

【搜索客社区日报】第2139期 (2025-11-04)
https://medium.com/%40ahbari.m ... c0e93
2. 为了能给mongodb和es做同步,我手搓了个工具(需要梯子)
https://medium.com/%40chiefdfo ... 3496c
3. 日志输出分析的中场战事(需要梯子)
https://medium.com/%40jasonner ... 08939
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://medium.com/%40ahbari.m ... c0e93
2. 为了能给mongodb和es做同步,我手搓了个工具(需要梯子)
https://medium.com/%40chiefdfo ... 3496c
3. 日志输出分析的中场战事(需要梯子)
https://medium.com/%40jasonner ... 08939
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
【搜索客社区日报】第2138期 (2025-11-03)
https://elasticstack.blog.csdn ... 70474
2、Elastic AI agent builder 介绍(二)
https://elasticstack.blog.csdn ... 89733
3、Elastic Observability 中的 Streams 如何简化保留管理
https://elasticstack.blog.csdn ... 73819
4、DeepAgent源码流程解读
https://mp.weixin.qq.com/s/NBQPMcvcEeAVGq2qT9-hVw
5、【万字长文】大模型训练推理和性能优化算法总结和实践
https://mp.weixin.qq.com/s/zUz5Y0DOFa2XL5AI_j34FA
编辑:Muse
更多资讯:http://news.searchkit.cn
https://elasticstack.blog.csdn ... 70474
2、Elastic AI agent builder 介绍(二)
https://elasticstack.blog.csdn ... 89733
3、Elastic Observability 中的 Streams 如何简化保留管理
https://elasticstack.blog.csdn ... 73819
4、DeepAgent源码流程解读
https://mp.weixin.qq.com/s/NBQPMcvcEeAVGq2qT9-hVw
5、【万字长文】大模型训练推理和性能优化算法总结和实践
https://mp.weixin.qq.com/s/zUz5Y0DOFa2XL5AI_j34FA
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
使用 Docker Compose 轻松实现 INFINI Console 离线部署与持久化管理
系列回顾与引言
在我们的 INFINI 本地环境搭建系列博客中:
- 第一篇《搭建持久化的 INFINI Console 与 Easysearch 容器环境》,我们深入探讨了如何使用基础的
docker run命令,一步步构建起 Console 和 Easysearch 服务,并重点解决了数据持久化的问题。 - 第二篇《使用 Docker Compose 简化 INFINI Console 与 Easysearch 环境搭建》,我们学习了如何利用 Docker Compose 的声明式配置,将多容器应用的定义和管理变得更加简洁高效。
- 第三篇《一键启动:使用 start-local 脚本轻松管理 INFINI Console 与 Easysearch 本地环境》,我们介绍了如何在联网环境下,一键安装 INFINI Console。
接下来,我们将聚焦于离线环境,详细讲解如何使用 Docker Compose 部署 INFINI Console 和 Easysearch。

简介
INFINI Console 是一款强大的集群管理与可观测性平台,而 INFINI Easysearch 则是一个轻量级、高性能的搜索与分析引擎。官方提供的离线部署包将两者整合,非常适合在无外网或需要快速搭建演示环境的场景下使用。

本文将详细介绍如何下载资源、正确加载镜像、以及最关键的——如何根据您的需求修改 docker-compose.yml 中的各项配置。
1. 准备工作
请确保您的环境中已安装以下软件:
- Docker
- Docker Compose
2. 下载离线资源
从官方地址下载两个核心文件:
infini-console.tar.gz: 包含docker-compose.yml和相关脚本。infini-console-easysearch-1.14.2.tar: 包含infinilabs/console和infinilabs/easysearch的 Docker 镜像。
wget https://release.infinilabs.com/easysearch/archive/offline/amd64/infini-console.tar.gz
wget https://release.infinilabs.com/easysearch/archive/offline/amd64/infini-console-easysearch-1.14.2.tar3. 正确加载 Docker 镜像
注意:infini-console-easysearch-1.14.2.tar 是一个包含多个镜像的归档包,不能直接使用 docker load 加载。
正确的加载步骤如下:
-
创建目录并解压镜像归档包:
mkdir -p images tar -xvf infini-console-easysearch-1.14.2.tar -C images这会将
console.tar和easysearch.tar等文件解压到images/目录中。 -
批量加载所有镜像:
cd images ls *.tar | xargs -I {} docker load -i {}该命令会自动为目录下的每个
.tar文件执行docker load操作。 - 验证镜像加载结果:
docker images您应该能看到
infinilabs/console:1.29.8和infinilabs/easysearch:1.14.2等镜像。
4. 修改配置文件
解压 infini-console.tar.gz 后,找到 .env 文件。所有自定义配置都应在此文件中修改。
以下是各项配置的详细说明和修改建议:
核心路径配置
WORK_DIR_ABS=/data/infini-console- 作用: 定义所有持久化数据(日志、配置、索引)的根目录。
- 修改建议: (必改) 强烈建议修改为您服务器上一个有足够空间的路径,例如
/opt/infini-console。确保该目录存在且 Docker 拥有写入权限。
网络配置
APP_NETWORK_NAME=infini-local-net- 作用: 定义 Docker 内部网络的名称。
- 修改建议: 通常无需修改。
Console 配置
CONSOLE_IMAGE=infinilabs/console
CONSOLE_VERSION_TAG=1.29.8
CONSOLE_CONTAINER_NAME=infini-console
CONSOLE_PORT_HOST=9000
CONSOLE_PORT_CONTAINER=9000- 作用: 定义 Console 的镜像、版本、容器名及端口映射。
- 修改建议:
CONSOLE_PORT_HOST: 如果宿主机的9000端口已被占用,请修改为其他可用端口(如8080)。
Easysearch 配置
EASYSEARCH_IMAGE=infinilabs/easysearch
EASYSEARCH_VERSION_TAG=1.14.2
EASYSEARCH_NODES=1
EASYSEARCH_CLUSTER_NAME=infini-console- 作用: 定义 Easysearch 的镜像、版本、节点数和集群名。
- 修改建议:
EASYSEARCH_NODES: 单机部署保持1即可。
访问与安全配置
EASYSEARCH_INITIAL_ADMIN_PASSWORD=ShouldChangeme123.- 作用: 设置 Easysearch
admin用户的初始密码。 - 修改建议: (必改) 请务必将其替换为一个强密码。登录 Console 时需要使用此密码。
EASYSEARCH_HTTP_PORT_HOST=9200
EASYSEARCH_TRANSPORT_PORT_HOST=9300- 作用: 定义 Easysearch HTTP 和 Transport 接口在宿主机上的映射端口。
- 修改建议: 如果
9200或9300端口冲突,请修改。
JVM 参数配置
ES_JAVA_OPTS_DEFAULT="-Xms8g -Xmx8g"- 作用: 设置 Easysearch 的 JVM 堆内存大小。
- 修改建议: (必改) 请根据服务器物理内存进行调整,避免超过物理内存的 50%。
- 8GB 内存服务器: 建议设为
-Xms2g -Xmx2g。 - 16GB 内存服务器: 建议设为
-Xms4g -Xmx4g。
- 8GB 内存服务器: 建议设为
数据持久化路径
CONSOLE_HOST_DATA_SUBPATH_REL=console/data
CONSOLE_HOST_LOGS_SUBPATH_REL=console/logs
EASYSEARCH_HOST_NODES_BASE_SUBPATH_REL=easysearch- 作用: 定义数据和日志在
WORK_DIR_ABS下的相对子路径。 - 修改建议: 通常无需修改。
5. 启动服务
完成配置修改后,在 docker-compose.yml 所在目录下执行:
docker-compose up -d等待服务完全启动。
6. 访问控制台
打开浏览器,访问 http://<你的服务器IP>:9000。
使用默认用户名 admin 和您在 EASYSEARCH_INITIAL_ADMIN_PASSWORD 中设置的密码进行初始化。
总结
通过以上步骤,您可以灵活地部署一套功能完整的 INFINI Console + Easysearch 环境。关键在于理解并根据实际情况修改 .env 文件中的参数,特别是 WORK_DIR_ABS、EASYSEARCH_INITIAL_ADMIN_PASSWORD 和 ES_JAVA_OPTS_DEFAULT,这能确保部署的稳定性和安全性。
希望这篇详细的指南能帮助您顺利完成部署!
作者:罗厚付,极限科技(INFINI Labs)云上产品设计与研发负责人,拥有多年安全风控及大数据系统架构经验,主导过多个核心产品的设计与落地,日常负责运维超大规模 ES 集群(800+节点/1PB+数据)。
原文:https://infinilabs.cn/blog/2025/console-easysearch-with-docker-compose-offline/
系列回顾与引言
在我们的 INFINI 本地环境搭建系列博客中:
- 第一篇《搭建持久化的 INFINI Console 与 Easysearch 容器环境》,我们深入探讨了如何使用基础的
docker run命令,一步步构建起 Console 和 Easysearch 服务,并重点解决了数据持久化的问题。 - 第二篇《使用 Docker Compose 简化 INFINI Console 与 Easysearch 环境搭建》,我们学习了如何利用 Docker Compose 的声明式配置,将多容器应用的定义和管理变得更加简洁高效。
- 第三篇《一键启动:使用 start-local 脚本轻松管理 INFINI Console 与 Easysearch 本地环境》,我们介绍了如何在联网环境下,一键安装 INFINI Console。
接下来,我们将聚焦于离线环境,详细讲解如何使用 Docker Compose 部署 INFINI Console 和 Easysearch。
简介
INFINI Console 是一款强大的集群管理与可观测性平台,而 INFINI Easysearch 则是一个轻量级、高性能的搜索与分析引擎。官方提供的离线部署包将两者整合,非常适合在无外网或需要快速搭建演示环境的场景下使用。
本文将详细介绍如何下载资源、正确加载镜像、以及最关键的——如何根据您的需求修改 docker-compose.yml 中的各项配置。
1. 准备工作
请确保您的环境中已安装以下软件:
- Docker
- Docker Compose
2. 下载离线资源
从官方地址下载两个核心文件:
infini-console.tar.gz: 包含docker-compose.yml和相关脚本。infini-console-easysearch-1.14.2.tar: 包含infinilabs/console和infinilabs/easysearch的 Docker 镜像。
wget https://release.infinilabs.com/easysearch/archive/offline/amd64/infini-console.tar.gz
wget https://release.infinilabs.com/easysearch/archive/offline/amd64/infini-console-easysearch-1.14.2.tar3. 正确加载 Docker 镜像
注意:infini-console-easysearch-1.14.2.tar 是一个包含多个镜像的归档包,不能直接使用 docker load 加载。
正确的加载步骤如下:
-
创建目录并解压镜像归档包:
mkdir -p images tar -xvf infini-console-easysearch-1.14.2.tar -C images这会将
console.tar和easysearch.tar等文件解压到images/目录中。 -
批量加载所有镜像:
cd images ls *.tar | xargs -I {} docker load -i {}该命令会自动为目录下的每个
.tar文件执行docker load操作。 - 验证镜像加载结果:
docker images您应该能看到
infinilabs/console:1.29.8和infinilabs/easysearch:1.14.2等镜像。
4. 修改配置文件
解压 infini-console.tar.gz 后,找到 .env 文件。所有自定义配置都应在此文件中修改。
以下是各项配置的详细说明和修改建议:
核心路径配置
WORK_DIR_ABS=/data/infini-console- 作用: 定义所有持久化数据(日志、配置、索引)的根目录。
- 修改建议: (必改) 强烈建议修改为您服务器上一个有足够空间的路径,例如
/opt/infini-console。确保该目录存在且 Docker 拥有写入权限。
网络配置
APP_NETWORK_NAME=infini-local-net- 作用: 定义 Docker 内部网络的名称。
- 修改建议: 通常无需修改。
Console 配置
CONSOLE_IMAGE=infinilabs/console
CONSOLE_VERSION_TAG=1.29.8
CONSOLE_CONTAINER_NAME=infini-console
CONSOLE_PORT_HOST=9000
CONSOLE_PORT_CONTAINER=9000- 作用: 定义 Console 的镜像、版本、容器名及端口映射。
- 修改建议:
CONSOLE_PORT_HOST: 如果宿主机的9000端口已被占用,请修改为其他可用端口(如8080)。
Easysearch 配置
EASYSEARCH_IMAGE=infinilabs/easysearch
EASYSEARCH_VERSION_TAG=1.14.2
EASYSEARCH_NODES=1
EASYSEARCH_CLUSTER_NAME=infini-console- 作用: 定义 Easysearch 的镜像、版本、节点数和集群名。
- 修改建议:
EASYSEARCH_NODES: 单机部署保持1即可。
访问与安全配置
EASYSEARCH_INITIAL_ADMIN_PASSWORD=ShouldChangeme123.- 作用: 设置 Easysearch
admin用户的初始密码。 - 修改建议: (必改) 请务必将其替换为一个强密码。登录 Console 时需要使用此密码。
EASYSEARCH_HTTP_PORT_HOST=9200
EASYSEARCH_TRANSPORT_PORT_HOST=9300- 作用: 定义 Easysearch HTTP 和 Transport 接口在宿主机上的映射端口。
- 修改建议: 如果
9200或9300端口冲突,请修改。
JVM 参数配置
ES_JAVA_OPTS_DEFAULT="-Xms8g -Xmx8g"- 作用: 设置 Easysearch 的 JVM 堆内存大小。
- 修改建议: (必改) 请根据服务器物理内存进行调整,避免超过物理内存的 50%。
- 8GB 内存服务器: 建议设为
-Xms2g -Xmx2g。 - 16GB 内存服务器: 建议设为
-Xms4g -Xmx4g。
- 8GB 内存服务器: 建议设为
数据持久化路径
CONSOLE_HOST_DATA_SUBPATH_REL=console/data
CONSOLE_HOST_LOGS_SUBPATH_REL=console/logs
EASYSEARCH_HOST_NODES_BASE_SUBPATH_REL=easysearch- 作用: 定义数据和日志在
WORK_DIR_ABS下的相对子路径。 - 修改建议: 通常无需修改。
5. 启动服务
完成配置修改后,在 docker-compose.yml 所在目录下执行:
docker-compose up -d等待服务完全启动。
6. 访问控制台
打开浏览器,访问 http://<你的服务器IP>:9000。
使用默认用户名 admin 和您在 EASYSEARCH_INITIAL_ADMIN_PASSWORD 中设置的密码进行初始化。
总结
通过以上步骤,您可以灵活地部署一套功能完整的 INFINI Console + Easysearch 环境。关键在于理解并根据实际情况修改 .env 文件中的参数,特别是 WORK_DIR_ABS、EASYSEARCH_INITIAL_ADMIN_PASSWORD 和 ES_JAVA_OPTS_DEFAULT,这能确保部署的稳定性和安全性。
希望这篇详细的指南能帮助您顺利完成部署!
收起阅读 »作者:罗厚付,极限科技(INFINI Labs)云上产品设计与研发负责人,拥有多年安全风控及大数据系统架构经验,主导过多个核心产品的设计与落地,日常负责运维超大规模 ES 集群(800+节点/1PB+数据)。
原文:https://infinilabs.cn/blog/2025/console-easysearch-with-docker-compose-offline/
搜索百科(6):Meilisearch — Rust 打造的轻量级搜索新锐
大家好,我是 INFINI Labs 的石阳。
欢迎关注 《搜索百科》 专栏!每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
在之前的几期中,我们认识了搜索技术的基石 Lucene、企业级搜索先锋 Solr、搜索界的“流量明星” Elasticsearch 以及它的分叉兄弟 OpenSearch 和 ES 国产替代方案 Easysearch。它们大多基于 Lucene 构建,形成了庞大且功能丰富的生态。
今天,我们将介绍一位“非主流”选手:一款基于 Rust 编写、主打“快”和“简单”的现代搜索引擎——Meilisearch。它以全新的姿态,为开发者带来了不同的搜索体验。

Meilisearch 概述
Meilisearch 是一款开源的、用 Rust 编写的即时搜索引擎。它提供了一个快速、轻量且可定制的搜索 API,旨在为用户提供毫秒级的搜索体验。
它的核心优势在于为应用内搜索和电商搜索等对延迟敏感的场景提供了出色的用户体验。
- 首次发布:2020 年
- 最新版本:1.24.0(截止 2025 年 10 月)
- 核心语言:Rust
- 开源协议:MIT License
- 官方网址:https://www.meilisearch.com/
- GitHub 仓库:https://github.com/meilisearch/meilisearch
诞生故事
Meilisearch 的故事始于 2018 年,当时法国工程师 Quentin de Quelen 在开发一个电商项目时,发现现有的搜索引擎要么太重量级,要么配置太复杂。他想要一个"开箱即用"的搜索解决方案,能够快速集成到应用中,并提供优秀的搜索体验。
于是,他决定用 Rust 语言从头编写一个搜索引擎。选择 Rust 是因为其出色的性能、内存安全性和并发能力,非常适合构建高性能的搜索核心。
项目最初只是一个内部工具,但随着功能的完善和社区的反馈,Meilisearch 在 2019 年正式开源,并迅速获得了开发者的青睐。2020 年,团队获得了 150 万美元的种子轮融资,正式成立了 Meilisearch 公司。
核心特性
Meilisearch 在设计上做了大量的取舍,专注于核心的搜索功能,但做到了极致。
- 极速响应:核心目标是实现 50 毫秒以下的响应时间,即使在大型数据集中也能提供“所见即所得”的搜索体验。
- 零配置:开箱即用,部署和索引数据都非常简单,不需要预定义 Schema 或复杂的配置文件。
- 相关的默认值:内置一个强大的 相关性排名(Relevance Ranking) 算法,结合 Typos(拼写错误)、Word Proximity(词语距离)和 Attributes(字段权重)等因素,无需额外调优即可获得高质量的搜索结果。
- 语言无关性:支持多种语言的分词与搜索,能很好地处理中文、日文等非拉丁语系文本。
- 无分布式架构:为了追求极致的速度和简单性,Meilisearch 被设计为单机搜索引擎,不支持开箱即用的分布式集群,这简化了运维,但也限制了其 PB 级数据的处理能力。
对比优势:Meilisearch vs Lucene/ES 体系
Meilisearch 与基于 Lucene 的 Elasticsearch 体系,在设计哲学上有着本质区别:
| 特性 | Meilisearch | Elasticsearch |
|---|---|---|
| 核心目标 | 极速的应用内搜索体验 | 分布式搜索、日志分析、可观测性 |
| 基础架构 | 单机、轻量级 | 分布式集群(主从节点、分片) |
| 核心语言 | Rust | Java(基于 Lucene) |
| 性能瓶颈 | 单机 CPU / 内存限制 | 分布式协调开销 |
| 上手难度 | 简单,开箱即用,REST API | 相对复杂,需要了解集群、分片等概念 |
| 数据规模 | 适合中小型数据集(GB 级别) | 适合大型和超大型数据集(TB/PB 级别) |
| 全文检索 | 依赖内置的强相关性算法 | 依赖 Lucene 强大的分词、查询解析器 |
总结:
- 如果你的应用需要超低延迟、简单部署、数据量在 GB 级别,并且搜索是应用的核心功能,Meilisearch 是一个极佳的选择。
- 如果你的需求涉及日志分析、大规模数据存储、集群高可用和复杂的聚合分析,那么 Elasticsearch 仍然是更成熟和全面的解决方案。
快速上手:5 分钟体验 Meilisearch
部署 Meilisearch 非常简单,你甚至不需要 Docker,只需一个命令即可运行。
1. 运行 Meilisearch
# 安装 Meilisearch
curl -L https://install.meilisearch.com | sh
# 启动 Meilisearch
meilisearch --master-key 'aStrongMasterKey'
# 或使用 Docker
docker run -it --rm -p 7700:7700 getmeili/meilisearch:latest --master-key 'aStrongMasterKey'2. 添加索引(创建 Index)
Meilisearch 不需要预先定义索引结构(Schema-less)。
curl -X POST 'http://localhost:7700/indexes' \
-H 'Authorization: Bearer aStrongMasterKey' \
-H 'Content-Type: application/json' \
--data-binary '{
"uid": "movies",
"primaryKey": "id"
}'3. 索引文档(添加 Documents)
curl -X POST 'http://localhost:7700/indexes/movies/documents' \
-H 'Authorization: Bearer aStrongMasterKey' \
-H 'Content-Type: application/json' \
--data-binary '[
{"id": 1, "title": "泰坦尼克号", "genres": ["剧情", "爱情"]},
{"id": 2, "title": "黑客帝国", "genres": ["科幻", "动作"]}
]'4. 执行搜索
# 搜索关键词 "泰坦"
curl -X GET 'http://localhost:7700/indexes/movies/search?q=泰坦'返回结果:
{
"hits": [
{
"id": 1,
"title": "泰坦尼克号",
"genres": ["剧情", "爱情"]
}
],
"offset": 0,
"limit": 20,
"estimatedTotalHits": 1,
"processingTimeMs": 1,
"query": "泰坦"
}注意 processingTimeMs: 1,这是 Meilisearch 速度的最好证明!
5. 场景演示
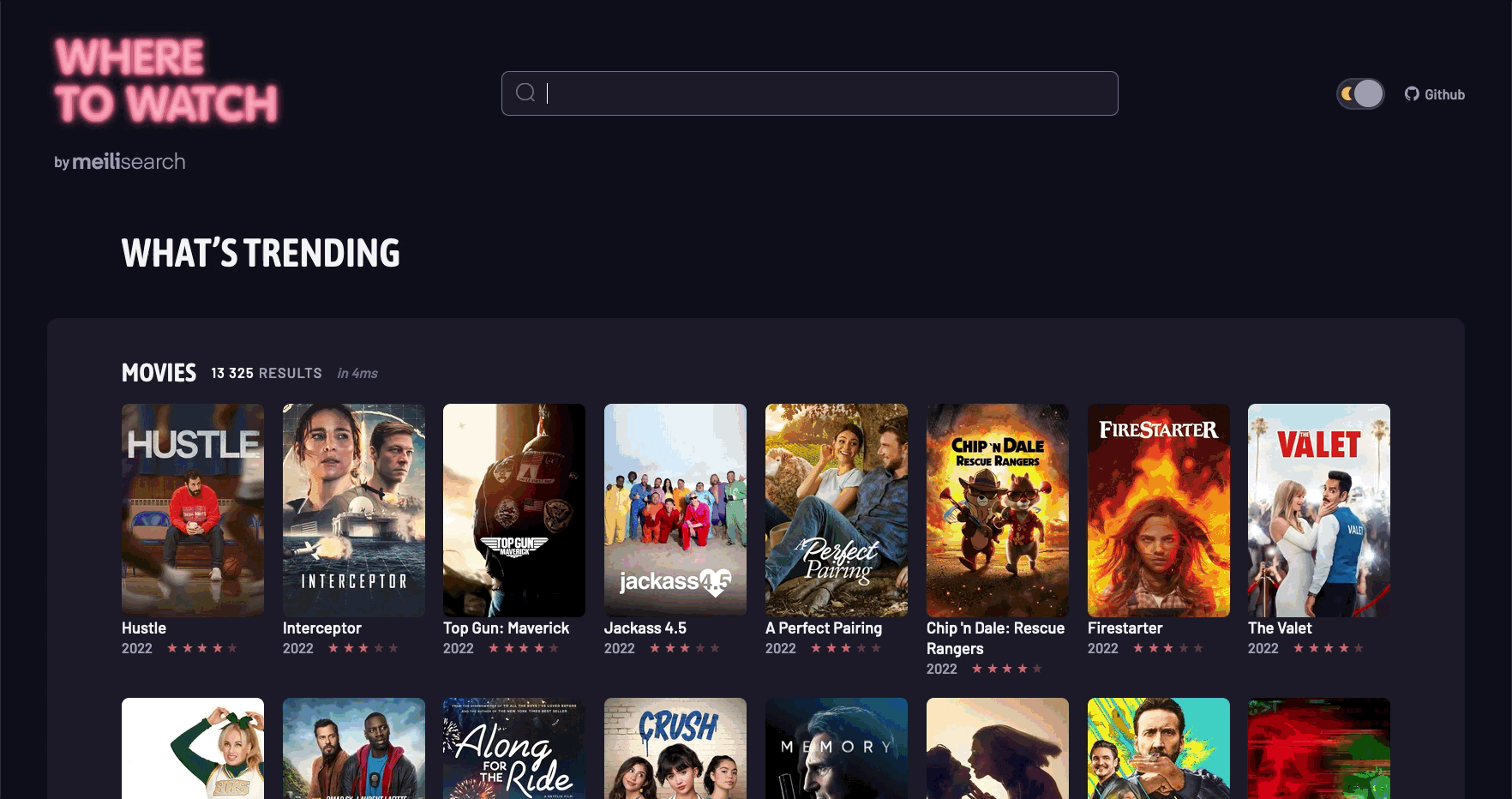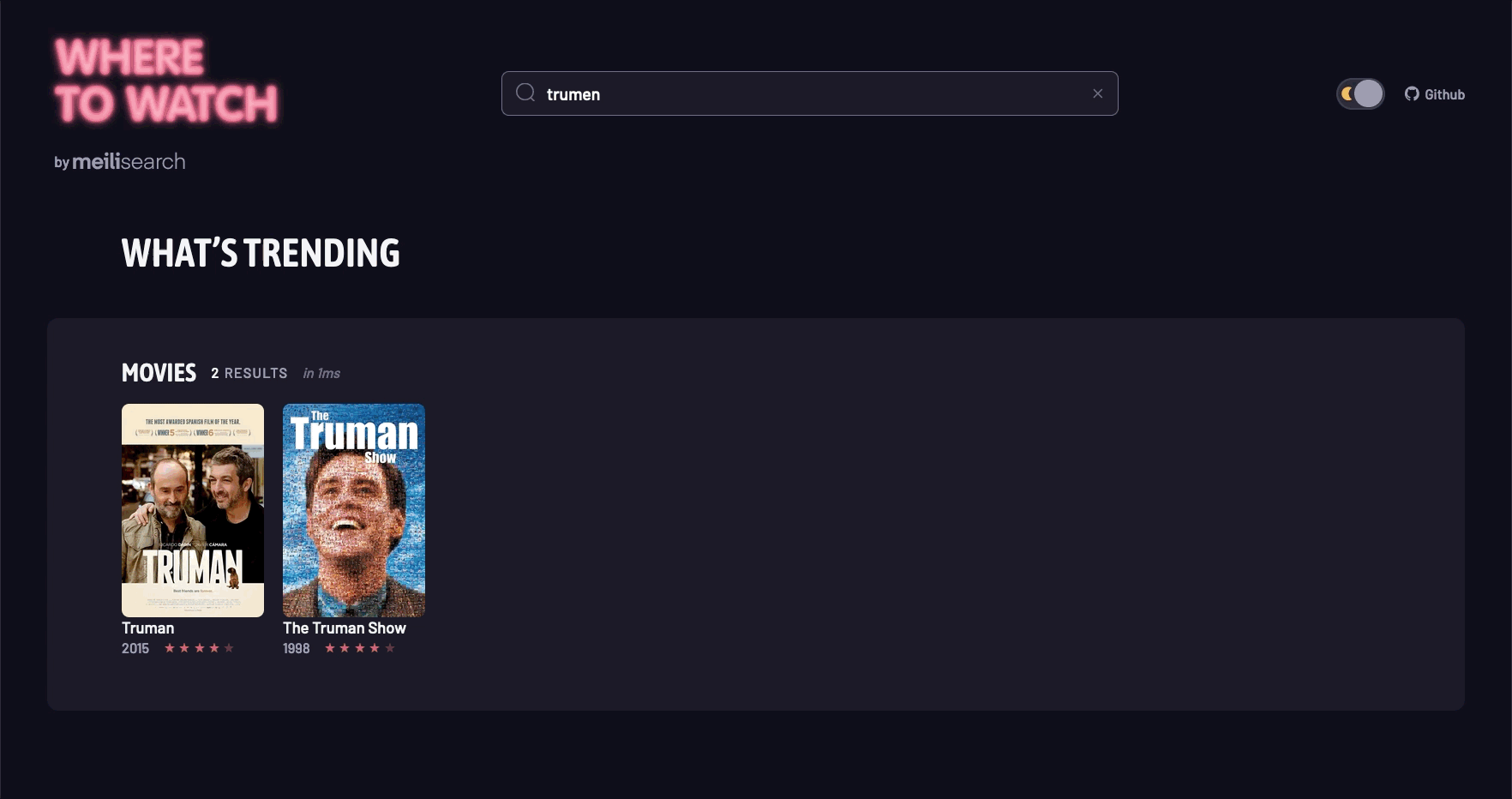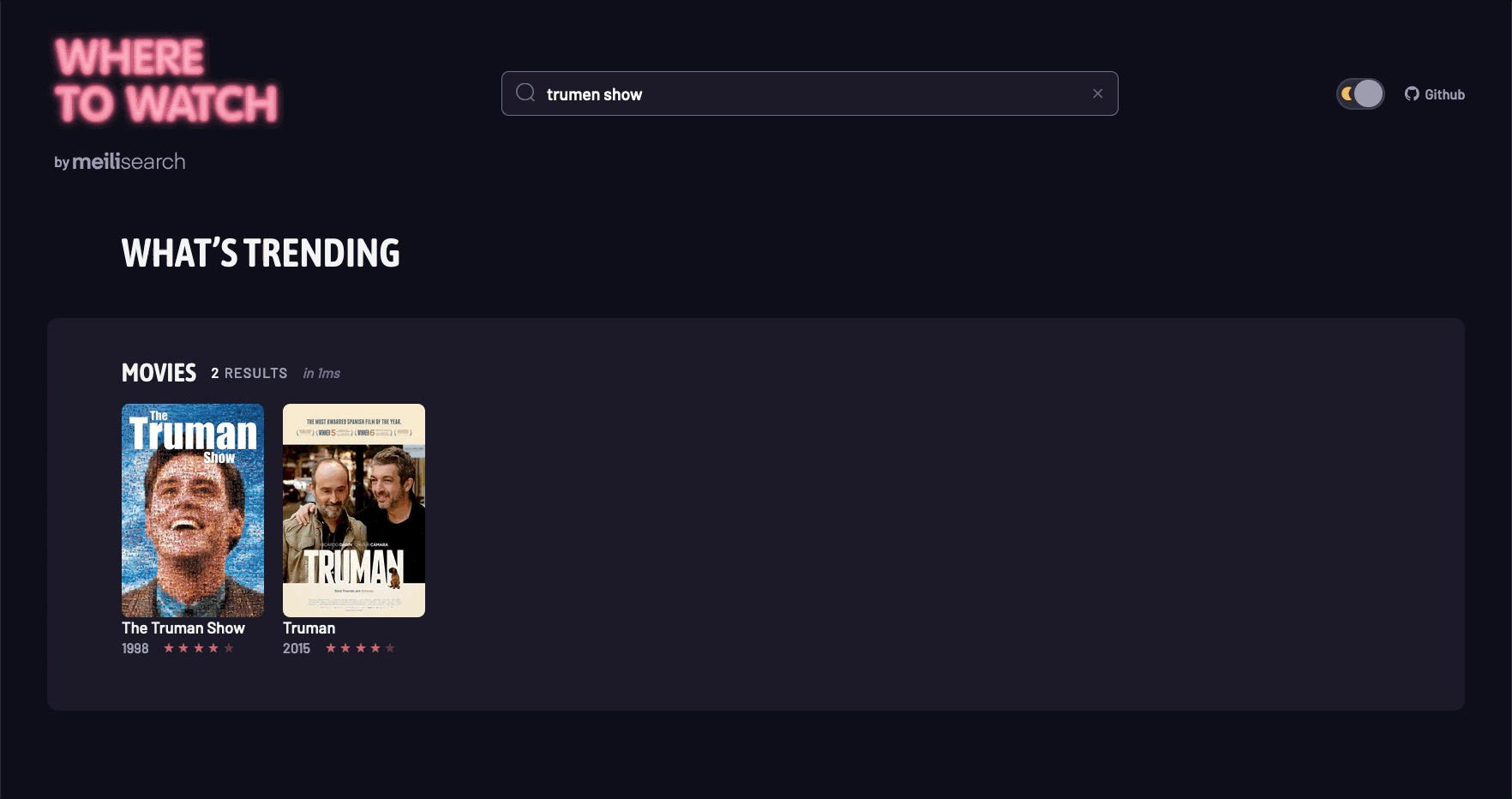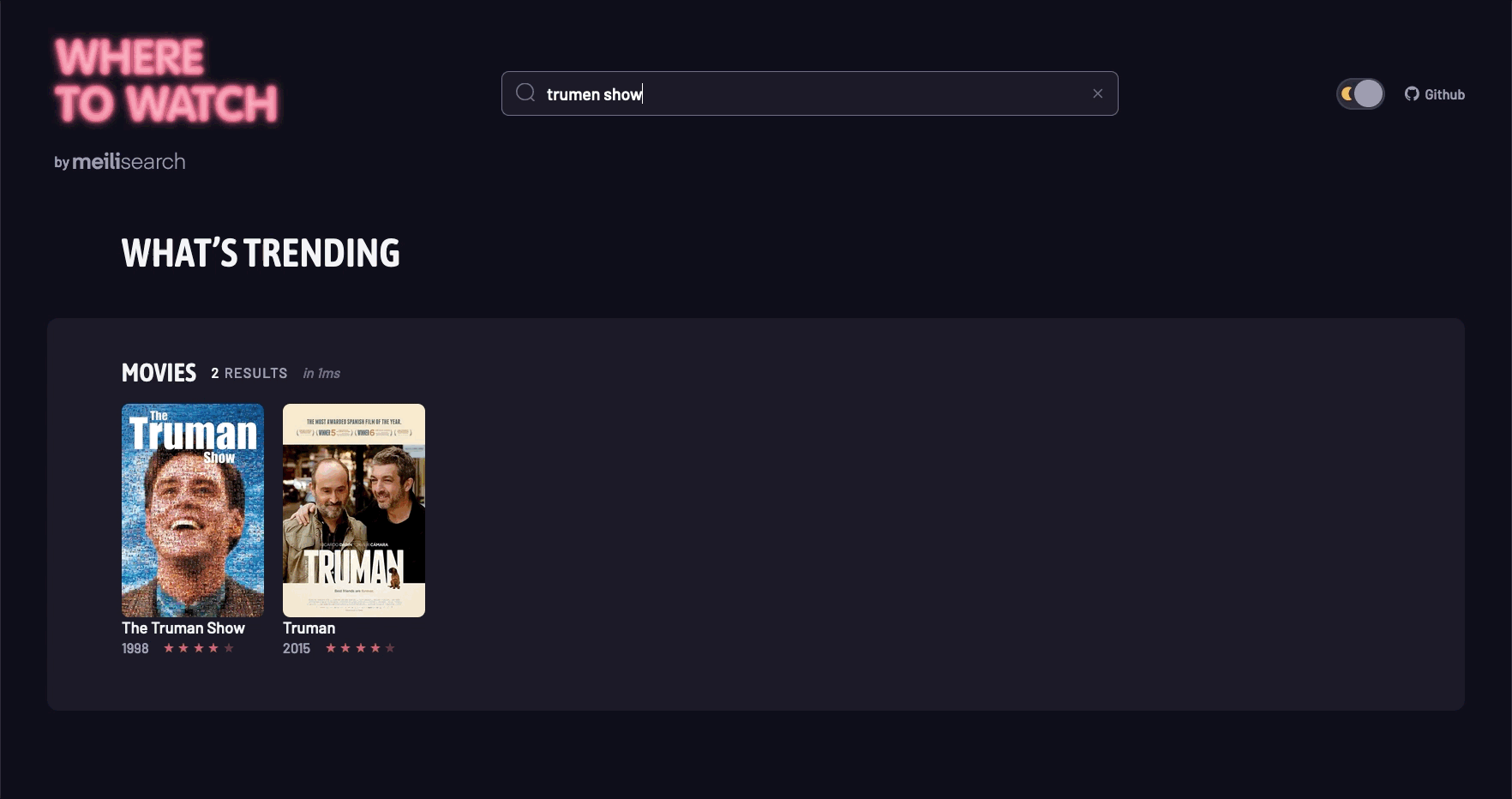
结语
Meilisearch 的出现,代表了新一代搜索引擎对于开发者体验和即时性的追求。它在应用内搜索领域展现了强大的竞争力,证明了不必依赖 Lucene 的庞大体系,也能打造出极致性能的搜索产品。
虽然它还无法完全取代 Elasticsearch 在日志分析、可观测性等大型分布式场景的地位,但在许多新兴应用和对搜索速度有极高要求的场景中,它无疑是一个值得尝试的开源新星。
🚀 下期预告
下一篇我们将把目光转向搜索领域的云端先锋 —— Algolia。作为搜索即服务(Search-as-a-Service)的开创者,Algolia 如何以其卓越的 API 设计、惊人的搜索速度和精准的相关性排序,重新定义云端搜索体验?
💬 三连互动
- 你会把 ES/Solr 换成 Meilisearch 吗?
- 在你的应用中,搜索延迟达到多少毫秒你会觉得无法接受?
- 在什么场景下你会考虑使用 Meilisearch 而不是 Elasticsearch?
对搜索技术感兴趣的朋友,也欢迎加我微信(ID:lsy965145175)备注“搜索百科”,拉你进 搜索技术交流群,一起探讨与学习!
✨ 推荐阅读
- 搜索百科(5):Easysearch — 自主可控的国产分布式搜索引擎
- 搜索百科(4):OpenSearch — 开源搜索的新选择
- 搜索百科(3):Elasticsearch — 搜索界的"流量明星"
- 搜索百科(2):Apache Solr — 企业级搜索的开源先锋
- 搜索百科(1):Lucene — 打开现代搜索世界的第一扇门
🔗 参考资源
大家好,我是 INFINI Labs 的石阳。
欢迎关注 《搜索百科》 专栏!每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
在之前的几期中,我们认识了搜索技术的基石 Lucene、企业级搜索先锋 Solr、搜索界的“流量明星” Elasticsearch 以及它的分叉兄弟 OpenSearch 和 ES 国产替代方案 Easysearch。它们大多基于 Lucene 构建,形成了庞大且功能丰富的生态。
今天,我们将介绍一位“非主流”选手:一款基于 Rust 编写、主打“快”和“简单”的现代搜索引擎——Meilisearch。它以全新的姿态,为开发者带来了不同的搜索体验。
Meilisearch 概述
Meilisearch 是一款开源的、用 Rust 编写的即时搜索引擎。它提供了一个快速、轻量且可定制的搜索 API,旨在为用户提供毫秒级的搜索体验。
它的核心优势在于为应用内搜索和电商搜索等对延迟敏感的场景提供了出色的用户体验。
- 首次发布:2020 年
- 最新版本:1.24.0(截止 2025 年 10 月)
- 核心语言:Rust
- 开源协议:MIT License
- 官方网址:https://www.meilisearch.com/
- GitHub 仓库:https://github.com/meilisearch/meilisearch
诞生故事
Meilisearch 的故事始于 2018 年,当时法国工程师 Quentin de Quelen 在开发一个电商项目时,发现现有的搜索引擎要么太重量级,要么配置太复杂。他想要一个"开箱即用"的搜索解决方案,能够快速集成到应用中,并提供优秀的搜索体验。
于是,他决定用 Rust 语言从头编写一个搜索引擎。选择 Rust 是因为其出色的性能、内存安全性和并发能力,非常适合构建高性能的搜索核心。
项目最初只是一个内部工具,但随着功能的完善和社区的反馈,Meilisearch 在 2019 年正式开源,并迅速获得了开发者的青睐。2020 年,团队获得了 150 万美元的种子轮融资,正式成立了 Meilisearch 公司。
核心特性
Meilisearch 在设计上做了大量的取舍,专注于核心的搜索功能,但做到了极致。
- 极速响应:核心目标是实现 50 毫秒以下的响应时间,即使在大型数据集中也能提供“所见即所得”的搜索体验。
- 零配置:开箱即用,部署和索引数据都非常简单,不需要预定义 Schema 或复杂的配置文件。
- 相关的默认值:内置一个强大的 相关性排名(Relevance Ranking) 算法,结合 Typos(拼写错误)、Word Proximity(词语距离)和 Attributes(字段权重)等因素,无需额外调优即可获得高质量的搜索结果。
- 语言无关性:支持多种语言的分词与搜索,能很好地处理中文、日文等非拉丁语系文本。
- 无分布式架构:为了追求极致的速度和简单性,Meilisearch 被设计为单机搜索引擎,不支持开箱即用的分布式集群,这简化了运维,但也限制了其 PB 级数据的处理能力。
对比优势:Meilisearch vs Lucene/ES 体系
Meilisearch 与基于 Lucene 的 Elasticsearch 体系,在设计哲学上有着本质区别:
| 特性 | Meilisearch | Elasticsearch |
|---|---|---|
| 核心目标 | 极速的应用内搜索体验 | 分布式搜索、日志分析、可观测性 |
| 基础架构 | 单机、轻量级 | 分布式集群(主从节点、分片) |
| 核心语言 | Rust | Java(基于 Lucene) |
| 性能瓶颈 | 单机 CPU / 内存限制 | 分布式协调开销 |
| 上手难度 | 简单,开箱即用,REST API | 相对复杂,需要了解集群、分片等概念 |
| 数据规模 | 适合中小型数据集(GB 级别) | 适合大型和超大型数据集(TB/PB 级别) |
| 全文检索 | 依赖内置的强相关性算法 | 依赖 Lucene 强大的分词、查询解析器 |
总结:
- 如果你的应用需要超低延迟、简单部署、数据量在 GB 级别,并且搜索是应用的核心功能,Meilisearch 是一个极佳的选择。
- 如果你的需求涉及日志分析、大规模数据存储、集群高可用和复杂的聚合分析,那么 Elasticsearch 仍然是更成熟和全面的解决方案。
快速上手:5 分钟体验 Meilisearch
部署 Meilisearch 非常简单,你甚至不需要 Docker,只需一个命令即可运行。
1. 运行 Meilisearch
# 安装 Meilisearch
curl -L https://install.meilisearch.com | sh
# 启动 Meilisearch
meilisearch --master-key 'aStrongMasterKey'
# 或使用 Docker
docker run -it --rm -p 7700:7700 getmeili/meilisearch:latest --master-key 'aStrongMasterKey'2. 添加索引(创建 Index)
Meilisearch 不需要预先定义索引结构(Schema-less)。
curl -X POST 'http://localhost:7700/indexes' \
-H 'Authorization: Bearer aStrongMasterKey' \
-H 'Content-Type: application/json' \
--data-binary '{
"uid": "movies",
"primaryKey": "id"
}'3. 索引文档(添加 Documents)
curl -X POST 'http://localhost:7700/indexes/movies/documents' \
-H 'Authorization: Bearer aStrongMasterKey' \
-H 'Content-Type: application/json' \
--data-binary '[
{"id": 1, "title": "泰坦尼克号", "genres": ["剧情", "爱情"]},
{"id": 2, "title": "黑客帝国", "genres": ["科幻", "动作"]}
]'4. 执行搜索
# 搜索关键词 "泰坦"
curl -X GET 'http://localhost:7700/indexes/movies/search?q=泰坦'返回结果:
{
"hits": [
{
"id": 1,
"title": "泰坦尼克号",
"genres": ["剧情", "爱情"]
}
],
"offset": 0,
"limit": 20,
"estimatedTotalHits": 1,
"processingTimeMs": 1,
"query": "泰坦"
}注意 processingTimeMs: 1,这是 Meilisearch 速度的最好证明!
5. 场景演示
结语
Meilisearch 的出现,代表了新一代搜索引擎对于开发者体验和即时性的追求。它在应用内搜索领域展现了强大的竞争力,证明了不必依赖 Lucene 的庞大体系,也能打造出极致性能的搜索产品。
虽然它还无法完全取代 Elasticsearch 在日志分析、可观测性等大型分布式场景的地位,但在许多新兴应用和对搜索速度有极高要求的场景中,它无疑是一个值得尝试的开源新星。
🚀 下期预告
下一篇我们将把目光转向搜索领域的云端先锋 —— Algolia。作为搜索即服务(Search-as-a-Service)的开创者,Algolia 如何以其卓越的 API 设计、惊人的搜索速度和精准的相关性排序,重新定义云端搜索体验?
💬 三连互动
- 你会把 ES/Solr 换成 Meilisearch 吗?
- 在你的应用中,搜索延迟达到多少毫秒你会觉得无法接受?
- 在什么场景下你会考虑使用 Meilisearch 而不是 Elasticsearch?
对搜索技术感兴趣的朋友,也欢迎加我微信(ID:lsy965145175)备注“搜索百科”,拉你进 搜索技术交流群,一起探讨与学习!
✨ 推荐阅读
- 搜索百科(5):Easysearch — 自主可控的国产分布式搜索引擎
- 搜索百科(4):OpenSearch — 开源搜索的新选择
- 搜索百科(3):Elasticsearch — 搜索界的"流量明星"
- 搜索百科(2):Apache Solr — 企业级搜索的开源先锋
- 搜索百科(1):Lucene — 打开现代搜索世界的第一扇门
🔗 参考资源
收起阅读 »【搜索客社区日报】第2137期 (2025-10-31)
https://cloud.tencent.com/deve ... 11830
2、什么是搜索相关性:你需要了解的一切
https://meilisearch.com.cn/blog/search-relevance
3、使用 Docker Compose 轻松实现 INFINI Console 离线部署与持久化管理
https://infinilabs.cn/blog/202 ... fline
4、为什么我应该考虑 Meilisearch 而不是 Elasticsearch?
https://meilisearch.com.cn/blo ... earch
5、如何使用 INFINI Gateway 增量迁移 ES 数据
https://blog.csdn.net/yangmf20 ... 60004
编辑:Fred
更多资讯:http://news.searchkit.cn
https://cloud.tencent.com/deve ... 11830
2、什么是搜索相关性:你需要了解的一切
https://meilisearch.com.cn/blog/search-relevance
3、使用 Docker Compose 轻松实现 INFINI Console 离线部署与持久化管理
https://infinilabs.cn/blog/202 ... fline
4、为什么我应该考虑 Meilisearch 而不是 Elasticsearch?
https://meilisearch.com.cn/blo ... earch
5、如何使用 INFINI Gateway 增量迁移 ES 数据
https://blog.csdn.net/yangmf20 ... 60004
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2136期 (2025-10-29)
https://mp.weixin.qq.com/s/KZpeyLpxZWOORyvmwqOeGQ
2.日志存储成本降低90%:Loki+S3架构实战PB级日志管理方案
https://mp.weixin.qq.com/s/lLTy-ogW7zMoORh8XvnWEw
3.数据库巡检进入智能时代:异常检测算法的落地实践
https://mp.weixin.qq.com/s/AhXvRlrV4GoR3cLsARzAFQ
4.低内存基准测试在 DiskBBQ 和 HNSW BBQ 中
https://elasticstack.blog.csdn ... 95397
5.在 Elastic 中使用 GPU 推理进行语义搜索
https://elasticstack.blog.csdn ... 97780
编辑:kin122
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/KZpeyLpxZWOORyvmwqOeGQ
2.日志存储成本降低90%:Loki+S3架构实战PB级日志管理方案
https://mp.weixin.qq.com/s/lLTy-ogW7zMoORh8XvnWEw
3.数据库巡检进入智能时代:异常检测算法的落地实践
https://mp.weixin.qq.com/s/AhXvRlrV4GoR3cLsARzAFQ
4.低内存基准测试在 DiskBBQ 和 HNSW BBQ 中
https://elasticstack.blog.csdn ... 95397
5.在 Elastic 中使用 GPU 推理进行语义搜索
https://elasticstack.blog.csdn ... 97780
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2135期 (2025-10-28)
1. 全文搜索,传统DB做错了什么?ES做对了什么?(需要梯子)
https://medium.com/%40harshgha ... cf8e1
2. 需要向量引擎?搞一个!(需要梯子)
https://medium.com/%40yzh0623/ ... e0a15
3. 数据库的实时同步,Flink一把梭(需要梯子)
https://rahmat-wibowo21.medium ... 576e3
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
1. 全文搜索,传统DB做错了什么?ES做对了什么?(需要梯子)
https://medium.com/%40harshgha ... cf8e1
2. 需要向量引擎?搞一个!(需要梯子)
https://medium.com/%40yzh0623/ ... e0a15
3. 数据库的实时同步,Flink一把梭(需要梯子)
https://rahmat-wibowo21.medium ... 576e3
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
【搜索客社区日报】第2134期 (2025-10-27)
https://elasticstack.blog.csdn ... 74404
2、Elasticsearch:隔离环境中的高级向量搜索
https://elasticstack.blog.csdn ... 74013
3、在 Elastic Observability 中,启用 TSDS 集成可节省高达 70% 的指标存储
https://elasticstack.blog.csdn ... 15817
4、Agent下半场!比Prompt更重要的是「上下文工程」,Anthropic首次系统阐述
https://mp.weixin.qq.com/s/pFo4hGAAgmYEQUJcC6otkw
5、一文读懂传统RAG、多模态RAG、Agentic RAG与GraphRAG
https://mp.weixin.qq.com/s/pNUymIuRACOy2QG9Et4v0Q
编辑:Muse
更多资讯:http://news.searchkit.cn
https://elasticstack.blog.csdn ... 74404
2、Elasticsearch:隔离环境中的高级向量搜索
https://elasticstack.blog.csdn ... 74013
3、在 Elastic Observability 中,启用 TSDS 集成可节省高达 70% 的指标存储
https://elasticstack.blog.csdn ... 15817
4、Agent下半场!比Prompt更重要的是「上下文工程」,Anthropic首次系统阐述
https://mp.weixin.qq.com/s/pFo4hGAAgmYEQUJcC6otkw
5、一文读懂传统RAG、多模态RAG、Agentic RAG与GraphRAG
https://mp.weixin.qq.com/s/pNUymIuRACOy2QG9Et4v0Q
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2133期 (2025-10-23)
https://mp.weixin.qq.com/s/ki5Tq-kTnzadfTbiqEItOg
2.蚂蚁的 SGLang 高效实践:DeepSeek R1 on H20
https://mp.weixin.qq.com/s/LBQ1YMyOjlNo4w0dGxwtJA
3.英伟达携手LMCache:用 Dynamo解锁KV缓存性能新突破
https://mp.weixin.qq.com/s/UzArWDs_TAiW4CiDEL9IyQ
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/ki5Tq-kTnzadfTbiqEItOg
2.蚂蚁的 SGLang 高效实践:DeepSeek R1 on H20
https://mp.weixin.qq.com/s/LBQ1YMyOjlNo4w0dGxwtJA
3.英伟达携手LMCache:用 Dynamo解锁KV缓存性能新突破
https://mp.weixin.qq.com/s/UzArWDs_TAiW4CiDEL9IyQ
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2132期 (2025-10-22)
https://medium.com/data-scienc ... 54a63
2.从零到智能代理的实战指南(搭梯)
http://medium.com/data-science ... dd099
3.50 个 LLMs 面试问题终极列表(搭梯)
https://medium.com/data-scienc ... 756ee
编辑:kin122
更多资讯:http://news.searchkit.cn
https://medium.com/data-scienc ... 54a63
2.从零到智能代理的实战指南(搭梯)
http://medium.com/data-science ... dd099
3.50 个 LLMs 面试问题终极列表(搭梯)
https://medium.com/data-scienc ... 756ee
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2131期 (2025-10-21)
https://marius-ciclistu.medium ... 1777e
2. 怎么在Ubuntu里搭存储体系(需要梯子)
https://medium.com/%40yogeshwa ... 51d0b
3. 用ES深入挖掘集群行为和内存堆栈信息(需要梯子)
https://manish-dixit.medium.co ... 9e84c
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://marius-ciclistu.medium ... 1777e
2. 怎么在Ubuntu里搭存储体系(需要梯子)
https://medium.com/%40yogeshwa ... 51d0b
3. 用ES深入挖掘集群行为和内存堆栈信息(需要梯子)
https://manish-dixit.medium.co ... 9e84c
编辑:斯蒂文
更多资讯:http://news.searchkit.cn 收起阅读 »
搜索百科(5):Easysearch — 自主可控的国产分布式搜索引擎
大家好,我是 INFINI Labs 的石阳。
欢迎关注 《搜索百科》 专栏!每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
在上一篇我们介绍了 OpenSearch —— 那个因协议争议而诞生的开源搜索分支。今天,我们把目光转向国内,聊聊极限科技研发的一款轻量级搜索引擎:Easysearch。
引言
在搜索技术的世界里,从 Lucene 的出现到 Solr、Elasticsearch 的崛起,搜索引擎技术已经发展了二十余年。然而,随着开源协议的变更与国际形势的变化,国产自主搜索引擎的需求愈发迫切。在这样的背景下,Easysearch 作为一款自主可控、轻量高效、兼容 Elasticsearch 的分布式搜索引擎应运而生,为国内企业带来了全新的选择。
Easysearch 概述
Easysearch 是一款分布式搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析、AI 集成等。Easysearch 衍生自开源协议 Apache 2.0 的 Elasticsearch 7.10 版本,并不断往前迭代更新,紧跟 Lucene 最新版本的更新。Easysearch 可以替代 Elasticsearch,同时添加和完善多项企业级功能。
- 首次发布:2023 年 4 月
- 最新版本:1.15.4(截止 2025 年 10 月)
- 主导企业:极限科技 (INFINI Labs)
- 官方网址:https://easysearch.cn
诞生背景:为什么要有 Easysearch?
Easysearch 由极限科技(INFINI Labs)团队推出。项目的起点源于团队长期在搜索引擎和大数据领域的深厚实践积累,团队深刻认识到国内企业在使用 Elasticsearch 时普遍面临以下痛点:
- 开源协议变化带来的商业风险 —— Elastic 于 2021 年将许可更改为 SSPL,导致社区分裂,增加了企业在合规和商用上的不确定性;
- 高并发与高可靠性场景下对稳定可控方案的需求 —— 企业级应用亟需一个性能可靠、可深度优化的搜索基础设施;
- 技术栈自主可控的迫切需求 —— 随着国产化进程加快,国内生态中缺乏轻量化、易部署、且完全可控的搜索引擎产品;
- 本地化服务与快速响应能力的缺口 —— 国内企业更需要本地团队提供高效的技术支持与服务,对本土化、个性化功能需求能得到及时响应与反馈。
基于这些考虑,Easysearch 在设计之初就明确了目标:构建一款兼容 Elasticsearch API、简洁易用、性能出众且完全自主可控的国产搜索引擎。
核心特性
- 轻量级:安装包大小不到 60 MB,安装部署简洁,资源占用低,开箱即用;
- 跨平台:支持主流操作系统和 CPU 架构,支持国产信创运行环境;
- 高性能:针对不同场景进行的极致优化,可用更少硬件成本获得更高服务性能,降本增效。
- 稳定可靠:修复大量内核问题,解决内存泄露,集群卡顿、查询缓慢等问题,久经严苛业务环境考验。
- 安全增强:默认就提供完整的企业级安全功能,支持 LDAP/AD 集成,支持索引、文档、字段粒度细权管控。
- 兼容性强:兼容 Elasticsearch 7.x 的 REST API 和数据格式,迁移成本低;
- 可视化运维:无需 Kibana 即可通过内置 Web UI 插件界面管理索引、节点与监控指标等。
对比优势
| 对比维度 | Easysearch | Elasticsearch | OpenSearch |
|---|---|---|---|
| 用户协议 | 社区免费+商业授权 | SSPL/AGPL v3 | Apache 2.0 |
| API 兼容性 | 高度兼容 ES | 原生 | 高度兼容 ES |
| 最小安装体积 | 57MB | 482MB | 682MB |
| 部署复杂度 | 简单 | 中等 | 相对复杂 |
| 信创环境支持 | 全面兼容 | 无 | 无 |
| 可视化管理 | 开箱即用管理后台 | 需独立部署 Kibana | 需独立部署 OpenSearch Dashboards |
| 本地化与中文支持 | 强 | 弱 | 弱 |
| AI 插件支持 | 较弱 | 强 | 较强 |
| 社区与生态 | 快速成长中 | 成熟广泛 | 活跃增长 |
快速开始:5 分钟体验 Easysearch
1. 使用 Docker 启动
# 直接运行镜像使用随机密码(数据及配置未持久化)
docker run --name easysearch \
--ulimit memlock=-1:-1 \
-p 9200:9200 \
infinilabs/easysearch:1.15.42. 验证集群状态
curl -ku "username:password" -X GET "https://localhost:9200/"返回结果示例:
{
"name": "easysearch-node",
"cluster_name": "easysearch-6yhwn91v80gf",
"cluster_uuid": "Gfu_fuF1QViJfeUWVbiFCA",
"version": {
"distribution": "easysearch",
"number": "1.15.4",
"distributor": "INFINI Labs",
"build_hash": "9110128946b0af3de639966cfa74b5498346949d",
"build_date": "2025-10-14T03:30:41.948590Z",
"build_snapshot": false,
"lucene_version": "8.11.4",
"minimum_wire_lucene_version": "7.7.0",
"minimum_lucene_index_compatibility_version": "7.7.0"
},
"tagline": "You Know, For Easy Search!"
}3. 索引与搜索示例
# 写入文档
curl -ku "username:password" -X POST "https://localhost:9200/my_index/_doc" -H 'Content-Type: application/json' -d'
{
"title": "Easysearch 入门",
"content": "这是一个轻量级搜索引擎的示例文档。",
"tags": ["搜索", "国产", "轻量级"]
}'
# 搜索文档
curl -ku "username:password" -X GET "https://localhost:9200/my_index/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"content": "搜索引擎"
}
}
}'4. 使用 Easysearch UI
Easysearch 提供了轻量级界面化管理功能,不再依赖第三方组件即可对集群进行管理,真正做到开箱即用。如果你安装了 Easysearch UI 插件或者下载捆绑包,可通过 https://localhost:9200/\_ui/ 访问,进行节点、索引、分片、查询调试和监控查看等管理。
图 1:系统登录
图 2:集群概览
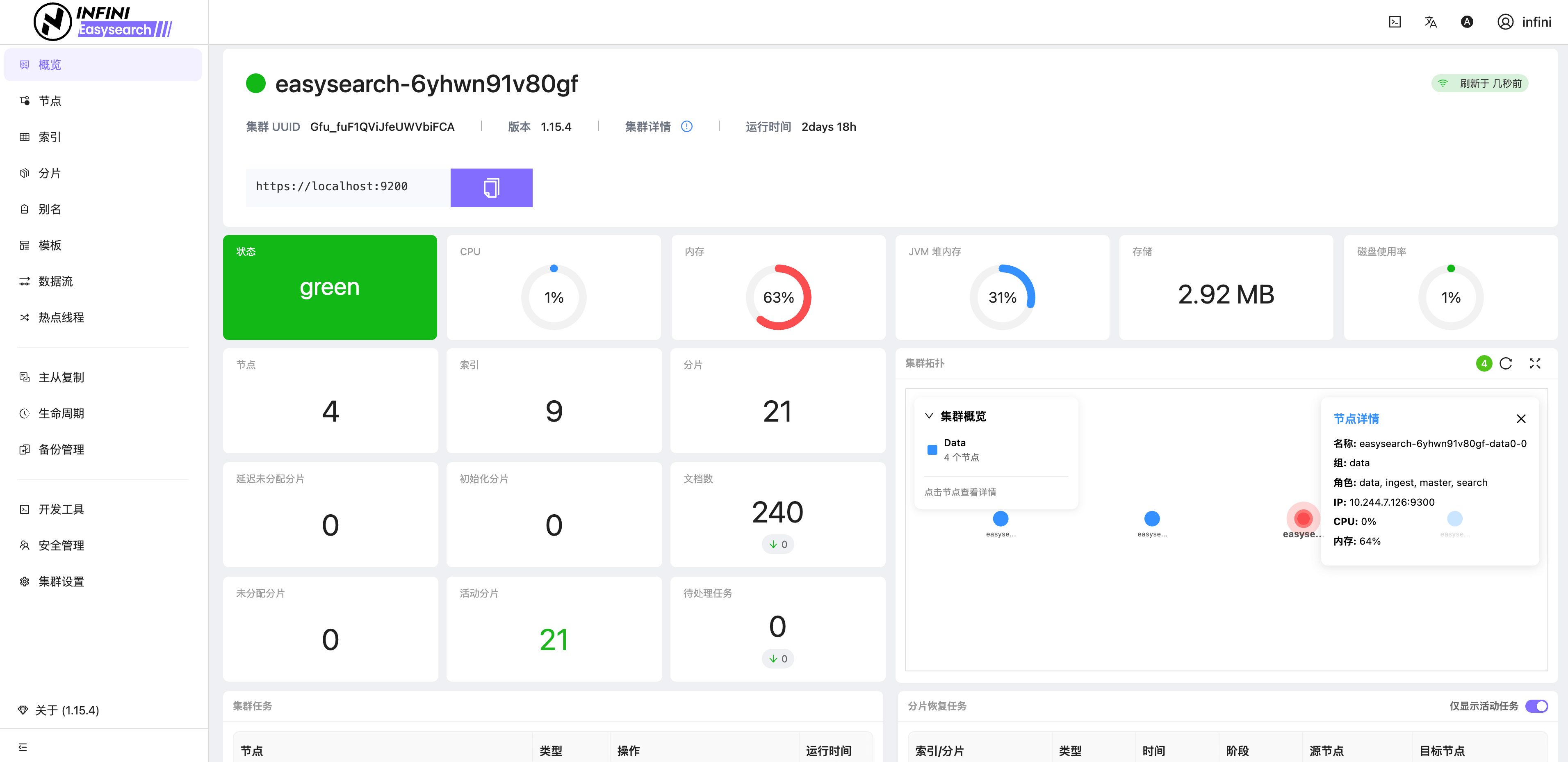
图 3:节点列表
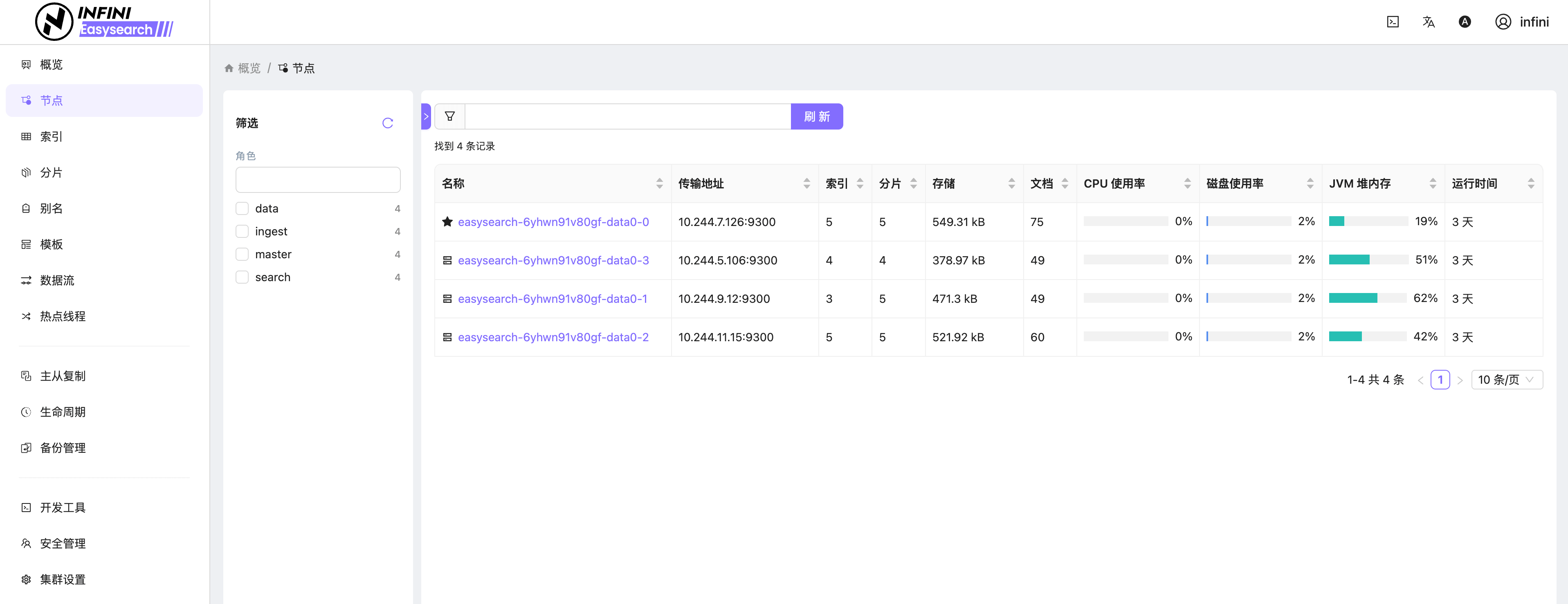
图 4:节点概览
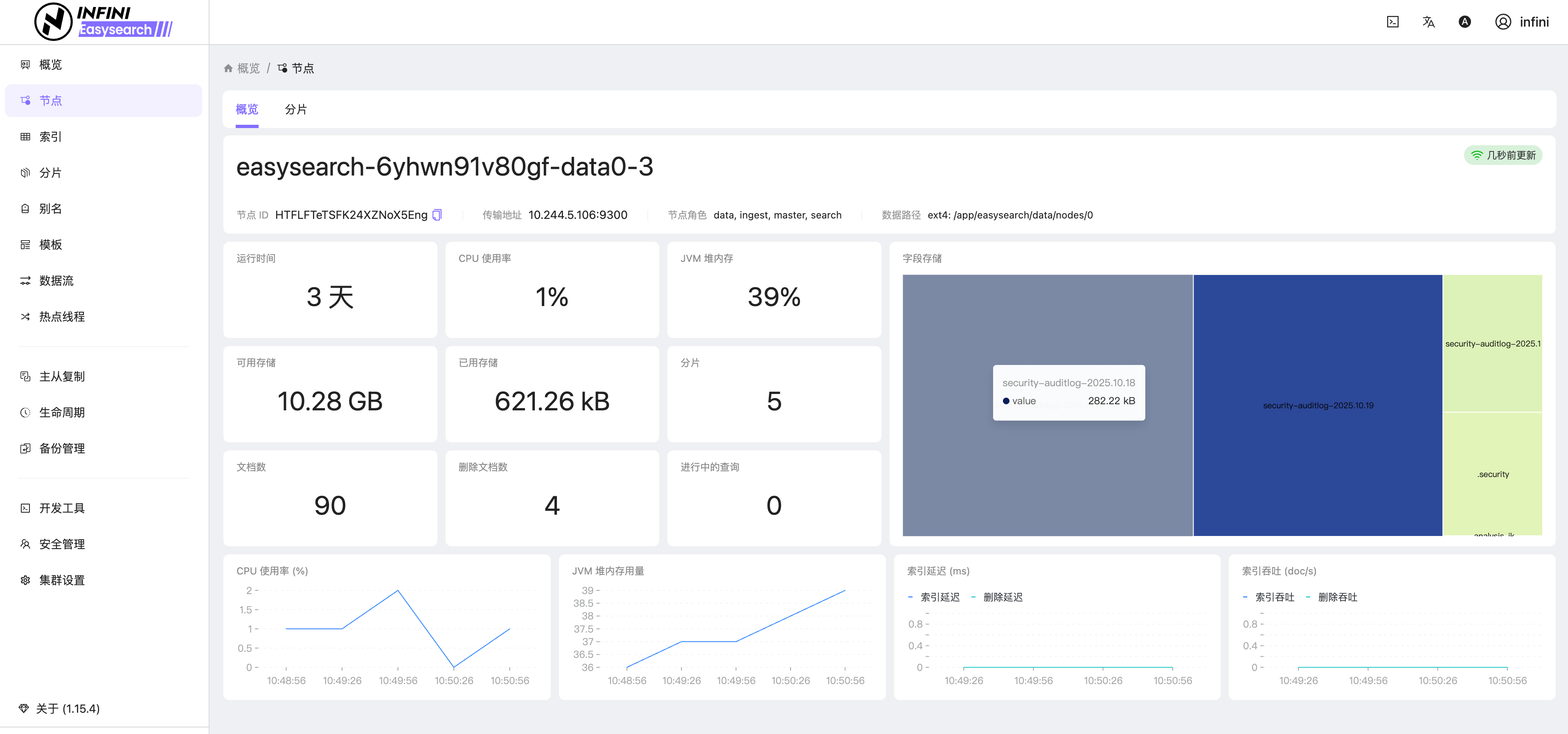
图 5:索引列表
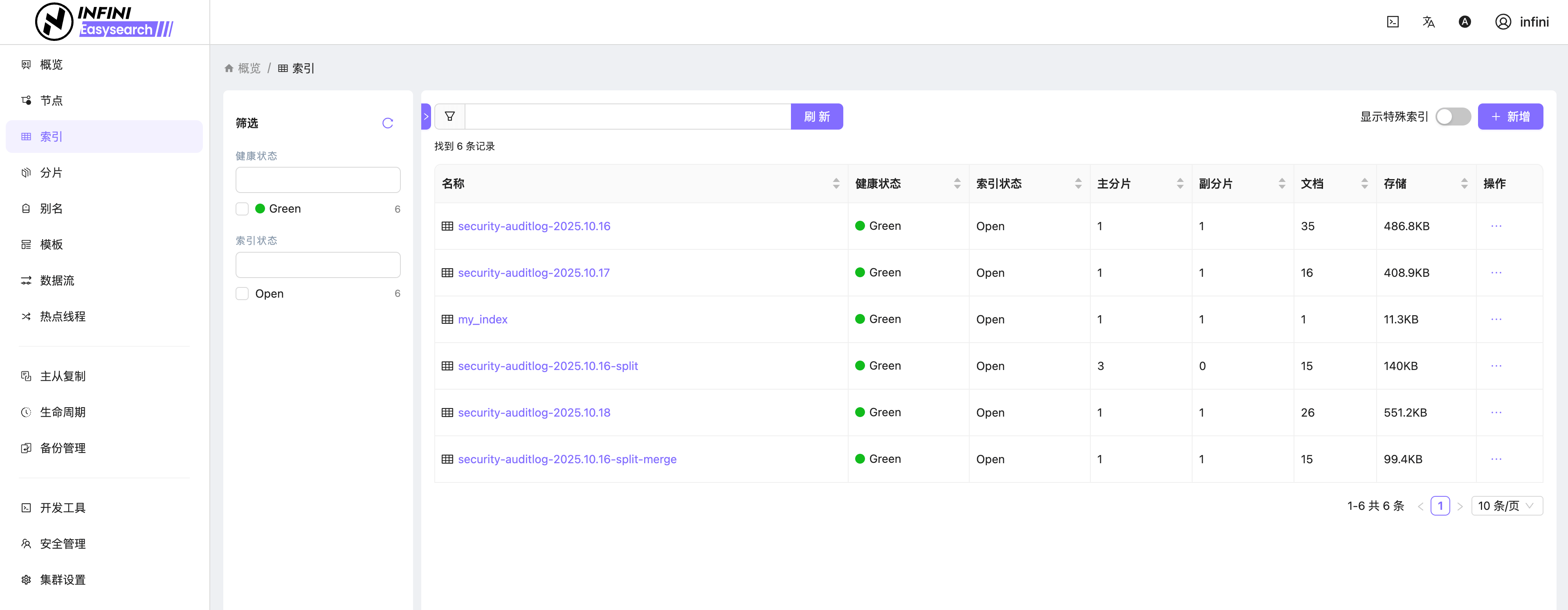
图 6:索引概览
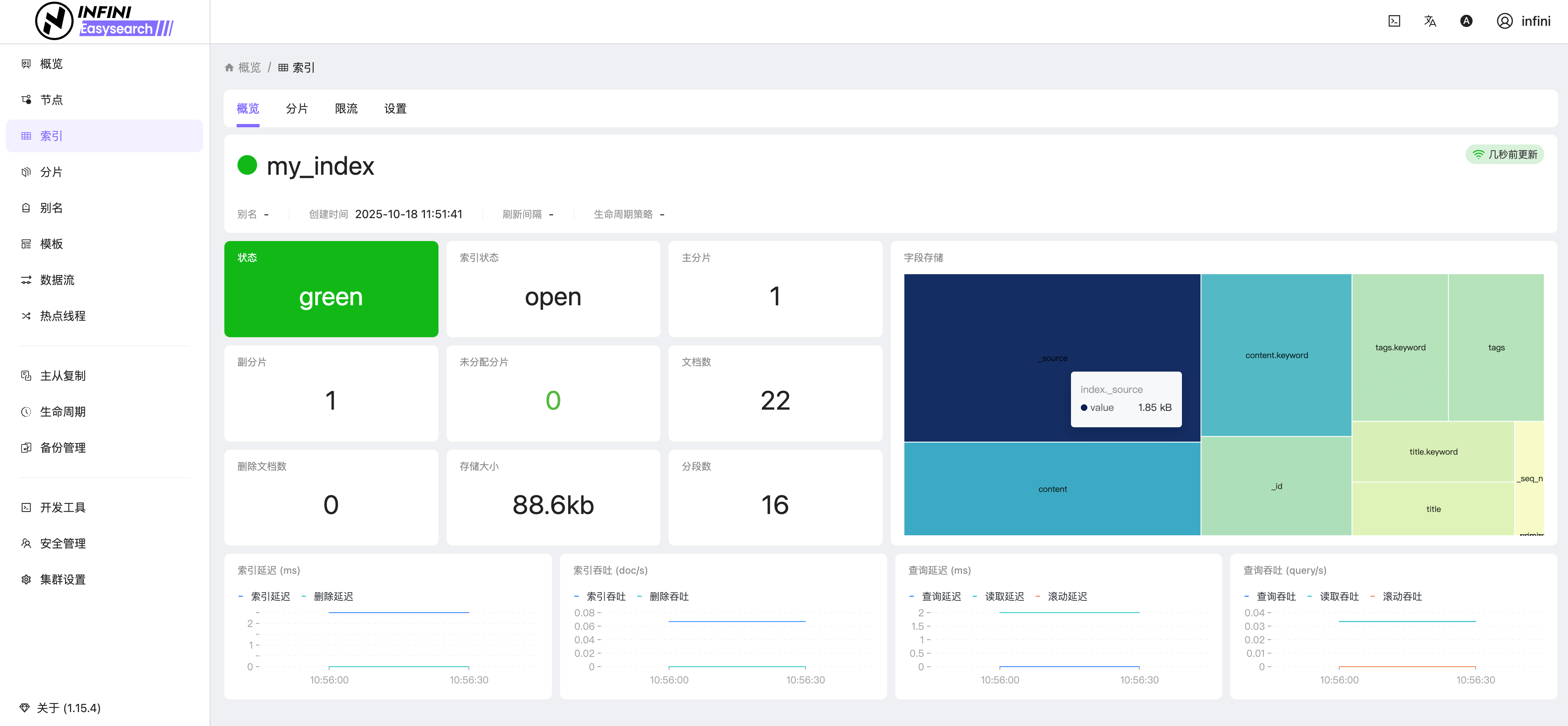
图 7:分片管理
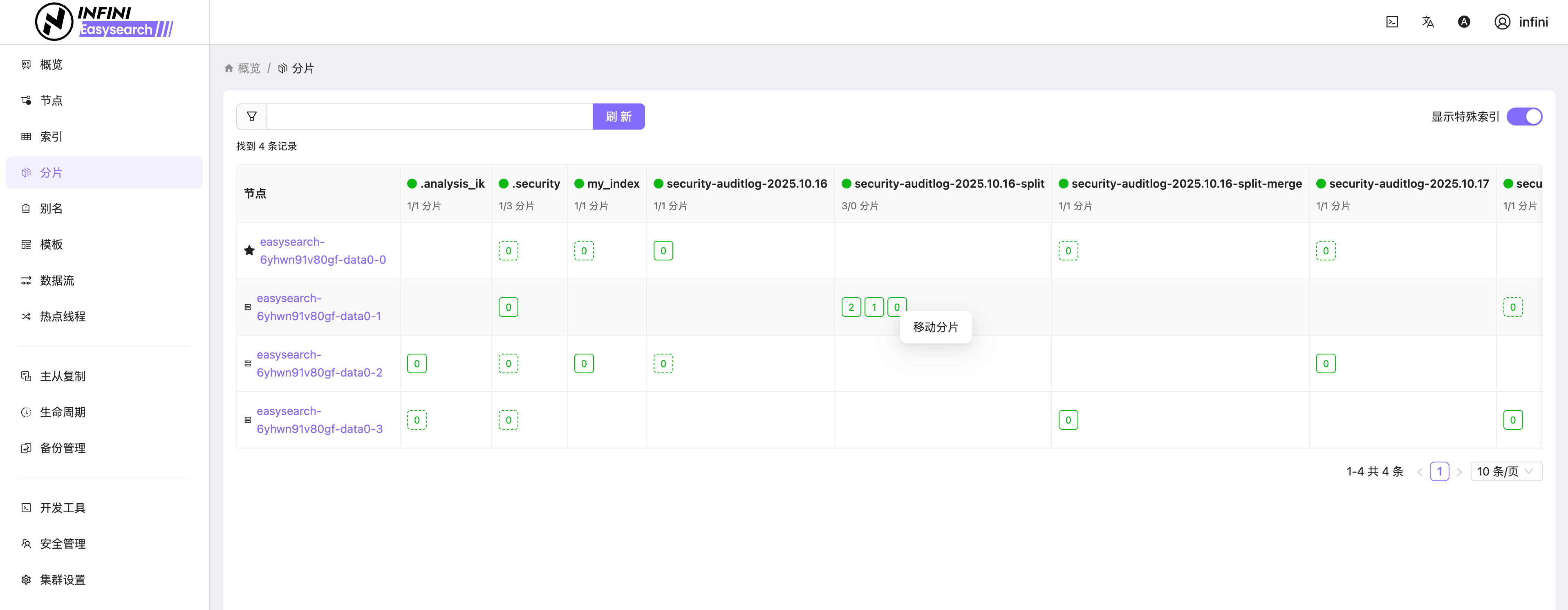
图 8:开发工具
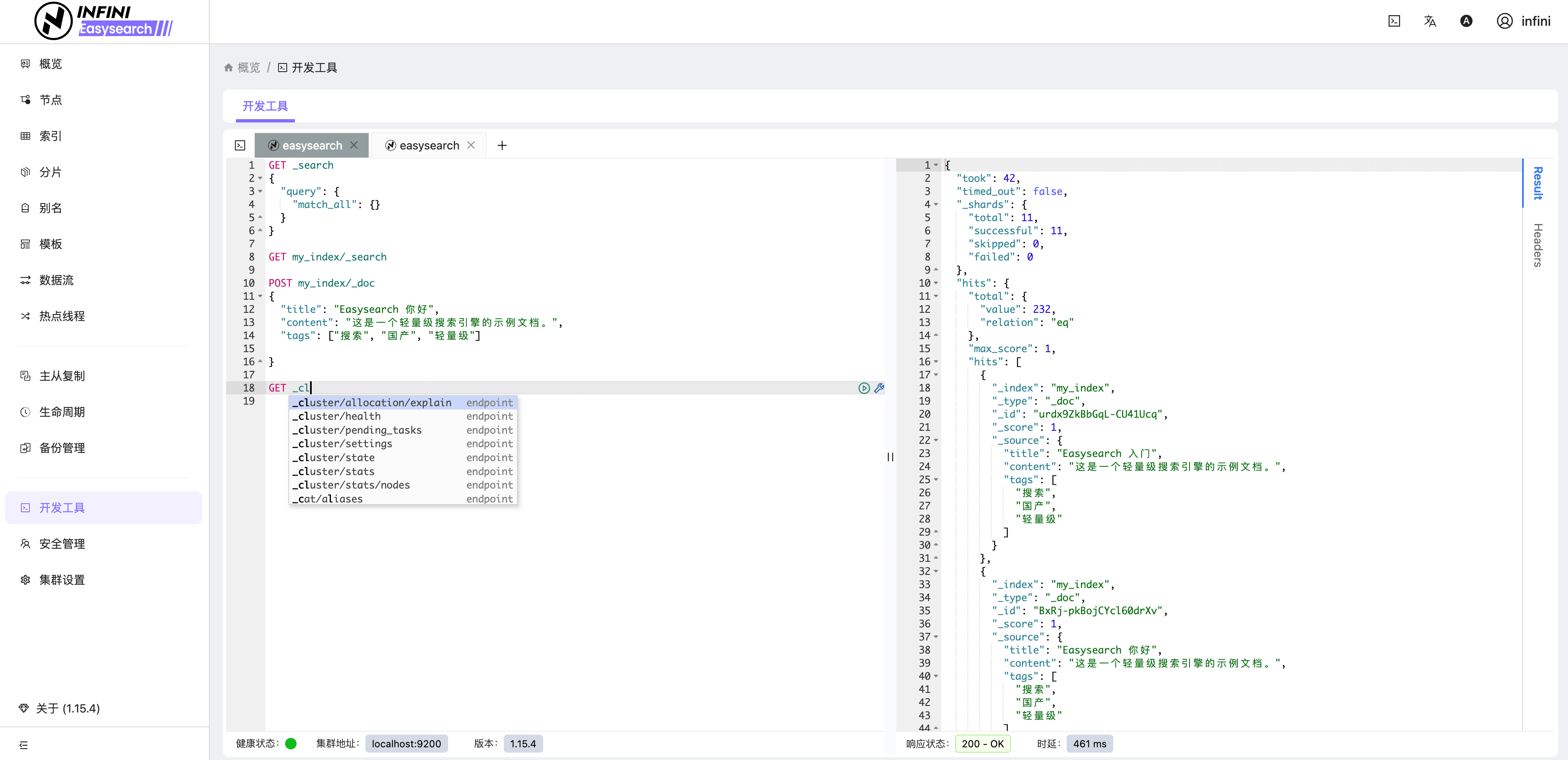
以上仅列出了一些基本功能,其他如安全管理、主从复制、备份管理、生命周期管理等更多高级功能由于篇幅限制不一一展示,有兴趣的朋友可自行部署探索。
结语
Easysearch 的诞生,不仅填补了国产搜索引擎在分布式与轻量化领域的空白,也让更多企业在面对开源协议变动与外部技术依赖时,拥有了更加安全、灵活、可控的选择。
它既是国产替代方案的有力代表,更是新一代搜索技术生态的积极探索者,为企业级实时搜索与分析带来新的可能。
🚀 下期预告
下一篇我们将介绍 一款 AI 驱动的现代搜索引擎 - Meilisearch,基于 Rust 构建的开源搜索引擎,性能高、部署简单。号称比 Elasticsearch 快 10 倍,真的这么牛吗?
💬 三连互动
- 你是否在使用或考虑国产搜索替代方案?
- 在实际项目中,你最看重搜索引擎的哪些特性?(性能、兼容性、运维、成本)
- 对 Easysearch 有什么功能上的期待?
对搜索技术感兴趣的朋友,也欢迎加我微信(ID:lsy965145175)备注“搜索百科”,拉你进 搜索技术交流群,一起探讨与学习!
✨ 推荐阅读
- 搜索百科(4):OpenSearch — 开源搜索的新选择
- 搜索百科(3):Elasticsearch — 搜索界的"流量明星"
- 搜索百科(2):Apache Solr — 企业级搜索的开源先锋
- 搜索百科(1):Lucene — 打开现代搜索世界的第一扇门
🔗 参考资源
原文:https://infinilabs.cn/blog/2025/search-wiki-5-easysearch/
大家好,我是 INFINI Labs 的石阳。
欢迎关注 《搜索百科》 专栏!每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
在上一篇我们介绍了 OpenSearch —— 那个因协议争议而诞生的开源搜索分支。今天,我们把目光转向国内,聊聊极限科技研发的一款轻量级搜索引擎:Easysearch。
引言
在搜索技术的世界里,从 Lucene 的出现到 Solr、Elasticsearch 的崛起,搜索引擎技术已经发展了二十余年。然而,随着开源协议的变更与国际形势的变化,国产自主搜索引擎的需求愈发迫切。在这样的背景下,Easysearch 作为一款自主可控、轻量高效、兼容 Elasticsearch 的分布式搜索引擎应运而生,为国内企业带来了全新的选择。
Easysearch 概述
Easysearch 是一款分布式搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析、AI 集成等。Easysearch 衍生自开源协议 Apache 2.0 的 Elasticsearch 7.10 版本,并不断往前迭代更新,紧跟 Lucene 最新版本的更新。Easysearch 可以替代 Elasticsearch,同时添加和完善多项企业级功能。
- 首次发布:2023 年 4 月
- 最新版本:1.15.4(截止 2025 年 10 月)
- 主导企业:极限科技 (INFINI Labs)
- 官方网址:https://easysearch.cn
诞生背景:为什么要有 Easysearch?
Easysearch 由极限科技(INFINI Labs)团队推出。项目的起点源于团队长期在搜索引擎和大数据领域的深厚实践积累,团队深刻认识到国内企业在使用 Elasticsearch 时普遍面临以下痛点:
- 开源协议变化带来的商业风险 —— Elastic 于 2021 年将许可更改为 SSPL,导致社区分裂,增加了企业在合规和商用上的不确定性;
- 高并发与高可靠性场景下对稳定可控方案的需求 —— 企业级应用亟需一个性能可靠、可深度优化的搜索基础设施;
- 技术栈自主可控的迫切需求 —— 随着国产化进程加快,国内生态中缺乏轻量化、易部署、且完全可控的搜索引擎产品;
- 本地化服务与快速响应能力的缺口 —— 国内企业更需要本地团队提供高效的技术支持与服务,对本土化、个性化功能需求能得到及时响应与反馈。
基于这些考虑,Easysearch 在设计之初就明确了目标:构建一款兼容 Elasticsearch API、简洁易用、性能出众且完全自主可控的国产搜索引擎。
核心特性
- 轻量级:安装包大小不到 60 MB,安装部署简洁,资源占用低,开箱即用;
- 跨平台:支持主流操作系统和 CPU 架构,支持国产信创运行环境;
- 高性能:针对不同场景进行的极致优化,可用更少硬件成本获得更高服务性能,降本增效。
- 稳定可靠:修复大量内核问题,解决内存泄露,集群卡顿、查询缓慢等问题,久经严苛业务环境考验。
- 安全增强:默认就提供完整的企业级安全功能,支持 LDAP/AD 集成,支持索引、文档、字段粒度细权管控。
- 兼容性强:兼容 Elasticsearch 7.x 的 REST API 和数据格式,迁移成本低;
- 可视化运维:无需 Kibana 即可通过内置 Web UI 插件界面管理索引、节点与监控指标等。
对比优势
| 对比维度 | Easysearch | Elasticsearch | OpenSearch |
|---|---|---|---|
| 用户协议 | 社区免费+商业授权 | SSPL/AGPL v3 | Apache 2.0 |
| API 兼容性 | 高度兼容 ES | 原生 | 高度兼容 ES |
| 最小安装体积 | 57MB | 482MB | 682MB |
| 部署复杂度 | 简单 | 中等 | 相对复杂 |
| 信创环境支持 | 全面兼容 | 无 | 无 |
| 可视化管理 | 开箱即用管理后台 | 需独立部署 Kibana | 需独立部署 OpenSearch Dashboards |
| 本地化与中文支持 | 强 | 弱 | 弱 |
| AI 插件支持 | 较弱 | 强 | 较强 |
| 社区与生态 | 快速成长中 | 成熟广泛 | 活跃增长 |
快速开始:5 分钟体验 Easysearch
1. 使用 Docker 启动
# 直接运行镜像使用随机密码(数据及配置未持久化)
docker run --name easysearch \
--ulimit memlock=-1:-1 \
-p 9200:9200 \
infinilabs/easysearch:1.15.42. 验证集群状态
curl -ku "username:password" -X GET "https://localhost:9200/"返回结果示例:
{
"name": "easysearch-node",
"cluster_name": "easysearch-6yhwn91v80gf",
"cluster_uuid": "Gfu_fuF1QViJfeUWVbiFCA",
"version": {
"distribution": "easysearch",
"number": "1.15.4",
"distributor": "INFINI Labs",
"build_hash": "9110128946b0af3de639966cfa74b5498346949d",
"build_date": "2025-10-14T03:30:41.948590Z",
"build_snapshot": false,
"lucene_version": "8.11.4",
"minimum_wire_lucene_version": "7.7.0",
"minimum_lucene_index_compatibility_version": "7.7.0"
},
"tagline": "You Know, For Easy Search!"
}3. 索引与搜索示例
# 写入文档
curl -ku "username:password" -X POST "https://localhost:9200/my_index/_doc" -H 'Content-Type: application/json' -d'
{
"title": "Easysearch 入门",
"content": "这是一个轻量级搜索引擎的示例文档。",
"tags": ["搜索", "国产", "轻量级"]
}'
# 搜索文档
curl -ku "username:password" -X GET "https://localhost:9200/my_index/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"content": "搜索引擎"
}
}
}'4. 使用 Easysearch UI
Easysearch 提供了轻量级界面化管理功能,不再依赖第三方组件即可对集群进行管理,真正做到开箱即用。如果你安装了 Easysearch UI 插件或者下载捆绑包,可通过 https://localhost:9200/\_ui/ 访问,进行节点、索引、分片、查询调试和监控查看等管理。
图 1:系统登录
图 2:集群概览
图 3:节点列表
图 4:节点概览
图 5:索引列表
图 6:索引概览
图 7:分片管理
图 8:开发工具
以上仅列出了一些基本功能,其他如安全管理、主从复制、备份管理、生命周期管理等更多高级功能由于篇幅限制不一一展示,有兴趣的朋友可自行部署探索。
结语
Easysearch 的诞生,不仅填补了国产搜索引擎在分布式与轻量化领域的空白,也让更多企业在面对开源协议变动与外部技术依赖时,拥有了更加安全、灵活、可控的选择。
它既是国产替代方案的有力代表,更是新一代搜索技术生态的积极探索者,为企业级实时搜索与分析带来新的可能。
🚀 下期预告
下一篇我们将介绍 一款 AI 驱动的现代搜索引擎 - Meilisearch,基于 Rust 构建的开源搜索引擎,性能高、部署简单。号称比 Elasticsearch 快 10 倍,真的这么牛吗?
💬 三连互动
- 你是否在使用或考虑国产搜索替代方案?
- 在实际项目中,你最看重搜索引擎的哪些特性?(性能、兼容性、运维、成本)
- 对 Easysearch 有什么功能上的期待?
对搜索技术感兴趣的朋友,也欢迎加我微信(ID:lsy965145175)备注“搜索百科”,拉你进 搜索技术交流群,一起探讨与学习!
✨ 推荐阅读
- 搜索百科(4):OpenSearch — 开源搜索的新选择
- 搜索百科(3):Elasticsearch — 搜索界的"流量明星"
- 搜索百科(2):Apache Solr — 企业级搜索的开源先锋
- 搜索百科(1):Lucene — 打开现代搜索世界的第一扇门
🔗 参考资源
收起阅读 »原文:https://infinilabs.cn/blog/2025/search-wiki-5-easysearch/
【搜索客社区日报】第2130期 (2025-10-20)
https://elasticstack.blog.csdn ... 73147
2、如何使用 Synonyms UI 上传和管理 Elasticsearch 同义词 - 9.1
https://elasticstack.blog.csdn ... 10683
3、Simple MCP Client - 连接到 Elasticsearch MCP 并进行自然语言搜索
https://elasticstack.blog.csdn ... 10379
4、使用 n8n 和 MCP 创建 AI 代理
https://elasticstack.blog.csdn ... 30621
5、通过 A2A 协议将 Elastic Agent 连接到 Gemini Enterprise
https://elasticstack.blog.csdn ... 84944
编辑:Muse
更多资讯:http://news.searchkit.cn
https://elasticstack.blog.csdn ... 73147
2、如何使用 Synonyms UI 上传和管理 Elasticsearch 同义词 - 9.1
https://elasticstack.blog.csdn ... 10683
3、Simple MCP Client - 连接到 Elasticsearch MCP 并进行自然语言搜索
https://elasticstack.blog.csdn ... 10379
4、使用 n8n 和 MCP 创建 AI 代理
https://elasticstack.blog.csdn ... 30621
5、通过 A2A 协议将 Elastic Agent 连接到 Gemini Enterprise
https://elasticstack.blog.csdn ... 84944
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2129期 (2025-10-17)
https://www.51cto.com/article/827405.html
2、Elasticsearch 备份:方案篇
https://infinilabs.cn/blog/2025/es-backup-plans/
3、Elasticsearch 备份:snapshot 镜像使用篇
https://infinilabs.cn/blog/202 ... shot/
4、Easysearch 的写入流程(一):refresh
https://mp.weixin.qq.com/s/8SGHZK0_SV9m17Skbd1ymg
5、快手提出端到端生成式搜索框架 OneSearch,让搜索“一步到位”!
https://blog.csdn.net/kuaishou ... 60200
编辑:Fred
更多资讯:http://news.searchkit.cn
https://www.51cto.com/article/827405.html
2、Elasticsearch 备份:方案篇
https://infinilabs.cn/blog/2025/es-backup-plans/
3、Elasticsearch 备份:snapshot 镜像使用篇
https://infinilabs.cn/blog/202 ... shot/
4、Easysearch 的写入流程(一):refresh
https://mp.weixin.qq.com/s/8SGHZK0_SV9m17Skbd1ymg
5、快手提出端到端生成式搜索框架 OneSearch,让搜索“一步到位”!
https://blog.csdn.net/kuaishou ... 60200
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2128期 (2025-10-16)
https://mp.weixin.qq.com/s/MfGEaxVvTpS2puzUcU0cQA
2.推理速度 10 倍提升,蚂蚁集团开源业内首个高性能扩散语言模型推理框架 dInfer
https://mp.weixin.qq.com/s/B9ZE0uJb3CmeNLRbj41dgA
3.智能体设计模式:Agentic Design Patterns 中文版电子书分享
https://mp.weixin.qq.com/s/ayWxq_2IYNwMPk3NeXIcyA
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/MfGEaxVvTpS2puzUcU0cQA
2.推理速度 10 倍提升,蚂蚁集团开源业内首个高性能扩散语言模型推理框架 dInfer
https://mp.weixin.qq.com/s/B9ZE0uJb3CmeNLRbj41dgA
3.智能体设计模式:Agentic Design Patterns 中文版电子书分享
https://mp.weixin.qq.com/s/ayWxq_2IYNwMPk3NeXIcyA
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »

