

【搜索客社区日报】第1843期 (2024-06-21)
https://mp.weixin.qq.com/s/HjvPTPdkBvqJrpomDvZjRg
2、Elasticsearch 的基数统计在大数据量下有什么办法能做到 100% 准确度吗?
https://mp.weixin.qq.com/s/iVqIKAwFFKEOkw5bL3QfGA
3、How AI Will Change the World of Search
https://opster.com/blogs/how-a ... arch/
4、INFINI Labs 推出开源项目与教育机构免费许可证计划,可申请 Easysearch 等产品企业版。
https://infinilabs.cn/community/
编辑:Fred
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/HjvPTPdkBvqJrpomDvZjRg
2、Elasticsearch 的基数统计在大数据量下有什么办法能做到 100% 准确度吗?
https://mp.weixin.qq.com/s/iVqIKAwFFKEOkw5bL3QfGA
3、How AI Will Change the World of Search
https://opster.com/blogs/how-a ... arch/
4、INFINI Labs 推出开源项目与教育机构免费许可证计划,可申请 Easysearch 等产品企业版。
https://infinilabs.cn/community/
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1842期 (2024-06-20)
https://mp.weixin.qq.com/s/VX1IToCVP4nNuqMVM8J45w
2.与 Cohere 和 Elastic 一起探索可能的艺术(需要梯子)
https://www.youtube.com/watch?v=P3NUAfVuRns
3.让我看看是谁写的慢查询
https://www.elastic.co/blog/wh ... -14-0
4.试完刚刚开源的Stable Diffusion3,我觉得能打败它的只有下一代
https://mp.weixin.qq.com/s/EmKIfmCiTTwSePyb3EHrSA
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/VX1IToCVP4nNuqMVM8J45w
2.与 Cohere 和 Elastic 一起探索可能的艺术(需要梯子)
https://www.youtube.com/watch?v=P3NUAfVuRns
3.让我看看是谁写的慢查询
https://www.elastic.co/blog/wh ... -14-0
4.试完刚刚开源的Stable Diffusion3,我觉得能打败它的只有下一代
https://mp.weixin.qq.com/s/EmKIfmCiTTwSePyb3EHrSA
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
INFINI Labs 助力开源与教育:免费许可证计划全面升级

在数字化浪潮席卷全球的今天,INFINI Labs 深刻认识到开源项目和教育机构在技术创新与人才培养中的核心作用。因此,我们郑重推出全新升级的免费许可证计划,旨在全球范围内为开源社区和教育界提供有力支持,共同推动软件生态的繁荣与进步。
一、产品实力与荣誉
1.INFINI Pizza:实时搜索的新纪元

- 在第十三届“数据技术嘉年华”(DTC2024)上,INFINI Labs 发布了划时代的搜索引擎——INFINI Pizza,标志着搜索型数据库迈入实时搜索的新纪元。
- INFINI Pizza 凭借先进的设计理念与架构,以及独有的专利技术,实现了对海量数据的无限伸缩,提供高效、准确的实时数据搜索能力
2.行业标杆案例
- INFINI Labs 荣获中国信通院大数据“星河”标杆案例,其中移动云搜索数据库案例更是荣选为数据库标杆案例。
- 该案例基于移动云 Easysearch 数据库,通过创新的多集群协同模式,实现了数据高性能存取,展现出极高的经济价值与社会价值。
3.国家发明专利认可
- INFINI Labs 的多项自主研发技术获得国家发明专利授权,这些成果彰显了公司在大数据领域的技术实力与创新精神。
二、品牌与行业地位
-
INFINI Labs 作为搜索型数据库产品领域的领军企业,积极参与行业标准的制定与推动。
- 其核心产品 INFINI Easysearch 荣获信通院首批可信搜索型数据库产品证书,再次印证了公司在行业中的领先地位。
三、产品介绍

-
INFINI Easysearch:作为 Elasticsearch 的国产化替代方案,提供高度兼容性与卓越性能,满足企业级需求。
-
INFINI Console:轻量级多集群、跨版本搜索基础设施统一管控平台,助力企业高效管理搜索集群。
-
INFINI Gateway:专为 Elasticsearch 打造的高性能应用网关,提供丰富的功能特性与卓越性能。
-
INFINI Loadgen:支持多种搜索引擎的轻量级压测工具,为企业提供强大的数据加载与测试能力。
- INFINI Pizza:引领实时搜索时代的新星,为企业提供高效、准确的实时数据搜索解决方案。
四、免费许可证计划
1.教育机构学术许可证
-
面向全球公立或私立学校、职业学校、大学等教育机构,提供非商业用途的软件使用许可。
- 有效期一年,符合条件的教育机构可继续申请。
2.开源项目许可证
-
面向非商业开源项目开发者,要求项目拥有活跃社区并在其官网添加 INFINI Labs 的链接。
- 许可证免费,有效期一年,符合条件的项目可继续申请。
五、申请方式
符合条件的开源项目和教育机构可通过访问 INFINI Labs 官方网站,轻松提交申请,我们将尽快审核并回复。
申请链接:https://infinilabs.cn/community
六、结语
INFINI Labs 以全新升级的免费许可证计划为契机,与全球开源社区和教育界携手合作,共同推动软件生态的创新与发展。让我们共同迎接更加美好的未来!
七、关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。

在数字化浪潮席卷全球的今天,INFINI Labs 深刻认识到开源项目和教育机构在技术创新与人才培养中的核心作用。因此,我们郑重推出全新升级的免费许可证计划,旨在全球范围内为开源社区和教育界提供有力支持,共同推动软件生态的繁荣与进步。
一、产品实力与荣誉
1.INFINI Pizza:实时搜索的新纪元
- 在第十三届“数据技术嘉年华”(DTC2024)上,INFINI Labs 发布了划时代的搜索引擎——INFINI Pizza,标志着搜索型数据库迈入实时搜索的新纪元。
- INFINI Pizza 凭借先进的设计理念与架构,以及独有的专利技术,实现了对海量数据的无限伸缩,提供高效、准确的实时数据搜索能力
2.行业标杆案例
- INFINI Labs 荣获中国信通院大数据“星河”标杆案例,其中移动云搜索数据库案例更是荣选为数据库标杆案例。
- 该案例基于移动云 Easysearch 数据库,通过创新的多集群协同模式,实现了数据高性能存取,展现出极高的经济价值与社会价值。
3.国家发明专利认可
- INFINI Labs 的多项自主研发技术获得国家发明专利授权,这些成果彰显了公司在大数据领域的技术实力与创新精神。
二、品牌与行业地位
-
INFINI Labs 作为搜索型数据库产品领域的领军企业,积极参与行业标准的制定与推动。
- 其核心产品 INFINI Easysearch 荣获信通院首批可信搜索型数据库产品证书,再次印证了公司在行业中的领先地位。
三、产品介绍
-
INFINI Easysearch:作为 Elasticsearch 的国产化替代方案,提供高度兼容性与卓越性能,满足企业级需求。
-
INFINI Console:轻量级多集群、跨版本搜索基础设施统一管控平台,助力企业高效管理搜索集群。
-
INFINI Gateway:专为 Elasticsearch 打造的高性能应用网关,提供丰富的功能特性与卓越性能。
-
INFINI Loadgen:支持多种搜索引擎的轻量级压测工具,为企业提供强大的数据加载与测试能力。
- INFINI Pizza:引领实时搜索时代的新星,为企业提供高效、准确的实时数据搜索解决方案。
四、免费许可证计划
1.教育机构学术许可证
-
面向全球公立或私立学校、职业学校、大学等教育机构,提供非商业用途的软件使用许可。
- 有效期一年,符合条件的教育机构可继续申请。
2.开源项目许可证
-
面向非商业开源项目开发者,要求项目拥有活跃社区并在其官网添加 INFINI Labs 的链接。
- 许可证免费,有效期一年,符合条件的项目可继续申请。
五、申请方式
符合条件的开源项目和教育机构可通过访问 INFINI Labs 官方网站,轻松提交申请,我们将尽快审核并回复。
申请链接:https://infinilabs.cn/community
六、结语
INFINI Labs 以全新升级的免费许可证计划为契机,与全球开源社区和教育界携手合作,共同推动软件生态的创新与发展。让我们共同迎接更加美好的未来!
七、关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »
【搜索客社区日报】第1841期 (2024-06-19)
https://mp.weixin.qq.com/s/CB5PZbvdzjxDmewnkbyN_w
2.Kibana 一步步可视化实战构建步骤全集
https://mp.weixin.qq.com/s/rsk5qnmxjXkgRUL9lVxzZA
3. 通过 LLM 将文本转化为图形:预训练、提示还是调整?(搭梯)
https://medium.com/%40peter.la ... 65360
4.IntelligentGraph = 知识图谱 + 嵌入式分析(搭梯)
https://medium.com/%40peter.la ... 92204
编辑:kin122
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/CB5PZbvdzjxDmewnkbyN_w
2.Kibana 一步步可视化实战构建步骤全集
https://mp.weixin.qq.com/s/rsk5qnmxjXkgRUL9lVxzZA
3. 通过 LLM 将文本转化为图形:预训练、提示还是调整?(搭梯)
https://medium.com/%40peter.la ... 65360
4.IntelligentGraph = 知识图谱 + 嵌入式分析(搭梯)
https://medium.com/%40peter.la ... 92204
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1840期 (2024-06-18)
1. 李宏毅教授写的深度学习教程,很可以
https://github.com/datawhalechina/leedl-tutorial
2. 一个还不错的python入门教程
https://inventwithpython.com/bigbookpython/
3. 我在国内想无痛使用ChatGPT,yes
https://chatanywhere.apifox.cn/
https://github.com/chatanywhere/GPT_API_free
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
1. 李宏毅教授写的深度学习教程,很可以
https://github.com/datawhalechina/leedl-tutorial
2. 一个还不错的python入门教程
https://inventwithpython.com/bigbookpython/
3. 我在国内想无痛使用ChatGPT,yes
https://chatanywhere.apifox.cn/
https://github.com/chatanywhere/GPT_API_free
编辑:斯蒂文
更多资讯:http://news.searchkit.cn 收起阅读 »
搜索客 Meetup 讲师招募啦~,欢迎大家提交分享议题

搜索客 Meetup 正式启动讲师招募啦!这是一个由搜索客社区精心组织策划的线下线上技术交流活动,我们诚挚邀请各位技术大咖、行业精英踊跃提交演讲议题。Meetup 活动将聚焦AI 与搜索领域的最新动态,以及数据实时分析、日志分析、安全等领域的深度探讨。
分享主题范围供参考:
* 人工智能、机器学习与 AI 应用
* 检索增强生成(RAG)
* 向量检索
* AI 大模型混合搜索
* 语义搜索、NLP 与自然语言处理
* Elasticsearch 技术实践、解读、扩展开发
* OpenSearch 技术实践、解读、扩展开发
* Easysearch 技术实践、解读、扩展开发
* 日志领域的实践与案例
* 安全领域的实践与案例
* 搜索领域的实践与案例
* APM 领域的实践与案例
* 指标分析的实践与案例
* BI 商业应用分析案例
* 架构变迁与平台化实践
* 性能调优与分布式
* 数据接入与 ETL 数据处理
* 大数据分析与实时性
* 数据可视化分析与展现
* 自动化运维、DevOps、AIOps
* 开源与社区建设
* 任何与搜索技术有关的酷话题
申请方式:
我们热切期待您的精彩分享!
演讲时长为30-45分钟(含提问环节),申请截止时间长期有效。请通过以下链接提交您的演讲议题:http://cfp.searchkit.cn

让我们一起在搜索客 Meetup 的舞台上,共同探索技术的无限可能!
免责声明:
社区倡导干货接地气的分享,主办方会根据提交过来的议题统一进行严格筛选,如有未通过还请谅解。
关于 搜索客(SearchKit)社区:
搜索客社区由 Elasticsearch 中文社区进行全新的品牌升级,以新的 Slogan:“搜索人自己的社区” 为宣言。汇集搜索领域最新动态、精选干货文章、精华讨论、文档资料、翻译与版本发布等,为广大搜索领域从业者提供更为丰富便捷的学习和交流平台。社区官网: https://searchkit.cn 。
搜索客 Meetup 正式启动讲师招募啦!这是一个由搜索客社区精心组织策划的线下线上技术交流活动,我们诚挚邀请各位技术大咖、行业精英踊跃提交演讲议题。Meetup 活动将聚焦AI 与搜索领域的最新动态,以及数据实时分析、日志分析、安全等领域的深度探讨。
分享主题范围供参考:
* 人工智能、机器学习与 AI 应用
* 检索增强生成(RAG)
* 向量检索
* AI 大模型混合搜索
* 语义搜索、NLP 与自然语言处理
* Elasticsearch 技术实践、解读、扩展开发
* OpenSearch 技术实践、解读、扩展开发
* Easysearch 技术实践、解读、扩展开发
* 日志领域的实践与案例
* 安全领域的实践与案例
* 搜索领域的实践与案例
* APM 领域的实践与案例
* 指标分析的实践与案例
* BI 商业应用分析案例
* 架构变迁与平台化实践
* 性能调优与分布式
* 数据接入与 ETL 数据处理
* 大数据分析与实时性
* 数据可视化分析与展现
* 自动化运维、DevOps、AIOps
* 开源与社区建设
* 任何与搜索技术有关的酷话题
申请方式:
我们热切期待您的精彩分享!
演讲时长为30-45分钟(含提问环节),申请截止时间长期有效。请通过以下链接提交您的演讲议题:http://cfp.searchkit.cn
让我们一起在搜索客 Meetup 的舞台上,共同探索技术的无限可能!
免责声明:
社区倡导干货接地气的分享,主办方会根据提交过来的议题统一进行严格筛选,如有未通过还请谅解。
关于 搜索客(SearchKit)社区:
搜索客社区由 Elasticsearch 中文社区进行全新的品牌升级,以新的 Slogan:“搜索人自己的社区” 为宣言。汇集搜索领域最新动态、精选干货文章、精华讨论、文档资料、翻译与版本发布等,为广大搜索领域从业者提供更为丰富便捷的学习和交流平台。社区官网: https://searchkit.cn 。 收起阅读 »
【搜索客社区日报】第1839期 (2024-06-17)
https://www.salesforce.com/blog/vector-database/
2、【数据分析】推断统计学及Python实现
https://blog.csdn.net/2301_818 ... 00556
3、【DevOps】Logstash详解:高效日志管理与分析工具
https://blog.csdn.net/benshu_0 ... 10588
4、SuperCLUE:中文通用大模型综合性测评基准
https://www.clue.ai/superclue.html
5、Easysearch 精确搜索【老杨玩搜索】
https://mp.weixin.qq.com/s/xUp_VmMiv2O70Sqlpleqcg
编辑:Muse
更多资讯:http://news.searchkit.cn
https://www.salesforce.com/blog/vector-database/
2、【数据分析】推断统计学及Python实现
https://blog.csdn.net/2301_818 ... 00556
3、【DevOps】Logstash详解:高效日志管理与分析工具
https://blog.csdn.net/benshu_0 ... 10588
4、SuperCLUE:中文通用大模型综合性测评基准
https://www.clue.ai/superclue.html
5、Easysearch 精确搜索【老杨玩搜索】
https://mp.weixin.qq.com/s/xUp_VmMiv2O70Sqlpleqcg
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1838期 (2024-06-14)
1、达梦数据成为国内专注于数据库领域的、国产数据库行业首家上市公司
https://www.modb.pro/db/1801061969906176000
2、微软技术社区:做RAG?向量搜索还不够
https://mp.weixin.qq.com/s/O_62Ds8ySHikT78kXpDSIA
3、阿里云 OpenSearch RAG 应用实践
https://mp.weixin.qq.com/s/wuA8wOIz-0PgnmoN-uHoSw
4、极限网关助力好未来 Elasticsearch 容器化升级
https://infinilabs.cn/blog/202 ... rade/
编辑:Fred
更多资讯:http://news.searchkit.cn
1、达梦数据成为国内专注于数据库领域的、国产数据库行业首家上市公司
https://www.modb.pro/db/1801061969906176000
2、微软技术社区:做RAG?向量搜索还不够
https://mp.weixin.qq.com/s/O_62Ds8ySHikT78kXpDSIA
3、阿里云 OpenSearch RAG 应用实践
https://mp.weixin.qq.com/s/wuA8wOIz-0PgnmoN-uHoSw
4、极限网关助力好未来 Elasticsearch 容器化升级
https://infinilabs.cn/blog/202 ... rade/
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1837期 (2024-06-13)
https://mp.weixin.qq.com/s/0tVUCgoRtYG5UoWv96RG2g
2.从 0 到 1 搭建亿级商品 ES 搜索引擎
https://mp.weixin.qq.com/s/zooHb5BuiYO2hx5Ii73wnw
3.分析时序数据:从 InfluxQL 到 SQL 的演变
https://mp.weixin.qq.com/s/ZBFnkt51UIPlhuDC5shrlw
4.实测完快手的AI视频「可灵」后,我觉得这才是第一个中国版Sora
https://mp.weixin.qq.com/s/zBFiDy7UaJgwOiwl6rjifw
5.one-api 通过标准的 OpenAI API 格式访问所有的大模型
https://github.com/songquanpeng/one-api
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/0tVUCgoRtYG5UoWv96RG2g
2.从 0 到 1 搭建亿级商品 ES 搜索引擎
https://mp.weixin.qq.com/s/zooHb5BuiYO2hx5Ii73wnw
3.分析时序数据:从 InfluxQL 到 SQL 的演变
https://mp.weixin.qq.com/s/ZBFnkt51UIPlhuDC5shrlw
4.实测完快手的AI视频「可灵」后,我觉得这才是第一个中国版Sora
https://mp.weixin.qq.com/s/zBFiDy7UaJgwOiwl6rjifw
5.one-api 通过标准的 OpenAI API 格式访问所有的大模型
https://github.com/songquanpeng/one-api
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1836期 (2024-06-12)
https://medium.com/neo4j/graph ... 19683
2.Elasticsearch 为时间序列数据带来存储优势
https://blog.csdn.net/UbuntuTo ... 91306
3.RAG需要的一些文本分块的方法(搭梯)
https://medium.com/%40hasanabo ... 43d80
4.利用Langchain实现代理RAG(搭梯)
https://medium.com/the-ai-foru ... 6a3b5
编辑:kin122
更多资讯:http://news.searchkit.cn
https://medium.com/neo4j/graph ... 19683
2.Elasticsearch 为时间序列数据带来存储优势
https://blog.csdn.net/UbuntuTo ... 91306
3.RAG需要的一些文本分块的方法(搭梯)
https://medium.com/%40hasanabo ... 43d80
4.利用Langchain实现代理RAG(搭梯)
https://medium.com/the-ai-foru ... 6a3b5
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
极限网关助力好未来 Elasticsearch 容器化升级
极限网关在好未来的最佳实践案例,轻松扛住日增百 TB 数据的流量,助力 ES 从物理机到云原生架构的改造,实现了流控、请求分析、安全管理、无缝迁移等场景。一次完美的客户体验~
背景
物理机架构时代
2022 年,好未来整个日志 Elasticsearch 拥有数十套服务集群,几百台物理机。这么多台机器耗费成本非常高,而且还要花费很大精力去维护。在人力资源有限情况下,存在非常多的弊端,运行成本高,不仅是机器折旧还有机柜等费用。
流量特征
这是来自某个业务线,如下图 1,真实流量,潮汐性非常明显。好未来有很多条业务线,几乎跟这个趋势都一致的,除了个别业务有“续报”、“开课”等活动特殊情况。潮汐性带来的问题就是高峰期 CPU、内存资源是可以消耗很高;低峰期资源使用量非常低,由于是物理架构,这些资源无法给其他业务线共享。
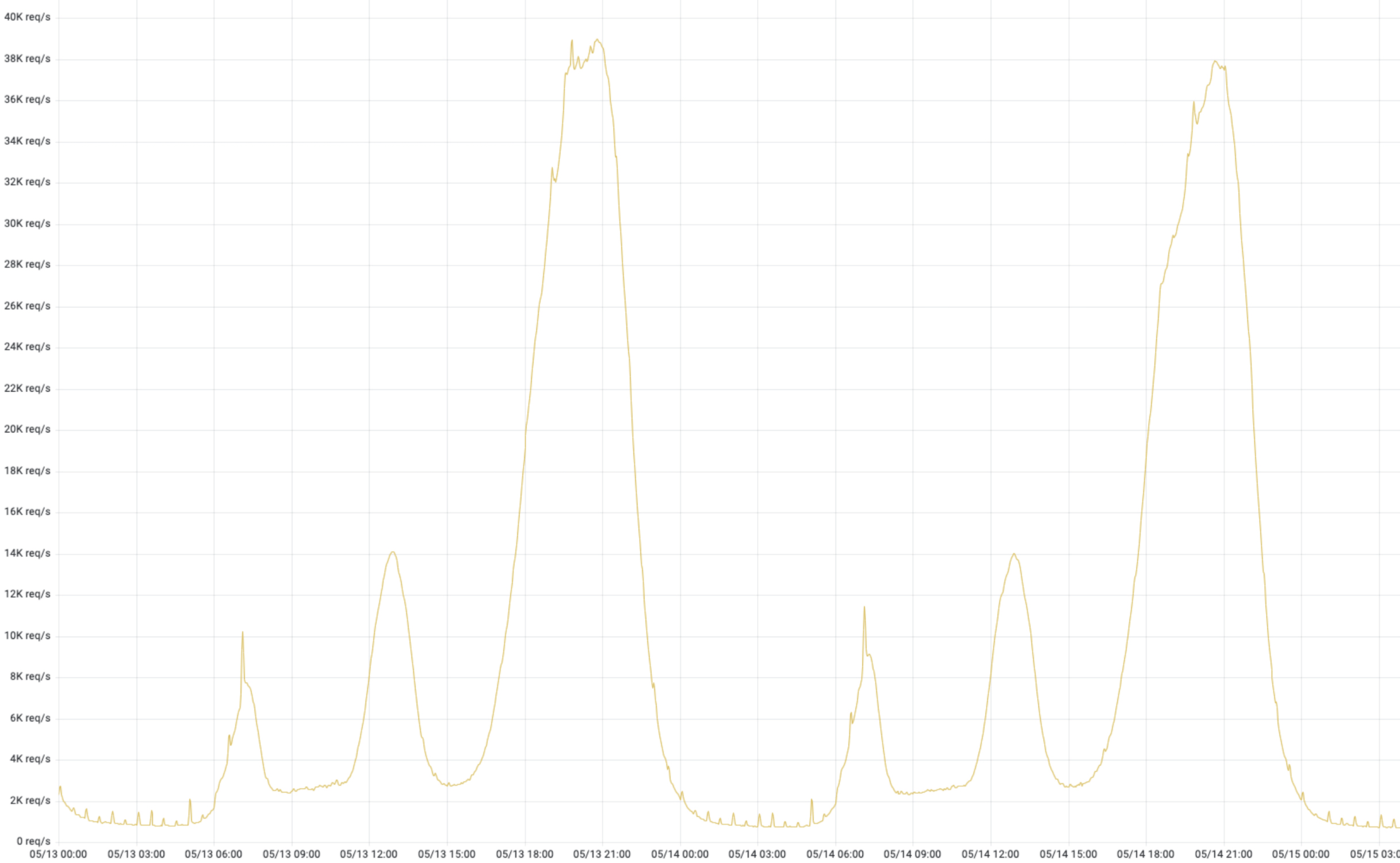
降本增效-容器化改造原动力
日志服务对成本的空前的压力促使我们推进 Elasticsearch 进行架构改造;如何改造,改造成什么样子,这两个问题一直是推进改造原动力。业界能够同时对水平扩展和垂直扩展就是 K8S,我们开始对 Elasticsearch 改造成能在 K8S 上运行进行探索,从而提升 CPU、内存利用率。
物理机时代,没办法把资源动态的扩缩,动态调配,资源隔离,单靠人力操作调度成本太高,几乎无法完成;集群对内存资源需求要比 CPU 资源大很多,由于机器型号配置是固定的,无法“定制”,这也会导致成本居高不下。所以,无论从那个方面来讲,容器化优势非常明显,既能够优化成本,也能够降低运维复杂度。
ES 容器化改造
进行架构升级重点难点- API 服务
改造过程,我们遇到了很多问题,比如容器 ES 版本和物理机 ES 版本不一致,如何让 ES API 能够兼容不同的 ES 版本,由于版本的不兼容,导致无法直接使用原有的 tribenode 进行服务,怎么提供一个高可用的 Elasticsearch API 服务。我们考虑到多个方面,比如使用官方推荐的 proxy 模式、第三方服务等进行选择,经过多方面对比,选择了极限网关 进行 tribenode 替换。
原始 ES API 服务痛点
- API 访问没有流量控制
- 可观测性差,而且稳定性一般
- 版本兼容性差
物理机时代 API 架构
在物理机时代 ES 集群,API 架构如图 2,可以明显看到 tribe node 对所有 ES 集群的“侵入性”是非常大的,这就带来了很多问题,比较严重的就是单个集群对 ES tribenode 的影响和版本升级带来的不兼容问题。

混合时代 API 架构
通过图 3,我们可以看到,极限网关对于版本兼容性很好,能够适配不同的版本。因此,最终选择极限网关作为下一代 ES API 服务方。

里程碑:全部 ES 集群容器化
在 2023 年 3 月份,通过 Elastic 官方 ECK 模式,完成全部日志 ES 集群容器化改造,拥有数百节点,1PB+ 数据存储,每日新增数据 100T 左右。紧接着,除了日志服务外,同时支持了好未来多条业务线。

极限网关实践
下面主要讲述了,为什么选择极限网关,以及极限网关在好未来落地、应用这些内容。
为什么选择极限网关?
学习成本低
我们可以从文档中看到极限网关,其架构简洁,语法简单,直观易懂。学习成本比较低,上手非常快,对新手友好。
性能强悍
经过压测,发现极限网关速度非常快,且针对 Elasticsearch 做了非常细致的优化,能成倍提升写入和查询的速度。
安全性高
支持多种认证方式,最简单的账号密码认证,可以给自定义多个账户密码,大大简化了 Elasticsearch 的安全设置,同时,还可以支持 LDAP 安全验证。
跨版本支持
我们容器化改造过程需要兼容不同版本的 Elasticsrearch,极限网关针对不同的 Elasticsearch 版本做了兼容和针对性处理,能够让业务代码无缝的进行适配,后端 Elasticsearch 集群版本升级能够做到无缝过渡,降低版本升级和数据迁移的复杂度,非常匹配我们的业务场景。
灵活可扩展
可灵活对每个请求进行干预和路由,支持路由的智能学习,内置丰富的过滤器,通过配置动态修改每个请求的处理逻辑,也支持通过插件来进行扩展,满足我们对流量的控制,尤其是限流、用户、IP 等这些功能非常实用。
启用安全策略-为 API 服务保驾护航
痛点
在升级之前使用 tribe 作为 API 服务提供后端,几乎相当于裸奔,没有任何认证策略;另外,tribe 本身的稳定性也有问题,官方在新版本逐渐废弃这种 CCS(跨集群搜索),期间出现多次服务崩溃。
极限网关解决问题
极限网关通过,“basic_auth” 插件,提供最基本的安全校验,使用起来非常方便;同时,极限网关提供 LDAP 插件,可以接入公共的 LDAP 服务,对所有的访问用户进行校验,安全策略对所有的用户生效,不用担心因为 IP 问题泄漏数据等。
强大的过滤功能
在使用 ES 集群过程中,许多场景,需要对请求进行控制、限制等操作。在这方便,感受到了极限网关强大的产品力。比如下面的两个场景
对异常流量进行限流
- 支持对 IP 限流
- 支持对 hostname 限流
- 支持 header 限流
对异常用户进行封禁
当 Elasticsearch 是通过 Basic Auth 或者 LDAP 方式来进行身份认证的时候,request_user_filter 过滤器可用来按请求的用户名信息来进行过滤。操作起来也非常简单,只需要 request_user_filter 这一个过滤器。
- request_user_filter:
include:
- "elastic"
exclude:
- "Ryan"总结来讲,主要有这些方面的功能:

优秀的可观测性
痛点
改造前经常为看不到直观的数据指标感到头疼,查看指标需要多个地方同时打开,去筛选,查找,非常繁琐,付出的成本非常大。为此,大家都再考虑如何优化这种情况,无奈优先级比较低,一直没有真正的投入时间去优化这块。
完美解决
使用了极限网关,通过收集请求日志,非常清晰的收集到想要的数据,具体如下:
- 总体方面:
- 流量曲线
- 状态码占比
- 缓存统计
- 每台网关请求流量
- 细节方面:
- 打印每次请求语句
- 可以查看请求到具体 ES 节点流量
- 可以查看过滤器的列表
通过下图,我们可以从管理视角直观的看到各种信息,这对于管理员来讲,省时省力,方便快捷。

意外收获:无缝迁移业务 Elasticsearch 上云
由于前期日志业务上云,受到非常好的反馈,多个业务线期望能够上云上服务,达到降本增效的目的。
支持双写
数据可以通过极限网关同时写入两个 ES 集群,能够保障数据完全一致,安全可靠。
无缝切换
切换很丝滑,影响非常小,能够让外界几乎感受不到服务波动。

通过使用极限网关,自建 ES 集群可以无缝的迁移上云,在整个迁移的过程中,两套集群通过网关进行了解耦,在迁移的过程中还能实现版本的无缝升级,极大降低了迁移成本,提高迁移效率,多次验证服务稳定可靠。
极限网关流量概览
这是其中一套极限网关的流量统计。用这部分数据进行巡检,一目了然,做到全局的掌控,提高感知力度。


极限网关使用总结
极限网关提供一系列高性能和高可靠性的网关服务。使用这样的服务给我们带来以下好处:
- 可观测性好:极限网关可以动态的对 Elasticsearch 运行过程中请求进行拦截和分析,通过指标和日志来了解集群运行状态,这些指标可以用于提升性能和业务优化。
- 增强安全性:包含先进的安全机制,如 basicauth、LDAP 等支持,保护用户数据不受未授权访问和各种网络威胁的侵害。
- 高稳定性:通过冗余设计和故障转移机制,极限网关能够确保网络服务的高可用性,即使在某些组件发生故障时也能保持服务不中断,单版本最长服务超过 15 个月。
- 易于管理:通过提供 INFINI Console 简洁直观的管理界面,让用户能够轻松配置和监控网络状态,提升管理效率。
- 客户支持:良好的客户服务支持可以帮助用户快速解决使用过程中遇到的问题,提供专业的技术指导。
综上所述,极限网关为用户提供了一个高速、安全、稳定且易于管理的 ES 网关,适合对网络性能有较高要求的个人和企业用户。
未来规划
第一阶段,完成了日志 ES 集群,所有集群的容器化改造,合并,成功的把成本降低了 60%以上。这期间积累了丰富容器化经验,为业务 ES 集群上容器做了良好的铺垫;成本优势和运维优势吸引越来越多的业务接入到容器化 ES 集群。
提升 ES 集群效能--新技术应用&&版本升级
- 极限科技官方推荐的 Easysearch 在压缩率,查询速度等等方面有很多的优势,通过长时间的测试稳定性,新特性,对比云原生的 ES 集群,根据测试结果,给“客户”提供多种选择,这也是工作重点之一。
- 我们当前使用的 ES 版本是 6.8,已经远远落后于官方版本,今年我们计划在选择合适的集群升级 ES 版本,拥抱更多官方提供的特性。
混合(多)云架构支持
随着越来越多的 ES 集群在机房的 K8S 集群部署,这里资源出现了紧张局面。 我们尝试在云上部署自建 ES 集群,弥补机房资源有限,无法大规模扩容,同时能够支持多活场景,满足更多客户的不同需求。混合云主要实现以下几种能力:
1、扩缩容:满足不同业务灵活适配
混合(多)云部署,可以让负载内部私有云 ES,同时部署到公有云,提升扩展 IT 基础设施不仅局限于 CPU、内存,还有存储。比如某一个业务要做活动,预估流量“大爆发”,需要提前准备大规模资源,在机房内根本来不及采购扩容支持,然而在公有云上就能很方便扩容、缩容。在云上搭建 ES 集群,设置满足需求的数量、容量、配置,配合极限网关路由策略,精准的把控流量流向。

2、灾备:紧急情况快速部署,恢复 ES 集群读写
当机房级别大规模故障,部分业务实现了多活,单一的机房故障不会影响其服务能力,而此时比如日志查看等仍有需求,为了满足这部分“客户”需求,可以在云上 K8S 集群,快速搭建 ES 集群,恢复日志读写功能。

参考文档:
- https://infinilabs.cn/docs/latest/gateway
- https://www.elastic.co/guide/en/cloud-on-K8S/current/K8S-overview.html
作者:张华勋,前新浪 CDN 研发,工作主要涉及 Mysql、MongoDB、Redis、Elasticsearch、流量调度等组件和系统,以及运维自动化、平台化等工作。现就职于好未来。
关于好未来
好未来(NYSE:TAL)是一家以内容能力与科技能力为基础,以科教、科创、科普为战略方向,助力人的终身成长,并持续探索创新的科技公司。 好未来的前身学而思成立于 2003 年,2010 年在美国纽交所正式挂牌交易。好未来以“爱与科技助力终身成长”为使命,致力成为持续创新的组织。更多参见:https://www.100tal.com/
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。

极限网关在好未来的最佳实践案例,轻松扛住日增百 TB 数据的流量,助力 ES 从物理机到云原生架构的改造,实现了流控、请求分析、安全管理、无缝迁移等场景。一次完美的客户体验~
背景
物理机架构时代
2022 年,好未来整个日志 Elasticsearch 拥有数十套服务集群,几百台物理机。这么多台机器耗费成本非常高,而且还要花费很大精力去维护。在人力资源有限情况下,存在非常多的弊端,运行成本高,不仅是机器折旧还有机柜等费用。
流量特征
这是来自某个业务线,如下图 1,真实流量,潮汐性非常明显。好未来有很多条业务线,几乎跟这个趋势都一致的,除了个别业务有“续报”、“开课”等活动特殊情况。潮汐性带来的问题就是高峰期 CPU、内存资源是可以消耗很高;低峰期资源使用量非常低,由于是物理架构,这些资源无法给其他业务线共享。
降本增效-容器化改造原动力
日志服务对成本的空前的压力促使我们推进 Elasticsearch 进行架构改造;如何改造,改造成什么样子,这两个问题一直是推进改造原动力。业界能够同时对水平扩展和垂直扩展就是 K8S,我们开始对 Elasticsearch 改造成能在 K8S 上运行进行探索,从而提升 CPU、内存利用率。
物理机时代,没办法把资源动态的扩缩,动态调配,资源隔离,单靠人力操作调度成本太高,几乎无法完成;集群对内存资源需求要比 CPU 资源大很多,由于机器型号配置是固定的,无法“定制”,这也会导致成本居高不下。所以,无论从那个方面来讲,容器化优势非常明显,既能够优化成本,也能够降低运维复杂度。
ES 容器化改造
进行架构升级重点难点- API 服务
改造过程,我们遇到了很多问题,比如容器 ES 版本和物理机 ES 版本不一致,如何让 ES API 能够兼容不同的 ES 版本,由于版本的不兼容,导致无法直接使用原有的 tribenode 进行服务,怎么提供一个高可用的 Elasticsearch API 服务。我们考虑到多个方面,比如使用官方推荐的 proxy 模式、第三方服务等进行选择,经过多方面对比,选择了极限网关 进行 tribenode 替换。
原始 ES API 服务痛点
- API 访问没有流量控制
- 可观测性差,而且稳定性一般
- 版本兼容性差
物理机时代 API 架构
在物理机时代 ES 集群,API 架构如图 2,可以明显看到 tribe node 对所有 ES 集群的“侵入性”是非常大的,这就带来了很多问题,比较严重的就是单个集群对 ES tribenode 的影响和版本升级带来的不兼容问题。
混合时代 API 架构
通过图 3,我们可以看到,极限网关对于版本兼容性很好,能够适配不同的版本。因此,最终选择极限网关作为下一代 ES API 服务方。
里程碑:全部 ES 集群容器化
在 2023 年 3 月份,通过 Elastic 官方 ECK 模式,完成全部日志 ES 集群容器化改造,拥有数百节点,1PB+ 数据存储,每日新增数据 100T 左右。紧接着,除了日志服务外,同时支持了好未来多条业务线。
极限网关实践
下面主要讲述了,为什么选择极限网关,以及极限网关在好未来落地、应用这些内容。
为什么选择极限网关?
学习成本低
我们可以从文档中看到极限网关,其架构简洁,语法简单,直观易懂。学习成本比较低,上手非常快,对新手友好。
性能强悍
经过压测,发现极限网关速度非常快,且针对 Elasticsearch 做了非常细致的优化,能成倍提升写入和查询的速度。
安全性高
支持多种认证方式,最简单的账号密码认证,可以给自定义多个账户密码,大大简化了 Elasticsearch 的安全设置,同时,还可以支持 LDAP 安全验证。
跨版本支持
我们容器化改造过程需要兼容不同版本的 Elasticsrearch,极限网关针对不同的 Elasticsearch 版本做了兼容和针对性处理,能够让业务代码无缝的进行适配,后端 Elasticsearch 集群版本升级能够做到无缝过渡,降低版本升级和数据迁移的复杂度,非常匹配我们的业务场景。
灵活可扩展
可灵活对每个请求进行干预和路由,支持路由的智能学习,内置丰富的过滤器,通过配置动态修改每个请求的处理逻辑,也支持通过插件来进行扩展,满足我们对流量的控制,尤其是限流、用户、IP 等这些功能非常实用。
启用安全策略-为 API 服务保驾护航
痛点
在升级之前使用 tribe 作为 API 服务提供后端,几乎相当于裸奔,没有任何认证策略;另外,tribe 本身的稳定性也有问题,官方在新版本逐渐废弃这种 CCS(跨集群搜索),期间出现多次服务崩溃。
极限网关解决问题
极限网关通过,“basic_auth” 插件,提供最基本的安全校验,使用起来非常方便;同时,极限网关提供 LDAP 插件,可以接入公共的 LDAP 服务,对所有的访问用户进行校验,安全策略对所有的用户生效,不用担心因为 IP 问题泄漏数据等。
强大的过滤功能
在使用 ES 集群过程中,许多场景,需要对请求进行控制、限制等操作。在这方便,感受到了极限网关强大的产品力。比如下面的两个场景
对异常流量进行限流
- 支持对 IP 限流
- 支持对 hostname 限流
- 支持 header 限流
对异常用户进行封禁
当 Elasticsearch 是通过 Basic Auth 或者 LDAP 方式来进行身份认证的时候,request_user_filter 过滤器可用来按请求的用户名信息来进行过滤。操作起来也非常简单,只需要 request_user_filter 这一个过滤器。
- request_user_filter:
include:
- "elastic"
exclude:
- "Ryan"总结来讲,主要有这些方面的功能:
优秀的可观测性
痛点
改造前经常为看不到直观的数据指标感到头疼,查看指标需要多个地方同时打开,去筛选,查找,非常繁琐,付出的成本非常大。为此,大家都再考虑如何优化这种情况,无奈优先级比较低,一直没有真正的投入时间去优化这块。
完美解决
使用了极限网关,通过收集请求日志,非常清晰的收集到想要的数据,具体如下:
- 总体方面:
- 流量曲线
- 状态码占比
- 缓存统计
- 每台网关请求流量
- 细节方面:
- 打印每次请求语句
- 可以查看请求到具体 ES 节点流量
- 可以查看过滤器的列表
通过下图,我们可以从管理视角直观的看到各种信息,这对于管理员来讲,省时省力,方便快捷。
意外收获:无缝迁移业务 Elasticsearch 上云
由于前期日志业务上云,受到非常好的反馈,多个业务线期望能够上云上服务,达到降本增效的目的。
支持双写
数据可以通过极限网关同时写入两个 ES 集群,能够保障数据完全一致,安全可靠。
无缝切换
切换很丝滑,影响非常小,能够让外界几乎感受不到服务波动。
通过使用极限网关,自建 ES 集群可以无缝的迁移上云,在整个迁移的过程中,两套集群通过网关进行了解耦,在迁移的过程中还能实现版本的无缝升级,极大降低了迁移成本,提高迁移效率,多次验证服务稳定可靠。
极限网关流量概览
这是其中一套极限网关的流量统计。用这部分数据进行巡检,一目了然,做到全局的掌控,提高感知力度。
极限网关使用总结
极限网关提供一系列高性能和高可靠性的网关服务。使用这样的服务给我们带来以下好处:
- 可观测性好:极限网关可以动态的对 Elasticsearch 运行过程中请求进行拦截和分析,通过指标和日志来了解集群运行状态,这些指标可以用于提升性能和业务优化。
- 增强安全性:包含先进的安全机制,如 basicauth、LDAP 等支持,保护用户数据不受未授权访问和各种网络威胁的侵害。
- 高稳定性:通过冗余设计和故障转移机制,极限网关能够确保网络服务的高可用性,即使在某些组件发生故障时也能保持服务不中断,单版本最长服务超过 15 个月。
- 易于管理:通过提供 INFINI Console 简洁直观的管理界面,让用户能够轻松配置和监控网络状态,提升管理效率。
- 客户支持:良好的客户服务支持可以帮助用户快速解决使用过程中遇到的问题,提供专业的技术指导。
综上所述,极限网关为用户提供了一个高速、安全、稳定且易于管理的 ES 网关,适合对网络性能有较高要求的个人和企业用户。
未来规划
第一阶段,完成了日志 ES 集群,所有集群的容器化改造,合并,成功的把成本降低了 60%以上。这期间积累了丰富容器化经验,为业务 ES 集群上容器做了良好的铺垫;成本优势和运维优势吸引越来越多的业务接入到容器化 ES 集群。
提升 ES 集群效能--新技术应用&&版本升级
- 极限科技官方推荐的 Easysearch 在压缩率,查询速度等等方面有很多的优势,通过长时间的测试稳定性,新特性,对比云原生的 ES 集群,根据测试结果,给“客户”提供多种选择,这也是工作重点之一。
- 我们当前使用的 ES 版本是 6.8,已经远远落后于官方版本,今年我们计划在选择合适的集群升级 ES 版本,拥抱更多官方提供的特性。
混合(多)云架构支持
随着越来越多的 ES 集群在机房的 K8S 集群部署,这里资源出现了紧张局面。 我们尝试在云上部署自建 ES 集群,弥补机房资源有限,无法大规模扩容,同时能够支持多活场景,满足更多客户的不同需求。混合云主要实现以下几种能力:
1、扩缩容:满足不同业务灵活适配
混合(多)云部署,可以让负载内部私有云 ES,同时部署到公有云,提升扩展 IT 基础设施不仅局限于 CPU、内存,还有存储。比如某一个业务要做活动,预估流量“大爆发”,需要提前准备大规模资源,在机房内根本来不及采购扩容支持,然而在公有云上就能很方便扩容、缩容。在云上搭建 ES 集群,设置满足需求的数量、容量、配置,配合极限网关路由策略,精准的把控流量流向。
2、灾备:紧急情况快速部署,恢复 ES 集群读写
当机房级别大规模故障,部分业务实现了多活,单一的机房故障不会影响其服务能力,而此时比如日志查看等仍有需求,为了满足这部分“客户”需求,可以在云上 K8S 集群,快速搭建 ES 集群,恢复日志读写功能。
参考文档:
- https://infinilabs.cn/docs/latest/gateway
- https://www.elastic.co/guide/en/cloud-on-K8S/current/K8S-overview.html
作者:张华勋,前新浪 CDN 研发,工作主要涉及 Mysql、MongoDB、Redis、Elasticsearch、流量调度等组件和系统,以及运维自动化、平台化等工作。现就职于好未来。
关于好未来
好未来(NYSE:TAL)是一家以内容能力与科技能力为基础,以科教、科创、科普为战略方向,助力人的终身成长,并持续探索创新的科技公司。 好未来的前身学而思成立于 2003 年,2010 年在美国纽交所正式挂牌交易。好未来以“爱与科技助力终身成长”为使命,致力成为持续创新的组织。更多参见:https://www.100tal.com/
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
【搜索客社区日报】第1835期 (2024-06-11)
1. ES 下云实战(需要梯子)
https://medium.com/lazypay-eng ... c3355
2. 新版的ChatGPT越狱prompt(需要梯子)
https://x.com/MooenyChu/status/1798950081577840782
3. (据说是)Google内部的API文档
https://hexdocs.pm/google_api_ ... .html
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
1. ES 下云实战(需要梯子)
https://medium.com/lazypay-eng ... c3355
2. 新版的ChatGPT越狱prompt(需要梯子)
https://x.com/MooenyChu/status/1798950081577840782
3. (据说是)Google内部的API文档
https://hexdocs.pm/google_api_ ... .html
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
INFINI Labs 产品更新 | Easysearch 1.8.2 发布优化 CCR 性能

INFINI Labs 产品又更新啦~,包括 Easysearch v1.8.2、Gateway、Console、Agent、Loadgen v1.26.0。本次各产品更新了很多亮点功能,如 Easysearch 优化 CCR 同步性能;Gateway 增加了 HTTP 请求动态域名路由功能,移除了安全相关的 Filter,进一步提升 Gateway 稳定性;Console 修复了多个已知问题,如当文档数过亿时单位换算错误,修复了因采集延迟导致指标图表显示异常,修复了多行查询中包含 SQL 查询异常等问题。欢迎大家下载体验。
以下是本次更新的详细说明。
INFINI Easysearch v1.8.2
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。
Easysearch 本次更新如下:
Bug fix
- 修复 source_reuse 与 object 字段为 enable: false 时的冲突
Improvements
- 升级部分依赖包版本,Commons-collections to 3.2.2, Snakeyaml to 2.0
- 优化 CCR 同步性能及调整 CCR 全局配置参数
- 优化插件配置命名,去除"plugins."
- 优化配置文件目录获取命名
INFINI Console v1.26.0
INFINI Console 是一款非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管, 企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 在线体验: http://demo.infini.cloud (用户名/密码:readonly/readonly)。
Console 本次更新如下:
Bug fix
- 修复监控数据布局
- 修复命令存储权限
- 修复多行请求包含 SQL 语法
- 修复文档数过亿时换算错误
- 修复导入低版本 v1.6.0 告警规则缺少字段问题
- 修复当 buck_size 小于 60 秒时,因指标采集延迟导致指标显示异常问题
INFINI Gateway v1.26.0
INFINI Gateway 是一个面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway 可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
Gateway 本次更新如下:
Improvements
- feat: add wildcard_domain filter
- chore: remove security filter and translog_viewer
INFINI Framework
INFINI Framework 是 INFINI Labs 各产品依赖的内部核心公共代码库。
Framework 本次更新如下:
Improvements
- feat: support dynamic app setting
- feat: add cluster settings query args
- feat: add gateway config
- feat: add http interceptor
- feat: return host info in info api
- feat: add util to convert string to float
- feat: use common app setting api to instead of auth setting api
- feat: crontab task support multi crontab expression
- fix: skip submit empty bulk requests
- feat: support ccr api
- fix: get latest offset should compare segment first
- fix: wrong use of zstd with vfs
- fix: prevent close closed channel
- fix: panic on error while saving keystore
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
您还可以通过邮件联系我们:hello@infini.ltd
或者拨打我们的热线电话:(+86) 400-139-9200
欢迎加入 Discord 聊天室:https://discord.gg/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。

关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
INFINI Labs 产品又更新啦~,包括 Easysearch v1.8.2、Gateway、Console、Agent、Loadgen v1.26.0。本次各产品更新了很多亮点功能,如 Easysearch 优化 CCR 同步性能;Gateway 增加了 HTTP 请求动态域名路由功能,移除了安全相关的 Filter,进一步提升 Gateway 稳定性;Console 修复了多个已知问题,如当文档数过亿时单位换算错误,修复了因采集延迟导致指标图表显示异常,修复了多行查询中包含 SQL 查询异常等问题。欢迎大家下载体验。
以下是本次更新的详细说明。
INFINI Easysearch v1.8.2
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。
Easysearch 本次更新如下:
Bug fix
- 修复 source_reuse 与 object 字段为 enable: false 时的冲突
Improvements
- 升级部分依赖包版本,Commons-collections to 3.2.2, Snakeyaml to 2.0
- 优化 CCR 同步性能及调整 CCR 全局配置参数
- 优化插件配置命名,去除"plugins."
- 优化配置文件目录获取命名
INFINI Console v1.26.0
INFINI Console 是一款非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管, 企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 在线体验: http://demo.infini.cloud (用户名/密码:readonly/readonly)。
Console 本次更新如下:
Bug fix
- 修复监控数据布局
- 修复命令存储权限
- 修复多行请求包含 SQL 语法
- 修复文档数过亿时换算错误
- 修复导入低版本 v1.6.0 告警规则缺少字段问题
- 修复当 buck_size 小于 60 秒时,因指标采集延迟导致指标显示异常问题
INFINI Gateway v1.26.0
INFINI Gateway 是一个面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway 可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
Gateway 本次更新如下:
Improvements
- feat: add wildcard_domain filter
- chore: remove security filter and translog_viewer
INFINI Framework
INFINI Framework 是 INFINI Labs 各产品依赖的内部核心公共代码库。
Framework 本次更新如下:
Improvements
- feat: support dynamic app setting
- feat: add cluster settings query args
- feat: add gateway config
- feat: add http interceptor
- feat: return host info in info api
- feat: add util to convert string to float
- feat: use common app setting api to instead of auth setting api
- feat: crontab task support multi crontab expression
- fix: skip submit empty bulk requests
- feat: support ccr api
- fix: get latest offset should compare segment first
- fix: wrong use of zstd with vfs
- fix: prevent close closed channel
- fix: panic on error while saving keystore
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
您还可以通过邮件联系我们:hello@infini.ltd
或者拨打我们的热线电话:(+86) 400-139-9200
欢迎加入 Discord 聊天室:https://discord.gg/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »【搜索客社区日报】第1834期 (2024-06-07)
https://mp.weixin.qq.com/s/R4XZ5vDCifa-a3CaQSxP6g
2. 使用 OpenSearch 进行语义搜索:架构选项和基准
https://opensearch.org/blog/se ... arks/
3. Elasticsearch index 设置 false,为什么还可以被检索到?
https://mp.weixin.qq.com/s/VLw76QM-ySPvavHz62BHzA
4. ClickHouse vs Elasticsearch:十亿行数据的较量
https://mp.weixin.qq.com/s/JnCjUoOKx6ZgAn-eOvlLOg
编辑:Fred
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/R4XZ5vDCifa-a3CaQSxP6g
2. 使用 OpenSearch 进行语义搜索:架构选项和基准
https://opensearch.org/blog/se ... arks/
3. Elasticsearch index 设置 false,为什么还可以被检索到?
https://mp.weixin.qq.com/s/VLw76QM-ySPvavHz62BHzA
4. ClickHouse vs Elasticsearch:十亿行数据的较量
https://mp.weixin.qq.com/s/JnCjUoOKx6ZgAn-eOvlLOg
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1833期 (2024-06-06)
https://www.infoq.cn/article/icykhdkpgkmbe7mbdklj
2.史上最强 AI 翻译诞生了!拳打谷歌,脚踢 DeepL
https://mp.weixin.qq.com/s/h_Oqlkd4b6vqAILUrERrJw
3.夜天之书 #98 Rust 程序库生态合作的例子
https://mp.weixin.qq.com/s/EoRYeA6y2BDsiTxd0bpDQQ
4.史上最强的SQL审核工具,求挑战
https://mp.weixin.qq.com/s/_78WJBDtEJot1syC6Qoi_w
5.深入理解Sora技术原理|得物技术
https://mp.weixin.qq.com/s/e1DqTa1Tgyi4OWpgwrj48Q
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://www.infoq.cn/article/icykhdkpgkmbe7mbdklj
2.史上最强 AI 翻译诞生了!拳打谷歌,脚踢 DeepL
https://mp.weixin.qq.com/s/h_Oqlkd4b6vqAILUrERrJw
3.夜天之书 #98 Rust 程序库生态合作的例子
https://mp.weixin.qq.com/s/EoRYeA6y2BDsiTxd0bpDQQ
4.史上最强的SQL审核工具,求挑战
https://mp.weixin.qq.com/s/_78WJBDtEJot1syC6Qoi_w
5.深入理解Sora技术原理|得物技术
https://mp.weixin.qq.com/s/e1DqTa1Tgyi4OWpgwrj48Q
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »

