT.ALIASADD xs student
"OK"给索引student起个xs的别名,一个索引可以起多个别名
1.6.2 修改别名
1.6.3 删除别名
123.232.112.84:0>FT.ALIASDEL xs
"OK"作者:架构师公众号
来源:https://mp.weixin.qq.com/s/TmCXx3rLjLPggvOFjGqS9w
版权申明:内容来源网络,仅供学习研究,版权归原创者所有。如有侵权烦请告知,我们会立即删除并表示歉意。谢谢!
记某客户的一次 Elasticsearch 无缝数据迁移
Elasticsearch • yangmf2040 发表了文章 • 0 个评论 • 7465 次浏览 • 2024-04-02 14:16
背景
客户需要将 Elasticsearch 集群无缝迁移到移动云,迁移过程要保证业务的最小停机时间。
实现方式
通过采用成熟的 INFINI 网关来进行数据的双写,在集群的切换恢复过程中来记录数据变更,待全量数据恢复之后再追平后面增量数据,追平增量之后,进行校验确保数据一致再进行流量的切换。
总体流程
总体迁移流程如下:
- 客户业务代码,切流量,双写。(新增的变更都会记录在网关本地,但是暂停消费到移动云)
- 暂停网关移动云这边的增量数据消费。
- 迁移 11 月的数据,快照,快照上传到 S3;
- 下载 S3 的文件到移动云。
- 恢复快照到移动云的 11 月份的索引。
- 开启网关移动云这边的增量消费。
- 等待增量追平(接近追平)。
- 按照时间条件(如:时间 A,当前时间往前 30 分钟),验证文档数据量,Hash 校验等等。
- 停业务的写入,网关,腾讯云的写入(10 分钟)。
- 等待剩余的增量追完。
- 对时间 A 之后的,增量进行校验。
- 切换所有流量到移动云,业务端直接访问移动云 ES。
总体的迁移时间:
- 11 月备份时间(30 分钟)19 号开始
- 备份下载到移动云的时间(2-3 天)
- 备份恢复到移动云集群的时间(30 分钟)
- 11 月份增量备份(20 分钟)(双写开始)(21 号)
- 11 月份增量下载到移动云(6 小时)
- 11 月份增量恢复时间(20 分钟)
- 追增量数据(8 个小时产生的数据,需要 1 个小时)
- 校验比对(存量 1 个小时)
- 流量暂停,增量的校验(10 分钟)
- 切换(1 分钟)
总体流程如下示意图:
ES 集群信息
- ES 版本 7.10.1
- 2个热节点 3个温节点 总数 1.9 TB
- 索引 1041, 分片2085
- 无自定义插件
- 有 update_bu_query 使用
- 有 delete_by_query 使用
- 吞吐量没有测试过,当前日增文档数 1 千多万,目标日增加上亿
迁移操作手册(参考)
环境
- 自建 ES 5.4.2
- 自建 ES 5.6.8
- 自建 ES 7.5.0
- 极限网关服务器 1
- 极限网关服务器 2
- 云端负载均衡 1 (监听 9200 端口,指向极限网关服务器 1/2 的 8000 端口)
- 云端负载均衡 2 (监听 9200 端口,指向极限网关服务器 1/2 的 8001 端口)
场景描述
若干个自建 Elasticsearch 集群需要平滑迁移到移动云,业务不停写、不做代码改动。
数据架构
通过将应用端流量走网关的方式,请求同步转发给自建 ES,网关记录所有的写入请求,并确保顺序在云端 ES 上重放请求,两侧集群的各种故障都妥善进行了处理,从而实现透明的集群双写,实现安全无缝的数据迁移。
业务端如果已经部署在云上,可以使用云上的 SLB 服务来访问网关,确保后端网关的高可用,如果业务端和极限网关还在企业内网,可以使用极限网关自带的 4 层浮动 IP 来确保网关的高可用。
数据描述
以数据从自建集群 5.4.2 迁移到云上的 5.6.16 为例进行说明,执行步骤依次说明。
执行步骤
部署 INFINI Gateway
为了保证数据的无缝透明迁移,通过 INFINI Gateway 来进行双写。
-
系统调优
参考此文档。
- 下载程序
[root@iZbp1gxkifg8uetb33pvcoZ ~]# mkdir /opt/gateway [root@iZbp1gxkifg8uetb33pvcoZ ~]# cd /opt/gateway/ [root@iZbp1gxkifg8uetb33pvcoZ gateway]# wget http://release.infinilabs.com/gateway/snapshot/gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz --2022-05-19 10:16:25-- http://release.infinilabs.com/gateway/snapshot/gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz 正在解析主机 release.infinilabs.com (release.infinilabs.com)... 120.79.205.193 正在连接 release.infinilabs.com (release.infinilabs.com)|120.79.205.193|:80... 已连接。 已发出 HTTP 请求,正在等待回应... 200 OK 长度:7430568 (7.1M) [application/octet-stream] 正在保存至: “gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz”
100%[==============================================================================================================================================>] 7,430,568 22.8MB/s 用时 0.3s
2022-05-19 10:16:25 (22.8 MB/s) - 已保存 “gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz” [7430568/7430568])
[root@iZbp1gxkifg8uetb33pvcoZ gateway]# tar vxzf gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz gateway-linux-amd64 gateway.yml sample-configs/ sample-configs/elasticsearch-with-ldap.yml sample-configs/indices-replace.yml sample-configs/record_and_play.yml sample-configs/cross-cluster-search.yml sample-configs/kibana-proxy.yml sample-configs/elasticsearch-proxy.yml sample-configs/v8-bulk-indexing-compatibility.yml sample-configs/use_old_style_search_response.yml sample-configs/context-update.yml sample-configs/elasticsearch-route-by-index.yml sample-configs/hello_world.yml sample-configs/entry-with-tls.yml sample-configs/javascript.yml sample-configs/log4j-request-filter.yml sample-configs/request-filter.yml sample-configs/condition.yml sample-configs/cross-cluster-replication.yml sample-configs/secured-elasticsearch-proxy.yml sample-configs/fast-bulk-indexing.yml sample-configs/es_migration.yml sample-configs/index-docs-diff.yml sample-configs/rate-limiter.yml sample-configs/async-bulk-indexing.yml sample-configs/elasticssearch-request-logging.yml sample-configs/router_rules.yml sample-configs/auth.yml sample-configs/index-backup.yml
3. 修改配置
将网关提供的示例配置拷贝,并根据实际集群的信息进行相应的修改,如下:[root@iZbp1gxkifg8uetb33pvcoZ gateway]# cp sample-configs/cross-cluster-replication.yml 5.4.2TO5.6.16.yml
首先修改集群的身份信息,如下:

然后修改集群的注册信息,如下:

根据需要修改网关监听的端口,以及是否开启 TLS (如果应用客户端通过 http 协议访问 ES,请将entry.tls.enabled 值改为 false),如下:

不同的集群可以使用不同的配置,分别监听不同的端口,用于业务的分开访问。
4. 启动网关
启动网关并指定刚刚创建的配置,如下:[root@iZbp1gxkifg8uetb33pvcoZ gateway]# ./gateway-linux-amd64 -config 5.4.2TO5.6.16.yml
/ \ /\ / \/\/ / /\ \ \/\ /_/\ / /\///\ / /\/\ \ \/ \/ //\_ / / /\/ \/ / // \ /\ / \/ \ ___/\/ \/\/ \/ \/ \/_/ _/_/
[GATEWAY] A light-weight, powerful and high-performance elasticsearch gateway. [GATEWAY] 1.6.0_SNAPSHOT, 2022-05-18 11:09:54, 2023-12-31 10:10:10, 73408e82a0f96352075f4c7d2974fd274eeafe11 [05-19 13:35:43] [INF] [app.go:174] initializing gateway. [05-19 13:35:43] [INF] [app.go:175] using config: /opt/gateway/5.4.2TO5.6.16.yml. [05-19 13:35:43] [INF] [instance.go:72] workspace: /opt/gateway/data1/gateway/nodes/ca2tc22j7ad0gneois80 [05-19 13:35:43] [INF] [app.go:283] gateway is up and running now. [05-19 13:35:50] [INF] [actions.go:358] elasticsearch [primary] is available [05-19 13:35:50] [INF] [api.go:262] api listen at: http://0.0.0.0:2900 [05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [primary] hosts: [] => [192.168.0.19:9200] [05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [backup] hosts: [] => [es-cn-tl32p9fkk0006m56k.elasticsearch.aliyuncs.com:9200] [05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [primary] hosts: [] => [192.168.0.19:9200] [05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [backup] hosts: [] => [es-cn-tl32p9fkk0006m56k.elasticsearch.aliyuncs.com:9200] [05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [primary] hosts: [] => [192.168.0.19:9200] [05-19 13:35:50] [INF] [entry.go:322] entry [my_es_entry/] listen at: https://0.0.0.0:8000 [05-19 13:35:50] [INF] [module.go:116] all modules are started
5. 后台运行[root@iZbp1gxkifg8uetb33pvcoZ gateway]# nohup ./gateway-linux-amd64 -config 5.4.2TO5.6.16.yml &
6. 应用授权curl -XPOST http://localhost:2900/_license/apply -d' { "license": "XXXXXXXXXXXXXXXXXXXXXXXXX" }'
#### 部署 INFINI Console
为了方便在多个集群之间快速切换,使用 INFINI [Console](https://infinilabs.cn/products/console/) 来进行管理。
1. 下载安装[root@iZbp1gxkifg8uetb33pvcpZ console]# wget http://release.infinilabs.com/console/snapshot/console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz --2022-05-19 10:57:24-- http://release.infinilabs.com/console/snapshot/console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz 正在解析主机 release.infinilabs.com (release.infinilabs.com)... 120.79.205.193 正在连接 release.infinilabs.com (release.infinilabs.com)|120.79.205.193|:80... 已连接。 已发出 HTTP 请求,正在等待回应... 200 OK 长度:13576234 (13M) [application/octet-stream] 正在保存至: “console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz”
100%[==============================================================================================================================================>] 13,576,234 33.2MB/s 用时 0.4s
2022-05-19 10:57:25 (33.2 MB/s) - 已保存 “console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz” [13576234/13576234])
[root@iZbp1gxkifg8uetb33pvcpZ console]# tar vxzf console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz console-linux-amd64 console.yml
2. 修改配置[root@iZbp1gxkifg8uetb33pvcpZ console]# cat console.yml
for the system cluster, please use Elasticsearch v7.3+
elasticsearch:
- name: default
enabled: true
monitored: false
endpoint: http://es-cn-7mz2p9fty0007frx0.elasticsearch.aliyuncs.com:9200
basic_auth:
username: elastic
password: XXXXXX
discovery:
enabled: false
...
-
启动服务
[root@iZbp1gxkifg8uetb33pvcpZ console]# ./console-linux-amd64 -service install Success [root@iZbp1gxkifg8uetb33pvcpZ console]# ./console-linux-amd64 -service start Success - 访问后台
访问该主机的 9000 端口,即可打开 Console 后台,http://x.x.x.x:9000/
打开菜单 [System][Cluster] ,注册当前需要管理的 Elasticsearch 集群和网关地址,用来快速管理,如下:
测试 INFINI Gateway
为了验证网关是否正常工作,我们通过 INFINI Console 来快速验证一下。
首先通过走网关的接口来创建一个索引,并写入一个文档,如下:
查看 5.4.2 集群的数据情况,如下:
查看集群 5.6.16 的数据情况,如下:
说明网关配置都正常,验证结束。
调整网关的消费策略
因为我们需要在全量数据迁移之后,才能进行增量数据的追加,在全量数据迁移完成之前,我们应该暂停增量数据的消费。修改网关配置里面 Pipeline consume-queue_backup-to-backup和 consume-queue_primary-failure-to-backup的参数 auto_start为 false,表示不自动启动该任务,具体配置方法如下:
修改完配置之后,需要重新启动网关。
为了方便管理,可以使用 INFINI Console 来注册和管理网关,如下:
待全量迁移完成之后,可以通过后台的 Task 管理来进行后续的任务启动、停止,如下:
切换流量
接下来,将业务正常写的流量切换到网关,也就是需要把之前指向 ES 5.4.2 的地址指向网关的地址,如果 5.4.2 集群开启了身份验证,业务端代码同样需要传递身份信息,和 5.4.2 之前的用法保持不变。
切换流量到网关之后,用户的请求还是以同步的方式正常访问自建集群,网关记录到的请求会按顺序记录到 MQ 里面,但是消费是暂停状态。
如果业务端代码使用的 ES 的 SDK 支持 Sniff,并且业务代码开启了 Sniff,那么应该关闭 Sniff,避免业务端通过 Sniff 直接链接到后端的 ES 节点,所有的流量现在应该都只通过网关来进行访问。
全量数据迁移
在流量迁移到网关之后,我们开始对自建 Elasticsearch 集群的数据进行全量迁移到云端 Elasticsearch 集群。
全量迁移已有的数据的方式有很多种:
- 通过快照的方式进行恢复
- 使用工具来导出导入,如: ESM
如果索引数量很多的话,可以按照索引依次进行导入,同时需要注意将 Mapping 和 Setting 提前导入。
以现在 5.4 集群的索引来为例,目前的待迁移索引为 demo_5_4_2,只有4 个文档:
我们使用网关自带的迁移功能来进行数据迁移,拷贝自带的样例文件,如下:
[root@iZbp1gxkifg8uetb33pvcpZ gateway]# cp sample-configs/es_migration.yml 5.4TO5.6.yml修改其中代表集群和索引的相关配置,可以根据需要配置是否需要重命名索引和统一 Type( 用于跨版本统一 Type),如下图红框位置:
创建好模板和索引,如果目标集群不允许动态创建文档,需要提前创建好索引,如下图:
然后就可以开始数据的迁移了,执行网关程序并指定刚刚定义的配置,如下:
执行完成后,可以确认下数据的情况,如下图:
全量数据至此导入完成。
增量数据迁移
在全量导入的过程中,可能存在数据的增量修改,不过这部分请求都已经完整记录下来了,我们只需要开启网关的消费任务即可将挤压的请求应用到云端的 Elasticsearch 集群。
示例操作如下:
如果从 5.6 的集群来看的话,这部分的修改还没同步过来,如下:
这部分增量的数据变更,在网关层面都进行了完整记录,我们只需要开启网关的增量消费任务,如下:
通过观察队列是否消费完成来判断增量数据是否做完,如下:
现在我们再看一下 5.6 集群的数据情况,如下:
数据的增量更新就过来了。
执行数据比对
由于集群内部的数据可能比较多,我们需要进行一个完整的比对才能确保数据的完整性,可以通过网关自带的数据比对工具来进行,将样例自带的文件拷贝一份,如下:
[root@iZbp1gxkifg8uetb33pvcpZ gateway]# cp sample-configs/index-docs-diff.yml 5.4DIFF5.6.yml修改需要比对的集群和索引信息,可以加上过滤条件,如时间范围窗口来进行增量 Diff,如下图:
执行网关程序,并指定该配置文件,如下图:
如图,两个集群完全一致。
切换集群
如果验证完之后,两个集群的数据已经完全一致了,可以将程序切换到新集群,或者将网关的配置里面的主备进行互换,同步写 5.6 集群。
双集群在线运行一段时间,待业务完全验证之后,再安全下线旧集群,如遇到问题,也可以随时回切到老集群。
小结
通过使用极限网关,自建 ES 集群可以安全无缝的迁移到移动云 ES,在迁移的过程中,两套集群通过网关进行了解耦,两套集群的版本也可以不一样,在迁移的过程中还能实现版本的无缝升级。
如有任何问题,请随时联系我,期待与您交流!
Elasticsearch 国产化
Easysearch • yangmf2040 发表了文章 • 0 个评论 • 4957 次浏览 • 2024-03-16 16:36
背景
Elasticsearch 这些年来在搜索领域一直是领头羊。国内也有非常多的企业在使用 Elasticsearch 来做查询搜索、数据分析、安全分析等等。甚至一些很重要的行业、系统都在使用 Elasticsearch。在使用 Elasticsearch 的道路上狂飙的时候,我们也观察到了一些问题:
- Elasticsearch 不再是开源软件了。
- Elastic 公司退出了中国直销市场,不提供本土化支持了。
- 国家对信创、自主可控的战略化布局。
- 国际形势从合作共赢到自闭对垒。
- Elasticsearch 软件本身安全问题频发。
- Elasticsearch 软件在性能、稳定性和扩展性方面存在很大的提升空间。
基于以上这些问题,推出一个 Elasticsearch 国产化解决方案就很有必要了。我们的解决方案是推出一款名为 Easysearch 的软件,作为 Elasticsearch 国产化替代 。
出发点是在兼容原 Elasticsearch 软件的基础之上,完善更多的企业级功能,同时提高产品的性能、稳定性和扩展性。
下面我将从几个方面简单介绍下 Easysearch 软件。
兼容性
支持原生 Elasticsearch 的 DSL 查询语法,原业务代码无需调整。 支持 SQL ,方便熟悉 SQL 的开发人员上手分析数据。 兼容 Elasticsearch 的 SDK。 兼容现有索引存储格式。 支持冷热架构和索引生命周期,真正做到无缝衔接。
功能增强
提供企业级的安全管理,可对接 LDAP、AD 认证。 重构分布式架构,保持稳定的同时,能支持更大规模的数据。 在不降低性能的同时,实现更高压缩比的数据压缩,直接节省磁盘 40% 以上。 支持 KNN、异步搜索、数据脱敏、可搜索快照、审计等企业级功能。
容灾
支持基于 CDC 的集群复制技术,实现同版本间的容灾。
支持基于请求双写的复制技术,实现跨版本容灾。
信创
全面适配国产 CPU、操作系统,并获得厂家认证。
迁移方案
支持原索引存储格式,可通过快照备份直接恢复到 Easysearch 集群。
提供迁移工具,直接可视化操作迁移数据。
简单的介绍就到这里了,更多信息请访问:https://www.infinilabs.com/products/easysearch
最后
如有需要请联系我,让我们一起位祖国的信创事业添砖加瓦。
如何防止 Elasticsearch 服务 OOM?
Easysearch • yangmf2040 发表了文章 • 0 个评论 • 3951 次浏览 • 2024-02-26 10:12
Elasticsearch(简称:ES) 和传统关系型数据库有很多区别, 比如传统数据中普遍都有一个叫“最大连接数”的设置。目的是使数据库系统工作在可控的负载下,避免出现负载过高,资源耗尽,谁也无法登录的局面。
那 ES 在这方面有类似参数吗?答案是没有,这也是为何 ES 会被流量打爆的原因之一。
针对大并发访问 ES 服务,造成 ES 节点 OOM,服务中断的情况,极限科技旗下的 INFINI Gateway 产品(以下简称 “极限网关”)可从两个方面入手,保障 ES 服务的可用性。
- 限制最大并发访问连接数。
- 限制非重要索引的请求速度,保障重要业务索引的访问速度。
下面我们来详细聊聊。
架构图
所有访问 ES 的请求都发给网关,可部署多个网关。
限制最大连接数
在网关配置文件中,默认有最大并发连接数限制,默认最大 10000。
entry:
- name: my_es_entry
enabled: true
router: my_router
max_concurrency: 10000
network:
binding: $[[env.GW_BINDING]]
# See `gateway.disable_reuse_port_by_default` for more information.
reuse_port: true使用压测程序测试,看看到达10000个连接后,能否限制新的连接。
超过的连接请求,被丢弃。更多信息参考官方文档。
限制索引写入速度
我们先看看不做限制的时候,测试环境的写入速度,在 9w - 15w docs/s 之间波动。虽然峰值很高,但不稳定。
接下来,我们通过网关把写入速度控制在最大 1w docs/s 。
对网关的配置文件 gateway.yml ,做以下修改。
env: # env 下添加
THROTTLE_BULK_INDEXING_MAX_BYTES: 40485760 #40MB/s
THROTTLE_BULK_INDEXING_MAX_REQUESTS: 10000 #10k docs/s
THROTTLE_BULK_INDEXING_ACTION: retry #retry,drop
THROTTLE_BULK_INDEXING_MAX_RETRY_TIMES: 10 #1000
THROTTLE_BULK_INDEXING_RETRY_DELAY_IN_MS: 100 #10
router: # route 部分修改 flow
- name: my_router
default_flow: default_flow
tracing_flow: logging_flow
rules:
- method:
- "*"
pattern:
- "/_bulk"
- "/{any_index}/_bulk"
flow:
- write_flow
flow: #flow 部分增加下面两段
- name: write_flow
filter:
- flow:
flows:
- bulking_indexing_limit
- elasticsearch:
elasticsearch: prod
max_connection_per_node: 1000
- name: bulking_indexing_limit
filter:
- bulk_request_throttle:
indices:
"test-index":
max_bytes: $[[env.THROTTLE_BULK_INDEXING_MAX_BYTES]]
max_requests: $[[env.THROTTLE_BULK_INDEXING_MAX_REQUESTS]]
action: $[[env.THROTTLE_BULK_INDEXING_ACTION]]
retry_delay_in_ms: $[[env.THROTTLE_BULK_INDEXING_RETRY_DELAY_IN_MS]]
max_retry_times: $[[env.THROTTLE_BULK_INDEXING_MAX_RETRY_TIMES]]
message: "bulk writing too fast" #触发限流告警message自定义
log_warn_message: true
再次压测,test-index 索引写入速度被限制在了 1w docs/s 。
限制多个索引写入速度
上面的配置是针对 test-index 索引的写入速度控制。如果想添加其他的索引,新增一段配置即可。 比如,我允许 abc 索引写入达到 2w docs/s,test-index 索引最多不超过 1w docs/s ,可配置如下。
- name: bulking_indexing_limit
filter:
- bulk_request_throttle:
indices:
"abc":
max_requests: 20000
action: drop
message: "abc doc写入超阈值" #触发限流告警message自定义
log_warn_message: true
"test-index":
max_bytes: $[[env.THROTTLE_BULK_INDEXING_MAX_BYTES]]
max_requests: $[[env.THROTTLE_BULK_INDEXING_MAX_REQUESTS]]
action: $[[env.THROTTLE_BULK_INDEXING_ACTION]]
retry_delay_in_ms: $[[env.THROTTLE_BULK_INDEXING_RETRY_DELAY_IN_MS]]
max_retry_times: $[[env.THROTTLE_BULK_INDEXING_MAX_RETRY_TIMES]]
message: "bulk writing too fast" #触发限流告警message自定义
log_warn_message: true限速效果如下
限制读请求速度
我们先看看不做限制的时候,测试环境的读取速度,7w qps 。
接下来我们通过网关把读取速度控制在最大 1w qps 。
继续对网关的配置文件 gateway.yml 做以下修改。
- name: default_flow
filter:
- request_path_limiter:
message: "Hey, You just reached our request limit!" rules:
- pattern: "/(?P<index_name>abc)/_search"
max_qps: 10000
group: index_name
- elasticsearch:
elasticsearch: prod
max_connection_per_node: 1000再次进行测试,读取速度被限制在了 1w qps 。
限制多个索引读取速度
上面的配置是针对 abc 索引的写入速度控制。如果想添加其他的索引,新增一段配置即可。 比如,我允许 abc 索引读取达到 1w qps,test-index 索引最多不超过 2w qps ,可配置如下。
- name: default_flow
filter:
- request_path_limiter:
message: "Hey, You just reached our request limit!"
rules:
- pattern: "/(?P<index_name>abc)/_search"
max_qps: 10000
group: index_name
- pattern: "/(?P<index_name>test-index)/_search"
max_qps: 20000
group: index_name
- elasticsearch:
elasticsearch: prod
max_connection_per_node: 1000
多个网关限速
限速是每个网关自身的控制,如果有多个网关,那么后端 ES 集群收到的请求数等于多个网关限速的总和。
本次介绍就到这里了。相信大家在使用 ES 的过程中也遇到过各种各样的问题。欢迎大家来我们这个平台分享自己的问题、解决方案等。如有任何问题,请随时联系我,期待与您交流!
用 Easysearch 帮助大型车企降本增效
Easysearch • yangmf2040 发表了文章 • 0 个评论 • 6017 次浏览 • 2024-02-02 15:15
最近某头部汽车集团需要针对当前 ES 集群进行优化,背景如下: ES 用于支撑包括核心营销系统、管理支持系统、财务类、IT 基础设施类、研发、自动驾驶等多个重要应用,合计超 50 余套集群,累计数据超 1.5PB 。 本文针对其中一个 ES 集群进行分享,该集群原本使用的是 ES 7.3.2 免费版,数据已经 130TB 了,14 个节点。写入数据时经常掉节点,写入性能也不稳定,当天的数据写不完。迫切需要新的解决方案。 分析业务场景后总结需求要点:主要是写,很少查。审计需求,数据需要长期保存。 这个需求比较普遍,处理起来也很简单:
- 使用 Easysearch 软件,只需少量节点存储近两天的数据。
- 索引设置开启 ZSTD 压缩功能,节省磁盘空间。
- 每天索引数据写完后,第二天执行快照备份存放到 S3 存储。
- 备份成功后,删除索引释放磁盘空间。
- 需要搜索数据时,直接从快照搜索。
将近期的数据,存放到本地磁盘,保障写入速度。写入完毕的索引,在执行快照备份后,可删除索引,释放本地磁盘空间。
Easysearch 配置要点
path.repo: ["/S3-path"]
node.roles: ["data","search"]
node.search.cache.size: 500mb- path.repo : 指定 S3 存储路径,上传快照用。
- node.roles : 只有 search 角色的节点,才能去搜索快照中的数据。
- node.search.cache.size : 执行快照搜索时的,缓存大小。
更多信息请参考官方文档。
旧数据迁移
通过 Console 将原 ES 集群的数据,迁移到新 Easysearch 集群。迁移时,复制 mapping 和 setting,并在 setting 中添加如下设置。
"codec": "ZSTD",
"source_reuse": true,
原索引数据量大,可拆分成多个小任务。
迁移完,索引存储空间一般节省 50% 左右。
原索引 279GB ,迁移完后 138GB。
搜索快照数据
挂载快照后,搜索快照里的索引和搜索本地的索引,语法完全一样。
如何判断一个索引是在快照还是本地磁盘呢?可以查看索引设置里的 settings.index.store.type
如果是 remote_snapshot ,说明是快照中的数据。如果是空值,则是集群本地的数据。
这次迁移,节省了 6 台主机资源。更重要的是,用上对象存储后,主机磁盘空间压力骤减。
这次介绍就到这里了,有问题联系我。
关于 Easysearch
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
【搜索客社区日报】第1769期 (2024-01-05)
社区日报 • laoyang360 发表了文章 • 0 个评论 • 4146 次浏览 • 2024-01-05 15:41
开启安全功能 ES 集群就安全了吗?
Easysearch • yangmf2040 发表了文章 • 0 个评论 • 4944 次浏览 • 2023-12-27 10:38
背景
经常跟 ES 打交道的朋友都知道,现在主流的 ES 集群安全方案是:RBAC + TLS for Internal + HTTPS 。
作为终端用户一般只需要关心用户名和密码就行了。作为管理和运维 ES 的人员来说,可能希望 ES 能提供密码策略来强制密码强度和密码使用周期。遗憾的是 ES 对密码强度和密码使用周期没有任何强制要求。如果不注意,可能我们天天都在使用“弱密码”或从不修改的密码(直到无法登录)。而且 ES 对连续的认证失败,不会做任何处理,这让 ES 很容易遭受暴力破解的入侵。
那还有没有别的办法,进一步提高安全呢? 其实,网关可以来帮忙。
虽然网关无法强制提高密码复杂度,但可以提高 ES 集群被暴力破解的难度。
大家都知道,暴力破解--本质就是不停的“猜”你的密码。以现在的 CPU 算力,一秒钟“猜”个几千上万次不过是洒洒水,而且 CPU 监控都不带波动的,很难发现异常。从这里入手,一方面,网关可以延长认证失败的过程--延迟返回结果,让破解不再暴力。另一方面,网关可以记录认证失败的情况,做到实时监控,有条件的告警。一旦出现苗头,可以使用网关阻断该 IP 或用户发来的任何请求。
场景模拟
首先,用网关代理 ES 集群,并在 default_flow 中增加一段 response_status_filter 过滤器配置,对返回码是 401 的请求,跳转到 rate_limit_flow 进行降速,延迟 5 秒返回。
- name: default_flow
filter:
- elasticsearch:
elasticsearch: prod
max_connection_per_node: 1000
- response_status_filter:
exclude:
- 401
action: redirect_flow
flow: rate_limit_flow
- name: rate_limit_flow
filter:
- sleep:
sleep_in_million_seconds: 5000
其次,对于失败的认证,我们可以通过 Console 来做个看板实时分析,展示。
折线图、饼图图、柱状图等,多种展示方式,大家可充分发挥。
最后,可在 Console 的告警中心,配置对应的告警规则,实时监控该类事件,方便及时跟进处置。
效果测试
先带上正确的用户名密码测试,看看返回速度。
0.011 秒返回。再使用错误的密码测试。
整整 5 秒多后,才回返结果。如果要暴力破解,每 5 秒钟甚至更久才尝试一个密码,这还叫暴力吗?
看板示例
此处仅仅是抛砖引玉,欢迎大家发挥想象。
告警示例
建立告警规则,用户 1 分钟内超过 3 次登录失败,就产生告警。
可在告警中心查看详情,也可将告警推送至微信、钉钉、飞书、邮件等。
查看告警详情,是 es 用户触发了告警。
最后,剩下的工作就是对该账号的处置了。如果有需要可以考虑阻止该用户或 IP 的请求,对应的过滤器文档在这里,老规矩加到 default_flow 里就行了。
如果小伙伴有其他办法提升 ES 集群安全,欢迎和我们一起讨论、交流。我们的宗旨是:让搜索更简单!
给 ES 插上向量检索的翅膀 | DataFunSummit 2023 峰会演讲内容速达
Elasticsearch • liaosy 发表了文章 • 0 个评论 • 3126 次浏览 • 2023-07-12 18:37
近日,由 DataFun 主办的 DataFunSummit 2023 数据基础架构峰会 圆满落下帷幕,本次峰会邀请了腾讯、百度、字节、极限科技、Zilliz 等众多企业技术专家为大家带来分布式存储以及向量数据库的架构原理、性能优化与实践解析分享。
在 向量数据库架构与实践论坛 中,极限科技搜索引擎研发工程师张磊受邀出席做了《给 ES 插上向量检索的翅膀》的主题演讲。据介绍,本次演讲主要介绍了 Elasticsearch(ES)与向量技术的融合,展示其在不同行业中的应用场景和优势,同时也对 ES 与向量的技术细节进行详细讨论,并通过具体案例演示如何利用向量提升搜索能力。
讲师介绍
张磊,极限科技 Easysearch 引擎研发工程师,2013 年开始接触 Elasticsearch,10 余年搜索相关经验,之前主要做一些围绕 Elasticsearch 在日志检索和公安大数据相关业务的开发,对 Elasticsearch 和 Lucene 源码比较熟悉,目前专注于公司内部搜索产品的开发。
《给 ES 插上向量检索的翅膀》PPT 内容
更多 PPT 内容参见 https://elasticsearch.cn/slides/322
关于 Easysearch
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 衍生自基于开源协议 Apache 2.0 的 Elasticsearch 7.10 版本。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
INFINI 产品更新啦 20220923
资讯动态 • liaosy 发表了文章 • 0 个评论 • 3526 次浏览 • 2022-09-23 22:47

今天 INFINI Labs 为大家又带来了一波产品更新,请查阅。
INFINI Gateway v1.8.0
极限网关本次迭代更新如下:
- 修复上下文条件 consumer_has_lag参数和 配置、文档不一致的 Bug。
- 修改备集群故障,主集群不能正常写数据的 Bug。
- 修复 Bulk 请求处理异常造成数据复制不一致的问题。
- 修复请求日志里面关于 Bulk 统计数据丢失的问题。
- 修复大并发情况下,请求体为空的异常。
INFINI Console v0.6.0
口碑爆棚的 Elasticsearch 多集群管控平台 INFINI Console 更新如下:
- 新增主机概览。

- 新增主机监控。

- 节点概览新增日志查看功能(需安装 Agent)。

- Insight 配置框新增 Search 配置。
- 优化 Discover 时间范围 Auto Fit,设为15分钟。
- 优化 Discover 保存搜索,会保存当前的字段过滤和 Insight 图表配置。
- 优化本地列表搜索查找,支持通配符过滤。
- 优化告警规则必填字段标记显示。
- 修复了 Discover 字段过滤白屏问题。
- 修复了 Discover 表格添加字段后排序失效问题。(感谢@卢宝贤反馈)
- 修复了 Elasticsearch 8.x 删除文档报错不兼容的问题。(感谢@卢宝贤反馈)
- 修复了创建新索引不成功时,异常处理的问题。
- 修复了低版本浏览器js不兼容导致集群注册不成功的问题。
- 修复了开发工具中使用加载命令失败报错的问题。
INFINI Agent v0.2.0
数据采集工具探针(INFINI Agent)更新如下:
- 新增按节点读日志文件列表的API
- 新增读具体日志文件内容的API
- 新增 Elasticsearch 节点掉线后的基础信息保存
- 新增主机在线状态的采集
- 新增基于 Centos 的 Docker 镜像
- 新增主机配置信息采集: 操作系统信息、磁盘大小、内存大小、CPU配置等
- 新增主机指标的采集: CPU使用率、磁盘使用率、磁盘IO、内存使用率、swap 使用率、网络IO等
- 新增 Elasticsearch 进程信息采集
- 修复发现 Elasticsearch 进程时频繁提示端口访问错误的Bug
- 修复 Elasticsearch 节点地址为 0.0.0.0 时无法获取节点信息的Bug
- 修复 CPU 指标数据显示异常的Bug
- 修复 stats API 在 Windows 平台的兼容性
INFINI Framework 2000923
INFINI Framework 也带来了很多改进:
- 重构了磁盘队列压缩相关配置,支持段文件的压缩。
- 当集群不可用的情况下,跳过集群节点元数据的获取。
- 完善节点可用性检测,避免频繁的不可用状态切换。
- 修复 Elasticsearch 主机地址为空的异常。
- 完善本地磁盘队列文件的清理,避免删除正在使用的文件。
期待反馈
如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs)中的对应项目中提交 Feature Request 或提交 Bug。
- INFINI Gateway: https://github.com/infinilabs/gateway
- INFINI Console: https://github.com/infinilabs/console/issues
- 下载地址: https://www.infinilabs.com/#/download
您还可以通过邮件联系我们:hello@infini.ltd
或者拨打我们的热线电话:(+86) 400-139-9200
也欢迎大家微信扫码添加小助手,加入用户群讨论,或者扫码加入我们的知识星球一起学习交流。

感谢大家的围观,祝大家周末愉快。
有了这两个小脚本,不需要再傻乎乎地手动安装 Elasticsearch了
Elasticsearch • spoofer 发表了文章 • 0 个评论 • 3581 次浏览 • 2022-03-11 19:40
在学习 ES 前一般都需要安装 ES,虽然 ES 可以开箱即用,但如果要学习分布式特性的时候,需要安装多个节点,这个时候还是有点工作量的。下面提供两个小脚本,一个是在 Ubuntu 中安装 3 节点的 ES 伪集群,一个是在 docker 中安装3节点 ES 集群。除了安装 ES 外,脚本还提供了对应版本的 Kibana、Cerebro 0.9.4 的安装。
1、在 Ubuntu 中安装 ES 7.13
这里我们采取下载 ES 安装包并且解压安装的方式,并没有走 Ubuntu apt 的方式。ES 的安装非常简单,这里先献上安装脚本。
下面介绍比较重要的配置项:
-
discovery.seed_hosts 在开箱即用的情境下(本机环境)无需配置,ES 会自动扫描本机的 9300 到 9305 端口。一旦进行了网络环境配置,这个自动扫描操作就不会执行。discovery.seed_hosts 配置为 master 候选者节点即可。如果需要指定端口的话,其值可以为:["localhost:9300", "localhost:9301"]
-
cluster.initial_master_nodes 指定新集群 master 候选者列表,其值为节点的名字列表。如果配置了 node.name: my_node_1,所以其值为 ["my_node_1"],而不是 ip 列表 !
- network.host 和 http.port 是 ES 提供服务的监听地址和端口,线上一定不能配置 ip 为 0.0.0.0,这是非常危险的行为!!!
怎么样来理解这个 discovery.seed_hosts 和 cluster.initial_master_nodes 呢?
cluster.initial_master_nodes 是候选者列表,一般我们线上环境候选者的数量比较少,毕竟是用来做备用的。而且这个配置只跟选举 master 有关,也就是跟其他类型的节点没有关系。就算你有100个数据节点,然后经常增加或者剔除都不需要动这个列表。
discovery.seed_hosts 这个可以理解为是做服务或者节点发现的,其他节点必须知道他们才能进入集群~ 一般配置为集群的master 候选者的列表。
但是这些 master 候选者(组织联系人)可能经常变化,那怎么办呢?这个配置项除了支持 ip 外还支持域名 ~所以可以用域名来解决这个问题,其他节点的配置上写的是域名,域名解析到对应的 ip,如果机器挂了,新的节点 ip 换了,就把域名解析到新的ip即可,这样其他节点的配就不用修改了。所以非 master 候选节点要配 discovery.seed_hosts (组织联系人)
除了修改 ES 服务配置外,还需要配置 JVM 的配置,我们主要配置服务占用的堆内存的大小。JVM 配置需要以下几点:
- 这两个 jvm 的配置必须配置一样的数值。启动时就分配好内存空间,避免运行时申请分配内存造成系统抖动。
- Xmx不要超过机器内存的 50%,留下些内存供 JVM 堆外内存使用
- 并且Xmx不要超过 32G。建议最大配置为 30G。接近 32G,JVM 会启用压缩对象指针的功能,导致性能下降。具体可以参考:a-heap-of-trouble。
安装成功后,可以访问: ES:localhost:9211
Kibana: localhost:5601
cerebro: localhost:9800
2、在docker 中安装 ES 7.13
在做一切工作之前,我们必须安装 docker。如果你已经安装好了 docker、docker-compose,可以访问我为你准备的 docker-compose.yaml 文件。
如果你没有安装 docker,完整的教程可以参考在 docker 中安装 ES 文档。
下载此文件,将文件保存为 docker-compose.yaml 后,进入这个文件的目录,执行以下指令即可:
docker-compose up如果你没有下载镜像文件,docker-compose 会自动帮你下载镜像,并且启动容器。
如果 docker-compose 启动失败,说是无权限链接 docker 的话,其报错如下:
Got permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock:
Get "http://%2Fvar%2Frun%2Fdocker.sock/v1.24/containers/json?all=1&filters=%7B%22label%22%3A%7B%22com.docker.compose.project%3Ddocker_es%22%3Atrue%7D%7D&limit=0":
dial unix /var/run/docker.sock: connect: permission denied可以运行以下指令临时修改:
sudo chmod 666 /var/run/docker.sock
其原因是因为你的 docker 用了 root 启动了。
最后可以访问:
cerebro:ip:9000
Kibana:ip:5601
Elasticsearch: ip:9200,ip:9202,ip:9203
其他学习资料
在 docker image 中安装 Elasticsearch 插件
最后附上我写的小册,欢迎刚入门的朋友来订阅~

