

【搜索客社区日报】第2152期 (2025-11-26)
https://medium.com/%40marinell ... f5713
2. Elasticsearch 到本地 LLM0(搭梯)
https://medium.com/%40darkly_s ... f57e7
3. 使用 LLM、MCP 和 Ollama 通过自然语言查询 Elasticsearch
https://david-dudu-zbeda.mediu ... b7b43
编辑:kin122
更多资讯:http://news.searchkit.cn
https://medium.com/%40marinell ... f5713
2. Elasticsearch 到本地 LLM0(搭梯)
https://medium.com/%40darkly_s ... f57e7
3. 使用 LLM、MCP 和 Ollama 通过自然语言查询 Elasticsearch
https://david-dudu-zbeda.mediu ... b7b43
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2150期 (2025-11-24)
https://elasticstack.blog.csdn ... 50222
2、你的第一个 Elastic Agent:从单个查询到 AI 驱动的聊天(二)
https://elasticstack.blog.csdn ... 64514
3、介绍一种新的向量存储格式:DiskBBQ
https://mp.weixin.qq.com/s/CcDoX6AktlrKhTJuiJAsag
4、Elasticsearch 混合搜索 - Hybrid Search
https://mp.weixin.qq.com/s/PW8W9UDuSCoYrQgVwRfmWQ
5、为什么 LLM 搞不定复杂任务?ReAct 与 Reflexion 技术综述
https://mp.weixin.qq.com/s/GJIjxwGQ0tMBj3if1FU9sw
编辑:Muse
更多资讯:http://news.searchkit.cn
https://elasticstack.blog.csdn ... 50222
2、你的第一个 Elastic Agent:从单个查询到 AI 驱动的聊天(二)
https://elasticstack.blog.csdn ... 64514
3、介绍一种新的向量存储格式:DiskBBQ
https://mp.weixin.qq.com/s/CcDoX6AktlrKhTJuiJAsag
4、Elasticsearch 混合搜索 - Hybrid Search
https://mp.weixin.qq.com/s/PW8W9UDuSCoYrQgVwRfmWQ
5、为什么 LLM 搞不定复杂任务?ReAct 与 Reflexion 技术综述
https://mp.weixin.qq.com/s/GJIjxwGQ0tMBj3if1FU9sw
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
INFINI Labs 产品更新 | Coco AI v0.9 与 Easysearch v2.0 全新功能上线,全面支持 GitLab 合并请求(MR)自动 AI Review

INFINI Labs 产品更新发布!此次更新主要包括:Coco AI v0.9 全面支持 GitLab 合并请求(MR)自动 AI Review,并重构为插件流水线架构,新增 Neo4j、MongoDB 等 10+ 数据源连接器,开启“AI+开发”协同新范式;Easysearch v2.0 正式发布,内置轻量级管理 UI,无需依赖 Kibana,实现集群“开箱即管”,Lucene 升级至 9.12.2,性能全面提升;INFINI Console、Gateway、Agent、Loadgen v1.30 统一基于 Framework v1.3 升级,全面支持 Easysearch 2.0 与 OpenSearch 3.x,新增百分比聚合、子目录代理等关键能力。详情见 Release Notes。
Coco AI v0.9
Coco AI 是一款完全开源、跨平台的企业级智能搜索与助手系统,专为现代企业打造。它通过统一搜索入口,连接企业内外部的异构数据源,融合大模型能力,帮助团队高效访问知识,智能决策协作。
Coco AI 本次详细更新记录如下:
Coco AI 客户端 v0.9
🚀 功能特性 (Features)
- feat: 支持通过快捷键切换分组 #911
- feat: 支持从设置页面打开日志文件夹
- feat: 支持使用 home 和 end 键移动光标
- feat: 支持使用 page up 和 page down 键移动选中条
- feat: 规范化多级菜单的标签结构
- feat: 当父插件类型为 Extension 时,搜索父插件可以搜到子插件
- feat: 支持使用 modifier key 和回车对话 AI 助手
- feat: 允许在光标位于开头时返回
- feat(插件兼容性): 插件描述文件添加 minimum_coco_version 字段进行版本检查
- feat: 实现紧凑窗口模式
- feat: 实现设置项搜索延迟和本地搜索结果权重
- feat: 添加主窗口透明度设置
- feat: 添加从默认模式回答紧凑模式的延迟设置
✈️ 改进优化 (Improvements)
- refactor: 优化搜索结果的排序逻辑 #910
- style: 为图片添加深色投影 #912
- chore: 为 Web 组件添加跨域配置 #921
- refactor: 若 AXUIElementSetAttributeValue() 失败则进行重试 #924
- refactor(calculator): 若表达式为 "num => num" 格式则跳过计算 #929
- chore: 使用自定义日志目录 #930
- chore: 将 tauri_nspanel 升级至 v2.1 #933
- refactor: show_coco/hide_coco 现已在 macOS 上改用 NSPanel 的相关方法 #933
- refactor: 将 convert_pages() 流程封装为函数 #934
- refactor(post-search): 从每个查询源至少收集 2 份文档 #948
- refactor: custom_version_comparator() 现已支持语义化版本比较 #941
- chore: 让主窗口垂直居中 #959
- refactor(view extension): 通过本地 HTTP 服务器加载 HTML/资源文件 #973
🐛 问题修复(Bug Fixes)
- fix: 修复服务列表自动更新的问题 #913
- ix: 修复聊天内容重复的问题 #916
- fix: 修复固定窗口(Pinned Window)快捷键失效的问题 #917
- fix: 修复从另一显示器操作焦点窗口时,窗口管理扩展失效的问题 #919
- fix(窗口管理插件): 修复“下一个/上一个桌面”功能失效的问题 #926
- fix: 修复页面频繁闪烁的问题 #935
- fix(view extension): 修复通过快捷键打开扩展时搜索栏 UI 显示异常的问题 #938
- fix: 修复全选文本后无法删除的问题 #943
- fix: 修复在聊天和搜索页面之间切换时的抖动问题 #955
- fix: 修复重复显示登录成功提示的问题 #977
- fix: 修复 Quick AI 无法继续对话的问题 #979
Coco App 相关截图:


Coco AI 服务端 v0.9
💥 重大变更(Breaking Changes)
- refactor: 将连接器重构为基于流水线(Pipeline)模式 (#545) #545
- refactor: 重新实现安全功能;需重新运行设置程序
🚀 功能特性 (Features)
- feat: 新增 Neo4j 连接器 #539
- feat: 新增内置商店 #551
- feat: 基于 RBAC 的安全机制
- feat: 用户级数据所有权与共享功能
- feat: 管理界面增加权限校验
- feat: 新增路由权限验证
- feat: 新增用户实体卡片
- feat: 文档管理增加视图功能
- feat: 新增 Webhooks 管理界面 (#558)
- feat: 新增 GitLab 合并事件的 Webhook 处理器
- feat: 集成扩展商店
- feat: 支持编辑连接器处理器配置
- feat: 支持配置 Base Path 以自定义服务端点
- feat: 名称字段增加拼音支持
- feat: 新增 MongoDB 连接器
🐛 问题修复(Bug Fixes)
- fix: 修复切换扩展类型后重置搜索关键词的问题
- fix: 修复全屏小部件的相关问题
✈️ 改进优化 (Improvements)
- refactor: 为深色模式添加悬停背景效果
- chore: 修复文档搜索功能
- chore: 格式化日期
- refactor: 更新初始值
- chore: 修复数据源名称缺失的问题
- chore: 安装完成后隐藏弹窗
- chore: 基于框架变更进行重构
- chore: 为支持深度思考(DeepThink)获取更多文档 #577
- chore: 启用搜索后将首页更改为搜索页 #541
- chore: 更新搜索 API 以支持查询 DSL #550
- chore: 默认按创建时间排序
- chore: 调整多语言配置
- chore: 用户表单增加确认密码字段
- chore: 调整连接器类型
- chore: 调整连接器 OAuth 重定向设置
- refactor: 为集成功能进行重构
- refactor: 移除集成配置中的 Token
- chore: 编辑用户时禁用邮箱字段
- chore: 调整搜索设置
Coco Server 相关截图:



Easysearch v2.0
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
Easysearch 本次更新如下:
💥 重大变更(Breaking Changes)
- 正式发布 Easysearch 2.0 版本,底层 Lucene 更新到 9.12.2
- 新增 ui 插件,为 Easysearch 提供了轻量级界面化管理功能,不再依赖第三方对集群进行管理,真正做到开箱即用
🚀 功能特性 (Features)
- 兼容 1.15.x 版本的索引,可无缝升级
- 新增 UI 插件,涵盖从集群,节点,索引,到分片等不同维度的监控和管理功能
- 支持关闭 security 进入 UI
✈️ 改进优化 (Improvements)
- range 查询,按数字类型字段排序,相比旧版本效率大幅提升
Easysearch UI 相关截图:



Console v1.30
INFINI Console 是一款开源的非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管,企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 本次详细更新记录如下:
🚀 功能特性 (Features)
- feat: 支持百分比聚合
- feat: 为初始化管理员用户增加密码强度校验 (#250)
- feat: 支持 Nginx 代理下的子目录路径 (#243)
🐛 问题修复(Bug Fixes)
- fix: 修复了索引映射 (mapping) 在滚动查询 (scroll) 后不正确的问题 (#248)
- fix: 修复索引 mapping 在滚动操作之后不对的问题
- fix: 修复集群监控设置显示错误
✈️ 改进优化 (Improvements)
- chore: 删除集群后减少 Agent 上报异常错误日志输出 (#258)
- 此版本包含了底层 Framework v1.3 的更新,解决了一些常见问题,并增强了整体稳定性和性能。虽然 Console 本身没有直接的变更,但从 Framework 中继承的改进间接地使 Console 受益。
Gateway v1.30
INFINI Gateway 是一个开源的面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway 可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
Gateway 本次更新如下:
🚀 功能特性 (Features)
- feat(rewrite_to_bulk):使文档更新兼容 Elasticsearch 6.x (#112)
🐛 问题修复(Bug Fixes)
- fix: 修复心跳连接的潜在泄漏问题 (#107)
✈️ 改进优化 (Improvements)
- 改进 ReverseProxy 的锁机制和节点发现逻辑 (#111)
- 此版本包含了底层 Framework v1.3 的更新,解决了一些常见问题,并增强了整体稳定性和性能。虽然 Gateway 本身没有直接的变更,但从 Framework 中继承的改进间接地使 Gateway 受益。
Agent v1.30
INFINI Agent 负责采集和上传 Elasticsearch, Easysearch, Opensearch 集群的日志和指标信息,通过 INFINI Console 管理,支持主流操作系统和平台,安装包轻量且无任何外部依赖,可以快速方便地安装。
Agent 本次更新如下:
🚀 功能特性 (Features)
在 Kubernetes 环境下通过环境变量 http.port 探测 Easysearch 的 HTTP 端口
✈️ 改进优化 (Improvements)
- 此版本包含了底层 Framework v1.3 的更新,解决了一些常见问题,并增强了整体稳定性和性能。虽然 Agent 本身没有直接的变更,但从 Framework 中继承的改进间接地使 Agent 受益。
Loadgen v1.30
INFINI Loadgen 是一款开源的专为 Easysearch、Elasticsearch、OpenSearch 设计的轻量级性能测试工具。
Loadgen 本次更新如下:
✈️ 改进优化 (Improvements)
- 此版本包含了底层 Framework v1.3 的更新,解决了一些常见问题,并增强了整体稳定性和性能。虽然 Loadgen 本身没有直接的变更,但从 Framework 中继承的改进间接地使 Loadgen 受益。
Framework 1.3.0
INFINI Framework 是 INFINI Labs 基于 Golang 的产品的核心基础,已开源。该框架以开发者为中心设计,简化了构建高性能、可扩展且可靠的应用程序的过程。
Framework 本次更新如下:
🚀 功能特性 (Features)
- feat: add delete by query v2 #194
- feat: support aggregation queries in orm
- feat: add support for query_string query
- feat: allow to read http request body multi-times #212
- feat: add support for Elasticsearch cat allocation API
- feat: support custom write operation type for indexing_merge processor
- feat: add util to parse time with local timezone #217
- feat: add PKCS#12 certificate support for http client config
- feat: add security module, with rbac,sharing,oauth client etc.
- feat: add entity_card module
- feat: add abstract layer for user or teams search
- feat: add util to normalize folder path
- feat: add some string utils
- feat: allow force update all mappings for existing indices
- feat: add several http filters
- feat: add util to execute http requests via curl
🐛 问题修复 (Bug Fixes)
- fix: localhost/127.0.0.1 with noproxy #185
- fix: cluster metadata lost #200
- fix: fix security permission cache
- fix: fix incorrect queue capacity check
✈️ 改进 (Improvements)
- chore: less logging for session store change #180
- refactor: initialize index schema using index template
- chore: add generate secure string util func #183
- chore: add validate secure func #184
- refactor: refactoring security structs #191
- refactor: refactoring schema init logic, disable index based template #188
- chore: use safe special chars #190
- chore: reduce log with agent #193
- chore: add util to register http handler #206
- chore: allow access application settings for ui #209
- refactor: refactoring query string parser #216
- chore: update default fuzziness to 3 #215
- chore: avoid using same session name for mulit instances #221
- refactor: refactoring pipeline #222
- chore: enhance bulk indexing - stricter offset validation and improved error handling #224
- refactor: refactoring http utils #226
- refactor: refactoring search response, add score support
- refactor: refactoring ORM module, add generic security hooks
- refactor: add boolean query to orm query builder
- refactor: refactoring access_token, simplify login info
- refactor: move RegisterAllowOriginFunc to core
更多详情请查看以下各产品的 Release Notes 或联系我们的技术支持团队!
- Coco AI App
- Coco AI Server
- INFINI Easysearch
- INFINI Gateway
- INFINI Console
- INFINI Agent
- INFINI Loadgen
- INFINI Framework
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
下载地址: https://infinilabs.cn/download
邮件:hello@infini.ltd
电话:(+86) 400-139-9200
Discord:https://discord.gg/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。

关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
INFINI Labs 产品更新发布!此次更新主要包括:Coco AI v0.9 全面支持 GitLab 合并请求(MR)自动 AI Review,并重构为插件流水线架构,新增 Neo4j、MongoDB 等 10+ 数据源连接器,开启“AI+开发”协同新范式;Easysearch v2.0 正式发布,内置轻量级管理 UI,无需依赖 Kibana,实现集群“开箱即管”,Lucene 升级至 9.12.2,性能全面提升;INFINI Console、Gateway、Agent、Loadgen v1.30 统一基于 Framework v1.3 升级,全面支持 Easysearch 2.0 与 OpenSearch 3.x,新增百分比聚合、子目录代理等关键能力。详情见 Release Notes。
Coco AI v0.9
Coco AI 是一款完全开源、跨平台的企业级智能搜索与助手系统,专为现代企业打造。它通过统一搜索入口,连接企业内外部的异构数据源,融合大模型能力,帮助团队高效访问知识,智能决策协作。
Coco AI 本次详细更新记录如下:
Coco AI 客户端 v0.9
🚀 功能特性 (Features)
- feat: 支持通过快捷键切换分组 #911
- feat: 支持从设置页面打开日志文件夹
- feat: 支持使用 home 和 end 键移动光标
- feat: 支持使用 page up 和 page down 键移动选中条
- feat: 规范化多级菜单的标签结构
- feat: 当父插件类型为 Extension 时,搜索父插件可以搜到子插件
- feat: 支持使用 modifier key 和回车对话 AI 助手
- feat: 允许在光标位于开头时返回
- feat(插件兼容性): 插件描述文件添加 minimum_coco_version 字段进行版本检查
- feat: 实现紧凑窗口模式
- feat: 实现设置项搜索延迟和本地搜索结果权重
- feat: 添加主窗口透明度设置
- feat: 添加从默认模式回答紧凑模式的延迟设置
✈️ 改进优化 (Improvements)
- refactor: 优化搜索结果的排序逻辑 #910
- style: 为图片添加深色投影 #912
- chore: 为 Web 组件添加跨域配置 #921
- refactor: 若 AXUIElementSetAttributeValue() 失败则进行重试 #924
- refactor(calculator): 若表达式为 "num => num" 格式则跳过计算 #929
- chore: 使用自定义日志目录 #930
- chore: 将 tauri_nspanel 升级至 v2.1 #933
- refactor: show_coco/hide_coco 现已在 macOS 上改用 NSPanel 的相关方法 #933
- refactor: 将 convert_pages() 流程封装为函数 #934
- refactor(post-search): 从每个查询源至少收集 2 份文档 #948
- refactor: custom_version_comparator() 现已支持语义化版本比较 #941
- chore: 让主窗口垂直居中 #959
- refactor(view extension): 通过本地 HTTP 服务器加载 HTML/资源文件 #973
🐛 问题修复(Bug Fixes)
- fix: 修复服务列表自动更新的问题 #913
- ix: 修复聊天内容重复的问题 #916
- fix: 修复固定窗口(Pinned Window)快捷键失效的问题 #917
- fix: 修复从另一显示器操作焦点窗口时,窗口管理扩展失效的问题 #919
- fix(窗口管理插件): 修复“下一个/上一个桌面”功能失效的问题 #926
- fix: 修复页面频繁闪烁的问题 #935
- fix(view extension): 修复通过快捷键打开扩展时搜索栏 UI 显示异常的问题 #938
- fix: 修复全选文本后无法删除的问题 #943
- fix: 修复在聊天和搜索页面之间切换时的抖动问题 #955
- fix: 修复重复显示登录成功提示的问题 #977
- fix: 修复 Quick AI 无法继续对话的问题 #979
Coco App 相关截图:
Coco AI 服务端 v0.9
💥 重大变更(Breaking Changes)
- refactor: 将连接器重构为基于流水线(Pipeline)模式 (#545) #545
- refactor: 重新实现安全功能;需重新运行设置程序
🚀 功能特性 (Features)
- feat: 新增 Neo4j 连接器 #539
- feat: 新增内置商店 #551
- feat: 基于 RBAC 的安全机制
- feat: 用户级数据所有权与共享功能
- feat: 管理界面增加权限校验
- feat: 新增路由权限验证
- feat: 新增用户实体卡片
- feat: 文档管理增加视图功能
- feat: 新增 Webhooks 管理界面 (#558)
- feat: 新增 GitLab 合并事件的 Webhook 处理器
- feat: 集成扩展商店
- feat: 支持编辑连接器处理器配置
- feat: 支持配置 Base Path 以自定义服务端点
- feat: 名称字段增加拼音支持
- feat: 新增 MongoDB 连接器
🐛 问题修复(Bug Fixes)
- fix: 修复切换扩展类型后重置搜索关键词的问题
- fix: 修复全屏小部件的相关问题
✈️ 改进优化 (Improvements)
- refactor: 为深色模式添加悬停背景效果
- chore: 修复文档搜索功能
- chore: 格式化日期
- refactor: 更新初始值
- chore: 修复数据源名称缺失的问题
- chore: 安装完成后隐藏弹窗
- chore: 基于框架变更进行重构
- chore: 为支持深度思考(DeepThink)获取更多文档 #577
- chore: 启用搜索后将首页更改为搜索页 #541
- chore: 更新搜索 API 以支持查询 DSL #550
- chore: 默认按创建时间排序
- chore: 调整多语言配置
- chore: 用户表单增加确认密码字段
- chore: 调整连接器类型
- chore: 调整连接器 OAuth 重定向设置
- refactor: 为集成功能进行重构
- refactor: 移除集成配置中的 Token
- chore: 编辑用户时禁用邮箱字段
- chore: 调整搜索设置
Coco Server 相关截图:
Easysearch v2.0
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
Easysearch 本次更新如下:
💥 重大变更(Breaking Changes)
- 正式发布 Easysearch 2.0 版本,底层 Lucene 更新到 9.12.2
- 新增 ui 插件,为 Easysearch 提供了轻量级界面化管理功能,不再依赖第三方对集群进行管理,真正做到开箱即用
🚀 功能特性 (Features)
- 兼容 1.15.x 版本的索引,可无缝升级
- 新增 UI 插件,涵盖从集群,节点,索引,到分片等不同维度的监控和管理功能
- 支持关闭 security 进入 UI
✈️ 改进优化 (Improvements)
- range 查询,按数字类型字段排序,相比旧版本效率大幅提升
Easysearch UI 相关截图:
Console v1.30
INFINI Console 是一款开源的非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管,企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 本次详细更新记录如下:
🚀 功能特性 (Features)
- feat: 支持百分比聚合
- feat: 为初始化管理员用户增加密码强度校验 (#250)
- feat: 支持 Nginx 代理下的子目录路径 (#243)
🐛 问题修复(Bug Fixes)
- fix: 修复了索引映射 (mapping) 在滚动查询 (scroll) 后不正确的问题 (#248)
- fix: 修复索引 mapping 在滚动操作之后不对的问题
- fix: 修复集群监控设置显示错误
✈️ 改进优化 (Improvements)
- chore: 删除集群后减少 Agent 上报异常错误日志输出 (#258)
- 此版本包含了底层 Framework v1.3 的更新,解决了一些常见问题,并增强了整体稳定性和性能。虽然 Console 本身没有直接的变更,但从 Framework 中继承的改进间接地使 Console 受益。
Gateway v1.30
INFINI Gateway 是一个开源的面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway 可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
Gateway 本次更新如下:
🚀 功能特性 (Features)
- feat(rewrite_to_bulk):使文档更新兼容 Elasticsearch 6.x (#112)
🐛 问题修复(Bug Fixes)
- fix: 修复心跳连接的潜在泄漏问题 (#107)
✈️ 改进优化 (Improvements)
- 改进 ReverseProxy 的锁机制和节点发现逻辑 (#111)
- 此版本包含了底层 Framework v1.3 的更新,解决了一些常见问题,并增强了整体稳定性和性能。虽然 Gateway 本身没有直接的变更,但从 Framework 中继承的改进间接地使 Gateway 受益。
Agent v1.30
INFINI Agent 负责采集和上传 Elasticsearch, Easysearch, Opensearch 集群的日志和指标信息,通过 INFINI Console 管理,支持主流操作系统和平台,安装包轻量且无任何外部依赖,可以快速方便地安装。
Agent 本次更新如下:
🚀 功能特性 (Features)
在 Kubernetes 环境下通过环境变量 http.port 探测 Easysearch 的 HTTP 端口
✈️ 改进优化 (Improvements)
- 此版本包含了底层 Framework v1.3 的更新,解决了一些常见问题,并增强了整体稳定性和性能。虽然 Agent 本身没有直接的变更,但从 Framework 中继承的改进间接地使 Agent 受益。
Loadgen v1.30
INFINI Loadgen 是一款开源的专为 Easysearch、Elasticsearch、OpenSearch 设计的轻量级性能测试工具。
Loadgen 本次更新如下:
✈️ 改进优化 (Improvements)
- 此版本包含了底层 Framework v1.3 的更新,解决了一些常见问题,并增强了整体稳定性和性能。虽然 Loadgen 本身没有直接的变更,但从 Framework 中继承的改进间接地使 Loadgen 受益。
Framework 1.3.0
INFINI Framework 是 INFINI Labs 基于 Golang 的产品的核心基础,已开源。该框架以开发者为中心设计,简化了构建高性能、可扩展且可靠的应用程序的过程。
Framework 本次更新如下:
🚀 功能特性 (Features)
- feat: add delete by query v2 #194
- feat: support aggregation queries in orm
- feat: add support for query_string query
- feat: allow to read http request body multi-times #212
- feat: add support for Elasticsearch cat allocation API
- feat: support custom write operation type for indexing_merge processor
- feat: add util to parse time with local timezone #217
- feat: add PKCS#12 certificate support for http client config
- feat: add security module, with rbac,sharing,oauth client etc.
- feat: add entity_card module
- feat: add abstract layer for user or teams search
- feat: add util to normalize folder path
- feat: add some string utils
- feat: allow force update all mappings for existing indices
- feat: add several http filters
- feat: add util to execute http requests via curl
🐛 问题修复 (Bug Fixes)
- fix: localhost/127.0.0.1 with noproxy #185
- fix: cluster metadata lost #200
- fix: fix security permission cache
- fix: fix incorrect queue capacity check
✈️ 改进 (Improvements)
- chore: less logging for session store change #180
- refactor: initialize index schema using index template
- chore: add generate secure string util func #183
- chore: add validate secure func #184
- refactor: refactoring security structs #191
- refactor: refactoring schema init logic, disable index based template #188
- chore: use safe special chars #190
- chore: reduce log with agent #193
- chore: add util to register http handler #206
- chore: allow access application settings for ui #209
- refactor: refactoring query string parser #216
- chore: update default fuzziness to 3 #215
- chore: avoid using same session name for mulit instances #221
- refactor: refactoring pipeline #222
- chore: enhance bulk indexing - stricter offset validation and improved error handling #224
- refactor: refactoring http utils #226
- refactor: refactoring search response, add score support
- refactor: refactoring ORM module, add generic security hooks
- refactor: add boolean query to orm query builder
- refactor: refactoring access_token, simplify login info
- refactor: move RegisterAllowOriginFunc to core
更多详情请查看以下各产品的 Release Notes 或联系我们的技术支持团队!
- Coco AI App
- Coco AI Server
- INFINI Easysearch
- INFINI Gateway
- INFINI Console
- INFINI Agent
- INFINI Loadgen
- INFINI Framework
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
下载地址: https://infinilabs.cn/download
邮件:hello@infini.ltd
电话:(+86) 400-139-9200
Discord:https://discord.gg/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »【搜索客社区日报】第2143期 (2025-11-10)
https://elasticstack.blog.csdn ... 58980
2、使用 Mastra 和 Elasticsearch 构建具有语义回忆功能的知识 agent
https://elasticstack.blog.csdn ... 18025
3、从 Kubernetes 上的 Windows 容器中摄取 IIS 日志
https://elasticstack.blog.csdn ... 41232
4、“Elasticsearch api 难用的一批”,是吗?你看最新版本的官方文档了吗?
https://mp.weixin.qq.com/s/fMES2ktGm5wqvt5RTzIsiQ
5、十分钟速通大模型原理!从函数到神经网络
https://mp.weixin.qq.com/s/NBfN36tv_7TlJBA41OkqUA
编辑:Muse
更多资讯:http://news.searchkit.cn
https://elasticstack.blog.csdn ... 58980
2、使用 Mastra 和 Elasticsearch 构建具有语义回忆功能的知识 agent
https://elasticstack.blog.csdn ... 18025
3、从 Kubernetes 上的 Windows 容器中摄取 IIS 日志
https://elasticstack.blog.csdn ... 41232
4、“Elasticsearch api 难用的一批”,是吗?你看最新版本的官方文档了吗?
https://mp.weixin.qq.com/s/fMES2ktGm5wqvt5RTzIsiQ
5、十分钟速通大模型原理!从函数到神经网络
https://mp.weixin.qq.com/s/NBfN36tv_7TlJBA41OkqUA
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2149期 (2025-11-21)
https://mp.weixin.qq.com/s/MHgjrSl4XJ4MY7e4Lx0DdA
2、Zleap 技术解密:后 RAG 时代已来,SAG 重新定义 AI 搜索
https://mp.weixin.qq.com/s/sz8VfSaVy9IB67sd2Mb37Q
3、Elasticsearch 避坑指南:我在项目中总结的 14 条实用经验
https://mp.weixin.qq.com/s/L5cVKgWxAoe-JuFYgTN71g
4、yudao-cloud搜索引擎:Elasticsearch 集成与全文检索
https://blog.csdn.net/gitblog_ ... 97464
5、如何使用 INFINI Gateway 增量迁移 ES 数据
https://blog.csdn.net/yangmf20 ... 60004
编辑:Fred
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/MHgjrSl4XJ4MY7e4Lx0DdA
2、Zleap 技术解密:后 RAG 时代已来,SAG 重新定义 AI 搜索
https://mp.weixin.qq.com/s/sz8VfSaVy9IB67sd2Mb37Q
3、Elasticsearch 避坑指南:我在项目中总结的 14 条实用经验
https://mp.weixin.qq.com/s/L5cVKgWxAoe-JuFYgTN71g
4、yudao-cloud搜索引擎:Elasticsearch 集成与全文检索
https://blog.csdn.net/gitblog_ ... 97464
5、如何使用 INFINI Gateway 增量迁移 ES 数据
https://blog.csdn.net/yangmf20 ... 60004
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2148期 (2025-11-20)
https://mp.weixin.qq.com/s/4MjtS-qUV19mnIfMgNbEdw
2.RAG 系统里面最难搞定的是哪个部分?
https://mp.weixin.qq.com/s/Qx8j5ttoLBNZVI5WhqBBiA
3.Cohere × vLLM:共享内存让多模态推理吞吐量提升70%
https://mp.weixin.qq.com/s/--mJ81mDt0tu2jY77Tv5Rg
4.Gemini3.0发布,真有那么神?10个实测案例给你答案
https://mp.weixin.qq.com/s/pjz4nuKfizKWPWdMEDBcbg
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/4MjtS-qUV19mnIfMgNbEdw
2.RAG 系统里面最难搞定的是哪个部分?
https://mp.weixin.qq.com/s/Qx8j5ttoLBNZVI5WhqBBiA
3.Cohere × vLLM:共享内存让多模态推理吞吐量提升70%
https://mp.weixin.qq.com/s/--mJ81mDt0tu2jY77Tv5Rg
4.Gemini3.0发布,真有那么神?10个实测案例给你答案
https://mp.weixin.qq.com/s/pjz4nuKfizKWPWdMEDBcbg
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2147期 (2025-11-19)
https://elasticstack.blog.csdn ... 66787
2. Elasticsearch:如何在 ES|QL 中使用 FORK 及 FUSE 命令来实现混合搜索 - 9.1+
https://elasticstack.blog.csdn ... 39180
3. 一人成军?这5款人工智能工具让这一切成为现实。
https://medium.com/ai-in-plain ... 811fd
4. 多智能体生命周期模型:演示效果出色,实际生产效果糟糕。
https://medium.com/ai-in-plain ... a4b93
编辑:kin122
更多资讯:http://news.searchkit.cn
https://elasticstack.blog.csdn ... 66787
2. Elasticsearch:如何在 ES|QL 中使用 FORK 及 FUSE 命令来实现混合搜索 - 9.1+
https://elasticstack.blog.csdn ... 39180
3. 一人成军?这5款人工智能工具让这一切成为现实。
https://medium.com/ai-in-plain ... 811fd
4. 多智能体生命周期模型:演示效果出色,实际生产效果糟糕。
https://medium.com/ai-in-plain ... a4b93
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2146期 (2025-11-18)
1. 用真实数据来体验用文本和语义搜索(需要梯子)
https://medium.com/%40robin_27 ... 5e760
2. 没想到吧,还能拿时序index来提升搜索性能(需要梯子)
https://medium.com/engineering ... a3036
3. 拿docker在家撸个ELK集群玩玩吧(需要梯子)
https://medium.com/%40dipakras ... b32fe
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
1. 用真实数据来体验用文本和语义搜索(需要梯子)
https://medium.com/%40robin_27 ... 5e760
2. 没想到吧,还能拿时序index来提升搜索性能(需要梯子)
https://medium.com/engineering ... a3036
3. 拿docker在家撸个ELK集群玩玩吧(需要梯子)
https://medium.com/%40dipakras ... b32fe
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
【搜索客社区日报】第2145期 (2025-11-17)
https://elasticstack.blog.csdn ... 86809
2、在 Elasticsearch 中为结构化文档配置递归分块
https://elasticstack.blog.csdn ... 22870
3、如何在 Azure AKS 上自动部署 Elasticsearch
https://elasticstack.blog.csdn ... 00954
4、Elasticsearch:如何创建知识库并使用 AI Assistant 来配置连接器
https://elasticstack.blog.csdn ... 33395
5、在 Elasticsearch 中使用 A2A 协议和 MCP 创建一个 LLM agent 新闻室
https://elasticstack.blog.csdn ... 23264
编辑:Muse
更多资讯:http://news.searchkit.cn
https://elasticstack.blog.csdn ... 86809
2、在 Elasticsearch 中为结构化文档配置递归分块
https://elasticstack.blog.csdn ... 22870
3、如何在 Azure AKS 上自动部署 Elasticsearch
https://elasticstack.blog.csdn ... 00954
4、Elasticsearch:如何创建知识库并使用 AI Assistant 来配置连接器
https://elasticstack.blog.csdn ... 33395
5、在 Elasticsearch 中使用 A2A 协议和 MCP 创建一个 LLM agent 新闻室
https://elasticstack.blog.csdn ... 23264
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
Coco AI 参选 Gitee 2025 最受欢迎开源软件!您的每一票,都是对中国开源的硬核支持
「Gitee 2025 年度开源项目评选」火热进行中!

Coco AI 正在参加 Gitee 2025 最受欢迎的开源软件投票活动, 👉 快来给我投票吧!一起见证中国开源力量,谢谢你宝贵的一票!
扫码 or 点击 直达链接,进入投票页面:

投票直达链接:https://gitee.com/activity/2025opensource?ident=IEZ3FS
🥥 什么是 Coco AI
Coco AI 是 极限科技(INFINI Labs) 重磅推出一款完全开源、跨平台的企业级智能搜索与助手系统,专为现代企业打造。它通过统一搜索入口,连接企业内外部的异构数据源,融合大模型能力,帮助团队高效访问知识,智能决策协作。
Coco 官网:https://coco.rs
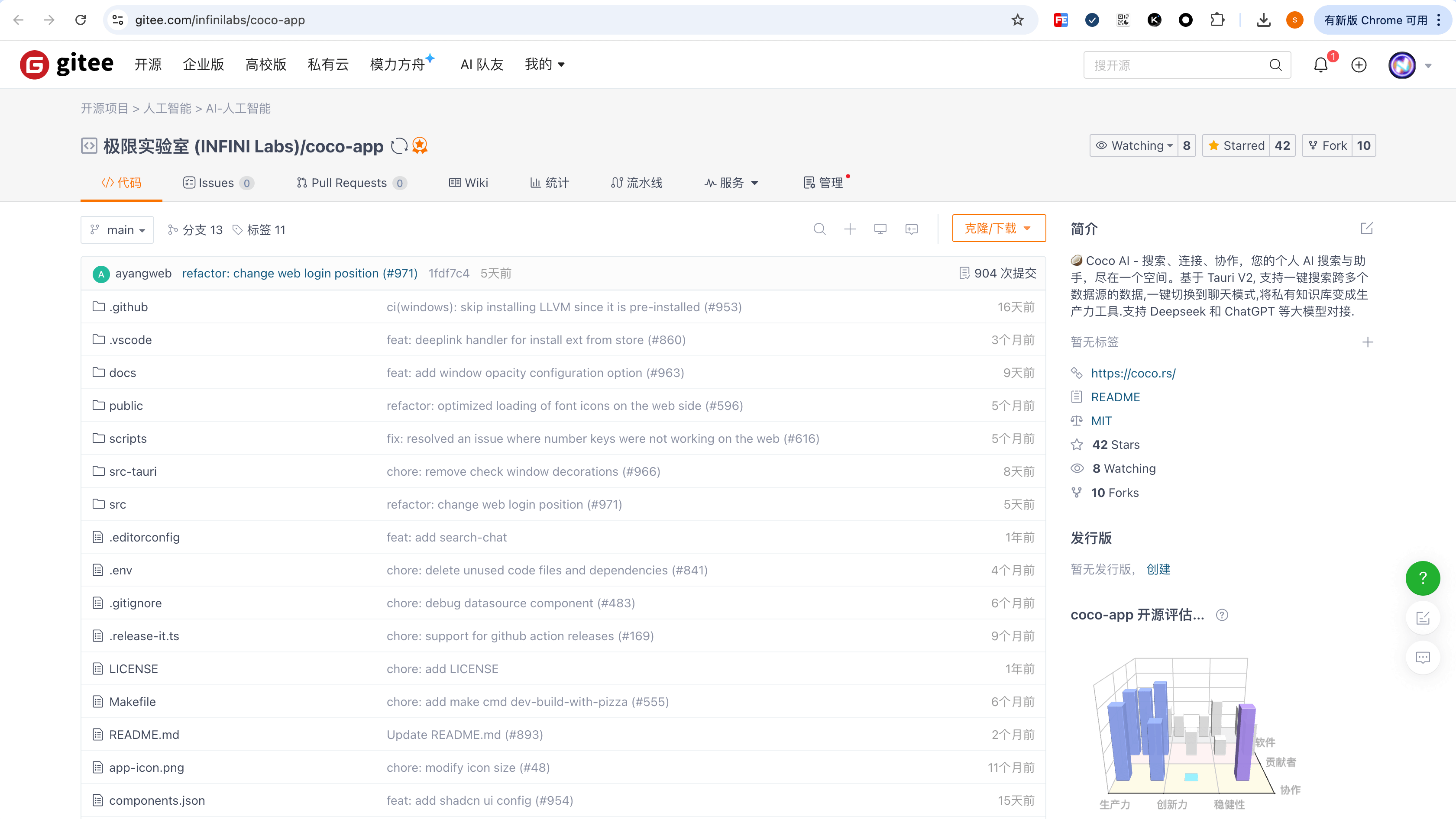
Gitee 主页:https://gitee.com/infinilabs/coco-app (来个 Star ⭐️ 吧)
Coco Demo 视频:https://www.bilibili.com/video/BV1yKT7zoEed/
👉 快来给我投票吧!麻烦大家动动发财手,支持一下,谢谢!!!
如何投票?
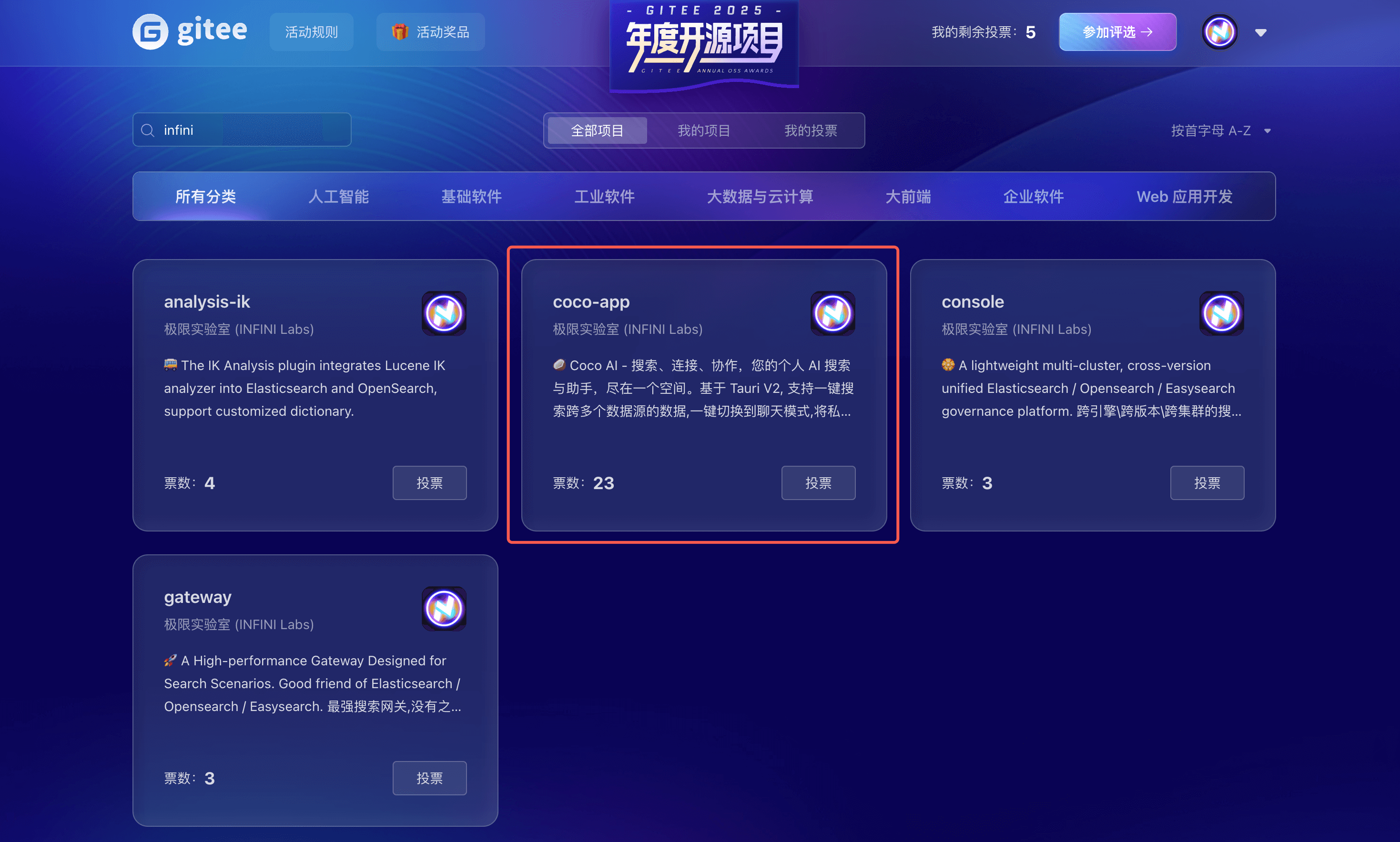
打开 Gitee 活动页面,搜索框输入 infini,找到 Coco 项目,即可参与投票。
同时也欢迎给 INFINI Labs 开源项目:analysis-ik、gateway、console 投票。
活动链接:https://gitee.com/activity/2025opensource


🎁 投票福利
添加小助手微信(INFINI-Labs)提供「已投票」截图,加入抽奖群,抽 5 位送 Coco AI 定制 T 恤 或 暖冬时尚围巾,抽奖礼品将在公示后 15 个工作日内寄送。
投票截止日期:2026-01-09
抽奖日期:2026-01-10
抽奖礼品

关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
「Gitee 2025 年度开源项目评选」火热进行中!
Coco AI 正在参加 Gitee 2025 最受欢迎的开源软件投票活动, 👉 快来给我投票吧!一起见证中国开源力量,谢谢你宝贵的一票!
扫码 or 点击 直达链接,进入投票页面:
投票直达链接:https://gitee.com/activity/2025opensource?ident=IEZ3FS
🥥 什么是 Coco AI
Coco AI 是 极限科技(INFINI Labs) 重磅推出一款完全开源、跨平台的企业级智能搜索与助手系统,专为现代企业打造。它通过统一搜索入口,连接企业内外部的异构数据源,融合大模型能力,帮助团队高效访问知识,智能决策协作。
Coco 官网:https://coco.rs
Gitee 主页:https://gitee.com/infinilabs/coco-app (来个 Star ⭐️ 吧)
Coco Demo 视频:https://www.bilibili.com/video/BV1yKT7zoEed/
👉 快来给我投票吧!麻烦大家动动发财手,支持一下,谢谢!!!
如何投票?
打开 Gitee 活动页面,搜索框输入 infini,找到 Coco 项目,即可参与投票。
同时也欢迎给 INFINI Labs 开源项目:analysis-ik、gateway、console 投票。
活动链接:https://gitee.com/activity/2025opensource
🎁 投票福利
添加小助手微信(INFINI-Labs)提供「已投票」截图,加入抽奖群,抽 5 位送 Coco AI 定制 T 恤 或 暖冬时尚围巾,抽奖礼品将在公示后 15 个工作日内寄送。
投票截止日期:2026-01-09
抽奖日期:2026-01-10
抽奖礼品
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »【搜索客社区日报】第2144期 (2025-11-11)
今天双十一,有同学要通宵值班的么
1. 全文搜索那些事儿(需要梯子)
https://medium.com/%40ali012wk ... ac691
2. 日志采集那些事儿(需要梯子)
https://medium.com/%40nuwanmad ... e8a01
3. ES分词器和0停机reindex那些事儿(需要梯子)
https://medium.com/%40mohamads ... 04ccc
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
今天双十一,有同学要通宵值班的么
1. 全文搜索那些事儿(需要梯子)
https://medium.com/%40ali012wk ... ac691
2. 日志采集那些事儿(需要梯子)
https://medium.com/%40nuwanmad ... e8a01
3. ES分词器和0停机reindex那些事儿(需要梯子)
https://medium.com/%40mohamads ... 04ccc
编辑:斯蒂文
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2142期 (2025-11-07)
https://my.oschina.net/infinilabs/blog/18698205
2、在 Elasticsearch 中解析 JSON 字段
https://my.oschina.net/u/3343882/blog/18697269
3、如何减少 Elasticsearch 集群中的分片数量
https://my.oschina.net/u/3343882/blog/18696474
4、深度探索:Spring 借助 Easy-ES 开启 Elasticsearch 操作实战篇章
https://mp.weixin.qq.com/s/tip7c9N0v6tOsMN5m2hKWA
5、AI 搜索的黑科技?OpenSearch 的 DeepSearch 究竟“深”藏着什么秘密?
https://mp.weixin.qq.com/s/QoENaBQ9LPO_youvIZG3_A
编辑:Fred
更多资讯:http://news.searchkit.cn
https://my.oschina.net/infinilabs/blog/18698205
2、在 Elasticsearch 中解析 JSON 字段
https://my.oschina.net/u/3343882/blog/18697269
3、如何减少 Elasticsearch 集群中的分片数量
https://my.oschina.net/u/3343882/blog/18696474
4、深度探索:Spring 借助 Easy-ES 开启 Elasticsearch 操作实战篇章
https://mp.weixin.qq.com/s/tip7c9N0v6tOsMN5m2hKWA
5、AI 搜索的黑科技?OpenSearch 的 DeepSearch 究竟“深”藏着什么秘密?
https://mp.weixin.qq.com/s/QoENaBQ9LPO_youvIZG3_A
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2141期 (2025-11-06)
https://mp.weixin.qq.com/s/S6un8mBPE53HlpYrgNs6Nw
2.在 vLLM 上运行 NVIDIA Nemotron 多模态推理智能体
https://mp.weixin.qq.com/s/QSAyMD90gzxJApgV6i5T6Q
3.Apache RocketMQ × AI:面向 Multi-Agent 的事件驱动架构
https://mp.weixin.qq.com/s/dAz-Vp3YJ09i64zXPABBsA
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/S6un8mBPE53HlpYrgNs6Nw
2.在 vLLM 上运行 NVIDIA Nemotron 多模态推理智能体
https://mp.weixin.qq.com/s/QSAyMD90gzxJApgV6i5T6Q
3.Apache RocketMQ × AI:面向 Multi-Agent 的事件驱动架构
https://mp.weixin.qq.com/s/dAz-Vp3YJ09i64zXPABBsA
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2140期 (2025-11-05)
https://elasticstack.blog.csdn ... 71471
2.Quickwit:云原生搜索分析引擎的全面介绍
https://blog.csdn.net/gitblog_ ... 34475
3.超详细指南:Quickwit分布式集群部署与负载均衡实战
https://blog.csdn.net/gitblog_ ... 34289
编辑:kin122
更多资讯:http://news.searchkit.cn
https://elasticstack.blog.csdn ... 71471
2.Quickwit:云原生搜索分析引擎的全面介绍
https://blog.csdn.net/gitblog_ ... 34475
3.超详细指南:Quickwit分布式集群部署与负载均衡实战
https://blog.csdn.net/gitblog_ ... 34289
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
⚡ 闪电直播 - INFINI Demo Show
本活动由 极限科技(INFINI Labs)组织举办,旨在让大家在 30 分钟内快速了解 INFINI Labs 最新产品动态与使用技巧。
活动将在每双周周二下午 17:00 准时开始,每期由不同的 INFINI Labs 产研同学参与分享,没有花哨的 PPT,直接上手 Demo 演示实战。
分享话题涵盖:

📢 下期预告
时间:2025-11-18 17:00 ~ 17:30
直播地址:极限实验室视频号
活动详情:https://infini.yuque.com/infini/products/em17dnves2s6yz31
欢迎关注极限实验室视频号进行预约和观看回放视频。

本活动由 极限科技(INFINI Labs)组织举办,旨在让大家在 30 分钟内快速了解 INFINI Labs 最新产品动态与使用技巧。
活动将在每双周周二下午 17:00 准时开始,每期由不同的 INFINI Labs 产研同学参与分享,没有花哨的 PPT,直接上手 Demo 演示实战。
分享话题涵盖:
📢 下期预告
时间:2025-11-18 17:00 ~ 17:30
直播地址:极限实验室视频号
活动详情:https://infini.yuque.com/infini/products/em17dnves2s6yz31
欢迎关注极限实验室视频号进行预约和观看回放视频。

