

【搜索客社区日报】第2118期 (2025-09-19)
https://mp.weixin.qq.com/s/suapJUsZHRjyUB4YP839aA
2、DeepSeek 论文登上 Nature 封面,AI 大模型首次通过同行评审
https://www.oschina.net/news/372895
3、Elasticsearch — 搜索界的 “流量明星” | 搜索百科(3)
https://my.oschina.net/infinilabs/blog/18692163
4、Apache Solr — 企业级搜索的开源先锋 | 搜索百科(2)
https://my.oschina.net/infinilabs/blog/18691887
5、Easysearch 国产替代 Elasticsearch:8 大核心问题解读
https://mp.weixin.qq.com/s/Tt1yQjMZX2ctqsLpC2qqUQ
编辑:Fred
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/suapJUsZHRjyUB4YP839aA
2、DeepSeek 论文登上 Nature 封面,AI 大模型首次通过同行评审
https://www.oschina.net/news/372895
3、Elasticsearch — 搜索界的 “流量明星” | 搜索百科(3)
https://my.oschina.net/infinilabs/blog/18692163
4、Apache Solr — 企业级搜索的开源先锋 | 搜索百科(2)
https://my.oschina.net/infinilabs/blog/18691887
5、Easysearch 国产替代 Elasticsearch:8 大核心问题解读
https://mp.weixin.qq.com/s/Tt1yQjMZX2ctqsLpC2qqUQ
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2117期 (2025-09-18)
https://mp.weixin.qq.com/s/ccOO0cbEaRUBCa2AXI5H3Q
2.构建一个基于事件驱动代理和 Knative 的韧性 AI 分诊系统
https://mp.weixin.qq.com/s/SVZqs9iK7RvKbvbFHxY-fA
3.新鲜出炉 vLLM Office Hours #32 的核心内容
https://mp.weixin.qq.com/s/JWZFtYA3mNwszdxzbna3yg
4.大会日程公布!PyCon China 2025
https://mp.weixin.qq.com/s/tOFRr5a6IWChhjSdNy3Huw
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/ccOO0cbEaRUBCa2AXI5H3Q
2.构建一个基于事件驱动代理和 Knative 的韧性 AI 分诊系统
https://mp.weixin.qq.com/s/SVZqs9iK7RvKbvbFHxY-fA
3.新鲜出炉 vLLM Office Hours #32 的核心内容
https://mp.weixin.qq.com/s/JWZFtYA3mNwszdxzbna3yg
4.大会日程公布!PyCon China 2025
https://mp.weixin.qq.com/s/tOFRr5a6IWChhjSdNy3Huw
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
Easysearch 国产替代 Elasticsearch:8 大核心问题解读
近年来,随着数据安全与自主可控需求的不断提升,越来越多的企业开始关注国产化的搜索与日志分析解决方案。作为极限科技推出的国产 Elasticsearch 替代产品,Easysearch 凭借其对搜索场景的深入优化、轻量级架构设计以及对 ES 生态的高度兼容,成为众多企业替代 Elasticsearch 的新选择。

我们在近期与用户的交流中,整理出了大家最关心的八大问题,并将它们浓缩为一篇技术解读,希望帮助你快速了解 Easysearch 的优势与定位。
用户最关心的八大问题
- Easysearch 对数据量的支撑能力如何,能应对 PB 级数据存储吗?
答:完全可以。Easysearch 支持水平扩展,通过增加节点即可线性提升存储与计算能力。在实际应用中,已成功支撑 PB 级日志与检索数据。同时,其存储压缩率相比 Elasticsearch 7.10.2 平均高出 2.5~3 倍,显著节省硬件成本。
- 在高并发写入场景下,Easysearch 和 ES 的性能差异有多大?
答:在相同硬件配置下,使用 Nginx 日志进行 bulk 写入压测,Easysearch 在多种分片配置下的写入性能相比 Elasticsearch 7.10.2 提升 40%-70%,更适合高并发写入场景。
- 是否支持中文分词?需要额外插件吗?
答:中文分词一直是 Elasticsearch 用户的「必装插件」。而在 Easysearch 中,中文分词是开箱即用的,同时支持 ik、pinyin 等主流分词器,还能自定义词典,方便电商、内容平台等场景。
- 从 ES 迁移到 Easysearch 是否复杂?会影响业务吗?
答:迁移往往是国产替代的最大顾虑。为此,Easysearch 提供了 极限网关 工具,支持全量同步和实时增量同步。迁移过程中业务可继续读写,只需短暂切换连接地址,几乎无感知。
- 监控与运维工具是否完善?是否支持 Kibana?
答:Easysearch 提供完整的监控与运维体系。从 Easysearch 1.15.x 版本起自带 Web UI 管理控制台(类似简化版 Kibana),支持索引管理、查询调试、权限控制等功能。同时还提供 INFINI Console 实现多集群管理与深度监控等。也可以通过配置让 Kibana 连接 Easysearch(部分高级功能可能受限)。
- 小型团队技术能力有限,用 Easysearch 运维难度高吗?
答:Easysearch 的一大设计理念就是降低运维门槛。Easysearch 提供一键部署脚本,减少手动配置参数,支持自动分片均衡与故障节点恢复,无需专职运维人员也能稳定运行,非常适合技术资源有限的团队。
- Easysearch 是否支持数据备份与恢复?操作复杂吗?
答:支持快照(Snapshot),可备份到本地磁盘或对象存储(S3、OSS 等)。恢复时仅需执行快照恢复命令,满足企业级数据安全需求。
- 对比 ES,Easysearch 在使用体验上最大的不同是什么?
答:Easysearch 保持与 Elasticsearch 类似的接口与查询 DSL,用户几乎无学习成本即可上手。同时,它针对国产化环境和搜索场景做了优化,运维更轻量,成本更可控。
结语:Easysearch,国产化搜索的新选择
作为一款国产自主可控的搜索与日志分析引擎,Easysearch 不仅继承了 Elasticsearch 的核心能力,更在性能、易用性、资源效率和中文支持等方面进行了深度优化。对于希望实现国产化替代、降低运维成本、提升系统性能的企业来说,Easysearch 是一个值得认真考虑的新选择。

如果你正在评估 Elasticsearch 的替代方案,不妨从 Easysearch 开始,体验更轻量、更高效的搜索新架构。
如需了解更多技术细节与使用案例,欢迎访问官方文档与社区资源:
- Easysearch 官网文档
- Elasticsearch VS Easysearch 性能测试
- 使用 Easysearch,日志存储少一半
- Kibana OSS 7.10.2 连接 Easysearch
- 自建 ES 集群通过极限网关无缝迁移到云上
- INFINI Console 一站式的数据搜索分析与管理平台

近年来,随着数据安全与自主可控需求的不断提升,越来越多的企业开始关注国产化的搜索与日志分析解决方案。作为极限科技推出的国产 Elasticsearch 替代产品,Easysearch 凭借其对搜索场景的深入优化、轻量级架构设计以及对 ES 生态的高度兼容,成为众多企业替代 Elasticsearch 的新选择。
我们在近期与用户的交流中,整理出了大家最关心的八大问题,并将它们浓缩为一篇技术解读,希望帮助你快速了解 Easysearch 的优势与定位。
用户最关心的八大问题
- Easysearch 对数据量的支撑能力如何,能应对 PB 级数据存储吗?
答:完全可以。Easysearch 支持水平扩展,通过增加节点即可线性提升存储与计算能力。在实际应用中,已成功支撑 PB 级日志与检索数据。同时,其存储压缩率相比 Elasticsearch 7.10.2 平均高出 2.5~3 倍,显著节省硬件成本。
- 在高并发写入场景下,Easysearch 和 ES 的性能差异有多大?
答:在相同硬件配置下,使用 Nginx 日志进行 bulk 写入压测,Easysearch 在多种分片配置下的写入性能相比 Elasticsearch 7.10.2 提升 40%-70%,更适合高并发写入场景。
- 是否支持中文分词?需要额外插件吗?
答:中文分词一直是 Elasticsearch 用户的「必装插件」。而在 Easysearch 中,中文分词是开箱即用的,同时支持 ik、pinyin 等主流分词器,还能自定义词典,方便电商、内容平台等场景。
- 从 ES 迁移到 Easysearch 是否复杂?会影响业务吗?
答:迁移往往是国产替代的最大顾虑。为此,Easysearch 提供了 极限网关 工具,支持全量同步和实时增量同步。迁移过程中业务可继续读写,只需短暂切换连接地址,几乎无感知。
- 监控与运维工具是否完善?是否支持 Kibana?
答:Easysearch 提供完整的监控与运维体系。从 Easysearch 1.15.x 版本起自带 Web UI 管理控制台(类似简化版 Kibana),支持索引管理、查询调试、权限控制等功能。同时还提供 INFINI Console 实现多集群管理与深度监控等。也可以通过配置让 Kibana 连接 Easysearch(部分高级功能可能受限)。
- 小型团队技术能力有限,用 Easysearch 运维难度高吗?
答:Easysearch 的一大设计理念就是降低运维门槛。Easysearch 提供一键部署脚本,减少手动配置参数,支持自动分片均衡与故障节点恢复,无需专职运维人员也能稳定运行,非常适合技术资源有限的团队。
- Easysearch 是否支持数据备份与恢复?操作复杂吗?
答:支持快照(Snapshot),可备份到本地磁盘或对象存储(S3、OSS 等)。恢复时仅需执行快照恢复命令,满足企业级数据安全需求。
- 对比 ES,Easysearch 在使用体验上最大的不同是什么?
答:Easysearch 保持与 Elasticsearch 类似的接口与查询 DSL,用户几乎无学习成本即可上手。同时,它针对国产化环境和搜索场景做了优化,运维更轻量,成本更可控。
结语:Easysearch,国产化搜索的新选择
作为一款国产自主可控的搜索与日志分析引擎,Easysearch 不仅继承了 Elasticsearch 的核心能力,更在性能、易用性、资源效率和中文支持等方面进行了深度优化。对于希望实现国产化替代、降低运维成本、提升系统性能的企业来说,Easysearch 是一个值得认真考虑的新选择。
如果你正在评估 Elasticsearch 的替代方案,不妨从 Easysearch 开始,体验更轻量、更高效的搜索新架构。
如需了解更多技术细节与使用案例,欢迎访问官方文档与社区资源:
- Easysearch 官网文档
- Elasticsearch VS Easysearch 性能测试
- 使用 Easysearch,日志存储少一半
- Kibana OSS 7.10.2 连接 Easysearch
- 自建 ES 集群通过极限网关无缝迁移到云上
- INFINI Console 一站式的数据搜索分析与管理平台
搜索百科(3):Elasticsearch — 搜索界的“流量明星”
大家好,我是 INFINI Labs 的石阳。
欢迎关注 《搜索百科》 专栏!每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
前两篇我们探讨了搜索技术的基石 Apache Lucene 和企业级搜索解决方案 Apache Solr。今天,我们来聊聊一个真正改变搜索游戏规则,但也充满争议的产品 — Elasticsearch。

引言
如果说 Lucene 是幕后英雄,那么 Elasticsearch 就是舞台中央的明星。借助 REST API、分布式架构、强大的生态系统,它让搜索 + 分析成为“马上可用”的服务形式。
在日志平台、可观察性、安全监控、AI 与语义检索等领域,Elasticsearch 的名字几乎成了默认选项。
Elasticsearch 概述
Elasticsearch 是一个开源的分布式搜索和分析引擎,构建于 Apache Lucene 之上。作为一个检索平台,它可以实时存储结构化、非结构化和向量数据,提供快速的混合和向量搜索,支持可观测性与安全分析,并以高性能、高准确性和高相关性实现 AI 驱动的应用。
- 首次发布:2010 年 2 月
- 最新版本:9.1.3(截止 2025 年 9 月)
- 核心依赖:Apache Lucene
- 开源协议:AGPL v3
- 官方网址:https://www.elastic.co/elasticsearch/
- GitHub 仓库:https://github.com/elastic/elasticsearch
起源:从食谱搜索到全球“流量明星”
Elasticsearch 的故事始于以色列开发者 Shay Banon。2010 年,当时他在学习厨师课程的妻子需要一款能够快速搜索食谱的工具。虽然当时已经有 Solr 这样的搜索解决方案,但 Shay 认为它们对于分布式场景的支持不够完善。

基于之前开发 Compass(一个基于 Lucene 的搜索库)的经验,Shay 开始构建一个完全分布式的、基于 JSON 的搜索引擎。2010 年 2 月,Elasticsearch 的第一个版本发布。
随着用户日益增多、企业级需求增强,Shay 在 2012 年创立了 Elastic 公司,把 Elasticsearch 不仅作为开源项目,也逐渐商业化运营起来,包括提供托管服务、企业支持,加入 Logstash 日志处理、Kibana 可视化工具等,Elastic 公司也逐渐从一个纯搜索引擎项目演变为一个更广泛的“数据搜索与分析”平台。
协议变更:开源和商业化的博弈
Elasticsearch 的发展并非一帆风顺。其历史上最具转折性的事件当属与 AWS 的冲突及随之而来的开源协议变更。

- 早期:Apache 2.0 协议
2010 年 Shay Banon 开源 Elasticsearch 时,最初采用的是 Apache 2.0 协议。Apache 2.0 属于宽松的自由协议,允许任何人免费使用、修改和商用(包括 SaaS 模式)。这帮助 Elasticsearch 快速壮大,成为事实上的“搜索引擎标准”。
- 协议变更:应对云厂商“白嫖”
随着 Elasticsearch 的流行,像 AWS(Amazon Web Services) 等云厂商直接将 Elasticsearch 做成托管服务,并从中获利。Elastic 公司认为这损害了他们的商业利益,因为云厂商“用开源赚钱,却没有回馈社区”。2021 年 1 月,Elastic 宣布 Elasticsearch 和 Kibana 不再采用 Apache 2.0,改为 双重协议:SSPL + Elastic License。这一步导致社区巨大分裂,AWS 带头将 Elasticsearch 分叉为 OpenSearch,并继续以 Apache 2.0 协议维护。
- 再次转向开源:AGPL v3
2024 年 3 月,Elastic 宣布新的版本(Elasticsearch 8.13 起)又新增 AGPL v3 作为一个开源许可选项。AGPL v3 既符合 OSI 真正开源标准,又能约束云厂商闭源托管服务,同时修复社区关系,Elastic 希望通过重新拥抱开源,减少分裂,吸引开发者回归。
Elasticsearch 从宽松到收紧,再到回归开源,是在社区生态与商业利益间寻找平衡的过程。
基本概念
要学习 Elasticsearch,得先了解其五大基本概览:集群、节点、分片、索引和文档。
- 集群(Cluster)
由一个或多个节点组成的整体,提供统一的搜索与存储服务。对外看起来像一个单一系统。
- 节点(Node)
集群中的一台服务器实例。节点有不同角色:
- Master 节点:负责集群管理(分片分配、元数据维护)。
- Data 节点:存储数据、处理搜索和聚合。
- Coordinating 节点:接收请求并调度任务。
- Ingest 节点:负责数据写入前的预处理。
- 索引(Index)
类似于传统数据库的“库”,按逻辑组织数据。一个索引往往对应一个业务场景(如日志、商品信息)。
- 分片(Shard)
为了让索引能水平扩展,Elasticsearch 会把索引拆分为多个 主分片,并为每个主分片创建 副本分片,提升高可用和查询性能。
- 文档(Document)
Elasticsearch 存储和检索的最小数据单元,通常是 JSON 格式。多个文档组成一个索引。
集群架构
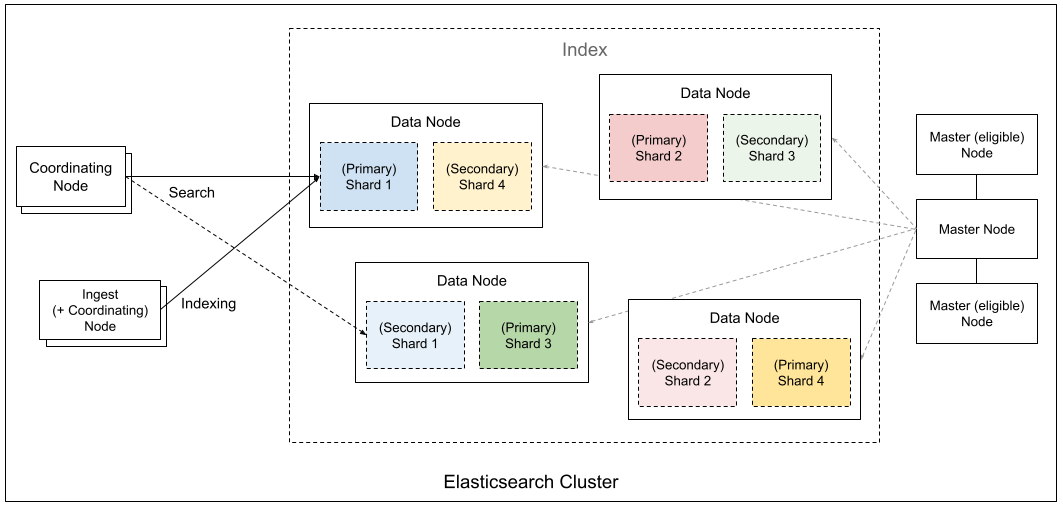
Elasticsearch 通过 Master、Data、Coordinating、Ingest 等不同角色节点的协作,将数据切分成分片并分布式存储,实现了高可用、可扩展的搜索与分析引擎架构。
快速开始:5 分钟体验 Elasticsearch
1. 使用 Docker 启动
# 拉取最新镜像
docker pull docker.elastic.co/elasticsearch/elasticsearch:9.1.3
# 启动单节点集群
docker run -d --name elasticsearch \
-p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e "xpack.security.enabled=false" \
docker.elastic.co/elasticsearch/elasticsearch:9.1.32. 验证安装
# 检查集群状态
curl -X GET "http://localhost:9200/"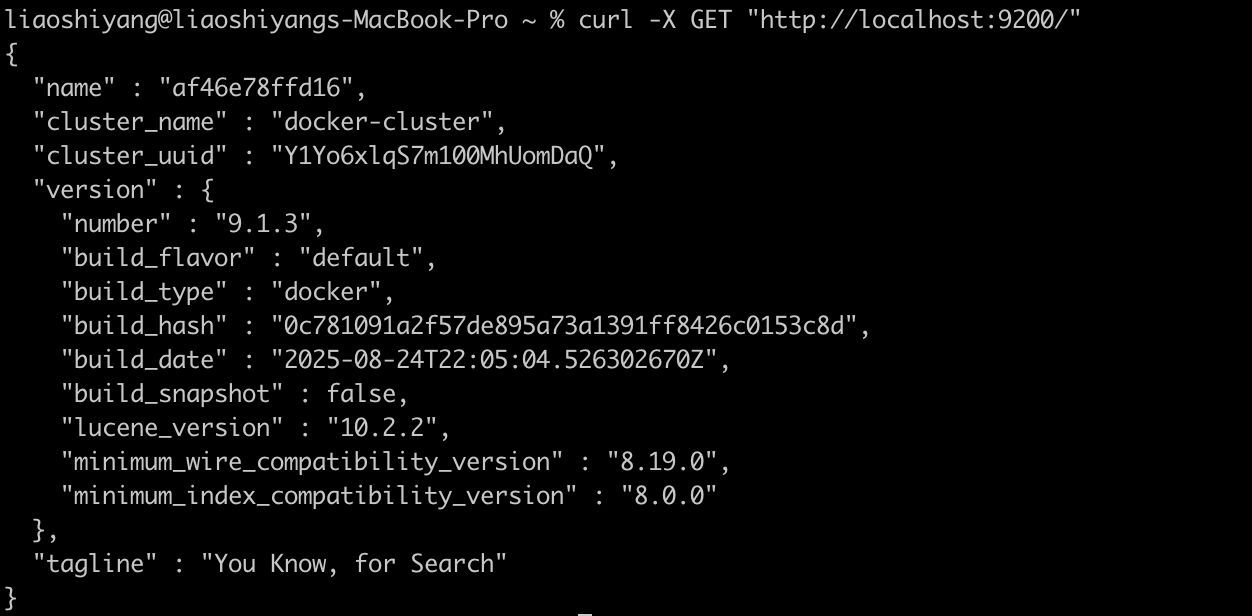
3. 索引文档
# 索引文档
curl -X POST "http://localhost:9200/myindex/_doc" -H 'Content-Type: application/json' -d'
{
"title": "Hello Elasticsearch",
"description": "An example document"
}'
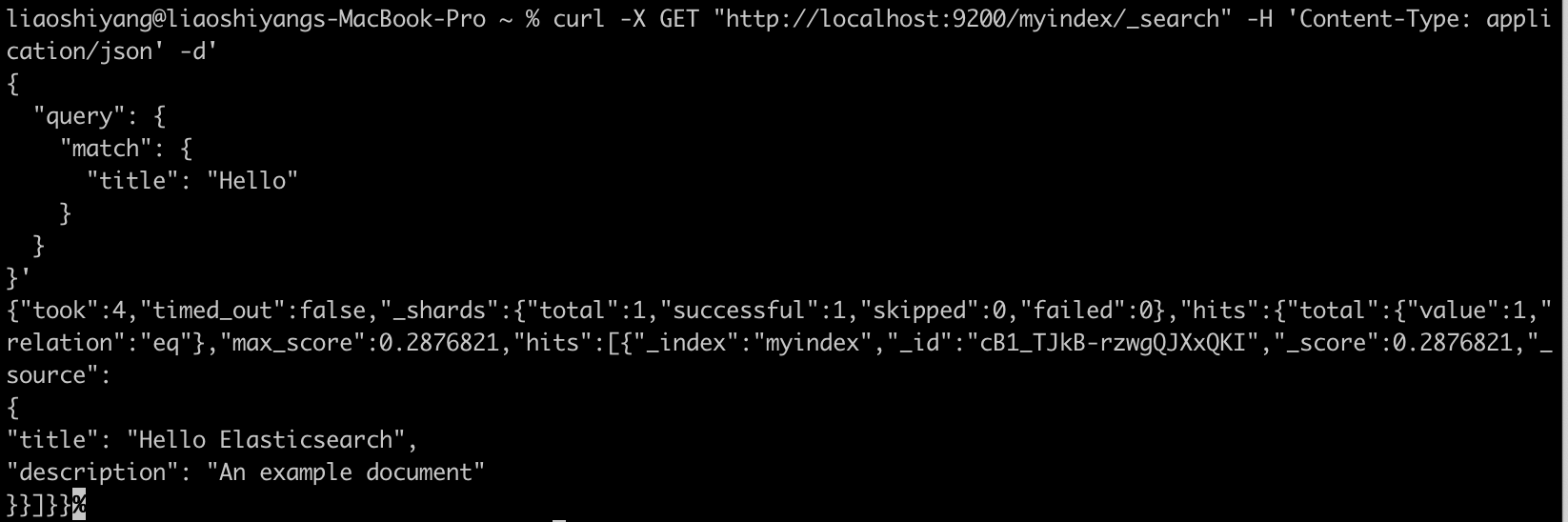
3. 搜索文档
# 搜索文档
curl -X GET "http://localhost:9200/myindex/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"title": "Hello"
}
}
}'
结语
Elasticsearch 是搜索与分析领域标杆性的产品。它将 Lucene 的能力包装起来,加上分布式、易用以及与数据可视化、安全监控等功能的整合,使搜索引擎从专业技术逐渐变为“随手可用”的基础设施。
虽然协议变动、与 OpenSearch 的分叉引发争议,但它在企业与开发者群体中的实际应用价值依然难以替代。
🚀 下期预告
下一篇我们将介绍 OpenSearch,探讨这个 Elasticsearch 分支项目的发展现状、技术特点以及与 Elasticsearch 的详细对比。如果您有特别关注的问题,欢迎提前提出!
💬 三连互动
- 你或公司最近在用 Elasticsearch 吗?拿来做了什么场景?
- 在 Elasticsearch 和 OpenSearch 之间做过技术选型?
- 对 Elasticsearch 的许可证变化有什么看法?
对搜索技术感兴趣的朋友,也欢迎加我微信(ID:lsy965145175)备注“搜索百科”,拉你进 搜索技术交流群,一起探讨与学习!
✨ 推荐阅读
🔗 参考
原文:https://infinilabs.cn/blog/2025/search-wiki-3-elasticsearch/
大家好,我是 INFINI Labs 的石阳。
欢迎关注 《搜索百科》 专栏!每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
前两篇我们探讨了搜索技术的基石 Apache Lucene 和企业级搜索解决方案 Apache Solr。今天,我们来聊聊一个真正改变搜索游戏规则,但也充满争议的产品 — Elasticsearch。
引言
如果说 Lucene 是幕后英雄,那么 Elasticsearch 就是舞台中央的明星。借助 REST API、分布式架构、强大的生态系统,它让搜索 + 分析成为“马上可用”的服务形式。
在日志平台、可观察性、安全监控、AI 与语义检索等领域,Elasticsearch 的名字几乎成了默认选项。
Elasticsearch 概述
Elasticsearch 是一个开源的分布式搜索和分析引擎,构建于 Apache Lucene 之上。作为一个检索平台,它可以实时存储结构化、非结构化和向量数据,提供快速的混合和向量搜索,支持可观测性与安全分析,并以高性能、高准确性和高相关性实现 AI 驱动的应用。
- 首次发布:2010 年 2 月
- 最新版本:9.1.3(截止 2025 年 9 月)
- 核心依赖:Apache Lucene
- 开源协议:AGPL v3
- 官方网址:https://www.elastic.co/elasticsearch/
- GitHub 仓库:https://github.com/elastic/elasticsearch
起源:从食谱搜索到全球“流量明星”
Elasticsearch 的故事始于以色列开发者 Shay Banon。2010 年,当时他在学习厨师课程的妻子需要一款能够快速搜索食谱的工具。虽然当时已经有 Solr 这样的搜索解决方案,但 Shay 认为它们对于分布式场景的支持不够完善。
基于之前开发 Compass(一个基于 Lucene 的搜索库)的经验,Shay 开始构建一个完全分布式的、基于 JSON 的搜索引擎。2010 年 2 月,Elasticsearch 的第一个版本发布。
随着用户日益增多、企业级需求增强,Shay 在 2012 年创立了 Elastic 公司,把 Elasticsearch 不仅作为开源项目,也逐渐商业化运营起来,包括提供托管服务、企业支持,加入 Logstash 日志处理、Kibana 可视化工具等,Elastic 公司也逐渐从一个纯搜索引擎项目演变为一个更广泛的“数据搜索与分析”平台。
协议变更:开源和商业化的博弈
Elasticsearch 的发展并非一帆风顺。其历史上最具转折性的事件当属与 AWS 的冲突及随之而来的开源协议变更。
- 早期:Apache 2.0 协议
2010 年 Shay Banon 开源 Elasticsearch 时,最初采用的是 Apache 2.0 协议。Apache 2.0 属于宽松的自由协议,允许任何人免费使用、修改和商用(包括 SaaS 模式)。这帮助 Elasticsearch 快速壮大,成为事实上的“搜索引擎标准”。
- 协议变更:应对云厂商“白嫖”
随着 Elasticsearch 的流行,像 AWS(Amazon Web Services) 等云厂商直接将 Elasticsearch 做成托管服务,并从中获利。Elastic 公司认为这损害了他们的商业利益,因为云厂商“用开源赚钱,却没有回馈社区”。2021 年 1 月,Elastic 宣布 Elasticsearch 和 Kibana 不再采用 Apache 2.0,改为 双重协议:SSPL + Elastic License。这一步导致社区巨大分裂,AWS 带头将 Elasticsearch 分叉为 OpenSearch,并继续以 Apache 2.0 协议维护。
- 再次转向开源:AGPL v3
2024 年 3 月,Elastic 宣布新的版本(Elasticsearch 8.13 起)又新增 AGPL v3 作为一个开源许可选项。AGPL v3 既符合 OSI 真正开源标准,又能约束云厂商闭源托管服务,同时修复社区关系,Elastic 希望通过重新拥抱开源,减少分裂,吸引开发者回归。
Elasticsearch 从宽松到收紧,再到回归开源,是在社区生态与商业利益间寻找平衡的过程。
基本概念
要学习 Elasticsearch,得先了解其五大基本概览:集群、节点、分片、索引和文档。
- 集群(Cluster)
由一个或多个节点组成的整体,提供统一的搜索与存储服务。对外看起来像一个单一系统。
- 节点(Node)
集群中的一台服务器实例。节点有不同角色:
- Master 节点:负责集群管理(分片分配、元数据维护)。
- Data 节点:存储数据、处理搜索和聚合。
- Coordinating 节点:接收请求并调度任务。
- Ingest 节点:负责数据写入前的预处理。
- 索引(Index)
类似于传统数据库的“库”,按逻辑组织数据。一个索引往往对应一个业务场景(如日志、商品信息)。
- 分片(Shard)
为了让索引能水平扩展,Elasticsearch 会把索引拆分为多个 主分片,并为每个主分片创建 副本分片,提升高可用和查询性能。
- 文档(Document)
Elasticsearch 存储和检索的最小数据单元,通常是 JSON 格式。多个文档组成一个索引。
集群架构
Elasticsearch 通过 Master、Data、Coordinating、Ingest 等不同角色节点的协作,将数据切分成分片并分布式存储,实现了高可用、可扩展的搜索与分析引擎架构。
快速开始:5 分钟体验 Elasticsearch
1. 使用 Docker 启动
# 拉取最新镜像
docker pull docker.elastic.co/elasticsearch/elasticsearch:9.1.3
# 启动单节点集群
docker run -d --name elasticsearch \
-p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e "xpack.security.enabled=false" \
docker.elastic.co/elasticsearch/elasticsearch:9.1.32. 验证安装
# 检查集群状态
curl -X GET "http://localhost:9200/"
3. 索引文档
# 索引文档
curl -X POST "http://localhost:9200/myindex/_doc" -H 'Content-Type: application/json' -d'
{
"title": "Hello Elasticsearch",
"description": "An example document"
}'
3. 搜索文档
# 搜索文档
curl -X GET "http://localhost:9200/myindex/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"title": "Hello"
}
}
}'
结语
Elasticsearch 是搜索与分析领域标杆性的产品。它将 Lucene 的能力包装起来,加上分布式、易用以及与数据可视化、安全监控等功能的整合,使搜索引擎从专业技术逐渐变为“随手可用”的基础设施。
虽然协议变动、与 OpenSearch 的分叉引发争议,但它在企业与开发者群体中的实际应用价值依然难以替代。
🚀 下期预告
下一篇我们将介绍 OpenSearch,探讨这个 Elasticsearch 分支项目的发展现状、技术特点以及与 Elasticsearch 的详细对比。如果您有特别关注的问题,欢迎提前提出!
💬 三连互动
- 你或公司最近在用 Elasticsearch 吗?拿来做了什么场景?
- 在 Elasticsearch 和 OpenSearch 之间做过技术选型?
- 对 Elasticsearch 的许可证变化有什么看法?
对搜索技术感兴趣的朋友,也欢迎加我微信(ID:lsy965145175)备注“搜索百科”,拉你进 搜索技术交流群,一起探讨与学习!
✨ 推荐阅读
🔗 参考
收起阅读 »原文:https://infinilabs.cn/blog/2025/search-wiki-3-elasticsearch/
【搜索客社区日报】第2116期 (2025-09-16)
https://medium.com/%40chaoskis ... 3fc93
2. Debian里的全家桶一把梭,服务器初始化不就会了吗(需要梯子)
https://medium.com/%40yossifhe ... b9cdf
3. 向量搜索怎么搞?教你个简单的玩法(需要梯子)
https://surenk.medium.com/vect ... 3a8b0
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://medium.com/%40chaoskis ... 3fc93
2. Debian里的全家桶一把梭,服务器初始化不就会了吗(需要梯子)
https://medium.com/%40yossifhe ... b9cdf
3. 向量搜索怎么搞?教你个简单的玩法(需要梯子)
https://surenk.medium.com/vect ... 3a8b0
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
搜索百科(2):Apache Solr — 企业级搜索的开源先锋
大家好,我是 INFINI Labs 的石阳。
欢迎回到 《搜索百科》 专栏!每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
上一篇我们认识了搜索技术的基石 Apache Lucene,今天我们将继续这个旅程,了解基于 Lucene 构建的第一个成功商业级搜索平台 —— Apache Solr。

Solr 是什么?
Solr 是一款极速的开源多模态搜索平台,基于 Apache Lucene 的全文、向量和地理空间搜索能力构建而成。Solr 具备高可靠性、可扩展性和容错性,支持分布式索引、复制与负载均衡查询,提供自动故障转移与恢复、集中化配置等功能。如今,Solr 为全球众多大型互联网网站提供搜索和导航功能。
- 首次发布:2004 年,2006 年进入 Apache
- 最新版本:截至 2025 年,已更新至 9.x 系列
- 核心依赖:Apache Lucene
- 开源协议:Apache License 2.0
- 官方网址:https://solr.apache.org
- GitHub 仓库:https://github.com/apache/solr
它的定位是:把 Lucene 打造成独立的企业级搜索服务。相比 Lucene 需要写代码调用,Solr 提供了 Web 管理界面、REST API 和配置文件,让开发者更容易上手。
起源:从网站搜索到 Apache 顶级项目
Solr(读作"solar")的故事始于 2004 年,当时 CNET 公司的开发人员 Yonik Seeley 需要为其新闻网站构建一个搜索功能。虽然 Lucene 提供了强大的核心搜索能力,但直接使用 Lucene 需要编写大量 Java 代码,缺乏开箱即用的功能。
Seeley 决定在 Lucene 之上构建一个更易用的搜索服务器,于是 Solr 诞生了。最初的目标很明确:通过 HTTP/XML 接口提供搜索服务,让任何编程语言都能轻松集成搜索功能。
2006 年,Solr 捐赠给 Apache 基金会,2007 年成为顶级项目。2010 年,Solr 与 Lucene 项目合并,形成了今天我们所知的 Apache Lucene/Solr 项目。
技术架构
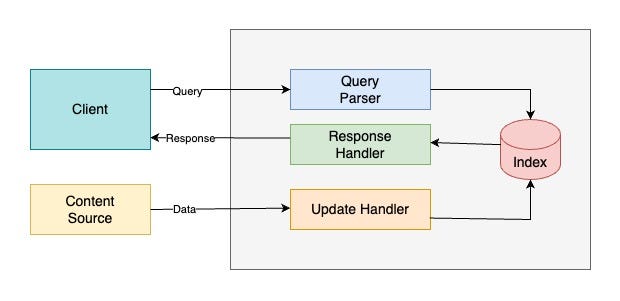
Index(索引)
Apache Solr 的索引就像是用于管理结构化 / 非结构化数据的“数据库”。它以便于分析和全文检索的方式存储数据。
Query Parser(查询解析器)
所有由客户端提交的查询都会由查询解析器处理。
Response Handler(响应处理器)
响应处理器负责为客户端生成合适格式的响应(如 JSON/XML/CSV)。
Update Handler(更新处理器)
更新处理器用于索引操作,即对索引中的数据进行插入、更新和删除。例如,如果我们希望 MySQL 数据与 Apache Solr 保持同步,就需要创建一个负责同步的更新处理器。
功能亮点
- 全文检索:高效支持关键词搜索、布尔查询、短语匹配等。
- 分面搜索(Faceted Search):可以对搜索结果进行分类和聚合统计。
- 分布式架构(SolrCloud):支持集群部署、自动分片、副本和容错。
- 丰富的数据接口:提供 RESTful API,支持 JSON、XML、CSV 等多种格式的数据交互。
- 扩展性与可定制性:通过插件机制支持多语言分词、排序、评分模型等个性化定制。
- 地理位置搜索:内置空间搜索能力,支持基于经纬度的范围查询和排序。
对比: Solr vs Elasticsearch 如何选择?
虽然两者都基于 Lucene,但在设计哲学上有所不同:
| 特性 | Apache Solr | Elasticsearch |
|---|---|---|
| 定位 | 企业级搜索服务器 | 分布式搜索和分析引擎 |
| API | 更标准化,遵循传统 REST | 更灵活,JSON 原生 |
| 分布式 | 需要 ZooKeeper 协调 | 内置分布式协调 |
| 上手难度 | 相对简单,开箱即用 | 学习曲线较陡峭 |
| 生态系统 | 搜索功能更丰富 | 分析和可视化更强 |
| 适用场景 | 传统企业搜索、电商 | 日志分析、实时监控 |
简单来说:Solr 更像"精装房",开箱即用;Elasticsearch 更像"毛坯房",需要更多自定义但更灵活。
快速开始:5 分钟搭建 Solr 服务
1. 下载和安装
# 下载 8.x 版 Solr
wget https://dlcdn.apache.org/solr/solr/8.11.4/solr-8.11.4.tgz
# 解压
tar -xzf solr-8.11.4.tgz
# 启动 Solr(单机模式)
cd solr-8.11.4
bin/solr start2. 创建 Core
# 创建测试 Core
bin/solr create -c test_core
# 查看 Core 状态
bin/solr status3. 索引文档
# 使用 curl 索引 JSON 文档
curl http://localhost:8983/solr/test_core/update -d '
[
{"id": "1", "title": "Solr 入门指南", "content": "Apache Solr 是企业级搜索平台"},
{"id": "2", "title": "搜索技术演进", "content": "从 Lucene 到 Solr 的技术发展"}
]' -H 'Content-type:application/json'
# 提交更改
curl http://localhost:8983/solr/test_core/update -d '<commit/>' -H 'Content-type:application/xml'4. 执行搜索
# 搜索"Solr"
curl "http://localhost:8983/solr/test_core/select?q=content:Solr"
# 使用 JSON 格式返回
curl "http://localhost:8983/solr/test_core/select?q=content:Solr&wt=json"执行搜索返回结果:
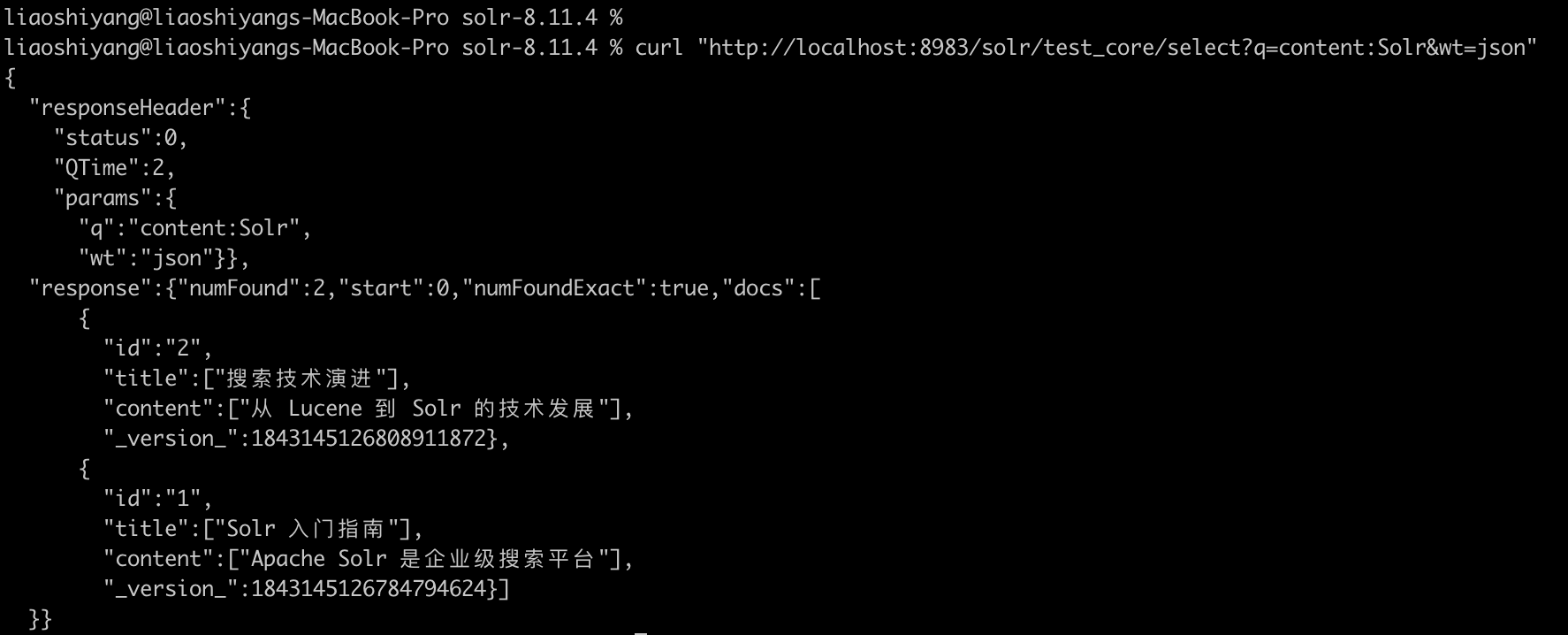
访问 http://localhost:8983/solr 即可使用 Solr 的管理界面。
Dashboard:
Core Admin:
结语
从最初的公司内部工具,到成为全球范围内广泛使用的开源搜索引擎,Apache Solr 见证并推动了搜索技术的进化。尽管近年来 Elasticsearch、向量数据库和 AI 驱动的搜索技术逐渐崛起,但 Solr 依然是许多企业可靠且成熟的选择。它的故事不仅属于开源社区,也代表了搜索技术发展的一个重要阶段。
🚀 下期预告
在下一篇「搜索百科」中,我们将介绍它的明星兄弟 —— Elasticsearch。
💬 三连互动
- 你现在还在用 Solr 吗?
- 在 Solr 和 Elasticsearch 之间做过技术选型?
- 遇到过有趣的 Solr 使用案例或挑战?
对搜索技术感兴趣的朋友,也欢迎加我微信(ID:lsy965145175)备注“搜索百科”,拉你进 搜索技术交流群,一起探讨与学习!
✨ 推荐阅读
🔗 参考
大家好,我是 INFINI Labs 的石阳。
欢迎回到 《搜索百科》 专栏!每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
上一篇我们认识了搜索技术的基石 Apache Lucene,今天我们将继续这个旅程,了解基于 Lucene 构建的第一个成功商业级搜索平台 —— Apache Solr。
Solr 是什么?
Solr 是一款极速的开源多模态搜索平台,基于 Apache Lucene 的全文、向量和地理空间搜索能力构建而成。Solr 具备高可靠性、可扩展性和容错性,支持分布式索引、复制与负载均衡查询,提供自动故障转移与恢复、集中化配置等功能。如今,Solr 为全球众多大型互联网网站提供搜索和导航功能。
- 首次发布:2004 年,2006 年进入 Apache
- 最新版本:截至 2025 年,已更新至 9.x 系列
- 核心依赖:Apache Lucene
- 开源协议:Apache License 2.0
- 官方网址:https://solr.apache.org
- GitHub 仓库:https://github.com/apache/solr
它的定位是:把 Lucene 打造成独立的企业级搜索服务。相比 Lucene 需要写代码调用,Solr 提供了 Web 管理界面、REST API 和配置文件,让开发者更容易上手。
起源:从网站搜索到 Apache 顶级项目
Solr(读作"solar")的故事始于 2004 年,当时 CNET 公司的开发人员 Yonik Seeley 需要为其新闻网站构建一个搜索功能。虽然 Lucene 提供了强大的核心搜索能力,但直接使用 Lucene 需要编写大量 Java 代码,缺乏开箱即用的功能。
Seeley 决定在 Lucene 之上构建一个更易用的搜索服务器,于是 Solr 诞生了。最初的目标很明确:通过 HTTP/XML 接口提供搜索服务,让任何编程语言都能轻松集成搜索功能。
2006 年,Solr 捐赠给 Apache 基金会,2007 年成为顶级项目。2010 年,Solr 与 Lucene 项目合并,形成了今天我们所知的 Apache Lucene/Solr 项目。
技术架构
Index(索引)
Apache Solr 的索引就像是用于管理结构化 / 非结构化数据的“数据库”。它以便于分析和全文检索的方式存储数据。
Query Parser(查询解析器)
所有由客户端提交的查询都会由查询解析器处理。
Response Handler(响应处理器)
响应处理器负责为客户端生成合适格式的响应(如 JSON/XML/CSV)。
Update Handler(更新处理器)
更新处理器用于索引操作,即对索引中的数据进行插入、更新和删除。例如,如果我们希望 MySQL 数据与 Apache Solr 保持同步,就需要创建一个负责同步的更新处理器。
功能亮点
- 全文检索:高效支持关键词搜索、布尔查询、短语匹配等。
- 分面搜索(Faceted Search):可以对搜索结果进行分类和聚合统计。
- 分布式架构(SolrCloud):支持集群部署、自动分片、副本和容错。
- 丰富的数据接口:提供 RESTful API,支持 JSON、XML、CSV 等多种格式的数据交互。
- 扩展性与可定制性:通过插件机制支持多语言分词、排序、评分模型等个性化定制。
- 地理位置搜索:内置空间搜索能力,支持基于经纬度的范围查询和排序。
对比: Solr vs Elasticsearch 如何选择?
虽然两者都基于 Lucene,但在设计哲学上有所不同:
| 特性 | Apache Solr | Elasticsearch |
|---|---|---|
| 定位 | 企业级搜索服务器 | 分布式搜索和分析引擎 |
| API | 更标准化,遵循传统 REST | 更灵活,JSON 原生 |
| 分布式 | 需要 ZooKeeper 协调 | 内置分布式协调 |
| 上手难度 | 相对简单,开箱即用 | 学习曲线较陡峭 |
| 生态系统 | 搜索功能更丰富 | 分析和可视化更强 |
| 适用场景 | 传统企业搜索、电商 | 日志分析、实时监控 |
简单来说:Solr 更像"精装房",开箱即用;Elasticsearch 更像"毛坯房",需要更多自定义但更灵活。
快速开始:5 分钟搭建 Solr 服务
1. 下载和安装
# 下载 8.x 版 Solr
wget https://dlcdn.apache.org/solr/solr/8.11.4/solr-8.11.4.tgz
# 解压
tar -xzf solr-8.11.4.tgz
# 启动 Solr(单机模式)
cd solr-8.11.4
bin/solr start2. 创建 Core
# 创建测试 Core
bin/solr create -c test_core
# 查看 Core 状态
bin/solr status3. 索引文档
# 使用 curl 索引 JSON 文档
curl http://localhost:8983/solr/test_core/update -d '
[
{"id": "1", "title": "Solr 入门指南", "content": "Apache Solr 是企业级搜索平台"},
{"id": "2", "title": "搜索技术演进", "content": "从 Lucene 到 Solr 的技术发展"}
]' -H 'Content-type:application/json'
# 提交更改
curl http://localhost:8983/solr/test_core/update -d '<commit/>' -H 'Content-type:application/xml'4. 执行搜索
# 搜索"Solr"
curl "http://localhost:8983/solr/test_core/select?q=content:Solr"
# 使用 JSON 格式返回
curl "http://localhost:8983/solr/test_core/select?q=content:Solr&wt=json"执行搜索返回结果:
访问 http://localhost:8983/solr 即可使用 Solr 的管理界面。
Dashboard:
Core Admin:
结语
从最初的公司内部工具,到成为全球范围内广泛使用的开源搜索引擎,Apache Solr 见证并推动了搜索技术的进化。尽管近年来 Elasticsearch、向量数据库和 AI 驱动的搜索技术逐渐崛起,但 Solr 依然是许多企业可靠且成熟的选择。它的故事不仅属于开源社区,也代表了搜索技术发展的一个重要阶段。
🚀 下期预告
在下一篇「搜索百科」中,我们将介绍它的明星兄弟 —— Elasticsearch。
💬 三连互动
- 你现在还在用 Solr 吗?
- 在 Solr 和 Elasticsearch 之间做过技术选型?
- 遇到过有趣的 Solr 使用案例或挑战?
对搜索技术感兴趣的朋友,也欢迎加我微信(ID:lsy965145175)备注“搜索百科”,拉你进 搜索技术交流群,一起探讨与学习!
✨ 推荐阅读
🔗 参考
收起阅读 »
【搜索客社区日报】第2115期 (2025-09-15)
https://developer.damo-academy ... 25861
2、带地图的 RAG:多模态 + 地理空间 在 Elasticsearch 中
https://elasticstack.blog.csdn ... 52848
3、使用 LangExtract 和 Elasticsearch
https://elasticstack.blog.csdn ... 07715
4、使用 OpenTelemetry 从你的日志中获取更多信息
https://elasticstack.blog.csdn ... 46828
5、Elasticsearch 索引字段删除,除了 Reindex 重建索引还有没有别的解决方案?
https://mp.weixin.qq.com/s/IJxEQc59t4kn6ex_YGmYAQ
编辑:Muse
更多资讯:http://news.searchkit.cn
https://developer.damo-academy ... 25861
2、带地图的 RAG:多模态 + 地理空间 在 Elasticsearch 中
https://elasticstack.blog.csdn ... 52848
3、使用 LangExtract 和 Elasticsearch
https://elasticstack.blog.csdn ... 07715
4、使用 OpenTelemetry 从你的日志中获取更多信息
https://elasticstack.blog.csdn ... 46828
5、Elasticsearch 索引字段删除,除了 Reindex 重建索引还有没有别的解决方案?
https://mp.weixin.qq.com/s/IJxEQc59t4kn6ex_YGmYAQ
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2114期 (2025-09-12)
https://elasticsearch.cn/article/15557
2、AI写代码,第一稿95%都没用?一名工程师的Claude Code六周实录
https://blog.csdn.net/csdnnews ... 33438
3、如何使用极限网关实现 Easysearch 数据迁移?
https://blog.csdn.net/yangmf20 ... 55265
4、你有没有想过不额外安装 Kibana,就能实现集群核心指标数据的可视化?
https://mp.weixin.qq.com/s/YQIJG8auOxslINg90MBafA
5、在 Coco AI 中接入 WordPress RSS,实现文章秒级搜索
https://blog.csdn.net/weixin_3 ... 03720
编辑:Fred
更多资讯:http://news.searchkit.cn
https://elasticsearch.cn/article/15557
2、AI写代码,第一稿95%都没用?一名工程师的Claude Code六周实录
https://blog.csdn.net/csdnnews ... 33438
3、如何使用极限网关实现 Easysearch 数据迁移?
https://blog.csdn.net/yangmf20 ... 55265
4、你有没有想过不额外安装 Kibana,就能实现集群核心指标数据的可视化?
https://mp.weixin.qq.com/s/YQIJG8auOxslINg90MBafA
5、在 Coco AI 中接入 WordPress RSS,实现文章秒级搜索
https://blog.csdn.net/weixin_3 ... 03720
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2113期 (2025-09-11)
https://blog.modelcontextproto ... view/
2.大模型推理革命:从 GPT-5 到 vLLM Semantic Router
https://mp.weixin.qq.com/s/F6pGYNhLVxyW4It9-QtklQ
3.OpenAI Codex 零基础入门指南
https://mp.weixin.qq.com/s/HHceGuE46llL-ZS9T0hiXA
4.使用 NVIDIA Dynamo 部署 PD 分离推理服务
https://mp.weixin.qq.com/s/6_oRs7p6wwL1HqnKr8yC5Q
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://blog.modelcontextproto ... view/
2.大模型推理革命:从 GPT-5 到 vLLM Semantic Router
https://mp.weixin.qq.com/s/F6pGYNhLVxyW4It9-QtklQ
3.OpenAI Codex 零基础入门指南
https://mp.weixin.qq.com/s/HHceGuE46llL-ZS9T0hiXA
4.使用 NVIDIA Dynamo 部署 PD 分离推理服务
https://mp.weixin.qq.com/s/6_oRs7p6wwL1HqnKr8yC5Q
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
搜索百科(1):Lucene —— 打开现代搜索世界的第一扇门
大家好,我是 INFINI Labs 的石阳。
这是《搜索百科》系列文章,每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
搜索技术看似专业,但它早已深度融入我们的日常生活。无论是电商搜索、知识检索,还是 AI 语义搜索、RAG、向量检索,背后都有经典与新兴技术的结合。希望这个系列能帮大家建立更清晰的认知,也欢迎留言交流。
引言:为什么先写 Lucene?

如果你曾用 GitHub 搜代码、用电商网站搜商品,或者在日志平台里“捞”报错,你就已经享受了 Lucene 的红利——只是自己还不知道。今天,让我们认识下这位“幕后大佬”,看看它如何以一己之力,孵化了整个现代搜索江湖。没有它,就没有 Elasticsearch 的锋芒,也没有 Solr 的稳健。讲搜索,不从 Lucene 开始,就像讲武侠不提《易筋经》——根基都丢了。
诞生故事:一个程序员的“副业”成果
Lucene 的诞生颇具传奇色彩。它的创造者 Doug Cutting(后来也是 Hadoop 的创始人之一)在 1997 年开始开发 Lucene,最初是为了给他的个人项目——一个网络爬虫和搜索引擎——提供搜索能力。

当时,市面上并没有成熟的开源搜索库可用,Doug 决定自己写一个。他在业余时间一点点打磨,最终在 1999 年发布了第一个版本。2001 年,Lucene 加入了 Apache 软件基金会,成为 Apache 的第一个开源搜索项目。
有趣的是,Lucene 的名字并不是来自什么技术术语,而是取自 Doug Cutting 妻子的中间名——Lucene。这也让这个项目多了一丝浪漫的色彩。
Lucene 概述
Apache Lucene,是一个用 Java 编写的高性能、全文搜索引擎库。它不是那种你下载下来就能直接用的“搜索软件”,而是一个底层库,就像乐高积木里的基础砖块,虽然不起眼,但没有它,很多搜索产品根本搭不起来。
Lucene 提供了强大的索引和查询能力,支持分词、倒排索引、相关性评分、模糊查询、布尔查询等一系列功能。它是 Elasticsearch、Solr、Easysearch、OpenSearch 等现代搜索引擎的核心引擎。
- 首次发布:1999 年
- 最新版本:截至 2025 年 9 月,Lucene 已更新至
10.2.x系列 - 开源协议:Apache License 2.0(商业友好)
- 官网:https://lucene.apache.org/
- GitHub:https://github.com/apache/lucene
社区生态
虽然已经 25 岁"高龄",Lucene 的社区却依然活力满满。作为 Apache 软件基金会的顶级项目,它拥有:
- 100+ 活跃贡献者
- 每月都有新的 commit 和 issue 处理
- 每年发布 2-4 个主要版本
- 完善的文档和活跃的邮件列表
虽然不像 Elasticsearch 那样“出圈”,但在开发者和企业内部系统中仍有广泛使用。
功能亮点:为什么大家都爱它?
- 高性能全文检索内核:倒排索引、短语/布尔/通配符/模糊查询、相关性打分。
- 面向工程的可扩展分析链:分词器、过滤器、同义词、停用词、高亮、排序等。
- 近邻向量检索(KNN):原生支持高维向量的最近邻搜索,为语义检索/RAG 奠基。 
- 嵌入式 & 纯 Java:作为库嵌入任意 Java 应用,掌控细粒度行为与性能。
- 成熟稳定的版本线:9.x 与 10.x 并行演进,兼顾稳定与新特性。
对比优势:Lucene vs 世界
| 产品 | 类型 | 与 Lucene 的关系 |
|---|---|---|
| Elasticsearch | 分布式引擎 | 基于 Lucene,提供分布式、RESTful 接口 |
| Apache Solr | 搜索平台 | 基于 Lucene,提供 Web 管理界面和更多功能 |
| Meilisearch | 轻量引擎 | 不基于 Lucene,用 Rust 编写,主打易用性 |
Lucene 是底层引擎,而其他产品是在它之上构建的完整解决方案。如果你想要完全控制搜索逻辑,Lucene 是最佳选择;如果你想要开箱即用的搜索服务,可以考虑 Elasticsearch 或 Solr。
快速上手:10 分钟体验 Lucene
虽然 Lucene 需要写一些 Java 代码,但其实入门并不复杂。
1. 环境准备
// Maven 依赖
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>10.xx.xx</version>
</dependency>2. 创建你的第一个索引
// 创建分析器(支持中文)
Analyzer analyzer = new StandardAnalyzer();
// 创建索引
Directory directory = FSDirectory.open(Paths.get("index"));
IndexWriterConfig config = new IndexWriterConfig(analyzer);
IndexWriter writer = new IndexWriter(directory, config);
Document doc = new Document();
doc.add(new TextField("content", "欢迎来到 Lucene 的世界", Field.Store.YES));
writer.addDocument(doc);
writer.close();3. 执行搜索
// 搜索 "Lucene"
Query query = new TermQuery(new Term("content", "lucene"));
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
TopDocs results = searcher.search(query, 10);
System.out.println("找到 " + results.totalHits + " 条结果");几行 Java 代码,就能完成一个迷你搜索引擎。
结语
Apache Lucene 虽然不是面向最终用户的产品,但它是搜索技术的基石。几乎所有现代搜索引擎都离不开它。如果你对搜索技术有兴趣,学习 Lucene 是理解搜索引擎工作原理的最佳途径。
🚀 下期预告
下一篇,我将介绍 Lucene 的第一个"孩子"—— Apache Solr,看看这个基于 Lucene 的企业级搜索平台如何让搜索变得更简单。
💬 三连互动
- 你或公司最近在用 Lucene 吗?拿来做了什么场景?
- 你觉得 Lucene 最香 / 最坑的点是什么?
- 下一期想先看 Solr 还是 Elasticsearch ?留言告诉我,我来插队!
对搜索技术感兴趣的朋友,也欢迎加我微信(ID:lsy965145175)备注“搜索百科”,拉你进 搜索技术交流群,一起探讨与学习!
大家好,我是 INFINI Labs 的石阳。
这是《搜索百科》系列文章,每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
搜索技术看似专业,但它早已深度融入我们的日常生活。无论是电商搜索、知识检索,还是 AI 语义搜索、RAG、向量检索,背后都有经典与新兴技术的结合。希望这个系列能帮大家建立更清晰的认知,也欢迎留言交流。
引言:为什么先写 Lucene?
如果你曾用 GitHub 搜代码、用电商网站搜商品,或者在日志平台里“捞”报错,你就已经享受了 Lucene 的红利——只是自己还不知道。今天,让我们认识下这位“幕后大佬”,看看它如何以一己之力,孵化了整个现代搜索江湖。没有它,就没有 Elasticsearch 的锋芒,也没有 Solr 的稳健。讲搜索,不从 Lucene 开始,就像讲武侠不提《易筋经》——根基都丢了。
诞生故事:一个程序员的“副业”成果
Lucene 的诞生颇具传奇色彩。它的创造者 Doug Cutting(后来也是 Hadoop 的创始人之一)在 1997 年开始开发 Lucene,最初是为了给他的个人项目——一个网络爬虫和搜索引擎——提供搜索能力。
当时,市面上并没有成熟的开源搜索库可用,Doug 决定自己写一个。他在业余时间一点点打磨,最终在 1999 年发布了第一个版本。2001 年,Lucene 加入了 Apache 软件基金会,成为 Apache 的第一个开源搜索项目。
有趣的是,Lucene 的名字并不是来自什么技术术语,而是取自 Doug Cutting 妻子的中间名——Lucene。这也让这个项目多了一丝浪漫的色彩。
Lucene 概述
Apache Lucene,是一个用 Java 编写的高性能、全文搜索引擎库。它不是那种你下载下来就能直接用的“搜索软件”,而是一个底层库,就像乐高积木里的基础砖块,虽然不起眼,但没有它,很多搜索产品根本搭不起来。
Lucene 提供了强大的索引和查询能力,支持分词、倒排索引、相关性评分、模糊查询、布尔查询等一系列功能。它是 Elasticsearch、Solr、Easysearch、OpenSearch 等现代搜索引擎的核心引擎。
- 首次发布:1999 年
- 最新版本:截至 2025 年 9 月,Lucene 已更新至
10.2.x系列 - 开源协议:Apache License 2.0(商业友好)
- 官网:https://lucene.apache.org/
- GitHub:https://github.com/apache/lucene
社区生态
虽然已经 25 岁"高龄",Lucene 的社区却依然活力满满。作为 Apache 软件基金会的顶级项目,它拥有:
- 100+ 活跃贡献者
- 每月都有新的 commit 和 issue 处理
- 每年发布 2-4 个主要版本
- 完善的文档和活跃的邮件列表
虽然不像 Elasticsearch 那样“出圈”,但在开发者和企业内部系统中仍有广泛使用。
功能亮点:为什么大家都爱它?
- 高性能全文检索内核:倒排索引、短语/布尔/通配符/模糊查询、相关性打分。
- 面向工程的可扩展分析链:分词器、过滤器、同义词、停用词、高亮、排序等。
- 近邻向量检索(KNN):原生支持高维向量的最近邻搜索,为语义检索/RAG 奠基。 
- 嵌入式 & 纯 Java:作为库嵌入任意 Java 应用,掌控细粒度行为与性能。
- 成熟稳定的版本线:9.x 与 10.x 并行演进,兼顾稳定与新特性。
对比优势:Lucene vs 世界
| 产品 | 类型 | 与 Lucene 的关系 |
|---|---|---|
| Elasticsearch | 分布式引擎 | 基于 Lucene,提供分布式、RESTful 接口 |
| Apache Solr | 搜索平台 | 基于 Lucene,提供 Web 管理界面和更多功能 |
| Meilisearch | 轻量引擎 | 不基于 Lucene,用 Rust 编写,主打易用性 |
Lucene 是底层引擎,而其他产品是在它之上构建的完整解决方案。如果你想要完全控制搜索逻辑,Lucene 是最佳选择;如果你想要开箱即用的搜索服务,可以考虑 Elasticsearch 或 Solr。
快速上手:10 分钟体验 Lucene
虽然 Lucene 需要写一些 Java 代码,但其实入门并不复杂。
1. 环境准备
// Maven 依赖
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>10.xx.xx</version>
</dependency>2. 创建你的第一个索引
// 创建分析器(支持中文)
Analyzer analyzer = new StandardAnalyzer();
// 创建索引
Directory directory = FSDirectory.open(Paths.get("index"));
IndexWriterConfig config = new IndexWriterConfig(analyzer);
IndexWriter writer = new IndexWriter(directory, config);
Document doc = new Document();
doc.add(new TextField("content", "欢迎来到 Lucene 的世界", Field.Store.YES));
writer.addDocument(doc);
writer.close();3. 执行搜索
// 搜索 "Lucene"
Query query = new TermQuery(new Term("content", "lucene"));
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
TopDocs results = searcher.search(query, 10);
System.out.println("找到 " + results.totalHits + " 条结果");几行 Java 代码,就能完成一个迷你搜索引擎。
结语
Apache Lucene 虽然不是面向最终用户的产品,但它是搜索技术的基石。几乎所有现代搜索引擎都离不开它。如果你对搜索技术有兴趣,学习 Lucene 是理解搜索引擎工作原理的最佳途径。
🚀 下期预告
下一篇,我将介绍 Lucene 的第一个"孩子"—— Apache Solr,看看这个基于 Lucene 的企业级搜索平台如何让搜索变得更简单。
💬 三连互动
- 你或公司最近在用 Lucene 吗?拿来做了什么场景?
- 你觉得 Lucene 最香 / 最坑的点是什么?
- 下一期想先看 Solr 还是 Elasticsearch ?留言告诉我,我来插队!
对搜索技术感兴趣的朋友,也欢迎加我微信(ID:lsy965145175)备注“搜索百科”,拉你进 搜索技术交流群,一起探讨与学习!
收起阅读 »
【搜索客社区日报】第2112期 (2025-09-10)
https://blog.gopenai.com/elast ... e0ddb
2.使用 Elasticsearch 增强 RAG:深入了解高级搜索功能(搭梯)
https://medium.com/%40hiconcep ... 99d86
3.将网站转变为LLM的知识库(搭梯)
https://medium.com/data-scienc ... 7c1d3
编辑:kin122
更多资讯:http://news.searchkit.cn
https://blog.gopenai.com/elast ... e0ddb
2.使用 Elasticsearch 增强 RAG:深入了解高级搜索功能(搭梯)
https://medium.com/%40hiconcep ... 99d86
3.将网站转变为LLM的知识库(搭梯)
https://medium.com/data-scienc ... 7c1d3
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2111期 (2025-09-09)
https://carlylrichmond.medium. ... 8b19f
2. 把opensearch换成minisearch得不得行?(需要梯子)
https://medium.com/collaborne- ... f7395
3. 能hold住数据持续增长的ES吗?(需要梯子)
https://medium.com/%40tumersev ... 49ac7
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://carlylrichmond.medium. ... 8b19f
2. 把opensearch换成minisearch得不得行?(需要梯子)
https://medium.com/collaborne- ... f7395
3. 能hold住数据持续增长的ES吗?(需要梯子)
https://medium.com/%40tumersev ... 49ac7
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
【搜索客社区日报】第2110期 (2025-09-08)
https://elasticstack.blog.csdn ... 14513
2、使用 cloud-native Elasticsearch 与 ECK 运行
https://elasticstack.blog.csdn ... 09367
3、什么是上下文工程 (Context Engineering)?
https://elasticstack.blog.csdn ... 32162
4、转变数据交互:在 Amazon Bedrock AgentCore Runtime 上部署 Elastic 的 MCP 服务器以构建 agentic AI 应用程序
https://elasticstack.blog.csdn ... 24592
5、初探:从0开始的AI-Agent开发踩坑实录
https://mp.weixin.qq.com/s/7Lt3WKmHoQY5HifnPFjxoQ
编辑:Muse
更多资讯:http://news.searchkit.cn
https://elasticstack.blog.csdn ... 14513
2、使用 cloud-native Elasticsearch 与 ECK 运行
https://elasticstack.blog.csdn ... 09367
3、什么是上下文工程 (Context Engineering)?
https://elasticstack.blog.csdn ... 32162
4、转变数据交互:在 Amazon Bedrock AgentCore Runtime 上部署 Elastic 的 MCP 服务器以构建 agentic AI 应用程序
https://elasticstack.blog.csdn ... 24592
5、初探:从0开始的AI-Agent开发踩坑实录
https://mp.weixin.qq.com/s/7Lt3WKmHoQY5HifnPFjxoQ
编辑:Muse
更多资讯:http://news.searchkit.cn
收起阅读 »
【搜索客社区日报】第2109期 (2025-09-05)
https://mp.weixin.qq.com/s/gMSu2yzX7BT56EvTlxiCgA
2、得物灵犀搜索推荐词分发平台演进 3.0
https://my.oschina.net/u/5783135/blog/18690593
3、检索升级实践:亲手打造 “更聪明” 的文档理解系统!
https://my.oschina.net/u/8690838/blog/18690372
4、基于极限网关实现 Elasticsearch 到 Easysearch 集群数据迁移实战
https://blog.csdn.net/yangmf20 ... 55265
5、Elasticsearch 的 JVM 基础知识:指标、内存和监控
https://elasticstack.blog.csdn ... 75147
编辑:Fred
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/gMSu2yzX7BT56EvTlxiCgA
2、得物灵犀搜索推荐词分发平台演进 3.0
https://my.oschina.net/u/5783135/blog/18690593
3、检索升级实践:亲手打造 “更聪明” 的文档理解系统!
https://my.oschina.net/u/8690838/blog/18690372
4、基于极限网关实现 Elasticsearch 到 Easysearch 集群数据迁移实战
https://blog.csdn.net/yangmf20 ... 55265
5、Elasticsearch 的 JVM 基础知识:指标、内存和监控
https://elasticstack.blog.csdn ... 75147
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2108期 (2025-09-04)
https://mp.weixin.qq.com/s/fgVMx5JOw77JlNVSgh0UCw
2.Elastic 数据采集全面转向 OpenTelemetry
https://mp.weixin.qq.com/s/b8Wa1RKIyGB58o0RIcwweQ
3.Agent 架构综述:从 Prompt 到 Context
https://mp.weixin.qq.com/s/pIcZPDqYzXrE3i6Zh4sr-Q
4.玩疯了!盘点文生图模型Nano Banana的热门提示词
https://mp.weixin.qq.com/s/LOt-pZ7-cxXdf3KEmxpkWQ
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/fgVMx5JOw77JlNVSgh0UCw
2.Elastic 数据采集全面转向 OpenTelemetry
https://mp.weixin.qq.com/s/b8Wa1RKIyGB58o0RIcwweQ
3.Agent 架构综述:从 Prompt 到 Context
https://mp.weixin.qq.com/s/pIcZPDqYzXrE3i6Zh4sr-Q
4.玩疯了!盘点文生图模型Nano Banana的热门提示词
https://mp.weixin.qq.com/s/LOt-pZ7-cxXdf3KEmxpkWQ
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »

