

【搜索客社区日报】第1863期 (2024-07-19)
https://infinilabs.cn/blog/2024/news-20240718/
2、较 ClickHouse 降低 50% 成本,湖仓一体在B站的演进
https://dbaplus.cn/news-131-5889-1.html
3、LangChain 实战:RAG 遇上大模型,运维革命就开始了……
https://dbaplus.cn/news-73-5978-1.html
4、OpenSearch 的演进与语义检索技术革新
https://blog.csdn.net/kunpengt ... 16513
编辑:Fred
更多资讯:http://news.searchkit.cn
https://infinilabs.cn/blog/2024/news-20240718/
2、较 ClickHouse 降低 50% 成本,湖仓一体在B站的演进
https://dbaplus.cn/news-131-5889-1.html
3、LangChain 实战:RAG 遇上大模型,运维革命就开始了……
https://dbaplus.cn/news-73-5978-1.html
4、OpenSearch 的演进与语义检索技术革新
https://blog.csdn.net/kunpengt ... 16513
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1862期 (2024-07-18)
https://mp.weixin.qq.com/s/lpT-8yQA8wAcxdjuBc88Ew
2.AIGC 提示词可视化编辑器 OPS
https://github.com/Moonvy/OpenPromptStudio
3.Facebook 为什么要弃用 Git?
https://mp.weixin.qq.com/s/n2UVEx8giKROJR9NWZB8pA
4.机场出租车恶性循环与国产数据库怪圈
https://mp.weixin.qq.com/s/uccjOkAR1zgur6tftHkzMg
5.被AI加持后的夸克,强大的让我有些陌生
https://mp.weixin.qq.com/s/RZ6J3v79bLOv6vhAm4nYLw
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/lpT-8yQA8wAcxdjuBc88Ew
2.AIGC 提示词可视化编辑器 OPS
https://github.com/Moonvy/OpenPromptStudio
3.Facebook 为什么要弃用 Git?
https://mp.weixin.qq.com/s/n2UVEx8giKROJR9NWZB8pA
4.机场出租车恶性循环与国产数据库怪圈
https://mp.weixin.qq.com/s/uccjOkAR1zgur6tftHkzMg
5.被AI加持后的夸克,强大的让我有些陌生
https://mp.weixin.qq.com/s/RZ6J3v79bLOv6vhAm4nYLw
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
Easysearch 新特性:写入限流功能介绍
背景
在 Easysearch 的各种使用场景中,高写入吞吐量的场景占了很大一部分,由此也带来了一些使用上的问题,很多用户由于使用经验不足,对集群的写入压测进行的不够充分,不能很好的规划集群的写入量。
导致经常发生以下问题:
- 写入吞吐量过大对内存影响巨大,引发节点 OOM,节点掉线问题。
- 对 CPU 和内存的占用严重影响了其他的查询业务的响应。
- 以及磁盘 IO 负载增加,挤占集群的网络带宽等问题。
之前就有某金融保险类客户遇到了因业务端写入量突然猛增导致数据节点不停的 Full GC,进而掉入了不停的掉线,上线,又掉线的恶性循环中。当时只能建议用户增加一个类似“挡板”的服务,在数据进入到集群之前进行拦截,对客户端写入进行干预限流:

这样做虽然有效,但是也增加了整个系统的部署复杂性,提高了运维成本。
根据客户的实际场景,Easysearch 从 1.8.0 版本开始引入了节点和 Shard 级别的限流功能,不用依赖第三方就可以限制写入压力,并在 1.8.2 版本增加了索引级别的写入限流。 注意:所有写入限流都是针对各数据节点的 Primary Shard 写入进行限流的,算上副本的话吞吐量要乘以 2。
限流示意图:
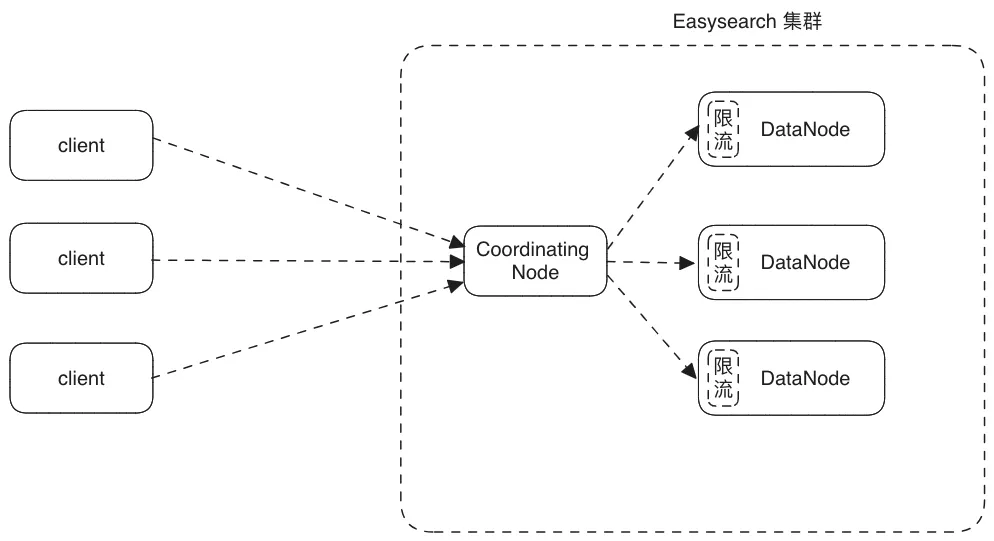
下面是限流前后相同数据节点的吞吐量和 CPU 对比:
测试环境:
ip name http port version role master
10.0.0.3 node-3 10.0.0.3:9209 9303 1.8.0 dimr -
10.0.0.3 node-4 10.0.0.3:9210 9304 1.8.0 im -
10.0.0.3 node-2 10.0.0.3:9208 9302 1.8.0 dimr -
10.0.0.3 node-1 10.0.0.3:9207 9301 1.8.0 dimr *测试索引配置:
PUT test_0
{
"settings": {
"number_of_replicas": 1,
"number_of_shards": 3
}
}压测工具:采用极限科技的 INFINI Loadgen 压测,这款压测工具使用简单,可以方便对任何支持 Rest 接口的库进行压测。
压测命令:
./loadgen-linux-amd64 -d 180 -c 10 -config loadgen-easy-1.8.yml压测 180 秒,10 个并发,每个 bulk 请求 5000 条。
节点级别限流
通过 INFINI Console 监控指标可以看到,限流之前的某个数据节点,CPU 占用 10%,每秒写入 40000 条左右:

在 Cluster Settings 里配置,启用节点级别限流,限制每个节点的每秒最大写入 10000 条,并在默认的 1 秒间隔内进行重试,超过默认间隔后直接拒绝。
PUT _cluster/settings
{
"transient": {
"cluster.throttle.node.write": true,
"cluster.throttle.node.write.max_requests": 10000,
"cluster.throttle.node.write.action": "retry"
}
}限流后,CPU 占用降低了约 50%,算上副本一共 20000 条每秒:

Shard 级别限流
设置每个分片最大写入条数为 2000 条每秒
PUT _cluster/settings
{
"transient": {
"cluster.throttle.shard.write": true,
"cluster.throttle.shard.write.max_requests": 2000,
"cluster.throttle.shard.write.action": "retry"
}
}集群级别的监控,同样是只针对主 Shard。

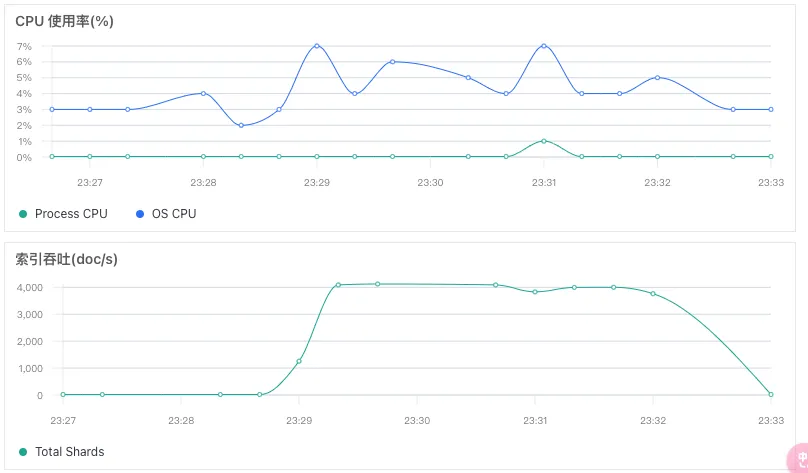
从 Console 的监控指标可以看出,索引 test_0 的 Primary indexing 维持在 6000 左右,正好是 3 个主分片限制的 2000 的写入之和。

再看下数据节点监控,Total Shards 表示主分片和副本分片的写入总和即 4000,单看主分片的话,正好是 2000.
索引级别限流
有时,集群中可能某个索引的写入吞吐过大而影响了其他业务,也可以针对特定的索引配置写入限制。 可以在索引的 Settings 里设置当前索引每秒写入最大条数为 6000:
PUT test_0
{
"settings": {
"number_of_replicas": 1,
"number_of_shards": 3,
"index.throttle.write.max_requests": 6000,
"index.throttle.write.action": "retry",
"index.throttle.write.enable": true
}
}下图索引的 Primary indexing 在 6000 左右,表示索引的所有主分片的写入速度限制在了 6000。

总结
通过本次测试对比,可以看出限流的好处:
-
有效控制写入压力: 写入限流功能能够有效限制每个节点和每个 Shard 的写入吞吐量,防止因写入量过大而导致系统资源被过度消耗的问题。
-
降低系统资源占用: 在限流前,某数据节点的 CPU 占用率约为 10%。限流后,CPU 占用率显著降低至约 5%,减少了约 50%。这表明在高并发写入场景下,写入限流功能显著降低了系统的 CPU 负载。
-
提高系统稳定性: 通过控制写入吞吐量,避免了频繁的 Full GC 和节点掉线问题,从而提升了系统的整体稳定性和可靠性。
- 保障查询业务性能: 写入限流功能减少了写入操作对 CPU 和内存的占用,确保其他查询业务的响应性能不受影响。
综上所述,写入限流功能在高并发写入场景下表现出色,不仅有效控制了写入压力,还显著降低了系统资源占用,从而提高了系统的稳定性和查询业务的性能。
关于 Easysearch 有奖征文活动

无论你是 Easysearch 的老用户,还是第一次听说这个名字,只要你对 INFINI Labs 旗下的 Easysearch 产品感兴趣,或者是希望了解 Easysearch,都可以参加这次活动。
详情查看:Easysearch 征文活动
作者:张磊
原文:https://infinilabs.cn/blog/2024/easysearch-new-feature-write-throttling-introduction/
背景
在 Easysearch 的各种使用场景中,高写入吞吐量的场景占了很大一部分,由此也带来了一些使用上的问题,很多用户由于使用经验不足,对集群的写入压测进行的不够充分,不能很好的规划集群的写入量。
导致经常发生以下问题:
- 写入吞吐量过大对内存影响巨大,引发节点 OOM,节点掉线问题。
- 对 CPU 和内存的占用严重影响了其他的查询业务的响应。
- 以及磁盘 IO 负载增加,挤占集群的网络带宽等问题。
之前就有某金融保险类客户遇到了因业务端写入量突然猛增导致数据节点不停的 Full GC,进而掉入了不停的掉线,上线,又掉线的恶性循环中。当时只能建议用户增加一个类似“挡板”的服务,在数据进入到集群之前进行拦截,对客户端写入进行干预限流:
这样做虽然有效,但是也增加了整个系统的部署复杂性,提高了运维成本。
根据客户的实际场景,Easysearch 从 1.8.0 版本开始引入了节点和 Shard 级别的限流功能,不用依赖第三方就可以限制写入压力,并在 1.8.2 版本增加了索引级别的写入限流。 注意:所有写入限流都是针对各数据节点的 Primary Shard 写入进行限流的,算上副本的话吞吐量要乘以 2。
限流示意图:
下面是限流前后相同数据节点的吞吐量和 CPU 对比:
测试环境:
ip name http port version role master
10.0.0.3 node-3 10.0.0.3:9209 9303 1.8.0 dimr -
10.0.0.3 node-4 10.0.0.3:9210 9304 1.8.0 im -
10.0.0.3 node-2 10.0.0.3:9208 9302 1.8.0 dimr -
10.0.0.3 node-1 10.0.0.3:9207 9301 1.8.0 dimr *测试索引配置:
PUT test_0
{
"settings": {
"number_of_replicas": 1,
"number_of_shards": 3
}
}压测工具:采用极限科技的 INFINI Loadgen 压测,这款压测工具使用简单,可以方便对任何支持 Rest 接口的库进行压测。
压测命令:
./loadgen-linux-amd64 -d 180 -c 10 -config loadgen-easy-1.8.yml压测 180 秒,10 个并发,每个 bulk 请求 5000 条。
节点级别限流
通过 INFINI Console 监控指标可以看到,限流之前的某个数据节点,CPU 占用 10%,每秒写入 40000 条左右:
在 Cluster Settings 里配置,启用节点级别限流,限制每个节点的每秒最大写入 10000 条,并在默认的 1 秒间隔内进行重试,超过默认间隔后直接拒绝。
PUT _cluster/settings
{
"transient": {
"cluster.throttle.node.write": true,
"cluster.throttle.node.write.max_requests": 10000,
"cluster.throttle.node.write.action": "retry"
}
}限流后,CPU 占用降低了约 50%,算上副本一共 20000 条每秒:
Shard 级别限流
设置每个分片最大写入条数为 2000 条每秒
PUT _cluster/settings
{
"transient": {
"cluster.throttle.shard.write": true,
"cluster.throttle.shard.write.max_requests": 2000,
"cluster.throttle.shard.write.action": "retry"
}
}集群级别的监控,同样是只针对主 Shard。
从 Console 的监控指标可以看出,索引 test_0 的 Primary indexing 维持在 6000 左右,正好是 3 个主分片限制的 2000 的写入之和。
再看下数据节点监控,Total Shards 表示主分片和副本分片的写入总和即 4000,单看主分片的话,正好是 2000.
索引级别限流
有时,集群中可能某个索引的写入吞吐过大而影响了其他业务,也可以针对特定的索引配置写入限制。 可以在索引的 Settings 里设置当前索引每秒写入最大条数为 6000:
PUT test_0
{
"settings": {
"number_of_replicas": 1,
"number_of_shards": 3,
"index.throttle.write.max_requests": 6000,
"index.throttle.write.action": "retry",
"index.throttle.write.enable": true
}
}下图索引的 Primary indexing 在 6000 左右,表示索引的所有主分片的写入速度限制在了 6000。
总结
通过本次测试对比,可以看出限流的好处:
-
有效控制写入压力: 写入限流功能能够有效限制每个节点和每个 Shard 的写入吞吐量,防止因写入量过大而导致系统资源被过度消耗的问题。
-
降低系统资源占用: 在限流前,某数据节点的 CPU 占用率约为 10%。限流后,CPU 占用率显著降低至约 5%,减少了约 50%。这表明在高并发写入场景下,写入限流功能显著降低了系统的 CPU 负载。
-
提高系统稳定性: 通过控制写入吞吐量,避免了频繁的 Full GC 和节点掉线问题,从而提升了系统的整体稳定性和可靠性。
- 保障查询业务性能: 写入限流功能减少了写入操作对 CPU 和内存的占用,确保其他查询业务的响应性能不受影响。
综上所述,写入限流功能在高并发写入场景下表现出色,不仅有效控制了写入压力,还显著降低了系统资源占用,从而提高了系统的稳定性和查询业务的性能。
关于 Easysearch 有奖征文活动
无论你是 Easysearch 的老用户,还是第一次听说这个名字,只要你对 INFINI Labs 旗下的 Easysearch 产品感兴趣,或者是希望了解 Easysearch,都可以参加这次活动。
详情查看:Easysearch 征文活动
收起阅读 »作者:张磊
原文:https://infinilabs.cn/blog/2024/easysearch-new-feature-write-throttling-introduction/
【搜索客社区日报】第1859期 (2024-07-15)
https://infinilabs.cn/blog/202 ... tion/
2. 中文大模型基准测评2024年上半年报告
https://report.oschina.net/api ... o.pdf
3. ClickHouse 24.6 版本发布说明
https://mp.weixin.qq.com/s/JrAikqoUMjHHuaLEHZptew
4. 斯坦福年度《人工智能指数报告》的十条重要结论
https://cn.weforum.org/agenda/ ... t-cn/
5. 面壁智能首席科学家刘知远:大模型的“摩尔定律”是模型知识密度持续增强
https://www.tsinghua.edu.cn/info/1182/112713.htm
编辑:Muse
更多资讯:http://news.searchkit.cn
https://infinilabs.cn/blog/202 ... tion/
2. 中文大模型基准测评2024年上半年报告
https://report.oschina.net/api ... o.pdf
3. ClickHouse 24.6 版本发布说明
https://mp.weixin.qq.com/s/JrAikqoUMjHHuaLEHZptew
4. 斯坦福年度《人工智能指数报告》的十条重要结论
https://cn.weforum.org/agenda/ ... t-cn/
5. 面壁智能首席科学家刘知远:大模型的“摩尔定律”是模型知识密度持续增强
https://www.tsinghua.edu.cn/info/1182/112713.htm
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】 第1861期 (2024-07-17)
https://mp.weixin.qq.com/s/L_inW26azHHmp7n3WVBrZg
2.Elasticsearch:介绍 retrievers - 搜索一切事物
https://blog.csdn.net/UbuntuTo ... 61405
3.LLM,GPT-1 — 生成式预训练 Transformer(搭梯)
https://towardsdatascience.com ... 96d3b
4.LLM,GPT-2——语言模型是无监督的多任务学习者(搭梯)
https://towardsdatascience.com ... 1f808
5.LLM,GPT-3:语言模型是小样本学习者(搭梯)
https://towardsdatascience.com ... 1b466
编辑:kin122
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/L_inW26azHHmp7n3WVBrZg
2.Elasticsearch:介绍 retrievers - 搜索一切事物
https://blog.csdn.net/UbuntuTo ... 61405
3.LLM,GPT-1 — 生成式预训练 Transformer(搭梯)
https://towardsdatascience.com ... 96d3b
4.LLM,GPT-2——语言模型是无监督的多任务学习者(搭梯)
https://towardsdatascience.com ... 1f808
5.LLM,GPT-3:语言模型是小样本学习者(搭梯)
https://towardsdatascience.com ... 1b466
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1860期 (2024-07-16)
https://klingai.kuaishou.com/
2. 一个还不错的语音复制模型
https://github.com/babysor/MockingBird
https://zhuanlan.zhihu.com/p/425692267
3. 一个算法比赛相关信息的收录站
https://oi-wiki.org/
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://klingai.kuaishou.com/
2. 一个还不错的语音复制模型
https://github.com/babysor/MockingBird
https://zhuanlan.zhihu.com/p/425692267
3. 一个算法比赛相关信息的收录站
https://oi-wiki.org/
编辑:斯蒂文
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1858期 (2024-07-12)
https://www.oschina.net/news/301339
2、高级 RAG 检索策略之流程与模块化
https://mp.weixin.qq.com/s/WeAcAevUPemPKhQLhId3Vg
3、下一代 RAG 技术来了!微软正式开源 GraphRAG:大模型行业将迎来新的升级?
https://www.infoq.cn/article/sqaUMyNg6B8OrCcwg4vo
4、电商场景下 ES 搜索引擎的稳定性治理实践
https://mp.weixin.qq.com/s/fAgAgWWYJbbfcGGx1BpLsw
5、玩转 Easysearch 语法
https://infinilabs.cn/blog/202 ... ntax/
编辑:Fred
更多资讯:http://news.searchkit.cn
https://www.oschina.net/news/301339
2、高级 RAG 检索策略之流程与模块化
https://mp.weixin.qq.com/s/WeAcAevUPemPKhQLhId3Vg
3、下一代 RAG 技术来了!微软正式开源 GraphRAG:大模型行业将迎来新的升级?
https://www.infoq.cn/article/sqaUMyNg6B8OrCcwg4vo
4、电商场景下 ES 搜索引擎的稳定性治理实践
https://mp.weixin.qq.com/s/fAgAgWWYJbbfcGGx1BpLsw
5、玩转 Easysearch 语法
https://infinilabs.cn/blog/202 ... ntax/
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
邀请函 | 极限科技全新搜索引擎 INFINI Pizza 亮相 2024 可信数据库发展大会!

过去一年,在全球 AI 浪潮和国家数据局成立的推动下,数据库产业变革不断、热闹非凡。2024 年,站在中国数字经济产业升级和数据要素市场化建设的时代交汇点上,“2024 可信数据库发展大会” 将于 2024 年 7 月 16-17 日在北京悠唐皇冠假日酒店隆重召开,大会将以 “自主、创新、引领” 为主题,以期进一步推动全球数据库产业进步,共同开创可信数据库行业的新时代。
届时,极限科技(INFINI Labs)创始人兼 CEO 曾勇 将于 7 月 17 日下午在 搜索与分析型数据库&多模数据库分论坛 发表主题演讲 《下一代万亿级实时搜索引擎的设计与思考》 ,主要介绍下一代纯实时搜索新引擎 INFINI Pizza 的设计思路与软件架构的思考以及复杂场景下的搜索需求和挑战,敬请期待!


关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。

过去一年,在全球 AI 浪潮和国家数据局成立的推动下,数据库产业变革不断、热闹非凡。2024 年,站在中国数字经济产业升级和数据要素市场化建设的时代交汇点上,“2024 可信数据库发展大会” 将于 2024 年 7 月 16-17 日在北京悠唐皇冠假日酒店隆重召开,大会将以 “自主、创新、引领” 为主题,以期进一步推动全球数据库产业进步,共同开创可信数据库行业的新时代。
届时,极限科技(INFINI Labs)创始人兼 CEO 曾勇 将于 7 月 17 日下午在 搜索与分析型数据库&多模数据库分论坛 发表主题演讲 《下一代万亿级实时搜索引擎的设计与思考》 ,主要介绍下一代纯实时搜索新引擎 INFINI Pizza 的设计思路与软件架构的思考以及复杂场景下的搜索需求和挑战,敬请期待!
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
玩转 Easysearch 语法

什么是 Easysearch
Elasticsearch 是一个基于 Apache Lucene 的开源分布式搜索和分析引擎,它被广泛应用于全文搜索、结构化搜索和分析等多种场景中。作为 Elasticsearch 的国产化替代方案,Easysearch 不仅保持了与原生 Elasticsearch 的高度兼容性,还在功能、性能、稳定性和扩展性方面进行了全面提升。对于开发团队来说,从 Elasticsearch 切换到 Easysearch 不需要做任何业务代码的调整,确保了无缝衔接和平滑迁移。
Easysearch 是基于 Elasticsearch 7.10.2 开源版本二次开发,所以支持 Elasticsearch 原始的 Query DSL 语法,基本的 SQL 语法,并且兼容现有 Elasticsearch 的 SDK,使得应用无需修改代码即可进行迁移。其平滑的迁移特性,如基于网关的无缝跨版本迁移与升级,提供了随时安全回退的能力。
在之前的文章中,我们已经介绍了 Easysearch 的搭建 和 可视化工具的使用,今天我们将探讨 Easysearch 集群的基本概念和常用的 API。
Easysearch 集群的核心概念
Easysearch 集群由以下几个核心概念构成:
- 节点(Node):集群中的单个服务器,负责存储数据并参与集群的索引和搜索功能。
- 集群(Cluster):由一个或多个节点组成,拥有唯一的集群名,协同完成数据索引和查询任务。
- 索引(Index):存储相关数据的容器,类似于关系数据库中的数据库,一个索引包含多个文档。
- 文档(Document):索引中的基本数据单位,相当于关系数据库中的行。
- 字段(Field):文档中的一个属性,相当于数据库中的列。
- 分片(Shard):为了提高性能和扩展性,索引可以被分割成多个分片,每个分片是索引的一个部分。
- 副本(Replica):分片的副本,用于提高数据的可靠性和在节点出现故障时的可用性。
通过多个 API,例如 _cluster/health 和 _cluster/stats,用户可以轻松查看集群的健康状态和详细信息,这些信息对于维护和优化 Easysearch 集群至关重要。
无论是在性能的提升,还是在功能的兼容性方面,Easysearch 都为用户提供了一个强大的搜索引擎平台,让从 Elasticsearch 到 Easysearch 的迁移变得无缝且高效。掌握其核心概念和 API 的使用,将帮助开发者更好地利用这些工具来构建和优化他们的搜索解决方案。

查看集群信息
在 Easysearch 中,可以通过多个 API 来查看集群的各种信息,包括集群的健康状况、节点信息和索引状态。以下是一些常用的查看集群信息的 API 和示例:
查看集群健康状况
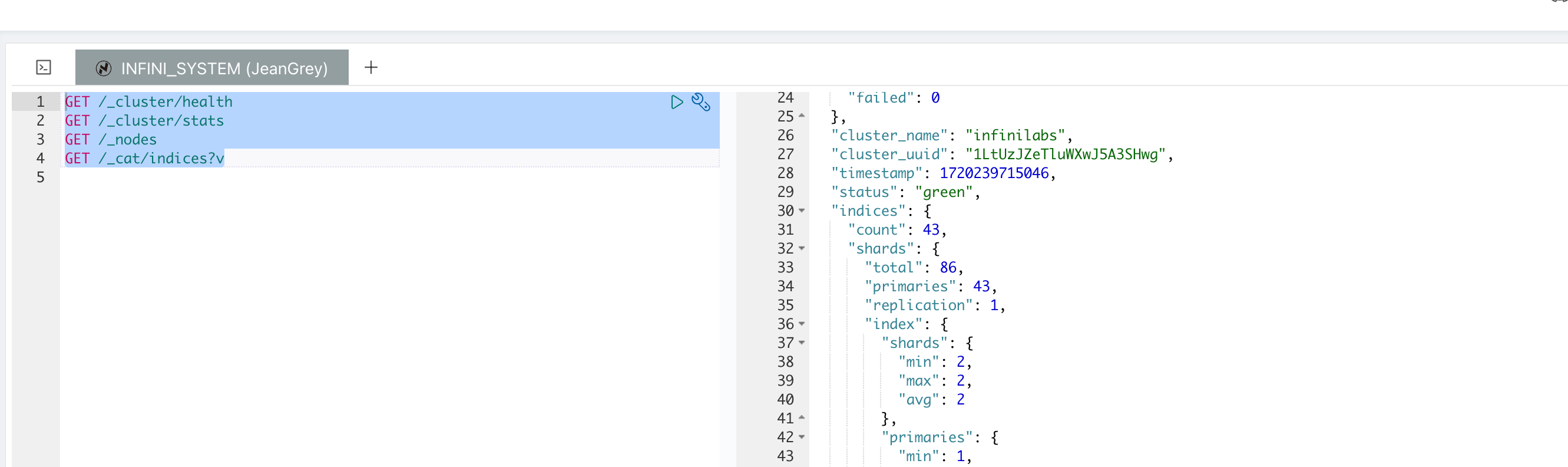
_cluster/health API 可以查看集群的健康状态,包括集群是否处于正常状态、节点数量、分片状态等。
GET /_cluster/health示例响应:
{
"cluster_name": "my_cluster",
"status": "green",
"timed_out": false,
"number_of_nodes": 3,
"number_of_data_nodes": 3,
"active_primary_shards": 5,
"active_shards": 10,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100.0
}查看集群状态
_cluster/stats API 可以查看集群的详细状态,包括索引、节点、分片等信息。
GET /_cluster/stats示例响应:
{
"cluster_name": "my_cluster",
"status": "green",
"indices": {
"count": 10,
"shards": {
"total": 20,
"primaries": 10,
"replication": 1.0,
"index": {
"shards": {
"min": 1,
"max": 5,
"avg": 2.0
}
}
}
},
"nodes": {
"count": {
"total": 3,
"data": 3,
"coordinating_only": 0,
"master": 1,
"ingest": 2
},
"os": {
"available_processors": 12,
"allocated_processors": 12
},
"process": {
"cpu": {
"percent": 10
},
"open_file_descriptors": {
"min": 100,
"max": 300,
"avg": 200
}
}
}
}查看节点信息
_nodes API 可以查看集群中节点的详细信息,包括节点角色、IP 地址、内存使用情况等。
GET /_nodes示例响应:
{
"cluster_name": "my_cluster",
"nodes": {
"node_id_1": {
"name": "node_1",
"transport_address": "192.168.1.1:9300",
"host": "192.168.1.1",
"ip": "192.168.1.1",
"roles": ["master", "data", "ingest"],
"os": {
"available_processors": 4,
"allocated_processors": 4
},
"process": {
"cpu": {
"percent": 10
},
"open_file_descriptors": 200
}
},
"node_id_2": {
"name": "node_2",
"transport_address": "192.168.1.2:9300",
"host": "192.168.1.2",
"ip": "192.168.1.2",
"roles": ["data"],
"os": {
"available_processors": 4,
"allocated_processors": 4
},
"process": {
"cpu": {
"percent": 15
},
"open_file_descriptors": 150
}
}
}
}查看索引状态
_cat/indices API 可以查看集群中所有索引的状态,包括文档数、存储大小、分片数等信息。
GET /_cat/indices?v示例响应:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open index_1 SxNUd84vRl6QH5P7g0T4Vg 1 1 0 0 230b 230b
green open index_2 NxEYib4yToCnA1PpQ8P4Xw 5 1 100 1 10mb 5mb这些 API 可以帮助你全面了解 Easysearch 集群的状态和健康状况,从而更好地管理和维护集群。
增删改查操作
在 Easysearch 中,增删改查操作是管理数据和索引的基本功能。以下是如何使用这些操作的详细示例。
创建索引
创建一个新的索引,并指定分片和副本的数量:
PUT /my_index
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}删除索引
删除一个不再需要的索引:
DELETE /my_index添加文档
通过 POST 或 PUT 请求向索引中添加文档:
POST /my_index/_doc/1
{
"name": "John Doe",
"age": 30,
"occupation": "Engineer"
}PUT /my_index/_doc/1
{
"name": "John Doe",
"age": 30,
"occupation": "Engineer"
}
POST 和 PUT 方法用于不同的操作,尽管它们都可以用于添加或更新文档,但它们的行为有所不同。
POST /my_index/_doc/1 方法用于创建或替换一个文档。如果指定的文档 ID 已经存在,POST 请求将更新整个文档(不会合并字段)。如果文档 ID 不存在,它将创建一个新的文档。
POST /my_index/_doc/1
{
"name": "John Doe",
"age": 30,
"occupation": "Engineer"
}PUT /my_index/_doc/1 方法通常用于创建一个新的文档,或者完全替换一个已存在的文档。与 POST 类似,如果指定的文档 ID 已经存在,PUT 请求将替换整个文档。
PUT /my_index/_doc/1
{
"name": "John Doe",
"age": 30,
"occupation": "Engineer"
}1.使用场景:
POST:更适合用于添加或部分更新文档,即使文档 ID 已经存在。PUT:更适合用于创建或完全替换文档。
2.ID 自动生成:
POST请求可以不提供文档 ID,此时 Easysearch 会自动生成一个文档 ID。PUT请求必须提供文档 ID,如果未提供,则会返回错误。
3.部分更新:
POST请求可以用于部分更新(通过_updateAPI)。PUT请求用于完全替换文档,不支持部分更新。
如果文档 ID 已经存在,POST 和 PUT 都会覆盖整个文档,并且效果是一样的。但是,通常 POST 用于提交数据,而 PUT 用于上传和替换资源。
1.使用 POST 方法添加或更新文档:
POST /my_index/_doc/1
{
"name": "John Doe",
"age": 30,
"occupation": "Engineer"
}2.使用 PUT 方法添加或更新文档:
PUT /my_index/_doc/1
{
"name": "John Doe",
"age": 30,
"occupation": "Engineer"
}在这两个示例中,结果都是在索引 my_index 中创建或更新文档 ID 为 1 的文档。无论使用 POST 还是 PUT,如果文档 ID 已存在,都会覆盖原有的文档内容。
新建文档
使用 _create 方法新建文档,如果文档已经存在则返回错误:
PUT /my_index/_create/1
{
"a": 1
}如果尝试新建已存在的文档,将会出现如下错误:
{
"error": {
"root_cause": [
{
"type": "version_conflict_engine_exception",
"reason": "[1]: version conflict, document already exists (current version [1])",
"index_uuid": "1xWdHLTaTm6l6HbqACaIEA",
"shard": "0",
"index": "my_index"
}
],
"type": "version_conflict_engine_exception",
"reason": "[1]: version conflict, document already exists (current version [1])",
"index_uuid": "1xWdHLTaTm6l6HbqACaIEA",
"shard": "0",
"index": "my_index"
},
"status": 409
}获取文档
通过 ID 获取文档的详细信息:
GET /my_index/_doc/1更新文档
更新文档的特定字段,保留原有字段:
POST /my_index/_update/1
{
"doc": {
"age": 31
}
}删除文档
通过 ID 删除指定的文档:
DELETE /my_index/_doc/1查询所有文档
查询索引中的所有文档:
GET /my_index/_search
{
"query": {
"match_all": {}
}
}这个是 《老杨玩搜索》中总结的图,可以作为“小抄”来记忆:

批量操作 (_bulk API)
_bulk API 用于在一次请求中执行多个索引、删除和更新操作,这对于批量处理大规模数据非常有用,可以显著提高性能和效率。以下是 _bulk API 的基本使用示例:
POST /my_index/_bulk
{ "index": { "_id": "1" } }
{ "name": "John Doe", "age": 30, "occupation": "Engineer" }
{ "index": { "_id": "2" } }
{ "name": "Jane Doe", "age": 25, "occupation": "Designer" }
{ "update": { "_id": "1" } }
{ "doc": { "age": 31 } }
_bulk API 的请求体由多个操作和文档组成。每个操作行包含一个动作描述行和一个可选的源文档行。动作描述行指明了操作的类型(例如,index、create、delete、update)以及操作的元数据。源文档行则包含了实际的数据。
每个操作之间需要用换行符分隔,并且请求体最后必须以换行符结尾。
POST /_bulk
{ "index": { "_index": "a", "_id": "1" } }
{ "name": "John Doe", "age": 30, "occupation": "Engineer" }
{ "index": { "_index": "b", "_id": "2" } }
{ "name": "Jane Doe", "age": 25, "occupation": "Designer" }
{ "update": { "_index": "a", "_id": "1" } }
{ "doc": { "age": 31 } }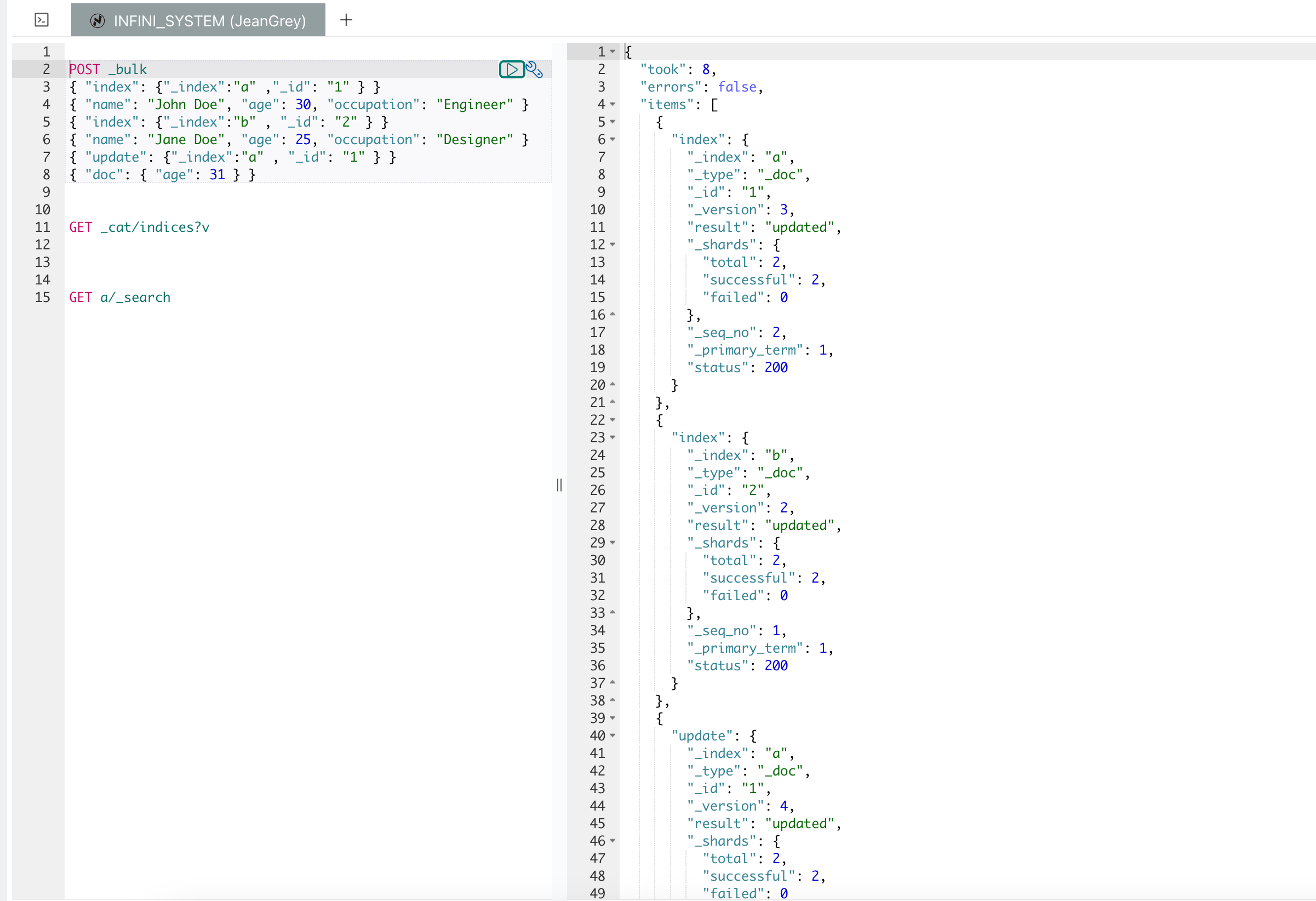
分词器
在 Easysearch 中,分词器(Analyzer)用于将文本分解为词项(terms),是全文搜索和文本分析的基础。分词器通常由字符过滤器(Character Filters)、分词器(Tokenizer)和词项过滤器(Token Filters)组成。以下是关于分词器的详细介绍:
1.字符过滤器(Character Filters):在分词之前对文本进行预处理。例如,去除 HTML 标签,替换字符等。
2.分词器(Tokenizer):将文本分解为词项(tokens)。这是分词过程的核心。
3.词项过滤器(Token Filters):对词项进行处理,如小写化、去除停用词、词干提取等。

只有 text 字段支持全文检索,返回的结果根据相似度打分,我们一起看下
POST /index/_mapping
{
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}.POST /index/_mapping
- 这个部分表示要向名为
index的索引添加或更新映射设置。
2.“properties”
properties定义了索引中文档的字段结构。在这个例子中,定义了一个名为content的字段。
3.“content”
- 定义了名为
content的字段。
4.“type”: “text”
type 字段指定 content 字段的数据类型为 text。text 类型适用于需要分词和全文搜索的字段。
5.“analyzer”: “ik_max_word”
analyzer 字段指定索引时使用的分词器为ik_max_word。ik_max_word 是 IK 分词器中的一种,它会尽可能多地将文本分解为更多的词项。
6.“search_analyzer”: “ik_smart”
search_analyzer 字段指定搜索时使用的分词器为ik_smart。ik_smart 是 IK 分词器中的另一种,它会更智能地进行分词,以提高搜索的准确性。
当然,在设置这个 mapping 的时候可以使用同样的分词器,也可以使用不同的分词器。这里介绍下 IK 分词器:
- IK 分词器是一种中文分词器,适用于中文文本的分词。IK 分词器有两种分词模式:
ik_max_word和ik_smart。ik_max_word:将文本尽可能多地切分成词项,适用于需要更高召回率的场景。ik_smart:进行最智能的分词,适用于需要更高精度的搜索场景。
这个 DSL 的设置意味着,在向这个索引添加或更新文档时,content 字段的文本会使用ik_max_word 分词器进行分词处理,以确保文本被尽可能多地切分成词项。而在搜索时,content 字段的文本会使用ik_smart 分词器进行分词处理,以提高搜索的准确性和相关性。
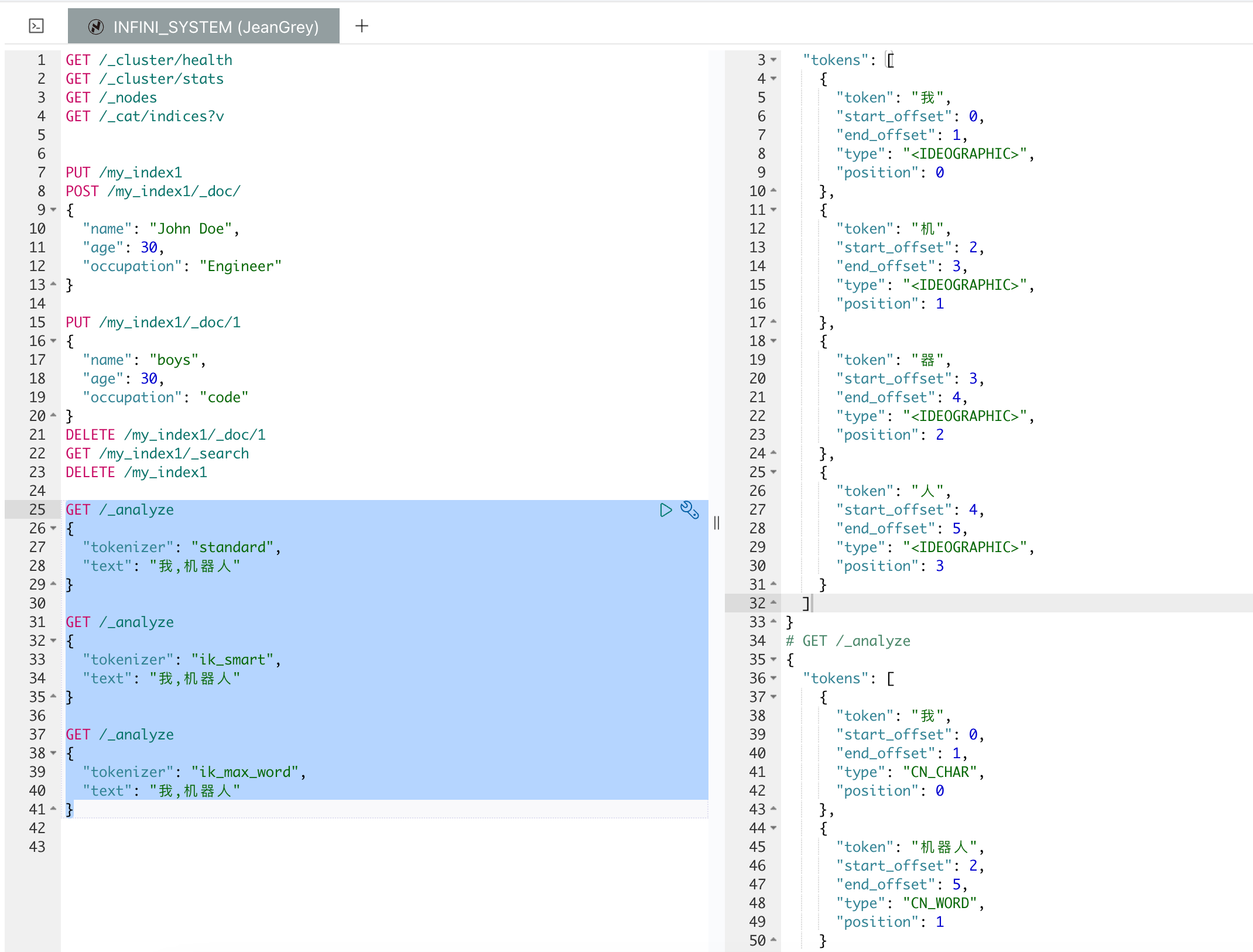
以下是关于 standard,ik_smart,ik_max_word 这几个分词器的对比:
GET /_analyze
{
"tokenizer": "standard",
"text": "我,机器人"
}
GET /_analyze
{
"tokenizer": "ik_smart",
"text": "我,机器人"
}
GET /_analyze
{
"tokenizer": "ik_max_word",
"text": "我,机器人"
}结果如下:
# GET /_analyze (standard)
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "机",
"start_offset": 2,
"end_offset": 3,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "器",
"start_offset": 3,
"end_offset": 4,
"type": "<IDEOGRAPHIC>",
"position": 2
},
{
"token": "人",
"start_offset": 4,
"end_offset": 5,
"type": "<IDEOGRAPHIC>",
"position": 3
}
]
}
# GET /_analyze(ik_smart)
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "机器人",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 1
}
]
}
# GET /_analyze (ik_max_word)
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "机器人",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 1
},
{
"token": "机器",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 2
},
{
"token": "人",
"start_offset": 4,
"end_offset": 5,
"type": "CN_CHAR",
"position": 3
}
]
}
如果使用了不存在的分词器会出现这个错误。
{
"error": {
"root_cause": [
{
"type": "illegal_argument_exception",
"reason": "failed to find global tokenizer under [simple]"
}
],
"type": "illegal_argument_exception",
"reason": "failed to find global tokenizer under [simple]"
},
"status": 400
}精确搜索/正则表达式搜索/通配符
在 Easysearch 中,精确搜索、正则表达式搜索和通配符搜索是三种不同的搜索方式,各有其应用场景和特点:
1.精确搜索 (Term Query):
- 精确搜索用于查找与搜索词完全匹配的文档。
- 不进行分词处理,通常用于关键字、ID、标签等字段的精确匹配。
- 适用于结构化数据或不需要分词的字段(如数字、日期、布尔值等)。
{
"query": {
"term": {
"status": "active"
}
}
}2.正则表达式搜索 (Regexp Query):
- 正则表达式搜索用于基于正则表达式模式匹配的文档搜索。
- 支持复杂的字符串匹配模式,但性能可能较低,特别是当数据量较大时。
- 适用于需要灵活且复杂匹配条件的搜索。
{
"query": {
"regexp": {
"content": "Easysearch .*powerful"
}
}
}3.通配符搜索 (Wildcard Query):
- 通配符搜索用于通过通配符模式匹配文档。
- 支持 ?(匹配单个字符)和 *(匹配零个或多个字符)。
- 性能相对较差,因为通配符搜索可能需要扫描大量数据。
{
"query": {
"wildcard": {
"username": "john*"
}
}
}- 精确搜索:用于需要绝对匹配特定词语或不需要分词的字段。例如,查找特定用户 ID 或状态。
- 正则表达式搜索:用于需要复杂字符串模式匹配的场景,但要谨慎使用,避免性能问题。
- 通配符搜索:用于简单模式匹配,但同样需要注意性能影响,尽量避免在大数据集上频繁使用。
接下来看这个例子,我们将使用批量导入数据,然后进行几种不同类型的查询,包括精确查询、通配符查询和正则表达式查询。
POST /users/_bulk
{ "index": { "_index": "users", "_id": 1 }}
{ "username": "john_doe", "status": "active", "email": "john.doe@example.com", "bio": "John loves Easysearch and open-source technologies." }
{ "index": { "_index": "users", "_id": 2 }}
{ "username": "jane_doe", "status": "inactive", "email": "jane.doe@example.com", "bio": "Jane is a data scientist working with big data." }
{ "index": { "_index": "users", "_id": 3 }}
{ "username": "john_smith", "status": "active", "email": "john.smith@example.com", "bio": "John enjoys hiking and nature." }
{ "index": { "_index": "users", "_id": 4 }}
{ "username": "alice_jones", "status": "active", "email": "alice.jones@example.com", "bio": "Alice is a software engineer specialized in JavaScript." }
{ "index": { "_index": "users", "_id": 5 }}
{ "username": "bob_jones", "status": "inactive", "email": "bob.jones@example.com", "bio": "Bob is an AI enthusiast and machine learning expert." }1.精确查询:查询状态为 “active” 的用户。
GET /users/_search
{
"query": {
"term": {
"status": "active"
}
}
}2.通配符查询:查询 bio 字段中包含 “John” 开头的词。
GET /users/_search
{
"query": {
"wildcard": {
"bio": "John*"
}
}
}3.正则表达式查询:查询用户名以 “john” 开头的用户
GET /users/_search
{
"query": {
"regexp": {
"username": "john.*"
}
}
}通过这些例子,你可以看到如何在 Easysearch 中使用批量导入数据,然后使用各种查询方法来检索特定条件的数据。这些查询方法可以帮助你高效地搜索和分析数据,以满足不同的业务需求。
这里同样是《老杨玩搜索》中总结的“小抄”来方便记忆:



多字段查询
在 Easysearch 中,多字段查询允许您在多个字段上同时执行搜索,以获取更精确的结果。最常用的多字段查询类型是 multi_match 查询。multi_match 查询是 match 查询的扩展,能够在多个字段中搜索指定的关键词。
multi_match 查询支持多种匹配模式,如 best_fields、most_fields、cross_fields、phrase 和 phrase_prefix。以下是各模式的简要介绍:
- best_fields:默认模式,选择匹配度最高的字段。
- most_fields:计算每个字段的匹配度,然后将匹配度相加。
- cross_fields:将多个字段视为一个字段进行匹配,适用于分析文本被分散到多个字段的情况。
- phrase:短语匹配,确保词项顺序与查询相同。
- phrase_prefix:短语前缀匹配,允许词项的部分匹配。
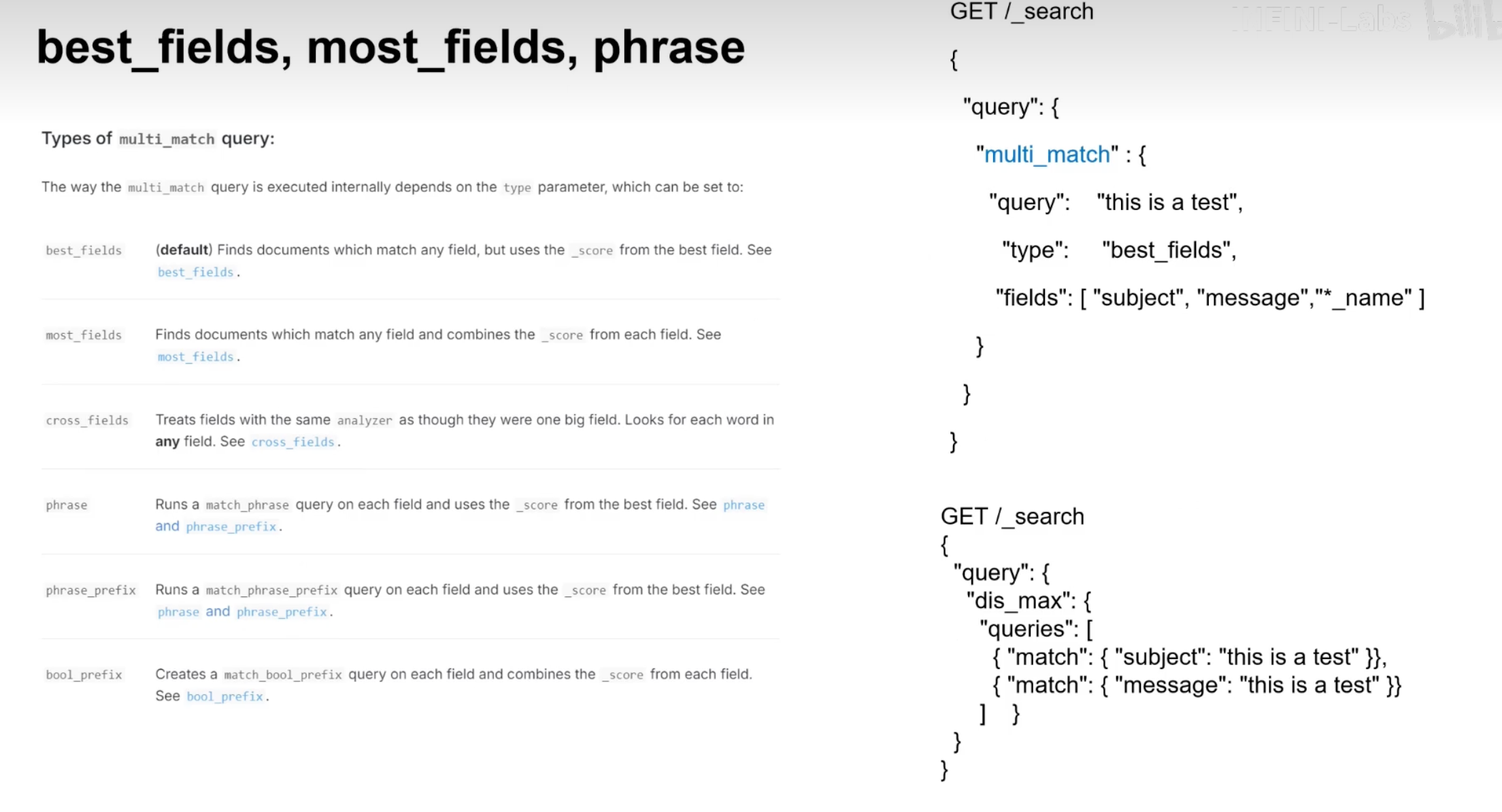
我们先导入一些示例数据到一个索引 documents 中:
POST /documents/_bulk
{ "index": { "_id": 1 } }
{ "title": "Easysearch Guide", "content": "This is an introductory guide to Easysearch ." }
{ "index": { "_id": 2 } }
{ "title": "Advanced Easysearch ", "content": "This guide covers advanced topics in Easysearch ." }
{ "index": { "_id": 3 } }
{ "title": "Easysearch in Action", "content": "Practical guide to Easysearch usage." }
{ "index": { "_id": 4 } }
{ "title": "Learning Easysearch ", "content": "Beginner's guide to learning Easysearch ." }我们将使用 multi_match 查询在 title 和 content 字段中同时搜索关键词。
1.基本 multi_match 查询:
POST /documents/_search
{
"query": {
"multi_match": {
"query": "guide",
"fields": ["title", "content"]
}
}
}2.指定匹配模式为 best_fields:
POST /documents/_search
{
"query": {
"multi_match": {
"query": "guide",
"fields": ["title", "content"],
"type": "best_fields"
}
}
}3.指定匹配模式为 most_fields:
POST /documents/_search
{
"query": {
"multi_match": {
"query": "guide",
"fields": ["title", "content"],
"type": "most_fields"
}
}
}4.使用 cross_fields 模式:
POST /documents/_search
{
"query": {
"multi_match": {
"query": "Easysearch guide",
"fields": ["title", "content"],
"type": "cross_fields"
}
}
}5.短语匹配 (phrase):
POST /documents/_search
{
"query": {
"multi_match": {
"query": "introductory guide",
"fields": ["title", "content"],
"type": "phrase"
}
}
}6.短语前缀匹配 (phrase_prefix):
POST /documents/_search
{
"query": {
"multi_match": {
"query": "introductory gui",
"fields": ["title", "content"],
"type": "phrase_prefix"
}
}
}- query:要搜索的关键词或短语。
- fields:要搜索的字段列表,可以包含一个或多个字段。
- type:指定匹配模式,默认为 best_fields。
使用 multi_match 查询,您可以在多个字段上同时执行搜索,获得更精确和全面的结果。通过指定不同的匹配模式,您可以调整查询行为以满足特定的搜索需求。无论是基本关键词匹配、短语匹配还是跨字段匹配,multi_match 查询都提供了强大的功能来处理复杂的搜索场景。
除此之外,还可以使用 boost 参数用于调整特定字段的权重,从而影响搜索结果的相关性评分。multi_match 查询支持为不同字段设置不同的 boost 值,以便在搜索结果中优先显示某些字段的匹配项。

布尔查询
布尔查询是 Easysearch 中非常强大且灵活的一种查询方式,它允许用户通过组合多个查询条件来实现复杂的搜索需求。布尔查询使用 bool 查询类型,可以包含以下几种子句:must、filter、must_not 和 should。每种子句都有其特定的用途和语义。
1.must:
- 包含在
must数组中的查询条件必须匹配,类似于逻辑上的 AND 操作。 - 如果有多个条件,所有条件都必须满足,文档才会被包含在结果集中。
2.filter:
- 包含在
filter数组中的查询条件必须匹配,但它不会影响评分。 filter子句通常用于对性能要求较高的过滤操作,因为它不计算相关性评分。
3.must_not:
- 包含在
must_not数组中的查询条件必须不匹配,类似于逻辑上的 NOT 操作。 - 如果有任何一个条件匹配,文档就会被排除在结果集之外。
4.should:
- 包含在
should数组中的查询条件至少匹配一个。 - 如果布尔查询中没有
must子句,则至少要匹配一个should子句。 should子句在计算相关性评分时也有影响。
5.minimum_should_match:
- 指定
should子句中至少需要满足的条件数量。

首先,我们需要创建一个名为 books 的索引,并定义它的映射(mappings)。映射用于指定每个字段的数据类型。在这个例子中,类别和书名字段都被定义为 keyword 类型,这是因为我们需要进行精确匹配查询。
PUT /books
{
"mappings": {
"properties": {
"类别": { "type": "keyword" },
"书名": { "type": "keyword" }
}
}
}接下来,我们使用批量操作(bulk API)将一些示例数据导入到 books 索引中。这些数据包括不同类别的书籍。
POST /books/_bulk
{ "index": { "_id": 1 } }
{ "类别": "文学", "书名": "我的阿勒泰" }
{ "index": { "_id": 2 } }
{ "类别": "文学", "书名": "平凡的世界" }
{ "index": { "_id": 3 } }
{ "类别": "科学", "书名": "时间简史" }
{ "index": { "_id": 4 } }
{ "类别": "文学", "书名": "百年孤独" }
{ "index": { "_id": 5 } }
{ "类别": "文学", "书名": "红楼梦" }现在,我们使用布尔查询来搜索类别为“文学”并且书名为“我的阿勒泰”的文档。这里使用的是 must子句,表示查询结果必须满足所有条件。
POST /books/_search
{
"query": {
"bool": {
"must": [
{ "term": { "类别": "文学" } },
{ "term": { "书名": "我的阿勒泰" } }
]
}
}
}我们还可以使用 filter 子句来执行相同的查询。filter 子句用于过滤文档,且不会影响文档的相关性评分。这在不需要计算相关性评分时可以提高查询性能。
POST /books/_search
{
"query": {
"bool": {
"filter": [
{ "term": { "类别": "文学" } },
{ "term": { "书名": "我的阿勒泰" } }
]
}
}
}当我们执行上述查询时,期望返回的结果是 books 索引中类别为“文学”且书名为“我的阿勒泰”的文档。无论是使用 must 还是 filter 子句,结果应该都是:
{
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"hits": [
{
"_index": "books",
"_id": "1",
"_source": {
"类别": "文学",
"书名": "我的阿勒泰"
}
}
]
}
}

POST /_search
{
"query": {
"bool": {
"must": [
{ "term": { "user.id": "kimchy" } }
],
"filter": [
{ "term": { "tags": "production" } }
],
"must_not": [
{
"range": {
"age": { "gte": 10, "lte": 20 }
}
}
],
"should": [
{ "term": { "tags": "env1" } },
{ "term": { "tags": "deployed" } }
],
"minimum_should_match": 1,
"boost": 1.0
}
}
}must子句:必须匹配的条件,文档必须包含user.id为kimchy。filter子句:过滤条件,文档必须包含tags为production,但不会影响评分。must_not子句:不匹配的条件,文档的age字段不能在 10 到 20 之间。should子句:可选匹配条件,至少需要匹配一个should子句中的条件。这里要求tags字段匹配env1或deployed。minimum_should_match:至少需要匹配一个 should 子句中的条件。boost:提升查询的整体评分。
为了展示这个 DSL ,我们需要创建一个索引并导入一些数据。假设我们要在 Easysearch 中创建一个索引 users ,并插入一些测试数据。
创建索引
PUT /users
{
"mappings": {
"properties": {
"user.id": { "type": "keyword" },
"tags": { "type": "keyword" },
"age": { "type": "integer" }
}
}
}批量导入数据
POST /users/_bulk
{ "index": { "_id": 1 } }
{ "user.id": "kimchy", "tags": ["production", "env1"], "age": 25 }
{ "index": { "_id": 2 } }
{ "user.id": "kimchy", "tags": ["production"], "age": 15 }
{ "index": { "_id": 3 } }
{ "user.id": "kimchy", "tags": ["deployed"], "age": 30 }
{ "index": { "_id": 4 } }
{ "user.id": "kimchy", "tags": ["test"], "age": 35 }
{ "index": { "_id": 5 } }
{ "user.id": "other", "tags": ["production"], "age": 25 }接下来执行布尔查询:
POST /users/_search
{
"query": {
"bool": {
"must": [
{ "term": { "user.id": "kimchy" } }
],
"filter": [
{ "term": { "tags": "production" } }
],
"must_not": [
{
"range": {
"age": { "gte": 10, "lte": 20 }
}
}
],
"should": [
{ "term": { "tags": "env1" } },
{ "term": { "tags": "deployed" } }
],
"minimum_should_match": 1,
"boost": 1.0
}
}
}根据以上查询,预期返回的结果应该符合以下条件:
user.id必须是kimchy(由must子句决定)。tags必须包含production(由filter子句决定)。age字段不在 10 到 20 之间(由must_not子句决定)。tags字段中至少包含env1或deployed中的一个(由should子句和minimum_should_match参数决定)。
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.3769134,
"hits": [
{
"_index": "users",
"_type": "_doc",
"_id": "1",
"_score": 1.3769134,
"_source": {
"user.id": "kimchy",
"tags": ["production", "env1"],
"age": 25
}
}
]
}
}SQL 搜索
Easysearch 直接支持 SQL 查询,无需额外安装插件,同时兼容 Elasticsearch 的 SQL 调用方式,还可以直接编写原生 SQL 查询。

以下是一些测试 SQL 语句的示例:
SELECT * FROM my_index;
SELECT * FROM my_index LIMIT 2;
SELECT * FROM my_index ORDER BY name;
SELECT name AS full_name, age FROM my_index WHERE age > 25;
SELECT name AS full_name, age FROM my_index WHERE age = 25;
SELECT * FROM my_index WHERE age IS NULL;
SELECT DISTINCT age FROM my_index;
SELECT MIN(age), MAX(age), AVG(age) FROM my_index;
SELECT age, COUNT(*) AS CNT FROM my_index GROUP BY age;
使用 Easysearch 执行 SQL 查询
Easysearch 提供了对直接使用 SQL 查询的支持。以下是如何在 Easysearch 中通过 POST 请求使用 _sql 端点进行查询的示例:
执行 SQL 查询非常简单,只需通过 POST 请求发送 SQL 查询即可。以下是一个示例:
POST /_sql
{
"query": "SELECT name AS full_name, age FROM my_index WHERE age > 25"
}你也可以规定返回 JSON 格式:
POST /_sql?format=json
{
"query": "SELECT name AS full_name, age FROM my_index WHERE age > 25"
}和 Elasticsearch 一样,Easysearch 允许你通过 POST 请求直接在集群上运行 SQL 查询,并返回查询结果。以下是一些常见的 SQL 查询示例及其对应的 POST 请求:
1.查询所有文档:
POST /_sql
{
"query": "SELECT * FROM my_index"
}2.限制返回文档数:
POST /_sql
{
"query": "SELECT * FROM my_index LIMIT 2"
}3.按字段排序:
POST /_sql
{
"query": "SELECT * FROM my_index ORDER BY name"
}4.筛选条件查询:
POST /_sql
{
"query": "SELECT name AS full_name, age FROM my_index WHERE age > 25"
}5.精确值查询:
POST /_sql
{
"query": "SELECT name AS full_name, age FROM my_index WHERE age = 25"
}6.查询空值:
POST /_sql
{
"query": "SELECT * FROM my_index WHERE age IS NULL"
}7.查询唯一值:
POST /_sql
{
"query": "SELECT DISTINCT age FROM my_index"
}8.聚合函数查询:
POST /_sql
{
"query": "SELECT MIN(age), MAX(age), AVG(age) FROM my_index"
}9.分组统计:
POST /_sql
{
"query": "SELECT age, COUNT(*) AS CNT FROM my_index GROUP BY age"
}
多表操作的 SQL 语句
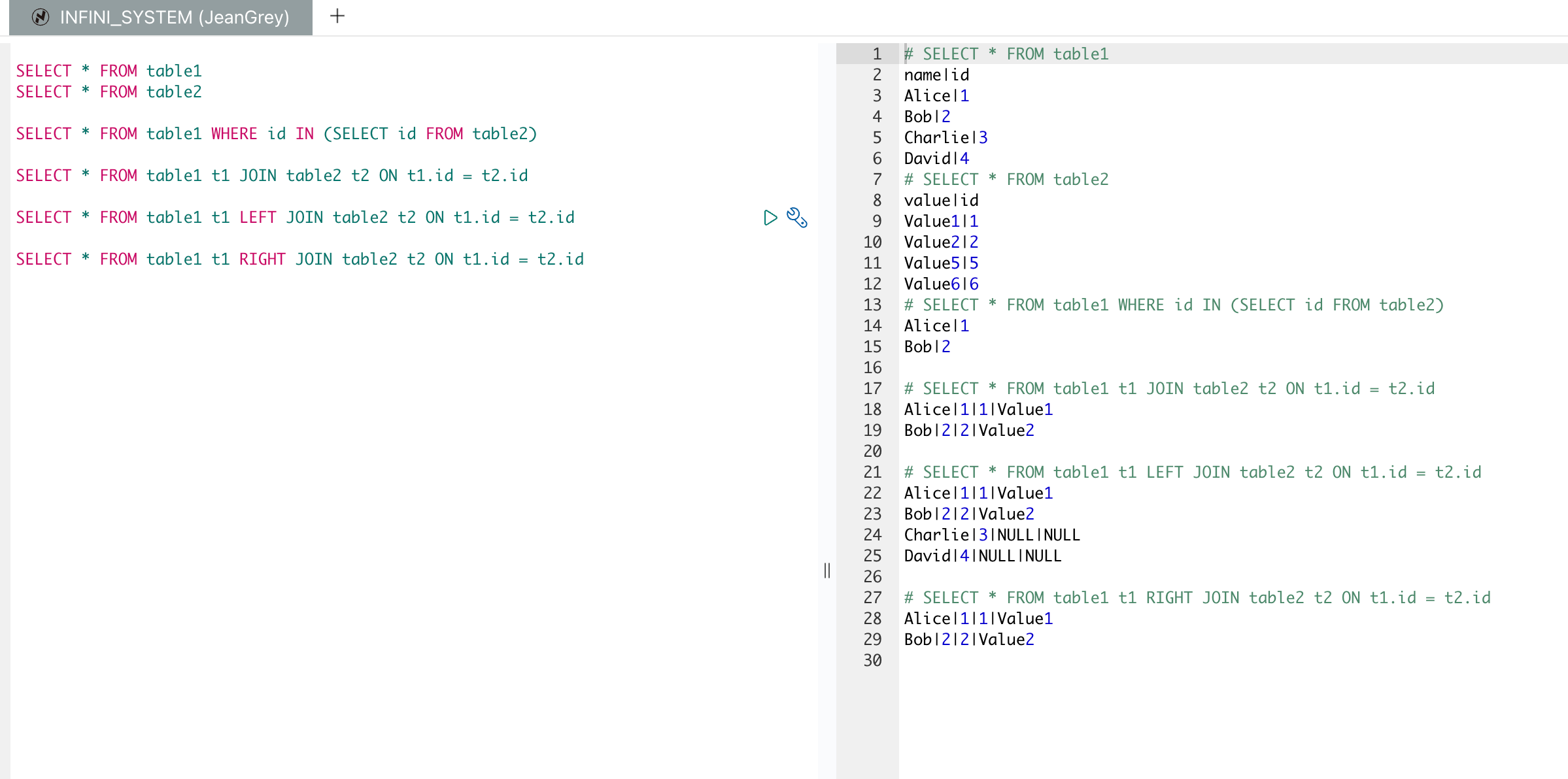
以下是多表操作的 SQL 语句及其解释:
1.子查询:
SELECT * FROM `table1` t1 WHERE t1.id IN (SELECT id FROM `table2`)这个查询从 table1 中选择所有字段的记录,其中这些记录的 id 在 table2 表中也存在。
2.内连接:
SELECT * FROM `table1` t1 JOIN `table2` t2 ON t1.id = t2.id这个查询进行内连接,从 table1 和 table2 中选择所有字段的记录,前提是 table1 和 table2 中 id 相等。
3.左连接:
SELECT * FROM `table1` t1 LEFT JOIN `table2` t2 ON t1.id = t2.id这个查询进行左连接,从 table1 和 table2 中选择所有字段的记录,即使 table2 中没有匹配的记录,也会返回 table1 中的所有记录,未匹配到的部分会用 NULL 填充。
4.右连接:
SELECT * FROM `table1` t1 RIGHT JOIN `table2` t2 ON t1.id = t2.id这个查询进行右连接,从 table1 和 table2 中选择所有字段的记录,即使 table1 中没有匹配的记录,也会返回 table2 中的所有记录,未匹配到的部分会用 NULL 填充。
假设我们有两个索引 table1 和 table2,对应于 SQL 中的两个表。
创建索引 table1:
PUT /`table1`
{
"mappings": {
"properties": {
"id": { "type": "integer" },
"name": { "type": "text" }
}
}
}创建索引 table2:
PUT /`table2`
{
"mappings": {
"properties": {
"id": { "type": "integer" },
"value": { "type": "text" }
}
}
}导入数据到 table1:
POST /`table1`/_bulk
{ "index": { "_id": 1 } }
{ "id": 1, "name": "Alice" }
{ "index": { "_id": 2 } }
{ "id": 2, "name": "Bob" }
{ "index": { "_id": 3 } }
{ "id": 3, "name": "Charlie" }
{ "index": { "_id": 4 } }
{ "id": 4, "name": "David" }导入数据到 table2:
POST /`table2`/_bulk
{ "index": { "_id": 1 } }
{ "id": 1, "value": "Value1" }
{ "index": { "_id": 2 } }
{ "id": 2, "value": "Value2" }
{ "index": { "_id": 5 } }
{ "id": 5, "value": "Value5" }
{ "index": { "_id": 6 } }
{ "id": 6, "value": "Value6" }导入数据后,可以使用 SQL 来执行这些查询:
1.子查询:
POST /_sql
{
"query": "SELECT * FROM `table1` WHERE id IN (SELECT id FROM `table2`)"
}2.内连接:
POST /_sql
{
"query": "SELECT * FROM `table1` t1 JOIN `table2` t2 ON t1.id = t2.id"
}3.左连接:
POST /_sql
{
"query": "SELECT * FROM `table1` t1 LEFT JOIN `table2` t2 ON t1.id = t2.id"
}4.右连接:
POST /_sql
{
"query": "SELECT * FROM `table1` t1 RIGHT JOIN `table2` t2 ON t1.id = t2.id"
}效果如下:
SQL 全文检索
match 和 match_phrase 是 Easysearch 中用于全文搜索的查询类型,它们在处理文本匹配方面有不同的用途:
1.match 查询:
match查询用于对文档进行全文搜索。- 它将搜索关键词进行分词,并对这些分词后的词项进行搜索。
- 适用于查询单个或多个字段,可以进行布尔操作(如 “AND”, “OR”)。
- 例如,搜索 “Easysearch is powerful” 会被分词为 "Easysearch ", “is”, “powerful” 三个词,然后对这三个词进行搜索,文档中包含这些词的都会被认为是匹配的。
{
"query": {
"match": {
"content": "Easysearch is powerful"
}
}
}2.match_phrase 查询:
match_phrase查询用于短语搜索。- 它要求搜索的短语必须在文档中出现且词的顺序相同,词之间的间隔也必须与查询中的短语相同。
- 适用于需要精确匹配短语的场景。
- 例如,搜索 “Easysearch is powerful” 时,只有包含这个确切短语的文档才会被认为是匹配的。
{
"query": {
"match_phrase": {
"content": "Easysearch is powerful"
}
}
}总结来说,match 更灵活,用于一般的关键词搜索,而 match_phrase 则用于需要精确匹配短语的搜索。
SQL 全文检索示例
我们先造一些数据,然后使用 SQL 来进行全文检索。
批量导入数据:
POST /table3/_bulk
{ "index": { "_id": 1 } }
{ "id": 1, "test": "The quick brown fox jumps over the lazy dog" }
{ "index": { "_id": 2 } }
{ "id": 2, "test": "Foxes are wild animals" }
{ "index": { "_id": 3 } }
{ "id": 3, "test": "Jump high to catch the ball" }
{ "index": { "_id": 4 } }
{ "id": 4, "test": "Some animals can jump very high" }
{ "index": { "_id": 5 } }
{ "id": 5, "test": "The lazy dog sleeps all day" }
{ "index": { "_id": 6 } }
{ "id": 6, "test": "The foxes jump all day" }执行全文检索的 SQL 查询:
SELECT * FROM table3;
SELECT * FROM table3 WHERE match(test, 'jump');
SELECT * FROM table3 WHERE match_phrase(test, 'foxes jump');
总结
随着数据量的不断增加,高效的数据搜索和分析变得尤为重要。Elasticsearch 以其强大的全文搜索能力和灵活的数据处理能力成为行业标准。Easysearch 作为 Elasticsearch 的优化版本,不仅继承了其强大的功能,还在性能和安全性上做了进一步的提升,为企业提供了一个高效、稳定且易于迁移的搜索引擎解决方案。通过深入了解这些技术和实践其应用,开发者和企业能够更好地利用这些工具来应对现代数据挑战,推动业务的持续发展和创新。
关于 Easysearch 有奖征文活动
无论你是 Easysearch 的老用户,还是第一次听说这个名字,只要你对 INFINI Labs 旗下的 Easysearch 产品感兴趣,或者是希望了解 Easysearch,都可以参加这次活动。
详情查看:Easysearch 征文活动
作者:韩旭,亚马逊云技术支持,亚马逊云科技技领云博主,目前专注于云计算开发和大数据领域。
原文:https://infinilabs.cn/blog/2024/mastering-easysearch-syntax/
什么是 Easysearch
Elasticsearch 是一个基于 Apache Lucene 的开源分布式搜索和分析引擎,它被广泛应用于全文搜索、结构化搜索和分析等多种场景中。作为 Elasticsearch 的国产化替代方案,Easysearch 不仅保持了与原生 Elasticsearch 的高度兼容性,还在功能、性能、稳定性和扩展性方面进行了全面提升。对于开发团队来说,从 Elasticsearch 切换到 Easysearch 不需要做任何业务代码的调整,确保了无缝衔接和平滑迁移。
Easysearch 是基于 Elasticsearch 7.10.2 开源版本二次开发,所以支持 Elasticsearch 原始的 Query DSL 语法,基本的 SQL 语法,并且兼容现有 Elasticsearch 的 SDK,使得应用无需修改代码即可进行迁移。其平滑的迁移特性,如基于网关的无缝跨版本迁移与升级,提供了随时安全回退的能力。
在之前的文章中,我们已经介绍了 Easysearch 的搭建 和 可视化工具的使用,今天我们将探讨 Easysearch 集群的基本概念和常用的 API。
Easysearch 集群的核心概念
Easysearch 集群由以下几个核心概念构成:
- 节点(Node):集群中的单个服务器,负责存储数据并参与集群的索引和搜索功能。
- 集群(Cluster):由一个或多个节点组成,拥有唯一的集群名,协同完成数据索引和查询任务。
- 索引(Index):存储相关数据的容器,类似于关系数据库中的数据库,一个索引包含多个文档。
- 文档(Document):索引中的基本数据单位,相当于关系数据库中的行。
- 字段(Field):文档中的一个属性,相当于数据库中的列。
- 分片(Shard):为了提高性能和扩展性,索引可以被分割成多个分片,每个分片是索引的一个部分。
- 副本(Replica):分片的副本,用于提高数据的可靠性和在节点出现故障时的可用性。
通过多个 API,例如 _cluster/health 和 _cluster/stats,用户可以轻松查看集群的健康状态和详细信息,这些信息对于维护和优化 Easysearch 集群至关重要。
无论是在性能的提升,还是在功能的兼容性方面,Easysearch 都为用户提供了一个强大的搜索引擎平台,让从 Elasticsearch 到 Easysearch 的迁移变得无缝且高效。掌握其核心概念和 API 的使用,将帮助开发者更好地利用这些工具来构建和优化他们的搜索解决方案。
查看集群信息
在 Easysearch 中,可以通过多个 API 来查看集群的各种信息,包括集群的健康状况、节点信息和索引状态。以下是一些常用的查看集群信息的 API 和示例:
查看集群健康状况
_cluster/health API 可以查看集群的健康状态,包括集群是否处于正常状态、节点数量、分片状态等。
GET /_cluster/health示例响应:
{
"cluster_name": "my_cluster",
"status": "green",
"timed_out": false,
"number_of_nodes": 3,
"number_of_data_nodes": 3,
"active_primary_shards": 5,
"active_shards": 10,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100.0
}查看集群状态
_cluster/stats API 可以查看集群的详细状态,包括索引、节点、分片等信息。
GET /_cluster/stats示例响应:
{
"cluster_name": "my_cluster",
"status": "green",
"indices": {
"count": 10,
"shards": {
"total": 20,
"primaries": 10,
"replication": 1.0,
"index": {
"shards": {
"min": 1,
"max": 5,
"avg": 2.0
}
}
}
},
"nodes": {
"count": {
"total": 3,
"data": 3,
"coordinating_only": 0,
"master": 1,
"ingest": 2
},
"os": {
"available_processors": 12,
"allocated_processors": 12
},
"process": {
"cpu": {
"percent": 10
},
"open_file_descriptors": {
"min": 100,
"max": 300,
"avg": 200
}
}
}
}查看节点信息
_nodes API 可以查看集群中节点的详细信息,包括节点角色、IP 地址、内存使用情况等。
GET /_nodes示例响应:
{
"cluster_name": "my_cluster",
"nodes": {
"node_id_1": {
"name": "node_1",
"transport_address": "192.168.1.1:9300",
"host": "192.168.1.1",
"ip": "192.168.1.1",
"roles": ["master", "data", "ingest"],
"os": {
"available_processors": 4,
"allocated_processors": 4
},
"process": {
"cpu": {
"percent": 10
},
"open_file_descriptors": 200
}
},
"node_id_2": {
"name": "node_2",
"transport_address": "192.168.1.2:9300",
"host": "192.168.1.2",
"ip": "192.168.1.2",
"roles": ["data"],
"os": {
"available_processors": 4,
"allocated_processors": 4
},
"process": {
"cpu": {
"percent": 15
},
"open_file_descriptors": 150
}
}
}
}查看索引状态
_cat/indices API 可以查看集群中所有索引的状态,包括文档数、存储大小、分片数等信息。
GET /_cat/indices?v示例响应:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open index_1 SxNUd84vRl6QH5P7g0T4Vg 1 1 0 0 230b 230b
green open index_2 NxEYib4yToCnA1PpQ8P4Xw 5 1 100 1 10mb 5mb这些 API 可以帮助你全面了解 Easysearch 集群的状态和健康状况,从而更好地管理和维护集群。
增删改查操作
在 Easysearch 中,增删改查操作是管理数据和索引的基本功能。以下是如何使用这些操作的详细示例。
创建索引
创建一个新的索引,并指定分片和副本的数量:
PUT /my_index
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}删除索引
删除一个不再需要的索引:
DELETE /my_index添加文档
通过 POST 或 PUT 请求向索引中添加文档:
POST /my_index/_doc/1
{
"name": "John Doe",
"age": 30,
"occupation": "Engineer"
}PUT /my_index/_doc/1
{
"name": "John Doe",
"age": 30,
"occupation": "Engineer"
}
POST 和 PUT 方法用于不同的操作,尽管它们都可以用于添加或更新文档,但它们的行为有所不同。
POST /my_index/_doc/1 方法用于创建或替换一个文档。如果指定的文档 ID 已经存在,POST 请求将更新整个文档(不会合并字段)。如果文档 ID 不存在,它将创建一个新的文档。
POST /my_index/_doc/1
{
"name": "John Doe",
"age": 30,
"occupation": "Engineer"
}PUT /my_index/_doc/1 方法通常用于创建一个新的文档,或者完全替换一个已存在的文档。与 POST 类似,如果指定的文档 ID 已经存在,PUT 请求将替换整个文档。
PUT /my_index/_doc/1
{
"name": "John Doe",
"age": 30,
"occupation": "Engineer"
}1.使用场景:
POST:更适合用于添加或部分更新文档,即使文档 ID 已经存在。PUT:更适合用于创建或完全替换文档。
2.ID 自动生成:
POST请求可以不提供文档 ID,此时 Easysearch 会自动生成一个文档 ID。PUT请求必须提供文档 ID,如果未提供,则会返回错误。
3.部分更新:
POST请求可以用于部分更新(通过_updateAPI)。PUT请求用于完全替换文档,不支持部分更新。
如果文档 ID 已经存在,POST 和 PUT 都会覆盖整个文档,并且效果是一样的。但是,通常 POST 用于提交数据,而 PUT 用于上传和替换资源。
1.使用 POST 方法添加或更新文档:
POST /my_index/_doc/1
{
"name": "John Doe",
"age": 30,
"occupation": "Engineer"
}2.使用 PUT 方法添加或更新文档:
PUT /my_index/_doc/1
{
"name": "John Doe",
"age": 30,
"occupation": "Engineer"
}在这两个示例中,结果都是在索引 my_index 中创建或更新文档 ID 为 1 的文档。无论使用 POST 还是 PUT,如果文档 ID 已存在,都会覆盖原有的文档内容。
新建文档
使用 _create 方法新建文档,如果文档已经存在则返回错误:
PUT /my_index/_create/1
{
"a": 1
}如果尝试新建已存在的文档,将会出现如下错误:
{
"error": {
"root_cause": [
{
"type": "version_conflict_engine_exception",
"reason": "[1]: version conflict, document already exists (current version [1])",
"index_uuid": "1xWdHLTaTm6l6HbqACaIEA",
"shard": "0",
"index": "my_index"
}
],
"type": "version_conflict_engine_exception",
"reason": "[1]: version conflict, document already exists (current version [1])",
"index_uuid": "1xWdHLTaTm6l6HbqACaIEA",
"shard": "0",
"index": "my_index"
},
"status": 409
}获取文档
通过 ID 获取文档的详细信息:
GET /my_index/_doc/1更新文档
更新文档的特定字段,保留原有字段:
POST /my_index/_update/1
{
"doc": {
"age": 31
}
}删除文档
通过 ID 删除指定的文档:
DELETE /my_index/_doc/1查询所有文档
查询索引中的所有文档:
GET /my_index/_search
{
"query": {
"match_all": {}
}
}这个是 《老杨玩搜索》中总结的图,可以作为“小抄”来记忆:
批量操作 (_bulk API)
_bulk API 用于在一次请求中执行多个索引、删除和更新操作,这对于批量处理大规模数据非常有用,可以显著提高性能和效率。以下是 _bulk API 的基本使用示例:
POST /my_index/_bulk
{ "index": { "_id": "1" } }
{ "name": "John Doe", "age": 30, "occupation": "Engineer" }
{ "index": { "_id": "2" } }
{ "name": "Jane Doe", "age": 25, "occupation": "Designer" }
{ "update": { "_id": "1" } }
{ "doc": { "age": 31 } }
_bulk API 的请求体由多个操作和文档组成。每个操作行包含一个动作描述行和一个可选的源文档行。动作描述行指明了操作的类型(例如,index、create、delete、update)以及操作的元数据。源文档行则包含了实际的数据。
每个操作之间需要用换行符分隔,并且请求体最后必须以换行符结尾。
POST /_bulk
{ "index": { "_index": "a", "_id": "1" } }
{ "name": "John Doe", "age": 30, "occupation": "Engineer" }
{ "index": { "_index": "b", "_id": "2" } }
{ "name": "Jane Doe", "age": 25, "occupation": "Designer" }
{ "update": { "_index": "a", "_id": "1" } }
{ "doc": { "age": 31 } }
分词器
在 Easysearch 中,分词器(Analyzer)用于将文本分解为词项(terms),是全文搜索和文本分析的基础。分词器通常由字符过滤器(Character Filters)、分词器(Tokenizer)和词项过滤器(Token Filters)组成。以下是关于分词器的详细介绍:
1.字符过滤器(Character Filters):在分词之前对文本进行预处理。例如,去除 HTML 标签,替换字符等。
2.分词器(Tokenizer):将文本分解为词项(tokens)。这是分词过程的核心。
3.词项过滤器(Token Filters):对词项进行处理,如小写化、去除停用词、词干提取等。
只有 text 字段支持全文检索,返回的结果根据相似度打分,我们一起看下
POST /index/_mapping
{
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}.POST /index/_mapping
- 这个部分表示要向名为
index的索引添加或更新映射设置。
2.“properties”
properties定义了索引中文档的字段结构。在这个例子中,定义了一个名为content的字段。
3.“content”
- 定义了名为
content的字段。
4.“type”: “text”
type 字段指定 content 字段的数据类型为 text。text 类型适用于需要分词和全文搜索的字段。
5.“analyzer”: “ik_max_word”
analyzer 字段指定索引时使用的分词器为ik_max_word。ik_max_word 是 IK 分词器中的一种,它会尽可能多地将文本分解为更多的词项。
6.“search_analyzer”: “ik_smart”
search_analyzer 字段指定搜索时使用的分词器为ik_smart。ik_smart 是 IK 分词器中的另一种,它会更智能地进行分词,以提高搜索的准确性。
当然,在设置这个 mapping 的时候可以使用同样的分词器,也可以使用不同的分词器。这里介绍下 IK 分词器:
- IK 分词器是一种中文分词器,适用于中文文本的分词。IK 分词器有两种分词模式:
ik_max_word和ik_smart。ik_max_word:将文本尽可能多地切分成词项,适用于需要更高召回率的场景。ik_smart:进行最智能的分词,适用于需要更高精度的搜索场景。
这个 DSL 的设置意味着,在向这个索引添加或更新文档时,content 字段的文本会使用ik_max_word 分词器进行分词处理,以确保文本被尽可能多地切分成词项。而在搜索时,content 字段的文本会使用ik_smart 分词器进行分词处理,以提高搜索的准确性和相关性。
以下是关于 standard,ik_smart,ik_max_word 这几个分词器的对比:
GET /_analyze
{
"tokenizer": "standard",
"text": "我,机器人"
}
GET /_analyze
{
"tokenizer": "ik_smart",
"text": "我,机器人"
}
GET /_analyze
{
"tokenizer": "ik_max_word",
"text": "我,机器人"
}结果如下:
# GET /_analyze (standard)
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "机",
"start_offset": 2,
"end_offset": 3,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "器",
"start_offset": 3,
"end_offset": 4,
"type": "<IDEOGRAPHIC>",
"position": 2
},
{
"token": "人",
"start_offset": 4,
"end_offset": 5,
"type": "<IDEOGRAPHIC>",
"position": 3
}
]
}
# GET /_analyze(ik_smart)
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "机器人",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 1
}
]
}
# GET /_analyze (ik_max_word)
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "机器人",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 1
},
{
"token": "机器",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 2
},
{
"token": "人",
"start_offset": 4,
"end_offset": 5,
"type": "CN_CHAR",
"position": 3
}
]
}
如果使用了不存在的分词器会出现这个错误。
{
"error": {
"root_cause": [
{
"type": "illegal_argument_exception",
"reason": "failed to find global tokenizer under [simple]"
}
],
"type": "illegal_argument_exception",
"reason": "failed to find global tokenizer under [simple]"
},
"status": 400
}精确搜索/正则表达式搜索/通配符
在 Easysearch 中,精确搜索、正则表达式搜索和通配符搜索是三种不同的搜索方式,各有其应用场景和特点:
1.精确搜索 (Term Query):
- 精确搜索用于查找与搜索词完全匹配的文档。
- 不进行分词处理,通常用于关键字、ID、标签等字段的精确匹配。
- 适用于结构化数据或不需要分词的字段(如数字、日期、布尔值等)。
{
"query": {
"term": {
"status": "active"
}
}
}2.正则表达式搜索 (Regexp Query):
- 正则表达式搜索用于基于正则表达式模式匹配的文档搜索。
- 支持复杂的字符串匹配模式,但性能可能较低,特别是当数据量较大时。
- 适用于需要灵活且复杂匹配条件的搜索。
{
"query": {
"regexp": {
"content": "Easysearch .*powerful"
}
}
}3.通配符搜索 (Wildcard Query):
- 通配符搜索用于通过通配符模式匹配文档。
- 支持 ?(匹配单个字符)和 *(匹配零个或多个字符)。
- 性能相对较差,因为通配符搜索可能需要扫描大量数据。
{
"query": {
"wildcard": {
"username": "john*"
}
}
}- 精确搜索:用于需要绝对匹配特定词语或不需要分词的字段。例如,查找特定用户 ID 或状态。
- 正则表达式搜索:用于需要复杂字符串模式匹配的场景,但要谨慎使用,避免性能问题。
- 通配符搜索:用于简单模式匹配,但同样需要注意性能影响,尽量避免在大数据集上频繁使用。
接下来看这个例子,我们将使用批量导入数据,然后进行几种不同类型的查询,包括精确查询、通配符查询和正则表达式查询。
POST /users/_bulk
{ "index": { "_index": "users", "_id": 1 }}
{ "username": "john_doe", "status": "active", "email": "john.doe@example.com", "bio": "John loves Easysearch and open-source technologies." }
{ "index": { "_index": "users", "_id": 2 }}
{ "username": "jane_doe", "status": "inactive", "email": "jane.doe@example.com", "bio": "Jane is a data scientist working with big data." }
{ "index": { "_index": "users", "_id": 3 }}
{ "username": "john_smith", "status": "active", "email": "john.smith@example.com", "bio": "John enjoys hiking and nature." }
{ "index": { "_index": "users", "_id": 4 }}
{ "username": "alice_jones", "status": "active", "email": "alice.jones@example.com", "bio": "Alice is a software engineer specialized in JavaScript." }
{ "index": { "_index": "users", "_id": 5 }}
{ "username": "bob_jones", "status": "inactive", "email": "bob.jones@example.com", "bio": "Bob is an AI enthusiast and machine learning expert." }1.精确查询:查询状态为 “active” 的用户。
GET /users/_search
{
"query": {
"term": {
"status": "active"
}
}
}2.通配符查询:查询 bio 字段中包含 “John” 开头的词。
GET /users/_search
{
"query": {
"wildcard": {
"bio": "John*"
}
}
}3.正则表达式查询:查询用户名以 “john” 开头的用户
GET /users/_search
{
"query": {
"regexp": {
"username": "john.*"
}
}
}通过这些例子,你可以看到如何在 Easysearch 中使用批量导入数据,然后使用各种查询方法来检索特定条件的数据。这些查询方法可以帮助你高效地搜索和分析数据,以满足不同的业务需求。
这里同样是《老杨玩搜索》中总结的“小抄”来方便记忆:
多字段查询
在 Easysearch 中,多字段查询允许您在多个字段上同时执行搜索,以获取更精确的结果。最常用的多字段查询类型是 multi_match 查询。multi_match 查询是 match 查询的扩展,能够在多个字段中搜索指定的关键词。
multi_match 查询支持多种匹配模式,如 best_fields、most_fields、cross_fields、phrase 和 phrase_prefix。以下是各模式的简要介绍:
- best_fields:默认模式,选择匹配度最高的字段。
- most_fields:计算每个字段的匹配度,然后将匹配度相加。
- cross_fields:将多个字段视为一个字段进行匹配,适用于分析文本被分散到多个字段的情况。
- phrase:短语匹配,确保词项顺序与查询相同。
- phrase_prefix:短语前缀匹配,允许词项的部分匹配。
我们先导入一些示例数据到一个索引 documents 中:
POST /documents/_bulk
{ "index": { "_id": 1 } }
{ "title": "Easysearch Guide", "content": "This is an introductory guide to Easysearch ." }
{ "index": { "_id": 2 } }
{ "title": "Advanced Easysearch ", "content": "This guide covers advanced topics in Easysearch ." }
{ "index": { "_id": 3 } }
{ "title": "Easysearch in Action", "content": "Practical guide to Easysearch usage." }
{ "index": { "_id": 4 } }
{ "title": "Learning Easysearch ", "content": "Beginner's guide to learning Easysearch ." }我们将使用 multi_match 查询在 title 和 content 字段中同时搜索关键词。
1.基本 multi_match 查询:
POST /documents/_search
{
"query": {
"multi_match": {
"query": "guide",
"fields": ["title", "content"]
}
}
}2.指定匹配模式为 best_fields:
POST /documents/_search
{
"query": {
"multi_match": {
"query": "guide",
"fields": ["title", "content"],
"type": "best_fields"
}
}
}3.指定匹配模式为 most_fields:
POST /documents/_search
{
"query": {
"multi_match": {
"query": "guide",
"fields": ["title", "content"],
"type": "most_fields"
}
}
}4.使用 cross_fields 模式:
POST /documents/_search
{
"query": {
"multi_match": {
"query": "Easysearch guide",
"fields": ["title", "content"],
"type": "cross_fields"
}
}
}5.短语匹配 (phrase):
POST /documents/_search
{
"query": {
"multi_match": {
"query": "introductory guide",
"fields": ["title", "content"],
"type": "phrase"
}
}
}6.短语前缀匹配 (phrase_prefix):
POST /documents/_search
{
"query": {
"multi_match": {
"query": "introductory gui",
"fields": ["title", "content"],
"type": "phrase_prefix"
}
}
}- query:要搜索的关键词或短语。
- fields:要搜索的字段列表,可以包含一个或多个字段。
- type:指定匹配模式,默认为 best_fields。
使用 multi_match 查询,您可以在多个字段上同时执行搜索,获得更精确和全面的结果。通过指定不同的匹配模式,您可以调整查询行为以满足特定的搜索需求。无论是基本关键词匹配、短语匹配还是跨字段匹配,multi_match 查询都提供了强大的功能来处理复杂的搜索场景。
除此之外,还可以使用 boost 参数用于调整特定字段的权重,从而影响搜索结果的相关性评分。multi_match 查询支持为不同字段设置不同的 boost 值,以便在搜索结果中优先显示某些字段的匹配项。
布尔查询
布尔查询是 Easysearch 中非常强大且灵活的一种查询方式,它允许用户通过组合多个查询条件来实现复杂的搜索需求。布尔查询使用 bool 查询类型,可以包含以下几种子句:must、filter、must_not 和 should。每种子句都有其特定的用途和语义。
1.must:
- 包含在
must数组中的查询条件必须匹配,类似于逻辑上的 AND 操作。 - 如果有多个条件,所有条件都必须满足,文档才会被包含在结果集中。
2.filter:
- 包含在
filter数组中的查询条件必须匹配,但它不会影响评分。 filter子句通常用于对性能要求较高的过滤操作,因为它不计算相关性评分。
3.must_not:
- 包含在
must_not数组中的查询条件必须不匹配,类似于逻辑上的 NOT 操作。 - 如果有任何一个条件匹配,文档就会被排除在结果集之外。
4.should:
- 包含在
should数组中的查询条件至少匹配一个。 - 如果布尔查询中没有
must子句,则至少要匹配一个should子句。 should子句在计算相关性评分时也有影响。
5.minimum_should_match:
- 指定
should子句中至少需要满足的条件数量。
首先,我们需要创建一个名为 books 的索引,并定义它的映射(mappings)。映射用于指定每个字段的数据类型。在这个例子中,类别和书名字段都被定义为 keyword 类型,这是因为我们需要进行精确匹配查询。
PUT /books
{
"mappings": {
"properties": {
"类别": { "type": "keyword" },
"书名": { "type": "keyword" }
}
}
}接下来,我们使用批量操作(bulk API)将一些示例数据导入到 books 索引中。这些数据包括不同类别的书籍。
POST /books/_bulk
{ "index": { "_id": 1 } }
{ "类别": "文学", "书名": "我的阿勒泰" }
{ "index": { "_id": 2 } }
{ "类别": "文学", "书名": "平凡的世界" }
{ "index": { "_id": 3 } }
{ "类别": "科学", "书名": "时间简史" }
{ "index": { "_id": 4 } }
{ "类别": "文学", "书名": "百年孤独" }
{ "index": { "_id": 5 } }
{ "类别": "文学", "书名": "红楼梦" }现在,我们使用布尔查询来搜索类别为“文学”并且书名为“我的阿勒泰”的文档。这里使用的是 must子句,表示查询结果必须满足所有条件。
POST /books/_search
{
"query": {
"bool": {
"must": [
{ "term": { "类别": "文学" } },
{ "term": { "书名": "我的阿勒泰" } }
]
}
}
}我们还可以使用 filter 子句来执行相同的查询。filter 子句用于过滤文档,且不会影响文档的相关性评分。这在不需要计算相关性评分时可以提高查询性能。
POST /books/_search
{
"query": {
"bool": {
"filter": [
{ "term": { "类别": "文学" } },
{ "term": { "书名": "我的阿勒泰" } }
]
}
}
}当我们执行上述查询时,期望返回的结果是 books 索引中类别为“文学”且书名为“我的阿勒泰”的文档。无论是使用 must 还是 filter 子句,结果应该都是:
{
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"hits": [
{
"_index": "books",
"_id": "1",
"_source": {
"类别": "文学",
"书名": "我的阿勒泰"
}
}
]
}
}
POST /_search
{
"query": {
"bool": {
"must": [
{ "term": { "user.id": "kimchy" } }
],
"filter": [
{ "term": { "tags": "production" } }
],
"must_not": [
{
"range": {
"age": { "gte": 10, "lte": 20 }
}
}
],
"should": [
{ "term": { "tags": "env1" } },
{ "term": { "tags": "deployed" } }
],
"minimum_should_match": 1,
"boost": 1.0
}
}
}must子句:必须匹配的条件,文档必须包含user.id为kimchy。filter子句:过滤条件,文档必须包含tags为production,但不会影响评分。must_not子句:不匹配的条件,文档的age字段不能在 10 到 20 之间。should子句:可选匹配条件,至少需要匹配一个should子句中的条件。这里要求tags字段匹配env1或deployed。minimum_should_match:至少需要匹配一个 should 子句中的条件。boost:提升查询的整体评分。
为了展示这个 DSL ,我们需要创建一个索引并导入一些数据。假设我们要在 Easysearch 中创建一个索引 users ,并插入一些测试数据。
创建索引
PUT /users
{
"mappings": {
"properties": {
"user.id": { "type": "keyword" },
"tags": { "type": "keyword" },
"age": { "type": "integer" }
}
}
}批量导入数据
POST /users/_bulk
{ "index": { "_id": 1 } }
{ "user.id": "kimchy", "tags": ["production", "env1"], "age": 25 }
{ "index": { "_id": 2 } }
{ "user.id": "kimchy", "tags": ["production"], "age": 15 }
{ "index": { "_id": 3 } }
{ "user.id": "kimchy", "tags": ["deployed"], "age": 30 }
{ "index": { "_id": 4 } }
{ "user.id": "kimchy", "tags": ["test"], "age": 35 }
{ "index": { "_id": 5 } }
{ "user.id": "other", "tags": ["production"], "age": 25 }接下来执行布尔查询:
POST /users/_search
{
"query": {
"bool": {
"must": [
{ "term": { "user.id": "kimchy" } }
],
"filter": [
{ "term": { "tags": "production" } }
],
"must_not": [
{
"range": {
"age": { "gte": 10, "lte": 20 }
}
}
],
"should": [
{ "term": { "tags": "env1" } },
{ "term": { "tags": "deployed" } }
],
"minimum_should_match": 1,
"boost": 1.0
}
}
}根据以上查询,预期返回的结果应该符合以下条件:
user.id必须是kimchy(由must子句决定)。tags必须包含production(由filter子句决定)。age字段不在 10 到 20 之间(由must_not子句决定)。tags字段中至少包含env1或deployed中的一个(由should子句和minimum_should_match参数决定)。
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.3769134,
"hits": [
{
"_index": "users",
"_type": "_doc",
"_id": "1",
"_score": 1.3769134,
"_source": {
"user.id": "kimchy",
"tags": ["production", "env1"],
"age": 25
}
}
]
}
}SQL 搜索
Easysearch 直接支持 SQL 查询,无需额外安装插件,同时兼容 Elasticsearch 的 SQL 调用方式,还可以直接编写原生 SQL 查询。
以下是一些测试 SQL 语句的示例:
SELECT * FROM my_index;
SELECT * FROM my_index LIMIT 2;
SELECT * FROM my_index ORDER BY name;
SELECT name AS full_name, age FROM my_index WHERE age > 25;
SELECT name AS full_name, age FROM my_index WHERE age = 25;
SELECT * FROM my_index WHERE age IS NULL;
SELECT DISTINCT age FROM my_index;
SELECT MIN(age), MAX(age), AVG(age) FROM my_index;
SELECT age, COUNT(*) AS CNT FROM my_index GROUP BY age;
使用 Easysearch 执行 SQL 查询
Easysearch 提供了对直接使用 SQL 查询的支持。以下是如何在 Easysearch 中通过 POST 请求使用 _sql 端点进行查询的示例:
执行 SQL 查询非常简单,只需通过 POST 请求发送 SQL 查询即可。以下是一个示例:
POST /_sql
{
"query": "SELECT name AS full_name, age FROM my_index WHERE age > 25"
}你也可以规定返回 JSON 格式:
POST /_sql?format=json
{
"query": "SELECT name AS full_name, age FROM my_index WHERE age > 25"
}和 Elasticsearch 一样,Easysearch 允许你通过 POST 请求直接在集群上运行 SQL 查询,并返回查询结果。以下是一些常见的 SQL 查询示例及其对应的 POST 请求:
1.查询所有文档:
POST /_sql
{
"query": "SELECT * FROM my_index"
}2.限制返回文档数:
POST /_sql
{
"query": "SELECT * FROM my_index LIMIT 2"
}3.按字段排序:
POST /_sql
{
"query": "SELECT * FROM my_index ORDER BY name"
}4.筛选条件查询:
POST /_sql
{
"query": "SELECT name AS full_name, age FROM my_index WHERE age > 25"
}5.精确值查询:
POST /_sql
{
"query": "SELECT name AS full_name, age FROM my_index WHERE age = 25"
}6.查询空值:
POST /_sql
{
"query": "SELECT * FROM my_index WHERE age IS NULL"
}7.查询唯一值:
POST /_sql
{
"query": "SELECT DISTINCT age FROM my_index"
}8.聚合函数查询:
POST /_sql
{
"query": "SELECT MIN(age), MAX(age), AVG(age) FROM my_index"
}9.分组统计:
POST /_sql
{
"query": "SELECT age, COUNT(*) AS CNT FROM my_index GROUP BY age"
}
多表操作的 SQL 语句
以下是多表操作的 SQL 语句及其解释:
1.子查询:
SELECT * FROM `table1` t1 WHERE t1.id IN (SELECT id FROM `table2`)这个查询从 table1 中选择所有字段的记录,其中这些记录的 id 在 table2 表中也存在。
2.内连接:
SELECT * FROM `table1` t1 JOIN `table2` t2 ON t1.id = t2.id这个查询进行内连接,从 table1 和 table2 中选择所有字段的记录,前提是 table1 和 table2 中 id 相等。
3.左连接:
SELECT * FROM `table1` t1 LEFT JOIN `table2` t2 ON t1.id = t2.id这个查询进行左连接,从 table1 和 table2 中选择所有字段的记录,即使 table2 中没有匹配的记录,也会返回 table1 中的所有记录,未匹配到的部分会用 NULL 填充。
4.右连接:
SELECT * FROM `table1` t1 RIGHT JOIN `table2` t2 ON t1.id = t2.id这个查询进行右连接,从 table1 和 table2 中选择所有字段的记录,即使 table1 中没有匹配的记录,也会返回 table2 中的所有记录,未匹配到的部分会用 NULL 填充。
假设我们有两个索引 table1 和 table2,对应于 SQL 中的两个表。
创建索引 table1:
PUT /`table1`
{
"mappings": {
"properties": {
"id": { "type": "integer" },
"name": { "type": "text" }
}
}
}创建索引 table2:
PUT /`table2`
{
"mappings": {
"properties": {
"id": { "type": "integer" },
"value": { "type": "text" }
}
}
}导入数据到 table1:
POST /`table1`/_bulk
{ "index": { "_id": 1 } }
{ "id": 1, "name": "Alice" }
{ "index": { "_id": 2 } }
{ "id": 2, "name": "Bob" }
{ "index": { "_id": 3 } }
{ "id": 3, "name": "Charlie" }
{ "index": { "_id": 4 } }
{ "id": 4, "name": "David" }导入数据到 table2:
POST /`table2`/_bulk
{ "index": { "_id": 1 } }
{ "id": 1, "value": "Value1" }
{ "index": { "_id": 2 } }
{ "id": 2, "value": "Value2" }
{ "index": { "_id": 5 } }
{ "id": 5, "value": "Value5" }
{ "index": { "_id": 6 } }
{ "id": 6, "value": "Value6" }导入数据后,可以使用 SQL 来执行这些查询:
1.子查询:
POST /_sql
{
"query": "SELECT * FROM `table1` WHERE id IN (SELECT id FROM `table2`)"
}2.内连接:
POST /_sql
{
"query": "SELECT * FROM `table1` t1 JOIN `table2` t2 ON t1.id = t2.id"
}3.左连接:
POST /_sql
{
"query": "SELECT * FROM `table1` t1 LEFT JOIN `table2` t2 ON t1.id = t2.id"
}4.右连接:
POST /_sql
{
"query": "SELECT * FROM `table1` t1 RIGHT JOIN `table2` t2 ON t1.id = t2.id"
}效果如下:
SQL 全文检索
match 和 match_phrase 是 Easysearch 中用于全文搜索的查询类型,它们在处理文本匹配方面有不同的用途:
1.match 查询:
match查询用于对文档进行全文搜索。- 它将搜索关键词进行分词,并对这些分词后的词项进行搜索。
- 适用于查询单个或多个字段,可以进行布尔操作(如 “AND”, “OR”)。
- 例如,搜索 “Easysearch is powerful” 会被分词为 "Easysearch ", “is”, “powerful” 三个词,然后对这三个词进行搜索,文档中包含这些词的都会被认为是匹配的。
{
"query": {
"match": {
"content": "Easysearch is powerful"
}
}
}2.match_phrase 查询:
match_phrase查询用于短语搜索。- 它要求搜索的短语必须在文档中出现且词的顺序相同,词之间的间隔也必须与查询中的短语相同。
- 适用于需要精确匹配短语的场景。
- 例如,搜索 “Easysearch is powerful” 时,只有包含这个确切短语的文档才会被认为是匹配的。
{
"query": {
"match_phrase": {
"content": "Easysearch is powerful"
}
}
}总结来说,match 更灵活,用于一般的关键词搜索,而 match_phrase 则用于需要精确匹配短语的搜索。
SQL 全文检索示例
我们先造一些数据,然后使用 SQL 来进行全文检索。
批量导入数据:
POST /table3/_bulk
{ "index": { "_id": 1 } }
{ "id": 1, "test": "The quick brown fox jumps over the lazy dog" }
{ "index": { "_id": 2 } }
{ "id": 2, "test": "Foxes are wild animals" }
{ "index": { "_id": 3 } }
{ "id": 3, "test": "Jump high to catch the ball" }
{ "index": { "_id": 4 } }
{ "id": 4, "test": "Some animals can jump very high" }
{ "index": { "_id": 5 } }
{ "id": 5, "test": "The lazy dog sleeps all day" }
{ "index": { "_id": 6 } }
{ "id": 6, "test": "The foxes jump all day" }执行全文检索的 SQL 查询:
SELECT * FROM table3;
SELECT * FROM table3 WHERE match(test, 'jump');
SELECT * FROM table3 WHERE match_phrase(test, 'foxes jump');
总结
随着数据量的不断增加,高效的数据搜索和分析变得尤为重要。Elasticsearch 以其强大的全文搜索能力和灵活的数据处理能力成为行业标准。Easysearch 作为 Elasticsearch 的优化版本,不仅继承了其强大的功能,还在性能和安全性上做了进一步的提升,为企业提供了一个高效、稳定且易于迁移的搜索引擎解决方案。通过深入了解这些技术和实践其应用,开发者和企业能够更好地利用这些工具来应对现代数据挑战,推动业务的持续发展和创新。
关于 Easysearch 有奖征文活动
无论你是 Easysearch 的老用户,还是第一次听说这个名字,只要你对 INFINI Labs 旗下的 Easysearch 产品感兴趣,或者是希望了解 Easysearch,都可以参加这次活动。
详情查看:Easysearch 征文活动
收起阅读 »作者:韩旭,亚马逊云技术支持,亚马逊云科技技领云博主,目前专注于云计算开发和大数据领域。
原文:https://infinilabs.cn/blog/2024/mastering-easysearch-syntax/
【搜索客社区日报】第1857期 (2024-07-11)
https://mp.weixin.qq.com/s/oKf_GyKUXoSnRwrkgbyLgQ
2.跟踪 Linux:文件完整性监控用例
https://www.elastic.co/blog/tr ... -case
3.AI产品榜|2024 年 6 月共 37 个重要榜单,新增出海 APP 增长榜
https://mp.weixin.qq.com/s/fQw3CB_9b0vHjixf6otesw
4.当Kimi悄悄的进军浏览器,他们好像在下一盘很大的棋。
https://mp.weixin.qq.com/s/hrkF1N4yzWfOgb-O2TlZew
5.突破 ES 引擎局限性在用户体验场景中的优化实践
https://mp.weixin.qq.com/s/W7Qyr-f5hOLjGgOA1M9jsw
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/oKf_GyKUXoSnRwrkgbyLgQ
2.跟踪 Linux:文件完整性监控用例
https://www.elastic.co/blog/tr ... -case
3.AI产品榜|2024 年 6 月共 37 个重要榜单,新增出海 APP 增长榜
https://mp.weixin.qq.com/s/fQw3CB_9b0vHjixf6otesw
4.当Kimi悄悄的进军浏览器,他们好像在下一盘很大的棋。
https://mp.weixin.qq.com/s/hrkF1N4yzWfOgb-O2TlZew
5.突破 ES 引擎局限性在用户体验场景中的优化实践
https://mp.weixin.qq.com/s/W7Qyr-f5hOLjGgOA1M9jsw
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
Easysearch 数据可视化和管理平台:INFINI Console 使用介绍

上次在《INFINI Easysearch 尝鲜 Hands on》中,我们部署了两个节点的 Easysearch,并设置了 Console 进行集群监控。今天,我们将介绍 INFINI Console 的使用。
Dashboard
INFINI Console 是一个功能强大的数据管理和分析平台,其仪表盘页面提供了直观简洁的界面,使用户能够快速了解系统状态并进行管理操作。本文将详细介绍仪表盘页面的各项功能。
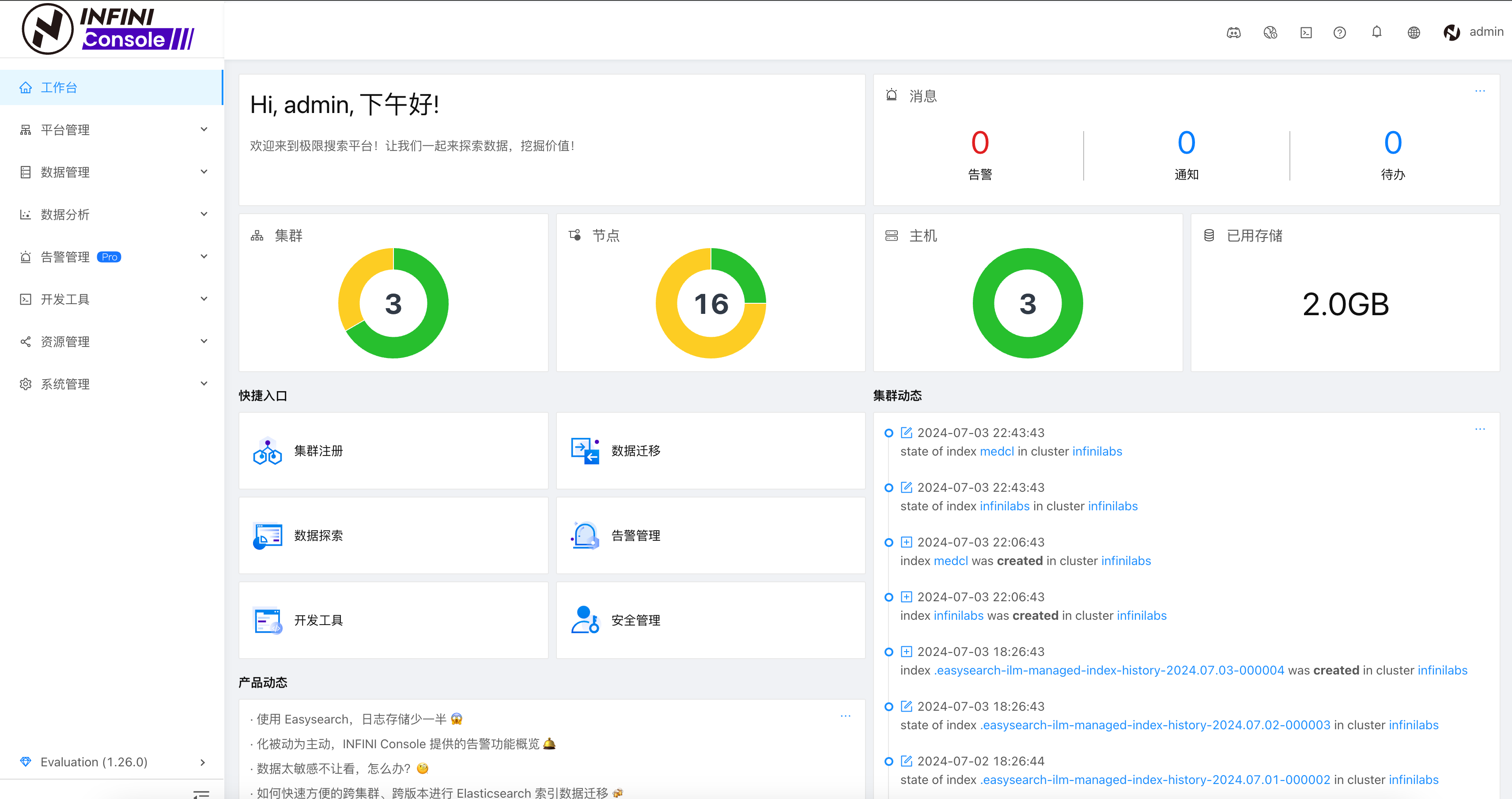
仪表盘顶部显示系统的实时告警、通知和待办事项的数量,当前数据显示:
- 告警:0 条
- 通知:0 条
- 待办:0 条
在仪表盘的中心区域,用户可以看到几项关键的系统概览信息:
- 集群数量:当前有 3 个集群正在运行。
- 节点数量:系统中有 16 个节点。
- 主机数量:共有 3 台主机。
- 已用存储:系统已使用存储空间为 2.0GB。
仪表盘页面还提供了几个常用操作的快速入口,方便用户迅速访问常用功能:
- 集群注册:用户可以通过此入口快速注册新的集群。
- 数据探索:用户可以访问数据探索工具,对系统中的数据进行分析和查询。
- 告警管理:提供对告警信息的管理功能,用户可以查看和处理告警。
- 安全管理:安全管理入口帮助用户维护系统的安全设置和策略。
仪表盘右侧显示了集群的动态信息,包括最近的操作日志。例如:
- 2024-07-03 22:43:43,index medcl 在 cluster infiniLabs 中的状态更新。
- 2024-07-03 22:06:43,index medcl 在 cluster infiniLabs 中被创建。
集群管理页面
集群管理页面主要分为几个部分:顶部的功能选项卡、中部的集群列表、以及右侧的筛选和排序选项。

页面顶部的功能选项卡包括以下几项:
- Clusters (集群):显示当前系统中的所有集群。
- Nodes (节点):显示集群中的节点详细信息。
- Indices (索引):显示集群中的索引信息。
- Hosts (主机):显示系统中的主机信息。
集群列表展示了每个集群的详细信息,包括:
- 集群名称:每个集群的名称,如 “infinilabs”、“mycluster”、“INFINI_SYSTEM (JeanGrey)”。
- 集群健康状态:以颜色条的形式显示最近 14 天的集群健康状态(绿色表示健康,黄色表示有警告)。
- 节点数量:集群中包含的节点数量。
- 索引数量:集群中的索引数量。
- 分片数量:集群中的分片数量。
- 文档数量:集群中存储的文档数量。
- 磁盘使用率:集群的磁盘使用情况。
- JVM 堆内存使用率:集群的 JVM 堆内存使用情况。
- 索引速率:当前集群的索引速率(每秒索引数)。
- 搜索速率:当前集群的搜索速率(每秒搜索数)。
页面右侧提供了丰富的筛选和排序选项,可以根据以下条件筛选和排序集群:
- 健康状态 (Health Status):根据集群的健康状态筛选,如绿色(健康)和黄色(警告)。
- 分布 (Distribution):根据集群的分布类型筛选,如 “easysearch” 和 “elasticsearch”。
- 版本 (Version):根据集群使用的软件版本筛选,如 Easysearch 1.8.2 和 Elasticsearch 7.10.2。
- 区域 (Region):根据集群所在的区域筛选,如 “china” 和 “default”。
- 标签 (Tags):根据自定义标签进行筛选。
接下来分别介绍节点、索引和主机层面的信息,这些监控指标与集群层面大同小异。
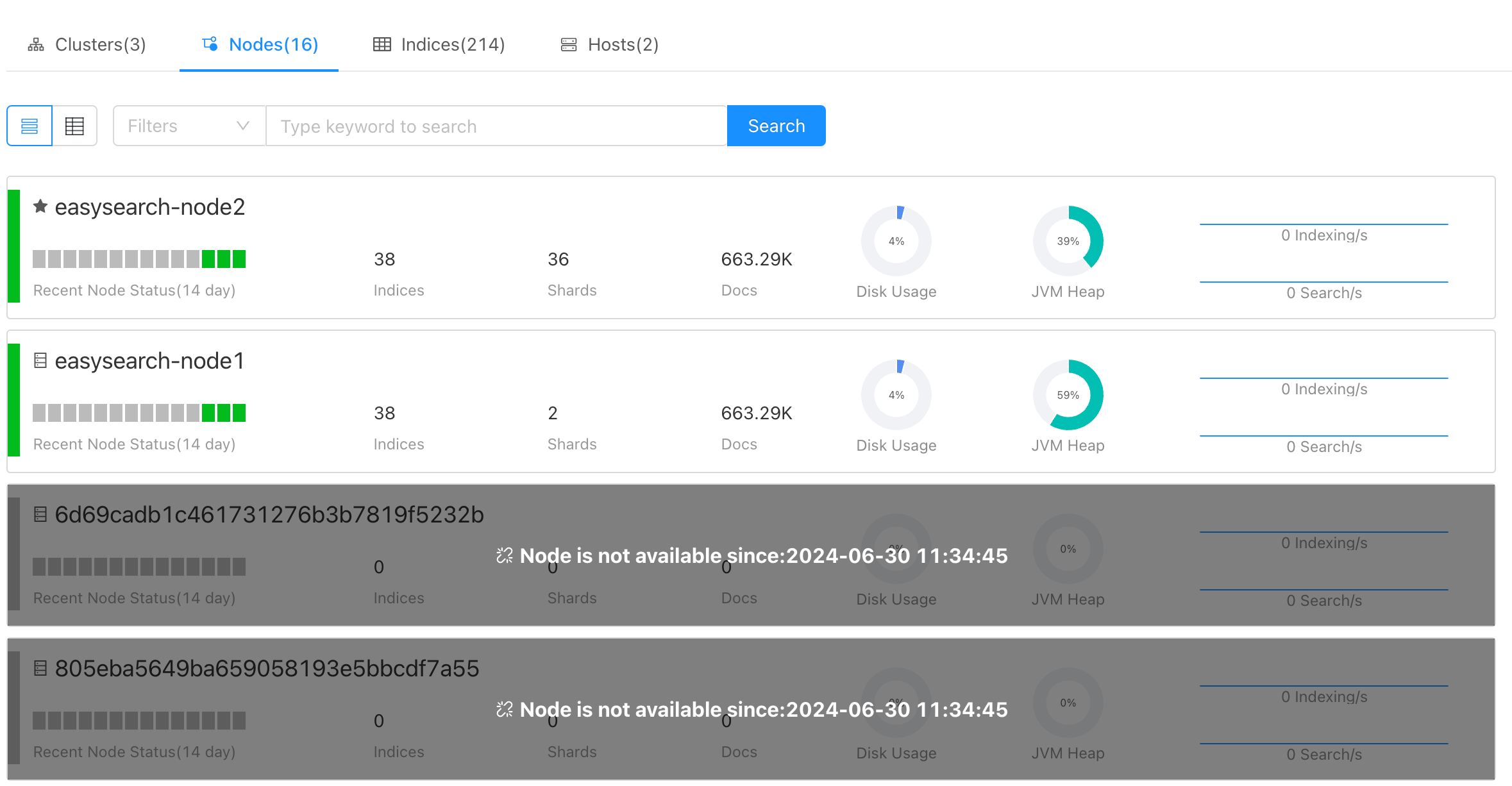
节点监控
索引监控

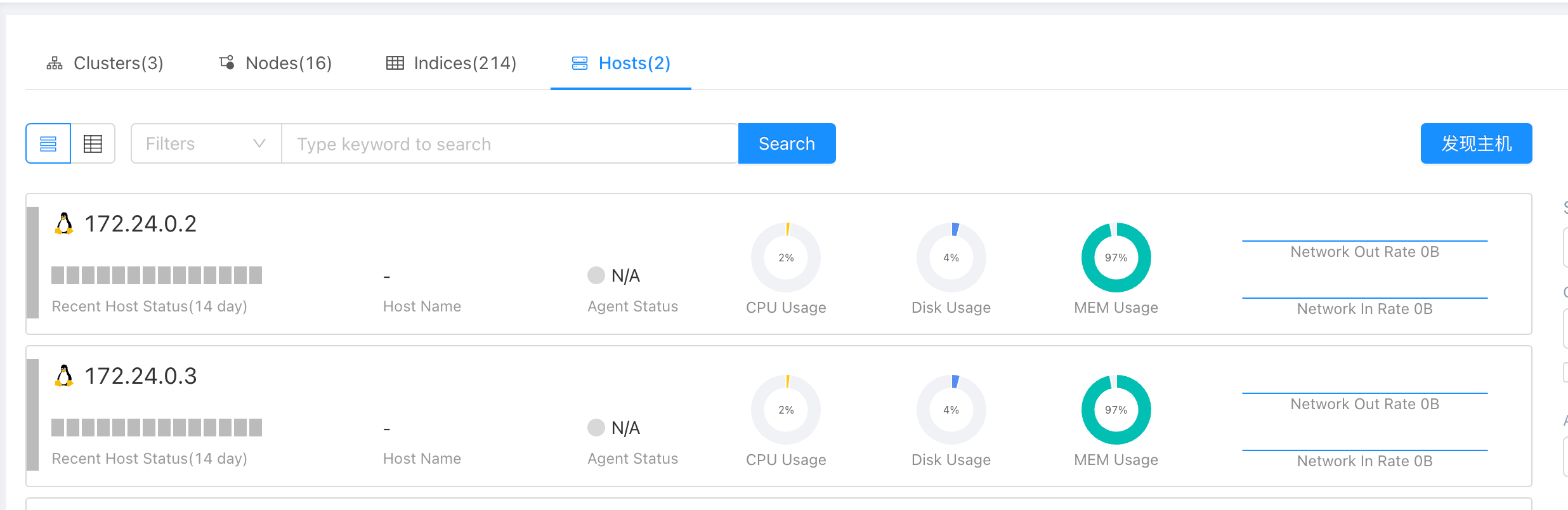
主机监控
包括了常规的 CPU、内存、磁盘、网络的监控。
监控指标页面
监控报表页面提供了对集群运行状况的详细监控和分析功能。用户可以选择最近 15 分钟、1 小时、24 小时等不同时间范围查看数据,并手动点击刷新按钮更新数据,以获取最新的监控信息。
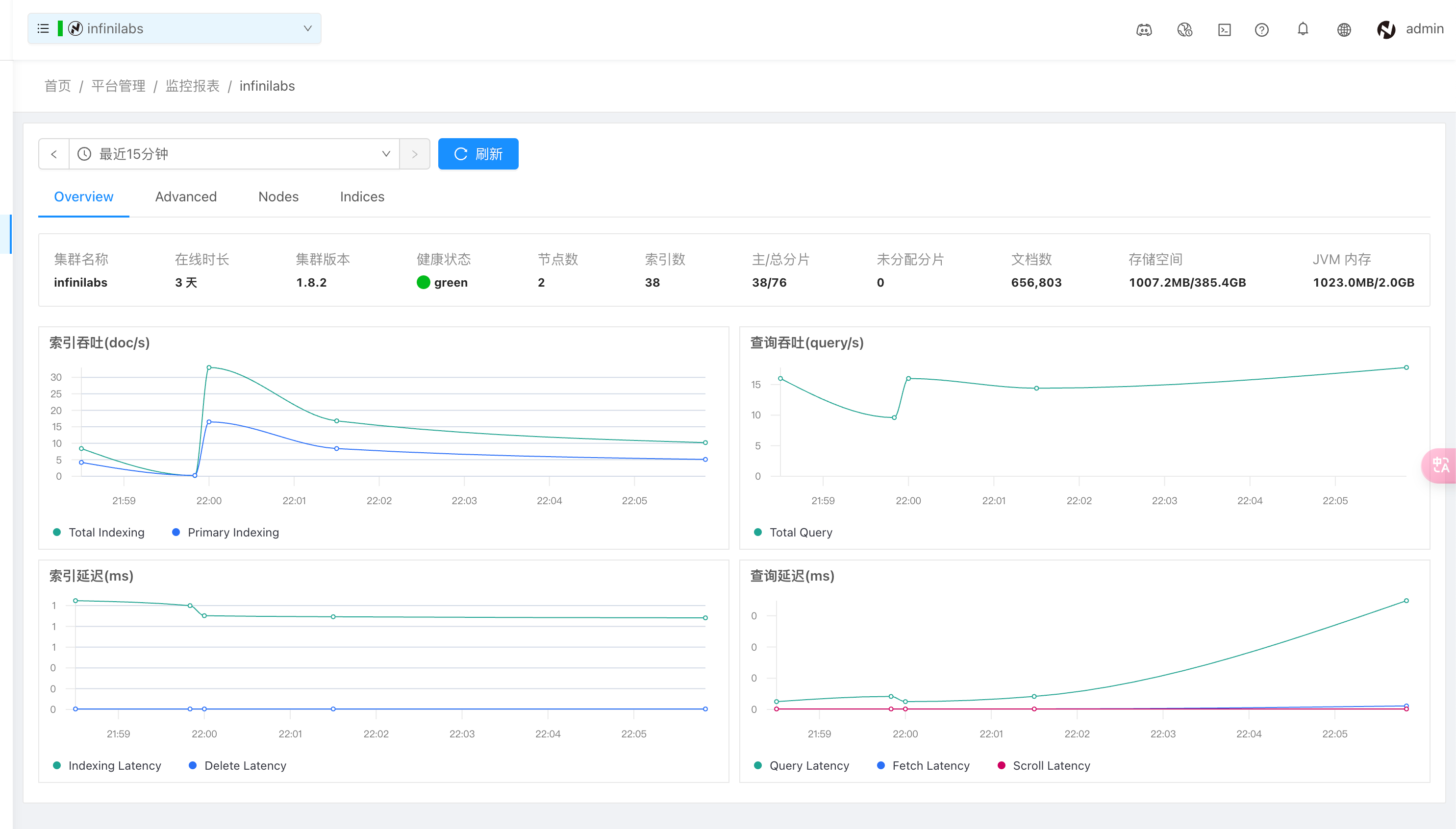
概览信息
显示当前集群的基本状态,包括:
- 集群名称:如 “infinilabs”。
- 在线时长:如 “3 天”。
- 集群版本:如 “1.8.2”。
- 健康状态:如 “green”。
- 节点数:如 “2”。
- 索引数:如 “38”。
- 主/总分片:如 “38/76”。
- 未分配分片:如 “0”。
- 文档数:如 “656,803”。
- 存储空间:如 “1007.2MB/385.4GB”。
- JVM 内存:如 “1023.0MB/2.0GB”。
监控报表页面还提供了多个性能指标的图表,包括:
索引吞吐 (doc/s)
- Total Indexing:总索引吞吐量。
- Primary Indexing:主分片的索引吞吐量。
查询吞吐 (query/s)
- Total Query:总查询吞吐量。
索引延迟 (ms)
- Indexing Latency:索引延迟时间。
- Delete Latency:删除操作的延迟时间。
查询延迟 (ms)
- Query Latency:查询延迟时间。
- Fetch Latency:获取操作的延迟时间。
- Scroll Latency:滚动操作的延迟时间。
点击“Advance”可以查看更多监控指标:
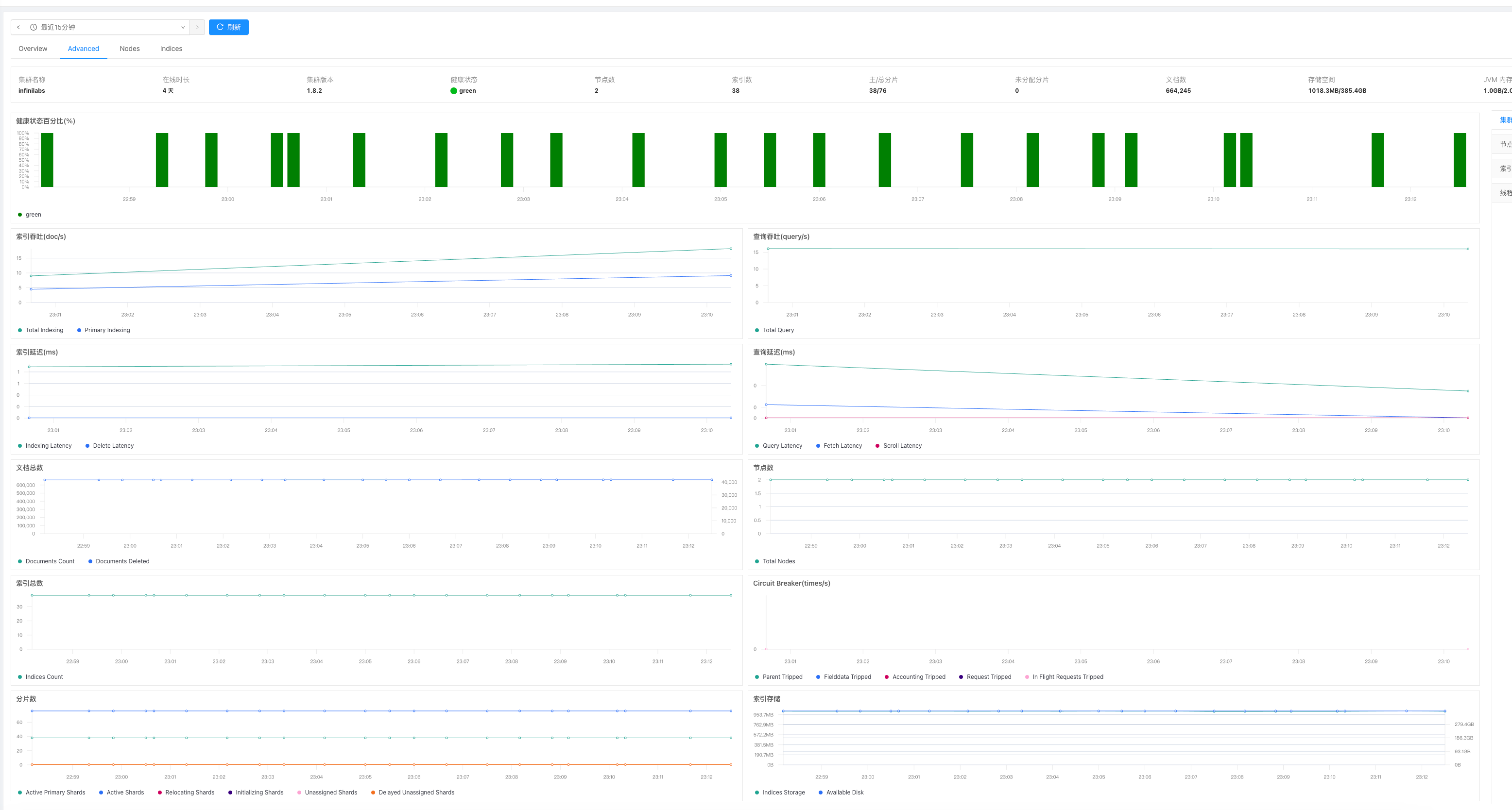
节点级别性能监控
包括 CPU、负载、JVM 内存、剩余使用空间及磁盘空间、集群启动时间和索引读写情况。
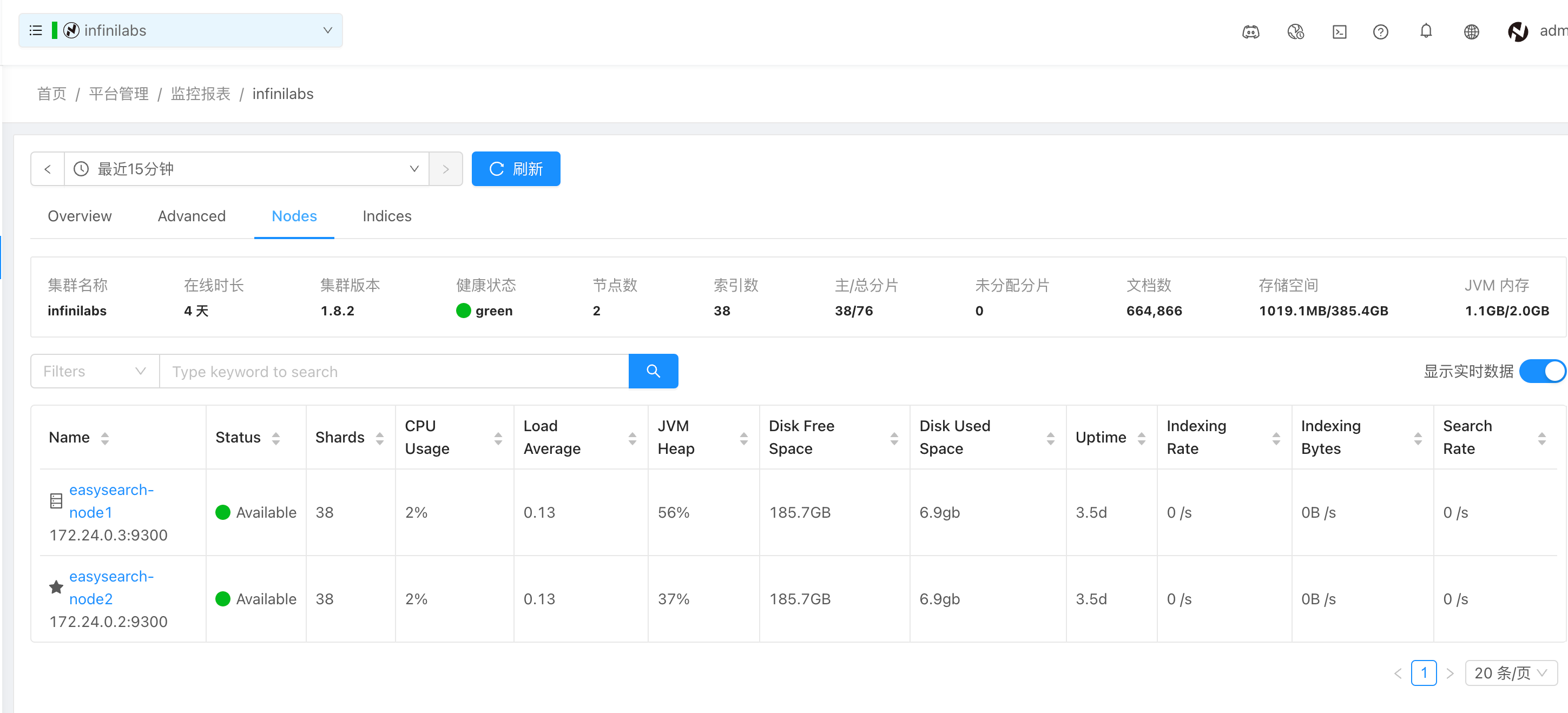
索引级别监控
包括集群内索引的数量、状态、主分片和副本分片数量、文档条数和占用空间。
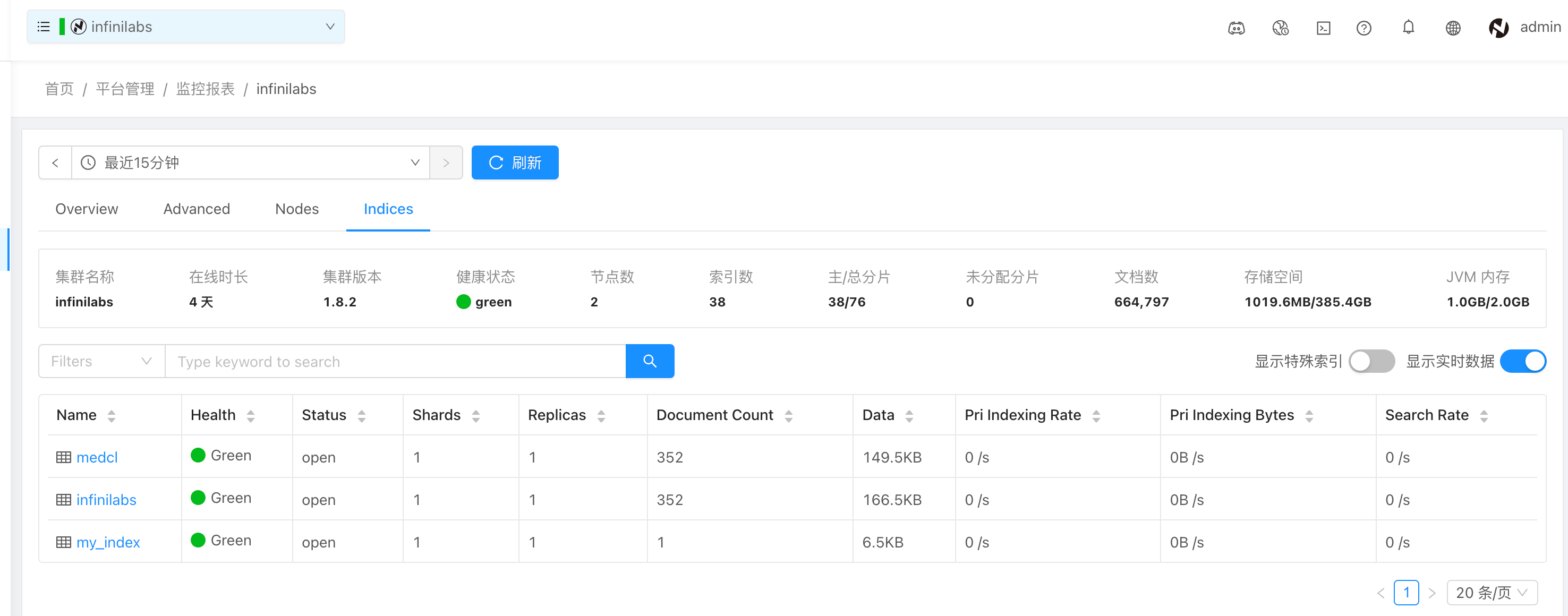
集群动态页面
提供集群中各类事件和活动的详细记录和监控功能。

别名管理
别名管理页面提供了对索引别名的管理功能,使用户可以方便地管理和配置 Elasticsearch/EasySearch 的索引别名。
创建别名
可以通过 DSL 创建别名。例如,创建一个名为 my_index_alias 的别名指向 my_index:
POST /_aliases
{
"actions": [
{
"add": {
"index": "my_index",
"alias": "my_index_alias"
}
}
]
}删除别名
删除一个别名同样可以通过 REST API 实现:
POST /_aliases
{
"actions": [
{
"remove": {
"index": "my_index",
"alias": "my_index_alias"
}
}
]
}索引轮换
索引轮换是一种常用的索引管理策略,特别适用于日志和时间序列数据的场景。通过索引轮换,用户可以在索引达到一定条件(如大小或文档数量)时,创建一个新的索引来继续存储数据,而旧的索引可以继续用于查询。
- 设置写别名:创建一个指向当前写入索引的别名,例如 current_write_index。
- 定义索引轮换条件:可以基于索引的大小、文档数量或时间来定义轮换条件。
- 索引并更新写别名指向这个新索引。
创建初始索引并设置写别名:
PUT /my_index-000001
{
"aliases": {
"current_write_index": {}
}
}使用 /_rollover API 定义轮换条件并执行轮换:
POST /current_write_index/_rollover
{
"conditions": {
"max_age": "7d",
"max_docs": 1000000
},
"settings": {
"number_of_shards": 1
},
"aliases": {
"current_write_index": {}
}
}通过这种方式,查询操作可以透明地访问所有历史数据,而写操作总是指向最新的索引。
在 INFINI Console 中提供了可视化创建索引及别名的方式。页面右上角提供了新建按钮,用户可以通过点击该按钮创建新的索引别名,填写别名名称、关联索引、索引路由、搜索路由和过滤查询等配置。
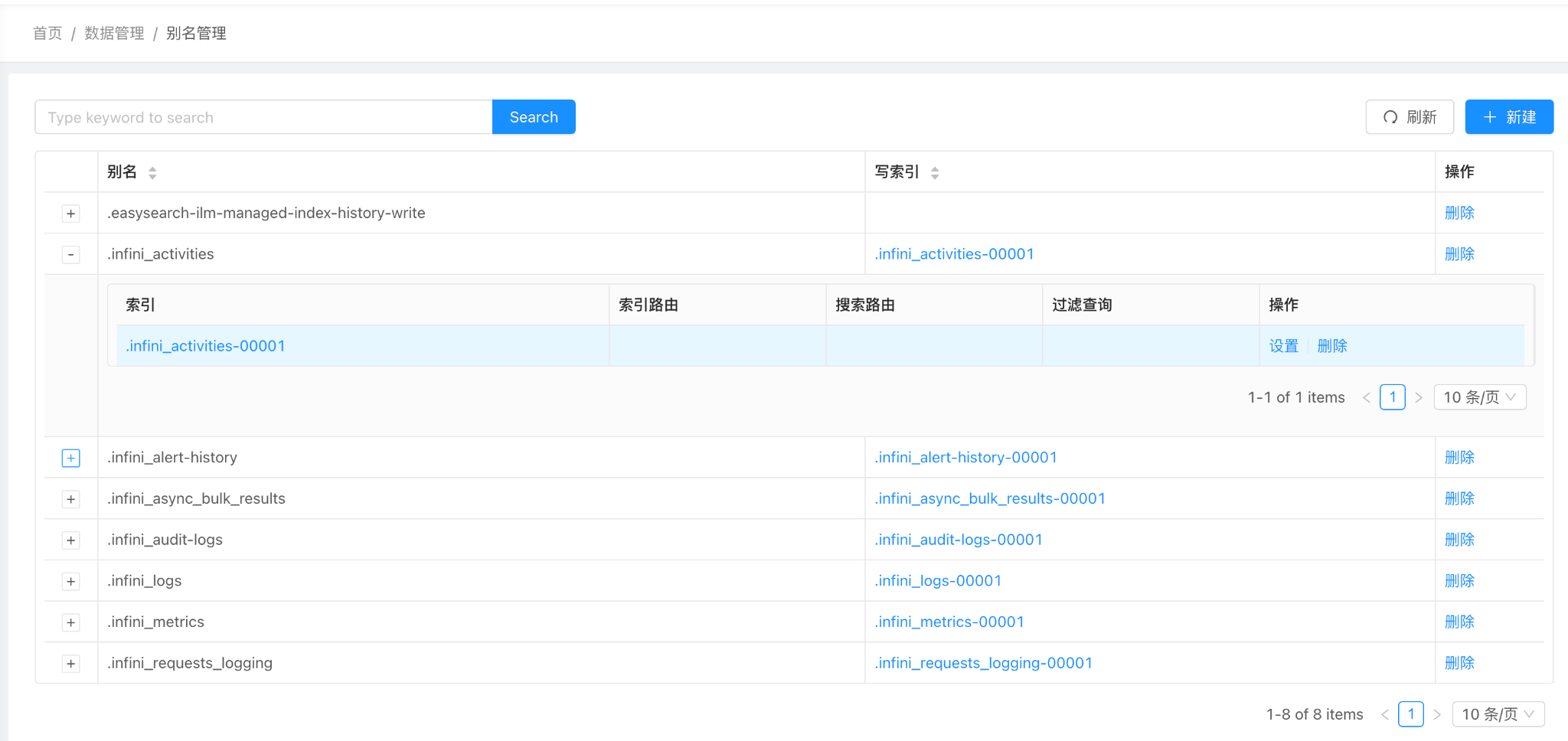
平台监控
展示了多个关键指标的监控图表,包括:
- 健康状态 (Health):显示系统当前的健康状态。如果没有数据,则显示“暂无数据”。
- 引擎分布 (Engines):展示系统中不同搜索引擎的分布情况,例如 EasySearch 和 Elasticsearch 的比例。图表显示当前 EasySearch 占 67%,Elasticsearch 占 33%。
- 提供商 (Providers):显示系统中使用的云服务提供商信息。在示例中,所有资源都托管在 AWS 上。
- JDK 版本 (JDK):显示系统中使用的 JDK 版本信息。在示例中,所有节点都使用 JDK 版本 11.0.20。
- 磁盘使用情况 (Disk Utilization) - Top 10:显示磁盘使用率最高的前 10 个节点。在示例中,easysearch-node1 和 easysearch-node2 的磁盘使用率均为 4%。
- JVM 使用情况 (JVM Utilization) - Top 10:展示 JVM 使用率最高的前 10 个节点。在示例中,infinilabs 集群的 easysearch-node1 和 easysearch-node2 节点的 JVM 使用情况有详细的时间序列数据,显示了不同时间点的使用率变化。
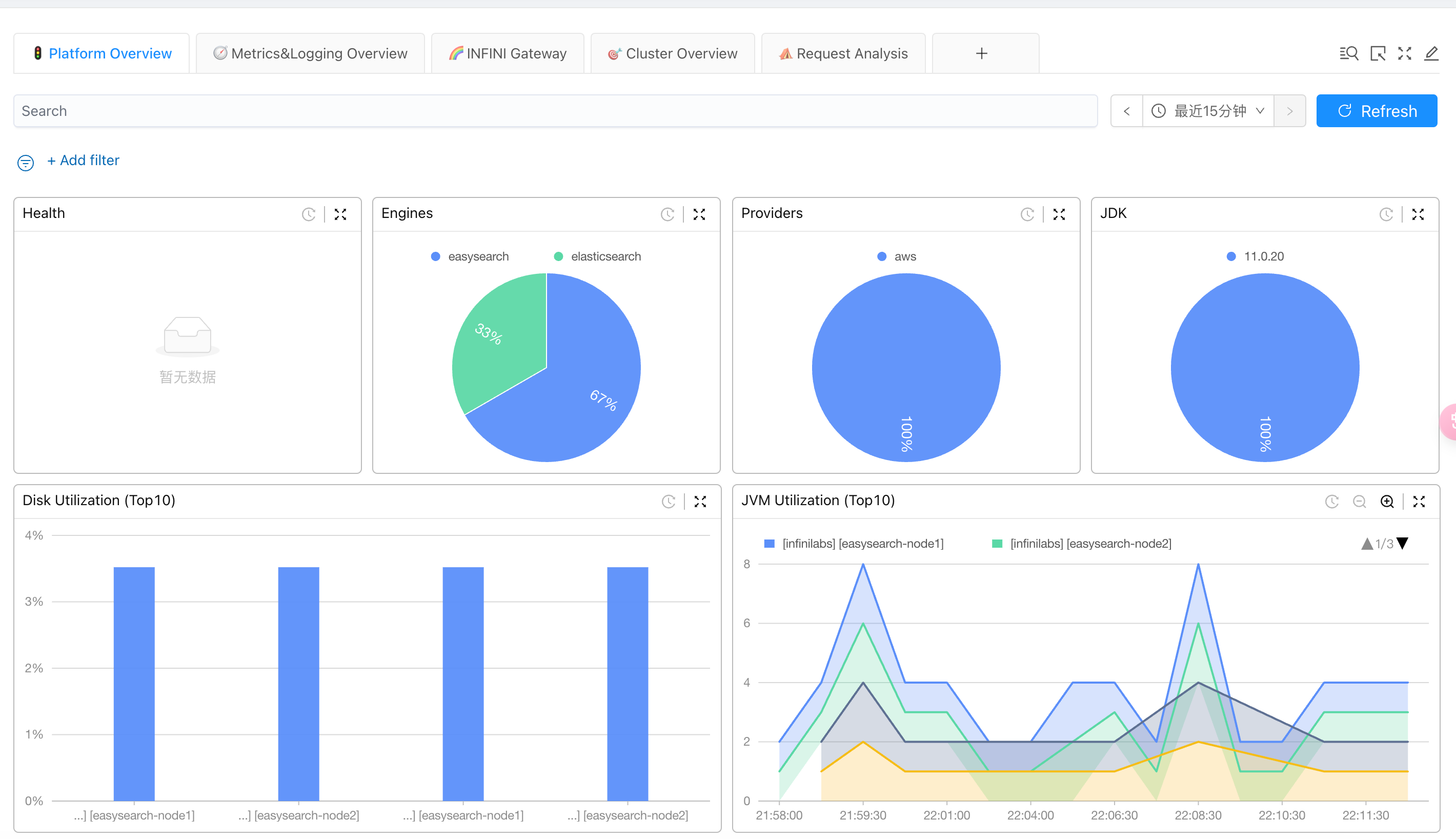
我们还能够看到更多指标:

数据探索
在数据探索里,可以根据时间、字段等条件对索引或者视图下的数据进行搜索查询和分析,类似 Kibana 的 Discover。

这里可以看到集群的警报,目前集群运行良好,没有任何警报。
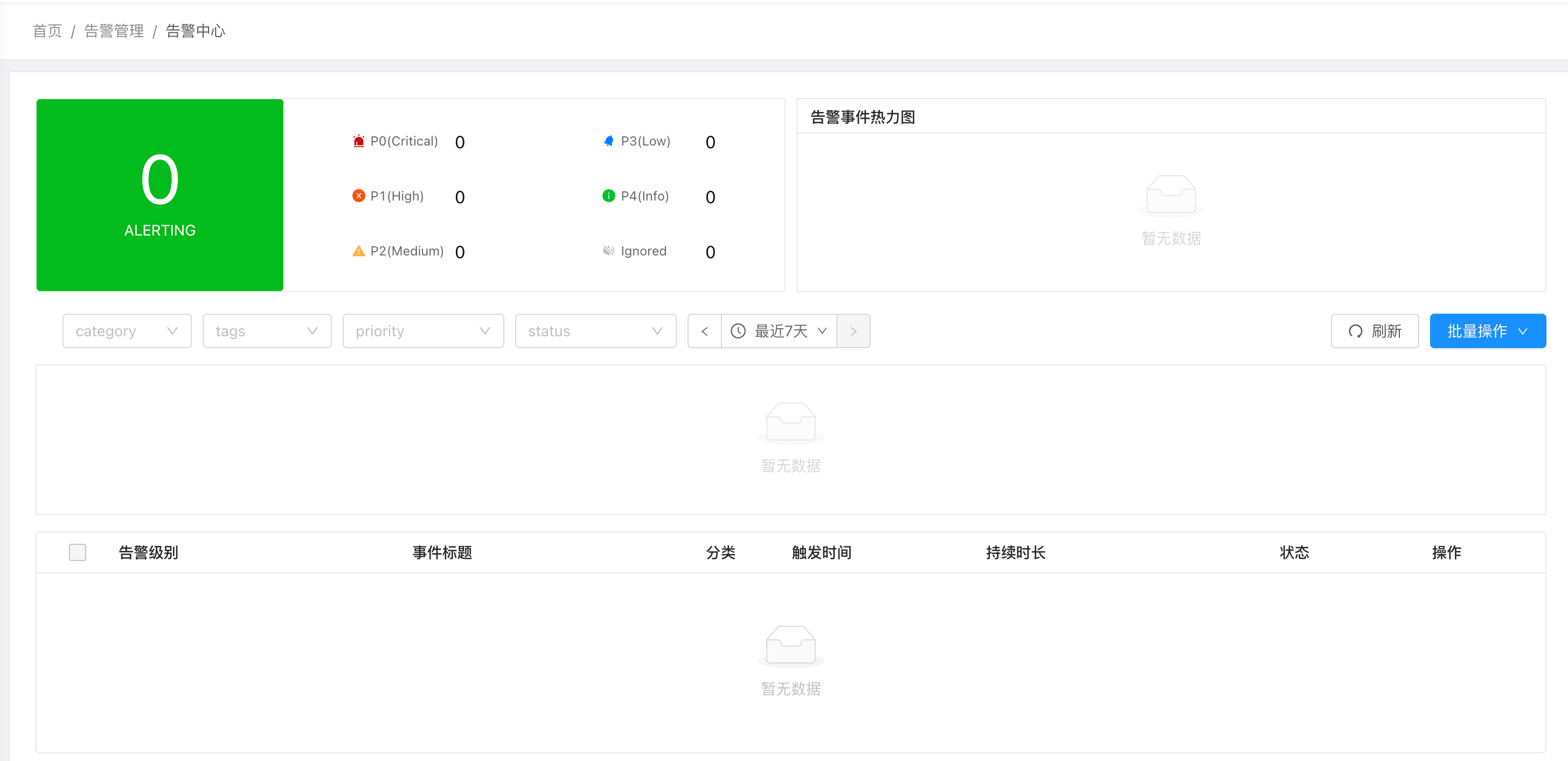
内部会预设一些警报规则,如下:

点进去一个请求,比如磁盘的警告,可以针对不同的使用量设置不同的警告级别和通知。

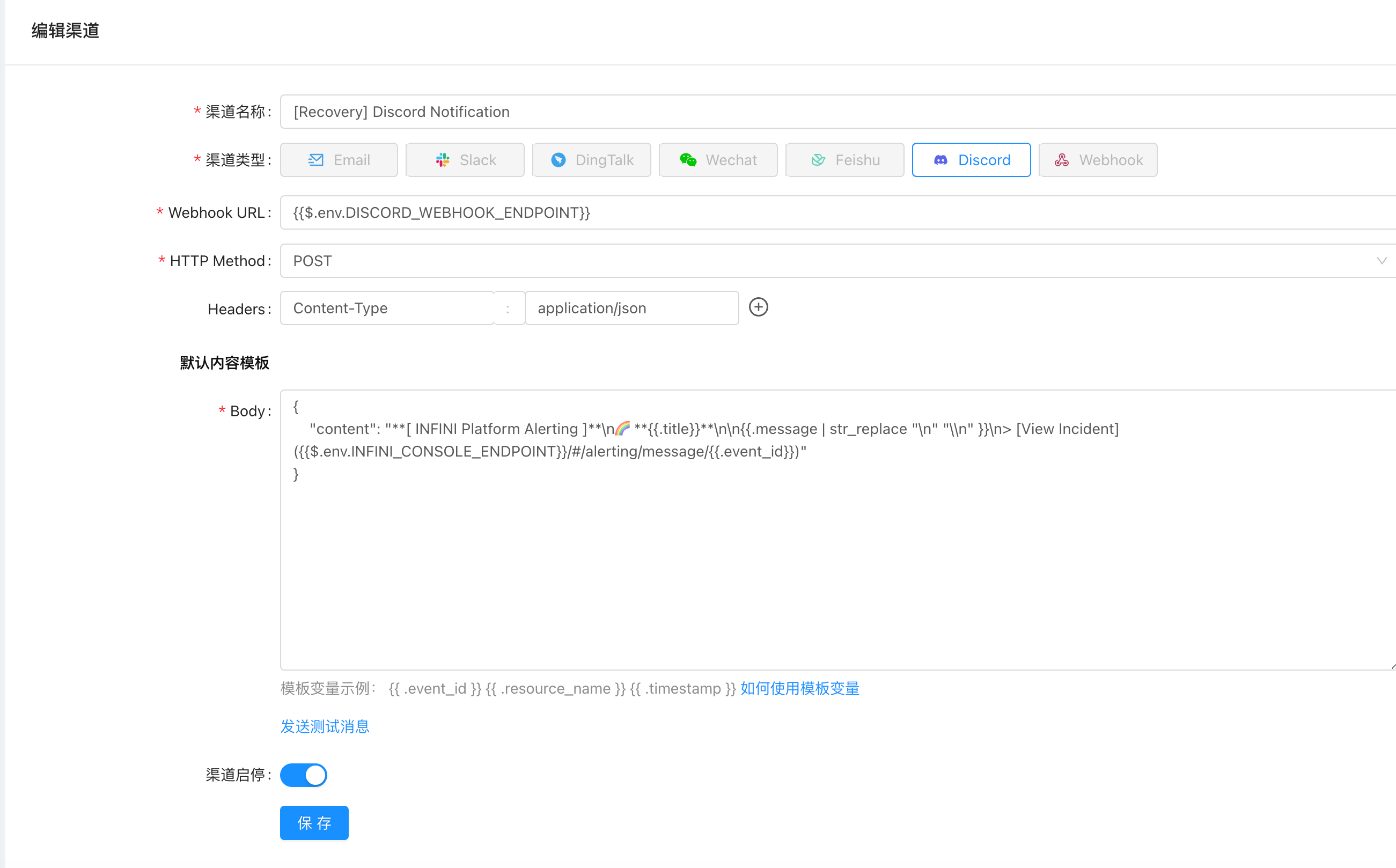
这里针对警报设置警报,可以看到现在支持很多平台,Discord、飞书、邮件、微信、Slack 以及钉钉。

点击进去可以查看,对于社交软件而言,其实是使用 Webhook 进行通知,除此之外也支持配置邮件服务器和自定义的 Webhook 进行通知。
开发工具
Console 的开发工具相当于 Kibana DevTool 的升级版,使用上基本没有大的区别,除了支持 DSL 之外,还支持多集群 Tab 切换、常用命令快速 Load、SQL 查询等。

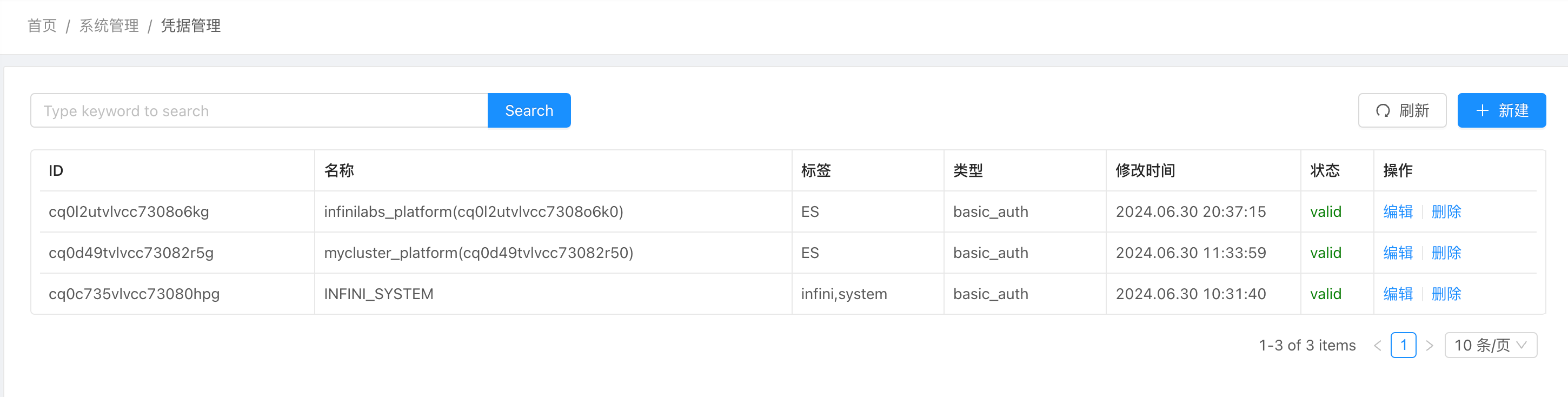
集群连接凭证管理
可以看到连接这三个集群的凭证管理,目前都是有效的。
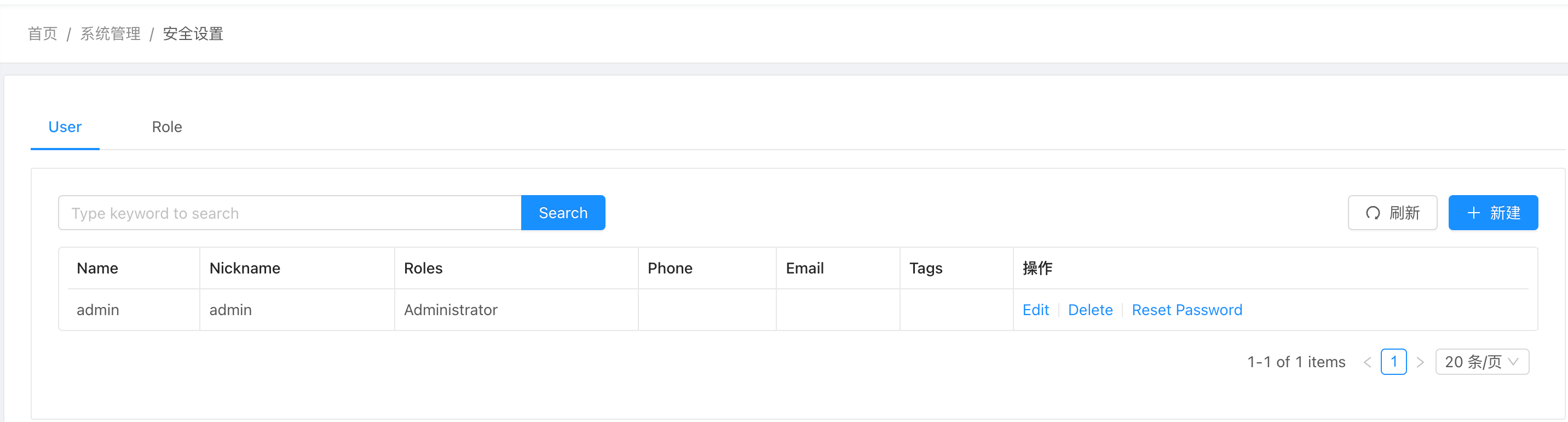
后台用户授权
可以添加用户以及修改 Console 管理界面的密码。目前设置了 admin 账号。
审计日志
追踪对集群的操作,捕获查看集群监控信息以及集群索引的操作。

结论
INFINI Console 的仪表盘页面集成了系统的关键信息和快捷操作入口,使用户可以高效地管理和监控系统。通过详细的概览信息、实时的告警通知、快速的功能入口和动态日志,用户能够对系统的运行状态一目了然,并快速响应各种管理需求。这个设计不仅提升了用户的工作效率,还确保了系统的安全和稳定运行。
INFINI Console 的集群管理页面提供了对系统集群的全面监控和管理功能。通过详细的集群信息展示、便捷的功能选项卡切换以及丰富的筛选和排序功能,用户可以高效地管理和监控系统中的集群状态。这不仅提升了运维效率,还确保了系统的稳定运行和高效管理。
INFINI Console 的节点管理页面提供了对集群节点的全面监控和管理功能。通过详细的节点信息展示、便捷的功能选项卡切换以及丰富的筛选和搜索功能,用户可以高效地管理和监控系统中的节点状态,从而提升运维效率,确保系统的稳定运行和高效管理。
INFINI Console 的监控报表页面提供了对集群运行状况的全面监控和分析功能。通过详细的概览信息和多个性能指标图表,用户可以高效地监控和管理集群的运行状态。这不仅提升了系统运维效率,还确保了集群的稳定运行和高效管理。
通过这些功能,INFINI Console 为用户提供了全面的系统管理工具,帮助他们高效地应对各种运维挑战,确保系统的高效、安全、稳定运行。
关于 Easysearch 有奖征文活动
无论你是 Easysearch 的老用户,还是第一次听说这个名字,只要你对 INFINI Labs 旗下的 Easysearch 产品感兴趣,或者是希望了解 Easysearch,都可以参加这次活动。
详情查看:Easysearch 征文活动
作者:韩旭,亚马逊云技术支持,亚马逊云科技技领云博主,目前专注于云计算开发和大数据领域。
原文:https://blog.csdn.net/weixin_38781498/article/details/140077785
上次在《INFINI Easysearch 尝鲜 Hands on》中,我们部署了两个节点的 Easysearch,并设置了 Console 进行集群监控。今天,我们将介绍 INFINI Console 的使用。
Dashboard
INFINI Console 是一个功能强大的数据管理和分析平台,其仪表盘页面提供了直观简洁的界面,使用户能够快速了解系统状态并进行管理操作。本文将详细介绍仪表盘页面的各项功能。
仪表盘顶部显示系统的实时告警、通知和待办事项的数量,当前数据显示:
- 告警:0 条
- 通知:0 条
- 待办:0 条
在仪表盘的中心区域,用户可以看到几项关键的系统概览信息:
- 集群数量:当前有 3 个集群正在运行。
- 节点数量:系统中有 16 个节点。
- 主机数量:共有 3 台主机。
- 已用存储:系统已使用存储空间为 2.0GB。
仪表盘页面还提供了几个常用操作的快速入口,方便用户迅速访问常用功能:
- 集群注册:用户可以通过此入口快速注册新的集群。
- 数据探索:用户可以访问数据探索工具,对系统中的数据进行分析和查询。
- 告警管理:提供对告警信息的管理功能,用户可以查看和处理告警。
- 安全管理:安全管理入口帮助用户维护系统的安全设置和策略。
仪表盘右侧显示了集群的动态信息,包括最近的操作日志。例如:
- 2024-07-03 22:43:43,index medcl 在 cluster infiniLabs 中的状态更新。
- 2024-07-03 22:06:43,index medcl 在 cluster infiniLabs 中被创建。
集群管理页面
集群管理页面主要分为几个部分:顶部的功能选项卡、中部的集群列表、以及右侧的筛选和排序选项。
页面顶部的功能选项卡包括以下几项:
- Clusters (集群):显示当前系统中的所有集群。
- Nodes (节点):显示集群中的节点详细信息。
- Indices (索引):显示集群中的索引信息。
- Hosts (主机):显示系统中的主机信息。
集群列表展示了每个集群的详细信息,包括:
- 集群名称:每个集群的名称,如 “infinilabs”、“mycluster”、“INFINI_SYSTEM (JeanGrey)”。
- 集群健康状态:以颜色条的形式显示最近 14 天的集群健康状态(绿色表示健康,黄色表示有警告)。
- 节点数量:集群中包含的节点数量。
- 索引数量:集群中的索引数量。
- 分片数量:集群中的分片数量。
- 文档数量:集群中存储的文档数量。
- 磁盘使用率:集群的磁盘使用情况。
- JVM 堆内存使用率:集群的 JVM 堆内存使用情况。
- 索引速率:当前集群的索引速率(每秒索引数)。
- 搜索速率:当前集群的搜索速率(每秒搜索数)。
页面右侧提供了丰富的筛选和排序选项,可以根据以下条件筛选和排序集群:
- 健康状态 (Health Status):根据集群的健康状态筛选,如绿色(健康)和黄色(警告)。
- 分布 (Distribution):根据集群的分布类型筛选,如 “easysearch” 和 “elasticsearch”。
- 版本 (Version):根据集群使用的软件版本筛选,如 Easysearch 1.8.2 和 Elasticsearch 7.10.2。
- 区域 (Region):根据集群所在的区域筛选,如 “china” 和 “default”。
- 标签 (Tags):根据自定义标签进行筛选。
接下来分别介绍节点、索引和主机层面的信息,这些监控指标与集群层面大同小异。
节点监控
索引监控
主机监控
包括了常规的 CPU、内存、磁盘、网络的监控。
监控指标页面
监控报表页面提供了对集群运行状况的详细监控和分析功能。用户可以选择最近 15 分钟、1 小时、24 小时等不同时间范围查看数据,并手动点击刷新按钮更新数据,以获取最新的监控信息。
概览信息
显示当前集群的基本状态,包括:
- 集群名称:如 “infinilabs”。
- 在线时长:如 “3 天”。
- 集群版本:如 “1.8.2”。
- 健康状态:如 “green”。
- 节点数:如 “2”。
- 索引数:如 “38”。
- 主/总分片:如 “38/76”。
- 未分配分片:如 “0”。
- 文档数:如 “656,803”。
- 存储空间:如 “1007.2MB/385.4GB”。
- JVM 内存:如 “1023.0MB/2.0GB”。
监控报表页面还提供了多个性能指标的图表,包括:
索引吞吐 (doc/s)
- Total Indexing:总索引吞吐量。
- Primary Indexing:主分片的索引吞吐量。
查询吞吐 (query/s)
- Total Query:总查询吞吐量。
索引延迟 (ms)
- Indexing Latency:索引延迟时间。
- Delete Latency:删除操作的延迟时间。
查询延迟 (ms)
- Query Latency:查询延迟时间。
- Fetch Latency:获取操作的延迟时间。
- Scroll Latency:滚动操作的延迟时间。
点击“Advance”可以查看更多监控指标:
节点级别性能监控
包括 CPU、负载、JVM 内存、剩余使用空间及磁盘空间、集群启动时间和索引读写情况。
索引级别监控
包括集群内索引的数量、状态、主分片和副本分片数量、文档条数和占用空间。
集群动态页面
提供集群中各类事件和活动的详细记录和监控功能。
别名管理
别名管理页面提供了对索引别名的管理功能,使用户可以方便地管理和配置 Elasticsearch/EasySearch 的索引别名。
创建别名
可以通过 DSL 创建别名。例如,创建一个名为 my_index_alias 的别名指向 my_index:
POST /_aliases
{
"actions": [
{
"add": {
"index": "my_index",
"alias": "my_index_alias"
}
}
]
}删除别名
删除一个别名同样可以通过 REST API 实现:
POST /_aliases
{
"actions": [
{
"remove": {
"index": "my_index",
"alias": "my_index_alias"
}
}
]
}索引轮换
索引轮换是一种常用的索引管理策略,特别适用于日志和时间序列数据的场景。通过索引轮换,用户可以在索引达到一定条件(如大小或文档数量)时,创建一个新的索引来继续存储数据,而旧的索引可以继续用于查询。
- 设置写别名:创建一个指向当前写入索引的别名,例如 current_write_index。
- 定义索引轮换条件:可以基于索引的大小、文档数量或时间来定义轮换条件。
- 索引并更新写别名指向这个新索引。
创建初始索引并设置写别名:
PUT /my_index-000001
{
"aliases": {
"current_write_index": {}
}
}使用 /_rollover API 定义轮换条件并执行轮换:
POST /current_write_index/_rollover
{
"conditions": {
"max_age": "7d",
"max_docs": 1000000
},
"settings": {
"number_of_shards": 1
},
"aliases": {
"current_write_index": {}
}
}通过这种方式,查询操作可以透明地访问所有历史数据,而写操作总是指向最新的索引。
在 INFINI Console 中提供了可视化创建索引及别名的方式。页面右上角提供了新建按钮,用户可以通过点击该按钮创建新的索引别名,填写别名名称、关联索引、索引路由、搜索路由和过滤查询等配置。
平台监控
展示了多个关键指标的监控图表,包括:
- 健康状态 (Health):显示系统当前的健康状态。如果没有数据,则显示“暂无数据”。
- 引擎分布 (Engines):展示系统中不同搜索引擎的分布情况,例如 EasySearch 和 Elasticsearch 的比例。图表显示当前 EasySearch 占 67%,Elasticsearch 占 33%。
- 提供商 (Providers):显示系统中使用的云服务提供商信息。在示例中,所有资源都托管在 AWS 上。
- JDK 版本 (JDK):显示系统中使用的 JDK 版本信息。在示例中,所有节点都使用 JDK 版本 11.0.20。
- 磁盘使用情况 (Disk Utilization) - Top 10:显示磁盘使用率最高的前 10 个节点。在示例中,easysearch-node1 和 easysearch-node2 的磁盘使用率均为 4%。
- JVM 使用情况 (JVM Utilization) - Top 10:展示 JVM 使用率最高的前 10 个节点。在示例中,infinilabs 集群的 easysearch-node1 和 easysearch-node2 节点的 JVM 使用情况有详细的时间序列数据,显示了不同时间点的使用率变化。
我们还能够看到更多指标:
数据探索
在数据探索里,可以根据时间、字段等条件对索引或者视图下的数据进行搜索查询和分析,类似 Kibana 的 Discover。
这里可以看到集群的警报,目前集群运行良好,没有任何警报。
内部会预设一些警报规则,如下:
点进去一个请求,比如磁盘的警告,可以针对不同的使用量设置不同的警告级别和通知。
这里针对警报设置警报,可以看到现在支持很多平台,Discord、飞书、邮件、微信、Slack 以及钉钉。
点击进去可以查看,对于社交软件而言,其实是使用 Webhook 进行通知,除此之外也支持配置邮件服务器和自定义的 Webhook 进行通知。
开发工具
Console 的开发工具相当于 Kibana DevTool 的升级版,使用上基本没有大的区别,除了支持 DSL 之外,还支持多集群 Tab 切换、常用命令快速 Load、SQL 查询等。
集群连接凭证管理
可以看到连接这三个集群的凭证管理,目前都是有效的。
后台用户授权
可以添加用户以及修改 Console 管理界面的密码。目前设置了 admin 账号。
审计日志
追踪对集群的操作,捕获查看集群监控信息以及集群索引的操作。
结论
INFINI Console 的仪表盘页面集成了系统的关键信息和快捷操作入口,使用户可以高效地管理和监控系统。通过详细的概览信息、实时的告警通知、快速的功能入口和动态日志,用户能够对系统的运行状态一目了然,并快速响应各种管理需求。这个设计不仅提升了用户的工作效率,还确保了系统的安全和稳定运行。
INFINI Console 的集群管理页面提供了对系统集群的全面监控和管理功能。通过详细的集群信息展示、便捷的功能选项卡切换以及丰富的筛选和排序功能,用户可以高效地管理和监控系统中的集群状态。这不仅提升了运维效率,还确保了系统的稳定运行和高效管理。
INFINI Console 的节点管理页面提供了对集群节点的全面监控和管理功能。通过详细的节点信息展示、便捷的功能选项卡切换以及丰富的筛选和搜索功能,用户可以高效地管理和监控系统中的节点状态,从而提升运维效率,确保系统的稳定运行和高效管理。
INFINI Console 的监控报表页面提供了对集群运行状况的全面监控和分析功能。通过详细的概览信息和多个性能指标图表,用户可以高效地监控和管理集群的运行状态。这不仅提升了系统运维效率,还确保了集群的稳定运行和高效管理。
通过这些功能,INFINI Console 为用户提供了全面的系统管理工具,帮助他们高效地应对各种运维挑战,确保系统的高效、安全、稳定运行。
关于 Easysearch 有奖征文活动
无论你是 Easysearch 的老用户,还是第一次听说这个名字,只要你对 INFINI Labs 旗下的 Easysearch 产品感兴趣,或者是希望了解 Easysearch,都可以参加这次活动。
详情查看:Easysearch 征文活动
收起阅读 »作者:韩旭,亚马逊云技术支持,亚马逊云科技技领云博主,目前专注于云计算开发和大数据领域。
原文:https://blog.csdn.net/weixin_38781498/article/details/140077785
INFINI Easysearch 尝鲜 Hands on

INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个自主可控的轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
Easysearch 支持原生 Elasticsearch 的 DSL 查询语法,确保原业务代码无需调整即可无缝迁移。同时,极限科技还支持 SQL 查询,为熟悉 SQL 的开发人员提供更加便捷的数据分析方式。此外,Easysearch 兼容 Elasticsearch 的 SDK 和现有索引存储格式,支持冷热架构和索引生命周期管理,确保用户能够轻松实现数据的无缝衔接。
安装
安装脚本
无论是 Linux 还是 Mac 都是这个一键脚本
curl -sSL http://get.infini.cloud | bash -s -- -p easysearch同时也提供了二进制的安装包:
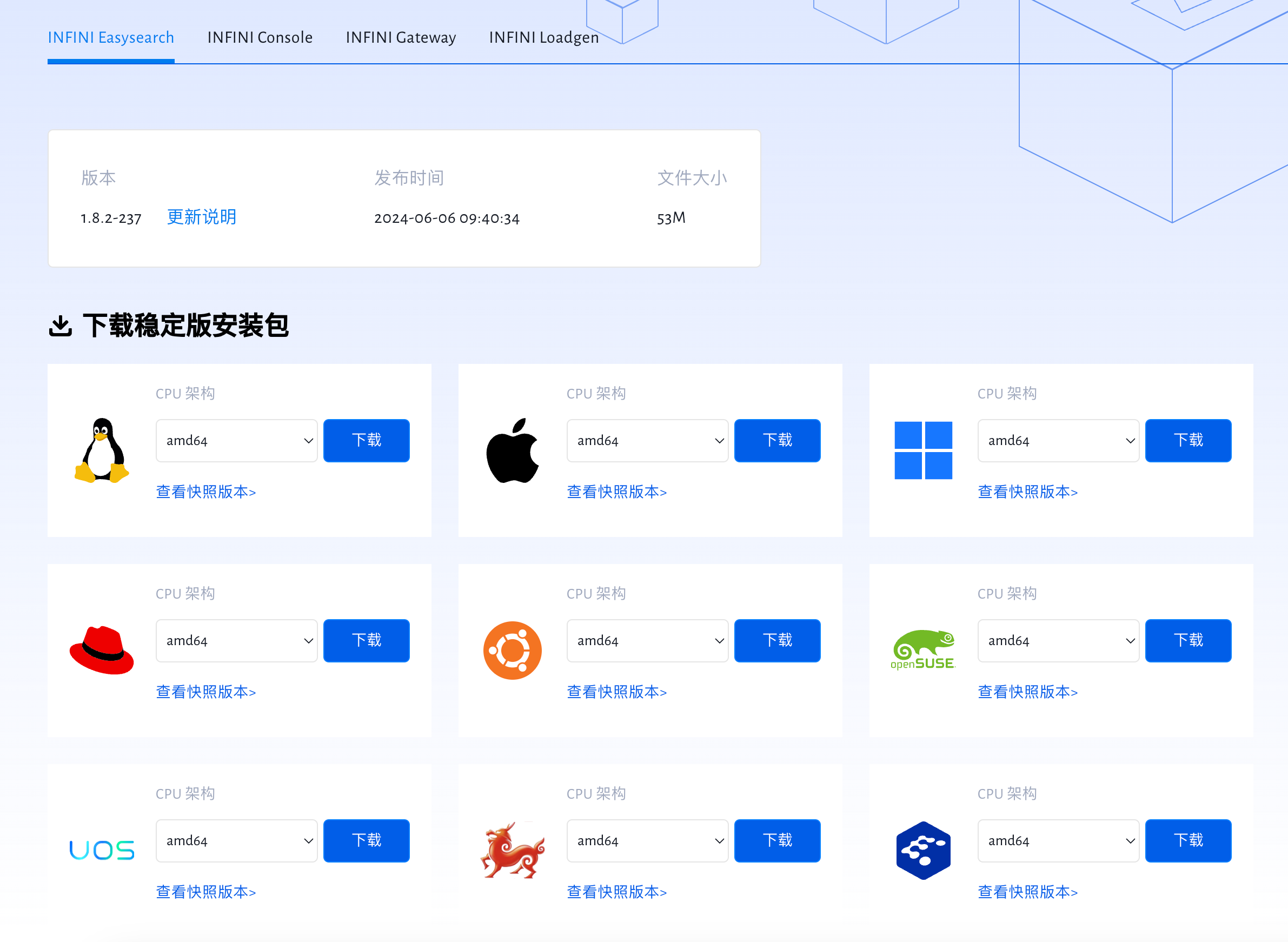
如果不想整理 JAVA 环境问题,还可以使用这个 https://release.infinilabs.com/easysearch/stable/bundle/
docker 部署
官方提供了 Docker Compose 样例,包括三个服务:
- easysearch-node1
- easysearch-node2
- console
以下是详细说明:
版本控制:
- version: '3' 表示使用 Docker Compose 文件的第 3 版格式。
服务定义:
-
easysearch-node1 和 easysearch-node2:
- 这两个服务使用相同的 Docker 镜像 infinilabs/easysearch:latest 来组成双节点的集群。
- 容器运行时使用用户和组 ID 602:602。
- 设置了 ES_JAVA_OPTS 环境变量以配置 Java 虚拟机的内存。
- ulimits 选项配置了内存锁定和文件描述符的限制,以提升性能。
- 容器内的配置、数据和日志目录通过卷映射到主机目录中,以便于数据持久化。
- 服务暴露特定端口,使外部能够访问容器中的服务。
- 两个节点均加入名为 esnet 的自定义网络中。
-
console:
- 该服务使用镜像 infinilabs/console:1.26.0-1552(该镜像没有 latest,需要手动把 latest 更改位特定的版本号)。
- 同样通过卷将数据和日志目录映射到主机。
- 暴露 9000 端口用于 Web 界面访问。
- 使用 links 功能链接到 easysearch-node1 和 easysearch-node2,简化容器之间的通信。
- 设置了时区环境变量 TZ 为 Asia/Shanghai。
网络配置:
- esnet 网络使用 bridge 驱动,提供一个隔离的网络环境,配置了特定的子网 172.24.0.0/16,以确保服务之间的网络通信。
version: '3'
services:
easysearch-node1:
user: "602:602"
image: infinilabs/easysearch:latest
container_name: easysearch-node1
hostname: easysearch-node1
environment:
- "ES_JAVA_OPTS=-Xms1g -Xmx1g"
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
volumes:
- $PWD/ezs1/config:/app/easysearch/config
- $PWD/ezs1/data:/app/easysearch/data
- $PWD/ezs1/logs:/app/easysearch/logs
ports:
- 9201:9200
- 9301:9300
networks:
- esnet
easysearch-node2:
user: "602:602"
image: infinilabs/easysearch:latest
container_name: easysearch-node2
hostname: easysearch-node2
environment:
- "ES_JAVA_OPTS=-Xms1g -Xmx1g"
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
volumes:
- $PWD/ezs2/config:/app/easysearch/config
- $PWD/ezs2/data:/app/easysearch/data
- $PWD/ezs2/logs:/app/easysearch/logs
ports:
- 9202:9200
- 9302:9300
networks:
- esnet
console:
image: infinilabs/console:1.26.0-1552
container_name: console
hostname: console
volumes:
- $PWD/console/data:/data
- $PWD/console/log:/log
networks:
- esnet
ports:
- 9000:9000
links:
- easysearch-node1:es1
- easysearch-node2:es2
environment:
- TZ=Asia/Shanghai
networks:
esnet:
driver: bridge
ipam:
config:
- subnet: 172.24.0.0/16尽管在这里官方提供了详细的命令,完全可以使用这个 docker-compose up 来进行替代。其他的脚本解释如下:
init.sh
#!/bin/bash
# 获取当前脚本所在目录的绝对路径
CUR_DIR=$(cd $(dirname $0); pwd)
# 创建必要的目录结构
mkdir -p $CUR_DIR/console/{data,log}
mkdir -p $CUR_DIR/{ezs1,ezs2}/{data,logs}
# 设置目录的拥有者和权限
chown -R 1000:1000 $CUR_DIR/console
chown -R 602:602 $CUR_DIR/{ezs1,ezs2}
chmod -R 0600 $CUR_DIR/{ezs1,ezs2}/config
# 设置 config 目录的子目录权限
find $CUR_DIR/{ezs1,ezs2}/config -type d -print0 | xargs -0 chmod 750reset.sh
#!/bin/bash
# 获取当前脚本所在目录的绝对路径
CUR_DIR=$(cd $(dirname $0); pwd)
# 定义确认函数
function confirm() {
display_str=$1
default_ans=$2
if [[ $default_ans == 'y/N' ]]; then
must_match='[yY]'
else
must_match='[nN]'
fi
read -p"${display_str} [${default_ans}]:" ans
[[ $ans == $must_match ]]
}
# 提示用户确认删除所有数据
confirm "RISK WARN: Delete all data!!!" 'y/N' && echo || exit
# 删除 console、ezs1 和 ezs2 的数据和日志文件
rm -rvf $CUR_DIR/console/{data,log}/*
rm -rvf $CUR_DIR/{ezs1,ezs2}/{data,logs}/*start.sh
#!/bin/bash
# 使用 Docker Compose 启动 ezs2 项目中的服务
docker-compose -p ezs2 upstop.sh
#!/bin/bash
# 使用 Docker Compose 关闭并移除 ezs2 项目中的所有服务
docker-compose -p ezs2 down在我的电脑中,可以看到成功启动的容器。

https://infinilabs.cn/docs/latest/easysearch/getting-started/install/docker-compose/
Console 连接
设置集群连接参数,比如域名端口,用户名密码。
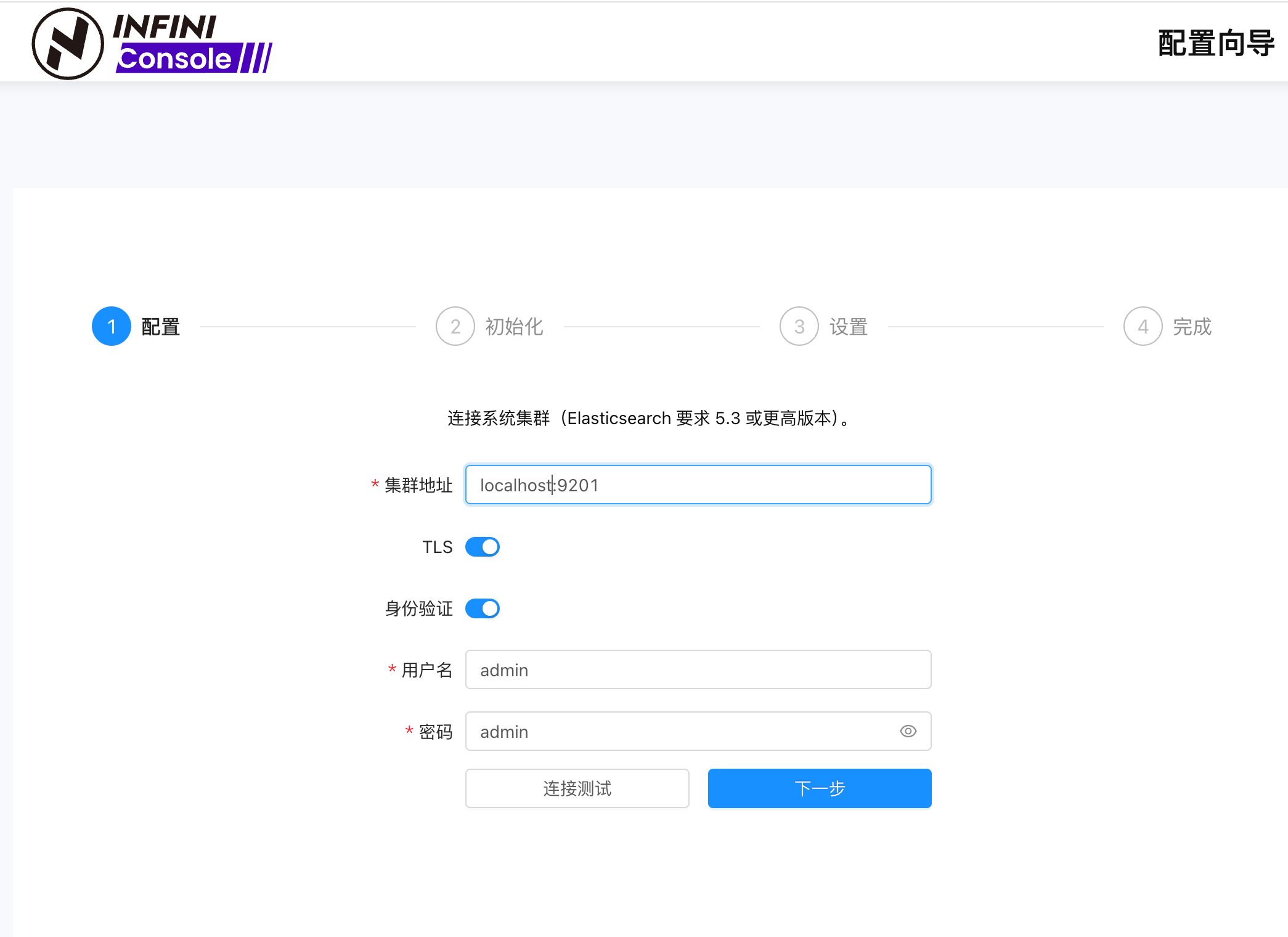
初始化,这里会新建索引,写一些 sample 数据。
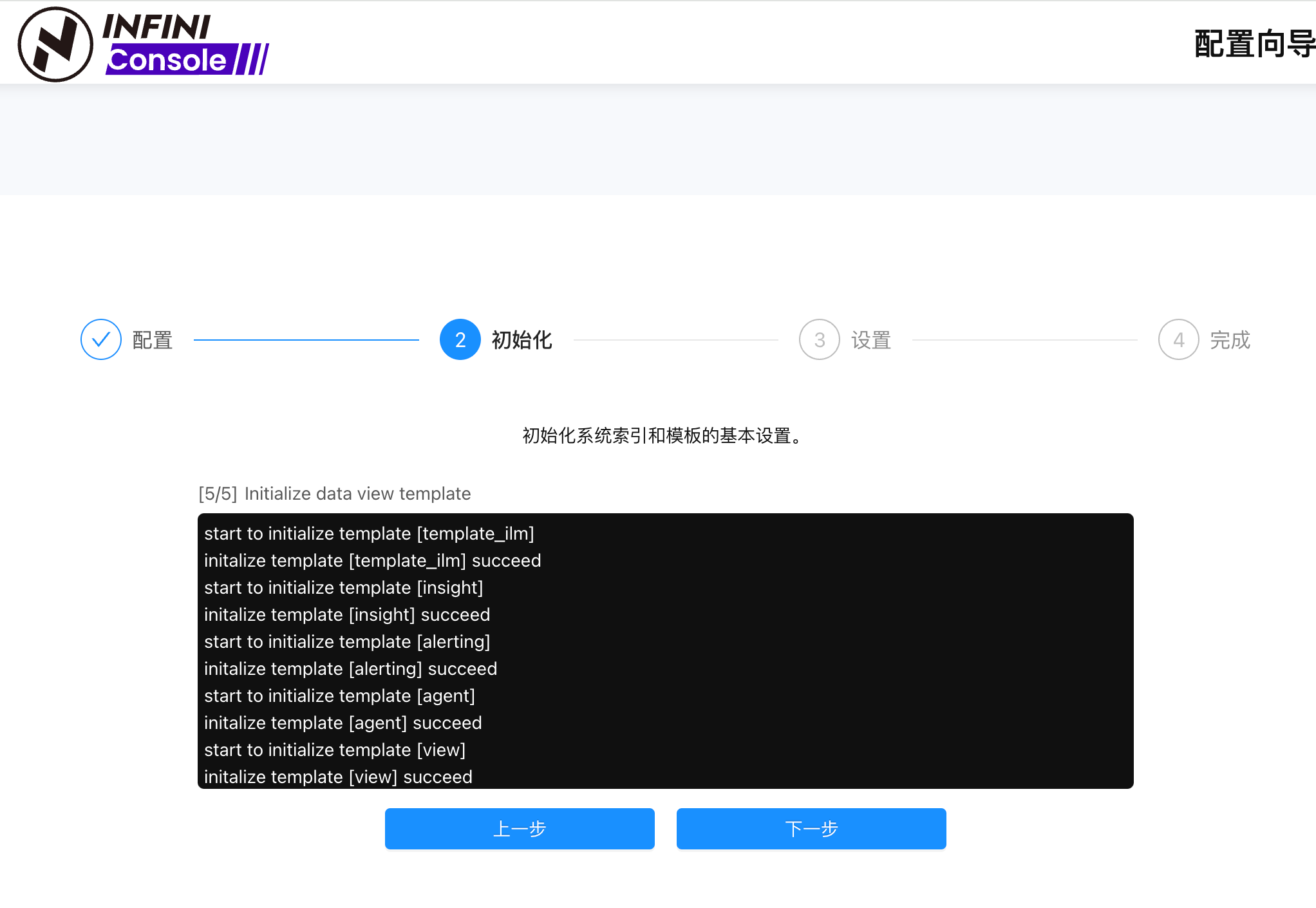
设置后台管理的密码,后期使用这个登录控制台。
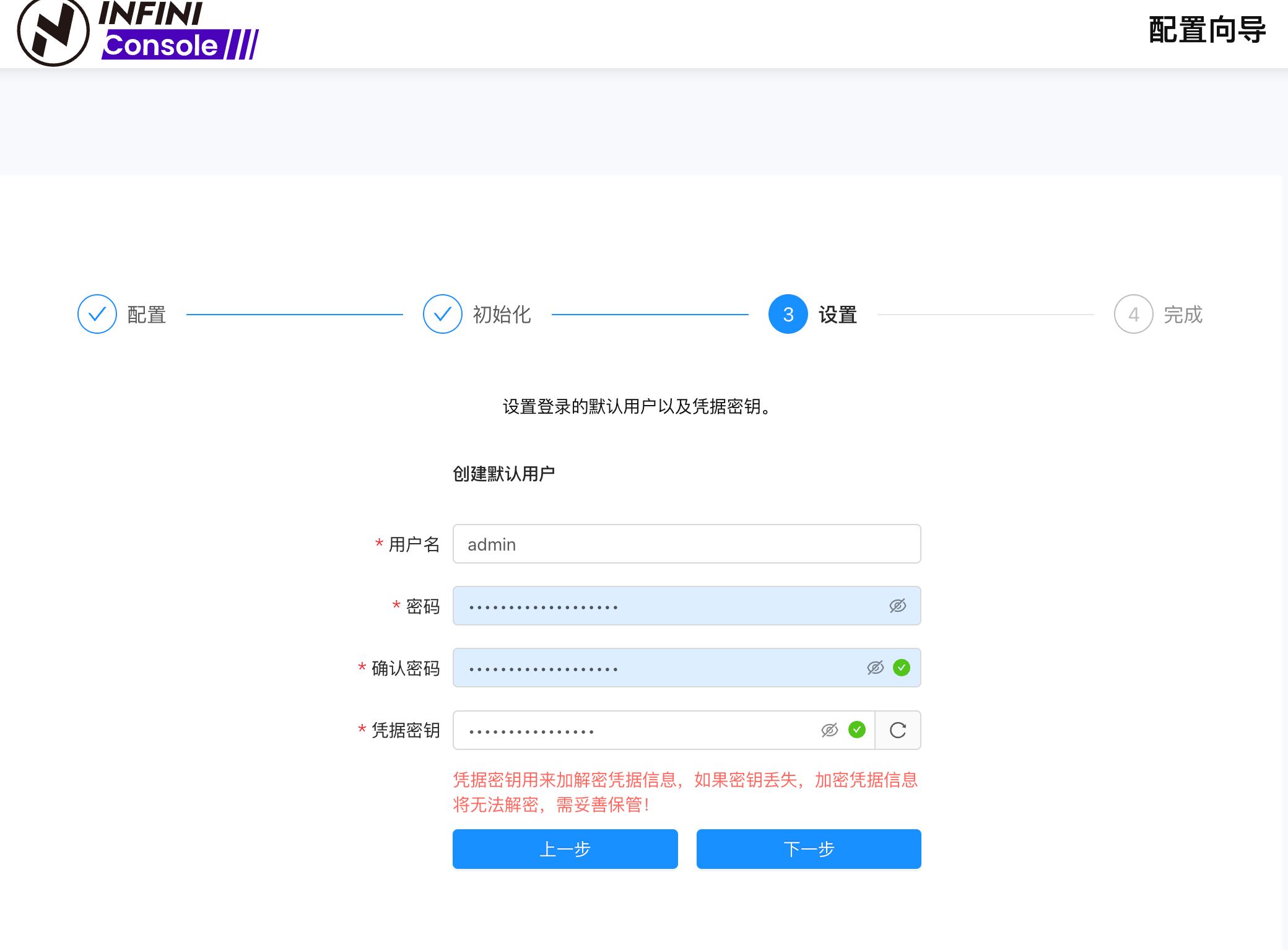
检查配置,完成集群关联。
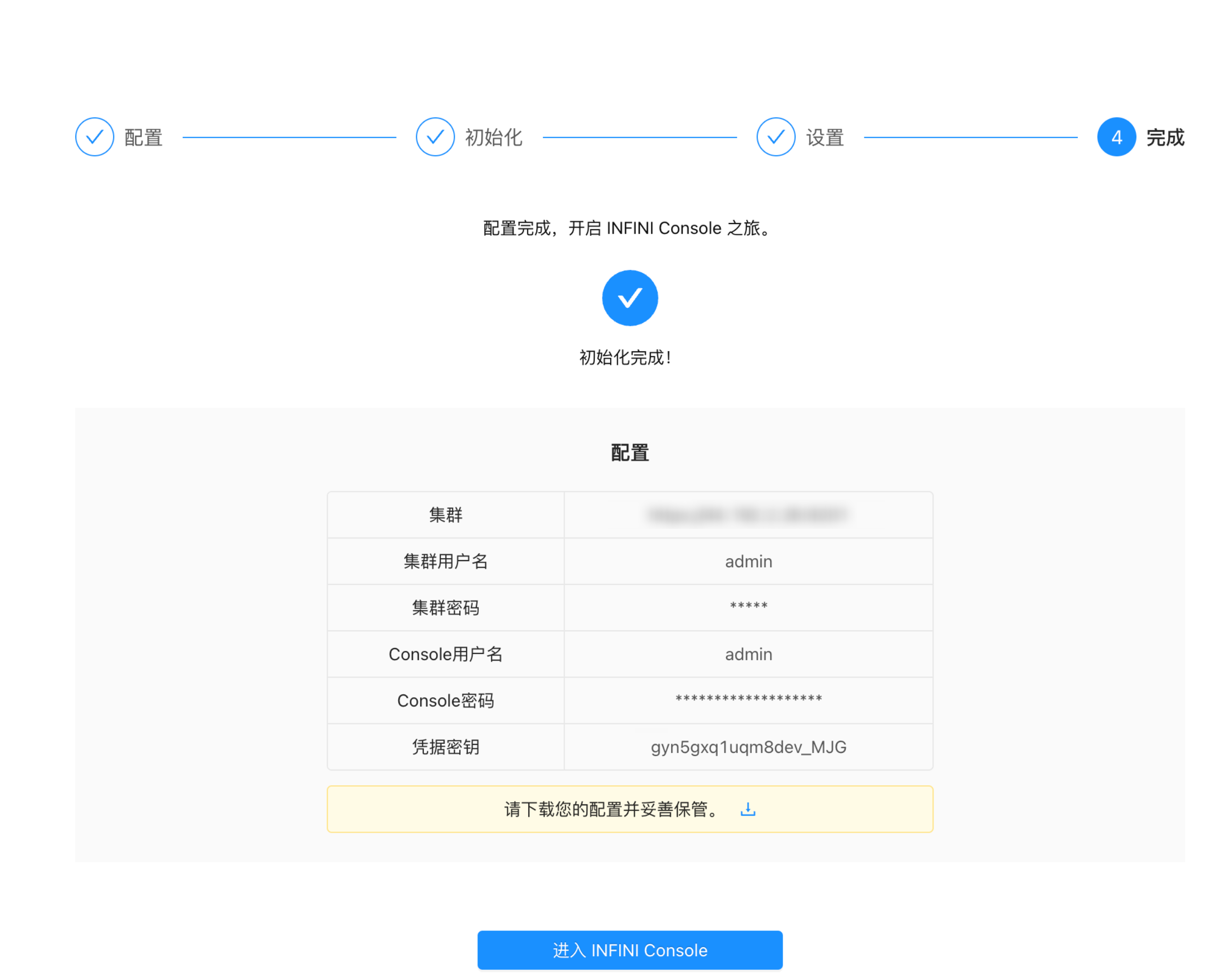
这个是后台管理界面,除了用户名密码之外,也支持单点登录:

跨引擎、跨版本、跨集群 独一份!

使用自带的面板进行查看节点数量:
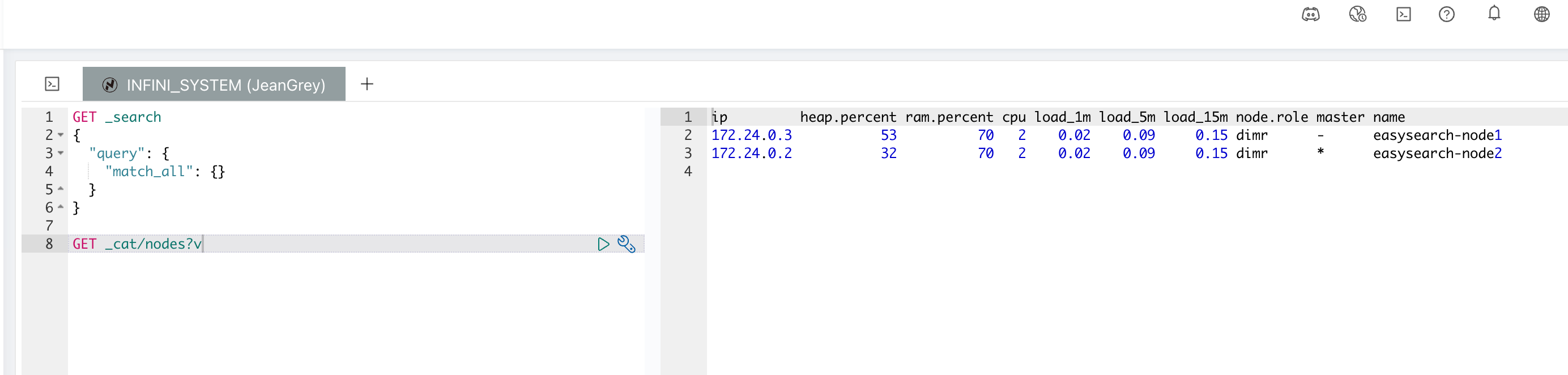
同时也支持 REST 风格的 API 来进行查询。

接下来使用 Console 连接 Amazon 的 OpenSearch:
同样是输入集群的 URL,用户名和密码。
然后可以拿到集群的信息,比如地址,版本号,集群状态,节点数量。

最后看到连接成功的信息。

我们可以在集群管理中看到 Easysearch 的集群和我们刚刚添加的 OpenSearch 集群。

是否开源?目前还没有开放源代码。
关于 Easysearch 有奖征文活动
无论你是 Easysearch 的老用户,还是第一次听说这个名字,只要你对 INFINI Labs 旗下的 Easysearch 产品感兴趣,或者是希望了解 Easysearch,都可以参加这次活动。
详情查看:Easysearch 征文活动
作者:韩旭,亚马逊云技术支持,亚马逊云科技技领云博主,目前专注于云计算开发和大数据领域。
原文:https://blog.csdn.net/weixin_38781498/article/details/140077785
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个自主可控的轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
Easysearch 支持原生 Elasticsearch 的 DSL 查询语法,确保原业务代码无需调整即可无缝迁移。同时,极限科技还支持 SQL 查询,为熟悉 SQL 的开发人员提供更加便捷的数据分析方式。此外,Easysearch 兼容 Elasticsearch 的 SDK 和现有索引存储格式,支持冷热架构和索引生命周期管理,确保用户能够轻松实现数据的无缝衔接。
安装
安装脚本
无论是 Linux 还是 Mac 都是这个一键脚本
curl -sSL http://get.infini.cloud | bash -s -- -p easysearch同时也提供了二进制的安装包:
如果不想整理 JAVA 环境问题,还可以使用这个 https://release.infinilabs.com/easysearch/stable/bundle/
docker 部署
官方提供了 Docker Compose 样例,包括三个服务:
- easysearch-node1
- easysearch-node2
- console
以下是详细说明:
版本控制:
- version: '3' 表示使用 Docker Compose 文件的第 3 版格式。
服务定义:
-
easysearch-node1 和 easysearch-node2:
- 这两个服务使用相同的 Docker 镜像 infinilabs/easysearch:latest 来组成双节点的集群。
- 容器运行时使用用户和组 ID 602:602。
- 设置了 ES_JAVA_OPTS 环境变量以配置 Java 虚拟机的内存。
- ulimits 选项配置了内存锁定和文件描述符的限制,以提升性能。
- 容器内的配置、数据和日志目录通过卷映射到主机目录中,以便于数据持久化。
- 服务暴露特定端口,使外部能够访问容器中的服务。
- 两个节点均加入名为 esnet 的自定义网络中。
-
console:
- 该服务使用镜像 infinilabs/console:1.26.0-1552(该镜像没有 latest,需要手动把 latest 更改位特定的版本号)。
- 同样通过卷将数据和日志目录映射到主机。
- 暴露 9000 端口用于 Web 界面访问。
- 使用 links 功能链接到 easysearch-node1 和 easysearch-node2,简化容器之间的通信。
- 设置了时区环境变量 TZ 为 Asia/Shanghai。
网络配置:
- esnet 网络使用 bridge 驱动,提供一个隔离的网络环境,配置了特定的子网 172.24.0.0/16,以确保服务之间的网络通信。
version: '3'
services:
easysearch-node1:
user: "602:602"
image: infinilabs/easysearch:latest
container_name: easysearch-node1
hostname: easysearch-node1
environment:
- "ES_JAVA_OPTS=-Xms1g -Xmx1g"
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
volumes:
- $PWD/ezs1/config:/app/easysearch/config
- $PWD/ezs1/data:/app/easysearch/data
- $PWD/ezs1/logs:/app/easysearch/logs
ports:
- 9201:9200
- 9301:9300
networks:
- esnet
easysearch-node2:
user: "602:602"
image: infinilabs/easysearch:latest
container_name: easysearch-node2
hostname: easysearch-node2
environment:
- "ES_JAVA_OPTS=-Xms1g -Xmx1g"
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
volumes:
- $PWD/ezs2/config:/app/easysearch/config
- $PWD/ezs2/data:/app/easysearch/data
- $PWD/ezs2/logs:/app/easysearch/logs
ports:
- 9202:9200
- 9302:9300
networks:
- esnet
console:
image: infinilabs/console:1.26.0-1552
container_name: console
hostname: console
volumes:
- $PWD/console/data:/data
- $PWD/console/log:/log
networks:
- esnet
ports:
- 9000:9000
links:
- easysearch-node1:es1
- easysearch-node2:es2
environment:
- TZ=Asia/Shanghai
networks:
esnet:
driver: bridge
ipam:
config:
- subnet: 172.24.0.0/16尽管在这里官方提供了详细的命令,完全可以使用这个 docker-compose up 来进行替代。其他的脚本解释如下:
init.sh
#!/bin/bash
# 获取当前脚本所在目录的绝对路径
CUR_DIR=$(cd $(dirname $0); pwd)
# 创建必要的目录结构
mkdir -p $CUR_DIR/console/{data,log}
mkdir -p $CUR_DIR/{ezs1,ezs2}/{data,logs}
# 设置目录的拥有者和权限
chown -R 1000:1000 $CUR_DIR/console
chown -R 602:602 $CUR_DIR/{ezs1,ezs2}
chmod -R 0600 $CUR_DIR/{ezs1,ezs2}/config
# 设置 config 目录的子目录权限
find $CUR_DIR/{ezs1,ezs2}/config -type d -print0 | xargs -0 chmod 750reset.sh
#!/bin/bash
# 获取当前脚本所在目录的绝对路径
CUR_DIR=$(cd $(dirname $0); pwd)
# 定义确认函数
function confirm() {
display_str=$1
default_ans=$2
if [[ $default_ans == 'y/N' ]]; then
must_match='[yY]'
else
must_match='[nN]'
fi
read -p"${display_str} [${default_ans}]:" ans
[[ $ans == $must_match ]]
}
# 提示用户确认删除所有数据
confirm "RISK WARN: Delete all data!!!" 'y/N' && echo || exit
# 删除 console、ezs1 和 ezs2 的数据和日志文件
rm -rvf $CUR_DIR/console/{data,log}/*
rm -rvf $CUR_DIR/{ezs1,ezs2}/{data,logs}/*start.sh
#!/bin/bash
# 使用 Docker Compose 启动 ezs2 项目中的服务
docker-compose -p ezs2 upstop.sh
#!/bin/bash
# 使用 Docker Compose 关闭并移除 ezs2 项目中的所有服务
docker-compose -p ezs2 down在我的电脑中,可以看到成功启动的容器。
https://infinilabs.cn/docs/latest/easysearch/getting-started/install/docker-compose/
Console 连接
设置集群连接参数,比如域名端口,用户名密码。
初始化,这里会新建索引,写一些 sample 数据。
设置后台管理的密码,后期使用这个登录控制台。
检查配置,完成集群关联。
这个是后台管理界面,除了用户名密码之外,也支持单点登录:
跨引擎、跨版本、跨集群 独一份!
使用自带的面板进行查看节点数量:
同时也支持 REST 风格的 API 来进行查询。
接下来使用 Console 连接 Amazon 的 OpenSearch:
同样是输入集群的 URL,用户名和密码。
然后可以拿到集群的信息,比如地址,版本号,集群状态,节点数量。
最后看到连接成功的信息。
我们可以在集群管理中看到 Easysearch 的集群和我们刚刚添加的 OpenSearch 集群。
是否开源?目前还没有开放源代码。
关于 Easysearch 有奖征文活动
无论你是 Easysearch 的老用户,还是第一次听说这个名字,只要你对 INFINI Labs 旗下的 Easysearch 产品感兴趣,或者是希望了解 Easysearch,都可以参加这次活动。
详情查看:Easysearch 征文活动
收起阅读 »作者:韩旭,亚马逊云技术支持,亚马逊云科技技领云博主,目前专注于云计算开发和大数据领域。
原文:https://blog.csdn.net/weixin_38781498/article/details/140077785
搜索客社区日报 第1856期 (2024-07-10)
https://medium.com/%40tobintom ... 7d3f6
2.一文详谈20多种RAG优化方法
https://mp.weixin.qq.com/s/xMsPh8qicRD395vjFR250A
3.使用 Elasticsearch 进行大规模向量搜索的设计原则
https://cloud.tencent.com/deve ... 33788
4.Elasticsearch:结合稀疏、密集和地理字段
https://blog.csdn.net/UbuntuTo ... 70973
编辑:kin122
更多资讯:http://news.searchkit.cn
https://medium.com/%40tobintom ... 7d3f6
2.一文详谈20多种RAG优化方法
https://mp.weixin.qq.com/s/xMsPh8qicRD395vjFR250A
3.使用 Elasticsearch 进行大规模向量搜索的设计原则
https://cloud.tencent.com/deve ... 33788
4.Elasticsearch:结合稀疏、密集和地理字段
https://blog.csdn.net/UbuntuTo ... 70973
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1855期 (2024-07-09)
https://www.promptingguide.ai/zh
2. 一些优秀的prompt示例和优化的技巧
https://github.com/sarthakrastogi/quality-prompts
3. 一组很有参考价值的prompt组织技巧(需要梯子)
https://www.youtube.com/watch?v=2djqKsRXt_Q
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://www.promptingguide.ai/zh
2. 一些优秀的prompt示例和优化的技巧
https://github.com/sarthakrastogi/quality-prompts
3. 一组很有参考价值的prompt组织技巧(需要梯子)
https://www.youtube.com/watch?v=2djqKsRXt_Q
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
【搜索客社区日报】第1854期 (2024-07-08)
https://mp.weixin.qq.com/s/4JuN2xFLv8nrtbBiRG3-kw
2. 认识新的 Google AI 助手 Gemini
https://www.sqlservercentral.c ... emini
3. 理解和实施 Medprompt
https://towardsdatascience.com ... 77c91
4. 人工智能中的性别偏见简介
https://thegradient.pub/gender-bias-in-ai/
5. GraphRAG:用于复杂数据发现的新工具现已在 GitHub 上发布
https://www.microsoft.com/en-u ... thub/
编辑:Muse
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/4JuN2xFLv8nrtbBiRG3-kw
2. 认识新的 Google AI 助手 Gemini
https://www.sqlservercentral.c ... emini
3. 理解和实施 Medprompt
https://towardsdatascience.com ... 77c91
4. 人工智能中的性别偏见简介
https://thegradient.pub/gender-bias-in-ai/
5. GraphRAG:用于复杂数据发现的新工具现已在 GitHub 上发布
https://www.microsoft.com/en-u ... thub/
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »

