

【搜索客社区日报】第2176期 (2026-01-07)
https://aws.plainenglish.io/fr ... 41909
2. 构建多智能体云系统:使用 Strands Agents 进行 AI 专家的协调(搭梯)
https://medium.com/globant/orc ... ff2ee
3. 使用 Strands Agent Framework 构建 AI 代理的快速指南(搭梯)
https://chinsj.medium.com/quic ... 4c017
4. Elasticsearch:性能悖论 - 当更慢的代码并不会拖慢你
https://blog.csdn.net/UbuntuTo ... 51004
5. 在 Elasticsearch 中通过乘法增强来影响 BM25 排名
https://blog.csdn.net/UbuntuTo ... 82382
6. 如何通过个性化、分群感知排序来提升电商搜索相关性
https://elasticstack.blog.csdn ... 98807
7. 使用 Elasticsearch 的 Profile API 对比 dense vector 搜索性能
https://blog.csdn.net/UbuntuTo ... 15338
编辑:kin122
更多资讯:http://news.searchkit.cn
https://aws.plainenglish.io/fr ... 41909
2. 构建多智能体云系统:使用 Strands Agents 进行 AI 专家的协调(搭梯)
https://medium.com/globant/orc ... ff2ee
3. 使用 Strands Agent Framework 构建 AI 代理的快速指南(搭梯)
https://chinsj.medium.com/quic ... 4c017
4. Elasticsearch:性能悖论 - 当更慢的代码并不会拖慢你
https://blog.csdn.net/UbuntuTo ... 51004
5. 在 Elasticsearch 中通过乘法增强来影响 BM25 排名
https://blog.csdn.net/UbuntuTo ... 82382
6. 如何通过个性化、分群感知排序来提升电商搜索相关性
https://elasticstack.blog.csdn ... 98807
7. 使用 Elasticsearch 的 Profile API 对比 dense vector 搜索性能
https://blog.csdn.net/UbuntuTo ... 15338
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2175期 (2026-01-06)
https://www.elastic.co/search- ... earch
2. 用ES来驱动agent行不行?(需要梯子)
https://www.elastic.co/search- ... guide
3. 大声说,是谁让windows里的工具无所遁形呀?(需要梯子)
https://medium.com/%40szarubin ... a9316
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://www.elastic.co/search- ... earch
2. 用ES来驱动agent行不行?(需要梯子)
https://www.elastic.co/search- ... guide
3. 大声说,是谁让windows里的工具无所遁形呀?(需要梯子)
https://medium.com/%40szarubin ... a9316
编辑:斯蒂文
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2174期 (2026-01-05)
https://mp.weixin.qq.com/s/xi1CDRtgYmL8W5PEn7tXAw
2、使用 Elasticsearch 中的结构化输出创建可靠的 agents
https://elasticstack.blog.csdn ... 11541
3、如何使用 LangChain 和 Elasticsearch 构建 agent 知识库
https://blog.csdn.net/UbuntuTo ... 85234
4、Jina-VLM:小型多语言视觉语言模型
https://blog.csdn.net/UbuntuTo ... 52397
5、Elasticsearch:探索 CLIP 替代方案
https://blog.csdn.net/UbuntuTo ... 22575
编辑:Muse
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/xi1CDRtgYmL8W5PEn7tXAw
2、使用 Elasticsearch 中的结构化输出创建可靠的 agents
https://elasticstack.blog.csdn ... 11541
3、如何使用 LangChain 和 Elasticsearch 构建 agent 知识库
https://blog.csdn.net/UbuntuTo ... 85234
4、Jina-VLM:小型多语言视觉语言模型
https://blog.csdn.net/UbuntuTo ... 52397
5、Elasticsearch:探索 CLIP 替代方案
https://blog.csdn.net/UbuntuTo ... 22575
编辑:Muse
更多资讯:http://news.searchkit.cn
收起阅读 »
APM(二):监控 Python 服务
上一篇我们已经安装好了 Skywalking 和 Easysearch,这次我们来写个简单的 Python 服务,并把它的服务调用信息发送给 Skywalking,通过 Skywalking 的 Web UI 进行展示。
启动后端服务
先启动好后端服务,包括 Skywalking 和 Easysearch。启动完成后能通过 Web UI 访问 Skywalking。

构建 Python 服务
我们编写一个简单的 Flask 服务程序,只要访问 localhost:8081/a 就会返回 "Hello, I'm Service A!" 信息。
from flask import Flask
app = Flask(__name__)
@app.route('/a', methods=['GET'])
def service_b():
return "Hello, I'm Service A!"
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8081)运行前,要安装好依赖。
pip3 install flask
pip3 install apache-skywalking依赖关系展示如下:

设置环境变量
为了让服务能成功把相关信息发送到 Skywalking 后端,启动前我们还要设置两个环境变量告诉服务程序该往哪里发送信息。
export SW_AGENT_COLLECTOR_BACKEND_SERVICES=localhost:11800
export SW_AGENT_NAME=AService-python启动 Python 程序
一切准备妥当后,运行我们的服务程序。
sw-python run python3 AService.py程序启动后会监听 8081 端口。

我们通过浏览器访问下。

在 Skywalking 的 Web UI 上查看服务的信息是否采集到。




可以看到服务 A 的调用信息都已经被记录到 Skywalking 中了。
作者:杨帆,极限科技(INFINI Labs)高级解决方案架构师、《老杨玩搜索》栏目 B 站 UP 主,拥有十余年金融行业服务工作经验,熟悉 Linux、数据库、网络等领域。目前主要从事 Easysearch、Elasticsearch 等搜索引擎的技术支持工作,服务国内私有化部署的客户。
上一篇我们已经安装好了 Skywalking 和 Easysearch,这次我们来写个简单的 Python 服务,并把它的服务调用信息发送给 Skywalking,通过 Skywalking 的 Web UI 进行展示。
启动后端服务
先启动好后端服务,包括 Skywalking 和 Easysearch。启动完成后能通过 Web UI 访问 Skywalking。
构建 Python 服务
我们编写一个简单的 Flask 服务程序,只要访问 localhost:8081/a 就会返回 "Hello, I'm Service A!" 信息。
from flask import Flask
app = Flask(__name__)
@app.route('/a', methods=['GET'])
def service_b():
return "Hello, I'm Service A!"
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8081)运行前,要安装好依赖。
pip3 install flask
pip3 install apache-skywalking依赖关系展示如下:
设置环境变量
为了让服务能成功把相关信息发送到 Skywalking 后端,启动前我们还要设置两个环境变量告诉服务程序该往哪里发送信息。
export SW_AGENT_COLLECTOR_BACKEND_SERVICES=localhost:11800
export SW_AGENT_NAME=AService-python启动 Python 程序
一切准备妥当后,运行我们的服务程序。
sw-python run python3 AService.py程序启动后会监听 8081 端口。
我们通过浏览器访问下。
在 Skywalking 的 Web UI 上查看服务的信息是否采集到。
可以看到服务 A 的调用信息都已经被记录到 Skywalking 中了。
收起阅读 »作者:杨帆,极限科技(INFINI Labs)高级解决方案架构师、《老杨玩搜索》栏目 B 站 UP 主,拥有十余年金融行业服务工作经验,熟悉 Linux、数据库、网络等领域。目前主要从事 Easysearch、Elasticsearch 等搜索引擎的技术支持工作,服务国内私有化部署的客户。
【搜索客社区日报】第2172期 (2025-12-30)
https://medium.com/%40moditham ... f4674
2. 用ES+Kibana构建最棒的dashboard(需要梯子)
https://medium.com/%40alexsham ... 56493
3. 承担风险?来用osquery把它们抓出来(需要梯子)
https://detect.fyi/threat-hunt ... e735a
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://medium.com/%40moditham ... f4674
2. 用ES+Kibana构建最棒的dashboard(需要梯子)
https://medium.com/%40alexsham ... 56493
3. 承担风险?来用osquery把它们抓出来(需要梯子)
https://detect.fyi/threat-hunt ... e735a
编辑:斯蒂文
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2171期 (2025-12-29)
https://elasticstack.blog.csdn ... 51787
2、使用 LocalAI 和 Elasticsearch 构建本地 RAG 应用
https://elasticstack.blog.csdn ... 24721
3、更快、更清晰地在 Discover 中分析 traces
https://elasticstack.blog.csdn ... 24101
4、使用 Elastic Cloud Serverless 扩展批量索引
https://elasticstack.blog.csdn ... 23943
5、Elasticsearch:性能悖论 - 当更慢的代码并不会拖慢你
https://elasticstack.blog.csdn ... 51004
编辑:Muse
更多资讯:http://news.searchkit.cn
https://elasticstack.blog.csdn ... 51787
2、使用 LocalAI 和 Elasticsearch 构建本地 RAG 应用
https://elasticstack.blog.csdn ... 24721
3、更快、更清晰地在 Discover 中分析 traces
https://elasticstack.blog.csdn ... 24101
4、使用 Elastic Cloud Serverless 扩展批量索引
https://elasticstack.blog.csdn ... 23943
5、Elasticsearch:性能悖论 - 当更慢的代码并不会拖慢你
https://elasticstack.blog.csdn ... 51004
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2170期 (2025-12-25)
https://mp.weixin.qq.com/s/gr7 ... e%3D1
2.从开发者视角观察 OceanBase 开源的 AI 产品御三家
https://mp.weixin.qq.com/s/mLsSP_o9K6M8nHZIJa1QRg
3.vLLM-Omni 扩散缓存加速:TeaCache 与 Cache-DiT
https://mp.weixin.qq.com/s/Z382Re_iFEsACDLtQnMf-g
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/gr7 ... e%3D1
2.从开发者视角观察 OceanBase 开源的 AI 产品御三家
https://mp.weixin.qq.com/s/mLsSP_o9K6M8nHZIJa1QRg
3.vLLM-Omni 扩散缓存加速:TeaCache 与 Cache-DiT
https://mp.weixin.qq.com/s/Z382Re_iFEsACDLtQnMf-g
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2169期 (2025-12-24)
https://blog.csdn.net/UbuntuTo ... 15338
2. 通过 Elasticsearch 中的 function score query 按利润和受欢迎程度提升电商搜索效果
https://elasticstack.blog.csdn ... 44357
3. 如何构建用于法律文件的极速矢量搜索
https://medium.com/%40adlumal/ ... d55ea
编辑:kin122
更多资讯:http://news.searchkit.cn
https://blog.csdn.net/UbuntuTo ... 15338
2. 通过 Elasticsearch 中的 function score query 按利润和受欢迎程度提升电商搜索效果
https://elasticstack.blog.csdn ... 44357
3. 如何构建用于法律文件的极速矢量搜索
https://medium.com/%40adlumal/ ... d55ea
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2168期 (2025-12-23)
1. 搞RAG?先试试ES吧!(需要梯子)
https://medium.com/%40jan.nctu ... bf22f
2. 人生中价值十亿的错误之配置错误(需要梯子)
https://blog.ironcorelabs.com/ ... -----
3. K8S中的ES之数据节点预热(需要梯子)
https://medium.com/daangn/runn ... -----
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
1. 搞RAG?先试试ES吧!(需要梯子)
https://medium.com/%40jan.nctu ... bf22f
2. 人生中价值十亿的错误之配置错误(需要梯子)
https://blog.ironcorelabs.com/ ... -----
3. K8S中的ES之数据节点预热(需要梯子)
https://medium.com/daangn/runn ... -----
编辑:斯蒂文
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2167期 (2025-12-22)
https://elasticstack.blog.csdn ... 44357
2、使用 LocalAI 和 Elasticsearch 构建本地 RAG 个人知识助手
https://elasticstack.blog.csdn ... 65475
3、使用 Node.js Elasticsearch 客户端索引大型 CSV 文件
https://elasticstack.blog.csdn ... 08761
4、Elasticsearch:构建一个 AI 驱动的电子邮件钓鱼检测
https://elasticstack.blog.csdn ... 92232
5、Kibana:使用 ES|QL 构建地图,对国家或地区的指标进行对比
https://elasticstack.blog.csdn ... 11567
编辑:Muse
更多资讯:http://news.searchkit.cn
https://elasticstack.blog.csdn ... 44357
2、使用 LocalAI 和 Elasticsearch 构建本地 RAG 个人知识助手
https://elasticstack.blog.csdn ... 65475
3、使用 Node.js Elasticsearch 客户端索引大型 CSV 文件
https://elasticstack.blog.csdn ... 08761
4、Elasticsearch:构建一个 AI 驱动的电子邮件钓鱼检测
https://elasticstack.blog.csdn ... 92232
5、Kibana:使用 ES|QL 构建地图,对国家或地区的指标进行对比
https://elasticstack.blog.csdn ... 11567
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
INFINI Labs 产品更新 | Coco AI v0.10 × Easysearch v2.0 联袂上线:UI 全面重构,体验焕然一新

此次更新主要包括 Coco AI v0.10.0 更换全新的 UI 组件,服务端新增 milvus 和 dropbox 连接器;Easysearch v2.0.2 正式发布, 新增嵌入文档语义搜索,优化内置 UI 响应速度,无需依赖 Kibana,实现集群“开箱即管”;INFINI Console、Gateway、Agent、Loadgen v1.30.1 统一基于 Framework v1.4.0 升级,优化本地磁盘队列数据消费。详情见 Release Notes。
Coco AI 0.10
Coco AI 是一款完全开源、跨平台的企业级智能搜索与助手系统,专为现代企业打造。它通过统一搜索入口,连接企业内外部的异构数据源,融合大模型能力,帮助团队高效访问知识,智能决策协作。
Coco AI 本次详细更新记录如下:
Coco AI 客户端 0.10
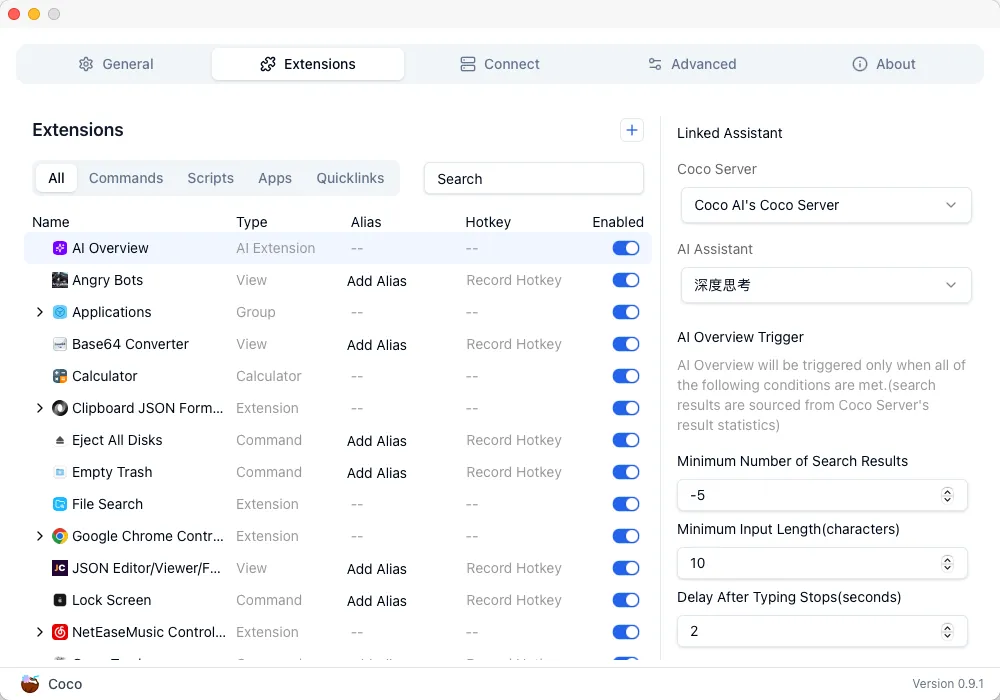
🚀 功能特性 (Features)
- 扩展程序 UI 支持可调整窗口大小

- 添加打开按钮以启动已安装的扩展程序
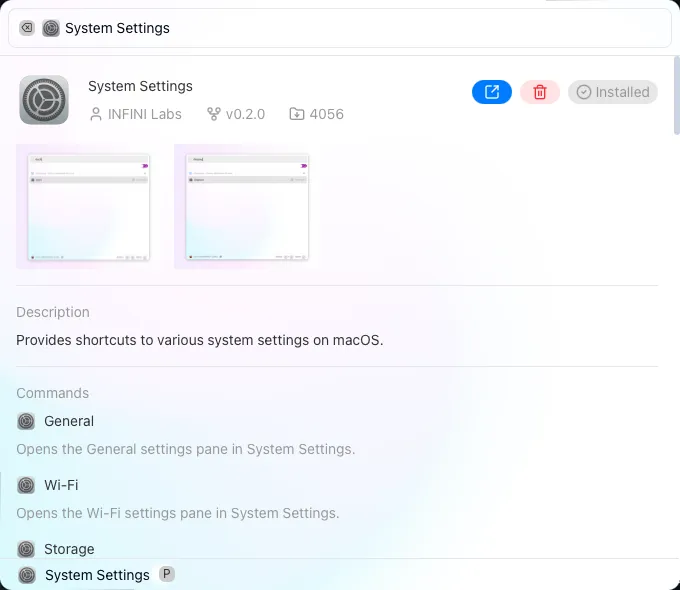
✈️ 改进优化 (Improvements)
- 将应用程序和文件搜索视为普通扩展
- 通过深度链接安装扩展失败时,显示错误消息(而非错误代码)
- 用 shadcn/ui 组件替换旧组件
🐛 问题修复(Bug Fixes)
- 修复输入框高度异常问题
- 为 Extension.minimum_coco_version 实现自定义序列化
Coco AI 服务端 0.10
🚀 功能特性 (Features)
- 新增 milvus 连接器
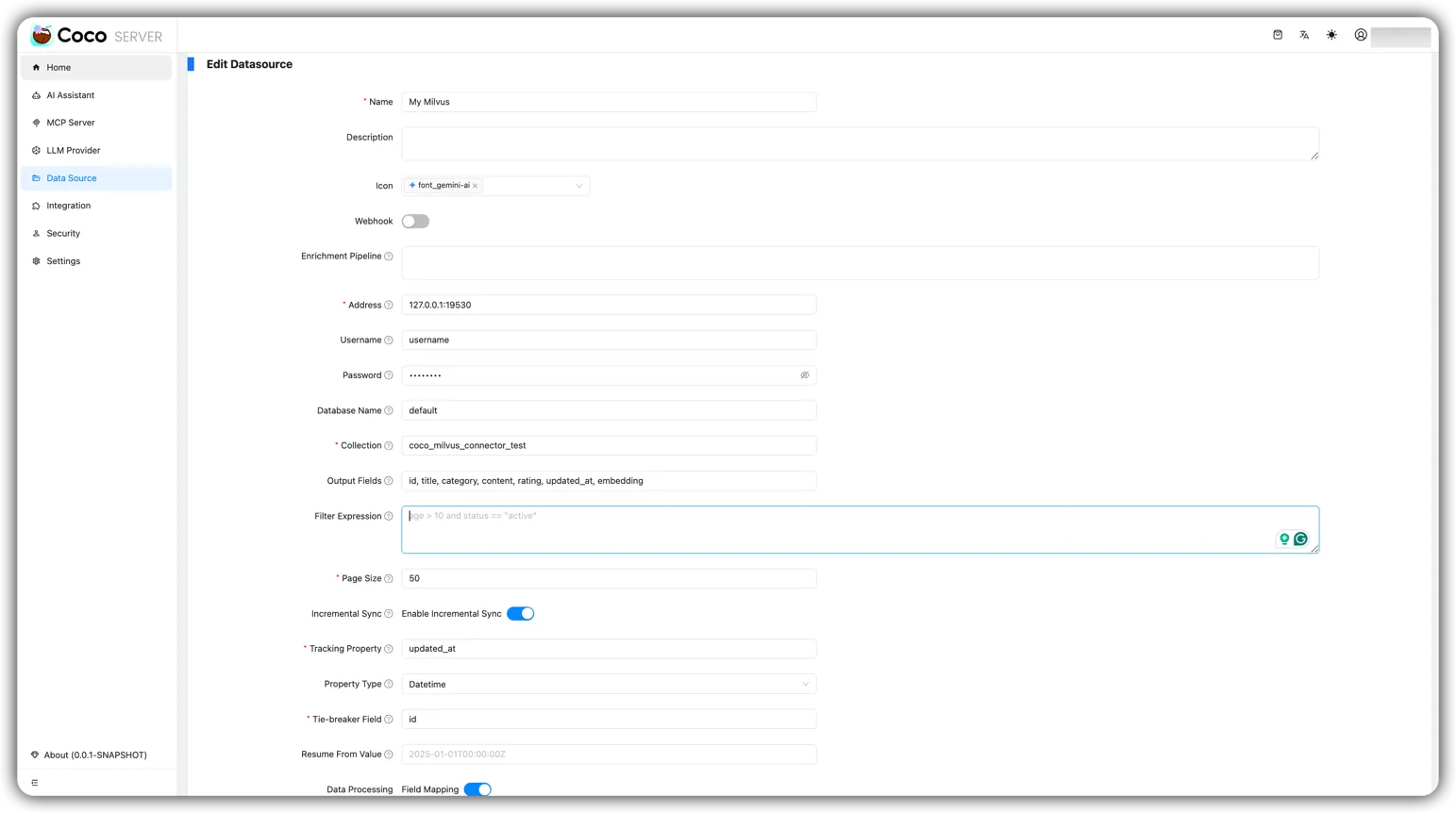
- 新增 dropbox 连接器
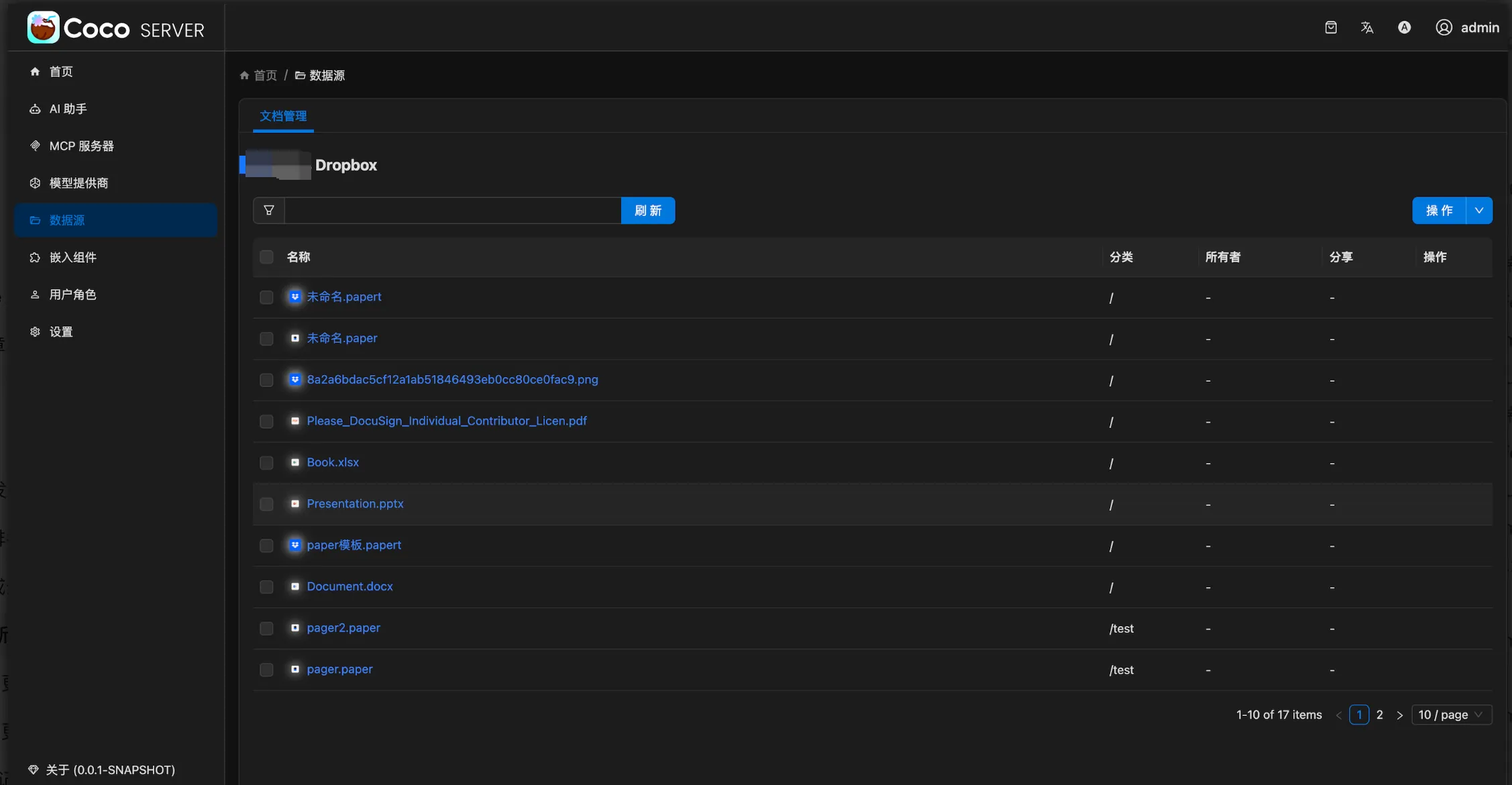
🐛 问题修复(Bug Fixes)
- 修复搜索 API 中图标绝对 URL 的解析问题
- 修复集成商店读取剪贴板数据后的显示问题
✈️ 改进优化 (Improvements)
- 移除分页并在全屏模式下添加无限滚动
Easysearch v2.0.2
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
Easysearch 本次更新如下:
💥 重大变更(Breaking Changes)
- 正式发布 Easysearch 2.0.2 版本,底层 Lucene 更新到 9.12.2
- 新增 ui 插件,为 Easysearch 提供了轻量级界面化管理功能,不再依赖第三方对集群进行管理,真正做到开箱即用
🚀 功能特性 (Features)
- 语义搜索新增支持 NestedQueryBuilder
- KNN mapping 的 L 和 k 参数支持大小写不敏感,提升易用性
✈️ 改进优化 (Improvements)
- UI 插件静态文件支持 gzip 压缩,加快页面加载
- 优化了图标资源大小
- 调整了内部构建流程和 CSP 策略
🐛 问题修复(Bug Fixes)
- 修复了开发者工具的主题颜色显示问题
Console v1.30.1
INFINI Console 是一款开源的非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管,企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 本次详细更新记录如下:
🚀 功能特性 (Features)
- 支持 Easysearch 2.x 和 Opensearch 3.x
✈️ 改进优化 (Improvements)
- 此版本包含了底层 Framework v1.4.0 的更新,解决了一些常见问题,并增强了整体稳定性和性能。虽然 Console 本身没有直接的变更,但从 Framework 中继承的改进间接地使 Console 受益。
Gateway v1.30.1
INFINI Gateway 是一个开源的面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway 可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
Gateway 本次更新如下:
✈️ 改进优化 (Improvements)
- 此版本包含了底层 Framework v1.4.0 的更新,解决了一些常见问题,并增强了整体稳定性和性能。虽然 Gateway 本身没有直接的变更,但从 Framework 中继承的改进间接地使 Gateway 受益。
Agent v1.30.1
INFINI Agent 负责采集和上传 Elasticsearch, Easysearch, Opensearch 集群的日志和指标信息,通过 INFINI Console 管理,支持主流操作系统和平台,安装包轻量且无任何外部依赖,可以快速方便地安装。
Agent 本次更新如下:
🚀 功能特性 (Features)
- 在 Kubernetes 环境下通过环境变量 http.port 探测 Easysearch 的 HTTP 端口
✈️ 改进优化 (Improvements)
- 此版本包含了底层 Framework v1.4.0 的更新,解决了一些常见问题,并增强了整体稳定性和性能。虽然 Agent 本身没有直接的变更,但从 Framework 中继承的改进间接地使 Agent 受益。
Loadgen v1.30.1
INFINI Loadgen 是一款开源的专为 Easysearch、Elasticsearch、OpenSearch 设计的轻量级性能测试工具。
Loadgen 本次更新如下:
✈️ 改进优化 (Improvements)
- 此版本包含了底层 Framework v1.4.0 的更新,解决了一些常见问题,并增强了整体稳定性和性能。虽然 Loadgen 本身没有直接的变更,但从 Framework 中继承的改进间接地使 Loadgen 受益。
Framework 1.4.0
INFINI Framework 是 INFINI Labs 基于 Golang 的产品的核心基础,已开源。该框架以开发者为中心设计,简化了构建高性能、可扩展且可靠的应用程序的过程。
Framework 本次更新如下:
🚀 功能特性 (Features)
- 为 curl 添加 p12 证书支持(#239)
- 从 util 中移除 curl(#242)
- 优先使用集群名称(#243)
- 为 access_token 添加标签(#244)
- 为用户主体(principal)添加头像配置(#246)
🐛 问题修复 (Bug Fixes)
- 修复重复写入和未写入的问题(#234)
- 当 filePath 为绝对路径时,检查其是否存在(#241)
✈️ 改进 (Improvements)
- 改进 TryGetFileAbsPath() 的 panic 错误信息(#240)
更多详情请查看以下各产品的 Release Notes 或联系我们的技术支持团队!
- Coco AI App
- Coco AI Server
- INFINI Easysearch
- INFINI Gateway
- INFINI Console
- INFINI Agent
- INFINI Loadgen
- INFINI Framework
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
下载地址: https://infinilabs.cn/download
邮件:hello@infini.ltd
电话:(+86) 400-139-9200
Discord:https://discord.gg/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。

关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
此次更新主要包括 Coco AI v0.10.0 更换全新的 UI 组件,服务端新增 milvus 和 dropbox 连接器;Easysearch v2.0.2 正式发布, 新增嵌入文档语义搜索,优化内置 UI 响应速度,无需依赖 Kibana,实现集群“开箱即管”;INFINI Console、Gateway、Agent、Loadgen v1.30.1 统一基于 Framework v1.4.0 升级,优化本地磁盘队列数据消费。详情见 Release Notes。
Coco AI 0.10
Coco AI 是一款完全开源、跨平台的企业级智能搜索与助手系统,专为现代企业打造。它通过统一搜索入口,连接企业内外部的异构数据源,融合大模型能力,帮助团队高效访问知识,智能决策协作。
Coco AI 本次详细更新记录如下:
Coco AI 客户端 0.10
🚀 功能特性 (Features)
- 扩展程序 UI 支持可调整窗口大小
- 添加打开按钮以启动已安装的扩展程序
✈️ 改进优化 (Improvements)
- 将应用程序和文件搜索视为普通扩展
- 通过深度链接安装扩展失败时,显示错误消息(而非错误代码)
- 用 shadcn/ui 组件替换旧组件
🐛 问题修复(Bug Fixes)
- 修复输入框高度异常问题
- 为 Extension.minimum_coco_version 实现自定义序列化
Coco AI 服务端 0.10
🚀 功能特性 (Features)
- 新增 milvus 连接器
- 新增 dropbox 连接器
🐛 问题修复(Bug Fixes)
- 修复搜索 API 中图标绝对 URL 的解析问题
- 修复集成商店读取剪贴板数据后的显示问题
✈️ 改进优化 (Improvements)
- 移除分页并在全屏模式下添加无限滚动
Easysearch v2.0.2
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
Easysearch 本次更新如下:
💥 重大变更(Breaking Changes)
- 正式发布 Easysearch 2.0.2 版本,底层 Lucene 更新到 9.12.2
- 新增 ui 插件,为 Easysearch 提供了轻量级界面化管理功能,不再依赖第三方对集群进行管理,真正做到开箱即用
🚀 功能特性 (Features)
- 语义搜索新增支持 NestedQueryBuilder
- KNN mapping 的 L 和 k 参数支持大小写不敏感,提升易用性
✈️ 改进优化 (Improvements)
- UI 插件静态文件支持 gzip 压缩,加快页面加载
- 优化了图标资源大小
- 调整了内部构建流程和 CSP 策略
🐛 问题修复(Bug Fixes)
- 修复了开发者工具的主题颜色显示问题
Console v1.30.1
INFINI Console 是一款开源的非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管,企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 本次详细更新记录如下:
🚀 功能特性 (Features)
- 支持 Easysearch 2.x 和 Opensearch 3.x
✈️ 改进优化 (Improvements)
- 此版本包含了底层 Framework v1.4.0 的更新,解决了一些常见问题,并增强了整体稳定性和性能。虽然 Console 本身没有直接的变更,但从 Framework 中继承的改进间接地使 Console 受益。
Gateway v1.30.1
INFINI Gateway 是一个开源的面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway 可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
Gateway 本次更新如下:
✈️ 改进优化 (Improvements)
- 此版本包含了底层 Framework v1.4.0 的更新,解决了一些常见问题,并增强了整体稳定性和性能。虽然 Gateway 本身没有直接的变更,但从 Framework 中继承的改进间接地使 Gateway 受益。
Agent v1.30.1
INFINI Agent 负责采集和上传 Elasticsearch, Easysearch, Opensearch 集群的日志和指标信息,通过 INFINI Console 管理,支持主流操作系统和平台,安装包轻量且无任何外部依赖,可以快速方便地安装。
Agent 本次更新如下:
🚀 功能特性 (Features)
- 在 Kubernetes 环境下通过环境变量 http.port 探测 Easysearch 的 HTTP 端口
✈️ 改进优化 (Improvements)
- 此版本包含了底层 Framework v1.4.0 的更新,解决了一些常见问题,并增强了整体稳定性和性能。虽然 Agent 本身没有直接的变更,但从 Framework 中继承的改进间接地使 Agent 受益。
Loadgen v1.30.1
INFINI Loadgen 是一款开源的专为 Easysearch、Elasticsearch、OpenSearch 设计的轻量级性能测试工具。
Loadgen 本次更新如下:
✈️ 改进优化 (Improvements)
- 此版本包含了底层 Framework v1.4.0 的更新,解决了一些常见问题,并增强了整体稳定性和性能。虽然 Loadgen 本身没有直接的变更,但从 Framework 中继承的改进间接地使 Loadgen 受益。
Framework 1.4.0
INFINI Framework 是 INFINI Labs 基于 Golang 的产品的核心基础,已开源。该框架以开发者为中心设计,简化了构建高性能、可扩展且可靠的应用程序的过程。
Framework 本次更新如下:
🚀 功能特性 (Features)
- 为 curl 添加 p12 证书支持(#239)
- 从 util 中移除 curl(#242)
- 优先使用集群名称(#243)
- 为 access_token 添加标签(#244)
- 为用户主体(principal)添加头像配置(#246)
🐛 问题修复 (Bug Fixes)
- 修复重复写入和未写入的问题(#234)
- 当 filePath 为绝对路径时,检查其是否存在(#241)
✈️ 改进 (Improvements)
- 改进 TryGetFileAbsPath() 的 panic 错误信息(#240)
更多详情请查看以下各产品的 Release Notes 或联系我们的技术支持团队!
- Coco AI App
- Coco AI Server
- INFINI Easysearch
- INFINI Gateway
- INFINI Console
- INFINI Agent
- INFINI Loadgen
- INFINI Framework
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
下载地址: https://infinilabs.cn/download
邮件:hello@infini.ltd
电话:(+86) 400-139-9200
Discord:https://discord.gg/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »【搜索客社区日报】第2166期 (2025-12-19)
https://my.oschina.net/infinilabs/blog/18902610
2、Easy-Es 2.1.0-easysearch 版本发布
https://infinilabs.cn/blog/202 ... ease/
3、图解 Elasticsearch 慢查询诊断流程
https://mp.weixin.qq.com/s/aysQlr3OyK50GI2JlKJ1cQ
4、程序员爆哭!我们让 COCO AI 接管 GitLab 审查后,团队直接起飞:连 CTO 都说“这玩意儿比人靠谱多了”
https://my.oschina.net/infinilabs/blog/18966328
5、APM(一): Skywalking 与 Easyearch 集成
https://infinilabs.cn/blog/202 ... arch/
编辑:Fred
更多资讯:http://news.searchkit.cn
https://my.oschina.net/infinilabs/blog/18902610
2、Easy-Es 2.1.0-easysearch 版本发布
https://infinilabs.cn/blog/202 ... ease/
3、图解 Elasticsearch 慢查询诊断流程
https://mp.weixin.qq.com/s/aysQlr3OyK50GI2JlKJ1cQ
4、程序员爆哭!我们让 COCO AI 接管 GitLab 审查后,团队直接起飞:连 CTO 都说“这玩意儿比人靠谱多了”
https://my.oschina.net/infinilabs/blog/18966328
5、APM(一): Skywalking 与 Easyearch 集成
https://infinilabs.cn/blog/202 ... arch/
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
🔥 程序员爆哭!我们让 COCO AI 接管 GitLab 审查后,团队直接起飞:连 CTO 都说“这玩意儿比人靠谱多了”
我直接讲结论:
**把 COCO AI 接入 GitLab 做自动代码审核之后,我们团队的开发效率被硬生生抬了一个时代。**
没夸张。不是优化 10% 或 20%。是 ——
> **开发效率 x3**
> **Bug 暴露率 x4**
> **Review 时间 ÷10**
更夸张的是,连我们 CTO 都说:
**“这玩意儿比人审得狠,也比人稳定。”**
程序员则在角落瑟瑟发抖:
**“以前写代码是骗过人,现在要骗过神。”**
今天我就把整个故事公开,让你看看真正的 AI 审查是什么狠劲。
## 01 |为什么你们团队的代码审查永远做不好?因为你们还在靠人。
你们团队是不是这样?
- 开发提个 MR,等两天没人看
- Reviewer 随便扫一眼就点 Approve
- 线上事故后互相甩锅
- 业务压得 reviewer 根本没空认真审
- 新人写代码没人看,雷悄悄埋进去
- 老工程师被拉满,耗死在重复劳动里
别骗自己了,这不是“流程问题”。
这是 **时代问题**。
靠人审代码?
那是 2018 年的玩法。
现在是 **AI 审代码** 的时代。
谁先用,谁就是下一代团队。
## 02 | COCO AI 接入 GitLab 后,第一天就把我们吓了一跳
!(https://infinilabs.cn/img/blog ... /2.png)
MR 刚发起,COCO AI 立刻跳出来:
**“代码已接收,正在审查……”**
几十秒后——
**啪!三十条问题丢你脸上。**
而且不是小问题,都是致命的:
- 并发 map 读写直接 panic
- goroutine 不关,泄漏到天荒地老
- defer 在循环里疯狂堆
- SQL 拼接漏洞肉眼可见
- ctx 没传,超时失控
- 错误没处理,线上一炸就是大事故
- 魔法数字到处飞,迟早坑死同事
我们团队瞬间安静了。
程序员盯着屏幕:**“这谁写的?哦是我自己。”**
## 03 | COCO AI 到底有多狠?它审代码完全不给人留面子。
你在代码里犯过的错,它全看得见。
它的风格就是四个字:**不留活口**。
它会直接给你分析:
### ⚠ 逻辑错误?直接点名。
> 第 87 行你 return true 可能放大权限,严重安全风险。
### ⚠ 并发不安全?当场抓包。
> 这里的 map 没加锁,线上必崩,别侥幸了。
### ⚠ 性能差?它骂你。
> strings.Split 一秒钟几十次,你不怕 CPU 烧?
> 建议换 Cut 或者预编译正则。
### ⚠ 可读性差?它批你。
> 你这函数 160 行,是准备写回忆录?
### ⚠ 测试没写?它戳破你。
> 缺反例测试,别装了,我知道你赶进度。
它不拍马屁,不做样子,不搞关系,不吹彩虹屁,
**它只针对代码,不针对人。**
**它只认问题,不认面子。**
这就是 AI 审查的力量。
## 04 |更离谱的是:接 GitLab 只要 30 行代码
这玩意儿接入 GitLab 简直轻到离谱。
流程就是三步:
1. GitLab MR → Webhook → 你的服务
2. 把 Diff 丢给 COCO AI
3. 把审查结果评论回 MR
Go 代码甚至可以一屏写完:
```go
func handleMR(w http.ResponseWriter, r *http.Request) {
req := parseWebhook(r)
diff := gitlab.GetDiff(req)
review := coco.ReviewCode(diff)
gitlab.PostComment(req, review.Content)
}
```
连新手工程师看了都说:
**“这接入成本也太爽了吧?”**
## 05 |我给你看真实的团队指标,绝不是嘴上吹
!(https://infinilabs.cn/img/blog ... /3.png)
三个月统计(真实数据):
| 指标 | 接入前 | 接入后 |
| ---------------- | --------- | --------------------------- |
| 平均 MR 审查时间 | 1–2 天 | **5–20 分钟** |
| Reviewer 工作量 | 爆满 | **骤降 70%** |
| 严重 Bug 暴露率 | 20% 左右 | **80% ** |
| 线上事故 | 7 次/季度 | **2 次/季度**(还都小事故) |
| 新人代码质量 | 不敢看 | **像有老司机在手把手教** |
更爽的是:
**COCO AI 还把老工程师解放出来做更重要的事情。**
这才是 AI 的正确使用方式。
## 06 |你以为 AI 是玩具?错。它是未来的生产力。
这不是一个“用不用”的问题。
这是一个“想不想被时代淘汰”的问题。
未来三年,软件团队会被两种力量碾压:
- **用 AI 的团队**
- **被用 AI 的团队压死的团队**
选择权不在你手里,趋势已经发生。
## 07 |更狠的还在后面:COCO 正在做这些
我们内部已在测试:
- GitHub PR 自动审查
- IDE 实时调试 实时审查
- 全仓扫描的“技术体检报告”
- 自动生成修复 patch
- AI 识别架构风险、循环依赖、隐藏 bug 链
- 一键优化整个模块
一句话:
**COCO AI 会把你团队的代码质量拉到一个你无法想象的高度。**
## 结语:如果你团队现在还靠人审代码,那你们已经落后了。
别再幻想靠人力提升研发效率。
别再指望审查不出事故。
别再让高级工程师死在重复劳动里。
把代码审查交给 AI,
把工程师从地狱里解放出来。
如果你想让团队变强、变快、变稳,
那你需要的,不是更多人,
而是 **COCO AI 做你的 GitLab Reviewer。**
## 关于 COCO AI
COCO AI 是一款完全开源、跨平台的企业级智能搜索与助手系统,专为现代企业打造。它通过统一搜索入口,连接企业内外部的异构数据源,融合大模型能力,帮助团队高效访问知识,智能决策协作。
官网:<https://coco.rs>
Github:<https://github.com/infinilabs/coco-app>
我直接讲结论:
**把 COCO AI 接入 GitLab 做自动代码审核之后,我们团队的开发效率被硬生生抬了一个时代。**
没夸张。不是优化 10% 或 20%。是 ——
> **开发效率 x3**
> **Bug 暴露率 x4**
> **Review 时间 ÷10**
更夸张的是,连我们 CTO 都说:
**“这玩意儿比人审得狠,也比人稳定。”**
程序员则在角落瑟瑟发抖:
**“以前写代码是骗过人,现在要骗过神。”**
今天我就把整个故事公开,让你看看真正的 AI 审查是什么狠劲。
## 01 |为什么你们团队的代码审查永远做不好?因为你们还在靠人。
你们团队是不是这样?
- 开发提个 MR,等两天没人看
- Reviewer 随便扫一眼就点 Approve
- 线上事故后互相甩锅
- 业务压得 reviewer 根本没空认真审
- 新人写代码没人看,雷悄悄埋进去
- 老工程师被拉满,耗死在重复劳动里
别骗自己了,这不是“流程问题”。
这是 **时代问题**。
靠人审代码?
那是 2018 年的玩法。
现在是 **AI 审代码** 的时代。
谁先用,谁就是下一代团队。
## 02 | COCO AI 接入 GitLab 后,第一天就把我们吓了一跳
!(https://infinilabs.cn/img/blog ... /2.png)
MR 刚发起,COCO AI 立刻跳出来:
**“代码已接收,正在审查……”**
几十秒后——
**啪!三十条问题丢你脸上。**
而且不是小问题,都是致命的:
- 并发 map 读写直接 panic
- goroutine 不关,泄漏到天荒地老
- defer 在循环里疯狂堆
- SQL 拼接漏洞肉眼可见
- ctx 没传,超时失控
- 错误没处理,线上一炸就是大事故
- 魔法数字到处飞,迟早坑死同事
我们团队瞬间安静了。
程序员盯着屏幕:**“这谁写的?哦是我自己。”**
## 03 | COCO AI 到底有多狠?它审代码完全不给人留面子。
你在代码里犯过的错,它全看得见。
它的风格就是四个字:**不留活口**。
它会直接给你分析:
### ⚠ 逻辑错误?直接点名。
> 第 87 行你 return true 可能放大权限,严重安全风险。
### ⚠ 并发不安全?当场抓包。
> 这里的 map 没加锁,线上必崩,别侥幸了。
### ⚠ 性能差?它骂你。
> strings.Split 一秒钟几十次,你不怕 CPU 烧?
> 建议换 Cut 或者预编译正则。
### ⚠ 可读性差?它批你。
> 你这函数 160 行,是准备写回忆录?
### ⚠ 测试没写?它戳破你。
> 缺反例测试,别装了,我知道你赶进度。
它不拍马屁,不做样子,不搞关系,不吹彩虹屁,
**它只针对代码,不针对人。**
**它只认问题,不认面子。**
这就是 AI 审查的力量。
## 04 |更离谱的是:接 GitLab 只要 30 行代码
这玩意儿接入 GitLab 简直轻到离谱。
流程就是三步:
1. GitLab MR → Webhook → 你的服务
2. 把 Diff 丢给 COCO AI
3. 把审查结果评论回 MR
Go 代码甚至可以一屏写完:
```go
func handleMR(w http.ResponseWriter, r *http.Request) {
req := parseWebhook(r)
diff := gitlab.GetDiff(req)
review := coco.ReviewCode(diff)
gitlab.PostComment(req, review.Content)
}
```
连新手工程师看了都说:
**“这接入成本也太爽了吧?”**
## 05 |我给你看真实的团队指标,绝不是嘴上吹
!(https://infinilabs.cn/img/blog ... /3.png)
三个月统计(真实数据):
| 指标 | 接入前 | 接入后 |
| ---------------- | --------- | --------------------------- |
| 平均 MR 审查时间 | 1–2 天 | **5–20 分钟** |
| Reviewer 工作量 | 爆满 | **骤降 70%** |
| 严重 Bug 暴露率 | 20% 左右 | **80% ** |
| 线上事故 | 7 次/季度 | **2 次/季度**(还都小事故) |
| 新人代码质量 | 不敢看 | **像有老司机在手把手教** |
更爽的是:
**COCO AI 还把老工程师解放出来做更重要的事情。**
这才是 AI 的正确使用方式。
## 06 |你以为 AI 是玩具?错。它是未来的生产力。
这不是一个“用不用”的问题。
这是一个“想不想被时代淘汰”的问题。
未来三年,软件团队会被两种力量碾压:
- **用 AI 的团队**
- **被用 AI 的团队压死的团队**
选择权不在你手里,趋势已经发生。
## 07 |更狠的还在后面:COCO 正在做这些
我们内部已在测试:
- GitHub PR 自动审查
- IDE 实时调试 实时审查
- 全仓扫描的“技术体检报告”
- 自动生成修复 patch
- AI 识别架构风险、循环依赖、隐藏 bug 链
- 一键优化整个模块
一句话:
**COCO AI 会把你团队的代码质量拉到一个你无法想象的高度。**
## 结语:如果你团队现在还靠人审代码,那你们已经落后了。
别再幻想靠人力提升研发效率。
别再指望审查不出事故。
别再让高级工程师死在重复劳动里。
把代码审查交给 AI,
把工程师从地狱里解放出来。
如果你想让团队变强、变快、变稳,
那你需要的,不是更多人,
而是 **COCO AI 做你的 GitLab Reviewer。**
## 关于 COCO AI
COCO AI 是一款完全开源、跨平台的企业级智能搜索与助手系统,专为现代企业打造。它通过统一搜索入口,连接企业内外部的异构数据源,融合大模型能力,帮助团队高效访问知识,智能决策协作。
官网:<https://coco.rs>
Github:<https://github.com/infinilabs/coco-app> 收起阅读 »
【搜索客社区日报】第2165期 (2025-12-18)
https://lmsys.org/blog/2025-12-17-minisgl/
2.Encoder Disaggregation:让多模态推理服务的尾延迟更稳
https://mp.weixin.qq.com/s/96ErFSwmAezrfYcVRulA4g
3.Kubernetes 智能 Agent 运行时
https://mckinsey.github.io/agents-at-scale-ark/
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://lmsys.org/blog/2025-12-17-minisgl/
2.Encoder Disaggregation:让多模态推理服务的尾延迟更稳
https://mp.weixin.qq.com/s/96ErFSwmAezrfYcVRulA4g
3.Kubernetes 智能 Agent 运行时
https://mckinsey.github.io/agents-at-scale-ark/
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2164期 (2025-12-17)
https://mp.weixin.qq.com/s/yQyLMIF2nigRhhBuORCQ7w
2. 打破 IK 分词“架构陷阱”——阿里云 ES Serverless 索引级词典的完美热更新实践
https://mp.weixin.qq.com/s/TykXYrt76QGbsDPrD5xTkg
3. Elasticsearch:在分析过程中对数字进行标准化
https://elasticstack.blog.csdn ... 01945
编辑:kin122
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/yQyLMIF2nigRhhBuORCQ7w
2. 打破 IK 分词“架构陷阱”——阿里云 ES Serverless 索引级词典的完美热更新实践
https://mp.weixin.qq.com/s/TykXYrt76QGbsDPrD5xTkg
3. Elasticsearch:在分析过程中对数字进行标准化
https://elasticstack.blog.csdn ... 01945
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »

