

从 OpenAI 停服看中国市场:国产替代崛起的机遇与挑战

一、OpenAI 停服事件背景
OpenAI 自 2020 年推出 GPT-3 以来,在全球范围内引起了极大的反响。其强大的自然语言处理能力使其成为许多企业和开发者的首选工具。然而,2024 年 6 月 25 日,许多中国用户收到了一封来自 OpenAI 的邮件,邮件中明确表示,自 2024 年 7 月 9 日起,OpenAI 将停止对中国内地和香港地区提供 API 服务。

这一事件引发了国内开发者和企业的广泛讨论,特别是在人工智能技术应用逐渐深入的背景下,OpenAI 的停服无疑会对中国市场产生一定的影响。在 AI 技术迅猛发展的当下,许多中国企业和开发者依赖 OpenAI 的 API 进行各种应用的开发。尤其是在大模型技术领域,不少初创公司通过“套壳”OpenAI 技术快速推向市场。所谓“OpenAI 套壳”,是指一些公司仅对 OpenAI 的技术进行表面包装和小改动,而未进行深度创新 。OpenAI CEO 山姆·奥特曼曾明确指出,简单包装 OpenAI 技术的公司难以长久生存。此次 API 服务的终止,意味着这些企业需要寻找新的技术支持,或者在短时间内加速自主研发 。
二、国产替代的挑战与机遇
OpenAI 停止对中国提供 API 服务将对国内 AI 行业带来短期冲击,但从长远来看,这也可能成为推动国内 AI 技术自主创新和研发的契机。国内企业将被迫加大自主研发力度,减少对外部技术的依赖,从而推动国产 AI 技术的发展 。虽然目前国内大模型企业在技术上与 OpenAI 存在一定差距,但已有不少公司在不断赶超。例如,百度的文心大模型、科大讯飞的星火大模型以及清华智谱的 ChatGLM 基础模型,都在性能上逐渐逼近甚至超过了 GPT-4 。从现状来看,国内大模型厂商已经逐步进入了性能提升的关键期,应用场景从办公、生活拓展到医疗、工业、教育等领域。
三、Elasticsearch 国产化替代的需求

Elasticsearch(简称 ES)作为一种开源的分布式搜索和分析引擎,以其强大的搜索能力和高效的数据处理能力,广泛应用于各种大数据和搜索相关业务场景。然而,随着国际政治环境的变化和技术壁垒的加剧,依赖国外技术的风险日益凸显。在这种背景下,推动 Elasticsearch 的国产化替代至关重要,既能保障国家信息安全,也能促进国内技术自主创新和产业发展。
首先,依赖国外技术可能带来技术封锁风险,一旦国外企业因政治或经济原因停止服务,中国企业的业务连续性和数据安全性将受到威胁。推动国产化替代有助于规避这些风险,保障数据安全和业务的稳定运行。国外搜索引擎和数据库系统通常为西方市场优化,未必适合中国市场。例如,Elasticsearch 在处理中文信息时需要额外的插件和调整,而国产替代方案可以更好地适应本地化需求,同时确保数据存储和处理符合国家法律法规。
其次,推动 Elasticsearch 的国产化替代有助于激发国内企业的创新活力,减少对国外技术的依赖,提升在搜索和大数据领域的核心竞争力。采用国产替代方案不仅能够降低企业的技术成本,还能构建自主的技术生态系统,减少对外部的依赖。与此同时国产化替代也有助于提升国内技术人才水平,通过自主研发和技术创新培养出高水平的技术人才,推动技术创新和产业升级。
在性能和安全方面,Elasticsearch 在数据保护和性能方面存在不足。开源版本不具备数据保护功能,用户必须付费获得相关的安全功能。2021 年 Elastic 公司将其开源软件许可证变更为双授权许可,可能带来安全风险。此外,Elasticsearch 在数据读写性能和集群扩展上也存在技术挑战,进一步推动了国产替代的需求。
四、Easysearch:国产替代的优秀范例

在 OpenAI 退出中国市场的背景下,国产技术的重要性日益凸显。作为国产搜索引擎技术的代表,Easysearch 展示了强大的替代潜力。
Easysearch 是一款基于国内自主研发的高性能搜索引擎,其核心引擎基于开源的 Apache Lucene。与 Elasticsearch 相比,Easysearch 不仅提供了相当的功能,还进行了更具针对性的优化。
-
轻量级:Easysearch 的安装包小于 50MB,部署安装简单,适合企业快速上手。
-
跨平台支持:Easysearch 支持主流操作系统和 CPU 架构,兼容国产信创环境,确保多样化环境下的稳定运行。
-
高性能:Easysearch 针对不同的使用场景进行了优化,以更低的硬件成本提供更高的服务性能,从而实现降本增效。
-
安全增强:Easysearch 默认提供完整的企业级安全功能,支持 LDAP/AD 集成,能够对索引、文档和字段级别进行粒度化权限管控,确保数据的安全性和隐私性。
-
稳定可靠:Easysearch 修复了大量内核问题,解决了内存泄露、集群卡顿和查询缓慢等问题,经过严苛的业务环境考验,保证了其稳定性和可靠性。
- 简单易用:Easysearch 提供了企业级管理后台,运营标准化和自动化,使用户能够通过简单的页面操作实现专家级的运维管理工作。
Easysearch 特别注重数据安全和隐私保护,所有数据都在国内处理和存储,符合数据主权要求。这对关注数据安全和隐私的企业尤为重要,能够有效保障数据的安全性和合规性。
Easysearch 致力于构建一个开放的技术生态,通过丰富的开发者资源和支持,为国内开发者提供了一个强大的技术平台。
-
兼容性:Easysearch 兼容 Elasticsearch 的语法,支持 Elasticsearch 原有的 Query DSL 和 SQL 语法,并且兼容现有的 Elasticsearch SDK。这样,企业和开发者可以平滑地迁移到 Easysearch,无需修改现有代码。
-
中文适配:Easysearch 在功能上进行了中文适配,能够更好地支持中文搜索和分析,满足本地化需求。
-
功能增强:Easysearch 不断完善和增强企业级功能,使其在搜索业务场景中保持简洁与易用性,同时提升功能的丰富度和深度。
-
信创适配:Easysearch 支持信创环境,确保在国产环境中也能平稳运行和使用。
- 平滑迁移:Easysearch 基于网关实现了无缝的跨版本迁移与升级,用户可以随时安全回退,确保系统的持续稳定性。
Easysearch 作为国产搜索引擎技术的代表,展示了国产替代的强大潜力。通过自主研发和技术创新,Easysearch 不仅提供了强大的功能和性能,还确保了数据安全和隐私保护。它为国内企业和开发者提供了一个可靠的技术平台,推动了国产技术的发展和应用。未来,随着更多国产技术的崛起,中国将在全球技术领域占据更加重要的地位。
五、结束语
随着 OpenAI 服务在国内的终止,中国 AI 市场迎来了自主创新的机遇。国内企业如百度、科大讯飞等正加速自主研发,缩小技术差距。同时,在搜索引擎领域,极限科技推出 Easysearch 搜索引擎为 Elasticsearch 国产替代提供了新的选择。展望未来,国产技术的持续创新将助力中国在全球技术领域占据更重要的地位。
关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。

作者:Muses
一、OpenAI 停服事件背景
OpenAI 自 2020 年推出 GPT-3 以来,在全球范围内引起了极大的反响。其强大的自然语言处理能力使其成为许多企业和开发者的首选工具。然而,2024 年 6 月 25 日,许多中国用户收到了一封来自 OpenAI 的邮件,邮件中明确表示,自 2024 年 7 月 9 日起,OpenAI 将停止对中国内地和香港地区提供 API 服务。
这一事件引发了国内开发者和企业的广泛讨论,特别是在人工智能技术应用逐渐深入的背景下,OpenAI 的停服无疑会对中国市场产生一定的影响。在 AI 技术迅猛发展的当下,许多中国企业和开发者依赖 OpenAI 的 API 进行各种应用的开发。尤其是在大模型技术领域,不少初创公司通过“套壳”OpenAI 技术快速推向市场。所谓“OpenAI 套壳”,是指一些公司仅对 OpenAI 的技术进行表面包装和小改动,而未进行深度创新 。OpenAI CEO 山姆·奥特曼曾明确指出,简单包装 OpenAI 技术的公司难以长久生存。此次 API 服务的终止,意味着这些企业需要寻找新的技术支持,或者在短时间内加速自主研发 。
二、国产替代的挑战与机遇
OpenAI 停止对中国提供 API 服务将对国内 AI 行业带来短期冲击,但从长远来看,这也可能成为推动国内 AI 技术自主创新和研发的契机。国内企业将被迫加大自主研发力度,减少对外部技术的依赖,从而推动国产 AI 技术的发展 。虽然目前国内大模型企业在技术上与 OpenAI 存在一定差距,但已有不少公司在不断赶超。例如,百度的文心大模型、科大讯飞的星火大模型以及清华智谱的 ChatGLM 基础模型,都在性能上逐渐逼近甚至超过了 GPT-4 。从现状来看,国内大模型厂商已经逐步进入了性能提升的关键期,应用场景从办公、生活拓展到医疗、工业、教育等领域。
三、Elasticsearch 国产化替代的需求
Elasticsearch(简称 ES)作为一种开源的分布式搜索和分析引擎,以其强大的搜索能力和高效的数据处理能力,广泛应用于各种大数据和搜索相关业务场景。然而,随着国际政治环境的变化和技术壁垒的加剧,依赖国外技术的风险日益凸显。在这种背景下,推动 Elasticsearch 的国产化替代至关重要,既能保障国家信息安全,也能促进国内技术自主创新和产业发展。
首先,依赖国外技术可能带来技术封锁风险,一旦国外企业因政治或经济原因停止服务,中国企业的业务连续性和数据安全性将受到威胁。推动国产化替代有助于规避这些风险,保障数据安全和业务的稳定运行。国外搜索引擎和数据库系统通常为西方市场优化,未必适合中国市场。例如,Elasticsearch 在处理中文信息时需要额外的插件和调整,而国产替代方案可以更好地适应本地化需求,同时确保数据存储和处理符合国家法律法规。
其次,推动 Elasticsearch 的国产化替代有助于激发国内企业的创新活力,减少对国外技术的依赖,提升在搜索和大数据领域的核心竞争力。采用国产替代方案不仅能够降低企业的技术成本,还能构建自主的技术生态系统,减少对外部的依赖。与此同时国产化替代也有助于提升国内技术人才水平,通过自主研发和技术创新培养出高水平的技术人才,推动技术创新和产业升级。
在性能和安全方面,Elasticsearch 在数据保护和性能方面存在不足。开源版本不具备数据保护功能,用户必须付费获得相关的安全功能。2021 年 Elastic 公司将其开源软件许可证变更为双授权许可,可能带来安全风险。此外,Elasticsearch 在数据读写性能和集群扩展上也存在技术挑战,进一步推动了国产替代的需求。
四、Easysearch:国产替代的优秀范例
在 OpenAI 退出中国市场的背景下,国产技术的重要性日益凸显。作为国产搜索引擎技术的代表,Easysearch 展示了强大的替代潜力。
Easysearch 是一款基于国内自主研发的高性能搜索引擎,其核心引擎基于开源的 Apache Lucene。与 Elasticsearch 相比,Easysearch 不仅提供了相当的功能,还进行了更具针对性的优化。
-
轻量级:Easysearch 的安装包小于 50MB,部署安装简单,适合企业快速上手。
-
跨平台支持:Easysearch 支持主流操作系统和 CPU 架构,兼容国产信创环境,确保多样化环境下的稳定运行。
-
高性能:Easysearch 针对不同的使用场景进行了优化,以更低的硬件成本提供更高的服务性能,从而实现降本增效。
-
安全增强:Easysearch 默认提供完整的企业级安全功能,支持 LDAP/AD 集成,能够对索引、文档和字段级别进行粒度化权限管控,确保数据的安全性和隐私性。
-
稳定可靠:Easysearch 修复了大量内核问题,解决了内存泄露、集群卡顿和查询缓慢等问题,经过严苛的业务环境考验,保证了其稳定性和可靠性。
- 简单易用:Easysearch 提供了企业级管理后台,运营标准化和自动化,使用户能够通过简单的页面操作实现专家级的运维管理工作。
Easysearch 特别注重数据安全和隐私保护,所有数据都在国内处理和存储,符合数据主权要求。这对关注数据安全和隐私的企业尤为重要,能够有效保障数据的安全性和合规性。
Easysearch 致力于构建一个开放的技术生态,通过丰富的开发者资源和支持,为国内开发者提供了一个强大的技术平台。
-
兼容性:Easysearch 兼容 Elasticsearch 的语法,支持 Elasticsearch 原有的 Query DSL 和 SQL 语法,并且兼容现有的 Elasticsearch SDK。这样,企业和开发者可以平滑地迁移到 Easysearch,无需修改现有代码。
-
中文适配:Easysearch 在功能上进行了中文适配,能够更好地支持中文搜索和分析,满足本地化需求。
-
功能增强:Easysearch 不断完善和增强企业级功能,使其在搜索业务场景中保持简洁与易用性,同时提升功能的丰富度和深度。
-
信创适配:Easysearch 支持信创环境,确保在国产环境中也能平稳运行和使用。
- 平滑迁移:Easysearch 基于网关实现了无缝的跨版本迁移与升级,用户可以随时安全回退,确保系统的持续稳定性。
Easysearch 作为国产搜索引擎技术的代表,展示了国产替代的强大潜力。通过自主研发和技术创新,Easysearch 不仅提供了强大的功能和性能,还确保了数据安全和隐私保护。它为国内企业和开发者提供了一个可靠的技术平台,推动了国产技术的发展和应用。未来,随着更多国产技术的崛起,中国将在全球技术领域占据更加重要的地位。
五、结束语
随着 OpenAI 服务在国内的终止,中国 AI 市场迎来了自主创新的机遇。国内企业如百度、科大讯飞等正加速自主研发,缩小技术差距。同时,在搜索引擎领域,极限科技推出 Easysearch 搜索引擎为 Elasticsearch 国产替代提供了新的选择。展望未来,国产技术的持续创新将助力中国在全球技术领域占据更重要的地位。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »作者:Muses
【搜索客社区日报】第1853期 (2024-07-05)
https://mp.weixin.qq.com/s/J92AOb9HGQDb4FqqJUPGhQ
前沿重器[51] | 聊聊搜索系统4:query理解
https://mp.weixin.qq.com/s/R4njGbiz_yT0wqN4by0uDg
Elasticsearch 是什么?工作原理是怎么样的?
https://mp.weixin.qq.com/s/UXzFg6LbHCifeObiLsXAMA
INFINI Easysearch 尝鲜 Hands on
https://mp.weixin.qq.com/s/OLdD3KkgXK5Q4e2RDzMD8Q
编辑:Fred
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/J92AOb9HGQDb4FqqJUPGhQ
前沿重器[51] | 聊聊搜索系统4:query理解
https://mp.weixin.qq.com/s/R4njGbiz_yT0wqN4by0uDg
Elasticsearch 是什么?工作原理是怎么样的?
https://mp.weixin.qq.com/s/UXzFg6LbHCifeObiLsXAMA
INFINI Easysearch 尝鲜 Hands on
https://mp.weixin.qq.com/s/OLdD3KkgXK5Q4e2RDzMD8Q
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1852期 (2024-07-04)
https://www.warp.dev/blog/agent-mode
2.为什么都放弃了LangChain?
https://mp.weixin.qq.com/s/mtaXOGFw3852F1RsZNqF4Q
3.Kimi 推出上下文缓存
https://mp.weixin.qq.com/s/GCluooWoeMoZHPAtKeiSDA
4.如何用 AI 打造全能网页抓取工具?
https://mp.weixin.qq.com/s/JZskQhlntazMLBVjVt4RmA
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://www.warp.dev/blog/agent-mode
2.为什么都放弃了LangChain?
https://mp.weixin.qq.com/s/mtaXOGFw3852F1RsZNqF4Q
3.Kimi 推出上下文缓存
https://mp.weixin.qq.com/s/GCluooWoeMoZHPAtKeiSDA
4.如何用 AI 打造全能网页抓取工具?
https://mp.weixin.qq.com/s/JZskQhlntazMLBVjVt4RmA
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】 第1851期 (2024-07-03)
https://towardsdatascience.com ... c0e79
2.相似性搜索, Part 2: 乘积量化(搭梯)
https://towardsdatascience.com ... 97701
3.相似性搜索, Part 3: 混合倒排索引和乘积量化(搭梯)
https://towardsdatascience.com ... 765fa
4.相似性搜索, Part 4: Hierarchical Navigable Small World (HNSW)(搭梯)
https://towardsdatascience.com ... 87d37
5.相似性搜索, Part 5: 局部敏感哈希 (LSH)
https://towardsdatascience.com ... 88203
编辑:kin122
更多资讯:http://news.searchkit.cn
https://towardsdatascience.com ... c0e79
2.相似性搜索, Part 2: 乘积量化(搭梯)
https://towardsdatascience.com ... 97701
3.相似性搜索, Part 3: 混合倒排索引和乘积量化(搭梯)
https://towardsdatascience.com ... 765fa
4.相似性搜索, Part 4: Hierarchical Navigable Small World (HNSW)(搭梯)
https://towardsdatascience.com ... 87d37
5.相似性搜索, Part 5: 局部敏感哈希 (LSH)
https://towardsdatascience.com ... 88203
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1850期 (2024-07-02)
https://medium.com/%40sahintal ... 03d94
2. ElasticSearch 和 [Mistral.AI](http://Mistral.AI) 产生的奇妙的化学反应(需要梯子)
https://medium.com/%40felixpra ... 92dbf
3. 一个agent搭建教程,还挺详细的
https://fw7qiozbnjr.feishu.cn/ ... 6an4b
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://medium.com/%40sahintal ... 03d94
2. ElasticSearch 和 [Mistral.AI](http://Mistral.AI) 产生的奇妙的化学反应(需要梯子)
https://medium.com/%40felixpra ... 92dbf
3. 一个agent搭建教程,还挺详细的
https://fw7qiozbnjr.feishu.cn/ ... 6an4b
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
【搜索客社区日报】第1849期 (2024-07-01)
https://mp.weixin.qq.com/s/7dPr0B4-Pb8q9_ouaoM8Cg
2、【ClickHouse招贤贴】Senior Software Engineer (C++)- Mandarin Speaking
https://mp.weixin.qq.com/s/5016wk5nXiH0OoxWmrysOQ
3、相当广泛的数据库技术内容,包括数据库管理、优化、和最新趋势
https://www.databasejournal.com/
4、使用 GPT-4 查找 GPT-4 的错误
https://openai.com/index/findi ... pt-4/
5、Distill,一个结合可视化和互动内容,侧重于解释人工智能和深度学习技术的网站
https://distill.pub/
6、Docker 终极初学者指南
https://machinelearningmastery ... cker/
编辑:Muse
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/7dPr0B4-Pb8q9_ouaoM8Cg
2、【ClickHouse招贤贴】Senior Software Engineer (C++)- Mandarin Speaking
https://mp.weixin.qq.com/s/5016wk5nXiH0OoxWmrysOQ
3、相当广泛的数据库技术内容,包括数据库管理、优化、和最新趋势
https://www.databasejournal.com/
4、使用 GPT-4 查找 GPT-4 的错误
https://openai.com/index/findi ... pt-4/
5、Distill,一个结合可视化和互动内容,侧重于解释人工智能和深度学习技术的网站
https://distill.pub/
6、Docker 终极初学者指南
https://machinelearningmastery ... cker/
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1848期 (2024-06-28)
https://infinilabs.cn/blog/202 ... ases/
2、RAG 标准和腾讯云 ES 的技术实践
https://mp.weixin.qq.com/s/mY2KgCon6T7_OsJThVerRA
3、AI颠覆摩尔定律,未来超线性发展趋势预测,2028达到临界点
https://mp.weixin.qq.com/s/tY1TEFSkKPwYqzlf9whjDQ
4、一个 AI 搜索引擎 ThinkAny
https://mp.weixin.qq.com/s/25eXZi1QgGYIPpXeDzkQrg
编辑:Fred
更多资讯:http://news.searchkit.cn
https://infinilabs.cn/blog/202 ... ases/
2、RAG 标准和腾讯云 ES 的技术实践
https://mp.weixin.qq.com/s/mY2KgCon6T7_OsJThVerRA
3、AI颠覆摩尔定律,未来超线性发展趋势预测,2028达到临界点
https://mp.weixin.qq.com/s/tY1TEFSkKPwYqzlf9whjDQ
4、一个 AI 搜索引擎 ThinkAny
https://mp.weixin.qq.com/s/25eXZi1QgGYIPpXeDzkQrg
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1844期 (2024-06-24)
https://mp.weixin.qq.com/s/D_urlhWTJN-F4tPd7OyYfw
2、国内AI大模型已近80个,哪个最有前途?
https://www.zhihu.com/question ... 23584
3、DB 大咖对话 | 数据要素与人工智能对我国数据库技术和产业的影响
https://www.infoq.cn/article/OVogOUR5HtKoou9x8ugC
4、一文掌握大模型数据准备、模型微调、部署使用全流程
https://blog.csdn.net/qq_35082 ... 83093
编辑:Muse
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/D_urlhWTJN-F4tPd7OyYfw
2、国内AI大模型已近80个,哪个最有前途?
https://www.zhihu.com/question ... 23584
3、DB 大咖对话 | 数据要素与人工智能对我国数据库技术和产业的影响
https://www.infoq.cn/article/OVogOUR5HtKoou9x8ugC
4、一文掌握大模型数据准备、模型微调、部署使用全流程
https://blog.csdn.net/qq_35082 ... 83093
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1847期 (2024-06-27)
https://mp.weixin.qq.com/s/owmZbeGstpMbCBCPaK7tqw
2.从 OpenAI 到其他大模型,使用 Higress 30 秒完成迁移
https://mp.weixin.qq.com/s/flJqyljT8AebrFFKG1LZIg
3.4 万 star!一款快如闪电的开源搜索引擎,太快了!
https://mp.weixin.qq.com/s/udeF1B_LJ3GBOPc6GAniSg
4.我体验完刚发布的Claude3.5,发现最强的是这个新功能
https://mp.weixin.qq.com/s/BojNcrz1gZi1aJ__jJWUmg
5.百度和阿里的前高管都来卷AI搜索了,Genspark 和 kFind 打得过 Perplexity 么?
https://mp.weixin.qq.com/s/-pjSJFJ-tzkg-oPxoX1-Cg
6.干货下载|腾讯云 ES RAG 如何支持微信读书实现AI问书功能?
https://mp.weixin.qq.com/s/QoazoK3RGmZI9ZflnUdM1A
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/owmZbeGstpMbCBCPaK7tqw
2.从 OpenAI 到其他大模型,使用 Higress 30 秒完成迁移
https://mp.weixin.qq.com/s/flJqyljT8AebrFFKG1LZIg
3.4 万 star!一款快如闪电的开源搜索引擎,太快了!
https://mp.weixin.qq.com/s/udeF1B_LJ3GBOPc6GAniSg
4.我体验完刚发布的Claude3.5,发现最强的是这个新功能
https://mp.weixin.qq.com/s/BojNcrz1gZi1aJ__jJWUmg
5.百度和阿里的前高管都来卷AI搜索了,Genspark 和 kFind 打得过 Perplexity 么?
https://mp.weixin.qq.com/s/-pjSJFJ-tzkg-oPxoX1-Cg
6.干货下载|腾讯云 ES RAG 如何支持微信读书实现AI问书功能?
https://mp.weixin.qq.com/s/QoazoK3RGmZI9ZflnUdM1A
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
天命人, 你在吗?快拿走你的《黑神话:悟空》游戏,去开启神话冒险!Easysearch 有奖征文活动来袭!
第一章:神秘的召唤
在一个普通的早晨,INFINI Labs 的办公室里,阳光透过窗户洒进来,给每个人带来了一天的好心情。就在这时,办公室的公告板上突然出现了一张神秘的海报,上面写着:
“天命人, 你在吗?快拿走你的《黑神话:悟空》游戏,去开启神话冒险!”

这张海报立刻吸引了小编的目光,心中升起了一股好奇心,这究竟是怎样的一个活动?而且,《黑神话:悟空》竟然作为奖品!这可是大家期待已久的国产大作!
第二章:拨开迷雾
《黑神话:悟空》 是一款基于《西游记》改编的中国神话动作角色扮演游戏,由中国游戏公司 Game Science 开发。游戏以其出色的画面和创新的玩法在全球范围内引起了广泛关注,是 2024 年最受期待的国产游戏大作,将于 8 月 20 日正式发售。
在游戏中,玩家将化身“天命之人”——孙悟空,踏上惊险刺激的西游冒险之旅。游戏不仅高度还原了《西游记》中的经典场景和角色,还融入了大量原创元素,带来全新的剧情体验。
第三章:踏上征途
作为“天命之人”,你将穿越重重险阻,挑战强大的妖魔鬼怪,探索神秘的古代遗迹,揭开传说背后的秘密。游戏中充满了紧张刺激的战斗场景和丰富多样的任务,让你能沉浸在这个神话般的世界中。
不要犹豫,加入我们,一起踏上征途,成为传说的一部分吧!
INFINI Labs 首期征文活动来袭!!!
无论你是 Easysearch 的老用户,还是第一次听说这个名字,只要你对 INFINI Labs 旗下的 Easysearch 产品感兴趣,或者是希望了解 Easysearch,都可以参加这次活动。
征文主题:
- 使用体验:分享你在学习和使用 Easysearch 的体验感受、反馈。
- 案例实践:分享你在工作使用 Easysearch 的案例和实践经验。
- 版本对比:对比不同版本的 Easysearch,聊聊各自的优劣和特点。
- 性能测评:对 Easysearch 的性能进行详细测评,展示其在各种使用场景下的表现。
- 功能解析:深入剖析 Easysearch 的独特功能,让更多人了解它的强大之处。
- 国产替代:探讨 Easysearch 在 Elasticsearch 国产替代中的重要意义及实战经验。
为了帮助首次了解 Easysearch 的小伙伴,我们还会提供技术支持,让你轻松上手,畅快写作。
第四章:创作你的传奇
无论你是哪个领域的爱好者,这次活动都是你展示才华的绝佳机会。拿起笔,写下你的故事,分享你与 Easysearch 的点滴,畅谈你对《黑神话:悟空》的期待。
我们期待着每一个参与者的精彩作品,也期待着与你一起在《黑神话:悟空》的世界中共赴一场史诗级的冒险!
活动时间:即日起至 8 月 20 日
参与方式:微信联系 INFINI Labs 小编(INFINI-Labs),请在加好友时备注【Easysearch 征文】字样。

奖品设置:
- 一等奖:1 名,《黑神话:悟空》游戏数字豪华版
- 二等奖:2 名,《黑神话:悟空》游戏数字标准版
- 三等奖:若干名,INFINI Labs 定制礼品
拿起你的笔,登录 INFINI Labs 社区,开始你的征文之旅。你的故事,我们在这里等你!
活动补充说明
Easysearch 是什么?
Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个自主可控的轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。 与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。 官网文档:https://infinilabs.cn/docs/latest/easysearch
征文时间
文章征集:即日起 - 8 月 15 日
文章评审:2024 年 8 月 16 日 - 8 月 19 日
获奖公示:2024 年 8 月 20 日
参与方式
添加 INFINI Labs 小助手微信(INFINI-Labs),进行文章投稿(文章形式不限,如:开源中国、CSDN、微信公众号、掘金、知乎、Markdown、Word、在线文档等)。 使用过程中遇到任何问题,欢迎随时反馈给小助手。
征文要求
- 主题要求:围绕 Easysearch,包括但不限于使用心得、案例实践、功能解析、性能测评、数据迁移、容灾、安全、国产替代、我与 Easysearch 的故事等。
- 文章标题:需包含 Easysearch 关键词,如:Easysearch 入门指南 xxx、如何使用 Easysearch xxx、Easysearch 助力 xxx 等。
- 文章内容:正文字数建议 800 以上,且要求内容结构完整、文字通顺、代码规范、无错别字、尽量做到图文并茂。
- 原创要求:提交的稿件需为原创作品,不得侵犯他人知识产权。
- 加分项:有借鉴性、实用性、创新性。
所有提交投稿文章经由 INFINI Labs 征文组委会进行审核,最终分级别选出一批入围作品,并给予相应奖品。
评奖规则
入围文章排名,分为【组委会打分】和【互动拉票得分】
- 组委会打分:100 分值,权重 60 %
- 内容质量(40%):文章内容符合征文主题,具备原创性、独特性、高质量。
- 创新性(20%):文章内容的创新性,鼓励投稿者用 Easysearch 去完成创造性、有挑战性的任务,并拿到一定的结果。
- 实用性(20%):可以对社区其他用户来带来学习和帮助,获得实用的经验。
- 清晰度(20%):整篇文章是否清晰的被叙述出来,有重点,排版美观,图文并茂。
- 互动拉票得分:100 分值,权重 40%。根据阅读量、点赞量、收藏量三个指标聚合计算。
- 阅读量:每 100 次阅读得 10 分,上限 50 分。
- 点赞量:每个赞得 1 分,上限 30 分。
- 收藏量:每个收藏得 2 分,上限 20 分。
- 加权分数相等时,组委会得分高者排名优先。
说明:
- 征文将由参与者自行公开发布或提交 INFINI Labs 转发,发布后至评审前一天互动数据有效。
- 严禁刷量和作弊,比如短时间内异常增长的阅读量或点赞量,组委会有权对刷量和作弊文章取消评奖资格。
- 投稿者可以对评分规则提出疑问或建议,并根据反馈进行适当调整。
奖品设置
奖品分级别设置,根据文章综合评分由高到低排序,详细见下表。
| 奖项 | 人数 | 标准 | 奖品 |
|---|---|---|---|
| 一等奖 | 1 人 | 文章具有代表性及影响力, 综合评分由高到低 |
《黑神话:悟空》数字豪华版一套 |
| 二等奖 | 2 人 | 综合评分由高到低 | 《黑神话:悟空》数字标准版一套 |
| 三等奖 | 若干人 | 综合评分由高到低 | 咖啡杯 / 指甲套装 |

其他说明
- 文章文体不限,可以选择与 Easysearch 相关的任何内容。
- 文章必须原创,凡发现转载、抄袭等侵权行为,取消活动参与资格。
- 参加征文活动的文章作者拥有著作权,INFINI Labs 拥有使用权。
- 本次活动每位用户可投递多篇文章,但同一用户最终只能获奖一次。
- 本次活动最终解释权归 INFINI Labs 所有。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
原文:https://infinilabs.cn/blog/2024/easysearch-essay-competition-wukong/
第一章:神秘的召唤
在一个普通的早晨,INFINI Labs 的办公室里,阳光透过窗户洒进来,给每个人带来了一天的好心情。就在这时,办公室的公告板上突然出现了一张神秘的海报,上面写着:
“天命人, 你在吗?快拿走你的《黑神话:悟空》游戏,去开启神话冒险!”
这张海报立刻吸引了小编的目光,心中升起了一股好奇心,这究竟是怎样的一个活动?而且,《黑神话:悟空》竟然作为奖品!这可是大家期待已久的国产大作!
第二章:拨开迷雾
《黑神话:悟空》 是一款基于《西游记》改编的中国神话动作角色扮演游戏,由中国游戏公司 Game Science 开发。游戏以其出色的画面和创新的玩法在全球范围内引起了广泛关注,是 2024 年最受期待的国产游戏大作,将于 8 月 20 日正式发售。
在游戏中,玩家将化身“天命之人”——孙悟空,踏上惊险刺激的西游冒险之旅。游戏不仅高度还原了《西游记》中的经典场景和角色,还融入了大量原创元素,带来全新的剧情体验。
第三章:踏上征途
作为“天命之人”,你将穿越重重险阻,挑战强大的妖魔鬼怪,探索神秘的古代遗迹,揭开传说背后的秘密。游戏中充满了紧张刺激的战斗场景和丰富多样的任务,让你能沉浸在这个神话般的世界中。
不要犹豫,加入我们,一起踏上征途,成为传说的一部分吧!
INFINI Labs 首期征文活动来袭!!!
无论你是 Easysearch 的老用户,还是第一次听说这个名字,只要你对 INFINI Labs 旗下的 Easysearch 产品感兴趣,或者是希望了解 Easysearch,都可以参加这次活动。
征文主题:
- 使用体验:分享你在学习和使用 Easysearch 的体验感受、反馈。
- 案例实践:分享你在工作使用 Easysearch 的案例和实践经验。
- 版本对比:对比不同版本的 Easysearch,聊聊各自的优劣和特点。
- 性能测评:对 Easysearch 的性能进行详细测评,展示其在各种使用场景下的表现。
- 功能解析:深入剖析 Easysearch 的独特功能,让更多人了解它的强大之处。
- 国产替代:探讨 Easysearch 在 Elasticsearch 国产替代中的重要意义及实战经验。
为了帮助首次了解 Easysearch 的小伙伴,我们还会提供技术支持,让你轻松上手,畅快写作。
第四章:创作你的传奇
无论你是哪个领域的爱好者,这次活动都是你展示才华的绝佳机会。拿起笔,写下你的故事,分享你与 Easysearch 的点滴,畅谈你对《黑神话:悟空》的期待。
我们期待着每一个参与者的精彩作品,也期待着与你一起在《黑神话:悟空》的世界中共赴一场史诗级的冒险!
活动时间:即日起至 8 月 20 日
参与方式:微信联系 INFINI Labs 小编(INFINI-Labs),请在加好友时备注【Easysearch 征文】字样。
奖品设置:
- 一等奖:1 名,《黑神话:悟空》游戏数字豪华版
- 二等奖:2 名,《黑神话:悟空》游戏数字标准版
- 三等奖:若干名,INFINI Labs 定制礼品
拿起你的笔,登录 INFINI Labs 社区,开始你的征文之旅。你的故事,我们在这里等你!
活动补充说明
Easysearch 是什么?
Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个自主可控的轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。 与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。 官网文档:https://infinilabs.cn/docs/latest/easysearch
征文时间
文章征集:即日起 - 8 月 15 日
文章评审:2024 年 8 月 16 日 - 8 月 19 日
获奖公示:2024 年 8 月 20 日
参与方式
添加 INFINI Labs 小助手微信(INFINI-Labs),进行文章投稿(文章形式不限,如:开源中国、CSDN、微信公众号、掘金、知乎、Markdown、Word、在线文档等)。 使用过程中遇到任何问题,欢迎随时反馈给小助手。
征文要求
- 主题要求:围绕 Easysearch,包括但不限于使用心得、案例实践、功能解析、性能测评、数据迁移、容灾、安全、国产替代、我与 Easysearch 的故事等。
- 文章标题:需包含 Easysearch 关键词,如:Easysearch 入门指南 xxx、如何使用 Easysearch xxx、Easysearch 助力 xxx 等。
- 文章内容:正文字数建议 800 以上,且要求内容结构完整、文字通顺、代码规范、无错别字、尽量做到图文并茂。
- 原创要求:提交的稿件需为原创作品,不得侵犯他人知识产权。
- 加分项:有借鉴性、实用性、创新性。
所有提交投稿文章经由 INFINI Labs 征文组委会进行审核,最终分级别选出一批入围作品,并给予相应奖品。
评奖规则
入围文章排名,分为【组委会打分】和【互动拉票得分】
- 组委会打分:100 分值,权重 60 %
- 内容质量(40%):文章内容符合征文主题,具备原创性、独特性、高质量。
- 创新性(20%):文章内容的创新性,鼓励投稿者用 Easysearch 去完成创造性、有挑战性的任务,并拿到一定的结果。
- 实用性(20%):可以对社区其他用户来带来学习和帮助,获得实用的经验。
- 清晰度(20%):整篇文章是否清晰的被叙述出来,有重点,排版美观,图文并茂。
- 互动拉票得分:100 分值,权重 40%。根据阅读量、点赞量、收藏量三个指标聚合计算。
- 阅读量:每 100 次阅读得 10 分,上限 50 分。
- 点赞量:每个赞得 1 分,上限 30 分。
- 收藏量:每个收藏得 2 分,上限 20 分。
- 加权分数相等时,组委会得分高者排名优先。
说明:
- 征文将由参与者自行公开发布或提交 INFINI Labs 转发,发布后至评审前一天互动数据有效。
- 严禁刷量和作弊,比如短时间内异常增长的阅读量或点赞量,组委会有权对刷量和作弊文章取消评奖资格。
- 投稿者可以对评分规则提出疑问或建议,并根据反馈进行适当调整。
奖品设置
奖品分级别设置,根据文章综合评分由高到低排序,详细见下表。
| 奖项 | 人数 | 标准 | 奖品 |
|---|---|---|---|
| 一等奖 | 1 人 | 文章具有代表性及影响力, 综合评分由高到低 |
《黑神话:悟空》数字豪华版一套 |
| 二等奖 | 2 人 | 综合评分由高到低 | 《黑神话:悟空》数字标准版一套 |
| 三等奖 | 若干人 | 综合评分由高到低 | 咖啡杯 / 指甲套装 |
其他说明
- 文章文体不限,可以选择与 Easysearch 相关的任何内容。
- 文章必须原创,凡发现转载、抄袭等侵权行为,取消活动参与资格。
- 参加征文活动的文章作者拥有著作权,INFINI Labs 拥有使用权。
- 本次活动每位用户可投递多篇文章,但同一用户最终只能获奖一次。
- 本次活动最终解释权归 INFINI Labs 所有。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »原文:https://infinilabs.cn/blog/2024/easysearch-essay-competition-wukong/
构建Elasticsearch专家Bot的详细步骤指南
构建Elasticsearch专家Bot的详细步骤指南
步骤1: 文档搜集
- 利用专业工具搜集Elasticsearch 8.13.2版本的官方文档,确保文档的完整性和准确性。如:Elasticsearch文档
步骤2: 知识库建立
- 在coze.cn平台上创建一个专门的知识库,命名清晰,便于管理和识别。
步骤3: 文档上传
- 将搜集到的Elasticsearch文档上传至新创建的知识库,确保文档格式适合后续的检索和分析。
步骤4: Bot创建
- 在coze.cn上创建一个新的Bot,命名为“Elasticsearch专家”,为其设定一个专业且引人注目的形象。
步骤5: 知识库配置
- 将步骤2中的知识库与新创建的Bot进行关联,确保Bot能够访问和利用这些文档资源。
步骤6: 功能插件集成
- 为Bot添加以下功能插件,以提供更全面的服务:
- 必应搜索引擎(Bing Web Search):扩展信息检索范围。
- 代码执行器(CodeRunner):实现代码的即时测试与验证。
- 微信搜索(WeChat Search):增加中文信息源的覆盖。
步骤7: 人设与回复逻辑定制
- 设定Bot的人设,明确其专业领域和能力,如:“我是Elasticsearch的专家,随时准备解答你的疑问。”
- 利用coze平台的AI技术,优化Bot的回复逻辑,确保其回答既准确又具有针对性。
步骤8: 测试与调整
- 在Bot设置完成后,进行全面的测试,确保其能够正确理解和回应各种查询。
- 根据测试反馈,调整Bot的交互逻辑和回答内容,以提高用户满意度。
步骤9: 发布与分享
- 完成所有设置和测试后,点击发布,使Bot正式上线。
- 通过Bot页面的商店功能,将你的“Elasticsearch专家”Bot分享给你的伙伴们,让他们也能享受到这一强大的学习工具。
步骤10: 持续优化与更新
- 定期回顾Bot的表现,根据用户反馈进行持续的优化和功能更新。
- 随着Elasticsearch版本的迭代,及时更新知识库内容,确保Bot提供的信息始终最新。
通过遵循这些步骤,你不仅能够构建一个功能全面的Elasticsearch专家Bot,而且能够确保它随着时间的推移不断进化,满足用户日益增长的需求。这将是一个不仅能提供文档查询,还能执行代码和搜索网络的智能助手,极大地提升你的Elasticsearch学习之旅。
构建Elasticsearch专家Bot的详细步骤指南
步骤1: 文档搜集
- 利用专业工具搜集Elasticsearch 8.13.2版本的官方文档,确保文档的完整性和准确性。如:Elasticsearch文档
步骤2: 知识库建立
- 在coze.cn平台上创建一个专门的知识库,命名清晰,便于管理和识别。
步骤3: 文档上传
- 将搜集到的Elasticsearch文档上传至新创建的知识库,确保文档格式适合后续的检索和分析。
步骤4: Bot创建
- 在coze.cn上创建一个新的Bot,命名为“Elasticsearch专家”,为其设定一个专业且引人注目的形象。
步骤5: 知识库配置
- 将步骤2中的知识库与新创建的Bot进行关联,确保Bot能够访问和利用这些文档资源。
步骤6: 功能插件集成
- 为Bot添加以下功能插件,以提供更全面的服务:
- 必应搜索引擎(Bing Web Search):扩展信息检索范围。
- 代码执行器(CodeRunner):实现代码的即时测试与验证。
- 微信搜索(WeChat Search):增加中文信息源的覆盖。
步骤7: 人设与回复逻辑定制
- 设定Bot的人设,明确其专业领域和能力,如:“我是Elasticsearch的专家,随时准备解答你的疑问。”
- 利用coze平台的AI技术,优化Bot的回复逻辑,确保其回答既准确又具有针对性。
步骤8: 测试与调整
- 在Bot设置完成后,进行全面的测试,确保其能够正确理解和回应各种查询。
- 根据测试反馈,调整Bot的交互逻辑和回答内容,以提高用户满意度。
步骤9: 发布与分享
- 完成所有设置和测试后,点击发布,使Bot正式上线。
- 通过Bot页面的商店功能,将你的“Elasticsearch专家”Bot分享给你的伙伴们,让他们也能享受到这一强大的学习工具。
步骤10: 持续优化与更新
- 定期回顾Bot的表现,根据用户反馈进行持续的优化和功能更新。
- 随着Elasticsearch版本的迭代,及时更新知识库内容,确保Bot提供的信息始终最新。
通过遵循这些步骤,你不仅能够构建一个功能全面的Elasticsearch专家Bot,而且能够确保它随着时间的推移不断进化,满足用户日益增长的需求。这将是一个不仅能提供文档查询,还能执行代码和搜索网络的智能助手,极大地提升你的Elasticsearch学习之旅。
收起阅读 »搜索型数据库的技术发展历程与趋势前瞻
概述
随着数字科技的飞速发展和信息量的爆炸性增长,搜索引擎已成为我们获取信息的首选途径之一,典型的代表厂商如 Google。然而,随着用户需求的不断演变,传统的搜索技术已经无法满足人们对信息的实时性、个性化和多样性的需求。
在企业内部,这种需求更加显著。随着企业数字化转型的持续深化,非结构化数据正日益成为各类组织数据增长的主要来源,也是数据体系中至关重要的组成部分,蕴含着巨大的价值。如何高效地存储和利用非结构化数据的重要性也日益凸显。企业需要更高效地管理和检索内部的海量数据,以支持业务决策和运营需求。

据 IDC 数据预计,到 2025 年,80%的数据将是非结构化数据;而根据 Gartner 的数据显示,从 2019 年到 2024 年,非结构化数据容量预计将增加两倍。然而,目前非结构化数据面临着表现形式多样、管理复杂性高、价值挖掘难度大等诸多挑战。传统的数据库系统往往无法满足企业对实时性和多样性的搜索需求,为了解决这些挑战,以自动分词、倒排索引、相关度计算、向量检索引擎等技术为核心构建的搜索型数据库应运而生。这些数据库自上世纪 90 年代诞生以来不断发展演进,正在成为数据库领域中不可或缺的一个重要分支。
什么是搜索型数据库?
搜索型数据库早期又称全文数据库,或者企业搜索引擎,是一种专门用于存储和管理大规模文本数据,并支持高效的文本搜索和信息检索的数据库系统,不过随着技术不断发展和应用场景日益丰富,目前搜索型数据库不仅仅可以处理长文本数据,也可以处理常见的数值、日期等结构化数据,IP、地理位置信息、图片、音视频等非结构化数据,搜索型数据库的应用范畴不断拓展,正在由支撑业务系统检索加速、IT 运维可观测性、聚合查询分析等向多场景、多模态数据搜索方向发展。

典型的搜索数据库一般具有以下特点:
- 灵活的索引能力:搜索数据库能够处理多种类型的数据,包括文本、图像、音频、视频等非结构化数据。它们采用自动分词、倒排索引等技术,能够高效地处理不同格式和类型的数据,提供灵活的搜索和检索功能。
- 高效的查询性能:搜索数据库具有高效的查询处理能力,能够快速索引和检索大规模的数据。借助优化的索引结构和查询算法,搜索数据库能够在短时间内准确地返回与查询相关的结果,提高用户的搜索效率,常用于解决关系型数据库的高并发检索需求。
- 支持复杂的搜索功能:搜索数据库提供多样化的搜索功能,包括全文检索、模糊搜索、精确搜索、范围搜索、向量搜索、地理信息检索等。用户可以根据不同的需求和场景,灵活地选择和组合不同的搜索功能,以获取符合期望的搜索结果。
- 高性能和可扩展性:搜索数据库具有高性能和可扩展性的特点,能够处理大规模数据和高并发访问。它们采用分布式架构和并行计算技术,实现了水平扩展,能够满足不断增长的数据量和用户访问量的需求。
综上所述,搜索数据库具有处理非结构化数据、实时搜索和更新、多样化的搜索功能、个性化推荐和智能搜索、高性能和可扩展性、全面的搜索结果展示等特点,是处理大规模数据和提供高效搜索服务的重要工具。
搜索型数据库的应用场景
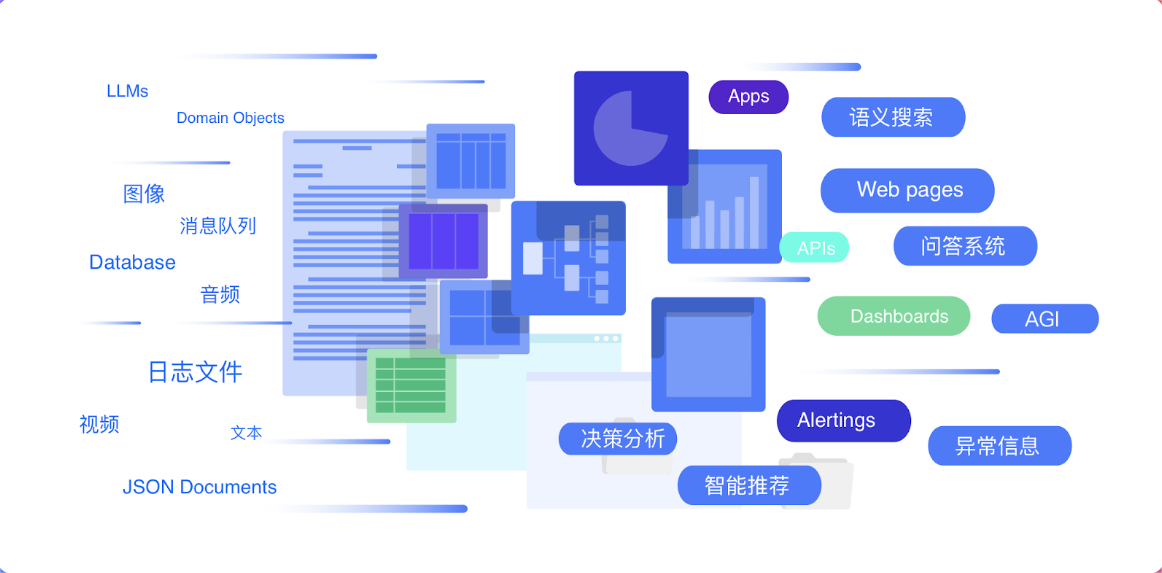
搜索型数据库在各行各业都有广泛的应用,以下是一些典型的应用场景:
- 零售和电商:在零售和电商行业,搜索型数据库被广泛应用于产品搜索和推荐系统中。通过搜索功能,顾客可以轻松查找所需商品,而个性化推荐系统则可以根据用户的搜索历史和行为习惯推荐相关的产品,提高购物体验和交易转化率。
- 医疗保健:在医疗保健行业,搜索型数据库被用于医学文献检索、疾病诊断和药物搜索等方面。医生和研究人员可以利用搜索功能找到相关的医学文献和研究成果,帮助诊断疾病和制定治疗方案。
- 金融服务:在金融服务行业,搜索型数据库被用于金融数据检索、市场分析和投资决策等方面。投资者可以通过搜索功能查找相关的金融数据和市场资讯,帮助他们做出更加准确的投资决策。
- 制造业:在制造业中,搜索型数据库被用于生产过程监控、质量控制和故障诊断等方面。工程师可以利用搜索功能查找相关的生产数据和技术资料,帮助他们解决生产中的问题和挑战。
- 媒体和娱乐:在媒体和娱乐行业,搜索型数据库被用于内容检索、版权管理和用户推荐等方面。用户可以通过搜索功能查找感兴趣的新闻、音乐和视频等内容,而个性化推荐系统则可以根据用户的搜索历史和偏好推荐相关的内容。
- 教育和培训:在教育和培训行业,搜索型数据库被用于学习资源检索、课程管理和学习分析等方面。学生和教师可以利用搜索功能查找相关的学习资源和课程内容,而学习分析系统则可以分析学生的搜索行为和学习表现,为教学提供参考和支持。
- IT 运维可观测性:通过搜索型数据库,可以实时监控系统的运行状况、性能指标和日志数据,帮助运维团队及时发现和解决系统故障、性能问题和异常情况,确保系统的稳定运行。
- 安全监测和威胁检测:利用搜索型数据库对系统的安全日志进行审计和监控,监测用户的访问行为和系统操作,及时发现异常行为和安全事件。同时,搜索型数据库还可以与威胁情报数据集成,对内部日志数据进行关联分析,快速识别并应对各种安全威胁和攻击行为,保障系统和数据的安全。
综上所述,搜索型数据库在各行各业都发挥着重要作用,数据规模从 GB 到 PB 不等,体现在生活中的方方面面,为用户提供了高效、准确和个性化的信息搜索和检索服务,推动了各行业的发展和进步。随着搜索技术的不断创新和发展,搜索型数据库在各行业中的应用将会越来越广泛,并持续为用户带来更加便捷和智能的搜索体验。
搜索型数据库的发展历程
搜索型数据库的发展历程可以概括如下四个阶段:
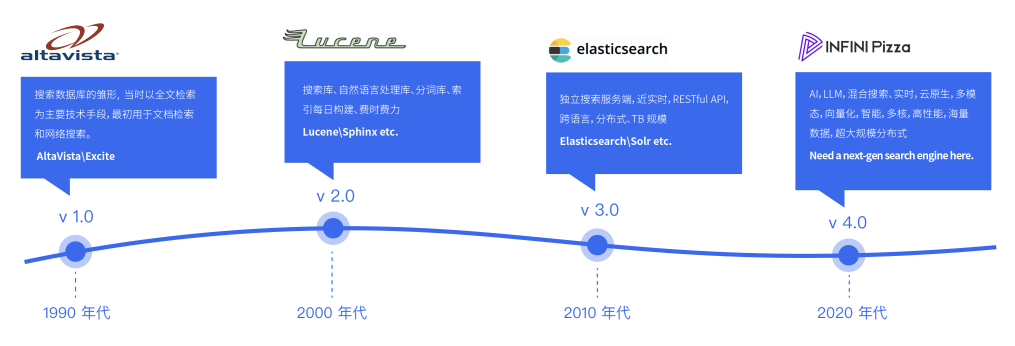
- 起步阶段(1990 年代):搜索数据库的雏形开始于上世纪 90 年代,当时以全文检索为主要技术手段,最初用于文档检索和网络搜索。典型代表包括 AltaVista、Excite 等。
- 技术突破(2000 年代):随着互联网的快速发展,搜索数据库开始应用于更多领域,如电子商务、社交网络等。Lucene、Sphinx 等开源搜索引擎的出现推动了搜索技术的进步。
- 商业化发展(2010 年代):搜索数据库进入商业化阶段,以 Elasticsearch 等为代表的商业搜索引擎崭露头角。企业开始大规模应用搜索数据库来管理和检索大量数据。
-
智能化转型(2020 年代):随着人工智能技术的发展,搜索数据库逐渐向智能化转型,开始引入机器学习、自然语言处理等技术,提供个性化推荐和智能搜索服务。同时,搜索数据库也在更多领域得到应用,如医疗保健、金融服务等。
综上所述,搜索数据库经历了从起步阶段到技术突破、商业化发展再到智能化转型的发展历程,表明了其在信息检索领域的重要性和不断演进的趋势,不并断推动着搜索技术的进步和应用范围的扩展。随着人工智能技术的不断成熟,搜索数据库将会在智能化、个性化等方面取得更大的进步,为用户提供更加优质的搜索体验。
搜索型数据库的发展情况
搜索型数据库市场上已经有不少成熟的产品和厂商,但是总的来说,搜索型数据库的界限范围有点模糊,当然其他数据库也有同样的问题,有很多数据库既是文档数据库,又是多模态数据库,还是向量数据库等等,而常见的搜索型数据库主要诞生于:
- 由搜索引擎内核库发展而来的搜索数据库,如 Elasticsearch
- 由其他数据库扩展而来的搜索数据库,如 Postgres Full-Text Search
- 从零开始整体设计的搜索数据库:如 INFINI Pizza
通过流行的 DB-Engines 的搜索引擎排行榜,可以初探国外主流的搜索型数据库的流行趋势,如下图:

可以看到 Elastic 公司的 Elasticsearch 还是依旧保持强悍,自从 Elasticsearch 十多年前掀翻了 Splunk 的桌子,硬生生的在日志领域杀出一条新路,随后大杀四方,碾压整个搜索行业,霸榜至今。Elastic 商业化增长稳健,2023 年收入超过 10 亿美金。

OpenSearch 是由 AWS 发起的 Elasticsearch 开源分支,起因是由于 Elastic 针对云厂商采取的协议变更为 Elastic+SSPL,OpenSearch 基于 Apache 2.0 协议的 Elasticsearch 7.10 版本衍生而来,目前也具备了一定的用户基础。

Splunk 是一款用于搜索、监控和分析大规模机器生成的数据的软件平台,主要用于日志和安全分析领域,属于商业闭源产品。2023 年中被思科(Cisco) 以 230 亿美元现金收购,瞬间刷爆朋友圈。另外有意思的是,前四名除了 Splunk,底层都是 Lucene 内核。
MarkLogic 成立于 2001 年,自我定位是一个 NoSQL 多模态数据库厂商,也是商业闭源软件,生态成熟但是系统过于复杂,学习曲线较陡, 2023 年初被 Progress Software 以 3.55 亿美元收购算是一个比较好的结局。

当然了,除了榜上的这些产品,还有很多优秀的挑战者正摩拳擦掌,跃跃欲试。如下面的这些项目: vespa、Rockset、Doris,Clickhouse、quickwit、Pinot、SingleStore、qdrant、milvus、algolia、meilisearch、typesense、Manticore Search 等等。这些项目不一定都是自己定位是搜索型数据库,有侧重在 AI 领域的,有侧重在实时分析领域的等等,可谓各有千秋,不过都具备一定的搜索和分析能力,不出意外,基本上每家都要号称吊打 Elasticsearch 一番。
国内搜索型数据库的发展情况
搜索型数据库已经成为企业事实上的重要基础设施,而国内搜索型数据库的发展近些年也是开始得到重视,2023 年初,由中国信通院云计算与大数据研究所牵头,依托中国通信标准化协会大数据技术标准推进委员会,联合拓尔思、极限科技、星环科技等 30 余家企业编制的《搜索型数据库技术要求》正式出炉,该标准已成为行业内搜索型数据库技术选型和产品开发的风向标,极限科技的 INFINI Easysearch 率先通过了该标准。
墨天轮社区也开辟了搜索型数据库的排行榜,共有 6 家企业的产品上榜:

国内搜索型数据库的市场还在起步阶段,厂商和可选的产品也还比较少,不过随着市场的成熟,相信未来将迎来一波高速的发展。
搜索型数据库的趋势前瞻
技术在演变,场景在演变,数据也在演变,搜索数据库领域的发展也呈现出多个显著的趋势,这些趋势将进一步推动搜索技术的演进和应用范围的扩展。笔者观测到的主要的发展趋势包括以下方向供参考:
1. 趋势一:实时搜索与分析
-
实时搜索是搜索数据库领域的一个重要发展趋势,业务应用都在朝实时方向演进,用户对信息的即时性需求不断增加,要求搜索结果能够及时反映最新的数据和内容。
-
实时搜索技术通过实时索引和实时更新机制,能够实现快速的数据检索和更新,提供与时俱进的搜索结果,满足用户对信息的即时性需求。
- 目前以 Lucene 为内核的搜索型数据库基本上都只能做到 NRT(近实时)搜索,并且频繁更新带来的挑战和资源的浪费比较高,如果能做到更高效的实时性,可以大大提升用户的搜索体验和实时决策能力。
2. 趋势二:多模态混合搜索
-
多模态搜索是指在搜索过程中同时考虑多种信息形式,如文本、图像、视频等,以提高搜索结果的准确性和全面性。
-
这种技术能够通过分析和理解多种信息形式之间的关联性,为用户提供更加全面、丰富的搜索结果,适用于需要综合不同媒体形式的搜索场景。
- 现实世界的数据越来越复杂化,非结构化数据的利用的场景也越来越多,多模态可以为业务提供更加灵活的分析和探索能力,混合搜索的能力非常具有吸引力。
3. 趋势三:AI 智能语义搜索
-
大模型、AI 智能搜索技术的探索可谓是一日千里,通过利用人工智能技术来实现搜索过程中的智能化、语义化和个性化,结合自然语言处理、机器学习等技术分析用户意图,提供更加智能、个性化的搜索服务。
-
随着大模型的兴起,搜索数据库开始采用像 RAG(Retriever-Reader for Generative Question Answering)这样的大型预训练模型来提升搜索的效果。RAG 模型结合了检索器和阅读器的功能,能够实现更加准确和全面的搜索结果,为用户提供更加智能和个性化的搜索服务。
- 搜索型数据库可谓是 AI 落地最好的是试验田,Elasticsearch 通过拥抱 AI 和大模型,目前股价又重回巅峰,可喜可贺。
4. 趋势四:云原生、存算分离、Serverless
-
随着云计算技术的发展,搜索数据库正逐渐向云原生架构转变。云原生搜索数据库利用容器化、微服务架构等技术,实现了更高的灵活性、可扩展性和容错性,为企业提供了更加稳定和高效的搜索服务,并且成本更低,更加弹性。
-
存算分离是搜索数据库发展的另一重要趋势。通过将存储与计算分离,搜索数据库可以更好地适应数据存储和计算需求的变化,提高系统的性能和效率。存算分离技术使得搜索数据库能够实现更高的并发访问和更快的数据处理速度,为用户提供更加流畅和稳定的搜索体验。
- Serverless 提供开箱即用的体验,成本更低,使用更加灵活,也是目前很多搜索服务提供商正在积极探索的方向。
5. 趋势五:增强现实搜索
- 随着增强现实技术的发展,尤其是 Apple 发布的头戴式 Vision Pro,一部革命性的空间运算设备,将数位内容无缝融入实体世界,而搜索技术也将逐渐与增强现实相结合,为用户提供更加直观和沉浸式的搜索体验。增强现实搜索能够将搜索结果与现实世界相结合,结合 AI 技术为用户提供更加个性化和便捷的搜索服务,这是一个全新的领域,也意味着巨大的机会。
6. 趋势六:现代硬件的高效利用
-
现代硬件及软件运行环境已发生翻天覆地的变化, 片上计算,边缘计算,FPGA,DPU,GPU,一台设备几百核上 TB 内存已经成为现实,可运行之上的软件却还是停留在几十年前的架构。 如 Elasticsearch 其核心 Lucene(及类似实现) 是在 1997 建立的,距今已有 27 年了,虽然也在与时俱进,但是部分架构和设计理念已不具备先进性。
- 在现代的硬件上采用更先进的算法,更新的数据结构、更新的设计理论,利用最新的 CPU 指令集,向量化,批处理,充分发挥多核、大内存和 SSD 的优势,从而达到更高的效率,更低的成本,去解决之前不可能实现的问题,大有可为,也是下一代引擎需要关注的方向。

随着各类数据库功能的边界越来越模糊,应用场景高度交叉重叠,市场竞争也变得白热化,不过笔者认为垂直领域的搜索型数据库机会还是很大,而想做大而全的数据库产品已经没有太多的市场生存空间,一定要在垂直领域有特别专注的地方,我们 INFINI Labs 正在基于 Rust 研发的下一代搜索引擎 INFINI Pizza,就侧重于面向终端用户场景,解决海量数据更新情况下,同时满足高并发和低延迟的核心业务实时检索需求。
总结
综上所述,搜索数据库领域正处于快速发展的阶段。随着互联网数据量的不断增长和用户需求的不断变化,搜索数据库技术将不断创新和进步,以满足用户对信息获取的更加即时、个性化和多样化的需求。未来,随着人工智能技术的进一步发展和应用,搜索数据库将会变得更加智能化、普及化和多样化,为用户提供更加高效、准确和个性化的搜索服务,推动互联网信息的更加便捷获取和利用。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
概述
随着数字科技的飞速发展和信息量的爆炸性增长,搜索引擎已成为我们获取信息的首选途径之一,典型的代表厂商如 Google。然而,随着用户需求的不断演变,传统的搜索技术已经无法满足人们对信息的实时性、个性化和多样性的需求。
在企业内部,这种需求更加显著。随着企业数字化转型的持续深化,非结构化数据正日益成为各类组织数据增长的主要来源,也是数据体系中至关重要的组成部分,蕴含着巨大的价值。如何高效地存储和利用非结构化数据的重要性也日益凸显。企业需要更高效地管理和检索内部的海量数据,以支持业务决策和运营需求。
据 IDC 数据预计,到 2025 年,80%的数据将是非结构化数据;而根据 Gartner 的数据显示,从 2019 年到 2024 年,非结构化数据容量预计将增加两倍。然而,目前非结构化数据面临着表现形式多样、管理复杂性高、价值挖掘难度大等诸多挑战。传统的数据库系统往往无法满足企业对实时性和多样性的搜索需求,为了解决这些挑战,以自动分词、倒排索引、相关度计算、向量检索引擎等技术为核心构建的搜索型数据库应运而生。这些数据库自上世纪 90 年代诞生以来不断发展演进,正在成为数据库领域中不可或缺的一个重要分支。
什么是搜索型数据库?
搜索型数据库早期又称全文数据库,或者企业搜索引擎,是一种专门用于存储和管理大规模文本数据,并支持高效的文本搜索和信息检索的数据库系统,不过随着技术不断发展和应用场景日益丰富,目前搜索型数据库不仅仅可以处理长文本数据,也可以处理常见的数值、日期等结构化数据,IP、地理位置信息、图片、音视频等非结构化数据,搜索型数据库的应用范畴不断拓展,正在由支撑业务系统检索加速、IT 运维可观测性、聚合查询分析等向多场景、多模态数据搜索方向发展。
典型的搜索数据库一般具有以下特点:
- 灵活的索引能力:搜索数据库能够处理多种类型的数据,包括文本、图像、音频、视频等非结构化数据。它们采用自动分词、倒排索引等技术,能够高效地处理不同格式和类型的数据,提供灵活的搜索和检索功能。
- 高效的查询性能:搜索数据库具有高效的查询处理能力,能够快速索引和检索大规模的数据。借助优化的索引结构和查询算法,搜索数据库能够在短时间内准确地返回与查询相关的结果,提高用户的搜索效率,常用于解决关系型数据库的高并发检索需求。
- 支持复杂的搜索功能:搜索数据库提供多样化的搜索功能,包括全文检索、模糊搜索、精确搜索、范围搜索、向量搜索、地理信息检索等。用户可以根据不同的需求和场景,灵活地选择和组合不同的搜索功能,以获取符合期望的搜索结果。
- 高性能和可扩展性:搜索数据库具有高性能和可扩展性的特点,能够处理大规模数据和高并发访问。它们采用分布式架构和并行计算技术,实现了水平扩展,能够满足不断增长的数据量和用户访问量的需求。
综上所述,搜索数据库具有处理非结构化数据、实时搜索和更新、多样化的搜索功能、个性化推荐和智能搜索、高性能和可扩展性、全面的搜索结果展示等特点,是处理大规模数据和提供高效搜索服务的重要工具。
搜索型数据库的应用场景
搜索型数据库在各行各业都有广泛的应用,以下是一些典型的应用场景:
- 零售和电商:在零售和电商行业,搜索型数据库被广泛应用于产品搜索和推荐系统中。通过搜索功能,顾客可以轻松查找所需商品,而个性化推荐系统则可以根据用户的搜索历史和行为习惯推荐相关的产品,提高购物体验和交易转化率。
- 医疗保健:在医疗保健行业,搜索型数据库被用于医学文献检索、疾病诊断和药物搜索等方面。医生和研究人员可以利用搜索功能找到相关的医学文献和研究成果,帮助诊断疾病和制定治疗方案。
- 金融服务:在金融服务行业,搜索型数据库被用于金融数据检索、市场分析和投资决策等方面。投资者可以通过搜索功能查找相关的金融数据和市场资讯,帮助他们做出更加准确的投资决策。
- 制造业:在制造业中,搜索型数据库被用于生产过程监控、质量控制和故障诊断等方面。工程师可以利用搜索功能查找相关的生产数据和技术资料,帮助他们解决生产中的问题和挑战。
- 媒体和娱乐:在媒体和娱乐行业,搜索型数据库被用于内容检索、版权管理和用户推荐等方面。用户可以通过搜索功能查找感兴趣的新闻、音乐和视频等内容,而个性化推荐系统则可以根据用户的搜索历史和偏好推荐相关的内容。
- 教育和培训:在教育和培训行业,搜索型数据库被用于学习资源检索、课程管理和学习分析等方面。学生和教师可以利用搜索功能查找相关的学习资源和课程内容,而学习分析系统则可以分析学生的搜索行为和学习表现,为教学提供参考和支持。
- IT 运维可观测性:通过搜索型数据库,可以实时监控系统的运行状况、性能指标和日志数据,帮助运维团队及时发现和解决系统故障、性能问题和异常情况,确保系统的稳定运行。
- 安全监测和威胁检测:利用搜索型数据库对系统的安全日志进行审计和监控,监测用户的访问行为和系统操作,及时发现异常行为和安全事件。同时,搜索型数据库还可以与威胁情报数据集成,对内部日志数据进行关联分析,快速识别并应对各种安全威胁和攻击行为,保障系统和数据的安全。
综上所述,搜索型数据库在各行各业都发挥着重要作用,数据规模从 GB 到 PB 不等,体现在生活中的方方面面,为用户提供了高效、准确和个性化的信息搜索和检索服务,推动了各行业的发展和进步。随着搜索技术的不断创新和发展,搜索型数据库在各行业中的应用将会越来越广泛,并持续为用户带来更加便捷和智能的搜索体验。
搜索型数据库的发展历程
搜索型数据库的发展历程可以概括如下四个阶段:
- 起步阶段(1990 年代):搜索数据库的雏形开始于上世纪 90 年代,当时以全文检索为主要技术手段,最初用于文档检索和网络搜索。典型代表包括 AltaVista、Excite 等。
- 技术突破(2000 年代):随着互联网的快速发展,搜索数据库开始应用于更多领域,如电子商务、社交网络等。Lucene、Sphinx 等开源搜索引擎的出现推动了搜索技术的进步。
- 商业化发展(2010 年代):搜索数据库进入商业化阶段,以 Elasticsearch 等为代表的商业搜索引擎崭露头角。企业开始大规模应用搜索数据库来管理和检索大量数据。
-
智能化转型(2020 年代):随着人工智能技术的发展,搜索数据库逐渐向智能化转型,开始引入机器学习、自然语言处理等技术,提供个性化推荐和智能搜索服务。同时,搜索数据库也在更多领域得到应用,如医疗保健、金融服务等。
综上所述,搜索数据库经历了从起步阶段到技术突破、商业化发展再到智能化转型的发展历程,表明了其在信息检索领域的重要性和不断演进的趋势,不并断推动着搜索技术的进步和应用范围的扩展。随着人工智能技术的不断成熟,搜索数据库将会在智能化、个性化等方面取得更大的进步,为用户提供更加优质的搜索体验。
搜索型数据库的发展情况
搜索型数据库市场上已经有不少成熟的产品和厂商,但是总的来说,搜索型数据库的界限范围有点模糊,当然其他数据库也有同样的问题,有很多数据库既是文档数据库,又是多模态数据库,还是向量数据库等等,而常见的搜索型数据库主要诞生于:
- 由搜索引擎内核库发展而来的搜索数据库,如 Elasticsearch
- 由其他数据库扩展而来的搜索数据库,如 Postgres Full-Text Search
- 从零开始整体设计的搜索数据库:如 INFINI Pizza
通过流行的 DB-Engines 的搜索引擎排行榜,可以初探国外主流的搜索型数据库的流行趋势,如下图:
可以看到 Elastic 公司的 Elasticsearch 还是依旧保持强悍,自从 Elasticsearch 十多年前掀翻了 Splunk 的桌子,硬生生的在日志领域杀出一条新路,随后大杀四方,碾压整个搜索行业,霸榜至今。Elastic 商业化增长稳健,2023 年收入超过 10 亿美金。
OpenSearch 是由 AWS 发起的 Elasticsearch 开源分支,起因是由于 Elastic 针对云厂商采取的协议变更为 Elastic+SSPL,OpenSearch 基于 Apache 2.0 协议的 Elasticsearch 7.10 版本衍生而来,目前也具备了一定的用户基础。
Splunk 是一款用于搜索、监控和分析大规模机器生成的数据的软件平台,主要用于日志和安全分析领域,属于商业闭源产品。2023 年中被思科(Cisco) 以 230 亿美元现金收购,瞬间刷爆朋友圈。另外有意思的是,前四名除了 Splunk,底层都是 Lucene 内核。
MarkLogic 成立于 2001 年,自我定位是一个 NoSQL 多模态数据库厂商,也是商业闭源软件,生态成熟但是系统过于复杂,学习曲线较陡, 2023 年初被 Progress Software 以 3.55 亿美元收购算是一个比较好的结局。
当然了,除了榜上的这些产品,还有很多优秀的挑战者正摩拳擦掌,跃跃欲试。如下面的这些项目: vespa、Rockset、Doris,Clickhouse、quickwit、Pinot、SingleStore、qdrant、milvus、algolia、meilisearch、typesense、Manticore Search 等等。这些项目不一定都是自己定位是搜索型数据库,有侧重在 AI 领域的,有侧重在实时分析领域的等等,可谓各有千秋,不过都具备一定的搜索和分析能力,不出意外,基本上每家都要号称吊打 Elasticsearch 一番。
国内搜索型数据库的发展情况
搜索型数据库已经成为企业事实上的重要基础设施,而国内搜索型数据库的发展近些年也是开始得到重视,2023 年初,由中国信通院云计算与大数据研究所牵头,依托中国通信标准化协会大数据技术标准推进委员会,联合拓尔思、极限科技、星环科技等 30 余家企业编制的《搜索型数据库技术要求》正式出炉,该标准已成为行业内搜索型数据库技术选型和产品开发的风向标,极限科技的 INFINI Easysearch 率先通过了该标准。
墨天轮社区也开辟了搜索型数据库的排行榜,共有 6 家企业的产品上榜:
国内搜索型数据库的市场还在起步阶段,厂商和可选的产品也还比较少,不过随着市场的成熟,相信未来将迎来一波高速的发展。
搜索型数据库的趋势前瞻
技术在演变,场景在演变,数据也在演变,搜索数据库领域的发展也呈现出多个显著的趋势,这些趋势将进一步推动搜索技术的演进和应用范围的扩展。笔者观测到的主要的发展趋势包括以下方向供参考:
1. 趋势一:实时搜索与分析
-
实时搜索是搜索数据库领域的一个重要发展趋势,业务应用都在朝实时方向演进,用户对信息的即时性需求不断增加,要求搜索结果能够及时反映最新的数据和内容。
-
实时搜索技术通过实时索引和实时更新机制,能够实现快速的数据检索和更新,提供与时俱进的搜索结果,满足用户对信息的即时性需求。
- 目前以 Lucene 为内核的搜索型数据库基本上都只能做到 NRT(近实时)搜索,并且频繁更新带来的挑战和资源的浪费比较高,如果能做到更高效的实时性,可以大大提升用户的搜索体验和实时决策能力。
2. 趋势二:多模态混合搜索
-
多模态搜索是指在搜索过程中同时考虑多种信息形式,如文本、图像、视频等,以提高搜索结果的准确性和全面性。
-
这种技术能够通过分析和理解多种信息形式之间的关联性,为用户提供更加全面、丰富的搜索结果,适用于需要综合不同媒体形式的搜索场景。
- 现实世界的数据越来越复杂化,非结构化数据的利用的场景也越来越多,多模态可以为业务提供更加灵活的分析和探索能力,混合搜索的能力非常具有吸引力。
3. 趋势三:AI 智能语义搜索
-
大模型、AI 智能搜索技术的探索可谓是一日千里,通过利用人工智能技术来实现搜索过程中的智能化、语义化和个性化,结合自然语言处理、机器学习等技术分析用户意图,提供更加智能、个性化的搜索服务。
-
随着大模型的兴起,搜索数据库开始采用像 RAG(Retriever-Reader for Generative Question Answering)这样的大型预训练模型来提升搜索的效果。RAG 模型结合了检索器和阅读器的功能,能够实现更加准确和全面的搜索结果,为用户提供更加智能和个性化的搜索服务。
- 搜索型数据库可谓是 AI 落地最好的是试验田,Elasticsearch 通过拥抱 AI 和大模型,目前股价又重回巅峰,可喜可贺。
4. 趋势四:云原生、存算分离、Serverless
-
随着云计算技术的发展,搜索数据库正逐渐向云原生架构转变。云原生搜索数据库利用容器化、微服务架构等技术,实现了更高的灵活性、可扩展性和容错性,为企业提供了更加稳定和高效的搜索服务,并且成本更低,更加弹性。
-
存算分离是搜索数据库发展的另一重要趋势。通过将存储与计算分离,搜索数据库可以更好地适应数据存储和计算需求的变化,提高系统的性能和效率。存算分离技术使得搜索数据库能够实现更高的并发访问和更快的数据处理速度,为用户提供更加流畅和稳定的搜索体验。
- Serverless 提供开箱即用的体验,成本更低,使用更加灵活,也是目前很多搜索服务提供商正在积极探索的方向。
5. 趋势五:增强现实搜索
- 随着增强现实技术的发展,尤其是 Apple 发布的头戴式 Vision Pro,一部革命性的空间运算设备,将数位内容无缝融入实体世界,而搜索技术也将逐渐与增强现实相结合,为用户提供更加直观和沉浸式的搜索体验。增强现实搜索能够将搜索结果与现实世界相结合,结合 AI 技术为用户提供更加个性化和便捷的搜索服务,这是一个全新的领域,也意味着巨大的机会。
6. 趋势六:现代硬件的高效利用
-
现代硬件及软件运行环境已发生翻天覆地的变化, 片上计算,边缘计算,FPGA,DPU,GPU,一台设备几百核上 TB 内存已经成为现实,可运行之上的软件却还是停留在几十年前的架构。 如 Elasticsearch 其核心 Lucene(及类似实现) 是在 1997 建立的,距今已有 27 年了,虽然也在与时俱进,但是部分架构和设计理念已不具备先进性。
- 在现代的硬件上采用更先进的算法,更新的数据结构、更新的设计理论,利用最新的 CPU 指令集,向量化,批处理,充分发挥多核、大内存和 SSD 的优势,从而达到更高的效率,更低的成本,去解决之前不可能实现的问题,大有可为,也是下一代引擎需要关注的方向。
随着各类数据库功能的边界越来越模糊,应用场景高度交叉重叠,市场竞争也变得白热化,不过笔者认为垂直领域的搜索型数据库机会还是很大,而想做大而全的数据库产品已经没有太多的市场生存空间,一定要在垂直领域有特别专注的地方,我们 INFINI Labs 正在基于 Rust 研发的下一代搜索引擎 INFINI Pizza,就侧重于面向终端用户场景,解决海量数据更新情况下,同时满足高并发和低延迟的核心业务实时检索需求。
总结
综上所述,搜索数据库领域正处于快速发展的阶段。随着互联网数据量的不断增长和用户需求的不断变化,搜索数据库技术将不断创新和进步,以满足用户对信息获取的更加即时、个性化和多样化的需求。未来,随着人工智能技术的进一步发展和应用,搜索数据库将会变得更加智能化、普及化和多样化,为用户提供更加高效、准确和个性化的搜索服务,推动互联网信息的更加便捷获取和利用。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »
【搜索客社区日报】 第1846期 (2024-06-26)
https://jeongiitae.medium.com/ ... 2c10c
2.HanLP在海外文章的应用
https://mp.weixin.qq.com/s/uhWC7ywcTqsgW-6G8GALbQ
3. Elasticsearch:倒数排序融合 - Reciprocal rank fusion - 8.14
https://blog.csdn.net/UbuntuTo ... 60065
编辑:kin122
更多资讯:http://news.searchkit.cn
https://jeongiitae.medium.com/ ... 2c10c
2.HanLP在海外文章的应用
https://mp.weixin.qq.com/s/uhWC7ywcTqsgW-6G8GALbQ
3. Elasticsearch:倒数排序融合 - Reciprocal rank fusion - 8.14
https://blog.csdn.net/UbuntuTo ... 60065
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1845期 (2024-06-25)
https://github.com/karpathy/LLM101n
2. 可以拿来私有部署的llm外壳
https://github.com/lobehub/lobe-chat
3. AI 领域宝藏博主宝玉老师的博客,超多很实用的干货内容
https://baoyu.io/blog
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://github.com/karpathy/LLM101n
2. 可以拿来私有部署的llm外壳
https://github.com/lobehub/lobe-chat
3. AI 领域宝藏博主宝玉老师的博客,超多很实用的干货内容
https://baoyu.io/blog
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
喜报!极限科技新获得一项国家发明专利授权:“搜索数据库的正排索引处理方法、装置、介质和设备”
近日,极限数据(北京)科技有限公司(简称:极限科技)新获得一项国家发明专利授权,专利名为 “搜索数据库的正排索引处理方法、装置、介质和设备”,专利号:ZL 2024 1 0479400.9,授权日为 2024 年 6 月 21 日,标志着极限科技在数据库搜索技术领域的自主创新能力再次得到国家级认可。

创新技术,提升搜索效率
该专利的核心创新点在于将正排索引与倒排索引在逻辑上进行分离,通过专门设计的正排索引结构,实现了文档的高效写入。这种创新方法不仅提高了搜索过程的灵活性,而且使得正排索引结构能够支持实时搜索,避免了传统搜索技术中必须等待数据落盘后才能进行搜索的限制,从而显著提升了搜索效率。
自主研发,持续创新
极限科技自成立以来,始终坚持自主研发和技术创新的道路。公司的研发团队由一批经验丰富的工程师组成,他们在数据库技术、搜索引擎和大数据处理等领域拥有深厚的专业知识和实践经验。此次专利的获得,是极限科技在自主研发道路上的又一重要里程碑,展现了公司在技术创新方面的持续努力和卓越成就。
行业领先,未来可期
极限科技的这项发明专利不仅为公司带来了技术上的突破,也为整个行业的发展提供了新的思路和方向。随着大数据时代的到来,高效的搜索技术对于信息的快速获取和处理至关重要。极限科技的这一创新成果,有望推动相关行业的技术进步,为用户带来更加流畅和精准的搜索体验。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
近日,极限数据(北京)科技有限公司(简称:极限科技)新获得一项国家发明专利授权,专利名为 “搜索数据库的正排索引处理方法、装置、介质和设备”,专利号:ZL 2024 1 0479400.9,授权日为 2024 年 6 月 21 日,标志着极限科技在数据库搜索技术领域的自主创新能力再次得到国家级认可。
创新技术,提升搜索效率
该专利的核心创新点在于将正排索引与倒排索引在逻辑上进行分离,通过专门设计的正排索引结构,实现了文档的高效写入。这种创新方法不仅提高了搜索过程的灵活性,而且使得正排索引结构能够支持实时搜索,避免了传统搜索技术中必须等待数据落盘后才能进行搜索的限制,从而显著提升了搜索效率。
自主研发,持续创新
极限科技自成立以来,始终坚持自主研发和技术创新的道路。公司的研发团队由一批经验丰富的工程师组成,他们在数据库技术、搜索引擎和大数据处理等领域拥有深厚的专业知识和实践经验。此次专利的获得,是极限科技在自主研发道路上的又一重要里程碑,展现了公司在技术创新方面的持续努力和卓越成就。
行业领先,未来可期
极限科技的这项发明专利不仅为公司带来了技术上的突破,也为整个行业的发展提供了新的思路和方向。随着大数据时代的到来,高效的搜索技术对于信息的快速获取和处理至关重要。极限科技的这一创新成果,有望推动相关行业的技术进步,为用户带来更加流畅和精准的搜索体验。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »

